Fakultas Ilmu Komputer
Universitas Brawijaya 1978
Segmentasi Pelanggan Menggunakan Metode Fuzzy C-Means Clustering Berdasarkan LRFM Model Pada Toko Sepatu
(Studi Kasus: Ride Inc Kota Malang)
Muhammad Taufik Dharmawan1, Nanang Yudi Setiawan2, Fitra Abdurrachman Bachtiar3 Program Studi Sistem Informasi, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Ride Inc. merupakan toko sepatu kulit yang berdiri pada tahun 2012 di Kota Malang. Data pelanggan yang dimiliki belum dimanfaatkan untuk mendapatkan nilai yang mampu membantu Ride Inc. dalam menyusun strategi bisnis untuk mendapatkan dan mempertahankan pelanggan. Segmentasi pelanggan merupakan pembagian kelompok terhadap pelanggan yang memiliki kemiripan karakteristik dan mampu memberikan informasi dari kelompok tersebut. Karakteristik pelanggan dapat dilihat dengan menerapkan model LRFM (Length, Recency, Frequency, dan Monetary). Metode clustering yang digunakan adalah Fuzzy C-Means. Elbow method digunakan untuk membantu proses penentuan jumlah cluster yang baik secara iteratif dengan menampilkan hasil berupa grafik. Data yang digunakan dari Ride Inc. adalah data transaksi pelanggan sejumlah 668 data transaksi dan 522 pelanggan pada periode Juli 2017 hingga Maret 2018. Hasil jumlah cluster berdasarkan elbow method adalah dua cluster dan tiga cluster yang kemudian diimplementasikan ke dalam Fuzzy C-Means. Analisis segmen pelanggan berdasarkan LRFM model berupa peringkat dari kelompok pelanggan yang menguntungkan dengan melihat nilai L, F, dan M tertinggi dan R terendah. Visualisasi dashboard menjadi output penelitian berdasarkan nilai LRFM yang diberikan ke Ride Inc. Hasil rata-rata dari uji usability dari 2 responden adalah 65 yang berarti pihak Ride Inc. menerima visualisasi dashboard tersebut.
Kata kunci: segmentasi pelanggan, LRFM model, fuzzy c-means, elbow method, dashboard.
Abstract
Ride Inc. is a leather shoe store established in 2012 in the city of Malang. Customer data owned has not been utilized to obtain values that are able to help Ride Inc. in creating business strategies to gain and retain customers. Customer segmentation is groups of customers who have a similarity of characteristics that able to provide information. The characteristics of customers can be seen by applying LRFM (Length, Recency, Frequency, and Monetary) model. Methods used in grouping customers are Fuzzy C-Means clustering. Elbow method used to help the process of determining the best number of clusters iteratively. The data used from the Ride Inc. are 522 customers data in the period of July 2017 until March 2018. The results shows that there are two and three clusters that formed based on elbow method that are then implemented into the Fuzzy C-Means. Customer segment analysis based on the LRFM model formed in the rank of profitable customer group based on the highest value of L, F, and also M and the lowest R. Dashboard visualization become the output of the research based on the value of the given LRFM to Ride Inc. The average score of usability testing from 2 respondents is 65. This means that Ride Inc. receive the dashboard visualization.
Keywords: customer segmentation, LRFM model, fuzzy c-means, elbow method, dashboard.
1. PENDAHULUAN
Ride Inc. merupakan bisnis yang bergerak pada bidang fashion, khususnya sepatu dengan bahan dasar kulit untuk laki-laki dan wanita.
Ride Inc telah berdiri sejak tahun 2011 di Kota
Malang yang dikelola oleh Zacharia Lukkyta sebagai pendiri dan teman-temannya. Terdapat dua sistem penjualan yang digunakan Ride Inc.
yaitu, ready-to-wear atau membuat stok terhadap sepatu dan made-to-order atau pembuatan sepatu ketika ada pelanggan yang
memesan. Pelanggan yang melakukan pemesanan made-to-order dapat memilih bahan-bahan yang diinginkan, seperti jenis kulit.
