–
Fakultas Ilmu Komputer
Universitas Brawijaya 2744
Optimasi Fuzzy Time Series Dengan Algoritme Genetika Untuk
Meramalkan Jumlah Pengangguran di Jawa Timur
Radifah1 , Budi Darma Setiawan2, Randy Cahya Wihandika3
1,2,3Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya
Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Pengangguran menjadi salah satu masalah penting yang terjadi di Indonesia. Pengangguran yang tinggi berdampak pada tingkat perekonomian dan kemiskinan warga Indonesia khususnya di Jawa Timur. Karena dengan meningkatnya jumlah pengangguran dapat mengurangi pendapatan dan produktivitas masyarakat. Beberapa faktor penyebab meningkatnya jumlah pengangguran membuat pemerintah mengalami kesulitan dalam mengatasi jumlah pengangguran tiap tahunnya yang mengalami naik turun. Sehingga dengan memprediksi jumlah pengangguran di Jawa Timur dapat mempermudah pemerintah dalam mengatasi jumlah pengangguran dan memperluas tenaga kerja khususnya di Jawa Timur. Pada penelitian ini, dilakukan peramalan menggunakan Fuzzy Time Series menggunakan Algoritme Genetika. Nilai parameter algoritme genetika terbaik adalah dengan melakukan pengujian terhadap parameter algoritme genetika dan menghasilkan nilai rata-rata fitness terbaik. Hasil pengujian parameter algoritme genetika adalah dengan ukuran populasi ke 525, kombinasi crossover rate dan
mutation rate ke 0,8 dan 0,2 dan pada generasi ke 1100 dengan nilai rata-rata fitness paling optimal yaitu
13,840314614 dengan nilai Root Mean Square Error (RMSE) sebesar 0,0722526928.
Kata kunci: Peramalan, Pengangguran, Fuzzy Time Series, Algoritme Genetika.
Abstract
Unemployment becomes one of the important points that are occurred in Indonesia. High unemployment rate has an impact on the economic and poverty levels of Indonesians especially in East Java. The increase number of unemployment can reduce the income and productivity of society. Several factors that are causing the increase of unemployment make the government difficult to overcome the numbers of unemployment annually that experience ups and downs. So, by predicting the number of unemployment in East Java, it can facilitate the government in overcoming the unemployment rate and expanding the workforce especially in East Java. The method that is used in this study is Fuzzy Time Series that use Genetic Algorithm. The best genetic algorithm parameter values are by testing to the genetic algorithm parameters and producing the best average fitness value. The result of genetic algorithm parameter test are with the population size of 525, the combination of crossover rate and mutation rate of 0,8 and 0,2 and at generation of 1200 which reaches the most optimal average fitness value is 13,840314614 with Root Mean Square Error(RMSE) value equal to 0,0722526928.
Keywords: Forecasting, Unemployment, Fuzzy Time Series, Genetic Algorithm.
1. PENDAHULUAN
Pembangunan ekonomi merupakan suatu usaha untuk meningkatkan taraf hidup masyarakat dan memperluas kesempatan kerja untuk menghasilkan pendapatan yang merata. Dalam memenuhi hal tersebut maka dibutuhkan suatu pekerjaan, namun untuk mendapatkan suatu pekerjaan tersebut masih menjadi masalah utama yang disebabkan dengan adanya kesenjangan dan ketebatasan lapangan pekerjaan yang tersedia sehingga meningkatkan jumlah
pengangguran. Pengangguran menjadi salah satu pokok penting yang terjadi di Indonesia. Pengangguran yang tinggi berdampak pada tingkat perekonomian dan kemiskinan warga Indonesia khususnya di Jawa Timur. Karena dengan meningkatnya jumlah pengangguran dapat mengurangi pendapatan dan produktivitas masyarakat.
kerja sebesar 20.497.900 orang. Meskipun jumlah pengangguran di tahun 2016 mengalami penurunan dibandingkan pada tahun 2015 (Sobtv, 2016).
Menurut laporan BPS Jatim, Tingkat Pengangguran Terbuka (TPT) Jawa Timur pada bulan Agustus 2016 sedikit meningkat disbanding bulan Februari 2016 dari 4,14% menjadi 4,21%, namun ada kemungkinan pada tahun selanjutnya akan mengalami kenaikan lagi. Karena dari tahun ke tahun jumlah tingkat pengangguran selalu mengalami naik turun (BPS, 2016).
