49 3.1 Objek Penelitian
Menurut Nuryaman dan Christina (2015) objek penelitian adalah karakteristik yang melekat pada subjek penelitian. Karakteristik ini jika diberikan nilai maka nilainya akan bervariasi (berbeda) antarindividu satu dengan yang lainnya. Objek dalam penelitian ini adalah laporan keuangan perusahaan perbankan yang telah diaudit dan dipublikasikan di Bursa Efek Indonesia untuk periode 2015-2017.
3.2 Metode Penelitian
Menurut Edison (2012:8) dalam bukunya mengungkapkan metode penelitian ilmiah adalah sebagai berikut:
“Metode penelitian adalah suatu teknik atau suatu cara dalam rangka memperoleh solusi terhadap suatu permasalahan yang dilakukan berdasarkan kaidah-kaidah yang berlaku umum, terukur, rasional, logis serta didasarkan pada interelasi dan intergritas yang sistematis dari fakta-fakta, beban prasangka dan mengandung objektivitas.”(Edison, 2012) Metode yang digunakan dalam penelitian ini adalah metode explanatory. Menurut Nuryaman dan Christina (2015) metode explanatory adalah sebagai berikut :
“Penelitian eksplanatori adalah penelitian yang tujuannya memperoleh jawaban tentang bagaimana dan mengapa suatu fenomena terjadi. Tujuan penelitain ini untuk menjelaskan atau membuktikan bagaimana hubungan antarvariabel penelitian. Hubungan tersebut dapat berbentuk: kolerasional, kausalitas (sebab akibat).”
3.2.1 Populasi dan Sampel Penelitian 3.2.1.1 Populasi Penlitian
Menurut Sekaran dan Bougie (2017:53), populasi diartikan sebagai keseluruhan kelompok orang, kejadian, atau hal-hal yang ingin peneliti investigasi kemudian dibuat opini berdasarkan statistik sampel. Suatu populasi yang telah ditentukan dan dibatasi oleh peneliti jika diketahui dan dapat disusun seluruh anggotanya kedalam suatu daftar, maka daftar anggota populasi tersebut dinamakan
sampling frame.
Populasi pada penelitian ini adalah perusahaan perbankan yang terdaftar di Bursa Efek Indonesia periode 2015-2017 yang berjumlah 43 perusahaan.
3.2.1.2 Sampel Penelitian
Menurut Sekaran dan Bougie (2017:54), sampel adalah sebagian dari populasi. Sampel terdiri atas sejumlah anggota yang dipilih dari populasi. Dengan kata lain, beberapa, namun tidak semua, elemen populasi membentuk sampel. Sampel juga dapat diartikan sebagai subkelompok atau sebagian dari populasi. Dengan mempelajari sampel, peneliti mampu menarik kesimpulan yang dapat digeneralisasikan terhadap populasi ketertarikan (yang diminati).
Sedangkan definisi sampel menurut Nuryaman dan Christina (2015:101) adalah bagian dari populasi, sampel berisi beberapa anggota yang dipilih dari populasi. Dengan kata lain, yang membentuk sampel hanyalah beberapa elemen populasi saja, bukan seluruh elemen.
Teknik sampling yang digunakan dalam penelitian ini adalah non
probability sampling dengan metode purposive sampling. Menurut Nuryaman dan
Christina (2015:109) mengungkapkan bahwa:
“Purposive sampling adalah sampel yang diambil sesuai dengan namanya, yaitu dengan maksud atau tujuan tertentu. Seorang atau seuatu diambil sebagai sampel karena peneliti menganggap bahwa seseorang atau sesuatu tersebut memiliki informasi atau karakteristik yang sesuai dengan keperluan penelitiannya.”