Data yang dimiliki oleh Ride Inc. adalah data pelanggan dari kedua sistem. Namun, penerapan Customer Relationship Management (CRM) terhadap data tersebut belum digunakan sebagai strategi bisnis. Data pelanggan hanya digunakan untuk menghitung penghasilan setiap bulan. Selain itu, terdapat kendala dalam penentuan jumlah setiap tipe kulit yang dibeli untuk pembuatan setiap tipe sepatu. Terjadi kerugian pada Ride Inc. yang disebabkan oleh kedua kendala tersebut seperti sepatu yang tidak terjual. Berdasarkan hal tersebut dilakukannya pengelompokkan pelanggan dengan metode partitioning method dalam clustering yang dapat mengelompokkan data secara langsung berbasis jarak dan terdapat minimal satu objek dalam cluster.
Implementasi metode clustering dengan Fuzzy C-Means dibantu dengan model LRFM (length, recency, frequency, dan monetary) sebagai variabel bantuan dalam pemetaan nilai- nilai pelanggan yang akan digunakan sebagai acuan dalam penerapan strategi bisnis.
Pemetaan pelanggan dilakukan berdasarkan nomor unik dari pelanggan atau id pelanggan.
Implementasi dilakukan dalam perangkat lunak R. Setelah mendapatkan hasil clustering yang valid dan terverifikasi, dilakukan pembuatan visualisasi dashboard menggunakan software Power BI sebagai keluaran penelitian ini yang akan direkomendasikan kepada pihak Ride Inc.
2. LANDASAN KEPUSTAKAAN 2.1 Clustering
Clustering merupakan salah satu metode dalam data mining. Menurut Han dan Kamber (2006) clustering merupakan cara mengidentifikasi daerah padat dan jarang dalam suatu objek yang bertujuan untuk menemukan pola distribusi secara keseluruhan dan korelasi yang menarik antar atribut. Analisis cluster telah banyak digunakan dalam berbagai hal, contohnya adalah dalam bisnis, clustering dapat membantu bidang pemasaran dalam menemukan kelompok pelanggan berdasarkan pola pembelian dan dalam bidang biologi, clustering dapat digunakan untuk mengkategorikan gen dengan fungsi serupa.
Oleh karena itu, clustering juga disebut sebagai
segmentasi data karena dapat mengelompokkan partisi dari data yang besar dan ditetapkan ke dalam kelompok sesuai kemiripannya. Sebagai salah satu metode dari data mining, analisis cluster dapat digunakan sebagai alat untuk mendapatkan wawasan mengenai distribusi data guna mengamati masing-masing cluster dan berfokus pada kelompok tertentu untuk diamati lebih lanjut.
2.2 LRFM Model
LRFM model merupakan model pengembangan dari RFM model yang merupakan metode untuk menganalisis nilai pelanggan untuk segmentasi pasar. RFM model memiliki tiga atribut yaitu, recency yang didefinisikan sebagai cara melihat pembelian terakhir dari pelanggan dengan hari atau bulan, frequency yang didefinisikan sebagai jumlah pembelian yang dilakukan dalam jangka waktu tertentu dan monetary didefinisikan sebagai jumlah rata-rata uang yang dikeluarkan dalam jangka waktu tertentu. Menurut Wu dkk. (2014) RFM model tidak dapat membedakan pelanggan mana yang memiliki hubungan jangka pendek atau jangka panjang terhadap perusahaan. Oleh karena itu, terdapat pertimbangan dalam penambahan jangka panjang (Length), yang didefinisikan sebagai jumlah periode waktu dari pembelian pertama hingga pembelian terakhir.
2.3 Fuzzy C-Means
K-Means clustering merupakan metode clustering yang sederhana dan sering digunakan karena mampu mengelompokkan data dalam jumlah banyak dengan waktu yang relatif cepat dan efisien (Santosa, 2007). Selain K-Means, terdapat metode lain seperti Fuzzy C-Means merupakan metode unsupervised yang kuat untuk analisis data dan konstruksi model serta objek antara beberapa kelas tidak dipaksa sepenuhnya untuk dimiliki oleh satu kelas, melainkan dengan memiliki derajat keanggotaan antara 0 hingga 1 yang menunjukkan keanggotan objek (Suganya dan Shanthi, 2012).
2.4 Elbow Method
Metode Elbow menurut Makwana dan Kodinariya (2013) adalah metode visual yang digunakan untuk menentukan jumlah cluster
Fakultas Ilmu Komputer, Universitas Brawijaya
yang tepat pada sebuah dataset dengan cara kerja tahap awal memulai k=2 dan akan terus bertambah setiap step selagi menghitung nilai variabel. Grafik yang dihasilkan akan turun secara drastis sebelum akhirnya menjadi stabil dan disitulah nilai k yang optimum.