Beberapa penyebab meningkatnya jumlah pengangguran adalah tidak ada biaya untuk melanjutkan pendidikan bagi lulusan SMA atau SMK yang berpotensi jumlah pengangguran bertambah, minimimnya informasi tentang tenaga kerja yang tersedia dan kebutuhan usaha dari sisi kualitas yang masih rendah di Jawa Timur. Dengan beberapa faktor tersebut pemerintah mengalami kesulitan dalam mengatasi jumlah pengangguran tiap tahunnya yang mengalami naik turun. Sehingga dengan memprediksi jumlah pengangguran di Jawa Timur dapat mempermudah pemerintah dalam mengatasi tingkat pengangguran dan memperluas tenaga kerja khususnya di Jawa Timur.
Prediksi merupakan suatu proses untuk memperkirakan sesuatu yang akan terjadi di masa mendatang berdasarkan data masa lalu dengan masa sekarang untuk mendapatkan hasil yang mendekati hasil nyata. Terdapat 2 teknik dalam prediksi, yaitu kualitatif digunakan jika data di masa lalu tidak ada, kurang atau kurang akurat dan kuantitatif yang berdasarkan atas data kuantitatif di masa lalu (Berutu, 2013).
Metode ini telah dilakukan oleh beberapa peneliti. Salah satunya adalah penelitian untuk penjualan dengan metode fuzzy time seies ruey
chyn tsaur. Pada penelitian tersebut dengan
menghitung nilai adjust untuk hasil ramalan pada tahun 2005 di dapat nilai yang akurat dan hasilnya lebih kecil dari data yang sebelumnya (Berutu, 2013). Penelitian lain juga dilakukan dalam memprediksi jumlah penduduk provisi DKI Jakarta dengan menggunakan metode
average-based fuzzy time series models, hasil yang di dapat dari penelitian tersebut adalah dilihat dari nilai AFER menunjukkan bahwa metode ini mendekati nilai 0 sehingga memilki tingkat akurasi yang baik, namun metode ini tidak cocok untuk memprediksi lebih dari jangka 1 waktu ke depan (Sukriyawati, 2015).
Berdasarkan latar belakang diatas maka pada skripsi ini dilakukan penelitian dengan suatu metode peramalan untuk jumlah pengangguran di Jawa Timur menggunakan
fuzzy time series dan dioptimasi dengan
algoritme genetika guna untuk mendapatkan tingkat akurasi yang tinggi dan tingkat kesalahan yang rendah. Pada penelitian ini diharapkan dapat membantu pemerintah dalam memprediksi jumlah pengangguran tahun mendatang, sehingga pemerintah bisa memperluas lapangan pekerjaan dan menurunkan jumlah pengangguran, selain itu pemerintah juga bisa mengetahui progres dari tahun sebelumnya.
Artikel ini disusun dengan struktur sebagai berikut:
Bab 1 Pendahuluan. Menjelaskan latarbelakang dan tujuan dari Meramalkan Jumlah Pengangguran Menggunakan Optimasi
Fuzzy Time Series di Jawa Timur.
Bab 2 Dasar Teori. Menjelaskan teori-teori yang mendukung dan mendasari penulisan penelitian tentang Meramalkan Jumlah Pengangguran Menggunakan Metode Optimasi
Fuzzy Time Series di Jawa Timur.
Bab 3 Perancangan dan Implementasi. Menjelaskan perancangan dari system yang akan di rancang dan implementasi metode Optimasi
Fuzzy Time Series untuk meramalkan jumlah
pengangguran di Jawa Timur dari hasil perancangan yang dilakukan.
Bab 4 Pengujian dan Analisis. Menjelaskan pengujian terhadap parameter-parameter algoritma genetika dan analisis dari tiap pengujian yang dilakukan.
Bab 5 Kesimpulan. Menjelaskan kesimpulan dari hasil artikel yang dibuat.
2. DASAR TEORI
2.1 Pengangguran
Pengangguran merupakan orang yang tergolong dalam angkatan kerja yang belum memiliki pekerjaan tetapi ingin mendapatkan suatu pekerjaan. Dalam masalah pengangguran yang paling utama adalah ekonomi makro yang menyebabkan tingkat pendapatan nasional dan tingkat kemakmuran kurang tercapai secara maksimal. Berdasarkan pengertian tentang pengangguran diatas, pengangguran dapat dibedakan menjadi 3 kelompok, yaitu :
a. Pengangguran terselubung (disguised
unemployment) yang berarti tenaga kerja
b. Setengah menganggur (under
unemployment) adalah tenaga kerja yang
tidak bekerja secara optimal karena tidak ada lapangan pekerjaan.
c. Pengangguran terbuka (open
unemployment) adalah tenaga kerja yang
tidak memiliki pekerjaan.
