STATISTIK
TEORI
BIOSTATISTIK DESKRIPTIF
R. HIDAYAT.M.Cs
Darmais Press-Padangsidimpuan
ISBN
Teori Statistik (Biostatistik Deskriptif) Oleh : R. Hidayat.M.Cs
Copyright@2015 Darmais Press
Dilarang mengcopy sebagian atau seluruh isi buku ini Tanpa izin tertulis dari penerbit
Hak Cipta dilindungi Undang-undang Rencana Kulit : Abim
Layout, Montase, Setter : Abim Diterbitkan Oleh :
Darmais Press
STIKes Darmais Padangsidimpuan
KATA PENGANTAR
Puji dan Syukur Kami panjatkan ke Hadirat Tuhan ynag maha Esa, Karena
berkat limpahan Rahmat dan karuniya-Nya sehingga kami dapat menyelesaikan buku
ini dengan baik. Dalam buku ini kami membahas tentang Teori Statistik (Biostatistik
Deskriptif).
Buku ini dibuat dengan berbagai informasi, masukan serta dorongan dari
berbagai pihak, kami mengucapkan terimakasih terutama kepada Ketua dan Pembina
Yayasan Perguruan Karya Bunda Langga Padangsidimpuan yang telah memberikan
darongan dan bantuan baik moril maupun spiritual.
Kami menyadari bahwa masih banyak kekurangan yang mendasar pada buku
ini. Oleh karena itu kami mengharapkan pembaca untuk memberikan saran serta kritik
yang dapat membangun kami, kritik konstruktif dari pembaca sangat kami harapkan
untuk penyempurnaan buku selanjutnya.
Akhir kata semoga buku ini dapat memberikan manfaat bagi kita sekalian.
Padangsidimpuan, 2015
i
DAFTAR ISI
Halaman
KATA PENGANTAR ... i
DAFTAR ISI ... ii
BAB I STATISTIK ... 1
A. Istilah-istilah Dalam Statistik ... 1
B Penyajian Data Statistik ... 7
C Penyajian Data Dalam Bentuk Diagram ... 14
D Ukuran Statistik Data ... 25
BAB II KONSEP BIOSTATISTIK ... 50
2.1 Devinisi ……….. ... 50
2.2 Ruang Lingkup Statistik……… ... 50
2.3 Tipe Variabel……… ... 51
2.4 Sumber Data Kesehatan……… ... 53
2.5 Skala Pengukuran……… ... 54
2.6 Metode Pengumpulan Data……… ... 55
ii
BAB III PENYAJIAN DATA ... 58
3.1 Pengerian ... ... 58
3.2 Jenis Penyajian Tabel Dan Kegunaannya ... 58
BAB IV TENDENSI SENTRAL ... 67
4.1 Ukuran Tendensi Sentral ... 67
4.2 Data Berkelompok ... 69
4.3 Ukuran Penyimpangan…... 73
Bab V SKALA DATA ……… ... 86
Bab VI CARA PENGAMBILAN SAMPLING… ... 89
6.1 Definisi dan Pengertian……. ... 89
6.2 Simpel Random Sampling ... 90
6.3 System Matic Sampling ….. ... 92
6.4 Stratafikasi Sampling …….….. ... 94
6.5 Sampel Size ……….. ... 98
Bab VII MERUMUSKAN HIPOTESIS… ... 100
7.1 Pengertian ……..………. ... 100
7.2 Jenis Hipotesis …………. ... 100
iii
Bab VIII UJI HIPOTESIS UNTUK MEAN… ... 106
8.1 Pengujian Hipotesis……. ... 106
8.2 Jenis Hipotesis ... 107
8.3 Daerah Penolakan Hipotesis ….. ... 109
Bab IX UJI SATU POPULASI … ... 112
Bab X UJI STATISTIK 2 POPULASI …... 115
Bab XI KORELASI PEARSON ... 119
11.1 Korelasi Pearson……. ... 119
11.2 Kasus Korelasi ... 120
Bab XII REVIEW DAN LATIHAN ... 122
1
BAB I
STATISTIK
Dalam statistika, angka dikumpulkan dan diatur sedemikian rupa sehingga orang
dapat memahaminya, menarik kesimpulan, dan membuat perkiraan berdasarkan angka
– angka itu.
A. Istilah – istilah Dalam Statistik
1. Pengertian Statistika, Statistik, Populasi, dan Sampel
Agar suatu permasalahan dapat diuraikan, maka diperlukan keterangan –
keterangan penunjang yang terkait. Keterangan – keterangan tersebut dapat berupa
angka atau yang lainnya.
Keterangan – keterangan berupa angka disebut data kuantitatif, sedangkan
keterangan – keterangan bukan angka disebut data kualitatif. Data kuantitatif itu sendiri
dibedakan menjadi 2 macam yaitu, data diskrit dan data kontinu. Data diskrit diperoleh
dari hasil penghitungan, sedangkan data kontinu diperooleh dari hasil pengukuran.
Permasalahan Data
Data Kuantitatif
Data kualitatif
2 Statistika adalah suatu disiplin ilmu yang penting pada dewasa ini, antara lain
untuk memperbaiki teori – teori statistika yang sudah ada, ataupun member gambaran
tentang hasil suatu penyelidikan / percobaan.
Satistika berkaitan dengan pengumpulan informasi/keterangan, penyajian dalam
bentuk daftar, diagram, atau grafik sehingga memudahkan untuk dianalisa , yang
selanjutnya disimpulkan dan diambil kesimpulan.
Setiap informasi atau keterangan yang diperoleh disebut datum, dalam bentuk
jamak adalah data. Tahap statistika hanya berusaha melukiskan dan menganalisa
kelompok data tanpa menarik kesimpulan disebut statistika deskriptif, sedangkan tahap
statistika yang berkaitan dengan kondisi suatu kesimpulan diambil disebut statistika
inferensi atau statistika induktif.
Definisi ;
Statistika adalah ilmu pengetahuan tentang metode pengumpulan, pengolaha,
penafsiran, dan penarikan kesimpulan dari data penelitian.
Perhatikan kalimat – kalimat berikut ini :
a. Lima puluh juta pemirsa ≤V di Indonesia menyaksikan sinetron Si Doel Anak
Sekolahan .
b. Delapan dari sepuluh aktris menggunakan pasta gigi X.
3 Kalimat di atas menyangkut himpunan yang universal, yaitu semua pemirsa TV
di Indonesia, semua aktris, dan semua baterai. Dalam statistika, himpunan universal
(semesta) dengan karakteristik tertentu disebut populasi. Pada praktiknya, pengamatan
terhadap populasi tidak dapat dilakukan sebab membutuhkan waktu yang lama,
memerlukan biaya yang besar, ataupun merusak populasi itu sendiri, misalnya
mungkinkah kita menanyai semua pemirsa TV di Indonesia ? Mungkinkah kita
menanyai semua aktris tentang merek pasta gigi yang mereka gunakan ?
Bagaimanakah jika semua baterai kita tes daya tahannya ?
Untuk keperluan itu, kita dapat menggunakan atau mengambil contoh yang
dipilih dari populasi, yang disebut sampel. Jadi, sampel adalah himpunan bagian dari
populasi.Metode statistika tentang cara mengambil sampel yang tepat disebut teknik
sampling. Nilai – nilai yang diperoleh dari sampel disebut statistik. Statistik inilah yang
digunakan untuk men-duga populasi. Nilai – nilai populasi disebut parameter.
Dalam statistika, ada 3 macam ukuran penting, yaitu :
1. Ukuran pemusatan data : rataan hitung (mean), modus, dan median
2. Ukuran letak data : kuartil dan desil
3. Ukuran penyebaran data : rentang antar kuartil, simpangan kuartil, simpangan
4 2. Pengumpulan, Pembulatan, dan Pemeriksaan terhadap Data
Usaha untuk memperoleh informasi yang objektif merupakan langkah yang
penting dalam suatu penyelidikan (observasi). Hal ini berkaitan dengan tujuan
penyelidikan itu sendiri. Sesuai dengan tujuan penyelidikan, maka pengumpulan data
dapat dilakukan dengan metode :
1. Pengamatan (observasi), yaitu cara pengumpulan data dengnan
mengamati secara langsung subjek yang diteliti.
2. Penelusuran literature, yaitu cara pengumpulan data dengan
menggunakan sebagian atau seluruh data yang telah ada dari peneliti
sebelumnya. Penelusuran literature disebut juga pengamatan tidak
langsung.
3. Penggunaan kuesioner (angket), yaitu cara pengumpulan data dengan
menggunkan daftar pertanyaan (angket) atau daftar isian terhadap subjek
yang teliti.
4. Wawancara (interview), yaitu cara pengumpulan data dengan langsung
mengadakan Tanya jawab kepada subjek yan diteliti.
Data yang diperoleh disebut data mentah.
Berdasarkan banyaknya data yang diambil, cara pengumpulan data dibagi atas dua
5 1. Sensus, yaitu cara pengumpulan data, di mana data diperoleh dari setiap
anggota populasi.
2. Sampling, yaitu cara pengumpulan data, di mana hanya sebagian anggota
populasi (sampel) saja yang diteliti. Akan tetapi, dari sebagian anggota populasi
ini diharapkan dapat menggambarkan keadaan populasi yang sebenarnya.
Selanjutnya, setelah data diperoleh, untuk mendapatkan gambaran tentan apa yan
diteliti, peneliti harus melakukan penganalisisan data.
