1
2
3
i TATA TERTIB PRAKTIKUM STATISTIKA INDUSTRI DAN
PENELITIAN OPERASIONAL TAHUN AJARAN 2016-2017
PERATURAN UMUM
1. Praktikan wajib mengetahui semua informasi terkait pelaksanaan praktikum
2. Praktikan wajib memenuhi seluruh kelengkapan dan persyaratan praktikum, dan membawa hal-hal yang dibutuhkan untuk pelaksanaan praktikum (data, peralatan, dll.) sesuai dengan modul praktikum yang diikuti.
3. Segala bentuk plagiarisme akan dikenakan sanksi sesuai dengan aturan institusi Universitas Telkom.
4. Praktikan wajib menggunakan peralatan laboratorium sesuai dengan ketentuan teknis yang diatur laboratorium.
5. Praktikan wajib menjaga ketenangan, ketertiban, kebersihan, dan kerapihan laboratorium saat kegiatan praktikum.
6. Praktikan wajib menjaga sopan santun dan etika kepada sesama rekan, asisten, dosen, laboran, serta teknisi laboratorium.
PELAKSANAAN PRAKTIKUM
1. Praktikan wajib mengikuti seluruh rangkaian kegiatan praktikum
2. Jadwal rangkaian kegiatan praktikum akan diumumkan oleh laboratorium. Praktikan wajib mengetahui informasi dan mengikuti jadwal tersebut.
3. Praktikan wajib hadir tepat waktu pada saat pelaksanaan praktikum. Keterlambatan mengikuti praktikum akan mengakibatkan konsekuensi:
a. Terlambat < 15 menit: maka praktikan diperbolehkan mengikuti praktikum dan tidak ada tambahan waktu untuk pelaksanaan kegiatan (tes awal, praktek, dll.) di 15 menit pertama tersebut.
b. Terlambat lebih dari 15 menit: praktikan tidak diperbolehkan mengikuti praktikum.
4. Syarat kelulusan praktikum adalah praktikan mengikuti dan lulus semua modul praktikum.
Nilai minimal untuk dapat lulus di modul praktikum adalah nilai total 50.
5. Jika praktikan berhalangan hadir karena sakit, maka diwajibkan menyerahkan surat keterangan dokter maksimal 3 hari setelah pelaksanaan praktikum. Jika tidak, maka dianggap tidak mengikuti praktikum modul bersangkutan.
6. Praktikum susulan
ii
a. Praktikum susulan diberikan kepada praktikan yang tidak dapat mengikuti praktikum dikarenakan oleh:
i. Sakit, ditunjukkan dengan dokumen surat keterangan Dokter/ Rumah Sakit.
ii. Penugasan institusi, ditunjukkan dengan dokumen surat keterangan resmi penugasan institusi (Universitas/ Fakultas).
iii. Keperluan keluarga yang mendesak, ditunjukkan dengan dokumen surat keterangan permohonan ijin dari orang tua/ wali.
b. Prosedur pendaftaran dan dokumen lainnya di luar poin 6.a. yang dibutuhkan untuk penyelenggaraan praktikum susulan akan diinformasikan oleh laboratorium.
c. Praktikan wajib mengetahui jadwal pendaftaran dan pelaksanaan praktikum susulan.
d. Praktikan wajib memenuhi semua syarat untuk mengikuti praktikum susulan.
7. Tukar Jadwal
a. Praktikan dapat melakukan tukar jadwal praktikum dengan alasan yang dapat dipertanggungjawabkan dan dapat diterima seluruh asisten Laboratorium SIPO 2016 paling lambat 1x24 jam sebelum praktikum dilaksanakan dengan mengisi form tukar jadwal.
8. Pakaian
a. Praktikan wajib menggunakan pakaian yang sesuai dengan ketetapan Universitas Telkom, yaitu pada hari Senin-Rabu mengenakan kemeja putih dengan celana panjang/rok warna biru (bukan jeans), Kamis dan Sabtu mengenakan kemeja dengan celana panjang/rok warna biru (bukan jeans), serta pada hari Jumat mengenakan batik dengan celana panjang/rok warna biru (bukan jeans).
b. Rambut mahasiswa pria harus rapi, tidak melebihi kerah kemeja yang dikenakan dan tidak boleh diikat.
c. Praktikan wajib memakai sepatu saat akan mengikuti praktikum Laboratorium SIPO.
KELENGKAPAN PRAKTIKUM
1. Praktikan wajib memenuhi persyaratan administrasi dan akademis yang telah diumumkan oleh Laboratorium SIPO.
2. Praktikan wajib memenuhi kelengkapan persyaratan setiap modul (persyaratan tambahan akan diumumkan di mading atau website Laboratorium SIPO sebelum praktikum modul bersangkutan dimulai).
iii
3. Praktikan wajib mencetak kartu praktikum pada kertas concorde dan dilengkapi dengan foto 3x4 oleh setiap anggota kelompok dan ditempel pada bagian kiri bawah kartu praktikum serta terdapat cap Laboratorium SIPO.
4. Praktikan wajib membawa kartu praktikum setiap kegiatan praktikum berlangsung.
5. Apabila kartu praktikum hilang, maka praktikan dapat mengganti kartu praktikum maksimal satu kali penggantian dan segera meminta cap Laboratorium SIPO kepada asisten untuk legalisir sebelum praktikum selanjutnya.
TES AWAL
1. Tes Awal dilakuan di setiap awal praktikum pada semua modul.
2. Tes Awal dapat bersifat individu atau kelompok
3. Tes Awal dilakukan dalam bentuk tes praktik, tulis, lisan, atau bentuk lain yang akan ditetapkan kemudian.
LUCKY NUMBER
1. Lucky Number adalah sesi dimana satu perwakilan dari satu shift praktikum mendapatkan Lucky Number untuk menjelaskan materi modul yang akan dipelajari dalam sesi praktikum.
2. Apabila praktikan yang mendapatkan Lucky Number dapat menjelaskan materi modul yang sedang dipelajari maka akan mendapatkan poin “+2” dan anggota FRI dari praktikan yang bersangkutan akan mendapatkan poin “+1”
3. Apabila praktikan yang mendapatkan Lucky Number tidak dapat menjelaskan materi modul yang sedang dipelajari maka seluruh anggota FRI dari praktikan yang bersangkutan mendapat poin “-1”
4. Praktikan yang mendapatkan Lucky Number dapat dibantu oleh rekan satu FRI-nya ketika menjelaskan materi modul yang akan dipelajari dalam sesi praktikum
TES AKHIR
1. Tes Akhir dilaksanakan di setiap akhir praktikum pada semua modul.
2. Tes Akhir dilakukan dalam bentuk tes praktik atau bentuk lain yang akan ditetapkan kemudian.
iv KOMPONEN PENILAIAN
Modul Komponen Penilaian
Tes Awal Praktikum Tes Akhir Tugas Laporan
1a 10% 30% 20% 40%
1b 10% 30% 25% 35%
2 25% 40% 35% -
3 20% 50% 30% -
4 20% 30% 25% 25%
5 20% 25% 25% 30%
6 25% 50% 25% -
7 20% 45% 35% -
8 15% 30% 30% 25%
1 MODUL 1a
TEKNIK SAMPLING
TUJUAN PRAKTIKUM
1. Memahami definisi dari sampel dan istilah-istilah lain yang terkait.
2. Mengetahui cara pengambilan sampel yang tepat dengan berbagai metode yang ada.
3. Membandingkan antara metode yang satu dengan metode yang lain dalam pengambilan sampel.
4. Mengaplikasikan studi kasus ke dalam software Microsoft Excel.
ALAT PRAKTIKUM 1. Komputer
2. Modul Praktikum SIPO 2016 3. Software Microsoft Excel LANGKAH PRAKTIKUM
Simple Random Sampling
PT SIPO akan memilih sampel dari dosen-dosen Telkom Univeristy untuk mengetahui sikap dosen-dosen tersebut terhadap pelaksanaan program “5 hari kerja”. Peneliti yang ditugaskan menggunakan langkah-langkah sebagai berikut untuk memilih sampel. Jumlah populasi dosen - dosen tersebut adalah 300. Dengan besar sampel yang dikehendaki 10% dari 300. PT SIPO harus meminta daftar nama dosen Telkom Univeristy. Dengan menggunakan daftar tersebut masing-masing dosen oleh peneliti diberi nomer dari 000-299. Jadi berapa dosen yang akan dipilih oleh PT SIPO untuk mengetahui sikap dosen?
Langkah Penyelesaian
a. Menentukan Populasi Penelitian.
Gambar 1. 1 Populasi Simple Random Sampling
2
b. Menentukan Jumlah Sampel Penelitian.
