PENDAHULUAN
Latar Belakang
Manusia dianugrahi oleh Tuhan dua telinga yang memiliki fungsi untuk menangkap sinyal-sinyal suara. Namun untuk mengoptimalkan dari fungsi telinga tersebut manusia harus belajar memahami dan mengenali sinyal-sinyal suara yang masuk.
Begitu juga untuk mengenali sebuah nada.
Untuk seorang perfect pitch dalam mengenali sebuah nada adalah hal yang mudah karena telah melalui tahap latihan yang lama. Perfect pitch adalah kemampuan seseorang dalam mengenali dan mengidentifikasi nada-nada dari sebuah sinyal. Namun untuk seorang yang tidak memiliki kemampuan perfect pitch akan mengalami kesulitan dalam mengenali sebuah nada, sehingga dibutuhkan latihan untuk memiliki kemampuan perfect pitch.
Pengolahan Sinyal Digital (Digital Signal Processing) saat ini telah memegang peranan yang penting dalam ilmu pengetahuan dan teknologi. Salah satunya adalah pengenalan suara (voice recognition). Seperti penelitian yang telah dilakukan oleh Rudy Adipranata dan Resmana tentang pengenalan suara manusia. Dalam penelitian tersebut membahas tentang bagaimana cara mengenali suara manusia dari sebuah sinyal menggunakan jaringan saraf tiruan (Adipranata dan Resmana 1999). Selain untuk pengenalan suara manusia, pengenalan suara juga dapat dipakai dalam berbagai hal, salah satunya adalah pengenalan chord seperti penelitian yang telah dilakukan oleh Elgar Wisnudisastra dan Agus Buono pada tahun 2009 (Wisnudisastra dan Buono 2009). Pada penelitian tersebut, pemodelan chord pada gitar menggunakan codebook.
Penelitian Elgar Wisnudisastra ini hanya sampai pada pengenalan chord tidak sampai nada-nada penyusun dari chord. Tidak semua orang mengetahui semua jenis chord bahkan chord-chord miring. Untuk itu dibutuhkan pengenalan lebih mendalam untuk chord hingga nada-nada penyusun dari chord tersebut.
Tujuan
Penelitian ini bertujuan untuk mengidentifikasi campuran nada pada suara piano menggunakan codebook sebagai pemodelan nada dan banyaknya campuran nada.
Ruang Lingkup
Adapun ruang lingkup dari penelitian ini antara lain:
1. Campuran nada yang akan dikenali hanya campuran nada pada satu octave dan maksimal 2 campuran nada.
2. Suara yang dikenali hanya dimainkan dengan cara ditekan secara serentak.
3. Suara yang dikenali hanya suara piano pada keyboard Yamaha PSR 3000.
Manfaat Penelitian
Penelitian ini diharapkan dapat membantu bagi masyarakat dalam mengenali dan mengidentifikasi campuran nada pada sebuah suara piano.
TINJAUANPUSTAKA Nada dan Chord
Nada adalah bunyi yang beraturan yang memiliki frekuensi tunggal tertentu. Setiap nada memiliki tinggi nada atau tala tertentu menurut frekuensinya. Terdapat 7 nada dasar yaitu : C = do, De = re, E = mi, F = fa, G = sol, A = la, B = si. Masing-masing dari nada dasar tersebut memiliki frekuensi yang berbeda-beda. Jarak antar nada disebut interval. Interval dari deretan nada C-D-E-F- G-A-B adalah 1-1-1/2-1-1-1/2. Jarak enam antara dua nada yang sama disebut satu octave. Contohnya adalah jarak antara nada C1 sampai nada C2. Nada C2 berada satu octave di atas nada C1.
Nada natural tersebut dapat dinaikkan atau diturunkan ½ nada. Nada yang dinaikkan ½ nada diberi simbol # (kres), sedangkan nada yang diturunkan ½ nada diberi simbol b (mol).
Misal nada C dinaikkan ½ maka akan menjadi C# (C kres / Cis). Jika nada B diturunkan ½ maka akan menjadi Bb (B mol). Untuk nada E jika dinaikkan ½ maka akan menjadi E# atau sama dengan nada F karena jarak nada E dengan nada F adalah ½. Begitu pula pada nada B ke C. Untuk lebih jelasnya dapat dilihat pada Gambar 1.
Chord merupakan gabungan dari nada- nada yang dibunyikan secara serentak yang berfungsi sebagai pengiring dalam lagu maupun permainan musik (Hendro 2004).
