PERINGKASAN DOKUMEN TUGAS AKHIR SECARA OTOMATIS MENGGUNAKAN METODE
TF-IDF DAN K-MEANS
REPOSITORY
OLEH
SYNTIA NABILLA NIM. 1603122701
PROGRAM STUDI SISTEM INFORMASI JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS RIAU
PEKANBARU
PERINGKASAN DOKUMEN TUGAS AKHIR SECARA OTOMATIS MENGGUNAKAN METODE TF-IDF DAN K-MEANS
Syntia Nabilla, Aidil Fitriansyah
Mahasiswa Program Studi S1 Sistem Informasi Jurusan Ilmu Komputer
Fakultas Matematika dan Ilmu Pengetahuan Alam Kampus Bina Widya Pekanbaru, 28293, Indonesia
ABSTRACT
Understanding the final assignment with multiple pages takes a long time and it’s not efficient sometimes. This research was made to create automatic summarizing. The data used is chapter IV of the final assignment of the student Information System who graduated in 2018.. Process of the text preprocessing is divided into several parts, case folding, filtering, stemming and tokenizing. After the data passed through the text preprocessing process, the data will be weighted using Term Frequency-Inverse Document Frequency (TF-IDF) method. Then the process of grouping can be done by using k-means clustering method. Testing use compression rate showed 89.06%
information in the document successfully summarized and testing use silhouette coefficient shows an average value of 0.202920986 with the mean quality of the cluster in the good category.
Keywords : Compression Rate, K-Means, Silhouette Coefficient, Text Preprocessing, Text Mining, TF-IDF.
ABSTRAK
Memahami suatu tugas akhir dengan banyak halaman membutuhkan waktu yang lama dan kurang efisien. Penelitian ini bertujuan untuk membuat suatu peringkasan secara otomatis.
Data yang digunakan yaitu bab IV tugas akhir mahasiswa program studi Sistem Informasi lulusan tahun 2018. Untuk tahap text preprocessing dibagi menjadi beberapa bagian yakni case folding, filtering, stemming dan tokenizing. Setelah data melewati tahap text preprocessing, maka dilakukan pembobotan kata menggunakan metode Term Frequency- Inverse Document Frequency (TF-IDF). Untuk metode pengelompokan menggunakan K- Means. Pengujian menggunakan Compression Rate menunjukan 89.06% informasi didalam dokumen berhasil diringkas dan pengujian menggunakan Silhouette Coefficient menunjukan rata-rata nilai sebesar 0.202920986 dengan artian kualitas cluster dalam kategori baik.
Kata Kunci : Compression Rate, K-Means, Silhouette Coefficient, Text Preprocessing, Text Mining, TF-IDF.
PENDAHULUAN
Untuk memahami satu tugas akhir dengan banyak halaman membutuhkan waktu yang lama dan kurang efisien. Perlu adanya peringkasan terhadap tugas akhir tersebut.
Peringkasan otomatis yaitu teknik pembuatan ringkasan dari sebuah data secara otomatis dengan memanfaatkan aplikasi yang dijalankan pada komputer untuk menghasilkan informasi yang paling penting dari teks aslinya. Teknik yang digunakan dalam peringkasan otomatis yaitu Text Mining dan Text Preprocessing. Selain teknik Text Mining dan Text Preprocessing terdapat pendekatan lain yaitu menggunakan metode Term Frequency-Inverse Document Frequency (TF-IDF) dan K-Means. Pada tahap akhir, dilakukan pemilihan dokumen pada tiap cluster berdasarkan bobot dokumen yang paling tinggi menjadi hasil ringkasan.
METODE PENELITIAN
a. Teknik Pengumpulan Data
Objek penelitian yang digunakan adalah data skripsi. Adapun teknik pengumpulan data yang digunakan adalah:
1. Studi Literatur
Studi literatur yaitu pengumpulan data yang berkaitan dengan topik penelitian seperti buku, jurnal, laporan penelitian, dan informasi yang bersumber dari internet.