2.5 Dashboard
Enterprise Dashboard merupakan alat untuk menampilkan informasi dalam bentuk tabel, laporan serta indikator visual dan informasi tersebut akan ditampilkan secara visual di layar dengan cara yang memudahkan pengguna dalam mengawasi dan mengelola inisiatif bisnisnya (Malik, 2005). Sedangkan Few (2006) menggunakan terminologi Information Dashboard yang berarti tampilan visual dari informasi yang dibuat untuk dapat mengawasi kinerja organisasi dan mampu memudahkan pengguna dalam mencapai tujuan tertentu.
2.6 System Usability Scale (SUS)
System Usability Scale (SUS) merupakan metode pengujian terhadap pengguna dari tampilan antarmuka sistem berupa kuesioner berisi 10 instrumen yang diperkenalkan oleh Brooke (1986). Penilaian terhadap kuesioner tersebut dimulai dari 1 yang berarti sangat tidak setuju hingga 5 yang berarti sangat setuju dengan kondisi seperti berikut (Sauro, 2011):
1. Pernyataan ganjil merupakan pernyataan positif yang nilainya didapat dengan cara mengurangi nilai dengan 1.
2. Pernyataan genap merupakan pernyataan negatif yang nilainya didapat dengan cara mengurangi 5 dengan nilai.
3. Hasil dari pernyataan genap dan ganjil memiliki rentang 0 hingga 4.
4. Hasil adalah total dari item genap dan item ganjil dikalikan dengan 2.5 dan memiliki hasil nilai dengan rentang 0 hingga 100.
3. METODOLOGI
Metodologi penelitian menggunakan alur seperti pada Gambar 1.
Gambar 1. Diagram Alur Penelitian Alur penelitian dimulai dengan pemahaman bisnis dan identifikasi masalah melalui wawancara non-formal untuk mengetahui informasi dari bisnis Ride Inc dengan pendirinya. Selanjutnya melakukan studi literatur dengan mencari referensi serupa yang dapat memecahkan masalah serupa.
Referensi bisa berasal dari jurnal nasional Studi literatur
Pengumpulan data
Preprocessing data
Clustering menggunakan Fuzzy C-Means Pemahaman bisnis
dan identifikasi masalah
Uji validitas hasil clustering
Uji verifikasi hasil clustering
Pembuatan visualisasi hasil
clustering
Analisis hasil usability testing
Kesimpulan dan saran
ataupun internasional dan e-book. Setelah mempelajari literatur, pengumpulan data dilakukan terhadap Ride Inc sesuai yang dibutuhkan penelitian, yaitu data pelanggan.
Tahap selanjutnya adalah melakukan penelitian yang dimulai dari preprocessing data dengan mengolah data sesuai kebutuhan LRFM model. Penggunaan metode elbow sebelum masuk ke tahap clustering data berfungsi sebagai acuan jumlah cluster yang digunakan.
Data yang sudah siap dipakai kemudian diimplementasikan ke dalam proses clustering menggunakan metode fuzzy c-means dengan tools R. Hasil dari proses clustering adalah mengetahui persebaran dan cluster pada setiap data.
Setelah mendapatkan hasil, dilakukan uji validitas terhadap cluster dengan membandingkan nilai terhadap jumlah cluster yang digunakan dengan metode Modified Partition Coefficient (MPC), Davies Bouldin’s Index, dan packages ClValid dalam tools R.
Kemudian dilakukan uji verifikasi terhadap hasil cluster dengan menggunakan metode Euclidean distance untuk mengetahui cluster pada setiap data telah sesuai atau tidak. Proses terakhir dalam clustering adalah melakukan analisis dari setiap cluster untuk mengetahui karakteristik setiap kelompok baik yang menguntungkan ataupun tidak bagi Ride Inc.
Tahap berikutnya adalah membuat visualisasi dashboard berdasarkan nilai LRFM model untuk rekomendasi kepada Ride Inc.
Alur selanjutnya adalah melakukan usability testing dari visualisasi dashboard terhadap pihak Ride Inc untuk mengetahui layak tidaknya sistem tersebut dengan menggunakan metode System Usability Scale (SUS).
Kemudian dilakukan pengambilan kesimpulan dari penelitian untuk menjawab setiap rumusan masalah. Tahap terakhir adalah pembuatan saran untuk penelitian selanjutnya.
