10
KAJIAN PUSTAKA
2.1 Computer-Aided Mammography
Computer-Aided Mammography (CAM) merupakan suatu sistem yang bertujuan membantu para ahli patologi dalam melakukan deteksi dan klasifikasi terhadap kanker dengan berdasarkan pada mammogram. Suatu sistem CAM biasanya terdiri atas dua modul yang lebih kecil yang dikenal dengan nama
Computer-Aided Detection (CAD) dan Computer-Aided Diagnosis (CADx)
(N.Md. Yusof, N.A.M. Isa, dan H.A.M. Sakim, 2007). Sesuai dengan namanya, CAD berfungsi untuk melakukan deteksi di dalam suatu mammogram. Obyek yang ingin dideteksi adalah gumpalan-gumpalan yang dicurigai merupakan kanker. Tujuan terakhir dari CAD adalah melakukan deteksi terhadap gumpalan-gumpalan yang mencurigakan secara otomatis sehingga mengurangi tingkat kesalahan yang mungkin saja dilakukan oleh para ahli patologi dalam melakukan deteksi. Alternatif lain dari penggunaan CAD adalah dengan memberikan sang ahli pilihan terhadap daerah tertentu yang memang dicurigai memiliki kanker sehingga proses deteksi hanya dilakukan terhadap daerah tersebut saja, namun dengan cara ini artinya sang ahli harus sudah menyadari terlebih dahulu bahwa ada kemungkinan terdapatnya gumpalan kanker di daerah tersebut.
Fungsi dari CADx adalah mengklasifikasikan gumpalan-gumpalan yang berhasil ditemukan pada CAD ke dalam kelas tertentu. Pada penelitian umumnya, kelas-kelas yang digunakan adalah normal, benign, dan malignant. Namun, beberapa peneliti menggunakan lima variasi kelas yaitu negatif, benign, memiliki
kemungkinan sebagai benign, keabnormalan yang mencurigakan, dan kemungkinan besar kanker. Tujuan utama dari CADx adalah membantu para ahli patologi mengelompokkan kelas-kelas yang mungkin dimiliki oleh sebuah gumpalan tanpa memerlukan penyelidikan lebih dalam terhadap si penderita.
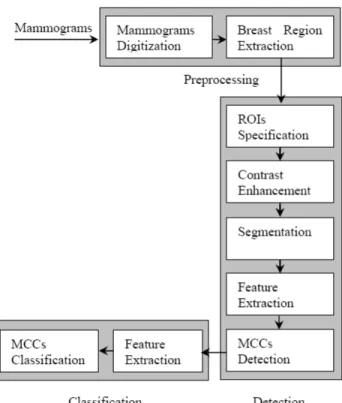
Gambar 2.1 Diagram Blok Sistem CAM.
Gambar 2.1 merupakan diagram blok yang menyatakan langkah-langkah yang dimiliki oleh sistem CAM yang ada saat ini pada umumnya. Biasanya, tidak semua blok dalam diagram tersebut dimiliki oleh suatu sistem CAM secara lengkap. Seperti yang terlihat pada gambar 2.1 bahwa suatu sistem CAM umumnya terdiri atas tiga modul yaitu prapemrosesan, deteksi, dan klasifikasi.
Pada tahap prapemrosesan, akan dilakukan hal-hal yang bertujuan mempermudah proses-proses selanjutnya. Awalnya, apabila mammogram tersebut belum merupakan sebuah mammogram digital, maka mammogram tersebut akan dikonversi menjadi sebuah mammogram digital sehingga dapat diproses lebih lanjut oleh komputer. Langkah selanjutnya adalah memisahkan antara latar belakang dengan bagian yang merupakan sebuah payudara. Pemisahan ini perlu dilakukan karena pada dasarnya sepertiga dari mammogram adalah sebuah latar belakang yang menyimpan informasi yang sangat minim sehingga hanya akan membuang waktu komputasi apabila diikutsertakan dalam proses-proses lainnya.
Tahap deteksi, yang merupakan modul CAD, tujuan utamanya adalah menemukan gumpalan-gumpalan yang dicurigai memiliki kemungkinan sebagai kanker. Hingga saat ini ada dua pendekatan yang digunakan oleh para peneliti dalam tahap deteksi ini. Pendekatan pertama melibatkan peran serta sang ahli untuk menentukan lokasi yang diduga sebagai kanker untuk mempersempit ruang pencarian. Kelemahannya, sang ahli harus memiliki dugaan terlebih dahulu mengenai lokasi kanker dan sistem berfungsi memperkuat dugaan tersebut, sehingga apabila ternyata sang ahli gagal dalam menarik dugaan, kemungkinan besar kanker tidak akan berhasil ditemukan kecuali apabila si penderita mengalami pemeriksaan lebih lanjut. Pendekatan kedua adalah proses pendeteksian yang benar-benar dilakukan secara otomatis dimana sistem akan menemukan gumpalan-gumpalan yang diduga sebagai kanker dengan sendirinya. Pendekatan kedua ini adalah hasil yang diharapkan mampu dicapai oleh suatu sistem CAD yang utuh, namun hingga sekarang ini masih sangat sulit dilakukan disebabkan karena karakteristik dari mammogram itu sendiri, dimana di dalamnya
terdapat jaringan-jaringan yang saling tumpang tindih sehingga mempersulit proses deteksi. Dalam tahap deteksi, penentuan region of interest (ROI) bertujuan untuk mempersempit ruang pencarian terhadap gumpalan. ROI adalah suatu daerah dalam mammogram yang diduga memiliki gumpalan-gumpalan yang berpotensi sebagai kanker. Penentuan ROI ini dapat dilakukan secara manual oleh ahli patologi atau dilakukan secara otomatis oleh sistem. Selanjutnya proses contrast enhancement bertujuan untuk meratakan porsi intensitas warna yang terdapat dalam ROI sehingga diharapkan dengan adanya proses ini membuat gumpalan menjadi lebih “nyata” apalagi bila gumpalan-gumpalan tersebut tertindih oleh jaringan lainnya. Selanjutnya, proses segmentasi akan memisahkan antara daerah yang merupakan gumpalan dan daerah yang bukan. Daerah yang merupakan gumpalan kemudian akan mengalami proses ekstraksi fitur, yang berfungsi mengambil fitur-fitur penting yang dimiliki oleh gumpalan tersebut. Fitur tersebut harus mampu membedakan antara apakah suatu bagian merupakan gumpalan atau bukan sehingga dapat dimanfaatkan dalam proses deteksi untuk menentukan apakah fitur tersebut menunjukkan gumpalan yang mencurigakan atau tidak.
Proses klasifikasi (modul CADx) bertujuan untuk mengelompokkan gumpalan-gumpalan mencurigakan yang berhasil ditemukan sebelumnya ke dalam kelas tertentu. Kelas tersebut umumnya terdiri atas tiga yaitu normal, malignant, dan benign. Proses ini terdiri atas dua langkah yaitu ekstraksi fitur dan klasifikasi gumpalan. Proses ekstraksi fitur bertujuan menghasilkan fitur unik yang mampu membedakan satu kelas dengan kelas-kelas lainnya. Fitur ini dapat saja diperoleh dari hasil ekstraksi fitur yang dilakukan pada saat deteksi sehingga
akan lebih efisien, daripada menggunakan fitur baru yang memerlukan algoritma lain. Fitur-fitur yang dihasilkan kemudian akan digunakan sebagai input untuk melakukan klasifikasi. Proses klasifikasi akan mengelompokkan gumpalan tersebut ke dalam kelas tertentu dan merupakan produk akhir dari keseluruhan sistem CAM.
