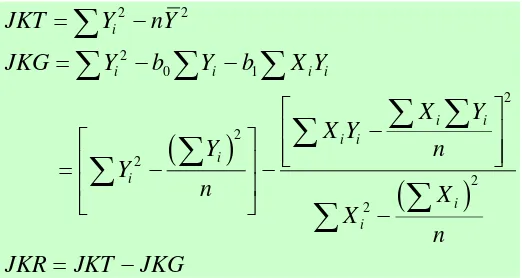BUKU AJAR EKONOMETRIKA
Oleh:
ANWAR
ANAS ZAINI
SUPARMIN
SRI SUPARTININGSIH
JURUSAN SOSIAL EKONOMI PERTANIAN
FAKULTAS PERTANIAN
DAFTAR ISI
Halaman
Kata Sambutan Dekan ……….. ii
Kata Pengantar ……… iii
Daftar Isi ……… iv
Pendahuluan ..………,,,,,,,,, 3
Regresi Linier Sederhana …….……….. 10
Regresi Linier Berganda ……….……… 20
Asumsi Klasik ………... 28
Pengujian Asumsi Klasik ……… 32
Regresi dengan Variabel Dummy ………. 40
Model Regresi Logistik (Logit Model) …….……….. 49
Regresi Multinomial Logit ……… 56
Model Persamaan Simultan ……… 64
BAB I. PENDAHULUAN
Teori ekonomi mencoba mendefinisikan hubungan-hubungan antara
berbagai variabel ekonomi dalam bentuk matematis. Tujuannya untuk
membantu memahami fenomena ekonomi dalam dunia nyata. Teori-teori
tersebut harus diuji dengan data empiris dari dunia nyata. Jika data empiris
membenarkan hubungan yang dimaksudkan oleh teori, maka teori tersebut
dapat diterima, kalau tidak maka teori tersebut harus ditolak.
Untuk memberikan suatu pedoman yang lebih baik bagi keperluan
perumusan kebijakan ekonomi, maka perlu diketahui hubungan-hubungan
kuantitatif antara variabel-variabel ekonomi. Umpamanya, jika investasi
ditingkatkan 15%, berapa besar penghasilan nasional diperkirakan akan
meningkat sebagai akibat kenaikan investasi tersebut. Ukuran-ukuran kuantitatif
diperoleh dari data yang diambil dalam dunia nyata. Jika suatu teori cocok
dengan data aktual, maka teori tersebut dapat diterima sebagai teori yang sahih
(valid).Jika teori itu tidak sesuai dengan perilaku yang diamati, maka teori itu
harus ditolak, atau dimodifikasi berdasarkan bukti data empiris.
Bidang ilmu yang melakukan evaluasi teori-teori ekonomi secara
kuantitatif disebut ilmu ekonometrika. Ekonometrika adalah suatu ilmu yang
mengkombinasikan teori ekonomi dan statistika ekonomi, dengan tujuan
menyelidiki dukungan empiris dari hukum skematis yang dibangun oleh teori
ekonomi. Dengan memanfaatkan ilmu ekonomi, matematika dan statistika,
Ilmu Ekonometrika didefinisikan sebagai ilmu sosial yang menerapkan
peralatan teori ekonomi, matematika, dan statistika inferensi untuk
menganalisis fenomena ekonomi.
Ilmu ekonometrika juga didefinisikan sebagai suatu analisis kuantitatif
dari fenomena ekonomi nyata berdasarkan perkembangan teori dan
pengamatan yang dikaitkan metode-metode inferensi yang sesuai.
Ekonometrika adalah suatu hasil pandangan yang lebih jauh mengenai
peranan ekonomi yang berisikan penggunaan statistika matematika pada data
ekonomi secara empirik menunjang pada model yang dibentuknya melalui
matematika ekonomi untuk mendapatkan hasil numerik.
Dalam arti sempit, ekonometrika adalah pengukuran aktivitas ekonomi
(economic measurement).
Ilmu ekonometrika dibedakan menjadi dua cabang yaitu ekonometrika
teoritis dan ekonometrika terapan. Ekonometrika teoritis berkaitan dengan
pengembangan metode yang tepat untuk mengukur hubungan-hubungan
ekonomi yang digambarkan oleh model ekonometrika. Metode ini dapat
diklasifikasikan ke dalam dua kelompok, yaitu :
1. Metode atau teknik persamaan tunggal, diterapkan untuk satu hubungan
atau satu persamaan.
2. Metode atau teknik persamaan simultan diterapkan untuk seluruh persamaan
dalam model secara simultan. Model simultan adalah model yang
Bidang ilmu ekonometrika teoritis juga menerangkan asumsi-asumsi dari
berbagai metode, sifat-sifat, dan apa yang akan terjadi dengan sifat-sifat itu bila
satu atau lebih asumsi-asumsi tidak dipenuhi (dilanggar).
Ekonometrika terapan menggambarkan nilai praktis dari penelitian
ekonometrika. Jadi mencakup penerapan (aplikasi) teknik-teknik ekonometrika
yang dikembangkan dalam ekonometrika teoritis, pada berbagai bidang teori
ekonomi untuk keperluan pengujian atau pembuktian teori dan peramalan.
Dewasa ini semakin banyak studi empiris dalam bidang permintaan dan
penawaran pasar, fungsi produksi, fungsi biaya, fungsi konsumsi dan investasi,
yang dilaksanakan melalui ekonometrika. Penerapan ekonometrika telah
memungkinkan studi-studi tersebut mencapai hasil-hasil numerik yang sangat
berguna bagi pada perencana.
Berdasarkan hubungan-hubungan pada teori ekonomi itu prosedur atau
tahapan ekonometrika meliputi langkah-langkah sebagai berikut :
1. Merumuskan persamaan matematis yang menggambarkan hubungan antara
berbagai variabel ekonomi, seperti yang diterangkan oleh teori ekonomi
(spesifikasi).
2. Merancang metode dan prosedur berdasarkan teori statistika, untuk
mendapatkan sampel yang mewakili dunia nyata.
3. Menyusun metode estimasi parameter hubungan-hubungan yang dilukiskan
pada langkah pertama (penaksiran).
4. Menyusun metode statistika untuk keperluan pengujian validitas teori,
dengan menggunakan parameter-parameter yang telah didapat pada
5. Mengembangkan metode peramalan ekonomi ataupun implikasi kebijakan
berdasarkan parameter-parameter yang telah ditaksir (aplikasi atau penerapan).
Jadi, prinsipnya ekonometrika membantu dalam mencapai tiga tujuan
pokok, yaitu :
a. Membuktikan atau menguji validitas teori-teori ekonomi (verifikasi).
b. Menghasilkan taksiran-taksiran numerik bagi koefisien-koefisien hubungan
ekonomi yang selanjutnya bisa digunakan untuk keperluan kebijakan
ekonomi (penaksiran).
c. Meramalkan nilai besaran-besaran ekonomi di masa yang akan datang
dengan derajat probabilitas tertentu (peramalan).
Metodologi Ekonometrika
Teori Konsumsi Keynesian, dasar hukum psikologi ….. adalah bahwa
orang-orang (laki-laki dan perempuan) dalam mempergunakan pendapatannya
secara rata-rata, meningkatnya konsumsi mereka disebabkan oleh
meningkat-nya pendapatan, tetapi peningkatan konsumsi tersebut tidak mencakup seluruh
peningkatan pendapatan. Secara ringkas Postulat Keynes tersebut menyajikan
marginal propensity to consume (MPC) yaitu tingkat perubahan konsumsi untuk perubahan pendapatan sebesar satu unit, yang nilainya berkisar antara
nol dan satu. Untuk menguji hal tersebut maka ahli Ekonometrika harus
mengikuti proses berikut:
a. Spesifikasi Model Ekonometrika
Walaupun Postulat Keynes memberikan hubungan yang positif antara
hubungan kedua peubah tersebut. Ahli Ekonomi Matematika merumuskan
bentuk hubungan fungsi konsumsi sebagai : Y = A + B X ; dimana Y =
pengeluaran konsumsi dan X = pendapatan, asumsinya deterministik (pasti).
Tetapi dalam peubah ekonomi hubungan-hubungan tersebut pada
umumnya tidak pasti. Selain pendapatan masih ada peubah lain yang juga
berpengaruh terhadap pengeluaran konsumsi, seperti tanggungan, umur, dan
lain-lain.
Untuk menanggulangi ketidakpastian hubungan tersebut, ahli Ekonometrika
memodifikasi fungsi konsumsi menjadi: Y = A + B X + u ; u = galat
b. Estimasi
Setelah menspesifikasikan model ekonometrika, selanjutnya menduga
atau mengestimasi (nilai-nilai numerik) parameter-parameter model dari data
yang tersedia. Estimasi ini akan memberikan arti empirik bagi teori ekonomi.
Jika dari suatu penelitian fungsi konsumsi Keynesian diperoleh B=0,80 nilai ini
tidak hanya menunjukan suatu estimat numerik MPC, tapi juga menunjang
hipotesis Keynes bahwa MPC selalu lebih kecil dari satu.
c. Verifikasi (pengujian)
Setelah mengestimasi parameter, selanjutnya menguji apakah kriteria
yang dianalisis memenuhi harapan menurut teori. Misalnya dari teori, MPC
diharapkan oleh Keynes bernilai positif dan lebih kecil dari satu. Hasil penelitian
diperoleh MPC = 0,9, walaupun secara numerik memenuhi nilai yang kurang
dari satu, tapi haruslah diyakinkan benar-benar kurang dari satu, untuk itu perlu
Bentuk Fungsional Model Regresi
1. Model Elastisitas (Log Linier atau Double Log)
Yi = Bo XiB1eui
Model ini merupakan bentuk model regresi dua variabel yang linier
dalam parameter tetapi tidak linier dalam variabel. Bentuk tersebut dapat
diubah menjadi :
Ln Yi = ln Bo + B1 ln Xi + ui
dimana ln = logaritma natural, atauelog ... dengan e = 2,7182818.