4. Hasil Penelitian 4.1 Pemetaan LRFM
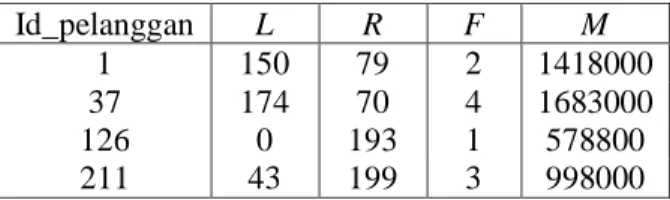
Tahap ini merupakan pemetaan nilai kebutuhan LRFM (length, recency, frequency, dan monetary) berdasarkan data pelanggan.
Variabel length, recency, dan frequency menggunakan variabel tanggal dan monetary menggunakan variabel harga. Hasil dari pemetaan nilai LRFM dapat dilihat pada Tabel 1.
Id_pelanggan L R F M
1 150 79 2 1418000
37 174 70 4 1683000
126 0 193 1 578800
211 43 199 3 998000
4.2 Preprocessing Data
Dalam tahap ini terdapat tiga proses, antara lain data transformation menggunakan metode logarithmic, data cleaning dengan menggunakan script dari Klodian Dhana (2016), dan normalisasi data dengan metode Min-Max. Data transformation dilakukan karena data masih bersifat tidak konsisten atau memiliki jarak yang jauh setiap variabelnya.
Karena didalam variabel length masih terdapat nilai 0, maka menurut Elliot (1977) perlu dilakukan penambahan nilai 1 terhadap variabel tersebut. Hasil dari transformasi data dapat dilihat pada Tabel 2.
Tabel 2. Nilai Hasil Transformasi Data
Id_pelanggan L R F M
1 2,17 1,9 0,47 6,15
37 2,24 1,85 0,69 6,22
126 0 2,28 0,3 5,76
211 1,64 2,07 0,6 5,99 Variabel L, R, F, dan M adalah Length, Recency, Frequency, dan Monetary. Tahap selanjutnya adalah data cleaning untuk menghapus outliers. Hasil yang didapat adalah tidak terdapat outliers pada variabel recency.
Sedangkan pada variabel monetary terdapat 1,9% atau sebesar 10 outliers yang dihapus.
Variabel length dan frequency tidak dilakukan penghapusan outliers karena nilai yang menguntungkan jumlahnya hanya 11,8% atau sebesar 62 dan jika dilakukan, maka nilai yang menguntungkan akan dianggap outliers. Data yang mengandung outliers dapat dilihat dalam Tabel 3.
Tabel 3. Data Hasil Proses Penghapusan Outliers
Id_pelanggan L R F M
68 2,03 2 0,6 NA
271 1,72 1,93 0,84 NA
296 1,7 1,87 0,69 NA
337 0 1,91 0,69 NA
357 1,62 1,83 0,9 NA
506 1,5 1,96 0,84 NA
Fakultas Ilmu Komputer, Universitas Brawijaya
523 0 2,39 0,3 NA
524 0 2,36 0,3 NA
525 0 1,64 0,3 NA
526 0 1,44 0,3 NA
Nilai NA merupakan data yang terdeteksi sebagai outliers.
4.3 Clustering
Tahap clustering terbagi menjadi beberapa proses, yaitu penentuan jumlah cluster dengan elbow method dan implementasi metode clustering dengan fuzzy c-means. Hasil cluster ditunjukkan melalui grafik pada Gambar 2.
Gambar 2. Hasil Elbow Method
Pada gambar tersebut ditunjukkan penurunan drastic terakhir terletak diantara 2 dan 4, dimana titik tersebut menunjukkan angka 3 yang berarti hasil dari implementasi dari metode elbow menghasilkan 3 cluster. Untuk pengimplementasian metode clustering, jumlah cluster yang digunakan adalah 2 dan 3 cluster untuk membandingkan validitas dan performa cluster yang lebih baik.