Dalam implementasinya, tidak semua langkah-langkah yang terdapat di dalam diagram blok tersebut dilakukan, dan sebaliknya seringkali ditemukan proses-proses di luar diagram blok tersebut. Inti utama dari CAM, seperti yang telah dijelaskan sebelumnya, adalah deteksi, yaitu komponen CAD, dan klasifikasi, yaitu komponen CADx. Proses yang secara langsung menunjang hal ini hanyalah ekstraksi fitur dan klasifikasi, dimana proses-proses lainnya adalah opsional karena hanya berfungsi sebagai penunjang atau membantu otomatisasi. Karenanya, metode yang digunakan dalam kedua proses tersebut memegang peranan yang paling penting atas keberhasilan dari keseluruhan sistem CAM.
2.1.1 Kajian Penelitian Terkait CAM
Penelitian mengenai CAM sudah dilakukan selama bertahun-tahun dan berbagai metodologi telah dicoba pada bidang ini. Penelitian-penelitian tersebut tentunya akan memberikan informasi yang berharga mengenai perkembangan dari permasalahan ini. Bagian selanjutnya akan membahas secara singkat mengenai penelitian-penelitian terkait dengan sistem CAM.
1. B. Verma dan J. Zakos (2001) membuat sebuah tulisan berjudul “A Computer-Aided Diagnosis System for Digital Mammograms Based on
Fuzzy-Neural and Feature Extraction Techniques” menggunakan metode fuzzy untuk mendeteksi daerah-daerah yang mencurigakan pada suatu mammogram. Hal ini dilakukan dengan menyapu seluruh gambar menggunakan jendela berukuran 16 x 16. Kemudian, eksperimen dilakukan terhadap sejumlah metode ekstraksi fitur untuk mendapatkan satu atau kombinasi fitur yang mampu mendiskriminasi dengan tepat. Dari eskperimen ini didapatkan 4 metode ekstraksi fitur terbaik, yaitu entropy, jumlah pixel, histogram, dan deviasi standar. Klasifikasi ke dalam kelas benign atau malignant kemudian dilakukan dengan menggunakan ANN dengan berdasarkan pada fitur-fitur yang diperoleh dari langkah sebelumnya. Hasil pengujian menunjukkan bahwa metodologi tersebut mampu memberikan hasil yang cukup baik terhadap proses deteksi mau pun klasifikasi.
2. A. Wróblewska et al. (2003) dalam tulisannya berjudul “Segmentation and Feature Extraction for Reliable Classification of Microcalcifications in
Digital Mammograms” membahas mengenai deteksi dan klasifikasi
kanker dengan berdasarkan pada mammogram. Pada metodologinya, penelitian ini menggunakan kombinasi dari beberapa metode untuk menemukan gumpalan yang mencurigakan. Awalnya, mammogram mengalami operasi morfologi white top-hat. Kemudian, dengan berdasarkan pada suatu threshold yang didapatkan melalui perhitungan rata-rata, gambar tersebut disegmentasi menjadi beberapa kelompok. Untuk mengurangi jumlah segmen yang harus diuji, maka segmen yang memiliki ukuran terlalu kecil akan dibuang. Selanjutnya, segmen-segmen
tersebut akan mengalami ekstraksi fitur. Metode ekstraksi fitur yang digunakan di sini lebih dari satu, dimana dalam pengujiannya metode-metode tersebut dipilih dengan dua cara, yaitu secara subyektif, berdasarkan pada studi literatur yang dilakukan oleh peneliti, dan secara otomatis, dengan menggunakan metode learning vector quantisation. Selanjutnya, klasifikasi dilakukan dengan menggunakan artificial neural
network (ANN). Dalam pengujiannya, metodologi yang menggunakan
metode ekstraksi fitur yang dipilih secara subyektif, memberikan hasil yang lebih baik dibandingkan dengan yang dipilih secara otomatis. Namun, hasil akhir pengujian memberikan nilai yang kurang memuaskan dimana tingkat kesalahan masih cukup tinggi baik dalam deteksi mau pun klasifikasi.
3. N.Md. Yusof, N.A.M. Isa, dan H.A.M. Sakim (2007) pada tulisannya berjudul “Computer-Aided Detection and Diagnosis for
Microcalcifications in Mammogram: a Review” melakukan survei
terhadap penelitian-penelitian terkait dengan CAD dan CADx yang dilakukan pada antara tahun 2000 sampai dengan 2006. Penelitian terbaru, yang dilakukan oleh Xu et al., menggunakan fitur-fitur yang diperoleh dari teknik morfologi. Fitur-fitur ini kemudian akan digunakan sebagai vektor input yang akan diklasifikasikan dengan menggunakan multi-layer perceptron. Hasil dari percobaan yang dilakukan menunjukkan bahwa penggunaan cara ini mampu memberikan hasil yang sangat memuaskan. 4. Y. I. A. Rejani, S. T. Selvi (2008) dalam tulisannya berjudul “Digital
Networks” menggunakan fitur-fitur berupa gradient mean dari ROI, gradient mean dari pembatas, varian nilai keabuan, varian jarak pembatas, area, dan kepadatan. Kumpulan fitur-fitur ini adalah vektor yang akan digunakan oleh pengklasifikasi berbasis jaringan saraf tiruan dengan back
propagation (BPNN). Dengan menggunakan metodologi ini diperoleh
hasil yang cukup baik.
5. J. Bozek, M. Mustra, K. Delac, dan M. Grgic (2009) melakukan serangkaian survey terhadap penelitian-penelitian CAD dan CADx dan menuangkannya ke dalam sebuah tulisan yang berjudul “A Survey of
Image Processing Algorithms in Aigital Mammography”. Survei ini
dilakukan terhadap penelitian-penelitian yang dilakukan antara tahun 2004 dan 2008, dan memuat sebanyak delapan resensi. Dalam salah satu resensinya, Li et al. mengaplikasikan penggunaan beberapa fitur yang digabungkan sebagai vektor, dan menggunakan jaringan saraf tiruan Bayessian sebagai pengklasifikasi.Metodologi ini memberikan hasil yang cukup baik.
2.2 Ekstraksi Fitur
Secara umum, ekstraksi fitur dapat dikatakan sebagai suatu proses pengekstrakan informasi tersembunyi yang terdapat di dalam suatu data yang biasanya berukuran sangat besar dan isinya seringkali redundan. Proses ekstraksi fitur yang dipilih dengan tepat akan menghasilkan informasi yang relevan dari kumpulan data yang dapat digunakan untuk merepresentasikan kumpulan data
tersebut dengan ukuran yang lebih kecil. Dalam konteks computer vision, fitur dipandang sebagai sepotong informasi yang relevan untuk menyelesaikan masalah yang berkaitan dengan tugas perhitungan dalam suatu aplikasi. Ekstraksi fitur adalah suatu operasi yang dilakukan terhadap gambar yang menghasilkan suatu nilai yang menyatakan keberadaan suatu fitur dalam bagian gambar yang dimaksud. Biasanya, keberadaan fitur ini dinyatakan dengan angka, atau dengan menggunakan suatu boolean (pernyataan benar-salah). Di luar dari area pemrosesan gambar sendiri, istilah ekstraksi fitur juga banyak digunakan pada information retrieval.
Data yang dapat diperoleh dari suatu gambar digital tanpa memerlukan pemrosesan lebih lanjut oleh komputer sebenarnya hanyalah pixel dan nilai intensitas warna yang terdapat pada pixel tersebut. Data itulah yang harus diolah lebih lanjut untuk memperoleh informasi. Sekumpulan pixel seringkali memiliki intensitas warna yang sama, apalagi apabila pixel tersebut terdapat pada satu wilayah yang sama. Kumpulan warna tersebut dapat dipandang sebagai suatu data yang redundan dan berukuran sangat besar, namun memiliki informasi yang tersembunyi di dalamnya. Di sinilah proses ekstraksi fitur dalam computer vision berperan untuk menemukan informasi-informasi tersembunyi tersebut. Informasi-informasi yang didapatkan dari proses ekstraksi fitur inilah yang akan digunakan untuk mengidentifikasi isi dari gambar.