Model ini akan linier dalam parameter Bo dan B1, serta linier pula dalam
ln variabelnya (Y dan X).
2. Model Semilog
Misalkan model yang dihadapi adalah :
Ln Yi = Ao + A1 Xi + ui ... (1) atau
Yi = Bo + B1 ln Xi + ui ... (2)
Kedua model tersebut dinamakan model semilog, karena hanya terdapat
bentuk log dalam salah satu ruas persamaan saja.
Dalam model (1) bisa ditunjukkan, bahwa koefisien A1 merupakan
ukuran perubahan proporsional Y yang relatif konstan dari
perubahan-perubahan nilai X yang diketahui, yaitu :
A1 = Perubahan Relatif Y / Perubahan Absolut X
Dengan demikian jika hasil observasi data dapat kita ketahui perubahan
absolut X dan perubahan Y yang merupakan persentase, maka model tersebut
Model-model ini kebanyakan dipergunakan dalam “growth models”
(model untuk kurva pertumbuhan) dari waktu ke waktu, seperti dalam bidang
penelitian ekspor, impor, tenaga kerja, produktivitas tenaga kerja, dan lain-lain.
Seperti halnya model (1), maka dalam model (2) koefisien B1 dapat
ditentukan menurut :
B1 = Perubahan Absolut Y / Perubahan Relatif X
Jadi, koefisien B1 merupakan ukuran perubahan Y yang mutlak dari
perubahan-perubahan nilai X yang proporsional (persentase).
Dengan demikian jika hasil observasi data dapat kita ketahui perubahan
absolut Y dan perubahan X yang merupakan persentase, maka model tersebut
BAB II. REGRESI LINIER SEDERHANA
Dalam kehidupan sehari-hari sering kali ingin diketahui hubungan antar
peubah, misalnya hubungan antara: prestasi belajar dengan IQ, tingkat
pendidikan ibu dengan gizi balita, dan sebagainya. Umumnya suatu peubah
bersifat mempengaruhi peubah yang lainnya. Peubah yang mempengaruhi
disebut peubah bebas sedangkan yang dipengaruhi disebut sebagai peubah
tak bebas atau peubah terikat.
Secara kuantitatif hubungan antara peubah bebas dan peubah terikat
dapat dimodelkan dalam suatu persamaan matematik, sehingga dapat diduga
nilai suatu peubah terikat bila diketahui nilai peubah bebasnya. Persamaan
matematik yang menggambarkan hubungan antara peubah bebas dan terikat
sering disebut persamaan regresi.
Persamaan regresi dapat terdiri dari satu atau lebih peubah bebas dan
satu peubah terikat. Persamaan yang terdiri dari satu peubah bebas dan satu
peubah terikat disebut persamaan regresi sederhana, sedangkan yang terdiri
dari satu peubah terikat dan beberapa peubah bebas disebut persamaan
regresi berganda. Regresi dapat dipisahkan menjadi regresi linear dan regresi
non linear.
Misalkan kita mempunyai sejumlah data berpasangan {(xi, yi), i = 1, 2, 3, . . ., n} data itu dapat diplotkan atau digambarkan pada bidang Kartesius yang
disebut sebagai diagram pencar atau diagram hambur. Dari diagram pencar
dapat diperkirakan hubungan antara peubah-peubah itu apakah mempunyai
Regresi linear sederhana adalah persamaan regresi yang
menggam-barkan hubungan antara satu peubah bebas (X) dan satu peubah tak bebas
(Y), dimana hubungan keduanya dapat digambarkan sebagai suatu garis lurus.
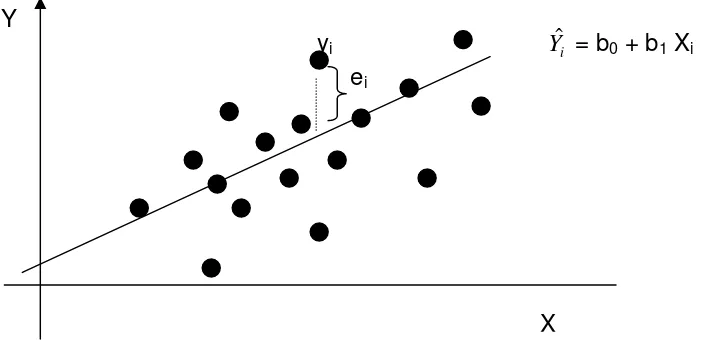
Hubungan kedua peubah tersebut dapat dituliskan dalam bentuk persamaan:
Yi=0+1Xi + i...
Y = Peubah tak bebas, X = Peubah bebas, 0 = intersep/perpotongan dengan
sumbu tegak, 1 = Kemiringan/gradien, i error yang saling bebas dan
menyebar normalN(0,2)i= 1, 2, …,n.
Dalam kenyataan seringkali kita tidak dapat mengamati seluruh anggota
populasi, sehingga hanya mengambil sampel misalkan sampel itu berukuran n
dan ditulis sebagai {(xi , yi), i = 1, 2, 3, . . ., n}. Persamaan yang diperoleh adalah dugaan dari persamaan (12.1) dan dapat dituliskan sebagai:
i
Yˆ = b0+ b1Xi
b0 adalah penduga untuk0, dan b1adalah penduga untuk1.
Untuk peubah bebas xi nilai pengamatan yi tidak selalu tepat berada pada garis Yi
~
= 0 + 1Xi (garis regresi populasi) atau Yˆi = b0 + b1 Xi (garis regresi sampel).
yi Yˆi = b0+ b1Xi ei
Gambar 1. Garis penduga hubungan antara peubah X dan Y Y
Terdapat simpangan sebesar ei(untuk sampel) atau εi (untuk populasi),
Anggapan/asumsi dalam analisis regresi linear sederhana dengan model
Yi=o+1Xi + εi adalah:.
Pendugaan Parameter
β
0dan
β
1Untuk menduga nilai parameter 0 dan 1 terdapat bermacam-macam metode, misalnya metode kuadrat terkecil (least square method), metode
kemungkinan maksimum (maximum likelihood method), metode kuadrat terkecil terboboti (weighted least square method), dsb.
Disini metode yang digunakan adalah metode kuadrat terkecil, karena
mudah dikerjakan secara manual. Prinsip dasar metode kuadrat terkecil adalah
meminimumkan jumlah kuadrat simpangan atau Jumlah Kuadrat Galat
(JKG) =
Dengan menggunakan bantuan pelajaran kalkulus, diperoleh nilai dugaan
Dengan demikian dapat diperoleh hubungan;
Contoh 1.
Diketahui data percobaanSubjek i 1 2 3 4 5 6 7 8 9
xi 1,5 1,8 2,4 3,0 3,5 3,9 4,4 4,8 5,0 yi 4,8 5,7 7,0 8,3 10,9 12,4 13,1 13,6 15,3 Tentukan persamaan regresi dugaan
Jawab :
Dengan menggunakan kalkulator dapat dengan mudah dihitung
9
(9)(345, 09) (30, 3)(91,1)
2, 9303 (9)(115,11) 30, 3
b
bo= 10,1222 – (2,9303)(3,3667) = 0,2568
Jadi persamaan regresi dugaan Yˆ = 0,26 + 2,93X
Pengujian terhadap Model Regresi
Proses selanjutnya setelah melakukan pendugaan parameter model
regresi sederhana adalah pengujian terhadap model regresi apakah signifikan
atau tidak, yang dapat dilakukan dengan dua cara yaitu ANAVA dengan uji F
dan uji parsial dengan uji t.
Uji bagi1=0 lawan10 melalui ANAVA
Hipotesis
H0:1=0 (Tidak ada hubungan linear antara X dan Y) H1:10 (Ada hubungan linear antara X dan Y)
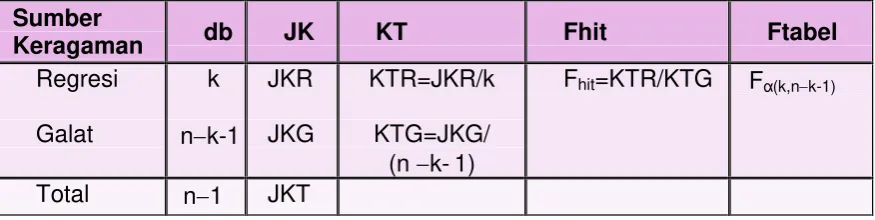
Tabel 1. Anava untuk pengujian pada model regresi linear sederhana
Sumber
Keragaman db JK KT Fhit Ftabel
Regresi
Ho ditolak jika Fhit > Ftabel, yang berarti model regresi signifikan atau ada hubungan liner anatara X dan Y.
Statistik uji adalah : Statistik uji adalah :
dengan
Kriteria keputusan :
H0 ditolak jika | thit| > tα/2(n2)
Perhitungan untuk uji hipotesis menggunakan data Contoh 1.