Pengangguran juga disebabkan karena beberapa faktor, diantaranya ketidakseimbangan antara jumlah angkatan kerja dengan kesempatan kerja, ketidakseimbagan struktur lapangan kerja dan ketidakseimbangan antara kebutuhan jumlah tenaga kerja dengan penyedia tenaga kerja terdidik (Muhdar, 2015).
2.2 Prediksi
Prediksi merupakan suatu kegiatan untuk memperkirakan sesuatu yang akan terjadi di masa yang akan mendatang dengan melakukan perhitungan yang tepat untuk mendapatkan hasil prediksi yang akurat. Berdasarkan sifatnya, prediksi dibedakan menjadi dua macam, yaitu (Berutu, 2013):
a. Peramalan Kualitatif
Peramalan kualitatif merupakan peramalah yang datanya kurang jelas, tidak berupa angka atau nilai, hanya berdasarkan pendapat suatu pihak
b. Peramalan Kuantitatif
Peramalan kuantitatif merupakan peramalan yang berupa angka atau nilai dan datanya berupa data kuantitatif.
2.3 Fuzzy Time Series (FTS)
Fuzzy time series berbeda dengan time
series, perbedaan paling utama ada pada nilai yang digunakan dalam prediksi yang merupakan bilangan riil dalam humpunan fuzzy untuk himpunan semsta yang ditentukan.
Fuzzy .time series adalah proses peramalan
dengan menggunakan data-data historis dan dengan prinsip fuzzy. Definsi fuzzy time series
adalah dengan dimisalkan Y(t) (t= ...,0,1,2,...), adlah himpunan bagian dari R yang menjadi himpunan semesta dimana himpunan fuzzy
ƒ(i)(t)(i = 1,2,3,..) telah didefinisikan
sebelumnya dan jadikan F(t) menjadi kumpulan
dari ƒ(i)(t)(i = 1,2,3,..). maka F(t) dinyatakan sebagai fuzzy time series terhadap Y(t) (t= ...,0,1,2,...).
Berikut langkah-langkah dalam metode peramalan menggunakan Fuzzy Time Series
(Haris, Santoso & Rahmawati, 2015) :
a. Membagi himpunan semesta U menjadi sejumlah interval yang sama, U = [Dmin,
Dmax].
b. Mendefiniskan fuzzy set dari Universe of Discourse dengan menjadikan A1, A2,...Ak
menjadi himpunan fuzzzy dengan variabel linguistiknya ditentukan sesuai dengan keadaan semesta (Universe of Discourse) c. Memfuzzifikasikan data historis.
d. Bagi fuzzy logical relationship menjadi beberapa bagian berdasarkan sisi kiri, langkah ini biasa disebut fuzzy logical
relationship group (FLRG).
e. Menghitung defuzzifikasi dari nilai keluaran peramalan. Defuzzifikasi merupakan proses mengubah nilai keluaran fuzzy menjadi bilangan crisp kembali. Ada tiga prinsip pada proses defuzzifikasi, yaitu :
- Jika hasil fuzzikfikasi pada tahun i
adalah Aj dan hanya ada satu FLR pada
FLRG yaitu dengan posisi di sisi kiri adalah Aj seperti rumus berikut :
Aj Ak
Dimana Aj dan Ak adalah himpunan
fuzzy dan nilai maksimum keanggotaan
fuzzynya terdapat pada interval uk, dan
sebagaimana rumusan berikut : Aj Ak1, Ak2, ... , Akn,
keanggotaan maksimum dari himpunan
fuzzy Aj terjadi pada interval uj adalah
mj, maka hasil peramalan untuk tahun i
+ 1 adalah mj.