Chord memiliki bentuk dan corak yang berbeda sesuai dengan nada-nada yang membentuknya. Chord biasanya terdiri dari
tiga nada (triad), misalnya chord C terdiri atas C, E, dan G.
Gambar 1 Nada dasar pada piano.
Pemrosesan Sinyal Suara
Sinyal suara merupakan gelombang yang tercipta dari tekanan udara yang berasal dari paru-paru yang berjalan melewati lintasan suara menuju mulut dan rongga hidung (Al- Akaidi 2007). Pemrosesan suara itu sendiri merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan (Buono 2009).
Sinyal secara umum dapat dikategorikan sesuai dengan peubah bebas waktu, yaitu:
1. Sinyal waktu kontinyu: kuantitas sinyal terdefinisi pada setiap waktu dalam selang kontinyu. Sinyal waktu kontinyu disebut juga sinyal analog.
2. Sinyal waktu diskret: kuantitas sinyal terdefinisi pada waktu diskret tertentu, yang dalam hal ini jarak antar waktu tidak harus sama.
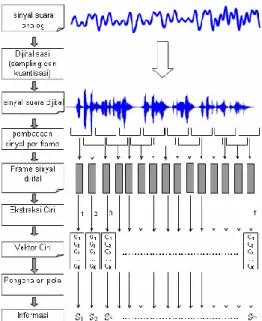
Secara umum proses transformasi tersebut terdiri atas digitalisasi sinyal analog, ekstraksi ciri dan diakhiri dengan pengenalan pola untuk klasifikasi, seperti yang terlihat pada Gambar 2.
Pengolahan sinyal analog menjadi sinyal digital dapat dilakukan melalui dua tahap yaitu sampling dan kuantisasi (Jurafsky 2007).
Sampling adalah suatu proses untuk membagi suatu sinyal kontinyu (sinyal analog) dalam interval waktu yang telah ditentukan.
Sampling ini dilakukan dengan mengubah sinyal analog menjadi sinyal digital dalam fungsi waktu. Pengubahan bentuk sinyal ini bertujuan untuk mempermudah memproses sinyal masukan yang berupa analog karena sinyal analog memiliki kepekaan terhadap noise yang rendah, sehingga sulit untuk memproses sinyal tersebut. Nilai dari hasil sampling tersebut dibulatkan ke nilai terdekat (rounding), atau bisa juga dengan pemotongan bagian sisa (truncating) sehingga menghasilkan sinyal suara digital dengan
mengekspresikannya menggunakan sejumlah digit tertentu dan proses ini yang dikenal dengan kuantisasi.
Gambar 2 Tahapan transformasi sinyal suara menjadi informasi (Jurafsky dalam Buono 2009).
Sinyal suara digital kemudian dilakukan proses pembacaan sinyal disetiap frame dengan lebar frame tertentu yang saling tumpang tindih. Proses ini dikenal dengan proses frame blocking. Barisan frame berisi informasi yang lengkap dari sebuah sinyal suara. Informasi yang terdapat dalam frame- frame tersebut direpresentasikan dengan cara pengekstraksian ciri sehingga dihasilkan vektor-vektor yang nantinya digunakan dalam pengenalan pola.
Ekstraksi Sinyal Suara
Ekstraksi ciri merupakan proses untuk menentukan satu nilai atau vektor yang dapat dipergunakan sebagai penciri objek atau individu (Buono 2009). Terdapat banyak cara untuk merepresentasikan parameter sinyal suara, seperti Linear Prediction Coding (LPC), Mel-Frequency Cepstrum Coefficients (MFCC), dll.
