METODE BOOTSTRAP DAN APLIKASINYA
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Program Studi Matematika
Oleh:
Amelia Enrika
NIM: 083114001
PROGRAM STUDI MATEMATIKA, JURUSAN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
i
METODE BOOTSTRAP DAN APLIKASINYA
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Program Studi Matematika
Oleh:
Amelia Enrika
NIM: 083114001
PROGRAM STUDI MATEMATIKA, JURUSAN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
BOOTSTRAP METHOD AND ITS APPLICATIONS
Thesis
Presented as Partial Fulfillment of the Requirements
to Obtain the Sarjana Sains Degree in Mathematics
By:
Amelia Enrika
Student Number: 083114001
MATHEMATICS STUDY PROGRAM, DEPARTMENT OF MATHEMATICS
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
To reach a port, we must sail
Sail, not tie at anchor
Sail, not drift.
-Franklin Roosevelt-
vii
ABSTRAK
Tulisan ini membahas tentang metode bootstrap yang prinsipnya adalah memperlakukan sampel acak asli sebagai populasi, kemudian melakukan resampel sebanyak 𝑏𝑏 kali sebanyak mungkin, sehingga diharapkan distribusi dari sampel bootstrap tersebut mendekati normal. Dengan demikian, distribusi sampling bootstrap tersebut dapat digunakan untuk memberikan penjelasan tentang distribusi sampling, serta distribusi populasi.
Aplikasi metode bootstrap dalam statistika yang dibahas adalah pada pendugaan parameter populasi rata-rata, galat standar dan koefisien regresi linear berganda, serta pendugaan selang kepercayaan untuk rata-rata populasi dan koefisien regresi linear berganda. Pada pendugaan parameter rata-rata populasi dan galat standar digunakan metode bootstrap biasa, sedangkan untuk pendugaan selang kepercayaannya digunakan metode persentil bootstrap. Persentil bootstrap membentuk selang kepercayaan (1− 𝛼𝛼)% dengan cara mengambil data persentil ke (𝛼𝛼⁄2)100 dan (1−(𝛼𝛼⁄2))100 sebagai batas bawah dan atas selang, dari 𝑏𝑏 buah replikasi bootstrap. Pada regresi linear berganda, metode bootstrap dibedakan menjadi dua, yaitu resampling pasangan terurut observasi dan resampling galat dari model regresi linear berganda. Selang kepercayaan koefisien regresi dipadukan antara kedua metode tersebut dengan metode persentil bootstrap.
Pendugaan parameter populasi dengan bootstrap dianggap cukup mendekati parameter penduga asli dan distribusinya mendekati normal seiring membesarnya nilai 𝑏𝑏 dan selang kepercayaan yang dibentuk dengan persentil bootstrap selalu menghasilkan selang yang lebih sempit dibandingkan dengan selang kepercayaan secara teoritis dengan tingkat signifikansi yang sama.
viii
ABSTRACT
This thesis discusses bootstrap method which treats original random sample as a population. The original random sample was resampled 𝑏𝑏 times as many as we can, so that the bootstrap sampling distribution approximates the normal distribution. Thus, the bootstrap distribution could be used to explain the sampling distribution and the population distribution.
Bootstrap method is applied in estimation of population mean, standard error, and multiple linear regression coefficients. In the estimation of mean and standard error of population, we use ordinary bootstrap method, while percentile bootstrap is used to estimate the confidence interval. Percentile bootstrap constructs a (1− 𝛼𝛼)100% confidence interval by taking the (𝛼𝛼⁄2)100 and
(1−(𝛼𝛼⁄2))100 percentile data of 𝑏𝑏 bootstrap replications as a lower limit and upper limit respectively. In multiple linear regression, there are two bootstrap methods, those are pair observation resampling and error/residual resampling. Confidence interval of regression coefficient is built by combining those two methods and percentile bootstrap.
The use of bootstrap method to estimate the population parameter is considered close to ordinary estimator and its distribution is approximate normal distribution as the increasing the value of 𝑏𝑏. At the same level of significance, the percentile bootstrap confidence interval always narrower than theoretical confidence interval.
x
KATA PENGANTAR
Puji dan syukur penulis haturkan kepada Tuhan Yesus Kristus atas berkat
dan rahmat-Nya sehingga penulis dapat menyelesaikan skripsi ini.
Penulis dapat menyusun skripsi ini bukan hanya atas kemampuan dan usaha
penulis semata, tetapi juga berkat bantuan dan dukungan berbagai pihak, oleh
karena itu penulis ingin mengucapkan terima kasih kepada:
1. Bapak Ir. Ig. Aris Dwiatmoko, M.Sc. selaku dosen pembimbing yang telah
dengan sabar memberikan pengarahan dan bimbingan selama proses
penyusunan skripsi ini.
2. Ibu Lusia Krismiyati Budiasih, S.Si., M.Si. selaku Ketua Program Studi
Matematika yang telah memberikan banyak nasehat dan bimbingan selama
penyusunan skripsi, serta Ibu Ch. Enny Murwaningtyas, S.Si., M.Si. yang
telah memberikan banyak bimbingan dalam hal akademik dan perkuliahan.
3. Seluruh bapak dan ibu dosen yang telah memberikan banyak ilmu
pengetahuan kepada penulis.
4. Perpustakaan Universitas Sanata Dharma dan staf sekretariat yang telah
memberikan fasilitas dan kemudahan pembelajaran, serta administrasi bagi
penulis selama masa perkuliahan.
5. Keluarga tersayang, yaitu kedua orang tua, beserta kedua saudari penulis:
Seniyawati dan Novia Paulien yang banyak direpotkan, tetapi terus
memberikan semangat, dukungan, dan doa kepada penulis.
6. Aga Hutama Tirta yang tidak kunjung bosan dan lelah mendukung,
menyemangati, menasehati dan mendengarkan keluh kesah penulis selama
proses penyusunan skripsi ini.
7. Teman-teman penulis: Shelli Moniaga dan Agustina Viktrisia Lily Hertati
yang selalu membantu, serta menyertai penulis dengan doa dan semangat.
Tak lupa terima kasih kepada Irene Saskia atas jempolnya yang setia
xi
8. Teman-teman angkatan 2008 dan 2007 dari Program Studi Matematika yang
telah memberikan banyak pengalaman berharga, baik suka maupun duka,
dalam pembelajaran maupun kehidupan sehari-hari.
9. Semua pihak yang telah membantu penulis, tetapi tidak dapat disebutkan satu
persatu.
Hal yang juga disadari oleh penulis adalah masih banyaknya kekurangan
yang terdapat dalam tulisan ini, namun diharapkan agar hasil tulisan ini tetap
dapat memberikan manfaat bagi kemajuan ilmu pengetahuan, khususnya dalam
bidang matematika serta bagi pembaca tulisan ini. Kritik dan saran yang
membangun sangat penulis harapkan bagi kesempurnaan skripsi ini.
Yogyakarta, Desember 2011
xii
DAFTAR ISI
Halaman
HALAMAN JUDUL ……… i
HALAMAN JUDUL DALAM BAHASA INGGRIS ……… ii
HALAMAN PERSETUJUAN PEMBIMBING ……….. iii
HALAMAN PENGESAHAN ………... iv
HALAMAN PERSEMBAHAN ……… v
HALAMAN PERNYATAAN KEASLIAN KARYA ……….. vi
HALAMAN ABSTRAK ……….. vii
HALAMAN ABSTRACT ………. viii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ……….. ix
KATA PENGANTAR ………... x
DAFTAR ISI ………. xii
DAFTAR GAMBAR ……… xv
DAFTAR TABEL ………. xvi
DAFTAR PROGRAM ……….. xix
BAB I PENDAHULUAN A. Latar Belakang Masalah ………. 1
B. Perumusan Masalah ………... 7
C. Pembatasan Masalah ………. 7
D. Tujuan Penulisan ………... 8
xiii
F. Metode Penulisan ……….. 8
G. Sistematika Penulisan ……… 9
BAB II LANDASAN TEORI A. Teori Sampling 1. Sampling ……… 11
2. Bilangan Random ……….. 14
3. Pembangkit Bilangan Random ……….. 15
4. Distribusi Sampling ……… 16
B. Estimasi 1. Estimasi Titik ………. 26
2. Estimasi Interval ………. 26
C. Regresi Linear Berganda 1. Model Regresi Linear Berganda ……… 28
2. Metode Kuadrat Terkecil ……….. 30
3. Sifat-Sifat Penduga Kuadrat Terkecil ……… 32
4. Selang Kepercayaan Untuk Parameter Regresi ………. 34
BAB III METODE BOOTSTRAP A. Prinsip Dasar Dan Algoritma Metode Bootstrap ………. 35
B. Aplikasi Pendekatan Galat Standar Dari Mean Dengan Metode Bootstrap ………. 46
BAB IV APLIKASI METODE BOOTSTRAP
A. Metode Persentil Bootstrap
xiv
Metode Persentil Bootstrap ……… 54
2. Pembentukan Selang Kepercayaan Dengan Metode Persentil Bootstrap ………. 57
B. Regresi Linear Bootstrap 1. Metode Bootstrap Untuk Pendugaan Parameter Dalam Regresi Linear Berganda ……… 64
a. Algoritma Metode Bootstrap Untuk Meresampling Observasi ……….. 65
b. Algoritma Metode Bootstrap Untuk Meresampling Galat ………. 72
2. Pembentukan Selang Kepercayaan Bootstrap Untuk Parameter Regresi ……… 79
BAB V PENUTUP A. Kesimpulan ……… 87
B. Saran ……….. 88
DAFTAR PUSTAKA ……….. 89
xv
DAFTAR GAMBAR
Halaman
GAMBAR 1.1. ... 4
GAMBAR 2.1. ... 25
GAMBAR 2.2. ... 25
GAMBAR 3.1. ... 35
GAMBAR 3.2. ... 41
GAMBAR 3.3. ... 42
GAMBAR 3.4. ... 42
GAMBAR 3.5. ... 44
GAMBAR 3.6. ... 45
GAMBAR 3.7. ... 115
GAMBAR 3.8. ... 52
GAMBAR 4.1. ... 116
GAMBAR 4.2. ... 66
GAMBAR 4.3. ... 66
GAMBAR 4.4. ... 117
GAMBAR 4.5. ... 118
GAMBAR 4.6. ... 75
GAMBAR 4.7. ... 119
xvi
DAFTAR TABEL
Halaman
TABEL 3.1. ……… 91
TABEL 3.2. ………... 91
TABEL 3.3. ……… 91
TABEL 3.4. ……… 92
TABEL 3.5. ……… 92
TABEL 3.6. ……… 93
TABEL 4.1. ……… 94
TABEL 4.2. ……… 94
TABEL 4.3. ……… 95
TABEL 4.4. ……… 95
TABEL 4.5. ……… 96
TABEL 4.6. ……… 97
TABEL 4.7. ……… 98
TABEL 4.8. ……… 99
TABEL 4.9. ……… 100
TABEL 4.10. ………. 101
TABEL 4.11. ……….. 102
TABEL 4.12. ………. 102
xvii
TABEL 4.14. ………. 103
TABEL 4.15. ………. 103
TABEL 4.16. ………. 103
TABEL 4.17. ………. 104
TABEL 4.18. ………. 104
TABEL 4.19. ………. 104
TABEL 4.20. ………. 105
TABEL 4.21. ………. 105
TABEL 4.22. ………. 106
TABEL 4.23. ………. 106
TABEL 4.24. ………. 106
TABEL 4.25. ………. 107
TABEL 4.26. ………. 107
TABEL 4.27. ………. 107
TABEL 4.28. ………. 108
TABEL 4.29. ………. 108
TABEL 4.30. ………. 108
TABEL 4.31. ………. 109
TABEL 4.32. ………. 109
TABEL 4.33. ………. 109
xviii
TABEL 4.35. ………. 110
TABEL 4.36. ………. 111
xix
DAFTAR PROGRAM
Halaman
PROGRAM 3.1. ……… 121
PROGRAM 4.1. ……… 123
PROGRAM 4.2. ……… 124
PROGRAM 4.3. ……… 127
PROGRAM 4.4. ……… 130
BAB I PENDAHULUAN
A. Latar Belakang Masalah
Sampling, yang berarti pengambilan sampel sering digunakan oleh para
statistikawan atau ilmuwan untuk mempermudah penelitian mereka, karena
ketidakmungkinan peneliti untuk mengobservasi objek-objek populasi secara
menyeluruh. Keterbatasan biaya, waktu, tenaga peneliti dan juga kesulitan
pe-ngumpulan data populasi adalah alasan-alasan dilakukannya sampling.
