15
PREDIKSI LULUS TEPAT DAN TIDAK TEPAT WAKTU
MAHASISWA MENGGUNAKAN ALGORITMA K-MEANS
Hasbul Bahar
Teknik Informatika STT Nurul Jadid Probolinggo
ABSTRACT
Universities are educational units being the last chance for someone who want to pursue knowledge through formal education. The number of students who graduate on time becomes an indicator of success of public and private universities. Many studies on predicting students’ on-time graduation have been conducted. In this study, data mining predictive methods was conducted, namely k-Means algorithm which was applied to the data of students who graduated on time and late. K-means algorithm is one of the algorithms in the Data Mining methods. Based on the results of measuring the performance of the algorithm by using cross validation, confusion matrix and ROC curve test methods, it was found that the k-Means had an accuracy value of 84.43% and the value was lower than the neural network method value (90.41%). The AUC value for the neural network method showed the highest value of 0.946 and the value of the k-means method was 0.500. However, there were time differences when testing, which were 1 second for k-means algorithm and 10 seconds for neural network method.
Keywords : Prediction of students’ on-time and late graduation, Data Mining, K-Means algorithm,and Neural Network
1. PENDAHULUAN
1.1 Latar Belakang
Perguruan tinggi merupakan satuan pendidikan yang menjadi terminal terakhir bagi seseorang yang berpeluang belajar setinggi-tingginya melalui jalur pendidikan sekolah [1]. Perguruan tinggi saat ini dituntut untuk memiliki keunggulan bersaing dengan memanfaatkan semua sumber daya yang dimiliki. Selain sumber daya sarana, prasarana dan manusia, sistem informasi merupakan satu sumber daya yang dapat digunakan untuk meningkatkan keunggulan bersaing. Sistem informasi dapat digunakan untuk mendapatkan, mengolah dan menyebarkan informasi untuk menunjang kegiatan operasional sehari – hari sekaligus menunjang kegiatan pengambilan keputusan strategis.
Strategi baru dalam memperbaiki dan meningkatkan kualitas bangsa melalui pendidikan yang berkualitas perlu diupayakan sehingga menghasilkan manusia yang unggul, cerdas, dan kompetitif. Strategi tersebut terkait dengan tiga pilar utama dalam pembangunan pendidikan nasional yaitu: peningkatan pemerataan dan akses pendidikan, peningkatan mutu, relevansi dan daya saing serta manejemen bersih dan transparan sehingga masyarakat memiliki citra yang baik (good governance).
16
Untuk itu, setiap perguruan tinggi selalu melakukan evaluasi performa mahasiswanya. Hasil evaluasi tersebut disimpan dalam basis data akademik sehingga data tersebut dapat digunakan sebagai pendukung keputusan oleh manajemen perguruan tinggi. Salah satu variable indikator efisiensi proses pendidikan adalah informasi mengenai lama masa studi mahasiswa. Hal ini akan terjadi secara berulang pada perguruan tinggi. Jumlah data yang banyak ini membuka peluang untuk dihasilkan informasi yang berguna bagi pihak universitas.
Dalam hal penggalian informasi mahasiswa pada sebuah data yang berukuran besar (mempunyai record dan jumlah field yang cukup banyak) tidak dapat dilakukan dengan mudah. Teknologi data mining merupakan merupakan bidang penelitian inter disiplin yang intinya adalah interseksi antara machine learning, statistik dan database.
Pengolahan data mahasiswa sebelumnya menggunakan beberapa metode data mining yaitu AL Cripps [5] melakukan penelitian penggunaan ANN untuk memprediksi perfomansi akademik berupa presentasi kelulusan, masa studi, dan GPA. penelitian tersebut menggunakan data akademis yang diperoleh selama mahasiswa kuliah. variable prediktor yang digunakan pada penelitian tersebut adalah usia, jenis kelamin, skor American College Testing
(ACT), ras dan kemampuan membaca.
Meinanda [6] menggunakan neural network untuk memprediksi lama masa studi Sarjana, dengan arsitektur Multilayer Perceptron (MLP) dari penelitian ini ditemukan bahwa lama masa studi dipengaruhi oleh Indeks Prestasi Kumulatif (IPK), jumlah mata kuliah yang diambil, jumlah mata kuliah mengulang, dan jumlah pengambilan mata kuliah tertentu.
Hilda [7] melakukan Prediksi Kelulusan Mahasiswa dengan Komparasi Metode klasifikasi Data Mining, penelitian ini dilakukan perbandingan metode data mining yaitu algoritma C4.5, naïve bayes dan neural network.
Untuk itu dalam kesempatan penelitian yang tersedia berdasarkan penelitian sebelumnya akan dilakukan penelitian menggunakan metode K-Means. Karena metode tersebut dapat lebih banyak focus untuk memahami dalam cluster yang dapat dimengerti untuk menemukan persamaan dan perbedaan antar pola dan untuk memperoleh kesimpulan yang bermanfaat dalam prediksi lulus tepat dan tidak tepat waktu mahasiswasehingga diperoleh metode dengan akurasi prediksi yang terbaik.