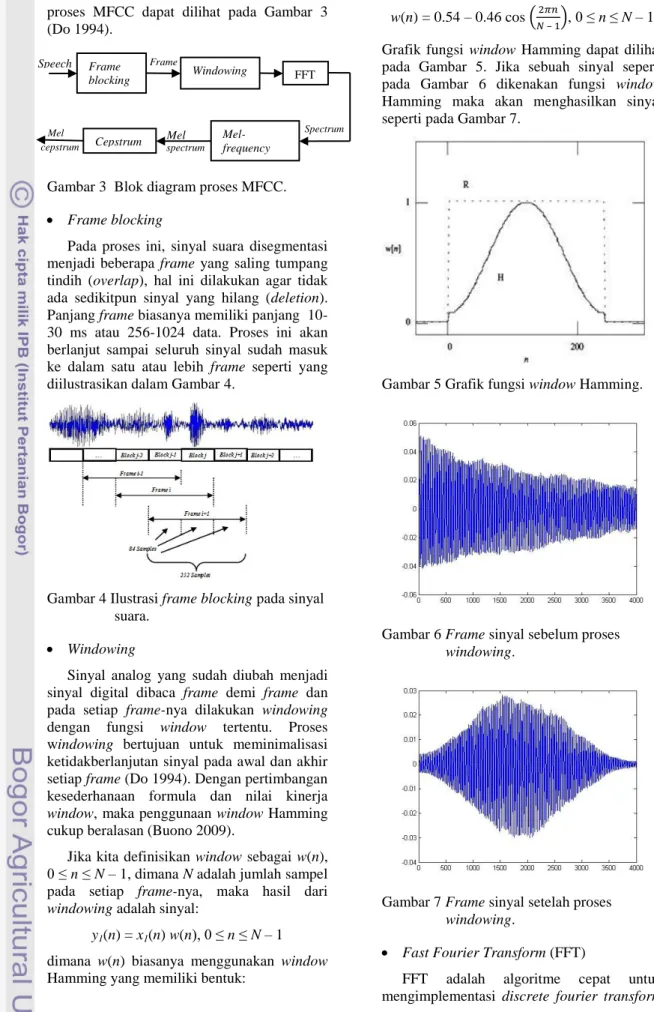
MFCC merupakan cara yang paling sering digunakan pada berbagai bidang area pemrosesan suara, karena dianggap cukup baik dalam merepresentasikan ciri sebuah sinyal. Cara kerja MFCC didasarkan pada perbedaan frekuensi yang dapat ditangkap oleh telinga manusia sehingga mampu merepresentasikan sinyal suara sebagaimana manusia merepresentasikannya. Blok diagram
proses MFCC dapat dilihat pada Gambar 3 (Do 1994).
Gambar 3 Blok diagram proses MFCC.
Frame blocking
Pada proses ini, sinyal suara disegmentasi menjadi beberapa frame yang saling tumpang tindih (overlap), hal ini dilakukan agar tidak ada sedikitpun sinyal yang hilang (deletion).
Panjang frame biasanya memiliki panjang 10- 30 ms atau 256-1024 data. Proses ini akan berlanjut sampai seluruh sinyal sudah masuk ke dalam satu atau lebih frame seperti yang diilustrasikan dalam Gambar 4.
Gambar 4 Ilustrasi frame blocking pada sinyal suara.
Windowing
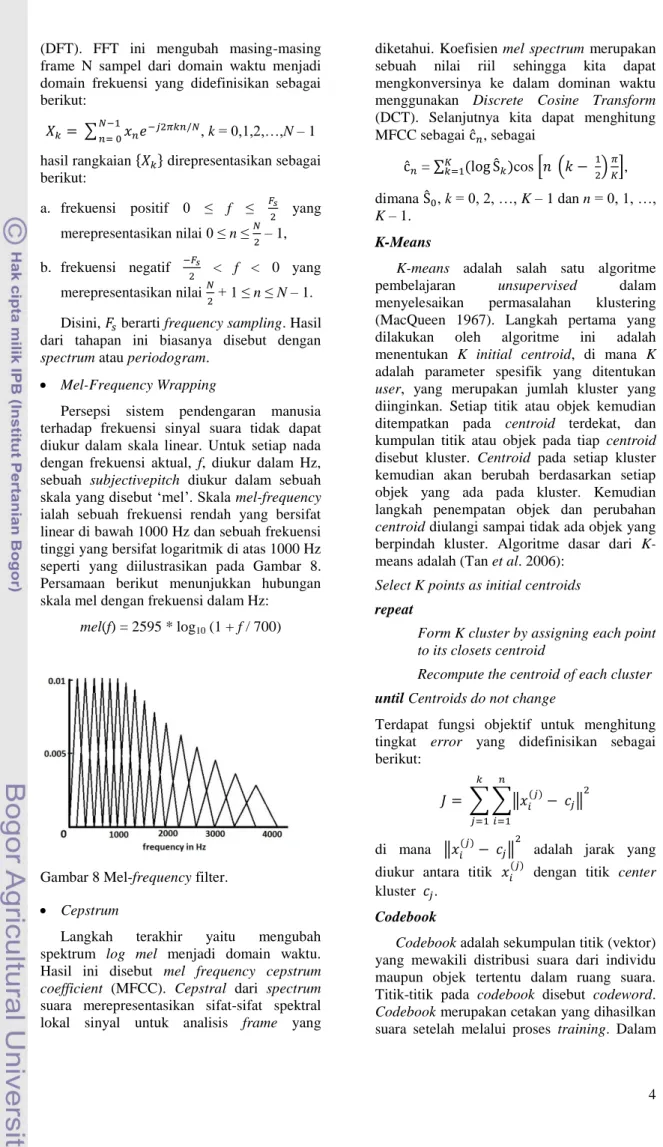
Sinyal analog yang sudah diubah menjadi sinyal digital dibaca frame demi frame dan pada setiap frame-nya dilakukan windowing dengan fungsi window tertentu. Proses windowing bertujuan untuk meminimalisasi ketidakberlanjutan sinyal pada awal dan akhir setiap frame (Do 1994). Dengan pertimbangan kesederhanaan formula dan nilai kinerja window, maka penggunaan window Hamming cukup beralasan (Buono 2009).