Gambar 1. 2 Sampel Simple Random Sampling
c. Nomor random permulaan ditentukan dengan memilih nomor sembarang menggunakan fungsi RANDBETWEEN pada Microsoft Excel dari 0-2999 seperti berikut :
Gambar 1. 3 Pengaplikasian Fungsi RANDBETWEEN pada Simple Random Sampling
b. Karena populasi mempunyai 300 anggota kita hanya memerhatikan tiga digit terakhir dari nomor tersebut, jadi dalam hal ini angka tersebut adalah 298.
c. Ada dosen diberi nomor 298, oleh karena itu guru termasuk terpilih sebagai sampel.
d. Nomor selanjutnya adalah 1399. tiga digit terakhir adalah 399. Karena hanya ada 300 dosen, tidak ada dosen yang diberi nomor 399. Oleh karena itu nomor tersebut tidak termasuk sebagai sampel.
e. Dengan menggunakan langkah-langkah tersebut nomor-nomor sisanya 146, 233, 025 terpilih sebagai sampel, langakah ini akan dipakai untuk nomor-nomor selanjutnya sehingga 30 guru terpilih.
f. Intrepretasikan hasil.
Systematic Random Sampling
PT SIPO akan memilih sampel dari dosen- dosen Universitas Telkom untuk mengetahui sikap dosen -dosen tersebut terhadap pelaksanaan program “5 hari kerja”. Peneliti yang ditugaskan menggunakan langkah-langkah sebagai berikut untuk memilih sampel. Jumlah populasi dosen-dosen tersebut adalah 100. Dengan besar sampel yang dikehendaki 10% dari 100. PT SIPO harus meminta daftar nama dosen Universitas Telkom. Dengan menggunakan daftar tersebut masing-masing dosen oleh peneliti diberi nomor dari 00-99. Jadi berapa dosen yang akan dipilih oleh PT SIPO untuk mengetahui sikap dosen?
3
Langkah Penyelesaian
a. Menentukan Populasi Penelitian
Gambar 1. 4 Populasi Systematic Random Sampling
b. Menentukan Jumlah Sampel Penelitian
Gambar 1. 5 Sampel Systematic Random Sampling
c. Menentukan nilai k, dengan membagi jumlah populasi dengan jumlah sampel
Gambar 1. 6 Menentukan Nilai k pada Systematic Random Sampling
d. Membuat Tabel daftar dosen dengan nomor urut dari 0-99 dengan jumlah baris 10 yang didapat dari nilai k.
Gambar 1. 7 Tabel Systematic Random Sampling
e. Nomor random permulaan ditentukan dengan memilih nomor sembarang menggunakan fungsi RANDBETWEEN pada Microsoft Excel dari 0-9.
4
Gambar 1. 8 Pengaplikasian Fungsi RANDBETWEEN pada Systematic Random Sampling
f. Misal angka yang keluar dari hasil random adalah angka 2, maka pada baris yang terdapat angka yang pada kasus ini adalah baris ketiga maka terpilih menjadi sampel
Gambar 1. 9 Penentuan Baris Sampel
g. Interpretasikan Hasil
Stratified Random Sampling
PT SIPO ingin mengambil sampel dari semua dosen Statistika Industri di Universitas Telkom, yaitu S1, S2, dan S3. Dari tiap tingkat Universitas terdapat persentasi dari jumlah dosen Statistika Industri. Perbandingan dalam mengambil sampel dosen Statistika Industri adalah 50% dari S1, 30% dari S2 dan 20% dari S3. Jumlah populasi dosen Statistika Industri adalah 300 dosen. Dengan besar sampel yang dikehendaki adalah 10% dari 300. Sehingga berapa banyak sampel yang mewakili dosen Statistika Industi dari Universitas Telkom?
Langkah Penyelesaian
a. Menentukan Populasi Penelitian
Gambar 1. 10 Populasi Stratified Random Sampling
b. Menenukan Jumlah Sampel Penilitian
Gambar 1. 11 Sampel Stratified Random Sampling
c. Menentukan Variabel Minat
5
Gambar 1. 12 Variabel Minat Stratified Random Sampling
d. Menentukan Klasifikasi Anggota Populasi
Gambar 1. 13 Klarifikasi Anggota Populasi Stratified Random Sampling
e. Selanjutnya untuk menetukan sampel yang terpilih dapat menggunakan simple random sampling ataupun systematic random sampling,
f. Intrepretasikan Hasil
Cluster Sampling
PT SIPO ingin mengambil sampel dosen Statistika Industri di Universitas yang ada di Bandung dengan tingkat pendidikan S2. Jumlah populasi dosen Statistika Industri S2 adalah 300 dosen, dengan besar sampel yang dikehendaki 10% dari 300. PT SIPO telah mempunyai daftar semua Universitas di Bandung, yaitu 30 Universitas. Dengan metode Cluster berapa jumlah anggota cluster yang mewakili Universitas di Bandung?
Langkah Penyelesaian
a. Daftar Universitas yag berada di Bandung dan jumlah dosen S2 di setiap Universitas
Tabel 1. 1 Daftar Universitas
No Nama Universitas Jumlah Dosen
1 Universitas Telkom 12
2 ITB 15
3 UNISBA 9
4 UNPAD 10
5 UNPAR 11
6 UPI 10
7 UNIKOM 6
8 UIN 10
9 POLMAN 8
10 POLBAN 10
6
b. Menentukan Populasi Penelitian
Gambar 1. 14 Populasi Cluster Sampling
c. Menentukan Jumlah Sampel Penelitian
Gambar 1. 15 Sampel Cluster Sampling
d. Menentukan Cluster yang logis
Gambar 1. 16 Penentuan Cluster
e. Menentukan Taksiran Jumlah Rata-Rata Dosen di Univeristas yang berada di Bandung
11 IPDN 9
12 STSI 11
13 MARANATA 10
14 ITENAS 9
15 UNLA 8
16 UNPAS 8
17 WIDIYATAMA 8
18 UNAI 10
19 UNBAR 10
20 LP3I 11
21 BSI 10
22 UMB 11
23 STISI 10
24 UNKE 11
25 UNJANI 10
26 USB 10
27 UNINUS 9
28 ITSB 10
29 UNAS PASIM 11
30 ITHB 13
Rata-Rata 10
7
Gambar 1. 17 Taksiran Jumlah Rata-rata
f. Menentukan Jumlah Cluster
Gambar 1. 18 Jumlah Cluster
g. Menentukan Univeristas yang terpilih menggunakan bilangan random
Gambar 1. 19 Cluster Random
h. Interpretasikan Hasil
8 MODUL 1b
PENGOLAHAN DAN PENYAJIAN DATA STATISTIKA DESKRIPTIF
TUJUAN PRAKTIKUM
1. Praktikan mampu memahami konsep statistika deskriptif
2. Praktikan mampu memahami konsep pengolahan dan penyajian data
3. Praktikan mampu melakukan pengolahan dan penyajian data dengan menggunakan software Microsoft Excel 2013 dan IBM SPSS 23.0
ALAT PRAKTIKUM 4. Komputer
5. Modul Praktikum SIPO 2016 6. Software IBM SPSS 23.0 7. Software Microsoft Excel 2013
LANGKAH PRAKTIKUM
Studi Kasus
Seorang peneliti ingin melakukan observasi terhadap 30 mahasiswa dengan melakukan penyebaran kuesioner yang berisi pertanyaan tentang kemampuan dasar dan tes psikologi.
Berdasarkan hasil penyebaran kuesioner tersebut, diberikan penilaian dan dilakukan perhitungan sehingga diperoleh data nilai IQ seperti data dibawah. Anda diminta untuk membantu peneliti dalam mengolah dan menyajikan data hasil kuesioner yang diperoleh berdasarkan informasi yang diberikan. Gunakan selang kepercayaan 95%!
Tabel 1b.1 Nilai IQ dan Jenis Kelamin Responden
No Responden Nilai IQ Jenis Kelamin (JK)
1 100 L
2 94 L
3 120 L
4 134 P
5 118 P
6 130 P
7 109 L
9
No Responden Nilai IQ Jenis Kelamin (JK)
8 89 P
9 135 P
10 108 P
11 128 P
12 99 L
13 146 P
14 115 L
15 126 P
16 124 L
17 113 L
18 104 P
19 94 P
20 116 L
21 143 P
22 139 L
23 123 P
24 111 L
25 95 P
26 103 L
27 148 L
28 119 P
29 108 P
30 121 L
Tabel 1b.2 Klasifikasi Nilai IQ dan Kategori Nilai IQ
Klasifikasi IQ
Kriteria IQ Rentangan IQ Kategori IQ
Sangat Superior 140-169 1
Superior 120-139 2
Rata-Rata Tinggi 110-119 3
Normal 90-109 4
Rata-Rata Rendah 80-89 5
Tabel 1b.3 Kategori Jenis Kelamin
Jenis Kelamin (JK)
