Rancang Bangun Aplikasi E-Complaint Berbasis Web Dengan Algoritma Naive Bayes Classifier Untuk Klasifikasi Keluhan (Studi Kasus: Universitas Multimedia Nusantara)
Bebas
227
0
0
Teks penuh
(2) RANCANG BANGUN APLIKASI E-COMPLAINT BERBASIS WEB DENGAN ALGORITMA NAIVE BAYES CLASSIFIER UNTUK KLASIFIKASI KELUHAN (Studi Kasus: Universitas Multimedia Nusantara). SKRIPSI. Diajukan sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer (S.Kom.). Vannia Ferdina 13110110052. PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS TEKNIK DAN INFORMATIKA UNIVERSITAS MULTIMEDIA NUSANTARA TANGERANG 2017. Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(3) Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(4) Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(5) HALAMAN MOTO. “Janganlah hendaknya kamu kuatir tentang apapun juga, tetapi nyatakanlah dalam segala hal keinginanmu kepada Allah dalam doa dan permohonan serta ucapan syukur.”. Filipi 4:6. iv Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(6) KATA PENGANTAR. Puji syukur kepada Tuhan Yang Maha Esa atas segala berkat dan karuniaNya sehingga skripsi dengan judul “Rancang Bangun Aplikasi E-Complaint Berbasis Web dengan Algoritma Naive Bayes Classifier untuk Klasifikasi Keluhan (Studi Kasus: Universitas Multimedia Nusantara)” ini dapat tersusun dengan baik. Skripsi ini diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Komputer pada Program Studi Teknik Informatika, Fakultas Teknik dan Informatika, Universitas Multimedia Nusantara. Penulisan skripsi ini tidak terlepas dari dukungan, bantuan, dan bimbingan dari berbagai pihak. Oleh karena itu, penulis mengucapkan terima kasih kepada: 1. Dr. Ninok Leksono, Rektor Universitas Multimedia Nusantara, 2. Kanisius Karyono, S.T., M.T., Dekan Fakultas Teknik dan Informatika Universitas Multimedia Nusantara, 3. Maria Irmina P., S.Kom., M.T., Ketua Program Studi Teknik Informatika Universitas Multimedia Nusantara, yang memberikan dukungan dan motivasi bagi penulis untuk menyelesaikan skripsi, 4. Marcel Bonar Kristanda, S.Kom., M.Sc. dan Seng Hansun, S.Si., M.Cs., yang telah membimbing, mendukung, dan memotivasi penulis dalam melaksanakan penelitian dan penyusunan skripsi, serta telah menerima penulis dengan baik untuk berkonsultasi, 5. Ika Angela, Ketua DKBM UMN Periode 2016-2017, dan Gandhi Pranata, Koordinator Divisi Kesejahteraan Mahasiswa DKBM UMN Generasi 7, yang. v Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(7) telah mendukung penulis dalam proses pengumpulan data, perancangan, dan pembangunan aplikasi, 6. Seluruh pengurus DKBM UMN Generasi 7 yang telah mendukung penulis selama pembangunan dan pengujian aplikasi, 7. Bapak Gamaliel Kristianto, Network Administrator Universitas Multimedia Nusantara, yang telah membantu penulis dalam proses implementasi aplikasi, 8. Orang tua, adik, dan keluarga tercinta, yang telah memberikan doa, dukungan, bantuan, dan motivasi bagi penulis dalam penyusunan skripsi, 9. Sylvie Stephanie dan Vincentius Kurniawan, yang telah memberikan inspirasi, dukungan, bantuan, dan motivasi bagi penulis dalam penyusunan skripsi, 10. Vania Chandra, Nesha Viatika Sari, Junitania Ryanto, Michaela Irene, Devin Ryan Riota, Junius Primavera, Christian Wijasa, Keshia Tiffany, Christopher Derian, Handy Wijaya, Alfian Setyo, Arvin Vinsensius, dan teman-teman seperjuangan skripsi yang tidak dapat disebutkan satu per satu, yang telah mendukung penulis dalam menyelesaikan skripsi, 11. Semua pihak yang tidak dapat disebutkan satu per satu, yang telah membantu dan mendukung penyusunan skripsi. Semoga skripsi ini dapat bermanfaat, baik sebagai sumber informasi maupun sumber inspirasi bagi pembaca, khususnya mahasiswa Universitas Multimedia Nusantara. Tangerang, Agustus 2017. Vannia Ferdina. vi Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(8) RANCANG BANGUN APLIKASI E-COMPLAINT BERBASIS WEB DENGAN ALGORITMA NAIVE BAYES CLASSIFIER UNTUK KLASIFIKASI KELUHAN (Studi Kasus: Universitas Multimedia Nusantara). ABSTRAK. Dalam konteks universitas, keluhan merupakan bentuk umpan balik dari mahasiswa yang penting untuk diperhatikan dalam upaya menghadapi persaingan dalam industri pendidikan tinggi. Di Universitas Multimedia Nusantara, mahasiswa dapat menyampaikan keluhan melalui organisasi Dewan Keluarga Besar Mahasiswa (DKBM) UMN. Namun, berdasarkan studi fisibilitas yang dilakukan, tingkat kepuasan mahasiswa terhadap sistem penyampaian keluhan yang ada hanya mencapai tingkat cukup. Dari sisi DKBM UMN, keluhan yang masuk masih dikelola dan diklasifikasikan secara manual ke dalam kategori-kategori yang telah ditetapkan dan belum dapat berjalan secara maksimal. Untuk memudahkan pengelolaan keluhan, dilakukan perancangan dan pembangunan aplikasi ecomplaint berbasis web dengan algoritma Naive Bayes Classifier untuk klasifikasi keluhan. Hasil pengujian membuktikan bahwa algoritma Naive Bayes Classifier dapat mengklasifikasi keluhan dengan nilai precision sebesar 91.86%, recall sebesar 84.48%, f-1 score sebesar 86.29%, dan nilai rata-rata akurasi sebesar 86%. Selain itu, pengujian aplikasi terhadap DKBM UMN dan mahasiswa UMN membuktikan bahwa aplikasi e-complaint dapat memudahkan pengelolaan keluhan dan memudahkan mahasiswa dalam mengajukan keluhan. Kata kunci: Algoritma Naive Bayes Classifier, e-complaint, keluhan, text classification, text mining.. vii Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(9) DESIGN AND DEVELOPMENT OF WEB BASED E-COMPLAINT APPLICATION USING NAIVE BAYES CLASSIFIER ALGORITHM FOR COMPLAINT CLASSIFICATION (Case Study: Universitas Multimedia Nusantara). ABSTRACT In university’s terms, complaints are a form of feedback from students which is important to be noticed in facing the competition in the higher education industry. In Universitas Multimedia Nusantara, students can deliver their complaints through an organization named Dewan Keluarga Besar Mahasiswa (DKBM) UMN. However, based on the feasibility studies conducted, the level of students’ satisfaction with the existing complaint system only reaches a sufficient level. From the DKBM UMN’s side, complaints are still managed and classified manually into predefined categories and have not be able to run optimally. To facilitate the management of complaints, the design and development of web based e-complaint application using Naive Bayes Classifiers algorithm for complaint classification is conducted. The experimental result proves that Naive Bayes Classifiers algorithm can classify complaints with precision value on 91.86%, recall value on 84.48%, f-1 score value on 86.29%, and average accuracy value on 86%. Furthermore, the test of application on DKBM UMN and UMN’s students proves that e-complaint application can facilitate the management of students’ complaints and facilitate students in filling complaints. Keywords: complaint, e-complaint, Naive Bayes Classifier algorithm, text classification, text mining.. viii Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(10) DAFTAR ISI. HALAMAN JUDUL................................................................................................ i LEMBAR PENGESAHAN SKRIPSI .................................................................... ii PERNYATAAN TIDAK MELAKUKAN PLAGIAT .......................................... iii HALAMAN MOTO .............................................................................................. iv KATA PENGANTAR ............................................................................................ v ABSTRAK ............................................................................................................ vii ABSTRACT ......................................................................................................... viii DAFTAR ISI .......................................................................................................... ix DAFTAR TABEL .................................................................................................. xi DAFTAR GAMBAR ............................................................................................ xii BAB I PENDAHULUAN ....................................................................................... 1 1.1 Latar Belakang ........................................................................................... 1 1.2 Rumusan Masalah...................................................................................... 4 1.3 Batasan Masalah ........................................................................................ 4 1.4 Tujuan Penelitian ....................................................................................... 5 1.5 Manfaat Penelitian ..................................................................................... 5 1.6 Sistematika Penulisan ................................................................................ 5 BAB II LANDASAN TEORI ................................................................................. 7 2.1 Studi Fisibilitas .......................................................................................... 7 2.2 Skala Likert................................................................................................ 8 2.3 Stratified Random Sampling ..................................................................... 