BAB 2
LANDASAN TEORI
2.1. Katak Sawah
Katak sawah merupakan salah satu jenis katak yang memiliki nama latin Fejerfarya cancrivora. Katak sawah sesuai dengan namanya banyak dijumpai di daerah persawahan, rawa-rawa dan selokan. Katak sawah juga kerap muncul di daerah-daerah buatan manusia seperti kebun yang tidak terawat, tanah yang memiliki banyak genangan dan areal kolam. Katak yang kerap muncul di daerah buatan manusia sering mengganggu dan menjadi hama bagi manusia karena habitat asli mereka yang sudah hilang,
Katak sawah memiliki bentuk yang bervariasi, mulai dari yang berukuran kecil sampai berukuran besar sesuai dengan ketersediaan jumlah makanan yang ada di alam. Tetapi rata-rata ukuran katak jantan dewasa sekitar 60 mm dan katak betina dewasa sekitar 70-80 mm SVL (snout to vent length, dari moncong ke anus). Katak sawah memiliki badan berwarna coklat gelap yang menyerupai lumpur dengan corak-corak gelap yang tidak beraturan seperti yang terlihat pada Gambar 2.1. Tangan dan kaki juga kerap memiliki corak-corak gelap.
Katak sawah bereproduksi dengan bertelur, mirip seperti ikan yang pembuahannya dilakukan di luar rahim katak betina. Katak jantan mengeluarkan suara-suara menggoda yang menarik perhatian betina untuk berkembang biak (Duellmen and Trueb, 1986). Katak betina tidak pernah mengeluarkan suara terlebih dahulu untuk menarik perhatian, melainkan hanya mengeluarkan suara ketika merespon suara-suara yang dikeluarkan katak jantan. Jika suara katak jantan sudah dibalas oleh suara katak betina, maka katak jantan akan mengganti jenis suaranya menjadi suara pacaran dan mulai saling mencari untuk melakukan proses perkembang biakan. Suara-suara yang dikeluarkan katak akan berhenti ketika mereka mulai melakukan proses perkembang biakan dan mulai menghasilkan telur-telur.
Berdasarkan data yang dihimpun Badan Pusat Statistik Indonesia, lahan persawahan di seluruh Indonesia yang dialih fungsikan untuk kepentingan lainnya pada rentang tahun 2002-2010 mengalami pengurangan rata-rata 56.000 – 60.000 ha per tahun. Hal ini tentu saja berdampak pada katak sawah yang berhabitat di areal persawahan. Katak sawah akan mencari habitat lain yang memiliki kemiripan dengan habitat aslinya. Mereka akan tumbuh dan berkembang biak di areal buatan manusia. Misalnya ketika katak sawah menghuni areal kolam yang digunakan pembudidaya untuk mengembangbiakkan ikan sebagai penopang hidup. Katak sawah akan menjadi predator dan akan merugikan pembudidaya.
Ketika katak masih menjadi kecebong, kecebong akan menguasai makanan yang menjadi sumber nutrisi anakan ikan di kolam, menguasai wilayah tempat tinggal anakan ikan yang menyebabkan kurangnya kandungan oksigen di dalam kolam dan air kolam menjadi tambah keruh akibat sisa metabolisme kecebong (Amri & Toguan, 2008). Katak sawah dewasa juga tak kalah berbahayanya dari kecebong, anakan ikan dan telur-telur kerap menjadi santapan katak-katak kelaparan yang kehilangan habitat. Pergeseran alih fungsi lahan persawahan merubah pola hidup katak sawah yang mulai mejadi hama dan menciptakan kerugian bagi manusia. Pengendalian populasi katak hijau sebagai hama sangat dibutuhkan agar jumlah populasi katak hijau di ekosistem seimbang dan manusia tidak mengalami kerugian.
