PENERAPAN DATA MININGPADA PERUSAHAAN RITAIL PAKAIAN UNTUK MEMPREDIKSI KETERSEDIAAN JENIS BARANG
DENGAN MENGGUNAKAN ALGORITMA F P-GROWTH
Elisabet Septyana Eka Enykawati, 115314011
F akultas Sains dan Teknologi, Universitas Sanata Dharma Yogyakarta
ABSTRAK- Data mining merupakan salah satu proses yang digunakan untuk menemukan informasi dalam sekumpulan data. Informasi yang dihasilkan tersebut berupa pola yang dapat digunakan sebagai acuan dalam penentuan keputusan. Dalam data mining terdapat beberapa teknik dimana penggunannya disesuaikan pada masalah yang ada. Pada permasalahan prediksi jenis barang yang tersedia dalam perusahaan retail digunakan teknik association rule. Dalam penelitian ini penulis menggunakan algoritma FP–Growth yang digunakan untuk membantu dalam proses analisa dari sekumpulan data penjualan. Hasil akhir dari proses pengolahan data penjualan adalah pola asosiasi. Pola asosiasi yang dimaksud adalah hubungan suatu barang terjual bersamaan dengan barang apa dalam transaksi penjualan. Hasil analisa dari pola tersebut dapat direkomendasikan kepada pemilik perusahaan sebagai acuan dalam pengambilan keputusan dalam penyediaan jenis barang untuk meningkatkan penjualan.
Kata kunci : data mining, algoritma asosiasi, FP-Growth.
I. PENDAHULUAN a. Latar Belakang
Perkembangan teknologi informasi yang berpengaruh besar pada pertumbuhan bisnis Perusahaan bersaing untuk menciptakan inovasi baru untuk menarik masyarakat. Aset utama dari sebuah perusahaan tersebut adalah kepuasan konsumen terhadap ketersediaan produk yang ada. Tidak tersedianya barang yang di cari berpengaruh pada kepuasan konsumen serta pendapatan perusahaan. Oleh karena itu dibutuhkan suatu prediksi untuk mengetahui jenis barang yang harus tersedia dalam perusahaan. Prediksi jenis barang yang harus tersedia dapat diketahui dengan mengamati data transaksi penjualan. Di dalam data mining terdapat beberapa teknik salah satunya adalah teknik association rule. Teknik association rule dapat memberikan gambaran / pola – pola tertentu yang sering muncul bersamaan.Dalam teknik association rule terdapat sebuah algoritma FP–Growth yang dapat digunakan menentukan prediksi jenis barang yang harus tersedia .
Algoritma FP–Growth merupakan pengembangan dari algoritma apriori.
Algoritma apriori membutuhkan scanning data berulang untuk menentukan frequent itemset. Algoritma FP–Growth yang hanya membutuhkan sebanyak dua kali scanning untuk menentukan frequent itemset. Dalam menentukan frequent Itemset pada algoritma FP–Growth digunakan pohon prefix yang biasa disebut FP–tree. Penggunaan FP–tree akan mempercepat dalam proses penentuan frequent Itemset. Apabila frequent Itemset tersebut memiliki nilai kurang dari min_sup, maka frequent Itemset tidak akan digunakan. Selanjutnya frequent Itemset yang berada di atas min_sup maupun sama dengan min_sup digunakan. Hasil akhir dari proses tersebut berupa pola produk yang sering dibeli oleh konsumen.
b.Rumusan Masalah
1. Bagaimana menerapkan algoritma FP- Growth dalam memprediksi jenis barang yang harus tersedia pada perusahaan XYZ ?
c. Tujuan Penelitian
1. Membantu perusahaan XYZ dalam memprediksi jenis barang yang harus tersedia dengan menggunakan algoritma FP- Growth
2. Menguji keakuratan algoritma FP-Growth dalam jenis barang yang harus tersedia dalam perusahaan XYZ.
d.Batasan Masalah
1. Data yang digunakan adalah data transaksi penjualan perusahaan XYZ yang bergerak di bidang retail.
2. Data awal barang disumsikan dengan jumlah 200.
3. Teknik Asosiasi yang digunakan untuk analisis data yaitu menggunakan algoritma FP – Growth
e. Metode Penelitian
Penelitian ini digunakan beberapa metodologi penelitian yaitu :
1. Metode Pengumpulan Data 2. Metode Analisis Data
II.LANDASAN TEORI a. Pengertian Data Mining
Data mining adalah proses mengolah data, dimana data sebagai masukan yang diproses akan menghasilkan output yang tidak hanya berisi informasi namun ada sebuah pengetahuan yang dapat di ambil. Dari pengetahuan yang didapatkan akan diolah menjadi wisdom yang sangat bermanfaat.