1.2 Rumusan Masalah
Dari latar belakang masalah di atas, dapat disimpulkan bahwa banyak algoritma penelitian sebelumnya telah dilakukan dengan hasil dan tingkat akurasi belum mendekati sempurna dalam prediksi lulus tepat waktu mahasiswa, sehingga pertanyaan penelitian (research question) pada penelitian ini diarahkan untuk menyelesaikan masalah:
“Bagaimana memprediksi lulus tepat dan tidak tepat waktu mahasiswa dalam menempuh akademik menggunakan algoritma K-Means?”
17
1.3 Tujuan
Berdasarkan latar belakang dan rumusan masalah diatas, penelitian ini bertujuan untuk mengaplikasikan Algoritma K-Means pada prediksi lulus tepat dan tidak tepat waktu mahasiswa dalam menempuh akademik.
1.4 Manfaat
1. Manfaat Praktis
Hasil penelitian ini diharapkan dapat membantu administrasi akademik untuk memberikan peringatan dini dan pembimbingan awal bagi mahasiswa yang kemungkinan tidak lulus tepat waktu.
2. Manfaat Teoritis
Hasil penelitian ini diharapkan dapat memberikan kontribusi keilmuan pada penelitian Algoritma K-Means bagi praktisi atau peneliti lain untuk diterapkan pada kasus penelitian lain, dengan karakteristik penggunaan algoritma ini dalam pengelolahan data mahasiswa khususnya untuk prerdiksi lulus tepat dan tidak tepat waktu mahasiswa.
3. Manfaat Kebijakan
Diharapkan Algoritma K-Means dapat menghasilkan suatu model yang dapat mendukung aplikasi akademik bagi institusi yang ada. Hal ini adalah potensi besar bagi institusi untuk menentukan kebijaksaan strategis bagi institusi dalam kelulusan mahasiswa.
2. TINJAUAN PUSTAKA
2.1 Penelitian Terkait
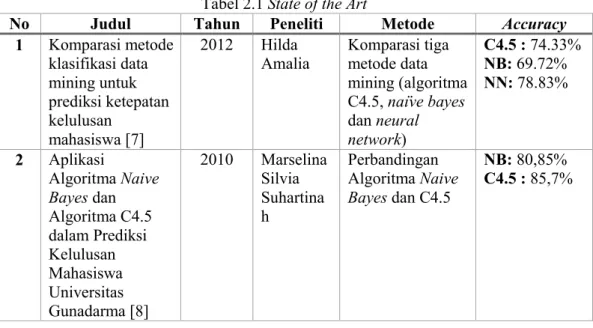
Berikut ini beberapa penelitian terkait prediksi lulus tepat dan tidak tepat waktu mahasiswa dengan beberapa metode yang digunakan dalam State of the Art sebagaimana dalam tabel 2.1. berikut:
Tabel 2.1 State of the Art
No Judul Tahun Peneliti Metode Accuracy
1 Komparasi metode klasifikasi data mining untuk prediksi ketepatan kelulusan mahasiswa [7] 2012 Hilda Amalia Komparasi tiga metode data mining (algoritma C4.5, naïve bayes dan neural network) C4.5 : 74.33% NB: 69.72% NN: 78.83% 2 Aplikasi Algoritma Naive Bayes dan Algoritma C4.5 dalam Prediksi Kelulusan Mahasiswa Universitas Gunadarma [8] 2010 Marselina Silvia Suhartina h Perbandingan Algoritma Naive Bayes dan C4.5 NB: 80,85% C4.5 : 85,7%
18 3 Prediksi masa studi Sarjana Menggunakan Artificial Neural Network [6]
2009 Meinanda Neural Network Arftifical Neural Network dengan arsitektur Multilayer Perceptron dalam memprediksi lama masa studi merupakan model terbaik Dari hasil penelitian diatas, Meinanda, [6] melakukan prediksi masa studi sarjana menggunakan Artifical Neural Network dengan arsitektur
Multilayer Perceptron (MLP). Hasil penelitian ini dapat disimpulkan bahwa (a) variable indeks Prestasi Kumulatif (IPK), jumlah mata kuliah yang diambil, jumlah mata kuliah mengulang, dan jumlah pengambilan mata kuliah tertentu mempengaruhi masa studi, (b) dalam melakukan prediksi masa studi, model regresi akan menghasilkan prediksi masa studi, (c) Arftifical Neural Network
dengan arsitektur Multilayer Perceptron dalam memprediksi lama masa studi merupakan model terbaik.
Hilda, [7] memprediksi ketepatan kelulusan mahasiswa dengan metode klasifikasi data mining. Dalam penelitian ini dilakukan perbandingan metode
data mining yaitu algoritma C4.5, naïve bayes dan neural network yang diaplikasikan pada data kelulusan mahasiswa baik yang lulus tepat waktu dan yang terlambat lulus. Hasil penelitian ini menunjukkan bahwa Neural Network
memiliki nilai akurasi yang paling tinggi 78,19%, diikuti oleh Metode Algoritma C4.5 dengan nilai akurasi 74,33%, kemudian Metode Naïve Bayes dengan nilai akurasi 69,72%. Nilai AUC untuk metode neural network menunjukan nilai tertinggi yakni 0,848 dan yang terendah adalah metode naïve bayes yaitu 69,72.