Ba-nyak metode sampling yang telah diciptakan oleh para peneliti, sebagai contoh
Metode Sampel Acak Sederhana, Metode Stratifikasi, Metode Cluster, dan
se-bagainya. Dari metode sampling ini, muncul pengembangannya, yaitu
resam-pling. Selama beberapa dekade terakhir, telah dilakukan pengembangan
me-tode resampling, Meme-tode Jackknife, Meme-tode Cross-validation dan Meme-tode
Bootstrap merupakan teknik resampling yang sering digunakan para peneliti
dalam menganalisis data.
Dalam kondisi praktis dan statistikal, bentuk distribusi sampling jarang
diketahui secara pasti. Pendekatan parametrik tradisional lebih menekankan
pendugaan distribusi sampling dibandingkan pembuatan inferensi terhadap
pa-rameter populasi dari sebuah sampel. Cara yang digunakan adalah dengan
mengasumsikan bentuk distribusi sampling dari parameter penduga yang
dike-tahui sifat-sifat probabilitasnya (contohnya distribusi normal atau
eksponen-sial). Dalam pendekatan parametrik tradisional, parameter dari distribusi
perhitungan secara analitik menggunakan rumus yang rumit. Namun sering
kali ditemukan kendala berkaitan dengan distribusi sampling. Biasanya
ken-dala tersebut berupa kesulitan mendekati distribusi sampling secara analitik,
baik karena perhitungan yang terlalu sulit atau rumus yang rumit. Selain itu,
pendekatan secara analitik menggunakan asumsi-asumsi tertentu seperti
ben-tuk distribusi, apakah data tersebut normal atau tidak, ataupun bergantung
pa-da Teorema Limit Pusat. Papa-da kenyataannya secara praktis, terkapa-dang para
peneliti tidak bisa bergantung pada asumsi-asumsi tersebut. Kesulitan untuk
mendekati distribusi sampling secara analitik tersebut menyebabkan data tidak
bisa diolah secara analitik. Akibatnya, parameter populasi pun sulit untuk
di-dekati secara analitik. Maka dari itu, banyak dilakukan riset untuk mengolah
data secara langsung dengan komputer untuk menanggulangi
masalah-masalah tersebut.
Perkembangan teknologi komputer yang sangat signifikan dalam
bebe-rapa dekade terakhir ini memberikan pengaruh yang besar dalam bidang
statis-tika. Analisis data menjadi lebih mudah dilakukan dengan adanya otomatisasi
penggambaran grafik dan perhitungan data. Studi statistikal yang melibatkan
himpunan data yang besar dan kompleks sekarang ini mampu dianalisa
de-ngan lebih mudah, sehingga juga berpengaruh pada efisiensi biaya penelitian.
Penelitian dapat dilakukan lebih cepat dan lebih sedikit biaya dibandingkan
dulu karena banyak muncul metode yang menerapkan komputasi yang
sebe-lumnya tidak terpikirkan untuk pendugaan parameter populasi, pembentukan
Pada tahun 1979, Bradley Efron mengembangkan metode Bootstrap
un-tuk pertama kalinya. Metode resampling yang berbasis komputer ini, bukan
metode resampling yang pertama kali muncul. Menurut Kvam dan Vidakovic
(2007), sebelum Metode Bootstrap, ada metode permutasi Fisher, Pitman, dan
metode Jackknife, tetapi metode Bootstrap adalah metode resampling yang
paling populer yang digunakan para peneliti pada saat ini. Metode ini sangat
popular di kalangan para peneliti karena metode ini langsung mengolah data,
menggunakan komputer sebagai pengolah datanya. Lagipula, para peneliti
ti-dak membutuhkan hitungan teoritis untuk mencapai parameter populasi
tu-juannya. Bootstrap baru-baru dikembangkan karena sangat bergantung pada
kecanggihan teknologi komputer untuk melakukan perhitungannya. Dengan
menyimulasikan langsung data-data yang ada, bootstrap menghindarkan kita
dari pembuatan model dan asumsi-asumsi yang tak dibutuhkan tentang
para-meter. Secara imajinatif, metode ini seolah-olah menarik diri sendiri dengan
tali sepatu sendiri (dengan mengambil sampel dari sampel itu sendiri)
diban-ding menggantungkan diri pada bantuan luar (dari asumsi-asumsi parametrik).
Dari sisi tersebut, metode bootstrap terlihat seperti sebuah prosedur
nonpara-metrik. Kenyataannya, bootstrap merupakan teknik resampling yang
meli-batkan bentuk parametrik dan nonparametrik, tetapi pada esensinya,
merupa-kan prosedur yang lebih bersifat empiris.
Efron menganalogikan istilah bootstrap dengan cerita rakyat Inggris,
ya-itu cerita Petualangan Baron von Munchausen. Dikisahkan sang Baron
ta-li sepatunya sendiri. Keadaan di mana sang Baron menggunakan tata-li
sepa-tunya sendiri untuk menyelamatkan dirinya, inilah yang dianalogikan Efron
dalam metode Bootstrap.
Peneliti menggunakan sampel dari sampel itu sendiri untuk mengetahui
parameter populasi. Efron ingin mendeskripsikan metode ini dengan istilah
bootstrap untuk membantu kita memahami karakteristik dari suatu estimator
tanpa bantuan dari model probabilitas tambahan atau asumsi-asumsi
parame-trik. Ketika memperkenalkan versi bootstrap, Efron termotivasi oleh dua
ma-salah yang paling penting dalam statistika terapan, yaitu penentuan penduga
untuk suatu parameter tujuan dan evaluasi dari keakuratan dari penduga
terse-but melalui galat standar dari penduga dan penentuan selang kepercayaan
un-tuk parameter tujuan tersebut. Sampel asli yang pertama kali diambil
dipan-dang sebagai suatu populasi karena sampel asli sebanyak 𝑛𝑛 buah itu dianggap
mewakili karakteristik-karakteristik dari populasi (karena pengambilannya
di-lakukan secara acak). Karena perlakuan itu, metode bootstrap tidak
memerlu-kan asumsi kuat terhadap distribusi sampling dari statistik penduga untuk
mendekati distribusi samplingnya. Jadi begitu pula dengan resampel atau
sampel bootstrap yang diambil dengan pengembalian juga dianggap
merepre-sentasikan populasi sama halnya seperti bila kita mengambil banyak sampel
dari populasi. Banyak dilakukan simulasi dari data-data sampel yang telah
tersedia sangatlah menguntungkan peneliti atau statistikawan. Hal itu
meng-hindarkan kita dari pembuatan asumsi-asumsi yang tidak dibutuhkan tentang
parameter dan model. Bila dibandingkan dengan pendekatan parametrik
tradi-sional, metode bootstrap memuat lebih banyak repetisi dari komputasi data
sampel untuk mendekati bentuk distribusi sampling suatu statistik bila
diban-ding asumsi distribusional yang kuat ataupun formula analitik. Kelebihan
yang lain dari metode ini adalah dapat diterapkan seberapapun sulitnya
ke-mungkinan pencapaian nilai penduga parameter populasi. Para peneliti
ba-nyak menggunakan metode ini untuk diterapkan dalam berbagai bidang,
con-tohnya di bidang psikologi, geologi, ekonometrika, biologi, teknik, kimia dan
akunting. Bootstrap sering digunakan pada bidang-bidang tersebut karena
se-ring kali para peneliti hanya memiliki data sampel yang sangat sedikit.
Metode ini sering digunakan ketika distribusi sampling dari statistik
ti-dak dapat diasumsikan berdistribusi normal (seperti mengestimasi koefisien
regresi dengan Ordinary Least Square), atau ketika distribusi sampling tidak
analitik. Selain itu, bila ukuran populasinya cukup besar sehingga sulit untuk
menentukan kerangka sampel, lebih baik dilakukan resampling dengan
me-tode ini.
Dalam statistika, kita mengenal penduga parameter populasi berupa
se-lang kepercayaan. Sese-lang kepercayaan suatu parameter θ dibentuk dengan
menentukan suatu selang nilai yang dengan peluang besar memuat parameter
yang diduga (parameter populasi) dan erornya harus minimum. Bentuk selang
kepercayaan ada tiga, yaitu:
�∞,𝜃𝜃�𝑈𝑈�,�𝜃𝜃�𝐿𝐿,∞�,�𝜃𝜃�𝐿𝐿,𝜃𝜃�𝑈𝑈�
dengan 𝜃𝜃�𝑈𝑈 adalah batas atas selang dan 𝜃𝜃�𝐿𝐿 adalah batas bawah selang. Dalam tulisan ini, akan diulas bagaimana membentuk selang kepercayaan tersebut
de-ngan metode Bootstrap. Pembentukan selang kepercayaan yang akan diulas
adalah pembentukan selang kepercayaan dengan metode Persentil Bootstrap.
