BAB II
KAJIAN PUSTAKA
Pada bagian kajian pustaka ini, akan disajikan pengertian umum tentang istilah-istilah yang digunakan dalam penelitian ini serta teori-teori dan penjelasan-penjelasan yang mendasarinya dengan segala kekuatan dan kelemahannya dan bagaimana teori-teori tersebut diimplementasikan serta penelitian-penelitian terdahulu yang berhubungan dengan penelitian ini. Teori-teori dan penjelasan-penjelasan serta implementasinya, yang mempunyai kekuatan akan dijadikan landasan dalam pengumpulan dan analisis data, sedangkan yang mempunyai kelemahan akan dijadikan bahan perbandingan.
2.1 Pengertian Istilah/Penjelasan dan Kerangka Teori 2.1.1 Pengertian Istilah/Penjelasan
2.1.1.1 Korespondensi Bunyi
Langacker (1972:329-230) mengatakan bahwa alat metode komparatif adalah korespondensi bunyi sistematis dalam bahasa-bahasa berkerabat. Dia mengatakan perbedaan-perbedaan bentuk fonetis dalam perangkat korespondensi bersifat sistematis. Bunyi-bunyi yang berkorespondensi tidak harus sama tetapi muncul secara teratur pada posisi yang sama dalam kata-kata yang mirip baik dari segi bentuk maupun arti.
Dalam penjelasan tersebut, dia tidak menggunakan istilah perangkat korespondensi fonemis, tetapi menggunakan istilah korespondensi bunyi yang datanya adalah data fonetis.
Crowley (1992:93) mengatakan bahwa korespondensi bunyi adalah perangkat bunyi dalam kata-kata berkerabat yang dipantulkan oleh satu proto-bahasa. Crowley (1992:106) menjelaskan bahwa perangkat korespondensi bunyi melibatkan bunyi-bunyi yang mirip secara fonetis.
Seperti Langacker, dia tidak menggunakan istilah perangkat korespondensi fonetis atau perangkat korespondensi fonemis, melainkan menggunakan istilah perangkat korespondensi bunyi (sound correspondence), korespondensi vokal (vowel correspondence), dan korespondensi konsonan (consonant correspondence). Namun, dia mengatakan, “….here we are trying to analyse the phonemes of the proto-language by using the sound correspondences as the ‘phonetic’ raw data.”
Penjelasan tersebut berarti bahwa untuk menganalisis proto-bahasa digunakan korespondensi bunyi sebagai data mentah fonetis. Artinya, data yang digunakan dalam perangkat korespondensi bunyi adalah data fonetis alih-alih data fonemis. Itulah sebabnya mengapa dalam langkah-langkah melakukan rekonstruksi, tidak disebutkan langkah mengubah data fonetis menjadi data fonemis. Crowley (1992:75-89) menggunakan data fonemis untuk menganalisis apakah perubahan proto-fonem berwujud perubahan fonetis yang mengakibatkan perubahan fonemis atau tidak. Menurut dia, perubahan fonetis tanpa perubahan fonemik berwujud alofon atau subfonem sedangkan perubahan fonetis dengan perubahan fonemis berwujud menghilangnnya fonem, pertambahan fonem, dan refonemisasi (perubahan satu fonem dengan fonem lain).
Sementara itu, Hock (1988:562) memakai istilah korespondensi bunyi secara rekuren dan sistematis, alih-alih perangkat korespondensi fonemis. Dalam penjelasannya, dia menggunakan data fonetis.
Untuk maksud yang sama, korespondensi bunyi, Keraf (1991:49) mengganti istilah korespondensi bunyi dengan istilah korespondensi fonemis atas alasan bahwa hukum bunyi mengandung tendensi adanya ikatan yang ketat. Dia tidak menjelaskan apakah perangkat korespondensi bunyi berwujud fonetis atau fonemis. Namun, dia menggunakan data fonetis dalam penjelasannya. Hal itu dapat dilihat dari fakta bahwa dia tidak mereduksi data fonetis menjadi data fonemis sebelum melakukan rekonstruksi. Artinya, penggunaan perangkat korespondensi fonemis hanya sebatas penggunaan istilah dan tidak bermaksud bahwa data korespondensi bunyi haruslah data fonemis.
Jika tidak hati-hati, seorang peneliti akan tersesat setelah membaca istilah perangkat korespondensi fonemis. Ia akan menggunakan data fonemis dalam korespondensi bunyi. Atas dasar itu, peneliti akan menggunakan perangkat korespondensi bunyi seperti yang digunakan Langacker (1972:329-230) dan Crowley (1992:93).
Keraf (1991:49) memberikan penjelasan yang lebih jauh tentang korespondensi fonemis. Dikatakannya, korespondensi fonemis adalah fonem-fonem yang terdapat pada posisi yang sama dalam pasangan kata yang mempunyai kesamaan atau kemiripan bentuk dan makna.
Korespondensi fonemis dapat dilihat pada sepuluh bilangan utama dalam bahasa Indo-Eropa.
Glos Yunani Latin Sanskerta Gotik satu oinos unus ekas ains
dua dyo duo dva twai tiga treis tres travas threis
empat tettaras quattuor catvaras fidwor lima pente quinque panca
fimf
enam heks sex sas saih tujuh hepta septem sapta
sibun
delapan okto octo asta ahtau sembilan en-nea novem nava niun
sepuluh deka decem dasa taihum
Data di atas menunjukkan perangkat korespondensi, yakni d-d-d-t yang terdapat pada glos dua dan sepuluh. Perangkat korespondensi lain adalah h-s-s-s, yaitu perangkat fonem konsonan awal pada glos enam dan tujuh. Perangkat korespondensi ketiga adalah e-e-a-i, yang merupakan perangkat korespondensi vokal pertama pada glos sepuluh dan tujuh.
Menurut Keraf, perangkat korespondensi pada satu pasang kata tidak cukup dan masih merupakan indikasi adanya perangkat korespondensi tersebut. Sehubungan dengan itu, perangkat tersebut harus diuji pada sebanyak mungkin pasangan kata pada bahasa-bahasa yang dibandingkan. Hal itu penting untuk menghindarkan faktor kebetulan atau penghilangan korespondensi yang seharusnya ada dan pemaksaan perangkat yang tidak berkorespondensi menjadi perangkat berkorespondensi. Keterdapatan secara berulang dan teratur perangkat korespondensi disebut rekurensi fonemis (phonemic recurrance).
Rekurensi fonemis dapat dilihat pada contoh berikut:
Glos b.Inggris b.Jerman b.Belanda b.Denmark b.Swedia orang mn man man man
man
tangan hnd hant hant hn hand
kaki fut fu:s vu:t fo: fo:t
jari fig fier vier feer fier
rumah haws haws hs hu:s hu:s
m.dingin wint vinter winter vendr vinter
m.panas sm zomer zo:mer sm smar
minum drik triken drike dreg drika
bawa bri brien bree bre bria
hidup livd le:pte le:vde le:v le:vde
Untuk glos rumah pada data di atas, terdapat perangkat korespondensi
h h h h h
aw aw u u
s s s s s
Dari ketiga perangkat korespondensi tersebut, perangkat korespondensi aw:aw::u:u mengalami rekurensi seperti terlihat pada data berikut:
Glos b.Inggris b.Jerman b.Belanda b.Denmark b.Swedia tikus maws maws ms mu:s
mu:s
kutu laws laws ls lu:s lu:s
keluar awt awt t u:d u:t
coklat brawn brawn brn bru:n bru:n
Dalam bahasa-bahasa Austronesia, Keraf (1991: 51) memberikan contoh: kata hidung dalam bahasa Melayu: hidung, Batak: igung, dan Sunda: irung. Dari data tersebut dapat ditarik perangkat korenspondensi yang diperkirakan akan mengalami rekurensi fonemis, yakni d-g-r yang terlihat dalam:
h i d u i g u i r u
Pada data yang mencukupi, d-g-r diperkirakan akan terjadi berulang dan teratur (rekuren).
Untuk menghindarkan dikeluarkannya fonem tertentu dari perangkat korespondensi karena kelihatan sangat berbeda dari fonem-fonem lainnya (seperti dijelaskan sebelumnya), Keraf mengatakan bahwa ko-okurensi (co-occurance) harus dicermati. Ko-okurensi adalah gejala-gejala tambahan yang terjadi sedemikian rupa pada kata-kata berkerabat yang dapat mengaburkan kemiripan makna dan bentuk serta korespondensi fonetis.
Menurut Keraf (1991:55), kata baru dalam bahasa Melayu adalah baru, bahasa Jawa: weru, bahasa Karo: mbaru, dan bahasa Lamalera: fu. Karena kata fu identik dengan fu busur, ada kecenderungan peneliti untuk mengeluarkan kata tersebut dari pasangan kata berkerabat sehingga fonem /f/ tidak dimasukkan dalam perangkat korespondensi b:w:b:f. Namun, karena gejala yang sama terdapat dalam bahasa itu dan bahasa-bahasa Nusantara lainnya, /f/ dalam kata fu baru tetap merupakan anggota perangkat korespondensi tadi atas dasar, fu berkerabat dengan kata baru. Kata fu telah mengalami kontraksi dari bentuk baru-waru-weru(n)-wehu-weu-fu. Mula-mula fonem /r/ menjadi /h/ yang kemudian
hilang dari bentuk tersebut. Kedua vokal yang mengapit /h/ mengalami proses sandi dan berubah menjadi /u/.
Gejala hilangnya /r/ antarvokal (intervocalic r) merupakan hal yang umum terjadi dalam bahasa-bahasa Nusantara. Misalnya, kata turut, dalam bahasa Melayu adalah turut dan tut dalam bahasa Jawa. Contoh lain, kata beras dalam bahasa Jawa mengalami proses perubahan sebagai berikut: berat-behat-beat-bot; beras-behas-beas-wos atau beras-weras-wehas-weas-wos.
Keraf juga menjelaskan, penentuan perangkat korespondensi harus terlepas dari analogi, yakni menjadikan ko-okurensi dalam bahasa-bahasa berkerabat sebagai dasar untuk memasukkan fonem-fonem dari dari bahasa-bahasa lain dalam perangkat korespondensi fonemis. Misalnya, kata pikir yang berasal dari bahasa Arab, fikir dirasakan sudah merupakan kata bahasa Melayu. Atas dasar itu, kemungkinan peneliti akan menjadikan f-p sebagai perangkat korespondensi fonemis dalam bahasa-bahasa berkerabat Nusantara. Penentuan perangkat korespondensi seperti ini didasarkan pada analogi yang salah.