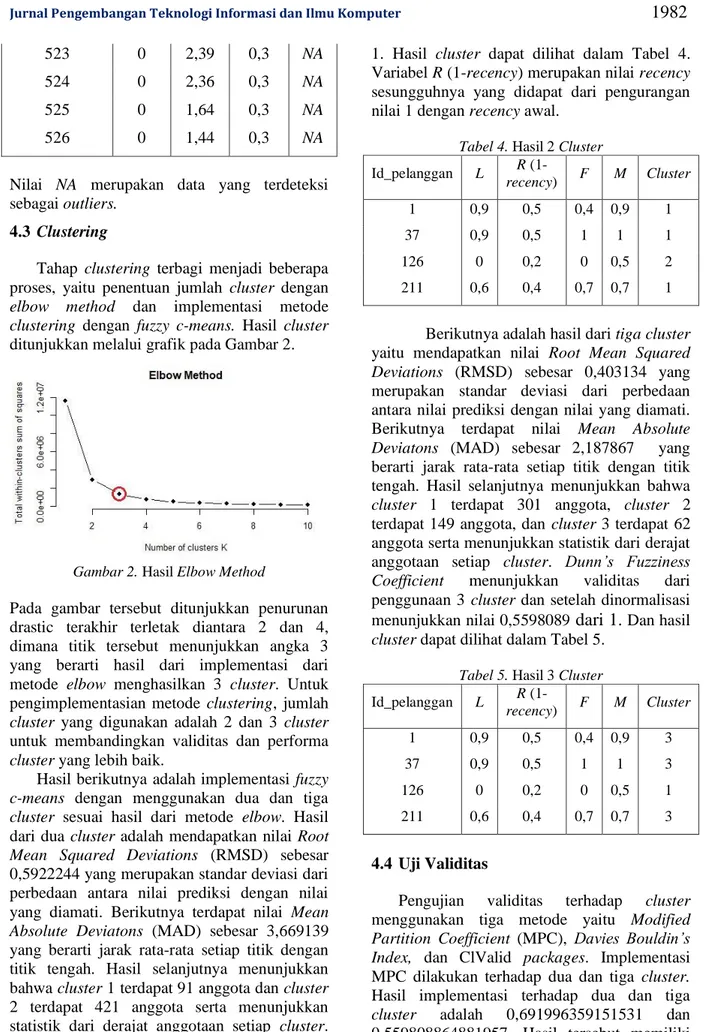
Hasil berikutnya adalah implementasi fuzzy c-means dengan menggunakan dua dan tiga cluster sesuai hasil dari metode elbow. Hasil dari dua cluster adalah mendapatkan nilai Root Mean Squared Deviations (RMSD) sebesar 0,5922244 yang merupakan standar deviasi dari perbedaan antara nilai prediksi dengan nilai yang diamati. Berikutnya terdapat nilai Mean Absolute Deviatons (MAD) sebesar 3,669139 yang berarti jarak rata-rata setiap titik dengan titik tengah. Hasil selanjutnya menunjukkan bahwa cluster 1 terdapat 91 anggota dan cluster 2 terdapat 421 anggota serta menunjukkan statistik dari derajat anggotaan setiap cluster.
Dunn’s Fuzziness Coefficient menunjukkan validitas dari penggunaan 2 cluster dan setelah dinormalisasi menunjukkan nilai 0.691996 dari
1. Hasil cluster dapat dilihat dalam Tabel 4.
Variabel R (1-recency) merupakan nilai recency sesungguhnya yang didapat dari pengurangan nilai 1 dengan recency awal.
Tabel 4. Hasil 2 Cluster Id_pelanggan L R (1-
recency) F M Cluster
1 0,9 0,5 0,4 0,9 1
37 0,9 0,5 1 1 1
126 0 0,2 0 0,5 2
211 0,6 0,4 0,7 0,7 1
Berikutnya adalah hasil dari tiga cluster yaitu mendapatkan nilai Root Mean Squared Deviations (RMSD) sebesar 0,403134 yang merupakan standar deviasi dari perbedaan antara nilai prediksi dengan nilai yang diamati.
Berikutnya terdapat nilai Mean Absolute Deviatons (MAD) sebesar 2,187867 yang berarti jarak rata-rata setiap titik dengan titik tengah. Hasil selanjutnya menunjukkan bahwa cluster 1 terdapat 301 anggota, cluster 2 terdapat 149 anggota, dan cluster 3 terdapat 62 anggota serta menunjukkan statistik dari derajat anggotaan setiap cluster. Dunn’s Fuzziness Coefficient menunjukkan validitas dari penggunaan 3 cluster dan setelah dinormalisasi menunjukkan nilai 0,5598089 dari 1. Dan hasil cluster dapat dilihat dalam Tabel 5.
