1
PERBANDINGAN KLASIFIKASI KNN DAN NAIVE BAYESIAN SERTA PERBANDINGAN CLUSTERING SIMPLE K-MEANS YANG MENGGUNAKAN DISTANCE FUNCTION MANHATTAN DISTANCE DAN EUCLIDIAN DISTANCE
PADA DATASET “Dresses_Attribute_Sales”
Mirza Triyuna Putra Mahasiswa Jurusan Informatika
Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Syiah Kuala
KOPELMA Darussalam Banda Aceh 23111 Telp (+62)85213783445
Email : [email protected] Tugas Ujian Tengah Semester (UTS)
Data Mining Lanjut
ABSTRAK
Klasifikasi merupakan metode analisis data yang digunakan untuk membentuk model yang mendeskripsikan kelas data yang penting, atau model yang memprediksikan trend data. Pada klasifikasi ini data yang digunakan yaitu dresses_atribut_sales yang terdiri dari 14 class diantaranya style, price, rating, size, dan lain-lain yang terkait dengan atribut model pakaian. Klasifikasi yang akan digunakan sebagai perbandingan hasil yaitu K-Nearest Neighbor (KNN) Classifier dan Naive Bayesian Classifier. Hasil summary dari kedua klasifikasi akan menentukan jenis klasifikasi mana yang lebih cocok diterapkan pada dataset tersebut. Selain itu, akan dilakukan juga perbandingan hasil clustering metode Simple K-Means yang menggunakan algortima distance function Manhattan Distance dan Euclidian Distance. Perbandingan clustering dilakukan untuk melihat perbedaan pembagian kelas pada kedua function tersebut. Software pendukung yang digunakan adalah Weka.
Kata Kunci : knn classifier, naive bayesian klassifier, simple k-means, manhattan distance, euclidian distance, dresses_atribut_sales..
1. PENDAHULUAN 1.1. Latar Belakang
Perkembangan data mining (DM) yang pesat tidak terlepas dari perkembangan teknologi informasi yang memungkinkan data dalam jumlah besar terakumulasi. Seiring dengan semakin dibutuhkannya data mining, muncul beberapa algoritma untuk memproses Data dalam jumlah besar, diantaranya yaitu K-Nearest Neightbor (KNN) Classifier dan Naive Bayesian classifier. Selain klasifikasi, data dalam jumlah besar juga dapat dikelompokkan ke dalam beberapa bagian berdasarkan kedekatan-kedekatan yang dimiliki. Agar data- data tersebut dapat dikelompokkan dengan mudah, salah satu algortima yang dapat digunakan yaitu simple K-Means.
Klasifikasi adalah proses pembelajaran secara terbimbing (supervised learning) [1].
Klasifikasi Naive Bayesian Adalah metode classifier yang berdasarkan probabilitas dan Teorema Bayesian dengan asumsi bahwa setiap variabel X bersifat bebas (independence) [2]. Klasifikasi KNN merupakan metode klasifikasi yang menentukan label (class) dari suatu objek baru berdasarkan class yang mayoritas dari k- neighbor dalam traing set [3].
Clustering adalah suatu metode pengelompokan berdasarkan ukuran kedekatan (kemiripan) [4]. Salah satu jenis algoritma yang dapat digunakan pada metode ini yaitu Simple K-Means. Pada algortima simple k-means sendiri terdapat teknik pengelompokan dengan
2 empat fungsi core, yaitu chebyshevDistance, ManhattanDistance, dan EuclidianDistance.
ManhattanDistance dan EuclidianDistance merupakan fungsi core yang paling sering digunakan dan memberikan hasil lebih baik dibandingkan dua fungsi core lainnya.
Perbandingan metode klasifikasi dilakukan untuk menentukan jenis klasifikasi yang paling cocok digunakan dengan data yang memiliki class atribut dan kategori atribut seperti dataset dresses_atribut_sales.
Sedangkan perbandingan metode clustering dilakukan untuk melihat perbedaan pengelompokan terhadap data yang sama dengan metode k-means dan hanya dibedekan fungsi core yang digunakan.