2.1.1.2 Metode Komparatif
Menurut Langacker (1972:329), metode komparatif (comparative method) adalah teknik untuk menentukan keberhubungan secara genetis sekelompok bahasa dan untuk merekonstruksi proto-bahasa yang menurunkan bahasa-bahasa tersebut.
Sementara itu, Hock (1988:556) mengatakan bahwa metode komparatif adalah metode untuk menemukan kemiripan bentuk-bentuk bahasa-bahasa
berkerabat yang tidak terjadi secara kebetulan, melainkan karena adanya asumsi bahwa bahasa-bahasa tersebut diturunkan oleh proto-bahasa yang sama.
2.1.1.3 Pasangan Kata Berkerabat
Langacker (1972:331) mengatakan bahwa satuan-satuan leksikal dalam bahasa-bahasa berkerabat dikatakan kognat apabila diturunkan oleh unsur leksikal yang sama dalam proto-bahasa. Misalnya, pater dalam bahasa Latin, pater dalam bahasa Junani, pita dalam bahasa Sansakerta, dan father dalam bahasa Inggris adalah kognat karena dapat ditelusuri perkembangannya dari satu bentuk proto-Indo Eropa.
Dia menambahkan bahwa kata-kata kognat berhubungan satu sama lainnya dalam bentuk korespondensi bunyi yang menunjukkan perkembangan bentuk proto-bahasa dalam evolusi historis bahasa-bahasa yang diturunkannya.
Menurut Crowley (1992:90), perangkat bunyi dikatakan berkerabat apabila direfleksikan satu proto-bahasa dan didistribusikan dalam kata-kata yang mempunyai kesamaan atau kemiripan bentuk dan arti.
Gudschinsky (1956:132), menggunakan istilah pasangan berkerabat (cognate sets) untuk perangkat korespondensi bunyi. Dia memerinci prosedur yang harus diikuti untuk membandingkan kata-kata dan menetapkan kriteria-kriteria dalam menentukan apakah pasangan-pasangan kata yang dibandingkan berkerabat atau tidak. Menurutnya, dalam perbandingan, yang dibandingkan adalah fonem dengan fonem, fonem dengan klaster fonem atau klaster fonem dengan klaster fonem. Perbandingan hanya dapat dilakukan antara fonem dengan fonem atau antara fonem dengan klaster fonem dalam posisi yang dapat
dibandingkan (comparable sets). Prosedur perbandingan tersebut telah dijelaskan pada bagian terdahulu.
Selanjutnya, Gudschinsky (1956:132) menjelaskan bahwa setelah diketahui pasangan fonem-fonem atau pasangan fonem-klaster fonem yang dapat dibandingkan, kriteria penentuan pasangan-pasangan yang berkerabat adalah sebagai berikut:
1. pasangan itu identik (misalnya [a]:[a], [c]:[c]). Pasangan-pasangan yang dibandingkan mirip secara fonetis ([p]:[b], [t]:[d], dan lain-lain). Pasangan-pasangan itu berbeda akibat lingkungan (conditioning factors). Misalnya, [i]: [a] dalam ciki (dialek Huatla, Meksiko) dan caki (dialek Mazatec, Meksiko) 'kayu bakar' dianggap berkerabat karena perbedaan pengucapan [c] merupakan penyebab berubahnya [i] menjadi [a] atau sebaliknya.
2. Pasangan-pasangan itu muncul berulang dalam pasangan-pasangan kata lainnya pada posisi yang dapat dibandingkan. Misalnya, [š] dalam dialek Ixcatec berkerabat dengan [1] dalam dialek Mazatec karena pasangan [š]:[1] muncul pada kata-kata lain yang dibandingkan yakni [šwi] : [p1] ‘api’ dan pada [šu]:[lao]. Dua buah kata yang dibandingkan hanya dapat dikatakan berkerabat apabila paling sedikit tiga pasangan fonem dengan fonem, fonem dengan klaster fonem atau klaster fonem dengan klaster fonem berkerabat. Jika dalam kata-kata yang dibandingkan terdapat kurang dari tiga fonem yang berkerabat, maka kata-kata tersebut tidak berkerabat.
Penjelasan Langacker, Crowley, Gudschinsky, dan Keraf di atas saling melengkapi sehingga rekonstruksi proto dan pengelompokan bbB dapat dilakukan dengan lebih akurat.
2.1.1.4 Rekonstruksi Proto-bahasa
Menurut Kridalaksana (1983:144), rekonstruksi adalah metode untuk memperoleh moyang bersama dari suatu kelompok bahasa yang berkerabat dengan membandingkan ciri-ciri bersama atau dengan menentukan perubahan-perubahan yang dialami sebuah bahasa sepanjang sejarahnya. Kridalaksana juga menyebutkan, proto-bahasa adalah awalan yang bermakna ‘purba’ dan dipakai dalam istilah, seperti proto-Indo-Eropa, proto-Germania, dan sebagainya. Karena proto adalah awalan, dalam penelitian ini, akan digunakan istilah proto-bahasa (proto-bbB) alih-alih bahasa proto.
Menurut Crowley (1992:104) rekonstruksi adalah perkiraan tentang kemungkinan bentuk proto-bahasa dengan menelesuri perubahan-perubahan yang terjadi di antara proto-bahasa dengan bahasa-bahasa berkerabat yang diturunkannnya (sister languages).
Meskipun Crowley tidak mendefinisikan secara eksplisit istilah proto, tetapi kedua definisi tersebut sama-sama menyatakan bahwa rekonstruksi proto-bahasa adalah penelusuran perubahan-perubahan bentuk yang terjadi dalam sejarah perkembangan proto-bahasa dan bahasa atau bahasa-bahasa berkerabat yang diturunkannya. Untuk menyatakan maksud yang sama, Mbete (2009:31) mengatakan, rekonstruksi adalah peracikan atau perancangbangunan kembali sistem bahasa purba berdasarkan data dan fakta kebahasaan yang berpijak pada bahasa-bahasa kerabat.
Walaupun Kridalaksana dan Mbete menggunakan istilah moyang dan purba, dalam penelitian ini, kedua istilah itu tidak digunakan dan menggantikannya dengan istilah proto. Ada beberapa alasan peneliti menggunakan istilah proto. Pertama, istilah proto sudah merupakan istilah bahasa Indonesia dan digunakan dalam kamus umum dan kamus linguistik, termasuk Kamus Linguistik karya Kridalaksana (1983). Kedua, istilah-istilah ilmu pengetahuan, termasuk linguistik perlu diarahkan ke keseragaman untuk memudahkan pemahaman masyarakat internasional (misalnya, kata kerja dipadankan dengan verba, kata benda dipadankan dengan nomina, dan kata sifat dipadankan dengan ajektiva). Ketiga, istilah proto-bahasa telah digunakan secara luas oleh peneliti-peneliti linguistik historis komparatif di Indonesia.
Crowley (1992:91) mengatakan bahwa bentuk-bentuk proto-bahasa dapat direkonstruksi dari refleksi-refleksi yang terdapat dalam bahasa-bahasa yang berkerabat dengan menggunakan metode komparatif untuk mengetahui perubahan-perubahan yang telah terjadi di antara proto-bahasa dengan bahasa-bahasa yang diturunkannya. Untuk mengetahui perubahan-perubahan tersebut, dilakukan perbandingan atas refleksi-refleksi bentuk pada bahasa-bahasa berkerabat yang diperkirakan berasal dari atau dipantulkan oleh satu proto-bahasa.
Crowley (1992:96) selanjutnya menjelaskan, untuk melakukan rekonstruksi bentuk-bentuk proto-bahasa, dilakukan beberapa langkah sebagai berikut:
Langkah pertama adalah memisahkan kata atau kata-kata yang berkerabat dari kata-kata yang tidak berkerabat. Misalnya, tafuafi ‘membuat api’ harus dikeluarkan dari data:
b.Tonga b. Samoa b. Rarotong b. Hawai Glos
tafuafi sia ika hia membuat api
Langkah kedua adalah menentukan korespondensi bunyi pada bahasa-bahasa yang berkerabat seperti pada glos dilarang pada data berikut:
b.Tonga t a p u
b.Samoa t a p u
b.Rarotong t a p u
b.Hawai k a p u
Perangkat korespondensi dalam data tersebut adalah t-t-t-k, a-a-a-a, p-p-p-p, dan u-u-u-u.
Langkah ketiga adalah memeriksa perangkat bunyi berkorespondensi yang mempunyai perbedaan untuk menentukan proto-fonemnya seperti pada data berikut.
b.Tonga b.Samoa b.Rarotong b.Hawai
t t t k
n
Perbedaan perangkat bunyi pada data pertama adalah t-k dan pada data kedua adalah -n. Ada kemungkinan, /*t/ atau /*k/ adalah proto dari t dan k serta /* / atau /*n/ adalah proto dari /* / atau /*n/. Namun karena /t/ dan // mempunyai distribusi paling luas atau rekurensi paling luas pada data yang ada, maka /*t/ dan /*/ adalah fonem-fonem proto dalam keempat bahasa tersebut.
Langkah ketiga tersebut sering tidak dapat diaplikasikan jika tidak ada fonem yang mempunyai distribusi paling luas dalam suatu perangkat korespondensi seperti dalam contoh berikut:
b.Tonga b.Samoa b.Rarotong b.Hawai
Pada data itu /k/ dan / / mempunyai distribusi yang sama. Untuk mengatasi masalah tersebut, perlu diingat bahwa perubahan bunyi harus berlangsung secara alamiah atau wajar. Proto-fonem /k/ dan / / yang lebih alamiah atau wajar adalah /*k/, alih-alih // karena perubahan /k/ menjadi / / (/k/ → / /) merupakan perubahan yang sangat umum terjadi melalui proses pelemahan atau lenisi. Perubahan // menjadi /k/ (// →/k/) sangat jarang terjadi.(meskipun mungkin) melalui proses penguatan (fortisi).
