PERBANDINGAN METODE NAIVE BAYES DAN DECISION TREE
PADA MASALAH SENTIMENT ANALYSIS
Riki Ruli Siregar 1), Anung B. Ariwibowo 2) 1) Teknik Informatika STT PLN Jakarta
E-mail: [email protected]
2) Jurusan Teknik Informatika Fakultas Teknologi Industri Universitas Trisakti E-mail: [email protected]
Abstrak
Masalah klasifikasi sentimen (sentiment classification) adalah sebuah permasalahan di mana sebuah dokumen teks diberi label sentimen positif, negatif, atau netral berdasarkan opini yang terkandung di dalam teks tersebut. Penelitian ini menyelidiki efektivitas berbagai ciri atau fitur dari dokumen teks dan juga efektivitas berbagai metode pengelompokan (classifiers) untuk permasalahan klasifikasi sentimen. Studi sebelumnya menunjukkan bahwa fitur unigram yang mempertimbangkan setiap kata di dalam ulasan sebagai fitur klasifikasi, beserta dengan fitur Part-of-Speech, menghasilkan akurasi 81,5% pada koleksi dokumen teks ulasan perfilman. Penelitian ini menggunakan fitur leksikon subjektifitas sebagai alternatif pencarian solusi dari masalah klasifikasi sentimen. Hasil awal menunjukkan bahwa metode yang diusulkan dalam penelitian efektif ini dan handal untuk tugas klasifikasi sentimen dengan meningkatkan tingkat akurasi menjadi 82,4% menggunakan skema klasifikasi Naive Bayes. Namun hasil ini masih berada di bawah metode ringkasan subjektif menggunakan minimum cuts.
Kata kunci: information retrieval, sentiment classification, sentiment analysis, decision tree, naive bayes
Pendahuluan
Sentimen analisis adalah bidang penelitian yang berfokus pada analisis komputasional dari teks evaluatif atau dokumen yang dibuat oleh user. Konten yang dibuat oleh user dapat berasal dari blog, situs jejaring sosial, situs-situs review pelanggan, dan situs lain yang menawarkan kesempatan bagi konsumen untuk berbagi pengetahuan dan pengalaman menggunakan sebuah produk barang atau jasa. Sumber konten juga dapat berupa hal-hal yang merupakan pikiran atau pendapat orang lain, dan ini menjadi bagian penting dari informasi yang digunakan banyak orang selama proses pengambilan keputusan (Pang dan Lee, 2008). Sebagai contoh, kebanyakan orang meminta saran dari teman-teman mereka untuk merekomendasikan seorang montir mobil atau untuk menjelaskan siapa yang akan mereka pilih dalam pemilu lokal, meminta surat referensi dari kolega untuk melamar pekerjaan, atau membaca dokumen Consumer Reports untuk memutuskan apa jenis dan merek mesin cuci yang akan dibeli.
Sentimen analisis dapat diaplikasikan dalam berbagai ragam hal. Sebagai contoh, perusahaan ingin mengetahui pendapat publik tentang layanan atau produk mereka, sistem rekomendasi (recommendation systems) perlu secara otomatis melakukan personalisasi terhadap sistem mereka berdasarkan informasi umpan balik dari para penggunanya, dan alat-alat penempatan iklan (ad placement tools) perlu menemukan laman web yang memuat pendapat positif tentang sebuah layanan atau produk, dan banyak lagi contoh lainnya. Sekarang, Internet dan Web telah memungkinkan masyarakat untuk mencari tahu tentang pendapat dan pengalaman dari sejumlah orang yang bukan kenalan pribadi atau kritikus profesional yang terkenal (Pang dan Lee, 2008).
up/down) atau simbol bintang dalam rentang jumlah satu hingga lima buah. Label dan skor ini mewakili pandangan umum pengguna tentang entitas tertentu (Pang dan Lee, 2008; Liu, 2009).
Dalam klasifikasi sentimen diperlukan sekumpulan ciri atau fitur representatif untuk menentukan polaritas dari ulasan pengguna. Dalam masalah sentiment analysis, kata-kata yang mengandung opini seperti "menakjubkan" dan "mengerikan" memiliki nilai lebih penting. Akurasi tugas klasifikasi sentimen sangat tergantung pada himpunan fitur yang dipilih. Penelitian ini menyelidiki efektivitas berbagai ciri atau fitur dari dokumen teks berupa ulasan film (movie review) dan juga efektivitas berbagai metode pengelompokan (classifiers) untuk permasalahan klasifikasi sentimen.
