BIASA DAN SUPPORT VECTOR MACHINE BERBASIS
PARTICLE SWARM OPTIMIZATION UNTUK PREDIKSI GEMPA
BUMI
Oleh :
MUHAMMAD RUSDI
P31.2013.01441
Tesis diajukan sebagai salah satu syarat untuk memperoleh gelar
Magister Komputer
PROGRAM PASCASARJANA
MAGISTER TEKNIK INFORMATIKA
UNIVERSITAS DIAN NUSWANTORO
PENGESAHAN STATUS TESIS
JUDUL : PERBANDINGAN ALGORITMA SUPPORT VECTOR MACHINE BIASA DAN SUPPORT VECTOR MACHINE BERBASIS PARTICLE SWARM OPTIMIZATION UNTUK PREDIKSI GEMPA BUMI
NAMA : MUHAMMAD RUSDI NPM : P31.2013.01441
mengijinkan Tesis Magister Komputer ini disimpan di Perpustakaan Universitas Dian Nuswantoro dengan syarat-syarat kegunaan sebagai berikut:
1. Tesis adalah hak milik Universitas Dian Nuswantoro
2. Perpustakaan Universitas Dian Nuswantoro dibenarkan membuat salinan untuk tujuan referensi saja.
3. Perpustakaan juga dibenarkan membuat salinan Tesis ini sebagai bahan pertukaran antar institusi pendidikan tinggi.
4. Berikan tanda sesuai dengan kategori Tesis
Sangat Rahasia
Jl. Tembus Mantuil Basirih Ulu Rt.18 Banjarmasin
Tanggal Tanggal
PERNYATAAN PENULIS
JUDUL : PERBANDINGAN ALGORITMA SUPPORT VECTOR MACHINE BIASA DAN SUPPORT VECTOR MACHINE BERBASIS PARTICLE SWARM OPTIMIZATION UNTUK PREDIKSI GEMPA BUMI
NAMA : MUHAMMAD RUSDI NPM : P31.2013.01441
“Saya menyatakan dan bertanggungjawab dengan sebenarnya bahwa Tesis ini adalah hasil karya saya sendiri kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya. Jika pada waktu selanjutnya ada pihak lain yang mengklaim bahwa Tesis ini sebagai karyanya, yang disertai dengan bukti-bukti yang cukup, maka saya bersedia untuk dibatalkan gelar Magister Komputer saya beserta segala hak dan
kewajiban yang melekat pada gelar tersebut” Semarang, 2015
Agus Setiawan Penulis
PERSETUJUAN TESIS
JUDUL : PERBANDINGAN ALGORITMA SUPPORT VECTOR MACHINE BIASA DAN SUPPORT VECTOR MACHINE BERBASIS PARTICLE SWARM OPTIMIZATION UNTUK PREDIKSI GEMPA BUMI
NAMA : MUHAMMAD RUSDI NPM : P31.2013.01441
Tesis ini telah diperiksa dan disetujui, Semarang, 2015
Pembimbing Utama Pembimbing Pembantu
Direktur MTI UDINUS
PENGESAHAN TESIS
JUDUL : PERBANDINGAN ALGORITMA SUPPORT VECTOR MACHINE BIASA DAN SUPPORT VECTOR MACHINE BERBASIS PARTICLE SWARM OPTIMIZATION UNTUK PREDIKSI GEMPA BUMI
NAMA : MUHAMMAD RUSDI NPM : P31.2013.01441
Tesis ini telah diujikan dan dipertahankan dihadapan Dewan Penguji pada Sidang Tesis tanggal maret 2015. Menurut pandangan kami, Tesis ini memadai dari segi
kualitas maupun kuantitas untuk tujuanpenganugrahan gelar Magister Komputer (M.Kom.)
Semarang, 2015
Ketua Peguji Anggota
Anggota
ABSTRAK
Gempa yang merupakan fenomena alam secara periodik yang terjadi di seluruh belahan bumi akibat adanya gaya pembangkit pasang surut yang utamanya berasal dari matahari dan bulan. Tujuan penulisan Tesis ini adalah untuk menganalisa hasil gempa bumi di Sumara Utara. Metode yang diusulkan adalah membandingkan SVM dan SVM-PSO yang menggunakan data dari instansi terkait khususnya di daerah Sumatra Utara,. Masing-masing algoritma akan implementasikan dengan menggunakan RapidMiner 5.1
Pengukuran kinerja dilakukan dengan menghitung rata-rata error yang terjadi melalui besaran Root Mean Square Error (RMSE) .Semakin kecil nilai dari masing-masing parameter kinerja ini menyatakan semakin dekat nilai prediksi dengan nilai sebenarnya. Dengan demikian dapat diketahui algoritma yang lebih akurat.
Kata Kunci: Tinggi Muka Air ,RMSE Support vector machines, PSO
Segala Puji Bagi Allah SWT, Tuhan seru sekalian alam, bersyukur atas selesainya Tesis dengan judul “PERBANDINGAN ALGORITMA SUPPORT VECTOR MACHINE BIASA DAN SUPPORT VECTOR MACHINE BERBASIS PARTICLE SWARM OPTIMIZATION UNTUK PREDIKSI GEMPA BUMI” dapat penulis selesaikan sesuai rencana. Bantuan dan dukungan dari berbagai pihak tidak ternilai besarnya. Penulis berterimakasih kepada:
1. Allah SWT, serta junjungan besar Nabi Muhammad SAW.
2. Kedua Orang Tua dan adik tersayang yang selalu memberikando’a dan semangat.
3. Bapak Dr. Ir. Edi Noersasongko, M.Kom selaku Rektor Universitas Dian Nuswantoro.
4. Bapak Dr. Abdul Syukur, MM selaku Direktur Program Pascasarjana Universitas Dian Nuswantoro dan Pembimbing yang memberikan motivasi dalam penyelesaian tesis ini.
5. Bapak Catur Supriyono, M.C.S selaku dosen dan pembimbing Tesis yang telah memberikan pengetahuan dan bimbingannya dalam penyusunan Tesis ini.
6. Bapak Purwanto, S.Si, M.Kom, Ph.D, ibu Ika Novita Desi, S.Kom, M.C.S dan bapak H. Himawan, M.Kom selaku Penguji yang berkenan untuk menguji tesis ini, memberi masukan bagi penulis sehingga tesis ini menjadi layak dan diharapkan memberikan manfaat.
7. Seluruh Staff Akademika Universitas Dian Nuswantoro Semarang, atas segala bantuan dalam pemecahan masalah, sumbangan pemikiran, perhatian, harapan dan doa yang telah diberikan dalam penyusunan tesis ini.
8. Keluarga Besar Universitas Kalimantan Selatan, khususnya bapak H. M. Muflih yang telah memberikan bantuan fasilitas, dorongan serta kesempatan bagi penulis untuk melanjutkan studi.
9. Teman-teman Udinus Banjarmasin angkatan XXII, atas kebersamaan dan dorongan dalam menulis tesis ini.
dan hidayah-Nya kepada kita semua.
Penulis menyadari adanya keterbatasan penulisan ini, maka kritik, saran, dan masukan yang membangun akan sangat membantu penulis dalam penelitian selanjutnya. Semoga tulisan ini dapat bermanfaat bagi ilmu pengetahuan dan pembaca. Amiin ya Robbal Alamiin.