2. Observasi
Observasi yaitu pengamatan secara langsung terhadap arsip data skripsi yang berupa CD pada prodi SI jurusan Ilmu Komputer FMIPA Universitas Riau lulusan tahun 2018.
b. Peralatan yang Digunakan 1. Perangkat Keras (Hardware)
a) Laptop Samsung dengan processor AMD E1-1500 APU with Radeon ™ HD Graphics (2CPUs),~1,5GHz
b) RAM berkapasitas 2GB
c) Printer Cannon MP2270 untuk mencetak laporan 2. Perangkat Lunak (software)
a) Sistem Operasi Windows 10 Pro 64-bit b) Microsoft Office Word 2016
c) Microsoft Office Excel 2016 d) Xampp versi 3.2.2
e) Sublime Text 3
f) Mozilla Firefox untuk browser menjalankan kode program.
c. Term Frequency-Inverse Document Frequency (TF-IDF)
TF-IDF merupakan metode menentukan seberapa jauh keterhubungan kata (term) terhadap teks dengan memberikan bobot pada setiap kata. (Herwijayanti, Ratnawati and Muflikhah, 2018)
Rumus yang digunakan adalah (Langgeni dkk., 2010) :
𝑊(𝑑, 𝑡) = 𝑇𝐹(𝑑, 𝑡) ... (2.1) dimana :
TF(d,t) : term frequency dari term t di text d.
𝐼𝐷𝐹(𝑡) = log ( 𝑁
𝑑𝑓(𝑡)) ... (2.2) dimana :
N : total jumlah text / dokumen pada koleksi df(t) : jumlah dokumen yang mengandung term t
𝑇𝐹𝐼𝐷𝐹(𝑑, 𝑡) = 𝑇𝐹(𝑑, 𝑡) ∙ 𝐼𝐷𝐹(𝑡) ... (2.3) d. K-Means
Clustering dokumen dengan K-Means dasar algoritmanya adalah sebagai berikut (Langgeni dkk., 2010) :
1. Inisialisasi cluster.
2. Masukkan setiap dokumen ke cluster yang paling cocok berdasarkan ukuran kedekatan dengan centroid.
Centroid adalah vektor term yang dianggap sebagai titik tengah cluster.
Ukuran kedekatan yang digunakan adalah Cosine Similiarity berdasarkan Persamaan (2.4).
3. Setelah semua dokumen masuk ke cluster. Hitung ulang centroid cluster berdasarkan dokumen yang berada di dalam cluster tersebut.
Untuk menghitung centroid cluster ke-i, digunakan rumus mencari rata-rata : 𝑣𝑖𝑗 =∑ 𝑥𝑘𝑗
𝑁𝑖 𝑘=1
𝑁𝑖 ... (2.4) dimana :
𝑣𝑖𝑗 : centroid ke-i atribut term j
𝑥𝑘𝑗 : nilai atribut term j pada data anggota k
𝑁𝑖 : jumlah data yang menjadi anggota cluster ke-i
4. Jika centroid tidak berubah maka stop. Jika berubah, kembali ke langkah 2.
e. Improved K-Means
Improved K-Means merupakan modifikasi algoritma K-Means standar untuk meningkatkan akurasi dan efisiensi dan berfokus pada penentuan jumlah cluster.
(Wihandika and Fauzi, 2017).Jumlah cluster didapat dengan menggunakan rumus estimasi, rumus yang digunakan adalah (Suyanto, 2017):
𝑘 = √𝑛2 ... (2.5) Langkah-langkah dari algoritma Improved K-Means yang merupakan kombinasi antara metode optimasi jarak dan densitas dijelaskan sebagai berikut :
1. Hitung jarak antara setiap pasangan dua objek data yang berada dalam dataset D menggunakan Euclidean Distance.
𝑑(𝑥𝑖, 𝑥𝑗) = √(𝑥𝑖1− 𝑥𝑗1)2+ (𝑥𝑖2− 𝑥𝑗2)2+ ⋯ + (𝑥𝑖𝑚− 𝑥𝑗𝑚)2 ... (2.6)
2. Hitung rata-rata jarak.
𝑀𝑒𝑎𝑛𝐷𝑖𝑠𝑡 = 1
𝐶2𝑛x ∑ 𝑑(𝑥𝑖, 𝑥𝑗) ... (2.7) dimana C merupakan kombinasi pasangan jarak.