2.4 Algoritme Genetika
seperti pada bidang industri, fisika, biologi, ekonomi, sosiologi dan lain-lain yang sering menghadapi masalah kompleks dan sulit diatasi. Algoritme genetika digunakan dalam penjadwalan produksi, optimasi penugasan mengajar bagi dosen, optimasi persedian barang, distribusi produk, penentuan komposisi pakan ternak, penyusunan rute dan jadwal kunjungan wisata yang efisien (Mahmudy, 2015)
Ada beberapa silkus algoritme genetika yang diperkenalkan oleh David Goldberg, yaitu:
a. Membangun Generasi Awal
Langkah pertama dalam algortima genetika adalah membangun populasi awal dengan cara memilih individu secara acak. Langkah ini dilakukan untuk mencari solusi yang paling optimal.
b. Representasi Kromosom
Langkah kedua adalah representasi kromosom. Representasi kromosom adalah proses pemetaan suatu solusi dalam suatu penyelesaian masalah menjadi string kromosom. String kromosom ini terdiri dari sejumlah gen yang menggambarkan variabel keputusan (Mahmudy, 2013). Algortima genetika memiliki representasi kromosom yang berbeda-beda dalam setiap permasalahan karena tidak semua permasalah memiliki model representasi yang cocok, misalnya representasi biner, real, integer
dan permutasi.
c. Persilangan (Crossover)
Crossover dilakukan dengan memilih 2
parent secara random dari populasi, crossover
ditentukan oleh crossover rate(cr) untuk menyatakan ratio ofspring, sehingga offspring
yang didapat adalah cr x popzise. Sebagai contoh, jika diketahui nilai cr adalah 0.4 dan nilai popsize 3 maka ada 0.4 x 3 = 1.2 (dibulatkan menjadi 2) offspring (Mahmudy, 2013). Secara umum mekanisme crossover adalah sebagai berikut:
Memilih dua buah kromosom sebagai
parent.
Memilih secara acak populasi dalam kromosom menjadi dua segmen dari kromosom parent yang terpisah.
Menukar segmen kromosom parent
sehingga menghasilkan kromosom anak.
Pada algoritme genetika terdapat beberapa macam metode crossover yang sering digunakan yaitu one cut point crossover dan extended
intermediete crossover. Metode one cut point
crossover digunakan untuk representasi biner
dan permutasi. Metode extended intermediete
crossover digunakan untuk representasi
realcode (Mahmudy, 2013).
Pada masalah optimasi peramalan tingkat pengangguran ini metode crossover yang dapat digunakan adalah metode one cut point
crossover. One cut point adalah suatu proses
untuk memilih dua individu yang terpilih untuk dijadikan parent kemudian menukar kromosom pada area yang dipilih.
Misalkan terdapat dua parent terpilih yang memiliki 9 kromosom. Dalam kromosom tersebut ditentukan one cut point secara random dengan cut point pada posisi ke 5.
Terdapat 5 gen dengan cut point pada posisi ke-3
Parent 1
Parent2
Setelah proses crossover child yang didapat dari kedua parent adalah sebagai berikut :
Child 1
Child 2
d. Mutasi
Mutasi dilakukan dengan memilih satu induk secara acak dari populasi yang ada. Metode mutasi yang digunakan adalah dengan memilih satu titik acak kemudian mengubah nilai gen pada titik tersebut. Misalkan jika ditentukan nilai mr adalah 0.2 dan popsize
adalah 3 maka ada 0.2 x 3 = 0.6 (dibulatkan menjadi 1) offspring yang akan dihasilkan dari proses mutasi (Mahmudy, 2013).
Metode mutasi yang sering digunakan adalah insertion mutation, repciprocal exchange
mutation dan random mutation. Metode
insertion mutation adalah metode mutasi dengan
cara memilih gen secara acak kemudian disisipkan pada posisi gen lain yang dipilih secara acak.
Metode random mutation adalah dengan menambah atau mengurangi nilai gen yang terpilih dengan nilai gen sebelah kiri lebih kecil dari nilai gen sebelah kanan. Metode random
mutation menggunakan persamaan (1):
-0,9 -0,85 -0,54 0,62 1,4
-0,73 -0,51 -0,3 0,94 1,73
-0,9 -0,85 -0,54 0,94 1,73
𝑋 = 𝑋𝑖 + 𝑟 (𝑚𝑎𝑥𝑖 − 𝑚𝑖𝑛𝑖) (1) Dimana,
𝑋𝑖 : nilai gen terpilih
𝑟 : bilangan random [-0,1 sampai 0,1]
𝑚𝑎𝑥𝑖 : nilai maksimum dari nilai individu terpilih
𝑚𝑖𝑛𝑖 : nilai minimum dari nilai individu terpilih
Pilih gen secara acak
parent
ganti nilai gen yang dipilih dengan nilai baru
offspring
e. Perhitungan Nilai Fitness
Menghitung nilai fitness digunakan untuk mencari individu terbaik. Individu terbaik akan dipilih menjadi solusi terbaik dalam menyelesaikan masalah. Semakin besar nilai
fitness yang didapat maka semakin baik
individu tersebut menjadi calon solusi.
