PENDAHULUAN Latar Belakang
Beberapa situs berita di Indonesia seperti Kompas, Okezone, Tempo, Antara dan lain sebagainya telah menggunakan RSS dalam menyajikan sindikasi berita.
Jumlah berita yang disindikasikan oleh situs berita tersebut akan terus berkembang seiring dengan berjalannya waktu. Oleh karena itu perlu dikembangkan sebuah fasilitas temu kembali informasi yang dapat mengeksplorasi data tesebut secara efisien. Hal ini bertujuan untuk memudahkan pengguna mendapatkan berita yang relevan dengan yang diinginkan. Tujuan
1. Mengimplementasikan temu kembali informasi untuk dokumen berita berbahasa Indonesia dengan format RSS.
2. Menelaah kinerja sistem yang dibangun dalam mengembalikan jawaban yang relevan dari kumpulan dokumen berita berbahasa Indonesia.
Ruang Lingkup
Korpus terdiri atas dokumen berita berbahasa Indonesia dengan format RSS 2.0, berjumlah 173 dokumen RSS. Untuk pengujian sistem digunakan 10 kueri percobaan.
Manfaat
Dari penelitian ini diharapkan terbentuk sebuah engine yang dapat menemukembalikan dokumen berita dengan format RSS berdasarkan kueri yang diberikan pengguna.
TINJAUAN PUSTAKA Temu Kembali Informasi
Temu kembali informasi berkaitan dengan representasi, penyimpanan, pengorganisasian dan pengaksesan informasi. Sistem temu kembali informasi menyediakan kemudahan akses informasi bagi pengguna. Pengguna harus menerjemahkan kebutuhan informasinya ke dalam bentuk kueri. Dengan adanya kueri yang diberikan oleh pengguna, tujuan utama dari sistem temu kembali informasi adalah mengembalikan informasi yang relevan dengan kueri dan informasi yang tidak relevan sesedikit mungkin (Baeza-Yates & Ribeiro-Neto 1999).
RSS
Really Simple Syndication (RSS) merupakan turunan dari bahasa XML. Extensible Markup Language (XML) adalah format teks yang sederhana dan sangat fleksibel yang diambil dari SGML (ISO 8879). RSS adalah suatu format yang digunakan untuk sindikasi berita dan isi dari situs seperti berita, termasuk situs berita besar seperti Wired, situs komunitas yang berorientasi berita seperti Slashdot, dan weblog pribadi. Maksud dari sindikasi di sini adalah sebuah situs yang memiliki RSS Feed dapat dibaca isinya tanpa harus mengunjungi situs yang bersangkutan. RSS tidak hanya untuk berita. Hampir semua hal yang bisa dipilah-pilah menjadi bagian-bagian diskret dapat disindikasi melalui RSS: halaman "recent changes" dari sebuah wiki, changelog dari CVS checkins, bahkan juga sejarah revisi dari sebuah buku. (XML 2002).
Parsing
Untuk pemrosesan, dokumen dipilih menjadi unit-unit yang lebih kecil contohnya berupa kata, frasa atau kalimat. Unit hasil pemrosesan disebut sebagai token. Dalam proses ini biasanya juga digunakan sebuah daftar kata yang tidak digunakan (stoplist) karena tidak signifikan dalam membedakan dokumen atau kueri, misalnya kata-kata tugas seperti yang, hingga, dan dengan. Proses parsing akan menghasilkan daftar istilah beserta informasi tambahan seperti frekuensi dan posisi yang akan digunakan dalam proses selanjutnya (Ridha 2002).
Stemming
Stemming adalah proses penghilangan prefiks dan sufiks dari kueri dan istilah-istilah dokumen (Grossman 2002). Stemming dilakukan atas dasar asumsi bahwa kata-kata yang sama memiliki makna yang serupa. Dalam hal keefektifan stemming dapat meningkatkan recall dengan mengurangi bentuk-bentuk kata ke bentuk kata dasarnya. Selain itu proses stemming juga dapat mengurangi ruang penyimpanan indeks (Ridha 2002).