Bahwa /*k/ merupakan proto-fonem /k/ dan / / dapat dikuatkan dengan proto-fonem Polinesia berikut:
Bilabial Alveolar Velar
Hambat *p *t
Nasal *m *n *
Karena sistem fonologis bahasa selalu seimbang, kekosongan velar hambat /k/, alih-alih // untuk mengimbangi velar nasal harus diisi. Itulah sebabnya mengapa /*k/ ditetapkan sebagai proto-fonem, sehingga bagan di atas menjadi sebagai berikut:
Bilabial Alveolar Velar Hambat *p *t *k
Nasal *m *n *
Untuk melakukan rekonstruksi, perlu diingat ketentuan-ketentuan berikut:
Setiap rekonstruksi harus mengandung perubahan bunyi yang umum terjadi atau logis (lihat jenis-jenis perubahan bunyi pada bagian berikut kajian teori ini).
Setiap rekonstruksi harus mengandung sesedikit mungkin perubahan bunyi dari proto-bahasa ke bahasa-bahasa berkerabat yang diturunkannya.
Setiap rekonstruksi harus menutup kekosongan sistem fonologis berimbang, alih-alih menciptakan sistem fonologi yang tidak berimbang atau logis. Contoh sistem fonologis berimbang, jika sebuah bahasa mempunyai dua vokal bulat belakang (misalnya, /u/ dan /o/, diprediksi bahwa bahasa itu mempunyai dua vokal tidak bulat depan (misalnya, /i/ dan /e/).
Depan Belakang
Tinggi i u
Sedang e o
Rendah a
Contoh sistem fonologis yang tidak berimbang, sebuah bahasa mempunyai vokal depan tinggi /i/ dan vokal depan sedang /e/ tetapi tidak mempunyai vokal tinggi belakang.
Depan Belakang
Tinggi i -
Sedang e o
Rendah a
Sebuah proto-fonem tidak perlu direkonstruksi jika data yang cukup tidak tersedia dalam bahasa-bahasa berkerabat yang diturunkannya.
Untuk menyimpulkan penjelasan di atas, Crowley (1992:110) memberikan petunjuk tentang metode rekonstruksi sebagai berikut:
1. memilah bentuk-bentuk yang nampak berkerabat dan mengabaikan bentuk-bentuk yang tidak berkerabat;
2. melakukan inventarisasi lengkap perangkat korespondensi dalam bahasa-bahasa yang dibandingkan (termasuk bunyi-bunyi yang identik; perlu
diperhatikan korespondensi di mana suatu bunyi berkorespondensi dengan );
3. mengelompokkan perangkat-perangkat korespondensi yang mempunyai pantulan-pantulan yang mirip secara fonetis;
4. menemukan bukti adanya distribusi komplementer atau kontrastif antara bunyi-bunyi yang dicurigai sebagai perangkat korespondensi;
5. menganggap sebagai fonem lain setiap perangkat korespondensi yang tidak mempunyai distribusi komplementer dengan perangkat korespondensi lain;
6. melakukan perkiraan atas bentuk proto-fonem dengan menggunakan kriteria berikut:
a. Fonem proto yang dipilih harus logis. Artinya, perubahan-perubahan bunyi tersebut menjadi bunyi-bunyi dalam bahasa-bahasa yang diturunkannya harus dapat dijelaskan dalam konteks perubahan-perubahan bunyi bahasa yang secara umum terjadi dalam bahasa-bahasa yang ada di dunia.
b. Bunyi yang mempunyai distribusi paling luas dalam bahasa-bahasa berkerabat paling mungkin sebagai proto-fonem.
c. Sebuah bunyi yang berkorespondensi dengan kekosongan bunyi () pada daftar fonem rekonstruksi juga mungkin merupakan proto-fonem salah satu dari perangkat-perangkat korespondensi.
d. Sebuah bunyi yang tidak ada dalam bahasa-bahasa berkerabat tidak perlu direkonstruksi jika tidak ada alasan yang cuku p untuk melakukannya.
7. Menganggap setiap perangkat korespondensi yang mempunyai distribusi komplementer mempunyai satu proto-fonem dengan menggunakan kriteria nomor 6 untuk merekonstruksi bentuknya.
Mengenai rekonstruksi proto-fonem, Langacker (1972:334) menjelaskan bahwa apabila proto-fonem ditunjukkan oleh refleks yang sama dalam semua bahasa berkerabat, maka proto-segmen yang mewakili perangkat korespondensi dalam bahasa-bahasa tersebut adalah sama.
Dia juga mengatakan bahwa jika sebuah proto-segmen berkembang secara berlainan dalam satu bahasa berkerabat atau lebih sesuai dengan lingkungan, proto-segmen direpresentasikan dalam dua perangkat korespondensi atau lebih seperti terlihat pada contoh berikut:
Glos Comanche Hopi Yaqui
kaki tama tama katek
duduk kari kati katek
Pada posisi awal kata, *t dipantulkan dalam ketiga bahasa untuk glos kaki. Namun, *t pada posisi di antara dua vokal (intervocalic) berkembang dengan cara yang berbeda yakni *t dalam bahasa Hopi dan Yaqui dan *r dalam bahasa Comanche untuk glos duduk. Atas dasar itu, *t adalah proto-fonem perangkat korespondensi t-t-t pada posisi awal kata dan r-t-t pada posisi di antara dua vokal.
Untuk menentukan proto-fonem dalam perangkat korespondensi yang di dalamnya terdapat bunyi yang berdistribusi terluas diterapkan prinsip distribusi terluas (majority wins) seperti dijelaskan pada The Comparative Method and Linguistic Reconstruction
Mengenai hal yang sama, Keraf (1991:61) menjelaskan bahwa sebuah fonem yang distribusinya paling banyak dalam sejumlah bahasa berkerabat dapat dianggap merupakan pantulan linear dari proto-fonem.
Apabila prinsip distribusi terluas tidak dapat diterapkan, Crowley (1992:99) mengatakan bahwa data perangkat korespondensi dapat diperluas dengan menggunakan data bahasa yang paling dekat atau data proto-bahasa yang menurunkannya,
Menurut Dempwolf (1938), rekonstruksi dapat dilakukan dengan dua cara yakni rekonstruksi internal (internal reconstruction) dan rekonstruksi komparatif (comparative reconstruction). Rekonstruksi internal adalah rekonstruksi dengan membandingkan satu bahasa dalam dua atau lebih kurun waktu. Misalnya, bahasa Inggris Kuno dibandingkan dengan bahasa Inggris Pertengahan, dan/atau bahasa Inggris Moderen. Rekonstruksi komparatif adalah rekonstruksi yang membandingkan dua atau lebih bahasa kontemporer yang berkerabat. Rekonstruksi internal sama dengan yang dikatakan Mbete (2009:15) yakni dari bawah ke atas (bottom-up) dan rekonstruksi dari atas ke bawah (top down) dengan menggunakan sistem etimon dan bunyi proto-bahasa hasil rekonstruksi yang ada seperti proto-Austronesia (PAN).
2.1.1.5 Kosakata Dasar
Menurut Hartmann dkk, (1973: 250) kosakata dasar (basic core vocabulary) adalah kata-kata yang menunjuk konsep dan situasi yang bersifat umum dan mendasar dalam semua kegiatan manusia.
Karena bersifat umum dan mendasar, kosakata dasar pasti dimiliki semua bahasa mulai dari masa pra-sejarahnya hingga menjadi bahasa atau bahasa-bahasa
kontemporer. Bentuk-bentuk kosakata dasarlah yang berkembang dari proto-bahasa ke bentuk-bentuk proto-bahasa atau proto-bahasa-proto-bahasa berkerabat.
Analisis diakronis (analisis perkembangan bahasa dari waktu ke waktu) menggunakan kata-kata yang dipantulkan dari proto-bahasa ke bahasa atau bahasa-bahasa yang diturunkannya, sebagai data. Atas dasar itu, telaah leksikostatistik dan rekonstruksi proto-bahasa menggunakan kosakata dasar sebagai data.
Swadesh (1952:109) mengatakan bahwa kosakata dasar mencakup kata-kata yang menunjuk kata-kata-kata-kata ganti, kata-kata-kata-kata bilangan, anggota-anggota tubuh (dan sifat atau aktivitasnya), alam dan sekitarnya, alat-alat perlengkapan sehari-hari.
Pada mulanya, Swadesh membuat daftar kosakata dasar yang terdiri atas 200 kata sebagai dasar perbandingan. Akan tetapi, atas pertimbangan akurasi data dan pengalaman-pengalaman di lapangan, Swadesh (1955) memodifi-kasi daftar tersebut dan merumuskan daftar kosakata dasar yang terdiri atas 100 kata, lihat Towards Greater Accuracy in Lexicostatistics Dating (1955). Mengenai jumlah kosakata dasar, para linguis mempunyai jumlah kata yang berbeda. Ogden ( 1930:72), misalnya, mempunyai 850 kata dalam daftar kosakatanya dan Stokhof (1980:78-99) mempunyai 1.645 kata.
Daftar kosakata Swadesh mengandung kelemahan-kelemahan yang bersumber dari penetapan 200 atau 100 kata yang termasuk dalam kosakata dasar yang dikatakan Swadesh dapat diterapkan kepada semua bahasa. Penerapan prinsip-prinsip mengenai kosakata dasar tidak mutlak sama dalam semua bahasa karena setiap bahasa mempunyai keunikan di samping keuniversalan. Setidaknya, dapat dicatat di bawah ini berbagai kelemahan penerapan daftar kosakata tersebut:
1. Dengan asumsi bahwa kosakata dasar dapat diperoleh dari kata-kata yang menunjuk alam dan sekitarnya, Swadesh telah memasukkan kata-kata snow 'salju', ice 'es', dan freeze 'beku' dalam daftar 200 kosakata dasarnya. Akan tetapi sesungguhnya, ketiga kata itu bukanlah kosakata dasar di daerah-daerah tropis karena sifat-sifat atau gejala-gejala alam seperti itu tidak ada. Pengenalan kelompok-kelompok masyarakat terhadap alam berbeda-beda sesuai dengan perbedaan sifat-sifat dan gejala-gejala alam itu sendiri.