Teknik-teknik ekstraksi fitur yang sering diterapkan kepada sebuah gambar digital secara garis besar dapat dikelompokkan menjadi tiga yaitu warna, bentuk, dan tekstur. Walau pun terdapat teknik-teknik yang tidak termasuk ke dalam tiga kelompok itu, teknik-teknik yang berasal dari ketiga kelompok itu
merupakan teknik yang banyak dikenal dan sering digunakan dalam melakukan proses ekstraksi fitur. Seringkali kombinasi dari beberapa teknik ekstraksi fitur yang berasal dari kelompok berbeda digunakan untuk memberikan hasil yang lebih akurat.
2.2.1 Warna
Teknik-teknik ekstraksi fitur yang terdapat dalam kelompok ini, menggunakan distribusi warna yang dimiliki oleh suatu gambar sebagai fitur yang utama. Teknik yang cukup terkenal dan sering digunakan salah satunya adalah histogram warna. Histogram warna adalah suatu grafik yang berisi nilai-nilai yang melambangkan distribusi warna yang terdapat dalam suatu gambar. Histogram cukup dikenal karena biaya perhitungannya yang murah dan konsepnya yang mudah dipahami.
Gambar 2.2 Contoh Histogram.
Namun, histogram dipandang tidak mampu memberikan fitur yang cukup relevan untuk mengidentifikasi suatu gambar. Hal ini disebabkan karena dalam kasus tertentu, dua gambar dengan isi yang benar-benar berbeda bisa saja secara kebetulan memiliki distribusi warna yang mirip, sehingga akhirnya teknik ini
jarang digunakan dalam sistem yang membutuhkan ekstraksi fitur yang akurat dan diskriminatif. Para peneliti memandang bahwa kekurangan dari histogram ini disebabkan karena tidak adanya informasi spasial atau posisi dimana kumpulan warna tersebut. Penelitian-penelitian selanjutnya dalam kelompok ini berusaha menambahkan elemen spasial untuk melakukan ekstraksi fitur yang lebih baik diantaranya dengan membagi gambar menjadi wilayah-wilayah yang lebih kecil lalu kemudian dihitung histogramnya. Beberapa teknik yang cukup dikenal adalah Color Coherence Vector (CCV) (G. Pass et al., 1996) dan color correlogram (Huang et al., 1997).
2.2.2 Bentuk
Teknik-teknik ekstraksi fitur yang termasuk kedalam kelompok ini biasanya menggunakan bentuk sebagai sumber datanya dan seringkali mengabaikan elemen warna. Teknik-teknik ini menjanjikan potensi yang cukup besar dalam melakukan pengenalan obyek. Kesulitan utama yang dimiliki oleh teknik-teknik ini adalah perbedaan tampilan obyek yang disebabkan karena perubahan sudut pandang. Hal ini disebabkan karena setiap obyek yang ada pada dunia nyata sebenarnya adalah benda tiga dimensi sedangkan gambar merupakan media dua dimensi. Mingqiang et al. (2000) membahas lebih mendalam mengenai teori-teori dan teknik-teknik yang saat ini sedang berkembang dalam kelompok ini.
2.2.3 Tekstur
Tekstur adalah suatu pola visual yang memiliki homogenitas, yang bukan berasal dari keberadaan satu warna atau intensitas. Tekstur berisi informasi penting mengenai struktur permukaan dan hubungannya dengan area sekitarnya. Secara umum tekstur alami biasanya acak (contohnya adalah tekstur pohon, tanah, kulit), dan tekstur buatan memiliki pola periodik (contohnya adalah tekstur plastik, karpet). Tekstur dapat digunakan untuk melakukan klasifikasi terhadap suatu obyek, karena setiap obyek di dunia pasti memiliki tekstur tersendiri.
Secara umum, teknik ekstraksi fitur berdasarkan tekstur dapat dibagi ke dalam dua golongan besar yaitu structural dan statistical. Metode structural, yang diantaranya adalah morphological operator dan adjency graph, mengidentifikasi tekstur berdasarkan penyusun dasar struktur dan pola pemetaannya. Metode ini akan memberikan hasil yang lebih memuaskan apabila digunakan pada gambar yang memiliki pola yang hampir selalu sama. Metode statistical, yang diantaranya adalah Fourier power spectra, co-occurrence matrices, shift-invariant principal component analysis (SPCA), Tamura feature, Wold feature, Markov random field, fractal model, dan teknik multi-resolution filtering seperti Gabor dan wavelet transform, mengidentifikasi tekstur berdasarkan pada distribusi statistik dari intensitas yang terdapat dalam gambar (Rao et al., 2009).
Salah satu tujuan dari ekstraksi fitur dalam bidang pemrosesan gambar digital adalah meniru kemampuan manusia dalam mengenali suatu obyek walau pun dengan informasi yang terbatas atau tidak lengkap, dimana informasi di sini dapat dipandang sebagai fitur yang harus diekstrak. Karenanya, tidak salah
apabila cara kerja sistem penglihatan manusia dijadikan sebagai dasar untuk mengembangkan teknik-teknik ekstraksi fitur. Menurut teori analisa frekuensi, mata manusia menggunakan beberapa jalur frekuensi untuk melakukan pengenalan. Setiap jalur frekuensi tersebut hanya merespon terhadap sebagian bandwidth dari gambar yang terdapat pada retina. Karenanya, kita dapat beranggapan bahwa mata manusia bekerja sama seperti filter bandpass dan akan lebih memudahkan apabila sistem penglihatan dipandang sebagai bank filter yang terdiri atas beberapa filter, dimana setiap filter hanya merespon terhadap sejumlah area dengan frekuensi tertentu (Safavian dan Kasaei, 2004). Salah satu metode yang menerapkan teknik ini dan sering digunakan dalam proses ektraksi fitur terhadap gambar digital adalah transformasi wavelet.
2.3 Teori Transformasi Wavelet
Transformasi wavelet adalah salah satu teknik ekstraksi fitur yang sudah banyak digunakan pada berbagai penelitian, dan dipandang memiliki tingkat keberhasilan yang cukup tinggi. Pada awalnya, wavelet digunakan untuk melakukan analisis terhadap sinyal. Wavelet adalah fungsi matematika yang memotong-motong data menjadi kumpulan-kumpulan frekuensi yang berbeda-beda, sehingga masing-masing komponen tersebut dapat dipelajari dengan menggunakan skala resolusi yang berbeda-beda. Mulanya, wavelet digunakan untuk menganalisa sinyal yang merupakan kasus yang terjadi pada bidang satu dimensi. Namun, dalam perkembangannya, wavelet kemudian juga dapat diterapkan pada bidang dua dimensi, yaitu gambar.
2.3.1 Wavelet
Wavelet transform mulai diperkenalkan pada tahun 1980-an oleh Morlet dan Grossman sebagai fungsi matematis untuk merepresentasikan data atau fungsi sebagai alternatif transformasi-transformasi matematika yang lahir sebelumnya untuk menangani masalah resolusi. Sebuah wavelet merupakan gelombang singkat (small wave) yang energinya terkonsentrasi pada suatu selang waktu untuk memberikan kemampuan analisis transien, ketidakstasioneran, atau fenomena berubah terhadap waktu (time varying). Karakteristik dari wavelet antara lain adalah berosilasi singkat, translasi (pergeseran), dan dilatasi (skala). Kata “Wavelet” sendiri diberikan oleh Jean Morlet dan Alex Grossmann diawal tahun 1980-an, dan berasal dari bahasa Prancis, “ondelette” yang berarti gelombang kecil. Kata “onde” yang berarti gelombang kemudian diterjemahkan ke bahasa Inggris menjadi “wave”, lalu digabung dengan kata aslinya sehingga terbentuk kata baru “wavelet”.
