DETEKSI OUTLIER MENGGUNAKAN ALGORITMA
LOCAL CORRELATION INTEGRAL
(STUDI KASUS: DATA AKADEMIK MAHASISWA
TEKNIK INFORMATIKA UNIVERSITAS SANATA
DHARMA)
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer (S.Kom)
Program Studi Teknik Informatika
Disusun Oleh: Felisitas Brillianti
105314013
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
i
OUTLIER DETECTION USING
LOCAL CORRELATION INTEGRAL ALGORITHM
(STUDY CASE: ACADEMIC DATA OF STUDENTS OF
INFORMATICS ENGINEERING STUDY PROGRAM
SANATA DHARMA UNIVERSITY)
A Thesis
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree (S.Kom)
In Informatics Engineering Study Program
By:
Felisitas Brillianti 105314013
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iv
HALAMAN PERSEMBAHAN
“Bagi manusia hal ini tidak mungkin
,
tetapi bagi Allah segala sesuatu mungkin”
(Matius 19:26)
~NO PAIN NO GAIN~
v
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah saya sebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 14 Januari 2015 Penulis
vi
ABSTRAK
Data mining (penambangan data) adalah suatu proses untuk menemukan suatu pengetahuan atau informasi yang berguna dari data berskala besar. Sering
juga disebut sebagai bagian proses KDD (Knowledge Discovery in Databases) (Santosa, 2007).
Deteksi outlier merupakan salah satu bidang penelitian yang penting dalam mendeteksi perilaku yang tidak normal seperti deteksi mahasiswa yang nilai tes masuk universitasnya bagus tetapi pada saat kuliah mahasiswa tersebut mendapat nilai rendah.
Penelitian ini menggunakan algoritma Local Correlation Integral dengan teknik density-based. Data diambil dari data akademik Mahasiswa Program Studi Teknik Informatika Universitas Sanata Dharma angkatan 2007 dan 2008 yang meliputi nilai tes masuk dan nilai IPS semester 1-4.
Algoritma Local Correlation Integral (LOCI) merupakan salah satu algoritma yang memiliki kemampuan untuk mendeteksi outlier dalam sekumpulan data. Mendeteksi outlier dilakukan untuk menemukan data yang tidak konsisten dengan data lainnya. Data dianggap tidak konsisten (outlier) apabila data tersebut tidak memiliki tingkat kemiripan dengan data lainnya (Han & Kamber, 2006). Algoritma Local Correlation Integral (LOCI) dapat diimplementasikan pada sekumpulan data numerik untuk mendeteksi adanya outlier dengan pendekatan
density-based.
Hasil dari penelitian ini adalah sebuah perangkat lunak yang dapat
digunakan untuk mendeteksi outlier. Pengujian terhadap sistem ini meliputi tiga metode pengujian, yaitu pengujian Blackbox, pengujian efek perubahan nilai atribut terhadap hasil deteksi outlier, dan pengujian reviewer dan validitas pengguna.
Hasil pengujian dari ketiga jenis data tersebut dapat disimpulkan bahwa sistem pendeteksi outlier ini dapat menghasilkan output yang sesuai dengan yang diharapkan oleh pengguna.
vii
ABSTRACT
Mining data is a process to discover a useful knowledge or information from grand data. It is often said as part of the KDD (Knowledge Discovery in Databases)
process. (Santosa, 2007)
The outlier detection is one of the important researches in detecting the abnormal behavior namely detecting the students who have good marks in the university entrance test but after they join in the lecturing they get low marks.
This research uses the Local Correlation Integral algorithm in density-based technique. The data is taken from the academic data of the students of Sanata Dharma University, in Informatics Engineering Study Program, year 2007 and 2008 consisting the marks of the entrance test and the marks of Social Study semester 1
– 4.
The Local Correlation Integral Algorithm (LOCI) is one the algorithms that has ability to detect outlier in a group of data. Detecting outlier is done to discover the inconsistent data with the other data. Data is considered inconsistent (outlier) if the data do not have the grade of similarity to the other data (Han & Kamber, 2006). The Local Correlation Integral (LOCI) algorithm can be implemented in a group of numeric data to detect the existence of the outlier with density-based approach.
The result of this research is a set of software which can be used to detect outlier. The test of this system comprises 3 testing methods, namely The Blackbox testing, the testing of the change of attribute value toward the result of outlier detecting, and the testing of reviewer and the validity of the user.
The test results of the three types of data we can conclude that this outlier detection system can generate output as expected by the user.
viii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma Nama : Felisitas Brillianti
Nomor Mahasiswa : 105314013
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
DETEKSI OUTLIER MENGGUNAKAN ALGORITMA LOCAL CORRELATION INTEGRAL
(STUDI KASUS: DATA AKADEMIK MAHASISWA TEKNIK INFORMATIKA UNIVERSITAS SANATA DHARMA)
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya Dibuat di Yogyakarta
Pada tanggal: 14 Januari 2015 Yang menyatakan,
ix
KATA PENGANTAR
Puji dan syukur kepada Tuhan Yesus Kristus, atas segala berkat dan karunia sehingga penulis dapat menyelesaikan penelitian tugas akhir dengan judul “Deteksi
Outlier Menggunakan Algoritma Local Correlation Integral (Studi Kasus: Data
Akademik Mahasiswa Teknik Informatika Universitas Sanata Dharma)” dengan
baik. Tugas ini ditulis sebagai salah satu syarat memperoleh gelar sarjana komputer program studi Teknik Informatika, Fakultas Sains dan Teknologi Universitas Sanata Dharma.
Penelitian ini tidak dapat berjalan dengan baik tanpa adanya dukungan, semangat, motivasi dan bantuan dalam bentuk apapun yang telah diberikan oleh banyak pihak. Untuk itu penulis mengucapkan terimakasih yang sebesar-besarnya kepada:
1. Tuhan Yesus Kristus, Bunda Maria, dan Santa Felisitas yang telah memberikan anugerah sehingga penulis dapat menyelesaikan tugas akhir ini.
2. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku Dekan Fakultas Sains dan Teknologi.
3. Ibu Ridowati Gunawan, S.Kom., M.T. selaku Ketua Program Studi Teknik Informatika dan dosen pembimbing yang telah dengan sabar membimbing dan memberikan kesabaran, waktu, kebaikan, dan motivasi.
4. Bapak Albertus Agung Hadhiatma, M.T. dan Ibu Sri Hartati Wijono
S.Si., M.Kom. selaku dosen penguji atas kritik dan saran yang telah diberikan.
5. Ibu Agnes Maria Polina S.Kom., M.Sc. selaku Dosen Pembimbing Akademik.
x
7. Pihak sekretariat dan laboran yang turut membantu penulis dalam menyelesaikan tugas akhir ini.
8. Kedua orang tua tercinta Drs. Gregorius Suwarto dan Bernardia Kristiyanti. Terimakasih untuk setiap doa, kasih sayang, perhatian, dan dukungan yang selalu diberikan kepada saya.
9. Kedua saudara teryoi Stefanus Dandy dan Andreas Handyanta.
Terimakasih untuk dukungan yang selalu diberikan kepada saya.
10. Ari Auditianto S.T, Daniel Tomi Raharjo S.Kom, Agustinus Dwi Budi D S.Kom dan Valentinus Fetha Eka Saputra. Super big thanks untuk segala bantuan yang selalu diberikan kepada saya.
11. Kedua rekan kerja skripsi ini, Yustina Ayu Ruwidati dan Erlita Octaviani. Terimakasih telah saling berbagi ilmu serta suka duka dari awal hingga akhir penyelesaian skripsi ini.
12. Verena Pratita Adji, Fidelis Asterina Surya Prasetya, Ria Riska Topurmera, Hevea Forestta Perangin Angin, Novia Hillary Panjaitan, dan Ajeng Arsita Ambarwati. Terimakasih untuk persahabatan serta dukungan kalian.
13. Benedictus Resta Viandri, Martinus Betty Praditya, Afra Raras Santika, Rosalia Megasari, dan Christina Mega Citraningtyas terimakasih untuk hura-huranya.
14. Lufy, Mintul†, dan Ucek terimakasih atas kebersamaannya saat suka maupun duka.
15. Seluruh teman-teman kuliah Teknik Informatika 2010 (HMPS), terimakasih untuk kebersamaan kita selama menjalani masa perkuliahan.
xi
Penelitian tugas akhir ini masih memiliki banyak kekurangan. Untuk itu penulis sangat membutuhkan kritik dan saran untuk perbaikan dimasa yang akan datang. Semoga penelitian tugas akhir ini dapat membawa manfaat bagi semua pihak.
