PERBANDINGAN ALGORITMA DECISION TREE C4.5 DAN K-NEAREST NEIGHBOR (K-NN) DALAM MENDIAGNOSA PENYAKIT LIVER SKRIPSI
Teks penuh
Gambar

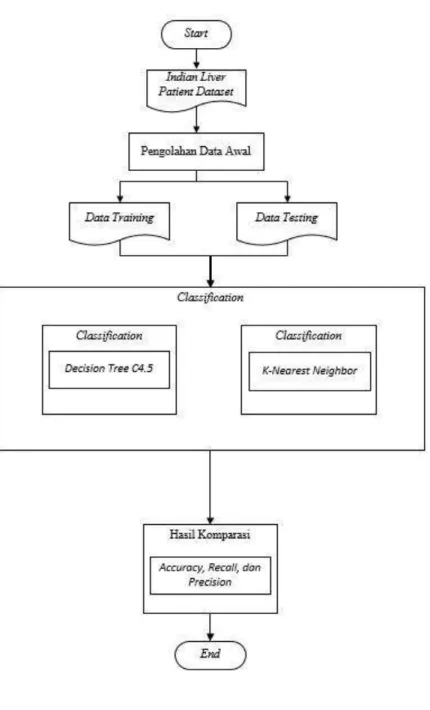
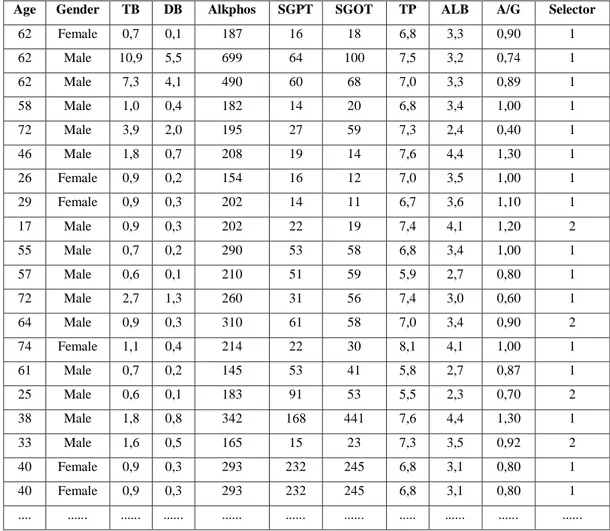
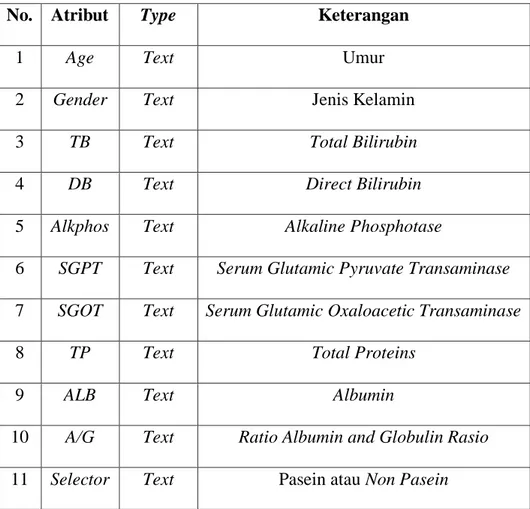
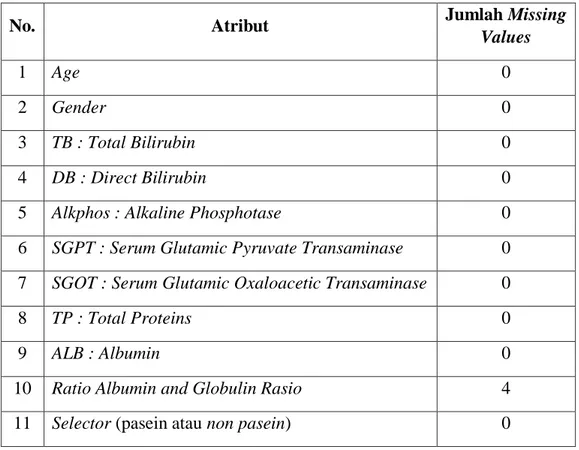
Dokumen terkait
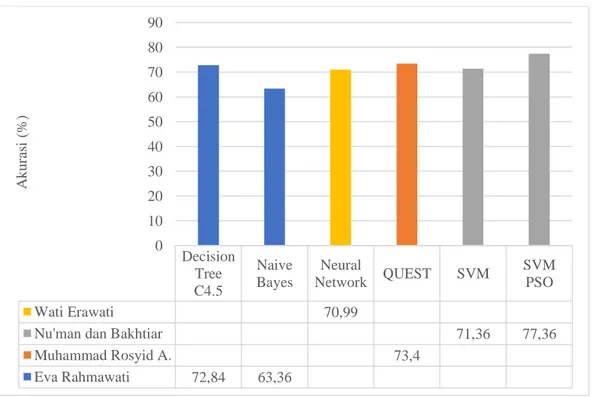
Selain itu Penelitian tentang algoritma tersebut sebelumnya juga pernah dilakukan oleh Lilis Setyowati dengan menggunakan algoritma decision tree C4.5,ada penelitian
Dalam melakukan identifikasi penyakit algoritma backpropagation akan menggunakan bobot-bobot yang ada dari hasil proses pelatihan untuk digunakan pada proses
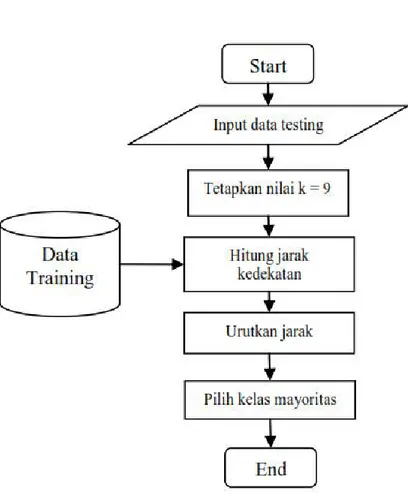
Dalam penelitian ini implementasi algoritma data mining menggunakan algoritma K-Nearest Neighbor, Algoritma ini dapat digunakan untuk membantu prediksi
Klasifikasi dan Evaluasi Dataset yang telah selesai dilakukan pembagian dan seleksi fitur menggunakan XGBoost dilanjutkan dengan proses klasifikasi pada K-Nearest Neighbor menggunakan
Data training dan data testing Adapun hasil penentuan kesamaan data penyakit diabetes mellitus dengan metode K-Nearest Neighbor menggunakan software Rapid Miner
Dari beberapa hasil penelitian sebelumnya (Prasetya, 2017) yang berjudul sistem rekomendasi E-Commerce dengan menggunakan metode algoritma K-Nearest Neighbor, pada
Sehingga dapat disimpulkan bahwa kombinasi parameter terbaik untuk klasifikasi data penyakit Hepatitis C dengan menggunakan algoritma K-Nearest Neigbor KNN yaitu metrik perhitungan
Artikel ini menjelaskan tentang algoritma K-Nearest Neighbor berbasis Particle Swarm Optimization untuk prediksi penyakit Ginjal