2.3.2 Perbandingan Dengan Transformasi Fourier
Sampai sekarang Fourier transform mungkin masih menjadi transformasi yang paling populer di area pemrosesan sinyal digital. Fourier transform memberikan informasi frekuensi dari sebuah sinyal, tapi tidak informasi waktu, sehingga frekuensi tersebut tidak dapat diketahui kapan terjadinya.
Karena itulah Fourier transform hanya cocok untuk sinyal stationari, yaitu sinyal yang informasi frekuensinya tidak berubah menurut waktu. Untuk menganalisa sinyal yang frekuensinya bervariasi di dalam waktu, diperlukan suatu
transformasi yang dapat memberikan resolusi frekuensi dan waktu disaat yang bersamaan, biasa disebut analisis multi resolusi (AMR). AMR dirancang untuk memberikan resolusi waktu yang baik dan resolusi frekuensi yang buruk pada frekuensi tinggi suatu sinyal, serta resolusi frekuensi yang baik dan resolusi waktu yang buruk pada frekuensi rendah suatu sinyal. Pendekatan ini sangat berguna untuk menganalisa sinyal dalam aplikasi-aplikasi praktis yang memang memiliki lebih banyak frekuensi rendah.
Wavelet transform adalah suatu AMR yang dapat merepresentasikan informasi waktu dan frekuensi suatu sinyal dengan baik. Wavelet transform menggunakan sebuah jendela modulasi yang fleksibel, ini yang paling membedakannya dengan Short-Time Fourier Transform (STFT), yang merupakan pengembangan dari Fourier transform. STFT menggunakan jendela modulasi yang besarnya tetap, ini menyebabkan dilema karena jendela yang sempit akan memberikan resolusi frekuensi yang buruk dan sebaliknya jendela yang lebar akan menyebabkan resolusi waktu yang buruk.
2.3.3 Wavelet Transform
Tahap pertama analisis wavelet adalah menentukan tipe wavelet atau mother wavelet yang akan digunakan. Hal ini perlu dilakukan karena fungsi wavelet sangat bervariasi. Beberapa contoh mother wavelet adalah Haar, Daubechies, Biortoghonal, Coiflets, Symlets, Morlet, Mexican Hat, dan Meyer. Setelah pemilihan mother wavelet, tahap selanjutnya adalah membentuk basis wavelet yang akan digunakan untuk mentransformasikan sinyal.
Wavelet transform memiliki kemampuan untuk menganalisis suatu data dalam domain waktu dan domain frekuensi secara simultan. Wavelet merupakan sebuah fungsi variable real t, diberi notasi ψt dalam ruang fungsi L2(R). Fungsi ini dihasilkan oleh parameter dilatasi dan translasi, yang dinyatakan dalam persamaan berikut.
Dimana :
a = parameter dilatasi b = parameter translasi
R = mengkondisikan nilai a dan b dalam nilai integer j = parameter dilatasi (parameter frekuensi atau skala) k = parameter waktu atau lokasi ruang
Z = mengkondisikan nilai j dan k dalam nilai integer
Fungsi persamaan yang pertama dikenalkan pertama kali oleh Grossman dan Morlet, sedangkan persamaan yang kedua dikenalkan oleh Daubechies. Kedua fungsi tersebut dapat dipandang sebagai mother wavelet, dan harus memenuhi kondisi yang menjamin terpenuhinya sifat ortogonalitas vektor.
Wavelet ransform dapat dibedakan menjadi dua tipe berdasarkan nilai parameter translasi dan dilatasinya, yaitu Continuous Wavelet Transform dan Discrete Wavelet Transform.
2.3.4 Continuous Wavelet Transform
Continuous Wavelet Transform (CoWT) didefinisikan oleh nilai parameter dilatasi (a) dan translasi (b) yang bervariasi secara kontinu, dimana a,b Є R dan a
≠ 0. Cara kerja CoWT adalah dengan menghitung konvolusi sebuah sinyal dengan sebuah mother wavelet pada setiap waktu. CoWT dapat diformulasikan dengan menggunakan rumus sebagai berikut.
Dimana f(t) adalah sinyal sebelum terjadinya transformasi.
2.3.5 Discrete Wavelet Transform
Prinsip dasar dari Discrete Wavelet Transform (DWT) adalah mendapatkan representasi waktu dan skala dari sebuah sinyal menggunakan teknik pemfilteran digital dan operasi sub-sampling. Pada proses awal, sinyal dilewatkan pada rangkain high pass filter (fungsi wavelet), yang berfungsi mengambil bagian dengan gradiasi intensitas tinggi, dan low pass filter (fungsi skala), yang berfungsi mengambil bagian dengan gradiasi intensitas rendah, kemudian setengah dari masing-masing keluaran diambil sebagai sample melalui operasi sub-sampling. Proses ini disebut sebagai proses dekomposisi satu tingkat. Keluaran dari low pass filter digunakan sebagai masukkan di proses dekomposisi tingkat berikutnya. Proses ini diulang sampai tingkat dekomposisi yang diinginkan. Wavelet yang menggunakan lebih dari satu tingkat dekomposisi seperti ini dikenal sebagai multi-level wavelet transform. Gabungan dari
keluaran-keluaran high pass filter dan keluaran-keluaran low pass filter terakhir disebut sebagai koefisien wavelet yang berisi informasi sinyal hasil transformasi yang telah terkompresi.
Pasangan high pass filter dan low pass filter yang digunakan harus merupakan quadrature mirror filter (QMF), yaitu pasangan filter yang memenuhi persamaan berikut:
dengan h[n] adalah high pass filter, g[n] adalah low pass filter dan L adalah panjang masing-masing filter.
Pada umumnya, CWT digunakan pada bidang-bidang seperti fisika, kimia, biologi, dan teknik dalam melakukan penelitian ilmiah. DWT lebih sering digunakan pada bidang-bidang rekayasa dan komputer, salah satunya adalah untuk melakukan ekstraksi fitur terhadap gambar dua dimensi.
2.3.6 Implementasi DWT Pada Gambar Digital Dua Dimensi
Pada kasus gambar digital, yang merupakan bidang dua dimensi, high pass filter dan low pass filter diterapkan dua kali. Pada tahap pertama pemfilteran dilakukan terhadap baris, yang kemudian dilanjutkan dengan pemfilteran pada kolom. Hasil pemfilteran tersebut dapat dilihat pada gambar 2.3.
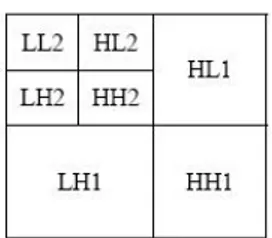
Gambar 2.3 Dekomposisi Tingkat Satu pada Bidang Dua Dimensi.
Dimana :
Jika pada suatu gambar diterapkan proses DWT dua dimensi dengan dekomposisi tingkat satu, maka akan menghasilkan empat buah subband, yaitu :
1. Koefisien Approksimasi (CA j+1) atau disebut juga subband LL. 2. Koefisien Detil Horisontal (CD(h) j+1) atau disebut juga subband HL. 3. Koefisien Detil Vertikal (CD(v) j+1) atau disebut juga subband LH. 4. Koefisien Detil Diagonal (CD(d) j+1) atau disebut juga subband HH.
Gambar 2.4 Susunan Subband Hasil Dekomposisi Tingkat Satu.
Pada saat proses dekomposisi tingkat selanjutnya ingin dilakukan, subband LL akan dijadikan sebagai obyek dekomposisi karena menyimpan sebagian besar
informasi dari gambar. Dekomposisi tingkat dua akan menyebabkan subband LL menghasilkan empat buah subband baru, yaitu subband LL2 (Koefisien Approksimasi 2), HL2 (Koefisien Detil Horisontal 2), LH2 (Koefisien Detil Vertikal 2), dan HH2 (Koefisien Detil Diagonal 2). Dan begitu juga seterusnya untuk dekomposisi-dekomposisi selanjutnya.