Kriteria-kriteria yang ditetapkan untuk dijadikan sampel dalam penelitian ini yaitu sebagai berikut:
Tabel 3.1
Hasil Purposive Sampling
Kriteria Jumlah
Jumlah perusahaan perbangkan yang terdaftar di Bursa
Efek Indonesia tahun 2015-2017 43
Perusahaan perbankan yang menggunakan mata uang asing sebagai mata uang pelaporan pada tahun 2015-2017
- Perusahaan perbankan yang yang tidak memiliki data
lengkap terkait dengan variabel yang digunakan (17)
Jumlah sampel penelitian 26
Tahun observasi 3
Jumlah Observasi Tahun 2015-2017 78
Berikut ini adalah nama-nama sampel perusahaan perbankan yang terdafar di Bursa Efek Indonesia periode 2015-2017, yaitu :
Tabel 3.2
Hasil Purposive Sampling
No Kode Perusahaan Nama Perusahaan
1 AGRO PT Bank Rakyat Indonesia Agroniaga Tbk
2 AGRS PT Bank Agris Tbk
3 BACA PT Bank Capital Indonesia Tbk
4 BBCA PT Bank Central Asia Tbk
5 BBKP PT Bank Bukopin Tbk
6 BBMD PT Bank Mestika Dharma Tbk
7 BBRI PT Bank Rakyat Indonesia (Persero) Tbk
8 BBYB PT Bank Yudha Bakti Tbk
9 BINA PT Bank Ina Perdana Tbk
10 BJBR PT Bank Pembangunan Daerah Jawa Barat
dan Banten Tbk
11 BJTM PT Bank Pembangunan Daerah Jawa
Timur Tbk
12 BMRI PT Bank Mandiri (Persero) Tbk
13 BNBA PT Bank Bumi Arta Tbk
14 BNGA PT Bank CIMB Niaga Tbk
15 BSIM PT Bank Sinarmas Tbk
16 BTPN PT Bank Tabungan Pensiunan Nasional
Tbk
17 BVIC PT Bank Victoria Internasional Tbk
18 DNAR PT Bank Dinar Indonesia Tbk
19 INPC PT Bank Artha Graha Internasional Tbk
20 MAYA PT Bank Mayapada Internasional Tbk
21 MCOR PT Bank China Cinstruction Bank
Indonesia Tbk
22 MEGA PT Bank Mega Tbk
23 NAGA PT Bank Mitraniaga Tbk
24 NOBU PT Bank Nationalnobu Tbk
25 PNBN PT Bank Bank Pan Indonesia Tbk
26 SDRA PT Bank Woori Saudara Indonesia Tbk
3.2.1.3 Unit Analisis
Menurut Nuryaman dan Christina (2015:5) unit analisis dapat disebut juga subjek penelitian. Unit analisis dapat berupa orang (manusia), organisasi, peristiwa, dan berbagi hal lainnya yang menjadi perhatian dalam kegiatan penelitian. Unit analisis dalam penelitian ini adalah organisasi yaitu perusahaan khususnya perusahaan perbankan yang terdaftar di Bursa Efek Indonesia periode 2015-2017. 3.2.2 Teknik Pengumpulan Data
Teknik pengumpulan data merupakan langkah yang paling strategis dalam penelitian, karena tujuan utama dari penelitian adalah mendapatkan data (Sugiyono, 2017:225). Teknik pengumpulan data yang dilakukan penulis dalam penelitian ini adalah sebgai berikut:
1. Studi Kepustakaan (Library Research)
Studi kepustakaan dilakukan untuk memperoleh landasan teoritis yang berhubungan dengan masalah yang diteliti. Penelitian ini dilakukan dengan membaca, menelaah dan meneliti jurnal-jurnal, buku dan literatur lainnya yang berhubungan erat dengan topik pada penelitian ini sehingga diperoleh informasi sebagai dasar teori dan acucuan untuk mengolah data yang diperoleh.