Pembobotan tf-idf
Pada saat pengindeksan, dokumen RSS diekstrak melalui proses parsing untuk mendapatkan istilah-istilah dari masing-masing dokumen. Untuk setiap pasangan istilah dan dokumen tersebut diberikan pembobotan tf-idf:
i idf j i tf j i idf tf− , = , × .
Untuk pembobotan istilah dalam dokumen dihitung dengan rumus berikut:
j i freq i j i freq j i tf , max , , = ,
di mana bobot kemunculan istilah dalam dokumen merupakan hasil bagi antara tingkat kepentingan istilah tersebut dalam dokumen
j i
tf, dengan tingkat kepentingannya pada keseluruhan dokumen dalam koleksi
( )
idft . Dengan(
freqi,j)
= banyaknya kemunculan istilah( )
i dalam dokumen, dan freqi ji ,
max =
kemunculan terbanyak
( )
f dari istilah dalam dokumen. Ukuran maxi freqi,j digunakan sebagai faktor normalisasi karena dokumen yang panjang cenderung memiliki lebih banyak istilah dan frekuensi istilah yang lebih tinggi. Tingkat kepentingan istilah terhadap keseluruhan dokumen dalam koleksi dihitung dengan rumus berikut: = i n N i idf log ,
dengan N adalah banyaknya dokumen dalam koleksi dan
( )
ni adalah banyaknya dokumen yang mengandung istilah( )
i .Selain pembobotan istilah pada dokumen, pembobotan juga dilakukan pada istilah kueri. Berikut ini adalah pembobotan yang digunakan untuk istilah kueri.
× × + = t df N q i freq i q i freq q i w log , max , 5 . 0 5 . 0 , ,
dengan freqi,q = banyaknya kemunculan istilah
( )
f dalam kueri, danq i freq
i ,
max =
kemunculan terbanyak
( )
f dari istilah dalam kueri (Baeza-Yates & Ribeiro-Neto 1999).Vector Space Model
Vector Space Model (VSM) merupakan salah satu model matematika yang digunakan untuk merepresentasikan sistem dan prosedur penemukembalian informasi yang merepresentasikan kueri dan dokumen dengan gugus istilah dan menghitung kesamaan global antara kueri dan dokumen (Salton 1989).
Dalam temu kembali informasi pada dokumen, VSM digunakan untuk memodelkan tingkat kesamaan antara dokumen dengan kueri. Pada umumnya pengukuran tingkat kesamaan dilakukan dengan cara menghitung kosinus sudut antara vektor kueri dengan dokumen. Kueri dan dokument dapat dinyatakan dalam vektor istilah sebagai berikut:
Q = (WQ(t1), WQ(t2), WQ(t3), ..., WQ(tn)), D = (WD(t1), WD(t2), WD(t3), ..., WD(tn)), dengan WQ(ti) adalah bobot istilah t dalam kueri dan WD(ti) adalah bobot istilah t dalam dokumen. Nilai WD(ti) adalah nilai tf-idf(ti).
Selanjutnya derajat kesamaan ρ
(
Q,D)
antara dokumen dan kueri dapat dihitung menggunakan kosinus sudut antara vektor D dan Q dengan rumus sebagai berikut: (Rahman 2006)(
,)
|( )
( )
. D Q i t D W i t Q W D Q ti D Q ∗ ∗ ∈ ∑ = ρ Recall – PrecisionRecall dan Precision adalah dua ukuran yang umum digunakan untuk mengevaluasi kualitas dari temu kembali informasi.
Dalam temu kembali informasi precision didefinisikan sebagai jumlah dari dokumen relevan yang ditemukembalikan dibagi dengan jumlah total dokumen yang ditemukembalikan dari hasil pencarian, sedangkan recall didefinisikan sebagai jumlah dari dokumen relevan ditemukembalikan dibagi dengan jumlah total dokumen relevan yang ada dalam koleksi.
Recall dan precission dapat dinyatakan sebagai berikut (Baeza-Yates & Ribeiro-Neto 1999). , Re R R A call= I , Pr A R A ecision= I
dengan A adalah jumlah dokumen yang ditemukembalikan, R adalah jumlah dokumen yang relevan dalam koleksi, dan A IR adalah jumlah dokumen relevan yang ditemukembalikan.