Jika kita definisikan window sebagai w(n), 0 ≤ n ≤ N – 1, dimana N adalah jumlah sampel pada setiap frame-nya, maka hasil dari windowing adalah sinyal:
y1(n) = x1(n) w(n), 0 ≤ n ≤ N – 1 dimana w(n) biasanya menggunakan window Hamming yang memiliki bentuk:
w(n) = 0.54 – 0.46 cos ( – ), 0 ≤ n ≤ N – 1 Grafik fungsi window Hamming dapat dilihat pada Gambar 5. Jika sebuah sinyal seperti pada Gambar 6 dikenakan fungsi window Hamming maka akan menghasilkan sinyal seperti pada Gambar 7.
Gambar 5 Grafik fungsi window Hamming.
Gambar 6 Frame sinyal sebelum proses windowing.
Gambar 7 Frame sinyal setelah proses windowing.
Fast Fourier Transform (FFT)
FFT adalah algoritme cepat untuk mengimplementasi discrete fourier transform Mel
spectrum Frame
Spectrum Speech
Mel cepstrum
Frame
blocking Windowing FFT
Cepstrum Mel-
frequency Wrapping
(DFT). FFT ini mengubah masing-masing frame N sampel dari domain waktu menjadi domain frekuensi yang didefinisikan sebagai berikut:
∑ , k = 0,1,2,…,N – 1 hasil rangkaian { } direpresentasikan sebagai berikut:
a. frekuensi positif 0 ≤ f ≤ yang merepresentasikan nilai 0 ≤ n ≤ – 1, b. frekuensi negatif < f < 0 yang
merepresentasikan nilai + 1 ≤ n ≤ N – 1.
Disini, berarti frequency sampling. Hasil dari tahapan ini biasanya disebut dengan spectrum atau periodogram.
Mel-Frequency Wrapping
Persepsi sistem pendengaran manusia terhadap frekuensi sinyal suara tidak dapat diukur dalam skala linear. Untuk setiap nada dengan frekuensi aktual, f, diukur dalam Hz, sebuah subjectivepitch diukur dalam sebuah skala yang disebut ‘mel’. Skala mel-frequency ialah sebuah frekuensi rendah yang bersifat linear di bawah 1000 Hz dan sebuah frekuensi tinggi yang bersifat logaritmik di atas 1000 Hz seperti yang diilustrasikan pada Gambar 8.
Persamaan berikut menunjukkan hubungan skala mel dengan frekuensi dalam Hz:
mel(f) = 2595 * log10 (1 + f / 700)
Gambar 8 Mel-frequency filter.
Cepstrum
Langkah terakhir yaitu mengubah spektrum log mel menjadi domain waktu.
Hasil ini disebut mel frequency cepstrum coefficient (MFCC). Cepstral dari spectrum suara merepresentasikan sifat-sifat spektral lokal sinyal untuk analisis frame yang
diketahui. Koefisien mel spectrum merupakan sebuah nilai riil sehingga kita dapat mengkonversinya ke dalam dominan waktu menggunakan Discrete Cosine Transform (DCT). Selanjutnya kita dapat menghitung MFCC sebagai , sebagai
= ∑ cos * ( ) +, dimana , k = 0, 2, …, K – 1 dan n = 0, 1, …, K – 1.