Marselina, [8] meneliti Prediksi kelulusan mahasiswa dengan Algoritma Naive Bayes dan C4.5. Hasil penelitian ini menunjukkan bahwa Algoritma C4.5 kesalahan yang dihasilkan dalam proses prediksi lebih sedikit karena melakukan klasifikasi record-record ke dalam kelas tujuan yang ada. Karena pada algoritma C4.5 setiap nilai dalam suatu atribut ditelusuri dan diproses untuk mendapatkan entropi masing - masing nilai yang digunakan untuk mencari ukuran masing - masing atribut.
2.2 Landasan Teori
2.2.1 Kelulusan Mahasiswa
Kelulusan mahasiswa merupakan hal yang penting diperhatikan, karena penurunan jumlah kelulusan akan menghilangkan jumlah pendapatan institusi dan mempengaruhi penilaian pemerintah serta mempengaruhi status akreditasi institusi [3].
19
Beberapa faktor dapat mempengaruhi kelulusan mahasiswa antara lain nilai akhir SMA, Indeks Prestasi Semester (IPS), gaji orang tua dan pekerjaan orang tua [11]. Indeks prestasi sering digunakan sebagai indikator penilaian akademik, banyak universitas memberi standar minimum yang sulit di peroleh mahasiswa [12]. Banyak variabel yang dapat digunakan dalam prediksi kelulusan mahasiswa seperti umur, status pernikahan, jumlah saudara [13]. Kegagalan mahasiswa baik drop out atau lulus tidak tepat waktu sangat tergantung pada sistem pendidikan yang digunakan institusi.
2.2.2 Algoritma Clustering
Secara umum gambar 2.1 menggambarkan pembagian algoritma
clustering sebagai berikut:
Gambar 2.1 Kategori Algoritma Clustering
Hierarchical clustering menentukan sendiri jumlah cluster yang dihasilkan. Hasil dari metode ini adalah suatu struktur data berbentuk pohon yang disebut dendogram dimana data dikelompokkan secara bertingkat dari yang paling bawah dimana tiap instance data merupakan satu cluster sendiri, hingga tingkat paling atas dimana keseluruhan data membentuk satu cluster besar berisi
cluster-cluster seperti gambar 2.2 dibawah ini:
20 Divisive hierarchical clustering mengelompokkan data dari kelompok yang terbesar hingga ke kelompok yang terkecil, yaitu masing-masing instance dari kelompok data tersebut. Sebaliknya, agglomerative hierarchical clustering
mulai mengelompokkan data dari kelompok yang terkecil hingga kelompok yang terbesar [21].
Partitional clustering yang mengelompokkan data ke dalam k cluster
dimana k adalah banyaknya cluster dari input user. Kategori ini biasanya memerlukan pengetahuan yang cukup mendalam tentang data dan proses bisnis yang memanfaatkannya untuk mendapatkan kisaran nilai input yang sesuai.
Clustering Large Data, dibutuhkan untuk melakukan clustering pada data yang volumenya sangat besar sehingga tidak cukup ditampung dalam memori komputer pasa suatu waktu. Biasanya untuk mengatasi masalah besarnya volume data, dicari teknik-teknik untuk meminimalkan berapa kali algoritma harus membaca seluruh data.
2.2.3 Algoritma K-Means
K-means merupakan salah satu metode data clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster / kelompok. Metode ini mempartisi ke dalam cluster / kelompok sehingga data yang memiliki karakteristik yang sama (High intra class similarity) dikelompokkan ke dalam satu cluster yang sama dan yang memiliki karakteristik yang berbeda (Law inter class similarity) dikelompokkan pada kelompok yang lain [3]. Proses klustering dimulai dengan mengidentifikasi data yang akan dikluster, Xij (i=1,...,n; j=1,...,m) dengan n adalah jumlah data yang akan dikluster
dan m adalah jumlah variabel. Pada awal iterasi, pusat setiap cluster ditetapkan secara bebas (sembarang), Ckj (k=1,...,k; j=1,...,m). Kemudian dihitung jarak
antara setiap data dengan setiap pusat kluster. Untuk melakukan penghitungan jarak data ke-i (xi) pada pusat kluster ke-k (ck), diberi nama (dik), dapat digunakan
formula Euclidean [2] seperti pada persamaan (1), yaitu:
Suatu data akan menjadi anggota dari kluster ke-k apabila jarak data tersebut ke pusat kluster ke-k bernilai paling kecil jika dibandingkan dengan jarak ke pusat kluster lainnya. Hal ini dapat dihitung dengan menggunakan persamaan (2) Selanjutnya,
Nilai pusat kluster yang baru dapat dihitung dengan cara mencari nilai rata-rata dari data-data yang menjadi anggota pada kluster tersebut, dengan menggunakan rumus pada persamaan 3:
21
Dimana xij kluster ke – k
p = banyaknya anggota kluster ke k Algoritma dasar dalam k-means adalah 1. Tentukan jumlah kluster (k), tetapkan pusat kluster sembarang.