Kategori JK
Laki-laki 1
Perempuan 2
10
Langkah Penyelesaian
1) Tabel Frekuensi dengan Menggunakan M.Excel 2013
1. Buka Software M.Excel, lalu lakukan pencarian Kategori JK dengan menggunakan fungsi IF seperti gambar di bawah ini
Gambar 1b.1 Mencari Kategori JK Menggunakan Rumus IF
2. Lakukan pencarian Kriteria IQ dengan menggunakan fungsi IF seperti gambar di bawah ini.
Gambar 1b.2 Mencari Kriteria IQ Menggunakan Rumus IF
3. Mencari Kategori IQ menggunakan fungsi VLOOKUP seperti gambar di bawah ini
Gambar 1b.3 Mencari Kategori IQ Menggunakan Rumus VLOOKUP
4. Mencari frekuensi pada Kategori IQ dengan menggunakan fungsi COUNTIF seperti gambar di bawah ini
Gambar 1b.4 Mencari Frekuensi Kategori IQ Menggunakan Rumus COUNTIF
11
5. Mencari frekuensi pada Kategori JK dengan menggunakan fungsi COUNTIF seperti gambar di bawah ini
Gambar 1b.5 Mencari Frekuensi Jenis Kelamin Menggunakan Rumus COUNTIF
6. Menghitung total Nilai IQ dengan menggunakan fungsi SUM seperti gambar di bawah ini
Gambar 1b.6 Menghitung Total Nilai IQ Menggunakan Rumus SUM
7. Menghitung banyaknya jumlah data Nilai IQ dengan menggunakan fungsi COUNT seperti gambar di bawah ini
Gambar 1b.7 Menghitung Banyaknya Data Menggunakan Rumus COUNT
8. Mencari nilai maksimum Nilai IQ dengan menggunakan fungsi MAX seperti gambar di bawah ini
Gambar 1b.8 Mencari Nilai Maksimum Menggunakan Rumus MAX
12
9. Mencari nilai yang paling banyak muncul (modus) pada data Nilai IQ dengan menggunakan fungsi MODE seperti gambar di bawah ini
Gambar 1b.12 Mencari Nilai Muncul Terbanyak Menggunakan Rumus MODE
10. Menghitung nilai standar deviasi data Nilai IQ dengan menggunakan fungsi STDEV seperti gambar di bawah ini
Gambar 1b.13 Menghitung Standar Deviasi Menggunakan Rumus STDEV
11. Menghitung nilai variansi data Nilai IQ dengan menggunakan fungsi VAR seperti gambar di bawah ini
13
Gambar 1b.14 Menghitung Variansi Menggunakan Rumus VAR
12. Menghitung nilai kemiringan data Nilai IQ dengan menggunakan fungsi SKEW seperti gambar di bawah ini
Gambar 1b.15 Menghitung Kemiringan Menggunakan Rumus SKEW
2) Tabel Frekuensi untuk Nilai IQ menggunakan IBM SPSS 23.0
Menu Frequencies atau analisis frekuensi pada IBM SPSS 23.0 dipakai untuk menghitung frekuensi data pada variabel untuk analisis statistik seperti mean, median, kuartil, persentil, standar deviasi, serta menampilkan grafik.
1. Buka software IBM SPSS 23.0, lalu klik Data View, copy data Nilai IQ, Jenis Kelamin, dan Kriteria IQ dari M.Excel lalu paste.
2. Kemudian klik Variable View dan definisikan ketiga variabel pada kolom NAME.
Baris pertama didefinisikan sebagai variabel NILAI_IQ, baris kedua didefinisikan
14
sebagai variabel KATEGORI_JK dan baris ketiga didefinisikan sebagai variabel KATEGORI_IQ. Type merupakan tipe data, dimana tipe data merupakan tipe Numeric. Pada kolom Measure, pilih Scale untuk variabel NILAI IQ, pilih Nominal untuk variabel KATEGORI JK dan pilih Ordinal untuk variabel KATEGORI IQ.
Gambar 1b.16 Pengisian Variabel View pada SPSS
3. Klik Values pada baris KATEGORI_JK, kemudian akan muncul kotak dialog seperti gambar dibawah ini
Gambar 1b.17 Pengisian Value pada SPSS (2)
Isikan kotak Value dengan kode 1 dan pada Label isikan “L”, kemudian klik Add.
Lakukan juga pengkodean 2 pada kotak Value dan “P” pada kotak Label, lalu klik Add>>OK
4. Klik Values pada baris KATEGORI_IQ, kemudian akan muncul kotak dialog seperti gambar dibawah ini
Gambar 1b.18Pengisian Value pada SPSS
15
Isikan kotak Value dengan kode 1, dan pada Label isikan “Sangat Superior”, kemudian klik Add. Lakukan juga pengkodean 2 pada kotak Value dan “Superior” pada kotak Label, lalu klik Add, lakukan hingga kode 5, dan pada Label isikan sesuai dengan kriteria masing-masing kode, lalu klik Add>>OK
5. Selanjutnya, klik Analyze >> Descriptive Statistics >> Frequencies
Gambar 1b.19 Langkah memilih alat analisis
6. Setelah itu, kotak dialog Frequencies akan tampil seperti berikut.
Gambar 1b.20 Kotak dialog Frequencies
7. Karena ingin membuat frekuensi dari variabel Nilai IQ, maka klik variabel NILAI_IQ, kemudian klik tanda , maka variabel Nilai IQ akan berpindah ke kolom Variable(s).
Kemudian klik pilihan Statistics, maka akan muncul tampilan berikut.
16
Gambar 1b.21 Dialog Box untuk Menginputkan Data pada Menu frequencies
Gambar 1b.22 Dialog Box pada Frequencies Statistics
Beri centang semua bagian pada box Central Tendency, Dispersion, dan Distribution. Sedangkan pada box Percentile Value beri centang pada Quartiles dan Percentile(s) masukkan 10 >> Add >> Continue, lalu masukkan kembali 90 >> Add
>> Continue.
8. Setelah itu klik menu Chart dan pilih Histograms untuk keseragaman data. Kemudian beri centang pada Show normal curve on histograms lalu klik Continue.
Gambar 1b. 23 Dialog Box pada Frequencies Charts
17
9. Klik OK dan akan muncul output seperti berikut.
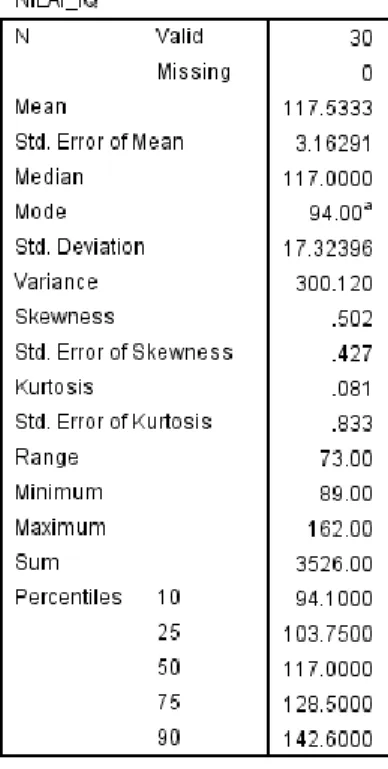
Gambar 1b.24 Output Statistics Nilai IQ
Gambar 1b.25 Histogram
Analisis Output Statistics
a) N adalah jumlah data (interpretasikan hasil).
b) Mean adalah rata-rata (interpretasikan hasil).
18
c) Standard error of mean, yaitu standar kesalahan untuk populasi yang diperkirakan dari sampel dengan menggunakan ukuran rata-rata (interpretasikan hasil).
d) Median adalah titik tengah, yaitu semua data diurutkan dan dibagi dua sama besar (interpretasikan hasil).
e) Mode adalah modus data (interpretasikan hasil).
f) Std.Deviation, yaitu ukuran penyebaran data dari rata-ratanya (interpretasikan hasil).
g) Minimum adalah nilai terendah (interpretasikan hasil).
h) Maximum adalah nilai tertinggi (interpretasikan hasil).
i) Range adalah jarak data, yaitu data maksimum dikurangi data minimum (interpretasikan hasil).
j) Interquartile Range, yaitu selisih antara nilai persentil yang ke-50 dan ke-75 (interpretasikan hasil).
k) Skewness, yaitu ukuran distribusi data. Untuk mengetahui apakah data terdistribusi normal atau tidak, maka dihitung rasio skewness dengan standard error of skewness (interpretasikan hasil).
l) Kurtosis; sama halnya dengan skewness, kurtosis juga digunakan untuk mengukur distribusi data. Untuk mengetahui apakah data terdistribusi dengan normal atau tidak, maka dihitung rasio kurtosis dengan standard error of kurtosis (interpretasikan hasil).
3) Tabel Frekuensi untuk Kategori JK dan Kategori IQ
Karena variabel Kategori JK dan Kategori IQ bukan data kuantitatif melainkan berupa data kualitatif, maka tidak perlu dilakukan deskripsi statistik seperti mean, median, standar deviasi, dan sebagainya.
1. Pilih menu Analyze, lalu pilih submenu Descriptive Statistics kemudian pilih submenu Frequencies. Klik variabel KATEGORI_JK, kemudian klik tanda , maka variabel KATEGORI_JK akan berpindah ke kolom Variable(s) seperti tampilan berikut.
