25
METODE PENELITIAN
3.1 Metodologi Penelitian
Penelitian mengenai pengaruh Service Quality terhadap Customer Loyalty dengan Brand Trust sebagai mediator, menggunakan penelitian asosiatif. Time Horizon yang digunakan adalah Cross-Sectional, dimana tiap subjek penelitian hanya diobservasi sekali saja. Hal ini tidak berarti bahwa semua subjek penelitian diamati pada waktu yang sama. Desain ini dapat mengetahui dengan jelas kaitannya hubungan sebab akibatnya.
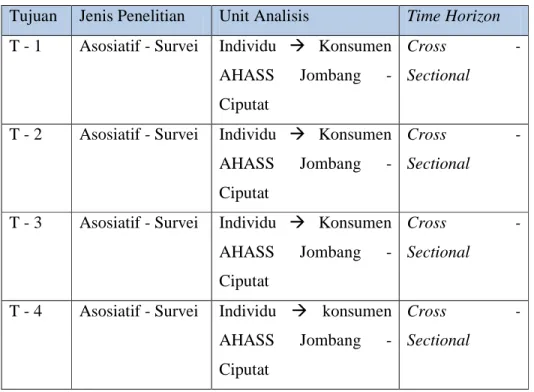
Tabel 3.1 Desain Penelitian
Tujuan Jenis Penelitian Unit Analisis Time Horizon T - 1 Asosiatif - Survei Individu Konsumen
AHASS Jombang - Ciputat
Cross -
Sectional
T - 2 Asosiatif - Survei Individu Konsumen AHASS Jombang - Ciputat
Cross -
Sectional
T - 3 Asosiatif - Survei Individu Konsumen AHASS Jombang - Ciputat
Cross -
Sectional
T - 4 Asosiatif - Survei Individu konsumen AHASS Jombang - Ciputat
Cross -
Sectional
Keterangan:
T-1 Untuk mengetahui dan menganalisa seberapa besar pengaruh positif antara Service Quality terhadap Brand Trust.
T-2 Untuk mengetahui dan menganalisa seberapa besar pengaruh positif antara Service Quality terhadap Customer Loyalty.
T-3 Untuk mengetahui dan menganalisa seberapa besar pengaruh positif antara Brand Trust terhadap Customer Loyalty.
T-4 Untuk mengetahui dan menganalisa seberapa besar pengaruh positif antara Service Quality terhadap Customer Loyalty dengan Brand Trust sebagai mediator.
3.2 Operasionalisasi Variabel Penelitian
Definisi operasionalisasi adalah penentuan konstruk sehingga menjadi variabel yang dapat diukur, yang dalam penelitian ini terdiri atas Service Quality, Brand Trust, dan Customer Loyalty. Variabel adalah karakteristik yang dapat diamati dari sesuatu (objek) dan mampu memberikan bermacam-macam nilai atau beberapa kategori (Riduwan dan Kuncoro, 2007:11).
Menurut Sekaran (2006:15), skala adalah suatu instrument atau mekanisme untuk membedakan individu yang terkait dengan variabel minat yang bisa dipelajari. Skala pengukuran adalah serangkaian aturan yang dibutuhkan untuk menguantitatifkan data dari pengukuran suatu variabel. Dalam melakukan analisis statistik, perbedaan jenis data akan sangat berpengaruh terhadap pemilihan model ataupun alat uji statistik yang akan digunakan.
Skala pengukuran yang dipakai adalah skala ordinal yang kemudian ditransformasikan menjadi data interval. Skala ordinal adalah skala yang mengurutkan data dari tingkat yang paling rendah ke tingkat yang paling tinggi atau sebaliknya dengan interval yang tidak harus sama. Umar Husein (2007:44). Skala interval adalah skala yang menunjukkan jarak antara satu data yang lain dan mempunyai bobot yang sama.
Instrumen pengukuran dengan menggunakan skala likert. Riduwan dan Kuncoro (2007:20), mengemukakan bahwa skala likert digunakan untuk mengukur sikap, pendapat, dan persepsi seseorang atau sekelompok tentang kejadian atau gejala sosial. Dengan menggunakan skala likert, maka variabel yang diukur
dijabarkan menjadi dimensi, dimensi dijabarkan menjadi sub variable kemudian sub variable dijabarkan lagi menjadi indikator-indikator yang dapat diukur. Akhirnya indikator-indikator yang terukur ini dapat dijadikan titik tolak untuk membuat item instrumen yang berupa pertanyaan atau pernyataan yang perlu dijawab oleh responden. Variabel penelitian adalah sesuatu hal yang berbentuk apa saja yang ditetapkan oleh peneliti untuk dipelajari sehingga diperoleh informasi tentang hal tersebut, kemudian ditarik kesimpulannya.