Metode Persentil Bootstrap menghasilkan selang kepercayaan yang lebih
pen-dek, variansi yang lebih kecil, dan tingkat kepercayaan yang lebih tinggi jika
dibandingkan dengan metode lain yang selama ini digunakan.
Metode Bootstrap juga dapat diterapkan pada regresi linear untuk
mere-sampling sampelnya dalam upaya mendekati koefisien-koefisien model
regre-si linear. Prinregre-sip resampling bootstrap dalam regreregre-si linear dibedakan
B. Perumusan Masalah
Permasalahan yang akan dibahas dalam tulisan ini akan dirumuskan
se-bagai berikut:
1. Apakah yang dimaksud dengan metode Bootstrap dan bagaimana landasan
teoritiknya?
2. Bagaimana penerapan metode Bootstrap pada pendugaan selang parameter
populasi dan parameter regresi linear berganda?
3. Bagaimana algoritma dan pemrograman MATLAB untuk pendugaan
se-lang parameter populasi dengan menggunakan metode Bootstrap?
4. Bagaimana algoritma dan pemrograman MATLAB untuk pendugaan
pa-rameter regresi dengan menggunakan metode Bootstrap?
C. Pembatasan Masalah
Penulis akan membatasi beberapa hal untuk uraian masalah yang akan
dibahas, yaitu:
1. Distribusi normal dan Student-t tidak dibahas dalam tulisan ini.
2. Pembentukan selang parameter populasi dengan prinsip Bootstrap dibatasi
hanya menggunakan metode Persentil Bootstrap.
3. Aplikasi metode bootstrap hanya dibatasi pada pendugaan parameter
rata-rata populasi, parameter koefisien regresi berganda, selang kepercayaan
D. Tujuan Penulisan
Tulisan ini disusun dengan tujuan agar dapat lebih memahami salah satu
teknik resampling yang sering digunakan dalam statistika, yaitu Metode
Boot-strap. Terlebih lagi, akan dipelajari prinsip Bootstrap dalam metode Persentil
Bootstrap untuk membangun selang kepercayaan parameter populasi. Selain
itu, prinsip bootstrap dalam regresi linear berganda juga dipelajari dalam
tuli-san ini. Sebagai tambahan, kitapun akan mempelajari bagaimana penerapan
prinsip-prinsip tersebut dalam pemrograman MATLAB. Tulisan ini juga
di-susun sebagai pemenuhan tugas akhir dalam Program Studi Matematika
Un-iversitas Sanata Dharma.
E. Manfaat Penulisan
Dengan memperlajari topik ini kita dapat mempelajari
kegunaan-kegunaan metode Bootstrap dalam membangun selang penduga parameter
po-pulasi dengan memanfaatkan data-data yang ada. Kita juga dapat mempelajari
prinsip bootstrap dalam pengambilan sampel dalam regresi linear berganda.
Terlebih dari itu, kita juga dapat menerapkan metode tersebut dalam algoritma
dan pemrograman MATLAB sehingga proses komputasi lebih efektif dan
efi-sien.
F. Metode Penulisan
Penulis menggunakan metode studi kepustakaan, yaitu dengan
sam-pling guna mencari perannya dalam membangun selang penduga parameter
populasi dan penduga parameter regresi linear berganda.
G. Sistematika Penulisan
BAB I. PENDAHULUAN
A. Latar Belakang Masalah
B. Perumusan Masalah
C. Pembatasan Masalah
D. Tujuan Penulisan
E. Manfaat Penulisan
F. Metode Penulisan
G. Sistematika Penulisan
BAB II. LANDASAN TEORI
A. Teori Sampling
B. Estimasi
C. Regresi Linear Berganda
BAB III. METODE BOOTSTRAP
A. Prinsip Dasar Dan Algoritma Metode Bootstrap
B. Aplikasi Pendekatan Galat standar Dari Mean Dengan Metode
BAB IV. APLIKASI METODE BOOTSTRAP
A. Metode Persentil Bootstrap
B. Regresi Bootstrap
BAB V. PENUTUP
A. Kesimpulan
B. Saran
DAFTAR PUSTAKA
BAB II
LANDASAN TEORI
A. Teori Sampling 1. Sampling
Dalam statistika, selalu ditemui istilah populasi atau semesta. Istilah
ini mengacu pada sekumpulan dari individu-individu atau atributnya, yang
dapat dispesifikasikan secara numerik. Contohnya, populasi dari berat
ba-dan, harga beras, dan sebagainya. Populasi yang memiliki elemen yang
terhingga jumlahnya disebut sebagai populasi terhingga. Contohnya
ada-lah populasi dari berat badan 48 siswa di suatu kelas. Istiada-lah yang juga
sering dijumpai adalah sampel. Sampel merupakan bagian yang terpilih
dari suatu populasi dan proses pemilihan bagian terpilih tersebut disebut
sebagai sampling.
Sampling atau penarikan sampel, bertujuan untuk memperoleh
in-formasi (sebanyak mungkin) yang mendukung pengamatan variabel
ter-tentu guna mendapatkan keterangan tentang suatu populasi. Secara
khu-sus, sampling dilakukan untuk mengestimasi parameter tertentu dari suatu
populasi. Pemilihan sampel harus dilakukan secara acak (sampling acak)
agar semua elemen populasi memiliki peluang yang sama untuk terpilih.
Bilangan random (yang akan dibahas dalam subbab berikutnya) digunakan
Definisi 2.1.
Diberikan 𝑁𝑁 dan 𝑛𝑛 yang mewakili banyaknya elemen dari ukuran populasi dan ukuran sampel secara berturut-turut. Bila samplingnya diperoleh
den-gan suatu cara sedemikian sehingga setiap dari �𝑁𝑁𝑛𝑛� buah sampel memiliki
probabilitas yang sama untuk terpilih, sampling tersebut dikatakan acak
dan hasilnya dikatakan sampel acak.
Dengan sampling sederhana, kita bermaksud melakukan sampling
acak secara bersamaan. Cara ini merupakan cara untuk memilih 𝑛𝑛 buah sampel acak dari 𝑁𝑁 anggota populasi, sehingga 𝐶𝐶𝑛𝑛𝑁𝑁 sampel yang berbeda memiliki peluang yang sama untuk dipilih. Dengan begitu, setiap sampel
memiliki probabilitas yang independen dan konstan. Tiap sampel diambil
satu-persatu setelah sebelumnya dinomori dari 1 sampai 𝑁𝑁. Kemudian, bi-langan-bilangan random bernilai di antara 1 sampai 𝑁𝑁 dibangkitkan dan digunakan untuk memilih secara acak.
Terdapat dua macam cara penarikan sampel berdasarkan
pengemba-lian sampel, yaitu sampling tanpa pengembalian dan sampling dengan
pe-ngembalian. Menurut buku Encyclopedia of Statistical Sciences (2006),
“Sampling is said to be with or without replacement according as to
whether or not the same member of the population may be selected more
than once.”, kemungkinan suatu anggota dari populasi dapat dipilih lebih
Bila sebuah sampel yang diambil pada pengambilan pertama tidak
dikembalikan sebelum pengambilan sampel yang kedua, dan begitu
sete-rusnya, maka cara ini disebut dengan sampling tanpa pengembalian.
Sam-pling dengan metode ini tidak termasuk dalam samSam-pling sederhana karena
probabilitas terpilihnya sampel tidak konstan. Pada sampling tanpa
pen-gembalian, pengambilan pertama pada sebuah himpunan sampel
berukur-an 𝑛𝑛 memiliki probabilitas sebesar 𝑛𝑛 𝑁𝑁⁄ . Pengambilan kedua memiliki probabilitas sebesar (𝑛𝑛 −1) (⁄ 𝑁𝑁 −1) karena anggota sampel dan populasi masing-masing berkurang 1 anggota dengan tidak dilakukannya
pengem-balian sampel. Begitu pula untuk pengambilan ketiga dan seterusnya.
Maka dari itu, untuk sampling tanpa pengembalian, probabilitas semua 𝑛𝑛 buah sampel dapat dipilih dalam 𝑁𝑁 kali pengambilan adalah:
𝑛𝑛
Pada sampling dengan pengembalian, sampel yang sebelumnya telah
diambil, dikembalikan terlebih dulu sebelum mengambil sampel
berikut-nya. Jadi, sampel ke-i dapat muncul 0,1,2, … ,𝑛𝑛 kali dalam himpunan sampelnya. Karena adanya pengembalian, seluruh unit sampel memiliki
peluang yang sama untuk dipilih, berapa kalipun sampel tersebut sudah
terpilih sebelumnya. Jadi, pada sampling dengan pengembalian,
probabili-tas masing-masing 𝑛𝑛 buah sampel untuk terpilih adalah 1⁄𝑁𝑁.
Alasan dilakukannya sampling yaitu, adalah suatu hal yang mustahil
bila seorang peneliti mengamati seluruh anggota dari populasi. Kalaupun
waktu dan sumber daya manusia yang tidak sedikit. Suatu populasi,
mi-salnya darah dalam tubuh manusia, tidak mungkin diobservasi seluruhnya
karena pengamatan seperti itu bersifat destruktif bagi populasi. Sering kali
pula populasi dianggap terlalu dinamis, dapat berubah-ubah
sewaktu-waktu, contohnya populasi penduduk suatu daerah. Sebenarnya
peng-amatan secara keseluruhan anggota populasi mungkin saja dilakukan dan
akan menghasilkan keterangan tentang populasi yang lebih tepat dan
aku-rat dibandingkan dengan mengamati sampel. Meskipun begitu, kita perlu
menjaga keseimbangan antara ketepatan hasil dengan banyaknya sumber
daya yang harus dikorbankan dengan mengamati populasi secara
menyelu-ruh. Karena itulah, para peneliti lebih memilih untuk mengamati sampel,
dengan syarat galat pengamatan diminimalisir daripada mengorbankan
ba-nyak sumber daya untuk penelitian populasi. Keterangan tentang populasi
dengan galat yang minimal dianggap cukup memuaskan bagi peneliti.
