8 BAB II
LANDASAN TEORI
Dalam penelitian ini diberikan beberapa teori yang diperlukan sebagai pendukung dalam pembahasan selanjutnya di antaranya adalah variabel random, regresi linier, metode kuadrat terkecil (MKT), uji simultan, uji asumsi regresi linier, outlier (pencilan), regresi robust, breakdown point, dan koefisien determinasi.
A. Variabel Random
Definisi 2.1. (Bain & Engelhardt, 1992:53) Variabel random 𝑋 merupakan fungsi yang memetakan setiap hasil yang mungkin 𝑒 pada ruang sampel 𝑆 dengan suatu bilangan riil 𝑥, sedemikian 𝑋(𝑒) = 𝑥.
Dengan simbol huruf besar 𝑋 menotasikan suatu variabel random, sedangkan simbol huruf kecil 𝑥 sebagai bilangan riil yang merupakan hasil nilai-nilai mungkin dari variabel random.
Dilihat dari segi nilainya, variabel random dibedakan menjadi 2, yaitu variabel random diskrit dan variabel random kontinu.
1. Variabel Random Diskrit
Definisi 2.2. (Bain & Engelhardt, 1992:56) Variabel random X disebut variabel random diskrit apabila himpunan semua nilai yang mungkin variabel random X adalah himpunan terhitung (countable), {x1, … , xn} atau {x1, x2, … }.
9
Contoh 2.2. Sebuah koin dilempar sebanyak 10 kali dan variabel random 𝑋 merupakan banyaknya sisi angka yang muncul. Dengan demikian, 𝑋 hanya dapat bernilai dari {0,1,2, … ,10}, 𝑋 disebut variabel random diskrit.
Dalam variabel random diskrit terdapat fungsi kepadatan peluang diskrit dan fungsi distribusi kumulatifnya. Berikut definisi untuk fungsi kepadatan peluang diskrit:
Definisi 2.3. (Bain & Engelhardt, 1992:56) Fungsi 𝑓(𝑥) = 𝑃(𝑋 = 𝑥), dengan 𝑥 = 𝑥1, 𝑥2, … , 𝑥𝑛, merupakan peluang untuk setiap nilai 𝑥 yang mungkin, disebut fungsi kepadatan peluang diskrit(𝑝𝑑𝑓).
Contoh 2.3. Jika sebuah dadu dilempar satu kali, maka terdapat 6 kemungkinan nilai yang akan terjadi. Peluang masing-masing kemungkinan adalah sama, yaitu:
𝑃(𝑋 = 1) = 1 6 𝑃(𝑋 = 4) = 1 6 𝑃(𝑋 = 2) = 1 6 𝑃(𝑋 = 5) = 1 6 𝑃(𝑋 = 3) = 1 6 𝑃(𝑋 = 6) = 1 6
Sedangkan untuk fungsi distribusi kumulatif variabel random diskrit didefinisikan sebagai berikut:
Defisini 2.4. (Bain & Engelhardt, 1992:58) Fungsi distribusi kumulatif (𝑐𝑢𝑚𝑢𝑙𝑎𝑡𝑖𝑣𝑒 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑡𝑖𝑜𝑛 𝑓𝑢𝑛𝑐𝑡𝑖𝑜𝑛/𝐶𝐷𝐹) dari variabel random 𝑋 didefinisikan untuk setiap bilangan riil𝑥, dengan𝐹(𝑥) = 𝑃(𝑋 ≤ 𝑥).
10
Hal itu berarti bahwa fungsi distribusi kumulatif adalah jumlahan nilai-nilai fungsi peluang untuk nilai-nilai 𝑋 lebih kecil atau sama dengan 𝑥. Fungsi 𝐹(𝑥) disebut fungsi distribusi kumulatif diskrit jika dan hanya jika memenuhi:
𝐹(𝑥) = 𝑃(𝑋 ≤ 𝑥) = ∑ 𝑓(𝑥𝑖) 𝑥𝑖≤𝑥
(2.1) Fungsi tersebut mempunyai sifat-sifat sebagai berikut:
(1) lim𝑥→−∞𝐹(𝑥) = 0 (2) lim𝑥→∞𝐹(𝑥) = 1
(3) limℎ→0+𝐹(𝑥 + ℎ) = 𝐹(𝑥)
(4) 𝑎 < 𝑏, maka 𝐹(𝑎) ≤ 𝐹(𝑏) (2.2)
Contoh 2.4. Sebuah dadu dilambungkan sebanyak satu kali, dengan ruang sampel 𝑆 = {1,2,3,4,5,6}. Peluang munculnya mata dadu kurang dari atau sama dengan 5 adalah: 𝐹(5) = 𝑃(𝑋 ≤ 5) = ∑ 𝑓(𝑥𝑖) 𝑥𝑖≤5 𝐹(5) = 𝑃(𝑋 ≤ 5) = 𝑓(1) + 𝑓(2) + 𝑓(3) + 𝑓(4) + 𝑓(5) 𝐹(5) = 𝑃(𝑋 ≤ 5) =1 6+ 1 6+ 1 6+ 1 6+ 1 6= 5 6
Jadi, peluang munculnya mata dadu kurang dari atau sama dengan 5 adalah 56. 2. Variabel Random Kontinu
Definisi 2.5. (Bain & Engelhardt, 1992:64) Variabel random 𝑋 disebut variabel random kontinu jika terdapat fungsi yang merupakan fungsi kepadatan
11
peluang (𝑝𝑑𝑓) dari 𝑋 sehingga fungsi distribusi kumulatifnya dapat ditunjukkan sebagai:
𝐹(𝑥) = ∫ 𝑓(𝑡) 𝑥
−∞
𝑑𝑡 (2.3)
Dari definisi di atas, maka fungsi kepadatan peluang dari variabel random kontinu merupakan turunan dari fungsi distribusi kumulatifnya. Sebuah fungsi 𝑓(𝑥) disebut fungsi kepadatan peluang dari variabel random kontinu 𝑋 jika memenuhi:
(1) (𝑥𝑖) ≥ 0, ∀𝑥𝑖 (2) ∫ 𝑓(𝑥)−∞∞ 𝑑𝑥 = 1
Contoh 2.5. Sebuah mesin memproduksi kawat tembaga, dan terdapat cacat di beberapa titik sepanjang kawat. Panjang kawat (dalam meter) yang diproduksi antara yang cacat dan yang baik sebanyak 𝑋 variabel random kontinu dengan persamaan pdf:
𝑓(𝑥) = {𝑐(1 − 𝑥)−3 0
, 𝑥 > 0 , 𝑥 ≤ 0
di mana 𝑐 konstan. Sehingga nilai 𝑐 dapat ditentukan sebagai berikut: 𝐹(𝑥) = ∫ 𝑓(𝑥) ∞ 0 𝑑𝑥 1 = ∫ 𝑐(1 − 𝑥)−3 ∞ 0 𝑑𝑥 = 𝑐 ∫(1 − 𝑥)−3 ∞ 0 𝑑𝑥
12 1 = 𝑐 [(1 − 𝑥)−2 −2 ]0 ∞ 1 = 𝑐 ((1 − 0) −2 2 ) 1 = 𝑐 (1 2) maka diperoleh nilai 𝑐 = 2.