Yogyakarta, 14 Januari 2015
xii
DAFTAR ISI
Halaman Judul
Halaman Judul (Bahasa Inggris) ... i
Halaman Persetujuan ... ii
Halaman Pengesahan ... iii
Halaman Persembahan ... iv
Halaman Pernyataan... v
Abstrak ... vi
Abstract ... vii
Halaman Persetujuan Publikasi Karya Ilmiah... viii
Kata Pengantar ... ix
Daftar Isi ... xii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Batasan Masalah ... 3
1.4 Tujuan Penelitian... 3
1.5 Manfaat Penelitian... 3
1.6 Metodologi Penelitian ... 3
1.7 Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 6
2.1 Data Mining... 6
2.1.1 Pengertian Data Mining ... 6
2.1.2 Fungsi Data Mining ... 9
2.2 Outlier Detection ... 10
2.2.1 Pengertian Outlier ... 10
2.2.2 Jenis Pendekatan Outlier ... 11
2.2.2.1 Statistik Based ... 11
2.2.2.2 Distance Based ... 11
xiii
2.2.2.4 Deviation Based ... 13
2.3 Algoritma Local Correlation Integral (LOCI) ... 13
2.3.1 Multi-Granuality Deviation Factor (MDEF) ... 13
2.3.2 Metode Local Correlation Integral (LOCI)... 16
2.4 Contoh Jalannya Algoritma ... 19
BAB III METODOLOGI PENELITIAN ... 25
3.1 Data yang Dibutuhkan ... 25
3.2 Pengolahan Data ... 25
3.2.1 Penggabungan Data (Data Integration) ... 25
3.2.2 Seleksi Data (Data Selection) ... 26
3.2.3 Transformasi Data (Data Transformation) ... 27
3.2.4 Penambangan Data (Data Mining) ... 32
3.2.5 Evaluasi Pola (Pattern Evaluation) ... 33
3.2.6 Presentasi Pengetahuan (Knowledge Presentation) 33 BAB IV ANALISA DAN PERANCANGAN SISTEM ... 35
4.1 Identifikasi Sistem ... 35
4.1.1 Diagram Use Case ... 36
4.1.2 Narasi Use Case ... 37
4.2 Perancangan Sistem Secara Umum ... 37
4.2.1 Input Sistem ... 37
4.2.2 Proses Sistem ... 39
4.2.3 Output Sistem ... 40
4.3 Perancangan Sistem... 40
4.3.1 Diagram Aktivitas ... 40
4.3.2 Diagram Kelas Analisis ... 41
4.3.3 Diagram Sequence ... 43
4.3.4 Diagram Kelas Desain ... 43
4.3.5 Rincian Algoritma Setiap Method Pada Tiap Kelas 44 4.4 Perancangan Struktur Data ... 65
4.4.1 Graf ... 65
xiv
4.5 Perancangan Antarmuka ... 67
4.5.1 Tampilan Halaman Awal ... 67
4.5.2 Tampilan Halaman Utama ... 67
4.5.3 Tampilan Halaman Bantuan ... 70
4.5.4 Tampilan Halaman Tentang ... 71
4.5.5 Tampilan Menu Keluar ... 72
4.5.6 Tampilan Halaman Pilih File ... 72
4.5.7 Tampilan Halaman Pilih Database ... 73
4.5.8 Tampilan Halaman Pilih Tabel ... 74
BAB V IMPLEMENTASI SISTEM ... 75
5.1 Impelementasi Antarmuka ... 75
5.1.1 Implementasi Halaman Awal ... 75
5.1.2 Implementasi Halaman Utama ... 76
5.1.3 Implementasi Halaman Pilih Database ... 80
5.1.4 Implementasi Halaman Tampil Tabel ... 81
5.1.5 Implementasi Halaman Bantuan ... 83
5.1.6 Implementasi Halaman Tentang ... 83
5.1.7 Implementasi Halaman Konfirmasi Keluar ... 84
5.1.8 Implementasi Pengecekan Masukan ... 85
5.2 Implementasi Struktur Data ... 88
5.2.1 Implementasi Kelas Graph.java ... 88
5.2.2 Implementasi Kelas Verteks.java ... 89
5.3 Implementasi Kelas ... 90
BAB VI PENGUJIAN DAN ANALISA PENGUJIAN ... 91
6.1 Rencana Pengujian ... 91
6.1.1 Hasil Pengujian Blackbox ... 93
6.1.1.1 Pengujian Input Data ... 93
6.1.1.2 Pengujian Koneksi Database ... 94
6.1.1.3 Pengujian Halaman Pilih Tabel ... 96
6.1.1.4 Pengujian Seleksi Atribut ... 96
xv
6.1.1.6 Pengujian Simpan Hasil Deteksi Outlier . 99
6.1.2 Kesimpulan Hasil Pengujian Blacbox ... 100
6.1.3 Hasil Pengujian Efek Perubahan Nilai Atribut Penambangan Data ... 100
6.1.3.1 Pengujian Dengan Data Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Tes Tertulis ... 100
6.1.3.2 Pengujian Dengan Data Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Prestasi ... 101
6.1.3.3 Pengujian Dengan Data Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Tes Tertulis dan Jalur Prestasi ... 101
6.1.4 Kesimpulan Hasil Pengujian Efek Perubahan Nilai Atribut Penambangan Data ... 102
6.1.5 Hasil Pengujian Review dan Validitas Pengguna .. 102
6.1.5.1 Perbandingan Perhitungan Manual dan Hasil Sistem ... 102
6.1.5.2 Kesimpulan Hasil Perbandingan Perhitungan Manual dengan Perhitungan Sistem ... 104
6.1.5.3 Hasil Deteksi dari Sistem untuk Pengujian Review dan Validitas oleh Pengguna ... 104
6.1.5.4 Kesimpulan Hasil Pengujian Review dan Validitas oleh Pengguna ... 107
6.2 Kelebihan dan Kekurangan Sistem ... 112
6.2.1 Kelebihan Sistem ... 112
6.2.2 Kekurangan Sistem ... 112
BAB VIII KESIMPULAN DAN SARAN ... 113
7.1 Kesimpulan ... 113
7.2 Saran ... 113
xvi
LAMPIRAN 1 Diagram Use Case ... 115
LAMPIRAN 2 Deskripsi Use Case ... 116
LAMPIRAN 3 Narasi Use Case ... 118
LAMPIRAN 4 Diagram Proses Umum Sistem ... 126
LAMPIRAN 5 Diagram Aktivitas ... 127
LAMPIRAN 6 Diagram Kelas Analisis ... 132
LAMPIRAN 7 Diagram Sequence ... 133
LAMPIRAN 8 Diagram Kelas Desain ... 138
LAMPIRAN 9 Diagram Kelas... 139
LAMPIRAN 10 Listing Program... 152
LAMPIRAN 11 Outlier Plot ... 230
xvii
DAFTAR GAMBAR
Gambar 2.1 Proses KDD ... 7
Gambar 2.2 Dataset dengan Outlier ... 10
Gambar 2.3 Definisi dari n dan n̂ ... 14
Gambar 3.1 Database “gudangdata” ... 26
Gambar 3.2 Isi tabel “fact_lengkap” ... 27
Gambar 4.1 Ilustrasi Struktur Data Graf ... 65
Gambar 4.2 Tampilan Halaman Utama ... 67
Gambar 4.3 Tampilan Halaman Utama Tab Preprosesing ... 68
Gambar 4.4 Tampilan Halaman Utama Tab Deteksi Outlier ... 69
Gambar 4.5 Tampilan Halaman Bantuan ... 70
Gambar 4.6 Tampilan Halaman Tentang ... 71
Gambar 4.7 Tampilan Menu Keluar... 72
Gambar 4.8 Tampilan Halaman Pilih File... 72
Gambar 4.9 Tampilan Halaman Pilih Database ... 73
Gambar 4.10 Tampilan Halaman Pilih Tabel ... 74
Gambar 5.1 Antarmuka Halaman Awal ... 76
Gambar 5.2 Kotak Dialog saat memilih File ... 77
Gambar 5.3 Antarmuka Halaman Utama (data file .xls tertampil) ... 78
Gambar 5.4 Kotak Seleksi Atribut ... 78
Gambar 5.5 Proses Deteksi Outlier ... 79
Gambar 5.6 Tampilan Hasil Outlier ... 79
Gambar 5.7 Tampilan Save Dialog ... 79
Gambar 5.8 Pesan Ketika Proses Penyimpanan Hasil Outlier Berhasil Dilakukan ... 80
Gambar 5.9 Antarmuka Halaman Pilih Database ... 80
Gambar 5.10 Antarmuka Halaman Pilih Database (Setelah Pengguna memilih Database ... 81
Gambar 5.11 Pesan Koneksi Berhasil ... 81
xviii
Gambar 5.13 Hasil Input Data dari Database ... 82
Gambar 5.14 Antarmuka Halaman Bantuan ... 83
Gambar 5.15 Antarmuka Halaman Tentang ... 84
Gambar 5.16 Antarmuka Halaman Konfirmasi Keluar ... 84
Gambar 5.17 Error Handling (1) ... 85
Gambar 5.18 Error Handling (2) ... 85
Gambar 5.19 Error Handling (3) ... 86
Gambar 5.20 Error Handling (4) ... 86
Gambar 5.21 Error Handling (5) ... 86
Gambar 5.22 Error Handling (6) ... 87
Gambar 5.23 Error Handling (7) ... 87
Gambar 5.24 Error Handling (8) ... 87
Gambar 2.25 Error Handling (9) ... 88
xix
DAFTAR TABEL
Tabel 2.1 Simbol dan Definisi ... 15
Tabel 2.2 Data 13 Mahasiswa ... 19
Tabel 2.3 Jumlah r-neighbors dari pi ... 20
Tabel 2.4 Jumlah r-neighbors dari pi... 21
Tabel 3.1 Contoh atribut sebelum dinormalisasi ... 28
Tabel 3.2 Contoh atribut setelah dinormalisasi ... 29
Tabel 3.3 Contoh atribut sebelum dinormalisasi ... 31
Tabel 3.4 Contoh atribut setelah dinormalisasi ... 32
Tabel 4.1 Tabel Keterangan Diagram Analisis ... 41
Tabel 4.2 Ilustrasi Struktur Data Matriks Dua Dimensi ... 66
Tabel 4.3 Ilustrasi Struktur Data Matriks Dia Dimensi Setelah Dilakukan Perhitungan Jarak antar Vertex ... 66
Tabel 5.1 Tabel Implementasi Kelas ... 90
Tabel 6.1 Tabel Rencana Pengujian ... 92
Tabel 6.2 Tabel Pengujian Input Data ... 93
Tabel 6.3 Tabel Pengujian Koneksi Database ... 94
Tabel 6.4 Tabel Pengujian Halaman Tampil Tabel ... 96
Tabel 6.5 Tabel Pengujian Seleksi Atribut ... 96
Tabel 6.6 Tabel Pengujian Deteksi Outlier ... 97
Tabel 6.7 Tabel Pengujian Simpan Hasil Deteksi Outlier... 99
Tabel 6.8 Tabel Jumlah Outlier Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Tes Tertulis Semester 1 dengan Nilai Radius yang berubah-ubah dan Nilai Alpha = 0.5 ... 100
Tabel 6.9 Tabel Jumlah Outlier Mahasiswa Teknik Informatika Angkatan 2007 dan 2008 Jalur Prestasi Semester 1 dengan Nilai Radius yang berubah-ubah dan Nilai Alpha = 0.5 ... 101
xx
Tabel 6.11 Tabel Data Set untuk Perbandingan Manual dan Sistem ... 103 Tabel 6.12 Tabel Perbandingan Hasil Deteksi Outlier Mahasiswa Angkatan 2007
Jalur Tes ... 104 Tabel 6.13 Tabel Hasil Perhitungan Sistem 2007-2008 Jalur Tes Tertulis 105 Tabel 6.14 Tabel Hasil Perhitungan Sistem 2007-2008 Jalur Prestasi... 106 Tabel 6.15 Tabel Hasil Perhitungan Sistem 2007-2008 Jalur Test dan Prestasi
1
BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
Di era globalisasi pendidikan merupakan salah satu kebutuhan manusia sehingga tidak dapat dipisahkan dari kehidupan sehari-hari. Penelitian dalam bidang pendidikan menggunakan teknik penambangan data yang telah banyak dilakukan saat ini. Penambangan data dalam bidang pendidikan berguna untuk mengembangkan sebuah metode untuk menemukan keunikan dari sebuah data yang berasal dari sistem pendidikan tersebut, dan menggunakan metode tersebut untuk lebih memahami mahasiswa, sehingga dapat dibuat sistem yang sesuai.