K-Means
K-means adalah salah satu algoritme pembelajaran unsupervised dalam menyelesaikan permasalahan klustering (MacQueen 1967). Langkah pertama yang dilakukan oleh algoritme ini adalah menentukan K initial centroid, di mana K adalah parameter spesifik yang ditentukan user, yang merupakan jumlah kluster yang diinginkan. Setiap titik atau objek kemudian ditempatkan pada centroid terdekat, dan kumpulan titik atau objek pada tiap centroid disebut kluster. Centroid pada setiap kluster kemudian akan berubah berdasarkan setiap objek yang ada pada kluster. Kemudian langkah penempatan objek dan perubahan centroid diulangi sampai tidak ada objek yang berpindah kluster. Algoritme dasar dari K- means adalah (Tan et al. 2006):
Select K points as initial centroids repeat
Form K cluster by assigning each point to its closets centroid
Recompute the centroid of each cluster until Centroids do not change
Terdapat fungsi objektif untuk menghitung tingkat error yang didefinisikan sebagai berikut:
∑ ∑‖ ‖
di mana ‖ ‖ adalah jarak yang diukur antara titik dengan titik center kluster .
Codebook
Codebook adalah sekumpulan titik (vektor) yang mewakili distribusi suara dari individu maupun objek tertentu dalam ruang suara.
Titik-titik pada codebook disebut codeword.
Codebook merupakan cetakan yang dihasilkan suara setelah melalui proses training. Dalam
pengenalan suara, masing-masing suara yang akan dikenali harus dibuatkan codebook-nya.
Codebook dibentuk dengan cara membentuk kluster semua vektor ciri yang dijadikan sebagai training set dengan menggunakan klustering algorithm. Algoritme klustering yang akan dipakai adalah algoritme K-means.
Ilustrasi codebook untuk setiap nada dapat dilihat pada Gambar 9.
Gambar 9 Codebook untuk setiap nada.
Seperti yang telah diilustrasikan pada Gambar 10, prinsip dasar dalam penggunaan codebook adalah setiap suara yang masuk akan dihitung jaraknya ke setiap codebook yang telah dibuat. Kemudian jarak setiap sinyal suara ke codebook dihitung sebagai jumlah jarak setiap frame sinyal suara tersebut ke setiap codeword yang ada pada codebook.
Kemudian dipilih codeword dengan jarak minimum. Setelah itu setiap sinyal suara yang masuk akan diidentifikasi berdasarkan jumlah dari jarak minimum tersebut.
Gambar 10 Ilustrasi prinsip dasar penggunaan codebook.
Perhitungan jarak dilakukan dengan menggunakan jarak euclid yang didefinisikan sebagai berikut:
∑
dimana x dan y adalah vektor yang akan dihitung jaraknya dengan D dimensi.
Jika dalam sinyal suara input O terdapat T frame dan merupakan masing- masing codeword yang ada pada codebook maka jarak sinyal input dengan codebook dapat dirumuskan:
∑ ( )
METODE PENELITIAN Kerangka Pemikiran
Penelitian ini dikembangkan dengan metode yang terdiri atas beberapa tahap yaitu:
(1) pengambilan data, (2) preprocessing, (3) pemodelan codebook, (4) evaluasi. Alur metode ini dapat dilihat pada Gambar 11.
Pengambilan Data
Suara yang akan digunakan dalam penelitian ini adalah suara grand piano yang terdapat di keyboard Yamaha PSR 3000. Nada yang diambil sebanyak 12 nada tunggal yang terdiri dari C, C#, D, D#, E, F, F#, G, G#, A, A#, dan B yang masing-masing akan diulang sebanyak 15 kali. Nada dua campuran diambil sebanyak 66 nada yang masing-masing akan diulang sebanyak 15 kali.
Nada yang telah diambil akan dibagi dua, yaitu data training dan data testing. Data training adalah 12 nada tunggal yang masing- masing nada 10 suara dan 66 nada dua campuran yang masing-masing nada 10 suara, sedangkan data testing adalah 66 nada campuran yang masing-masing nada lima suara dan 12 nada tunggal yang masing- masing nada lima suara. Total dari data training sebanyak 780 suara dan total dari data testing sebanyak 390 suara.
Data direkam langsung dengan keyboard melalui kabel yang dihubungkan langsung dengan komputer. Perekaman menggunakan software Matlab selama 1 detik, disimpan dalam file berformat WAV, dan sampling rate sebesar 11000 Hz. Proses perekaman dengan menekan secara serentak dengan tekanan yang berbeda. Tekanan yang diberikan ada yang keras, lembut, ditekan lama, dan sesaat.
Preprocessing
Pada tahap ini dilakukan proses pemotongan silent. Pemotongan silent ini dapat menfokuskan sinyal yang akan diteliti.
Setelah melalui tahap pemotongan silent sinyal akan diekstraksi ciri pada setiap nada
5 6
1 2
3 4
8 4
4 9
2 6
4 5
min min
C
New
=
=
=
Jarak New - C 3,6 + ... + 2,2 + ...