Dari perhitungan sebelumnya telah diperoleh:
Dengan demikian diperoleh:
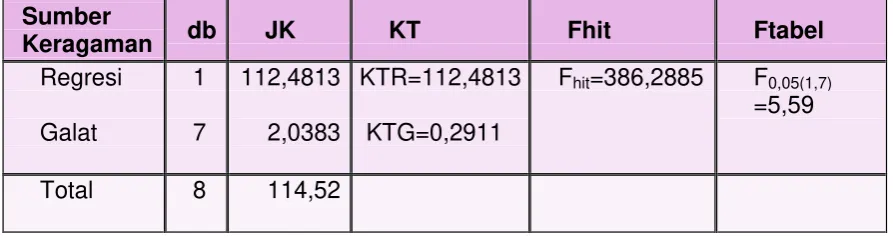
JKT = 1036,659. (10,1222)2= 114,52
JKG = 1036,65(0,2568) 91,1 – (2,9303) 345,09 = 2,0383
JKR = 945,55 –2,0383 = 112,4813
Tabel anava untuk data tersebut disajikan dalam Tabel 2.
Tabel 2. Anava untuk data pada Contoh 1
Sumber
Keragaman db JK KT Fhit Ftabel
Regresi
Fhit=386,2885 F0,05(1,7) =5,59
Total 8 114,52
Berdasarkan hasil pada Tabel 2 diperoleh nilai F hitung lebih besar
daripada nilai F tabel, sehingga H0 ditolak. Jadi ada hubungan linear antara variabel X dan Y.
Untuk uji parsial perlu dihitung terlebih dahulu nilai
dan
Jadi untuk uji signifikansi koefisien 1
thit=
2, 9303
19, 685
0,149
sedangkan untuk uji signifikansi konstanta diperoleh
thit=
0, 2568
0, 483 0, 532
Karena t tabel adalah t0,025;7= 2,365 maka H0ditolak untuk uji koefisien 1dan H0diterima untuk uji signifikansi konstanta.
Contoh 2
:Berikut adalah data Biaya Promosi dan Volume Penjualan PT BIMOIL
perusahaan Minyak Gosok.
bentuk umum persaman regresi linier sederhana : Y = a + bX
Peramalan dengan Persamaan Regresi Contoh 2:
Diketahui hubungan Biaya Promosi (X dalam Juta Rupiah) dan Y
(Volume penjualan dalam Ratusan Juta liter) dapat dinyatakan dalam
persamaan regresi linier berikut:
Y = 2,530 + 1,053 X
Perkirakan Volume penjualan jika, dikeluarkan biaya promosi Rp. 10 juta?
Jawab : Y = 2,530 + 1,053 X
X = 10
Y = 2,53 + 1,053 (10) = 2,53 + 10,53 = 13,06 (ratusan juta liter)
Volume penjualan = 13.06 x 100 000 000 liter
Korelasi Linier Sederhana
Koefisien Korelasi (r): ukuran hubungan linier peubah X dan Y
Nilai r berkisar antara (+1) sampai (-1)
Nilai r yang (+) ditandai oleh nilai b yang (+)
Nilai r yang (-) ditandai oleh nilai b yang (-)
Jika nilai r mendekati +1 atau r mendekati -1 maka X dan Y memiliki korelasi
linier yang tinggi. Jika nilai r = +1 atau r = -1 maka X dan Y memiliki korelasi
linier sempurna. Jika nilai r = 0 maka X dan Y tidak memiliki relasi (hubungan)
linier (dalam kasus r mendekati 0, anda dapat melanjutkan analisis ke regresi
eksponensial).
Koefisien Determinasi Sampel (r²)
Ukuran proporsi keragaman total nilai peubah Y yang dapat dijelaskan
Penetapan & Interpretasi Koefisien Korelasi dan Koefisien Determinasi
r
= r x r (dinyatakan dalam persen)Contoh 3
:Lihat Contoh 2, setelah mendapatkan persamaan Regresi Y = 2,530 + 1,053 X,
hitung koefisien korelasi (r) dan koefisien determinasi (r2). Gunakan data berikut (lihat Contoh 2)
790 676 1730 1600
120
Nilai r = 0,9857 menunjukkan bahwa peubah X (biaya promosi) dan Y (volume
penjualan) berkorelasi linier yang positif dan tinggi.
2
r
0 9857. ...2= 0,97165....= 97,17 %Nilai r2= 97,17% menunjukkan bahwa 97,17% proporsi keragaman nilai peubah
Y (volume penjualan) dapat dijelaskan oleh nilai peubah X (biaya promosi)
BAB III. REGRESI LINIER BERGANDA
Dalam regresi linier sederhana telah dipelajari analisis regresi yang
terdiri atas dua variabel. Dalam pembicaraan tersebut di mana analisisnya
terdiri atas sebuah variabel bebas X (independent variable) sering disebut variabel X atau prediktor, dan sebuah variabel tak bebas Y (dependent
variable) atau variabel Yatau variabel penjelaskan. Tentu dapat dengan mudah dimengerti bahwa, ada juga analisis regresi di mana terdapat lebih
dari dua variabel, yaitu analisis regresi di mana terdapat satu variabel
tergantung (variabel Y) yang diterangkan atau dijelaskan oleh lebih dari satu
variabel lain yang menerangkan (variabel X) atau analisis regresi di mana
terdapat lebih dari satu variabel yang tergantung (variabel Y) yang
diterangkan atau dijelaskan oleh lebih dari satu variabel lain yang
menerangkan (variabel X) yang disebut dengan analisis regresi berganda
multivariate atau analisis ragam multivariat (multivariate multiple regression).
Analisis regresi dengan satu variabel diterangkan atau variabel Y oleh
lebih dari sebuah variabel yang lain atau variabel bebas X, maka analisis
yang demikian ini dinamakan analisis regresi majemuk atau analisis regresi
berganda atau analisis regresi darab.
Sangatlah jelas bahwa dalam permasalahan ini, tidak cocok lagi
memakai perkataan atau istilah garis regresi, karena fungsi linier yang terdiri
dari tiga buah variabel, sudah tidak berbentuk grafik garis lagi, melainkan
Selanjutnya, jika variabel bebas lebih dari tiga buah, menyebabkan
penggambaran grafiknya sangat sulit dan bukan berbentuk bidang atau
ruang. Bentuknya dinamakan multi bidang atau berbidang banyak (hyper plane).
Grafik suatu fungsi akan berbentuk garis jika di dalam fungsi itu
hanya terdapat dua macam variabel, yang koordinatnya berdemensi dua
atau bidang. Sehingga dalam penggambaran grafik dari tiga macam variabel
dapat memakai istilah bidang regresi atau grafiknya berdemensi tiga atau
berdemensi ruang. Tetapi istilah inipun tidak dapat dipertahankan lagi secara
bebas jika telah dipergunakan fungsi regresi yang terdiri dari empat macam
atau lebih variabel yang dipergunakan. Sebagaimana halnya dalam analisis
regresi linier sederhana (lihat Tenaya et al., 1985), maka di dalam analisis
regresi berganda ini juga dapat dikenal adanya:
1). Analisis regresi linier berganda dan
2). Analisis regresi berganda kurvilinier atau analisis regresi berganda non
linier. Perbedaan dari kedua analisis di atas antara analisis regresi linier
berganda dengan analisis regresi berganda kurvilinier (non linier) didasarkan
atas perbedaan pada variabel-variabel bebas (variabel X) yang
menyusun-nya; atau di mana variabel Y yang berbentuk fungsi pangkat atau berpangkat
tidak sama dengan satu.
Untuk mempertegas masalah perbedaan antara analisismregresi linier
berganda dengan analisis regresi berganda non linier, diberikan batasan dan
1). Analisis regresi linier berganda didefinisikan adalah analisis regresi yang
variabel tak bebas Y ditentukan oleh sekurang-kurangnya dua variabel
bebas X dan setiap variabel X maupun variabel Y hanya berpangkat satu
(linier).
2). Analisis regresi berganda non linier didefinisikan adalah sebagai analisis
regresi di mana variabel tak bebas Y ditentukan oleh
sekurang-kurangnya dua variabel bebas X dan yang salah satu atau kedua macam
variabel mempunyai pangkat tidak sama dengan satu. Atau regresi di
mana variabel tak bebas Y dengan pangkat tidak sama dengan satu
ditentukan oleh sekurang-kurangnya dua variabel bebas X.
Regresi linear ganda adalah persamaan regresi yang menggambarkan
hubungan antara lebih dari satu peubah bebas (X) dan satu peubah tak bebas
(Y). Hubungan peubah-peubah tersebut dapat dituliskan dalam bentuk
persamaan:
Y = Peubah tak bebas, X = Peubah bebas, 0 = intersep/perpotongan dengan
sumbu tegak, 1, 2, ...., p1 = parameter model regresi, i saling bebas dan
menyebar normalN(0,2), dimana i= 1, 2, …,n
Persamaan regresi dugaannya adalah :
Hipotesis yang harus diuji dalam analisis regresi ganda adalah
H0:1=2= … =p-1= 0
H1: Tidak semuai (i = 1, 2,…,p1) sama dengan nol
0 1 1 2 2 1 , 1
i i i p i p i
Y X X X
0 1 1 2 2 1 , 1
ˆi i i p i p
Untuk mengestimasi atau menduga koefisien regresi bo, b1, b2, ……., bk digunakan persamaan berikut :
………
Untuk melakukan pendugaan parameter model regresi berganda dan
menguji signifikansinya dapat dilakukan secara manual (metode eliminasi) atau
dengan bantuan komputer.