Deteksi outlier merupakan salah satu bidang penelitian yang penting dalam mendeteksi perilaku yang tidak normal seperti deteksi nilai mahasiswa yang nilai tes masuk universitasnya bagus tetapi pada saat kuliah mahasiswa tersebut mendapat nilai yang rendah bahkan di keluarkan. Bermacam-macam metode telah dikembangkan baik berdasarkan teknik seperti distance-based,
clustering-based, dan density-based.
Universitas merupakan sebuah lembaga yang dirancang untuk pengajaran mahasiswa dibawah pengawasan dosen. Universitas Sanata Dharma merupakan sebuah lembaga pendidikan yang memiliki banyak data. Nilai akademik mahasiswa merupakan salah satu dari data yang di miliki Universitas Sanata Dharma. Nilai tersebut meliputi nilai tes masuk (PMB) dan nilai pada setiap semester. Untuk dapat menjadi mahasiswa Universitas Sanata Dharma, seorang calon mahasiswa harus mengikuti tes masuk. Dengan nilai tes masuk tersebut seseorang akan ditentukan apakah dapat menjadi mahasiswa atau tidak.
mahasiswa tersebut nilainya diatas batas tuntas maka mahasiswa tersebut dipertahankan dan dapat melanjutkan ke semester V.
Dalam penambangan data teknik untuk mengenali outlier dikenal dengan istilah Deteksi Outlier. Sebuah sumber data atau dataset pada umumnya mempunyai nilai-nilai pada setiap obyek yang tidak terlalu berbeda jauh dengan obyek lain. Akan tetapi terkadang pada data tersebut juga
ditemukan obyek-obyek yang mempunyai nilai atau sifat atau karakteristik yang berbeda dibandingkan dengan obyek pada umumnya.
Deteksi oulier adalah suatu teknik untuk mencari obyek dimana obyek tersebut mempunyai perilaku yang berbeda dibandingkan obyek-obyek pada umumnya. Teknik data mining dapat digunakan untuk mendeteksi adanya suatu outlier pada sebuah dataset. Teknik data mining yang digunakan adalah
Clustering-based, Distance-based dan Density-based.
Algoritma Local Correlation Integral (LOCI) merupakan salah satu algoritma yang memiliki kemampuan untuk mendeteksi outlier dalam sekumpulan data. Mendeteksi outlier dilakukan untuk menemukan data yang tidak konsisten dengan data lainnya. Data dianggap tidak konsisten (outlier) apabila data tersebut tidak memiliki tingkat kemiripan yang sesuai dengan data lainnya (Han & Kamber, 2006). Algoritma Local Correlation Integral
(LOCI) dapat diimplementasikan pada sekumpulan data numerik untuk
mendeteksi adanya outlier dengan pendekatan density-based.
1.2 Rumusan Masalah
Berdasarkan latar belakang diatas, rumusan masalah dari penelitian ini
adalah
1.3 Batasan Masalah
Batasan masalah pada penelitian ini adalah:
1. Algoritma yang dipakai adalah algoritma Local Correlation Integral (LOCI) dengan pendekatan density-based.
2. Data yang digunakan adalah data akademik mahasiswa Teknik Informatika Universitas Sanata Dharma Yogyakarta tahun angkatan
2007-2008.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk menerapkan algoritma Local Correlation Integral (LOCI) ke dalam sebuah sistem untuk mendeteksi
outlier dari data akademik mahasiswa Teknik Informatika Universitas Sanata Dharma Yogyakarta.
1.5 Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut:
1. Menambah wawasan tentang Algoritma Local Correlation Integral dalam mendeteksi outlier.
2. Membantu pihak program studi dalam mendeteksi outlier pada data akademik mahasiswa.
1.6 Metodologi Penelitian
Metodologi yang digunakan dalam penelitian ini adalah metode KDD (Knowledge Discovery in Database).
1. Pembersihan Data (Data Cleaning).
Proses membersihkan data yang tidak konsisten atau yang mengganggu.
Proses Data Cleanning mencakup antara lain membuang duplikasi data, memeriksa data yang tidak konsisten, dan memperbaiki kesalahan pada data.
2. Penggabungan Data (Data Integration)
3. Seleksi Data (Data Selection)
Proses menyeleksi data yang relevan. Data yang tidak sesuai akan dihilangkan.
4. Transformasi Data (Data Transformation)
Data yang sudah di seleksi selanjutnya di transformasikan ke dalam bentuk yang sesuai untuk ditambang.
5. Penambangan Data (Data Mining)
Proses mengekstrak informasi atau pengetahuan dari data dalam jumlah yang besar. Dalam penelitian ini, metode yang digunakan adalah metode analisis outlier dengan menggunakan pendekatan density based. Algoritma yang digunakan adalah Local Correlation Integral (LOCI). 6. Evaluasi Pola (Pattern Evaluation)
Proses mengidentifikasi apakah pola atau informasi yang ditemykan sesuai fakta atau hipotesa yang ada sebelumnya.
7. Presentasi Pengetahuan (Knowledge Presentation)
Proses merepresentasikan pola kepada pengguna ke dalam bentuk yang mudah dimengerti.
1.7 Sistematika Penulisan
Dalam penyusunan proposal tugas akhir ini penulis membagi dalam beberapa bab yaitu:
BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang secara umum, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian,
metodologi penelitian, dan sistematika penelitian secara keseluruhan.
BAB II LANDASAN TEORI
BAB III METODOLOGI PENELITIAN
Bab ini berisi tentang metode yang digunakan untuk menyelesaikan tugas akhir ini, yaitu menggunakan metode
Knowledge Discovery in Database (KDD).
BAB IV ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi tentang identifikasi sistem, perancangan sistem secara umum, perancangan sistem, perancangan struktur data, dan perancangan antarmuka yang akan dibuat.
BAB V IMPLEMENTASI SISTEM
Bab ini berisi tentang implementasi sistem deteksi outlier menggunakan algoritma Local Correlation Integral yang terdiri dari implementasi antarmuka, implementasi pengecekan masukan, implementasi struktur data dan implementasi kelas serta analisis dari masing-masing tampilan program.
BAB VI PENGUJIAN DAN ANALISIS PENGUJIAN
Bab ini berisi tentang tahap pengembangan sistem pendeteksi
outlier menggunakan algorotma Local Correlation Integral yaitu pengujian blackbox beserta kesimpulannya dan juga pengujian review dan validitas pengguna beserta kesimpulannya.
BAB VII KESIMPULAN DAN SARAN
6
BAB II
LANDASAN TEORI
2.1 Data Mining
2.1.1 Pengertian Data Mining
Data mining adalah suatu istilah yang digunakan untuk
menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan didalam database besar. (Turban et al, 2005).
Teknik data mining digunakan untuk memeriksa basis data berukuran besar sebagai cara untuk menemukan pola yang baru dan berguna. Tidak semua pekerjaan pencarian informasi dinyatakan sebagai data mining.
Beberapa pengertian data mining dari beberapa referensi:
1. Data mining adalah mencocokkan data dalam suatu model untuk
menemukan informasi yang tersembunyi dalam basis data (Dunham, 2002)
2. Data mining merupakan proses menemukan pola-pola didalam
data, dimana proses penemuan tersebut dilakukan secaa otomatis atau semi otomatis dan pola-pola yang ditemukan harus bermanfaat (Fayyad, Piatetsky-Shapiro, & Smyth, 1996)
3. Data mining atau Knowledge Discovery in Database (KDD)
berbeda, seperti clustering, data summarization, learning clasification rules (Dunham, 2002)
Data mining adalah sebuah bagian yang sangat penting dalam proses KDD (Knowledge Discovery in Database). Knowledge
Discovery in Databases (KDD) merupakan sekumpulan proses untuk
menentukan pengetahuan yang bermanfaat dari data.
