Pengelompokan Dokumen Berita Berbahasa Indonesia
Menggunakan Reduksi Fitur
Information Gain
dan
Singular Value
Decomposition
dalam
Fuzzy
C-MeansClustering
Yuita Arum Sari 1, Tesa Eranti Putri 2, Anggi Gustiningsih Hapsani 3 Fakultas Ilmu Komputer, Universitas Brawijaya1,3,
Unviersitas Airlangga2
Malang, Indonesia1,3
Surabaya, Indonesia2
Email : [email protected], [email protected]2, [email protected]3
Abstrak— Online newspapers and news are the current digital
information which the information update process is very easy and flexible. The ease of information update process allows news writers to upload new information at any time and anywhere. This cause the amount of news documents datas are very much and irregularly, need to do news groupings according to the content. Grouping news according to the content can help readers to read news with a particular topic according to their interests. The process of news information clustering is implemented in two steps, preprocessing and clustering documents. Preprocessing is done by implementing a combination method of Document Frequency (DF) and Information Gain (IG) Thresholding in Singular Value Decomposition (SVD). The SVD algorithm is chosen because it has ability to decompose the term-matrix of the document, thus obtaining a matrix that still holds important information with smaller dimension sizes. The clustering step is performed with the Fuzzy C-Means(FUZZY C-MEANS) clustering algorithm. The accuration results of the news documents clustering indicate that the clustering performed a fairly accurate categorization result with an average accuracy rate of 74.5% (IG threshold 0.5, k = 5). It shows that grouping Indonesian news using IG thresholding and SVD with FUZZY C- MEANSis achieved.
Intisari— Koran dan berita online merupakan media informasi
digital saat ini yang proses pembaruan informasinya sangat mudah dan fleksibel. Kemudahan ini memungkinkan penulis berita untuk mengunggah informasi baru di waktu kapanpun dan dimanapun. Hal ini menyebabkan data dokumen berita sangat banyak dan tidak teratur sehingga perlu dilakukan pengelompokan berita sesuai dengan kontennya. Pengelompokanberita sesuai content dapat membantu pembaca untuk membaca berita dengan topiktertentu sesuai dengan minatnya. Proses pengelompokan informasi berita diimplementasikan denganbeberapa tahap, yaitu preprocessing dan pengelompokan dokumen. Preprocessing dilakukan dengan mengimplementasikan metode kombinasi reduksi fitur Document Frequency (DF) dan Information Gain (IG) Thresholding dalamSingular Value Decomposition (SVD). Algoritme SVD
dipilih karena memiliki kemampuan untuk melakukan
dekomposisi pada matriks dokumen-term, sehingga diperoleh matriks yang masih menyimpan informasi penting dengan ukuran dimensi yang lebih kecil.Pada tahap pengelompokan dokumen berita dilakukandengan algoritme Fuzzy C-Means.
Hasil uji coba akurasipengelompokan dokumen berita
menunjukkan bahwa pengelompokan yang dilakukan memberikan hasil pengkategorian yang cukup akurat dengan tingkat akurasi
menunjukkan bahwa pengelompokan dokumen menggunakan
Kesadaran dan kepentingan untuk mengikuti perkembangan informasi dan berita terkini merupakan naluri manusia sebagai makhluk sosial.Sejak jaman purbakala, manusia telah saling bertukar informasi dan berita secara lisan dari mulut ke mulut. Berita seperti perang, kematian, kelahiran, atau kejadian penting lain yang terjadi pada suatu komunitas disebarkan secara langsung dari satu individu ke individu lainnya. Kehadiran tulisan dan ilmu literasi mengubah carapenyebaran informasi ini ke dalam bentuk yang lebih formal, yaitu media cetak. Salah satu media cetak tertua yang tercatat dalam sejarah muncul sejak sekitar tahun 202 SM di Cina [1]. Media cetak kuno lain berasal dari Eropa sekitar tahun 59 M. Namun, penyebaran media cetak ini hanya terbatas pada kalangan tertentu saja sehingga belum memenuhi syarat untuk dapat disebut sebagai koran. Media cetak pertama yang baru dapat dikategorikan sebagai koran merupakan temuan bangsa Eropa [2]. Pada perkembangannya ke depan nantinya, membaca koran menjadi salah satu rutinitas sehari-hari bagi sebagian besar masyarakat.
lebih menarik bagi generasi yang hidup di era teknologi informasi.