1.2. Rumusan Permasalahan
Perumusan masalah pada penulisan paper ini didasarkan pada bagaimana perbandingan dua metode klasifikasi dan dua fungsi core clustering terhadapa dataset dresses_atribut_sales. Dengan demikian, perumusan masalah yang akan dibahas dalam paper ini adalah sebagai berikut :
1. Bagaimana perbandingan hasil klasifikasi KNN dan Naive Bayesian terhadap dataset dresses_atribut_sales?
2. Bagaimana perbandingan hasil clustering Simple K-Means dengan fungsi core ManhattanDistance dan EuclidianDistance?
1.3. Batasan Permasalahan
Batasan masalah dalam papaer ini adalah metode klasifikasi yang digunakan hanya dua saja, yaitu KNN classifier dan Naive Bayesian classifier.
2. LANDASAN TEORI
2.1. K-Nearest Neigtbor Classifier
(k-NN atau KNN) adalah sebuah metode untuk melakukanklasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya
paling dekat dengan objek tersebut. Data pembelajaran diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data.
Ruang ini dibagi menjadi bagian-bagian berdasarkan klasifikasi data pembelajaran.
Nilai k yang terbaik untuk algoritma ini tergantung pada data; secara umumnya, nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antarasetiap klasifikasi menjadi lebih kabur. Nilai k yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation. Kasus khusus di mana klasifikasidiprediksikan berdasarkan data pembelajaran yang paling dekat (dengan kata lain, k = 1) disebut algoritma nearest neighbor. [5]
2.2. Naive Bayesian Classifier
Naïve Bayes adalah metode Bayesian Learning yang paling cepat dan sederhana.
Hal ini berasal dari teorema Bayes dan hipotesis kebebasan, menghasilkan klasifier statistik berdasarkan peluang. Ini adalah teknik sederhana, dan harus digunakan sebelum mencoba metode yang lebih kompleks.
Naïve Bayes dapat dirumuskan sebagai berikut : [6]
P(A|B) = 𝐏(𝐁|𝐀)𝐏(𝐀)
𝑷(𝑩) ......(1)
2.3. K-Means Clustering
Clustering adalah proses membuat pengelompokan, sehingga semua anggota dari tiap partisi mempunyai persamaan berdasarkan matrik tertentu. Sebuah klaster adalah sekumpulan objek yang digabung bersama karena persamaan atau kedekatannya. Clustering berdasarkan persamaannya adalah teknik yang mentranslasi ukuran yang intuitif menjadi ukuran yang kuantitatif [7].
3 3. PEMBAHASAN
3.1. Klasifikasi Metode Naive Bayesian
Metode klasifikasi Naive Bayesian menggunakan dua data, yaitu training set untuk menghasilkan model dan testing set untuk menguji keakuratan hasil klasifikasi.
Data training set diambil 80% dari total data secara keseluruhan, sedangkan data testing set diambil 20% sisa dari data secara keseluruhan.
Berikut tampilan data training set beserta hasil setelah diklasifikasi dengan metode Naive Bayes :
Gambar 3.1. Tampilan klasifikasi training set
Gambar 3.2. Hasil klasifikasi Naive Bayesian terhadap class atribut style training set
Dataset Dresses_Atribut_sales memiliki 11 class fitur bertype nominal, berikut tabel summary dari kesebelas class bertype nominal yang terdapat pada dataset dresses :
Nama Class Correctly Classified Instances
Incorrectly Classified Instances
Style 49.75 % 50.25 %
Price 55.0251 % 44.9749 %
Size 47.25 % 52.75 %
Season 36.4322 % 63.5678 % Neckline 54.386 % 45.614 % SleeveLength 45.25 % 54.75 %
Waiseline 56.6416 % 43.3584 % Material 42.3559 % 57.6441 % FabricType 54.8872 % 45.1128 % Decoration 44.8622 % 55.1378 % PatternType 47.8697 % 52.1303 %
Tabel 3.1. Summary Correctly dan Incorrectly Classified Instance Training set
Dari hasil di atas terlihat bahwasanya hampir semua class, tingkat kebenaran klasifikasinya berkisar diantara 36-56%.