B. Regresi Linier
Regresi linier adalah suatu metode dalam analisis statistika yang menjelaskan tentang hubungan antara variabel independen (variabel bebas) dan variabel dependen (variabel terikat). Variabel independen merupakan variabel yang keberadaannya tidak dipengaruhi oleh variabel lain. Sedangkan variabel dependen merupakan variabel yang keberadaannya dipengaruhi oleh variabel lain. Hubungan antar variabel yang dihasilkan dari analisis regresi disebut sebagai model regresi. Regresi linier terdiri dari dua jenis, yaitu regresi linier sederhana dan regresi linier berganda.
1. Regresi Linier Sederhana
Regresi linier sederhana merupakan model regresi untuk menyatakan hubungan antara satu variabel independen terhadap satu variabel dependen. Menurut Draper & Smith (1992:8) bentuk umum persamaan regresi linier sederhana dapat ditulis sebagai berikut:
13
dengan 𝑦𝑖 merupakan nilai variabel dependen pada observasi ke- 𝑖, 𝑥𝑖 merupakan nilai variabel independen pada observasi ke- 𝑖, 𝛽0 dan 𝛽1 merupakan parameter koefisien regresi, dan 𝜀𝑖 merupakan suatu error.
2. Regresi Linier Berganda
Regresi linier berganda merupakan model regresi untuk menyatakan hubungan antara lebih dari satu variabel independen terhadap satu variabel dependen. Model regresi linier berganda digunakan untuk menyelidiki pengaruh beberapa variabel independen terhadap variabel dependen. Adanya variabel independen yang lebih dari satu, dapat memberikan model regresi yang lebih teliti terhadap variabel dependen.
Menurut Montgomery & Peck (1992:118), model regresi linier berganda dengan 𝑘 variabel independen adalah sebagai berikut:
𝑌𝑖 = 𝛽0+ 𝛽1𝑋𝑖1+ 𝛽2𝑋𝑖2+ ⋯ + 𝛽𝑘𝑋𝑖𝑘 + 𝜀𝑖 atau dapat ditulis,
𝑦𝑖 = 𝛽0+ ∑𝑘 𝛽𝑗𝑥𝑖𝑗
𝑗=1 + 𝑒𝑖, 𝑖 =1,2,…,𝑛 (2.5) dengan 𝑦𝑖 merupakan nilai variabel dependen pada observasi ke- 𝑖, 𝑥𝑖𝑗 merupakan nilai variabel independen ke-𝑗 pada observasi ke-𝑖, 𝛽0 dan 𝛽𝑘 adalah parameter koefisien regresi, dan 𝑒𝑖 merupakan suatu error.
Parameter 𝛽1 dan 𝛽2 dalam model regresi linier berganda dikenal dengan nama koefisien regresi parsial (Montgomery & Peck, 1992:119), yang bermakna sebagai berikut:
a. Parameter 𝛽1 menunjukkan perubahan rata-rata variabel dependen untuk setiap kenaikan 𝑥1 satu satuan bila 𝑥2 dipertahankan konstan.
14
b. Parameter 𝛽2 menunjukkan perubahan rata-rata variabel dependen untuk setiap kenaikan 𝑥2 satu satuan bila 𝑥1 dipertahankan konstan.
C. Metode Kuadrat Terkecil (MKT)
Suatu model regresi dengan nilai parameter 𝛽0, 𝛽1, … , 𝛽𝑘 yang tidak diketahui, dapat dihitung nilai dugaannya dengan melakukan estimasi parameter menggunakan metode kuadrat terkecil. Menurut Gujarati (2006:126) metode kuadrat terkecil menyatakan bahwa estimasi parameter 𝛽̂0, 𝛽̂1, … , 𝛽̂𝑘 dipilih sedemikian sehingga jumlah kuadrat residu mempunyai nilai yang sekecil mungkin. Dalam hal ini berarti metode kuadrat terkecil digunakan untuk mengestimasi koefisien 𝛽0, 𝛽1, … , 𝛽𝑘, yaitu dengan meminimumkan jumlah kuadrat galat. Menurut Montgomery & Peck (1992:120), fungsi yang meminimumkan jumlah kuadrat galat tersebut adalah:
𝑆(𝛽0, 𝛽1, … , 𝛽𝑘) = ∑ 𝑒𝑖2 𝑛 𝑖=1 = ∑ (𝑦𝑖 − 𝛽0− ∑ 𝛽𝑗𝑥𝑖𝑗 𝑘 𝑗=1 ) 2 𝑛 𝑖=1 (2.6)
Fungsi 𝑆 akan diminimalkan dengan menentukan turunan terhadap 𝛽0, 𝛽1, … , 𝛽𝑘 dengan 𝜕𝛽𝜕𝑆 = 0 sehingga diperoleh:
𝜕𝑆 𝜕𝛽|𝛽 0,𝛽1,…,𝛽𝑘 = −2 ∑ (𝑦𝑖 − 𝛽0− ∑ 𝛽𝑗𝑥𝑖𝑗 𝑘 𝑗=1 ) 𝑛 𝑖=1 = 0
15
Selanjutnya nilai 𝛽0, 𝛽1, … , 𝛽𝑘 diestimasi menjadi 𝛽̂0, 𝛽̂1, … , 𝛽̂𝑘, sehingga diperoleh 𝜕𝑆 𝜕𝛽̂0 = −2 ∑ (𝑦𝑖 − 𝛽̂0− ∑ 𝛽̂𝑗𝑥𝑖𝑗 𝑘 𝑗=1 ) 𝑛 𝑖=1 = 0 (2.7) dan 𝜕𝑆 𝜕𝛽̂𝑗 = −2 ∑ (𝑦𝑖 − 𝛽̂0 − ∑ 𝛽̂𝑗𝑥𝑖𝑗 𝑘 𝑗=1 ) 𝑥𝑖𝑗 𝑛 𝑖=1 = 0 (2.8)
Dari persamaan (2.7) dan (2.8), menghasilkan persamaan normal kuadrat terkecil sebagai berikut:
𝑛𝛽̂0+ 𝛽̂1∑ 𝑥𝑖1 𝑛 𝑖=1 + 𝛽̂2∑ 𝑥𝑖2 𝑛 𝑖=1 + ⋯ + 𝛽̂𝑘∑ 𝑥𝑖𝑘 𝑛 𝑖=1 = ∑ 𝑦𝑖 𝑛 𝑖=1 𝛽̂0∑ 𝑥𝑖1 𝑛 𝑖=1 + 𝛽̂1∑ 𝑥𝑖12 𝑛 𝑖=1 + 𝛽̂2∑ 𝑥𝑖1𝑥𝑖2+ ⋯ + 𝑛 𝑖=1 𝛽̂𝑘∑ 𝑥𝑖1𝑥𝑖𝑘 𝑛 𝑖=1 = ∑ 𝑥𝑖1𝑦𝑖 𝑛 𝑖=1 𝛽̂0∑ 𝑥𝑖2 𝑛 𝑖=1 + 𝛽̂1∑ 𝑥𝑖1𝑥𝑖2 𝑛 𝑖=1 + 𝛽̂2∑ 𝑥𝑖22 𝑛 𝑖=1 + ⋯ + 𝛽̂𝑘∑ 𝑥𝑖2𝑥𝑖𝑘 𝑛 𝑖=1 = ∑ 𝑥𝑖2𝑦𝑖 𝑛 𝑖=1 𝛽̂0∑ 𝑥𝑖𝑘 𝑛 𝑖=1 + 𝛽̂1∑ 𝑥𝑖1𝑥𝑖𝑘 𝑛 𝑖=1 + 𝛽̂2∑ 𝑥𝑖2𝑥𝑖𝑘 𝑛 𝑖=1 + ⋯ + 𝛽̂𝑘∑ 𝑥𝑖𝑘2 𝑛 𝑖=1 = ∑ 𝑥𝑖1𝑦𝑖 𝑛 𝑖=1 (2.9) Solusi dari persamaan normal tersebut akan menjadi estimator kuadrat terkecil 𝛽̂0, 𝛽̂1, … , 𝛽̂𝑘.
Akan lebih mudah apabila model regresi berganda tersebut dinyatakan dalam matriks. Notasi matriks yang diberikan pada persamaan (2.5) adalah
16 𝒀 = 𝑿𝜷 + 𝒆 (2.10) dengan 𝒀 = [ 𝑦1 𝑦2 ⋮ 𝑦𝑛 ]; 𝑿 = [ 1 1 𝑥11 𝑥12 … 𝑥21 𝑥22 … 𝑥1𝑘 𝑥2𝑘 ⋮ ⋮ ⋮ ⋮ 1 𝑥𝑛1 𝑥𝑛2 … 𝑥𝑛𝑘 ]; 𝜷 = [ 𝛽0 𝛽1 ⋮ 𝛽𝑘 ]; 𝒆 = [ 𝑒1 𝑒2 ⋮ 𝑒𝑛 ]
Pada umumnya 𝒀 adalah matriks berukuran (𝑛 × 1), sedangkan 𝑿 adalah matriks berukuran (𝑛 × 𝑘), 𝜷 adalah matriks berukuran (𝑘 × 1), dan 𝒆 adalah matriks berukuran (𝑛 × 1). Error dapat diturunkan dari persamaan di atas, sehingga diperoleh:
𝒆 = 𝒀 − 𝑿𝜷 (2.11)
Menurut Montgomery & Peck (1992:120), fungsi yang meminimumkan jumlah kuadrat galat adalah:
𝑆(𝛽) = ∑ 𝑒𝑖2 𝑛
𝑖=1 = 𝑒12+ 𝑒
22+ ⋯ + 𝑒𝑛2 (2.12)
Persamaan aljabar di atas dapat diubah ke dalam bentuk matriks. Diketahui
𝒆 = [ 𝑒1 𝑒2 ⋮ 𝑒𝑛
] matriks ukuran (𝑛 × 1), maka terdapat transpose matriks 𝒆, yaitu
𝒆𝑻 = [𝑒1 𝑒2 … 𝑒
𝑛] yang merupakan matriks berukuran (1 × 𝑛). Sehingga persamaan (2.12) dapat ditulis sebagai:
𝑆(𝛽) = [𝑒1 𝑒2 … 𝑒𝑛] [ 𝑒1 𝑒2 ⋮ 𝑒𝑛 ] = 𝒆𝑻𝒆 (2.13) Maka diperoleh
17 𝑆(𝛽) = ∑ 𝑒𝑖2 𝑛 𝑖=1 = 𝒆𝑻𝒆 = (𝒀 − 𝑿𝜷)𝑻(𝒀 − 𝑿𝜷) = 𝒀𝑻𝒀 − 𝒀𝑻𝑿𝜷 − 𝜷𝑻𝑿𝑻𝒀 + 𝜷𝑻𝑿𝑻𝑿𝜷 = 𝒀𝑻𝒀 − 𝟐𝜷𝑻𝑿𝑻𝒀 + 𝜷𝑻𝑿𝑻𝑿𝜷 (2.14) Matriks 𝜷𝑻𝑿𝑻𝒀 adalah matriks berukuran (1 × 1), atau sebuah skalar, dan transpose 𝜷𝑻𝑿𝑻𝒀 = 𝒀𝑻𝑿𝜷 matriks berukuran (1 × 1) yang juga merupakan skalar.
Menurut Montgomery & Peck (1992:122), untuk menentukan estimator-estimator kuadrat terkecil, 𝛽̂ yang meminimumkan 𝑆(𝛽) yaitu dengan menentukan turunan parsial fungsi 𝑆(𝛽) terhadap 𝛽 sebagai berikut:
𝜕𝑆 𝜕𝛽 = 𝜕(𝒀𝑻𝒀 − 2𝜷𝑻𝑿𝑻𝒀 + 𝜷𝑻𝑿𝑻𝑿𝜷) 𝜕𝜷 = 𝜕(𝒀𝑻𝒀) 𝜕𝜷 − 2 𝜕(𝜷𝑻𝑿𝑻𝒀) 𝜕𝜷 + 𝜕(𝜷𝑻𝑿𝑻𝑿𝜷) 𝜕𝜷 = −2𝑿𝑻𝒀 + 2𝑿𝑻𝑿𝜷
Sehingga turunan parsial terhadap estimasi parameter 𝛽 menjadi, 𝜕𝑆
𝜕𝛽̂ =
𝜕(𝒀𝑻𝒀 − 2𝜷̂𝑻𝑿𝑻𝒀 + 𝜷̂𝑻𝑿𝑻𝑿𝜷̂) 𝜕𝜷
= −2𝑿𝑻𝒀 + 2𝑿𝑻𝑿𝜷̂ (2.15)
Agar diperoleh estimator-estimator kuadrat terkecil, maka harus meminimalkan turunan parsial fungsi 𝑆(𝛽) terhadap 𝛽̂ yang memenuhi 𝜕𝛽𝜕𝑆̂ = 0.
