ANALISIS ALGORITMA K-NN DAN NAÏVE BAYES UNTUK
KLASIFIKASI PEMBELIAN MOBIL
Yoga Religia
Magister Teknik Informatika Universitas Dian Nuswantoro Semarang
Abstrak
Klasifikasi merupakan salah satu teknik yang terdapat pada data mining. Dalam teknik klasifikasi terdapat beberapa algoritma yang dapat digunakan, dua diantaranya yaitu K-NN dan Naïve Bayes. Isi dari paper adalah tentang analisis perbandingan penggunaan algoritma K-NN dan Naïve Bayes untuk klasifikasi pembelian mobil. Dataset yang digunakan merupakan dataset global yang terdiri dari enam atribut dependent dan satu atribut independent. Akurasi yang dihasilkan menunjukkan untuk k-NN 87.81% sedangkan untuk Naïve Bayes menunjukkan presentase 93.99%.
Kata kunci : K-NN, Naïve Bayes, Klasifikasi, Pembelian Mobil
I. PENDAHULUAN
Data mining merupakan proses pengiriman informasi dari suatu algoritma (algoritma data mining) yang memiliki akses ke dalam data [1]. Dalam data mining terdapat beberapa teknik yaitu klasifikasi dan regresi. Klasifikasi merupakan teknik data mining yang digunakan untuk menentukan item dari dataset kedalam suatu kategori atau kelas. Tujuan dari klasifikasi adalah untuk memprediksi kelas target secara akurat pada setiap kasus dalam data [2]. K-NN dan Naïve Bayes adalah algoritma data mining yang dapat digunakan untuk melakukan klasifikasi.
K-NN adalah algoritma data mining yang dapat digunakan untuk melakukan regresi dan juga klasifikasi. K-NN pernah digunakan untuk menguji hubungan antara berat badan sebelum kehamilan, berat badan selama kehamilan dan dan juga indek massa tubuh (IBM) yang kaitannya dengan keguguran kehamilan. Dengan menggunakan K-NN dapat ditentukan
mana kehamilan yang baik dan mana yang akan mengalami keguguran. Hasil dari penelitian tersebut memperoleh akurasi sekitar 95% [3].
Naïve Bayes merupakan algoritma data mining yang dapat digunakan untuk melakukan klasifikasi. Naïve Bayes pernah diterapakan untuk mengklasifikasikan data berdimensi tinggi. Data berdimensi tinggi yang dimaksud adalah data yang memiliki proporsi atribut yang tidak relevan. Percobaan dilakukan dengan menggunakan document corpora dan gene micro-array datasets yang menunjukkan efisiensi yang sangat memuaskan dengan presentase sekitar 98% [4].
II. LANDASAN TEORI 2.1. K-NN / K-Nearest Neighbor
Algoritma K-Nearest Network (K-NN) merupakan algoritma klasifikasi berdasarkan K instances paling dekat denagn query instances yang diberikan dan kemudian melakukan pemilihan antara K tetangga yang terdekat untuk menghasilkan keluaran label dari query instances [7]. Algoritma K-NN mengansumsikan bahwa semua instances disimpan pada tempat yang sama dimana n merupakn fitur instances yang telah didefinisikan. Matrik distances yang digunakan adalah untuk mengukur jaran antara instances. Pada pengukuran jarak dapat menggunakan Manhattan distance dan Euclidean distance. Misalkan x dan y merupakan 2 instances yang didefinisikan sebagai <f1, f2,…,fn > maka menggunakan Manhattan dan Euclidean jaraknya didefinisikan sebagai d1(x,y) dan d2(x,y), sehingga dapat ditulis :
� , = ∑ | �� − � |
=
� , = √∑ | �� − � |
=
Bagian yang paling berpengaruh pada algoritma ini adalah nilai K. Nilai K yang terbaik pada algoritma ini dipengaruhi oleh data yang digunakan. Dengan mengguna- kan optimasi parameter dapat diperoleh nilai K yang sesuai. Pada tahapan training algoritma ini hanya melakukan penyimpanan vector-vektor fitur dan klasifikasi dari data training. Algoritma ini dapat menghasilkan data yang kuat (jelas) dan efektif apabila digunakan pada data yang berukuran besar.