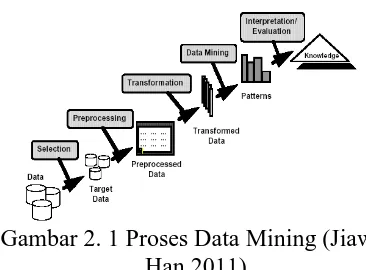
b.Proses Data Mining
Gambar 2. 1 Proses Data Mining (Jiawei Han,2011)
Data Cleaning yaitu proses menghilangkan noise dan data yang tidak konsisten. Data Integration yaitu proses dimana data dari berbagai sumber digabungkan. Data Selection yaitu proses penyeleksian data yang akan digunakan. Data Transformation yaitu proses data ditransformasikan dan digabungkan ke dalam sebuah bentuk yang sesuai dengan data mining. Data mining yaitu proses mencari pola atau informasi dalam data. Evaluation yaitu penerjemahan pola yang dihasilkan dari data mining. Knowledge Presentation yaitu proses visualisasi yang digunakan untuk memberikan gambaran pada pihak yang terkait.
c. Algoritma F requent Pattern Growth Algoritma FP-Growth adalah algoritma yang menggunakan teknik association rule. Algoritma ini lebih cepat daripada algoritma apriori. Pada algoritma apriori dilakukan iterasi secara berulang kali sehingga membutuhkan waktu yang lama untuk menyelesaikan. Algoritma apriori tidak dapat menangani data yang besar, sehingga algoritma FP-Growth dapat dijadikan sebagai solusi bagi permasalahan pada algoritma apriori yaitu masalah candidate set generation and test.
Beberapa istilah dalam algoritma FP-Growth :
1. : kumpulan dari
item – item yang ada dalam transaksi database
2. : transaksi yang ada dalam database dimana
merupakan transaksi yang
mengandung item yang berada pada I. 3. Support dari pattern A adalah angka dari
transaksi yang mengandung item A di dalam DB.
Dalam algoritma FP-Growth dikenal pula istilah frequent pattern tree( FP-tree) yaitu struktur pohon prefix yang digunakan untuk mendesain struktur frequent pattern mining secara efisien. Setiap node pada pohon diisi dengan 1 item. Setiap anak dari node merepresentasikan item yang berbeda dengan item yang ada pada induk. Sebuah root dalam pohon diinisialisasikan dengan nilai null. Dengan menggunakan FP-Tree, algoritma FP-growth dapat langsung mengekstrak frequent Itemset.
Langkah algoritma FP-growth :
1. Menentukan min_sup yang akan digunakan untuk menentukan rule. 2. Melakukan scanning pada data untuk
mendapatkan frekuensi item.
3. Seleksi item yang memiliki count kurang dari min_sup yang telah ditentukan. Item yang sesuai min_sup disimpan dalam list L, dan lakukan sorting secara descending.
4. Membentuk root FP-Tree yang diberi nilai dengan “null”.
5. Scan yang kedua untuk cabang dari FP-Tree sesuai dengan urutan transaksi pada list L. Nilai indeks dari item tersebut akan bertambah 1 apabila item sudah ada pada transaksi sebelumnya, apabila item belum ada pada transaksi sebelumnya akan membentuk cabang baru.
6. Berdasarkan list L pisahkan tiap frequent itemsets tanpa pengulangan. 7. Mengalisa FP-Tree yang telah terbentuk
dengan cara mencari frequent itemsets yang mengandung nilai ai lalu setarakan nilai frequent itemsets dengan nilai ai. Jumlahkan kedua nilai support frequent itemsets yang sama. Nilai yang diatas maupun sama dengan min_ sup lah yang menjadi rule. Lakukan berulang untuk semua subset yang ada pada FP-Tree. d. Lift Ratio
Lift Ratio merupakan ukuran yang digunakan untuk mengukur tingkat
keakuratan sebuah rule yang dihasilkan dari proses asosiasi.