18
Dengan menyelesaikan persamaan (2.15) di atas, akan diperoleh estimator untuk 𝛽, yaitu: 𝜕𝑆 𝜕𝛽̂ = 0 −2𝑿𝑻𝒀 + 2𝑿𝑻𝑿𝜷̂ = 0 2𝑿𝑻𝑿𝜷̂ = 2𝑿𝑻𝒀 𝑿𝑻𝑿𝜷̂ = 𝑿𝑻𝒀 (2.16)
Apabila kedua ruas dikalikan invers dari matriks (𝑿𝑻𝑿), maka estimasi terkecil dari 𝛽 diperoleh sebagai berikut:
(𝑿𝑻𝑿)−𝟏𝑿𝑻𝑿𝜷̂ = (𝑿𝑻𝑿)−𝟏𝑿𝑻𝒀
𝜷̂ = (𝑿𝑻𝑿)−𝟏𝑿𝑻𝒀 (2.17)
Diasumsikan bahwa invers matriks (𝑿𝑻𝑿)−𝟏 ada. Diperoleh matriks dari persamaan normal (2.16) yang identik dengan bentuk skalar pada persamaan (2.9). Dari persamaan (2.16) diperoleh:
[ 𝑛 ∑ 𝑥𝑖1 𝑛 𝑖=1 ∑ 𝑥𝑖2 𝑛 𝑖=1 … ∑ 𝑥𝑖𝑘 𝑛 𝑖=1 ∑ 𝑥𝑖1 𝑛 𝑖=1 ⋮ ∑ 𝑥𝑖𝑘 𝑛 𝑖=1 ∑ 𝑥𝑖12 𝑛 𝑖=1 ⋮ ∑ 𝑥𝑖𝑘𝑥𝑖1 𝑛 𝑖=1 ∑ 𝑥𝑖1𝑥𝑖2 𝑛 𝑖=1 ⋮ ∑ 𝑥𝑖𝑘𝑥𝑖2 𝑛 𝑖=1 ∑ 𝑥𝑖1 𝑛 𝑖=1 𝑥𝑖𝑘 ⋮ ∑ 𝑥𝑖𝑘2 𝑛 𝑖=1 ] [ 𝛽̂0 𝛽̂1 ⋮ 𝛽̂𝑘] = [ ∑ 𝑦𝑛 𝑖 𝑖=1 ∑ 𝑥𝑖1𝑦𝑖 𝑛 𝑖=1 ⋮ ∑ 𝑥𝑖𝑘𝑦𝑖 𝑛 𝑖=1 ]
Matriks 𝑿𝑻𝑿 adalah matriks persegi berukuran 𝑘 × 𝑘 dan 𝑿𝑻𝒀 adalah matriks 𝑘 × 1. Diagonal elemen matriks 𝑿𝑻𝑿 merupakan jumlah kuadrat kolom-kolom X, dan elemen-elemen selain diagonalnya merupakan perkalian elemen
19
dalam kolom X. Sedangkan elemen-elemen matriks 𝑿𝑻𝒀 adalah jumlah perkalian antar kolom X dan observasi Y.
Berdasarkan persamaan (2.10), dengan 𝛽 adalah parameter yang tidak diketahui, maka 𝛽 diestimasikan menjadi 𝛽̂ = (𝑋𝑇𝑋)−1𝑋𝑇𝑌. Sehingga estimasi 𝑌̂ yang sesuai dengan nilai 𝑌 yang diamati pada persamaan (2.10) menjadi
𝑌̂ = 𝑋𝛽̂
= 𝑿(𝑿𝑻𝑿)−𝟏𝑿𝑻𝒀 = 𝑯𝒀
dengan matriks persegi
𝑯 = 𝑿(𝑿𝑻𝑿)−𝟏𝑿𝑻 (2.18)
disebut sebagai matriks hat yaitu fungsi yang memetakan vektor nilai teramati ke dalam vektor nilai yang diestimasikan.
D. Uji Simultan
Uji simultan dilakukan untuk mengetahui apakah semua variabel independen secara bersama-sama (simultan) dapat berpengaruh terhadap variabel dependen. Pengujian dilakukan dengan menggunakan distribusi 𝐹, yaitu dengan membandingkan antara 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 dan 𝐹𝑡𝑎𝑏𝑒𝑙 = 𝐹𝛼(𝑘;𝑛−𝑘−1) (Sunyoto, 2011:16), dengan 𝛼 adalah taraf siginifikansi, 𝑘 banyaknya variabel independen, dan 𝑛 banyaknya pengamatan. Hipotesis yang digunakan adalah sebagai berikut:
𝐻0 : 𝛽1 = ⋯ = 𝛽𝑗 = 0, artinya tak satupun variabel independen berpengaruh secara signifikan terhadap variabel dependen.
20
𝐻1 : ∃ 𝛽𝑖 ≠ 0, artinya paling tidak ada satu variabel independen yang berpengaruh secara signifikan terhadap variabel dependen.
Kriteria dalam pengambilan keputusan yang dapat digunakan adalah terima 𝐻0 apabila nilai 𝐹ℎ𝑖𝑡𝑢𝑛𝑔< 𝐹𝑡𝑎𝑏𝑒𝑙 yang artinya bahwa tak satupun variabel independen berpengaruh secara signifikan terhadap variabel dependen.
E. Uji Parsial
Uji parsial dilakukan untuk mengetahui bagaimana pengaruh masing-masing variabel independen terhadap variabel dependen. Pengujian dilakukan dengan membandingkan antara 𝑡ℎ𝑖𝑡𝑢𝑛𝑔 dan 𝑡𝑡𝑎𝑏𝑒𝑙 = 𝑡(𝑛−𝑘,𝛼
2)
(Algifari, 1997:59) atau dapat juga dengan membandingkan nilai sig. terhadap 𝛼 yang telah ditentukan, dengan 𝛼 adalah taraf signifikansi, 𝑘 banyaknya variabel independen, dan 𝑛 banyaknya pengamatan. Hipotesis yang digunakan adalah sebagai berikut: 𝐻0 : 𝛽𝑖 = 0, artinya variabel independen ke- 𝑖 berpengaruh signifikan terhadap
variabel dependen, dengan 𝑖 = 1,2, . . , 𝑘.