Boleh jadi ketiga kata itu telah dikenal luas di daerah-daerah tropis berkat kemudahan mobilitas dan meluasnya pemakaian alat pendingin (freezer) belakangan ini. Namun, kata-kata ini bukan merupakan kosakata dasar di daerah beriklim tropis, termasuk daerah Austronesia, umumnya, dan daerah-daerah Batak, khususnya. Menyadari hal ini, Dyen (1962:53) mengeluarkan ketiga kata tersebut dalam penelitiannya terhadap bahasa-bahasa Melayu Polinesia. Bahkan Gudschinsky (1962), meskipun mempertahankan daftar 200 kosakata dasar versi Swadesh, memasukkan sejumlah kata yang berbeda dari kata-kata Swadesh dalam daftar kosakata dasarnya Hal ini mengakibatkan daftar 200 kosakata dasar Swadesh berbeda dengan daftar 200 kosakata Gudschinsky (clothing, cook, dance, terdapat dalam daftar Swadesh tetapi tidak terdapat dalam daftar Gudschinsky; dust, fly terdapat dalam daftar Gudschinsky tetapi tidak terdapat dalam daftar Swadesh). Rea dalam Lehman (1962) memakai daftar 100 kosakata yang sebagian berbeda dari daftar kosakata Swadesh. Lain lagi. Travis (1986), dalam penelitiannya terhadap bahasa-bahasa di Ambon, ia memakai
kata-kata yang berjumlah 210 yang diperolehnya dari hasil survei Summer Institute of Linguistics (SIL) di Maluku.
Perbedaan kosakata dasar dan perbedaan jumlah kata yang diterapkan para.
2. Dalam bahasa tertentu, daftar Swadesh kurang memperhatikan urutan prioritas kosakata. Meskipun, misalnya, kosakata dasar Swadesh merupakan kosakata dasar dalam bahasa-bahasa tertentu, tetapi kosakata lain mungkin lebih penting lagi dari kosakata tertentu yang ada dalam daftar Swadesh. Misalnya, kata-kata hamil, pagi, biru, coklat, ayah, ibu, dan sebagainya lebih penting daripada besi. Berdasarkan hal demikianlah, barangkali, Keraf (1991) mengganti sejumlah kata dalam daftar Swadesh dan melengkapinya dengan daftar 100 kosakata dasar. Memakai kata-kata yang kurang mesra dengan para pemakai bahasa yang diteliti berarti membuka kemungkinan munculnya kata-kata kosong. Pada hal, dalam studi komparatif, semakin sedikit data akan semakin kabur hasil penelitian leksikostatistik.
linguis menunjukkan bahwa daftar Swadesh tidak dapat diterapkan dalam semua bahasa. Berdasarkan fakta ini, peneliti akan menggabungkan kata-kata yang ada dalam daftar-daftar kosakata tersebut, kemudian memilih kata-kata yang sesuai dengan daerah-daerah dan budaya-budaya Batak. Peneliti menge-luarkan kata-kata yang kurang dekat dengan masyarakat Batak seperti rusa, telur kutu, dan lontar serta memasukkan kata-kata yang lebih sesuai seperti biru, coklat, pagi, hamil, ibu, ayah.
3. Dalam daftar Swadesh terdapat kata lie yang mempunyai makna ganda (ambigious meaning). Kata lie bisa berarti berbohong dan terletak. Jika alat penjaring data bermakna ganda, data yang
diperoleh kurang sahih dan hasil penelitian sudah barang tentu akan diragukan.
4. Sejumlah kata dalam daftar Swadesh kurang sesuai dengan bahasa-bahasa yang mengenal perbedaan pemakaian kosakata dasar pada siatuasi yang berbeda. Artinya, satu kata dalam daftar Swadesh boleh jadi mempunyai padanan lebih dari satu kata dalam bahasa yang mengenal perbedaan seperti itu. Jika masalah ini terjadi, akan timbul keraguan peneliti untuk menentukan kata mana dari kata-kata alternatif yang diberikan informan yang akan dibandingkan dengan kata dalam bahasa lain. Contoh, bahasa Toba mengenal kata mate, monding, marujung, mintop untuk kata dead 'mati' yang pemakaiannya masing-masing disesuaikan dengan situasi.
Tidaklah mudah bagi peneliti yang bukan orang Toba untuk memilih satu dari sejumlah kata alternatif di atas. Memakai kata dead dalam bahasa ini, seorang peneliti harus mengetahui kapan kata tersebut digunakan. Swadesh tidak memberikan solusi atas masalah seperti ini. Peneliti yang dihadapkan pada kasus seperti ini harus meminta informan untuk memakai kata itu dalam konteks. Lalu, dia harus memilih mana yang paling umum di antara kata-kata yang diberikan. Jika ternyata semua kata itu sama-sama umum, peneliti harus memilih kata pertama yang diucapkan informan atas dasar bahwa pengucapannya lebih spontan (lihat Travis, 1986). 5. Swadesh mengatakan bahwa kata-kata kerabat (cognates) adalah kata-kata yang mempunyai bentuk dan makna yang mirip atau sama. Tetapi kenyataan menunjukkan, ada beberapa kata dalam bahasa-bahasa nonkerabat yang mempunyai bentuk dan arti yang mirip atau sama yang tidak merupakan kata-kata kerabat. Misalnya, kata mata (bahasa Indonesia)
mempunyai kemiripan fonetis dan kesamaan makna dengan kata mati (bahasa Junani). Contoh lain, kata badh (bahasa Sudan) mempunyai kemiripan fonetis dan kesamaan makna dengan kata bad (bahasa Inggris). Kesamaan atau kemiripan tersebut tidaklah disebabkan oleh fakta bahwa kata mata dan mati serta badh dan bad merupakan kata-kata kerabat, melainkan disebabkan oleh faktor kebetulan. Bahasa Indonesia dan bahasa Junani serta bahasa Sudan dan bahasa Inggris tidak mempunyai kontak budaya yang erat.
Selain dari faktor kebetulan, kemiripan atau kesamaan bentuk dan arti dapat disebabkan oleh faktor peminjaman, seperti kata aljabar dalam bahasa Indonesia dan aljabar dalam bahasa Arab. Kata aljabar dalam bahasa Indonesia sudah barang tentu merupakan pinjaman dari bahasa Arab karena Indonesia dan Arab, pencetus istilah aljabar, mempunyai hubungan budaya yang sangat erat.
6. Swadesh tidak memberikan alasan mengapa ia tidak memakai kata morning 'pagi' untuk mendampingi kata afternoon 'siang' dan night 'malam'. Aneh kedengarannya jika ada kelompok masyarakat yang mengenal kata siang dan malam tidak mengenal kata pagi. Ia juga tidak menjelaskan mengapa dia tidak memakai kata-kata blue 'biru' dan brown 'coklat' untuk mendampingi kata-kata white 'putih', black 'hitam’, dan yellow 'kuning'. Memang ada kemungkinan bahwa tidak semua warna dasar dikenal kelompok masyarakat tertentu, tetapi Swadesh tidak memberitahukan mengapa blue dan brown tidak dipakai.
7. Swadesh (1952:13) mengatakan bahwa jika ada dua kata atau lebih dalam satu bahasa sebagai padanan alternatif bagi satu kata dalam bahasa lain, peneliti harus memilih satu dari kata-kata tersebut secara acak. la
memberikan alasan bahwa pemilihan secara acak terhadap kata-kata tertentu dalam satu bahasa akan mengimbangi pemilihan dengan teknik yang sama terhadap kata-kata dalam bahasa lain, sehingga perhitungan statistik tidak akan terpengaruh oleh pemilihan tersebut. Tetapi cara seperti itu dapat merugikan apabila teknik random kebetulan memilih kata-kata yang salah secara berulang dalam satu bahasa dan memilih kata-kata yang benar secara berulang dalam bahasa lain.
Untuk menghidarkan kekeliruan seperti itu, kata-kata alternatif tersebut harus diuji dalam konteks yang berbeda. Cara demikian akan memungkinkan peneliti dapat menentukan kata mana yang paling sesuai dengan kata yang ada dalam alat penjaring data. Yang menjadi kesulitan adalah hal bahwa peneliti dan informan mungkin tidak saling mengerti apabila harus membicarakan konteks pemakaian kata-kata tersebut.
8. Revisi Swadesh terhadap dattar kosakata dasar yang memuat 200 kata menjadi 100 untuk tujuan akurasi hasil penelitian boleh jadi justru mengaburkan, karena semakin sedikit jumlah data hasil perhitungan statistik akan semakin kabur. Swadesh boleh saja melakukan penyesuaian-penyesuaian dengan mengeluarkan kata-kata yang dianggap tumpang tindih. Tetapi setidaknya, dia masih dapat mempertahankan jumlah 200 kata, bahkan menambahkan kata-kata lain kepada daftar 200 kata itu. Tidak tertutup kemungkinan daftar 1.000 kata dasar dapat disusun. Kroeber (1955:97) mengatakan bahwa daftar 1.000 kata lebih baik daripada daftar 100 atau 200 kata. Pemakaian daftar 1.000 kata dasar jelas sangat menguntungkan karena kesalahan penentuan kata-kata kerabat dalam jumlah
yang kecil, misalkan 5 atau 10 pasang, tidak begitu mempengaruhi hasil statistik. Sebaliknya, jika terjadi kesalahan dalam jumlah yang sama dengan memakai daftar 100 kata, misalnya, kesalahan tersebut pasti akan sangat merugikan (lihat Gudschinsky, 1956:182). Atas argumentasi itulah, peneliti tidak memakai daftar 100 atau 200 kata.
Gudschinsky (1956) memodifikasi daftar kosakata dasar Swadesh dengan mengurangi, dan sekaligus menambah kosakata dasar Swadesh. Di antara kata-kata yang dikurangi itu adalah snow, ‘salju’, cook 'memasak, dan dance 'menari’, dan di antara kata-kata yang dimasukkannya itu adalah dust 'debu', fly 'terbang', dan sebagainya.
Di samping itu, Gudschinsky mengatakan bahwa suatu daftar kosakata dapat direvisi dengan menambah atau mengurangi sejumlah kata dari daftar tersebut sehingga kata-kata yang dipakai untuk menjaring data benar-benar sesuai dengan keadaan geografis dan budaya masyarakat pemakai bahasa yang diteliti. Ini berarti, kosakata dasar dalam setiap bahasa tidak mutlak sama, tetapi prinsip-prinsip mengenai keuniversalan kosakata dasar harus dijadikan sebagai landasan dalam menentukan suatu daftar kosakata dasar.
Gudschinsky menambahkan bahwa jika jumlah kosakata kerabat sangat kecil, satu kesalahan dalam penentuan pasangan kata kerabat akan berakibat fatal terhadap penghitungan tingkat kekerabatan.
Hockett (1955:89) menekankan,
The mathematical methods which are to be applied to the data are of statistical nature: the smaller the sample, the more vague the results.