2. Hitung jarak setiap data ke pusat klustermenggunakan persamaan (2.1). 3. Kelompokkan data ke dalam kluster yang dengan jarak yang paling pendek
menggunakan persamaan (2.2).
4. Hitung pusat kluster yang baru menggunakan persamaan (2.3)
Ulangi langkah 2 sampai dengan 4 hingga sudah tidak ada lagi data yang berpindah ke kluster yang lain
2.2.4 Evaluasi dan Validasi Metode
Dalam melakukan evaluasi pada algoritma K-Means dan Neural Network dilakukan dengan menggunakan model confusion matrix.
1. Confusion Matrix
Confusion Matrix merupakan alat (tools) visualisasi yang biasa digunakan pada supervised learning dan merupakan table matrix yang terdiri dari dua kelas, yaitu kelas yang dianggap sebagai positif dan kelas yang dianggap sebagai negatif [18]. Tiap kolom pada matriks adalah contoh kelas prediksi, sedangkan tiap baris mewakili kejadian di kelas yang sebenarnya.
Confusion matrix berisi informasi aktual (actual) dan prediksi (predicted) pada sisitem klasifikasi. Tabel 2.2 adalah contoh tabel confusion matrix yang menunjukan klasifikasi dua kelas.
Tabel 2.2 Model Confusion Matrix [19]
Predicted
Observed Class
Class = Yes Class = No Class = Yes A (true positive -
tp)
B (false negative-fn)
Class = No C (false positive - fp)
D (true negative- tn)
Keterangan:
True Positive (tp) = Proporsi positif dalam data set yang diklasifikasikan positif
True Negative (tn) = Proporsi negative dalam data set yang diklasifikasikan negative
False Positive (fp) = Proporsi negatif dalam data set yang diklasifikasikan potitif
False Negative (fn) = Proporsi negative dalam data set yang diklasifikasikan negatif
Berikut adalah persamaan model confusion matrix:
a. Nilai akurasi (acc) adalah proporsi jumlah prediksi yang benar. Dapat dihitung dengan menggunakan persamaan:
22
b. Sensitivity digunakan untuk membandingkan proporsi tp terhadap tupel yang positif, yang dihitung dengan menggunakan persamaan:
c. Specificity digunakan untuk membandingan proporsi tn terhadap tupel yang negatif, yang dihitung dengan menggunakan persamaan:
d. PPV (positive predictive value) adalah proporsi kasus dengan hasil diagnosa positif, yang dihitung dengan menggunakan persamaan:
e. NPV (negative predictive value) adalah proporsi kasus dengan hasil diagnosa negatif, yang dihitung dengan menggunakan persamaan:
2.3 Kerangka Pemikiran
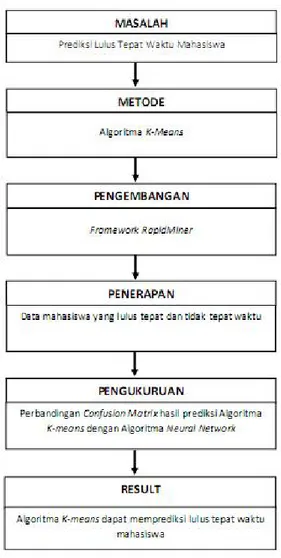
Dalam menyelesaikan penelitian, penulis membuat sebuah kerangka pemikiran yang berguna sebagai pedoman atau acuan penelitian ini sehingga penelitian dapat dilakukan secara konsisten. Penelitian ini terdiri dari beberapa tahap seperti terlihat pada gambar 2.4 kerangka pemikiran. Permasalahan pada penelitian ini adalah belum diketahuinya akurasi Algoritma K-Means untuk prediksi mahasiswa lulus tepat waktu.