𝐻1 : 𝛽𝑖 ≠ 0, artinya variabel independen ke- 𝑖 tidak berpengaruh signifikan terhadap variabel dependen, dengan 𝑖 = 1,2, . . , 𝑘.
Kriteria dalam pengambilan keputusan yang dapat digunakan adalah terima 𝐻0 apabila nilai 𝑡ℎ𝑖𝑡𝑢𝑛𝑔 > 𝑡𝑡𝑎𝑏𝑒𝑙 atau nilai 𝑠𝑖𝑔. < 𝛼 yang artinya bahwa variabel independen ke- 𝑖 berpengaruh signifikan terhadap variabel dependen.
21 F. Uji Asumsi Regresi Linier
Pada analisis model regresi, perlu dilakukan pengujian asumsi yang tujuannya untuk mengetahui apakah model yang dihasilkan baik atau tidak. Asumsi yang harus terpenuhi dalam analisis model regresi adalah normalitas galat, kehomogenan ragam, tidak terjadinya autokorelasi dan tidak adanya multikolinearitas.
1. Uji Normalitas
Pada regresi linier diasumsikan bahwa tiap sisaan (𝜀𝑖) berdistribusi normal dengan 𝜀𝑖~𝑁(0, 𝜎2) (Draper & Smith, 1992:103). Pendeteksian normalitas dapat ditentukan dengan uji Kolmogorov-Smirnov. Menurut Siegel (2011:59), uji
Kolmogorov-Smirnov didasarkan pada nilai 𝐷 atau deviasi maksimum, yaitu:
𝐷 = 𝑚𝑎𝑥|𝐹0(𝑋𝑖) − 𝑆𝑛(𝑋𝑖)|, 𝑖 = 1,2, … , 𝑛 (2.19) dengan 𝐹0(𝑋𝑖) adalah fungsi distribusi frekuensi kumulatif teoritis di bawah 𝐻0. Kemudian 𝑆𝑛(𝑋𝑖) adalah distribusi frekuensi kumulatif pengamatan sebanyak 𝑁 sampel. Asumsi normalitas akan terpenuhi jika nilai 𝐷 < 𝐷𝑡𝑎𝑏𝑒𝑙 atau 𝑝 − 𝑣𝑎𝑙𝑢𝑒 pada output SPSS lebih dari nilai taraf nyata (𝛼). Tabel uji Kolmogorov-Smirnov
dapat dilihat pada lampiran 10 (halaman 91).
2. Uji Homoskedastisitas
Salah satu asumsi klasik adalah homoskedastisitas atau non heteroskedastisitas yaitu asumsi yang menyatakan bahwa varian setiap sisaan tetap sama. Asumsi ini dapat ditulis sebagai berikut (Gujarati, 2006:146):
22
𝑉𝑎𝑟(𝜀𝑖) = 𝜎2, 𝑖 = 1,2, … , 𝑛 (2.20) 𝑛 menunjukkan jumlah pengamatan. Model regresi yang baik adalah tidak terjadi heteroskedastisitas. Salah satu pengujian untuk menentukan ada tidaknya masalah heteroskedastisitas adalah uji rankSpearman.
Menurut Siegel (2011:253), uji korelasi rank Spearman didefinisikan sebagai berikut: 𝑟𝑠 = 1 − 6 [ ∑𝑛 𝑑𝑖2 𝑖=1 𝑛(𝑛2− 1)] (2.21)
dengan 𝑑𝑖 adalah rank variabel dependen ke- 𝑖 dikurangi rank variabel independen ke- 𝑖, dan 𝑛 adalah banyaknya individual yang diranking. Adapun tahapannya sebagai berikut:
a. Menentukan ranking untuk masing-masing variabel 𝑋 dan variabel 𝑌, mulai dari 1 hingga 𝑛.
b. Menentukan harga 𝑑𝑖 = 𝑋𝑖− 𝑌𝑖 dan mengkuadratkan tiap-tiap harga 𝑑𝑖. Kemudian menjumlahkannya sehingga diperoleh ∑𝑛𝑖=1𝑑𝑖2.
c. Menghitung koefisien korelasi rank Spearman yang telah diberikan sebelumnya.
d. Dengan 𝑛 ≥ 10, signifikan dari 𝑟𝑠 yang disampel dapat diuji dengan pengujian t sebagai berikut:
𝑡 =𝑟𝑠√𝑛 − 2 √1 − 𝑟𝑠2
Jika nilai rank 𝑡 yang dihitung melebihi nilai 𝑡 kritis dengan derajat bebas 𝑛 − 2 maka 𝐻0 ditolak, artinya asumsi homoskedastisitas tidak terpenuhi.
23
Atau nilai sig. pada output SPSS lebih dari 𝛼, maka dapat disimpulkan bahwa
asumsi homoskedastisitas terpenuhi.
3. Uji Non Autokorelasi
Autokorelasi adalah suatu korelasi antara nilai variabel dengan nilai variabel yang sama pada selang waktu yang berlainan (Suharjo,2008:93). Menurut Sunyoto (2011:91), autokorelasi terjadi apabila ada korelasi secara linier antara kesalahan acak periode t dengan kesalahan acak periode (t − 1). Dalam hal ini dapat diartikan bahwa residu-residu yang berurutan saling berhubungan, yaitu 𝑒𝑡 berkorelasi dengan 𝑒𝑡−1. Dengan kata lain bahwa autokorelasi merupakan hubungan antara suatu variabel dengan dirinya sendiri. Pendeteksian autokorelasi dilakukan dengan menggunakan statistik uji runtutan (run test) (Draper & Smith, 1992:149-150).
Menurut Siegel (2011:67), pendekatan untuk distribusi sampling pada run test diuji dengan:
𝑧 =𝑟 − 𝜇𝑟 𝜎𝑟
(2.22) 𝑟 merupakan banyaknya run dengan mean sebagai berikut:
𝜇𝑟 = 2𝑛1𝑛2 𝑛1+ 𝑛2 + 1 dan standar deviasi:
𝜎𝑟 = √2𝑛1𝑛2(2𝑛1𝑛2− 𝑛1− 𝑛2) (𝑛1+ 𝑛2)2(𝑛1+ 𝑛2− 1)
24
Langkah-langkah yang dilakukan dalam run test adalah: a. Menyusun observasi-observasi 𝑛1 dan 𝑛2 menurut urutan waktu. b. Menghitung banyaknya run (𝑟).
c. Menghitung harga 𝑧 dan tolak 𝐻0 jika 𝑝 < 𝛼 untuk kasus satu sisi dan tolak 𝐻0 jika 2𝑝 < 𝛼 untuk kasus dua sisi.