Average Precision
Average precission adalah suatu ukuran evaluasi kinerja temu kembali yang diperoleh dengan menghitung rata-rata precision pada
berbagai tingkat recall, biasanya digunakan sebelas tingkat recall standar yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.
Adakalanya tingkat recall yang diperoleh tiap kueri berbeda dengan sebelas tingkat recall standar yang ada. Untuk kasus yang seperti ini dibutuhkan prosedur interpolasi. Jika rj,
}
{
0,1,2,...,10 ∈j adalah tingkat recall standar ke-
j
maka : 1 max ≤ ≤ + = j r r j r j r P P( )
r ,dengan demikian, precision interpolasi pada tingkat recall standar ke-j adalah precision tertinggi pada setiap tingkat recall antara j hingga
(
j+1)
(Baeza-Yates & Ribeiro-Neto 1999).Hash Function
Hash function adalah suatu metode yang digunakan untuk mengubah data yang ada menjadi sebuah bilangan yang relatif kecil (small number) yang akan menjadi “sidik jari” (fingerprint) dari data terebut. Fungsi ini memecah dan mengolah data untuk menghasilkan kode atau nilai hash-nya. Nilai dari suatu fungsi hash akan memiliki panjang yang tetap untuk masukan dengan panjang yang sembarang. Secara umum, fungsi hash memiliki beberapa sifat utama, yaitu : fungsi satu arah, artinya untuk suatu nilai fungsi hash y, sulit menemukan nilai input x yang memenuhi persamaan H(x)=y, dan collision free/resistant, artinya sulit untuk menemukan 2 buah nilai input yang memunyai nilai fungsi hash yang sama.
Salah satu fungsi hash yang banyak digunakan adalah Message Digest 5 (MD5). Algoritme MD-5 secara garis besar adalah mengambil pesan yang memunyai panjang variabel diubah menjadi ‘sidik jari’ atau ‘intisari pesan’ yang memunyai panjang tetap yaitu 128 bit.
METODE PENELITIAN Koleksi Dokumen
Dokumen berita yang akan digunakan pada penelitian berasal dari beberapa situs berita di Indonesia seperti Antara, Detik, Liputan 6, Kompas, Okezone, dan Tempo. Data yang digunakan adalah data dengan format RSS versi 2.0.
Pemilihan ukuran kesamaan
Beberapa ukuran kesamaan yang dapat digunakan dalam VSM di antaranya inner product, cosine, dice, jaccard, overlap dan asymmetric.
Pada penelitian yang dilakukan oleh Rorvig (1999), dibandingkan lima ukuran kesamaan (cosine, dice, jaccard, overlap, dan asymetric) hasil uji menunjukkan bahwa ukuran kesamaan cosine dan overlap memiliki kinerja temu kembali yang lebih baik dibanding yang lain. Hasil penelitian yang dilakukan oleh Rahman (2006) yang melakukan perbandingan kinerja empat ukuran kesamaan (cosine, dice, jaccard, dan overlap), hasil uji menunjukkan bahwa ukuran kesamaan cosine memberikan kinerja temu kembali yang lebih baik dibandingkan dengan tiga ukuran kesamaan lainnya. dice dan jaccard tidak jauh berbeda sedangkan overlap memiliki kinerja yang paling rendah.
Merujuk kepada hasil kedua penelitian tersebut maka ukuran kesamaan yang akan digunakan dalam penelitian ini adalah ukuran cosine.
Tahap-tahap Penelitian
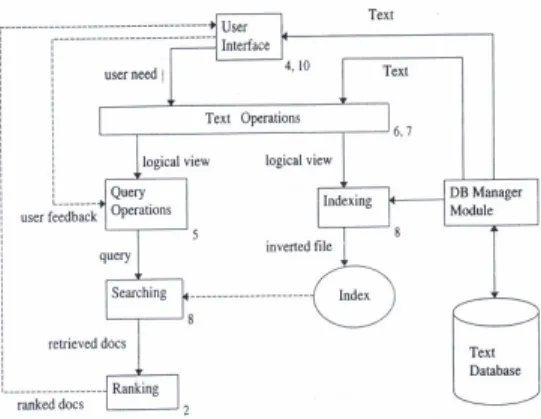
Gambar 1 menunjukkan gambaran sistem secara umum yang akan dibuat dalam penelitian ini
Gambar 1 Sistem temu kembali informasi (Baeza & Ribeiro 1999).