2. Bilangan Random
Sebelum teknologi komputer dan simulasi matematis berkembang
seperti sekarang ini, bilangan random biasanya didapat dari tabel bilangan
random yang disusun oleh L. H. C. Tippet. Tabel tersebut terdiri dari
10.400 buah bilangan empat digit. Bilangan random ini sangat diperlukan
untuk metode statistika yang bersifat probabilistik, seperti metode
dibang-kitkan dengan menggunakan komputer, sehingga simulasi matematis dapat
dilakukan dengan mudah.
Sifat bilangan random yang acak diterapkan untuk membangkitkan
nilai dari variabel-variabel random untuk sembarang distribusi. Bilangan
random dibangkitkan dengan menggunakan algoritma numerik. Algoritma
numerik tersebut membuat barisan bilangan yang bersifat deterministik.
Bila dilihat tanpa mengetahui algoritmanya, bilangan-bilangan tersebut
terlihat acak. Sifat acak yang sebenarnya didapatkan dari algoritma inilah
yang menyebabkan sifat semu dari bilangan random tersebut. Maka dari
itu, bilangan random sering kali disebut sebagai bilangan pseudorandom.
3. Pembangkit Bilangan Random
Cara yang paling sederhana untuk membangkitkan bilangan random
yaitu dengan menggunakan Linear Congruential Generators.
Langkah pertama dimulai dengan nilai awal 𝑥𝑥0, lalu secara rekursif menghitung nilai-nilai selanjutnya 𝑥𝑥𝑛𝑛, 𝑛𝑛 ≥1, dengan rumus:
𝑥𝑥𝑛𝑛 =𝑚𝑚𝑥𝑥𝑛𝑛−1+𝑐𝑐 modulo 𝑛𝑛
di mana 𝑚𝑚,𝑛𝑛 ∈ ℤ+ (ℤ+ adalah himpunan bilangan bulat positif) dan
𝑚𝑚𝑥𝑥𝑛𝑛−1 dapat dibagi oleh 𝑛𝑛 dan sisanya diambil sebagai nilai dari 𝑥𝑥𝑛𝑛.
Se-tiap 𝑥𝑥𝑛𝑛, nilainya bisa bernilai 0, 1, … ,𝑛𝑛 −1 dan nilai dari 𝑥𝑥𝑛𝑛⁄𝑛𝑛 lah yang disebut sebagai bilangan random. Bilangan ini diambil sebagai
Sebagai contoh, bila diambil 𝑚𝑚 = 13, 𝑐𝑐 = 0, 𝑛𝑛= 31, dan 𝑥𝑥0 = 1,
akan didapatkan deret sebagai berikut:
1, 13, 14, 27, 10, 6, 16, 22, …
Rumus rekursif untuk 𝑥𝑥𝑛𝑛 akan menghasilkan 30 bilangan bulat yang me-rupakan permutasi dari 1 sampai 30. Hal ini akan berulang ketika ketiga
puluh bilangan sudah termuat dalam 30 bilangan pertama dalam deret.
Pe-riode perulangan ini biasanya terjadi pada saat 𝑛𝑛 −1.
Sesuai dengan aturan bilangan random, kita telah mendapatkan
bari-san untuk 𝑥𝑥𝑛𝑛 dan untuk membangkitkan bilangan random, kita tinggal membagi masing-masing 𝑥𝑥𝑛𝑛 dengan 𝑛𝑛 = 31. Dengan begitu, kita akan mendapatkan barisan:
0.03225, 0.41935, 0.45161, 0.87097, 0.32258, 0.19355, 0.51613, 0.70968, …
Barisan bilangan itu disebut dengan bilangan pseudorandom.
Pada program MATLAB, bilangan random dapat dibangkitkan
de-ngan mudah, dede-ngan menggunakan fungsi tertentu. Matriks akan
dibang-kitkan dalam bentuk vektor kolom atau matriks. Fungsi pembangkit
bi-langan randomnya adalah
rand(n) dan rand(m,n)
di mana m adalah banyaknya baris dan n adalah banyaknya kolom.
4. Distribusi Sampling
Sebuah statistik pada dasarnya adalah penduga bagi parameter
popu-lasi tersebut. Statistik berkaitan erat dengan distribusi dari sampel yang
te-lah diamati. Distribusi ini yang menentukan kesimpulan tentang distribusi
dari populasi.
Definisi 2.2.
Statistik adalah sebuah fungsi dari variabel random yang dapat diobservasi
dalam sebuah sampel dan diketahui sebagai konstanta. Statistik digunakan
untuk membuat inferensi (estimasi atau keputusan) tentang parameter
po-pulasi yang tidak diketahui.
Karena statistik adalah fungsi dari variabel random yang diobservasi
dalam sebuh sampel, jadi statistik itu sendiri adalah variabel random.
Dis-tribusi probabilitas dari suatu statistik tersebut disebut distribusi sampling.
Untuk membentuk distribusi sampling secara teoritis dari sebuah statistik,
akan bergantung pada distribusi dari random variabel yang dapat
diobser-vasi pada sampel.
Distribusi sampling yang berkaitan dengan distribusi normal sangat
diperlukan karena dibutuhkan untuk mendekati distribusi normal. Hal ini
disebabkan oleh banyaknya pengamatan konkrit yang memiliki distribusi
yang dapat dimodelkan dengan distribusi normal. Misalkan diberikan
va-riabel random 𝑋𝑋1,𝑋𝑋2, … ,𝑋𝑋𝑛𝑛 yang dapat diobservasi pada suatu sampel acak, teorema berikut membentuk distribusi sampling dari statistik
Teorema 2.1.
Diberikan variabel random 𝑋𝑋1,𝑋𝑋2, … ,𝑋𝑋𝑛𝑛 yang secara independen berdis-tribusi normal dengan 𝑆𝑆(𝑋𝑋𝑡𝑡) =𝜇𝜇𝑡𝑡 dan 𝑉𝑉𝑚𝑚𝑛𝑛(𝑋𝑋𝑡𝑡) =𝜎𝜎𝑡𝑡2, 𝑡𝑡= 1,2, … ,𝑛𝑛.
Di-definisikan 𝑈𝑈 sebagai
𝑈𝑈 =� 𝑚𝑚𝑡𝑡𝑋𝑋𝑡𝑡
𝑛𝑛
𝑡𝑡=1
= 𝑚𝑚1𝑋𝑋1+𝑚𝑚2𝑋𝑋2 +⋯+𝑚𝑚𝑛𝑛𝑋𝑋𝑛𝑛
di mana 𝑚𝑚1,𝑚𝑚2, … ,𝑚𝑚𝑛𝑛 konstan. Maka 𝑈𝑈 adalah variabel random yang ber-distribusi normal dengan
𝑆𝑆(𝑈𝑈) =� 𝑚𝑚𝑡𝑡𝜇𝜇𝑡𝑡
𝑛𝑛
𝑡𝑡=1
𝑉𝑉𝑚𝑚𝑛𝑛(𝑈𝑈) =� 𝑚𝑚𝑡𝑡2𝜎𝜎
𝑡𝑡2 𝑛𝑛
𝑡𝑡=1 Bukti:
Karena 𝑋𝑋𝑡𝑡 berdistribusi normal dengan mean 𝜇𝜇𝑡𝑡 dan variansi 𝜎𝜎𝑡𝑡2, 𝑋𝑋𝑡𝑡 memiliki Fungsi Pembangkit Momen (FPM)
𝑛𝑛𝑋𝑋𝑡𝑡(𝑡𝑡) = exp�𝜇𝜇𝑡𝑡𝑡𝑡+
𝜎𝜎𝑡𝑡2𝑡𝑡2
2 �
maka dari itu, 𝑚𝑚𝑡𝑡𝑋𝑋𝑡𝑡 memiliki FPM
𝑛𝑛𝑚𝑚𝑡𝑡𝑋𝑋𝑡𝑡(𝑡𝑡) =𝑆𝑆(𝑃𝑃𝑡𝑡𝑚𝑚𝑡𝑡𝑋𝑋𝑡𝑡) =𝑛𝑛𝑋𝑋𝑡𝑡(𝑚𝑚𝑡𝑡𝑡𝑡) = exp�𝜇𝜇𝑡𝑡𝑚𝑚𝑡𝑡𝑡𝑡+
𝑚𝑚𝑡𝑡2𝜎𝜎𝑡𝑡2𝑡𝑡2
2 �
Karena 𝑋𝑋𝑡𝑡 independen, maka 𝑚𝑚𝑡𝑡𝑋𝑋𝑡𝑡 juga independen untuk 𝑡𝑡 = 1,2, … ,𝑛𝑛, maka
dengan 𝑚𝑚1 = 1⁄𝑛𝑛, 𝑡𝑡= 1,2, … ,𝑛𝑛.
Maka dari itu, Teorema 2.1 dapat digunakan untuk menyimpulkan bahwa
𝑋𝑋� berdistribusi normal dengan
𝑆𝑆(𝑋𝑋�) =𝑆𝑆 �1
Efron (1993) menjelaskan bahwa bila diberikan variabel random 𝑋𝑋 dengan fungsi probabilitas 𝑓𝑓(𝑋𝑋), nilai harapan 𝑆𝑆(𝑋𝑋), dan variansi
𝑉𝑉𝑚𝑚𝑛𝑛(𝑋𝑋), galat standar dari mean 𝑋𝑋�, yang dinotasikan sebagai 𝑆𝑆𝑆𝑆(𝑋𝑋�)
ada-lah akar dari variansi dari 𝑋𝑋�, yaitu
Teorema 2.3. (Teorema Limit Pusat)
maka fungsi distribusi dari 𝑈𝑈𝑛𝑛 akan mendekati fungsi distribusi normal stan-dar dengan 𝑛𝑛 → ∞.
Bukti:
Sebuah variabel random didefinisikan sebagai berikut
Mengingat bahwa fungsi pembangkit momen dari jumlahan
variabel-variabel random yang independen adalah perkalian dari fungsi pembangkit
momen individualnya masing-masing, maka
𝑛𝑛𝑛𝑛(𝑡𝑡) =�𝑛𝑛𝑍𝑍� 𝑡𝑡
𝑛𝑛 → ∞. Salah satu cara untuk menghitung nilai limit tersebut adalah
den-gan menggunakan ln𝑛𝑛𝑛𝑛(𝑡𝑡), di mana
di mana suku-suku selanjutnya dalam ekspansi tersebut melibatkan 𝑥𝑥3,𝑥𝑥4, dan seterusnya. Dengan dikalikan dengan 𝑛𝑛, tampak bahwa suku pertama,
me-miliki 𝑛𝑛 dengan pangkat positif pada penyebutnya. Maka dari itu, dapat ditunjukkan bahwa
lim
𝑛𝑛→∞ln𝑛𝑛𝑛𝑛(𝑡𝑡) =
𝑡𝑡2 2
atau
lim
𝑛𝑛→∞𝑛𝑛𝑛𝑛(𝑡𝑡) =𝑃𝑃 𝑡𝑡2
2
adalah fungsi pembangkit momen untuk variabel random normal standar.