Contoh 1 :
Berikut adalah data Volume Penjualan (juta unit) mobil dihubungkan dengan
variabel biaya promosi (
X
1 dalam juta rupiah/tahun) dan variabel biayapenambahan asesoris (
X
2 dalam ratusan ribu rupiah/unit).n = 6
Masukkan notasi-notasi ini dalam ketiga persamaan normal,
(i) n xi x y
Sehingga didapatkan tiga persamaan berikut:
(i) 6a + 31 b1 + 40 b2 = 50 (ii) 31 a + 187 b1 + 239 b2 = 296 (iii) 40 a + 239 b1 + 306 b2 = 379
Lakukan Eliminasi, untuk menghilangkan (a)
Selanjutnya, eliminasi (b1) dan dapatkan nilai (b2)
(v) 194 b1 + 236 b2 = 274 161 (iv) 161 b1 + 194 b2 = 226 194
(v) 31234 b1 + 37996 b2 = 44114 (iv) 31234 b1 + 37636 b2 = 43844
360 b2 = 270 b2 = 0,75
Dapatkan Nilai (b1) dan nilai (a) dengan melakukan substitusi, sehingga: (v) 194 b1 + 236 b2 = 274
Perhatikan b2= 0.75
194 b1 + 236 (0,75) = 274 194 b1 + 177 = 274 194 b1 = 97 b1 = 0,50 (i) 6a + 31 b1 + 40 b2 = 50
Perhatikan b1= 0,50 dan b2= 0,75
6a + 31 (0,50) + 40 (0,75) = 50
6a + 15,5 + 30 = 50
6a = 4,5
a = 0,75
Sehingga Persamaan Regresi Berganda
a + b1X1+ b2X2 dapat ditulis sebagai 0,75 + 0,50 X1+ 0,75 X2
Uji F atau Analisis Keragaman atau Analisis Varians Regresi
Dalam analisis keragaman yang merupakan uji F terhadap Ragam
Regresi (KT Regresi atau Kuadrat Tengah Regresi) dengan memakai
Dalam pengujian ini didasarkan pada pemecahan JK Total menjadi
komponen-komponennya yaitu JK Regresi dan JK Galat Regresi, yang
selanjutnya dijadikan Ragam Regresi dan Ragam Galat Regresi. Untuk
memudahkan dalam uji F ini biasanya dibuatkan tabel Analisis Keragaman
(Tabel Sidik Ragam Regresi atau Tabel Analisis Varians Regresi atau
ANAVA Regresi atau ANOVA Regresi) yang komponen-komponennya
seperti berikut.
Tabel Anava untuk pengujian pada model regresi linear berganda
Sumber
Keragaman db JK KT Fhit Ftabel
Regresi
Ho ditolak jika Fhit > Ftabel, yang berarti model regresi signifikan atau ada hubungan liner anatara X dan Y.
Korelasi Linier Berganda
Koefisien Determinasi Sampel untuk Regresi Linier Berganda diberi notasi
sebagai berikut
R
y.12 2 Sedangkan Koefisien Korelasi adalah akar positif Koefisien Determinasi atau
r
y.12 =R
y.122 danR
yJKG : Jumlah Kuadrat Galat
JKG
y
2
a
y
b
1
x y
1
b
2
x y
2Contoh 2 : Jika diketahui (dari Contoh 1)
n = 6
Maka tetapkan
R
y.12 2dan jelaskan arti nilai tersebut!
= 99,53% menunjukkan bahwa 99,53% proporsi keragaman nilai
peubah Y (volume penjualan) dapat dijelaskan oleh nilai peubah X (biaya
BAB IV. ASUMSI KLASIK
Formula atau rumus regresi diturunkan dari suatu asumsi data tertentu.
Dengan demikian tidak semua data dapat diterapkan regresi. Jika data tidak
memenuhi asumsi regresi, maka penerapan regesi akan menghasilkan estimasi
yang bias. Jika data memenuhi asumsi regresi maka estimasi (β) diperoleh
akan bersifat BLUE yang merupakn singkatan dari: Best, Linear, Unbiased,
Estimator.
Best artinya yang terbaik, dalam arti garis regresi merupakan estimasi
atau ramalan yang baik dari suatu sebaran data. Garis regresi merupakan cara
memahami pola hubungan antara dua seri data atau lebih. Garis regresi adalah
best jika garis itu menghasilkan error yang terkecil. Error itu sendiri adalah
perbedaan antara nilai observasi dan nilai yang diramalkan oleh garis regresi.
Jikabestdisertai sifatunbiasedmaka estimator regresi disebut efisien.
Linear.Estimator β disebut linearjika estimator itu merupakan fungsi linear dari sampel.
Rata-rata
x x xn
n X n
X 1
1 1 2 ...Adalah estimator yang linear, karena merupakan fungsi linear dari
nilai-nilai X. Nilai-nilai-nilai OLS juga merupakan klas estimator yang linear.
Unbiased. Suatu estimator dikatakan unbiasedjika nilai harapan dari estimator
β sama dengan nilai yang benar dari β.
Rata-rata β = β
Metode OLS (Ordinary Least Square) yang dirumuskan di atas merupakan klas penaksir yang memiliki sifat BLUE. OLS akan memiliki sifat
BLUE jika memenuhi asumsi-asumsinya, dari mana penurunan formula OLS
diturunkan. Gujarati (1995) mendaftar 10 asumsi yang mejadi syarat
penerapan OLS.
Asumsi 1: Linear Regression Model. Model regresi merupakan hubungan linear dalam parameter.
Y = a + b X + e
Untuk model regresi Y = a + b X + c X2+ e
Walaupun variabel X dikuadratkan tetap merupakan regresi yang linear dalam
parameter, sehingga OLS masih dapat diterapkan.
Asumsi 2: Nilai X adalah tetap dalam sampling yang diulang-ulang (X fixed in repeated sampling). Tepatnya bahwa nilai X adalah nonstochastic (tidak
random).
Asumsi 3: variabel pengganggu e memiliki rata-rata nol (zero mean of disturbance). Ini berarti garis regresi pada nilai X tertentu tepat di tengah-tengah sehingga rata-rata error yang di atas regresi dan di bawah garis regresi
kalau djumlahkan hasilnya nol.
Asumsi 4: Homoscedasticity atau variabel pengganggu e memiliki variance yang sama sepanjang observasi dari berbagai nilai X. Ini berarti data Y pada
Asumsi 5: No autocorrelation between the disturbance (tidak ada otokoreasiantara variabel e pada setiap nilai Xidan Xj).
E (e Xi ) (e Xj) = 0
Korelasi etdan et-1cukup rendah. Jelasnya perhatikan seri data pada contoh di atas.
Y X1 X2 et et-1
10.00 2.00 1.20 -1.4518
12.00 2.20 1.40 -0.2035 -1.4518
14.00 2.30 2.00 0.4741 -0.2035
15.00 2.20 2.30 1.0927 0.4741
16.00 2.40 2.60 1.1517 1.0927
16.00 2.80 2.80 0.0269 1.1517
17.00 2.70 3.50 -0.1117 0.0269
18.00 3.00 4.00 0.6179 -0.1117
18.00 3.00 4.20 0.9965 0.6179
20.00 3.40 4.00 0.6360 0.9965
0.6360
Jika korelasi etdan et-1rendah maka berarti tidak terdapat otokorelasidari e.
Asumsi 6: variabel X dan disturbance e tidak berkorelasi. Ini berarti kita data memisahkan pengaruh X atas Y dan pengaruh variabel e atas Y. Jika X
dan e berkorelasi maka pengaruh keduanya akan tumpang tindih (sulit
dipisahkan pengaruh masing-masing atas Y). Asumsi ini pasti terpenuhi jika X
adalah variabelnon randomataunonstochastic.
Asumsi 7: Jumlah observasi atau besar sampel n harus lebih dari jumlah parameter yang diestimate. Bahkan untuk menjamin terpenuhinya asumsi yang lain, sebaliknya n besar sampel harus cukup besar.
Asumsi 9: Model regresi secara benar terspesifikasi. Tidak ada spesifikasi yang bias. Artinya, kita sudah memasukkan variabel yang direkomendasikan
oleh teori dengan tepat. Atau juga kita tidak memasukkan variabel yang
sembarangan yang tidak jelas kaitannya. Spesifikasi ini juga menyankut bentuk
fungsi apakah parameter linear, dan juga bentuk X linear (pangkat 1) atau
kuadratik (berbentuk kurve U), atau kubik (bentuk S).
Asumsi 10: Tidak ada multikolinearitas antara variabel penjelas X1, X2 dan Xn. Jelasnya korelasi antar variabel penjelas tidak boleh sempurna atau sangat
tinggi.
Dari asumsi 10 di atas tidak semuanya perlu diuji. Sebagian cukup
hanya diasumsikan sedangkan sebagian yang lain memerlukan test.
Penyimpangan masing-masing asumsi juga tidak sama impaknya terhadap
regresi. Penyimpangan atau tidak terpenuhinya asumsi multikolinearitas
(asumsi 10) tidak mengganggu sepanjang uji t sudah signifikan. Hai ini
disebabkan oleh membesarnya standar error pada kasus multikolinearitas,
sehingga jika t = b/sb menjadi cenderung kecil sehingga jika t masih signifikan,
makamultikolienaritastidak perlu diatasi.