8 2.4 Pengukuran Efektivitas Sistem Informasi ................................................. 9 2.5 Pengukuran Kegunaan Piranti Lunak ........................................................ 9 2.6 E-Complaint............................................................................................. 11 2.7 Text Classification ................................................................................... 12 2.8 Class Imbalance ....................................................................................... 18 2.9 Algoritma Naive Bayes Classifier ........................................................... 19 2.10 Confusion Matrix ..................................................................................... 22 2.11 K-fold Cross Validation........................................................................... 24 BAB III METODE DAN PERANCANGAN SISTEM ........................................ 26 3.1 Metodologi............................................................................................... 26 3.1.1 Studi Fisibilitas ............................................................................. 26 3.1.2 Studi Literatur ............................................................................... 27 3.1.3 Perancangan Aplikasi .................................................................... 27 3.1.4 Pembangunan Aplikasi.................................................................. 27 3.1.5 Pengujian Aplikasi ........................................................................ 28 3.1.6 Evaluasi dan Dokumentasi Aplikasi ............................................. 28 3.2 Perancangan Aplikasi .............................................................................. 28 3.2.1 Arsitektur Sistem........................................................................... 29 3.2.2 Data Flow Diagram ....................................................................... 30 3.2.3 Site Map Aplikasi.......................................................................... 51 A. Site Map Aplikasi Mahasiswa UMN (Pengguna) ................... 51 B. Site Map Aplikasi DKBM UMN (Administrator) .................. 54 3.2.4 Flowchart Aplikasi ........................................................................ 57 A. Flowchart Aplikasi Mahasiswa UMN (Pengguna) ................. 57. ix Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(11) B. Flowchart Aplikasi DKBM UMN (Administrator) ................ 67 3.2.5 Entity Relationship Diagram ......................................................... 81 3.2.6 Skema Database ............................................................................ 83 3.2.7 Struktur Tabel................................................................................ 85 3.2.8 Perancangan Antarmuka Aplikasi ................................................. 93 A. Perancangan Antarmuka Aplikasi (Pengguna) ....................... 93 B. Perancangan Antarmuka Aplikasi (Administrator) ............... 104 BAB IV IMPLEMENTASI DAN UJI COBA .................................................... 117 4.1 Spesifikasi Perangkat ............................................................................. 117 4.2 Hasil Studi Fisibilitas............................................................................. 119 4.3 Implementasi Algoritma Naive Bayes Classifier .................................. 121 4.4 Implementasi Rancangan Aplikasi ........................................................ 125 4.4.1 Implementasi Rancangan Aplikasi untuk Pengguna ................... 125 4.4.2 Implementasi Rancangan Aplikasi untuk Administrator ............ 136 4.5 Hasil Uji Coba Klasifikasi dengan Algoritma Naive Bayes Classifier . 147 4.5.1 Hasil Pengujian dengan Confusion Matrix ................................. 147 4.5.2 Hasil Pengujian dengan 10-fold Cross Validation ...................... 148 4.6 Hasil Evaluasi Rancang Bangun Aplikasi ............................................. 149 4.6.1 Hasil Evaluasi Rancang Bangun Aplikasi terhadap Administrator .. ..................................................................................................... 149 4.6.2 Hasil Evaluasi Rancang Bangun Aplikasi terhadap Pengguna ... 151 BAB V SIMPULAN DAN SARAN ................................................................... 153 5.1 Simpulan ................................................................................................ 153 5.2 Saran ...................................................................................................... 154 DAFTAR PUSTAKA ......................................................................................... 156 DAFTAR LAMPIRAN ....................................................................................... 163. x Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(12) DAFTAR TABEL. Tabel 2.1 Kombinasi Awalan dan Akhiran yang Tidak Diizinkan ..................... 15 Tabel 2.2 Confusion Matrix ................................................................................ 22 Tabel 3.1 Deskripsi Tabel tb_admin_authentication .......................................... 85 Tabel 3.2 Deskripsi Tabel tb_admin_notification ............................................... 85 Tabel 3.3 Deskripsi Tabel tb_admin_profile ...................................................... 86 Tabel 3.4 Deskripsi Tabel tb_aspirasi ................................................................. 86 Tabel 3.5 Deskripsi Tabel tb_category ............................................................... 86 Tabel 3.6 Deskripsi Tabel tb_category_prob ...................................................... 87 Tabel 3.7 Deskripsi Tabel tb_faq ........................................................................ 87 Tabel 3.8 Deskripsi Tabel tb_katadasar .............................................................. 87 Tabel 3.9 Deskripsi Tabel tb_like ....................................................................... 88 Tabel 3.10 Deskripsi Tabel tb_log ........................................................................ 88 Tabel 3.11 Deskripsi Tabel tb_log_training.......................................................... 88 Tabel 3.12 Deskripsi Tabel tb_profile .................................................................. 89 Tabel 3.13 Deskripsi Tabel tb_reply ..................................................................... 89 Tabel 3.14 Deskripsi Tabel tb_status .................................................................... 90 Tabel 3.15 Deskripsi Tabel tb_stopword .............................................................. 90 Tabel 3.16 Deskripsi Tabel tb_training ................................................................. 90 Tabel 3.17 Deskripsi Tabel tb_user_authentication .............................................. 91 Tabel 3.18 Deskripsi Tabel tb_user_notification .................................................. 91 Tabel 3.19 Deskripsi Tabel tb_vocabulary ........................................................... 91 Tabel 3.20 Deskripsi Tabel tb_vocabulary_count ................................................ 92 Tabel 3.21 Deskripsi Tabel tb_vocabulary_prob .................................................. 92 Tabel 4.1 Interpretasi Persentase Kepuasan Pengguna ..................................... 119 Tabel 4.2 Hasil Rekapitulasi Tingkat Kepuasan Pengguna .............................. 119 Tabel 4.3 Interpretasi Persentase Tingkat Kegunaan Sistem ............................ 120 Tabel 4.4 Hasil Rekapitulasi Tingkat Kegunaan Sistem ................................... 120 Tabel 4.5 Rekapitulasi Perhitungan Precision, Recall, dan F-1 Score .............. 148 Tabel 4.6 Rekapitulasi Perhitungan Akurasi ..................................................... 149 Tabel 4.7 Interpretasi Persentase Hasil Kuesioner ............................................ 150 Tabel 4.8 Hasil Rekapitulasi Rata-Rata Persentase Skor Faktor Pengujian Aplikasi Terhadap Administrator ...................................................... 150 Tabel 4.9 Hasil Rekapitulasi Rata-Rata Persentase Skor Faktor Pengujian Aplikasi Terhadap Pengguna ............................................................ 152. xi Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
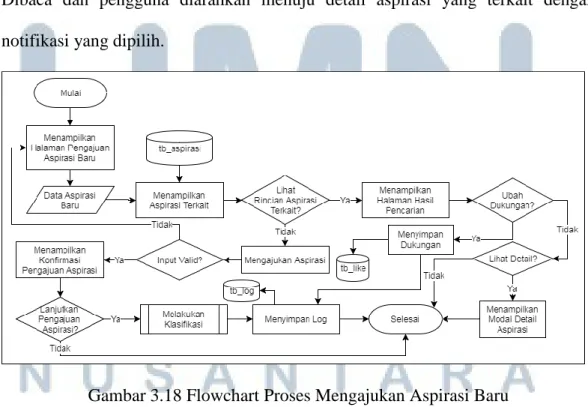
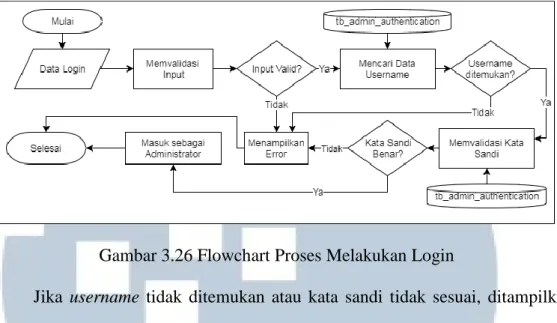
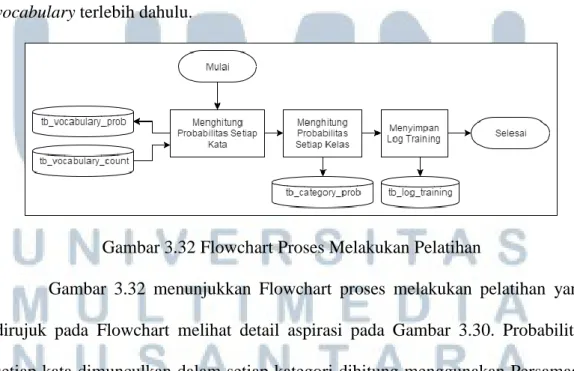
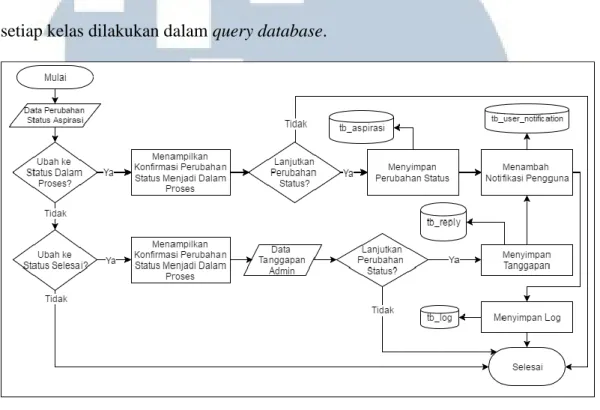