Semarang, Maret 2015 Penulis
PENGESAHANSTATUS TESIS...i
2.1.2 Jurnal dari Fazlina Ahmat Rusla, Zainazlan Md Zain dan Ramli Adnan Dengan Judul “Flood Water Level Prediction and Tracking Using Particle Filter Algorithm”...4
2.1.3 Jurnal dari Nguyen Cong Long dan Phayung Meesad Dengan Judul “Meta-heuristic Algorithms Applied to the Optimization of Type-1 and Type 2 TSK Fuzzy Logic Systems for Sea Water Level Prediction”...5
Prediction Using Extended Kalman Filter”...6
2.2.1 Beberapa Istilah Elevasi Muka Air...9
2.2.2 Pengertian Air...10
2.3 Data Mining...14
2.3.1 Cross industry Standard Process for Data Mining (CRISP– DM) ...15
2.3.2 Fungsi Data Mining...19
2.3.3 Support Vector Machine...22
2.4 Support Vector Machines with Particle Swarm...26
2.5 Parameter Evaluasi...30
2.5.1 Mean Absolute Percentage Error (MAPE)...31
2.5.2 Mean Square Error (MSE)...31
2.5.3 Root Mean Square Error (RMSE)...31
2.5.4 Mean Absolute Deviation (MAD)...32
4. BAB IV HASIL DAN PEMBAHASAN...40
4.1 Eksperimen dan Pengujian Model/Metode...40
Berbasis Particle Swarm Optimization...42
4.1.3 Support Vector Machines...47
5. BAB V PENUTUP...50
5.1 Kesimpulan...50
5.2 Saran...50
6. DAFTAR REFERENSI...51
7. LAMPIRAN...53
7.1 LAMPIRAN DATA TINGGI MUKA AIR TAHUN 2008-2012...53
7.1.1 Rekapitulasi Data...53
7.1.2 Data Tinggi Muka Air Tahun 2008...55
7.1.3 Data Tinggi Muka Air Tahun 2009...56
7.1.4 Data Tinggi Muka Air Tahun 2010...57
7.1.5 Data Tinggi Muka Air Tahun 2011...58
7.1.6 Data Tinggi Muka Air Tahun 2012...59
7.2 LAMPIRAN Hasil Uji dengan Rapidminer menggunakan SVM...60
7.3 LAMPIRAN Hasil Uji dengan Rapidminer menggunakan SVM - PSO...60
Tabel 3.1 Tinggi muka air tahun 2009...35 Tabel 4-1 Nilai RMSE...47
Gambar 4-1 design SVM di Rapidminer...40
Gambar 4-2 Design SVM di dalam X Validation...41
Gambar 4-4 Atribut Data di rubah menjadi label untuk SVM...41
Gambar 4-5 Hasil RMSE SVM...42
Gambar 4-6 Design model SVM – PSO...43
Grafik 3.1 Grafik Tinggi Muka Air tahun 2009...28 Grafik 4.1 Prediksi SVM-PSO...38
1. BAB I PENDAHULUAN
1.1 Latar Belakang
Gempa bumi merupakan suatu fenomena alam yang tidak dapat dihindari, tidak dapat diramalkan kapan terjadi dan berapa besarnya, serta akan menimbulkan kerugian baik harta maupun jiwa bagi daerah yang ditimpanya dalam waktu relatif singkat. Pada peristiwa tabrakan/tumbukan tersebut akan terjadinya gesekan antara dua atau lebih lempengan yang mengakibatkan adanya pelepasan ‘energi’ yang besar sekali, yang berpengaruh pada daerah-daerah yang lemah pada lempengan tersebut.Bila daerah lemah berada di daerah puncak, akan terjadi letusan gunung api yang diawali dengan adanya gempa vulkanik. Pada daerah di bawah, bila terjadi patahan pada lempengan, akan terjadi peristiwa gempa tektonik[1].
Indonesia terletak pada lokasi yang rawan gempa bumi. Pada beberapa tahun terakhir ini gempa bumi makin sering terjadi. Belum ada teknologi yang dapat meramalkan gempa bumi, sehingga seringkali gempa bumi banyak memakan korban jiwa. Mayoritas korban tewas disebabkan oleh runtuhnya bangunan. Banyak bangunan di Indonesia dibangun tanpa memerhatikan prinsip-prinsip rumah tahan gempa.
Dari gempa yang diakibatkan diatas maka diperlukan suatu bangunan yang tahan gempa dengan menentukan parameter dinamik absorber untuk meredam getaran pada bangunan, dengan menghitung nilai k, c ,dan m dari bangunan yang akan dibangun, sehingga gempa akan bisa diperkecil untuk menghindari korban jiwa[2].
yang sangat memuaskan. Secara efektif memecahkan masalah seperti sampel kecil, lebih-learning, dimensi tinggi, minimum lokal, dll Prediksi masa depan tren limpasan evolusi dengan model ini akan memberikan dasar bagi prediksiGempa bumi.[2]
Particle swarm optimization (PSO) adalah metode pencarian berbasis populasi dan diinisialisasi dengan populasi solusi acak yang disebut partikel (Abraham, 2006). [3] PSO termotivasi dari perilaku burung atau ikan dan termasuk kedalam optimasi teknologi baru. Metode optimasi sangat mudah diterapkan dan ada beberapa parameter untuk menyesuaikannya. Penelitian menggunakan metode particle swarm optimization pernah dilakukan oleh Sheng-Wei Fei (Fei, Miao, & Liu, 2009) dengan hasil penelitian menunjukan metode particle swarm optimization (PSO) dan support vector machine (SVM) mampu mengoptimalkan nilai akurasi yang baik. [4]
Dengan demikian maka saya penulis mencoba melakukan Perbandingan Algoritma Support Vector Machine Biasa Dan Support Vector Machine Berbasis Particle Swarm Optimization Untuk Prediksi Tinggi Muka Air.
1.2 Rumusan Masalah
Dari latar belakang masalah di atas, dapat disimpulkan bahwa terdapat banyak algotrima yang dapat dipakai untuk memprediksi gempa bumi, sehingga belum diketahui algoritma mana yang memiliki kinerja lebih akurat.
1.3 Tujuan Penelitian
Berdasarkan latar belakang masalah dan perumusan masalah diatas, maka penelitian ini bertujuan untuk Perbandingan Algoritma Support Vector Machine Biasa Dan Support Vector Machine Berbasis Particle Swarm Optimization Untuk gempa bumi.
1.4 Manfaat penelitian
2. Untuk mengetahui kekuatan struktur suatu bangunan.
2. BAB II LANDASAN TEORI
2.1 Related Research
2.1.1 Jaringan Saraf Tiruan Untuk Memprediksi Pola Pergerakan Titik Gempa Di Indonesia Dengan Algoritma Backpropagation
Metode penelitian merupakan satu cara yang digunakan untuk memperoleh informasi dan data yang lengkap, sehingga dalam pengambilan keputusan ataupun dalam hal pemecahan masalah bisa lebih maksimal.
Penelitian adalah suatu proses mencari sesuatu secara sistimatis dalam waktu tertentu dengan menggunakan metode ilmiah serta aturan yang berlaku. Dalam proses penelitian ini ditunjukan untuk lebih memahami proses pemecahan masalah yang berkaitan dengan prediksi dan penentuan prediksi pola pergerakan titik gempa bumi di Indonesia. Konseptualisasi proses tersebut kemudian dituangkan menjadi suatu metode penelitian lengkap dengan pola pengumpulan data yang diperlukan untuk melukiskan fenomena tersebut. Oleh karena itu metode yang digunakan dalam penelitian ini adalah backpropagation. [3]
2.1.2 Arslan, M. H., Korkmaz, H. H., and Gulay, F. G.: “Damage and failure pattern of prefabricated structures after major earthquakes in Turkey and shortfalls of the Turkish Earthquake code, Engineering Failure Analysis”, 13(4), 537–557, 2006.
disebabkan oleh gesekan sebagian besar dipisahkan dalam bentuk panas ke dalam bumi, dan beberapa yang dirasakan oleh kita sebagai shock atau dikenal sebagai energi seismik (gempa). Selain piring gesekan terjadi, retak juga dapat terjadi dalam piring itu sendiri.