Makalah ini selanjutnya disusun sebagai berikut: Bagian Studi Pustaka menjelaskan penelitian-penelitian terkait dan Bagian Metodologi menjelaskan metode yang diusulkan. Setelah itu Bagian Hasil Eksperimen menyajikan hasil eksperimen dan membahas efektivitas dari metode yang diusulkan. Terakhir, Bagian Kesimpulan memberikan simpulan laporan dan menyediakan beberapa topik lanjutan yang dapat dikembangkan dari penelitian ini.
Studi Pustaka
Tugas klasifikasi sentimen dapat didefinisikan sebagai berikut: Diberikan sepotong teks (misalnya ulasan tentang film), tugas dari klasifikasi sentimen adalah secara otomatis mendeteksi sentimen dari ulasan-ulasan yang ada secara keseluruhan tentang sebuah topik (dalam hal ini tentang produk film), atau secara lebih formal:
Klasifikasi Sentimen: Diberikan sebuah himpunan ulasan D = {d1... dn} tugasnya adalah
mengklasifikasikan setiap ulasan di ke dalam kelas positif atau negatif berdasarkan kelas sentimen
secara keseluruhan.
Penelitian-penelitian tentang klasifikasi sentimen menunjukkan bahwa sistem analisis sentimen (sentiment analysis) sangat tergantung kepada domain masalah yang dianalisis dan tingkat akurasi klasifikasi sentimen berbeda dari satu domain ke domain yang lain. Sebagai contoh, Turney (2002) menunjukkan bahwa dalam kerangka yang sama, akurasi klasifikasi sentimen untuk ulasan dari domain mobil dan bank (masing-masing 84% dan 80%) adalah lebih tinggi daripada ulasan untuk domain film dan perjalanan (masing-masing 65,83% dan 70,53%).
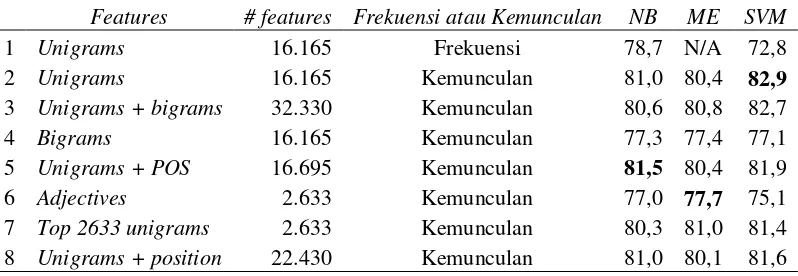
Pang et al. (2002) menunjukkan bahwa metode Support Vector Machine (SVM) dengan unigram dan bobot biner (muncul/tidak-muncul) sebagai fitur ciri memperoleh kinerja klasifikasi tertinggi pada dataset ulasan film (lihat baris 2 pada Tabel 1). Mereka membandingkan metode Naive Bayes, Maximum Entropy dan Support Vector Machine. Sedangkan untuk metode Naive Bayes, tingkat akurasi yang diraih adalah 81,5% yang merupakan acuan dasar bagi penelitian ini.
Tabel 1. Hasil klasifikasi sentimen oleh Pang et.al. (2002).
Features # features Frekuensi atau Kemunculan NB ME SVM
1 Unigrams 16.165 Frekuensi 78,7 N/A 72,8
2 Unigrams 16.165 Kemunculan 81,0 80,4 82,9
3 Unigrams + bigrams 32.330 Kemunculan 80,6 80,8 82,7
4 Bigrams 16.165 Kemunculan 77,3 77,4 77,1
5 Unigrams + POS 16.695 Kemunculan 81,5 80,4 81,9
6 Adjectives 2.633 Kemunculan 77,0 77,7 75,1
7 Top 2633 unigrams 2.633 Kemunculan 80,3 81,0 81,4
8 Unigrams + position 22.430 Kemunculan 81,0 80,1 81,6
Melville (2009) menggunakan informasi leksikal untuk mengelompokkan dokumen teks. Informasi leksikal yang digunakan adalah kamus berisi kata-kata sentiment untuk membangun sebuah model generative. Model ini digabungkan dengan sebuah model machine learning yang dibangun dengan proses pelatihan berdasarkan dokumen-dokumen yang sudah diberi label sentiment negatif atau positif. Kedua model tersebut kemudian digabungkan ke dalam sebuah Naïve Bayes classifier. Uji coba yang dilakukan terhadap dokumen korpus ulasan film menggunakan skema Naïve Bayes mendapatkan tingkat akurasi 80,81% (Melville, 2009).