3. Hitung nilai parameter densitas seluruh objek data yang berada dalam dataset D.
𝐷𝑒𝑛𝑠(𝑥𝑖) = ∑𝑛𝑗=1𝑢(𝑀𝑒𝑎𝑛𝐷𝑖𝑠𝑡 − 𝑑(𝑥𝑖, 𝑥𝑗)) ... (2.8) dimana 𝑢(𝑧) merupakan sebuah fungsi bernilai 1 jika z lebih besar dari 0 dan bernilai 0 jika sebaliknya.
4. Hitung rata-rata nilai parameter densitas dataset D.
5. Dengan menggunakan rata-rata densitas, tentukan objek data yang terisolasi dan hapus data ini dari D sehingga menghasilkan koleksi A yang memiliki nilai parameter densitas tertinggi.
𝐷𝑒𝑛𝑠(𝑥𝑖) < α x 𝑀𝑒𝑎𝑛𝐷𝑒𝑛𝑠(𝐷) ... (2.9) dimana α berada pada rentang 0 – 1 dalam menentukan data terisolasi.
6. Pilih objek data yang memiliki nilai parameter densitas tertinggi dari A sebagai nilai centroid awal klaster pertama, masukkan kedalam koleksi B, dan hapus dari A.
7. Dari koleksi A, pilih objek data yang memiliki jarak terjauh dari objek data yang berada dalam B sebagai nilai centroid awal klaster berikutnya, masukkan kedalam B, dan hapus dari A.
8. Ulangi langkah 7 hingga jumlah objek data k berada dalam koleksi B.
9. Berdasarkan k centroid awal klaster, lakukan K-Means untuk melakukan pengelompokan terhadap objek data. (Abdurasyid, Indriati and Perdana, 2018) f. Cosine Similiarity
Metode cosine similarity merupakan metode yang digunakan untuk menghitung similarity (tingkat kesamaan) antar dua buah objek.Kemiripan yang diberikan adalah 1 jika dua vektor x dan y sama, dan bernilai 0 jika kedua vektor x dan y berbeda (Prasetyo, 2014).
Berikut formula Cosine Similiarity untuk mengukur kesamaan antara dua vektor:
𝑐𝑜𝑠(𝑥, 𝑦) = 𝑥.𝑦
‖𝑥‖‖𝑦‖ ... (2.10) dimana tanda titik (.) melambangkan inner-product, . 𝒙. 𝒚 = ∑𝑟𝑖=1𝑥𝑖𝑦𝑖 , dan ‖𝒙‖ adalah panjang dari vektor x, ‖𝒙‖ = √∑𝑟𝑖=1𝑥𝑖2 .
g. Rasio Kompresi
Menurut (Setyadi, Khrisne and Suyadnya, 2018) rasio kompresi (compression rate) pada suatu ringkasan berfungsi untuk menentukan persentase panjang ringkasan yang ditampilkan. Perhitungan rasio kompresi adalah:
𝐶𝑜𝑚𝑝𝑟𝑒𝑠𝑠𝑖𝑜𝑛 𝑟𝑎𝑡𝑒 =Pj.Rngks Sistem
Jml.Teks Asli x100%.………...……….………...(2.11) h. Silhouette Coefficient
Silhouette Coefficient digunakan untuk melihat kualitas dan kekuatan cluster.
Tahapan perhitungan Silhouette Coefficient adalah sebagai berikut:
1. Hitung rata-rata jarak dari suatu data misalnya i dengan semua data lain yang berada didalam satu cluster(𝑎𝑖).
(𝑎𝑖) = |𝐴|−11 ∑ 𝑗 𝜖𝐴. 𝑗 ≠ 𝑖(𝑖, 𝑗)……….…..…………..(2.12) Dengan j adalah data lain dalam satu cluster A dan d(I,j) adalah jarak antara data I dengan J.
2. Hitung rata-rata jarak dari data i tersebut dengan semua data di cluster lain, dan diambil nilai terkecilnya.
𝑑(𝑖, 𝐶) = 1
|𝐴|∑ 𝑗 𝜖𝐶 𝑑(𝑖, 𝑗)……… …..…………..…...(2.13) Dengan 𝑑(𝑖, 𝐶) adalah jarak rata-rata data I dengan semua objek pada cluster lain 𝐶 dimana 𝐴 ≠ 𝐶.
