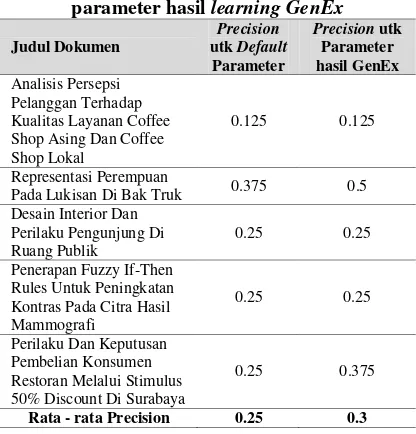
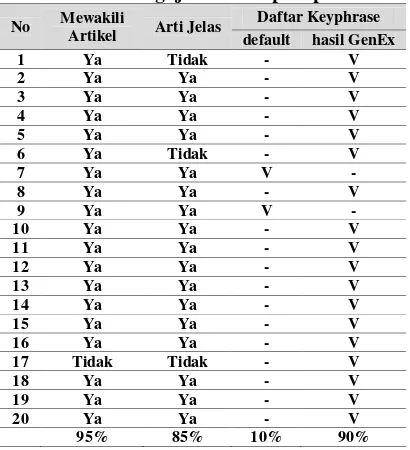
pengujian oleh responden menunjukkan bahwa 95 responden menyatakan bila keyphrase yang di-generate dapat mewakili artikelnya. Kedua hasil menunjukkan bahwa aplikasi ini telah berhasil menggenerate kata kunci (keyphrase) yang sesuai dan dapat mewakili arti
Teks penuh
Gambar
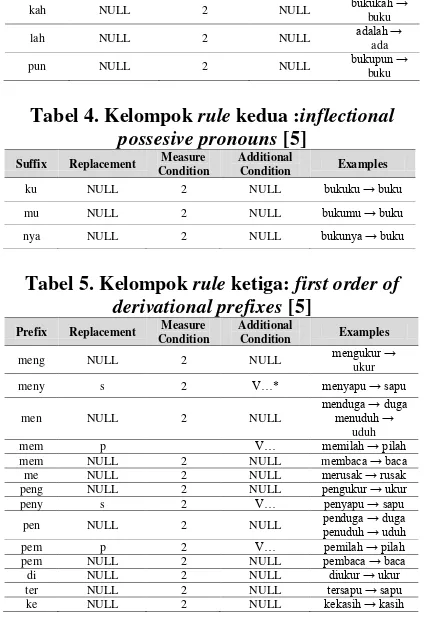
![Tabel 1. Daftar Parameter pada Extractor [1]](https://thumb-ap.123doks.com/thumbv2/123dok/1558056.2049157/2.595.316.523.299.400/tabel-daftar-parameter-pada-extractor.webp)
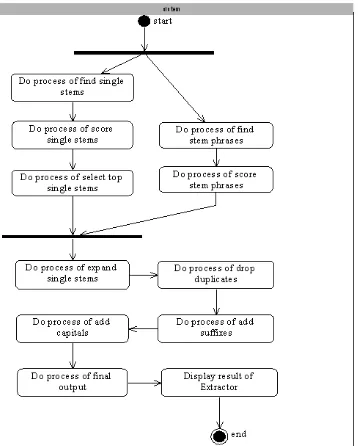
![Gambar 2. Langkah - langkah proses algoritma Extractor [1]](https://thumb-ap.123doks.com/thumbv2/123dok/1558056.2049157/3.595.314.520.475.590/gambar-langkah-langkah-proses-algoritma-extractor.webp)
Dokumen terkait
Melihat dari kasus tersebut di atas penyalahgunaan keadaan yang dilakukan oleh Tergugat I adalah jenis dari bentuk actual undue influence, di mana salah satu pihak
kabayan dan berbisik > !dah akang mah iya-iya sa0a biar saya yang ngat!r. > !dah akang mah iya-iya sa0a biar saya
Mereka diberi tayangan dan bahan bacaan (melalui Whattsapp group, Zoom, Google Classroom, Telegram atau media daring lainnya) terkait materi Dampak Mutasi pada Salingtemas
Seluruh data yang terkumpul akan dikupas pada pembahasan sekaligus menjawab pertanyaan penelitian tentang penggunaan prinsip-prinsip Islam dalam mendidik lanjut usia
diibaratkan seperti teknologi penginderaan jarak jauh menggunakan citra satelit yang digunakan untuk mendeteksi potensi sumber daya alam di suatu titik lokasi,
Hasil penelitian menunjukkan bahwa : (1) program pembagian tugas untuk pegawai dan staf Jurusan Keperawatan telah dibagi dan disesuaikan dengan tugas pokok dan
Kredit macet apapun sebabnya, pendapatan (bagi hasil) yang seharusnya diperoleh dan/atau kredit yang seharusnya kembali ke koperasi ternyata tidak dapat ditarik oleh
Perusahaan Belanda, yang kini hampir selama satu abad memperluas perdagangan- nya di Kerajaan Siam di bawah nenek moyang Duli Yang Maha Mulia Paduka Raja yang sangat luhur,