2.1.3 Jurnal dari Nguyen Cong Long dan Phayung Meesad Dengan Judul “Meta-heuristic Algorithms Applied to the Optimization of Type-1 and Type 2 TSK Fuzzy Logic Systems for Sea Water Level Prediction”
Indonesia sendiri merupakan pertemuan tiga lempeng yang sangat aktif, sehingga memicu terjadinya rentetan gempa bumi di sepanjang jalur pertemuan lempeng, namun tak seorangpun di seluruh dunia yang bisa memprediksi kapan gempa bumi tersebut akan terjadi. Hal ini bisa dilihat dari kejadian-kejadian sebelumnya bahwa titik-titik gempa bumi di Indonesia timbul secara acak dan tidak berurutan.
2.1.4 Binici H. : March 12 and June 6, 2005 Bingol–Karliova earthquakes and the damages caused by the material quality and low workmanship in the recent earthquakes, Engineering Failure Analysis, 14, 233–238, 2007.
Pertemuan pergerakan ketiga lempeng tersebut akan menghasilkan energi, jika tidak bisa lagi menahan desakan lempeng yang satu dengan lainnya. Akibat desakan pergerakan lempeng tersebut, maka akan terjadi patahan atau pelepasan energi yang pada akhirnya akan memicu terjadinya gempa bumi tektonik dan terkadang diiringi dengan tsunami. Sebagian dari pertemuan lempeng-lempeng bumi tersebut juga ada yang memicu terjadinya gunung api. Hal tersebut dapat dilihat pada sepanjang jalur pertemuan lempeng-lempeng bumi, selalu diiringi terbentuknya gunung api. Jika terjadi desakan energi dalam perut gunung api, maka hal ini dapat memicu terjadinya letusan gunung api diiringi dengan terjadinya gempa bumi vulkanik. Secara umum gempa bumi adalah peristiwa bergetarnya bumi akibat pelepasan energi di dalam bumi secara tiba-tiba yang ditandai dengan patahnya lapisan batuan pada kerak bumi.
2.1.5 Yanghong Tan, Yigang He. A Novel Method for Analog Fault Diagnosis Based on Neural Networks and Genetic Algorithms. Instrumentation and Measurement, IEEE Transactions on Volume 57, Issue 11, Nov.2008 Page(s) : 2631 – 2639.
Jaringan syaraf tiruan telah dilatih untuk melakukan fungsi yang kompleks dalam berbagai bidang aplikasi yang mencakup pengenalan pola terbaik, identifikasi, pengolahan suara, dan sistem kontrol. Saat ini jaringan saraf buatan telah digunakan untuk memecahkan masalah yang sulit bagi manusia atau komputer konvensional. Algoritma yang sebelumnya dilakukan dengan waktu yang lama dan tidak akurat ketika itu bukan hal yang sulit lagi. Beberapa aplikasi jaringan saraf tiruan adalah sebagai berikut :
b. mengenali pola (misalnya huruf, angka, suara atau tanda tangan) yang telah sedikit berubah.
c. Pemrosesan Sinyal, jaringan saraf buatan yang dapat digunakan untuk menekan kebisingan di saluran telepon.
2.2 Gempa Bumi
Gempa bumi adalah suatu peristiwa alam dimana terjadi getaran pada permukaan bumi akibat adanya pelepasan energi secara tiba-tiba dari pusat gempa. Energi yang dilepaskan tersebut merambat melalui tanah dalam bentuk gelombang getaran. Gelombang getaran yang sampai ke permukaan bumi disebut gempa bumi.[2]
2.2.1 Sifat Struktur
Sifat dari struktur yang menjadi syarat utama perencanaan bangunan tahan gempa adalah sebagai berikut:
1. Kekuatan (strength)
Kekuatan dapat kita artikan sebagai ketahanan dari struktur atau komponen struktur atau bahan yang digunakan terhadap beban yang membebaninya. Perencanaan kekuatan suatu struktur tergantung pada maksud dan kegunaan struktur tersebut.
2. Daktilitas (ductility)
Kemampuan suatu struktur gedung untuk mengalami simpangan pasca-elastik yang besar secara berulang kali dan bolak-balik akibat beban gempa di atas beban gempa yang menyebabkan terjadinya pelelehan pertama, sambil mempertahankan kekuatan dan kekakuan yang cukup, sehingga struktur gedung tersebut tetap berdiri, walaupun sudah berada dalam kondisi di ambang keruntuhan.
3. Kekakuan (stiffness)
2.2.2 Penyebab Terjadi Gempa Bumi
Banyak teori yang telah dikemukan mengenai penyebab terjadinya gempa bumi. Menurut pendapat para ahli, sebab-sebab terjadinya gempa adalah sebagai berikut:
1. Runtuhnya gua-gua besar yang berada di bawah permukaan tanah. 2. Namun, kenyataannya keruntuhan yng menyebabkan terjadinya
gempa bumi tidak pernah terjadi.
3. Tabrakan meteor pada permukaan bumi. Bumi merupakan salah satu planet yang ada dalam susunan tata surya. Dalam tata surya kita terdapat ribuan meteor atau batuan yang bertebaran mengelilingi orbit bumi. Sewaktu-waktu meteor tersebut jatuh ke atmosfir bumi dan kadang-kadang sampai ke permukaan bumi. Meteor yang jatuh ini akan menimbulkan getaran bumi jika massa meteor cukup besar. Getaran ini disebut gempa jatuhan, namun gempa ini jarang sekali terjadi. Kejadian ini sangat jarang terjadi dan pengaruhnya juga tidak terlalu besar.
5. Kegiatan tektonik. Semua gempa bumi yang memiliki efek yang cukup besar berasal dari kegiatan tektonik. Gaya-gaya tektonik biasa disebabkan oleh proses pembentukan gunung, pembentukan patahan, gerakan-gerakan patahan lempeng bumi, dan tarikan atau tekanan bagian-bagian benua yang besar. Gempa ini merupakan gempa yang umumnya berkekuatan lebih dari 5 skala Richter.
Dari berbagai teori yang telah dikemukan, maka teori lempeng tektonik inilah yang dianggap paling tepat. Teori ini menyatakan bahwa bumi diselimuti oleh beberapa lempeng kaku keras (lapisan litosfer) yang berada di atas lapisan yang lebih lunak dari litosfer dan lempemg-lempeng tersebut terus bergerak dengan kecepatan 8 km per tahun sampai 12 km per tahun. Pergerakan lempengan-lempengan tektonik ini.
menyebabkan terjadinya penimbunan energi secara perlahan-lahan. Gempa tektonik kemudian terjadi karena adanya pelepasan energi yang telah lama tertimbun tersebut.
Daerah yang paling rawan gempa umumnya berada pada pertemuan lempeng-lempeng tersebut. Pertemuan dua buah lempeng tektonik akan menyebabkan pergeseran relatif pada batas lempeng tersebut, yaitu:
1. Subduction, yaitu peristiwa dimana salah satu lempeng mengalah
dan dipaksa turun ke bawah. Peristiwa inilah yang paling banyak menyebabkan gempa bumi.
2. Extrusion, yaitu penarikan satu lempeng terhadap lempeng yang
lain.
3. Transcursion, yaitu terjadi gerakan vertikal satu lempeng terhadap
yang lainnya.