𝑏(𝑖) = min 𝐶 ≠ 𝐴 𝑑(𝑖, 𝐶) 3. Rumus Silhouette Coefficient:
𝑠(𝑖) = (𝑏(𝑖) − 𝑎(𝑖))/max (𝑎(𝑖), 𝑏(𝑖)) ………...…...(2.14) Dengan 𝑠(𝑖) adalah semua rata-rata pada semua kumpulan data. (Shoolihah, Furqon and Widodo, 2017)
HASIL DAN PEMBAHASAN
a. Pengumpulan Data
Hasil pengumpulan data diperoleh sebanyak 23 bab IV tugas akhir Jurusan Ilmu Komputer Program Studi Sistem Informasi lulusan tahun 2018 Universitas Riau.
b. Pemisahan Paragraf
Kumpulan data yang didapat akan dikonversi secara manual menjadi data berformat csv. Peneliti menggunakan tugas akhir Ardanil Maulana (1403114528) yang berjudul
“Sistem Identifikasi Kematangan Buah Kelapa Sawit Dengan Menggunakan Metode Naïve Bayes” sebagai contoh dari penerapan peringkasan tugas akhir secara otomatis menggunakan metode TF-IDF dan K-Means.Dari hasil konversi secara manual didapat 16 dokumen penyusun bab IV tugas akhir Ardanil Maulana (1403114528).
c. Text Preprocessing
Proses case folding, semua huruf di seluruh data diubah kedalam case yang sama menjadi huruf kecil, dan dilakukan proses pembersihan karakter. Proses filtering atau sering dikenal dengan istilah stopword removal adalah proses penghapusan kata yang tidak relevan dalam teks, kata-kata yang dianggap tidak deskriptif akan dihilangkan.
Proses stemming, kata-kata yang berimbuhan akan diubah menjadi kata dasar. Proses tokenizing, setiap dokumen akan dipotong berdasarkan tiap kata penyusunnya. Jumlah total term unik atau kata unik yang terdapat pada dokumen berjumlah 204 kata
d. Pembobotan TF-IDF
1. Term frequency yaitu menghitung jumlah frekuensi terhadap kemunculan kata dalam suatu dokumen. Kata yang dihitung adalah 204 kata unik terhadap 16 dokumen menggunakan persamaan (2.1).
2. Document frequency yaitu menghitung frekuensi dokumen yang mengandung kata t.
3. Inverse Document Frequency yaitu hasil log basis 10 dari jumlah seluruh data dibagi jumlah DF(t) menggunakan persamaan (2.2).
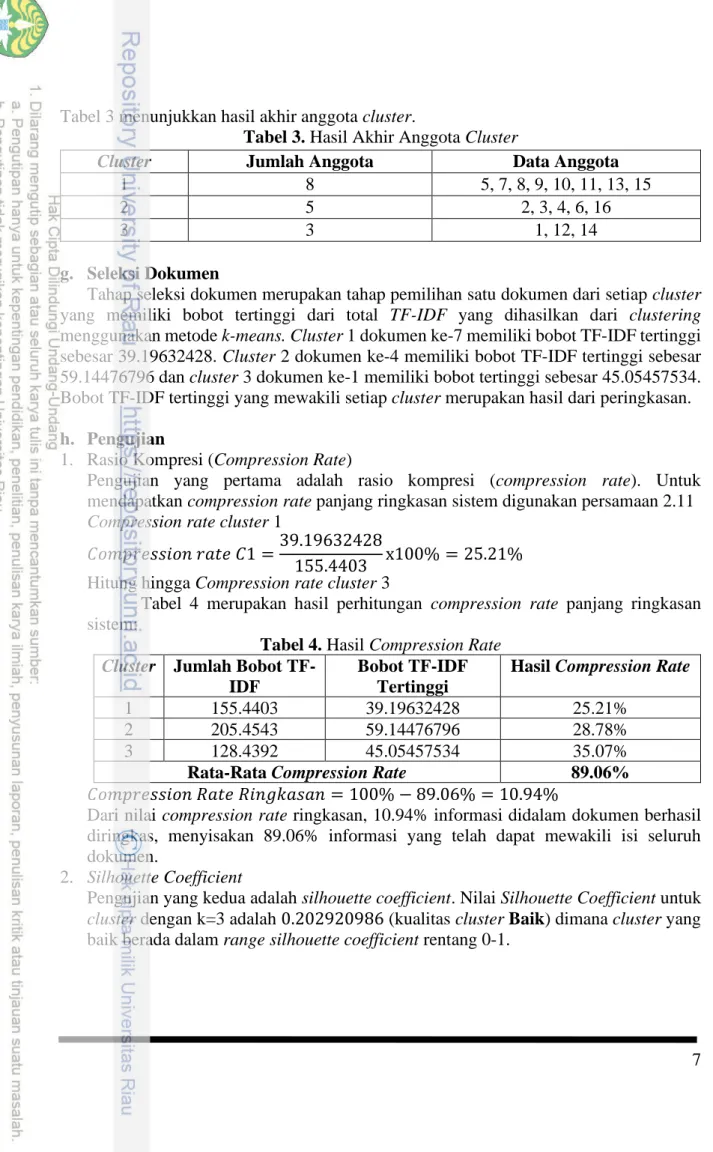
4. Term Frequency-Inverse Document Frequency yaitu hasil perkalian dari TF dan IDF menggunakan persamaan (2.3). Vektor hasil proses TF-IDF dapat dilihat pada tabel 1.