1. Variabel Service Quality
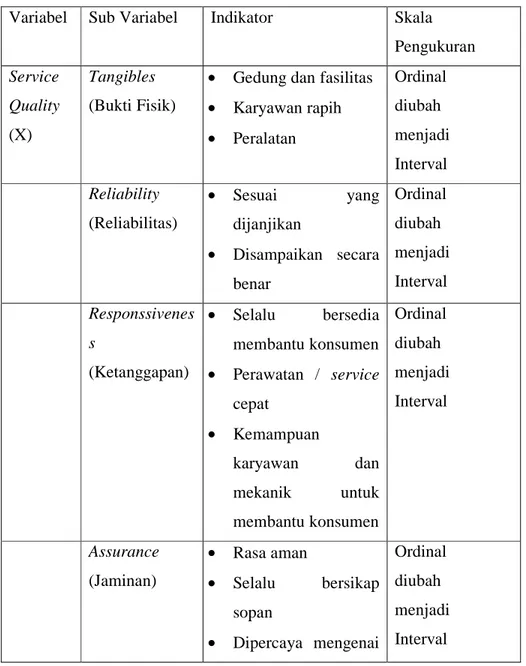
Tabel 3.2 Operasionalisasi Variabel Service Quality
Variabel Sub Variabel Indikator Skala
Pengukuran Service Quality (X) Tangibles (Bukti Fisik)
• Gedung dan fasilitas
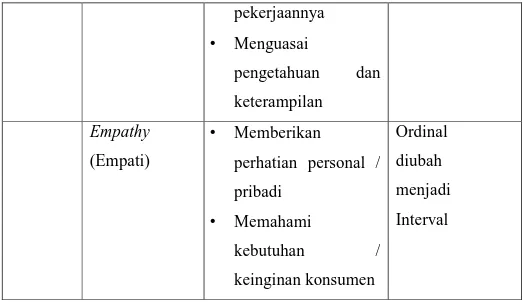
• Karyawan rapih • Peralatan Ordinal diubah menjadi Interval Reliability (Reliabilitas) • Sesuai yang dijanjikan • Disampaikan secara benar Ordinal diubah menjadi Interval Responssivenes s (Ketanggapan) • Selalu bersedia membantu konsumen • Perawatan / service cepat • Kemampuan karyawan dan mekanik untuk membantu konsumen Ordinal diubah menjadi Interval Assurance (Jaminan) • Rasa aman • Selalu bersikap sopan • Dipercaya mengenai Ordinal diubah menjadi Interval
pekerjaannya • Menguasai pengetahuan dan keterampilan Empathy (Empati) • Memberikan perhatian personal / pribadi • Memahami kebutuhan / keinginan konsumen Ordinal diubah menjadi Interval
2. Variabel Brand Trust
Tabel 3.3 Operasionalisasi Variabel Brand Trust
Variabel Sub Variabel Indikator Skala
Pengukuran Brand Trust (Y) Brand Reliability • Keyakinan konsumen • Kepentingan konsumen Ordinal diubah menjadi Interval Brand Intention • Kebutuhan konsumen
• Manfaat produk/Spare Part
Ordinal diubah menjadi Interval
3. Variabel Customer Loyalty
Tabel 3.4 Operasionaliasi Customer Loyalty
Variabel Sub Variabel Indikator Skala
Pengukuran Custome r Loyalty (Z) Melakukan pembelian yang • Perawatan/Service berkala • Perawatan/Service paling sedikit 2 kali Ordinal diubah menjadi
berulang secara teratur Interval Membeli antarlini produk dan jasa
• Produk yang bukan menjadi kebutuhan utamanya
• Membeli produk/spare part
Ordinal diubah menjadi Interval Merekomend asikan kepada orang lain • Word of Mouth • Mempromosikan Ordinal diubah menjadi Interval Menunjukkan kekebalan terhadap tarikan dari pesaing • Perawatan/service di satu tempat
• Tidak berpindah ke pesaing
Ordinal diubah menjadi Interval
3.3 Jenis dan Sumber Data Penelitian
Jenis dan sumber data yang digunakan dalam penelitian ini menggunakan data kuantitatif dengan sumber data primer. Data kuantitatif dapat disebut sebagai data berupa angka dalam arti sebenarnya. Data kuantitatif terbagi menjadi dua yaitu data interval dan ratio (Rahayu, 2005:63). Data menurut sumbernya mengacu kepada sumber perolehan data, yakni eksternal dan internal. Data internal adalah data yang bersumber dari keadaan atau kegiatan suatu organisasi atau kelompok. Misalnya data penjualan, data pelanggan dan data produksi suatu perusahaan. Data eksternal adalah data yang bersumber dari luar suatu organisasi atau kelompok, dalam hal ini data eksternal didapat dari responden melalui penyebaran kuisioner.