Gambar 2.5 Susunan Subband Hasil Dekomposisi Tingkat Dua.
Gambar 2.6 Wavelet Tree untuk Dekomposisi Tingkat Dua.
2.3.7 Permasalahan Pada DWT
Nick Kingsbury (1997), menyatakan bahwa DWT yang ada pada umumnya memiliki dua kelemahan. Dua kelemahan ini ditemukan dengan menggunakan serangkaian percobaan matematika terhadap proses wavelet transform yang ada. Hasil percobaan ini menemukan bahwa DWT sangat
dipengaruhi oleh pergeseran (dikenal sebagai shift invariance) dan memiliki informasi arah yang minim (hanya horizontal, vertikal, dan diagonal).
2.3.8 Complex Wavelet Transform
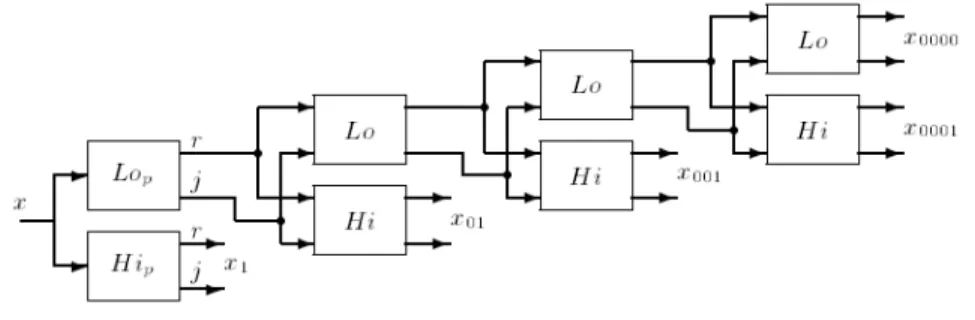
Kedua masalah tersebut, dapat dipecahkan oleh Complex Wavelet
Transform (CWT). CWT memiliki struktur subband yang sama dengan DWT,
namun menggunakan koefisien dan sampel output complex. Hal ini dapat dilihat pada gambar 2.7 dimana setiap blok merupakan filter complex.
Gambar 2.7 Subband CWT.
Gambar 2.7 menunjukkan bahwa pada setiap proses pemfilteran dihasilkan dua jenis output, yaitu real (r) dan imaginary (j). Terlihat pada gambar, bahwa setiap bagian mengalami dua kali pemfilteran yang menggunakan high pass filter dan low pass filter. Karena penggunaan dua kali pemfilteran tersebut, yang menghasilkan dua bagian yaitu nyata (r) dan khayalan (j), terjadi redundansi dengan perbandingan 2:1. Hal inilah yang melambangkan koefisien complex wavelet.
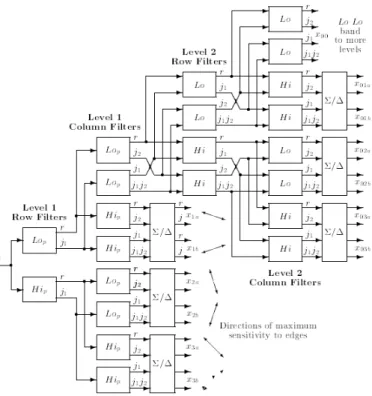
Pada bidang dua dimensi, penerapan CWT sama dengan DWT, dimana pemfilteran dilakukan terhadap baris lalu kemudian dilanjutkan pada kolom. Karena proses ini juga menggunakan dua kali pemfilteran, maka jumlah redundansi bahkan lebih besar daripada pada satu dimensi, yaitu 4:1. Jumlah redundansi ini dinyatakan dengan rumus 2d, dimana d adalah jumlah dimensi.
Gambar 2.8 Subband CWT pada Bidang Dua Dimensi.
2.3.9 Dual-Tree Complex Wavelet Transform
Namun, merancang sebuah filter complex bukan merupakan hal yang mudah. Hal ini disebabkan karena suatu filter complex yang benar, harus memenuhi beberapa persyaratan tertentu, diantaranya adalah rekonstruksi
sempurna dan mampu menghasilkan sinyal yang bersifat analitik. Dual-Tree
Complex Wavelet Transform (DT CWT) dikembangkan berdasarkan pengetahuan
bahwa ketidakpekaan terhadap pergeseran dapat dihasilkan oleh DWT dengan meningkatkan jumlah subband sebanyak dua kali pada setiap tingkat, dimana setiap subband menggunakan filter yang berbeda. Penggunaan dari dua subband ini akan menyebabkan jumlah output meningkat menjadi dua kali lipat pada setiap tingkat. Model ini akan memiliki karakteristik CWT, apabila dua bagian output tersebut dipandang sebagai sebagai bagian nyata dan khayalan.
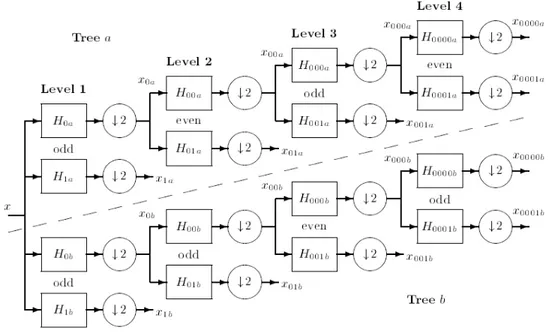
Gambar 2.9 Struktur Dual Tree.
Seperti yang telah disebutkan sebelumnya bahwa sebuah CWT harus menggunakan filter complex yang mampu memenuhi persyaratan tertentu, hal ini juga berlaku untuk DT CWT. Seperti yang telah dijelaskan sebelumnya, DT CWT menggunakan dua filter DWT yang berbeda panjangnya. Kedua filter tersebut
harus memenuhi persyaratan half-sample shift, yaitu keadaan dimana salah satu dari kedua filter tersebut harus memiliki selang sebesar setengah sampel terhadap filter lainnya. Hal ini dapat dicapai dengan menggunakan filter dengan panjang ganjil dan genap, yang digunakan secara bergantian pada setiap tingkat dekomposisi.
Penggunaan filter dengan panjang ganjil dan genap yang disebutkan sebelumnya memiliki kelemahan utama dimana penggunaannya menyebabkan strukstur sub-sampel menjadi tidak simetris. Karenanya, metode quarter shift (q-shift) kemudian digunakan untuk menutupi kelemahan ini. Pada metode q-shift, semua filter di atas tingkat 1 menggunakan filter dengan panjang genap dimana filter tersebut dirancang agar mampu memberikan selang sebanyak seperempat sampel. Untuk mampu memenuhi persyaratan selang sebanyak setengah sampel, filter pada pohon pertama merupakan kebalikan waktu dari filter pada pohon kedua. Berikut ini adalah filter-filter yang digunakan oleh N. Kingsbury untuk tingkat 1.
1. Filter Antonini dengan panjang 9,7. 2. Filter LeGall dengan panjang 5,3. 3. Filter Near-Symmetric panjang 5,7. 4. Filter Near-Symmetric panjang 13,19.
Dan filter-filter yang digunakan pada tingkat selanjutnya. 1. Filter q-shift 6,6.
2. Filter q-shift 10,10. 3. Filter q-shift 14,14.
Gambar 2.10 Contoh Penerapan DT CWT pada Gambar.
4. Filter q-shift 16,16. 5. Filter q-shift 18,18.
Penelitian menunjukkan bahwa kompleksitas filter yang digunakan akan berbanding lurus dengan derajat shift invariance yang dimiliki DT CWT.