Dengan begitu, kita dapat menyimpulkan bahwa 𝑈𝑈𝑛𝑛 memiliki fungsi dis-tribusi yang mendekati variabel random normal standar.
Galat standar adalah cara yang paling umum dan sederhana untuk
mengindikasikan keakuratan secara statistikal. Kita mengharapkan 𝑋𝑋� akan berada kurang dari satu galat standar dari 𝜇𝜇, ekspektasinya berkisar 68% dan kurang dari dua galat standar, ekspektasinya sekitar 95%. Persentase
tersebut berasal dari Teorema Limit Pusat, dalam kondisi umum, distribusi
dari 𝑋𝑋� akan mendekati distribusi normal seiring dengan membesarnya nilai
𝑛𝑛. Pada kondisi inilah metode Bootstrap lebih menguntungkan kita.
Teo-rema Limit Pusat tersebut tidak perlu dijadikan pedoman utama untuk
mendapatkan pernyataan keakuratan statistik penduga mengenai populasi.
Galat standar dari mean dapat kita dekati langsung dengan bootstrap.
Terdapat contoh yang sederhana yang menunjukkan keterbatasan
da-ri Teorema Limit Pusat. Dibeda-rikan 𝑋𝑋1,𝑋𝑋2, … ,𝑋𝑋𝑛𝑛 adalah variabel random yang saling independen dan nilai-nilainya memiliki dua kemungkinan,
berdistribusi binomial dengan 𝑛𝑛 kali ulangan dan probabilitas sukses sebe-sar 𝑝𝑝 dan 𝑌𝑌 adalah jumlahan dari 𝑋𝑋1,𝑋𝑋2, … ,𝑋𝑋𝑛𝑛.
𝑌𝑌= � 𝑋𝑋𝑡𝑡
𝑛𝑛
𝑡𝑡=1
Variabel random 𝑋𝑋1,𝑋𝑋2, … ,𝑋𝑋𝑛𝑛 saling independen karena ulangannya saling bebas. Maka dari itu, untuk 𝑛𝑛 yang besar, proporsi ulangan yang sukses adalah
𝑌𝑌 𝑛𝑛 =
1 𝑛𝑛 � 𝑋𝑋𝑡𝑡
𝑛𝑛
𝑡𝑡=1
= 𝑋𝑋�
Jadi 𝑋𝑋� akan memiliki distribusi sampling yang mendekati distribusi nor-mal dengan mean 𝑆𝑆(𝑋𝑋𝑡𝑡) =𝑝𝑝 dan 𝑉𝑉𝑚𝑚𝑛𝑛(𝑋𝑋𝑡𝑡)⁄𝑛𝑛= 𝑝𝑝(1− 𝑝𝑝)⁄𝑛𝑛.
Pendekatan normal untuk distribusi binomial akan bekerja dengan
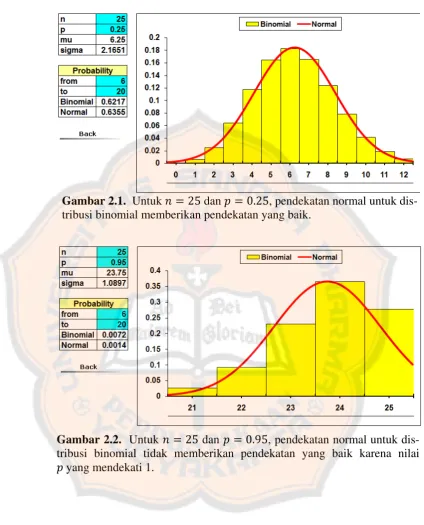
efektif untuk 𝑛𝑛 yang besar, tetapi ketika nilai 𝑝𝑝 mendekati 0 atau 1, atau dapat juga dikatakan nilai 𝑝𝑝 yang berada di sekitar 0.5, pendekatan ini ti-dak lagi efektif. Gambar 2.1 dan Gambar 2.2 berikut menggambarkan
ke-lemahan Teorema Limit Pusat dalam pendekatan normal untuk distribusi
binomial tersebut. Hal ini terjadi karena Teorema Limit Pusat memiliki
kesimetrisan dalam segi bentuk, dan untuk nilai 𝑝𝑝 yang berada di sekitar 0.5, distribusi binomial memiliki kesimetrisan, sehingga pendekatan
B. Estimasi
Penentuan penduga atau estimator untuk suatu parameter populasi
(con-tohnya: mean, proporsi, dll) merupakan salah satu masalah yang mendasar
da-lam statistika. Cara untuk mengestimasi penduga tersebut dibedakan menjadi
dua, yaitu estimasi titik dan estimasi interval.
Gambar 2.1. Untuk 𝑛𝑛= 25 dan 𝑝𝑝= 0.25, pendekatan normal untuk dis-tribusi binomial memberikan pendekatan yang baik.
Gambar 2.2. Untuk 𝑛𝑛 = 25 dan 𝑝𝑝= 0.95, pendekatan normal untuk dis-tribusi binomial tidak memberikan pendekatan yang baik karena nilai
Definisi 2.3.
Estimator adalah aturan yang menentukan bagaimana menghitung sebuah
penduga berdasarkan pengukuran (observasi) yang termuat dalam sebuah
sampel.
1. Estimasi Titik Definisi 2.4.
Penentuan suatu nilai tunggal yang dapat sebaik-baiknya mendekati nilai
parameter populasi yang tidak diketahui disebut sebagai estimasi titik.
Bila 𝜃𝜃 adalah parameter populasi dan 𝜃𝜃� adalah penduga dari 𝜃𝜃, maka kita berharap nilai-nilai dugaan akan berada di sekitar parameter yang
di-tuju. Ada banyak kemungkinan, bisa saja penduga akan berpusat di
seki-tar parameter tujuan ataupun tidak. Bila penduga berada di sekiseki-tar
para-meter tujuan, maka nilai harapan dari distribusi nilai dugaan akan sama
dengan parameter yang diduga (𝑆𝑆�𝜃𝜃��=𝜃𝜃). Sebagai contoh, 𝑋𝑋�, 𝑝𝑝̂, dan
𝑋𝑋�1− 𝑋𝑋�2 adalah penduga titik yang baik.
2. Estimasi Interval Definisi 2.5.
Penentuan suatu selang nilai yang dengan peluang besar memuat
Estimasi interval bertujuan untuk membangun suatu selang nilai dari
parameter tujuan yang berpeluang besar memuat nilai sebenarnya dari
pa-rameter tujuan. Selang kepercayaan dari papa-rameter populasi juga
diguna-kan untuk mengindikasidiguna-kan reliabilitas dari sebuah penduga.
Informasi-informasi yang terdapat pada sampel digunakan untuk membentuk dua
buah nilai yang membentuk batas atas dan batas bawah selang. Bila
dike-tahui 𝜃𝜃 dan 𝜃𝜃� (penduga dari 𝜃𝜃), maka berdasarkan batas atas dan bawah selang, terdapat tiga bentuk selang kepercayaan yaitu, �𝜃𝜃�𝑐𝑐,𝜃𝜃�𝑟𝑟�,�𝜃𝜃�𝑐𝑐,∞�,
dan �∞,𝜃𝜃�𝑟𝑟�.
Definisi 2.6.
Diberikan 𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛 memiliki fungsi distribusi probabilitas
𝑓𝑓(𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛;𝜃𝜃);𝜃𝜃 ∈ 𝛀𝛀, di mana 𝛀𝛀 adalah sebuah selang. Diketahui 𝐿𝐿 dan 𝑈𝑈 adalah statistik, misalkan 𝐿𝐿= 𝑐𝑐(𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛) dan 𝑈𝑈 = 𝑟𝑟(𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛). Bila dalam sebuah data percobaan 𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛,
ke-mudian telah dicari nilai 𝑐𝑐(𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛) dan 𝑟𝑟(𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛).
Selang �𝑐𝑐(𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛),𝑟𝑟(𝑥𝑥1,𝑥𝑥2, … , 𝑥𝑥𝑛𝑛)� dikatakan selang kepercayaan
(1− 𝛼𝛼)100% untuk 𝜃𝜃 bila
𝑃𝑃[𝑐𝑐(𝑥𝑥1, … ,𝑥𝑥𝑛𝑛) <𝜃𝜃 <𝑟𝑟(𝑥𝑥1, … ,𝑥𝑥𝑛𝑛)] = 1− 𝛼𝛼
di mana 0 < (1− 𝛼𝛼) < 1. Nilai observasi 𝑐𝑐(𝑥𝑥1, … ,𝑥𝑥𝑛𝑛) dan 𝑟𝑟(𝑥𝑥1, … ,𝑥𝑥𝑛𝑛)
secara berturut-turut disebut sebagai batas bawah dan batas atas selang
(1− 𝛼𝛼) adalah simbol untuk probabilitas dari selang kepercayaan atau juga disebut sebagai koefisien kepercayaan atau tingkat kepercayaan.
Tingkat kepercayaan ini menentukan seberapa sering atau seberapa besar
peluang sebuah selang memuat parameter populasi tujuan.
Bentuk selang pada Definisi 2.6 merupakan bentuk selang
keper-cayaan dua sisi sedangkan pada Definisi 2.7 berikut akan didefinisikan
bentuk selang kepercayaan satu sisi.
Definisi 2.7.