(13) DAFTAR GAMBAR. Gambar 3.1 Tahapan Penelitian .......................................................................... 26 Gambar 3.2 Arsitektur Sistem............................................................................. 29 Gambar 3.3 Context Diagram ............................................................................. 31 Gambar 3.4 Data Flow Diagram Level 1 ............................................................ 37 Gambar 3.5 Data Flow Diagram Level 2 Proses Mengelola Aspirasi ................ 39 Gambar 3.6 Data Flow Diagram Level 2 Mengelola DKBM Answer ............... 42 Gambar 3.7 Data Flow Diagram Level 2 Mengelola Profil ................................ 44 Gambar 3.8 Data Flow Diagram Level 2 Mengelola Akun Pengguna ............... 45 Gambar 3.9 Data Flow Diagram Level 2 Mengelola Data Pelatihan ................. 47 Gambar 3.10 Data Flow Diagram Level 2 Mengelola Notifikasi ......................... 49 Gambar 3.11 Data Flow Diagram Level 2 Mengelola Log Aktivitas ................... 50 Gambar 3.12 Site Map Aplikasi Mahasiswa UMN (Pengguna) ........................... 52 Gambar 3.13 Site Map Aplikasi DKBM UMN (Administrator) .......................... 55 Gambar 3.14 Flowchart Utama Aplikasi Mahasiswa UMN (Pengguna) .............. 58 Gambar 3.15 Flowchart Proses Mengatur Kata Sandi .......................................... 59 Gambar 3.16 Flowchart Proses Melakukan Login ................................................ 59 Gambar 3.17 Flowchart Proses Menampilkan Notifikasi ..................................... 60 Gambar 3.18 Flowchart Proses Mengajukan Aspirasi Baru ................................. 60 Gambar 3.19 Flowchart Proses Melakukan Klasifikasi ........................................ 61 Gambar 3.20 Flowchart Proses Melakukan Preprocessing ................................... 62 Gambar 3.21 Flowchart Proses Melihat Riwayat Aspirasi ................................... 63 Gambar 3.22 Flowchart Proses Melihat Detail Riwayat Aspirasi ........................ 64 Gambar 3.23 Flowchart Proses Melihat Aspirasi ................................................. 65 Gambar 3.24 Flowchart Proses Mengatur Profil .................................................. 66 Gambar 3.25 Flowchart Utama Aplikasi DKBM UMN (Administrator) ............. 68 Gambar 3.26 Flowchart Proses Melakukan Login ................................................ 69 Gambar 3.27 Flowchart Proses Menampilkan Notifikasi ..................................... 69 Gambar 3.28 Flowchart Proses Menambah Data Aspirasi ................................... 70 Gambar 3.29 Flowchart Proses Melihat Aspirasi Masuk ..................................... 71 Gambar 3.30 Flowchart Proses Melihat Detail Aspirasi ....................................... 72 Gambar 3.31 Flowchart Proses Menambah Data .................................................. 73 Gambar 3.32 Flowchart Proses Melakukan Pelatihan .......................................... 73 Gambar 3.33 Flowchart Proses Mengubah Status Aspirasi .................................. 74 Gambar 3.34 Flowchart Proses Mengatur Publikasi Aspirasi .............................. 75 Gambar 3.35 Flowchart Proses Mengatur Publikasi Tanggapan .......................... 75 Gambar 3.36 Flowchart Proses Mengelola DKBM Answer................................. 76 Gambar 3.37 Flowchart Proses Mengelola Pengguna .......................................... 77 Gambar 3.38 Flowchart Proses Mengelola Data Pelatihan ................................... 79 Gambar 3.39 Flowchart Proses Mengubah Data Pelatihan ................................... 80 Gambar 3.40 Flowchart Proses Mengelola Profil ................................................. 81 Gambar 3.41 Entity Relationship Diagram ........................................................... 82 Gambar 3.42 Skema Database .............................................................................. 84 Gambar 3.43 Rancangan Antarmuka Halaman Utama ......................................... 93 Gambar 3.44 Rancangan Antarmuka Halaman Lupa kata Sandi .......................... 94 Gambar 3.45 Rancangan Antarmuka Halaman Pengajuan Aspirasi Baru ............ 95. xii Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(14) Gambar 3.46 Rancangan Antarmuka Konfirmasi Pengajuan Aspirasi ................. 95 Gambar 3.47 Rancangan Antarmuka Informasi Pengajuan Aspirasi.................... 96 Gambar 3.48 Rancangan Antarmuka Halaman Riwayat Aspirasi ........................ 96 Gambar 3.49 Rancangan Antarmuka Halaman Detail Aspirasi............................ 97 Gambar 3.50 Rancangan Antarmuka Halaman Lihat Aspirasi ............................. 98 Gambar 3.51 Rancangan Antarmuka Modal Detail Aspirasi................................ 99 Gambar 3.52 Rancangan Antarmuka Halaman DKBM Answer ........................ 100 Gambar 3.53 Rancangan Antarmuka Halaman Tentang AKU ........................... 100 Gambar 3.54 Rancangan Antarmuka Menu Profil dan Keluar ........................... 101 Gambar 3.55 Rancangan Antarmuka Halaman Profil......................................... 101 Gambar 3.56 Rancangan Antarmuka Halaman Ubah Profil ............................... 102 Gambar 3.57 Rancangan Antarmuka Halaman Ubah Kata Sandi ...................... 103 Gambar 3.58 Rancangan Antarmuka Notifikasi ................................................. 103 Gambar 3.59 Rancangan Antarmuka Halaman Semua Notifikasi ...................... 104 Gambar 3.60 Rancangan Antarmuka Halaman Beranda .................................... 105 Gambar 3.61 Rancangan Antarmuka Halaman Aspirasi Masuk ........................ 105 Gambar 3.62 Rancangan Antarmuka Halaman Detail Aspirasi.......................... 106 Gambar 3.63 Rancangan Antarmuka Bagian Perubahan Kategori Aspirasi....... 107 Gambar 3.64 Rancangan Antarmuka Halaman DKBM Answer ........................ 107 Gambar 3.65 Rancangan Antarmuka Halaman Tambah Data DKBM Answer .. 108 Gambar 3.66 Rancangan Antarmuka Halaman Ubah Data DKBM Answer ...... 108 Gambar 3.67 Rancangan Antarmuka Halaman Tambah Aspirasi ...................... 109 Gambar 3.68 Rancangan Antarmuka Halaman Pengaturan Pengguna ............... 110 Gambar 3.69 Rancangan Antarmuka Halaman Pengaturan Kata Sandi Pengguna ............................................................................................................................. 111 Gambar 3.70 Rancangan Antarmuka Halaman Data Pengguna ......................... 111 Gambar 3.71 Rancangan Antarmuka Halaman Data Pelatihan .......................... 112 Gambar 3.72 Rancangan Antarmuka Konfirmasi Perubahan Data Pelatihan ..... 112 Gambar 3.73 Rancangan Antarmuka Halaman Tambah Data Pelatihan ............ 113 Gambar 3.74 Rancangan Antarmuka Halaman Ubah Data Pelatihan................. 114 Gambar 3.75 Rancangan Antarmuka Halaman Log Aktivitas............................ 114 Gambar 3.76 Rancangan Antarmuka Halaman Ubah Profil ............................... 115 Gambar 3.77 Rancangan Antarmuka Halaman Ubah Kata Sandi ...................... 115 Gambar 4.1 Potongan Kode Perhitungan Probabilitas Kata dengan Algoritma Naive Bayes Classifier.................................................................. 122 Gambar 4.2 Potongan Kode Perhitungan Probabilitas Kata yang Tidak Muncul pada Data Pelatihan ...................................................................... 122 Gambar 4.3 Potongan Kode Perhitungan Probabilitas Prior Kategori dengan Algoritma Naive Bayes Classifier ................................................ 123 Gambar 4.4 Potongan Kode Klasifikasi Aspirasi dengan Algoritma Naive Bayes Classifier ....................................................................................... 124 Gambar 4.5 Tampilan Antarmuka Halaman Utama ......................................... 125 Gambar 4.6 Tampilan Antarmuka Halaman Lupa Kata Sandi......................... 126 Gambar 4.7 Tampilan Antarmuka Halaman Informasi Pengiriman E-mail..... 126 Gambar 4.8 Tampilan Antarmuka Halaman Pengajuan Aspirasi Baru ............ 128 Gambar 4.9 Tampilan Antarmuka Modal Konfirmasi ..................................... 128 Gambar 4.10 Tampilan Antarmuka Informasi Pengajuan Aspirasi ................... 129 Gambar 4.11 Tampilan Antarmuka Halaman Riwayat Aspirasi ........................ 129. xiii Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(15) Gambar 4.12 Gambar 4.13 Gambar 4.14 Gambar 4.15 Gambar 4.16 Gambar 4.17 Gambar 4.18 Gambar 4.19 Gambar 4.20 Gambar 4.21 Gambar 4.22 Gambar 4.23 Gambar 4.24 Gambar 4.25 Gambar 4.26 Gambar 4.27 Gambar 4.28 Gambar 4.29 Gambar 4.30 Gambar 4.31 Gambar 4.32 Gambar 4.33 Gambar 4.34 Gambar 4.35 Gambar 4.36 Gambar 4.37 Gambar 4.38. Tampilan Antarmuka Halaman Detail Riwayat Aspirasi ............. 130 Tampilan Antarmuka Halaman Lihat Aspirasi ............................. 130 Tampilan Antarmuka Modal Detail Aspirasi ............................... 131 Tampilan Antarmuka Halaman DKBM Answer .......................... 131 Tampilan Antarmuka Halaman Tentang AKU ............................. 132 Tampilan Antarmuka Menu Profil dan Keluar ............................. 132 Tampilan Antarmuka Halaman Profil .......................................... 133 Tampilan Antarmuka Halaman Ubah Profil ................................. 134 Tampilan Antarmuka Halaman Ubah Kata Sandi ........................ 134 Tampilan Antarmuka Notifikasi ................................................... 135 Tampilan Antarmuka Halaman Semua Notifikasi........................ 135 Tampilan Antarmuka Halaman Beranda ...................................... 136 Tampilan Antarmuka Halaman Aspirasi Masuk .......................... 137 Tampilan Antarmuka Halaman Detail Aspirasi ........................... 138 Tampilan Antarmuka Ubah Kategori Aspirasi ............................. 138 Tampilan Antarmuka Halaman DKBM Answer .......................... 139 Tampilan Antarmuka Halaman Tambah Data DKBM Answer ... 139 Tampilan Antarmuka Halaman Ubah DKBM Answer ................ 140 Tampilan Antarmuka Halaman Tambah Aspirasi Baru ............... 141 Tampilan Antarmuka Halaman Pengaturan Pengguna ................. 142 Tampilan Antarmuka Halaman Pengaturan Reset Kata Sandi ..... 