Metodologi
Bagian ini menjelaskan tiga bagian utama yang menyusun eksperimen. Pertama, dataset yang digunakan dalam percobaan. Kedua, pendekatan yang diusulkan, mencakup arsitektur umum, ekstraksi ciri, dan kombinasi ciri. Terakhir, dibahas singkat tentang metode classifiers yang digunakan dalam percobaan.
Ada dua kelompok dataset yang digunakan dalam penelitian ini, keduanya ditulis dalam bahasa Inggris:
1) Movie Review Dataset (Pang et al, 2002). Dataset ini mengandung 1.000 ulasan positif dan 1.000 ulasan negatif yang sudah diolah dari dokumen ulasan film.
2) Leksikon Subyektivitas atau Subjectivity Lexicon (Wilson et al, 2005). Dataset ini mengandung 8.221 kata-kata sentimen yang diberi label berdasarkan polaritasnya (positif atau negatif) dan kekuatannya (kuat atau lemah). Sebagai contoh, kata "penyalahgunaan" adalah kata negatif yang kuat sementara kata "sangat baik" adalah sebuah kata positif yang kuat.
Dataset ulasan film (Movie Review Dataset) digunakan untuk mengevaluasi metode yang digunakan, dan leksikon subyektivitas digunakan sebagai sumber leksikal untuk mengekstrak fitur-fitur ciri. Pada dataset ini, kata-kata yang bersifat subjektif dalam kebanyakan konteks dianggap sebagai sangat subjektif dan kata-kata yang mungkin hanya memiliki penggunaan subjektif tertentu dianggap sebagai lemah subjektif. Hasil awal dari eksperimen menunjukkan bahwa metode yang diusulkan efektif dan handal untuk tugas klasifikasi sentimen.
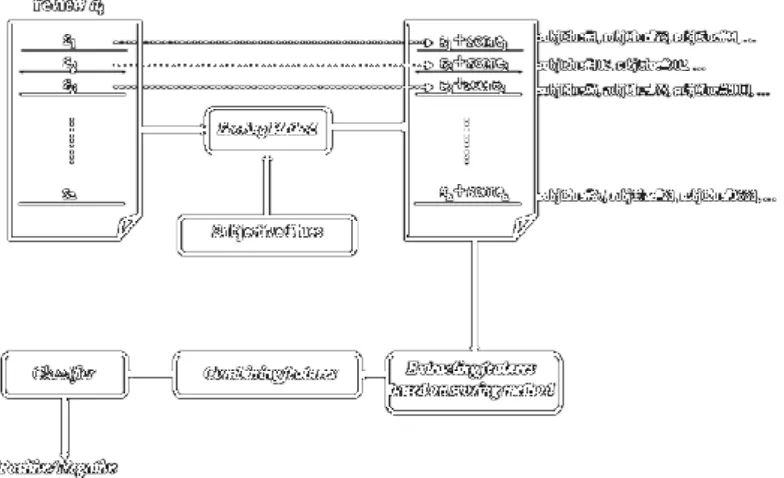
Arsitektur dari metode yang digunakan dapat dilihat dalam Gambar 1. Pendekatan yang digunakan berisi beberapa langkah. Pertama, kalimat-kalimat dari setiap ulasan diambil dan diberikan sebagai masukan bagi metode scoring. Untuk setiap kalimat, metode scoring mengidentifikasi petunjuk subjektif yang muncul dalam kalimat tersebut, dan juga menghitung skor total sentimen berdasarkan data set leksikon subyektivitas. Luaran dari metode scoring digunakan untuk ekstraksi ciri. Kemudian ciri yang diekstraksi digabungkan dengan beberapa cara berbeda dan memberikannya kepada berbagai classifiers sebagai masukan untuk mendeteksi polaritas sentimen setiap ulasan apakah sebagai sentimen positif atau negatif. Secara keseluruhan arsitektur berisi tiga komponen utama: Metode scoring, Ekstraksi fitur, dan Kombinasi fitur yang masing-masing dijelaskan pada bagian berikut.
Berdasarkan pada informasi dalam data petunjuk subjektif, nilai skor untuk setiap dokumen ulasan dapat dihitung. Satu dokumen ulasan berisi beberapa baris kalimat subyektif, dan untuk setiap kalimat diperiksa apakah kata subjektif muncul atau tidak muncul. Jika kata subjektif ditemukan dalam kalimat, sebuah skor ditetapkan untuk kata itu, berdasarkan polaritas dan tingkatan subjektif yang ditemukan dalam petunjuk subjektif. Ada dua polaritas dan dua tingkat subjektif yang digunakan dalam dataset, informasi ini memberikan empat kombinasi skor yang mungkin untuk setiap kata subjektif, yaitu kuat positif, lemah positif, lemah negatif, atau kuat negatif. Untuk setiap kombinasi ditetapkan skor masing-masing +1,0, +0,5, -0,5, dan -1,0. Untuk kata-kata non-subjektif lain yang ditemukan di setiap kalimat dokumen ulasan, ditetapkan skor netral 0,0.