Khusus mengenai rekonstruksi proto-bahasa, data yang tidak akurat dan terbatas akan melahirkan analisis yang tidak jelas dan membatasi jumlah perangkat korespondensi.
Seperti Swadesh, Gudschinsky dalam daftar kosakata dasarnya yang meru-pakan modifikasi atas daftar Swadesh, memakai kata yang bermakna ganda yaitu fly. Kata tersebut, jika tidak diikuti oleh keterangan, dapat membingungkan karena mengandung dua makna yang frekuensi pemakainya sama-sama tinggi yaitu terbang dan lalat. Di samping kelemahan itu, Gudschinsky juga memakai daftar kosakata yang jumlahnya tergolong kecil (200 kata). Daftar pendek seperti ini kurang ampuh mengatasi kekaburan studi komparatif jika peneliti membuat kesalahan dalam menentukan kata-kata kerabat.
Keraf (1990:91) mengatakan, ada 100 kata yang merupakan pengkhususan bagi wilayah Austronesia. Penjelasan tersebut melengkapi daftar kosakata dasar Swadesh, Gudschinsky, Rea, dan Travis.
Alasan Keraf untuk merumuskan daftar 100 kosakata itu adalah sebagian besar dari kata-kata tersebut sudah digunakan Kern dalam menentukan negeri asal bahasa-bahasa Austronesia. Dari daftar tersebut, dipilih kata-kata yang dianggap mesra dengan masyarakat Batak. Beberapa kata dikeluarkan dan sebagai penggantinya dimasukkan sejumlah kata yang merupakan pengkhususan bagi wilayah dan budaya Batak.
Dalam daftar kosakatanya, Keraf kelihatannya menerjemahkan secara langsung kosakata yang terdapat dalam daftar 200 kosakata Swadesh, tanpa mempertimbangkan masalah konteks. Hal demikian menyebabkan banyak kata terjemahan Keraf itu tidak merupakan isi (content) kosakata dasar sumbernya. Dia mungkin lupa bahwa apa yang dimaksud Swadesh (1951) dan
Gudschinsky (1956:175-210) dengan terjemahan bukanlah terjemahan yang terlepas dari konteks. Akibatnya, dia memuat kata-kata ekor dan hati yang masing-masing bermakna ambigu, jika tidak dilengkapi dengan keterangan. Kata ekor dapat ditafsirkan sebagai bagian dari organ tubuh hewan dan satuan untuk mengatakan jumlah hewan. Sama halnya, kata hati bisa ditafsirkan sebagai bagian organ tubuh manusia atau hewan dan perasaan manusia terhadap sesuatu. Pada hal, yang dimaksud Swadesh dengan ekor adalah tail 'organ tubuh hewan' dan hati adalah lever 'organ tubuh manusia'.
Selain daripada kekeliruan-keliruan itu, Keraf membuat kesalahan-kesalahan lain yang dapat menyesatkan seorang peneliti. Kesalahan-kesalahan tersebut adalah sebagai berikut:
Keraf Swadesh Terjemahan yang seharusnya busuk rotten (log) lapuk (kayu)
gosok scratch (itch) garuk (gatal) jatuh fall (drop) ter (jatuh) kulit skin (person) kulit (manusia) panas warm (weather) panas (cuaca) tongkat stick (wood) tongkat (kayu)
tahu know tahu (verba)
Seharusnya Keraf lebih hati-hati dalam menerjemahkan kata-kata tersebut. Andai kata seorang peneliti memakai daftar terjemahan ini, dan kebetulan membuat kesalahan-kesalahan dalam menentukan pasangan-pasangan kata kerabat, sudah dapat dibayangkan betapa kaburnya hasil penelitian yang dilakukan peneliti tersebut. Keraf tidak konsisten dengan apa yang dikatakannya pada Keraf (1991:134), bahwa seorang peneliti harus cermat dalam menentukan kosakata dasar dan pasangan-pasangan kata kerabat.
Travis (1986:23), dalam penelitiannya memakai daftar kosakata yang terdiri atas 210 kata. Daftar ini dapat dijadikan sebagai bahan bandingan
dalam penentuan kosakata dasar bbB. Travis juga mencatat cara memilih satu kata dari beberapa kata yang mungkin akan diberikan para informan sebagai padanan bagi satu kata dalam daftar kosakata, penjaring data.
Travis memilih satu dari beberapa kata yang diberikan informan sebagai padanan dari satu kata setelah melakukan pengecekan konteks pemakaian kata-kata. tersebut. Jika informannya tidak dapat menunjukkan kata mana yang lebih diinginkan, dia memilih kata yang pertama atas dasar bahwa pengucapan kata tersebut lebih spontan dari pengucapan kata-kata lain.
Menurut observasi yang dilakukan peneliti terhadap bahasa-bahasa Batak, adanya beberapa kata sebagai padanan satu kata dalam daftar penjaring data tidak dapat dielakkan.
Tarigan (1991:35) melengkapi teori Swadesh mengenai penentuan kata-kata apa saja yang termasuk dalam kosakata-kata dasar. Menurut Tarigan, kosakata-kata dasar mencakup istilah kekerabatan, seperti: ayah, ibu, anak, adik; nama-nama bagian tubuh, seperti kepala, rambut, mata, kata ganti (diri, penunjuk), seperti: saya, dia, kami, mereka, ini, itu; kata bilangan pokok, seperti satu, dua, tiga, sepuluh, seribu, sejuta; kata kerja pokok, seperti: makan, minum, tidur, bangun; kata keadaan pokok, seperti: suka, duka, senang, sehat, bersih; serta benda-benda universal, seperti: langit, bulan, bintang, matahari.
Berdasarkan kekuatan dan kelemahan berbagai daftar kosakata dasar di atas, peneliti membuat daftar 300 kata yang merupakan kombinasi dari daftar kosakata Swadesh (1952;1955), Gudschinsky (1956), Rea dalam Lehman (1962), Travis (1986), Keraf (1991), dan Tarigan (1991) yang disesuaikan dengan budaya dan keadaan daerah-daerah Batak.
2.1.1.6 Pengelompokan Bahasa
Tentang pengelompokan bahasa-bahasa berkerabat, Langacker (1972:339) menjelaskan bahwa kriteria dasar pengelompokan bahasa-bahasa berkerabat adalah inovasi bersama (shared innovation). Secara utuh, penjelasan tersebut dikutip di bawah ini:
The basic criterion for establishing subfamilies is shared innovation. If two or more languages have undergone a substantial number of common changes that have not occurred in any other daughters, it is likely that these languages constitute a subfamily and derive from a common pattern that does not underlie the other daughters.
Mengenai hal yang sama, Crowley (1992:163-164) mengatakan, bahasa-bahasa berkerabat dalam satu kelompok (subgroup) mempunyai tingkat kedekatan yang berbeda antara satu dengan yang lainnya. Tingkat kedekatan tersebut dijadikan sebagai landasan pengelompokan bahasa-bahasa berkerabat.
Hal itu dapat dilihat dari data berikut:
b.Inggris b. Belanda b. Jerman b. Perancis b.Italia b.Rusia wn e:n ains ce uno
adin
tu: twe: tsvai due dva i: dri: dʶai tʶwa tre
tri
fo: fi:r fi:ʶ katʶ kwatro tetire
faiv fif fynf sk tikwe pat
Terdapat keidentikan yang cukup untuk menempatkan keenam bahasa di atas dalam satu kelompok. Lebih jauh, terdapat keidentikan yang menunjukkan bahwa
bahasa Inggris, bahasa Jerman, dan bahasa Belanda lebih dekat antara satu dengan yang lain dibanding dengan ketiga bahasa lainnya. Sama halnya, bahasa Perancis dan bahasa Italia lebih dekat antara satu dengan yang lain dibanding dengan keempat bahasa lainnya. Sementara itu, bahasa Rusia terlihat berdiri sendiri. Hal ini menunjukkan dalam keluarga bahasa tersebut, terdapat tiga kelompok bahasa. Kelompok pertama terdiri atas bahasa Inggris, bahasa Belanda, dan bahasa Jerman. Kelompok kedua terdiri atas bahasa Perancis dan bahasa Italia. Kelompok ketiga terdiri atas hanya bahasa Rusia.
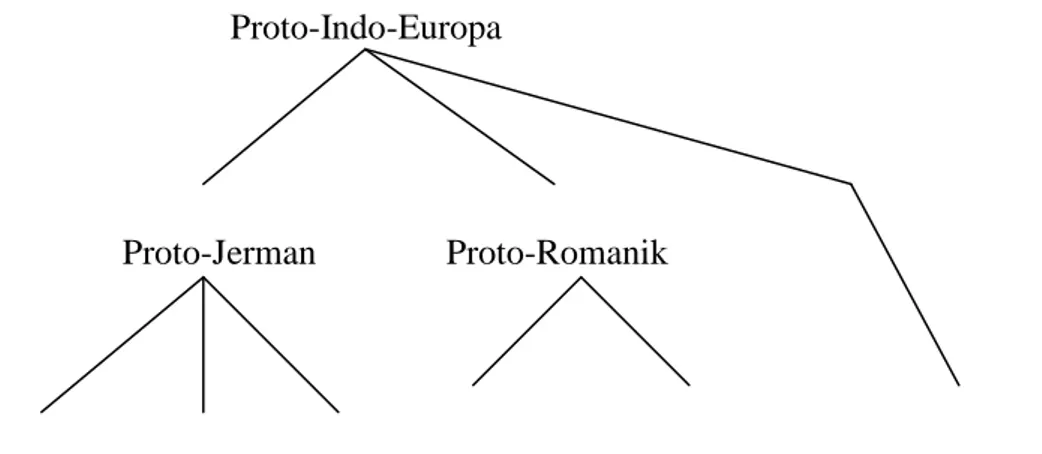
Pengelompokan tersebut dapat ditunjukkan dalam diagram pohon berikut: Proto-Indo-Europa
Proto-Jerman Proto-Romanik
b.Inggris b.Belanda b.Jerman b.Perancis b.Italia b.Rusia
Diagram 2.1 Pengelompokan Bahasa
Diagram tersebut menunjukkan bahwa bahasa Inggris, bahasa Belanda, dan bahasa Jerman diturunkan oleh bahasa yang sama, yakni proto-Jerman (proto-Germanic). Proto-Jerman dan ketiga bahasa lainnya diturunkan oleh bahasa yang sama, yakni proto-Indo-Eropa (proto-Indo-European).