2. Studi Dokumentasi
Penelitian ini menggunakan metode dokumentasi yaitu dengan cara mengumpulkan data tentang dokumen-dokumen yang berhubungan dengan penelitian ini. Data yang digunakan dalam penelitian ini adalah
laporan keuangan tahunan. perusahaan perbankan yang terdaftar di Bursa Efek Indonesia periode 2015-2017
3.2.3 Jenis dan Sumber Data
Menurut Nuryaman dan Christina (2015) menyebutkan bahwa jenis data penelitian terdiri dari :
1. Data Primer
Data primer adalah data yang diperoleh langsung dari sumber data, yaitu subjek atau benda, maka data tersebut dinamakan data primer, dan sumber datanya dinamakan sumber data primer
2. Data Sekunder
Data sekunder adalah data yang tersedia dan dibuat oleh pihak tertentu dalam bentuk dokumen dan sumber datanya dinamakan sumber data sekunder.
Jenis data yang digunakan dalam penelitian ini adalah data sekunder berupa laporan keuangan tahunan perusahaan perbankan yang trerdaftar di Bursa Efek Indonesia periode 2015-2017. Sedangkan sumber data penelitian ini adalah data sekunder yang bersumber dari www.idx.com.
3.2.4 Operasional Variabel Penelitian
Variabel penelitian yang dioperasikan dalam penelitian adalah objek dari penelitian, agar varaibel dapat diukur variabel harus dioperasionalkan kedalam bentuk nilai. Operasionalisasi variabel merupakan suatu cara pengoperasian
variabel sehingga diperoleh nilai dan gambaran secara nyata dari suatu variabel (Edison,2018:154). Nuryaman dan Christina (2015:90) mengungkapkan bahwa:
”Operasionalisasi variabel dilakukan dengan cara mengamati dimensi, sisi-sisi, ciri-ciri perilaku dari suatu konsep, kemudian menterjemahkan dalam elemen-elemen yang dapat diobservasi dan diukur agar dapat dibuat atau dikembangkan indeks pengukuran dari konsep-konsep tersebut. ”
Sesuai dengan judul penelitian, yaitu “Pengaruh Pajak Tangguhan dan Beban Pajak Kini terhadap Profitabilitas”, maka terdapat dua variabel dalam penelitian ini. Variabel-variabel tersebut adalah:
1. Variabel Bebas (Variabel Independen)
Variabel independen atau disebut juga variabel bebas, eksagenious atau variabel prediktor dan dinotasikan dalam suatu penelitan sebagai variabel X adalah variabel yang secara bebas dapat mempengaruhi variabel dependen atau variabel terikat atau dismpulkan variabel Y (Edison, 2018:67). Variabel independen dalam penelitian adalah Pajak Tangguhan dan Beban pajak Kini.
2. Variabel Terikat (Variabel Dependen)
Variabel dependen disebut juga variabel terikat, endogenious, variabel yang diprediksi adalah variabel yang menjadi perhatian utama dalampenelitian, variabel dependen ini adalah yang menjadi masalah dan merupakan fenomena penelitian yang dituju (Edsion, 2018:67). Variabel independen dalam penelitian adalah Profitabilitas.