Sebaliknya, penyimpangan asumsi homocedasticity dan autokorelasi
menyebabkan b pada sb sehingga t = b/sb menjadi tidak menentu. Walaupun t
sudah signfikan atau tidak signifikan tidak dapat memberi informasi yang
BAB V. PENGUJIAN ASUMSI KLASIK
Mutikolinearitas (Multicollinearity)
Multikolinearitas digunakan untuk menunjukkan adanya hubungan linear
di antara variabel bebas dalam model regresi. Bila variabel-variabel bebas
berkorelasi dengan sempurna, maka disebut multikolinieritas sempurna (perfect multicollinearity), sehingga penaksir metode kuadrat terkecil (OLS) tidak bisa ditentukan (indeterminate), varian dan kovarian dari penaksir-penaksir menjadi
tak terhingga besarnya (infinitely large).
Multikolinearitas pada hakekatnya adalah fenomena sampel dan
merupakan persoalan derajat (degree), bukan persoalan jenis (kind). Akibatnya multikolinearitas adalah: (1) penaksir kuadrat terkecil tidak bisa ditentukan
(indeterminate), (2) varians dan kovarians dari penaksir-penaksir menjadi tidak
terhingga besarnya (infinitely large). Pada kasus ini, statistik t cenderung tidak nyata (not significant) dan sensitif terhadap perubahan jumlah observasi,
meskipun merupakan penaksir yang tak bias (unbiased). Penanggulangannya antara lain dengan: (1) memperbesar ukuran sampel, (2) memasukkan
persamaan tambahan ke dalam model, (3) penggunaan informasi ekstra,
meliputi: (a) prior information, (b) metode transformasi variabel, (c) metode pooling data cross sectiondantimeseries.
Mendeteksi Multikolinearitas
Gejala yang biasanya dipakai untuk menandai adanya multikolinearitas
kesalahan baku (standar error) dari parameter-parameter regresi. Secara
sendiri-sendiri, tidak satupun dari gejala-gejala itu dipakai sebagai indikator
yang memuaskan mengenai adanya multikolinearitas, karena (Gunawan,
1995):
1. Kesalahan baku yang besar bisa terjadi karena berbagai sebab, dan tidak
hanya karena adanya hubungan-hubungan linier di antara variabel-variabel
bebas.
2. Koefisien korelasi parsial yang tinggi hanyalah suatu syarat yang cukup
(sufficient condition) tetapi bukan syarat yang perlu (necessary condition)
atau bukan kriteria yang tepat bagi adanya multikolinearitas.
3. Koefisien determinasi (R2y) mungkin saja tinggi, namun taksiran-taksiran mungkin tidak signifikan.
Sekalipun demikian, kombinasi dari ketiga kriteria tersebut akan
membantu dalam mendeteksi adanya multikolinearitas.
Tidak ada satu pun cara yang paling baik untuk mengetahui gejala
multikolinearitas. Salah satu cara yang umum digunakan untuk mendeteksi
adanya multikolinearitas adalah apabila nilai R2y sangat tinggi (> 0,70), nilai F-hitung sangat tinggi (signifikan), tetapi tidak satu pun atau sedikit sekali
koefisien regresi yang diuji dengan t-student (t-test) yang signifikan. Hal ini
menandakan multikolinearitas dalam model cukup serius. Selain itu, apabila
koefisien determinasi antara variabel tak bebas dengan semua variabel bebas
(R2y,x1,..,xk) lebih kecil daripada koefisien determinasi (R2x1,x2,..,xk) antar variabel bebas yang satu dengan sisanya berarti multikolinearitas dalam model
memisahkan pengaruh masing-masing variabel bebas terhadap variabel tak
bebasnya.
Teladan :
Untuk menggambarkan variasi yang ditimbulkan oleh gejala
multi-kolinearitas, berikut ini diajukan data hipotetis hubungan antara pendapatan
(X1) dan kekayaan (X2) terhadap pola konsumsi (Y).
Data dikutip dari Gujarati (1995), p 333
No Pola Konsumsi (Y) Pendapatan (X1) Kekayaan (X2)
1 70 80 810
2 65 100 1009
3 90 120 1273
4 95 140 1425
5 110 160 1633
6 115 180 1876
7 120 200 2052
8 140 220 2201
9 155 240 2435
10 150 260 2686
Hasil regresinya dapat dilihat pada tabel berikut.
LS // Dependent Variable is Y Date: 4-02-1997 / Time: 5:20 SMPL range: 1 - 10 Number of observations: 10
================================================================ VARIABLE COEFFICIENT STD. ERROR T-STAT. 2-TAIL SIG. ================================================================
Dari hasil analisis tersebut dapat dikatakan bahwa pendapatan (X1) dan
kekayaan (X2) menjelaskan sebesar 96,35 persen dari variasi pola konsumsi
(Y), tetapi tidak ada satu pun koefisien regresi yang signifikan. Lebih jauh lagi
bukan saja variabel kekayaan tidak nyata, tetapi juga bernilai negatif atau
tandanya berlainan dengan yang biasa dihipotesiskan (bertanda positif,
kekayaan meningkat maka pola konsumsi juga meningkat). Secara serentak
variabel X1 dan X2 bersifat nyata.
Berdasarkan contoh tersebut, jelas dapat kita lihat adanya gejala
multikolinearitas. Buktinya adalah nilai F-hitung sangat nyata, tetapi hasil uji-t
bagi setiap koefisien regresi tidak ada yang nyata, berarti bahwa kedua variabel
X1 dan X2 berhubungan sangat erat, yang tidak mungkin kita dapat
mengisolasi pengaruh individual dari pendapatan dan kekayaan. Apabila X1
dan X2 kita regresikan, akan diperoleh hasil sebagai berikut.
LS // Dependent Variable is X2 Date: 10-30-1997 / Time: 10:09 SMPL range: 1 - 10
Number of observations: 10
================================================================ VARIABLE COEFFICIENT STD. ERROR T-STAT. 2-TAIL SIG. ================================================================
C 7.5454545 29.475811 0.2559880 0.804 X1 10.190909 0.1642623 62.040474 0.000 ================================================================ R-squared 0.997926 Mean of dependent var 1740.000 Adjusted R-squared 0.997667 S.D. of dependent var 617.7312 S.E. of regression 29.83972 Sum of squared resid 7123.273 Durbin-Watson stat 2.077534 F-statistic 3849.020 Log likelihood -47.03207
================================================================
Hasil analisis ini jelas menunjukkan, bahwa antara X1 dan X2 terjadi
Sekarang bagaimana hubungan antara Y dengan pendapatan (X1) saja.
Hasil regresinya sebagai berikut :
LS // Dependent Variable is Y Date: 10-30-1997 / Time: 10:09 SMPL range: 1 - 10
Number of observations: 10
================================================================ VARIABLE COEFFICIENT STD. ERROR T-STAT. 2-TAIL SIG. ================================================================
C 24.454545 6.4138173 3.8127911 0.005 X1 0.5090909 0.0357428 14.243171 0.000 ================================================================ R-squared 0.962062 Mean of dependent var 111.0000 Adjusted R-squared 0.957319 S.D. of dependent var 31.42893 S.E. of regression 6.493003 Sum of squared resid 337.2727 Durbin-Watson stat 2.680127 F-statistic 202.8679 Log likelihood -31.78092
=================================================================
Dari hasil tersebut jelas terlihat, bahwa pendapatan (X1) sangat nyata
pengaruhnya terhadap pola konsumsi, sedangkan sebelumnya tidak nyata
pengaruhnya.
Lebih lanjut jika kita regresikan Y terhadap X2, kita peroleh hasil sebagai
berikut.
LS // Dependent Variable is Y Date: 10-30-1997 / Time: 10:09 SMPL range: 1 - 10
Number of observations: 10
================================================================ VARIABLE COEFFICIENT STD. ERROR T-STAT. 2-TAIL SIG. ================================================================
C 24.411045 6.8740968 3.5511639 0.007 X2 0.0497638 0.0037440 13.291656 0.000 ================================================================ R-squared 0.956679 Mean of dependent var 111.0000 Adjusted R-squared 0.951264 S.D. of dependent var 31.42893 S.E. of regression 6.938330 Sum of squared resid 385.1233 Durbin-Watson stat 2.417419 F-statistic 176.6681 Log likelihood -32.44428
Dari hasil ini pun, jelas terlihat bahwa kekayaan (X2) sekarang
berpengaruh sangat nyata terhadap pola konsumsi, sedangkan sebelumnya
tidak nyata pengaruhnya.
Jadi, berdasarkan analisis parsial tersebut memperlihatkan dengan jelas
adanya gejala multikolinearitas yang ekstrim, jika menghilangkan salah satu
variabel yang sangat erat hubungannya dalam model sering menimbulkan
kenyataan, bahwa variabel X yang lainnya signifikan secara statistik.