Gambar 2.1 adalah proses KDD menurut Jiawei Han dan Micheline Kamber:
Proses KDD terdiri dari langkah-langkah dibawah ini: 1. Pembersihan Data (Data Cleaning).
Proses membersihkan data yang tidak konsisten atau yang mengganggu. Proses Data Cleanning mencakup antara lain membuang duplikasi data, memeriksa data yang tidak konsisten, dan memperbaiki kesalahan pada data.
2. Penggabungan Data (Data Integration)
Proses menggabungkan data dari berbagai sumber. 3. Seleksi Data (Data Selection).
Proses menyeleksi data yang relevan. Data yang tidak sesuai akan dihilangkan.
4. Transformasi Data (Data Transformation)
Data yang sudah di seleksi selanjutnya di transformasikan ke dalam bentuk yang sesuai untuk ditambang.
5. Penambangan Data (Data Mining)
Proses mengekstrak informasi atau pengetahuan dari data dalam jumlah yang besar. Dalam penelitian ini, metode yang digunakan adalah metode analisis outlier dengan menggunakan pendekatan
density based. Algoritma yang digunakan adalah Local
Correlation Integral (LOCI). 6. Evaluasi Pola (Pattern Evaluation)
Proses mengidentifikasi apakah pola atau informasi yang ditemukan sesuai fakta atau hipotesa yang ada sebelumnya. 7. Presentasi Pengetahuan (Knowledge Presentation)
2.1.2 Fungsi Data Mining
Berikut fungsionalitas dan tipe data pola yang dapat ditemukan dengan data mining (Han & Kamber, 2006)
a. Deskripsi konsep: Karakterisasi dan diskriminasi.
Generalisasi, rangkuman, dan karaktiristik data kontras. Data dapat diasosiasikan dengan suatu kelas atau konsep.
b. Analis Asosiasi (korelasi dan hubungan sebab akibat)
Analisis asosiasi adalah pencarian aturan-aturan asosiasi yang menunjukkan kondisi-kondisi nilai atribut yang sering terjadi bersama-sama dalam sekumpulan data. Biasanya digunakan untuk menganalisa data transaksi.
c. Klasifikasi dan Prediksi
Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk memprediksikan kelas atau objek yang memiliki label kelas tidak diketahui. Model yang diturunkan didasarkan pada analisis dari training data (yaitu objek data yang memiliki label kelas yang diketahui).
d. Analisis Cluster (analisis pengelompokan)
Tidak seperti klasifikasi dan prediksi, yang menganalisis objek data yang diberi label kelas, clustering menganalisis objek data dimana label kelas tidak diketahui. Clustering dapat digunakan untuk menentukan label kelas yang tidak diketahui dengan cara
mengelompokkan data untuk membentuk kelas baru. Prinsip dalam clustering adalah memaksimalkan kemiripan intra-class
dan meminimumkan kemiripan interclass. e. Analisis Outlier
Teknik ini berguna dalam fraud detection dan rare events analysis.
f. Analisis Trend dan Evolusi
Analisis evolusi data menjelaskan dan memodelkan trend dari objek yang memiliki perilaku yang berubah setiap waktu. Teknik ini dapat meliputi karakterisasi, diskriminasi, asosiasi, klasifikasi,
atau clustering dari data yang berkaitan dengan waktu.
2.2 Outlier Detection
2.2.1 Pengertian Outlier
Outlier adalah sehimpunan data yang dianggap memiliki sifat yang berbeda dibandingkan dengan kebanyakan data lainnya. (Han & Kamber, 2006) Analis outlier dikenal juga dengan analisis anomali atau deteksi anomali (Atastina). Deteksi outlier adalah suatu teknik untuk mencari obyek yang mempunyai perilaku yang berbeda dari obyek-obyek lain. Teknik data mining dapat digunakan untuk mendeteksi adanya suatu anomali pada sebuah dataset. Dataset dengan outlier
dipaparkan pada gambar 2.2
Gambar 2.2 Dataset dengan Outlier
Outlier biasanya dianggap sebagai objek atau data yang
menjadi seribu jika data sudah berjumlah satu juta. Dengan demikian, deteksi outlier pada data yang menyimpang merupakan pekerjaan yang penting untuk berbagai keperluan dalam data mining (Prasetyo).
Beberapa metode yang dapat digunakan untuk pendeteksian
outlier adalah Statistik Based, Distance Based, Density Based, dan
Deviation Based.
2.2.2 Jenis Pendekatan Outlier
2.2.2.1 Statistik Based
Cara yang paling sederhana adalah cara statistik. Perlu dilakukan perhitungan rata-rata dan standar deviasi. Kemudian berdasarkan nilai tersebut dibuat fungsi threshold berpotensi untuk dinyatakan sebagai outlier.
Kelebihan dan kekurangan Statistik Based:
1. Jika pengetahuan data cukup (jenis distribusi data dan jenis uji yang diperlukan), maka pendekatan statistik akan sangat efektif).
2. Umumnya sulit menemukan fungsi distribusi dan jenis uji yang tepat untuk data.
3. Kebanyakan uji hanya cocok untuk single atribut.
4. Sulit untuk menentukan fungsi distribusi dan uji yang tepat untuk data berdimensi tinggi.
2.2.2.2 Distance Based
Sebuah metode pencarian outlier yang populer dengan menghitung jarak pada obyek tetangga terdekat (nearest
neighbor). Dalam pendekatan ini, satu obyek melihat
ketertetanggan antar obyek relatif sangat jauh maka dikatakan obyek tersebut tidak normal (Hendriyadi, 2009).
Kelebihan dan kekurangan Distance Based: 1. Pendekatannya cukup sederhana.
2. Basisdata yang besar akan memakan biaya yang besar.
3. Sangat tergantung pada nilai parameter yang dipilih. 4. Waktu proses mendeteksi outlier dan hasil deteksi kurang
akurat dibandingkan dengan metode Density-Based
(Hendriyadi, 2009)
2.2.2.3 Density Based
Metode density-based tidak secara eksplisit mengklasifikasikan sebuah obyek adalah outlier atau bukan, akan tetapi lebih kepada pemberian nilai kepada obyek sebagai derajat kekuatan, obyek tersebut dapat dikategorikan sebagai
outlier. Ukuran derajat kekuatan ini adalah local outlier factor
(LOF). Pendekatan untuk pencarian outlier ini hanya membutuhkan satu parameter yaitu MinPts, dimana MinPts
adalah jumlah tetangga terdekat yang digunakan untuk mendefinisikan local neighborhood suatu obyek. MinPts
diasumsikan sebagai jangkauan dari nilai MinPtsLB dan MinPtsUB. Nilai MinPtsLB dan MinPtsUB disarankan bernilai 10 dan 20. Akhirnya semua obyek dalam dataset
dihitung nilai LOFnya (Hendriyadi, 2009).
Kelebihan dan kekurangan Density Based:
1. Dapat digunakan untuk data yang kepadatannya berbeda. 2. Namun pemilihan parameter juga menjadi satu penentuan
3. Tanpa LOF objek yang berada pada cluster yang berbeda dapat dianggap outlier juga.
2.2.2.4 Deviation Based
Metode deviation based tidak menggunakan pengujian statistik ataupun perbandingan jarak untuk mengidentifikasi
sebuah outlier. Sebaliknya metode ini mengidentifikasi sebuah
outlier dengan memeriksa karakteristik utama dari obyek dalam sebuah kumpulan. Obyek yang memiliki karakteristik diluar karakteristik utama maka akan dianggap sebagai oulier (Han & Kamber, 2006).
2.3 Algoritma Local Correlation Integral (LOCI)
2.3.1 Multi-Granularity Deviation Factor (MDEF)
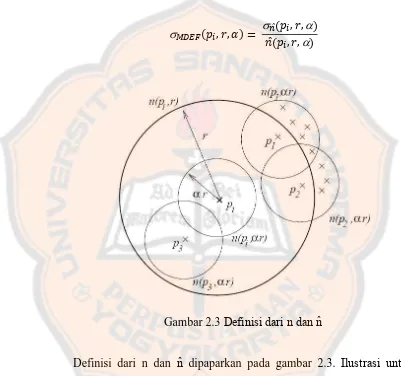
Multi-granuality deviation factor (MDEF), adalah ukuran untuk mengukur outlier-ness suatu objek pada lingkungannya (neighborhood) (Peter Cabens, 1998). Sedangkan adalah normalisasi standar deviasi dari MDEF.
Untuk setiap objek pi, r dan mendefinisikan Multi-granulality deviation factor (MDEF) pada radius r sebagai berikut:
��, �, � = ̂ � , �,̂ � , �, − � , � = − ̂ � ,� ,, ��
r-neighborhood untuk object pi selalu mengandung pi. Ini berarti
̂ � , �, > sehingga kuantitas diatas selalu di definisikan. Untuk perhitungan lebih cepat dari MDEF, kadang-kadang harus memperkirakan � ,� dan ̂ � , �, .
r-neighborhood) adalah neighborhood radius r, dimana mengumpulkan sample �,� untuk memperkirakan ̂ � , �, .
Ide pokok deteksi outlier bergantung pada standar deviasi dari jumlah r-neighborhood atas neighborhood dari pi.