Istilah yang digunakan dalam Lift Ratio adalah sebagai berikut :
a. Antecedent adalah sebab. Antecedent adalah item yang menjadikan item consequent.
b. Consequent adalah akibat. Consequent item barang yang dibeli karena suatu barang telah dibeli.
Dimanaconfidence :
∑ ∑ Antecedent disimbolkan dengan A sedangkan consequent disimbolkan dengan C
Sedangkan expected confidence :
∑ ∑
Nilai dari Lift Ratio dapat dibaca sebagai berikut :
a. Lift Ratio > 1 maka A dan C muncul lebih sering dari yang diharapkan b. Lift Ratio = 1 maka A dan C muncul
hampir selalu bersamaan
c. Lift Ratio< 1 maka A dan C muncul lebih jarang dari yang diharapkan
III.ANALISA DAN PEMBAHASAN Pengujian dilakukan pada data transaksi selama 3 hari yang memiliki jumlah item dan jumlah data transaksi yang berbeda. Pengujian dilakukan dengan menggunakan min_sup 1.5 % dari total transaksi yang ada
Pada saat peneliti data transaksi tanggal 1 April 2015 dengan jumlah data transaksi sebanyak 2245 dan jenis barang sebanyak 91 terdapat empat buah rule yang dihasilkan. Dari keempat rule yang dihasilkan terdapat satu buah rule yang memiliki nilai keakuratan tinggi yaitu kode K.KAKI(640) dan ACC(700) dengan support kedua barang tersebut adalah 0.56 persen, besar confidence adalah 0.589 ,besar nilai lift ratio adalah 4.08119. Waktu yang dibutuhkan untuk melakukan proses tersebut adalah 2 detik.
Tabel 3.2 Hasil proses tanggal 2
Pada saat peneliti data transaksi tanggal 2 April 2015 dengan jumlah data transaksi sebanyak 2450 dan jenis barang sebanyak 89 terdapat 6 buah rule yang dihasilkan. Dari keenam rule yang dihasilkan terdapat satu buah rule yang memiliki nilai keakuratan tinggi yaitu K.KAKI(640) dan ACC(700) dengan support kedua barang tersebut adalah 0.34 persen, besar confidence adalah 0.415, besar nilai lift ratio adalah 3.23806. Waktu yang dibutuhkan
untuk menjalankan proses tersebut adalah 2 detik.
Tabel 3.3 Hasil proses tanggal 3
Pada saat peneliti data transaksi tanggal 3 April 2015 dengan jumlah data transaksi sebanyak 2684 dan jenis barang sebanyak 91 terdapat 7 buah rule yang dihasilkan. Dari ketujuh rule yang dihasilkan terdapat satu buah rule yang memiliki nilai keakuratan tinggi yaitu adalah kode K.KAKI(640) dan ACC(700) dengan support kedua barang tersebut adalah 0.52 persen, besar confidence adalah 0.553, besar nilai lift ratio adalah 3.92659. Waktu yang dibutuhkan untuk melakukan proses tersebut adalah 3 detik
Dari beberapa uji coba yang telah dilakukan terdapat sebuah rule yang selalu memiliki nilai keakuratan tinggi yaitu barang K.KAKI(640) dengan ACC(700). Melalui nilai keakuratan data tersebut dapat dijadikan sebagai prediksi dalam penyediaan barang dalam perusahaan tersebut.
Ketika tanggal 1 April 2015 rule yang memiliki nilai akurasi tinggi adalah K.KAKI(640) dan ACC(700). Di asumsikan jumlah dari masing – masing jenis barang adalah 200. Pada tanggal tersebut penjualan K.KAKI(640) adalah sebesar 56 sehingga memiliki sisa item 144, sedangkan penjualan item ACC(700) adalah sebesar 165 sehingga memiliki sisa item 35. Pada tanggal 2 April 2015 rule tersebut juga memiliki tingkat keakuratan tertinggi. Penjualan K.KAKI(640) adalah sebesar 34 , sisa item dari hari sebelumnya adalah 144, sehingga memiliki sisa item pada tanggal 2 adalah 110, sedangkan penjualan item ACC(700) adalah sebesar 139 namun sisa item pada tanggal sebelumnya hanya 35. Oleh karena itu dilakukan penambahan item sebesar 200 seperti stok awal, sehingga sisa dari item tersebut adalah 96.