Untuk itu metode yang digunakan yaitu algoritma K-Means untuk memecahkan masalah dilakukan pengujian terhadap kinerja metode tersebut dengan membandingkan hasil metode sebelumnya. Pengujian metode dilakukan dengan model confusion matrix. Untuk mengembangkan aplikasi berdasarkan metode yang dibuat, digunakan tools Rapid Miner. Berikut pengambaran kerangka permikiran yang dilakukan:
23
Gambar 2.3 Kerangka Pemikiran
3. METODE PENELITIAN
Metode penelitian yang digunakan dalam penelitian ini adalah penelitian
Experiment. Penelitian eksperimen merupakan sebuah penyelidikan hubungan kausal menggunakan tes dikendalikan oleh peneliti. Penelitian eksperimen biasanya dilakukan dalam proyek pengembangan, evaluasi dan pemecahan masalah. Dalam penelitian eksperimen digunakan spesifikasi hardware dan software sebagai alat bantu dalam penelitian yaitu:
Tabel 3.1 Spesifikasi hardware dan software
Spesifikasi Tipe
Prosesor Intel Pentium Dual Core Memori 2 GB
24
Sistem Operasi Windows 7 Tools RapidMiner
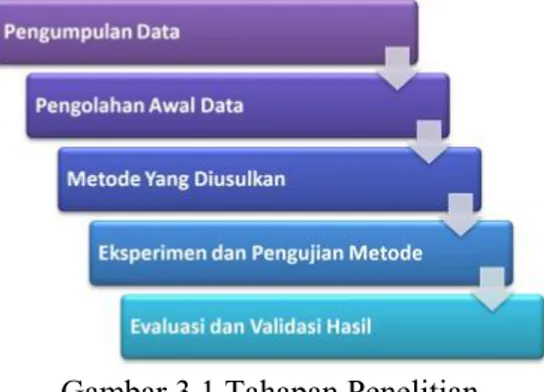
Pada penelitian ini, data yang digunakan adalah data kelulusan mahasiswa Sekolah Tinggi Teknologi Nurul Jadid. Data kelulusan mahasiswa tersebut diolah menggunakan metode data mining sehingga diperoleh satu metode yang paling akurat dan dapat digunakan sebagai rules dalam prediksi lulus tepat dan tidak tepat waktu mahasiswa. Dalam penelitian ini akan dilakukan beberapa langkah-langkah atau tahapan penelitian seperti yang digambarkan pada gambar 3.1.
Gambar 3.1 Tahapan Penelitian
Pada metode penelitian eksperimen, terdapat beberapa tahapan penelitian yang dilakukan seperti berikut:
1.Pengumpulan Data
Pada tahap ini dijelaskan bagaimana dan darimana data dalam penelitian ini didapatkan, meliputi data sekunder dan data primer. Data sekunder berisi tentang sumber pemerolehan data untuk keperluan penelitian, sedangkan data primer berisi tentang data yang dihasilkan dari penelitian.
2.Pengolahan awal data
Pada bagian ini dijelaskan tentang tahap awal data mining. Pengolahan awal data meliputi proses input data ke format yang dibutuhkan, pengelompokan dan penentuan atribut data, serta pemecahan data untuk digunakan dalam proses pembelajaran (training) dan pengujian (testing).
3.Model yang diusulkan
Pada tahap ini data dianalisis, dikelompokan variabel mana yang berhubungan dengan satu sama lainnya. Setelah data dianalisis lalu diterapkan model-model yang sesuai dengan jenis data. Pembagian data kedalam data latihan (training
data) dan data uji (testing data) juga diperlukan untuk pembuatan model. Metode yang diusulkan adalah Algoritma K-Means.
4.Eksperimen dan pengujian model
Pada bagian ini dijelaskan tentang langkah-langkah eksperimen meliputi cara pemilihan arsitektur yang tepat dari model atau metode yang diusulkan sehingga 24
25
didapatkan hasil yang dapat membuktikan bahwa metode yang digunakan adalah tepat.
5.Evaluasi dan validasi hasil
Pada bagian ini dijelaskan tentang evaluasi dan validasi hasil penerapan metode pada penelitian yang dilakukan. Penjelasan mengenai hal ini akan dipaparkan pada bab IV.
3.1.Metode Pengumpulan data
Pada penelitian ini digunakan pengumpulan data sekunder, yaitu data yang diperoleh dari database mahasiswa yang dimiliki oleh Sekolah Tinggi Teknologi Nurul Jadid yang berada di Paiton Probolinggo, yaitu melalui data server yang dimiliki oleh lembaga tersebut. Data yang diperoleh dari lembaga tersebut dalam penelitian ini adalah data mahasiswa tahun 2006 – 2008 dengan jumlah data sebanyak 501 record, dengan atribut No, NIM, Nama, Angkatan, Jenis Kelamin, IP Semester 1 – 8 dan Status Mahasiswa.
3.2.Metode Pengolahan Data Awal
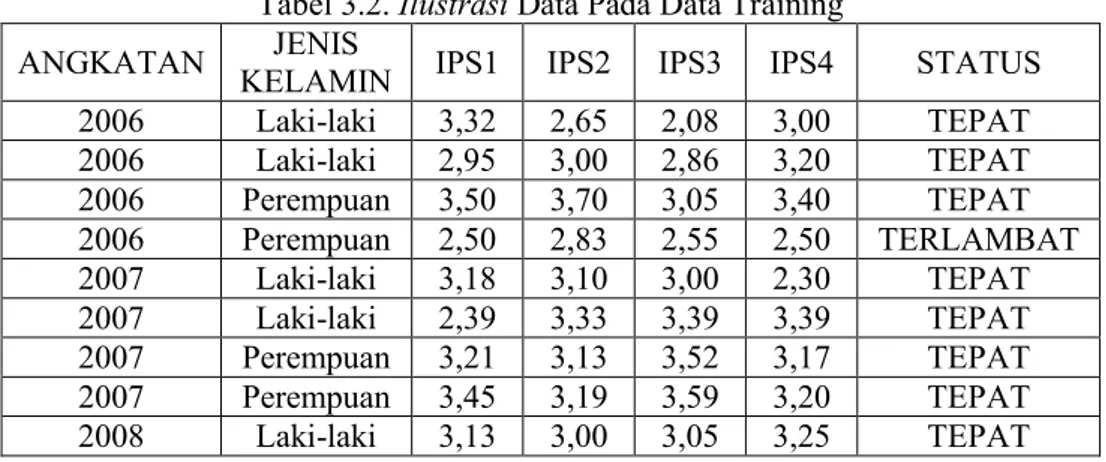
Jumlah data awal yang diperoleh dari pengumpulan data yaitu sebanyak 501 data, namun tidak semua data dapat digunakan dan tidak semua atribut digunakan karena harus melalui beberapa tahap pengolahan awal data (preparation data). Beberapa teknik yang dilakukan adalah sebagai berikut:
1.