4. Accretion, yaitu tabrakan lambat yang terjadi antara lempeng lautan
2.2.3 Parameter Dasar Gempa
Beberapa parameter dasar gempa bumi yang perlu kita ketahui, yaitu:
1. Hypocenter, yaitu tempat terjadinya gempa atau pergeseran tanah
didalam bumi.
2. Epicenter, yaitu titik yang diproyeksikan tepat berada di atas
hypocenter pada permukaan bumi.
3. Bedrock, yaitu tanah keras tempat mulai bekerjanya gaya gempa.
4. Ground acceleration, yaitu percepatan pada permukaan bumi akibat
gempa bumi.
5. Amplification factor, yaitu faktor pembesaran percepatan gempa
yang terjadi pada permukaan tanah akibat jenis tanah tertentu. 6. Skala gempa, yaitu suatu ukuran kekuatan gempa yang dapat diukur
dengan secara kuantitatif dan kualitatif. Pengukuran kekuatan gempa secara kuantitatif dilakukan pengukuran dengan skala Richter yang umumnya dikenal sebagai pengukuran magnitudo gempa bumi. Magnitudo gempa bumi adalah ukuran mutlak yang dikeluarkan oleh pusat gempa. Pendapat ini pertama kali dikemukakan oleh Richter dengan besar antara 0 sampai 9. Selama ini gempa terbesar tercatat sebesar 8,9 skala Richter terjadi di Columbia tahun 1906. Pengukuran kekuatan gempa secara kualitatif yaitu dengan melihat besarnya kerusakan yang diakibatkan oleh gempa. Kerusakan tersebut dapat dikatakan sebagai intensitas gempa bumi. Di Indonesia digunakan skala intensitas MMI (Modified Mercalli Intensity) versi tahun 1931. Perbandingan intensitas skala MMI dari nilai I hingga XII dapat dilihat.
2.2.4 Kerusakan Akibat Gempa Bumi
2. keruntuhan dan kerusakan dari lingkungan alam dan konstruksi.
2.2.4 Pengaruh Gempa Bumi Terhadap Bangunan
Gempa mempunyai pengaruh yang cukup besar terhadap bangunan sehingga harus diperhitungkan dengan benar dalam perencanaan struktur tahan gempa dengan tingkat keamanan yang dapat diterima.
Kekuatan dari gerakan tanah akibat gempa bumi pada beberapa tempat disebut intensitas gempa. Komponen-komponen dari gerakan tanah yang dicatat oleh alat pencatat gempa accelerograph untuk respons struktur adalah amplitudo, frekuensi, dan durasi. Selama terjadi gempa terdapat satu atau lebih puncak gerakan. Puncak ini merupakan efek maksimum dari gempa.
Selama terjadi gempa, bangunan mengalami perpindahan vertikal dan horizontal. Gaya gempa dalam arah vertikal hanya sedikit mengubah gaya gravitasi yang bekerja pada struktur yang umumnya direncanakan terhadap gaya vertikal dengan faktor keamanan yang cukup tinggi. Oleh sebab itu, struktur jarang runtuh akibat gaya gempa vertikal. Sebaliknya gaya gempa horizontal bekerja pada titik-titik yang lemah pada struktur yang tidak cukup kuat dan akan menyebabkan keruntuhan. Oleh karena itu, perancangan struktur tahan gempa adalah meningkatkan kekuatan struktur terhadap gaya horizontal yang umumnya tidak cukup.
Gerakan permukaan bumi menimbulkan gaya inersia pada struktur bangunan karena adanya kecenderungn massa bangunan (struktur) untuk mempertahankan dirinya. Besarnya gaya inersia mendatar F tergantung dari massa bangunan m, percepatan permukaan a dan sifat struktur. Apabila bangunan dan pondasinya kaku, maka menurut hukum kedua Newton . Dalam kenyataannya tidaklah demikian karena semua struktur tidaklah benar-benar sebagai massa yang kaku tetapi fleksibel.
2.3 Data Mining
prediksi, mereka meramalkan apa yang akan terjadidalam situasi baru dari data yang menggambarkan apa yang terjadi di masa lalu (Witten, Frank, & Hall, 2011).[14] Kakas data mining meramalkan tren dan sifat-sifat perilaku bisnis yang sangat berguna untuk mendukung pengambilan keputusan penting. Analisis yang diotomatisasi yang dilakukan oleh data mining melebihi yang dilakukan oleh sistem pendukung keputusan tradisional yang sudah banyak digunakan (Moertini, 2002). [15] Secara khusus, koleksi metode yang dikenal sebagai 'data mining' menawarkan metodologi dan solusi teknis untuk mengatasi analisis data medis dan konstruksi prediksi model (Bellazzi & Zupanb, 2008). [16]
Secara umum, tugas data mining dapat diklasifikasikan menjadi dua kategori: deskriptif dan prediktif. Tugas pertambangan deskriptif mengkarakterisasi sifat umum data dalam database pertambangan prediktif tugas data pada saat ini untuk membuat prediksi (Han & Kamber, 2007). [17].
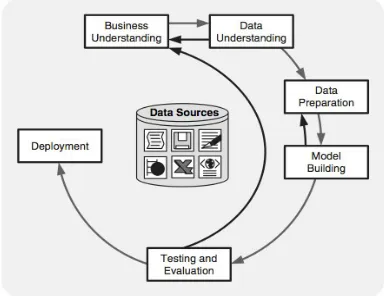
2.3.1 Cross industry Standard Process for Data Mining (CRISP– DM)
Dalam jurnal “Identifying Bank Frauds Using CRISP-DM and Decision trees” oleh Da Rocha & Timóteo (2010) mengatakan “metodologiCross Industri Standard Process for Data Mining (CRISP-DM) telah banyakdigunakan dalam industri oleh para ahli saat ini sebagai salah satu proses data mining untuk memecahkan suatu masalah”. Metodologi ini terdiri dari enam tahap proses siklus. Metodologi ini membuat data mining yang besar dapatdilakukan dengan lebih cepat, lebih ekonomis, dan mudah untuk diatur. Bahkan, data mining yang berukuran kecil pun dapat memperoleh keuntungan dari CRISP-DM (Olson & Delen, 2008:9). Berikut adalah enam tahap yang disebut sebagai siklus:
Business understanding meliputi penentuan tujuan bisnis, menilai situasi saat ini, menetapkan tujuan data mining, dan mengembangkan rencana proyek.
2. Data understanding
3. Data preparation
Setelah sumber data telah tersedia untuk diidentifikasi. Data tersebut perlu untuk dipilih, dibersihkan, dibangun ke dalam model yang diinginkan, dan diformat.Pembersihan data dan transformasi data dalam penyusunan pemodelan data perlu terjadi di tahap ini.
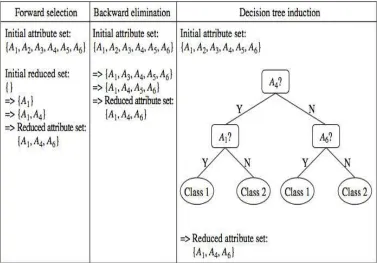
Gambar 2.1 Greedy (heuristic) methods for attribute subset selection. Sumber: (Han & Kamber, 2011, p104)
Terdapat beberapa teknik dalam mengolah data seperti Data Transformation, Data Reduction dan Data Cleaning, diantaranya :
1) Generalization
Mengubah data atribut low level menjadi atribut high level, contoh : atribut numerical menjadi ordinal.