Tabel 5. Hasil 3 Cluster Id_pelanggan L R (1-
recency) F M Cluster
1 0,9 0,5 0,4 0,9 3
37 0,9 0,5 1 1 3
126 0 0,2 0 0,5 1
211 0,6 0,4 0,7 0,7 3
4.4 Uji Validitas
Pengujian validitas terhadap cluster menggunakan tiga metode yaitu Modified Partition Coefficient (MPC), Davies Bouldin’s Index, dan ClValid packages. Implementasi MPC dilakukan terhadap dua dan tiga cluster.
Hasil implementasi terhadap dua dan tiga cluster adalah 0,691996359151531 dan 0,559808864881957. Hasil tersebut memiliki arti bahwa dua cluster merupakan cluster terbaik karena memiliki kecenderungan nilai
yang tidak monoton pada setiap data.
Pengujian kedua yaitu menggunakan Davies Bouldin’s Index. Pengujian dilakukan secara iteratif dengan menggunakan 2 hingga 10 cluster. Hasil terbaik merupakan nilai terendah dan diperoleh oleh dua cluster dengan nilai 0.86. Hasil tersebut menunjukkan setiap cluster memiliki jarak data satu sama lain yang sesuai.
Pengujian terakhir dilakukan dengan ClValid packages pada tools R. Packages tersebut berisi nilai connectivity, dunn index, dan silhouette width. Pengujian dilakukan secara iteratif dengan menggunakan 2 hingga 10 cluster. Hasil terbaik diperoleh dua cluster dengan nilai 0 pada connectivity, 0,4 pada dunn index, dan 0,61 pada silhouette width. Nilai connectivity semakin mendekati 0, maka data berada pada cluster yang tepat sedangkan semakin jauh dari 0, maka data berada cluster yang kurang tepat. Selain itu, nilai dunn index dilihat dari hasil yang mendekati nilai 1 karena semakin tinggi maka rasio jarak akan semakin kecil antara data pada cluster yang sama dengan cluster yang berbeda. Dan hasil silhouette width dilihat dari hasil yang mendekati 1 dengan alasan semakin tinggi tingkat kepercayaan cluster yang terkelompok dan tidak terkelompok.
4.5 Uji Verifikasi
Pengujian verifikasi dilakukan terhadap dua
dan tiga cluster pada setiap datanya dengan melihat kesesuaian cluster data dengan hasil dari penghitungan Euclidean distance. Untuk mendapatkan kesesuaian dari kedua hasil tersebut digunakan function identical pada bahasa pemrograman R. Hasil pada dua cluster adalah TRUE yang berarti cluster setiap data dalam dua cluster telah sesuai atau tidak ada perbedaan dengan penghitungan dengan Euclidean distance. Dan hasil pada tiga cluster juga mendapatkan TRUE yang berarti telah sesuai. Hasil verifikasi 2 dan 3 cluster dapat dilihat dalam Tabel 6 dan Tabel 7.
Tabel 6. Verifikasi 2 Cluster Id_pelangga
n
Fuzzy C- Mean
s
Jarak data ke
centroid Nilai Minimal
Hasil Valid
asi
1 2
1 1 0,2 1,3 0,2 1
37 1 0,4 2,1 0,4 1
126 2 0,6 0,03 0,03 2
211 1 0,1 1,1 0,1 1
Tabel 7. Verifikasi 3 Cluster Id_pelang
gan
Fuzz y C- Mea ns
Jarak data ke
centroid Nilai Minim al
Hasil Valida 1 2 3 si
1 1 1,3 1,2 0,1 0,13 3
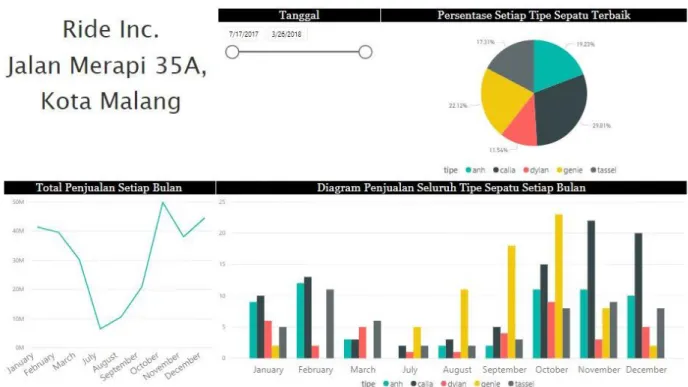
Gambar 3. Halaman Utama Dashboard
Fakultas Ilmu Komputer, Universitas Brawijaya
37 1 2,2 2 0,3 0,3 3
126 2 0,0
2 0,1 0,8 0,02 1
211 1 1,2 1,1
9 0,0
4 0,04 3
4.6 Visualisasi Dashboard
Visualisasi dashboard menggunakan jumlah cluster yang memperoleh nilai terbaik pada uji validitas, yaitu dua cluster. Visualisasi dashboard dibuat dengan menggunakan tools Power BI. Visualisasi menghasilkan tiga halaman, yaitu halaman utama, halaman cluster, dan halaman data 2 cluster. Gambar 3 merupakan tampilan dari halaman utama dashboard. Halaman utama menampilkan slider tanggal, persentase total setiap sepatu, grafik total penjualan setiap bulan pada periode Juli 2017 hingga Maret 2018 dan diagram penjualan setiap bulan berdasarkan tipe sepatu. Penjualan terbanyak dalam periode tersebut diperoleh tipe sepatu calla dengan transaksi sebanyak 69 kali.