19
Gambar 1b. 26 Dialog Box pada Frequencies
2. Klik Charts >> Pie Chart >> Continue seperti tampilan berikut.
Gambar 1b.27 Dialog Box pada Frequencies Chart
3. Klik menu Format >> Ascending Values >> Continue.
Gambar 1b. 28 Dialog Box pada Frequencies Format
4. Klik OK dan akan muncul tampilan seperti berikut.
Gambar 1b.29 Output Frequencies KATEGORI JK
20
Gambar 1b.30 Output Pie Chart
Interpretasikan hasil berdasarkan output Pie Chart diatas
Lakukan langkah-langkah yang sama untuk menampilkan Kategori IQ
1. Pilih menu Analyze, lalu pilih submenu Descriptive Statistics kemudian pilih submenu Frequencies. Klik variabel KATEGORI_IQ, kemudian klik tanda , maka variabel KATEGORI_IQ akan berpindah ke kolom Variable(s) seperti tampilan berikut.
Gambar 1b.31 Dialog Box pada Frequencies
2. Klik Charts >> Bar Chart >> Continue. Kemudian akan muncul tampilan seperti berikut.
21
Gambar 1b.32 Dialog Box pada Frequencies Chart
3. Klik menu Format >>Ascending Values >> Continue.
Gambar 1b.33 Dialog Box pada Frequencies Format
4. Klik OK dan akan muncul tampilan seperti berikut.
Gambar 1b.34 Output Frequencies Kategori IQ
22
Gambar 1b.35 Output Bar Chart
Interpretasikan hasil berdasarkan output Bar Chart di atas 4) Tabel Deskriptif untuk Nilai IQ menggunakan IBM SPSS 23.0
Menu Descriptive pada IBM SPSS 23.0 berfungsi untuk mengetahui skor-z dari suatu distribusi data dan menguji apakah data berdistribusi normal atau tidak. Untuk contoh kasus diambil dari data Nilai IQ yang telah didapatkan dari contoh kasus sebelumnya.
1. Klik Analyze >> Descriptive Statistics >> Descriptives. Kemudian klik variabel NILAI_IQ, lalu klik tanda , maka variabel NILAI_IQ akan berpindah ke kolom Variable(s) seperti tampilan berikut ini.
Gambar 1b. 36 Dialog Box pada Descriptives
2. Klik Options, kemudian beri centang pada pilihan Mean, Std.Deviation, Maximum, Minimum dan klik Continue seperti tampilan berikut ini.
23
Gambar 1b.37 Dialog Box pada Descriptive options
3. Kemudian, checklist kotak Save standardized values as variables kemudian klik OK seperti tampilan berikut ini.
Gambar 1b.38 Dialog Box pada Descriptives
4. Setelah klik OK, maka akan muncul output sebagai berikut.
Gambar 1b.39 Descriptive Statistics
5. Lihat kembali Data View SPSS. Selain NILAI_IQ, KATEGORI_JK dan KATEGORI_IQ, akan muncul variabel baru, yaitu Z NILAI_IQ seperti tampilan berikut.
24
Gambar 1b.40 Data view SPSS
Karena menggunakan selang kepercayaan 95%, maka batas nilai z-nya adalah sebesar - 1,96 s.d 1,96 (didapatkan dari tabel distribusi normal). Jika terdapat nilai z di luar batas tersebut, maka data tersebut merupakan data outlier dan perlu dilakukan pengambilan data ulang. Interprestasikan hasil.
25 MODUL 2
PENENTUAN DISTRIBUSI PELUANG KONTINU DAN DISKRIT
TUJUAN PRAKTIKUM Tujuan Umum
1. Praktikan mampu memahami konsep distribusi kontinu dan diskrit.
2. Praktikan mampu menyelesaikan masalah distirbusi kontinu dan diskrit menggunakan software Microsoft Excel dan SPSS
Tujuan Khusus
1. Praktikan mampu menyelesaikan kasus distribusi peluang diskrit dengan software Microsoft Excel dan SPSS untuk disribusi binomial dan poisson
2. Praktikan mampu menyelesaikan kasus Distribusi Peluang kontinu dengan software Microsoft Excel dan SPSS untuk distribusi normal dan eksponensial
ALAT DAN BAHAN PRAKTIKUM 1. Komputer
2. Modul Praktikum SIPO 2016 3. Software IBM SPSS 23.0 4. Software Ms. Excel
Distribusi Peluang Diskrit
1. Distribusi Binomial Studi Kasus
Sebuah tim peneliti hendak melakukan observasi terhadap polusi bahan organik yang terkandung dalam air. Diketahui bahwa setiap sampel memiliki kemungkinan 10%
mengandung polusi organik. Asumsikan bahwa sampel tersebut adalah independen terhadap polutan, carilah kemungkinan jika pada 18 sampel yang dianalisis terdiri dari:
a. 2 sampel mengandung polutan
b. setidaknya 4 sampel mengandung polutan c. 3 sampai 7 sampel mengandung polutan
26
Langkah Praktikum Diketahui:
Peluang = 10 % = 0.1
Banyak percobaan = 18 sampel Pembahasan Menggunakan SPSS Soal a
Ditanya P(X=2)?
1. Buka SPSS, pada Data View inputkan data yang diketahui seperti berikut.
Gambar 2. 1 Input Data pada Data View SPSS untuk Distribusi Binomial
2. Pilih menu Transform => Compute Variable
Gambar 2. 2Compute Variabel pada SPSS untuk Distribusi Binomial
3. Pada Target Value berikan nama probabilitas (bebas), pada Function Group pilih All, pada Function and Special Variables pilih Pdf.Binom. Lalu pada Numeric Expression ganti nilai “?” dengan data yang telah di inputkan sebelumnya.
Gambar 2. 3 Compute Variabel pada SPSS untuk Distribusi Binomial (2)
27
4. Snipping tool terlebih dahulu pada Numeric Expression yang digunakan, kemudian klik OK
5. Lihat hasil pada Data View
6. Lakukan screenshoot pada hasil yang didapatkan, kemudian copy dan paste pada software M.Excel, serta lakukan analisis.
Soal b
Ditanya P(X >= 4)?
1. Inputkan data yang diketahui pada Data View seperti berikut.
Gambar 2. 4 Input Data pada Data View SPSS untuk Distribusi Binomial (2)
2. Pilih menu Transform => Compute Variable
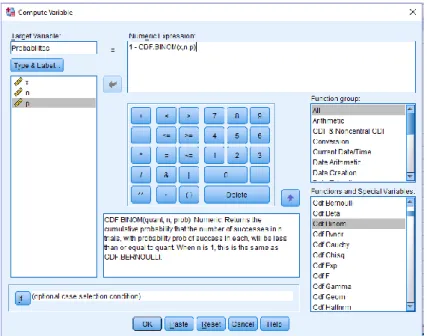
3. Pada Target Value berikan nama probabilitas (boleh bebas), pada Fucntion Group pilih All, pada Function and Special Variables pilih CDF.Binom. Lalu pada Numeric Expression ganti nilai “?” dengan data yang telah di inputkan sebelumnya.
Karena kita akan menghitung peluang P(X >= 4) maka pada Numeric Expression rumusannya kita ganti menjadi 1 - CDF.BINOM(x,n,p).
Gambar 2. 5 Compute Variabel pada SPSS untuk Distribusi Binomial (3)
28
4. Snipping tool terlebih dahulu pada Numeric Expression yang digunakan dan paste-kan pada software excel , kemudian klik OK.
5. Lihat hasil pada Data View.
6. Lakukan screenshoot pada hasil yang didapatkan, kemudian copy dan paste pada software M.Excel, serta lakukan analisis.
Soal c
Praktikan diminta untuk mengerjakan secara mandiri seperti langkah-langkah di atas.
Pembahasan Menggunakan M.Excel
1. Buka M.Excel dan isikan data yang diketahui seperti berikut.
Gambar 2. 6 Input Data pada Microsoft Excel Distribusi Binomial
2. Susunlah parameter input dan variable sesuai dengan studi kasus 3. Pilih menu Formula, lalu Insert Function
4. Pada Function Category pilih Statistical dan pada Function Name pilih BINOM.DIST, kemudian pilih OK
Gambar 2. 7 Insert Function pada Microsoft Excel Distribusi Binomial
5. Maka akan muncul tampilan seperti di bawah ini.
Pada menu Number_s masukkan nilai titik (x) yang akan dihitung peluangnya Pada menu Trials masukkan banyanya percobaan yang akan dilakukan (n)
Pada menu Probability_s masukkan besarnya nilai peluang “sukses” atau “gagal” (p) Pada menu Cumulative, masukkan:
29
a. True, jika peluang yang dihitung berdistribusi kumulatif P(X≤x) b. False, jika peluang yang dihitung berdistribusi peluang P(X=x)
Gambar 2. 8 Function Arguments pada Microsoft Excel Distribusi Binomial
6. Pilih OK, maka hasil perhitungan akan ditampilkan.
Jika nilai titiknya berupa interval maka langkah-langkahnya adalah sebagai berikut.