Tahapan-tahapan yang dilakukan dalam penelitian ini adalah :
Text operation
Proses yang dilakukan dalam text operation adalah proses parsing dan stemming.
1. Parsing
Parsing dilakukan dengan pengambilan token dari dokumen RSS dengan menggunakan XML Parser. Pada
proses ini yang termasuk ke dalam stoplist (daftar kata-kata buangan) akan diabaikan. Parsing dilakukan dalam dua tahap yaitu : • Parsing tahap satu
Parsing pada tahap satu bertujuan untuk mengambil dan memisahkan setiap berita menjadi token berita. Setiap token berita dalam dokumen RSS direpresentasikan dalam elemen item. Untuk mencegah adanya duplikasi berita maka digunakan hash function MD5 yang bertujuan untuk menghasilkan identitas yang unik untuk setiap token berita berdasarkan isi dari token tersebut.
• Parsing tahap dua
Parsing tahap dua bertujuan untuk parsing isi token berita yang didapat dari proses parsing tahap satu. Pada tahapan ini dilakukan parsing terhadap isi dari setiap token berita sehingga dihasilkan token istilah. Token istilah beserta identitas token berita digunakan dalam proses indexing.
2. Stemming
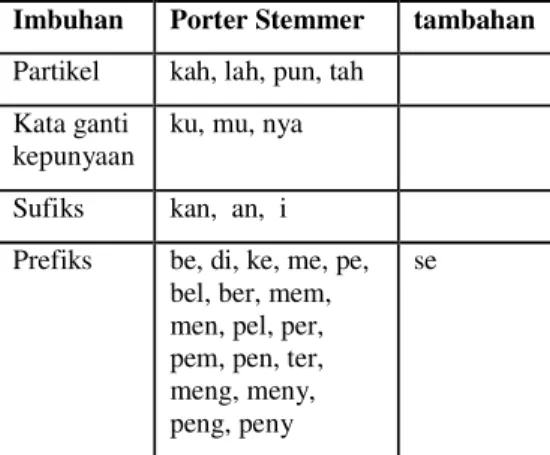
Stemming adalah proses pemotongan kata untuk mengembalikan kata ke bentuk dasarnya sehingga dapat meningkatkan hasil recall. Algoritme stemmer yang digunakan dalam penelitian ini diadopsi dari Tala stemmer. Tala stemmer memodifikasi algoritme Porter stemmer untuk bahasa Indonesia. Selain menggunakan daftar imbuhan dan aturan yang ada pada Tala stemmer, pada penelitian ini dilakukan penambahan aturan pemotongan dan imbuhan yang dapat dilihat pada Tabel 1 dan 2.
Bahasa Indonesia memiliki Struktur morfologi sebagai berikut:
[prefiks1] + [prefiks2] + kata dasar + [sufiks] + [kata ganti kepunyaan] + [partikel]
dengan tanda [ ] menunjukkan pilihan. Struktur tersebut dapat digunakan sebagai panduan dalam proses stemming. Desain dasar dari proses stemming dapat dilihat pada Gambar 2.
Pemotongan kata dilakukan dengan menghilangkan partikel, kata ganti kepunyaan, prefiks (awalan), infiks (sisipan), sufiks (akhiran), dan konfiks (gabungan antara prefiks dan sufiks).