Pada permasalahan ini, pencarian nilai
fitness menggunakan persamaan (2):
𝐹𝑖𝑡𝑛𝑒𝑠𝑠 = 𝑅𝑀𝑆𝐸1 2)
f. Seleksi
Seleksi adalah memilih individu dari himpunan populasi dan offpring yang dipertahankan pada generasi berikutnya. Individu dengan nilai fitness yang lebih besar akan memiliki peluang besar untuk dipilih sebagai individu terbaik. Metode seleksi yang sering digunakan adalah roulette wheel, dan
elitism selection (Mahmudy, 2013).
Cara kerja elitism selection ini adalah semua individu dan ofspring dalam populasi dikumpulkan dalam penampungan yang sama. Kemudian individu dan ofspring dengan nilai
fitness terbaik akan dipilih untuk generasi
selanjutnya. Pada metode ellitism, individu dengan nilai fitness terbaik akan selalu lolos dan
individu dengan nilai fitness rendah tidak mendapat kesempatan dipilih ke generasi selanjutnya untuk melakukan reproduksi. Contoh dari metode elitism selection (Mahmudy, 2013):
Dimisalkan terdapat himpunan individu dalam populasi dengan nilai popsize 5 :
Tabel 1. Himpunan Individu
Individu Fitness
P1 3,46
P2 2,29
P3 3,15
P4 3,27
P5 2,23
Terdapat juga himpunan offspring sebagai berikut:
Tabel 2. Himpunan Offspring
Individu Fitness
C1 1,85
C2 3,27
C3 2,17
Maka akan didapat himpunan individu yang lolos ke generasi berikutnya:
Tabel 3. Himpunan Individu Yang Lolos
P(t+1) Asal P(t) Fitness
P1 P1 3,46
P2 P4 3,27
P3 C2 3,27
P4 P3 3,15
P5 P2 2,29
3. PERANCANGAN DAN
IMPLEMENTASI
Proses optimasi Fuzzy Time Series
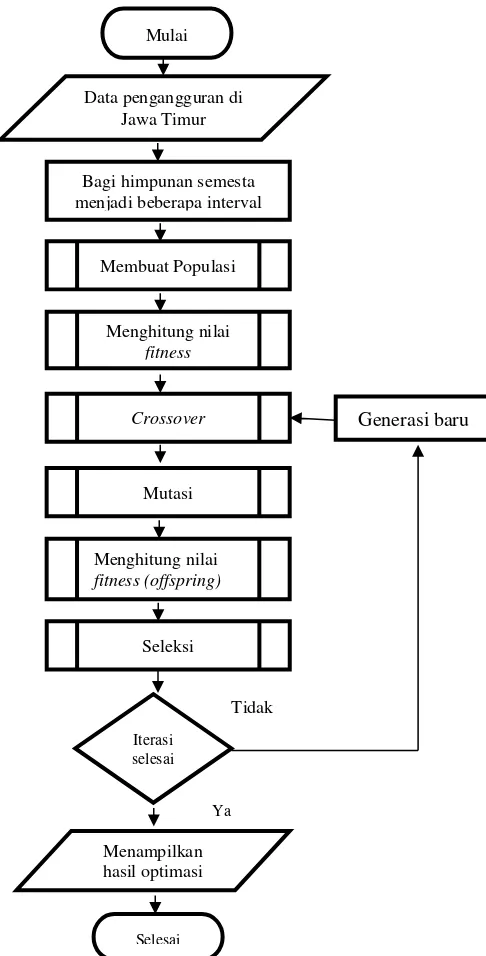
menggunakan algoritme genetika untuk meramalkan tingkat pengangguran ditunjukkan pada Gambar 1.
Implementasi sistem pada penelitian ini adalah sebagai berikut :
1. Pembuatan user interface dan penerapan metode optimasi fuzzy time series dalam program yang dibuat dengan bahasa pemrograman java.