Perusahaan media cetak kini selain terus memproduksi koran cetak mereka, juga mulai mengembangkan koran dalam bentuk digital dan situs berita online. Koran digital merupakan versi digital dari koran yang diterbitkan setiap hari dan diunggah ke situs. Sementara itu, berita online berisi informasi dan berita terbaru yang dapat di-update oleh penulis berita kapan saja [4][5]. Karena fleksibilitas itulah, tak jarang data dokumen berita yang masuk menjadi banyak dan tak teratur. Ketidak teraturan ini melahirkan konsep bahwa berita-berita yang masuk perlu disortir dan dikategorikan sesuai kontennya. Pengkategorian ini akan membantu pembaca berita digital untuk menemukan berita yang menarik minatnya daripada harus menelusuri daftar panjang berita yang muncul [6].
Terkait dengan permasalahan tersebut, diperlukan adanya solusi berupa sebuah sistem perangkat lunak cerdas yang mempunyai potensi untuk mengatasinya. Salah satunya adalah dengan mengekstrasi konten berita dan menjadikannya sebagai dasar pengkategorian berita. Preprocessing konten berita dilakukan dengan menggunakan kombinasi reduksi fitur
Document Frequency (DF) [7] dan Information Gain (IG)
Thresholding dalam Singular Value Decomposition (SVD) [8].
DF telah divalidasi dapat digunakan untuk seleksi fitur dalam teks yangmana fitur-fitur yang digunakan bisa berupa kata, frasa, n-gram atau atribut-atribut turunannya [9]. Seleksi fitur berperan penting dalam reduksi dimensi terutama pada dokumen berita yang memiliki banyak fitur yang terekstrasi. SVD dan IG merupakan kombinasi yang dapat digunakan untuk mengurangi dimensi tanpa mengurangi makna dari dokumen yang dimaksudkan [8]. Hasil dari dekomposisi dan seleksi fitur dikelompokkan, sehingga diperoleh fitur-fitur yang sesuai dengan harapan. Pengelompokan dokumen berita dilakukan dengan algoritme Fuzzy C-Means [10].
Algoritme kombinasi DF dan IG ini dipilih dengan asumsi dokumen berita yang diinputkan akan menghasilkan matriks dokumen-term yang ukurannya cukup besar. Oleh karena itu, diperlukan preprocessing dan filtering term penting dengan menggunakan kedua algoritme tersebut. Algoritme SVD dipilih karena memiliki kemampuan untuk melakukan dekomposisi pada matriks dokumen-term, sehingga diperoleh matriks yang masih menyimpan informasi penting namun ukuran dimensinya lebih kecil [11]. Sedangkan, Fuzzy C-Means dipilih untuk melakukan pengkategorian berita, dengan asumsi setiap dokumen berita memiliki sifat kekaburan dalam tema kontennya.
Pada paper ini terbagi menjadi 4 bagian yaitu yang pertama adalah bagian pendahuluan, kemudian bagian dataset pada subbab II, dan subbab III adalah hasil dan analisis, serta pada subbab terakhir IV adalah kesimpulan dan saran.
II. DATASET DAN METODOLOGI PENELITIAN Data yang digunakan diambil dari www.kompas.com
dengan mengambil 90 data berita dan kemudian menyimpan data tersebut ke dalam file plain text. Data diambil dari 3 kategori yaitu entertaint, olahraga, dan teknologi. Masing- masing kategori berisi 30 dokumen verita. Data diambil secara
manual, tidak menggunakan teknik crawling. Bahasa yang digunakan dalam dokumen berita sudah bahasa baku, sehingga tidak ada proses memperbaiki struktur kata atau kalimat terlebih dahulu.