Menurut Crowley, pengelompokan bahasa tidak didasarkan pada retensi bersama (shared retention) melainkan pada inovasi bersama inovasi ( shared innovation) bahasa-bahasa berkerabat. Menggunakan retensi bersama sebagai dasar pengelompokan bahasa tidak tepat karena terlalu banyak bunyi yang
mengalami retensi dalam bahasa-bahasa berkerabat. Inovasi dijadikan sebagai landasan pengelompokan bahasa didasarkan pada fakta bahwa inovasi dalam satu bahasa tidak mungkin terjadi secara tersendiri dan pasti mempunyai hubungan dengan inovasi pada bahasa-bahasa kerabatnya. Namun perlu diperhatikan bahwa inovasi bersama dapat terjadi secara kebetulan melalui proses perubahan paralel (parallel development or drift).
Misalnya, dalam banyak bahasa Oseanik moderen, konsonan hilang pada akhir kata ( C →/___#). Dalam bahasa Enggano, pulau di selatan Sumatera, inovasi yang sama juga terjadi. Namun, bahasa-bahasa Oseanik tidak berada dalam satu kelompok dengan bahasa Enggano karena bahasa ini tidak mempunyai kemiripan lain dengan bahasa-bahasa Oseanik. Atas dasar itu, faktor-faktor berikut harus dihindarkan:
a. perubahan bunyi yang sangat tidak biasa;
b. perubahan-perubahan fonologis, khususnya perubahan-perubahan yang tidak biasa terjadi secara bersamaan dalam bahasa-bahasa berkerabat;
c. perubahan yang berkorespondensi dengan perubahan-perubahan yang tidak ada hubungannya dengan perubahan-perubahan-perubahan-perubahan gramatikal dan semantik.
2.1.1.7 Kata Pinjaman
Langacker (1972:333). memberikan penjelasan mengenai kata-kata
pinjaman. Meskipun tidak dapat disangkal bahwa kosakata dasar bersifat uni-versal yang memperkecil kemungkinan adanya pinjam-meminjam, ada baiknya diperhatikan secara serius kemungkinan adanya kata-kata pinjaman. Dia mengatakan bahwa :
Borrowed lexical items often disobey otherwise general phonotactic restrictions of the borrowing language. Long lexical items that cannot be broken down into familiar morphemes are also likely to have been borrowed.
Sapir (1921:197) mempunyai pandangan yang senada dengan Langacker tersebut. Dia mengatakan bahwa kata-kata pinjaman sering melanggar sistem fonetik bahasa yang meminjam meskipun kata-kata pinjaman tersebut telah mengalami modifikasi fonetik.
Gudschinsky (1956) menjelaskan cara untuk menentukan kata-kata non-kerabat akibat adanya pinjaman baik dari bahasa-bahasa non-kerabat maupun bahasa--bahasa nonkerabat. Menurut Gudschinsky (1956:181), kata-kata dalam .bahasa yang diteliti yang mempunyai bentuk dan arti yang sama atau mirip dengan kata-kata dalam bahasa nonkerabat yang mempunyai atau pernah mempunyai hubungan budaya dengan bahasa yang, diteliti harus dicurigai sebagai kata-kata pinjaman.
Untuk menentukan kata-kata pinjaman dari bahasa-bahasa kerabat, harus dilihat frekuensi munculnya fonem-fonem tertentu dalam bahasa-bahasa yang dibandingkan. Fonem-fonem yang frekuensi pemunculannya sangat terbatas dianggap merupakan pinjaman dari bahasa yang menunjukkan frekuensi yang tinggi pemunculan fonem-fonem tersebut. Dalam membandingkan dialek Huautta dan San Miguel bahasa Mazatec, misalnya, terlihat bahwa kata n'ai 'ayah' dalam kedua dialek itu bukanlah kata-kata kerabat karena pemunculan ai dalam dialek San Miguel hanya terbatas pada istilah-istilah keagamaan, sedangkan dalam dialek Huautla, pemunculan klaster itu tidak terbatas.
Dalam penelitiannya terhadap delapan bahasa nusantara, Kridalaksana (1963-1973) mengatakan bahwa kata-kata yang sama bentuk dan artinya dalam dua bahasa nonkerabat dianggap sebagai pinjaman dari sesamanya. Kridalaksana yang mengutip Gudschinsky (1956:181) membuat kekeliruan dengan mengabaikan masalah kontak budaya antara dua bahasa nonkerabat. Persamaan bentuk dan arti tidak bisa dijadikan sebagai dasar untuk menentukan bahwa kata-kata tertentu merupakan pinjaman jika kedua bahasa dalam mana kata-kata-kata-kata itu dijumpai tidak mempunyai atau tidak pernah mempunyai kontak budaya.
Masalah lain yang perlu mendapat perhatian dalam penelitian tersebut ada-lah, Kridalaksana tidak menunjukkan penerapan rumus-rumus penentuan pasangan-pasangan kata kerabat dan penentuan waktu pisah bahasa-bahasa itu serta penentuan standar kesalahan. Langkah seperti ini akan menyulitkan pembaca untuk mengetahui apakah ada kekeliruan dalam penerapan rumus-rumus tersebut.
Uraian tentang kata-kata pinjaman (loan words) ini sangat diperlukan untuk menghindari kesalahan dalam pengumpulan dan pemilihan data yang termasuk dalam daftar kosakata dasar yang dijadikan peneliti sebagai alat penjaring data.
2.1.1.8 Kata-Kata Tabu
Teeter (1963) mengatakan bahwa kata-kata nonkerabat dapat terjadi akibat adanya faktor tabu atau dalam istilah Gillieron dalam V.Teeter verbal pathology.
Menurut Teeter, selain memperhatikan kata-kata kerabat, seorang peneliti perlu juga memperhatikan kata-kata nonkerabat yang muncul akibat adanya faktor tabu, karena hal ini akan mempengaruhi akurasi penelitian. Ada kalanya, pasangan kata tertentu mempunyai bentuk dan arti yang sangat berbeda akibat adanya faktor
tabu (dalam satu bahasa kata tertentu dianggap tabu, tetapi dalam bahasa lainnya kata yang sama dianggap tidak tabu). Jika faktor tabu tidak ada, kemungkin pa-sangan kata itu adalah berkerabat. Oleh karena itu, seorang peneliti harus menanyakan kepada informannya apakah ada di antara kata-kata yang diucapkan-nya itu merupakan pengganti kata-kata yang dianggap tabu.
Yang menjadi kesulitan dalam penerapan teori ini adalah kemungkin bahwa peneliti dan informan tidak akan saling mengerti dalam pembicaraan yang menyangkut masalah tabu.
Kontribusi penjelasan tentang kata-kata tabu dan pengaruhnya terhadap keabsahan data adalah untuk menghindarkan masuknya kata-kata kosong karena informan tidak menyebutkan padanan-padanan kata tertentu yang dianggap tabu.
2.1.1.9 Inovasi
Menurut Kridalaksana (1983:65), inovasi adalah perubahan bunyi, bentuk atau makna yang mengakibatkan terciptaanya kata baru.
2.1.1.10 Bahasa-bahasa Batak
Bahasa-bahasa Batak adalah bahasa-bahasa yang digunakan sebagai bahasa pengantar masyarakat etnik Batak di Tapanuli, Sumatera Utara. Menurut Sibarani (1997), sebagian besar masyarakat Batak bertempat tinggal di Tapanuli, sebagian lainnya di bagian Timur Laut Tapanuli yakni Simalungun, dan sebagian lainnya di sebelah Barat Laut Danau Toba yakni Tanah Karo (lihat peta pada lampiran penelitian ini). Dia menjelaskan, pembagian linguistik bahasa Batak terdiri atas bahasa Batak Toba, bahasa Batak Karo, bahasa Batak Simalungun, bahasa Batak Pakpak Dairi, dan bahasa Batak Angkola Mandailing.
Menurut http://id.wikipedia.org/wiki/Bahasa_Batak yang diunduh 20 Agustus 2013, bahasa-bahasa Batak adalah sekelompok bahasa yang dituturkan di Sumatera Utara. Kelompok ini dimasukkan ke dalam kelompok yang dijuluki Northwest Sumatra-Barrier Islands dalam rumpun bahasa Melayu-Polinesia. Berdasarkan sumber itu, bahasa-bahasa Batak terdiri atas tiga kelompok yakni kelompok Utara (bahasa Alas-Kluet, bahasa Dairi, dan bahasa Karo), kelompok Selatan (Toba, Angkola, dan Mandailing), dan perantara (bahasa Simalungun). Sementara itu, Keraf ( 1991:2009) menjelaskan, bahasa-bahasa Batak terdiri atas bahasa Toba, bahasa Karo, bahasa Simalungun, bahasa Angkola, bahasa Dairi, dan bahasa Alas.
Dalam penelitian ini, bahasa-bahasa Batak meliputi bahasa Toba, bahasa Simalungun, bahasa Pakpak Dairi, bahasa Angkola,bahasa Karo, dan bahasa Mandailing. Alasan peneliti untuk memisahkan bahasa Angkola Mandailing menjadi bahasa Angkola dan bahasa Mandailing adalah perkembangaan kedua bahasa telah menjadikan kedua bahasa mempunyai perbedaan yang semakin jauh.
2.2 Kerangka Teori
Teori yang digunakan dalam penelitian ini adalah teori tentang perubahan bahasa. Fakta bahwa bahasa terus mengalami perubahan melalui perkembangan atau inovasi adalah landasan linguistik historis komparatif yang mempelajari sejarah perkembangan proto-bahasa (parent language) menjadi bahasa-bahasa yang diturunkannya (sister languages). Fakta ini jugalah yang melandasi studi komparatif terhadap bahasa-bahasa yang berhubungan secara genetis untuk menemukan perangkat-perangkat korespondensi yang dapat dijadikan data untuk
melakukan rekonstruksi proto- bahasa, menentukan tingkat kekerabatan dan mengelompokkan bahasa-bahasa berkerabat. Atas dasar perubahan bahasa itulah penelitian ini dilakukan. Berkaitan dengan itu, teori tentang perubahan bahasa disajikan di bawah ini.