Autokorelasi
Autokorelasi (autocorrelation) berarti adanya korelasi antar gangguan, sehingga pembahasannya dipusatkan pada penyimpangan asumsi
non-autokorelasi (asumsi lainnya dipertahankan). Kasus bernon-autokorelasi ini
biasanya terdapat pada data time series, karena ganguan pada individu/
kelompok cenderung mempengaruhi gangguan pada individu/kelompok yang
sama pada periode berikutnya. Pada data cross section, masalah autokorelasi relatif jarang terjadi karena gangguan pada observasi yang berbeda berasal
dari individu yang berbeda. Pada data time series kasus heteroskedastis jarang terdapat karena selera individu relatif tidak mudah berubah. Penaksiran
koefisien pada kasus autokorelasi dengan metode OLS menghasilkan
penaksiran yang tak bias (unbiased), tetapi tidak efisien (inefficient). Banyak metode yang digunakan untuk menguji autokorelasi, namun yang paling banyak
digunakan adalah uji Durbin-Watson. Uji Durbin-Watson mengasumsikan
adanya hubungan antar ganguan i=i-1+i, yaitu mengikuti model otoregresif tingkat satu (first order autoregressive). Statistik d biasanya muncul dalam
berarti ada autokorelasi positif, (b) -2 ≤ d < 2 berarti tidak ada autokorelasi, nilai
d > 2 berarti ada autokorelasi positif. Autokorelasi bisa diobati antara lain
dengan metode Cochran-Orcutt, model penyesuaian parsial, dan model
autoregresif.
Heteroskedastisitas
Heteroskedastisitas (heteroscedasticity), berarti varians gangguan berbeda dari satu observasi ke observasi lainnya, sehingga setiap observasi
mempunyai reliabilitas berbeda. Kasus ini adalah penyimpangan kondisi ideal,
khususnya asumsi homoskedastisitas. Penaksiran kasus ini dengan OLS
merupakan penaksiran yang inefficient maskipun masih unbiased (OLS
bukanlah penaksiran tak bias yang memberikan varians terkecil). Adanya selera
yang berbeda antara individu/kelompok menyebabkan kasus
heteroske-dastisitas lebih sering dijumpai dalam data cross section daripada time series.
Pengujian heteroskedastisitas paling sederhana adalah dengan membuat
scatter plot antara studentized residual dengan nilai standardized predicted
yang diproses komputer. Ada beberapa cara mengkuantifikasi pola hubungan
antar varians gangguan, seperti uji korelasi rank Sperman, uji Golfeld-Quand,
Uji Park, dan uji Glejser. Pengobatan kasus ini antara lain: (1) mentransformasi
seluruh variabel dalam bentuk logaritma atau memperbaiki spesifikasi model;
(2) metode generalized least squares (GLS).
Penyembuhan Heteroskedastisitas
Heteroskedastisitas tidak merusak sifat ketidakbiasan dan konsistensi
adanya efisiensi ini membuat prosedur pengujian hipotesis yang biasa nilainya
diragukan, maka perlu tindakan penyembuhan.
Untuk mengurangi heteroskedastisitas, tindakan penyembuhan yang
umum digunakan adalah transformasi logaritma (Ln). Hal ini disebabkan karena
transformasi yang memampatkan skala untuk pengukuran variabel, mengurangi
perbedaan antara kedua nilai tadi dari sepuluh kali lipat menjadi perbedaan dua
kali lipat. Jadi, angka 80 adalah 10 kali angka 8, tetapi logaritma (Ln 80 =
4,3820) hanya dua kali besarnya Ln 8 (Ln 8 = 2,0794).
Misalnya model regresi asal sebagai berikut :
Yi = ao + a1X1 + e
kemudian kita transformasikan ke dalam bentuk logaritma sehingga menjadi :
Ln Yi = Ln ao + a1 Ln X1 + e
Selain cara tersebut, untuk mengatasi atau melakukan koreksi berkaitan
dengan adanya gejala heteroskedastisitas, adalah dengan melakukan
transformasi dalam bentuk membagi model regresi asal dengan salah satu
BAB VI. REGRESI DENGAN VARIABEL DUMMY
Variabel di dalam analisis regresi bisa debedakan menjadi dua yaitu
variabel kuantitatif dan variabel kualitatif. Model regresi pada bagian ini
memfokuskan pada regresi dengan variabel independen kualitatif. Harga,
volume produksi, volume penjualan, biaya promosi adalah beberapa contoh
variabel yang datanya bersifat kuantitatif. Namun, bila kita membicarakan
masalah jenis kelamin, tingkat pendidikan, status perkawinan, krisis ekonomi
maupun kenaikan harga BBM berarti kita membicarakan variabel bersifat
kualitatif.
Variabel-variabel kualitatif tersebut sangat mempengaruhi perilaku
agen-agen ekonomi. Variabel kualitatif ini bisa terjadi pada dara cross section maupun data time series. Misalnya dalam data cross section kita bisa
memasukkan jenis kelamin di dalam regresi dalam mempengaruhi volume
penjualan handphone. Begitu pula data kualitatif seperti kenaikan harga BBM
bisa kita masukkan di dalam regresi dalam mempengaruhi volume penjualan
dalam datatime series.
Ada kalanya kita melakukan suatu regresi dimana variabel penjelas atau
variabel tergantung berupa data kategorikal (sering disebut data nominal).
Misalnya laki-laki dan perempuan, desa-kota, industri pangan, sandang, dan
peralatan.
Contoh kita ingin mengetahui jenis kelamin, lokasi, dan industri terhadap upah,
1. Pengaruh jenis kelamin atas upah, modelnya,
Dimana DJK adalahDummyjenis kelamin (laki-laki dan wanita)
2. Pengaruh lokasi terhadap upah, apakah desa lebih rendah upahnya dari
kota, modelnya,
Upah = a + b1DLOK + e dimana DLOK adalahdummylokasi
3. Pengaruh industri terhadap upah, modelnya
Upah = a + b1DIND + e
dimana DIND adalahdummysetiap klasifikasi industri Untuk memudahkan lihat contoh data berikut:
Industri Kode Industri Upah
Pangan 31 500
Sandang 32 522
Sandang 32 530
Pangan 31 512
Peralatan logam 38 600
Peralatan logam 38 642
Pangan 31 540
Pangan 31 520
Sandang 32 580
Sandang 32 570
Cara Membuat Variabel
Dummy
Untuk dapat membedakan pengaruh masing-masing industri atas upah
kita akan membuat variabel dummy. Caranya adalah memberi nilai 1 pada kategori tersebut dan memberi nol bagi kategori lainnya data berubah menjadi
Industri Kode Industri Upah Dpangan Dsandang Dalat
Pangan 31 500 1 0 0
Sandang 32 520 0 1 0
Sandang 32 530 0 1 0
Pangan 31 520 1 0 0
Peralatan logam 38 600 0 0 1
Peralatan logam 38 640 0 0 1
Pangan 31 540 1 0 0
Pangan 31 520 1 0 0
Sandang 32 580 0 1 0
Sandang 32 570 0 1 0
Sekarang perhatikan upah rata-rata untuk masing-masing industri:
Pangan = 520 dummy, sedangkan yang satu akan berfungsi menjadi benchmark atau
pematok. Besarnyabenchmarktidak lain adalahinterceptatau nilai a.
Contoh:
Upah = a + b1Dsandang + b2Dalat + e Dari data di atas hasilnya adalah sebagai berikut
Upah = 520 + 30 Dsandang + 100 Dalat
Jadi rata-rata upah industri pangan yang tidak dimasukkan ke dalam model
menjadi intersep (benchmark) beda upah sandang terhadap pangan adalah
nilai b1=30 dan beda upah rata-rata industri peralatan terhadap industri pangan adalan 100.
Sebaliknya jika yang tidak dimasukkan dalam regresi adalah industri peralatan,
Upah = 620 - 100 Dpangan - 70 Dsandang
Sekarang intersep (a) menjadi rerata industri alat, dan beda upah pangan
terhadap industri alat adalah minus 100 dan beda upah industri alat adalah
minus 70.
Kesimpulannya jika kita punya n variabel dummy, maka kita dapat memasukkan n-1 variabel dalam model regresi, dan yang menjadi intersep
adalah nilai rata-rata variabel yang tidak dimasukkan.
Perhatikan cara memaknai parameter hasil regresi yang menggunakan dummy di atas.
Sekarang kita akan memasukkan data pendidikan pada data yang kita
miliki di atas, data lengkapnya menjadi sebagai berikut.
Industri Kode Industri Upah Dpangan Dsandang Dalat
Pangan 31 500 1 0 6
Sandang 32 520 0 1 9
Sandang 32 530 0 1 9
Pangan 31 520 1 0 9
Peralatan logam 38 600 0 0 12
Peralatan logam 38 640 0 0 11
Pangan 31 540 1 0 9
Pangan 31 520 1 0 6
Sandang 32 580 0 1 12
Sandang 32 570 0 1 9
Hasil di atas dapat kita ringkas dan sajikan sebagai berikut:
Makna hasil regresisekarang adalah sebagai berikut:
Upah = 448,4 - 18,62 Dsandang + 49,9 Dalat + 10,5 Pendidik (12,)** (-1,04) (2,287)** (2,486)**
R2 = 0,839
Pada tingkat pendidikan yang sama, maka upah industri sandang adalah
minus 18,6 di bawah industri pangan (industri yang tidak diikutkan dalam
regresi). Upah industri peralatan pada tingkat pendidikan yang sama adalah
49,9 di atas industri pangan. Mengapa angkanya menjadi semakin kecil dari
sebelumnya?
Hal ini disebabkan adanya perbedaan pendidikan di ketiga industri,
perbedaan upah tidak semata disebabkan oleh perbedaan industri tetapi juga
disebabkan oleh perbedaan pendidikan. Ini dapat juga dikatakan bahwa
pendidikan menjadi variabel KONTROL yan bertugas memurnikan pengaruh
perbedaan industri atas upah.