2. Inputan berupa data tahun yang akan dilakukan proses peramalan untuk tingkat pengangguran, jumlah populasi, crossover
rate, mutation rate, dan jumlah generasi.
3. Output sistem berupa nilai fitness terbaik dari proses hasil peramalan.
-0,9 -0,85 -0,54 0,94 1,73
Gambar 1. Diagram Alir Proses Fuzzy Time Series dengan Algoritme Genetika
4. PENGUJIAN DAN ANALISIS
Pengujian ini bertujuan untuk mendapatkan nilai yang paling optimal dari metode fuzzy time
series menggunakan algoritme genetika. Data
yang digunakan pada pengujian ini adalah data tahunan jumlah pengangguran di Jawa Timur dari tahun 1986 hingga 2016.
4.1 Pengujian dan Analisis Jumlah Populasi
Pengujian terhadap ukuran populasi dilakukan sebanyak 10 kali percobaan dengan jumlah ukuran populasi kelipatan 25 dari 100
sampai 600. Nilai parameter yang digunakan pada pengujian ini adalah kombinasi cr dan mr
0,5 dan 0,5, sedangkan jumlah generasinya sebanyak 1000. Hasil pengujian untuk ukuran populasi ditunjukkan pada Gambar 2.
Gambar 2. Grafik pengujian jumlah populasi
Berdasarkan Gambar 2 dapat dilihat bahwa semakin banyak nilai jumlah populasi maka semakin banyak peluang untuk menghasilkan nilai fitness terbaik. Pada percobaan ini nilai
fitness mengalami kenaikan saat jumlah
populasinya 150 sampai dengan 525, namun mengalami penurunan saat nilai jumlah populasinya 550 dan tidak mengalami perubahan yang signifikan pada nilai fitness sampai dengan jumlah populasi 600. Sehingga dari percobaan ini nilai paling optimal adalah saat jumlah populasi 525 dan rata-rata fitness yang dihasilkan sebesar 13,840314620. Hal ini dikarenakan setelah jumlah populasi ke 525 sulit mendapatkan nilai rata-rata fitness yang lebih baik..
4.2 Pengujian dan Analisis Kombinasi Cr
dan Mr
Pengujian kombinasi cr dan mr dilakukan sebanyak 10 kali dengan kelipatan 0,1, pengujian cr dimulai dari 0,1 sampai 0,9 dan pengujian mr dimulai dari 0,9 sampai 0,1. Ukuran popsize menggunakan ukuran populasi terbaik dari hasil pengujian ukuran populasi yang sudah dilakukan, yaitu 525 dan jumlah generasi yang digunakan sebanyak 1000. Hasil pengujian ini ditunjukkan pada Gmabar 3.
Berdasarkan Gambar 3 dapat dilihat bahwa nilai fitness cenderung naik jika niilai crossover
rate semakin tinggi dan nilai mutation rate
semakin rendah. Pada percobaan ini nilai fitness
mengalami kenaikan saat kombinasi cr dan mr =
13,8403141 13,8403142 13,8403143 13,8403144 13,8403145 13,8403146 13,8403147
100 150 200 250 300 350 400 450 500 550 600
Popsize Rata-rata fitness
Membuat Populasi
Menghitung nilai
fitness
Crossover
Mutasi Bagi himpunan semesta menjadi beberapa interval
yang sama Data pengangguran di
Jawa Timur
Menghitung nilai
fitness (offspring)
Seleksi
Menampilkan hasil optimasi
Generasi baru
Iterasi selesai
Ya Tidak
0,2 dan 0,8 sampai dengan kombinasi cr =0,8 dan mr = 0,2. Namun setelah cr = 0,9 dan mr = 0,1 nilai fitness mulai menurun lagi. Dari percobaan tersebut dapat disimpulkan bahwa nilai fitness paling optimal adalah saat kombinasi cr = 0,8 dan mr = 0,2 dengan nilai rata-rata fitness sebesar 13,840314616. Hal ini dikarenakan jika mr terlalu besar maka akan terjadi gangguan acak yang terlalu banyak sehingga menyebabkan anak akan kehilangan kemiripan dengan induknya.