4. Uji Non Multikolinearitas
Menurut Montgomery & Peck (1992:165), multikolinearitas terjadi karena terdapat korelasi yang cukup tinggi antara dua atau lebih variabel independen. Adanya multikolinearitas dapat mengganggu kesesuaian model kuadrat terkecil dan dalam beberapa kasus dapat mengakibatkan model yang dihasilkan menjadi tidak berguna.
VIF (Variance Inflation Factor) merupakan salah satu cara untuk mengukur besar kolinearitas dan didefinisikan oleh Montgomery & Peck (1992:192) sebagai berikut: 𝑉𝐼𝐹 = 1 1 − 𝑅𝑗2 (2.23) dengan 𝑅𝑗2 = 1 − 𝐽𝐾𝐺 (𝑛 − 1)𝑆𝑗2 (2.24) 𝑆𝑗2 = 𝑛 ∑𝑋𝑗2− (∑𝑋𝑗) 2 𝑛(𝑛 − 1) (2.25) 𝐽𝐾𝐺𝑗= ∑𝑋𝑗2−𝑏𝑗∑𝑋𝑗−𝑏𝑗+1∑𝑋𝑗+1𝑋𝑗−𝑏𝑗+2∑𝑋𝑗+2𝑋𝑗 (2.26)
25
di mana 𝑅𝑗2 adalah koefisien determinasi yang dihasilkan dari regresi antara dua atau lebih variabel independen, dengan salah satu variabel independen, misal 𝑋𝑗, diperlakukan sebagai fungsi variabel independen lainnya: 𝑋𝑗 = 𝑓(𝑋1, 𝑋2, … , 𝑋𝑘−1), dengan 𝑗 = 1,2, … , 𝑘 dan 𝑘 adalah banyaknya variabel independen (Gudono,2011:138). 𝑆𝑗2 sebagai ragam sampel ke-𝑗 dan 𝐽𝐾𝐺 adalah jumlah kuadrat galat. Hipotesis yang diuji adalah:
𝐻0 : Tidak terdapat multikolinearitas 𝐻1 : Terdapat multikolinearitas
Apabila nilai 𝑉𝐼𝐹 > 10 maka estimasi koefisien regresi dipengaruhi oleh multikolinearitas (Montgomery & Peck, 1992:317).
G. Outlier (Pencilan)
Outlier (pencilan) merupakan pengamatan yang jauh dari pusat data observasi dari data yang lainnya dan mungkin berpengaruh besar terhadap koefisien regresi (Pardoe, 2012:189). Menurut Hampel (2001:2), outlier adalah data yang tidak sesuai dengan pola yang ditetapkan oleh sebagian besar data. Aggarwal (2016:1) mendefinisikan outlier adalah titik data yang berbeda secara signifikan dari sisa data. Outlier juga didefinisikan sebagai pengamatan yang secara individu maupun kelompok memiliki pengaruh besar pada persamaan regresi dibandingkan dengan pengamatan lainnya (Turkan, Cetin, & Toktamis, 2012:148). Dari beberapa definisi tersebut, dapat diartikan bahwa outlier
26
merupakan titik ekstrim suatu data yang letaknya jauh dari pusat data atau menyimpang dari data pengamatan yang lain.
Pada analisis regresi, terdapat 3 tipe outlier yang berpengaruh terhadap estimasi kuadrat terkecil. Menurut Rousseeuw & Leroy (1987) mengenalkan 3 jenis outlier sebagai berikut:
1. Vertical Outlier
Merupakan semua pengamatan yang terpencil pada variabel dependen, tetapi tidak terpencil pada variabel independen. Keberadaan vertical outlier
berpengaruh terhadap estimasi kuadrat terkecil. 2. Good leverage point
Merupakan pengamatan yang terpencil pada variabel independen tetapi terletak dekat dengan garis regresi. Hal ini berarti pengamatan 𝑥𝑖 menjauh tetapi 𝑦𝑖 dekat dengan garis regresi. Keberadaan good leverage point tidak berpengaruh terhadap estimasi kuadrat terkecil, tetapi berpengaruh terhadap inferensi statistik karena dapat meningkatkan estimasi standar error.
3. Bad leverage point
Merupakan pengamatan yang terpencil pada variabel independen dan terletak jauh dari garis regresi. Keberadaan bad leverage point berpengaruh signifikan terhadap estimasi kuadrat terkecil, baik terhadap intercept maupun
slope dari persamaan regresi.
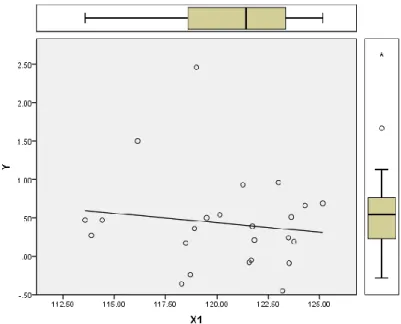
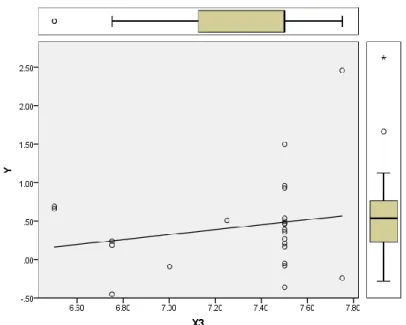
Berdasarkan data inflasi pada penelitian ini, maka dapat disajikan scatter plot sebagai berikut:
27
Gambar 1. Scatter plot antara Inflasi dan IHK
28
Gambar 3. Scatter plot antara Inflasi dan Suku Bunga
Berdasarkan Gambar 1, Gambar 2, dan Gambar 3 di atas, maka terlihat bahwa outlier terdapat pada variabel dependen, sehingga data inflasi termasuk ke dalam jenis vertical outlier.
Keberadaan data pencilan akan mengganggu dalam proses analisis data sehingga harus dihindari dalam banyak hal. Dalam kaitannya dengan analisis regresi, outlier dapat menyebabkan hal-hal berikut (Soemartini, 2007:7):
1. Residual yang besar dari model yang terbentuk. 2. Varians pada data tersebut menjadi lebih besar. 3. Taksiran interval memiliki rentang yang lebar.