Tabel 1. Vektor Hasil TF-IDF Dokumen adnan
(term 1)
adobe (term 2)
akurasi
(term 3) s/d web (term 204)
1 0 0 0 … 0
2 0 0 0 … 0
s/d…
15 0 0 3.634993639 … 0
16 0 0 0.726998728 … 0
e. Inisialisasi Centroid dengan Improved K-Means
Jumlah cluster didapatkan dengan persamaan 2.5. Berikut perhitungan mencari jumlah klaster dari 16 dokumen adalah 3 cluster. Hasil inisialisasi centroid awal klaster dari tahapan Improved K-Means dapat dilihat pada tabel 2.
Tabel 2. Centroid Awal Klaster
Cluster Centroid Cluster
1 Dokumen ke-8=[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.359021942, … ,0,]
2 Dokumen ke-2=[ 0, 0, 0, 0.726998727, 0, 1.277906196 … ,0]
3 Dokumen ke-1=[ 0, 0, 0, 0, 0, 4.2596873227,0,0,0,0,0,0 … ,0]
f. Clustering dengan K-Means
Berikut merupakan uraian langkah-langkah clustering menggunakan algoritma k- means:
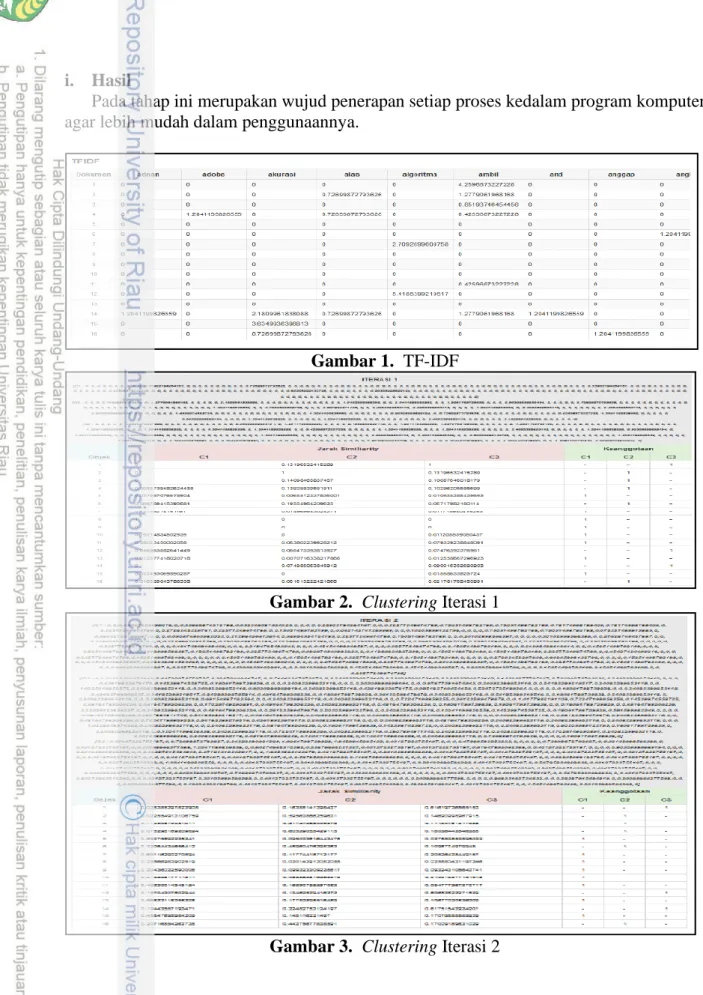
1. Menghitung jarak tiap data objek dengan masing-masing centroid klaster menggunakan Cosine Similiarity berdasarkan Persamaan (2.10).