Tabel 3.5 Jenis dan Sumber Data
Tujuan Data Sumber
Data
Jenis Data Teknik
Pengumpulan Data T-1 Service Quality dan
Brand Trust
Eksternal Kuantitatif Kuisioner
T-2 Service Quality dan Customer Loyalty
Eksternal Kuantitatif Kuesioner
T-3 Brand Trust dan
Customer Loyalty
Eksternal Kuantitatif Kuesioner
T-4 Service Quality,
Brand Trust, dan Customer Loyalty
Eksternal Kuantitatif Kuesioner
Sumber : Peneliti, 2014
3.4 Teknik Pengumpulan Data
Data diperoleh dari penyebaran kuesioner. Beberapa teknik pengumpulan data yaitu :
1. Kuesioner
Bertujuan untuk memperoleh informasi yang relevan dengan tujuan penelitian, dan memperoleh informasi dengan reliabilitas dan validitas setinggi mungkin.
2. Penelitian Kepustakaan
Membantu dalam menganalisis data dan sebagai landasan teori. Sumber yang diperoleh dari buku, jurnal, internet.
3.5 Teknik Pengambilan Sampel
Menurut Sugiyono (2004:73-74) teknik pada dasarnya dapat dikelompokkan menjadi dua yaitu Probability Sampling adalah teknik sampling (teknik pengambilan sampel) yang memberikan peluang yang sama bagi setiap unsur (anggota) populasi untuk dipilih menjadi anggota sampel dan Nonprobability Sampling adalah teknik
pengambilan sampel yang tidak memberi peluang/kesempatan sama bagi setiap unsur atau anggota populasi untuk dipilih menjadi sampel.
Dalam penelitian ini, penulis menggunakan Probability Sampling dan teknik Simple Random Sampling. Dikatakan simple (sederhana) karena pengambilan sampel anggota populasi dilakukan secara acak tanpa memperhatikan strata yang ada dalam populasi itu.
3.6 Teknik Pengolahan Sampel
Penentuan jumlah sampel (responden) menggunakan rumus dari Taro Yamane (dalam Ridwan dan Kuncoro, 2007:44), sebagai berikut :
Dimana : n = Jumlah sampel N = Jumlah populasi d2 = Presisi yang diterapkan
Berdasarkan rumus tersebut diperoleh jumlah sampel sebagai berikut :
(dibulatkan menjadi 100 responden)
3.7 Metode Analisis
Dalam penelitian ini, analisis diawali pada instrument penelitian yaitu kuesioner dengan menggunakan uji validasi dan reliabilitas setelah itu dilanjutkan dengan uji normalitas data kemudian melakukan pengolahan data lalu dilanjutkan dengan menggunakan analisis korelasi dan analisis jalur (Path Analysis). Tools yang digunakan dlaam pengolahan data tersebut adalah dengan program SPSS versi 16 for windows. Hasil dari pengolahan data tersebut dilakukan untuk menjawab tujuan-tujuan penelitian sehingga dapat diperoleh kesimpulan yang akan menuju pada pembuatan saran.
Bentuk dari model skala sikap yang sering digunakan adalah skala likert skala guttman, skala diferensial semantik, skala rating dan skala thurstone. Pada penelitian kali ini, peneliti akan menggunakan model skala sikap yaitu skala likert.
3.7.1.1 Skala Likert
Menurut Uma Sekaran (2006:197) skala likert menunjukkan seberapa kuat subjek terhadap respon, baik setuju ataupun tidak setuju. Dalam skala likert respon disajikan dalam sejumlah item yang terkait dengan konsep atau variabel yang diteliti yang kemudian disajikan dalam skala interval (interval scale).