Untuk penganmatan lebih lanjut, data dibedakan :
a) Data Kuantitatif, yaitu data berupa kumpulan angka, misalnya tinggi siswa,
banyaknya siswa yang tidak masuk hari ini di suatu sekolah.
Ditinjau dari cara memperolehnya, data kuantitatif dapat dibedakan menjadi
2macam, yaitu.
1. Data Cacahan
Data cacahan adalah data yang diperoleh dengan cara mencacah,
membilang, atau menghitung banyak objek. Sebagai contohh adalah data
tentang banyak petak sawah untuk masing – masing desa di lima desa.
2. Data Ukuran
Data ukuran adalah data yang diperoleh dengan cara mengukur besaran
objek. Sebagai contoh data tentang luas petak sawah dan data tentang berat
6 b) Data Kualitatif, yaitu data yang diamati berdasarkan atribut, misalnya pendapat
siswa terhadap pelajaran Matematika, seperti amat senang – senang – kurang
senang – tidak senang.
Untuk keperluan perhitungan maupun analisis, sering dikehendaki data
kuantitatif dalam bentuk yang lebih sederhana. Untuk menyederhanakan bilangan –
bilangan, diadakan aturan pembulatan sebagai berikut :
a. Aturan umum, yaitu jika kurang dari 0,5 dihilangkan dan jika sama atau lebih dari
0,5 menjadi 1,
Misal : 3,48 dibulatkan menjadi 3
2,5 dibulatkan menjadi 3
8,45678 dibulatkan menjadi 8,46 (sampai dua tempat desimal).
b. Aturan genap terdekat, yaitu kurang dari 0,5 dihilagkan, lebih dari 0,5 menjadi 1,
dan sama dengan 0,5 dihilangkan jika angka yang mendahului genap atau
menjadi 1 jika angka yang mendahului ganjil,
Misal : 6,948 dibulatkan menjadi 6,9 (sampai satu tempat desimal)
17,52 dibulatkan menjadi 18,00
12,50 dibulatkan menjadi 12,00
7 Sebelum data diolah lebih lanjut, perlu diadakan pemeriksaan data kembali. Hal
ini untuk menghindari kekeliruan dalam analisa maupun kesimpulan yang diambil.
Beberapa data yang dipandang meragukan hendaknya diyakini kebenarannya.
Kemungkinan kesalahan terjadi pada alat ukur, kesalahan mengukur, kekeliruan
mencatat, instruksi yang tidak jelas, atau kecerobohan dalam mengumpilkan data.
Semua kesalahan itu perlu diperhatiakan agar diperoleh data yang akurat.
B. PEYAJIAN DATA STASTITIK
Data statistic dapat disajiakan dalam beberapa bentuk, sesuai dengan jenis data.
Data statistic dapat berupa daftar bilangan yang mempunyai satuan yang sama atau
disebut data tunggal. Data dapat dinyatakan dalam bentuk daftar bilangan.
1. Daftar Bilangan
Data tunggal dapat dituliskan sebagai daftar bilangan sebagaimana contoh berikut.
Data niali matematika 10 anak kelas 2 SD adalah : 60, 75, 65, 80, 95, 74, 88, 87, 76
dan 90.
2. Tabel Distribusi Frekuensi
Tabel distribusi frekuensi dapat dibedakan menjadi 2, yaitu tabel distribusi frekuensi
data tunggal dan tabel distribusi frekuensi data berkelompok.
8 Penyajian data tunggal kerekuensi dilakukan dengan membuat tabel yang terdiri
atasrekuensi dilakukan dengan membuat tabel yang terdiri atas kolom, yaitu kolom nilai
(x), kolom turus dan kolom frekuensi (f)
Contoh 1.1
Skor tes matematika dari 50 siswa di suatu kelas adalah
29 25 28 22 24 25 28 26 26 24
23 25 26 21 23 26 27 23 28 30
27 27 24 26 25 25 24 21 25 22
25 25 27 24 23 27 25 26 23 26
23 27 25 24 26 25 24 22 24 26
Sajikan data di atas dalam daftar distribusi frekuensi tunggal !
9 b. Tabel Distribusi Frekuensi Data Berkelompok
Jika sekumpulan data memiliki jumlah dan variasi data yang cukup banyak,
maka data tersebut dapat disederhanakan dengan cara mengelompokkannya dalam
kelas – kelas. Dengan demikian diperoleh tabel distribusi frekuensi data berkelompok.
Beberapa istilah yang penting dalam membuat tabel distribusi frekuensi
berkelompok antara lain sebagai berikut
1) Kelas Interval
Kelas interval adalah kelas – kelas yang memuat beberapa data tertentu.
2) Batas Kelas
Batas kelas adalah nilai – nilai ujung yang terdapat pada suatu kelas interval
3) Tepi kelas
Tepi kelas adalah setengah dari jumlah batas atas dan batas bawah dua kelas
interval yan berurutan.
Tepi atas kelas (ta) adalah batas kelas ditambah setengah. Sedangkan tepi
bawah kelas (tb) adalah batas kelas dikurang setengah.
4) Panjang Kelas
I = interval Kelas R = jangkauan (data
10 Panjang kelas disebut juga lebar kelas atau interval kelas, yaitu selisih antara
tepi atas dan tepi bawah dari tiap kelas dalam kelas interval yang sama
5) Titik Tengah Kelas
Nilai titik tengah kelas adalah setengah dari jumlah tepi bawah kelas dan tepi
atas kelas.
c. Cara Menyusun Tabel Distribusi Kelompok
Beberapa langkah yang perlu diperhatiakn dalam menyusun tabel distribusi
frekuensi berkelompok adalah sebagai berikut.
Menentukan nilai data terbesar (xmaks) dan nilai data terkecil (xmin) kemudian ditentukan
jangkauannya (J) dengan rumus :
J = x
maks–
x
minMenentukan banyaknya kelas interval (k) dari n buah data adalah berdasarkan aturan
Sturgess, yaitu :
k = 1 + 3,3 log n
11 Menentukan daftar distribusi frekuensi dengan menetapkan kelas – kelas
sehingga nilai statistic minimum termuat dalam kelas interval terendah, tetapi tidak
harus sebagai batas bawah kelas. Selanjutnya, menetapkan frekuensi tiap kelas yang
dapat dilakukan dengan menggunakan turus atau bisa saja langsung dituliskan .
Contoh 1.2
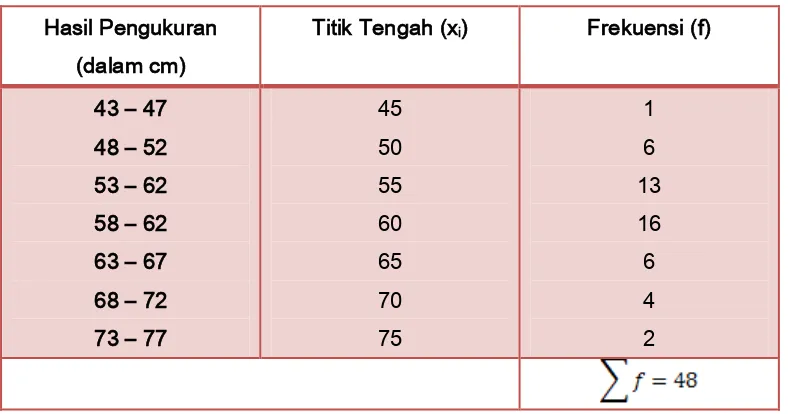
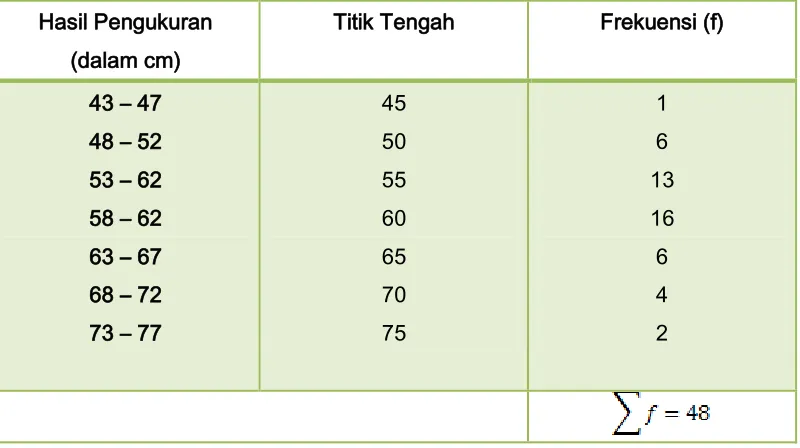
Dari 48 kali pengukuran lembaran kain (ketelitian sampai cm terdekat), diperoleh data
sebagai berikut.
54 50 53 54 60 56 62 54 58 65 71 58
58 65 56 58 52 70 74 62 52 62 58 60
70 73 45 60 56 54 52 53 67 54 59 64
57 49 48 56 58 58 60 64 63 68 57 59
Buatlah daftar distribusi frekuensi berkelompok dari data tersebut !
Jawab:
Data pengukuran tersebut terdidi dari 48 data, sehingga n = 48
Nilai statistic minimum , xmin = 45 , dan nilai statistic maksimum, xmaks=74
Jangkauan
Banyaknya kelas (k) = 1 + 3,3 log n = 1 +3,3 log 48 = 6,548…, dibulatkan ke atas
12 Panjang Kelas 4,14,…, dibulatkan ke atas menjadi tercakup dalam kelas
interval.