Data validation, untuk mengidentifikasi dan menghapus data (outlier/noise), data yang tidak konsisten, dan data yang tidak lengkap (missing value).2.
Data integration and Transformation, untuk meningkatkan akurasi dan efisiensi algoritma. Data yang digunakan dalam penulisan ini bernilai kategorikal. Data ditransformasikan ke dalam software RapidMiner.3.
Data size reduction and dicrtization, untuk memperoleh data set dengan jumlah atribut dan record yang lebih sedikit tetapi bersifat informatif. Dalam penelitian ini atribut yang tidak relevan seperti nim, nama, angkatan, jenis kelamin, indeks prestasi semester lima, enam, tujuh dan delapan dihapuskan seperti terlihat pada tabel 3.2.Tabel 3.2. Ilustrasi Data Pada Data Training ANGKATAN JENIS
KELAMIN IPS1 IPS2 IPS3 IPS4 STATUS 2006 Laki-laki 3,32 2,65 2,08 3,00 TEPAT 2006 Laki-laki 2,95 3,00 2,86 3,20 TEPAT 2006 Perempuan 3,50 3,70 3,05 3,40 TEPAT 2006 Perempuan 2,50 2,83 2,55 2,50 TERLAMBAT 2007 Laki-laki 3,18 3,10 3,00 2,30 TEPAT 2007 Laki-laki 2,39 3,33 3,39 3,39 TEPAT 2007 Perempuan 3,21 3,13 3,52 3,17 TEPAT 2007 Perempuan 3,45 3,19 3,59 3,20 TEPAT 2008 Laki-laki 3,13 3,00 3,05 3,25 TEPAT
26
2008 Laki-laki 3,29 3,07 3,15 2,81 TEPAT Dari 501 data, jumlah data yang lulus “TEPAT” yakni sebanyak 430 data dan jumlah data yang lulus “TERLAMBAT” sebanyak 71 data.
3.3.Metode Yang Diusulkan
Metode yang diusulkan pada penelitian ini berdasarkan state of the art
tentang prediksi lulus tepat dan tidak tepat waktu mahasiswa menggunakan
Clustering Data Mining. Metode yang diusulkan untuk pengolahan data mahasiswa adalah penggunaan algoritma K-Means. Data diolah dengan algoritma K-Means di implementasikan dengan RapidMiner 5.1, setelah diolah dan mengahasilkan model, maka terhadap model yang dihasilkan tersebut dilakukan pengujian menggunakan k-fold cross validation, kemudian dilakukan evaluasi dan validasi hasil dengan
confusion matrix. Tahap selanjutnya adalah memandingkan hasil akurasi model K-Means dengan metode sebelumnya Neural Network, sehingga diperoleh model dari metode mana yang memperoleh nilai akurasi tertinggi. Dalam tahapan ini akan dilakukan beberapa langkah-langkah metode yang diusulkan data yaitu seperti berikut:
Gambar 3.2 metode yang diusulkan
4. HASIL PENELITIAN DAN PEMBAHASAN
4.1 Hasil Eksperimen dan Pengujian Model
Pada tahap ini dilakukan eksperimen dan pengujian model yaitu menghitung dan mendapatkan rule yang ada pada model algoritma yang diusulkan. Setelah itu, diuji rule tadi kedalam model untuk mendapatkan hasil yang lebih baik.
4.1.1 Algoritma K-Means
Dalam melakukan pengujian data hasil prediksi lulus tepat waktu mahasiswa di Sekolah Tinggi Teknologi Nurul Jadid Tahun 2006 – 2009,
Example Data Set untuk model algoritma K-Means meliputi 501 examples, 6
special attribut, dan 8 regular attribute sebagaimana terlihat dalam gambar 4.1 berikut:
27
Gambar 4.1 Example Set Data View Algoritma K-Means
Untuk melakukan pengujian dengan menggunakan algoritma K-Means
adalah sebagai berikut: 1. Menentukan data
Sebagai salah satu metode K-Means cukup menggunakan data training, dari data tersebut dijadikan sebagai data training mahasiswa dapat dilihat pada tabel 3.2.