Secara keseluruhan metode penelitian dapat dilihat pada Gambar 1. Terdapat dua modul utama yang ada di dalam aplikasi ini. Pada modul preprocessing dan reduksi dimensi data, terdapat enam buah tahap yang harus dilalui oleh dokumen berita. Modul ini diawali dengan melakukan
preprocessing standar yang harus dilalui oleh setiap dokumen
teks yang akan diproses. Preprocessing tersebut terdiri atas
tokenizing, case folding, filtering, dan stemming Nazief-
Andriani. Dari preprocessing ini, term-term yang didapatkan akan disusun ke dalam sebuah matriks term-document (TDM) yang berisi frekuensi kemunculan term di setiap dokumen. Pembobotan kata dengan menggunakan konsep TF-IDF dilakukan setelahnya.
Karena ukuran matriks ini yang relatif besar, sistem dirancang untuk melakukan dua kali proses reduksi agar jumlah term yang banyak ini dapat dikurangi namun masih tetap menyimpan informasi penting. Term-term yang dianggap terlalu sering muncul atau sebaliknya jarang muncul akan dihapus sehingga mereduksi ukuran dimensi matriks. Proses reduksi ini dilakukan dengan dua metode, yaitu: TF-DF
thresholding dan IG thresholding. Hasil reduksi dimensi ini
akan diproses pada modul selanjutnya.
Pada modul dekomposisi dan pengelompokan, matriks TDM diproses untuk didekomposisi dengan menggunakan algoritme SVD. Penggunaan algoritme SVD ini ditujukan untuk mendapatkan matriks V yang digunakan dalam proses pengelompokan. Barulah setelah proses SVD ini selesai, pengelompokan dapat dilakukan dengan menggunakan algoritme Fuzzy C-Means. Sebenarnya, sebagai algoritme klastering, jumlah klaster yang dihasilkan oleh Fuzzy C-Means
ditentukan dari masukan pengguna atau dari aturan pencarian jumlah klastering. Namun, untuk membuktikan keefektifan penggunaan kombinasi algoritme, pada penelitian ini, jumlah klaster disesuaikan dengan jumlah kategori asal mula data dokumen berita, yaitu tiga klaster.
A. Preprocessing
Tahap preprocessing adalah tahap awal yang dilakukan untuk mempersiapkan suatu dokumen sebelum diproses pada tahap selanjutnya. Tujuan dari proses ini membuat data dokumen siap diproses dengan menghilangkannoise atau data yang tidak penting sehingga diharapkan dapat meningkatkan kemungkinan keberhasilan pada tahap pengelompokan nanti. Tahap preprocessing untuk pengelompokan dokumen berita terbagi menjadi beberapa tahap yaitu case folding, tokenizing,
filtering/stopword removal (penghilangan stopword),
stemming, tagging, dan analysing [12]. Tahap case folding
Setelah proses stopword removal selanjutnya adalah proses
tokenizing. Proses tokenizing (parsing) merupakan tahap
pengenalan token yang berada di dalam rangkaian teks.
Tokenizer adalah bagian dasar dari proses tokenizing dengan
mengekstraksi token dari teks. Pengetahuan bahasa diperlukan dalam tahap ini untuk menangani karakter khusus dan menentukan batasan satuan unit dalam dokumen [15].
Stemming merupakan tahap untuk mentransformasi kata-kata
dari suatu dokumen ke kata-kata dasar (root word) dengan menggunakan aturan tertentu. ada bahasa Indonesia, stemming
dilakukan dengan menghilangkan sufiks, prefiks, infiks dan konfiks [16].
Gambar.1. Gambaran sistem secara umum
B. Term Document Matrix (TDM)
TDM merupakan bentuk matriks yang menggambarkan frekuensi atau weighting dari dokumen dan fitur-fiturnya. Struktur data yang digunakan pada TDM pada penelitian ini adalah inverted index.Inverted Index merupakan struktur data berbentuk matriks, yang digunakan untuk mempermudah dalam merepresentasikan banyaknya kata yang muncul dalam dokumen teks [17].