2.2. Naïve Bayes
Teorema bayes yang dikenal juga sebagai Naïve Bayes dikemukakan oleh seorang pendeta presbyterian Inggris pada tahun 1763 yang bernama Thomas Bayes . Naïve Bayes ini kemudian disepurnakan oleh Laplace. Naïve Bayes merupakan sebuah algoritma yang memanfaatkan metode probabilitas dan statistik dengan memprediksi probabilitas dimasa depan berdasarkan pada masa sebelumnya. Pada dasarnya teorema bayes dapat dirumuskan sebagai berikut :
� | =P B|A ∗ P AP B
Pada rumus diatas dapat dilihat bahwa peluang kejadian A sebagai B ditentukan dari peluang B saat A, peluang A dan peluang B. pada pengaplikasiannya rumus tersebut akan dirubah menjadi [6] :
P |D =P D|P D∗ P
Jika Xt sebagai sample pengujian dan P(k|Xt) merupakan probabilitas dari Xt yang ditugaskan kedalam kelas k, maka
III. DATASET
Dataset yang digunakan dalam penelitian ini merupakan dataset global yang diambil dari situs Knowledge Extractionbased on Evolutionary Learning (Keel-Dataset). Data yang diambil merupakan data “Car” yang mana dari data Car tersebut memiliki 1.728 data yang terdiri dari 6 atribut dependent dan satu atribut independent.
Adapun atribut dependent yang dimiliki yaitu:
1. Buying dengan value: vhigh, high, medium, low.
2. Maint dengan value: vhigh, high, medium, low.
3. Doors dengan value: 2, 3, 4, 5more 4. Persons dengan value: 2, 4, more. 5. Lug_boot dengan value: small,
medium, big.
6. Safety dengan value: low, medium, high.
Sedangkan untuk atribut independent yaitu Acceptability dengan value unacc, acc.
IV. METODE PENELITIAN
Pada penelitian ini akan dilakukan tahapan-tahapan yang meliputi:
1. Penggunaan dataset yang mana dataset tersebut berasal dari Keel-Dataset, berupa dataset “Car”.
2. Penentuan algoritma yang digunakan. Adapun algoritma yang akan digunakan dalam penelitian ini yaitu algoritma K-NN dan Naïve Bayes.
3. Implementasi, implementasi pada penelitian ini akan menggunakan software RapidMiner 5.3.
4. Pengujian, untuk pengujian pada algoritma K-NN akan dilakukan 5 kali dengan memberikan nilai K yang berbeda pada setiap pengujian yaitu 1, 3, 5, 7 dan 9. Sedangkan untuk Naïve
Bayes akan menggunakan teknik split validation dan pengujian akan dilakukan sebanyak 5 kali dengan setiap pengujian dibagi menjadi data training dan data testing yaitu 90% & 10%, 80% &20%, 70% & 30%, 60% & 40%, 50% & 50%. 5. Analisis pengujian, yang akan dianalisis pada penelitian ini adalah accuracy, precision, recall dan AUC dari masing-masing algoritma.
6. Hasil pengujian, dalam penelitian ini akan dapat diketahui algoritma mana yang memiliki akurasi paling tinggi untuk dataset Car.
Adapun tahapan pada penelitian ini dapat dilihat pada gambar 3.1 :
Gambar 3.1 Tahapan Penelitian
V. HASIL PENGUJIAN 5.1. Hasil Pengujian K-NN
diperoleh accuracy, precision, dan recall k-NN sebagai berikut :
Gambar 5.1 Diagram Accuracy, Precision, Recall k-NN
Pada gambar 5.1 menunjukkan hasil accuracy untuk k=1 sebesar 81.66%, k=3 sebesar 86.75%, k=5 sebesar 89.12%, k=7 sebesar 89.47%, dan k=9 sebesar 92.07%. Hasil untuk precision diperoleh k=1 sebesar 98.60%, k=3 sebesar 99.01%, k=5 sebesar 99.13%, k=7 sebesar 99.14%, dan k=9 sebesar 98.99%. Hasil untuk recall diperoleh k=1 sebesar 40.30%, k=3 sebesar 57.03%, k=5 sebesar 64.83%, k=7 sebesar 65.97%, dan k=9 sebesar 74.71%. Sedangkan untuk AUC k-NN hasilnya adalah sebagai berikut:
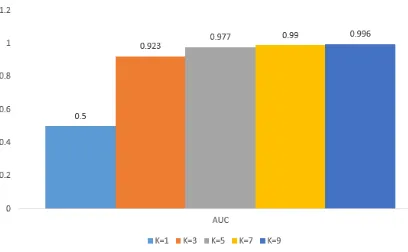
Gambar 5.2 Diagram AUC k-NN
Pada gambar 5.2 menunjukkan hasil AUCuntuk k=1 sebesar 0.500, k=3 sebesar 0.923, k=5 sebesar 0.977, k=7 sebesar 0.990, dan k=9 sebesar 0.996. Adapun secara keseluruhan hasil pengujian k-NN dapat dilihat pada tabel 5.1.