Nama Class Precission Recall F- Measure
Style 0.405 0.498 0.416
Price 0.493 0.55 0.507
Size 0.403 0.473 0.424
Season 0.318 0.364 0.323
Neckline 0.429 0.544 0.472 Sleeve
Length
0.38 0.453 0.405 Waiseline 0.494 0.566 0.515 Material 0.347 0.424 0.378 FabricType 0.459 0.549 0.49 Decoration 0.333 0.449 0.371 PatternType 0.426 0.479 0.416 Tabel 3.2. Precission, Recall dan F-Measure
Training set
Tabel di atas menampilkan average (nilai rata-rata) dari hasil Precission, Recall dan F-Measure tiap-tiap class. Nilai Precission berkisar pada rentang 31-49%, nilai Recall berada pada rentang 36-56%, dan nilai F- Measure pada rentang 37-51%.
Berikut tampilan data testing set beserta hasil setelah diklasifikasi dengan metode Naive Bayes :
Gambar 3.3. Tampilan klasifikasi testing set Berikut tampilan summary dari kesebelas class pada testing set :
4 Gambar 3.4. Hasil klasifikasi Naive Bayesian
Terhadap class atribut style testing set
Nama Class Correctly Classified Instances
Incorrectly Classified Instances
Style 42 % 58 %
Price 44 % 56 %
Size 35 % 65 %
Season 30 % 70 %
Neckline 44 % 56 %
SleeveLength 44 % 56 %
Waiseline 62 % 38 %
Material 39 % 61 %
FabricType 67 % 33 %
Decoration 45 % 55 %
PatternType 35 % 64 %
Tabel 3.3. Summary Correctly dan Incorrectly Classified Instance Testing set
Dari hasil di atas terlihat bahwasanya hampir semua class, tingkat kebenaran klasifikasinya berkisar diantara 30-67%.
Nama Class Precission Recall F- Measure
Style 0.325 0.42 0.359
Price 0.355 0.44 0.39
Size 0.283 0.35 0.305
Season 0.256 0.3 0.273
Neckline 0.376 0.44 0.406
Sleeve Length
0.374 0.44 0.404 Waiseline 0.565 0.62 0.577 Material 0.326 0.39 0.349 FabricType 0.617 0.67 0.627 Decoration 0.32 0.45 0.368 PatternType 0.358 0.42 0.386 Tabel 3.4. Precission, Recall dan F-Measure
Testing set
Tabel di atas menampilkan average (nilai rata-rata) dari hasil Precission, Recall dan F-Measure tiap-tiap class. Nilai Precission berkisar pada rentang 25%-61%, nilai Recall berada pada rentang 30-67%, dan nilai F-Measure pada rentang 27-62%.
3.2. Klasifikasi Metode KNN
Sama halnya seperti klasifikasi naive bayesian, metode klasifikasi KNN juga menggunakan dua data, yaitu training set dan testing set. Data testing digunakan untuk menguji keakuratan hasil. Data training set diambil 80% dari total data secara keseluruhan, sedangkan data testing set diambil 20% sisa dari data secara keseluruhan.
Berikut tampilan hasil klasifikasi KNN terhadap data training set.