Operasional variabel disajikan dalam bentuk tabel agar memahami konsep dan pengukuran variabel-variabel dalam penelitian ini, sebagai berikut:
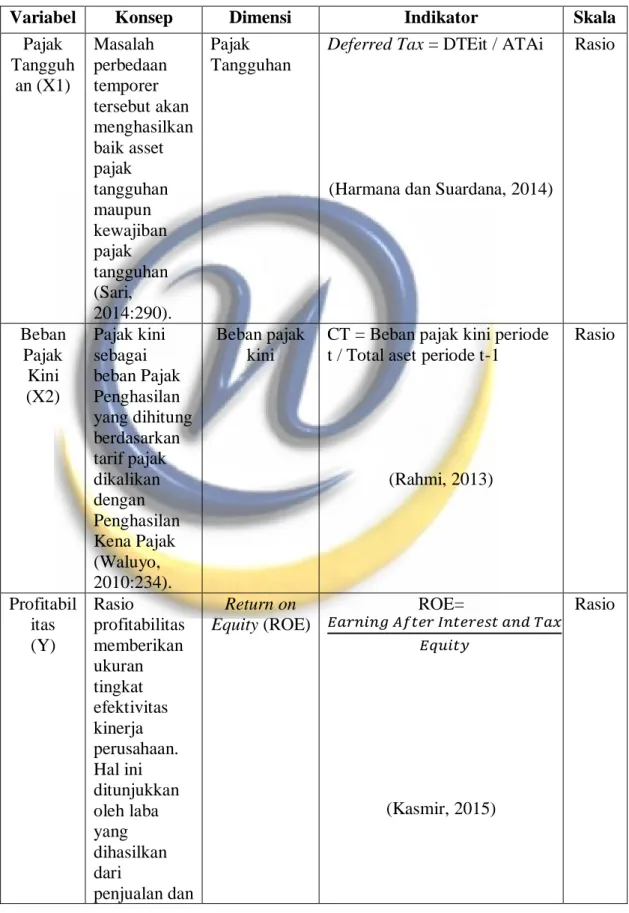
Tabel 3.2 Operasional Variabel
Variabel Konsep Dimensi Indikator Skala
Pajak Tangguh an (X1) Masalah perbedaan temporer tersebut akan menghasilkan baik asset pajak tangguhan maupun kewajiban pajak tangguhan (Sari, 2014:290). Pajak Tangguhan
Deferred Tax = DTEit / ATAi
(Harmana dan Suardana, 2014)
Rasio Beban Pajak Kini (X2) Pajak kini sebagai beban Pajak Penghasilan yang dihitung berdasarkan tarif pajak dikalikan dengan Penghasilan Kena Pajak (Waluyo, 2010:234). Beban pajak kini
CT = Beban pajak kini periode t / Total aset periode t-1
(Rahmi, 2013) Rasio Profitabil itas (Y) Rasio profitabilitas memberikan ukuran tingkat efektivitas kinerja perusahaan. Hal ini ditunjukkan oleh laba yang dihasilkan dari penjualan dan Return on Equity (ROE) ROE= 𝐸𝑎𝑟𝑛𝑖𝑛𝑔 𝐴𝑓𝑡𝑒𝑟 𝐼𝑛𝑡𝑒𝑟𝑒𝑠𝑡 𝑎𝑛𝑑 𝑇𝑎𝑥 𝐸𝑞𝑢𝑖𝑡𝑦 (Kasmir, 2015) Rasio
pendapatan investasi (Kasmir, 2015).
3.3 Metode Analisis Data
Analisisi data merupakan kegiatan mengelompokkan data, mengurutkan, memanipulasi, menyingkatnya agar mudah dibaca. Mengelompokkan data, yaitu membagi data menjadi beberapa kategori, atau bagian (Nuryaman dan Christina, 2015:117). Analisis data dalam penelitian ini menggunakan software Eviews 10. 3.3.1 Statistik Deskriptif
Statistik deskriptif memberikan gambaran atau deskripsi suatu data yang dilihat nilai rata-rata (mean), standar deviasi, varian, maksimum, minimum, sum,
range, kurtosis dan skewness (Ghozali, 2016:19). Di dalam penelitian ini, penulis
akan mendeskripsikan kondisi variabel pajak tangguhan, beban pajak kini dan profitabilitas.
3.3.2 Model Regresi Data Panel
Regresi menggunakan data panel (regresi data panel) artinya prosedur ini dipakai untuk menganalisis data kombinasi antara dua data runtutatan waktu (time
series) dan data silang (cross section) (Sarwono, 2017:29). Adapun model
persamaan analisis regresi data panel tersebut adalah sebagai berikut: Y = a + b1X1 + b2X2 + e
Sumber: Sugiyono (2017:275) Keterangan:
a = Konstanta
b1 = Koefisien Regresi Pajak Tangguhan X1 = Pajak Tangguhan
b2 = Koefisien Regresi Beban Pajak Kini X2 = Beban Pajak Kini
e = Standar error
3.3.3 Pemilihan Model Regresi Data Panel
Terdapat tiga model pendeketan dalam perhitungan modal regresi data panel yaitu model common effect (Pool Least Square/PLS), fixed effect (FEM), dan
random effect (REM). Berdasarkan hasil ketiga model yang telah diestimasi akan
dipilih model mana yang paling tepat atau sesuai dengan tujuan penelitian. Ada tiga uji yang digunakan untuk memilih teknik estimasi data panel, yaitu: uji chow, uji
Hausman, dan uji Langrange Multiplier (Widarjono, 2017:70).