143 Tampilan Antarmuka Data Pengguna........................................... 143 Tampilan Antarmuka Konfirmasi Reset Kata Sandi .................... 144 Tampilan Antarmuka Halaman Data Pelatihan ............................ 144 Tampilan Antarmuka Halaman Tambah Data Pelatihan .............. 145 Tampilan Antarmuka Halaman Atur Profil Administrator........... 146 Tampilan Antarmuka Halaman Log Aktivitas ............................. 147. xiv Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(16) BAB I PENDAHULUAN. 1.1. Latar Belakang Perkembangan dan perubahan lingkungan yang begitu cepat dan dramatis,. termasuk perubahan selera konsumen, kemajuan teknologi, serta perubahan sosial ekonomi, telah mempengaruhi sektor pendidikan tinggi sehingga mengakibatkan timbulnya persaingan bisnis dalam industri pendidikan tinggi yang begitu ketat (Tobari, 2015). Untuk menghadapi persaingan tersebut, setiap organisasi harus memiliki strategi yang sesuai untuk menghadapi tantangan dan ancaman yang muncul, baik pada saat ini maupun masa yang akan datang, dengan mempertimbangkan kekuatan dan kelemahan yang dimilikinya (Khotimah, 2012). Keluhan yang diberikan oleh pelanggan dalam pemakaian produk atau jasa merupakan suatu umpan balik dari kualitas produk atau jasa yang digunakan oleh pelanggan (Indriyani dan Mardiana, 2016). Dalam konteks universitas, keluhan mahasiswa terhadap pelayanan yang diberikan merupakan hal penting yang perlu diperhatikan karena bila tidak ditangani dengan benar dapat mengakibatkan perpindahan peserta didik menjadi semakin tinggi (Indriyani dan Mardiana, 2016). Di Universitas Multimedia Nusantara (UMN), keluhan dari mahasiswa, yang disebut dengan aspirasi, disalurkan melalui organisasi Dewan Keluarga Besar Mahasiswa (DKBM) UMN (Angela, 2017). Namun, berdasarkan studi fisibilitas yang dilakukan pada 14 Februari 2017 hingga 17 Februari 2017, tingkat penyampaian aspirasi melalui DKBM berada pada frekuensi jarang. Studi fisibilitas juga menunjukkan bahwa kepuasan dalam menggunakan media penyampaian tersebut hanya berada pada tingkat cukup. Hal tersebut dapat menjadi salah satu. 1 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(17) faktor yang mempengaruhi rendahnya tingkat penyampaian aspirasi mahasiswa UMN. Sistem penyampaian aspirasi yang dilakukan selama ini juga menimbulkan masalah bagi pengurus DKBM UMN. Angela (2017) selaku Ketua DKBM UMN periode 2016/2017 menyatakan bahwa media penyampaian aspirasi yang belum dapat memaksimalkan pemberian respon mengenai pemrosesan aspirasi kepada para mahasiswa menjadi salah satu penyebab rendahnya intensitas penyampaian aspirasi. Seluruh aspirasi dari mahasiswa juga diklasifikasikan secara manual ke dalam kategori-kategori tertentu oleh para pengurus DKBM agar dapat diteruskan kepada bagian-bagian terkait dan hal ini menguras waktu dan sumber daya manusia pengurus DKBM UMN, serta menimbulkan terjadinya kesalahan klasifikasi terhadap aspirasi yang masuk (Angela, 2017). Pada era teknologi, banyak aplikasi berbasis web dikembangkan dan sistem manajemen keluhan juga diimplementasikan secara online (Razali dan Jaafar, 2012). Penelitian yang dilakukan oleh Sarı dkk. (2013) menunjukkan bahwa eComplaint berbasis forum dan web membuka banyak peluang bagi perusahaan untuk memantau dan merespon keluhan pelanggan. Hal ini selaras dengan yang diutarakan oleh Summerfield (2015) bahwa aplikasi berbasis web cocok untuk kegiatan pemasaran dan komunikasi publik, serta memiliki beberapa kelebihan seperti tidak diperlukannya instalasi, dapat digunakan pada tipe perangkat apa saja, dan dapat di-update dengan mudah. Selain itu, Jaffar dkk. (2012) dan Abbas dkk. (2013) menegaskan bahwa kelebihan yang dimiliki sistem informasi penanganan keluhan secara online (e-complaint) mampu menjadi solusi terhadap permasalahan yang terjadi pada sistem penanganan keluhan di Institut Teknologi Telkom dan. 2 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(18) Kepolisian Malaysia. Oleh karena itu, sistem penyampaian keluhan secara online serupa juga dapat diterapkan di Universitas Multimedia Nusantara. Penelitian yang dilakukan Coussement dan Van den Poel (2008) menunjukkan bahwa dalam penanganan keluhan berbasis e-mail, metode yang dapat digunakan untuk mendukung pemrosesan keluhan yang efisien adalah penggunaan sistem klasifikasi otomatis karena dapat menghemat waktu dan tenaga kerja. Selain itu, menurut Zaugg (2007), pengguna e-complaint tidak perlu memikirkan keluhan yang dikirimkan termasuk dalam subjek apa atau harus ditujukan kepada bagian mana dalam perusahaan dan tugas untuk mengategorikan keluhan harus dilakukan secara otomatis oleh perangkat lunak. Algoritma Naive Bayes Classifier merupakan salah satu algoritma yang dapat digunakan untuk mengklasifikasi teks secara otomatis. Algoritma Naive Bayes Classifier sering digunakan sebagai standar dalam klasifikasi teks karena cepat dan mudah diimplementasikan (Rennie dkk., 2003). Penelitian yang dilakukan oleh McCallum dan Nigam (1998), Rennie dkk. (2003), Zhang (2004), dan Bhardwaj dan Pal (2011) menunjukkan bahwa algoritma Naive Bayes Classifier dapat menunjukkan performa klasifikasi yang amat baik dan dapat bekerja optimal walaupun jumlah data pelatihan kecil. Keuntungan penggunaan algoritma Naive Bayes Classifier antara lain mudah digunakan, hanya membutuhkan satu kali pemindaian data pelatihan, dan hanya membutuhkan sejumlah kecil data pelatihan untuk mengestimasi parameter yang dibutuhkan dalam klasifikasi (Bhardwaj dan Pal, 2011). Berdasarkan studi fisibilitas yang dilakukan (Lampiran 3), mahasiswa UMN merasa tertarik jika dibangun sebuah aplikasi yang dapat menjadi media. 3 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(19) penyampaian keluhan. Oleh karena itu, penelitian mengenai perancangan dan pembangunan aplikasi e-complaint berbasis web menggunakan algoritma Naive Bayes Classifier untuk klasifikasi keluhan dilakukan agar dapat digunakan sebagai sistem penyampaian keluhan di Universitas Multimedia Nusantara.. 1.2. Rumusan Masalah Berdasarkan latar belakang yang sudah dijelaskan sebelumnya, dapat. dirumuskan beberapa masalah sebagai berikut. 1.. Bagaimana cara merancang dan membangun aplikasi e-complaint berbasis web dengan algoritma Naive Bayes Classifier untuk klasifikasi keluhan?. 2.. Bagaimana mengukur tingkat kegunaan aplikasi e-complaint dalam memudahkan DKBM UMN mengelola keluhan mahasiswa UMN?. 1.3. Batasan Masalah Batasan-batasan masalah dalam penelitian ini adalah sebagai berikut.. 1.. Pengguna yang dimaksud dalam penelitian ini adalah mahasiswa UMN dan administrator yang dimaksud dalam penelitian ini adalah anggota divisi Kesejahteraan Mahasiswa DKBM UMN.. 2.. Aplikasi hanya dibuat untuk diimplementasikan di Universitas Multimedia Nusantara dan hanya mencakup penyampaian keluhan, klasifikasi keluhan, dan pemberian tanggapan dari DKBM UMN kepada mahasiswa UMN. Aplikasi ini tidak mencakup pemrosesan keluhan kepada pihak-pihak terkait pada Universitas Multimedia Nusantara.. 4 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(20) 3.. Kategori yang digunakan dalam klasifikasi keluhan mencakup lima kategori, yaitu Fasilitas, Akademik, Kegiatan, BEM, dan Lainnya, sesuai dengan kategori yang digunakan oleh DKBM UMN.. 4.. Keluhan dimasukkan menggunakan Bahasa Indonesia yang baik dan benar.. 1.4. Tujuan Penelitian Berdasarkan rumusan masalah, tujuan dilakukannya penelitian ini adalah. sebagai berikut. 1.. Merancang dan membangun aplikasi e-complaint berbasis web dengan menerapkan algoritma Naive Bayes Classifier untuk klasifikasi keluhan.. 2.. Mengukur tingkat kegunaan aplikasi e-complaint dalam memudahkan DKBM UMN mengelola keluhan mahasiswa UMN.. 1.5. Manfaat Penelitian Manfaat yang diharapkan dengan adanya penelitian ini adalah memudahkan. DKBM UMN untuk mengelola keluhan mahasiswa UMN dan memberikan informasi status pemrosesan keluhan kepada mahasiswa UMN.. 1.6. Sistematika Penulisan Sistematika penulisan yang digunakan dalam penyajian laporan skripsi ini. adalah sebagai berikut. BAB I PENDAHULUAN Bab ini berisi latar belakang masalah, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, dan sistematika penulisan.. 5 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(21) BAB II LANDASAN TEORI Bab ini menjelaskan landasan teori dan konsep dasar yang mendukung penelitian, yaitu studi fisibilitas, skala Likert, stratified random sampling, pengukuran efektivitas sistem informasi, pengukuran kegunaan piranti lunak, e-complaint, text classification, class imbalance, algoritma Naive Bayes Classifier, confusion matrix, dan k-fold cross validation. BAB III METODOLOGI DAN PERANCANGAN SISTEM Bab ini menjelaskan metode penelitian yang digunakan serta perancangan aplikasi yang dibangun. BAB IV IMPLEMENTASI DAN UJI COBA Bab ini berisi penjelasan mengenai implementasi dan hasil uji coba aplikasi kepada pengurus Dewan Keluarga Besar Mahasiswa Universitas Multimedia Nusantara dan mahasiswa Universitas Multimedia Nusantara. BAB V SIMPULAN DAN SARAN Bab ini berisi simpulan hasil penelitian dan saran pengembangan untuk penelitian selanjutnya.. 6 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(22) BAB II LANDASAN TEORI. 