Gambar 3. Grafik pengujian kombinasi cr dan mr
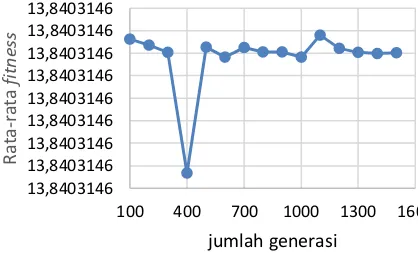
4.3 Pengujian dan Analisis Banyak Generasi
Pada pengujian banyak generasi dilakukan sebanyak 10 kali percobaan. Banyak generasi menggunakan kelipatan 100 dimulai dari generasi ke 100 sampai generasi ke 1500.
Popsize yang digunakan pada pengujian ini
menggunakan ukuran popsize terbaik dari hasil pengujian ukuran populasi, yaitu 525. Sedangkan kombinasi cr dan mr menggunakan kombinasi cr dan mr terbaik dari hasil pengujian yang sudah dilakukan. Hasil pengujian ini ditunjukkan pada pada Gambar 4.
Gambar 4. Grafik pengujian banyak generasi
Berdasarkan Gambar 4 dapat dilihat bahwa nilai fitness turun pada saat generasi ke 200
sampai generasi ke 400, tetapi setelah generasi ke 500 nilai fitness cenderung naik sesuai dengan bertambahnya jumlah generasi. Hal ini terjadi karena jika jumlah generasi semakin banyak untuk mendapatkan nilai yang optimal semakin besar. Namun pada saat generasi sebanyak 1200 mengalami penurunan, karena pada saat generasi ke 1100 sudah mendapatkan solusi yang terbaik. Sehingga pada percobaan ini didapat nilai yang paling optimal saat generasi sebanyak 1100 dengan nilai rata-rata fitness sebesar 13,840314618.
4.4 Analisis Hasil Pengujian
Berdasarkan tujuan dari algoritme genetika adalah mencari solusi optimal dari suatu permasalahan. Pada penelitian ini didapat nilai rata-rata fitness sebesar 13,84031458 dengan nilai RMSE sebesar 0,072252693 untuk pengujian terhadap ukuran populasi dengan
popsize 525 yang mencapai nilai rata-rata fitness
paling optimal. Kombinasi cr dan mr yang mencapai nilai paling optimal adalah 0,8 dan 0,2 menghasilkan rata-rata fitness sebesar 13,84031459 dengan nilai RMSE sebesar 0,0722526929 dan jumlah generasi ke 1200 yang mencapai nilai rata-rata fitness paling optimal sebesar 13,840314614 dengan nilai RMSE sebesar 0,0722526928.
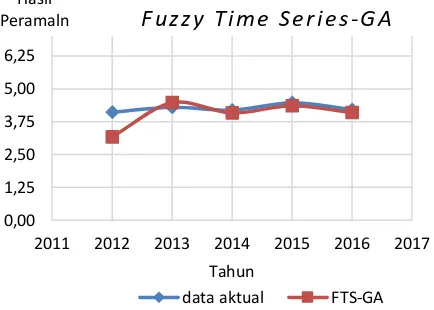
Untuk mengukur tingkat keakuratan dari FTS dan FTS-GA dilakukan percobaan terhadap data jumlah pengangguran dari tahun 2010-2016. Hasil dari percobaan yang dilakukan ditunjukkan pada Gambar 5 dan Gambar 6.
Gambar 5. Grafik Hasil Peramalan FTS
13,8403144
100 400 700 1000 1300 1600
Rat
2011 2012 2013 2014 2015 2016 2017
.
Gambar 6. Grafik Hasil Peramalan FTS-GA
Berdasarkan Gambar 5 dan Gambar 6 dapat dilihat bahwa nilai akurasi yang baik adalah pada saat dilakukan proses optimasi menggunakan algoritme genetika. Setelah melakukan beberapa pengujian parameter-parameter algoritme genetika, maka algoritme genetika mampu menyelesaikan masalah optimasi dalam meramalkan jumlah pengangguran di Jawa Timur.