3.3.3.1 Uji Chow
Uji chow digunakan untuk menentukan apakah model data panel diregresi dengan model common effect atau fixed effect (Widarjono, 2017:71). Untuk mengetahui model common effect atau model fixed effect yang akan dipilih, untuk estimasi data dapat dilakukan dengan perbandingan antara nilai Cross-section
Chi-square dan nilai profitabilitas. Hipotesis dalam uji ini adalah sebagaii berikut:
H0: Common Effect Model H1: Fixed Effect Model Keterangan:
Jika nilai probabilitas Cross-section Chi-square > 0.05; maka Ho diterima Pengujian dilakukan untuk menguji model data panel yang cocok untuk digunakan antara model common effect atau model fixed effect. Setelah terpilih salah satu model data panel dalam uji chow, maka perlu dilakukan penjualan selanjutnya yaitu uji hausman untuk memastikan bahwa model data panel yang cocok sama dengan uji chow.
3.3.3.2 Uji Hausman
Uji hausman digunakan untuk menentukan apakah model data panel di regresi dengan model fixed effect atau denga mondel random effect (Widarjono, 2017:73). Dalam data panel dapat terjadi gangguan baik antarwaktu (time series), antarindividu (cross-section) ataupun keduanya. Dengan adanya gangguan tersebut, terdapat dua alternatif metode dalam menaksir nilai regresi yaitu fixed
effect model (FEM) dan random effect model (REM). Untuk gangguan
antarindividu (cross-section) bersifat tetap maka digunakan fixed effect model (REM). Hipotesis dalam uji ini adalah sebagai berikut:
H0: Random Effect Model H1: Fixed Effect Model Keterangan:
Jika nilai probabilitas Cross-section Chi-square < 0,05; maka Ho ditolak Jika nilai probabilitas Cross-section Chi-square > 0.05; maka Ho diterima
Pengujian dilakukan untuk menguji model data panel yang cocok untuk digunakan antara model fixed effect atau model random effect. Jika model data panel yang diperoleh dalam uji hausman sama dengan model data panel yang di uji
dalam uji chow, maka tidak perlu dilakukan pengujian lanjutan yaitu langrange
multiplier. Namun, jika hasil antara uji hausman dan uji chow memiliki hasil yang
berbeda perlu dilakukan pengujian lanjutan yaitu uji langrange multiplier. 3.3.3.3 Uji Langrange Multiplier
Uji ini digunakan untuk menentukan apakah model data panel di regresi dengan model common effect atau model random effect (Widarjono, 2017:75). Hipotesis dalam uji ini adalah sebagai berikut:
H0: Common Effect Model H1: Fixed Effect Model Keterangan:
Jika nilai probabilitas Breusch-pagan < 0,05; maka Ho ditolak Jika nilai probabilitas Breusch-pagan > 0,05; maka Ho diterima
Pengujian dilakukan untuk menguji model data panel yang cocok untuk digunakan antara model common effect atau model random effect. Uji langrange multiplier dilakukan apabila hasil model data panel yang dihasilkan pada uji chouw dan uji
hausman tidak sesuai, maka diperlukan uji langrange multiplier.
3.3.4 Pengujian Asumsi Klasik
Pengujian regresi linier dapat dilakukan apabila memenuhi berbagai persyaratan dan kondisi yakni terpenuhinya pengujian ekonometrik, atau populer dinamakan asumsi klasik. Asumsi klasik harus dilakukan pengujian terlebih dahulu sehingga analisis regresi dapat dilakukan. (Edison, 2018:202).