Tabel distribusi frekuensi :
Hasil Pengukuran
d. Tabel Distribusi Frekuensi Komulatif dan Frekuensi Relatif
Tabel distribusi frekuensi kumulatif dapat disusun dari tabel distribusi frekuensi
berkelompok. Terdapat dua jenis frekuensi kumulatif, yaitu frekuensi kumulatif kurang
dari tepi atas dan frekuensi kumulatif lebih dari tapi bawah
Setiap frekuensi (fi) dalam tabel distribusi frekuensi yang dinyatakan dalam persentase
13 Selanjutnya, daftar distribusi frekuensi kumulatif relative dapat disusun dari daftar
distribusi frekuensi kumulatif.
Contoh 1.3
Buatlah tabel distribusi frekuensi kumulatif relative berdasarkan tabel Contoh 1.2
Jawab:
Berdasarkan tabel pada contoh 1.2 perhatikan perhitungan – perhitungan berikut.
Dengan cara perhitungan yang sama, akan kita dapatkan tabel distribusi frekuensi
14 C. PENYAJIAN DATA DALAM BENTUK DIAGRAM
1. Diagram Batang
Dalam penyajian dengan diagram batang, data disajikan dalam bentuk batang
persegi panjang yang di gambarkan vertical atau horizontal dengan lebar sama.
Disamping diagram batang tunggal, dikenal dua diagram batang yang lain, yaitu:
1. diagram batang majemuk
2. diagram batang bertingkat
Contoh 1.4
Sekelompok siswa mengadakan penelitian tentang tayangan swasta. Mereka
menanyakan, manakah yang lebih digemari tayangan ABTV atau CDTV kepada teman
– temannya di sekolah. Daftar di bawah ini menunjukkan hasil penelitian tersebut :
Yang
Menggemari
Kelas A Kelas B Kelas C Kelas D Kelas E Kelas F
AATV 30 26 26 23 17 11
15 Diagram batang informasi di atas dapat di gambarkan sebagai berikut :
2. Diagram Garis
Diagram garis digunakan untuk menyajikan data yang menunjukkan
perkembangan suatu data dari waktu ke waktu. Selain dibaca dan ditafsirkan , diagram
garis juga dipakai untuk memperkirakan suatu nilai yang belum diketahui. Dalam
memperkirakan nilai yang belum diketahui ini ada dua macam pendekatan, yaitu
pendekatan interpolasi linear dan pendekatan ekstrapolasi linear.
Diagram garis digambar pada bidang Cartecius. Sumbu X ditempati oleh waktu
pengamatan sedangkan sumbu Y ditempati oleh nilai data yang diamati.
Interpolasi Linear
Pendekatan interpolasi linear adalah menafsirkan atau memperkirakan suatu
16 Ekstrapolasi Linear
Pendekatan ekstrapolasi linear adalah menaksir atau memperkirakan suatu nilai
data yang terletak sesudah titik data terakhir yang diketahui. Ekstrapolasi semacam ini
dapat dilakukan dengan cara memperpanjang garis dalam arah ke kanan atas atau ke
kanan bawah tergantung pada kecenderungan nilai – nilai data sebelumnya.
Contoh 1.5
Data jumlah siswa yang lulus ke Perguruan Tinggi Negeri sepuluh tahun terakhir
tahun di Kabupaten Semarang
Tahun Jumlah siswa yang
17 Berikut diagram garis dari data di atas :
3. Diagram Lingkaran
Diagram lingkaran digunakan untuk
menunjukkan perbandingan antaritem data
dengan cara membagi lingkaran dalam juring –
juring lingkaran yang sudut pusatnya sesuai
dengan perbandingan tersebut.
Contoh 1.6
Daftar jumlah mahasiswa yang mengikuti ekastrakurikuler kesenian di setiap
Buatlah diagram lingakaran yang sesuai dengan data di atas
Jawab :
Jumlah selueuh siswa= 10 + 4 + 6 + 8 + 12 =44. Perbandingan dan persentase untuk masing – masing kelas adalah :
18 Jika diuah dalam ukuran derajat, maka diperoleh sudut pusat sebagai berikut.
Kelas A :
Kelas B :
Kelas C :
Kelas D :
Kelas E :
4. Histogram
Data ukuran (data kontinu) yang telah disusun dalam daftar distribusi frekuensi
dapat disajikan dalam bentuk diagram yang disebut histogram.Gambar histogram
berbentukdiagram batang di mana antara dua batang yang berdampingan saling
berimpit. Langkah – langkah untuk membuat histogram suatu data berkelompok adalah
sebagai berikut :
Menggambar sumbu horizontal (untuk nilai) dan sumbu vertical (untuk frekuensi)
Menggambar persegi panjang untuk setiap interval. Alas persegi panjang
menunjukkan panjang kelas (p), yaitu dari tepi bawah kelas sampai tepi atas
19 Di atas tiap persegi panjag dapat ditulis frekuensi masing – masing agar
histogram mudah dibaca.
Contoh 1.7
Gambarlah histogram dari data yang disajikan di bawah ini seperti contoh 1.2
54 50 53 54 60 56 62 54 58 65 71 58
58 65 56 58 52 70 74 62 52 62 58 60
70 73 45 60 56 54 52 53 67 54 59 64
57 49 48 56 58 58 60 64 63 68 57 59
Buatlah daftar distribusi frekuensi berkelompok dari data tersebut dan buatlah
20 Jawab :
Tabel distribusi frekuensi :
Dengan mengikuti langkah – langkah membuat histogram suatu data berkelompok,
histogram dari data tersebut diperlihatkan pada gambar di bawah ini Hasil Pengukuran
(dalam cm)
Titik Tengah Frekuensi (f)
21 5. Poligon
Jika titik – titik tengah dari sisi atas tiap persegi panjang yang berdekatan pada
histogram dihuungkan , maka akan diperoleh grafik garis yang disebut polygon
distribusi frekuesi.
Selain dengan cara tersebut, polygon distribusi frekuensi dapat dibuat dengan langkah
– langkah sebagai berikut :
Menambahkan satu kelas interval sebelum kelas pertama dan satu kelas interval
sesudah kelas terakhir.
Menentukan titik tengah setiap kelas
Menggambar sumbu horizontal dan sumbu vertical
Menggambar titik – titik dengan titik tengah kelas interval sebagai absis dan
frekuensi kelas interval sebagai ordinat
Menghubungkan titik – titik yang berdekatan dengan suatu aris lurus.
Contoh 1.8
Gambar polygon distribusi frekuensi dari data pada contoh 1.2
Dari 48 kali pengukuran lembaran kain (ketelitian sampai cm terdekat), diperoleh data sebagai
berikut.
54 50 53 54 60 56 62 54 58 65 71 58
58 65 56 58 52 70 74 62 52 62 58 60
70 73 45 60 56 54 52 53 67 54 59 64
22 Buatlah daftar distribusi frekuensi berkelompok dari data tersebut dan buatlah poligonnya !
Jawab :
Poligon distribusi dari data tersebut diperlhatkan oleh gambar di bawah Hasil Pengukuran
(dalam cm)
Titik Tengah Frekuensi (f)
23 6. Ogive
Tabel distribusi frekuensi kumulatif yang disajikan dalam bentuk kurva, disebut
polygon distribusi frekuensi kumulatif atau ogive. Ogive terdiri dari 2 macam yaitu ogive
positif (ogive kurang dari) dan ogive negatif (ogive lebih dari). Ogive positif dibentuk
dengan menghubungkan titik – titik , dengan tepi atas sebagai absis dan frekuensi
kumulatif sebagai ordinat. Sementara itu, ogive negatif dapat dibentuk dengan cara
menghubungkan titik –titik, dengan tepi bawah sebagai absis dan frekuensi kumulatif
sebagai ordinat.
Contoh 1.9
Gambarlah ogive dari data yang terdapat pada contoh 1.2
Dari 48 kali pengukuran lembaran kain (ketelitian sampai cm terdekat), diperoleh data
sebagai berikut.
54 50 53 54 60 56 62 54 58 65 71 58
58 65 56 58 52 70 74 62 52 62 58 60
70 73 45 60 56 54 52 53 67 54 59 64
57 49 48 56 58 58 60 64 63 68 57 59
Buatlah daftar distribusi frekuensi berkelompok dari data tersebut dan buatlah ogive
24 Jawab :
Perhatikan kembali tabel distribusi kumulatif yang terdapat pada Contoh 1.3
25 D. UKURAN STATISTIK DATA
1. Ukuran Pemusatan Data
a. Mean (Rataan Hitung)
Mean (rataan hitung) didefinisikan sebagai jumlah data kuantitatif dibagi
banyaknya data. Atau dapat dinyatakan sebagai jumlah seluruh data dibagi
banyaknya data. Notasi atau lambing / symbol untuk sampel dan populasi
dibedakan :
Sampel Populasi
Data
Banyaknya data
Rataan
X
n
X
N
Mean , dari data dirumuskan :
data tunggal
:26 Dengan : xi = titik tengah kelas interval
fi = frekuensi dari xi
k = banyaknya kelas interval
Selain menggunkan rumus dan cara di atas, kita dapat menentukan rataan dari
sekumpulan data dengan terlebih dahulu menentukan rataan sementaranya. Rataan
sementara biasanya diambil dari nilai tengah yang mempunyai frekuensi terbesar.