5. KESIMPULAN
Berdasarkan beberapa pengujian yang dilakukan, dapat ditarik kesimpulan sebagai berikut :
1. Dalam mengimplementasikan metode FTS
(Fuzzy Time Series) dengan menggunakan
algoritme genetika untuk meramalkan jumlah pengangguran di Jawa Timur. Langkah pertama yang dilakukan pada penelitian ini adalah membentuk himpunan
fuzzy secara random dari data yang
digunakan yang kemudian dilakukan optimasi menggunakan algoritme genetika. Setelah itu dilakukan pengujian terhadap parameter-parameter algoritme genetika, yaitu pengujian terhadap ukuran populasi, kombinasi crossover rate dan mutation rate, dan pengujian terhadap jumlah generasi. 2. Untuk mendapatkan nilai parameter
algoritme genetika terbaik adalah dengan melakukan pengujian terhadap parameter algoritme genetika dan menghasilkan nilai rata-rata fitness terbaik. Hasil pengujian parameter algoritme genetika adalah dengan ukuran populasi ke 525 menghasilkan nilai rata-rata fitness paling optimal yaitu 13,840314620 dengan nilai RMSE sebesar
0,0722526928, kombinasi crossover rate
dan mutation rate ke 0,8 dan 0,2 yang
mencapai nilai rata-rata fitness paling optimal yaitu 13,840314616 dengan nilai RMSE sebesar 0,0722526928 dan pada generasi ke 1100 yang mencapai nilai rata-rata fitness paling optimal yaitu 13,840314618 dengan nilai RMSE sebesar 0,0722526928.
6. DAFTAR PUSTAKA
Berutu, S.S., 2013. Peramalan Penjualan dengan Metode Fuzzy Time Series Ruey Chyn Tsaur. S2. Universitas Diponegoro. Tersedia di < http://eprints.undip.ac.id/41216/1/Sunn eng_Sandino_B.pdf> [Diakses 5 Januari 2017].
Disnaker, 2016. Tingkat Pengangguran Terbuka [online] Tersedia di < [Diakses 10 Desember 2016].
Fitra,M & Hakim.F.RB., 2015. Metode Fuzzy Time Series Stevenson Porter Dalam Meramalkan konsumsi Batubata di Indonesia. S1. Universitas Islam Indonesia. Tersedia di <https://publikasiilmiah.ums.ac.id/hand le/1
1617/5726?show=full> [Diakses 7 Januari 2017]
Gaxiola, F., Melin, P & Valdez, F., 2016. Optimization with Genetic Algorithm and Particle Swarm Optimization of Type-2 Fuzzy Integrator for Ensemble Neural Network in Time Series. IEEE, [e-journal] 16, 2067 – 2074. Tersedia melalui: IEEE Journal <http://ieeexplore.ieee.org/document/77 37946/> [5 April 2017]
Haris,M.S,. Santoso, E & Ratnawati,D.E,. 2015. Implementasi Metode Fuzzy Time Series Dengan Penentuan Interval Berbasis Rata – Rata Untuk Peramalan Data Penjualan Bulanan. Universitas Brawijaya Malang.
Muhdar,M.H. 2015. Potret Ketenagakerjaan, pengangguran, dan Kemiskinan di Indonesia. [online] Tersedia di :
2011 2012 2013 2014 2015 2016 2017
Hasil Peramaln
Tahun
F u z z y T i m e S e r i e s - G A
.php/ab/article/view/326/244> [Diakses 29 Desember 2016]
Mahmudy, Wayan firdaus. 2015, Algoritme Evolusi, Fakultas Ilmu Komputer Universitas Brawijaya.
Ningrum, 2010. Penerapan Algoritme Genetika Untuk Permasalahan Optimasi Distribusi Barang Dua Tahap.
Prabowo,2010. Penerapan Algoritme Genetika Untuk Permasalahan Optimasi Distribusi Barang Dua Tahap.
Pulindo, M., Melin, P & Castillo, O., 2013. Optimization of Type-2 Fuzzy Integration in Ensemble Neural Network for Predicting the US Dolar/MX Pesos Time Series. IEEE, [e-journal] 13, 1508
– 1512. Tersedia melalui : IEEE Journal <
http://ieeexplore.ieee.org/document/660 8626/> [5 April 2017]
Sobattv, 2016. Surabaya News [online]
Tersedia di
<http://surabayanews.co.id/2016/05/17/ 59354/jumlah-pengangguran-di-jatim-tercatat-849-ribu.html > [Diakses 10 Desember 2016].
Sukriyawati, G., 2015. Implementasi Metode Average-Based Fuzzy Time Series Models Pada Prediksi Jumlah Penduduk DKI Jakarta.S1. Universitas Brawijaya Malang.
T. Sutojo., Mulyanto, E., & Suhartono, V.,
2011. Kecerdasan Buatan. Yogyakarta.
ANDI.