2) Attribute construction
Penambahan atribut baru untuk kepentingan proses mining. 3) Attribute subset selection
Proses metode ini adalah untuk mencari atribut terbaik dariseluruh data set dan di masukkan ke dalam data set baru berdasarkan atribut terbaik yang telah dipilih.
b) Stepwise backward elimination
Proses metode ini adalah untuk mencari atribut yang tidak berkaitan dengan data mining yang dicari, lalu langsung menghapusnya dari data set.
c) Combination of forward selection and backward elimination Proses metode ini adalah penggabungan dari metodestepwise forward selection dan stepwise backward elimination.
d) Decision tree induction
Proses metode ini menggunakan algoritma decision tree, seperti algoritma ID3, C4.5, dan cart dalam mencari atribut yang terbaik.
4) Missing Value
Nilai null yang terdapat dalam data set dapat mengganggu pembuatan mining yang dilakukan. Ada 6 metode yang dapat digunakan dalam mengolah nilai null yang terdapat dalam data, yaitu :
Ignore the tuple: tidak menggunakan tuple yang memiliki nilai null.
Fill in the missing value manually: mengisi sendiri nilai null yang terdapat dalam data.
Use global constant to fill in the missing value: mengganti nilai null dengan label constant, seperti “Unknown”.
Use the attribute mean to fill in the missing value: mengganti nilai null dengan rata-rata yang dimiliki atribut.
Use the attribute mean for all samples belonging to the same class the given tuple: mengganti nilai null dengannilai rata-rata yang dimilik atribut berdasarkan target kelasyang dicari.
Use the most probable value to fill in the missing value: mengganti nilai null dengan nilai yang paling mungkin muncul berdasarkan atribut target kelas yang dicari.
Tujuan dari pemodelan data mining adalah untuk mencari hasil dari berbagai situasi yang ada. Alat perangkat lunak untuk data miningseperti visualisasi (mensplit data dan membangun hubungan) dan analisis kluster (untuk mengidentifikasikan variableberjalan dengan baik secara bersamaan) dapat berguna untuk analisis awal model yang akan digunakan. Pembagian data ke dalam set pelatihan dan pengujian juga diperlukan untuk pemodelan.
6) Evaluation
Hasil model harus dievaluasi sesuai tujuan bisnis pada tahap pertama (pemahaman bisnis).Evaluasi dilakukan dari hasil visualisasi dan perhitungan statistik pengujian berdasarkan pemodelan yang dibuat.Pada akhir dari tahap ini, keputusan penggunaan hasil data miningtelah ditentukan.
Deployment
Pembuatan dari model bukanlah akhir dari projek data mining. Meskipun tujuan dari pemodelan adalah untuk meningkatkan pengetahuan dari data, pengetahuan data tersebut perlu dibangun dengan terorganisasi dan dibuat pada satu bentuk yang dapat digunakan oleh pengguna.
2.3.2 Fungsi Data Mining
Banyak fungsi data mining yang dapat digunakan.Dalam kasus tertentu fungsi data mining dapat digabungkan untuk menjawab masalah yang dihadapi (Maclennan, Tang, & Crivat, 2009, 6). Berikut adalah fungsi data mining secara umum :
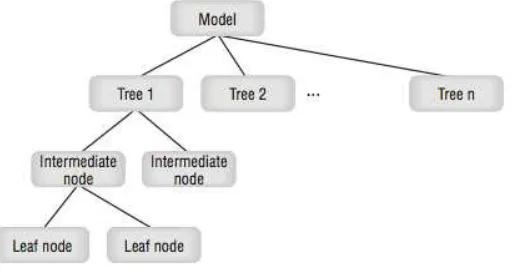
1. Classification
Fungsi dari Classification adalah untuk mengklasifikasikan suatu target class ke dalam kategori yang dipilih.
Gambar 2.3 Classification - Decision Tree Sumber: (Maclennan, Tang, & Crivat, 2009, p7)
2. Clustering
Fungsi dari clustering adalah untuk mencari pengelompokan atribut ke dalam segmentasi-segmentasi berdasarkan similaritas.
Sumber: (Maclennan, Tang, & Crivat, 2009, p7)
3. Association
Fungsi dari association adalah untuk mencari keterkaitan antara atribut atau item set, berdasarkan jumlah item yang muncul dan rule associationyang ada.
Gambar 2.5 Product Association Sumber: (Maclennan, Tang, & Crivat, 2009, p7)
4. Regression
Fungsi dari regression hampir mirip dengan klasifikasi.Fungsi dari regression adalah bertujuan untuk mencari prediksi dari suatu pola yang ada.
5. Forecasting
Gambar 2.6 Time Series
Sumber: (Maclennan, Tang, & Crivat, 2009, p8)
6. Sequence Analysis
Fungsi dari sequence analysis adalah untuk mencari pola urutan dari rangkaian kejadian.
7. Deviation Analysis
Fungsi dari devation analysis adalah untuk mencari kejadian langka yang sangat berbeda dari keadaan normal (kejadian abnormal).
2.3.3 Support Vector Machine
SVM adalah sebuah metode seleksi yang membandingkan parameter standar seperangkat nilai diskrit yang disebut kandidat set, dan mengambil salah satu yang memiliki akurasi klasifikasi terbaik (Dong, Xia, Tu, & Xing, 2007). SVM adalah salah satu alat yang paling berpengaruh dan kuat untuk memecahkan klasifikasi (Burges, 1998). Support Vector Machines (SVM) adalah seperangkat metode yang terkait untuk suatu metode pembelajaran, untuk kedua masalah klasifikasi dan regresi (Maimon, 2010). Dengan berorientasi pada tugas, kuat, sifat komputasi mudah dikerjakan, SVM telah mencapai sukses besar dan dianggap sebagai state-of-the-art classifier saat ini (Huang, Yang, King, & Lyu, 2008).
Konsep SVM dapat dijelaskan secara sederhana sebagai usaha mencari hyperplane terbaik yang berfungsi sebagai pemisah dua buah class pada input space. Untuk n-dimensional space, input data xi (i=1. . .k), dimana milik kelas 1 atau kelas 2 dan label yang terkait menjadi -1 untuk kelas 1 dan +1 untuk kelas 2. Gambar 1a memperlihatkan beberapa pattern yang merupakan anggota dari dua buah class: positif (dinotasikan dengan +1) dan negatif (dinotasikan dengan –1). Pattern yang tergabung pada class negatif disimbolkan dengan kotak, sedangkan pattern pada class positif, disimbolkan dengan lingkaran. Jika data input dapat dipisahkan secara linear, pemisahan hyper plane dapat diberikan dalam:
Proses pembelajaran dalam problem klasifikasi diterjemahkan sebagai upaya menemukan garis (hyperplane) yang memisahkan antara kedua kelompok tersebut. Berbagai alternatif garis pemisah (discrimination boundaries) ditunjukkan pada Gambar 2.2 (Nugroho, 2008).
Gambar 2. 2 SVM Berusaha Menemukan Hyperplane Terbaik Yang Memisahkan Kedua Class Negatif Dan Positif 2 (Nugroho, 2008)
vector. Upaya mencari lokasi hyperplane optimal ini merupakan inti dari proses pembelajaran pada SVM (Nugroho, 2008).
Data yang tersedia dinotasikan sebagai x ∈ R d sedangkan label
masing-masing dinotasikan yi ∈{-1+1} untuk i = 1,2,....,1 yang mana l adalah
banyaknya data. Diasumsikan kedua class –1 dan +1 dapat terpisah secara sempurna oleh hyperplane berdimensi d , yang didefinisikan: Diasumsikan kedua class –1 dan +1 dapat terpisah secara sempurna oleh hyperplane dirumuskan sebagai pattern yang memenuhi pertidaksamaan:
⃗
w .⃗x+b=−1 (2.4)
sedangkan pattern yang termasuk class +1 (sampel positif):
w.x + b = +1 (2.3) Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu 1/||w||. Hal ini dapat dirumuskan sebagai Quadratic Programming (QP) problem, yaitu mencari titik minimal persamaan 2.4, dengan memperhatikan constraint persamaan 2.5.