Untuk menghitung rata – rata bisa menggunakan rata – rata sementara.
Kesulitan dalam menghitung rata – rata adalah apabiladijumpai bilangan besar atau
tidak bulat.Untuk mengatasi hal ini, kita menyederhanakan data, yaitu dengan cara
memperkirakan nilai rata rata yang disebut rata – rata sementara. Caranya adalah
sebagai berikut:
a) Tetapkan rata – rata sementara , dipilih pada kelas yang mempunyai
frekuensi tertinggi dan letaknya di tengah.
b) Tentukan simpangan (deviasi) terhadap rata – rata sementara, dengan
rumus:
27 d) Atau jika dengan memfaktorkan interval kelasnya maka rumusnya
menjadi:
Contoh 1.10
Dua belas orang mengikuti pertandingan menembak pada jarak tertentu, setiap peserta
menembak 10 kali. Hasil tembakan yang mengenai sasaran dari tiap – tiap peserta
adalah 4, 8, 5, 8, 6, 4, 7, 7, 2, 3, 5, 7. Tentukan rataan tembakan yang menenai
sasaran!
Jawab :
Data Tunggal
Data di atas dipandang sebagai sampel, maka :
Data Kelompok
28 Jadi, rata – ratanya adalah 65,83
b. Modus (Nilai terbanyak)
Modus adalah nilai yang paling banyak muncul. Untuk data tunggal, modus
sangat mudah ditentukan, yaitu data yang yang mempunyai frekuensi terbanyak.
Modus mempunyai kelemahan, yaitu apabila kelompok data yang dimaksud memiliki
dua nilai modus (bimodal) atau lebih, atau tidak memiliki modus, misal : Data 5, 7, 8, 10,
10,12,12 memiliki dua modus yaitu 10 dan 12.
Nilai Frekuensi
(fi)
Titik Tengah (xi) (fixi)
40 – 49 4 44,5 178
50 – 59 6 54,5 327
60 – 69 10 64,5 645
70 – 79 4 74,5 298
80 – 89 4 84,5 338
29 Untuk data distribusi frekuensi dalam bentuk kelas – kelas interval, nilai modus
tidak dapat ditentukan dengan tepat tetapi dengan pendekatan. Ada yang berpendapat
nilai modus sama dengan nilai tengah kelas yang mempunyai frekuensi terbanyak.
Cara lain yang dianggap lebih tepat, yaitu dengan memperhatikan frekuensi kelas
sebelum dan sesudah kelas modus.
Rumus Modus :
Dengan :
b = batas bawah kelas modal, ialah kelas interval dengan frekuensi terbanyak
p = panjanng kelas modal
b1 = frekuensi kelas modal dikurangi frekuensi kelas interval dengan tanda kelas yang lebih
kecil sebelum tanda kelas modal
b 2 = frekuensi kelas modal dikurangi frekuensi kelas interval dengan tanda kelas yang lebih
30 Contoh 1.11
Suatu mesin yang memproduksi kaleng roti diperkirakan terdapat kesalahn. Dari penelitian
terhadap 200 kaleng roti , dicatat berat kaleng roti, disajikan pada daftar di bawah ini:
Langkah – langkah mengerjakan modus :
a) Kelas modal = kelas keempat
b) b = 289,5
c) b1 = 82 – 36 = 46
d) b2 = 82 – 50 = 32
31 Mo =
Mo = 291,26
c. Median
Median adalah nilai yan membagi data menjadi dua bagian yang sama
banyaknya setelah data diurutkan dari yang terkecil hingga yang terbesar.
Untuk mendapatkan nilai median dari daftar distribusi frekuensi kita dapat
menggunakan rumus median, selain itu kita juga bisa mendapatkan nilai median
menggunakan histogram, yang berarti median membagi histogram menjadi dua bagiab
yang sama luasnya.
Rumus Median :
Dengan :
b = batas bawah kelas median, ialah kelas dimana median akan terletak
p = panjang kelas median
n = ukuran sampel atau banayak data
F = jumlah semua fekuensi dengan tanda kelas lebih kecil dari tanda kelas median
32 Contoh 1.12
Suatu mesin yang memproduksi kaleng roti diperkirakan terdapat kesalahn. Dari
penelitian terhadap 200 kaleng roti , dicatat berat kaleng roti, disajikan pada daftar di
bawah ini:
Langkah – langkah untuk mengerjakan median :
i.
Frekuensi (f) Frekuensi
33 2. Ukuran Letak Data
a. Kuartil (Qi)
Kuartil adalah nilai yang membagi data menjadi 4 bagian yang sama banyak,
setelah data diurutkan dari yang terkecil hingga yang terbesar.
Terdapat 3 buah kuartil , yaitu kuartil bawah atau kuartil pertama dilambangkan
Q1, kuartil tengah atau kuartil kedua atau median dilambangkan q2, dan kuartil atas atau
kuartil ketiga dilambangkan Q3.
Sama halnya dengan median, maka nilai kuartil dapat dihitung dengan cara :
1. Menentukan kelas dimana kuatrtil itu terletak yaitu ,
2. Gunakan atruran :
Dengan :
n = jumlah data dan I =1,2,3…
b = batas bawah kelas Q, ialah kelas
interval di mana Qi akan terletak
p = panjang kelas Qi
F = fk = Jumlah frekuensi dengan tanda
kelas lebih kecil dari tanda kelas Qi
34 Contoh 1.13
Data Tunggal
Tentukan Q1, Q2, dan Q3 untuk data berikut!
1. 6, 8, 4, 2, 4, 7, 5, 4
2. 3, 5, 1, 5, 4, 7, 8, 4, 2
Jawab:
1. Banyak data, n = 8
Data yang telah diurutkan :
2, 4, 4, 4, 5, 6, 7, 8
Q1 Q2 Q3
Jadi, Q1 = 4 ; Q2 = 4,5 ; Q3 = 6,5.
2. Banyak data, n = 9
Data yang telah diurutkan :
1, 2, 3, 4, 4, 5, 5, 7, 8
Q1 Q2 Q3
Q1 =
Jadi, Q1 = 2,5 ; Q2 = 4 ; Q3 = 6
35 Data Berkelompok
Suatu mesin yang memproduksi kaleng roti diperkirakan terdapat kesalahn. Dari
penelitian terhadap 200 kaleng roti , dicatat berat kaleng roti, disajikan pada daftar di
Frekuensi (f) Frekuensi
36 b. Desil (Di)
Desil adalah nilai yang membagi data menjadi 10 bagian yang sama banyak ,
setelah data diurutkan dari yang terkecil hingga yang terbesar.
Untuk menentukan desil degunakan rumus sebagai berikut.
Contoh 1.14
Data Tunggal
Tentukan nilai desil ke-3 dari data berikut!
7 5 8 7 9 6 6 6 8 5 9 8 6 7 9
Jawab:
Data yang telah diurutkan : 5 5 6 6 6 6 7 7 7 8 8 8 9 9 9
Bnayak data, n = 15.
Desil k-3 adalahnilai yan terletak pada urutan ke
Dengan :
n = jumlah data dan i =1,2,3…
b = batas bawah kelas Di, ialah kelas
intervaldi mana Di akan terletak
p = panjang kelas Di
F = jumlah frekuensi dengan tanda
kelas lebih kecil dari tanda kelas Di
(frekensi kumulatif)
37 D3 = x4 + 0,8( x5– x4 ) = 6 + 0,8 (6 - 6) = 6
Jadi, nilai D3 adalah 6
Data Kelompok
Ambil data dari contoh 1.2
Suatu mesin yang memproduksi kaleng roti diperkirakan terdapat kesalahn. Dari
penelitian terhadap 200 kaleng roti , dicatat berat kaleng roti, disajikan pada daftar di
bawah ini:
Carilah nilai D2 dari data disamping !
Jawab:
Frekuensi (f) Frekuensi
38 c. Persentil (Pi)
Dalam hal ini kita juga dapat membagi sekelompok data menjadi seratus bbagian yang
sama banyak, sehingga terdapat 99 nilai pembagi yang disebut persentil. Untuk menghitung
nilai persentil digunakan rumus :
Dengan :
n = jumlah data dan I =1,2,3…
b = batas bawah kelas Pi , ialah kelas interval dimana Pi terletak
p = panjang kelas Pi
F = jumlah frekunsi dengan tanda kelas lebih kecil dari tanda kelas Pi
f = frekuensi Pi
\
Contoh 1.15
Data Berkelompok
Kita akan mengambil data dari Contoh 1.2
Suatu mesin yang memproduksi kaleng roti diperkirakan terdapat kesalahn. Dari
penelitian terhadap 200 kaleng roti , dicatat berat kaleng roti, disajikan pada daftar di
39 Berat Kaleng
(gram)
Frekuensi (f) Frekuensi
Kumulatif (fk)
Carilah nilai P3 dari data diatas!