Menurut Sekaran dan Bougie (2010:p152) skala Likert menjadi perdebatan banyak orang baik yang menganggap skala tersebut adalah onterval maupun ordinal. Meskipun demikian, skala likert umumnya diperlakukan sebagai skala interval.
Dimana dalam pemberian nilai digunakan skala likert dengan nilai (skor) sebagai berikut.
Tabel 3.6 Skala Likert
Keterangan Penilaian Sangat tidak setuju 1
Tidak setuju 2 Kurang setuju 3
Setuju 4
Sangat setuju 5 Sumber : Peneliti, 2014
3.7.2 Uji Validitas dan Reliabilitas
3.7.2.1 Uji Validitas
Riduwan dan Kuncoro (2007:216) menyatakan uji validitas dilakukan berkenaan dengan ketepatan alat ukur terhadap konsep yang diukur sehingga benar-benar mengukur apa yang seharusnya
diukur, berkaitan dengan pengujian validitas instrument menurut Riduwan (2004:109) menjelaskan bahwa validitas adalah suatu urutan yang menunjukkan tingkat keandalan suatu alat ukur. Untuk menguji validitas alat ukur, dapat menggunakan program SPSS 16.0 dengan langkah-langkah (dalam modul statistic) :
1. Hitung nilai “df” dengan rumus df = n – 2 (n = jumlah responden)
2. Hitung nilai “t” dengan cara : pilih menu “compute”, kemudian pilih sub menu “transform” pada kolom sebelah kiri diisi dengan “t”, dan sebelah kanan diisi dengan rumus “IDF.T(0.95,DF)”. Kemudian “ok”.
3. Hitung nilai “r” dengan cara : Pilih menu “compute”, kemudian pilih sub menu “transform” pada kolom sebelah kiri diisi dengan “r”, dan sebelah kanan diisi dengan rumus “t/sqrt(df+t**2)”. Kemudian “ok”.
4. Hitung “r hitung” dengan cara :
• Pilih menu “analyze”, pilih sub menu “scale”, pilih yang “reliability analyze”.
• Kemudian pada kolom item isi dengan variabel yang ingin dihitung.
• Pada bagian “model”, biarkan pilihan pada “Alpha”.
• Klik tombol “statistik”. Pada bagian “Descriptive for pilih semuanya (item, scale, if item deleted).
• Kemudian ok, maka akan keluar hasilnya.
Ketentuan validitas adalah r hitung > r table.r hitung dapat dilihat pada output kolom “Corrected Item-Total Correlation”.
3.7.2.2 Uji Reliabilitas
Dalam Riduwan dan Kuncoro (2007:220), uji reliabilitas dilakukan untuk mendapatkan tingkat ketepatan (keterandalan atau keajegan) alat pengumpul data (instrument) yang digunakan. Uji reliabilitas instrument dilakukan dengan rumus alpha. Metode mencari reliabilitas internal yaitu menganalisis reliabilitas alat ukur daru satu kali pengukuran.
Uji Reliabilitas didapat pada nilai “Alpha” dari output perhitungan uji validitas. Dimana nilai Alpha: kurang dari 0,600 dianggap buruk, dalam kisaran 0,700 bisa diterima, dan lebih dari 0,800 adalah baik. Menurut Sekaran (2006:182).
3.7.3 Uji Normalitas
Uji normalitas bertujuan untuk menguji apakah dalam model regresi variable pengganggu atau residual memiliki distribusi normal atau tidak.Uji normalitas dilakukan menggunakan grafik normal probability plot. Kemudian dibentuk satu-satu garis lurus diagonal, dan ploting data residual akan dibandingkan dengan garis diagonal tersebut. Dasar pengambilan keputusan memenuhi uji normalitas atau tidak, adalah sebagai berikut :
1. Jika data menyebar disekitar garis diagonal dan mengikuti arah garis diagonal atau grafik histogramnya menunjukan pola distribusi normal, maka model regresi memenuhi asumsi normalitas.
2. Jika data menyebar jauh dari diagonal dan/atau tidak mengikuti arah garis diagonal atau grafik histogram tidak menunjukkan pola distribusi normal, maka regresi tidak memenuhi asumsi normalitas.