Tabel 5.1 Hasil Pengujian k-NN Nilai K Akurasi Precision Recall AUC 1 81.66 98.60 40.30 0.500 3 86.75 99.01 57.03 0.923 5 89.12 99.13 64.83 0.977 7 89.47 99.14 65.97 0.990 9 92.07 98.99 74.71 0.996
Apabila hasil yang diperoleh diambil rata-rata maka diperoleh accuracy sebesar 87.814%, precision sebesar 98.974%, recall sebesar 60.568%, dan AUC sebesar 0.8772.
5.2. Hasil Pengujian Naïve Bayes
Berdasarkan hasil pengujian menggunakan RapidMiner 5.3, maka diperoleh accuracy, precision, dan recall Naïve Bayes sebagai berikut :
Gambar 5.3 Diagram Accuracy, Precision, Recall Naïve Bayes
sebesar 88.54%, training = 70% dan testing testing = 50% sebesar 91.47%. Sedangkan untuk AUC Naïve Bayes hasilnya adalah sebagai berikut:
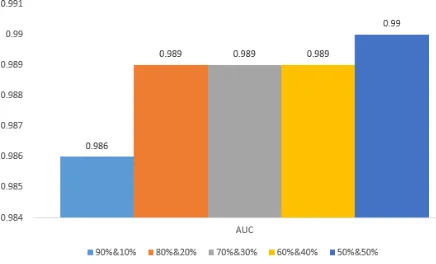
Gambar 5.4 Diagram AUC Naïve Bayes
Pada gambar 5.4 menunjukkan hasil keseluruhan hasil pengujian Naïve Bayes dapat dilihat pada tabel 5.2.
Tabel 5.2 Hasil Pengujian Naïve Bayes Training
& Testing
Akurasi Precision Recall AUC
90%&10 % 93.06 86.96 86.96 0.986
80%&20 % 94.51 88.54 95.65 0.989
70%&30 % 94.21 90.26 90.26 0.989
60%&40 % 93.63 90 89.15 0.989
50%&50 % 94.56 90.42 91.47 0.990
Apabila hasil yang diperoleh diambil rata-rata maka diperoleh accuracy sebesar 93.994%, precision sebesar 89.236%, recall sebesar 90.698%, dan AUC sebesar 0.9886.
5.3. Analisi Pengujian
Dari pengujian pada algoritma k-NN dan Naïve Bayes menggunakan dataset Car yang sudah dilakukan maka diperoleh perbandingan antara algoritma k-NN dan Naïve Bayes (NB) yang dapat dilihat pada tabel 5.3.
Tabel 5.3 Analisis Pengujian k-NN dan Naïve Bayes
Dari tabel 5.3 dapat dilihat bahwa algoritma k-NN hanya unggul pada bagian precision saja. Sedangkan untuk Naïve Bayes unggul pada bagian accuracy, recall, dan AUC.
VI. KESIMPULAN
perbandingan 0.877 (k-NN) dan 0.988 (Naïve Bayes).
VII.SARAN
Dalam penelitian analisis algoritma k-NN dan Naïve Bayes untuk klasifikasi pembelian mobil ini terdapat beberapa hal yang perlu diperhatikan supaya menjadi lebih baik kedepannya, diantaranya yaitu untuk dataset dan atribut didalamnya dapat menggunakan jumlah data dan atribut yang lebih banyak dan komplek.
DAFTAR PUSTAKA
[1] T. D. Bei, "An Information Theoretic Framework for Data Mining," pp. 564-572, 24 Agustus 2011.
[2] G. Kesavaraj and S. Sukumaran, "A Study On Classification Techniques in Data Mining," 6 July 2013.
[3] H. Qureshi, M. Khan, S. M. Aser and R. Hafiz, "Association of Pre-pregnancy Weight and Weight Gain with Perinatal Mortality," 23 Desember 2010.
[4] S. Wang and L. Chen, "Automated Feature Weighting in Naive Bayes for High-dimensional Data Classification," ACM 978-1-4503-1156-4/12/10, pp. 1243-1252, 2012.
[5] Keel-Dataset, http://sci2s.ugr.es/keel/ dataset/data/classification/car.zip,2015.
[6] A. Rane, N. Naik and J. Laxminarayana, "Performance Enhancement of K Nearest Neighbor Classification Algorithm Using 8-Bin Hashing and Feature Weighting," ACM 978-1-4503-2908-8/14/08, 2014.