Jawab:
Ukuran penyebaran data yang biasa digunakan untuk data tunggal antara lain rentang,
hamparan simpangan kuartil, simpangan rata – arta, ragam dan simpangan baku.
a. Rentang atau jangkauan (J)
Definisi :
40 Jangkauan data atau rentang data adalah selisih antara data terbeasar (xmaks) dengan
data terkecil (xmin).
b. Hamparan (H)
Definisi :
Jangkauan antarkuartil atau hamparan adalah selisih antara kuartil ketiga dengan kuartil
pertama
c. Simpangan Kuartil (Qd)
Definisi:
Jangkauan semi antarkuartil atau simpangan kuartil adalah setengah kali panjang
41 Contoh 1.16
Data Tunggal
Diketahui data: 3, 4, 4, 5, 7, 8, 9, 9, 10. Tentukan jangkauan, jangkauan antarkuartil,
dan simpangan kuartildari data tersebut
Jawab;
Daftar berikut menyatakan upah tiap jam untuk 65 pegawai di suatu pabrik.
42 Tentukanlah hamparan dan simpangan kuartil dari data di atas!
Jawab:
Q1= Rp 68,25 dan Q3 = Rp 90,75
Maka Hamparan(jangkauan atar Kuartil) Q3– Q1 = 90,75 – 68,25 = Rp 22,50
Simpangan Kuartil:
d. Simpangan Rata – rata
Simpanagan rata – rata atau deviasi rata – rata merupakan rata – rata jarak
suatu data terhadap rataan hitungannua. Nilai simpangan rata – rata (SR) untuk data
tunggal dapat ditentukan dengan rumus:
Dengan :
n = banyaknya data
xi = nilai data ke-i
43 Contoh 1.17
Tentukan simpangan rata – rata dari data:1, 3, 5, 8, 10, 12, 13.
Jawab:
Data Tunggal
n = 8
Jadi, simpangan rata = ratanya adalah 3,75
Data Kelompok
Nilai Frekuensi (fi) Titik Tengah
(xi)
40 – 49 4 44,5 21,17 84,68
50 – 59 6 54,5 11,17 67,02
60- 69 10 64,5 1,17 11,70
70 – 79 4 74,5 8,83 35,.32
80 – 89 4 84,5 18,83 75,32
90 – 99 2 94,5 28,83 57,66
44
e. Ragam dan Simpangan Baku
Misalnya data x1 , x2 , x3,… xn mempynyai rataan, maka ragamatau varians (S2) dapat
ditentukan dengan rumus:
Sementara itu, simpanngan baku atau deviasi baku (S) dapat ditentukan dengan
rumus:
Contoh 1.18
Hitunglah ragam dan simpangan bakudrai data: 1, 3, 4, 5, 8, 10, 12, 13
Jawab:
Data Tunggal
Data: 1, 3, 4, 8, 10, 12, 13
n = 8 dan =7, maka:
Dengan:
n = banyaknya data
xi = nilai data ke-i
45 (teliti hingga 2 tempat desimal).
Jadi, data tersebut mempunyai ragam , S2 = 17 dan simpangan baku , S= 4,12
46 Jadi, data tersebut mempunyai ragam (S2) = 45 dan simpangan baku (S) = 6,71
RANGKUMAN
1. Langkah – langkah membuat tabel distribusi frekuensi adalah sebagai berikut. a. Urutkan data dari data terkecil ke data terbesar
b. Tentukan jumlah kelas yang akan digunkan, dengan rumus: k = 1 + 3,3 log n
c. Tetapkan interval kelas, dengan rumus: , dengnan R = range
d. Tetapkan batas bawah kelas pertama.
2. Frekuensi relative ,
3. Ukuran pemusatan data
a. Rata – rata (Mean)
1) Rumus rata – rata data tunggal adalah
2) Rumus rata – rata untuk data yang diboboti adalah
3) Rumus rata – rata dengan rata – rata sementara adalah
47 b. Median (Me)
Median adalah data yang letaknya di tengah – tengah setelah data itu diurutkan,
Rumus median data kelompompok adalah
c. Modus (Mo)
Modus adalah data yang paling sering muncul atau yang mempunyai frekuensi
terbanyak.
Rumus modus data kelompok adalah
4. Ukuran Letak
a. Kuartil
Kuartil adalah letak yang membagi sekumpulan data yang telah diurutkan menjadi
empat bagian yang sama.
Terdapat tiga buah kuartil, yaitu kuartil bawah (Q1), kuartil tengah / median (Q2), dan
Kuartilatas (Q3)
Rumus umum kuartil data kelompok :
, untuk I = 1,2,3 ..
b. Desil
Desil adalah ukuran letak yang membagi sekumpulan data yang telah diurutkan
menjadi 10 bagian yang sama. Ada 9 bua desil , yaitu D1,D2,D3,…,Dn
Rumus umum desil untuk data kelompok adalah
, untuk i=1,2,3..
c. Persentil
Persentil adalah ukuran letak yangmembagi sekumpulan data yang telah diurutkan
48 Rumus umum menghitung persentil data kelompok adalah
5. Ukuran Penyebaran (dispersi)
Ada empat macam disperse, yaitu jangkauan, simpangan rata – rat, simpangan baku (standar deviasi) dan simpangan kuartil
Rumus – rumus ukuran penyebaran:
a. Jangkauan (R / J)
b. Simpangan rata – rata (SR)
c. Simpangan Baku (S)
1) Sampel yang berukuran besar (n>30)
2) Sampel yang berukuran kecil (n 30)
49 6. Ragam (varians) ditentukan dengan rumus:
50
BAB II
KONSEP BIOSTATISTIK
2.1DEFINISI
Statistik secara sempit diartikan sebagai data. Arti luas diartikan sebagai alat. Alat
untuk analisis, dan alat untuk membuat keputusan. Statistik digunakan untuk
membatasi cara-cara ilmiah untuk mengumpulkan, menyusun, meringkas, dan
menyajikan data penyelidikan.
2.2. RUANG LINGKUP STATISTIK
a. Statistik deskriptif
Statistik deskriptif adalah statistik yang digunakan untuk mengambarkan atau
menganalisis suatu statistik hasil penelitian tetapi tidak digunakan untuk
membuat kesimpulan yang lebih luas (generalisasi/inferensial). Penelitian tidak
bermaksud untuk membuat suatu kesimpulan terhadap populasi dari sampel
yang diambil, statistik yang digunakan adalah statistik deskriptif.
b. Statistik inferensial
Statistik inferensial adalah statistik yang digunakan untuk menganalisis data
51 diambil. Terdapat dua jenis statistik inferensial yaitu statistik parametrik dan
statistik non parametrik. Statistik parametrik digunakan untuk menganalisis data
yang berbentuk interval dan rasio sedangkan statistik non parametrik biasanya
digunakan untuk menganalisis data yang berbentuk nominal dan ordinal.
Statistik parametrik mensyaratkan bahwa distribusi data normal dan variansi data
harus sama sedangkan statistik non parametrik tidak memerlukan syarat
distribusi data normal dan variansi sama.
2.3. TIPE VARIABEL
Variabel penelitian merupakan suatu atribut atau suatu nilai dari orang, objek atau
kegiatan yang mempunyai variasi tertentu yang ditetapkan oleh peneliti untuk
dipelajari dan ditarik kesimpulan.
Berdasarkan jenisnya variabel penelitian antara lain:
52 Variabel independent sering disebut sebagai variabel bebas. Variabel bebas
merupakan variabel yang mempengaruhi atau menjadi sebab perubahan atau
timbulnya variabel dependent.
b. Variabel Dependent
Variabel dependent sering disubut sebagai variabel terikat. Variabel terikat
merupakan variabel yang dipengaruhi atau yang menjadi akibat karena adanya
variabel bebas.
c. Variabel Moderator
Variabel moderator merupakan variabel yang mempengaruhi (memperkuat atau
memperlemah) hubungan antara variabel infependent dengan dependent.
Variabel ini disebut juga sebagai variabel independent ke dua.
d. Variabel Intervening
Variabel intervening adalah variabel yang secara teoritis mempengaruhi
hubungan antara variabel independent dan variabel depandent, tetapi tidak
dapat diamati atau diukur.
e. Variabel Kontrol
Variabel kontrol merupakan variabel yang dikendalikan atau dibuat konstant
sehingga hubungan variabel dependent dan independent tidak dipengaruhi oleh
53 Contoh:
Variabel bebas Variabel terikat
\
2.4SUMBER DATA KESEHATAN
Data primer : merupakan data yang dikumpulkan oleh peneliti yang digunakan untuk
menjawab tujuan dari penelitian secara spesifik. Data primer dapat diperoleh dari
kegiatan survei, penelitian dilapangan.
Data skunder : merupakan data yang telah tersedia atau telah dikumpulkan oleh
orang atau lembaga tertentu, misal biro pusat statistic. Data sekunder dapat
diperoleh dari catatan laporan dinas kesehatan sebagai kegiatan surveilans di dinas
kesehatan.
Kepatuhan bidan
pencegahan infeksi Kejadian Infeksi pada BBL
Variabel Luar : Karakteristik Bidan
1. Tingkat pendidikan
2. Pengetahuan
54 2.5SKALA PENGUKURAN
Untuk menentukan teknik statistik mana yang akan digunakan untuk menguji
hipotesis maka harus diketahui terlebih dulu macam-macam data dan bentuk
hipotesis. Macam data dalam penelitian seperti pada gambar berikut:
Skala pengukuran:
a. Skala deskrit / Nominal
Skala deskrit atau nominal adalah data yang hanya dapat digolongkan secara
terpisah atau secara kategorik.
Contoh
Jenis kelamin (laki-laki-perempuan)
55 Data ordinal adalah data yang berbentuk rangking atau peringkat. Dimana jarak
antara satu rangking dengan rangking yang lainnya belum tentu sama.