Dasar pengambilan keputusan pada uji normalitas ini adalah sebagai berikut :
• Jika angka signifikan Uji Kolmogrov-Smirnov Sig > 0,05 maka data berdistribusi normal
• Jika angka signifikan Uji Kolmogrov-Smirnov Sig < 0,05 maka data berdistribusi tidak normal
Angka Sig. atau signifikansi dapat diperoleh dengan perhitungan test of normality atau plot melalui alat bantu SPSS 16.0 dengan tingkat kepercayaan 95% atau tingkat kesalahan 5% dan langkah-langkahnya sebagai berikut :
1. Pilih menu Analyze – Descriptive Statistics – Explore.
2. Memasukkan variable yang akan diuji sebarannya ke dalam kotak Dependent List. Setelah itu kita klik tombol Plots, yang akan memunculkan dialog box kedua.
3. Dalam dialog ini kita memilih opsi Normality plots with test, kemudian klik Continue dan OK.
3.7.4 Analisis Korelasi dan Regresi
Untuk jenis penelitian asosiatif, metode analisis yang digunakan adalah analisis korelasi, regresi sederhana dan regresi berganda.
Berdasarkan Riduwan dan Kuncoro (2007:62) apabila nilai koefisien korelasi pearson (r) = +1, maka korelasi atau hubungan positif dan sempurna. Apabila koefisien korelasi pearson (r) = -1, maka korelasi atau hubungannya negative dan sempurna. Arti positif disini misalkan hubungan antara variabel X dan Y (rxy) nilainya positif (+), makan hubungannya searah.
• Apabila X naik maka Y juga naik, jika X turun maka Y juga akan turun,
• Apabila Y naik maka X juga naik, jika Y turun maka X juga turun. Arti harga r akan dikonsultasikan dengan tabel nilai interprestasi r sebagai berikut :
Tabel 3.7 Interprestasi Koefisien Korelasi Nilai r Interval Koefisien Tingkat Hubungan
08 – 1.000 Sangat Kuat 0.6 – 0.799 Kuat 0.4 – 0.599 Cukup Kuat 0.2 – 0.399 Rendah 0.0 – 0.199 Sangat Rendah Sumber : Riduwan (2005:136)
Besar kecilnya sumbangan variabel X terhadap Y ditentukan dengan rumus koefisien determinan sebagai berikut :
KP : r2 x 100% Keterangan :
KP = Nilai Koefisien Determinan r = Nilai Koefisien Korelasi
Berdasarkan pendapat Riduwan dan Kuncoro (2007:62) pengujian signifikan yang berfungsi apabila ingin mencari makna generalisasi dari hubungan variabel X terhadap Y, maka hasil korelasi PPM tersebut di uji signifikan sebagai berikut.
Hipotesis :
• Ho : tidak ada hubungan yang signifikan antara variabel X dengan variabel Y
• Ha : ada hubungan yang signifikan antara variabel X dengan variabel Y
Dasar Pengambilan Keputusan :
• Jika nilai probabilitas 0,05 lebih atau sama dengan nilai probabilitas sig atau (0,05 < sig), maka Ho diterima Ha ditolak, artinya tidak signifikan.
• Jika nilai probabilitas 0,05 lebih besar atau sama dengan nilai probabilitas sig atau sig atau (0,05 > sig), maka Ho ditolak dan Ha diterima, artinya signifikan.
Berdasarkan pendapat riduwan dan engkos achmad kuncoro (2007:63), analisis korelasi ganda berfungsi untuk mencari besarnya hubungan antara dua variabel bebas (X) atau lebih secara simultan (bersama-sama) dengan variabel terikat (Y). Desain penelitian dan rumus korelasi ganda sebagai berikut :
Selanjutnya, untuk mengetahui signifikansi korelasi ganda bandingkan antara nilai probabilitas sig sebagai berikut.
• Ha : Variabel X1 dan X2 berhubungan secara simultan dan signifikan terhadap variabel Y.
• Ho : Variabel X1 dan X2 tidak berhubungan secara simultan dan signifikan terhadap variabel Y.
Dasar Pengambilan Keputusan :
• Jika nilai probabilitas 0,05 lebih kecil atau sama dengan nilai probabilitas Sig atau (0,05 < sig), maka Ho diterima dan Ha ditolak, artinya signifikan.
• Jika nilai probabilitas 0,05 lebih besar atau sama dengan nilai probabilitas Sig atau (0,05 > sig), maka Ho diterima dan Ha ditolak, artinya signifikan.