1. Susunlah parameter input dan variable sesuai dengan studi kasus 2. Pilih menu Formula, lalu Insert Function
3. Pada Function Category pilih Statistical dan pada Function Name pilih BINOM.DIST.RANGE, kemudian pilih OK
Gambar 2. 9 Insert Function pada Microsoft Excel Distribusi Binomial
4. Maka akan muncul tampilan seperti di bawah ini.
Pada menu Trials masukkan banyanya percobaan yang akan dilakukan (n)
Pada menu Probability_s masukkan besarnya nilai peluang “sukses” atau “gagal” (p) Pada menu Number_s masukkan nilai titik (x) pertama dari nilai interval yang akan dihitung peluangnya
Pada menu Number_s2 masukkan nilai titik (x) kedua dari nilai interval yang akan dihitung peluangnya
30
Gambar 2. 10 Function Arguments pada Microsoft Excel Distribusi Binomial
5. Pilih OK, maka hasil perhitungan akan ditampilkan.
2. Distribusi Poisson Studi Kasus
Kerusakan terjadi secara random sepanjang kabel tembaga di sebuah kawasan indsutri, diketahui bahwa jumlah kerusakan yang terjadi berdistribusi Poisson dengan rata-rata 2.3 kerusakan per millimeter. Anggap bahwa X merupakan jumlah kerusakan pada setiap 1 mm kabel, maka tentukan:
a. peluang terjadinya dua 2 kerusakan pada setiap 1 mm kabel tembaga b. peluang terjadinya 10 kerusakan pada setiap 5 mm kabel tembaga
c. peluang terjadinya setidaknya 1 kerusakan pada setiap 2 mm kabel tembaga
Langkah Praktikum Diketahui:
Rata rata = 2.3 permilimeter
Pembahasan Menggunakan SPSS Soal a
Ditanya: P(X = 2)?
1. Inputkan data pada Data View di SPSS seperti berikut.
Gambar 2. 11 Input Data pada Data View SPSS Distribusi Poisson
2. Pilih menu Transform => Compute Variable
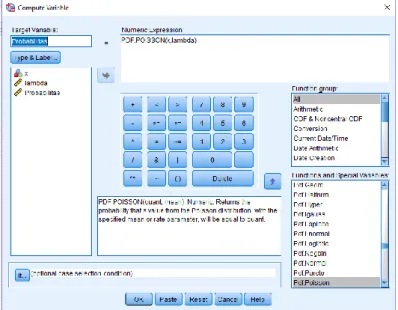
3. Pada Target Value berikan nama probabilitas (bebas), pada Function Group pilih All, pada Function and Special Variables pilih PDF.Poisson. Lalu pada Numeric Expression ganti nilai “?” dengan data yang telah di inputkan sebelumnya.
31
Gambar 2. 12 Compute Variable pada SPSS Distribusi Poisson
4. Snipping tool terlebih dahulu pada Numeric Expression yang digunakan dan paste-kan pada software excel , kemudian klik OK.
5. Lihat hasil pada Data View.
6. Lakukan screenshoot pada hasil yang didapatkan, kemudian copy dan paste pada software M.Excel, serta lakukan analisis.
Soal b
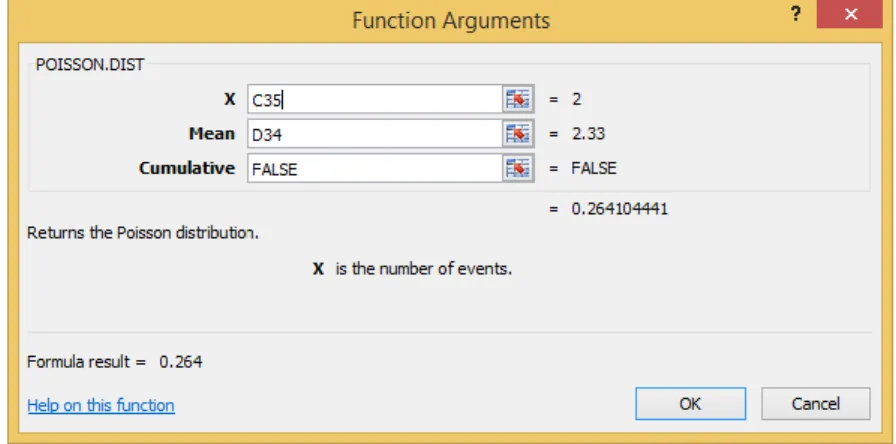
Ditanya: P(X = 5)?
Dimana: λ = 2,3 * 5 = 11,5
1. Inputkan data pada Data View di SPSS seperti yang diketahui pada studi kasus.
2. Pilih menu Transform => Compute Variable
3. Pada Target Value berikan nama probabilitas (bebas), pada Fucntion Group pilih All, pada Function and Special Variables pilih PDF.Poisson. Lalu pada Numeric Expression ganti nilai “?” dengan data yang telah di inputkan sebelumnya.
4. Kemudian klik OK, Lakukan screenshoot pada hasil yang didapatkan, kemudian copy dan paste pada software M.Excel, serta lakukan analisis.
Soal c
Ditanya: P(X ≥1)?
Dimana: λ = 2 x 2,3 = 4,6
1. Inputkan data pada Data View di SPSS seperti berikut.
32
Gambar 2. 13 Input Data pada Data View SPSS Distribusi Poisson (2)
2. Pilih menu Transform => Compute Variable
3. Pada Target Value berikan nama probabilitas (bebas), pada Fucntion Group pilih All, pada Function and Special Variables pilih CDF.Poisson. Lalu pada Numeric
Expression ganti nilai “?” dengan data yang telah di inputkan sebelumnya. Karena kita akan menghitung peluang P(X >= 1) maka pada Numeric Expression rumusannya kita ganti menjadi 1- CDF.POISSON(x,lambda)
Gambar 2. 14 Compute Variable pada SPSS Distribusi Poisson (2)
4. Snipping tool terlebih dahulu pada Numeric Expression yang digunakan dan paste-kan pada software excel , kemudian klik OK.
5. Lihat hasil pada Data View.
6. Lakukan screenshoot pada hasil yang didapatkan, kemudian copy dan paste pada software M.Excel, serta lakukan analisis.
Pembahasan Menggunakan M.Excel
1. Buka M.Excel dan isikan data yang diketahui sesuai dengan studi kasus 2. Susunlah parameter input dan variable sesuai dengan studi kasus
3. Pilih menu Formula, lalu Insert Function
4. Pada Function Category pilih Statistical dan pada Function Name pilih POISSON.DIST, kemudian pilih OK
33
Gambar 2. 15 Insert Function pada Microsoft Excel Distribusi Poisson
5. Maka akan muncul tampilan seperti di bawah ini.
Pada X masukkan nilai titik (x) yang akan dihitung peluangnya Pada Mean masukkan nilai rataan (λ)
Pada menu Cumulative, masukkan:
a. True, jika peluang yang dihitung berdistribusi kumulatif P(X≤x) b. False, jika peluang yang dihitung berdistribusi peluang P(X=x)
Gambar 2. 16 Function Arguments pada Microsoft Excel Distribusi Poisson
6. PIlih OK, maka hasil perhitungan akan ditampilkan
34
Distribusi Peluang Kontinu
1. Distribusi Normal Studi Kasus
Sebuah baja akan memuai jika dipanaskan, diketahui pemuaian baja tersebut berdistribusi normal dengan rataan 0,05 cm dan simpangan bakunya 0,01. Tentukan peluang bahwa pemuaian:
a. lebih dari 0,1 cm b. kurang dari 0,04 cm c. 0,025 sampai 0,065
Langkah Praktikum Diketahui:
Rata rata = 0,05 cm Standar deviasi = 0,01
Pembahasan Menggunakan SPSS Soal a
Ditanya: P(X>0,1)?
1. Inputkan data pada Data View di SPSS seperti berikut.
Gambar 2. 17 Input Data pada Data View SPSS Distribusi Normal
2. Pilih menu Transform => Compute Variable
3. Pada Target Value berikan nama probabilitas (bebas), pada Fucntion Group pilih All, pada Function and Special Variables pilih CDF.Normal. Lalu pada Numeric Expression ganti nilai “?” dengan data yang telah di inputkan sebelumnya. Karena kita akan menghitung peluang P(X >= 1) maka pada Numeric Expression rumusannya kita ganti menjadi 1- CDF.NORMAL(x,rata_rata,standar_deviasi)
35
Gambar 2. 18 Compute Variable pada SPSS Distribusi Normal
4. Snipping tool terlebih dahulu pada Numeric Expression yang digunakan dan paste-kan pada software excel , kemudian klik OK.
5. Lihat hasil pada Data View.
6. Lakukan screenshoot pada hasil yang didapatkan, kemudian copy dan paste pada software M.Excel, serta lakukan analisis.
Soal b
Ditanya : P(X<0,04)
1. Inputkan data pada Data View di SPSS seperti berikut.
Gambar 2. 19 Input Data pada Data View SPSS Distribusi Normal (2)
2. Pilih menu Transform => Compute Variable
3. Pada Target Value berikan nama probabilitas (bebas), pada Fucntion Group pilih All, pada Function and Special Variables pilih CDF.Normal. Lalu pada Numeric Expression ganti nilai “?” dengan data yang telah di inputkan sebelumnya. Karena kita akan menghitung peluang P(X >= 1) maka pada Numeric Expression rumusannya kita ganti menjadi CDF.NORMAL(x,rata_rata,standar_deviasi).