Pada tanggal 3 April 2015 rule tersebut juga memiliki tingkat keakuratan tertinggi. Penjualan K.KAKI(640) adalah sebesar 52 , sisa item dari hari sebelumnya adalah 110, sehingga memiliki sisa item pada tanggal 3 adalah 58, sedangkan penjualan item ACC(700) adalah sebesar 252 namun sisa item pada tanggal sebelumnya hanya 96. Oleh karena itu dilakukan penambahan item sebesar 200 seperti stok awal, sehingga sisa dari item tersebut adalah 44.
Dengan melihat penjelasan di atas, rule yang dihasilkan dari proses asosiasi sangat membantu perusahaan untuk menentukan jenis barang apa yang harus ditambahkan. Seperti hasil di atas, jenis ACC(700) selalu membutuhkan penambahan barang untuk
hari berikutnya sesuai dengan hasil yang telah diprediksi.
IV.KESIMPULAN DAN SARAN
Kesimpulan yang dapat diambil dari penelitian ini adalah :
1. Algoritma Frequent Pattern Growth (FP-Growth) dapat digunakan untuk melakukan pendekteksian jenis barang yang harus tersedia. Dengan melihat rule yang dihasilkan dari proses asosiasi dalam uji coba, item - item yang ada merupakan sebuah prediksi item akan di beli di kemudian hari. Item tersebut yang harus di prioritaskan untuk di sediakan dalam perusahaan tersebut.
2. Nilai dari min_sup berpengaruh pada pola yang dihasilkan. Semakin tinggi nilai min_sup semakin sedikit rule yang dihasilkan, semakin kecil min_sup maka rule yang dihasilkan semakin banyak. 3. Besar nilai support dan confidence
berpengaruh pada keakuratan menggunakan lift ratio. Ketika suatu rule memiliki support yang tinggi dan confidence yang tinggi maka rule tersebut memiliki tingkat akurasi yang besar, rule tersebut dapat dijadikan sebagai prediksi. Apabila suatu rule memiliki support yang rendah dan confidence yang rendah maka rule tersebut memiliki tingkat akurasi yang rendah yaitu memiliki nilai kurang dari 1, dan rule tersebut tidak dapat dijadikan sebagai prediksi. Sedangkan Apabila suatu rule memiliki support yang rendah dan confidence yang tinggi maka rule tersebut kemungkinan memiliki nilai akurasi yang tinggi dan dapat dijadikan sebagai prediksi.
maka waktu yang dibutuhkan semakin besar.
Saran yag dapat penulis sampaikan untuk penelitian ini adalah :
1. Penulis berharap agar sistem ini dapat dikembangkan sehingga dapat digunakan dengan data yang berasal dari luar database seperti .csv, dll 2. Penulis berharap agar sistem ini
dikembangkan agar dapat menggunakan data transaksi dalam database lebih dari satu tabel.
DAFTAR PUSTAKA
Agrawal,Rakesh,Ramakrishnan, Srikant. Fast Algoritms for Mining Association Rules, IBM Almaden Research Center 650 Harry Road, Sn Jose, CA 95120
Han, J dan Kamber, M. 21001. Data Mining : Concepts and Techniques. Morgan Kaufman. San Fransisco.
Han,J.,Pie, J., Y,Yin. 2000.Mining Frequent Patterns without Candidate Generation, School of Computing Science Simon Fraser University.
Hill,Mc Graw. 2007 The Complete Reference Java Seventh Edition.
Fomby Tom. July 2013. Association Rules(Aka Affinity Analysis or
Market Basket Analysis). Department of Economics Southern Methodist University Dallas, Texas 75275.
Tim Dosen USD. Quick Sort dan Merge Sort. Jurusan Teknik Informatika USD
McNicholas.P.D., T.B. Murphy, M. O’Regan. Standardising the Lift of an Association Rule. Department of Statistic, Trinity College Dublin, Ireland.
Sudiadiarta, I Gede, Market Basket Analysis Menggunakan Algoritma Frequent Pattern Growth(FP-Growth) Untuk Situs E-Commerce. Universitas Sanata Dharma Yogyakarta : Skripsi, 2006
Nurdiyanto, Amin. Penenerapan Algoritma Apriori Untuk Pencarian Pola Asosiasi Barang Pada Data Transaksi Penjualan(Studi Kasus
Pada Toko “Kafe Swalayan”).
Universitas Sanata Dharma Yogyakarta : Skripsi : 2009.
www.solver.com/association-rules-example