� , �, � = ̂ � , �,� , �,
Gambar 2.3 Definisi dari n dan n̂
Definisi dari n dan n̂ dipaparkan pada gambar 2.3. Ilustrasi untuk
definisi dari n dan n̂ misalnya � , � = , � ,� = , � ,� =
, dan ̂ � , �, = + + + = .
Dimana:
1. � , � merupakan jumlah r-neighbors dari pi. 2. � ,� merupakan jumlah r-neighbors dari pi.
3. ̂ � , �, merupakan rata-rata dari �,� pada r-neighbors dari
Setiap objek dapat dikatakan sebagai outlier dengan berdasarkan formula berikut:
� , �, > � � , �, �
Tabel 2.1 merupakan tabel yang berisi simbol yang digunakan algoritma Local Correlation Integral untuk mendeteksi outlier.
Tabel 2.1 Simbol dan Definisi
Simbol Definisi
�
Kumpulan Objek P = {p1, .,pi ..pN}.
N Jumlah data (|P| N).
� , � Jarak antara pi dan pj.
� , � Jumlah r-neighbors dari pi.
� ,� Jumlah r-neighbors dari pi.
n̂ � , �, Rata-rata dari �,� pada r-neighbors dari pi,
n̂ � , �, ∑� ��,� �,�
� , �
n̂ � , �, Standar deviasi dari �,� pada r-neighbors.
n̂ � , �, √∑� ��,� �,� , �� − n̂ � , �,
� , �, Multi-granuality deviation factor untuk pi pada radius r.
� , �, � Standar deviasi multi-granuality deviation factor.
� � , �, > � � , �, �
2.3.2 Metode Local Correlation Integral (LOCI)
Penelitian ini menggunakan algoritma Local Correlation Integral
(LOCI), ide utama dari LOCI adalah menandai objek sebagai outlier
jika di kepadatan lokal (local density) antara neighboors cukup besar. Untuk mendeteksi bahwa relative deviasi dari average local neighborhood density diperoleh. Penyimpangan ini disebut
multi-granularity-deviation factor (MDEF). Algoritma LOCI dalam
mendeteksi outlier menghitung nilai MDEF dan nilai MDEF untuk semua objek. Kemudian LOCI akan menandai suatu objek sebagai
outlier jika nilai nilai MDEF lebih besar tiga kali lipat dari nilai MDEF untuk radius yang sama (Peter Cabens, 1998). Algoritma ini diusulkan dalam (Spiros Papadimitriou, 2003). Algoritma LOCI tidak mempunyai parameter penting seperti k.
Objek yang dinyatakan sebagai outlier adalah objek yang memiliki nilai MDEF mendekati 1. Tujuannya adalah untuk ditandai
Langkah –langkah untuk menemukan outlier dideskripsikan sebagai berikut:
1. Menentukan jarak antar objek.
Untuk menentukan jarak antar objek menggunakan rumus
euclidean distance.
√∑ � − �
̂
=
2. Menghitung jumlah r-neighbors dari pi.
Jumlah tetangga yang jaraknya kurang dari sama dengan r.
3. Menghitung jumlah r-neighbors dari pi.
Jumlah tetangga yang jaraknya kurang dari sama dengan r.
4. Menghitung rata-rata dari n(p, r) pada r-neighbors dari pi.
n̂ � , �, ∑� ��,� �,�
� , �
5. Menghitung standar deviasi dari n(p, r) pada r-neighbors.
n̂ � , �, √∑� ��,� �,� , �� − n̂ � , �,
6. Menghitung Multy-granuality deviation factor untuk pipada
radius r.
��, �, � = ̂ � , �,̂ � , �, − � , � = − ̂ � ,� ,, ��
7. Menghitung standar deviasi Multy-granuality deviation factor.
8. Menghitung LOCI.
� , �, > � � , �, �
Outlier memiliki nilai MDEF mendekati 1. Tujuannya adalah sebagai outlier jika rasio antara MDEF dan MDEF melebihi konstanta yang diusulkan dalam publikasi asli menjadi 3. Berikut adalah implementasi dari algoritma Local Correlation Integral:
// Pre-processing Foreach pi
Perform a range-search
For Ni = {p | d(pi, p) ≤ rmax} From Ni, construct a sorted list Di
Of the critical and -critical distances of pi // Post-processing
Foreach pi:
For each radius r Di (ascending): Update n(pi, r) and n̂(pi, r, ) From n and n̂, compute
2.4 Contoh Jalannya Algoritma
Misalnya sebuah database memiliki sebuah objek dan dilambangkan sebagai P1, P2, P3, P4, P5, P6, P7, P8, P9, P10, P11, P12, dan P13. Dari objek
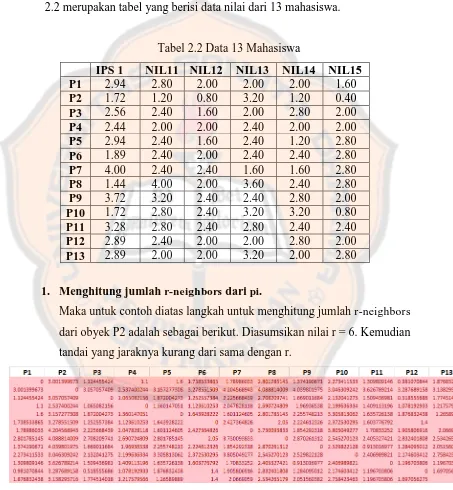
tersebut memiliki atribut nilai ips1, nil11, nil12, nil13, nil14, dan nil15. Tabel 2.2 merupakan tabel yang berisi data nilai dari 13 mahasiswa.
Tabel 2.2 Data 13 Mahasiswa
IPS 1 NIL11 NIL12 NIL13 NIL14 NIL15
P1 2.94 2.80 2.00 2.00 2.00 1.60
P2 1.72 1.20 0.80 3.20 1.20 0.40
P3 2.56 2.40 1.60 2.00 2.80 2.00
P4 2.44 2.00 2.00 2.40 2.00 2.00
P5 2.94 2.40 1.60 2.40 1.20 2.80
P6 1.89 2.40 2.00 2.40 2.40 2.80
P7 4.00 2.40 2.40 1.60 1.60 2.80
P8 1.44 4.00 2.00 3.60 2.40 2.80
P9 3.72 3.20 2.40 2.40 2.80 2.00
P10 1.72 2.80 2.40 3.20 3.20 0.80
P11 3.28 2.80 2.40 2.80 2.40 2.40
P12 2.89 2.40 2.00 2.00 2.80 2.00
P13 2.89 2.00 2.00 3.20 2.00 2.80
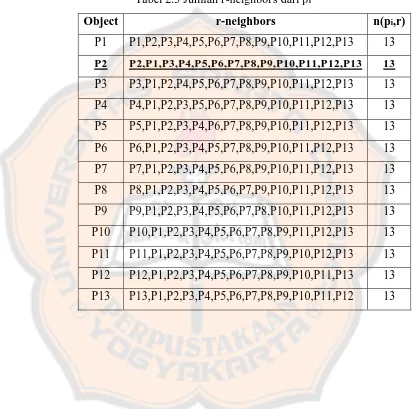
1. Menghitung jumlah r-neighbors dari pi.
Maka untuk contoh diatas langkah untuk menghitung jumlah r-neighbors
Tabel 2.3 merupakan tabel yang berisi tentang jumlah r-neighbors dari ke-13 obyek.
Tabel 2.3 Jumlah r-neighbors dari pi
Object r-neighbors n(pi,r)
P1 P1,P2,P3,P4,P5,P6,P7,P8,P9,P10,P11,P12,P13 13
P2 P2,P1,P3,P4,P5,P6,P7,P8,P9,P10,P11,P12,P13 13
P3 P3,P1,P2,P4,P5,P6,P7,P8,P9,P10,P11,P12,P13 13 P4 P4,P1,P2,P3,P5,P6,P7,P8,P9,P10,P11,P12,P13 13
P5 P5,P1,P2,P3,P4,P6,P7,P8,P9,P10,P11,P12,P13 13
P6 P6,P1,P2,P3,P4,P5,P7,P8,P9,P10,P11,P12,P13 13
P7 P7,P1,P2,P3,P4,P5,P6,P8,P9,P10,P11,P12,P13 13
P8 P8,P1,P2,P3,P4,P5,P6,P7,P9,P10,P11,P12,P13 13 P9 P9,P1,P2,P3,P4,P5,P6,P7,P8,P10,P11,P12,P13 13
P10 P10,P1,P2,P3,P4,P5,P6,P7,P8,P9,P11,P12,P13 13
P11 P11,P1,P2,P3,P4,P5,P6,P7,P8,P9,P10,P12,P13 13
P12 P12,P1,P2,P3,P4,P5,P6,P7,P8,P9,P10,P11,P13 13
2. Menghitung jumlah r-neighbors dari pi.
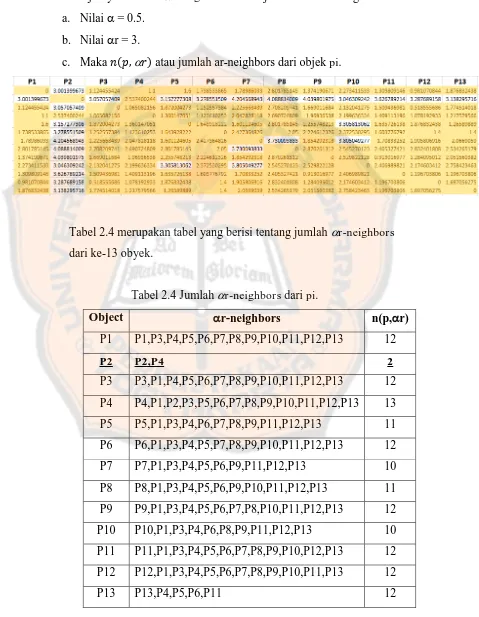
Selanjutnya mencari r-neighbors dari objek P2 adalah sebagai berikut: a. Nilai = 0.5.
b. Nilai r = 3.
c. Maka �,� atau jumlah ar-neighbors dari objek pi.