Selang Kepercayaan Satu Sisi
a. Bila
𝑃𝑃[𝑐𝑐(𝑥𝑥1, … ,𝑥𝑥𝑛𝑛) <𝜃𝜃] = 1− 𝛼𝛼
maka 𝑐𝑐(𝑥𝑥1, … ,𝑥𝑥𝑛𝑛) disebut sebagai batas bawah selang kepercayaan
(1− 𝛼𝛼)100% satu sisi b. Bila
𝑃𝑃[𝜃𝜃< 𝑟𝑟(𝑥𝑥1, … ,𝑥𝑥𝑛𝑛)] = 1− 𝛼𝛼
maka 𝑟𝑟(𝑥𝑥1, … ,𝑥𝑥𝑛𝑛) disebut sebagai batas atas selang kepercayaan
(1− 𝛼𝛼)100% satu sisi
C. Regresi Linear Berganda
1. Model Regresi Linear Berganda
Dalam analisis regresi, model regresi linear memuat dua variabel
ju-ga disebut sebaju-gai variabel respons), 𝑥𝑥𝑡𝑡𝑗𝑗 = (𝑥𝑥𝑡𝑡1,𝑥𝑥𝑡𝑡2, … ,𝑥𝑥𝑡𝑡𝑘𝑘) adalah
varia-bel independen atau regressor, di mana 𝑡𝑡= 1,2, … ,𝑛𝑛 dan 𝑗𝑗 = 1,2, … ,𝑘𝑘. Pada dasarnya, persamaan regresi linear merupakan kombinasi linear dari
𝑥𝑥𝑡𝑡𝑗𝑗 dan 𝛽𝛽𝑗𝑗.
𝑦𝑦𝑡𝑡 =� 𝛽𝛽𝑗𝑗𝑥𝑥𝑡𝑡𝑗𝑗 𝑘𝑘
𝑗𝑗=1
di mana 𝛽𝛽𝑗𝑗 = (𝛽𝛽1,𝛽𝛽2, … ,𝛽𝛽𝑘𝑘) adalah koefisien regresi yang merupakan tu-juan dari analisis regresi yang disimpulkan berdasarkan observasi 𝑥𝑥𝑡𝑡𝑗𝑗.
Ni-lai-nilai 𝛽𝛽𝑗𝑗 didekati dengan menggunakan 𝛽𝛽̂𝑗𝑗 sebagai penduga.
Struktur probabilitas dari model regresi linear biasanya dinyatakan
dalam bentuk matriks dan vektor adalah sebagai berikut.
2. Metode Kuadrat Terkecil
Metode kuadrat terkecil adalah sebuah prosedur untuk mendekati
pa-rameter yang tidak diketahui dari sebuah model linear. Pengilustrasian
prosedur ini secara sederhana adalah dengan mencocokkannya dengan
ga-ris lurus yang paling dekat dengan himpunan titik-titik. Bila kita
meng-inginkan untuk menentukan model
𝑦𝑦=𝛽𝛽0+𝛽𝛽1𝑥𝑥1+𝛽𝛽2𝑥𝑥2+⋯+𝛽𝛽𝑘𝑘𝑥𝑥𝑘𝑘+𝜀𝜀
di mana model tersebut linear dalam parameter 𝛽𝛽𝑡𝑡. Bila nilai-nilai penga-matan dinyatakan sebagai 𝑥𝑥𝑡𝑡1,𝑥𝑥𝑡𝑡2, … ,𝑥𝑥𝑡𝑡𝑘𝑘,𝑦𝑦𝑡𝑡 diambil secara acak dari suatu
populasi untuk 𝑡𝑡 = 1,2, … ,𝑛𝑛 dan 𝜀𝜀 adalah galatnya, yang memiliki nilai harapan 𝑆𝑆(𝜀𝜀|𝑥𝑥1,𝑥𝑥2, … ,𝑥𝑥𝑘𝑘) = 0 yang mengakibatkan 𝑆𝑆(𝜀𝜀) = 0. Agar lebih jelas, galat dari suatu model akhir regresi linear
𝑦𝑦�𝑡𝑡 =𝛽𝛽̂0+𝛽𝛽̂1𝑥𝑥𝑡𝑡1+𝛽𝛽̂2𝑥𝑥𝑡𝑡2+⋯+𝛽𝛽̂𝑘𝑘𝑥𝑥𝑡𝑡𝑘𝑘
adalah
𝜀𝜀𝑡𝑡 = 𝑦𝑦𝑡𝑡 − 𝑦𝑦�𝑡𝑡
𝜀𝜀𝑡𝑡 = 𝑦𝑦𝑡𝑡 − 𝛽𝛽̂0− 𝛽𝛽̂1𝑥𝑥𝑡𝑡1− 𝛽𝛽̂2𝑥𝑥𝑡𝑡2− ⋯ − 𝛽𝛽̂𝑘𝑘𝑥𝑥𝑡𝑡𝑘𝑘
Maka tujuan utama dari metode kuadrat terkecil adalah mencari
per-samaan yang meminimalkan jumlahan dari kuadrat selisih antara titik-titik
dan garisnya atau galatnya.
� 𝜀𝜀𝑡𝑡2 𝑛𝑛
𝑡𝑡=1
=��𝑦𝑦𝑡𝑡− 𝛽𝛽̂0− 𝛽𝛽̂1𝑥𝑥𝑡𝑡1− 𝛽𝛽̂2𝑥𝑥𝑡𝑡2− ⋯ − 𝛽𝛽̂𝑘𝑘𝑥𝑥𝑡𝑡𝑘𝑘� 2
𝑛𝑛
𝑡𝑡=1
Persamaan di atas adalah jumlahan kuadrat dari galat atau sering kali
atas minimum, akan memenuhi untuk seluruh nilai 𝛽𝛽𝑗𝑗 untuk 𝑗𝑗 = 0,1, … ,𝑘𝑘. Dengan mengambil turunan parsial dari persamaan kuadrat tersebut
terha-dap 𝛽𝛽𝑗𝑗 dan menyamakannya dengan nol, akan diperoleh
𝜕𝜕(∑𝑛𝑛 𝜀𝜀𝑡𝑡2
Keseluruh persamaan di atas akan diselesaikan dalam bentuk
ma-triks. Jumlahan pada ruas sebelah kanan, mengandung elemen-elemen
3. Sifat-Sifat Penduga Kuadrat Terkecil
Dalam metode kuadrat terkecil, terdapat sifat-sifat penduga yang
baik. Bila dipandang model umum regresi linear yang berbentuk
𝐘𝐘=𝐗𝐗𝛃𝛃+𝛆𝛆
dan dianggap bahwa 𝜀𝜀𝑡𝑡 saling bebas satu sama lain, serta 𝑆𝑆(𝜀𝜀𝑡𝑡) = 0,
𝑉𝑉𝑚𝑚𝑛𝑛(𝜀𝜀𝑡𝑡) =𝜎𝜎2, untuk setiap 𝑡𝑡 = 1,2, … ,𝑛𝑛. Dalam lambang matriks, ini
be-rarti 𝑉𝑉𝑚𝑚𝑛𝑛(𝜀𝜀𝑡𝑡) =𝜎𝜎2𝐼𝐼, bila 𝐼𝐼 menyatakan matriks satuan berukuran 𝑛𝑛×𝑛𝑛,
dengan demikian bila 𝐗𝐗 tidak memiliki distribusi sehingga diperlakukan sebagai konstanta, maka
𝑆𝑆(𝐘𝐘) =𝐗𝐗𝛃𝛃
dan
𝑉𝑉𝑚𝑚𝑛𝑛(𝑌𝑌) =𝜎𝜎2𝐼𝐼
Jadi sifat-sifat dari penduga 𝛃𝛃�= (𝐗𝐗′𝐗𝐗)−1𝐗𝐗′𝐘𝐘adalah a. Tak Bias (𝑆𝑆�𝛽𝛽̂𝑗𝑗�= 𝛽𝛽𝑗𝑗,𝑡𝑡= 0,1, … ,𝑘𝑘)
𝑆𝑆�𝛃𝛃��=𝑆𝑆((𝐗𝐗′𝐗𝐗)−1𝐗𝐗′𝐘𝐘) = (𝐗𝐗′𝐗𝐗)−1𝐗𝐗′𝐄𝐄(𝐘𝐘) = (𝐗𝐗′𝐗𝐗)−1𝐗𝐗′𝐗𝐗𝛃𝛃 =𝛃𝛃
b. Variansi Minimum 𝑉𝑉𝑚𝑚𝑛𝑛�𝛽𝛽̂𝑗𝑗�= 𝜎𝜎2𝑐𝑐
𝑡𝑡𝑡𝑡,𝑐𝑐𝑡𝑡𝑡𝑡 adalah elemen pada baris ke-𝑡𝑡 dan kolom ke-𝑡𝑡 dari matriks (𝐗𝐗′𝐗𝐗)−1
=𝜎𝜎2(𝐗𝐗′𝐗𝐗)−1
Variansi dari 𝛃𝛃� merupakan variansi minimum dari semua penduga tak bias. Hal ini dijamin oleh teorema Gauss-Markov berikut.
Teorema 2.4.
Penduga kuadrat terkecil 𝛃𝛃�= (𝐗𝐗′𝐗𝐗)−1𝐗𝐗′𝐘𝐘 memiliki variansi terkecil da-lam himpunan semua penduga linear tak bias.
Bukti:
Misalkan 𝛂𝛂 adalah penduga linear lain dari 𝛃𝛃yang juga tak bias, ka-rena itu 𝛂𝛂dapat di misalkan dengan bentuk berikut
𝛂𝛂= [(𝐗𝐗′𝐗𝐗)−𝟏𝟏𝐗𝐗′ +𝐔𝐔]𝐘𝐘
di mana 𝐔𝐔 adalah suatu matriks yang merupakan fungsi dari 𝐗𝐗, maka
𝐄𝐄(𝛂𝛂) =𝐄𝐄[((𝐗𝐗′𝐗𝐗)−𝟏𝟏𝐗𝐗′ +𝐔𝐔)𝐘𝐘]
= [(𝐗𝐗′𝐗𝐗)−𝟏𝟏𝐗𝐗′ +𝐔𝐔]𝐄𝐄(𝐘𝐘) = [(𝐗𝐗′𝐗𝐗)−𝟏𝟏𝐗𝐗′ +𝐔𝐔](𝐗𝐗𝛃𝛃) = (𝐗𝐗′𝐗𝐗)−𝟏𝟏𝐗𝐗′𝐗𝐗𝛃𝛃+𝐔𝐔𝐗𝐗𝛃𝛃 = (𝐼𝐼+𝐔𝐔𝐗𝐗)𝛃𝛃
agar 𝛂𝛂menjadi penduga tak bias dari 𝛃𝛃, maka 𝐔𝐔𝐗𝐗=𝟎𝟎. Jadi,
𝑉𝑉𝑚𝑚𝑛𝑛(𝛂𝛂) = ((𝐗𝐗′𝐗𝐗)−𝟏𝟏𝐗𝐗′ +𝐔𝐔)𝑉𝑉𝑚𝑚𝑛𝑛(𝐘𝐘)(𝐔𝐔′ +𝐗𝐗(𝐗𝐗′𝐗𝐗)−𝟏𝟏)
Karena 𝐔𝐔𝐗𝐗= 𝐗𝐗′𝐔𝐔′ =𝟎𝟎 dan matriks 𝐔𝐔𝐔𝐔′ adalah definit tak negatif, semua unsur diagonalnya berbentuk kuadrat. Jadi terbukti bahwa variansi
dari setiap unsur dari vektor 𝛂𝛂 selalu lebih besar atau paling kecil sama dengan variansi unsur 𝛃𝛃� yang bersesuaian. Seringkali 𝛃𝛃� disebut sebagai
Best Linear Unbiased Estimator (BLUE).