2.1. Studi Fisibilitas Menurut Kamus Besar Bahasa Indonesia, fisibilitas berarti sesuatu yang. dapat dilaksanakan; keterlaksanaan; kelaikan; kelayakan. Ketika masalah yang kompleks akan didefinisikan, secara umum dibutuhkan investigasi pendahuluan yang disebut dengan studi fisibilitas (Overton, 2007). Istilah studi fisibilitas digunakan secara luas dan mencakup studi apapun yang dapat membantu peneliti mempersiapkan penelitian skala penuh (Bowen dkk., 2009). Menurut Claase (2012) dan Overton (2007), tujuan dari studi fisibilitas adalah untuk menguji dan mengevaluasi kemungkinan sukses atau gagalnya upaya yang akan dilakukan, serta dilakukan sebagai tahap pertama dalam siklus pengembangan produk atau layanan. Studi fisibilitas digunakan untuk menentukan apakah ide-ide dan temuan relevan dan dapat berkelanjutan dalam suatu penelitian (Bowen dkk., 2009). Selain itu, studi fisibilitas digunakan untuk mendefinisikan secara tepat mengenai proyek apa yang dibuat dan apa isu-isu strategis yang perlu dipertimbangkan untuk menilai kelayakan atau kemungkinan kesuksesannya (Overton, 2007). Menurut Ries (2014), studi fisibilitas merupakan analisis dan evaluasi dari proyek yang diajukan untuk menentukan apakah proyek tersebut layak secara teknis, layak dalam estimasi biaya, dan akan menguntungkan. Studi fisibilitas menganalisis proyek, produk, atau layanan yang diajukan sesuai dengan tujuan performa yang diharapkan oleh organisasi, dan dapat termasuk evaluasi dari sistem yang sudah ada (Overton, 2007). Untuk studi fisibilitas, data dasar diperoleh melalui serangkaian pertanyaan dan pertemuan, dimana klien menyediakan. 7 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(23) beberapa riset, data, dan fakta yang dibutuhkan yang dikumpulkan dari berbagai sumber (Thompson, 2003). Jika suatu proyek terlihat layak dari hasil studi fisibilitas, langkah logika selanjutnya adalah menyusun perencanaan (Thompson, 2003).. 2.2. Skala Likert Skala Likert umumnya digunakan untuk mengukur rentang sikap dari. respon terhadap suatu pertanyaan atau pernyataan (Subedi, 2016). Menurut Sugiyono (2012), untuk menarik kesimpulan dari skala Likert, dilakukan perkalian terhadap jumlah responden yang menjawab setiap poin skala dikalikan dengan bobot poin tersebut. Hasil tersebut digunakan untuk mencari nilai rata-rata dan diubah dalam bentuk persentase untuk diinterpretasikan dan jarak interval persentase interpretasi dihitung dengan membagi nilai 100 dengan poin skala yang digunakan (Darmadi, 2011).. 2.3. Stratified Random Sampling Teknik pengambilan sampel yang digunakan dalam studi fisibilitas adalah. teknik stratified random sampling. Teknik ini digunakan jika dibutuhkan sampel acak dan sampel tersebut menjadi representasi dari populasi (Teddlie dan Yu, 2007). Stratified random sampling digunakan untuk mengambil sampel dari setiap subgroup sebagai representasi dari subgroup itu sendiri (Teddlie dan Yu, 2007). Dengan teknik ini, sampel diambil dari setiap kelas atau strata (Barreiro dan Albandoz, 2001). Menurut Hill (1998) dan Sugiyono (2012), jumlah sampel yang direkomendasikan adalah 30 atau lebih.. 8 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(24) 2.4. Pengukuran Efektivitas Sistem Informasi Definisi umum dari informasi adalah data yang telah diproses sehingga. lebih bermakna dengan menggunakan sejumlah transformasi atau pemrosesan data yang berbeda (Hardcastle, 2008). Menurut Hardcastle (2008), sistem dapat didefinisikan sebagai kumpulan komponen, yaitu input, proses, output, umpan balik, dan kontrol, yang bekerja bersamaan menuju suatu tujuan yang sama. Sistem informasi memiliki peran untuk menyediakan informasi kepada manajemen yang memungkinan manajemen untuk mengambil keputusan untuk memastikan organisasi terkontrol (Hardcastle, 2008). Kepuasan pengguna dari sistem informasi sering digunakan untuk menilai fungsionalitas sistem informasi (Balaban, 2009). Penggunaan suatu sistem dapat dibagi menjadi penggunaan offline, yaitu ketika interaksi antara pengguna dan sistem terbatas pada penggunaan laporan tercetak, dan penggunaan online, yaitu ketika pengguna berinteraksi dengan sistem melalui sebuah terminal (Cyrus, 1991). Cyrus (1991) mengklasifikasi berbagai pendekatan untuk mengukur efektivitas sistem informasi menjadi enam kategori, yaitu kepuasan pengguna, tingkat penggunaan sistem, performa atau kegunaan, produktivitas, analisis costbenefit, dan analisis nilai dari sistem informasi.. 2.5. Pengukuran Kegunaan Piranti Lunak Istilah usability (kegunaan) muncul sekitar 10 tahun yang lalu untuk. menggantikan istilah user friendly yang pada awal tahun 1980-an telah memunculkan sejumlah konotasi yang tidak diinginkan, kabur, dan subjektif (Bevan dkk., 1991). ISO 9241 mendefinisikan usability atau kegunaan sebagai sejauh mana suatu produk dapat digunakan oleh pengguna tertentu untuk mencapai. 9 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(25) tujuan yang telah ditentukan dengan efektivitas, efisiensi, dan kepuasan dalam konteks penggunaan tertentu (ISO, 1998). Menurut Ferré dkk. (2001), usability (kegunaan) bukan hanya berkaitan dengan antarmuka, melainkan berkaitan dengan lima atribut dasar, yaitu learnability, efisiensi, ingatan pengguna dari waktu ke waktu, tingkat error, dan kepuasan. Usability tidak dapat didefinisikan sebagai aspek yang spesifik dari sistem dan usability dari sistem berbeda-beda tergantung pada tujuan penggunaan dari sistem itu sendiri (Ferré dkk., 2001). Usability adalah faktor utama yang dapat dijadikan pedoman dalam pengukuran tingkat keberhasilan suatu implementasi sistem atau perangkat lunak (Sahfitri dan Ulfa, 2014). Tingkat usability menentukan apakah sistem tersebut akan bermanfaat, diterima oleh pengguna, dan bertahan lama dalam penggunaannya (Aelani dan Falahah, 2012). Untuk aplikasi pada umumnya, usability terdiri dari usefulness, satisfaction, dan ease of use (Lund, 2001). Menurut Lund (2001), faktor ease of use dapat dibedakan menjadi dua faktor, yaitu ease of learning dan ease of use. Pada umumnya, pengukuran usability dilakukan menggunakan serangkaian kuesioner dan salah satu jenis kuesioner yang dapat digunakan untuk mengukur faktor-faktor tersebut dalam sistem atau aplikasi adalah menggunakan USE Questionnaire (Aelani dan Falahah, 2012). USE merupakan akronim dari Usefulness, Satisfaction, dan Ease of Use (Lund, 2001). Beberapa penelitian yang sudah dilakukan menunjukkan bahwa evaluasi produk dapat mengacu pada tiga dimensi yang dicakup oleh USE Questionnaire, yaitu usefulness, satisfaction, dan ease of use (Aelani dan Falahah, 2012). Kuesioner ini menggunakan skala Likert tujuh tingkat dan pengguna diminta untuk memberikan tingkat persetujuan pada. 10 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(26) pernyataan-pernyataan dalam kuesioner (Lund, 2001). Hasil pengukuran kemudian diolah dan dianalisis baik terhadap masing-masing parameter atau terhadap keseluruhan parameter (Aelani dan Falahah, 2012).. 2.6. E-Complaint Keluhan pelanggan merupakan hal yang penting jika dilihat dari perspektif. manajemen relasi dengan pengguna dan merupakan mekanisme umpan balik yang penting agar suatu perusahaan dapat memantau kepuasan pelanggan terhadap suatu produk dan jasa (Sarı dkk., 2013). Keluhan umumnya muncul ketika terdapat kegagalan dalam layanan atau ketika sesuatu yang dijanjikan penyelenggara layanan tidak terpenuhi dan jika tidak ditangani dengan benar oleh organisasi, hal ini dapat menyebabkan hilangnya kepercayaan pelanggan terhadap organisasi tersebut (Au dkk., 2009). Dengan semakin meningkatnya penggunaan internet dalam. bisnis,. sejumlah. besar. perusahaan. menyediakan. layanan. yang. memungkinkan pelanggan untuk mengajukan keluhan secara online (Zaugg, 2006). Cara baru untuk mengelola umpan balik ini memberikan keuntungan bagi bisnis dan pelanggan lebih memilih menggunakan sistem pengajuan keluhan secara online untuk menggantikan komunikasi tertulis maupun sebagai pelengkap jalur komunikasi lain seperti telepon (Zaugg, 2007). Keluhan yang disampaikan secara online sering disebut dengan e-complaint (Tyrrell dan Woods, 2004). E-Complaint berbasis forum dan web membuka banyak peluang bagi perusahaan untuk memantau dan merespon keluhan pelanggan (Sarı dkk., 2013). Dengan e-complaint pelanggan dapat mengirimkan keluhannya kapan saja dan di mana saja (Zaugg, 2007). Dalam konteks e-democracy, e-complaint merupakan suatu layanan bagi masyarakat untuk menyampaikan keluhan dan opini. 11 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(27) kepada organisasi-organisasi pemerintahan dan keluhan ini dapat direspon dalam waktu yang singkat (Funilkul dan Chutimaskul, 2009). Pemerintah Dubai menyediakan sebuah web e-complaint yang dapat digunakan masyarakat untuk menyampaikan opini dan keluhannya. E-Complaint juga digunakan dalam industri pariwisata, khususnya perhotelan, untuk mengevaluasi keluhan pelanggan agar dapat melakukan perbaikan layanan (Lee dan Hu, 2004). Dalam penanganan keluhan secara online, faktor ease of use harus diperhatikan dan sistem penyampaian keluhan harus dibuat semudah mungkin (Zaugg, 2007). Idealnya, pelanggan tidak perlu memikirkan keluhan yang disampaikan termasuk dalam subjek apa atau harus diarahkan ke bagian spesifik mana dari organisasi dan tugas untuk mengategorikan keluhan harus dilakukan secara otomatis oleh perangkat lunak (Zaugg, 2007). Otomasi yang dilakukan tidak boleh melebihi batasan-batasan tertentu, misalnya, otomasi pemberian respon yang dapat memaksa pelanggan mengeluarkan usaha lebih untuk menyampaikan keluhan (Zaugg, 2007).. 