2. Pengujian data
Pengujian data dilakukan dengan menggunakan piranti lunak Rapid Miner
Gambar 4.2 berikut memperlihatkan alur pengujian Algoritma K-Means
dalam Rapid Miner.
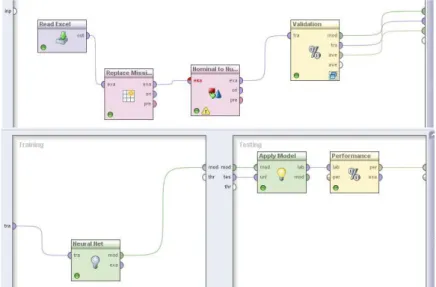
Gambar 4.2 Pengujian data metode Algoritma K-Means
Langkah awal pengolahnya adalah dengan mengambil data testing yang akan digunakan pada modul Read Excel kemudian dihubungkan dengan metode
clustering yang digunakan dalam pengujian data untuk menghasilkan performance yang lebih baik.
4.1.2 Neural Network
Neural network yang dihasilkan pada gambar 4.3 dengan atribut
preditor yang digunakan yaitu IP semester satu, IP semester dua, IP semester tiga, IP semester empat, IP semester lima, IP semester enam, IP semester tujuh dan IP semester delapan. Gambar 4.1 merupakan hasil eksperimen neural network.
28
Gambar 4.3 Pengujian data metode Neural Network 4.2 Evaluasi dan Validasi Metode
Metode clustering bisa dievaluasi berdasarkan kriteria seperti tingkat akurasi, kecepatan, kehandalan, skabilitas dan interpretabilitas [19]. Setelah data diolah maka dapat diuji tingkat akurasinya untuk melihat kinerja dari algoritma
K-Means.
Penelitian ini bertujuan untuk melihat akurasi lulus tepat dan tidak tepat waktu mahasiswa pada suatu universitas, menilai apakah dengan kriteria yang dimiliki mahasiswa dapat lulus tepat waktu atau tidak. Kemudian melakukan perbandingan dengan metode sebelumnya yakni neural network kemudian menganalisa akurasi dengan membandingkan kedua metode tersebut.
4.2.1 Algoritma K-Means
Tabel 4.1 evaluasi confusion matrix untuk metode algoritma K-Means. Diketahui tingkat akurasinya 84.43%, dan dari 501 sebanyak 341 data diprediksikan sesuai yaitu 341 data dan 4 data diprediksikan tepat tetapi ternyata telambat, dan sebanyak 74 diprediksi terlambat tetapi ternyata termasuk klastering tepat, dan sebanyak 82 diprediksi sesuai yaitu terlambat.
Tabel 4.1 Tabel Confusion Matrix Metode Algoritma K-Means
29 4.2.2 Neural Network
Hasil pengujian dengan metode neural network diperoleh accuracy
90.41%, sebanyak 394 data diprediksi seusai dengan kenyataan yaitu tepat, 27 data diprediski tepat ternyata terlambat, 21 diprediski terlambat tetapi ternyata tepat, dan 59 data diprediksi sesuai yaitu terlambat seperti terlihat pada Tabel 4.2 berikut:
Tabel 4.2 Tabel Confusion Matrix Metode Neural Network
4.3 Analisis Hasil Komparasi
Dari hasil pengujian data nilai mahasiswa angkatan 2006, 2007 dan 2008 diatas, model algoritma K-Means memiliki nilai akurasi sebesar 84.43% sedangkan nilai akurasi untuk model Neural Network sebesar 90.41% dengan selisih akurasi 5.98%, dapat dilihat pada Tabel 4.3 dibawah ini:
Tabel 4.3. Perbandingan Performance Metode
K-Means NN
Accuracy 84.43% 90.41%
AUC 0.500 0.946
Berdasarkan Tabel 4.3 diatas dapat dilihat bahwa nilai accuracy metode yang terbaik adalah neural network dengan nilai 90.41%, yang kedua adalah algoritma K-Means 84.43%. Jadi jika dilakukan perbandingan confusion matrix
akurasi yang terbaik adalah neural network karena nilai paling tinggi dalam mengukur akurasi TEPAT dan TERLAMBAT kelulusan mahasiswa, namun jika melihat hasil uji terdapat perbedaan waktu testing dimana neural network: 15 second dan k-means: 2 second seperti gambar 4.4 dibawah ini:
Gambar 4.4 Waktu Testing (K-Means Dan Neural Network)
Dari hasil data diatas dapat disimpulkan bahwa Neural Network
memiliki nilai lebih tinggi dalam prediksi lulus tepat dan tidak tepat waktu mahasiswa dengan nilai akurasi tertinggi yaitu 90.41% dan 84.43% untuk nilai akurasi K-Means.