36
Gambar 2. 20 Compute Variable pada SPSS Distribusi Normal (2)
4. Snipping tool terlebih dahulu pada Numeric Expression yang digunakan dan paste-kan pada software excel , kemudian klik OK.
5. Lihat hasil pada Data View.
6. Lakukan screenshoot pada hasil yang didapatkan, kemudian copy dan paste pada software M.Excel, serta lakukan analisis.
Soal c
Praktikan diminta untuk mengerjakan secara mandiri seperti langkah-langkah di atas.
Pembahasan Menggunakan M.Excel
1. Buka M.Excel dan isikan data yang diketahui sesuai dengan studi kasus 2. Susunlah parameter input dan variable sesuai dengan studi kasus
3. Pilih menu Formula, lalu Insert Function
4. Pada Function Category pilih Statistical dan pada Function Name pilih NORM.DIST, kemudian pilih OK
37
Gambar 2. 21 Insert Function pada Microsoft Excel Distribusi Normal
5. Maka akan muncul tampilan seperti di bawah ini.
Pada X masukkan nilai titik (x) yang akan dihitung peluangnya Pada Mean masukkan nilai rata-rata/mean
Pada menu Standard_dev masukkan nilai standar deviasi Pada menu Cumulative, masukkan:
a. True, jika peluang yang dihitung berdistribusi kumulatif P(X≤x) b. False, jika peluang yang dihitung berdistribusi peluang P(X=x)
Gambar 2. 22 Function Arguments pada Microsoft Excel Distribusi Normal
6. Pilih OK, dan lakukan analisis
2. Distribusi Eksponensial Studi Kasus
Dalam sebuah jaringan komputer yang besar, diketahui bahwa jumlah pengguna yang masuk ke dalam sistem dimodelkan sebagai distribusi poisson dengan rata rata 25 user yang masuk per jamnya. Berapakah probabilitas tidak ada pengguna yang masuk ke sistem dalam interval 6 menit?
38
Langkah Praktikum Diketahui :
λ = 25 user / jam x = 6 menit = 0.1 jam
Pembahasan menggunakan SPSS Ditanya: P(X > 0.1)?
1. Inputkan data yang diketahui pada pada Data View SPSS seperti berikut.
Gambar 2. 23 Input Data pada Data View SPSS Distribusi Eksponensial
2. Pilih menu Transform => Compute Variable
3. Isi Target Value dengan nama peluang (boleh bebas), pada Function Group pilih All =>
pada Functions and Special Variables pilih Cdf.Exp. Lalu, ganti tanda “?” pada Numeric Expression dengan nilai yang telah diinputkan sebelumnya, sebagai berikut.
Karena kita akan mencari P(X>6). Maka pada numeric expression kita tulis
Gambar 2. 24 Compute Variable pada SPSS Distribus Eksponensial
4. Snipping tool terlebih dahulu pada Numeric Expression yang digunakan dan paste-kan pada software excel , kemudian klik OK.
5. Lihat hasil pada Data View.
6. Lakukan screenshoot pada hasil yang didapatkan, kemudian copy dan paste pada software M.Excel, serta lakukan analisis.
39
Pembahasan Menggunakan M.Excel
1. Buka M.Excel dan isikan data yang diketahui sesuai dengan studi kasus.
2. Susunlah parameter input dan variable sesuai dengan studi kasus 3. Pilih menu Formula, lalu Insert Function
4. Pada Function Category pilih Statistical dan pada Function Name pilih EXPON.DIST, kemudian pilih OK
Gambar 2. 25 Insert Function pada Microsoft Excel Distribusi Eksponensial
5. Maka akan muncul tampilan seperti di bawah ini
Pada X masukkan nilai titik (x) yang akan dihitung peluangnya Pada Lambda masukkan nilai parameternya
Pada menu Cumulative, masukkan:
- True, jika peluang yang dihitung berdistribusi kumulatif P(X≤x) - False, jika peluang yang dihitung berdistribusi peluang P(X=x)
Gambar 2. 26 Function Arguments pada Microsoft Excel Distribusi Eksponensial
6. Pilih OK
7. P(X>0,1) = 1 – P(X<=0,1) = 1 – 0,91792 = 0,08208
40
SOAL LATIHAN MANDIRI
1. Sebuah akumulator mobil memiliki umur rata rata 5 tahun, dengan simpangan baku 0.8 tahun. Carilah peluang akumulator tersebut memiliki umur kurang dari 3 tahun
2. Sebuah ban mobil memiliki daya tahan dengan rata rata waktu sampai ban mobil itu rusak yaitu 6 tahun. Tentukanlah peluang, bahwa:
a. ban tersebut tidak akan rusak sampai 3 tahun kedepan.
b. ban tersebut tetap sehat sampai 10 tahun kedepan.
c. ban tersebut rusak dalam waktu tidak lebih dari 5 tahun.
3. Mesin untuk memproduksi baut dengan ukuran diameter rata rata 16 mm dengan standar deviasi 1 mm. Tentukan peluang, bahwa
a. baut memiliki ukuran diameter besar dari 18 mm b. baut memiliki ukuran antara 15 sampai 17 mm.
c. baut memiliki ukuran diameter lebih kecil dari 13 mm
4. Seorang teller bank didatangi nasabah dengan rata rata kedatangan 20 nasabah perhari.
Distribusi kedatangan pelanggan tersebut mengikuti distribusi poisson. Berpakakah peluang nasabah yang datang kurang dari 15 pelanggan dalam satu hari?. Berapakah peluang pelanggan yang datang yaitu antara 19 sampai 25 pelanggan dalam satu hari?
5. Dari 200 siswa yang ada di SMA Suka Makmur, sebanyak 50 orang mengakui bahwa meraka mengidap penyakit gangguan pernafasan. Seorang bidan dari pukesmas mengambil sampel sebanyak 20 dari siswa untuk dilakukan pemeriksaan. Berapakah peluang, bahwa:
a. 5 orang dari sampel mengidap penyakit pernapasan b. kurang dari 10 mengidap penyakit pernafasan
c. sebanyak 5 sampai 15 orang mengidap penyakit pernafasan.
41 MODUL 3
ANALISIS UNIVARIAT DAN BIVARIAT
TUJUAN PRAKTIKUM
1. Praktikan mengetahui dan memahami perbedaan analisis univariat dan bivariat.
2. Praktikan mengetahui cara menguji dan memahami mengenai statistika parametrik.
3. Praktikan mengetahui dan memahami uji-uji yang digunakan dalam statistika parametrik.
4. Praktikan mampu menyelesaikan contoh kasus terkait dengan statistika parametrik.
ALAT PRAKTIKUM 1. Komputer
2. Modul Praktikum SIPO 2017 3. Software IBM SPSS 23.0 4. Software Ms. Excel
LANGKAH PRAKTIKUM
Analisis Univariat A. Uji Kenormalan
Di salah satu bimbingan belajar telah dilakukan try out mata pelajaran Fisika. Terdapat 32 siswa yang mengikuti try out tersebut. Berikut merupakan data nilai 32 siswa pada try out mata pelajaran fisika. Apakah data tersebut berdistribusi normal atau tidak? Dalam pengambilan data peneliti menggunakan taraf kepercayaan 95%.
Tabel 3. 1 Studi Kasus Uji Kenormalan
No Nilai Fisika No Nilai Fisika
1 72 17 66
2 57 18 55
3 65 19 78
4 48 20 70
5 80 21 45
6 88 22 32
7 66 23 85
8 52 23 95
9 43 25 74
42
Tabel 3. 2 Studi Kasus Uji Kenormalan (lanjutan)
Langkah Penyelesaian
1. Buka software IBM SPSS 23.0.
2. Klik Data View dan masukkan data yang akan dihitung sesuai dengan variabelnya. Hasil pengisian data seperti berikut.
Gambar 3. 1 Data View Studi Kasus Uji Kenormalan
3. Deskripsikan data di Variable View. Lalu pilih jenis data Scale pada pilihan Measure.
No Nilai Fisika No Nilai Fisika
10 62 26 64
11 54 27 41
12 37 28 70
13 76 29 47
14 81 30 60
15 68 31 39
16 58 32 35
43
Gambar 3. 2 Variable View Studi Kasus Uji Kenormalan
4. Klik Analyze, pilih Nonparametric Tests. Pilih Legacy Dialogs, lalu pilih 1-Sample K- S. Maka akan muncul kotak dialog berikut.
Gambar 3. 3 Kotak Dialog One-Sample Kolmogorov-Smirnov Test
Masukkan variabel nilai fisika ke kotak Test Variable List dan pilih Normal pada pilihan Test Distribution.