Kemudian terdapat halaman 2 cluster yang berisi persentase isi dari jumlah setiap cluster, jumlah transaksi setiap tipe sepatu pada tiap- tiap cluster, dan 3D Scatterplot dari LRM (Length, Recency, dan Monetary), RFM (Recency, Frequency, dan Monetary) dan LRF (Length, Recency, dan Frequency) untuk merepresentasikan posisi setiap data berdasarkan cluster. Perbedaan anggota cluster adalah 17,77% atau 91 pelanggan pada cluster 1 dan 82,23% atau 421 pelanggan pada cluster 2.
Perbedaan pembelian tertinggi diperoleh tipe sepatu genie sebanyak 50 transaksi pada cluster 2 dan 19 pada cluster 1.
Halaman terakhir yaitu halaman data 2 cluster yang berisi tabel LRFM (Length, Recency, Frequency dan Monetary), diagram batang cluster berdasarkan variabel F atau frequency, tabel pelanggan terbaik berdasarkan frequency, pelanggan terbaik berdasarkan monetary dan kesimpulan. Hasil pada diagram batang cluster menunjukkan bahwa cluster 1 tidak terdapat pelanggan yang melakukan transaksi satu kali sedangkan cluster 2 tidak terdapat pelanggan yang melakukan transaksi sebanyak tiga dan empat kali.
4.7 Usability Testing
Pengujian usability menggunakan System Usability Scale (SUS) terhadap visualisasi dashboard menghasilkan 2
responden. Responden tersebut adalah founder dan co-founder dari Ride Inc. Total nilai pada responden pertama dan kedua masing-masing mendapatkan nilai 65. Setelah mendapatkan skor akhir, selanjutnya melakukan perhitungan rata-rata menggunakan persamaan dari Soleh (2005) seperti berikut:
𝑟𝑎𝑡𝑎 − 𝑟𝑎𝑡𝑎 = ∑ 𝑥𝑖
𝑁…
𝑛𝑖=1 (1)
Nilai 𝑥𝑖 merupakan nilai penjumlahan dari responden dan 𝑁 merupakan jumlah responden.
Hasil rata-rata dari kedua responden adalah 65.
Hasil tersebut menurut Brooke (2013) merupakan acceptability range kategori marginal tipe high yang berarti dapat diterima oleh pihak Ride Inc serta termasuk grade scale tipe D dan adjective rating tipe good.
5. Kesimpulan
Berdasarkan pemetaan dengan LRFM model, perilaku setiap segmen yang dapat dilihat pada perilaku setiap pelanggan pada setiap variabel length, recency, frequency, dan monetary dalam transaksi yang dilakukan di Ride Inc. Sedangkan implementasi clustering melewati beberapa proses, yaitu data preprocessing, penentuan cluster dengan metode elbow dan implementasi fuzzy c-means.
Data preprocessing meliputi data selection dari data pelanggan, data transformasi yang mengubah nilai menjadi stabil dan data normalisasi mengubah data transformasi menjadi normal dengan range 0 hingga 1.
Setelah itu, penerapan metode elbow menunjukkan penurunan signifikan terakhir pada jumlah 3 cluster. Dan implementasi fuzzy c-means menggunakan jumlah 2 dan 3 cluster untuk mendapatkan perbandingan jumlah cluster terbaik.