Inverted Index merupakan struktur data yang digunakan
untuk membuat pencarian secara keseluruhan guna mendapatkan frekuensi kata pada sebuah koleksi dokumen [18]. Bentuknya mirip dengan tabel antara dokumen dan jumlah frekuensi per kata dalam dokumen tersebut. Inverted
Index dapat digunakan untuk mengatasi permasalahan proses
pencarian dengan metode indexing jika jumlah atau ukuran matriks yang sangat besar, karena inverted index mempunyai kompleksitas algoritme sebesar (O(n)). metode indexing
memerlukan waktu yang berbanding lurus dengan jumlah datanya [19].
Gambar.2 Contoh TDM berdasarkan frekuensi
C. Pembobotan Kata-Dokumen
Pembobotan kata-dokumen dalam penelitian ini menggunakan Term Frequency Document Inverse Frequency
(TF-IDF).Terdapat tiga cara untuk menghitung nilai term frequency (TF), yaitu dengan menghitung frekuensi sebagai bobot, menghitung peluang kemunculan sebagai bobot (TF tanpa ternormalisasi), dan menghitung logaritma dari banyaknya kemunculan term (TF ternormalisasi). Dari ketiga fungsi tersebut, TF dengan normalisasi menghasilkan nilai pembobotan yang baik, karena dapat mengurangi efek panjang dari dokumen. TF ternormalisasi dihitung sebagai berikut [20]:
(1) dimana fi,j adalah frekuensi ternormalisasi, tfi,j adalah frekuensi kata i pada dokumen j, max tfi,j adalah frekuensi maksimum kata i pada dokumen j. Sementara TF-IDF pada kata
i dan dokumen j dapat ditulis sebagai berikut :
(3) dimana Wi,j adalah bobot kata i pada dokumen j , fi,j adalah frekuensi ternormalisasi, tfi,j adalah frekuensi kata i pada dokumen j, max tfi,j adalah frekuensi maksimum kata i pada dokumen j, D adalah banyaknya dokumen yang diinputkan/ banyaknya dokumen dalam corpus, dan dfi adalah banyaknya dokumen yang mengandung kata i.
D. DF Thresholding
m
m
batas yang telah ditentukan. Frekuensi dokumen adalah banyaknya kata yang muncul dalam dokumen.
Asumsi dasarnya adalah bahwa setiap kata, non-informatif atau tidakdalam prediksi kategori, berpengaruh dalam menentukan kinerja. Pada penelitian ini, kata yang memiliki DF<2 dan TF yang panjangnya lebih dari sama dengan setengah dokumen akan dihapus [21].
E. IG Thresholding
IG adalah salah satu atribut pengukuran seleksi data yang digunakan untuk memilih tes pada tiap atribut. Atribut dengan IG tertinggi dipilih sebagai tes atribut dari suatu node. Rumus mendapatkan IG dari sebuah matriks dokumen dapat dihitung dengan persamaan 4.
Dimana G adalah gain dari atribut, t adalah kata, maka G(t) adalah gain dari kata. c adalah kategori, dan p adalah nilai peluang kata terhadap kategori. Semakin besar nilai IG (w), semakin besar diskriminatif kekuatan w kata. Untuk corpus dokumen yang berisi n dokumen dan kata-kata d, kompleksitas perhitungan gain informasi adalah O (n · d · k) [22].
F. Singular Value Decomposition (SVD)
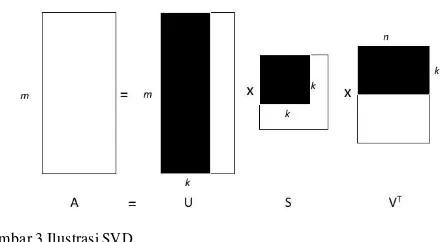
SVD merupakan model matematis yang digunakan untuk reduksi dimensi data. Proses SVD dilakukan dengan mendekomposisi matriks menjadi tiga bagian [23], seperti pada Gambar 3.Matriks U dan V adalah matriks othonormal, yang mana baris pada matriks U menggambarkan banyaknya baris pada matriks A, sementara kolom pada matriks V menggambarkan banyaknya kolom pada matriks A. k-rank digunakan untuk mereduksi dimensi dari matriks A. Matriks S merupakan matriks simetris yang berisi nilai positif di sepanjang diagonal, daerah selain diagonal berisi 0.