30
5. KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari hasil penelitian yang telah dilakukan pembuatan algoritma K-Means
dan neural network menggunakan data kelulusan mahasiswa untuk prediksi lulus tepat dan tidak tepat waktu mahasiswa. Model yang dihasilkan dikomparasi untuk dapat diketahui metode terbaik dalam prediksi lulus tepat dan tidak tepat waktu mahasiswa. Untuk mengukur kineja model digunakan confusion matrix dapat diketahui bahwa Metode algoritma K-Means menghasilkan nilai akurasi yaitu 84.43%. Metode neural network menghasilkan nilai akurasi 90.41%. Dari evaluasi
confusion matrix tersebut terlihat bahwa nilai akurasi tertinggi ada pada metode
neural network dengan Execution Time 2 second untuk K-Means dan 15 second
untuk neural network.
Dengan demikian metode neural network adalah metode yang terbaik untuk pemecahan masalah prediksi lulus tepat dan tidak tepat waktu mahasiswa dibandingkan dengan Algoritma K-Means.
5.2 Saran
Untuk meningkatkan nilai akurasi dari algoritma K-Means pada riset selanjutnya bisa dilakukan penambahan atribut dan melakukan seleksi atribut menggunakan algoritma genetika dan semacamnya dengan penggunaan data yang lebih besar.
31 DAFTAR PUSTAKA
[1] Nawawi, H., & M, M. (1994). Kebijaksanaan Pendidikan di Indonesia di tinjau dari Sudut Hukum. Yogyakarta: Gajah Mada University Press.
[2] Qudri, M. N., & Kalyankar, N. V. (2010). Drop Out Feature of Student Data for Academic Performance Using Decision Tree techniques. Global Journal of Computer Science and Technology , 2-4.
[3] Karamouzis, T. S., & Vrettos, A. (2008). An Artificial Neural Network for Predicting Student Graduation Outcomes. Preceeding of World Congress on Engineering and Computer Science , 978-988-98671-02.
[4] Ogor, E. N. (2007). Student Academic Performance Monitoring and Evaluation Using Data Mining Techniques. Fourth Congress of Electronics, Robotics and Automotive Mechanics .
[5] Al Cripp, (1996). ‘Using Artificial Neural Nets to Predict Academic Performance,' in ACM Symposium on Apllied Computing, 1996.
[6] Meinanda M.H. Annisa M, Muhandri N, Kadarsyah (2009). “Prediksi masa studi Sarjana Menggunakan Artificial Neural Network”
[7] Hilda, “ Komparasi Algoritma Klasifikasi Data Mining untuk Prediksi Kelulusan Mahasiswa”, M.Kom. thesis, Sekolah Tinggi Manajemen Informatika Dan Komputer Nusa Mandiri, Jakarta, 2012.
[8] Marselina, Ernanstuti (2010). “Graduation Prediction Of Gunadarma University Students Using Algorithm And Naive Bayes C4.5 Algorithm”
[9] Azwar, S. (2004). Penyusunan Skala Psikologi. Yogyakarta: Pustaka Pelajar.
[10] Siregar, A. R. (2006). Motivasi Belajar Mahasiswa ditinjau dari Pola Asuh. Medan: Usu Repository.
[11] Suhartinah, S. M., & Ernastuti. (2010). Graduation Prediction of Gunadarma University Students Using Algorithm and Naive Bayes C4.5 Algoritmh.
[12] Oyelade, A. J., Oladipupo, O. O., & Obagbuwa, I. C. (2010). Application of kmeans Clustering algorithm for predicting of Students Academic Performace. International Journal of Computer Science and Information Security , 292-295.
[13] Yingkuachat, J., Praneetpolgrang, P., & Kijsirikul, B. (2007). An Application Probabilitic Model to the Prediction of Student Graduation Using Bayesian Belief Network. ECTI Transaction on Computer and Technology , 63-71.
[14] Han, J., & Kamber, M. (2007). Data Mining Concepts and Techniques. San Fransisco: Mofgan Kaufan Publisher.
[15] Santosa, B. (2007). Data Mining Teknik Pemanfaat Data Untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu.
[16] Witten, H. I., Eibe, F., & Hall, A. M. (2011). Data Mining Machine Learning Tools and Techiques. Burlington: Morgan Kaufmann Publisher.
[17] Larose, D. T. (2005). Discovering Knowledge in Databases. New Jersey: John Willey & Sons Inc.
[18] Vercellis, C. (2009). Business Intelligent: Data Mining and Optimization for Decision Making. Southern Gate: John Willey & Sons Inc
32 [19] Gorunescu, Florin. (2011). Data Mining: Concepts and Techniques. Verlag
berlin Heidelberg: Springer
[20] Dunham, Margaret,H. (2003), Data Mining Introuctory and Advanced Topics, New Jersey, Prentice Hall.
[21] Kantardzic, Mehmed (2003), Data Mining Concepts Models, Methods, and Algorithms, New Jersey, IEEE
[22] Teddy, Kusumadewi (2008). Aplikasi K-Means untuk Pengelompokan Mahasiswa Berdasarkan Nilai Body Mass Index (BMI) & Ukuran Kerangka
[22] Riduwan. (2008). Metode dan Teknik Menyusun Tesis. Bandung: Alfabeta