5. Klik Exact. Pilih Asymptotic only kemudian klik Continue.
Gambar 3. 4 Kotak Dialog Exact Tests
6. Klik Options. Pilih Exclude cases listwise kemudian klik Continue.
44
Gambar 3. 5 Kotak Dialog One-Sample K-S: Option
7. Klik OK. Maka output akan muncul dengan tampilan sebagai berikut.
Gambar 3. 6 Output SPSS One-Sample Kolmogorov Smirnov Test
Analisis dan Pengujian Hipotesis 1. Hipotesis
H0 : Data nilai 32 siswa pada try out mata pelajaran fisika berasal dari distribusi normal
H1 : Data nilai 32 siswa pada try out mata pelajaran fisika tidak berasal dari distribusi normal
2. Statistik uji : Uji Kolmogorv-Smirnov 3. α = 0.05
4. Daerah kritis : H0 ditolak jika signifikansi penelitian ≤ α
5. Dari hasil pengolahan SPSS, diperoleh signifikansi penelitian = 0.200, bandingkan dengan α.
6. Kesimpulan: Interpretasikan hasil.
45
B. One Sample T-Test
Seorang mahasiswa ingin meneliti apakah rata-rata nilai Bahasa Inggris dari sampel yang diambil pada kelas 2 SMP Delima berbeda dengan rata-rata nilai populasinya. Diketahui rata- rata nilai populasi di SMP Delima sebesar 7.53. Setelah dilakukan penelitian menggunakan sampel sebanyak 10 responden, didapatkan data-data sebagai berikut. Gunakan taraf kepercayaan sebesar 95% dan data berdistribusi normal.
Tabel 3. 3 Studi Kasus One Sample T-Test
Responden Ke Nilai
1 7.75
2 8.00
3 7.96
4 8.80
5 8.10
6 7.60
7 8.04
8 7.05
9 7.70
10 7.10
Langkah Penyelesaian
1. Buka software IBM SPSS 23.0.
2. Klik Data View dan masukkan data yang akan dihitung sesuai dengan variabelnya. Hasil pengisian data seperti berikut.
Gambar 3. 7 Data View One Sample T-Test
46
3. Deskripsikan data di halaman Variable View. Lalu pilih jenis data Scale pada pilihan Measure.
Gambar 3. 8 Variable View One Sample T-Test
4. Klik Analyze, pilih Compare Means. Lalu pilih One-Sample T Test. Akan muncul kotak dialog berikut.
Gambar 3. 9 Kotak Dialog One-Sample T Test
Masukkan variabel Nilai ke kotak Test Variable(s) dan Test Value sebesar 7.53.
5. Klik Options, lalu akan muncul kotak dialog One Sample T Test: Options. Isi nilai Confidence Interval Percentage berdasarkan studi kasus yang diminta, yaitu sebesar 95%. Lalu pilih Exclude Cases Listwise pada Missing Values dan klik Continue.
Gambar 3. 10 Kotak Dialog One-Sample T Test: Options
6. Klik OK. Maka akan muncul output berikut.
47
Gambar 3. 11 Output SPSS One-Sample Statistics
Gambar 3. 12 Output SPSS One-Sample Test
Analisis dan Pengujian Hipotesis 1. Hipotesis
H0 : Rata-rata nilai Bahasa Inggris kelas 2 SMP Delima sama antara sampel dan populasinya
H1 : Rata-rata nilai Bahasa Inggris kelas 2 SMP Delima tidak sama antara sampel dan populasinya
2. Statistik uji : Uji T 3. α = 0.05
4. Daerah kritis : H0 ditolak jika signifikansi penelitian ≤ α
5. Dari hasil pengolahan SPSS, diperoleh signifikansi penelitian = 0.115, bandingkan dengan α.
6. Kesimpulan: Interpretasikan hasil.
C. Independent Sample T-Test
Seorang mahasiswa ingin membandingkan rata-rata IP di dua kelas yang berbeda pada semester 5, yaitu IP kelas A dan IP kelas B. Berikut merupakan data IP kedua kelas pada semester 5. Gunakan taraf kepercayaan sebesar 95% dan data berdistribusi normal.
Tabel 3. 4 Studi Kasus Independent Sample T-Test
IP Kelas A IP Kelas B
3.14 3.20
3.25 3.06
3.10 2.82
3.01 3.08
48
2.77 2.96
2.76 2.67
3.58 2.55
Langkah Penyelesaian
1. Buka software IBM SPSS 23.0.
2. Klik Data View dan masukkan data yang akan dihitung sesuai dengan variabelnya. Hasil pengisian data seperti berikut.
Gambar 3. 13 Data View Studi Kasus Independent Sample T-Test
Pada gambar di atas, IP untuk Kelas A dimisalkan dengan kode “1” dan IP untuk Kelas B dimisalkan dengan kode “2”.
3. Deskripsikan data di Variable View. Lalu pilih jenis data Scale pada IP dan pilih jenis data Nominal pada Kelas dalam pilihan Measure.
Gambar 3. 14 Variable View Independent Sample T-Test
4. Klik Analyze, pilih Compare Means. Lalu pilih Independent Samples T Test. Akan muncul dialog berikut.
49
Gambar 3. 15 Kotak Dialog Independent-Sample T Test
Masukkan variabel IP ke kotak Test Variable(s) dan variabel kelas ke kotak Grouping Variable.
5. Klik Define Groups. Masukkan kode 1 untuk Group 1 dan kode 2 untuk Group 2. Lalu klik Continue.
Gambar 3. 16 Kotak Dialog Define Groups
6. Klik Options, lalu akan muncul kotak dialog Independent Sample T Test: Options. Isi nilai Confidence Interval Percentage berdasarkan studi kasus yang diminta, yaitu sebesar 95%. Lalu pilih Exclude Cases Listwise pada Missing Values dan klik Continue.
Gambar 3. 17 Kotak Dialog Independent-Sample T Test: Options
7. Klik OK. Maka akan muncul output berikut.
50
Gambar 3. 18 Output SPSS Group Statistics
Gambar 3. 19 Output Independent Sample Test
Analisis dan Pengujian Hipotesis 1. Hipotesis
H0: Tidak ada perbedaan rata-rata IP kelas A dan IP kelas B H1: Ada perbedaan rata-rata IP kelas A dan IP kelas B 2. Statistik uji : Uji T
3. α = 0.05
4. Daerah kritis : H0 ditolak jika signifikansi penelitian ≤ α
5. Dari hasil pengolahan SPSS, diperoleh nilai signifikansi pada uji F > α (Sig. = 0.875 >
0.05) maka diasumsikan variansi kedua sampel sama sehingga pada tabel Independent Samples Test yang dibaca adalah sel pertama, yaitu Equal variances assumsed dengan nilai signifikansi penelitian = 0.218, bandingkan dengan α.
6. Kesimpulan: Interpretasikan hasil.
D. Paired Sample T-Test
Seorang mahasiswa akan melakukan penelitian terhadap nilai Statistika Industri terhadap nilai pre test dan nilai post test. Dari 10 responden didapatkan data sebagai berikut. Gunakan taraf kepercayaan sebesar 95% dan data berdistribusi normal.
Tabel 3. 5 Studi Kasus Paired Sample T-Test
Nilai Pre Test Nilai Post Test
65 78
55 66
56 60
63 67
46 60
63 75
50 80
51
48 55
53 78
45 68
Langkah Penyelesaian
1. Buka software IBM SPSS 23.0.
2. Klik Data View dan masukkan data yang akan dihitung sesuai dengan variabelnya. Hasil pengisian data seperti berikut.
Gambar 3. 20 Data View Paired Sample T Test
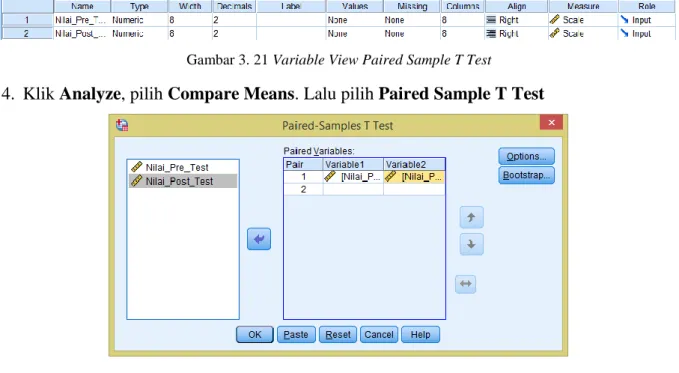
3. Deskripsikan data di halaman Variable View. Lalu pilih jenis data Scale pada pilihan Measure
Gambar 3. 21 Variable View Paired Sample T Test
4. Klik Analyze, pilih Compare Means. Lalu pilih Paired Sample T Test
Gambar 3. 22 Kotak Dialog Paired-Samples T Test
Masukkan variabel Nilai_Pre_Test ke kotak Variable1 dan masukkan variabel Nilai_Post_Test ke kotak Variable2.
52
5. Klik Options, lalu akan muncul kotak dialog Paired-Sample T Test: Options. Isi nilai Confidence Interval Percentage berdasarkan studi kasus yang diminta, yaitu sebesar 95%. Lalu pilih Exclude Cases Listwise pada Missing Values dan klik Continue.