Contoh
Tingkat pendidikan (SD, SMP, SMA, PT)
c. Skala Interval
Data interval adalah data yang jaraknya sama tetapi tidak mempunyai nilai nol
(0) absolut/mutlak.
Contoh
Suhu
d. Skala Rasio
Data rasio adalah data yang jaraknya sama dan mempunyai nilai nol mutlak.
Contoh
Berat badan
2.6METODE PENGUMPULAN DATA
Menurut Nan Lin, ada 4 metode pengumpulan data antara lain;
a. Metode observasi
Metode observasi adalah suatu metode pengumpulan data yang dilakukan oleh
peneliti untuk mencatat kejadian atau peristiwa dengan menyaksikannya.
56 Metode dokumentasi dilakukan jika tidak mungkin bagi peneliti untuk melakukan
kontak dengan pelaku atau subjek penelitian.
c. Metode survei
Survei merupakan suatu metode pengumpulan data yang mengunakan
instrumen kuesioner atau wawancara untuk mendapatkan tanggapan dari
responden yang disampel.
d. Metode eksperimen
Merupakan metode dengan melakukan perlakuan.
2.7SYARAT ALAT UKUR
Syarat alat ukur yang baik seharusnya memenuhi validitas dan reliabilitas dari
pengukuran.
Validitas
Validitas merupakan kesesuaian antara alat dan apa yang di ukur.
Reliabilitas
57
LATIHAN
1. Apa yang anda ketahui tentang statistik deskriptif dan statistik inferensial..?
2. Sebutkan jenis statistik inferensial..?
3. Apa syarat mengunakan statistik para metrik…?
4. Apa ciri-ciri skala data rasio, interval, ordinal dan nominal.
5. Rubahlah data dibawah ini ke dalam data rasio, interval, ordinal dan nominal..?
Data jumlah hari tidak masuk kerja bidan selama 1 tahun.
5 4 5 7 10 25 23 2 3 3 3 20 21 12
6 1 6 6 11 15 34 12 2 3 4 19 22 13
12 3 7 4 12 16 22 21 2 4 12 18 12 12
15 2 4 5 13 15 23 14 3 2 13 17 13 13
16 23 3 5 14 16 12 13 3 2 14 11 14 14
58
BAB III
PENYAJIAN DATA
A. PENGERTIAN
Setiap penelitian dapat disajikan dalam berbagai bentuk. Prinsip dasar penyajian data
adalah bagai mana data dapat komunikatif dan lengkap dalam arti data yang disajikan
dapat menarik perhatian pihak lain untuk membaca dan mudah memahami.
Beberapa penyajian data antara lain penyajian data dengan table, grafik, diagram
lingkaran dan pictogram.
B. JENIS PENYAJIAN TABEL DAN KEGUNAANNYA
1. Tabel
Penyajian data dalam bentuk table banyak digunakan karena lebih efisien dan
cukup komunikatif. Ada 2 macam table, yaitu table biasa dan table distribusi
frekuensi.
Setiap table berisi judul table, judul setiap kolom, nilai data dalam setiap kolom, dan
sumber data darimana data tersebut diperoleh. Table dapat disajikan berdasarkan
skala data (table data nominal, table data ordinal , dan table data interval.
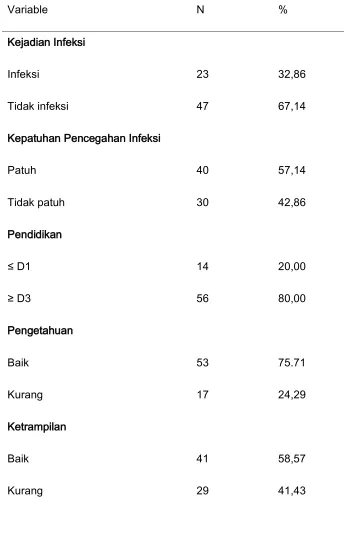
59 Tabel 1. Distribusi Frekuensi Karakteristik Subjek Penelitian Berdasarkan Variabel
Penelitian
60 Table 1. Menunjukan bahwa sebagian besar subjek penelitian tidak mengalami
kejadian infeksi 67,14%, patuh melakukan pencegahan infeksi 57,14%, pendidikan
D3 80%, pengetahuan baik 75,71%, dan ketrampilan 58,57%.
Berdasarkan persentase rata-rata ketrampilan bidan mencuci tangan, memakai
sarung tangan dan mengunakan alat terlihat pada table berikut:
b. Contoh table data ordinal
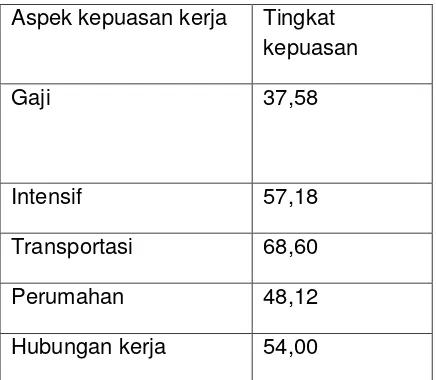
Table 2. Tingkat kepuasan kerja pegawai
Aspek kepuasan kerja Tingkat kepuasan
Gaji 37,58
Intensif 57,18
Transportasi 68,60
Perumahan 48,12
Hubungan kerja 54,00
Sumber: data biro kepegawaian
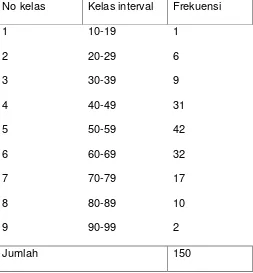
61 Table distribusi frekuensi nilai pelajaran statistic 150 mahasiswa.
No kelas Kelas interval Frekuensi
1 10-19 1
2 20-29 6
3 30-39 9
4 40-49 31
5 50-59 42
6 60-69 32
7 70-79 17
8 80-89 10
9 90-99 2
Jumlah 150
Hal-hal yang diperhatikan dalam table distribusi frekuensi
tabel distribusi mempunyai sejumlah kelas. Kelas interval tergantung penyaji
yang diinginkan
pada setiap kelas mempunyai kelas interval
setiap kelas interval mempunyai frekuensi
tabel merupakan ringkasan baris.
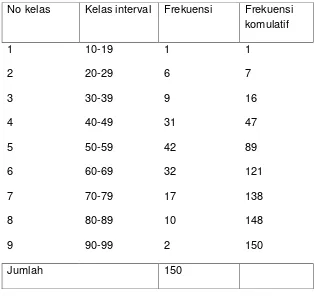
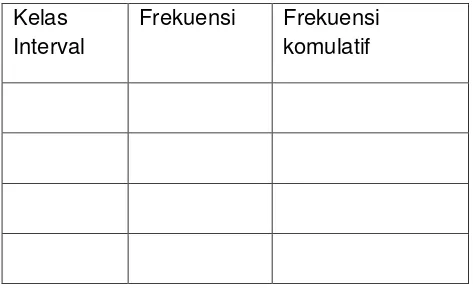
d. tabel distribusi komulatif
62
No kelas Kelas interval Frekuensi Frekuensi komulatif
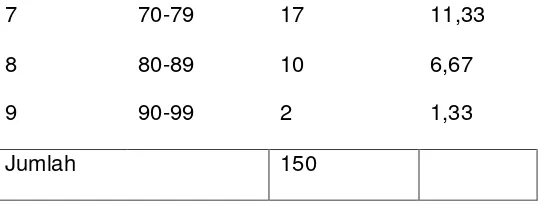
e. Tabel distribusi relatif
Table distribusi frekuensi nilai pelajaran statistic 150 mahasiswa.
63
7 70-79 17 11,33
8 80-89 10 6,67
9 90-99 2 1,33
Jumlah 150
2. Grafik
a. Grafik garis
Grafik biasanya digunakan untuk menunjukan perkembagan suatu keadaan atau
trend peningkatan atau penurunan sesuatu. Hal ini akan nampak secara visual
melalui garis dalam grafik.
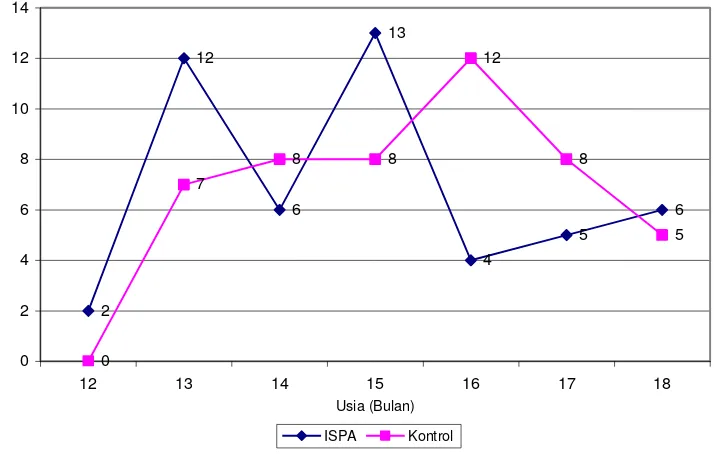
Contoh
karakteristik kejadian ISPA pada anak berdasarkan umur dapat dilihat pada
64
Gambar 5. Distribusi Frekuensi Kejadian ISPA menurut Umur
Gambar 5 menunjukkan bahwa pada kasus, puncak kejadian ISPA terjadi pada
usia 15 bulan sedangkan pada kontrol puncak kejadian ISPA terjadi pada usia 16
bulan. Usia yang relatif rendah frekuensi kejadian ISPA terjadi pada usia 12
bulan.
b. Grafik batang
Grafik batang biasanya disajikan untuk membandingkan dua karakteristik dari
subjek.