Gambar 3.Ilustrasi SVD
Langkah-langkah dari SVD dapat dijelaskan sebagai berikut: a) Membentuk matriks U
i. Perkalian antara matriks A.AT
ii. Menghitung nilai eigen dan vektor eigen dari A.AT
iii. Membentuk matriks y1 dengan nilai dari vector kolom adalah vektor eigenA.AT dengan
susunan kolom vector yang paling kiri merupakan hasil vektor eigen dari nilai eigen yang paling besar, dan vector eigen dengan nilai eigen yang paling kecil terletak di sebelah paling kanan dari matriks.
iv. Dengan menggunakan algoritme Gram- Schmidt, matriks U dibentuk dari matriks orthogonal y1.
b) Membentuk matriks V
i. Perkalian antara matriks AT.A
ii. Menghitung nilai eigen dan vektor eigen dari AT.A
iii. Membentuk matriks y2 dengan nilai dari vector
kolom adalah vektor eigenAT.A dengan
susunan kolom vector yang paling kiri merupakan hasil vektor eigen dari nilai eigen yang paling besar, dan vector eigen dengan nilai eigen yang paling kecil terletak di sebelah iv. Dengan menggunakan algoritme Gram-Vdengan nilai eigen terbesar sampai terkecil disusun secara diagonal mulai dari kolom pertama baris pertama (diagonal pertama).
G. Fuzzy C-Means Clustering
Logika fuzzy merupakan logika yang memiliki tingkat kekaburan atau fuzzyness. Logika ini menunjukkan bahwa tidak ada batasan yang jelas antara dua atau lebih hal yang berbeda (benar-salah, kiri-kanan). Artinya, suatu benda atau hal dapat menjadi benar-salah, berada di kategori A-B dan sekaligus dalam waktu yang bersamaan. Fuzzy C-Means
Clustering merupakan algoritme clustering atau
pengelompokan yang memanfaatkan logika fuzzy tersebut. Teknik Fuzzy C-Means clustering ini membagi sejumlah n data ke dalam sejumlah cluster fuzzy dan menemukan titik pusat cluster. Fuzzy C-Means clustering bertujuan agar nilai dari fungsi obyektif menjadi seminimal mungkin.
Konsep dari algoritme Fuzzy C-Means clustering ini terdiri atas beberapa langkah. Yang pertama adalah menentukan derajat keanggotaan awal setiap titik data terhadap setiap
cluster dengan nilai acak. Derajat keanggotaan ini akan
diletakkan pada matriks ukuran n data xc cluster. Kemudian dicari titik pusat cluster dengan persamaan 5.
yang mana nilai Vij merupakan pusat cluster ke-l pada atribut ke-j, w adalah parameter yang menentukan tingkat kekaburan antar cluster, Xij adalah data ke-i pada atribut
ke-j, µil adalah derajat keanggotaan data ke-i pada cluster ke-l. Atribut merupakan properti dari data yang menjadi dasar pengelompokan Fuzzy C-Means clustering. Dalam penelitian ini, jumlah atribut dari data adalah jumlah k dari perhitungan SVD. Dari sini, nilai fungsi obyektif untuk iterasi tersebut dicari dengan menggunakan persamaan 6 yang dapat dijabarkan sebagai berikut :
(6) yang mana Pt adalah nilai obyektif fungsi pada iterasi ke-t. Kemudian, derajat keanggotaan akan diperbaiki nilainya dengan menggunakan rumus yang dinyatakan dalam persamaan 7:
(7) Perulangan proses memperbaiki pusat cluster dan derajat keanggotaan seperti di atas akan terus berlangsung selama selisih nilai dari fungsi obyektif pada perulangan sekarang dan sebelumnya belum mencapai titik paling minimal atau iterasi belum berakhir. Nilai selisih fungsi obyektif didapatkan dengan persamaan 8:
<ε (8) Yang mana ε adalah galat (tingkat kesalahan) yang ditentukan dari awal.