4. Selang Kepercayaan Untuk Parameter Regresi
Dalam model regresi linear berganda, dapat pula ditentukan selang
kepercayaan untuk parameter regresi. Untuk 𝑛𝑛< 30, diberikan statistik
𝑡𝑡(𝑡𝑡,𝛼𝛼⁄2) dengan derajat bebas 𝑡𝑡 =𝑛𝑛 − 𝑝𝑝, di mana 𝑛𝑛 adalah ukuran sampel
dan 𝑝𝑝= 𝑘𝑘+ 1 ditentukan dari banyaknya parameter. Maka selang keper-cayaan (1− 𝛼𝛼)100% untuk 𝛽𝛽𝑡𝑡 adalah
𝛽𝛽̂𝑡𝑡 − 𝑡𝑡(𝑡𝑡,𝛼𝛼⁄2)𝑠𝑠�𝑐𝑐𝑡𝑡𝑡𝑡 <𝛽𝛽𝑡𝑡 <𝛽𝛽̂𝑡𝑡 +𝑡𝑡(𝑡𝑡,𝛼𝛼⁄2)𝑠𝑠�𝑐𝑐𝑡𝑡𝑡𝑡
dengan 𝑡𝑡= 0,1,2, … ,𝑘𝑘 di mana 𝑐𝑐𝑡𝑡𝑡𝑡 adalah elemen dari baris ke-𝑡𝑡 dan ko-lom ke-𝑡𝑡 dari matriks (𝐗𝐗′𝐗𝐗)−1 dan 𝑠𝑠 adalah penduga tak bias dari 𝜎𝜎 dan didefinisikan sebagai berikut.
𝑠𝑠2 =𝐘𝐘′𝐘𝐘 − 𝛃𝛃�′𝐗𝐗′𝐘𝐘 𝑛𝑛 − 𝑝𝑝
Variansi dari model regresi linear tersebut diduga dengan
BAB III
METODE BOOTSTRAP
A. Prinsip Dasar dan Algoritma Metode Bootstrap
Kvam dan Vidakovic (2007) menyatakan bahwa dengan resampling, kita
berniat untuk mengambil sampel acak dari sampel. Misalkan sampel yang
te-lah diambil adate-lah 𝑥𝑥1,𝑥𝑥2, … ,𝑥𝑥𝑛𝑛 dipandang sebagai sampel asli yang mewakili suatu populasi terhingga dengan ukuran n. Sampel baru (biasanya berukuran
n pula) diambil secara “sampling dengan pengembalian”, maka beberapa dari
n sampel asli dapat muncul lebih dari satu kali. Kumpulan sampel baru ini
disebut sampel bootstrap. Metode tersebut dinamakan dengan Metode
Boot-strap. Agar lebih dapat memahami metode bootstrap, Gambar 3.1
menje-laskan tahapannya dalam bentuk skema.
Dari sampel asli 𝑥𝑥1,𝑥𝑥2, … ,𝑥𝑥𝑛𝑛 diambil b buah sampel bootstrap. Setiap sampel bootstrap (x*1, x*2, …, x*b) memiliki n buah anggota yang diambil
se-𝑥𝑥∗1 𝑥𝑥∗2 𝑥𝑥∗𝑏𝑏
𝑠𝑠(𝑥𝑥∗1) 𝑠𝑠(𝑥𝑥∗2) … 𝑠𝑠(𝑥𝑥∗𝑏𝑏)
…
𝑋𝑋= {𝑥𝑥1,𝑥𝑥2, … ,𝑥𝑥𝑛𝑛} Sampel Asli
Sampel Bootstrap Replikasi bootstrap
cara sampling dengan pengembalian n kali dari data sampel asli. Replikasi
bootstraps(x*1), s(x*2), …, s(x*b) didapatkan dengan menghitung nilai statistik
tertentu, misalkan s(x) pada setiap sampel bootstrap. Akhirnya, standar
devia-si dari nilai-nilai s(x*1), s(x*2), …, s(x*b) adalah penduga dari galat standar dari
s(x). Galat standar inilah yang merupakan tujuan utama dari metode bootstrap,
yang kemudian dapat digunakan untuk membangun selang kepercayaan
boot-strap.
Secara umum, kita dapat mengurutkan langkah-langkah untuk metode
bootstrap secara umum. Misalkan pada suatu populasi, diambil 𝑛𝑛 buah sam-pel acak yaitu 𝑋𝑋= {𝑥𝑥1,𝑥𝑥2, … ,𝑥𝑥𝑛𝑛}. Dari 𝑛𝑛 buah sampel acak tersebut, akan di-ambil sebanyak 𝑏𝑏 unit sampel bootstrap, yaitu 𝑥𝑥∗1,𝑥𝑥∗2, … ,𝑥𝑥∗𝑏𝑏. Masing-masing unit sampel tersebut adalah vektor yang terdiri dari 𝑛𝑛 buah sampel yang diambil dengan pengembalian. Notasi bintang tersebut menandakan
bahwa vektor kumpulan data tersebut adalah hasil resampel dari sampel asli.
𝑋𝑋∗ bukanlah himpunan data sampel asli (𝑥𝑥).
Sampel bootstrap tersebut akan berupa vektor-vektor yang
masing-masing terdiri dari 𝑛𝑛 buah nilai. Nilai-nilai dari sampel asli dapat muncul be-berapa kali karena adanya pengembalian sampel sebelum pengambilan
kem-bali sampel berikutnya. Dengan begitu setiap sampel bootstrap juga bisa
me-miliki beberapa data asli yang terwakili lebih dari sekali, atau bahkan tidak
terwakili sama sekali. Maka dari itu, sampel bootstrap ini bisa saja sama
Pengambilan unit-unit sampel bootstrap dengan pengembalian dilakukan
sampai 𝑏𝑏 kali sehingga terdapat 𝑏𝑏 unit sampel bootstrap. Besarnya nilai 𝑏𝑏 umumnya diambil dalam jumlah yang besar, karena semakin besar nilai 𝑏𝑏, maka distribusi sampling yang didekati akan semakin mendekati distribusi
normal. Secara teoritis, besar nilai 𝑏𝑏 tidak pernah dibatasi, bisa sebesar mungkin, asal kita memiliki kesabaran untuk membentuk sampel-sampel
bootstrap tersebut. Lagipula, jikalau nilai 𝑏𝑏 terlampau besar, hal itu tidak lagi menjadi masalah karena semua proses penghitungan dilakukan dengan
kom-puter. Setelah didapatkan 𝑏𝑏 buah sampel bootstrap, hal yang dilakukan selan-jutnya adalah menghitung statistik dari masing-masing sampel bootstrap untuk
menduga galat standar dari parameter penduga yang disimbolkan 𝜃𝜃�. Statistik uji untuk masing-masing sampel bootstrap disimbolkan sebagai
𝑠𝑠(𝑥𝑥∗1),𝑠𝑠(𝑥𝑥∗2), … ,𝑠𝑠(𝑥𝑥∗𝑏𝑏). Statistik uji tersebut bisa berupa mean, median, atau proporsi. Seluruh standar deviasi dari statistik uji tersebut akan
diguna-kan untuk mengestimasi galat standar dari 𝑠𝑠(𝑥𝑥)atau 𝜃𝜃�. Pendugaan galat stan-dar stan-dari 𝜃𝜃� tersebut adalah tujuan utama dari metode bootstrap ini. Seluruh proses pendekatan nilai ini akan langsung menggunakan kalkulasi dengan
komputer tanpa memerlukan kalkulasi teoritis.
Untuk setiap pengambilan kesimpulan langsung berdasarkan
distribu-sinya, terlihat jelas bahwa sampel bootstrap tidak sebaik sampel asli. Bila kita
be-rubah-ubah dari sampel ke sampel. Hal ini disebabkan karena elemen-elemen
dari masing-masing sampel bootstrap bisa sama atau sama sekali berbeda
den-gan sampel asli seperti yang telah dijelaskan sebelumnya. Daripada kita
hanya dapat menghitung 𝜃𝜃�𝑛𝑛 sekali saja karena hanya dimiliki satu buah sam-pel sebanyak 𝑛𝑛, lebih baik kita meresampel (sebanyak tak hingga kali secara teoritis) dan membentuk sampel bootstrap. Sebuah meta-estimator dibentuk
dari estimator untuk estimator awal bagi parameter populasi. Dengan begitu,
sebenarnya kita telah membangun sebuah meta-estimator dari sampel
boot-strap (misalkan 𝜃𝜃�∗ =𝑠𝑠(𝑥𝑥∗)) dan meta-estimator tersebut menjelaskan tentang
𝜃𝜃�𝑛𝑛, bukan 𝜃𝜃. Bila kita membangun sampel bootstrap berulang kali, kita dapat
membentuk gambaran secara tak langsung tentang distribusi 𝜃𝜃�𝑛𝑛 dan dari situ, kita dapat membentuk suatu pernyataan tentang 𝜃𝜃.
Secara sederhana, metode bootstrap untuk pengambilan sampel dapat
di-tuliskan dalam algoritma berikut:
1. Bangun distribusi probabilitas empiris 𝑓𝑓̂(𝑥𝑥) dari sampel acak 𝑥𝑥1,𝑥𝑥2, … ,𝑥𝑥𝑛𝑛
dengan menempatkan probabilitas 1⁄𝑛𝑛 pada setiap titik di 𝑥𝑥1,𝑥𝑥2, … ,𝑥𝑥𝑛𝑛. Ini adalah fungsi distribusi empiris dari 𝑥𝑥, yang merupakan pendekatan (kemungkinan maksimum) maximum likelihood dari fungsi distribusi
pro-babilitas untuk populasi 𝑓𝑓(𝑥𝑥).