65
Air the/gula Susu Formula Air Tajin Nasi Buah Susu/Biskuit
3. Diagram
Diagram pie biasanya digunakan untuk mengabarkan berdasarkan proporsi. Misal
jenis kelamin.
66
LATIHAN
Latihan susunlah data tersebut dibawah ini dalam table distribusi frekunsi
5 4 5 7 10 25 23 2 3 3 3 20 21 12
6 1 6 6 11 15 34 12 2 3 4 19 22 13
12 3 7 4 12 16 22 21 2 4 12 18 12 12
15 2 4 5 13 15 23 14 3 2 13 17 13 13
16 23 3 5 14 16 12 13 3 2 14 11 14 14
2 3 4 4 13 15 14 15 4 9 15 16 15 15
1. Sajikan data tesebut dalam bentuk distribusi frekuensi
67
BAB IV
TENDENSI SENTRAL
4.1. UKURAN TENDENSI SENTRAL
DATA TUNGGAL
A. MEAN
Mean merupakana teknik penjelasan kelompok yang didasarkan atas nilai rata-rata
dari kelompok yang dimaksud. Rata-rata didapat dengan menjumlahkan data
seluruh individu dalam kelompok kemudian dibagi dengan jumlah individu yang ada
pada kelompok tersebut.
Range adalah nilai yang mewakili himpunan atau kelompok data. Nilai rata-rata
umumnya cenderung terletak di tengah suatu kelompok data yang disusun menurut
besar kecilnya nilai.
Rumus
n X mean i
Keterangan
68 ∑ = Jumlah
Xi = nilai x ke I sampai ke n
N = jumlah individu
Contoh soal
Suatu penelitian dilakukan di RS PKU muhammadiya tentang hasil tekanan darah
10 pasien hipertensi. Hasil penelitian adalah sebagai berikut:
90, 120, 160, 60, 180, 190, 90, 180, 70, 160.
Berdasarkan data tersebut berapa rata-rata tekanan darah pasien hipertensi
tersebut.
Median adalah satu teknik penjelasan kelompok yang didasarkan atas nilai tengah
dari kelompok data yang telah disusun urutannya dari yang terkecil sampai yang
terbesar, atau sebaliknya dari yang terbesar ke terkecil.
69 C. MODUS
Modus merupakan nilai yang sering muncul.
4.2. DATA BERKELOMPOK
Menghitung central tendensi pada data berkelompok.
A. Mean
Untuk menghitung mean dari data bergolong maka terlebih dahulu data tersebut
disusun menjadi tabel sebingga perhitungan akan lebih mudah.
Rumus
i i i
f x f median
Keterangan
Median = nilai tengah
Fi = jumlah data/sample
Xi = nilai tengah kelas interval.
Fi Xi = produk perkalian antara Fi pada tiap interval data dengan tanda kelas
Xi. Tanda kelas (Xi) adalah rata-rata dari nilai terrendah dan tertinggi setiap interval
70 Dilakukan penelitian di rumah sakit PKU muhammadiya Yogyakarta terhadap
50 bidan mengenai kemampuan bidan dalam penanganan pencegahan infeksi.
Data hasil penelitian adalah sebagai berikut:
No Kemampuan no Kemampuan no kemampuan
1 50 21 55 41 87
2 45 22 55 42 90
3 35 23 55 43 91
4 55 24 65 44 55
5 55 25 78 45 55
6 55 26 78 46 55
7 65 27 76 47 65
8 78 28 75 48 78
9 78 29 74 49 78
10 76 30 67 50 76
11 75 31 68 51 75
12 74 32 67 52 74
13 67 33 56 53 67
14 68 34 47 54 68
15 67 35 80 55 67
16 56 36 87 56 56
17 47 37 55 57 47
18 80 38 67 58 80
19 87 39 68 59 87
71
Table penolong
Interval nilai Xi Fi Fi FiXi
Berapa nilai median untuk data tersebut diatas..?
B. Median
Rumus Median pada data kelompok adalah sebagai berikut:
Median = nilai tengah data berkelompok
72 N = banyaknya data
P = panjang kelas interval
F = jumlah semua frekuensi sebelum kelas interval
F = frekuensi kelas median
Berdasarkan data diatas berapa median..?
C. Modus
Modus merupakan nilai yang sering muncul. Rumus yang digunakan dalam modus
adalah sebagai berikut:
B = batas bawah kelas interval dengan frekuensi terbanyak
P = panjang kelas interval
B1 = frekuensi pada kelas modus (frekuensi pada kelas interval terbanyak) dikurang
frekuensi kelas interval terdekat sebelumnya.
B2 = frekuensi kelas modus dikurangi frekunsi kelas interval berikutnya.
Latihan
73
4.3 UKURAN PENYIMPANGAN
a. Rentang
Rentang merupakan range (jarak) data yang terbesar dengan data yang terkecil.
Rumus
r t x
x
R
Keterangan
R= rentang
Xt = data terbesar dalam kelompok
Xr = data terkecil dalam kelompok.
Contoh
Suatu penelitian dilakukan di RS PKU muhammadiya tentang hasil tekanan darah
10 pasien hipertensi. Hasil penelitian adalah sebagai berikut:
90, 120, 160, 60, 180, 190, 90, 180, 70, 160.
Berdasarkan data tersebut berapa rentang tekanan darah pasien hipertensi
tersebut.
Jawab
Datat terbesar = 190
Data terkecil = 60
74
b. Varians
Varians merupakan jumlah kuadran semua deviasi nilai-nilai individu terhadap
rata-rata kelompok.
S= simpangan baku sampel
N= jumlah sampel
Xi = hasil pengamatan
= nilai rata-rata kelompok
Contoh
Suatu penelitian dilakukan di RS PKU muhammadiya tentang hasil tinggi badan 10
perawat 10. Hasil penelitian adalah sebagai berikut:
60, 70, 65, 80, 70, 65, 75, 80, 70, 75.
Berdasarkan data tersebut berapa variansi tinggi badan perawat tersebut.
Jawab
= 60 + 70 + 65 + 80 + 70 + 65 + 75 + 80 + 70 + 75= 710.
75
No Nilai Xi- Xi- 2
1 60 -11
2 70 -1
3 65 -6
4 80 9
5 70 -1
6 65 -6
7 75 4
8 80 9
9 70 -1
10 75 4
710 0 390
39 10 390
s
Jadi variansi untuk data diatas 39.
c. Simpangan Baku
Data tunggal
Simpangan baku (standart deviasi) merupakan akar dari variansi.
76
Suatu penelitian dilakukan di RS PKU muhammadiya tentang hasil tinggi badan 10
perawat 10. Hasil penelitian adalah sebagai berikut:
60, 70, 65, 80, 70, 65, 75, 80, 70, 75.
Berdasarkan data tersebut berapa variansi tinggi badan perawat tersebut.
Jawab
= 60 + 70 + 65 + 80 + 70 + 65 + 75 + 80 + 70 + 75= 710.
Dengan mengunakan tabel bantu
77
Variansi untuk data diatas 39.
Jadi simpangan baku 2
s
S = 39 6,24
Data kelompok
Contoh
Dilakukan penelitian di rumah sakit PKU muhammadiya Yogyakarta terhadap 50
bidan mengenai kemampuan bidan dalam penanganan pencegahan infeksi. Data
hasil penelitian adalah sebagai berikut:
78
13 67 33 56 53 67
14 68 34 47 54 68
15 67 35 80 55 67
16 56 36 87 56 56
17 47 37 55 57 47
18 80 38 67 58 80
19 87 39 68 59 87
20 86 40 66 60 96
Berapa variansi dari data tersebut.
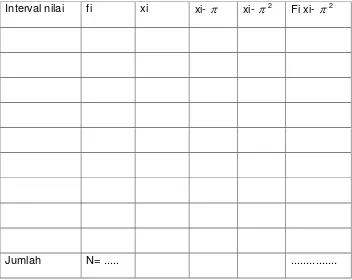
Tabel penolong
Interval nilai fi xi xi- xi- 2 Fi xi- 2
79 Jawab
...
2. Kwartil, Desil, dan Persentil
a. Kwartil
Kwartil merupakan nilai yang memisahkan tiap-tiap 25 persen frekuensi dalam
distribusi.
Dalam kwartil ada 3 macam yaitu kuartil pertama, kuartil 2 dan kwartil 3.
Rumus kwartil
Bb = batas bawah interval yang mengandung kwarti pertama
N = jumlah frekuensi distribusi
b
cf = frekuensi komulatif dibawah interval yang mengandung kwartil.
d
f = frekuensi dalam interval yang mengandung kwartil pertama.
80 Contoh
Dilakukan penelitian di rumah sakit PKU muhammadiya Yogyakarta terhadap 60
bidan mengenai kemampuan bidan dalam penanganan pencegahan infeksi.