H. Tipe Evaluasi
Tipe evaluasi yang digunakan untuk penelitian ini menggunakan accuracy. Perhitungan accuracy merupakan proses perhitungan nilai kebenaran dibagi dengan total keseluruhan dokumen di dalam suatu kelas atau kategori. Perhitungan accuracy ditunjukkan pada persamaan 9.
accuracy = correct / total (9)
yang dimaksud correct adalah jumlah dokumen benar yang dikembalikan oleh sistem, dan total merupakan total keseluruhan dokumen. Perhitungan akurasi dihitung per kelas.
III.HASIL PENELITIAN DAN ANALISIS
Harap Skenario uji coba dilakukan pada data dokumen berita yang diambil dari kompas.com secara acak, sebanyak 90 data, dengan 3 kategori, dimana pada masing-masing kategori terdapat 30 data file text. Pengujian dilakukan sebanyak 3 kali yaitu dengan menggunakan nilai IG thresholding 0,5 dan0,9, k-
rank 5, 15, dan 25. Hasil parameter tersebut menghasilkan
pengelompokan dokumen yang hasil akurasinya yang dihitung menggunakan accuracy.
Pada pengujian pertama yang ditunjukkan pada Gambar 4, akurasi yang paling tinggi menunjukkan angka 1 terletak pada kategori entertaint yang menngunakan nilai threshold 0,9 dan
k-rank 5. Secara keseluruhan pada pengujian pertama dapat
disimpulkan bahwa rata-rata yang dihasilkan pada pengujian pertama menunjukkan hasil akurasi optimal ketika threshold
0,5 dan k-rank 5 yaitu menghasilkan nilai rata-rata akurasi 0,83. Pada pengujian pertama rata-rata untuk nilai k-rank yang semakin kecil menghasilkan nilai akurasi yang tinggi dibandingkan nilai k-rank yang banyak. Faktor penyebabnya karena jika k-rank yang digunakan terlalu besar maka keterlibatan informasi yang didapatkan terlalu jauh relevansinya. Nilai threshold 0,5 efektif pada kasus ini, karena informasi yang dianggap penting bagi sistem dapat tertangkap, dan tidak hilang begitu banyak.
Pada pengujian kedua akurasi yang paling tinggi menunjukkan angka 0,97 terletak pada kategori tekno yang menggunakan nilai threshold 0,5 dan k-rank 5.Secara keseluruhan pada pengujian pertama dapat disimpulkan bahwa rata-rata yang dihasilkan pada pengujian pertama menunjukkan hasil akurasi optimal ketika threshold 0,5 dan k-rank 5 yaitu menghasilkan nilai rata-rata akurasi 0,88.
Sama dengan pengujian pertama, rata-rata untuk nilai k-rank
yang semakin kecil menghasilkan nilai akurasi yang tinggi dibandingkan nilai k-rank yang banyak. Faktor penyebabnya karena jika k-rank yang digunakan terlalu besar maka keterlibatan informasi yang didapatkan terlalu jauh relevansinya.Nilai threshold 0,5 efektif pada kasus ini, karena informasi yang dianggap penting bagi sistem dapat tertangkap, dan tidak hilang begitu banyak. Gambar 5 menunjukkan grafik pada pengujian kedua.
Gambar.4 Grafik hasil pengujian pertama
Gambar.6 Grafik hasil pengujian ketiga
Pada pengujian kedua akurasi yang paling tinggi menunjukkan angka 1 terletak pada kategori tekno yang menggunakan nilai threshold 0,5 dan k-rank 5. Secara keseluruhan pada pengujian pertama dapat disimpulkan bahwa rata-rata yang dihasilkan pada pengujian pertama menunjukkan hasil akurasi optimal ketika threshold 0,5 dan
k-rank 15 yaitu menghasilkan nilai rata-rata akurasi 0,86.