Gambar 3.5. Hasil klasifikasi KNN Terhadap class atribut style training set
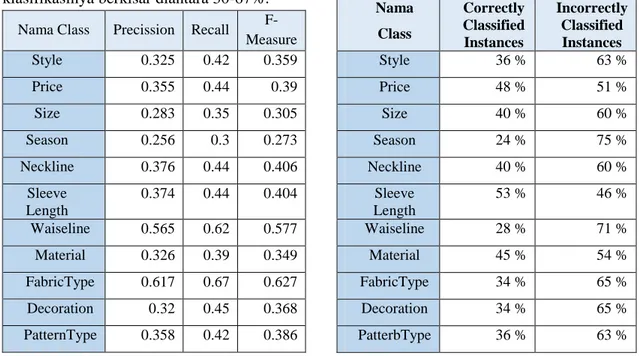
Berikut tabel Correctly dan Incorrectly classified instance yang dihasilkan dari tiap-tiap class :
Nama Class
Correctly Classified Instances
Incorrectly Classified Instances
Style 36 % 63 %
Price 48 % 51 %
Size 40 % 60 %
Season 24 % 75 %
Neckline 40 % 60 %
Sleeve Length
53 % 46 %
Waiseline 28 % 71 %
Material 45 % 54 %
FabricType 34 % 65 %
Decoration 34 % 65 %
PatterbType 36 % 63 %
Tabel 3.5. Summary Correctly dan Incorrectly Classified Instance KNN Training set
5 Dari hasil di atas terlihat bahwasanya hampir semua class, tingkat kebenaran klasifikasinya berkisar diantara 28-53%.
Nama Class Precission Recall F- Measure Style 0.373 0.363 0.367 Price 0.488 0.482 0.484 Size 0.396 0.4 0.397 Season 0.249 0.249 0.248 Neckline 0.43 0.436 0.432
Sleeve Length
0.402 0.398 0.399 Waiseline 0.523 0.531 0.524 Material 0.276 0.283 0.279 FabricType 0.453 0.456 0.451 Decoration 0.369 0.348 0.358 PatternType 0.355 0.341 0.347 Tabel 3.6. Precission, Recall dan F-Measure
Klasifikasi KNN Training set
Tabel di atas menampilkan average (nilai rata-rata) dari hasil Precission, Recall dan F-Measure tiap-tiap class. Nilai Precission berkisar pada rentang 24%-52%, nilai Recall berada pada rentang 24-53%, dan nilai F-Measure pada rentang 24-52%.
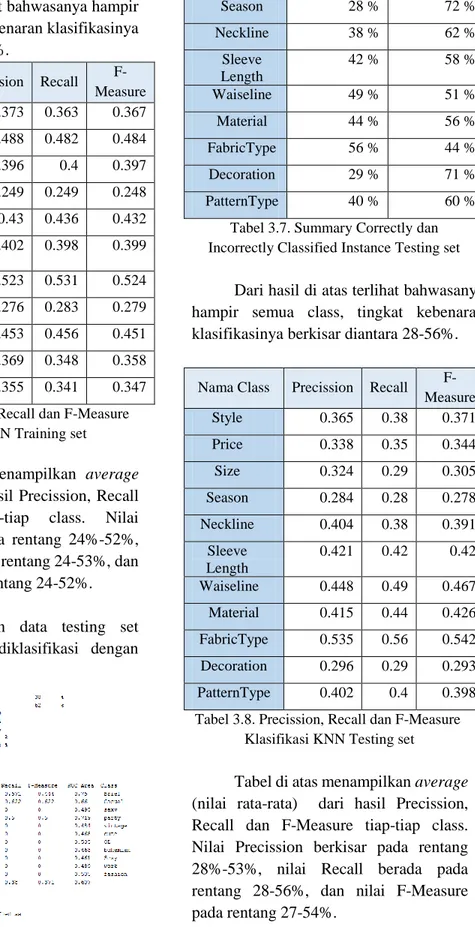
Berikut tampilan data testing set beserta hasil setelah diklasifikasi dengan metode KNN :
Gambar 3.5. Hasil klasifikasi KNN Terhadap class atribut style testing set
Berikut tabel Correctly dan Incorrectly classified instance yang dihasilkan dari tiap-tiap class :
Nama Class
Correctly Classified Instances
Incorrectly Classified
Instances
Style 38 % 62 %
Price 35 % 65 %
SIze 29 % 71 %
Season 28 % 72 %
Neckline 38 % 62 %
Sleeve Length
42 % 58 %
Waiseline 49 % 51 %
Material 44 % 56 %
FabricType 56 % 44 %
Decoration 29 % 71 %
PatternType 40 % 60 %
Tabel 3.7. Summary Correctly dan Incorrectly Classified Instance Testing set
Dari hasil di atas terlihat bahwasanya hampir semua class, tingkat kebenaran klasifikasinya berkisar diantara 28-56%.