2.2.1 Teori Perubahan Bahasa
Menurut McManis dkk., (1987:265-267), teori tentang perubahan bahasa bahwa bahasa-bahasa yang mempunyai kemiripan berhubungan satu dengan yang lain dan diturunkan oleh satu bahasa yang dinamakan proto-bahasa (proto-language) muncul pada abad ke-18. Teori tersebut diawali dengan pernyataan Sir William Jones bahwa kesamaan yang terdapat dalam bahasa Sanskrit, bahasa Junani, dan Latin Kuno dapat dijadikan sebagai bukti bahwa ketiga bahasa itu diturunkan oleh satu bahasa.
Teori Jones itu dikembangkan pada abad ke-19 dan kemudian dipengaruhi oleh teori evolusi Darwin tentang evolusi mahluk hidup. Pada saat itu, para sarjana berpendapat bahwa perkembangan bahasa dapat dianalogikan dalam banyak hal dengan fenomena biologis. Atas dasar itu, disimpulkan bahwa bahasa seperti organisme-organisme hidup lainnya mempunyai silsilah (family trees) dan moyang.
Pada tahun 1871, August Scleicher melahirkan teori yang dinamakan Teori Pohon Keluarga Bahasa atau Teori Silsilah Bahasa (Family Tree Theory). Teori ini menyebutkan, bahasa berubah dalam pola yang teratur dan dapat dijelaskan (Hipotesis Regularity Hypothesis ‘Hipotesis Keteraturan’) dan kesamaan antara satu bahasa dengan bahasa-bahasa lainnya disebabkan oleh hubungan genetis di antara bahasa-bahasa tersebut (Relatedness Hypothesis ‘Teori
Keberhubungan’). Untuk menunjukkan hubungan seperti itu, perlu dilakukan rekonstruksi terhadap proto-bahasa yang menurunkan bahasa-bahasa berkerabat. Teknik merekonstruksi proto-bahasa dinamakan comparative method ‘metode komparatif’.
Atas dasar analogi hubungan bahasa dengan manusia, teori tersebut menggunakan istilah proto-bahasa (mother atau parent language) dan bahasa-bahasa berkerabat (sister languages) yakni, bahasa-bahasa-bahasa-bahasa yang diturunkan proto-bahasa.
Namun, terdapat kelemahan teori pohon keluarga karena dapat menimbulkan dua pandangan yang salah tentang perubahan bahasa. Pertama, setiap bahasa mempunyai satu komunitas yang mempunyai bahasa yang sama tanpa adanya variasi internal dan tanpa adanya kontak antara bahasa-bahasa yang berkerabat. Kedua, proto-bahasa terpecah menjadi bahasa-bahasa turunannya secara tiba-tiba tanpa adanya tahapan-tahapan (intermediate stages).
Tidak ada bahasa yang mutlak berbeda atau terpisah dari bahasa-bahasa lainnya tetapi selalu terdiri atas dialek-dialek yang dapat digolongkan dalam satu bahasa dan selalu mempunyai kesamaan-kesamaan dengan bahasa-bahasa kerabatnya, meskipun berada dalam sub-kelompok yang berbeda. Penelitian tentang bahasa-bahasa kontemporer menunjukkan, bahasa tidak terpisah secara tiba-tiba melainkan secara perlahan-lahan dan teratur, yang dimulai dengan lahirnya dialek-dialek dan kemudian berubah menjadi bahasa-bahasa yang berbeda setelah mengalami perubahan secara perlahan-lahan dalam kurun waktu yang lama. Batas dua dialek atau dua bahasa tidak dapat dilakukan secara tepat karena sering dipengaruhi oleh faktor non-linguistik (misalnya, faktor politik).
Untuk mengatasi masalah ini, Johannes Schimidt menciptakan Wave Theory (Teori Gelombang) tahun (1872). Teori ini menyebutkan, perubahan perlahan-lahan yang terjadi dalam dialek, bahasa atau kelompok bahasa-bahasa, mirip dengan sebuah gelombang yang membesar dari satu titik di kolam tempat sebuah batu (sumber perubahan) terjatuh. Dialek-dialek terbentuk oleh tersebarnya perubahan-perubahan yang berbeda dari titik-titik sumber perubahan yang berbeda pada tingkat yang berbeda. Beberapa perubahan menguatkan satu sama lain dan beberapa perubahan lainnya melengkapi atau mempengaruhi secara parsial satu sama lain dalam batas tertentu, seperti gelombang-gelombang yang terjadi akibat dilemparkannya sejumlah batu ke dalam kolam yang saling menindi satu sama lain. Teori Gelombang itu menolak Teori Pohon Keluarga untuk mengatasi kedua pendapat yang salah tentang perkembangan bahasa
Teori Pohon Keluarga dan Teori Gelombang tidak dapat memberikan jawaban yang memuaskan dan akurat tentang perubahan bahasa dan keberhubungan bahasa-bahasa. Misalnya, bahasa-bahasa dapat menunjukkan persamaan linguistik meskipun bahasa-bahasa tersebut tidak berhubungan satu sama lain. Persamaan itu mungkin merupakan akibat peminjaman melalui kontak bahasa (language contact), pergeseran (perubahan-perubahan yang sama tanpa adanya hubungan satu sama lain dalam dialek-dialek atau bahasa-bahasa yang berbeda, persamaan jenis struktur morfologi, sintaksis dan alasan-alasan lain. Namun demikian Teori Pohon Keluarga dan Teori Gelombang sangat bermanfaat dalam studi perubahan bahasa.
Meskipun McManis dkk., (1987) mengatakan bahwa teori Keluarga Pohon Bahasa yang diciptakan Sir William Jones pada abad ke-18 merupakan teori pertama tentang hubungan genetis bahasa, menurut Finegan & Besnier
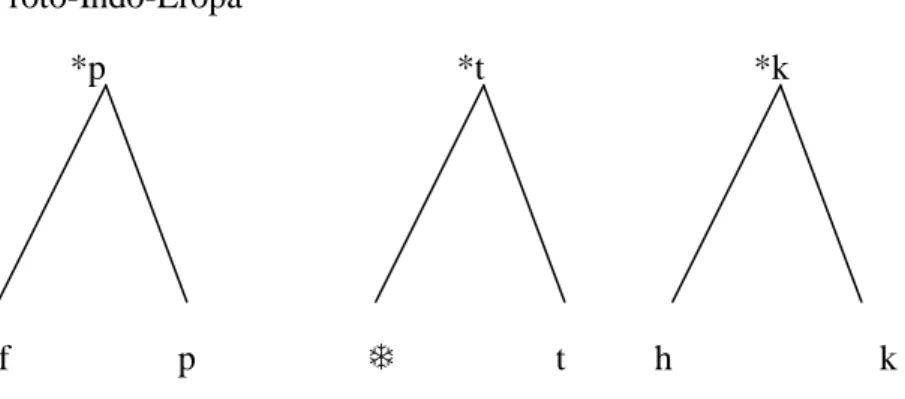
(1979), Grim telah menciptakan Grimm’s Law pada tahun 1822 untuk menjelaskan pergeseran bunyi secara teratur dari pra-Indo-Eropa ke bahasa Germanik dan Romance. Grimm mengatakan, pergeseran bunyi tersebut adalah sebagai berikut:
1. Hambat tidak bersuara (voiceless stops) bergeser menjadi frikatif tidak bersuara (voiceless fricatives: p > f, t > , k > h (lebih dikenal dengan p t k > f h)
2. Hambat bersuara (voiced stops) bergeser menjadi hambat tidak bersuara (voiced stops): b > p, d > t, g > k
3. Hambat aspirasi bersuara (voiced aspirated stops) bergeser menjadi hambat tak beraspirasi bersuara: b > b, d > d, g > g
Pergeseran-pergeseran bunyi tersebut digambarkan dengan ketiga diagram berikut:
Proto-Indo-Eropa
*p *t *k
f p t h k
Diagram 2.2 Pergeseran Bunyi Proto-Indo Eropa
Keteraturan pergeseran bunyi itulah yang kemudian dikenal dengan perangkat korespondensi dan merupakan landasan studi komparatif bahasa-bahasa yang berhubungan secara genetis.
Setelah lahirnya teori-teori pergeseran bunyi dan perkembangan bahasa seperti disebutkan di atas, banyak linguis yang membicarakan masalah yang sama,
tetapi tidak satu pun dari pembicaraan-pembicaraan tersebut yang mengungkapkan penemuan baru kecuali penerapannya dalam bahasa-bahasa yang berbeda.
Di bawah ini, disajikan penjelasan-penjelasan tentang pergeseran bunyi dan perkembangan bahasa serta penerapannya.
Bloomfield (1951:59) mengatakan,
“Written records of earlier speech, resemblance between languages, and varieties of local dialects, all show that languages change in the course of time.”
Untuk menguatkan penjelasan itu, dia memberikan contoh bahwa dalam naskah bahasa Inggris Kuno terdapat kata stan ‘stone’ yang interpretasi fonetisnya adalah sta:n dan jika disepakati bahwa dalam bahasa Inggris Moderen adalah stown, berarti a: dalam bahasa Inggris Kuno telah berubah menjadi ow dalam bahasa Inggris Moderen.
Tentang perubahan bahasa, Hock (1988: 1) mengatakan,
“From time immemorial people have been concerned about the fact that language changes and that languages become different as they change”.
Untuk menunjukkan perubahan itu, dia membandingkan Lord,s Prayer (Doa Bapak Kami) dalam bahasa Inggris Kuno, bahasa Inggris Pertengahan, Bahasa Inggris Pra-baru, dan bahasa Inggris Moderen.
Perubahan bahasa juga dibahas oleh Finegan dkk., (1989:277) dengan mengatakan,
It’s no secret that languages change over the years. All of us can recoqnize different speech patterns between one generation and the next. There are probably notable differences between the speech
patterns of your parents and your friends, and even greater ones between your grandparents and your friends. The most noticeable differences betweeen one generation and another are in vocabulary.
Finegan & Besnier memberikan contoh tentang perubahan bahasa, khusus dalam bidang fonologi. Kata nuclear diucapkan nuklir ratusan tahun yang lalu dan sekarang diucapkan nuklir serta realtor yang dulu diucapkan riltr sekarang diucapkan riltr. Perubahan tersebut merupakan rekonstruksi internal atau top-down yang membandingkan satu bahasa dalam waktu yang berbeda.
Sementara itu, Crowley (1992) menunjukkan perubahan bahasa dengan pernyataan berikut:
The concept of proto-langue and langue relationship both rest on the assumption that languages change. In fact, all languages change all the time. It is true to say that some languages change more than others, but all languages change nevertheless. But while all languages change, the change need not be in the same direction for all speakers.