Tabel 2.4 merupakan tabel yang berisi tentang jumlah r-neighbors
dari ke-13 obyek.
Tabel 2.4 Jumlah r-neighbors dari pi.
Object r-neighbors n(p,r)
P1 P1,P3,P4,P5,P6,P7,P8,P9,P10,P11,P12,P13 12
P2 P2,P4 2
P3 P3,P1,P4,P5,P6,P7,P8,P9,P10,P11,P12,P13 12
P4 P4,P1,P2,P3,P5,P6,P7,P8,P9,P10,P11,P12,P13 13
P5 P5,P1,P3,P4,P6,P7,P8,P9,P11,P12,P13 11 P6 P6,P1,P3,P4,P5,P7,P8,P9,P10,P11,P12,P13 12
P7 P7,P1,P3,P4,P5,P6,P9,P11,P12,P13 10
P8 P8,P1,P3,P4,P5,P6,P9,P10,P11,P12,P13 11
P9 P9,P1,P3,P4,P5,P6,P7,P8,P10,P11,P12,P13 12
P10 P10,P1,P3,P4,P6,P8,P9,P11,P12,P13 10 P11 P11,P1,P3,P4,P5,P6,P7,P8,P9,P10,P12,P13 12
P12 P12,P1,P3,P4,P5,P6,P7,P8,P9,P10,P11,P13 12
3. Menghitung rata-rata dari n(p,r) pada r-neighbors dari pi.
Selanjutnya adalah menghitung rata-rata dari �,� pada keseluruhan objek p pada r-neighborhood dari p.
4. Menghitung standar deviasi dari n(p,r) pada r-neighbors.
Setelah menghitung rata-rata �,� langkah selanjutnya adalah menghitung standar deviasi �,� pada r-neighbors.
5. Menghitung nilai MDEF untuk pi pada radius r.
6. Menghitung standar deviasi MDEF.
Dimana � , �, � = ̂ ��,�,
̂ ��,�, , yaitu normalisasi deviasi
̂ � , �, dari � ,� untuk � ��, � .
7. Menghitung kMDEF.
8. Local Correlation Integral
Jika nilai > � maka objek tersebut merupakan outlier, jika < � maka objek tersebut bukan termasuk outlier. Dari perhitungan di atas, objek P2 memiliki nilai > � . Maka dapat disimpulkan bahwa objek P2 termasuk outlier.
Yang menjadi outlier di Semester 1 adalah mahasiswa ke 2, pada Semester 2 yang menjadi outlier adalah mahasiswa ke 2, pada Semester 3 yang menjadi outlier
25
BAB III
METODOLOGI PENELITIAN
Pada bab ini berisi mengenai metode penambangan data yang digunakan yaitu metode Knowledge Discovery in Database (KDD) yang dikemukakan oleh Jiawei Han dan Kamber.
3.1 Data yang Dibutuhkan
Pada penelitian ini data yang digunakan adalah data akademik mahasiswa yang meliputi nilai indeks prestasi semester dari semester satu sampai semester empat dan nilai tes masuk mahasiswa program studi Teknik Informatika fakultas Sains dan Teknologi Universitas Sanata Dharma
Yogyakarta tahun angkatan 2007 dan 2008. Data tersebut diperoleh dari Gudang Data akademik mahasiwa Universitas Sanata Dharma hasil penelitian Rosa, dkk (2011). Data ini berupa script query yang berisi gudang data dengan format .sql kemudian data tersebut diolah.
Data yang digunakan dalam penelitian ini adalah data nilai hasil tes masuk mahasiswa melalui jalur tes tertulis dan jalur prestasi. Dan juga data nilai indeks prestasi mahasiswa dari semester satu sampai dengan semester empat.
3.2 Pengolahan Data
Berikut adalah tahapan yang dilakukan dalam pengolahan data:
3.2.1 Penggabungan Data (Data Integration)
Pada tahap ini mengekstrak skrip .sql tersebut di dalam SQLyog. Setelah skrip tersebut di eksrak akan menghasilkan sebuah
database bernama “gudangdata” yang terdiri dari dim_angkatan, dim,
dim_daftarsmu, dim_fakultas, dim_jeniskel, dim_kabupaten, dim_prodi, dim_prodifaks, dim_statuses, dan fact_lengkap2. Gambar
Gambar 3.1 Database “gudangdata”
3.2.2 Seleksi Data (Data Selection)
Pada tahap ini merupakan proses menyeleksi data yang relevan. Data yang tidak sesuai akan dihilangkan. Data dipilih dan diseleksi yang sesuai untuk dilakukan perhitungan, dimana data yang tidak relevan akan dibuang dari penelitian. Data yang digunakan terdapat
pada tabel ‘fact_lengkap2’ karena dalam tabel tersebut terdapat nilai
hasil seleksi tes masuk mahasiswa dan terdapat nilai indeks prestasi mahasiswa dari semester satu sampai dengan semester 4. Data yang dipakai adalah kolom ips1, ips2, ips3, ips3, ips4, nil11, nil12, nil13, nil14, nil15, dan final.
Kemudian menyeleksi kembali baris tersebut untuk mengambil data baris dengan sk_prodi = 27. Baris dengan sk_prodi = 27 merupakan data mahasiswa Teknik Informatika. Gambar 3.2
Gambar 3.2 Isi tabel “fact_lengkap”.
3.2.3 Transformasi Data (Data Transformation)
Tahap ini merupakan tahap untuk mentransformasikan data ke dalam bentuk yang sesuai untuk ditambang. Pada tahap ini, data yang akan di transformasi adalah atribut ips1, ips2, ips3, dan ips4 yang memiliki range nilai antara 0 sampai dengan 4.00. Untuk atribut nil11, nil12, nil13, nil14, dan nil15 memiliki range nilai antara 0 sampai dengan 10. Sedangkan nilai final memiliki range nilai antara 0 sampai dengan 100.
Data mentah perlu dilakukan proses transfiormasi untuk meningkatkan performanya. Salah satu cara transformasi yang
digunakan adalah dengan cara melakukan normalisasi.
Untuk melakukan transformasi menggunakan rumus min-max normalization:
′ = − � �
� �− � � new_ � �− _ � � + _ � �
1. Normalisasi atribut nil11, nil12, nil13, nil14, dan nil15
Pada tahap ini dilakukan normalisasi untuk menyamakan jangkauan nilai terhadap atribut ips1, ips2, ips3, dan ips4.
Misalnya nil11 akan dinormalisasi, nil11 adalah 8.00, kemudian dilakukan proses normalisasi. Tabel 3.1 merupakan tabel yang berisi data atribut nill11, nil12, nil13, nil14, dan nil15
yang belum di normalisasi.
Dimana:
minA= 0
maxA= 10
new_minA= 0
new_maxA= 4
v = 8.00
′= −
− − + = , ∗ + = ,
Tabel 3.1 Contoh atribut nil11, nil12, nil13, nil14, dan nil15 sebelum di normalisasi
No Ips1 Nil11 Nil12 Nil13 Nil14 Nil15
1 3.72 8.00 6.00 6.00 7.00 5.00
2 2.89 6.00 5.00 5.00 7.00 5.00
3 2.56 6.00 4.00 5.00 7.00 5.00
4 3.28 7.00 6.00 7.00 6.00 6.00
5 1.89 6.00 5.00 6.00 6.00 7.00 6 1.44 10.00 5.00 9.00 6.00 7.00
7 4.00 6.00 6.00 4.00 4.00 7.00
8 1.72 3.00 2.00 8.00 3.00 1.00
11 2.94 6.00 4.00 6.00 3.00 7.00
12 2.44 5.00 5.00 6.00 5.00 5.00 13 1.72 7.00 6.00 8.00 8.00 2.00
Nilai lama yang belum dinormalisasi yaitu 8.00 dikurangi nilai minimum dari atribut a, dimana nil11 mempunyai jarak
antara 0-10. Nilai maksimum dari atribut a yaitu 10 dikurangi nilai minimum dari atribut a yaitu 0. Kemudian hasil dari pengurangan nilai yang belum dinormalisasi dengan nilai minimum dari atribut a akan dibagi dengan hasil pengurangan nilai maksimum dari atribut a dan nilai minimum dari atribut a. Langkah selanjutnya adalah nilai maksimum baru dari atribut a dikurangi dengan nilai minimum baru dari atribut a.
Kemudian hasil pembagian nilai yang belum dinormalisasi dengan nilai minimum dari atribut a akan dibagi dengan hasil nilai maksimum dari atribut a dan nilai minimum dari atribut a akan dikalikan dengan hasil pengurangan nilai maksimum baru dari atribut a dengan nilai minimum baru dari atribut a. Dari hasil perkalian tersebut kan dikurangi dengan nilai minimum baru dari atribut a. Maka hasil penjumlahan tersebut akan menghasilkan nilai yang sudah dinormalisasi. Tabel 3.2 merupakan tabel yang berisi data atribut nill11, nil12, nil13, nil14, dan nil15 setelah di normalisasi.