Nama Class Precission Recall F- Measure Style 0.365 0.38 0.371 Price 0.338 0.35 0.344 Size 0.324 0.29 0.305 Season 0.284 0.28 0.278 Neckline 0.404 0.38 0.391
Sleeve Length
0.421 0.42 0.42 Waiseline 0.448 0.49 0.467 Material 0.415 0.44 0.426 FabricType 0.535 0.56 0.542 Decoration 0.296 0.29 0.293 PatternType 0.402 0.4 0.398 Tabel 3.8. Precission, Recall dan F-Measure
Klasifikasi KNN Testing set
Tabel di atas menampilkan average (nilai rata-rata) dari hasil Precission, Recall dan F-Measure tiap-tiap class.
Nilai Precission berkisar pada rentang 28%-53%, nilai Recall berada pada rentang 28-56%, dan nilai F-Measure pada rentang 27-54%.
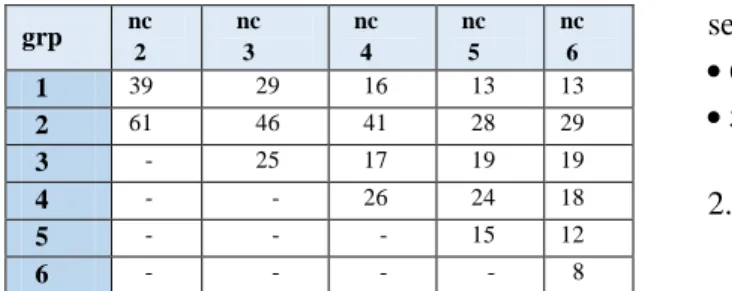
3.3. Clustering K-Means ManhattanDistance
Pada proses clustering, data yang digunakan yaitu data secara keseluruhan / 100% dari dataset Dresses_atribut_sales.
Nilai yang dibedakan untuk menguji hasil cluster yaitu numCluster dari tiap-tiap tes.
Berikut akan ditampilkan hasil cluster berdasarkan numCluster.
6
grp nc 2
nc 3
nc 4
nc 5
nc 6
1 39 29 16 13 13
2 61 46 41 28 29
3 - 25 17 19 19
4 - - 26 24 18
5 - - - 15 12
6 - - - - 8
Tabel 3.9. Pembagian grup hasil cluster ManhattanDistance
Tabel di atas menampilkan hasil clustering dengan nilai numCluster yang dari 2 s.d. 6. Hasil yang ditampilkan dalam bentuk persentase secara keseluruhan.
Clustering K-Means EuclidianDistance
Selain menggunakan algoritma manhattanDistance percobaan juga dilakukan pada algortima EuclidianDistance untuk membandingkan hasil dari kedua algortima.
Berikut akan ditampilkan hasil dari clustering EuclidianDistance.
grp nc 2
nc 3
nc 4
nc 5
nc 6
1 41 31 22 11 9
2 59 47 37 35 26
3 - 22 15 17 22
4 - - 26 24 20
5 - - - 13 14
6 - - - - 9
Tabel 3.10. Pembagian grup hasil cluster EuclidianDistance
4. PEMBAHASAN DAN ANALISA
Berdasarkan hasil pengujian pada bab sebelumnya, dapat dibahas dan dianalisa beberapa hal sebagai berikut.
1. Hasil klasifikasi Training set :
36-56 % (Naive Bayesian)
28-53 % (KNN)
Hasil klasifikasi Testing set :
37-67 % (Naive Bayesian)
28-56 % (KNN)
Precission, Recall, dan F-Measure Training set :
49%, 56%, 51% (Naive Bayesian)
52%, 53%, 52% (KNN)
Precission, Recall, dan F-Measure Testing set :
61%, 67%, 62% (Naive Bayesian)
53%, 56%, 54% (KNN)
2. Berdasarkan hasil di atas, sebenarnya tingkat keakuratan hasil dari kedua metode jauh dari baik. Hal ini karena hasil correct data jauh dari 100%.