3.3.4.1 Uji Multikolonieritas
Uji multikolonieritas bertujuan untuk menguji apakah model regresi ditemukan adanya kolerasi antar variabel bebas (independen). Model regresi yang baik seharusnya tidak terjadi kolerasi di antara variabel independen (Ghozali, 2016:103). Menurut Edison (2012:204) menjelaskan bahwa uji multikolinearitas sebagai syarat dalam melakukan analisis regresi ditujukan untuk menguji apakah antara variabel independen berkolerasi. Pengujian ini digunakan dengan pengukuran Variance Inflating Factors (VIF) ditujukan untuk melihat adanya gejala multikolinearitas antarvariabel independen. Batasan pengukuran gejala multikolinearitas didasarkan pada ketentuan berikut:
1. Nilai VIF < 10 menunjukkan tidak terjadi gejala multikolinearitas diantara variabel independen.
2. Nilai VIF > 10 menunjukkan terjadi gejala multikolinearitas diantara variabel independen.
3.3.4.2 Uji Autokolerasi
Uji autokolerasi bertujuan menguji apakah dalam model regresi linear ada kolerasi antara kesalahan pengganggu pada periode t dengan kesalahan pengganggu pada periode t-1 (sebelumnya). Autokolerasi muncul karena observasi yang berurutan sepanjang waktu berkaitan satu sama lainnya (Ghozali, 2016:107). Cara yang dapat dilakukan untuk mendeteksi ada atau tidaknya autokorelasi adalah dengan melakukan pengujian. Durbin Waston (DW). Pengambilan keputusan ada atau tidaknya autokorelasi dilihat dalam table 3.4 berikut ini.
Table 3.4
Kriteria Pengambilan Keputusan Uji Durbin Waston
Hipotesis Nol Keputusan Jika
Tidak ada autokorelasi positif Tolak 0<d<dl Tidak ada autokorelasi positif No decision dl≤d≤du Tidak ada autokorelasi negatif Tolak 4-dl<d<4 Tidak ada autokorelasi negatif No decision 4-du≤d≤d-dl Tidak ada autokorelasi positif
atau negatif
Tidak ditolak Du<d<4-du
3.3.4.3 Uji Heteroskedastisitas
Menurut Ghozali (2016:134) uji heteroskedastisitas bertujuan menguji apakah dalam model regresi terjadi ketidaksamaan variance dari residual satu pengamatan ke pengamatan yang lain. Jika variance dari residual satu pengamatan ke pengamatan lain tetap, maka disebut homoskedastisitas dan jika berbeda disebut heteroskedastisitas. Model regresi yang baik adalah yang homoskedastisitas atau tidak terjadi heteroskedastisitas. Penelitian uji heteroskedastisitas dilakukan dengan menggunakan Uji-White.
Uji-White yaitu dilakukan dengan meregresikan residual kuadrat sebagai
variabel dependen. Dengan variabel dependen ditambah dengan kuadrat variabel independen, kemudian ditambahkan lagi dengan perkalian dua variabel independen.
Prosedur pengujian dilakukan dengan hipotesis sebagai berikut:
H0 : Tidak terjadi gejala heteroskedastisitas pada model regresi
Pada tingkat signifikansi 0.05 apabila nilai probabilitas obs*R-square < 0.05 maka terjadi gejala heteroskedastisita, sebaliknya apabila nilai probabilitas obs*R-square > 0.05 maka tidak terjadi gejala heteroskedastisitas.
3.3.4.4 Uji Normalitas
Menurut Ghozali (2016:160), uji normalitas bertujuan untuk menguji apakah dalam model regresi, variabel dependen dan variabel independen keduanya mempunyai distribusi normal ataukah tidak. Uji normalitas dilakukan untuk mengetahui sifat distribusi data penelitian yang berfungsi untuk mengetahui sifat distribusi data penelitian yang berfungsi untuk mengetahui apakah sampel yang diambil normal atau tidak dengan menguji sebaran data yang dianalisis.