Tabel 3.2 Contoh atribut nil11, nil12, nil13, nil14, dan nil15 setelah di normalisasi
No Ips1 Nil11 Nil12 Nil13 Nil14 Nil15
1 3.72 3.20 2.40 2.40 2.80 2.00
2 2.89 2.40 2.00 2.00 2.80 2.00
3 2.56 2.40 1.60 2.00 2.80 2.00
5 1.89 2.40 2.00 2.40 2.40 2.80
6 1.44 4.00 2.00 3.60 2.40 2.80 7 4.00 2.40 2.40 1.60 1.60 2.80
8 1.72 1.20 0.80 3.20 1.20 0.40
9 2.89 2.00 2.00 3.20 2.00 2.80
10 2.94 2.80 2.00 2.00 2.00 1.60
11 2.94 2.40 1.60 2.40 1.20 2.80
12 2.44 2.00 2.00 2.40 2.00 2.00 13 1.72 2.80 2.40 3.20 3.20 0.80
2. Normalisasi nilai atribut final
Pada tahap ini dilakukan normalisasi untuk atribut final. Misalnya nilai final akan dinormalisasi, nilai final adalah 67.80, kemudian dilakukan proses normalisasi. Tabel 3.3 merupakan tabel yang berisi data atribut nill11, nil12, nil13, nil14, dan nil15
yang belum di normalisasi.
Dimana:
minA= 0
maxA= 100
new_minA= 0
new_maxA= 4
v = 67.80
′= . −
Tabel 3.3 Contoh atribut nil11, nil12, nil13, nil14, dan nil15 sebelum di normalisasi
No Ips1 Ips2 Ips3 Ips4 Final
1 2.06 2.32 2.91 3.00 67.80
2 2.72 2.50 2.96 2.38 67.75 3 3.33 3.48 3.78 3.48 69.41
4 2.39 3.00 2.43 2.82 71.60
5 2.11 2.71 2.43 2.45 73.75
6 3.00 2.96 2.61 3.29 67.57
7 3.72 3.56 3.43 3.67 78.67 8 3.44 3.04 2.88 3.48 71.33
9 2.17 2.70 3.09 3.63 72.00
10 3.89 3.75 3.00 3.62 77.00
11 2.89 3.68 2.88 3.76 72.99
12 3.11 3.08 2.78 3.48 68.17
13 2.00 2.00 2.29 3.00 77.10
Nilai lama yang belum dinormalisasi yaitu 67,80 dikurangi nilai minimum dari atribut a, dimana nilai final mempunyai jarak antara 0-100. Nilai maksimum dari atribut a yaitu 100 dikurangi dengan nilai minimum dari atribut a yaitu 0. Kemudian hasil dari
pengurangan nilai yang belum dinormalisasi dengan nilai minimum dari atribut a akan dibagi dengan hasil pengurangan nilai maksimum dari atribut a dan nilai minimum dari atribut a. Langkah selanjutnya adalah nilai maksimum baru dari atribut a di kurangi dengan nilai minimum baru dari atribut a.
perkalian tersebut akan dikurangi dengan nilai minimum baru dari atribut a. Maka hasil penjumlahan tersebut akan menghasilkan nilai yang sudah dinormalisasi. Tabel 3.4 merupakan tabel yang berisi data atribut nill11, nil12, nil13, nil14, dan nil15 yang belum di normalisasi.
Tabel 3.4 Contoh atribut nil11, nil12, nil13, nil14, dan nil15 setelah di normalisasi
No Ips1 Ips2 Ips3 Ips4 Final
Normalisasi
1 2.06 2.32 2.91 3.00 2.712
2 2.72 2.50 2.96 2.38 2.710
3 3.33 3.48 3.78 3.48 2.776
4 2.39 3.00 2.43 2.82 2.864 5 2.11 2.71 2.43 2.45 2.950
6 3.00 2.96 2.61 3.29 2.703
7 3.72 3.56 3.43 3.67 3.147
8 3.44 3.04 2.88 3.48 2.853
9 2.17 2.70 3.09 3.63 2.880 10 3.89 3.75 3.00 3.62 3.080
11 2.89 3.68 2.88 3.76 2.920
12 3.11 3.08 2.78 3.48 2.727
13 2.00 2.00 2.29 3.00 3.084
3.2.4 Penambangan Data (Data Mining)
di Universitas Sanata Dharma angkatan 2007 dan 2008 dari semester satu sampai dengan semester empat.
Pada tahap ini terdapat beberapa variabel yang digunakan, antara lain:
1. Variabel Input
Variabel input yang digunakan terdiri dari nil11, nil12, nil13,
nil14, nil15, dan nilai final. Dan terdiri dari nilai per semester yaitu nilai ips1, ips2, ips3, dan ips4.
2. Variabel output
Variabel output yang digunakan adalah data mahasiswa yang menjadi outlier dari hasil perhitungan dengan algoritma Local Correlation Integral dari data nilai hasil seleksi masuk dan nilai mahasiswa dari semester satu sampai dengan semester 4.
Keluaran ini berupa nomor urut mahasiswa, MDEF, KMDEF, jumlah outlier, dan lama deteksi outlier.
3.2.5 Evaluasi Pola (Pattern Evaluation)
Evaluasi pola merupakan proses mengidentifikasi apakah pola atau informasi yang ditemukan sesuai fakta atau hipotesa yang ada sebelumnya. Luaran yang diperoleh berupa data-data outlier
menggunakan algoritma Local Correlation Integral dan akan diuji kebenarannya oleh pemilik data apakah hipotesa outlier yang mereka miliki sama dengan hasil yang diperoleh sistem.
3.2.6 Presentasi Pengetahuan (Knowledge Presentation)
35
BAB IV
ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi tentang identifikasi sistem, perancangan sistem secara umum, perancangan sistem, perancangan struktur data, dan perancangan antarmuka yang akan dibuat.
4.1 Identifikasi Sistem
Universitas Sanata Dharma melakukan penerimaan mahasiswa baru setiap tahunnya. Seleksi penerimaan mahasiswa baru dibagi menjadi dua jalur, yaitu jalur prestasi dan jalur tes. Syarat untuk calon mahasiswa yang mengikuti jalur prestasi adalah melampirkan nilai akademik SMA/sederajat
kelas XI semester 1 dan 2, yang kemudian nilai-nilai tersebut akan dirata-rata dan menjadi nilai final. Calon mahasiswa yang mengikuti jalur tes diwajibkan mengikuti tes tertulis. Tes tertulis memiliki 5 komponen nilai yaitu nilai penalaran numerik, nilai penalaran verbal, nilai hubungan ruang, nilai bahasa Inggris, dan nilai kemampuan numerik. Calon mahasiswa yang mengikuti tes akan memiliki lima komponen tes tersebut, kelima komponen nilai tersebut akan dirata-rata dan akan menjadi nilai final.
Mahasiswa yang diterima di Universitas Sanata Dharma setiap semesternya akan dilakukan evaluasi untuk mengetahui tingkat pemahaman setiap mahasiswa, dan pada akhir semester setiap mahasiswa akan memperoleh nilai hasil belajar selama satu semester yang disebut Indeks Prestasi Semester (IPS).
Mahasiswa yang nilai tes masuk universitasnya tinggi belum tentu memiliki Indeks Prestasi Semester yang tinggi, dan mahasiswa yang nilai tes masuk universitasnya rendah belum tentu memiliki Indeks Prestasi Semester yang rendah. Mahasiswa dengan data yang unik ini disebut sebagai outlier.
perilaku yang tidak normal, salah satunya adalah mendeteksi nilai mahasiswa yang nilai tes masuk universitasnya bagus tetapi pada saat kuliah mahasiswa tersebut mendapatkan nilai yang rendah.
Dalam tugas akhir ini akan dijelaskan bagaimana proses mendeteksi
outlier dan proses pembuatan aplikasi untuk mendeteksi outlier
menggunakan algoritma Local Correlation Integral (LOCI). Algoritma LOCI
merupakan salah satu algoritma yang memiliki kemampuan untuk mendeteksi outlier dalam sekumpulan data. Algoritma LOCI dapat diimplementasikan pada sekumpulan data numerik untuk mendeteksi adanya outlier dengan pendekatan density-based.
Dalam penelitian ini data yang digunakan adalah data yang bertipe file (.xls) dan file (.csv) dan dari Basis Data, hasil output akan disimpan kedalam file Text Documents (.txt), Ms. Word (.doc), dan Ms. Excel (.xls).
4.1.1 Diagram Use Case
Dalam sebuah sistem akan selalu ada interaksi, di mana interaksi tersebut menggambarkan proses jalannya sistem tersebut dan fungsi dari sistem tersebut. Untuk menggambarkan interaksi tersebut, tugas akhir ini menggunakan diagram use case. Diagram use case digunakan untuk mengetahui fungsi apa saja yang ada di dalam sebuah sistem dan siapa saja yang berhak menggunakan fungsi-fungsi tersebut. Diagram use case menjelaskan secara sederhana fungsi sistem dari sudut pandang user.
Diagram use case yang digunakan adalah dapat dilihat pada
bagian lampiran 1.
Di dalam diagram use case akan ada 1 pengguna yang akan
memiliki fungsi seleksi atribut untuk menseleksi atribut yang tidak diikutsertakan dalam deteksi outlier.
Deskripsi use case dapat dilihat pada bagian lampiran 2.
4.1.2 Narasi Use Case
Untuk mengetahui detail Narasi Use Case secara keseluruhan
dapat dilihat pada bagian lampiran 3.
4.2 Perancangan Sistem Secara Umum
4.2.1 Input Sistem
Sistem yang dibangun dapat menerima masukan berupa data yang bertipe file excel (.xls) dan (.csv) atau data dalam tabel yang terdapat dalam basis data.