2.7. Text Classification Dalam kultur modern, teks merupakan bentuk paling umum dari pertukaran. informasi secara formal (Witten, 2004). Menurut Kamruzzaman dkk. (2010), terdapat sejumlah besar dokumen berbasis teks yang tersedia dalam bentuk elektronik. Pencarian pola pada data dapat dilakukan dengan data mining (Witten, 2004). Jika data mining berkaitan dengan proses mencari pola pada data, text mining berkaitan dengan proses mencari pola pada teks (Witten, 2004). Tujuan utama dari text mining adalah untuk memungkinkan pengguna mengekstrak informasi dari sumber yang berupa teks dan berkaitan dengan operasi-operasi seperti mendapatkan kembali informasi, klasifikasi, dan perangkuman (Korde dan. 12 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(28) Mahender, 2012). Text classification merupakan salah satu contoh dari text mining (Sebastiani, 2001). Text classification akan mengklasifikasikan dokumen berupa teks secara otomatis berdasarkan kategori-kategori yang telah ditetapkan sebelumnya, misalnya olahraga, politik, atau seni (Korde dan Mahender, 2012). Ketika mengklasifikasi suatu dokumen, tidak ada informasi lain yang digunakan selain isi dari dokumen itu sendiri dan dalam pendekatan machine learning, data pelatihan terdiri dari sekumpulan contoh dokumen yang berupa teks untuk setiap kategori (Witten, 2004). Menurut Witten (2004), model untuk setiap kategori dibangun menggunakan kata-kata (feature) yang ada dalam teks yang dijadikan data pelatihan, baik sebagian kecil maupun seluruh kata kecuali stopwords, beserta dengan jumlah kemunculannya (nilai dari feature). Model yang dihasilkan kemudian digunakan untuk memprediksi apakah kategori tersebut dapat disematkan pada dokumen baru berdasarkan kata-kata yang terdapat pada dokumen tersebut atau dapat juga memperhitungkan jumlah kemunculan masing-masing kata (Witten, 2004). Jika kata-kata dalam teks disebut dengan feature, dokumen direpresentasikan sebagai bag of words yang mengabaikan urutan kata-kata dan efek kontekstual dari urutan kata-kata tersebut (Witten, 2004). Tahap pertama dari proses klasifikasi teks adalah melakukan preprocessing (Vijayarani dkk., 2015). Menurut Korde dan Mahender (2012), umumnya, langkah yang dilakukan dalam preprocessing adalah sebagai berikut. 1.. Tokenisasi Dokumen diperlakukan sebagai sebuah string dan dipartisi menjadi daftar. token. Metode ini digunakan untuk mengolah konten dari teks menjadi kata-kata tunggal (Vijayarani dkk., 2015). Pada tahap ini, karakter-karakter tertentu seperti. 13 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(29) tanda baca juga dihilangkan (Harjanta, 2015). Sebelum tokenisasi dilakukan, semua huruf pada teks diubah menjadi huruf kecil atau huruf kapital semua (Harjanta, 2015). Dilakukan juga proses filter terhadap kata yang berawalan bukan huruf (Ganisaputra dan Tan, 2013). 2.. Penghapusan stopwords Proses ini merupakan proses penghapusan kata-kata yang tidak berpengaruh. pada sebuah proses klasifikasi (Hidayatullah dan Azhari, 2015). Contoh dari stopword bahasa Inggris adalah is, a, all, dan lain-lain (Ganisaputra dan Tan, 2013). Untuk Bahasa Indonesia, seperti nama bulan, kata ganti, kata hubung, dan lain-lain (Ganisaputra dan Tan, 2013). Preposisi (seperti kata “di”, “untuk”, “bersama”, “sampai dengan”, dan lain-lain) dan konjungsi (seperti kata “dan”, “atau”, “serta”, dan lain-lain) dalam Bahasa Indonesia juga dieliminasi dalam tahap ini (Firdaus dkk., 2014). 3.. Stemming Proses stemming mengonversi kata-kata menjadi kata dasarnya dan meliputi. pengetahuan linguistik yang bersifat language-dependent (Sharma dan Jain, 2015). Tujuan dari proses stemming adalah menghilangkan imbuhan-imbuhan baik itu berupa prefiks, sufiks, maupun konfiks yang ada pada setiap kata (Kurniawan dkk., 2012). Proses stemming dilakukan dengan menggunakan algoritma Nazief dan Adriani yang dapat melakukan stemming dengan presisi tinggi (Agusta, 2009). Algoritma Nazief dan Adriani memiliki tahapan sebagai berikut (Asian dkk., 2005). 1. Cari kata di dalam kamus. Jika ditemukan, diasumsikan bahwa kata tersebut adalah kata dasar dan algoritma berhenti. Jika tidak ditemukan, lakukan langkah 2.. 14 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(30) 2. Hilangkan inflectional suffixes bila ada. Dimulai dari inflectional particle (“lah”, “-kah”, “-tah”, dan “-pun”), kemudian possessive pronoun (“-ku”, “-mu”, dan “-nya”). Kemudian cari kata pada kamus. Jika ditemukan, algoritma berhenti. Jika kata tidak ditemukan dalam kamus, lakukan langkah 3. 3. Hilangkan derivation suffixes (“-an”, ”-i”). Cari kata di dalam kamus. Jika ditemukan, algoritma berhenti. Jika kata tidak ditemukan, lakukan langkah 3a. a. Jika akhiran “-an” dihapus dan ditemukan akhiran “-k”, akhiran “-k” dihapus. Lalu, lakukan langkah 4. Jika kata ditemukan, algoritma berhenti. Jika kata tidak ditemukan, lakukan langkah 3b. b. Akhiran yang telah dihapus (“-i”, “-an”, atau “-kan”) dikembalikan. 4. Hilangkan derivation prefix (“di-”, “ke-”, “se-”, “me-”, “be-”, “pe-”, “te-”) dengan iterasi maksimum tiga kali. a. Iterasi berhenti jika: . Terjadi kombinasi awalan dan akhiran yang dilarang seperti yang dijabarkan pada Tabel 2.1. Tabel 2.1 Kombinasi Awalan dan Akhiran yang Tidak Diizinkan (Agusta, 2009) Awalan bedikemese-. . Akhiran yang Tidak Diizinkan -i -an -i, -kan -an -i, -kan. Awalan yang dideteksi saat ini sama dengan awalan yang telah dihilangkan sebelumnya.. . Tiga awalan sudah dihilangkan.. 15 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(31) b. Identifikasi tipe awalan dan hilangkan. Awalan terdiri dari dua tipe, yaitu sebagai berikut. . Jika awalan dari kata adalah “di-”, “ke-”, dan “se-”, awalan dapat langsung dihilangkan dari kata.. . Jika awalan dari kata adalah “me-”, “be-”, “pe-”, dan “te-”, proses tambahan. dibutuhkan. untuk. melakukan. pemenggalan.. Aturan. pemenggalan kata dapat dilihat pada Lampiran 5. c. Jika kata tidak ditemukan dalam kamus, ulangi langkah 4. Jika ditemukan, algoritma berhenti. d. Lakukan recoding. Langkah ini dilakukan berdasarkan tipe awalan dan dapat menghasilkan kata yang berbeda. Aturan recoding dapat dilihat pada Lampiran 5. Recoding dilakukan dengan menambahkan karakter recoding di awal kata yang dipenggal. Karakter recoding adalah huruf kecil setelah tanda hubung (“-”) atau berada sebelum tanda kurung jika mengacu pada daftar aturan pemenggalan yang terlampir (Firdaus dkk., 2014). 5. Jika semua langkah gagal, input kata yang diuji pada algoritma ini dianggap sebagai kata dasar. Selain aturan stemming berdasarkan algoritma Nazief dan Adriani, terdapat beberapa aturan tambahan untuk mengatasi kegagalan stemming dalam beberapa jenis imbuhan. Aturan tersebut dijabarkan sebagai berikut (Asian dkk., 2005). 1.. Penambahan partikel “-pun” pada daftar inflectional suffix.. 2.. Jika sebuah kata diawali dengan “ber-” dan memiliki inflectional suffix “lah”, prefix dihapus sebelum suffix.. 16 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(32) 3.. Jika sebuah kata diawali dengan “ber-” dan memiliki derivation suffix “an”, prefix dihapus sebelum suffix.. 4.. Jika sebuah kata diawali dengan “men-” dan memiliki derivation suffix “i”, prefix dihapus sebelum suffix.. 5.. Jika sebuah kata diawali dengan “di-” dan memiliki derivation suffix “-i”, prefix dihapus sebelum suffix.. 6.. Jika sebuah kata diawali dengan “pe-” dan memiliki derivation suffix “-i”, prefix dihapus sebelum suffix.. 7.. Jika sebuah kata diawali dengan “ter-” dan memiliki derivation suffix “-i”, prefix dihapus sebelum suffix. Setelah melalui preprocessing, teks dapat diklasifikasikan menggunakan. beberapa pendekatan machine learning, yaitu supervised dan unsupervised learning (Tsarev dkk., 2013). Menurut Tsarev dkk. (2013), pada pendekatan supervised, kategori telah ditetapkan sebelumnya dan pemberian label kategori dilakukan terhadap set dokumen sampel atau dokumen pelatihan (training), sedangkan pada pendekatan unsupervised, yang disebut juga dengan document clustering, klasifikasi harus dilakukan seluruhnya tanpa referensi ke informasi eksternal (kategori tidak ditetapkan terlebih dahulu). Penelitian ini dilakukan menggunakan pendekatan supervised learning karena kategori telah ditetapkan sebelumnya dan dokumen sampel telah diberi label kategori yang sesuai. Salah satu algoritma pengklasifikasian teks yang menggunakan pendekatan supervised learning adalah algoritma Naive Bayes Classifier (Manning dkk., 2008).. 