Akan tetapi, model yang dihasilkan dapat dikatakan baik, karena hasil pengujian dari training set dan testing set meghasilkan persentase yang relatif pada rentang yang sama.
3. Jika ditinjau dari nilai precission, Recall, dan F-Measure hasilnya juga tidak bisa dikatakan baik. Hal ini juga karena nilai yang dihasilkan jauh dari 100%.
4. Hasil Clustering :
Jika ditinjau dari hasil clustering yang dilakukan, terlihat bahwasanya pembagian kelas-kelas oleh metode K-Means dengan algoritma
ManhattanDistance dan
EuclidianDistance memiliki kemiripan. Kemiripan yang dimaksud yaitu pada setiap numCluster memiliki urutan nilai terbesar ke terkecil pada kelas yang sama. Hanya saja, nilai yang dihasilkan menunjukkan sedikit perbedaan.
5. KESIMPULAN DAN SARAN 5.1. Kesimpulan
Berdasarkan hasil pembahasan dan analisa pada bab sebelumnya, dapat ditarik beberapa kesimpulan sebagai berikut :
1. Pemilihan metode terbaik adalah yang mempunyai tingkat akurasi yang tinggi dan juga dipastikan simpangan bakunya yang cenderung lebih kecil.
Dari data yang terangkum di atas, metode yang lebih baik untuk dataset Dresses_atribute_sales yaitu Naive Bayesian. Meskipun perbedaan yang dihasilkan tidak terlalu jauh berbeda, baik dari correctly dan incorrectly classified instance maupun nilai precission, recall, dan F-Measure.
2. Karena dataset dresses memiliki 3 class yang bernilai numerik, jika ingin
7 Melihat hasil klasifikasi yang bernilai numerik, maka harus digunakan metode KNN.
3. Metode K-Means cluster yang diterapkan pada percobaan ini, menghasilkan pembagian kelas yang relatif sama antara algoritma manhattanDistance dan EuclidianDistance.
5.2. Saran
Saran-saran yang bisa disampaikan dari hasil perobaan ini adalah sebagai berikut :
1. Untuk melihat dataset yang memiliki nilai class bertipe numerik, digunakan metode yang support terhadap data numerik. Dalam kasus ini yaitu KNN.
2. Jika ingin melihat data bertype nominal (nom), menurut hasil percobaan ini metode Naive Bayesian menghasilkan summary yang sedikit leih baik.
3. Metode clustering K-Means dengan algoritma ManhattanDistance dan EuclidianDistance menghasilkan kelas yang realtif sama, akan tetapi untuk hasil yang akurat perlu dilakukan penelitian yang lebih mendalam.
4. Perlu penelitian yang lebih mendalam untuk menarik kesimpulan secara akurat tehadap kedua masalah yang diangkat.
6.DAFTAR PUSTAKA
[1] Abidin, Taufik Fuadi, “Naive Bayesian Classifier”, Jurusan Informatika Unsyiah, bahan kuliah Data Mining program study Informatika FMIPA-Unsyiah
[2] Abidin, Taufik Fuadi, “Accuracy Measure; Preciisiion, Recallll & F- Measure”, Jurusan Informatika Unsyiah bahan kuliah Data Mining program study Informatika FMIPA-Unsyiah
[3] DMIR, “K-Nearest Neighbor Classifier”, Data Mining adn Information Retrievl – Research Grup, Jurusan Matematika FMIPA-Unsyiah
[4] Striyanto, Edi, “Clustering”, Electronic Engineering Polytechnic Institute of Surabaya (EEPIS)
[5] Peace, Alifah, “Metode KNN”, http://www.academia.edu/3660286/
Tgs_proposal
[6] A.W, Ebranda, Mardiani, Tinaliah,
“Penerapan Metode Naive Bayes untuk Sistem Klasifikasi SMS pada Smartphone Android”, Teknik Informatika STMIK MDP
[7] Yunita, “Analisis dan Implementasi Clustering Data Kategori Menggunakan Metode scaLable InforMation Bottleneck ( LIMBO )”, Tugas Akhir.