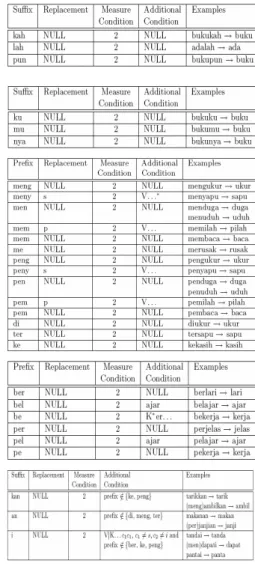
Hanya saja pemotongan imbuhan yang berupa sisipan sulit dilakukan untuk itu dalam penelitian ini sisipan atau infiks diabaikan. Daftar imbuhan dapat dilihat pada Tabel 1, sedangkan aturan pemotongan imbuhan dapat dilihat pada Gambar 3. Tabel 1 Daftar imbuhan untuk proses stemming hasil adopsi Tala stemmer
Tabel 2 Penambahan aturan pemotongan imbuhan
Imbuhan Penambahan Aturan C* men dan pen
V* + "t" *C
*V *V + "k" meng dan peng
*e - “e”
Gambar 2 Desain dasar dari Tala stemmer untuk bahasa Indonesia (Tala 2003). Imbuhan Porter Stemmer tambahan Partikel kah, lah, pun, tah
Kata ganti kepunyaan
ku, mu, nya Sufiks kan, an, i
Prefiks be, di, ke, me, pe, bel, ber, mem, men, pel, per, pem, pen, ter, meng, meny, peng, peny
Sebagaimana algoritme Tala, digunakan suatu fungsi penghitung ukuran kata untuk mencegah stemming menghasilkan stem yang terlalu pendek. Diasumsikan minimal stem hasil berukuran dua kecuali jika token berukuran kurang dari dua. Jumlah vokal dalam kata akan digunakan sebagai penentu ukuran kata kecuali kata-kata tanpa vokal yang terdiri atas tiga karakter atau lebih dianggap memiliki ukuran dua untuk mengakomodasi singkatan yang hanya terdiri atas konsonan (Ridha 2002).
Selain menggunakan daftar imbuhan proses stemming dalam penelitian ini menggunakan aturan gugus konsonan dalam proses pemotongannya, serta menggunakan kamus kata dasar bahasa Indonesia untuk melakukan pemeriksaan apakah kata yang dihasilkan merupakan kata dasar atau bukan.
Gambar 3 Lima aturan pemotongan imbuhan (Tala 2003).
Indexing
Pada tahapan ini dibangun sebuah indeks kata dari hasil text operation, dengan menggunakan teknik inverted index.
Searching
Proses pencarian kueri dilakukan dengan menghitung tingkat relevansi kueri dengan dokumen yang ada. Algoritme pencarian yang digunakan pada inverted index adalah Vocabulary search, yaitu kueri dicari di dalam perbendaharan kata yang terdapat pada indeks. Hal yang perlu ditekankan adalah kueri harus dipisahkan per kata (parsing).
Ranking
Pada tahapan ini dilakukan pengurutan dokumen berdasarkan tingkat relevansi antara kueri dan dokumen.
User Interface
Perancangan dan pembuatan user interface dari sistem yang akan menjembatani pengguna dengan sistem itu sendiri.
Evaluasi Sistem
Evaluasi dilakukan dengan mengukur kinerja temu kembali dengan menggunakan pendekatan recall–precission. Sistem akan mengembalikan daftar dokumen terurut menurun berdasarkan hasil fungsi kesamaan kueri dan dokumen.
Batasan dan asumsi
Batasan dan asumsi yang akan digunakan dalam penelitian ini adalah sebagai berikut :
1. Dokumen dan kueri menggunakan karakter ASCII.
2. Dokumen yang digunakan adalah dokumen berekstensi XML dengan format RSS versi 2.0.
3. Pengindeksan hanya dilakukan untuk isi dari elemen title dan description. Tag, atribut dan elemen lain seperti link dan pubdate tidak diindeks karena diangggap tidak terlalu penting dalam RSS berita. 4. Tidak ada kesalahan penulisan XML dalam
dokumen RSS.
5. Pengujian dilakukan dengan membandingkan kinerja sistem yang menggunakan pembobotan judul dengan pembobotan normal.
6. Istilah yang terdapat pada elemen title (judul berita) memiliki bobot dua kali lebih