Iterasi 1:
Jarak similaritas dokumen 1 dengan cluster 1 cos(𝑑1, 𝑐1) = 𝑑1. 𝑐1
‖𝑑1‖‖𝑐1‖= (0.0) + (0.0) + ⋯ + (0.0)
√02+ 02+ ⋯ + 02𝑥√02+ 02+ ⋯ + 02 = 0
= 1
Hitung hingga dokumen ke-16
2. Alokasikan tiap dokumen kedalam klaster terdekat yang memiliki jarak similiaritas tertinggi. Proses pengalokasian dokumen dilakukan hingga dokumen ke-16.
3. Hitung nilai centroid baru dengan menggunakan persamaan 2.4
4. Ulangi langkah 1 sampai langkah 3 hingga perhitungan hasil centroid baru untuk iterasi selanjutnya sama dengan centroid pada iterasi sebelumnya. Jika centroid baru dan centroid lama telah stabil atau convergent.
Tabel 3 menunjukkan hasil akhir anggota cluster.
Tabel 3. Hasil Akhir Anggota Cluster
Cluster Jumlah Anggota Data Anggota
1 8 5, 7, 8, 9, 10, 11, 13, 15
2 5 2, 3, 4, 6, 16
3 3 1, 12, 14
g. Seleksi Dokumen
Tahap seleksi dokumen merupakan tahap pemilihan satu dokumen dari setiap cluster yang memiliki bobot tertinggi dari total TF-IDF yang dihasilkan dari clustering menggunakan metode k-means. Cluster 1 dokumen ke-7 memiliki bobot TF-IDF tertinggi sebesar 39.19632428. Cluster 2 dokumen ke-4 memiliki bobot TF-IDF tertinggi sebesar 59.14476796 dan cluster 3 dokumen ke-1 memiliki bobot tertinggi sebesar 45.05457534.
Bobot TF-IDF tertinggi yang mewakili setiap cluster merupakan hasil dari peringkasan.
h. Pengujian
1. Rasio Kompresi (Compression Rate)
Pengujian yang pertama adalah rasio kompresi (compression rate). Untuk mendapatkan compression rate panjang ringkasan sistem digunakan persamaan 2.11 Compression rate cluster 1
𝐶𝑜𝑚𝑝𝑟𝑒𝑠𝑠𝑖𝑜𝑛 𝑟𝑎𝑡𝑒 𝐶1 =39.19632428
155.4403 x100% = 25.21%
Hitung hingga Compression rate cluster 3
Tabel 4 merupakan hasil perhitungan compression rate panjang ringkasan sistem:
Tabel 4. Hasil Compression Rate Cluster Jumlah Bobot TF-
IDF
Bobot TF-IDF Tertinggi
Hasil Compression Rate
1 155.4403 39.19632428 25.21%
2 205.4543 59.14476796 28.78%
3 128.4392 45.05457534 35.07%
Rata-Rata Compression Rate 89.06%
𝐶𝑜𝑚𝑝𝑟𝑒𝑠𝑠𝑖𝑜𝑛 𝑅𝑎𝑡𝑒 𝑅𝑖𝑛𝑔𝑘𝑎𝑠𝑎𝑛 = 100% − 89.06% = 10.94%
Dari nilai compression rate ringkasan, 10.94% informasi didalam dokumen berhasil diringkas, menyisakan 89.06% informasi yang telah dapat mewakili isi seluruh dokumen.