Membuktikan bahwa bahasa mengalami perubahan, Crowley menunjukkan perubahan bunyi p dalam bahasa Uradhi, Queensland Utara menjadi w dalam bahasa moderen seperti di bawah ini:
b. Uradhi
*pinta → winta tangan *pilu → wilu pinggul
Rekonstruksi itu sama dengan rekonstruksi sebelumnya, yakni rekonstruksi internal karena perbandingan dilakukan terhadap satu bahasa (Uradhi) dalam waktu yang berbeda. Perubahan bunyi dalam bahasa-bahasa berkerabat dengan rekonstruksi komparatif digambarkan Crowley dalam bahasa-bahasa Tonga, Samoa, Rarotong (yang dipakai di kepulauan Cook, dekat Tahiti) dan Hawai sebagi berikut:
b. Tongan b. Samoa b. Rarotong b. Hawai
tafa- tafa taa kaha samping
2.2.2 Rumus Perubahan Bunyi
Menurut Crowley (1992:66), perubahan bunyi terdiri atas perubahan bunyi tak bersyarat (unconditioned sound change) dan perubahan bunyi bersyarat (conditioned sound change). Perubahan bunyi tak bersyarat adalah perubahan bunyi yang dapat terjadi pada posisi-posisi yang berbeda dan sangat kecil kemungkinan terjadi akibat lingkungan. Perubahan bunyi bersyarat adalah perubahan bunyi yang diakibatkan oleh pengaruh bunyi yang berdekatan.
Crowley (1992:67-68), dalam penelitiannya terhadap sejumlah bahasa menggambarkan perubahan-perubahan bunyi sebagai berikut:
1. t→k {t} menjadi {k} 2. η → {η} hilang
3. t→ s/___ depan {t} menjadi {s} di depan vokal
V
4. x→k/s___ {x} menjadi {k} di belakang {s}
6. p→w/#___ {p} pada posisi awal menjadi {w}
7. bersuara→tak bersuara/___# konsonan bersuara menjadi konsonan tak bersuara C
8. V→/___# vokal-vokal pada akhir kata hilang 9. V→ /V (C)___
{nas} {nas}
Hock (1988: 26) merumuskan perubahan bunyi untuk dijadikan sebagai generalisasi seperti berikut:
1. a > b = a berubah menjadi b akibat perubahan bunyi 2. b < a = b berkembang dari a akibat perubahan bunyi
3. a > b/c ___ d = a berubah menjadi b … di lingkungan antara c dengan d (Variasi: a > b/c ___ , a > b/___ = setelah c, sebelum d) 4. a > b / c = a berubah menjadi b jika didahului dan/atau diikuti oleh c, misalnya
jika berdekatan dengan c
5. a > b/ ___ X d = a berubah menjadi b jika d mengikutinya, dengan adanya segmen X yang mempengaruhi, misalnya tidak dengan kontak langsung
6. a > b/ ___ (X) d = a berubah menjadi b jika d mengikutinya, dengan X opsional yang mempengaruhi
7. a > b / ___ Co c = a berubah menjadi b jika c mengikutinya, dengan atau tanpa konsonan yang mempengaruhi
2.2.3 Jenis-jenis Perubahan Bunyi
Proto-bahasa berkembang menjadi bahasa-bahasa kontemporer dengan adanya perubahan-perubahan bunyi dari bunyi-bunyi proto-bahasa.
Menurut Crowley (1992:38) terdapat sejumlah perubahan bunyi yakni lenisi, fortisi, afresis, apakop, sinkop, reduksi klaster, haplologi, eksresens, epentesis atau anaptiks, protesis, metatesis, fusi, unpaking, pemisahan vokal, asimilasi, disimilasi, perubahan tak normal, penghilangan fonem, dan penambahan fonem. Di samping perubahan-perubahan bunyi tersebut, Keraf (1991: 92) mencatat perubahan-perubahan bunyi lainnya, yakni perpanjangan pengimbang, labialisasi, dan paragog.
Di bawah ini disajikan penjelasan dan data Crowley (1992:38-51) tentang jenis-jenis perubahan bunyi tersebut.
2.2.3.1 Lenisi dan Fortisi
Lenisi (lenition) adalah perubahan bunyi dari keras menjadi lemah yakni bersuara (voiced) menjadi tidak bersuara (voiceless), misalnya b menjadi p. Perubahan bunyi keras b menjadi bunyi lemah p lebih mungkin terjadi dari p menjadi b. Tetapi perubahan bunyi lemah menjadi keras dapat terjadi meskipun sangat jarang. Perubahan tersebut dinamakan fortisi (fortition).
Lenisi juga mencakup perubahan akibat adanya penghilangan bunyi seperti diuraikan di bawah ini.
2.2.3.2 Afresis
Afresis (aphaeresis) adalah hilangnya konsonan awal pada suatu kata. Lihat contoh berikut:
b. Angkamuthi
*maji → aji makanan
*nani → ani tanah
*ampu → ampu gigi
2.2.3.3 Apokop
Apokop (apocope) adalah hilangnya bunyi vokal pada posisi akhir kata. Lihat contoh berikut:
b. Ambrym Tenggara
*utu → ut kutu
*aηo → a lalat
*asue → asu tikus
2.2.3.4 Sinkop
Sinkop (syncope) adalah hilangnya bunyi vokal pada posisi tengah kata. Lihat contoh berikut:
b. Lenakel
*namatana → nimrin matanya
(maskulin/feminin)
*nalimana → nelmin tangannya (makulin/feminin)
*masa → mha air pasang
2.2.3.5 Reduksi Klaster
Reduksi klaster adalah rangkaian konsonan (tanpa adanya bunyi vokal di antaranya) dengan menghilangkan satu atau lebih konsonan. Lihat contoh berklut ini:
b. Inggris b. Pidgin Melanesi
district distikt distrik distrik
post post pos
pos
ground gnd graun tanah
paint pint pen
cat
tanktk ta tanki
Dalam bahasa Inggris, kata government yang diucapkan dengan menghilangkan konsonan /n/ dalam gvmn alih-alih gvnmn merupakan reduksi klaster.
2.2.3.6 Haplologi
Haplologi (haplology) adalah perubahan akibat hilangnya suku kata secara menyeluruh ketika suku kata tersebut ditemukan pada suku kata berikutnya yang mirip dengan suku kata itu. Misalnya, kata library diucapkan dengan laibi alih-alih laibi.
2.2.3.7 Pertambahan Bunyi
Dalam bahasa Inggris Moderen, penutur sering mengucapkan something dengan menambahkan bunyi p sehingga menjadi smpi alih-alih smi. Kehadiran bunyi p tersebut merupakan contoh pertambahan bunyi. Pertambahan bunyi pada banyak bahasa terjadi pada konsonan pada akhir
kata melalui penambahan bunyi vokal sehingga membentuk struktur konsonan vokal (KV) dengan menghindarkan terbentuknya klaster pada akhir kata. Perhatikan contoh berikut:
b. Inggris b. Maori
calf ka:fe anak lembu
court ko:ti pengadilan
korofa golf golf
cook kuki memasak
map mapi peta
Ada beberapa jenis pertambahan bunyi seperti disebutkan di bawah ini.
2.2.3.8 Ekskresen
Ekskresen (excrescence) adalah penambahan satu konsonan ke antara dua konsonan lainnya dalam satu kata. Penyisipan konsonan p ke tengah m pada kata something merupakan contoh ekskresen. Ekskresen terjadi pada kata-kata lainnya dalam sejarah perkembangan bahasa Inggris dan kini telah dimasukkan dalam sistem ujaran bahasa Inggris seperti terlihat di bawah ini:
b.Inggris
*mti → mpti empty kosong
*ymle → imbl thimble sarung
jari
Bunyi stop eksresen dalam contoh di atas mempunyai titik artikulasi yang sama atau homorgan dengan bunyi nasal yang mendahuluinya. Bunyi-bunyi hambat tersebut ditambahkan untuk menutup velum yang terbuka pada saat memproduksi nasal sebelum memproduksi bunyi yang bukan nasal berikutnya.
2.2.3.9 Epentesis atau Anaptiksis
Epentesis (epenthesis) atau anaptiksis (anaptyxis) adalah penambahan vokal di tengah kata untuk memisahkan dua konsonan dalam satu klaster. Proses ini menghasilkan struktur suku kata konsonan vokal (CV) untuk menghindarkan klaster konsonan pada awal kata dan klaster konsonan pada akhir kata. Para penutur sejumlah dialek bahasa Inggris sering menambahkan schwa ke antara klaster konsonan pada posisi akhir kata film ‘pilem’ untuk menghasilkan film alih-alih film.
Epentesis juga terjadi dalam sejarah perkembangan bahasa Tok Pisin seperti terlihat pada contoh berikut ini:
b. Inggris b. Tok Pisin
black blk → bilak hitam
blue blu: → bulu biru
next nkst → nekis berikut
six siks → sikis enam
2.2.3.10 Protesis
Protesis (prothesis) adalah penambahan bunyi di depan kata. Lihat contoh berikut:
b. Motu
*api → lahi api
*asan → lada insang ikan
2.2.3.11 Metatesis
Metatesis (metathesis) adalah perubahan susunan atau posisi bunyi dalam satu kata, misalnya, kata relevant dengan revelant alih-alih relevant. Perubahan tersebut bukan merupakan penghilangan, penambahan atau pergeseran bunyi. Metatesis terjadi dalam sejarah perkembangan bahasa Inggris dan bentuk-bentuk yang mengalami perubahan telah diterima menjadi bentuk-bentuk yang standar. Misalnya, melalui metatesis, kata bird b:d dulu diucapkan bd alih-alih bd.
2.2.3.12 Fusi
Fusi (fusion) adalah perubahan bunyi yang diakibatkan oleh bergabungnya dua bunyi yang berbeda menjadi satu bunyi. Bunyi tunggal tersebut memiliki fitur-fitur kedua bunyi asal. Misalnya, bunyi m mempunyai fitur fonetik sebagai berikut: 1. bersuara (voiced) 2. bilabial 3. nasal 4. kontinuan (continuant) 5. konsonan, dan
bunyi a mempunyai fitur fonetik sebagai berikut:
1. bersuara (voiced) 2. rendah (low)
3. kontinuan (continuant) 4. vokal