Menggunakan nilai subjektif ini, setiap kalimat dalam dokumen ulasan akan mendapatkan sebuah skor. Dalam eksperimen, digunakan beberapa metode penghitungan skor. Metode pertama adalah melakukan penjumlahan terhadap skor nilai secara keseluruhan untuk setiap dokumen. Metode kedua menghitung rata-rata skor. Metode ketiga dan keempat masing-masing dilakukan dengan menghitung jumlah skor positif dan negatif untuk setiap dokumen.
Gambar 1. Alur pengolahan data analisis sentimen ulasan film.
Fitur atau ciri yang digunakan dalam percobaan diekstrak berdasarkan pada dua kelompok atribut. Kelompok pertama adalah atribut yang menangkap informasi dari kata-kata subjektif setiap dokumen ulasan. Kelompok kedua adalah atribut yang menangkap informasi nilai menggunakan metode scoring. Evaluasi representasi data dilakukan dengan membentuk beberapa kombinasi dari kedua kelompok atribut ini, seperti yang dicantumkan dalam bagian Eksperimen.
Data-data yang direpresentasikan dalam bentuk atribut ciri diolah dengan menggunakan dua skema mesin pembelajaran, yaitu Pohon Keputusan (Decision Tree) dan algoritma Naive Bayes. Naive Bayes classifier adalah metode classifier yang didasarkan pada penerapan teorema Bayes' dengan asumsi strong independence. Istilah yang lebih deskriptif untuk model probabilitas yang mendasari adalah "independent feature model". Asumsi kebebasan ciri yang dimilikinya berfungsi dengan baik untuk pengelompokan teks dalam tingkatan fitur kata. Jika atribut yang ada berjumlah besar, asumsi independensi memungkinkan parameter dari setiap atribut untuk dipelajari secara terpisah, hal ini sangat menyederhanakan proses pembelajaran.
Pohon keputusan menunjukkan kinerja yang bagus untuk masalah pengelompokan otomatis (Gabrilovich dan Markovitch, 2002). Dalam struktur pohon ini, leaves mewakili klasifikasi dan cabang mewakili konjungsi fitur yang mengarah pada hasil klasifikasi. Dalam analisis keputusan (decision analysis), sebuah pohon keputusan dapat digunakan untuk secara visual dan secara eksplisit merepresentasikan keputusan-keputusan dan pengambilan keputusan. Algoritma pohon keputusan yang digunakan dalam penelitian ini adalah algoritma J48 untuk pohon klasifikasi dan algoritma CART untuk pohon regresi.
Hasil Eksperimen dan Pembahasan
Percobaan dilakukan untuk mengevaluasi tingkat akurasi berbagai representasi fitur dan tingkat akurasi metode classifier NB (Naive Bayes), J48 dan CART. Terdapat empat eksperimen: - Pendekatan 1: Klasifikasi berdasarkan petunjuk subjektif muncul/tidaknya ciri. dilakukan
- Pendekatan 2: Klasifikasi berdasarkan fitur bobot petunjuk subjektif. Data direpresentasikan dengan menggabungkan frekuensi kemunculan kata dengan kelomok atribut scoring, sedangkan pendekatan ketiga menggabungkan informasi normalisasi frekuensi dengan kelompok atribut scoring.
- Pendekatan 3: Klasifikasi berdasarkan fitur normalisasi bobot dari Pendekatan 1.
- Pendekatan 4: Klasifikasi yang didasarkan hanya pada nilai skor fitur, yaitu: Jumlah, Rata-rata, Label sentimen negatif, dan Label sentimen positif.
Setiap percobaan menggunakan perangkat lunak pembelajaran mesin WEKA (Witten, 2011) sebagai alat bantu untuk melakukan klasifikasi dan persiapan data. Pembelajaran dan pengklasifikasian dilakukan berdasarkan 1.000 data pelatihan dan 1.000 data uji dengan skema 10-fold cross validation. Tabel 2 merangkum hasil eksperimen yang dilakukan.
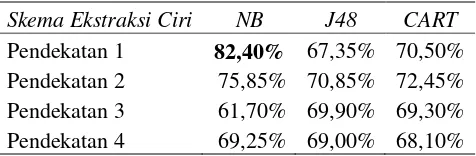
Tabel 2. Perbandingan tingkat akurasi classifier Naive Bayes dan Pohon Keputusan terhadap empat representasi ekstraksi ciri.