17 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(33) 2.8. Class Imbalance Sebagian besar data pada dunia nyata bersifat tidak seimbang dalam konteks. proporsi data yang tersedia untuk masing-masing kelas atau kategori (Huang dkk., 2006). Dalam klasifikasi, data disebut tidak seimbang jika suatu kelas atau kategori memiliki jumlah data yang relatif lebih kecil jika dibandingkan dengan kelas lainnya (Hoens dan Chawla, 2013). Kelas yang memiliki jumlah data relatif lebih banyak disebut dengan kelas mayoritas dan kelas yang memiliki jumlah data relatif lebih sedikit dibandingkan dengan kelas lainnya disebut dengan kelas minoritas (Longadge dkk., 2013). Menurut Blagus dan Lusa (2013), sering kali data pelatihan atau data pengujian yang dimiliki masing-masing kelas memiliki distribusi yang tidak seimbang dan hal ini memiliki konsekuensi pada proses pembelajaran, yaitu menghasilkan prediksi yang lemah untuk kelas minoritas dan cenderung mengklasifikasikan data baru ke dalam kelas mayoritas. Hal ini disebabkan oleh prinsip rancangan algoritma machine learning yang mengoptimasi akurasi klasifikasi secara keseluruhan yang berakibat pada kesalahan klasifikasi pada kelas minor (Longadge dkk., 2013). Penelitian yang dilakukan oleh Blagus dan Lusa (2013), Longadge dkk. (2013), Hoens dan Chawla (2013), dan Chawla dkk. (2004) menyatakan bahwa dalam klasifikasi dengan distribusi data yang tidak seimbang, data dari kelas minoritas akan lebih besar kemungkinannya untuk salah diklasifikasikan dibandingkan dengan data dari kelas mayoritas dan algoritma klasifikasi akan cenderung bias ke arah kelas mayoritas.. 18 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(34) 2.9. Algoritma Naive Bayes Classifier Klasifikasi merupakan isu fundamental dalam machine learning dan data. mining dan tujuan penggunaan algoritma dalam klasifikasi adalah untuk membentuk suatu model classifier berdasarkan sampel dengan label kelas tertentu (Zhang, 2004). Naive Bayes Classifier adalah algoritma klasifikasi yang berdasarkan probabilitas dan teorema Bayesian dengan asumsi bahwa setiap variabel bersifat bebas (independen) satu sama lain (Indriani, 2014). Asumsi bahwa atribut saling independen satu sama lain jika dilihat dari konteks kategorinya akan menyederhanakan proses pembelajaran (McCallum dan Nigam, 1998). Menurut Zhang (2004), algoritma Naive Bayes Classifier adalah salah satu algoritma yang paling efisien dan efektif dalam machine learning dan data mining yang disebabkan oleh asumsi independen yang dimilikinya. Algoritma Naive Bayes Classifier sering digunakan sebagai standar dalam klasifikasi teks karena cepat dan mudah diimplementasikan (Rennie dkk., 2003). Penelitian yang dilakukan oleh McCallum dan Nigam (1998) menunjukkan bahwa algoritma Naive Bayes Classifier dapat menunjukkan performa klasifikasi yang amat baik. Algoritma Naive Bayes Classifier juga tetap dapat bekerja dengan baik dan optimal walaupun dependensi antar feature sangat kuat (Zhang, 2004). Pengujian algoritma Naive Bayes Classifier menghasilkan rata-rata f-measure yang lebih tinggi dibandingkan dengan algoritma K-Nearest Neighbor dalam klasifikasi teks (Anggono dkk., 2009). Keuntungan penggunaan algoritma Naive Bayes Classifier antara lain mudah digunakan, hanya membutuhkan satu kali pemindaian data pelatihan, dan hanya membutuhkan sejumlah kecil data pelatihan untuk mengestimasi parameter yang dibutuhkan dalam klasifikasi (Bhardwaj dan Pal,. 19 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(35) 2011). Menurut Bhardwaj dan Pal (2011), walaupun menggunakan desain yang naif dan asumsi yang tampaknya terlalu disederhanakan, algoritma Naive Bayes Classifier bekerja cukup baik pada situasi dunia nyata yang kompleks. Terdapat dua model Naive Bayes Classifier yang umum digunakan (McCallum dan Nigam, 1998). Model pertama, yaitu Multi-variate Bernoulli, merepresentasikan. dokumen. sebagai. vektor. dari. atribut. biner. yang. mengindikasikan ada atau tidaknya suatu kata dalam dokumen dan jumlah kemunculan kata dalam dokumen tidak diperhitungkan (McCallum dan Nigam, 1998). Model kedua, yaitu model Multinomial, merepresentasikan dokumen sebagai satu set kumpulan kemunculan kata dan jumlah kemunculan setiap kata diperhitungkan (McCallum dan Nigam, 1998). Model Multinomial umumnya lebih baik dari model Multi-variate Bernoulli pada jumlah kosakata yang besar dan dapat mereduksi 27% kesalahan dibandingkan dengan model Multi-variate Bernoulli (McCallum dan Nigam, 1998). Model Multinomial memperlakukan dokumen sebagai urutan kata-kata dan diasumsikan bahwa posisi setiap kata independen satu sama lain (Rennie dkk. 2003). Menurut Aziz dkk. (2016), algoritma Naive Bayes Classifier model Multinomial memiliki dua asumsi, yaitu asumsi bag of words yang menyatakan bahwa posisi kata dalam dokumen tidak berpengaruh dan asumsi conditional independence yang menyatakan probabilitas setiap feature saling independen. Menurut Indriani (2014), Naive Bayes Classifier menempuh dua tahap dalam proses klasifikasi teks, yaitu tahap pelatihan dan tahap klasifikasi. Pada tahap pelatihan, dilakukan proses analisis terhadap dokumen sampel dan penentuan probabilitas prior bagi tiap kategori berdasarkan dokumen sampel (Indriani, 2014).. 20 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(36) Probabilitas kosakata 𝑊𝑡 dimunculkan pada kelas 𝐶 = 𝑘 dalam dokumen sampel (probabilitas likelihood) dihitung menggunakan Persamaan (2.1) (Shimodaira, 2014). 𝑁. 𝑃(𝑊𝑡 |𝐶 = 𝑘) =. 𝑘 𝑋 ∑𝑖=1 𝑖𝑡 𝑁. |𝑉|. 𝑘 𝑋 ∑𝑠=1 ∑𝑖=1 𝑖𝑠. …(2.1). Nilai 𝑋𝑖𝑡 merupakan frekuensi kemunculan kosakata 𝑊𝑡 dalam dokumen sampel 𝐷𝑖 pada kelas 𝑘. Nilai 𝑁𝑘 merupakan total dokumen sampel pada kelas 𝑘. 𝑁𝑘 Nilai ∑𝑖=1 𝑋𝑖𝑡 merupakan total frekuensi kemunculan kosakata 𝑊𝑡 dalam |𝑉| 𝑁𝑘 dokumen sampel 𝐷𝑖 pada kelas 𝑘, sementara nilai ∑𝑠=1 ∑𝑖=1 𝑋𝑖𝑠 merupakan total. kemunculan kosakata 𝑊𝑠 dalam dokumen sampel 𝐷𝑖 pada kelas 𝑘, dihitung untuk setiap kata 𝑊𝑠 di dalam 𝑉. Perhitungan probabilitas dengan Persamaan (2.1) menimbulkan masalah ketika terdapat satu kosakata yang tidak muncul sama sekali dalam dokumen sampel, yang menjadikan probabilitas bernilai 0 (Shimodaira, 2014). Hanya karena suatu kata tidak muncul dalam dokumen pada data pelatihan bukan berarti kata tersebut tidak akan muncul pada dokumen lainnya dalam kategori yang sama (Shimodaira, 2014). Oleh karena itu, diterapkan Laplace’s law of succession atau add one smoothing, dengan menambahkan nilai 1 pada kemunculan setiap kata. Pengukuran probabilitas dengan add one smoothing dilakukan dengan mengganti Persamaan (2.1) dengan Persamaan (2.2) (Shimodaira, 2014). 𝑁. 𝑃(𝑊𝑡 |𝐶 = 𝑘) =. 𝑘 𝑋 1+ ∑𝑖=1 𝑖𝑡 |𝑉|. 𝑁. 𝑘 𝑋 |𝑉|+∑𝑠=1 ∑𝑖=1 𝑖𝑠. …(2.2). Penyebut pada Persamaan (2.2) ditambahkan dengan total kosakata dalam dokumen sampel (|𝑉|) untuk memastikan probabilitas ternormalisasi setelah pembilang ditambah dengan nilai 1 (Shimodaira, 2014). 21 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(37) Pada tahap klasifikasi, perhitungan probabilitas posterior untuk setiap kelas pada dokumen uji, yaitu probabilitas kelas 𝐶 dimunculkan pada dokumen 𝐷, dilakukan menggunakan Persamaan (2.3) (Shimodaira, 2014). 𝑙𝑒𝑛 (𝐷). 𝑃(𝐶 |𝐷) ∝ 𝑃(𝐶) ∏ℎ=1. 𝑃(𝑈ℎ |𝐶). …(2.3). Nilai 𝑃(𝐶) merupakan probabilitas prior yang diperoleh dari total dokumen sampel pada kelas 𝐶 (𝑁𝑘 ) dibandingkan dengan total dokumen sampel (𝑁) pada tahap pelatihan. Nilai 𝑃(𝐶) dihitung dengan Persamaan (2.4) (Shimodaira, 2014). 𝑃(𝐶 = 𝑘) =. 𝑁𝑘. …(2.4). 𝑁. Nilai 𝑃(𝑈ℎ |𝐶) pada Persamaan (2.3) merupakan nilai probabilitas kata 𝑈ℎ di kelas 𝐶 yang merupakan kata ke ℎ pada dokumen uji 𝐷 yang didasarkan pada nilai dari perhitungan Persamaan (2.2) pada proses pelatihan (Shimodaira, 2014). Penentuan kelas kemudian dapat dilakukan dengan cara mencari nilai probabilitas posterior tertinggi (maximum a posteriori) (Aziz dkk, 2016). Jika nilai 𝑃(𝐶 = 𝑘 |𝐷) lebih besar dari nilai 𝑃(𝐶 = 𝑗 |𝐷) maka dapat disimpulkan bahwa dokumen 𝐷 terklasifikasi pada kelas 𝑘 (Shimodaira, 2014).. 2.10. Confusion Matrix Pengujian klasifikasi teks dengan algoritma Naive Bayes Classifier. dilakukan dengan mengukur nilai precision, recall, dan f-1 score yang mengacu pada penelitian McCallum dan Nigam (1998) dan Asch (2013). Perhitungan dilakukan dengan menggunakan confusion matrix seperti pada Tabel 2.2. Tabel 2.2 Confusion Matrix (Asch, 2013). Predicted label A Predicted not A. True label A TP (True Positive) FN (False Negative). True not A FP (False Positive) TN (True Negative). 22 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(38) Confusion matrix adalah sebuah tabel yang menyatakan jumlah data uji yang diklasifikasikan dengan benar dan jumlah data uji yang salah diklasifikasikan (Indriani, 2014). Keterangan dari Tabel 2.2 dijelaskan sebagai berikut (Indriani, 2014). . True positive (TP) merupakan jumlah dokumen dari kelas A yang benar diklasifikasikan sebagai kelas A.. . True Negative (TN) merupakan jumlah dokumen yang bukan merupakan kelas A yang benar diklasifikasikan sebagai bukan kelas A.. . False Positive (FP) merupakan jumlah dokumen yang bukan merupakan kelas A yang salah diklasifikasikan sebagai kelas A.. . False Negative (FN) merupakan jumlah dokumen dari kelas A yang salah diklasifikasikan sebagai bukan kelas A.. Precision merupakan pengukuran yang mengestimasi probabilitas kebenaran dari prediksi positif (Costa dkk., 2007). Perhitungan precision dari masing-masing kelas dapat dilakukan menggunakan Persamaan (2.5) (Asch, 2013). 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒𝑠. 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒𝑠+𝐹𝑎𝑙𝑠𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒𝑠. …(2.5). Recall merupakan proporsi sampel dari kelas positif yang benar diprediksi sebagai kelas positif dan digunakan untuk mengevaluasi sensitivitas dari classifier (Costa dkk., 2007). Perhitungan recall dari masing-masing kelas dapat dilakukan menggunakan Persamaan (2.6) (Asch, 2013). 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒𝑠. 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒𝑠+𝐹𝑎𝑙𝑠𝑒 𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒𝑠. …(2.6). Nilai f-1 score merupakan relasi antara label positif dari data dengan label yang diberikan oleh classifier dan mengkombinasikan nilai precision dan recall. 