2.4 Support Vector Machine
Support Vector Machine (SVM) merupakan salah satu teknik supervised learning dimana pembelajaran dilakukan dengan menggunakan data-data yang sudah jelas kelasnya. SVM merupakan nama untuk suatu himpunan metode yang dapat digunakan untuk melakukan klasifikasi dan regresi. Dalam penelitian ini, metode SVM yang digunakan adalah metode untuk melakukan klasifikasi. SVM didasarkan pada konsep bidang keputusan. Bidang keputusan berfungsi untuk memisahkan obyek-obyek yang memiliki kelas yang berbeda. Gambar 2.11
memberikan ilustrasi mengenai satu bidang keputusan yang memisahkan dua kelas, yaitu hijau dan merah.
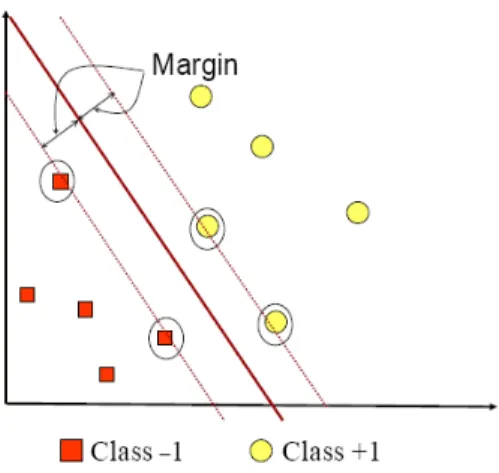
Gambar 2.11 Bidang Keputusan yang Memisahkan Dua Kelas.
Ide dasar dari SVM adalah menemukan fungsi hyperplane yang mampu memisahkan antara dua kelas dengan optimal. Optimal di sini artinya adalah hyperplane tersebut mampu memisahkan kedua kelas dengan margin yang maksimal. Margin adalah jarak antara garis hyperplane dengan anggota-anggota terdekat dari kedua kelas. Hal ini diilustrasikan pada gambar 2.12.
2.4.1 Mengapa SVM?
Walau pun hingga sekarang sudah banyak teknik klasifikasi yang dikembangkan, dan beberapa di antaranya sudah berhasil diimplementasikan ke dalam aplikasi yang digunakan dalam kehidupan sehari-hari, metode klasifikasi masih terus diteliti dan dikembangkan. SVM merupakan salah satu metode klasifikasi yang masih dapat digolongkan sebagai metode baru. Menurut survey yang dilakukan terhadap metode-metode klasifikasi yang ada saat ini, SVM menempati urutan pertama sebagai metode klasifikasi dengan tingkat akurasi tertinggi (Kotsiantis, 2007). Ditambah lagi, SVM merupakan suatu metode yang didasarkan pada statistik dan outputnya dapat dibuktikan secara matematis (berbeda dengan metode sejenis artificial neural network yang merupakan black box dan tidak dapat dijelaskan secara matematis kebenarannya).
Untuk lebih menjelaskan mengenai alasan penggunaan SVM, maka pada bagian berikut akan dijabarkan keuntungan-keuntungan yang dimiliki oleh SVM itu sendiri.
a. Dengan data yang terbatas, SVM tetap mampu melakukan klasifikasi dengan baik. Hal ini disebabkan karena pencarian solusi optimal yang dilakukan oleh SVM bertujuan untuk mencari solusi optimal berdasarkan data yang dimiliki sekarang ini, dan bukan bertujuan mencari solusi yang optimal untuk data yang tidak terbatas.
b. Masalah yang dihadapi oleh SVM adalah masalah optimasi quadratic, sehingga SVM pada akhirnya mampu memberikan nilai optimasi global.
c. SVM memiliki kemampuan generalisasi yang cukup baik. SVM memiliki kemampuan untuk memecahkan masalah non-linear dengan cara memetakan data ke dimensi yang lebih tinggi yang kemudian dipecahkan dengan menggunakan fungsi diskriminan linear.
d. SVM merupakan suatu teori yang berbasis pada statistik sehingga dapat dianalisa lebih lanjut.
e. SVM dapat diimplementasikan dengan mudah karena tergolong sebagai permasalahan quadratic programming, yaitu pencarian titik minimal dari suatu persamaan dengan memperhatikan konstrain yang dimiliki oleh persamaan tersebut.
f. Biaya komputasi lebih efisien apabila dibandingkan dengan teknik klasifikasi lainnya.
g. Masalah over-fitting, yaitu keadaan dimana suatu pengklasifikasi mampu mengklasifikasikan data-data pelatihan dengan baik namun gagal dalam mengklasifikasikan data-data pengujian, tidak terjadi pada SVM.
2.4.2 SVM Linear
Gambar 2.13 menunjukkan suatu hyperplane yang berbentuk garis. Hyperplane tersebut dapat dikatakan sebagai pengklasifikasi linear.
d p D t u a d P p D h Gam dalam gamb persamaan h Dimana w a titik pusat k untuk mend anggota kela dirumuskan Persamaan y putih. Dengan me hitam dan p mbar 2.13 me bar tersebut t hyperplane a adalah norm koordinat. D dapatkan ma as hitam, na dengan pers yang sama elakukan eli putih tersebu Gambar enggambark terdapat dua adalah sebag w mal bidang da alam persam argin yang m amun tetap d samaan seba w.xi – b juga dimilik w.xi – b < minasi, mak ut adalah r 2.13 Hyper kan hyperplan kelas yaitu h ai berikut. w.x – b = 0 an b adalah maan tersebu maksimal. H dapat memis agai berikut. b >= 1, untuk ki oleh hyp <= -1, untuk ka didapatk , sehingg rplane Linea ne linear dan hitam dan pu posisi relati ut, nilai w d Hyperplane sahkan kedu k yi = 1 perplane yan k yi = -1 kan bahwa j ga diketahu ar. n persamaan utih. Secara if hyperplan dan b harus yang terdek ua kelas ters ng dimiliki jarak dari h ui bahwa jar nnya. Di umum, ne terhadap ditentukan kat dengan sebut dapat oleh kelas hyperplane rak margin
antara hyperplane pembatas dengan kedua kelas tersebut dapat diperoleh dengan memaksimalkan , yang kemudian dapat disetarakan dengan meminimumkan . Selanjutnya, persamaan w.xi – b >= 1 dapat dimodifikasi sehingga
menghasilkan persamaan berikut.
yi(wi.x – b) - 1 >= 0
Selanjutnya, untuk menyelesaikan persoalan ini akan digunakan langrange multiplier, sehingga persamaan tersebut dapat diterjemahkan menjadi persamaan sebagai berikut.
Dimana ( nilai koefisien langrange ). Selanjutnya, nilai minimum Lp akan
terhadap w dapat diperoleh dengan menurunkan persamaan di atas terhadap w, sehingga diperoleh persamaan berikut.
Dan untuk mendapatkan minimum Lp terhadap b dapat diperoleh dengan
menurunkan persamaan di atas terhadap b, yang menghasilkan persamaan berikut.
Kemudian, persamaan disubstitusikan ke Lp dan membentuk dual
Dimana . Sehingga persoalan pencarian hyperplane dengan margin yang maksimal dapat dirumuskan dengan persamaan berikut.
Dengan demikian, nilai dapat ditentukan, yang kemudian digunakan untuk mencari nilai w. Nilai nantinya akan diperoleh untuk setiap data pelatihan, dimana data dengan > 0 merupakan support vector, dan data dengan = 0 bukan merupakan support vector. Setelah masalah tersebut berhasil dipecahkan, maka langkah selanjutnya adalah melakukan pengujian. Pengujian tersebut dilakukan terhadap data yang ingin diklasifikasi ( xd ) dengan berdasarkan pada
persamaan berikut.
Dimana xi adalah support vector, ns adalah jumlah support vector.