Dalam penelitian ini, data ulasan film diklasifikasikan menjadi dua kelas, negatif dan positif, berdasarkan tinjauan keseluruhan sentimen. Proses klasifikasi secara umum terdiri atas dua fase: ekstraksi ciri/fitur dan pembelajaran/klasifikasi. Untuk ekstraksi fitur, didefinisikan empat set fitur umum: muncul/tidaknya petunjuk subjektif, bobot petunjuk subjektif, normalisasi bobot petunjuk subjektif, dan skor numerik. Fitur skor numerik dirinci lebih lanjut berupa jumlah skor sentimen, rata-rata skor sentimen, dan rasio sentimen negatif/positif.
Dari vektor ciri yang dibagi menjadi data pelatihan dan data testing, tiga classifiers berbeda yaitu Naive Bayes, CART, dan J48, telah digunakan untuk pembelajaran dan klasifikasi, seperti diimplementasikan oleh perangkat lunak pembelajaran mesin WEKA (Witten, 2011). Untuk mengevaluasi keakuratan klasifikasi setiap classifier serta menilai kemampuan diskrimantif setiap ruang ciri, empat percobaan berbeda dilakukan. Tingkat akurasi masing-masing percobaan dilakukan dengan skema 10-fold cross validation.
Hasil percobaan menunjukkan bahwa akurasi yang diperoleh melalui representasi sederhana muncul/tidaknya petunjuk subjektif dan diklasifikasikan menggunakan metode NB mencapai akurasi tertinggi 82,40% (Tabel 2). Namun demikian representasi muncul/tidaknya petunjuk subjektif ternyata tidak menghasilkan tingkat akurasi yang baik jika menggunakan classifier J48 dan CART. Skema kedua classifier berbasis pohon keputusan itu memiliki tingkat akurasi yang lebih baik jika data direpresentasikan dengan nilai bobot, yaitu menggunakan pendekatan variasi ke-2. Proses normalisasi bobot dan membuang atribut petunjuk subjektif justru menurunkan tingkat akurasi untuk ketiga skema classifier.
Beberapa hal dapat dilakukan dalam penelitian selanjutnya. Pertama, beberapa fitur tidak menyediakan informasi yang cukup diskriminatif khususnya fitur-fitur yang jumlah pengulangannya sama atau hampir sama di kedua kelas positif dan negatif. Menghapus fitur seperti itu dapat meningkatkan kinerja klasifikasi, teknik reduksi fitur seperti Principal Component Analysis atau Support Vector Machines dapat dimanfaatkan untuk tujuan ini.
Dataset yang digunakan dalam penelitian ini ditulis dalam bahasa Inggris. Penelitian lanjutan dapat juga dilakukan untuk mempelajari efektivitas metode pembelajaran mesin yang digunakan untuk ulasan film dan leksikon subjektivitas yang ditulis dalam Bahasa Indonesia.
Daftar pustaka
Gabrilovich, Evgeniy dan Shaul Markovitch. 2002. Text categorization with many redundant features: using aggressive feature selection to make SVMs competitive with C4.5. ICML '04.
Liu, Bing. 2009. Sentiment Anlaysis and Subjectivity. Invited Chapter for the Handbook of Natural Language Processing, Second Edition.
Melville, Prem. 2009. Sentiment analysis of blogs by combining lexical knowledge with text classification. Proceeding of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, halaman 1275-1284.
Pang, Bo dan Lillian Lee. 2004. A Sentimental Education: Sentiment Analysis using Subjectivity Summarization based on Minimum Cuts. Proceedings of the ACL.
Pang, Bo dan Lillian Lee. 2009. Opinion mining and sentiment analysis. Foundations and Trends in Information Retrieval, Vol. 2, No 1-2, pp. 1–135.
Pang, Bo, Lillian Lee, dan Shivakumar Vaithyanathan. 2002. Thumbs up? Sentiment classification using machine learning techniques. Dalam EMNLP, halaman 79-86.
Tang, Huifeng, Songbo Tan, dan Xueqi Cheng. 2009. A survey on sentiment detection of reviews. Expert Systems with Applications, pp. 10760–10773.
Turney, Peter. 2002. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. ACL, halaman 417–424.
Wilson, Theresa, Janyce Wiebe, dan Paul Hoffmann. 2005. Recognizing Contextual Polarity in Phrase Level Sentiment Analysis. EMNLP.