Gambar 3. 23 Kotak Dialog Paired-Sample T Test: Options
6. Klik OK. Maka akan keluar output tersebut.
Gambar 3. 24 Output SPSS Paired Samples Statistics
Gambar 3. 25 Output SPSS Paired Samples Test
Analisis dan Pengujian Hipotesis 1. Hipotesis
H0: Rataan dari nilai Pre Test dan Post Test Statistika Industri sama H1: Rataan dari nilai Pre Test dan Post Test Statistika Industri tidak sama 2. Statistik uji : Uji T
3. α = 0.05
4. Daerah kritis : H0 ditolak jika signifikansi penelitian ≤ α
5. Dari hasil pengolahan SPSS, diperoleh signifikansi penelitian = 0.001, bandingkan dengan α.
6. Kesimpulan: Interpretasikan hasil.
53
Analisis Bivariat A. Korelasi Pearson
Seorang mahasiswa ingin mengetahui adakah hubungan antara IP mahasiswa dengan jam belajar mahasiswa di kelas TI3806. Berikut merupakan data IP mahasiswa dan jam belajar mahasiswa. Untuk menguji hipotesis tersebut gunakan α = 0.05. Diketahui data sudah berdistribusi normal
Tabel 3. 6 Studi Kasus Korelasi Pearson
IP Jam Belajar
3.5 3
2.77 1
3.2 3.5
2.8 3
3.6 3
2.75 2
2.9 1
3.4 3
3.0 2
2.00 1
Langkah Penyelesaian
1. Buka software IBM SPSS 23.0.
2. Klik Data View dan masukkan data yang akan dihitung sesuai variabelnya. Hasil pengisian data seperti berikut.
Gambar 3. 26 Data View Korelasi Pearson
3. Klik halaman Variable View, isi data yang diketahui pada kolom yang tersedia seperti gambar di bawah ini. Selanjutnya pilih tipe data Scale di kolom Measure untuk kedua data.
54
Gambar 3. 27 Variable View Korelasi Pearson
4. Klik Analyze → Correlate → Bivariate. Selanjutnya akan terbuka kotak dialog Bivariate Correlations. Klik variabel IP dan Jam_Belajar → masukkan ke kotak Variables. Lalu klik Pearson pada pilihan Correlation Coefficients dan klik Two – tailed pada Test of Significance serta pilih Flag significant correlations.
5. Klik Options, pilih Exclude cases listwise pada kotak Missing value.
Gambar 3. 28 Kotak Dialog Bivariate Correlations: Options
6. Klik Continue.
7. Klik OK.
8. Maka output akan muncul dengan tampilan sebagai berikut.
Gambar 3. 29 Output SPSS Correlations
Analisis dan Pengujian Hipotesis 1. Hipotesis
H0: Tidak ada hubungan antara IP mahasiswa dengan jam belajar mahasiswa H1: Ada hubungan antara IP mahasiswa dengan jam belajar mahasiswa 2. Statistik uji : Uji Bivariate Correlations
3. α = 0.05
4. Daerah kritis : H0 ditolak jika signifikansi penelitian ≤ α
5. Dari hasil pengolahan SPSS, diperoleh signifikansi penelitian = 0.020, bandingkan dengan
55
α.
6. Kesimpulan: Interpretasikan hasil.
B. Korelasi Parsial
Seorang peneliti ingin mengetahui hubungan antara jumlah produksi kopi (ton) terhadap nilai ekspor kopi (US$), di mana terdapat faktor tingkat inflasi (%) yang diduga mempengaruhi sehingga perlu dikendalikan. Pada penelitian ini, seorang ahli membuat pertanyaan berdasarkan dua variabel, yaitu jumlah produksi kopi dan nilai ekspor kopi serta variabel kontrol, yaitu tingkat inflasi kopi. Untuk menguji hipotesis tersebut gunakan α = 0.05
Tabel 3. 7 Studi Kasus Korelasi Parsial
Produksi (ton) Nilai Ekspor (US$) Inflasi
3000 300 2
5000 460 5
4500 350 6
3800 200 3
2700 198 5
8500 490 3
6500 400 2
3000 170 4
Langkah Penyelesaian
1. Buka software IBM SPSS 23.0.
2. Klik Data View dan masukkan data yang akan dihitung sesuai dengan variabelnya. Hasil pengisian data seperti berikut.
Gambar 3. 30 Data View Korelasi Parsial
3. Klik halaman Variable View, isi data yang diketahui pada kolom yang tersedia seperti gambar di bawah ini. Selanjutnya pilih tipe data Scale pada kolom Measure untuk ketiga data.
56
Gambar 3.31 Variable View Korelasi Parsial
4. Klik Analyze → Correlate → Partial. Selanjutnya akan terbuka kotak dialog Partial Correlations. Klik variabel Produksi dan Nilai_Ekspor → masukkan ke kotak Variables.
Klik variabel Inflasi masukkan ke kotak Controlling for. Lalu klik Two – tailed pada Test of Significance dan pilih Display actual significance level.
Gambar 3. 32 Kotak Dialog Partial Correlations
5. Klik Options, pilih Zero – order correlations pada kotak Statistics dan Exclude cases listwise pada kotak Missing value.
Gambar 3. 33 Kotak Dialog Partial Correlation: Options
6. Klik Continue.
7. Klik OK.
8. Maka output akan muncul dengan tampilan sebagai berikut.
57
Gambar 3. 34 Output SPSS Correlations
Analisis dan pengujian hipotesis 1. Hipotesis
H0 : Tidak terdapat hubungan yang signifikan antara jumlah produksi dengan nilai ekspor, jika tingkat inflasi dibuat tetap
H1 : Terdapat hubungan yang signifikan antara jumlah produksi dengan nilai ekspor, jika tingkat inflasi dibuat tetap
2. Statistik uji : Uji Partial Correlations 3. α = 0.05
4. Daerah kritis : H0 ditolak jika signifikansi penelitian ≤ α
5. Dari hasil pengolahan SPSS, diperoleh signifikansi penelitian = 0.015, bandingkan dengan α
6. Kesimpulan: Interpretasikan hasil.
C. Regresi Linear
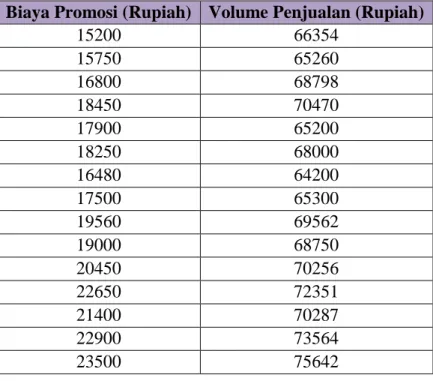
Seorang mahasiswa mengatakan bahwa volume penjualan suatu perusahaan jual beli mobil akan dipengaruhi oleh biaya promosi yang dilakukan perusahaan tersebut. Sehingga, mahasiswa tersebut ingin meneliti hubungan antara biaya promosi dan volume penjualan.
Apakah kedua variabel tersebut saling mempengaruhi atau tidak. Gunakan taraf signifikansi sebesar 5%.
58
Tabel 3. 8 Studi Kasus Regresi Linear
Biaya Promosi (Rupiah) Volume Penjualan (Rupiah)
15200 66354
15750 65260
16800 68798
18450 70470
17900 65200
18250 68000
16480 64200
17500 65300
19560 69562
19000 68750
20450 70256
22650 72351
21400 70287
22900 73564
23500 75642
Langkah Penyelesaian
1. Buka software IBM SPSS 23.0.
2. Klik Data View. Kemudian ketikkan data sesuai dengan variabel yang sudah didefinisikan.
Hasil pengisian data seperti berikut.
Gambar 3. 35 Data View Regresi Linear
3. Klik halaman Variable View, isi data yang diketahui pada kolom yang tersedia seperti gambar di bawah ini. Selanjutnya pilih tipe data Scale pada kolom Measure untuk kedua data.
Gambar 3. 36 Variable View Regresi Linear
59
4. Klik Analyze → Regression → Linier. Selanjutnya akan terbuka kotak dialog Linear Regression seperti berikut.
Gambar 3. 37 Kotak Dialog Regresi Linear
5. Klik Statistics. Pada pilihan Regression Coefficients checklist Estimates dan checklist Model Fit. Kemudian klik Continue seperti gambar berikut.
Gambar 3. 38 Kotak Dialog Regresi Linear: Statistics
6. Klik Plots. Klik pada pilihan SDRESID dan masukkan ke kotak Y, klik pada pilihan ZPRED dan masukkan ke kotak X. Aktifkan Histogram dan Normal probability plot seperti gambar berikut.
60
Gambar 3. 39 Kotak Dialog Regresi Linear: Plots
7. Klik Continue. Klik Save sehingga akan muncul kotak dialog seperti berikut.
Gambar 3. 40 Kotak Dialog Regresi Linear: Save
Pada pilihan Residuals, aktifkan Standardized, kemudian klik Continue.
8. Klik Option, sehingga akan muncul kotak dialog seperti berikut.