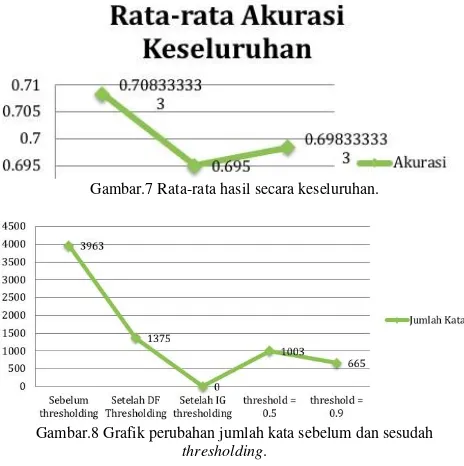
Secara kesuluruhan hasil pengujian, nilai hasil rata-rata akurasi tertinggi terdapat pada pengujian pertama. Nilai
threshold dicapai paling baik ketika 0,5 dan nilai k-rank
menunjukkan hasil yang optimal ketika nilai k-rank 5. Gambar
7 menunjukkan grafik hasil rata-rata akurasi keseluruhan pengujian, dimana pada pengujian pertama nilai rata-rata akurasi yang dicapai adalah 0,71, pengujian kedua 0,695 , dan hasil rata-rata akurasi pada pengujian ketiga adalah 0,70.Pada kasus ini, nilai threshold 0,5 menunjukkan nilai optimal, karena sistem menganggap bahwa dengan nilai tersebut informasi penting pada kata terambil dengan baik. Perubahan banyaknya jumlah kata sebelum dan setelah mengalami
thresholding ditunjukkan pada Gambar 8.
Gambar.7 Rata-rata hasil secara keseluruhan.
Gambar.8 Grafik perubahan jumlah kata sebelum dan sesudah
thresholding.
Pada 90 data, nilai matriks hasil reduksi DF mencapai 35% dari matriks awal. Reduksi IG dengan threshold 0,5 dihasilkan
1003 banyak kata, menunjukkan nilai reduksi 48% dari matriks DF, dan dengan threshold 0,9 menunjukkan hasil yang signifikan mencapai 665 kata atau 71% dari reduksi fitur DF. Dari pengujian pertama menggunakan 90 data terhadap kategori dalam reduksi fitur, menunjukkan hasil bahwa reduksi dengan menggunakan threshold 0,9 dapat mengurangi banyak dimensi kata. Pengurangan banyaknya kata ini membantu dalam menyempurnakan algoritme yang diusulkan.
IV.KESIMPULAN
Metode kombinasi reduksi fitur Document Frequency dan Information Gain Thresholding dalam Singular Value Decomposition dengan Fuzzy C-Means clustering dapat digunakan untuk melakukan pengelompokan dokumen berita dengan menggunakan kontennya sebagai dasar pengelompokan. Hasil penggunaan kombinasi reduksi dimensi matriks dengan menggunakan fitur Document Frequency dan Information Gain Thresholding menunjukkan bahwa term yang harus diproses oleh aplikasi dapat dikurangi jumlahnya secara signifikan.Hasil uji coba akurasi pengelompokan dokumen berita menunjukkan bahwa pengelompokan yang dilakukan dapat memberikan hasil pengkategorian yang cukup akurat dengan tingkat akurasi rata-rata 74,5 % (IG threshold 0,5, k =5).
Saran yang dapat digunakan sebagai perbaikan pada proses
preprocesing khususnya pada proses stemming. Sebaiknya
menggunakan algoritme improvisasi dari stemming Nazief- Andriani, agar akar kata yang dikembalikan akurasinya menjadi lebih baik dan mengambil dasar kata dengan baik.
REFERENSI
[1] Stephens, Michell. History of Newspapers. [online]. (http://www.nyu.edu/classes/stephens/Collier%27s%20page.htm, diakses tanggal 17 November 2012).
[2] Barber, Phil. 2015. A Brief History of Newspaper.www.historicpages.com. Diakses tanggal 17 April 2018. [3] Khare S K, Thapa N, dan Sahoo K C. Internet as a Source of Information :
A Survey. Annals of Library and Information Studies. Vol.54, December 2017, pp 201-206.
[4] Sanburn, Josh. 2011. A Brief Story of Digital News.www.content.time.com. Diakses tanggal 17 April 2018. [5] Hui, S. and Dechao, Z., 2016, May. A weighted topical document
embedding based clustering method for news text. In Information Technology, Networking, Electronic and Automation Control Conference, IEEE (pp. 1060-1065). IEEE.