Sistem ini membutuhkan masukan untuk memproses pencarian
outlier yaitu: 1. Radius atau r
Radius adalah sebuah parameter yang digunakan untuk
mendefinisikan r-neighborhood suatu obyek.
2. Alpha atau
Alpha adalah sebuah parameter skala yang digunakan untuk mendefinisikan r-neighborhood suatu obyek.
3. Konstanta atau k
Konstanta adalah sebuah parameter yang digunakan untuk
mendefinisikan konstanta.
a. Data Hasil Seleksi Masuk Jalur Tes
No Nama
Atribut Penjelasan Nilai
1 Nomor urut Atribut ini merupakan nomor untuk menunjukkan obyek mahasiswa.
1 - 126
2 Nil11 Atribut ini merupakan nilai komponen 1.
0.00 - 4.00
3 Nil12 Atribut ini merupakan nilai komponen 2.
0.00 - 4.00
4 Nil13 Atribut ini merupakan nilai komponen 3.
0.00 - 4.00
5 Nil14 Atribut ini merupakan nilai komponen 4.
0.00 - 4.00
6 Nil15 Atribut ini merupakan nilai komponen 5.
0.00 - 4.00
7 Final Atribut ini merupakan nilai rata-rata rapor siswa pada saat SMA/sederajat.
0.00-4.00
b. Data Hasil Seleksi Masuk Jalur Prestasi
No Nama
Atribut Penjelasan Nilai
1 Nomor urut
Atribut ini merupakan nomor untuk menunjukkan obyek mahasiswa.
1 - 126
2 Final Atribut ini merupakan nilai rata-rata rapor siswa pada saat SMA/sederajat.
c. Data Indeks Prestasi Semester
No Nama
Atribut Penjelasan Nilai
1 Nomor urut
Atribut ini merupakan nomor untuk menunjukkan obyek mahasiswa.
1 - 126
2 Ips1 Atribut ini merupakan Indeks Prestasi Semester 1.
0.00-4.00
4 Ips2 Atribut ini merupakan Indeks Prestasi Semester 2.
0.00-4.00
5 Ips3 Atribut ini merupakan Indeks Prestasi Semester 3.
0.00-4.00
6 Ips4 Atribut ini merupakan Indeks Prestasi Semester 4.
0.00-4.00
4.2.2 Proses Sistem
Tahap-tahap dalam proses sistem adalah sebagai berikut:
1. Pengambilan Data
Pada tahap pengambilan data, sistem akan mengambil data sesuai dengan pilihan user. Data tersebut berupa file .xls dan .csv
atau mengambil data dari tabel yang terdapat didalam database. Kemudian data yang dipilih oleh user tersebut akan ditampilkan
di dalam sistem, kemudian data tersebut diseleksi oleh user, yaitu menyeleksi atribut mana saja yang akan digunakan.
2. Perhitungan Jarak Obyek Data
3. Pencarian Outlier Bersadarkan Parameter r , , dan k Tahap selanjutnya adalah mencari outlier menggunakan algoritma Local Correlation Integral. Pada tahap ini sistem akan menerima inputan berupa parameter r, parameter tersebut untuk mencari r-neighborhood suatu obyek. Inputan kedua berupa parameter , dengan parameter untuk mencari
r-neighborhood suatu obyek. Inputan ketiga berupa parameter k
yang digunakan sebagai konstanta.
Diagram proses umum sistem menggunakan algoritma Local Correlation Integral dapat dilihat pada lampiran 4.
4.2.3 Output Sistem
Sistem yang dibuat akan menghasilkan data yang dinyatakan sebagai outlier. Hasil keluaran dari sistem tersebut adalah sebagai berikut:
1. Hasil outlier untuk setiap data beserta nilai atribut yang dimiliki. 2. Jumlah data.
3. Jumlah outlier. 4. Lama deteksi outlier.
4.3 Perancangan Sistem
4.3.1 Diagram Aktivitas
Diagram aktivitas berfungsi untuk menggambarkan aliran fungsionalitas sistem. Diagram aktivitas juga dapat digunakan untuk
menunjukkan alur kerja, dan untuk menjelaskan aktivitas yang terjadi di dalam sebuah use case.
1. Diagram Aktivitas Input Data dari File .xls atau .csv. 2. Diagram Aktivitas Input Data dari Tabel Database. 3. Diagram Aktivitas Deteksi Outlier.
5. Diagram Aktivitas Seleksi Atribut.
Untuk detail dari diagram aktivitas per use case dapat dilihat di lampiran 5.
4.3.2 Diagram Kelas Analisis
Diagram kelas analisis dapat dilihat pada lampiran 6.
Keterangan diagram analisis dipaparkan pada tabel 4.1.
Tabel 4.1 Tabel Keterangan Diagram Analisis
No Nama Kelas Jenis Keterangan
1 DatabaseController Entity Kelas ini digunakan untuk menampilkan data dari tabel database Oracle maupun mySQL berdasarkan tabel yang dipilih pengguna.
2 Graph Controller Kelas ini digunakan untuk membuat graph dan edge setiap verrteks. Dan untuk proses perhitungan outlier
menggunakan algoritma
Local Correlation Integral. 3 Seleksi Atribut Entity Kelas ini digunakan untuk
melakukan proses seleksi atribut, dan menyimpan atribut yang digunakan untuk
proses deteksi.
atribut yang digunakan untuk proses deteksi outlier.
5 CheckBoxTableModel Entity Kelas ini digunakan untuk membentuk dan mengatur seleksi atribut menjadi sebuah tabel model.
6 DataLoci Entity Kelas ini digunakan untuk menyimpan data hasil outlier. 7 KoneksiDataBase Controller Kelas ini digunakan untuk melakukan koneksi antara sistem dengan database.
8 LociTabelModel Entity Kelas ini digunakan untuk menampilkan DataLoci ke dalam tabel model.
9 HalamanAwal Boundary Kelas ini berisi tampilan awal yang digunakan untuk
menghubungkan ke halaman utama.
10 HalamanBantuan Boundary Kelas ini berisi tampilan informasi atau petunjuk
penggunaan sistem.
11 HalamanPilihDatabase Boundary Kelas ini berisi tampilan untuk memilih database yang digunakan untuk proses deteksi outlier.
13 HalamanPilihTabel Boundary Kelas ini berisi tampilan untuk memilih tabel basisdata yang akan digunakan untuk proses deteksi outlier.
14 HalamanTentang Boundary Kelas ini berisi tampilan informasi tentang sistem.
15 HalamaUtama Boundary Kelas ini berisi tentang tampilan halaman utama dari sistem yang terdiri dari proses input data, seleksi tabel, dan deteksi outlier.
4.3.3 Diagram Sequence
Diagram Sequence digunakan untuk menggambarkan perilaku pada setiap skenario dan digunakan untuk memberikan gambaran detail dari setiap diagram use case.
1. Diagram Sequence Input Data dari File .xls atau .csv. 2. Diagram Sequence Input Data dari Tabel Basisdata. 3. Diagram Sequence Deteksi Outlier.
4. Diagram Sequence Simpan Hasil Deteksi Outlier. 5. Diagram Sequence Seleksi Atribut.
Untuk penjelasan rinci dari masing-masing diagram sequence
dapat dilihat pada lampiran 7.
4.3.4 Diagram Kelas Desain
4.3.5 Rincian Algoritma Setiap Method Pada Tiap Kelas
1. Rincian Algoritma pada Method di Kelas
DatabaseController.
Nama Method Fungsi Method Algoritma Method
tampilTabelOracle(Co nnection conn)
Menampilkan seluruh daftar tabel yang ada di database Oracle.
1. Membuat kueri untuk menampilkan daftar tabel dari basisdata Oracle dengan sintaks: select table_name from user_tables user_tables.
2. Mengeksekusi kueri.
3. Mengembalikan nilai rset yang berisi daftar tabel yang ada pada basisdata Oracle.
tampilTabelMYSql (Connection conn)
Menampilkan seluruh dartar tabel yang ada di database mySQL.
1. Membuat kueri untuk menampilkan daftar tabel dari basisdata MySQL dengan sintaks: show tables.
2. Mengeksekusi kueri.
3. Mengembalikan nilai rset yang berisi daftar tabel yang ada pada basisdata mySQL.
selectTable(Connectio n conn, String namaTable)
Menampilkan isi tabel berdasarkan tabel yang dipilih.
1. Membuat kueri untuk menampilkan daftar tabel dari basisdata MySQL dengan sintaks: select * from + namaTable.
2. Mengeksekusi kueri.
3. Mengembalikan nilai rset yang berisi
daftar tabel yang sesuai dengan
2. Rincian Algoritma pada Method di Kelas KoneksiDatabase.
Nama Method Fungsi Method Algoritma Method
KoneksiDataBaseSQL (String url, String user, String password)
Melakukan koneksi ke Database MySQL.
1. Membuat koneksi basis data SQL ke dalam method connection = DriverManager.getConnection(url, user, password). Parameter tersebut dicocokkan dengan nilai dari inputan pengguna pada login ke dalam database.
2. Jika inputan benar maka kan muncul
pesan Koneksi Berhasil”.
3. JIka tidak maka akan muncul pesan error.
4. Mengembalikan connection.
KoneksiDataBaseOrac le(String url, String user, String password)
Melakukan koneksi ke Database Oracle
1. Membuat koneksi basis data Oracle
ke dalam method connection = DriverManager.getConnection(url, user, password). Parameter tersebut dicocokkan dengan nilai dari inputan pengguna pada login