23 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(39) (Sokolova dan Lapalme, 2009). Perhitungan f-1 score dari masing-masing kelas dapat dilakukan menggunakan Persamaan (2.7) (Asch, 2013). 𝐹 − 1 𝑠𝑐𝑜𝑟𝑒 =. 2 × 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑅𝑒𝑐𝑎𝑙𝑙 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑅𝑒𝑐𝑎𝑙𝑙. …(2.7). Terdapat dua metode yang dapat digunakan untuk menghasilkan hasil tunggal dari seluruh hasil pengukuran masing-masing kelas, yaitu macroaveraging dan microaveraging (Manning dkk., 2009). Macroaveraging secara sederhana akan merata-rata hasil penghitungan masing-masing kelas, sementara microaveraging akan mengumpulkan confusion matrix masing-masing kelas yang disebut dengan pooled table dan melakukan perhitungan berdasarkan pooled table tersebut (Manning dkk., 2009). Macroaveraging dapat memperhitungkan efektivitas dari kelas yang memiliki data uji sedikit (Manning dkk., 2009).. 2.11. K-fold Cross Validation Menurut Koppel dkk. (2002) dan Karimi dkk. (2015), pengujian akurasi. klasifikasi teks dapat dilakukan menggunakan k-fold cross validation. Cross validation adalah metode statistik untuk mengevaluasi algoritma learning dengan membagi data menjadi dua segmen, satu segmen digunakan untuk tahap pelatihan dan satu segmen lainnya digunakan untuk memvalidasi model (Refaeilzadeh dkk., 2009). Bentuk umum dari cross validation adalah k-fold cross validation (Refaeilzadeh dkk., 2009). Cross validation merupakan salah satu metode evaluasi yang paling populer dalam memprediksi error dalam klasifikasi (Karimi dkk., 2015). Dalam k-fold cross-validation, data dibagi menjadi k sub-bagian yang eksklusif dengan jumlah data yang relatif sama antar subbagian (Kohavi, 1995). Proses pelatihan dan pengujian dilakukan pada sejumlah k iterasi dan pada setiap 24 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(40) iterasi, digunakan subbagian yang berbeda untuk proses pengujian, sementara k-1 subbagian lainnya digunakan untuk proses pelatihan (Refaeilzadeh dkk., 2009). Evaluasi akhir adalah hasil rata-rata keseluruhan akurasi dari setiap langkah validasi k (Karimi dkk., 2015). Kelebihan dari metode k-fold cross validation adalah dalam metode ini, cara penempatan data tidak berpengaruh karena setiap data akan muncul satu kali pada data pengujian dan muncul sebanyak k-1 kali dalam data pelatihan (Polat dan Güneş, 2007). Menurut Refaeilzadeh dkk. (2009) dan Karimi dkk. (2015), jika dibandingkan dengan nilai k lain, 10-fold cross validation merupakan nilai k yang diterima sebagai metode yang paling dapat diandalkan karena dapat memberikan estimasi akurat terhadap error dari suatu model dari berbagai algoritma dan aplikasi.. 25 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(41) BAB III METODE DAN PERANCANGAN SISTEM. 3.1. Metodologi Metodologi. penelitian. yang. digunakan. dalam. perancangan. dan. pembangunan aplikasi e-complaint berbasis web dengan algoritma Naive Bayes Classifier untuk klasifikasi keluhan ini terdiri dari beberapa tahap, yaitu studi fisibilitas, studi literatur, perancangan dan pembangunan aplikasi, pengujian aplikasi, serta evaluasi dan dokumentasi.. Gambar 3.1 Tahapan Penelitian 3.1.1. Studi Fisibilitas Studi fisibilitas dilakukan untuk mengetahui efektivitas dari sistem. pengajuan aspirasi yang selama ini digunakan di Universitas Multimedia Nusantara. Studi fisibilitas ini memberikan gambaran mengenai permasalahan yang terjadi pada sistem yang sudah berjalan. Studi fisibilitas dilakukan dengan menyebarkan kuesioner secara online. Teknik pengambilan sampel yang digunakan dalam studi fisibilitas adalah stratified random sampling. Oleh karena itu, studi fisibilitas berupa kuesioner ini ditargetkan dengan jumlah responden minimal 30. 26 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(42) responden untuk setiap fakultas, yaitu Fakultas Teknik dan Informatika, Fakultas Bisnis, Fakultas Seni dan Desain, dan Fakultas Ilmu Komunikasi. Selain itu, studi fisibilitas berupa wawancara juga dilakukan dengan Ika Angela selaku Ketua Dewan Keluarga Besar Mahasiswa UMN 2016/2017. Variabel penelitian yang digunakan dalam studi fisibilitas adalah tingkat kepuasan pengguna dan tingkat kegunaan sistem. 3.1.2. Studi Literatur Studi literatur dilakukan untuk mempelajari teori-teori yang berkaitan. dengan perancangan dan pembangunan aplikasi, antara lain teori mengenai studi fisibilitas, skala Likert, stratified random sampling, pengukuran efektivitas sistem informasi, pengukuran kegunaan aplikasi, e-complaint, text classification, class imbalance, algoritma Naive Bayes Classifier, confusion matrix, dan k-fold cross validation. 3.1.3. Perancangan Aplikasi Perancangan aplikasi dilakukan dengan merancang fitur-fitur, alur aplikasi,. dan antarmuka aplikasi yang dibangun. Perancangan aplikasi dilakukan menggunakan arsitektur sistem, Data Flow Diagram, site map, Flowchart Diagram, Entity Relationship Diagram, skema database, struktur tabel, dan rancangan antarmuka aplikasi. 3.1.4. Pembangunan Aplikasi Pembangunan aplikasi merupakan tahap pembuatan kode program. berdasarkan fitur dan antarmuka yang telah dirancang sebelumnya. Tahap pelatihan klasifikasi teks juga dilakukan menggunakan data sampel yang diperoleh dari Dewan Keluarga Besar Mahasiswa UMN. Hal ini bertujuan untuk menemukan pola. 27 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(43) pengklasifikasian teks berdasarkan kategori yang telah ditetapkan menggunakan algoritma Naive Bayes Classifier. 3.1.5. Pengujian Aplikasi Tahap pengujian aplikasi web dilakukan dengan menggunakan USE. Questionnaire dengan skala Likert tujuh tingkat untuk mengukur variabel kegunaan dari aplikasi yang dibangun. Kuesioner diberikan kepada anggota divisi Kesejahteraan Mahasiswa DKBM UMN, ketua DKBM UMN, dan minimal 120 orang mahasiswa UMN dengan metode pengambilan sampel stratified random sampling. Pengukuran kegunaan dilakukan terhadap faktor usefulness, satisfaction, dan ease of use. Selain kegunaan aplikasi, variabel penelitian yang terlibat adalah perhitungan precision, recall, f-1 score, dan akurasi terhadap hasil klasifikasi dengan algoritma Naive Bayes Classifier menggunakan data uji yang diperoleh dari Dewan Keluarga Besar Mahasiswa UMN. 3.1.6. Evaluasi dan Dokumentasi Aplikasi Tahap evaluasi dilakukan dengan menganalisis hasil USE Questionnaire. yang digunakan untuk mengukur kegunaan dari aplikasi yang dibangun. Selain itu, dilakukan dokumentasi terhadap aplikasi dengan penulisan laporan mengenai perancangan dan pembangunan aplikasi beserta dengan hasil evaluasi dari pengujian aplikasi.. 3.2. Perancangan Aplikasi Perancangan aplikasi dilakukan dengan merancang arsitektur sistem, Data. Flow Diagram, site map, Flowchart Diagram, Entity Relationship Diagram, skema database, struktur tabel, dan perancangan antarmuka aplikasi.. 28 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(44) 3.2.1. Arsitektur Sistem Arsitektur sistem digunakan untuk merancang struktur sistem yang terdiri. dari aplikasi yang dibangun beserta dengan relasinya, baik relasi dengan sistem basis data maupun relasi dengan pengguna dan administrator dari aplikasi. Rancangan arsitektur sistem ditunjukkan pada Gambar 3.2.. Gambar 3.2 Arsitektur Sistem Pada Gambar 3.2, ditampilkan struktur dan relasi antara sistem basis data, aplikasi, dan pengguna. Aplikasi ini membagi hak akses menjadi dua, yaitu akses sebagai pengguna dan administrator. Aplikasi dengan hak akses sebagai pengguna maupun administrator terhubung dengan satu sistem basis data yang sama. Aplikasi berbasis web untuk pengguna digunakan oleh mahasiswa UMN, sedangkan aplikasi berbasis web untuk administrator digunakan oleh Divisi Kesejahteraan Mahasiswa DKBM UMN. Aplikasi untuk pengguna memiliki fitur-fitur untuk mengajukan dan melacak status pemrosesan aspirasi, sedangkan aplikasi untuk administrator memiliki fitur-fitur untuk mengelola aspirasi yang masuk dan informasi yang. 29 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(45) ditampilkan kepada pengguna. Aplikasi e-complaint ini diberi nama aplikasi AKU (Aspirasi KBM UMN). 3.2.2. Data Flow Diagram Data Flow Diagram digunakan untuk menggambarkan aliran data yang. keluar dan masuk dari aplikasi. Data Flow Diagram terbagi menjadi context diagram, Data Flow Diagram level 1, dan tujuh Data Flow Diagram level 2. Data Flow Diagram ini terdiri dari empat entitas, yaitu entitas Mahasiswa, entitas DKBM UMN, entitas Tala, dan entitas Bahtera. Entitas Tala merupakan sumber data untuk daftar stopword Bahasa Indonesia, sedangkan entitas Bahtera merupakan sumber data untuk daftar kata dasar Bahasa Indonesia. Context diagram terdiri dari 30 aliran data yang masuk ke sistem dan 37 aliran data yang keluar dari sistem. Context diagram ditunjukkan pada Gambar 3.3. Terdapat sepuluh aliran data yang masuk dari entitas Mahasiswa ke dalam sistem dan setiap aliran data terdiri dari beberapa item data. Aliran data data_login terdiri dari data username dan kata sandi. Aliran data data_lupa_kata_sandi terdiri dari data username.. 30 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
(46) 31. Gambar 3.3 Context Diagram. 31 Rancang Bangun Aplikasi..., Vannia Ferdina, FTI UMN, 2017.
Gambar
+7

Dokumen terkait