Pengujian normalitas didalam penelitian menggunakan software Eviews 10. Dalam software Eviews 10, normalitas sebuah data dapat dilihat dari gambar histogram, namun seringkali polanya tidak mengikuti bentuk kurva normal, sehingga sulit disimpulkan. Menurut Ghozali (2016:165), lebih mudah bila melihat koefisien Jarque-Bera dan probabilitasnya. Kedua angka ini bersifat saling mendukung, Jarque-Bera adalah uji statistik untuk mengetahui apakah data berdistribusi normal. Terdapat dua cara untuk melihat apakah data berdistribusi normal, yaitu:
1. Bila nilai Jarque-Bera (J-B) tidak signifikan (lebih kecil dari 2), maka distribusi data adalah normal.
2. Nilai Sig. atau signifikan atau probabilitas lebih besar dari 0.05, maka distribusi data adalah normal.
3.3.5 Pengujian Hipotesis secara Parsial (Uji t)
Menurut Ghozali (2016:62), uji statistik t pada dasarnya menunjukkan seberapa jauh pengaruh satu variabel independen terhadap variabel dependen dengan menganggap variabel independen lainnya konstan. Untuk menguji koefisien regresi secara parsial dari variabel-variabel bebas (X) terhadap variabel terikat (Y), selanjutnya pengujian dilakukan dengan mengunakan uji statistik t dengan kriteria penerimaan dan penolakan H0 adalah sebagai berikut:
1. Jika probabilitas < 0.05 maka variabel X secara parsial tidak memiliki pengaruh signifikan terhadap variabel Y.
2. Jika probabilitas > 0.05 maka variabel X secara parsial tidak memiliki pengaruh signifikan terhadap variabel Y
H0 menyatakan bahwa koefisien korelasi parsial untuk masing-masing variabel independen adalah tidak signifikan, sedangkan Ha menyatakan bahwa koefisien korelasi parsial untuk masing-masing variabel independen adalah signifikan.
3.3.6 Pengujian Hipotesis secara Simultan (Uji F)
Menurut Ghozali (2016:96) menjelaskan bahwa uji hipotesis ini dinamakan uji signifikan secara keseluruhan terhadap garis regresi yang diobservasi maupun estimasi, apakah Y berhubungan linear terhadap X1 dan X2. Kriteria pengambilan keputusannya:
1. Bila F hitung > F tabel atau probabilitas < nilai signifikan (sig ≤ 0,05), maka hipotesis tidak dapat ditolak, ini berarti bahwa secara simultan
variabel independent memiliki pengaruh sigginifikan terhadap variabel dependen.
2. Bila F hitung < F tabel atau probabilitas > nilai signifikan (sig ≥ 0,05), maka hipotesis diterima, ini berarti bahwa secara simultan variabel independen tidak mempunyai pengaruh signifikan terhadap variabel dependen.
3.3.7 Uji Koefisien Determinasi
Koefisien Determinasi (R2) pada intinya bertujuan untuk mengukur seberapa jauh kemampuan model dalam menerangkan variasi variabel dependen. Nilai koefisien determinasi adalah antara nol dan satu. Nilai (R2) yang kecil berarti kemampuan variabel-variabel independen dalam menjelaskan variasi variabel dependen amat terbatas. Nilai yang mendekati satu berarti variabel-variabel independen memberikan hampir semua informasi yang dibutuhkan untuk memprediksi variasi variabel dependen. Nilai koefisien determinasi lwbih akurat jika ditinjau dari nilai Adjusted R Square (Ghozali, 2016:95).
3.3.8 Penetapan Tingkat Signifikan
Tingkat siginfikan yang ditetapkan dalam penelitian ini adalah sebesar 5% atau 0.05 karena dinilai cukup untuk menguji hubungan antara variabel-variabel yang diuji atas menunjukkan bahwa korelasi antara kedua variabel cukup nyata. Tingkat signifikansi 0.05 artinya adalah kemungkinan besar dari hasil penarikan kesimpulan mempunyai probabilitas 95% atau toleransi kesalahan sebesar 5%.