Pengujian cluster terdiri dari uji validitas cluster dan uji verifikasi cluster. Tahap uji validitas cluster menggunakan metode Modified Partition Coefficient, Davies Bouldin's Index, dan packages ClValid yang berisi Connectivity, Dunn Index, dan Silhouette Width. Hasil dari implementasi ketiga metode pengujian menunjukkan bahwa 2 cluster adalah hasil yang optimal. Namun, hasil dari metode elbow menunjukkan nilai 3 untuk jumlah cluster terhadap penurunan terakhir yang signifikan, sehingga proses clustering dilakukan dua kali dengan jumlah 2 cluster. Selanjutnya, penerapan uji verifikasi cluster dengan
euclidean distance menghasilkan cluster yang sesuai dengan implementasi fuzzy c-means.
Terakhir, Visualisasi dashboard ditampilkan dalam bentuk interaktif dengan menggabungkan beberapa diagram dan grafik.
Diagram yang ditampilkan berupa diagram donat dan diagram batang. Diagram donat menampilkan persentase dari total penjualan setiap tipe sepatu dan persentase dari cluster yang dihasilkan. Diagram batang menampilkan penjualan seluruh tipe sepatu setiap bulannya, jumlah transaksi setiap tipe sepatu berdasarkan cluster, dan total pelanggan berdasarkan variabel frequency pada setiap cluster. Dan grafik yang ditampilkan berupa total penjualan dari Ride Inc setiap bulannya pada periode Juli 2017 hingga Maret 2018 yang mengalami kenaikan dan penurunan. Selain itu, hal yang ditampilkan adalah scatterplot 3D dari LRM, RFM, serta LRF untuk melihat persebaran data dan tabel yang menunjukkan pelanggan terbaik berdasarkan frequency dan monetary. Dan dilakukan pengujian usability dengan System Usability Scale (SUS) terhadap visualisasi dashboard. Terdapat dua responden yaitu founder dan co-founder Ride Inc dan menghasilkan nilai rata-rata 65 yang berarti visualisasi dashboard dapat diterima dengan kategori marginal tipe high.
6. DAFTAR PUSTAKA
Brooke, John. 1986. SUS – A Quick and Dirty Usability Scale. Redhatch Consulting, (Online), United Kingdom.
Elliott, J. M. 1977. Some Methods for The Statistical Analysis of Samples of Benthic Invertebrates. Second Edition.
Ambleside: Freshwater Biological Association.
Few, Stephen. 2006. Information Dashboard Design. First Edition. (Ebook). Italy:
O’Reilly Media, Inc.
Han, Jiawei dan Kamber, Micheline. 2006.
Data Mining: Concepts and Technologies. Second Edition. (Ebook).
Oxford: Elsevier.
Kodinariya, Trupti M. dan Makwana, Prashant R. 2013. Review on Determining Number of Cluster in K-Means Clustering. International Journal Advance Research in Computer Science and Management Studies, (Online), Volume 1, Issue 6,
(www.ijarcsms.com).
Malik, Shadan. 2005. Enterprise Dashboards:
Design and Best Practices for IT.
(Ebook). Canada: John Wiley & Sons, Inc.
Santosa, B. 2007. Data Mining Teknik Pengumpulan Data Untuk Keperluan Bisnis. Yogyakarta: GrahaIlmu.
Sauro, Jeff. 2011. Measuring Usability with The System Usability Scale (SUS).
https://measuringu.com/sus/. Diakses pada 29 Oktober 2018.
Savitri, Aulia Dewi dkk. 2018. Segmentasi Pelanggan Menggunakan Metode K- Means Clustering Berdasarkan Model RFM Pada Klinik Kecantikan (Studi Kasus: Belle Crown Malang). Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, Volume 2.
Soleh, Achmad Zanbar. 2005. Ilmu Statistik.
Cetakan Pertama. Bandung: Rekayasa Sains.
Suganya, R. dan Shanthi, R. 2012. Fuzzy C- Means Algorithm- A review.
International Journal of Scientific and Research Publications, Volume 2, Issue 11.
Wu, Hsin-Hung dkk. 2014. Analyzing Patients' Values by Applying Cluster Analysis and LRFM Model in a Pediatric Dental Clinic in Taiwan. The Scientific World Journal, Volume 2014.