L( ⃗w , b , a)=1
αi adalah Lagrange multipliers, yang bernilai nol atau positif (αi0). Nilai optimal dari persamaan (6) dapat dihitung dengan meminimalkan L terhadap w dan b , dan memaksimalkan L terhadap αi.
Dengan memperhatikan sifat bahwa pada titik optimal gradient L=0, persamaan langkah 2.7 dapat dimodifikasi sebagai maksimalisasi problem yang hanya mengandung αi saja, sebagaimana persamaan 2.8.
maximize:
∑
Dari hasil dari perhitungan ini diperoleh αi yang kebanyakan bernilai positif.
Data yang berkorelasi dengan αi yang positif inilah yang disebut sebagai
support vector machine.
2.3.3.1 Contoh Penerapan Metode Support Vector Machine
Untuk ilustrasi bagaimana SVM bekerja, mari kita ikuti dua contoh berikut. Satu adalah contoh dimana data yang ada bisa dipisahkan secara linier. Untuk contoh ini kita gunakan problem AND.
Contoh yang kedua adalah contoh untuk problem yang tidak bisa dipisahkan secara linier. Untuk contoh ini kita gunakan problem Exclusive OR (XOR). Problem AND adalah klasifikasi dua kelas dengan empat data (lihat Tabel 1). Karena ini problem linier, kernelisasi tidak diperlukan.
X1 X2 y
1 1 1
-1 1 -1
1 -1 -1
-1 -1 -1
dapatkan formulasi masalah optimisasi sebagai berikut: 1 dipastikan nilai variable slack ti=0. Jadi Kita bisa masukkan nilai C=0. Setelah menyelesaikan problem optimasi di atas didapat solusi
w1 = 1,w2 = 1, b = −1
Untuk menentukan output atau label dari setiap titik data/obyek kita gunakan fungsi g(x) = sign(x). Dengan fungsi sign ini semua nilai f(x)<0 diberi label −1 dan lainnya diberi label +1.
Untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linier formula SVM harus dimodifikasi karena tidak akan ada solusi yang ditemukan.
2.4 Support Vector Machines with Particle Swarm
Particle swarm optimization, disingkat sebagai PSO, didasarkan pada
perilaku sebuah kawanan serangga, seperti semut, rayap, lebah atau burung. Algoritma PSO meniru perilaku sosial organisme ini. Perilaku sosial terdiri dari tindakan individu dan pengaruh dari individu-individu lain dalam suatu kelompok.
Kata partikel menunjukkan, misalnya, seekor burung dalam kawanan burung. Setiap individu atau partikel berperilaku secara terdistribusi dengan cara menggunakan kecerdasannya (intelligence) sendiri dan juga dipengaruhi perilaku kelompok kolektifnya. Dengan demikian, jika satu partikel atau seekor burung menemukan jalan yang tepat atau pendek menuju ke sumber makanan, sisa kelompok yang lain juga akan dapat segera mengikuti jalan tersebut meskipun lokasi mereka jauh di kelompok tersebut.Metode optimasi yang didasarkan pada swarm intelligence ini disebut algoritma behaviorally inspired sebagai alternatif dari algoritma genetika, yang sering disebut evolution-based procedures. Algoritma PSO ini awalnya diusulkan oleh J. Kennedy and R.C. Eberhart [5]. Dalam konteks optimasi multivariabel, kawanan diasumsikan mempunyai ukuran tertentu atau tetap dengan setiap partikel posisi awalnya terletak di suatu lokasi yang acak dalam ruang multidimensi. Setiap partikel diasumsikan memiliki dua karakteristik: posisi dan kecepatan.
bagusnya kepada partikel yang lain dan menyesuaikan posisi dan kecepatan masing-masing berdasarkan informasi yang diterima mengenai posisi yang bagus tersebut. Sebagai contoh, misalnya perilaku burung-burung dalam kawanan burung. Meskipun setiap burung mempunyai keterbatasan dalam hal kecerdasan, biasanya ia akan mengikuti kebiasaan (rule) seperti berikut : 1. Seekor burung tidak berada terlalu dekat dengan burung yang lain 2. Burung tersebut akan mengarahkan terbangnya ke arah rata-rata
keseluruhan burung
3. Akan memposisikan diri dengan rata-rata posisi burung yang lain dengan menjaga sehingga jarak antar burung dalam kawanan itu tidak terlalu jauh
Dengan demikian perilaku kawanan burung akan didasarkan pada kombinasi dari 3 faktor simpel berikut:
1. Kohesi - terbang bersama 2. Separasi - jangan terlalu dekat
3. Penyesuaian(alignment) - mengikuti arah bersama
Jadi PSO dikembangkan dengan berdasarkan pada model berikut:
1. Ketika seekor burung mendekati target atau makanan (atau bisa minimum atau maximum suatu fungsi tujuan) secara cepat mengirim informasi kepada burung-burung yang lain dalam kawanan tertentu 2. Burung yang lain akan mengikuti arah menuju ke makanan tetapi tidak
secara langsung
3. Ada komponen yang tergantung pada pikiran setiap burung, yaitu memorinya tentang apa yang sudah dilewati pada waktu sebelumnya.
Model ini akan disimulasikan dalam ruang dengan dimensi tertentu dengan sejumlah iterasi sehingga di setiap iterasi, posisi partikel akan semakin mengarah ke target yang dituju (minimasi atau maksimasi fungsi).
Ini dilakukan hingga maksimum iterasi dicapai atau bisa juga digunakan kriteria penghentian yang lain.
Implementasi PSO
min f (x)dimana X(B)≤ X ≤ X(A) ……….(6)
dimana X (B) adalah batas bawah dan X (A) adalah batas atas dari X .
Prosedur PSO dapat dijabarkan dengan langkah-langkah sebagai berikut [5]: 1. Asumsikan bahwa ukuran kelompok atau kawanan (jumlah partikel) adalah N . untuk mengurangi jumlah evaluasi fungsi yang diperlukan untuk menemukan solusi, sebaiknya ukuran N tidak terlalu besar, tetapi juga tidak terlalu kecil,agar ada banyak kemungkinan posisi menuju solusi terbaik atau optimal. Jika terlalu kecil, sedikit kemungkinan menemukan posisi partikel yang baik. Terlalu besar juga akan membuat perhitungan jadi panjang.Biasanya digunakan ukuran kawanan adalah 20 sampai 30 partikel.
2. Bangkitkan populasi awal X dengan rentang X (B) dan X (A) secara random sehingga didapat X1, X2, ..., XN . Setelah itu, untuk mudahnya,partikel j dengan kecepatan pada iretasi I dinotasiakan sebagai X j(i) dan Vj(i) sehingga partikel-partikel awal ini akan menjadi X1(0), X2(0), ..., XN (0). Vektor Xj (0), (j = 1, 2, ..., N ) disebut partikel atau vektor koordinat dari partikel. (seperti kromosom dalam algoritma genetika). Evaluasi nilai fungsi tujuan untuk setiap partikel dan nyatakan dengan
X2(0), … , f[XN(0)]
f
[
X1(0)]
, f¿ ………..(7)3. Hitung kecepatan dari semua partikel. Semua partikel bergerak menuju titik optimal dengan suatu kecepatan. Awalnya semua kecepatan dari partikel diasumsikan sama dengan nol. Set iterasi i = 1.