2. Silhouette Coefficient
Pengujian yang kedua adalah silhouette coefficient. Nilai Silhouette Coefficient untuk cluster dengan k=3 adalah 0.202920986 (kualitas cluster Baik) dimana cluster yang baik berada dalam range silhouette coefficient rentang 0-1.
i. Hasil
Pada tahap ini merupakan wujud penerapan setiap proses kedalam program komputer agar lebih mudah dalam penggunaannya.
Gambar 1. TF-IDF
Gambar 2. Clustering Iterasi 1
Gambar 3. Clustering Iterasi 2
Gambar 4. Hasil Ringkasan KESIMPULAN
Berdasarkan penelitian yang telah dilakukan, dapat disimpulkan beberapa hal sebagai berikut:
1. Pembangunan peringkasan dokumen tugas akhir secara otomatis menggunakan metode TF-IDF dan k-means telah berhasil dilakukan.
2. Peringkasan dokumen tugas akhir menggunakan metode TF-IDF dan k-means kurang efektif untuk dilakukan.
3. Proses inisialisasi centroid menggunakan improved k-means efektif dilakukan untuk menghindari perubahan hasil ringkasan disetiap kali percobaan dan menghasilkan suatu ringkasan yang statis.
4. Compression rate ringkasan sistem mencapai 89.06%. Artinya informasi didalam dokumen berhasil diringkas, menyisakan 10.94% informasi yang telah dapat mewakili isi seluruh dokumen.
5. Cluster dengan k=3 memiliki kualitas cluster yang baik dengan nilai silhouette coefficient sebesar 0.202920986.
SARAN Saran dari penelitian ini adalah sebagai berikut:
1. Dibutuhkan pembangunan sistem yang lebih kompleks pada pengembangan sistem peringkasan dokumen yang akan dilakukan selanjutnya.
2. Dibutuhkan suatu cara atau algoritma dalam penentuan jumlah cluster agar cluster yang dihasilkan lebih optimal.
3. Metode ini dapat dikembangkan menggunakan perbandingan atau mengkombinasikan metode lain untuk mendapatkan hasil yang lebih optimal. Seperti yang telah dilakukan didalam penelitian, metode lain yang digunakan yaitu metode improved k-means pada proses inisialisasi centroid awal dan cosine similarity pada perhitungan jarak similaritas.
UCAPAN TERIMA KASIH
Penulis mengucapkan terima kasih kepada Bapak Aidil Fitriansyah,S.Kom., MIT yang telah membimbing, memberikan arahan, masukan, dan memotivasi serta membantu penelitian dan penulisan karya ilmiah ini.
DAFTAR PUSTAKA
Abdurasyid, M., Indriati, I. and Perdana, R. S. (2018) ‘Implementasi Metode Improved K-Means Untuk Mengelompokan Dokumen Jurnal Pengembangan Teknologi Informasi Dan Ilmu Komputer’, Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 2(10), 3939–3947.
Herwijayanti, B., Ratnawati, D. E. and Muflikhah, L. (2018) ‘Klasifikasi Berita Online dengan menggunakan Pembobotan TF-IDF dan Cosine Similarity’, Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 2(1), 306–312.
Langgeni, D. P., Baizal, Z. A., & Wibowo, Y. F. A. (2010). ‘Clustering Artikel Berita Berbahasa Indonesia Menggunakan Unsupervised Feature Selection’, Seminar Nasional Informatika 2010, 1–10.
Prasetyo, E. (2014). Data Mining: Mengolah Data Menjadi Informasi Menggunakan Matlab. Yogyakarta: Andi.
Setyadi, I. W. A., Khrisne, D. C. and Suyadnya, I. M. A. (2018) ‘Automatic Text Summarization Menggunakan Metode Graph dan Metode Ant Colony Optimization’, 17(1), 124–130.
Shoolihah, A.-, Furqon, M. T. and Widodo, A. W. (2017) ‘Implementasi Metode Improved K-Means untuk Mengelompokan Titik Panas Bumi’, 1(11), pp. 1270–
1276.
Suyanto. (2017). Data Mining: Untuk Klasifikasi dan Klasterisasi Data. Bandung:
Informatika Bandung.
Wihandika, R. C. and Fauzi, M. A. (2017) ‘Implementasi Algoritma Improved K-Means Pada Portal Jurnal Implementasi Algoritma Improved K-Means Pada Portal’, 1–9.