[6] Nguyen, M.N., Pham, C., Son, J. and Hong, C.S., 2016, October. Online learning-based clustering approach for news recommendation systems. In Network Operations and Management Symposium (APNOMS), 2016 18th Asia-Pacific(pp. 1-4). IEEE.
[7] Li, B., Yan, Q., Xu, Z. and Wang, G., 2015, October. Weighted Document Frequency for feature selection in text classification. In Asian Language Processing (IALP), 2015 International Conference on (pp. 132-135). IEEE.
[8] Reddy, G.S., 2016, September. Dimensionality reduction approach for high dimensional text documents. In Engineering & MIS (ICEMIS), International Conference on (pp. 1-6). IEEE.
[9] Sari, Y.A. and Puspaningrum, E.Y., 2013. Pencarian Semantik Dokumen Berita Menggunakan Essential Dimension of Latent Semantic Indexing dengan Memakai Reduksi Fitur Document Frequency dan Information Gain Thresholding. Seminar Nasional Teknologi Informasi dan Multimedia, STIMIK AMIKOM Yogyakarta.
Systems and Knowledge Discovery, 2008. FSKD'08. Fifth International Conference on (Vol. 1, pp. 57-61). IEEE.
[11] Sari, Yuita Arum, Achmad Ridok, and Marji. Penentuan Lirik Lagu Berdasarkan Emosi Menggunakan Sistem Temu Kembali Informasi dengan Metode Latent Semnatic Indexing (LSI). Song Lyrics Determination using Information Retrieval System with Reduction Dimension Singular Value Decomposition Method in Latent Semantic Indexing. Seminar Nasional Teknologi Infromasi dan Komputasi (SENASTIK). 2012. Pp. 73-79.
[12] Uysal, A.K. and Gunal, S., 2014. The impact of preprocessing on text classification. Information Processing & Management, 50(1), pp.104- 112.
[13] Shinde, M.R. and Gill, P.C., 2014. Pattern Discovery Techniques for the Text Mining and its Applications. International Journal of Science and Research (IJSR) ISSN (Online), pp.2319-7064.
[14] Tala, F.Z., 2003. A study of stemming effects on information retrieval in Bahasa Indonesia. Institute for Logic, Language and Computation, Universiteit van Amsterdam, The Netherlands.
[15] Ghalehtaki, R.A., Khotanlou, H. and Esmaeilpour, M., 2014, February. Evaluating preprocessing by turing machine in text categorization. In Intelligent Systems (ICIS), 2014 Iranian Conference on (pp. 1-6). IEEE.
[16] Septian, G., Susanto, A. and Shidik, G.F., 2017, October. Indonesian news classification based on NaBaNA. In Application for Technology of Information and Communication (iSemantic), 2017 International Seminar on (pp. 175-180). IEEE.
[17] Feldman, R. and Sanger, J., 2007. The text mining handbook: advanced approaches in analyzing unstructured data. Cambridge university press. [18] Giridharan, J. and Vairavan, S.V., 2014, March. Inverted index and
interval lists for keyword search. In Green Computing Communication and Electrical Engineering (ICGCCEE), 2014 International Conference on (pp. 1-4). IEEE.
[19] Sriyasa, W., 2009. Temu Kembali Informasi: Rekonstruksi Inverted Index dan Inplementasi Stopwords
[20] Zhu, D. and Xiao, J., 2011, October. R-tfidf, a Variety of tf-idf Term Weighting Strategy in Document Categorization. In Semantics Knowledge and Grid (SKG), 2011 Seventh International Conference on
(pp. 83-90). IEEE.
[21] Muflikhah, L. and Baharudin, B., 2009, November. Document Clustering using concept space and cosine similarity measurement. In Computer Technology and Development, 2009. ICCTD’09. International Conference on (Vol. 1, pp.58-62). IEEE.
[22] Wijayasekara, D., Manic, M. and McQueen, M. 2013, June. Information gain based dimensionality reduction in unsupervised text learning problems. In Education Technology and Computer (ICETC), 2010 2nd
International Conference on (Vol. 4, pp. V4-422). IEEE.