4. Pada iterasi ke-i, temukan 2 parameter penting untuk setiap partikel j yaitu:
(i) yang ditemukan sampai iterasi ke-i, Gbest ,dengan nilai fungsi tujuan paling kecil/minimum diantara semua partikel untuk semua iterasi sebelumnya, f [Xj (i)].
(b) Hitung kecepatan partikel j pada iterasi ke i dengan rumus sebagaiberikut:
Pbest , j−xj(i−1)+c2r2
[
Gbest−xi(i−1)]
, j=1, 2,… N Vj(i)=Vj(i−1)+clel¿………...(8)
dimana c1 dan c2 masing-masing adalah learning rates untuk kemampuan individu (cognitive) dan pengaruh sosial (group), dan r1 dan r2 bilangan random yang berdistribusi uniforml dalam interval 0 dan 1. Jadi parameters c1 dan c2 dmenunjukkan bobot dari memory (position) sebuah partikel terhadap memory (posisi) dari kelompok(swarm). Nilai dari c1 dan c2 biasanya adalah 2 sehingga perkalian c1r1 dan c2 r2 memastikan bahwa partikel-partikel akan mendekati target sekitar setengah selisihnya.
( c ) Hitung posisi atau koordinat partikel j pada iterasi ke-i dengan cara
Xj(i)=Xj(i−1)+Vj(i); j=1,2,… , N ………..(9)
Evaluasi nilai fungsi tujuan untuk setiap partikel dan nyatakan sebagai
f
[
X19i), f[
X2(i)]
, … , f¿ ¿ ………(10)5. Cek apakah solusi yang sekarang sudah konvergen. Jika posisi semua partikel menuju ke satu nilai yang sama, maka ini disebut konvergen. Jika belum konvergen maka langkah 4 diulang dengan memperbarui iterasi i = i + 1, dengan cara menghitung nilai baru dari Pbest,j dan
Gbest . Proses iterasi ini dilanjutkan sampai semua partikel menuju ke
satu titik solusi yang sama. Biasanya akan ditentukan dengan kriteria penghentian (stopping criteria), misalnya jumlah selisih solusi sekarang dengan solusi sebelumnya sudah sangat kecil.
2.5 Parameter Evaluasi
identifikasi model, ukuran akurasi diperlukan untuk membandingkan model-model alternatif satu sama lain dan untuk menentukan nilai parameter yang muncul dalam ekspresi untuk fungsi prediksi F. Untuk mengidentifikasi model prediksi yang paling akurat, masing-masing model dianggap diterapkan pada data masa lalu, dan model dengan total error minimum dipilih.
Kedua, setelah model prediksi telah dikembangkan dan digunakan untuk menghasilkan prediksi untuk masa mendatang, perlu untuk secara berkala menilai keakuratan, untuk mendeteksi kelainan dan kekurangan dalam model yang mungkin timbul di lain waktu. Evaluasi keakuratan prediksi pada tahap ini membuat mungkin untuk menentukan apakah model masih akurat atau memerlukan suatu revisi.Untuk mengevaluasi akurasi dan peramalan kinerja model berbeda, penelitian ini mengadopsi tiga indeks evaluasi: Percentage Error (MAPE), Mean Square Error (MSE) atau Root
Mean Square Error (RMSE) dan Mean Absolute Deviation (MAD).
Formula untuk menghitung indeks ini diberikan di bawah ini: 2.5.1 Mean Absolute Percentage Error (MAPE)
MeanAbsolute Percentage Error adalah nilai absolute dari persentase error
data terhadap mean, atau dapat dirumuskan sebagai berikut:
MAPE=
∑
|PrediksiAktual−Aktual|x100n
...
..(17)
2.5.2 Root Mean Square Error (RMSE)
Root Mean Square Error adalah penjumlahan kuadrat error atau selisih
antara nilai sebenarnya (aktual) dan nilai prediksi, kemudian membagi jumlah tersebut dengan banyaknya waktu data peramalan dan kemudian menarik akarnya, atau dapat dirumuskan sebagai berikut:
RMSE=
√
∑
(Aktual−Prediksi)2
2.5.3 Mean Absolute Deviation (MAD)
MeanAbsolute Deviation adalah nilai absolutdari penyimpangan data
terhadap mean, atau dapat dirumuskan sebagai berikut:
MAD=
∑
|Aktual−Prediksi|n
………….(20) 2.6 Pembandingan Algoritma
Membandingkan dua atau lebih algoritma dilakukan dengan membandingkan error yang dihasilkan masing-masing algoritma. Untuk mendapatkan perbedaan signifikan secara statistik maka dilakukanlah perbandingan.
2.6.1 Mean Square Error (MSE)
Mean Square Error adalah penjumlahan kuadrat error atau selisih antara
3. BAB III
METODE PENELITIAN
3.1 Perancangan Penelitian
Metode penelitian yang dilakukan adalah metode penelitian eksperimen, dengan tahapan penelitian seperti berikut:
1. Pengumpulan Data (Data Gathering)
2. Pengolahan Awal Data (Data Pre-processing)
3. Model/Metode Yang Diusulkan (Proposed Model/Method)
Metode yang diusulkan adalah metode perbandingan tingkat akurasi dari model algoritma soft computing yang dapat digunakan untuk memprediksi tinggi muka air.
4. Eksperimen dan Pengujian Metode (Method Test and Experiment) Masing-masing algoritma akan menggunakan data yang identik. Sebagian data digunakan sebagai data training dan sebagian lagi sebagai data checking. Perhitungan dengan masing-masing algoritma akan diulang beberapa kali untuk mendapatkan besaran parameter terbaik. 5. Evaluasi dan Validasi Hasil(Result Evaluation and Validation)
Evaluasi dilakukan dengan mengamati hasil prediksi menggunakan algoritma softcomputing. Validasi dilakukan dengan mengukur hasil prediksi dan juga dibanding dengan algoritma lain. Pengukuran kinerja dilakukan dengan membandingkan nilai error hasil prediksi masing-masing algoritma sehingga dapat diketahui algoritma yang lebih akurat.
3.2 Lokasi Pengambilan Data
Lokasi pengambilan data di daerah kota Sumatra Selatan data yang diperoleh dari instansi terkait yaitu data dari tahun 2010 sampai 2014. 3.3 Metode Pengumpulan data
Data Sekunder
Penelitian ini memakai data gempa bumi 2010-2014 yang terletak di daerah Sumatra Selatan.
Data Primer
Data yang diperoleh dari sumber data penelitian dimana Penelitian ini memakai data Gempa Bumi Sumatra Selatan dari tahun 2010 -2014 yang didapatkan Dari Badan Meteorologi, klimatologi dan geofisika .
1 12 23 34 45 56 67 78 89 100 111 122 133 144 155 166 177 188 199 210 221 232 243 254 265 276 287 298 309 320 331 342 353
- 75 150 225 300
Hidrograph TMA. Sungai Marabahan Tahun 2009
Hari
Grafik 3.1 Grafik Tinggi Muka Air tahun 2009
1 12 23 34 45 56 67 78 89 100 111 122 133 144 155 166 177 188 199 210 221 232 243 254 265 276 287 298 309 320 331 342 353
Grafik 3.2 Grafik Tinggi Muka Air tahun 2010
3.4 Metode Pengolahan Data Awal
Data yang didapatkan dari instasi terkait masih berupa data yang terdiri dari berbagai parameter, sehingga harus diolah terlebih dahulu dan di modifikasi yang dilakukan sesuai kebutuhan dalam hal ini dilakukan perubahan kategori data untuk mendapatkan hasil yang lebih baik.
kemudian data tersebut juga akan dibandingkan dengan beberapa altoritma seperti Support Vector Machine dengan Support Vector Berbasi Particle Swarm Optimization, yang digunakan untuk memprediksi tinggi muka air. Algoritma akan implementasikan dengan menggunakan RapidMiner 5.1.001.