Penolakan begitu saja suatu outlier bukanlah prosedur yang bijaksana. Adakalanya outlier memberikan informasi yang tidak bisa diberikan oleh titik data lainnya, misalnya karena outlier timbul dari kombinasi keadaan yang tidak biasa yang mungkin saja sangat penting dan perlu diselidiki lebih jauh. Sehingga dapat dilakukan penyisihan outlier dari data amatan, kemudian menganalisis
29
kembali tanpa data outlier tersebut. Oleh karena itu, suatu outlier perlu diperiksa secara seksama, baik secara grafis maupun statistik. Pendeteksian outlier dapat dilakukan dengan beberapa metode di bawah ini:
1. Boxplot
Metode boxplot digunakan untuk mendeteksi keberadaan outlier dengan menggunakan nilai kuartil dan jangkauan. Kuartil 1, 2, dan 3 akan membagi urutan data menjadi empat bagian. Jangkauan IQR (Interquartile Range) didefinisikan sebagai selisih kuartil 1 terhadap kuartil 3, atau IQR=Q3-Q1. Data-data outlier dapat ditentukan yaitu nilai yang kurang dari 1.5*IQR terhadap kuartil 1 dan nilai yang lebih dari 1.5*IQR terhadap kuartil 3 (Soemartini, 2007:9).
Gambar 4. Skema identifikasi outlier menggunakan IQR atau boxplot
2. Standardized Residual
Weisberg (2005) mendefinisikan standardized residual sebagai berikut:
𝑟𝑖 = 𝑒̂𝑖
30 di mana ℎ𝑖𝑖 = 𝑥𝑖′(𝑋′𝑋)−1𝑥
𝑖 adalah nilai leverage data ke-𝑖 dan merupakan elemen diagonal matriks hat 𝐻 = 𝑋(𝑋′𝑋)−1𝑋′. Standardized residual memiliki nilai
mean sama dengan nol dan nilai variansi sama dengan satu (Weisberg, 2005: 168-195).
Pendeteksian outlier dapat dilakukan dengan memperhatikan nilai-nilai
standardized residual. Jika nilai dari standardized residual lebih dari 3,5 atau kurang dari -3,5 maka data tersebut dikatakan sebagai outlier (Yaffee, 2002:35).
3. Cook’s Distance
Cook’s distance dirancang untuk mengukur perubahan 𝛽̂ saat pengamatan tertentu dihilangkan (Rawlings, Pantula, & Dickey, 1998:362). Cook (1977) mendefinisikan cook’s distance sebagai berikut:
𝐷𝑖 =
(𝛽̂(𝑖)− 𝛽̂)′(𝑋′𝑋)(𝛽̂
(𝑖)− 𝛽̂)
𝑝𝜎̂2 (2.28)
Menurut Weisberg (2005:200) komputasi Cook’s distance dapat ditulis sebagai:
𝐷𝑖 = 1 𝑝𝑟𝑖2
ℎ𝑖𝑖 1 − ℎ𝑖𝑖
dengan 𝑖 = 1,2, … , 𝑛 dan 𝐷𝑖 merupakan hasil kali ke-𝑖 antara standardized residual 𝑟𝑖 dengan nilai leverage ℎ𝑖𝑖. Sehingga 𝐷𝑖 dapat dirumuskan sebagai:
𝐷𝑖 = (1 𝑝) ( 𝑒̂𝑖2 𝜎̂2(1 − ℎ 𝑖𝑖)) ( ℎ𝑖𝑖 1 − ℎ𝑖𝑖) (2.29) dengan
31 𝑝 : banyaknya variabel independen ℎ𝑖𝑖 : nilai leverage data ke- 𝑖
Suatu titik data dikatakan outlier dari pendeteksian berdasarkan nilai
cook’s distance apabila nilai 𝐷𝑖 >𝑛4, dengan 𝑛 adalah banyaknya pengamatan (Yaffee, 2002:44).
H. Regresi Robust
Regresi robust diperkenalkan oleh Andrews pada tahun 1972. Regresi
robust merupakan metode regresi yang digunakan ketika distribusi dari error
tidak normal dan atau adanya beberapa outlier yang berpengaruh pada model (Olive, 2005:3). Suatu data dengan distribusi sisaan yang tidak normal dapat mengandung outlier dan outlier dapat mempengaruhi hasil estimasi dari kuadrat terkecil. Regresi robust merupakan alat yang dapat digunakan untuk menganalisa data yang mengandung outlier dan memberikan hasil yang resisten terhadap adanya outlier (Turkan, Cetin, & Toktamis, 2012). Efisiensi dan breakdown point
digunakan untuk menjelaskan ukuran ke-robust-an (kekekaran) dari estimasi
robust. Efisiensi digunakan untuk menjelaskan seberapa baiknya suatu estimasi
robust sebanding dengan metode kuadrat terkecil tanpa outlier. Semakin tinggi efisiensi dan breakdown point dari suatu estimator maka semakin resisten suatu model dalam menganalisa data yang mengandung outlier.
Menurut Chen (2002:1), terdapat 3 kelas masalah yang dapat ditangani dengan menggunakan teknik regresi robust, yaitu:
32
1. Masalah outlier yang terdapat pada variabel dependen. 2. Masalah outlier yang terdapat pada variabel independen.
3. Masalah outlier yang terdapat pada keduanya, yaitu variabel dependen dan variabel independen.
Banyak metode telah dikembangkan untuk mengatasi masalah outlier. Metode-metode estimasi dalam regresi robust, di antaranya:
1. Estimasi-M (Maximum likelihood type) merupakan metode yang diperkenalkan oleh Huber (1973) dan merupakan metode yang paling sederhana, baik dalam perhitungan maupun secara teoritis. Meskipun estimasi ini tidak cukup kekar dengan leverage point, namun estimasi ini tetap digunakan secara luas dalam menganalisa data dengan mengasumsikan bahwa sebagian besar data yang terkontaminasi outlier merupakan data pada variabel respon. Metode ini memiliki nilai breakdown point sebesar 1𝑛.
2. Estimasi-LMS (Least Median Squares) merupakan metode yang diperkenalkan oleh Hampel (1975).
3. Estimasi-LTS (Least Trimmed Squares) merupakan metode yang diperkenalkan oleh Rousseeuw (1984) dan memiliki nilai breakdown point
tinggi yaitu sebesar 50%.