3.7.5 Path Analysis
Path analysis diartikan oleh Bohrnstedt, 1974 (dalam Kusnendi, 2005:1) “a technique for estimating the effect’s a set independent variables has on a dependent variable from a set of observed correlations, given a set of hypothesized causal asymmetric relation among the variables”.
Jadi, model path analisis digunakan untuk menganalisis pola hubungan antar variable dengan tujuan untuk mengetahui pengaruh langsung maupun tidak langsung seperangkat variable bebas (eksogen) terhadap variable terikat (endogen).
Menurut Robert D. Rutherford, 1993 (dalam Sarwono, 2007:1), analisis jalur ialah suatu teknik untuk menganalisis hubungan sebab akibat yang terjadi pada regresi berganda jika variable bebasnya mempengaruhi variable tergantung tidak hanya secara langsung, tetapi juga secara tidak langsung.
Menurut Paul Webley, 1997 (dalam Sarwono, 2007:1), analisis jalur merupakan pengembangan langsung untuk regresi berganda dengan tujuan untuk memberikan estimasi tingkat kepentingan (magnitude) dan signifikan (significance) hubungan sebab akibat hipotetikal dalam seperangkat variabel. 3.7.6 Model Path Analysis
Riduwan (2007:3) mendefinisikan model analisis jalur terbagi menjadi 3 yaitu :
1. Model Korelasi
Dalam pemakaian model korelasi ini dipakai Korelasi Pearson Product Moment (r) untuk mengetahui derajat hubungan antara variable bebas (independent) dan variable terikat (dependent). 2. Model Regresi
Dalam pemakaian model regresi, digunakan persamaan regresi : Y = a + bX Meskipun model regresi dan path analysis sama-sama merupakan analisis regresi, tetapi penggunaan kedua model tersebut adalah berbeda. Hal ini diperjelas oleh Harun Al-Rasyid (1994:1-3) bahwa pola hubungan bagaimana yang ingin kita ungkapkan, apakah pola hubungan yang bisa digunakan untuk meramalkan atau menduga nilai sebuah variabel-respon Y atas dasar nilai tertentu beberapa variabel predictor X1, X2, …, Xk, atau pola hubungan yang mengisyaratkan besarnya pengaruh variable penyebab yang langsung secara sendiri-sendiri, maupun secara bersamaan.
3. Model Struktural
Model Struktural digunakan apabila setiap variabel terikat atau endogen (Y) secara unik keadaannya ditentukan oleh seperangkat variabel bebas atau eksogen (X). Jadi persamaannya Y = F (X1 ; X2 ; X3) dan Z = F (X1 ; X3 ; Y) merupakan persamaan struktural karena setiap persamaan menjelaskan hubungan kausal yaitu variabel eksogen X1 ; X2 dan X3 terhadap variabel endogen Y dan Z.
3.7.7 Manfaat Analisis Jalur
Manfaat model Path Analysis adalah untuk :
1. Penjelasan terhadap fenomena yang dipelajari atau permasalahan yang diteliti.
2. Prediksi nilai variabel terikat berdasarkan nilai variabel bebas, dan prediksi dengan Path Analysis ini bersifat kualitatif.
3. Faktor determinan, yaitu penentuan variabel bebas mana yang berpengaruh dominan terhadap variabel terikat, juga digunakan
untuk menelusuri mekanisme (jalur-jalur) pengaruh variabel bebas terhadap variabel terikat.
4. Pengujian model, menggunakan theory trimming, baik untuk uji reliabilitas (uji keajegan) konsep yang sudah ada ataupun uji pengembangan konsep baru.
3.7.8 Asumsi-asumsi Path Analysis
Asumsi yang mendasari Path Analysis sebagai berikut :
1. Pada model path analysis, hubungan antar variable bersifat linier, adaptif dan bersifat normal.
2. Hanya sistem aliran kausal ke satu arah artinya ada arah kausalitas yang terbalik.
3. Variable terikat (endogen) minimal dalam skala ukur interval dan ratio.
4. Menggunakan sampel probability sampling yaitu teknik pengambilan sampel untuk memberikan peluang yang sama pada setiap anggota populasi untuk dipilih menjadi anggota sampel. 5. Observed variables diukur tanpa kesalahan (instrument
pengukuran valid dan reliable artinya variable yang diteliti dapat diobservasi secara langsung.