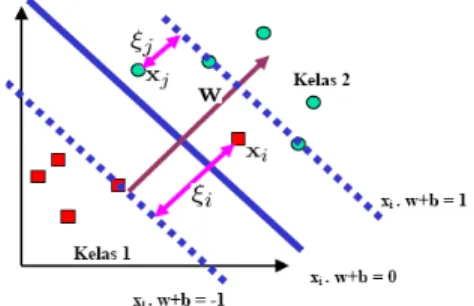
2.4.3 Soft Margin
Soft margin ditujukan untuk meningkatkan toleransi SVM terhadap data yang tidak dapat secara tepat dipisahkan ke dalam salah satu kelas. Tujuannya adalah melakukan pemisahan data dengan sebaik mungkin. Hal ini dilakukan dengan menambahkan elemen , yang melambangkan derajat misklasifikasi terhadap data xi. Dengan penambahan elemen tersebut, maka persamaan yang
digunakan sebelumnya untuk kelas pertama dapat diubah. w.xi – b >= 1 -
Dan persamaan untuk kelas kedua dapat diubah sebagai berikut. w.xi – b <= -1 +
Dengan demikian, permasalahan pencarian bidang pemisah terbaik dapat dimodifikasi sebagai berikut.
Dimana C adalah sebuah konstanta yang menentukan nilai pinalti yang diakibatkan oleh misklasifikasi data. Nilai C ini ditentukan oleh si pengguna. Persamaan tersebut hampir sama dengan persamaan yang digunakan pada SVM
linear, namun dengan penambahan aturan bahwa meminimumkan berarti meminimumkan error pada data pelatihan. Karenanya, permasalahan tersebut juga dapat dipecahkan dengan menggunakan Langrange Multiplier, sehingga bentuknya menjadi sebagai berikut.
Kemudian, permasalahan tersebut dapat dipecahkan dengan cara yang sama dengan cara pemecahan SVM linear, sehingga data tetap dapat dipisahkan secara linear. Di sini rentang nilai diperkecil menjadi 0 >= >= C.
2.4.4 SVM Non-Linear
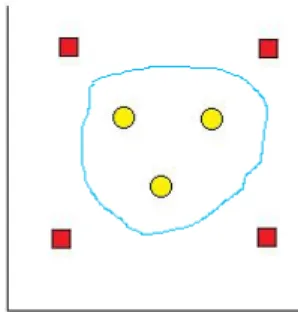
Dalam penerapannya di lapangan, seringkali ditemukan kasus-kasus yang tidak dapat dipecahkan oleh SVM linear. Salah satu pemecahan terhadap masalah tersebut adalah penggunaan soft margin namun, dalam beberapa kasus soft margin kurang tepat untuk diterapkan. Suatu model SVM yang lebih dikenal sebagai SVM non-linear kemudian dikembangkan untuk memecahkan masalah ini. Sesuai dengan namanya, SVM ini mampu menghasilkan hyperplane dengan persamaan non-linear, seperti yang terlihat pada gambar 2.15.
Gambar 2.15 Contoh Penyebaran Data dan Hyperplane Non-linear.
Ide dasar dari model SVM non-linear ini adalah memetakan data dari suatu bidang dengan dimensi tertentu, ke dalam bidang dengan dimensi yang lebih tinggi. Bidang tersebut kemudian dikenal dengan nama bidang input dan bidang fitur. Pemetaan dari bidang input ke bidang fitur (F) ini secara matematika dilambangkan dengan . Data hasil pemetaan tersebut dilambangkan dengan x ÆФ(x).
Gambar 2.16 Pemetaan Data dari Bidang Input ke Bidang Fitur, Disertai dengan Hyperplanenya.
Dengan menstubsitusikan lambang pada x Æ Ф(x) persamaan klasifikasi pada SVM linear, akan diperoleh persamaan baru sebagai berikut.
Namun, bidang fitur biasanya memiliki dimensi yang sangat tinggi, bahkan bisa mencapai tidak terhingga dan seringkali tidak diketahui sebelumnya. Hal ini menimbulkan permasalahan baru, yaitu perhitungan yang sangat rumit yang perlu dilakukan untuk memperoleh nilai . Daripada melakukan perhitungan rumit tersebut, akhirnya digunakan jalan pintas lain yang disebut dengan kernel trick yang dilambangkan dengan K(xi, xd). Fungsi kernel tersebut
memiliki kesetaraan dengan dot produk sehingga dapat dituliskan dengan formula sebagai berikut.
K(xi, xd) =
Sehingga dengan menstubtitusikan persamaan tersebut ke dalam persamaan klasifikasi SVM non-linear, akan diperoleh persamaan baru.
Fungsi kernel tersebut kemudian dapat disubtitusikan dengan implementasi riil-nya. Ada pun, tabel 2.1 mendaftarkan fungsi-fungsi kernel yang umum digunakan untuk memecahkan permasalahan SVM non-linear.
Tabel 2.1 Daftar Fungsi-fungsi Kernel.
Nama Kernel Persamaan
Linear K(xi, xd) = xiTxd
Polynomial K(xi, xd) = (γ.xiTxd + r)p, γ > 0
Sigmoid K(xi, xd) = tanh(γ.xiTxd + r), γ > 0
Radial Basis Function K(xi, xd) = exp(-γ|xi- xd|2), γ > 0
Gaussian
K(xi, xd) = exp(- | | ), > 0
2.4.5 SVM Multi-Kelas
Pada dasarnya, SVM dirancang hanya untuk masalah klasifikasi biner, dimana data yang terdapat di dalam suatu model SVM hanya mungkin terklasifikasi ke dalam dua kelas saja. Dalam kasus dunia nyata, kemampuan untuk melakukan klasifikasi hanya ke dalam dua kelas seringkali tidak cukup karena banyaknya variasi yang mungkin ditemui. Karenanya, digunakan cara tertentu untuk memungkinkan SVM mampu melakukan klasifikasi terhadap lebih dari dua kelas dimana caranya adalah dengan menggunakan lebih dari satu persamaan hyperplane. Hingga saat ini, ada tiga pendekatan yang dapat digunakan untuk memecahkan masalah SVM multikelas ini, yaitu metode one-against-all, one-against-one, dan directed acyclic graph. Pembahasan berikutnya akan membahas lebih dalam mengenai SVM multikelas dengan menggunakan contoh 3 kelas (A, B, dan C) kemungkinan klasifikasi.
2.4.5.1 One-against-all
Pada metode ini, sesuai dengan namanya, setiap data yang terdapat di dalam salah satu kelas SVM akan diadu/dibandingkan dengan gabungan dari data-data yang bukan merupakan anggota kelas tersebut. Hal ini berarti bahwa model SVM dibuat terhadap masing-masing kelas. Dalam contoh yang diberikan sebelumnya, setiap kelas A, B, dan C, akan memiliki persamaan hyperplane-nya masing-masing, yaitu hyperplane A (data A dibandingkan data bukan A), hyperplane B (data B dibandingkan data bukan B), dan hyperplane C (data C dibandingkan data bukan C). Hal ini berarti bahwa pengujian terhadap data input harus dilakukan minimal 1 kali (terhadap salah satu kelas) dengan maksimum 3 kali (terhadap keseluruhan kelas), tergantung kepada urutan pengujian dan data input itu sendiri.
2.4.5.2 One-againts-one
Pada metode ini, setiap data yang terdapat dalam salah satu kelas SVM akan diadu/dibandingkan dengan data dari salah satu kelas lainnya, dimana proses ini dilakukan terhadap setiap kelas yang ada. Hal ini menyebabkan setiap model SVM harus dibuat terhadap setiap rangkaian kelas satu-satu yang mungkin terjadi. Dalam contoh yang diberikan sebelumnya, setiap rangkaian kelas AB, BC, dan AC akan memiliki persamaan hyperplane masing-masing, yaitu hyperplane AB (data A dibandingkan data B), hyperplane BC (data B dibandingkan data C), dan hyperplane AC (data A dibandingkan data C). Walau pun jumlah model SVM yang dimiliki jumlahnya sama dengan model one-against-all, seiring dengan
bertambahnya jumlah kelas maka semakin bertambah banyak juga jumlah modelnya. Pengujian selalu dilakukan terhadap semua model, dimana hasil keanggotaan data input pada akhirnya diperoleh berdasarkan output dari setiap model dengan jumlah terbanyak (voting).