Data hasil penelitian adalah sebagai berikut:
No Kemampuan no Kemampuan No kemampuan
1 50 21 55 41 87
2 45 22 55 42 90
3 35 23 55 43 91
4 55 24 65 44 55
5 55 25 78 45 55
6 55 26 78 46 55
7 65 27 76 47 65
8 78 28 75 48 78
9 78 29 74 49 78
10 76 30 67 50 76
11 75 31 68 51 75
12 74 32 67 52 74
13 67 33 56 53 67
14 68 34 47 54 68
15 67 35 80 55 67
16 56 36 87 56 56
17 47 37 55 57 47
18 80 38 67 58 80
19 87 39 68 59 87
81 Berapa kuartil pertama, kedua dan ketiga dari data tersebut.
Tabel penolong mencari kuartil
Kelas Interval
Frekuensi Frekuensi komulatif
Jawab.
Latihan
b. Desil
Desil merupakan nilai yang memisahkan setiap 10 persen dari distribusi
kelompok.
Bb = batas bawah interval yang mengandung desil pertama
82 b
cf = frekuensi komulatif dibawah interval yang mengandung desil.
d
f = frekuensi dalam interval yang mengandung desil pertama.
i = lebar interval.
Contoh
Dilakukan penelitian di rumah sakit PKU muhammadiya Yogyakarta terhadap 50
bidan mengenai kemampuan bidan dalam penanganan pencegahan infeksi.
Data hasil penelitian adalah sebagai berikut:
No Kemampuan no Kemampuan No kemampuan
1 50 21 55 41 87
2 45 22 55 42 90
3 35 23 55 43 91
4 55 24 65 44 55
5 55 25 78 45 55
6 55 26 78 46 55
7 65 27 76 47 65
8 78 28 75 48 78
9 78 29 74 49 78
10 76 30 67 50 76
11 75 31 68 51 75
12 74 32 67 52 74
13 67 33 56 53 67
14 68 34 47 54 68
83
Berapa kuartil pertama, kedua dan ketiga dari data tersebut.
Tabel penolong mencari kuartil
Kelas Interval
Frekuensi Frekuensi komulatif
Berapa desil pertama..?
c. Persentil
Persentil merupakan nilai yang memisahkan setiap 1 persen pada distribusi
84 Pi = Persentil
Bb = batas bawah interval yang mengandung persentil pertama
N = jumlah frekuensi distribusi
b
cf = frekuensi komulatif dibawah interval yang mengandung persentil.
d
f = frekuensi dalam interval yang mengandung persentil pertama.
i = lebar interval.
Contoh
Dilakukan penelitian di rumah sakit PKU muhammadiya Yogyakarta terhadap 50
bidan mengenai kemampuan bidan dalam penanganan pencegahan infeksi.
Data hasil penelitian adalah sebagai berikut:
No Kemampuan No Kemampuan No kemampuan
1 50 21 55 41 87
2 45 22 55 42 90
3 35 23 55 43 91
4 55 24 65 44 55
5 55 25 78 45 55
6 55 26 78 46 55
7 65 27 76 47 65
8 78 28 75 48 78
9 78 29 74 49 78
10 76 30 67 50 76
85
12 74 32 67 52 74
13 67 33 56 53 67
14 68 34 47 54 68
15 67 35 80 55 67
16 56 36 87 56 56
17 47 37 55 57 47
18 80 38 67 58 80
19 87 39 68 59 87
20 86 40 66 60 96
Berapa persentil ke 20 dari data tersebut.
Tabel penolong mencari persentil
Kelas Interval
Frekuensi Frekuensi komulatif
86
BAB V
SKALA DATA
Pemahaman mengenai jenis skala data merupakan hal yang penting sebelum
mempelajari statistik yang lebih dalam. Untuk menentukan teknik statistik mana yang
akan digunakan untuk menguji hipotesis maka harus diketahui terlebih dulu
macam-macam data dan bentuk hipotesis. Macam data dalam penelitian seperti pada gambar
berikut:
Skala pengukuran:
a. Skala deskrit / Nominal
Skala deskrit atau nominal adalah data yang hanya dapat digolongkan secara
terpisah atau secara kategorik.
Contoh
87 b. Skala Ordinal
Data ordinal adalah data yang berbentuk rangking atau peringkat. Dimana jarak
antara satu rangking dengan rangking yang lainnya belum tentu sama.
Contoh
Tingkat pendidikan (SD, SMP, SMA, PT)
c. Skala Interval
Data interval adalah data yang jaraknya sama tetapi tidak mempunyai nilai nol
(0) absolut/mutlak.
Contoh
Suhu
d. Skala Rasio
Data rasio adalah data yang jaraknya sama dan mempunyai nilai nol mutlak.
Contoh
Berat badan
Latihan
Suatu penelitian dilakukan di Puskesmas A terhadap pengetahuan bidan dalam
pencegahan infeksi. Berdasarkan hasil penelitian diperoleh data sebagai berikut:
No Pengetahuan
88
2 60
3 45
4 55
5 35
6 70
7 85
8 95
9 65
10 85
Pertanyaan
1. Pada data tersaji tersebut diatas termasuk kedalam skala data apa..?
2. Rubahlah data tersebut menjadi data ordinal..?
89
BAB VI
CARA PENGAMBILAN SAMPLING
6.1DEFINISI DAN PENGERTIAN
Sebelum jauh melangkah mengenal bagaimana cara pengambilan sample dan
cara menentukan besar sample. Kita harus memahami bagaimana sample itu sendiri.
Sebenarnya banyak cara yang dapat dilakukan dalam kerangka sampling. Penentuan
cara pengambilan sampling lebih tergantung oleh peneliti itu sendiri, tetapi hal yang
penting disini adalah bagaimana sample itu dapat mewakili dari populasi yang akan
diteliti.
Mengapa dalam penelitian dilakukan sample dari populasi? Beberapa alas an
untuk melakukan sampling antara lain menghemat tenaga, waktu, biaya, materi dan
lainnya. Biasanya meneliti semua populasi biasannya akan menghadapi kendala meski
hasilnya akan lebih baik daripada sampling. Tetapi jika sampelnya tepat dan akurat,
benar-benar mewakili atau representative maka kesimpulan akan sama dengan meneliti
populasi. Untuk itu perlu yang perlu diperhitungkan dalam sample adalah bagaimana
cara pengambilan sample? Dan bagaimana menentukan jumlah sample? Harapan dari
ini salah satunya adalah bagaimana sample dapat mewakili dari populasi
90 random dan non random. Disamping itu dikenal beberapa cara penentuan besar
sample.
Dalam melakukan penentuan besar sample yang penting diingat adalah
bagaimana hipotesisnya dan desain penelitiannya? Pemilihan pengunaan rumus besar
sample akan sedikit banyak ditentukan oleh pola hipotesisnya dan desain yang ada
dalam penelitian. Pada prinsipnya roh yang ada dalam penelitian adalah hipotesis. Dan
salah satu instrument yang dapat digunakan dalam penentuan pengujian hipotesis
adalah dengan uji statistic. Penerapan uji statistic dalam penelitian tidak akan lepas dari
tipe hipotesis yang ada karena hipotesis akan cenderung menentukan uji statistic yang
tepat untuk digunakan. Selain itu yang penting diingat adalah skala data dari hasil
pengumpulan penelitian (skala nominal, ordinal, interval, dan skala rasio). Pada
prinsipnya cara pengambilan sample ada dua yang dikenal yaitu dengan cara random
dan cara non random.
6.2SIMPEL RANDOM SAMPLING
Pengambilan sampel acak sederhana menekankan sistem pengambilan sampel
yang didasarkan pada angka (bilangan) yang muncul. Keadaan ini dapat dilakukan
dengan memberi nomor dari seluruh populasi yang ada sebelum dilakukan
pengambilan sampel.
91 a. Menentukan nomer untuk setiap individu dalam populasi.
b. Melakukan proses acak (dapat dilakukan dengan tabel bilangan acak) untuk
mendapatkan n angka antara 1 dan N.
Misalnya
Suatu penelitian dilakukan di stikes Ahmad yani jika diketahui mahasiswa
stikes ahmad yani 200 mahasiswa sedangkan besar sampel yang diingikan
20 mahasiswa, bagaimana mengambil 20 mahasiswa dari 200 mahasiswa
ahmad yani?
Langkah
1. Memberi label (nomer) untuk setiap mahasiswa.
2. Lakukan proses acak. Proses acak dapat memanfaatkan bilangan
random. Misal
1214 0211 4761 3567
0265 6513 4323 0123
1113 4535 9564 1433
5462 4334 0095 3432
4353 0015 0056 3221
3549 0228 0547 2300
2118 0238 6568 1231
92 3. Melakukan pemilihan nomer bisa dengan menyamping ke kanan atau
kebawah.
4. Nomer 121 dianggap sebagai sampel pertama. Sampel ke dua dan
seterusnya dapat dilakukan dengan cara memilih ke samping kanan atau
ke bawah.
Kelebihan pengambilan sampel acak sederhana.
- Memberikan dasar probabilitas terhadap banyak teori statistik - Mudah dipahami
Kelemahan pengambilan sampel acak sederhana
- Menetapkan semua populasi dengan memberi nomer (angka) sebelum dilakukan pemilihan sampel.
- Sub-klaster dalam populasi memungkinkan untuk terpilih semua. - Individu yang terpilih memungkinkan sangat tersebar.
6.3SYSTEMATIC SAMPLING
Pengambilan sampel sistematik lebih meghemat waktu dan lebih sederhana.