4. Estimasi-S (Scale) merupakan metode yang diperkenalkan oleh Rousseeuw dan Yohai (1984) dan juga merupakan metode yang memiliki nilai breakdown point tinggi yaitu 50%. Kelebihannya metode ini memiliki efisiensi statistik yang lebih tinggi dari estimasi-LTS.
33
5. Estimasi-MM (Method of Moment) merupakan metode yang diperkenalkan oleh Yohai (1987). Metode ini merupakan metode yang menggabungkan estimasi-S dan estimasi-M. Metode ini memiliki nilai breakdown tinggi dan efisiensi statistik yang lebih tinggi dari estimasi-S.
Pada penelitian ini dipilih metode estimasi-S dan estimasi-LTS. Pemilihan metode estimasi-S berdasar pada penelitian terdahulu yang menyatakan bahwa estimasi-S merupakan metode estimasi terbaik dalam menangani masalah outlier. Sedangkan metode estimasi-LTS dipilih karena memiliki nilai breakdown point
yang mencapai 50%, sehingga setara dengan metode estimasi-S. Kemudian dalam penelitian ini akan ditentukan model regresi robust terbaik dari kedua metode estimasi tersebut dalam menangani outlier pada data Inflasi di Indonesia periode Agustsu 2014 – Juli 2016.
I. Breakdown Point
Breakdown point adalah salah satu cara yang digunakan untuk mengukur ke-robust-an (kekekaran) suatu estimator dalam mengatasi outlier (Yohai, 1987:643). Huber (2009:8) mendefinisikan breakdown point sebagai fraksi terkecil dari outlier yang menyebabkan nilai estimator menjadi berubah-ubah.
Breakdown point merupakan ukuran proporsi dari outlier yang dapat ditangani sebelum observasi tersebut mempengaruhi model prediksi.
Jika nilai breakdown point sebesar 50% maka estimasi model regresi dapat digunakan untuk mengatasi setengah dari outlier dan memberikan pengaruh baik bagi pengamatan lainnya. Sehingga semakin tinggi nilai presentase breakdown
34
point pada suatu estimator, maka estimator tersebut semakin robust, karena semakin besar nilai presentase breakdown point, maka semakin kuat juga suatu metode estimasi tersebut dalam menangani banyaknya outlier.
Regresi robust yang mempunyai breakdown point adalah regresi robust
dengan metode estimasi-S, MM, LTS, dan LMS. Estimasi-S dan estimasi-LTS
dapat digunakan untuk mengatasi masalah outlier dengan proporsi hingga 50%.
J. Koefisien Determinasi
Koefisien determinasi atau R-Square yang dilambangkan dengan 𝑅2 merupakan besaran yang digunakan untuk mengukur kebaikan model dari suatu garis regresi (Gujarati, 2006:161). Nilai R-Square memberikan gambaran tentang kesesuaian variabel independen dalam memprediksi variabel dependen. Koefisien determinasi juga didefinisikan sebagai kuadrat dari korelasi pada persamaan regresi. R-Square dirumuskan sebagai berikut:
𝑅2 =∑ (𝑌̂𝑖− 𝑌̅𝑖) 2 𝑛 𝑖=1 ∑𝑛𝑖=1(𝑌𝑖− 𝑌̅𝑖)2 (2.30)
dengan 𝑌̂𝑖 adalah nilai 𝑌 berdasarkan hasil estimasi dari persamaan regresi dan 𝑌̅𝑖 adalah nilai 𝑌 rata-rata data awal. Sifat dari R-Square adalah:
1. 𝑅2 bukan merupakan besaran negatif. 2. Batasnya adalah 0 ≤ 𝑅2 ≤ 1.
35
Nilai 𝑅2 berfungsi untuk menentukan seberapa besar proporsi variasi variabel dependen yang dijelaskan oleh variabel independen pada model yang digunakan. Apabila nilai 𝑅2 semakin dekat dengan 1, maka semakin baik kecocokan data dengan model. Sebaliknya, apabila nilai 𝑅2 semakin dekat dengan 0, maka semakin terbatas kecocokan data dengan model (Sembiring, 1995:55).
Namun Montgomery & Peck (1992:160) memaparkan bahwa nilai 𝑅2 yang besar tidak selalu berarti bahwa model regresi yang dihasilkan merupakan model yang baik. Hal ini disebabkan karena nilai 𝑅2 akan selalu meningkat apabila semakin banyak variabel yang ditambahkan ke dalam model. Akan tetapi variabel tambahan tersebut belum tentu berkondtribusi di dalam model, karena variabel yang ditambahkan bisa jadi merupakan variabel yang tidak diperlukan oleh model. Apabila penambahan variabel dilakukan begitu saja, dapat menjadikan model yang dihasilkan bersifat overfitting atau kesesuaian model yang dihasilkan terlalu tinggi.
Salah satu langkah untuk menghindari adanya overfitting model adalah dengan menggunakan adjusted-𝑅2 yang dilambangkan dengan 𝑅̅2. Adjusted-𝑅2
dihasilkan dengan menyesuaikan derajat kebebasan antara jumah kuadrat residu dan jumlah kuadrat totalnya (Draper & Smith, 1992:87). Adapun 𝑅̅2 didefinisikan sebagai berikut:
𝑅̅2 = 1 − [𝑛 − 1
𝑛 − 𝑝] (1 − 𝑅2)
36
dengan 𝑛 merupakan banyaknya data pengamatan dan 𝑝 merupakanbanyaknya variabel independen.
Menurut Gudono (2011:132), nilai 𝑅̅2 memiliki sifat-sifat sebagai berikut: 1. Jika jumlah variabel independen hanya satu (𝑘 = 1) , maka 𝑅2 = 𝑅̅2
2. Jika 𝑘 > 1 maka 𝑅2 > 𝑅̅2 3. 𝑅̅2 bisa negatif
Nilai 𝑅̅2 dapat memberi kuantitas yang sebanding dengan 𝑅2 dari model yang melibatkan sejumlah parameter berbeda. Tidak seperti 𝑅2, nilai 𝑅̅2 tidak selalu bertambah meskipun beberapa variabel ditambahkan ke dalam model. Nilai 𝑅̅2 akan cenderung stabil meski terdapat penambahan variabel. Pengujian dengan 𝑅̅2 secara obyektif untuk melihat pengaruh penambahan variabel bebas, apakah variabel tersebut mampu memperkuat variasi dalam menjelaskan variabel terikat. Model terbaik dapat ditentukan dengan melihat nilai 𝑅̅2 yang terbesar.