2. Dari distribusi probabilitas empiris tersebut, ambil sampel acak sederhana
sebanyak 𝑛𝑛 buah dengan pengembalian. Sampel inilah yang disebut sam-pel bootstrap. Notasikan kumpulan samsam-pel bootstrap ini dengan tanda
3. Hitung statistik yang dituju, yaitu 𝜃𝜃� (mean, proporsi, dst) untuk masing-masing sampel bootstrap. Notasikan dengan 𝜃𝜃�∗𝑏𝑏.
4. Ulangi langkah ke-2 dan ke-3 sebanyak 𝑏𝑏 kali, di mana 𝑏𝑏 adalah bilangan yang besar nilainya. Biasanya 𝑏𝑏 tidak dibatasi, tetapi diambil antara 50 sampai 200 untuk mengestimasi galat standar dari 𝜃𝜃� dan minimal 𝑏𝑏 berni-lai 1000 untuk mengestimasi interval kepercayaan di sekitar 𝜃𝜃�. (Mooney & Duval, 1993)
5. Bangun distribusi probabilitas dari 𝑏𝑏 buah 𝜃𝜃�∗𝑏𝑏 dengan menempatkan pro-babilitas 1⁄𝑏𝑏 pada setiap titik 𝜃𝜃�∗1,𝜃𝜃�∗2, … ,𝜃𝜃�∗𝑏𝑏. Distribusi ini adalah esti-masti bootstrap dari distribusi sampling 𝜃𝜃�, 𝑓𝑓∗(𝜃𝜃�∗).
Basis pendekatan bootstrap secara statistikal adalah memperlakukan
sampel seolah-olah sampel tersebut adalah populasi dan menerapkan metode
sampling Monte Carlo (random sampling) untuk membangkitkan pendekatan
empiris dari statistik distribusi samplingnya. Prosedur dalam metode
boot-strap secara garis besar adalah sebagai berikut:
Langkah 1: Resampling
Pada awal pengambilan sampel acak dari suatu populasi, biasanya hanya
diambil satu unit sampel acak berukuran 𝑛𝑛 buah (untuk selanjutnya akan dis-ebut sebagai sampel asli). Agar memiliki jumlah sampel yang lebih banyak,
maka dilakukan resampling dari satu buah sampel acak tersebut. Resampling
dilakukan dengan metode sampling dengan pengembalian dan berukuran sama
Setiap kali kita mengambil sebuah resampel acak dari sampel asli,
sam-pel tersebut dikembalikan terlebih dahulu sebelum dilakukannya pengambilan
resampel yang berikutnya, inilah yang dimaksud dengan resampling dengan
pengembalian. Dengan adanya pengembalian sampel, nilai-nilai observasi
pada sampel acak asli tersebut akan dapat diambil lebih dari sekali, ataupun
sama sekali tidak terambil. Bila yang dilakukan adalah sampling tanpa
pen-gembalian, yang akan kita dapatkan hanyalah satu buah sampel acak yang
me-rupakan permutasi dari sampel asli. Tak menutup kemungkinan pula, hasil
re-sampel akan sama dengan re-sampel asli. Kumpulan hasil rere-sampel baru ini
di-sebut sampel bootstrap.
Contoh berikut diharapkan dapat memberikan gambaran besar tentang
langkah di atas.
Contoh 3.1. (Sumber: Introduction of the Practice Statistics oleh D. Moore, hal. 16-3)
Di Amerika, banyak terdapat perusahaan yang menawarkan jasa layanan
telepon lokal. Bukanlah suatu ketertarikan publik untuk mendapati seluruh
perusahaan tersebut menggali jalan hanya untuk memendam kabel, jadi
peru-sahaan telepon lokal utama di setiap daerah harus (untuk bayaran tertentu)
berbagi jaringan dengan kompetitornya. Istilah legal untuk perusahaan
tele-pon lokal utama ini adalah Incumbent Local Exchange Carrier, ILEC. Para
Verizon adalah ILEC untuk suatu area besar di Amerika bagian timur,
seperti seharusnya, mereka harus menyediakan jasa perbaikan untuk
pelang-gan dari CLECs di area tersebut. Apakah Verizon memberikan layanan
per-baikan untuk pelanggan CLEC secepat (dalam rata-rata) seperti kepada
pe-langgannya sendiri? Bila tidak, itu keputusan pelanggan untuk meminta ganti
rugi. Komisi Perangkat Publik lokal memerlukan penggunaan dari tes uji sig-nifikansi untuk membandingkan waktu perbaikan untuk kedua grup pelanggan.
Waktu perbaikan jauh dari normal. Gambar 3.2 dan 3.3 menggambarkan
distribusi dari sampel random dari 1664 kali perbaikan untuk pelanggan
Veri-zon sendiri. Distribusinya memiliki ekor kanan yang sangat panjang.
Me-diannya adalah 3.59 jam, tetapi meannya adalah 8.41 jam dan waktu perbaikan
terlama adalah 191.6 jam. Kita ragu untuk menggunakan prosedur 𝑡𝑡 untuk da-ta seperti itu, teruda-tama karena ukuran sampel bagi pelanggan CLEC lebih kecil
dari pelanggan Verizon sendiri.
Gambar 3.2. Distribusi dari 1664 kali perbaikan untuk pelanggan Verizon.
Waktu perbaikan (dalam jam)
B
anya
knya
pe
rba
ik
Resampling dan sampling dengan pengembalian pada Contoh 3.1
dije-laskan dalam Gambar 3.4 berikut.
Gambar 3.3. Plot quantil normal untuk jumlah waktu perbaikan. Distribusinya sangat condong ke kanan.
Nilai normal
W
ak
tu
p
erb
aik
an
(d
ala
m ja
m)
𝑥𝑥∗1 𝑥𝑥∗2 𝑥𝑥∗3
Gambar 3.4. Kotak teratas adalah sampel acak asli dengan
𝑛𝑛 = 6 dari data Verizon. Tiga kotak di bawahnya adalah tiga unit resampel dari sampel asli (𝑏𝑏= 3). Beberapa nilai dari sam-pel asli muncul berulang kali dalam resamsam-pel.
𝑥𝑥̅∗1= 4.13 {1,57; 0,22; 19,67;
0,00; 0,22; 3,12}
{0,00; 2,20; 2,20; 2,20; 19,67; 1.57}
𝑥𝑥̅∗2= 4.64 𝑥𝑥̅∗3= 1.74 {0,22; 3,12; 1,57;
3,12; 2,20; 0,22}
Setelah dilakukan resampling, hal berikutnya yang dilakukan adalah
menghitung replikasi bootstrap (pada contoh ini akan dihitung rata-rata
sam-pel) untuk sampel asli dan setiap sampel bootstrap. Gambar 3.4 menunjukkan
bahwa bagaimana nilai replikasi bootstrap, dalam hal ini rata-rata sampel
bootstrap dapat berubah-ubah di setiap sampel bootstrap. Pada sampel
boot-strap ke-1, ke-2, dan ke-3, secara berturut-turut rata-ratanya adalah 4.13, 4.64,
dan 1.74. Nilai-nilai observasi dari sampel asli juga ada yang muncul
bebera-pa kali di sampel bootstrap.
Secara umum, rumus untuk menghitung rata-rata sampel bootstrap, yang
disimbolkan menjadi mean𝑏𝑏𝑛𝑛𝑛𝑛𝑡𝑡 adalah sebagai berikut.
mean𝑏𝑏𝑛𝑛𝑛𝑛𝑡𝑡 =1
𝑏𝑏 � 𝑥𝑥̅∗𝑡𝑡
𝑏𝑏
𝑡𝑡=1
Setelah itu, galat standar dari mean sampel bootstrap juga dapat
dipero-leh dengan rumus berikut ini.
SE𝑏𝑏𝑛𝑛𝑛𝑛𝑡𝑡 =� 1
𝑏𝑏 −1�(𝑥𝑥̅∗𝑡𝑡 −mean𝑏𝑏𝑛𝑛𝑛𝑛𝑡𝑡) 2
𝑏𝑏
𝑡𝑡=1
Langkah 2: Distribusi Bootstrap
Dari statistik yang telah dihitung nilainya, dapat diperoleh distribusi
samplingnya. Distribusi bootstrap dari sebuah statistik menghimpun seluruh
nilai-nilai tersebut dari hasil resampel pada Langkah 1. Distribusi bootstrap
inilah yang nantinya akan memberikan gambaran tentang distribusi sampling
Contoh 3.2.
Pada Contoh 3.1, kita menginginkan untuk mengestimasi rata-rata
popu-lasi untuk waktu perbaikan (𝜇𝜇), jadi statistiknya adalah mean sampel (𝑥𝑥̅). Untuk satu sampel random dari 1664 waktu perbaikan, 𝑥𝑥̅= 8.41 jam. Ketika kita meresampel, kita mendapatkan nilai-nilai yang berbeda untuk 𝑥𝑥̅, seperti yang kita inginkan bila kita mengambil sampel baru dari populasi seluruh
waktu perbaikan.
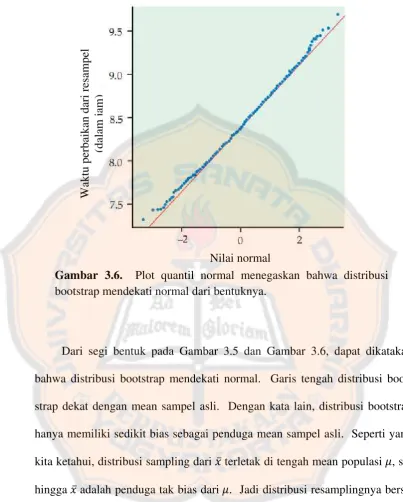
Gambar 3.5 dan Gambar 3.6 berikut menjelaskan tentang distribusi
boot-strap dari rata-rata dari 1000 buah resampel dari data waktu perbaikan Verizon,
menggunakan histogram terlebih dahulu dan kurva densitas, kemudian plot
kuantil normal. Garis lurus pada histogram menandakan rata-rata sebesar 8.41
dari sampel asli, dan garis putus-putus menandakan rata-rata dari sampel
boot-strap. Menurut prinsip bootstrap, distribusi bootstrap merepresentasikan
dis-tribusi sampling. Akan dibandingkan disdis-tribusi bootstrap dengan apa yang
ki-ta keki-tahui tenki-tang distribusi sampling.
Gambar 3.5. Distribusi Bootstrap untuk rata-rata 1000 resampel dari sampel waktu perbaikan Verizon.
Waktu perbaikan dari resampel (dalam jam) Rata-rata sampel asli