Contoh :
Menganalisis apakah masa kerja, tingkat pendidikan karyawan, dan jenis
kelamin mempengaruhi gaji karyawan. Pendidikan dikategorikan menjadi dua
yaitu Diploma dan Sarjana. Menggunakan data hipotetis sebanyak 20 karyawan
suatu perusahaan.
Yi = βo + β1 Xi + β2 D1 + β3 D2 + ei
Dimana :
Yi = gaji karyawan
Xi = masa kerja karyawan (tahun)
D1 = 1 jika sarjana dan 0 jika tidak (diploma)
Data 20 Karyawan di Perusahaan PT Maju Mundur
Gaji (juta) Masa_kerja Pendidikan Kelamin
2,700 11 0 0
3,400 3 1 1
3,900 18 0 1
3,400 14 0 1
4,800 9 1 1
2,200 3 0 1
6,400 15 1 1
6,230 17 1 0
4,200 20 0 1
2,065 2 0 0
3,510 4 1 0
2,500 5 0 1
2,800 8 0 1
2,975 14 0 0
5,890 15 1 0
3,105 15 0 0
3,200 2 1 1
3,365 19 0 0
3,850 5 1 0
6,910 20 1 0
Data dianalisis dengan SPSS dan hasil outputnya seperti pada tampilan berikut.
Model Summary
,958a ,917 ,901 ,45176
Model 1
R R Square
Adjusted R Square
Std. Error of the Estimate
Predictors: (Constant), Kelamin, Pendidikan, Masa_ kerja
a.
Nilai koefisien determinasi sebesar 0,917 artinya hasil regresi
kelamin mampu menjelaskan variasi gaji karyawan sebesar 91,7% dan sisanya
sebesar 9,3% dijelaskan oleh faktor lain di luar model.
ANOVAb
36,101 3 12,034 58,964 ,000a 3,265 16 ,204
Squares df Mean Square F Sig.
Predictors: (Constant), Kelamin, Pendidikan, Masa_kerja a.
Dependent Variable: Gaji b.
Nilai F-hitung sebesar 58,964 dan nilai F-tabel pada α=5% dengan df
(3,16) sebesar 3,24 (cari dalam tabel F). Nilai hitung lebih besar dari nilai
F-tabel sehingga kita menolak Ho. Bisa juga melihat nilai signifikansi sebesar
0,000 < α = 0,05 maka Ho ditolak (H1 diterima). Hasil regresi ini
mengindikasikan bahwa secara serentak variabel masa kerja, tingkat
pendidikan karyawan dan jenis kelamin secara nyata mempengaruhi gaji
karyawan.
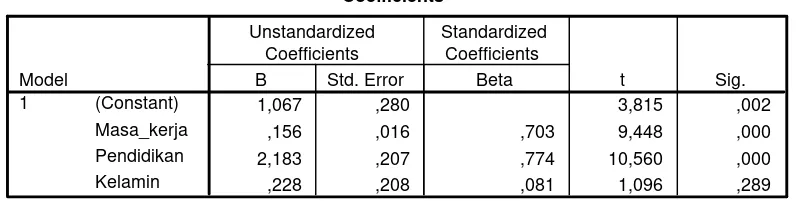
Coefficientsa
1,067 ,280 3,815 ,002
,156 ,016 ,703 9,448 ,000 2,183 ,207 ,774 10,560 ,000 ,228 ,208 ,081 1,096 ,289 (Constant)
Uji signifikansi variabel independen terhadap variabel dependen
menunjukkan bahwa nilai t-hitung variabel masa kerja sebesar 9,448; variabel
dummy tingkat pendidikan sebesar 10,560; dan variabel dummy jenis kelamin
sebesar 1,096. Sementara itu, nilai t-tabel uji dua sisi pada α=5% dengan df
dan dummy tingkat pendidikan signifikan pada α=5% (nilai hitung > nilai
t-tabel), sedangkan variabel dummy jenis kelamin tidak berpengaruh nyata. Bisa
juga membandingkan nilai Sig. (probabilitas atau p-value) jika lebih kecil dari alpha maka Ho ditolak, artinya variabel tersebut berpengaruh nyata terhadap
variabel dependen.
Hasil regresi mengindikasikan bahwa variabel kualitatif tingkat
pendidikan karyawan berpengaruh nyata terhadap gaji karyawan. Koefisien
regresi variabel dummy tingkat pendidikan sebesar 2,183 dapat diartikan gaji
karyawan berpendidikan sarjana lebih besar 2,183 juta dibandingkan dengan
gaji karyawan berpendidikan tidak sarjana dengan asumsi variabel lain tetap.
Variabel dummy jenis kelamin tidak signifikan maka dapat diartikan tidak ada
perbedaan gaji antara karyawan pria dan wanita dengan asumsi variabel lain
tetap. Koefisien regresi variabel dummy jenis kelamin 0,228 artinya gaji
karyawan pria lebih tinggi 0,228 juta dibandingkan dengan gaji karyawan wanita
tetapi secara statistik perbedaan itu tidak berbeda nyata.
Karyawan Sarjana dan Pria :
E(Yi | D1=1; D2=1, Xi) = (βo + β2 + β3) + β1Xi
Karyawan Tidak Sarjana dan Pria :
E(Yi | D1=0; D2=1, Xi) = (βo + β3) + β1Xi
Karyawan Sarjana dan Wanita :
E(Yi | D1=1; D2=0, Xi) = (βo + β2) + β1Xi
Karyawan Tidak Sarjana dan Wanita :
E(Yi | D1=0; D2=0, Xi) = βo + β1Xi
Gaji karyawan berpendidikan sarjana dan pria :
Y’ = (1,067 +2,183 + 0,228) + 0,156 Xi ===> Y’ = 3,478 + 0,156 Xi
Gaji karyawan berpendidikan tidak sarjana dan pria :
Y’ = (1,067 + 0,228) + 0,156 Xi ===> Y’ = 1,295 + 0,156 Xi
Gaji karyawan berpendidikan sarjana dan wanita :
Y’ = (1,067 + 2,183) + 0,156 Xi ===> Y’ = 3,250 + 0,156 Xi
Gaji karyawan berpendidikan tidak sarjana dan wanita : Y’ = 1,067 + 0,156 Xi
Latihan :
Sekarang buatlah analisis dengan data berikut.
INDUSTRI LABA KAPITAL
A 10 10
A 12 11
A 14 12
A 12 9
B 13 13
B 15 23
B 11 25
B 10 16
B 18 31
C 20 40
C 22 50
C 23 52
A 20 20
A 11 30
B 15 40
Buatlah model analisis yang menjawab pertanyaan penelitian berikut:
1. Apakah ketiga industri memiliki laba benar-benar yang berbeda? Buatlah dummyvariabelnya.
2. Apakah laba itu disebabkan oleh beda industri atau modal, berapa sumbangan masing-masing?
3. Mana variabel yang signifikan? 4. Tunjukkan ketepatan modelnya. 5. Ujilah asumsi klasiknya.
6. Sajikan hasil regresi secara internasional
BAB VII. MODEL REGRESI LOGISTIK (LOGIT MODEL)
Banyak kasus di dalam analisis regresi dimana variabel dependennya
bersifat kualitatif. Keputusan seseorang membeli mobil atau tidak. Keputusan
seorang konsumen membeli televisi merk Sonny atau bukan Sonny. Dua
contoh tersebut merupakan contoh variabel dependen yang mempunyai dua
kelas atau bersifat binari (binary). Tetapi sering kali kita juga menemukan
variabel dependen yang mempunyai lebih dari dua kelas (multinomial). Misalnya kemampuan nasabah bank di dalam membayar kreditnya.
Kemampuan nasabah ini bisa dikategorikan menjadi tiga, yaitu mereka yang
mampu membayar tepat waktu (repay), mereka yang membayar terlambat (late repay) dan mereka yang gagal membayar (default).
Kembali kepada kasus keputusan seseorang untuk membeli mobil,
jawaban yang kita peroleh adalah mereka yang membeli mobil atau mereka
yang tidak membeli mobil. Dengan kata lain respon setiap orang tersebut
bersifat dikotomis (binari). Pada bahasan variabel dummy, dalam model regresi
dimana variabel independen bersifat kualitatif maka kita harus
mengkuan-titatifkan variabel kualitatif ini agar regresi bisa dilakukan. Namun,
mengkuantitatifkan variabel kualitatif di dalam regresi juga berlaku untuk
variabel dependen bersifat kualitatif. Setiap variabel kualitatif di dalam regresi
baik variabel independen maupun dependen, kita akan mengambil nilai 1 jika
variabel mempunyai atribut dan nilai 0 jika tidak mengandung atribut. Dengan
mempunyai atribut dan angka 0 untuk variabel dependen yang tidak
mempunyai atribut. Metode ini sama dengan metode regresi dengan
menggunakan variabel independen kualitatif (regresi variabel dummy).
Contoh :
Mengaplikasikan model logit tentang keputusan seseorang untuk
membeli mobil atau tidak. Keputusan membeli mobil atau tidak dipengaruhi oleh
dua variabel yaitu jumlah pendapatan dan status pernikahan. Status pernikahan
merupakan variabel independen kualitatif.
Model Logit ===> ln (Pi / 1 – Pi) = Zi = βo + β1 X1 + β2 X2
dimana, P = probabilitas membeli mobil
X1 = jumlah pendapatan (juta per bulan)
X2 = status pernikahan (1 jika menikah dan 0 jika belum menikah)
Data hipotesis yang digunakan sebagai berikut.