6. Model yang dianalisis dispesifikasikan (diidentifikasi dengan benar berdasarkan teori-teori dan konsep-konsep yang relevan artinya model teori yang dikaji atau diuji dibangun berdasarkan kerangka teoritis tertentu yang mampu menjelaskan hubungan kausalitas antar variabel yang diteliti.
Menurut Riduwan & Kuncoro (2008:116), ada beberapa langkah pengujian analisis jalur (path analysis) yaitu sebagai berikut :
1. Merumuskan hipotesis dalam persamaan structural. Persamaan Sub-struktural 1 :
Persamaan Sub-Struktural 2 :
Keterangan :
= pengaruh variabel lain yang tidak diteliti atau kekeliruan pengukuran variabel
= koefisien regresi yang distandarkan atau koefisien jalur
Kategori hubungan dan pengaruh setiap variable independen terhadap variable dependen dalam model analisis jalur, ditetapkan pada tabel berikut ini :
Tabel 3.8 Kategori Hubungan Pengaruh Variabel pada Analisis Jalur Koefisien Path Daya/Pengaruh
0.05 – 0.09 Lemah
0.10 – 0.29 Sedang
0.30 ke atas Kuat
Sumber : Suwarno (1988:218)
2. Menghitung koefisien jalur lengkap, yang didasarkan pada koefisien regresi.
a. Gambarkan diagram jalur lengkap, tentukan sub-sub strukturnya dan rumuskan persamaan strukturalnya yang sesuai hipotesis yang diajukan.
Hipotesis : naik turunnya variable endogen (Y) dipengaruhi secara signifikan oleh variable eksogen (X).
Persamaan regresi berganda : Y = a + b1X1 + b2X2 + … + bnXn 3. Menghitung koefisien secara keseluruhan
a. Kaidah pengujian signifikan secara manual : menggunakan table F
b. Kaidah pengujian signifikan : program SPSS
• Jika nilai probabilitas 0.05 lebih kecil atau sama dengan nilai probabilitas sig atau [0.05 < sig], maka Ho diterima dan Ha ditolak, artinya tidak signifikan.
• Jika nilai probabilitas 0.05 lebih besar atau sama dengan nilai probabilitas sig atau [0.05 > sig], maka Ho ditolak dan Ha diterima, artinya signifikan.
4. Menghitung koefisien jalur secara individu
Selanjutnya untuk mengetahui signifikan analisis jalur bandingkan antara nilai probabilitas 0.05 dengan nilai probabilitas sig dengan dasar pengambilan keputusan sebagai berikut :
• Jika nilai probabilitas 0.05 lebih kecil atau sama dengan nilai probabilitas sig atau [0.05 < sig], maka Ho diterima dan Ha ditolak, artinya tidak signifikan.
• Jika nilai probabilitas 0.05 lebih besar atau sama dengan nilai probabilitas sig atau [0.05 > sig], maka Ho ditolak dan Ha diterima, artinnya signifikan.
3.8 Rancangan Uji Hipotesis
Hipotesis untuk penelitian ini berdasarkan identifikasi masalah yang ada, sebagai berikut:
(α) = 5 % = 0.05
Dasar pengambilan keputusan :
• Jika Sig ≥ 0.05 maka H0 diterima
• Jika Sig < 0.05 maka H0 ditolak
1. Untuk mengetahui pengaruh positif antara Service Quality terhadap Brand Trust
•H0 : tidak ada pengaruh positif antara Service Quality terhadap Brand Trust
•H1 : ada pengaruh positif antara Service Quality terhadap Brand Trust 2. Untuk mengetahui pengaruh positif Service Quality terhadap Customer
Loyalty
•H0 : tidak ada pengaruh yang positif antara Service Quality terhadap Customer Loyalty
•H1 : ada pengaruh pengaruh yang positif antara Organizational Justice terhadap Customer Loyalty
3. Untuk mengetahui pengaruh positif antara Brand Trust terhadap Customer Loyalty
•H0 : tidak ada pengaruh yang positif antara Brand Trust terhadap Customer Loyalty
•H1 : ada pengaruh yang positif antara Brand Trust terhadap Customer Loyalty
4. Untuk mengetahui pengaruh positif Service Quality terhadap Brand Trust dengan Customer Loyalty sebagai mediator
•H0 : tidak ada pengaruh positif Service Quality terhadap Brand Trust dengan Customer Loyalty sebagai mediator
•H1 : ada pengaruh positif Service Quality terhadap Brand Trust dengan Customer Loyalty sebagai mediator