2.4.5.3 Directed Acyclic Graph (DAG)
Metode ini menggunakan model SVM dengan jumlah dan persamaan yang sama dengan metode one-against-one hanya saja menggunakan runtutan penentuan keanggotaan kelas dengan cara yang berbeda. Apabila dalam metode one-against-one, setiap perbandingan data input terhadap model SVM akan menghasilkan output berupa keanggotaan kelas tersebut berdasarkan model tadi, maka pada DAG outputnya adalah sebaliknya. Contohnya dalam kasus, apabila suatu input data dibandingkan dengan hyperplane AB dan ternyata ditemukan bahwa input tersebut merupakan anggota kelas A, maka output dari proses tersebut dinyatakan sebagai bukan anggota B. Karena kelas tersebut bukan anggota B, maka persamaan yang tersisa yang mungkin diuji adalah AC, dan output dari pengujian tersebut adalah keanggotaan dari input, karena AC adalah persamaan terakhir yg mungkin diuji. Metode ini memungkinkan jumlah pengujian yang jauh lebih sedikit bila dibandingkan dengan metode one-against-one sehingga dapat dikatakan lebih efisien.
2.5 Kajian Penelitian Terkait DT CWT dan SVM
Penggunaan kombinasi dari DT CWT dan SVM dalam pemrosesan gambar bukan merupakan suatu hal yang baru. Beberapa tim peneliti telah mencoba menerapkan hal ini pada bidang dan obyek yang berbeda-beda, dan terbukti mampu memberikan hasil yang cukup memuaskan. Penelitian tersebut tentunya akan memberikan informasi yang cukup berharga mengenai dampak dari penggunaan kedua metodologi tersebut. Karenanya, bagian selanjutnya akan membahas secara singkat mengenai penelitian-penelitian yang telah berhasil menggunakan kombinasi DT CWT dan SVM dalam bidang pemrosesan gambar.
1. Z. Aghbari dan A. Makinouchi (2003) membuat tulisan berjudul “Semantic Approach to Image Database Classification and Retrieval”. Tujuan dari penelitian yang dilakukan adalah melakukan segmentasi terhadap gambar-gambar pemandangan alam dan menemukan kelas-kelas obyek yang terdapat di dalamnya berdasarkan pada pemahaman semantik seperti yang dilakukan oleh manusia. Dalam penelitian ini, DT CWT digunakan sebagai salah satu metode ekstraksi fitur. Dikatakan salah satu karena dalam penelitian ini digunakan 4 metode ekstraksi fitur yang masing-masing diterapkan pada kelas obyek yang berbeda-beda, tergantung pada semantiknya. Metodologinya diawali dengan segmentasi gambar menggunakan metode hill climbing. Hasil segmentasi tersebut kemudian diekstrak fiturnya dengan menggunakan 4 jenis metode, yaitu histogram warna HSV, Canny edge detector, Higher-order autocorrelation edge vector, dan DT CWT. Setelah fitur-fitur tersebut berhasil diekstrak, SVM digunakan untuk melakukan klasifikasi. Dalam
penelitian ini, digunakan fungsi kernel Gaussian yang dipercaya lebih akurat. Hasil pengujian menunjukkan hasil yang cukup memuaskan yang dimana precision mencapai angka antara 84% – 97%.
2. G. Y. Chen et al. (2006) menggunakan kombinasi dari DT CWT dan SVM untuk melakukan klasifikasi terhadap sidik telapak tangan dalam tulisannya yang berjudul “Palmprint Classification Using Dual-Tree Complex Wavelets”. Dalam metodologinya, DT CWT sebanyak 4 tingkat digunakan untuk melakukan ekstraksi dari sidik telapak tangan. Kemudian Fourier transform 2D diterapkan kepada setiap subband yang diperoleh dari proses DT CWT sebelumnya, untuk mendapatkan komposisi spektrum. Hasil dari ekstraksi fitur tersebut digunakan untuk melakukan pelatihan terhadap SVM dengan fungsi kernel Gaussian RBF. Selanjutnya, dilakukan pengujian terhadap tingkat klasifikasi dari metodologi tersebut. Dalam pengujian, 100 variasi gambar jenis sidik tangan dimana masing-masing jenis terdiri atas 6 gambar digunakan. Hasil pengujian menunjukkan bahwa metode ini memberikan hasil yang lebih baik dibandingkan dengan metode-metode yang digunakan sebelumnya.
3. G. Y. Chen et al. (2006) pada tulisannya berjudul “Pattern Recognition with SVM and Dual-tree Complex Wavelets” melaporkan penelitiannya mengenai penerapan DT CWT dan SVM pada pengenalan angka yang ditulis tangan. Langkah-langkah pemrosesan diawali dengan peletakan suatu titik di tengah gambar tulisan tangan yang dilanjutkan dengan pengskalaan hingga gambar tersebut berukuran 32 x 32. Kemudian, transformasi DT CWT dilakukan. Langkah tersebut diulang pada
keseluruhan data pelatihan. Setelah semua data selesai di proses, barulah pelatihan SVM dimulai. Langkah selanjutnya adalah melakukan pengujian terhadap keberhasilan pengenalan pola dari metodologi tersebut. Pada penelitian ini, sejumlah fungsi kernel digunakan sebagai eksperimen. Hasil akhirnya menyatakan bahwa fungsi kernel Gaussian RBF dan wavelet memberikan hasil yang terbaik. Dalam pelatihannya, digunakan 800 gambar tulisan tangan dan 400 lainnya pada tahap pengujian. Di sini, yang menjadi fokus pengujian adalah tulisan tangan 4 dan 9, karena kemiripan keduanya. Hasil pengujian memberikan hasil yang sangat baik dan merupakan peningkatan yang cukup tinggi bila dibandingkan dengan metode yang digunakan sebelumnya.
4. A. Mumtaz et al. (2008) dalam tulisannya berjudul “Enhancing Performance of Image Retrieval Systems Using Dual Tree Complex
Wavelet Transform and Support Vector Machines”, menggunakan DT
CWT dan SVM untuk meningkatkan performa pengambilan gambar dalam suatu sistem CBIR. Dalam penulisan ini, dikatakan bahwa terdapat hubungan non-linear antara vektor fitur dari setiap gambar, dimana hal ini dapat dieksploitasi dengan mudah oleh SVM. Pada metodologinya, DT CWT digunakan untuk melakukan ekstraksi fitur terhadap gambar-gambar pelatihan. Kemudian, hasil dari ekstraksi fitur tersebut digunakan sebagai data pelatihan terhadap SVM. SVM tersebut menggunakan fungsi kernel RBF, dan menggunakan metode one-against-all untuk mengatasi masalah multi-kelas. Langkah selanjutnya yang cukup menarik, jarak antara setiap gambar dengan setiap support vector dihitung, dikelompokkan untuk
membentuk vektor jarak, dan kemudian disimpan ke dalam database. Langkah-langkah yang telah disebutkan sebelumnya, dilakukan secara offline dan merupakan bagian dari proses pelatihan. Pada saat pengujian, sebuah input gambar akan diberikan, dimana input gambar tersebut kemudian akan diekstrak fiturnya dengan menggunakan DT CWT. Hasil ekstraksi fitur tersebut kemudian akan dihitung vektor jaraknya dan dibandingkan dengan vektor-vektor jarak yang terdapat di dalam database. Akhirnya, sejumlah gambar dengan jarak paling minimum dengan input gambar tersebut akan dikembalikan sebagai output. Dalam pengujiannya, digunakan 100 jenis gambar tekstur yang masing-masing jenis terdiri atas 16 gambar. Hasil dari pengujian metode ini dibandingkan dengan metode-metode yang digunakan sebelumnya dan menunjukkan peningkatan yang cukup signifikan.