No. Keptusan Pendptan S_nikah Lokasi Keluarga Penddkan
1 0 5,10 0 1 3 0
2 1 12,25 1 1 3 1
3 1 9,00 1 0 2 1
4 0 6,00 0 0 4 0
5 1 10,20 1 1 3 1
6 0 5,25 0 1 2 0
7 0 5,50 0 0 3 0
8 1 11,40 1 1 3 1
9 0 5,90 0 0 2 1
10 1 11,00 1 0 2 1
11 0 6,25 0 0 3 0
12 1 6,40 0 0 4 0
13 0 6,70 1 1 3 1
14 1 7,10 1 0 1 0
15 1 7,50 0 0 1 1
16 0 7,70 0 1 3 0
18 1 8,20 1 1 2 1
Data dianalisis dengan program SPSS, hasil output SPSS sebagai
berikut.
If weight is in effect, see classification table for the total number of cases.
Block 0: Beginning Block
Classification Tablea,b
Constant is included in the model. a.
Variables in the Equation
,268 ,368 ,530 1 ,467 1,308 Constant
Step 0
B S.E. Wald df Sig. Exp(B)
Variables not in the Equation
15,325 1 ,000 15,922 1 ,000 18,706 2 ,000 Pendptn
S_nikah Variables
Overall Statistics Step
0
Score df Sig.
Tampilan output SPSS di atas memberi informasi jumlah kasus yang
dianalisis ada 30 kasus tidak ada yang terlewatkan (missing). Classification Table menyajikan informasi tentang keakuratan prediksi. Dengan hanya
menggunakan konstanta, keakuratan prediksi sebesar 56,7%. Tampilan
Variables in the equationmenampilkan uji wald. Dengan hanya konstanta tanpa variabel pendapatan (X1) dan status pernikahaan (X2) tidak signifikan pada
α=5% dalam mempengaruhi keputusan seseorang dalam membeli mobil
(Sig 0,467 > α=0,05). Dengan demikian ada varfiabel independen yang
mempengaruhi keputusan memberi mobil.
Block 1: Method = Enter
Uji Serentak
Omnibus Tests of Model Coefficients
23,944 2 ,000 23,944 2 ,000 23,944 2 ,000 Step
Block Model Step 1
Chi-square df Sig.
perbedaan -2LL model dengan hanya konstanta dan model yang diestimasi.
Nilai Chi-squares model sebesar 23,944 dengan df sebesar 2 (Chi-square tabel
5,991) maka signifikan (Sig 0,000 < α=0,05) sehingga dapat disimpulkan bahwa
pendapatan dan status pernikahan mempengaruhi keputusan seseorang di
dalam membeli mobil.
Uji Goodness of Fit
Model Summary
17,110a ,550 ,738 Step
1
-2 Log likelihood
Cox & Snell R Square
Nagelkerke R Square
Estimation terminated at iteration number 6 because parameter estimates changed by less than ,001. a.
Model summary menunjukkan nilai Cox & Snell R square sebesar 0,550 berarti variabel pendapatan (X1) dan status pernikahan (X2) di dalam model
logit mampu menjelaskan perilaku seseorang dalam membeli mobil atau tidak
sebesar 55%. Sedangkan berdasarkan Nagelkerke R square sebesar 0,738
berarti variabel pendapatan (X1) dan status pernikahan (X2) di dalam model
logit mampu menjelaskan perilaku seseorang dalam membeli mobil atau tidak
sebesar 73,8%
Hosmer and Lemeshow Test
12,837 8 ,118 Step
1
Contingency Table for Hosmer and Lemeshow Test
The cut value is ,500 a.
Classification tables menunjukkan seberapa baik model mengelompokkan
kasus ke dalam dua kelompok baik yang tidak mempunyai mobil maupun yang
mempunyai mobil. Keakuratan prediksi secara menyeluruh sebesar 90%, hal ini
lebih baik dari model yang hanya dengan konstanta sebelumnya sebesar
56,7%. Sedangkan keakuratan prediksi yang tidak mempunyai mobil sebesar
92,3% dan yang mempunyai mobil sebesar 88,2%.
Variables in the Equation
1,001 ,493 4,121 1 ,042 2,720 1,035 7,146 2,443 1,242 3,869 1 ,049 11,511 1,009 131,369 -8,932 3,852 5,377 1 ,020 ,000
Pendptn S_nikah Constant Step
1a
B S.E. Wald df Sig. Exp(B) Lower Upper 95,0% C.I.for EXP(
Uji signifikansi variabel independen secara individual dengan
menggunakan uji Wald. Hasil uji menunjukkan bahwa variabel pendapatan (X1)
dan status pernikahan (X2) berpengaruh nyata terhadap keputusan seseorang
di dalam membeli mobil dengan tingkat signifikansi 5% (sig < α=0,05).
Persamaan regresi logistik Zi = -8,932 + 1,001 X1 + 2,443 X2
Interpretasi persamaan logistik menggunakan odd ratio atau Exp(B), untuk pendapatan (X1) odd ratio sebesar 2,720 dapat diartikan bahwa jika
pendapatan naik 1 unit (1 juta) maka rasio kemungkinan memiliki mobil dengan
yang tidak memiliki mobil naik dengan faktor 2,720 dengan asumsi variabel
status pernikahan tetap. Sementara itu odd ratio untuk status pernikahan (X2) sebesar 11,511 dapat diartikan bahwa rasio kemungkinan membeli mobil
dengan tidak membeli mobil untuk mereka yang menikah lebih tinggi daripada
yang belum menikah sebesar 11,511 kali dengan asumsi variabel pendapatan
tetap.
Persamaan regresi logistik dapat juga digunakan untuk melakukan
prediksi, misal individu mempunyai pendapatan 10 juta dan status pernikahan
sudah menikah (X2 =1) maka probabilitas memiliki mobil dapat dihitung sebagai
berikut.
Z = -8,932 + 1,001(10) + 2,443(1) = 3,521
Pi = (1 / 1 + e-Z) = (1 / 1 + 2,7182818^-3,521) = 0,97
Nilai prediksi probabilitas individu tersebut memiliki mobil sebesar 0,97
BAB VIII. REGRESI MULTINOMIAL LOGIT
Konsep regresi Multinomial Logit pada dasarnya sama dengan konsep regresi logistik lainnya. Namun demikian yang membedakannya adalah bahwa
dalam Model Regesi Multinomial Logit terdapat multiple interpretation dari hasil
analisis. (i) hasil regresi dengan Multinomial Logit dapat digunakan untuk menunjukkan relationship antara variabel independen dengan variabel
dependen, hasil ini dapat dilihat dari Likelihood ratio test. (ii) dengan menggunakan hasil pengujian parameter estimate, akan diperoleh hasil kemampuan klasifikasi (classifiacation) terhadap variabel kategori dependen
yang sebelumnya telah dilakukan pengelompokkan.
Dalam metode Regresi Multinomial Logit, variabel dependen dalam
bentuk non metric, sementara itu variabel bebasnya (independent variables) dalam bentuk metric atau dichotomous variabeles. Dengan demikian
pengujiannya tidak menggunakan distribusi t atau F, namun menggunakan
distribusi chi-square (χ2). Dalam pengujian Regresi Multinomial Logit nilai variabel kategori bersifat probabilistik, dimana terdapat kemungkinan data
variabel X tersebut mampu mengklasifikasikan variabel terikat menjadi kategori
pertama, kedua atau kemungkinan masuk klasifikasi kelompok ketiga.
Pengujian signifikansi model multinomial logit dilakukan dengan melihat
hasil pengujian model fitting information. Hasil ini menunjukkan overall test, kelayakan model dapat dilihat dari nilai double likelihood (2LL). Suatu model
dapat dikatakan layak apabila nilai -2LL pada model final lebih kecil jika
dibandingkan dengan nilai -2LL pada model awal (interceipt only). Hal ini menunjukkan bahwa model multinomial logit bermanfaat (a usefull model).
Sementara itu kemampuan model dalam mengklasifikasikan kategori variabel
dependen apabila suatu subjek dimasukkan dapat dilihat dari hasil classification
atau predicted dengan observed, kategori mana yang dapat diprediksikan lebih baik, hasilnya dapat dilihat dari nilai persentase masing-masing kategori.
Contoh :
Mengaplikasikan model multinomial logit tentang keputusan seseorang
untuk membeli mobil atau tidak. Keputusan seseorang terdiri dari tiga
kemungkinan yaitu membeli mobil dengan tunai (3), membeli mobil dengan
kredit (2) dan tidak membeli mobil (1). Ada dua variabel yang mempengaruhi
keputusan tersebut yaitu jumlah pendapatan dan status pernikahan. Status
pernikahan merupakan variabel independen kualitatif.
Model Multinomial Logit ===> ln (Pi / Pj) = Zi = βo + β1 X1 + β2 X2
Dimana: P = probabilitas kategori ke i dan j
X1 = jumlah pendapatan (juta per bulan)
X2 = status pernikahan (1 jika menikah dan 0 jika belum menikah)
Data hipotesis yang digunakan sebagai berikut.
No. Keptusan Pendptan S_nikah
1 3 9,90 0
2 1 5,25 0
3 1 7,70 0
4 1 5,80 0
5 3 11,40 1
6 1 6,00 0
7 3 12,00 1
8 2 6,40 0
10 1 6,95 0
Hasil analisis dengan program SPSS seperti berikut
Case Processing Summary
The dependent variable has only one value observed in 30 (100,0%) subpopulations.