3.5 Eksperimen dan Pengujian Model/Metode
Algoritma yang akan di usulkan dalam penelitian ini yaitu prediksi Gempa Bumi yang menggunakan data dari instansi dari provinsi Sumatra Selatan tahun 2010-2014 dan Evaluasi akan dilakukan dengan mengamati hasil prediksi Gempa Bumi dari penerapan Support Vector Machine dengan Support Vector Berbasi Particle Swarm Optimization.
MeanAbsolutePercentageError (MAPE), MeanAbsoluteDeviation (MAD),
Normalized Mean Square Error (NMSE) . Semakin kecil nilai dari
masing-masing parameter kinerja ini menyatakan semakin dekat nilai prediksi dengan nilai sebenarnya. Dengan demikian dapat diketahui algoritma yang lebih akurat.
3.6 Evaluasi dan Validasi Hasil
Evaluasi dilakukan dengan menganalisis dan membandingkan hasil prediksi Tinggi Muka air dari Algoritma Support Vector Machine dengan Support Vector Berbasi Particle Swarm Optimization.
Pengukuran kinerja dilakukan dengan menghitung rata-rata error yang terjadi melalui besaran Root Mean Square Error (RMSE).
4. BAB IV
HASIL DAN PEMBAHASAN
4.1 Eksperimen dan Pengujian Model/Metode
Algoritma yang diusulkan dalam penelitian ini akan diterapkan pada data tinggi muka air pada tahun 2008-2012 yang didapatkan dari instansi kota Marabahan Kalimantan.
untuk membandingkan Support Vector Machines dengan Support Vector Machines Berbasis Particle swarm optimization dalam penelitian ini di terapkan pada data Tinggi Muka Air 2008-2012. Data tinggi muka air ini akan di proses menggunakan Rapidminer.
4.1.1 Model Support Vector Machines(SVM)
Model design Support Vector Machine (SVM) menggunakan rapidminer
menggunakan windowing. Adapun Design model yang di gunakan dalam rapidminer sebagai berikut :
Untuk design di dalam Validasi di masukan default Model untuk Traning, dan untuk testing dimasukan Apply Model dan Performansce. Dari performance di hasilkan akurasi berupa Root Mean Square Error (RMSE). Design model rapidminer sebagai berikut :
Gambar 4-2 Design SVM di dalam X Validation
Gambar di atas menjelaskan atribut Data’ di rubah menjadi label, ini sebagai target untuk di prediksi menggunakan Support Vector Machine.
Hasil dari percobaan di Rapidminer berupa root Means Square Error
sebagai berikut
Gambar 4-4 Hasil RMSE SVM
Hasil dari proses Rapidminer menggunakan Support Vector Machine menghasilkan RMSE 10.191.
4.1.2 Model Support Vector Machine dengan Support Vector Machine Berbasis Particle Swarm Optimization
Design model Support Vector Machines Berbasis Particle Swarm
Gambar 4-5 Design model SVM – PSO
Gambar di atas adalah design keseluruhan Support Vector Machines
Berbasis Particle Swarm Optimization yang dibuat di Rapidminer
Gambar di atas menjelaskan atribut Data’ di rubah menjadi label, ini sebagai target untuk di prediksi menggunakan Support Vector Machines Berbasis
Particle Swarm Optimization.
Gambar 4-8 Design model rapidminer di dalam prediksi
Gambar 4-9 Design model di dalam X Validasi
Di dalam polynominal by binomial classification ada Support Vector
Machines Berbasis Particle Swarm Optimization bawaan dari rapidminer.
Gambar 4-10 Design model di dalam X Validasi
Sumber hasil sceen shot expriment Gambar 4-11 Hasil RMSE dari SVM - PSO
Hasil RMSE di perlihatkan dari gambar 4.11 diatas.
Gambar 4-12 Hasil Kernel Model
Grafik 4.2 Prediksi SVM-PSO
Hasil grafik 4.1 prediksi yang dihasilkan dari SVM-PSO dilihat dari grafik diatas.
4.1.3 Support Vector Machines
Hasil penelitian ini menghasilkan Root Mean Squered Error (RMSE)
dari algoritma Support Vector Machines pada tabel 4.1
Tabel 4-2 Nilai RMSE
X Validation Nilai RMSE
2 10.876
3 10.711
5 10.267
6 9.904
7 9.973
8 9.993
9 9.887
10 9.720
4.1.4 Support Vector Machines Berbasis Particle Swarm Optimizition Hasil penelitian ini menghasilkan Root Mean Squered Error (RMSE)
dari algoritma Support Vector Machines Berbasis Particle Swarm
Optimizition 4.2
Tabel 4-2 Nilai RMSE
X Validation Nilai RMSE
2 42.029
3 37.973
4 41.902
5 10.267
7 38.463
8 38.914
9 37.841
10 37.685
4.1.5 Hasil Perbandingan Algoritma Support Vector Machine Biasa Dan Support Vector Machine Berbasis Particle Swarm Optimization Untuk Prediksi Tinggi Muka Air.
Berdasarkan hasil perbandingan antara Support Vector Machines
dan Support Vector Machines Berbasis Particle Swarm Optimizition pada
tabel dibawah ini:
Tabel 4-3 Nilai Perbandingan RMSE SVM DAN SVM - PSO
Validation RMSE (SVM) RMSE(SVM-PSO)
2 10.876 42.029
3 10.711 37.973
4 10.663 41.902
5 10.267 10.267
6 9.904 38.146
7 9.973 38.463
8 9.993 38.914
10 9.720 37.685
5. BAB V PENUTUP
5.1 Kesimpulan
Dari hasil penelitan dapat disimpulkan :
1. Algoritma Support Vector Machines hasilnya lebih rendah RMSE
nya dibandingkan dengan Support Vector Machines Berbasis PSO.
a. Dari hasil penelitin Support Vector Machines nilai RMSE nya lebih rendah dibandingkan dengan Support Vector Machines Berbasis PSO.
b. Hasil RMSE untuk Support Vector Machines adalah 9.720.
c. Seangkan Hasil RMSE Support Vector Machines Berbasis PSO
adalah 37.685 dengan demikian penulis mengusulkan agar menghasilkan prediksi yang lebih akurat dari penelitian ini, diperlukan penelitian tahap berikutnya dengan algoritma lainnya. 5.2 Saran
Analisis dan perbandingan mengenai tinggi muka air dengan mengunakan berbagai algoritma ini hanya menempatkan akurasi (berdasar nilai error ) sebagai factor uji.
Dari hal tersebut untuk penelitian yang akan datang, untuk pengujian yang lebih baik maka perlu diperhatikan :
6. LAMPIRAN
6.1 LAMPIRAN DATA TINGGI MUKA AIR TAHUN 2008-2012
6.1.1 Rekapitulasi Data
6.2 LAMPIRAN Hasil Uji dengan Rapidminer menggunakan SVM
7. DAFTAR REFERENSI
[1] Y. P. Prihatmaji, “PERANCANGAN PUSAT PEMBELAJARAN GEMPA DI BANTUL ( Pendekatan Pengalaman Ruang untuk Pembelajaran ),” vol. 35, no. 2, pp. 152–163, 2007.
[2] “Makalah tentang Gempa,” pp. 1–4.
[3] R. Sovia, S. Barat, and S. Barat, “Jaringan Saraf Tiruan Untuk Memprediksi Pola Pergerakan Titik Gempa Di Indonesia Dengan Algoritma Backpropagation.”
[4] U. S. Utara, “Teori Dasar Gempa Bumi.”