2.2. Voice Recognition
kata berdasarkan suaranya (Rudrapal, et. al., 2012). Voice recognition melakukan identifikasi dengan mencocokkan informasi yang terkandung di dalam suatu sinyal suara yang masuk dengan sinyal suara yang menjadi referensi dalam proses identifikasi. Informasi ini berupa karakteristik sinyal suara yang meliputi intonasi suara, pola suara, kerapatan sinyal suara dan lain sebagainya. Hal ini dikarenakan tiap-tiap objek penghasil suara memiliki karakterisitik sinyal suara yang disebabkan oleh susunan anatomi penghasil suara yang berbeda-beda. Misalnya suara jangkrik dengan suara katak, suara yang dihasilkan kedua hewan tersebut memiliki karakterisitik yang berbeda karena struktur susunan anatomi penghasil suara yang dimiliki katak dan jangkrik berbeda. Bahkan untuk manusia, tiap-tiap orang memiliki karakteristik sinyal suara yang berbeda-beda karena walaupun susunan anatominya sama tetapi tiap organ penyusun anatominya memiliki ukuran yang berbeda-beda.
Voice recognition telah banyak digunakan untuk mengatasi permasalahan yang muncul dalam kehidupan sehari. Biasanya permasalahan-permasalahan yang ditangani menyangkut keamanan dan kenyaman. Permasalahan-permasalahan tersebut bisa dibagi menjadi tiga jenis permasalahan utama, yaitu autentikasi, pengawasan dan forensik (Singh, et. al., 2012).
2.2.1. Autentikasi
Proses autentikasi merupakan proses validasi yang berkaitan dengan keamanan untuk mengakses suatu hal. Biasanya nomor PIN atau password untuk mengakses suatu hal yang sifatnya pribadi mudah lupa dan memiliki tingkat kemanan yang rendah. Nomor PIN dan password rentan untuk dibajak karena biasanya terdiri dari susunan karakter yang bisa diproses dengan acak oleh komputer. Voice recognition mengatasi masalah ini dengan menjadikan sinyal suara sebagai pengganti nomor PIN atau password untuk mengakses suatu hal yang sifatnya pribadi. Hal ini dikarenakan tiap orang memiliki karakteristik sinyal suara yang berbeda-beda. Sehingga mengecilkan resiko nomor PIN dan password dibajak untuk keuntungan sebelah pihak.
2.2.2. Pengawasan
akan menentukan pihak kemanan dalam mengambil keputusan dalam pencegahan tindak kriminalitas atau pencegahan suatu hal yang sifatnya merugikan.
2.2.3. Forensik
Forensik merupakan suatu kumpulan informasi yang dibentuk dari data dan fakta dari berbagai kejadian untuk membuktikan suatu kejadian. Hal ini bisanya digunakan di dalam proses hukum untuk mengadili dan membuktikan suatu tindakan kriminal. Voice recognition akan mengidentifikasi apakah suara yang menjadi bukti dari suatu tindakan kriminal, suara tersangka atau bukan. Meskipun hasil speaker recognition tidak bisa secara langsung menghasilkan kesimpulan yang bisa dijadikan acuan, setidaknya hasil
speaker recognition bisa menjadi bahan pertimbangan pihak kemanan untuk mengadili dan membuktikan suatu tindakan kriminal.
2.3. Mel-Frequency Cepstral Coefficients (MFCC)
Algoritma ini merupakan algoritma yang berfungsi untuk mengekstrak ciri suatu sinyal suara dengan merubah sinyal suara menjadi vektor-vektor akustik yang digunakan dalam proses klasifikasi. Algoritma ini diperkenalkan oleh Davis dan Mermelstein pada tahun 1980. MFCC merupakan algoritma ekstraksi fitur yang paling efektif dan paling banyak dipakai oleh banyak peneliti. Alur pemrosesan MFCC dibuat menyerupai alur pemrosesan sistem indra manusia dalam menangkap sinyal suara agar hasil ekstraksi fiturnya mendekati persepsi yang dihasilkan indra pendengaran manusia (Davis & Mermelstein, 1980). Algoritma MFCC mampu menghasilkan data seminimal mungkin tanpa menghilangkan informasi-informasi penting yang ada pada sinyal suara dan hal inilah yang menjadi kelebihan utama dari algoritma ini. Urutan dan cara kerja MFCC dapat dijelaskan sebagai berikut (Davis & Mermelstein, 1980).
2.3.1. Pre-processing
Pre-emphasis menimalisasi noise yang mungkin masih ada pada suatu sinyal suara dengan menyeimbangkan nilai amplitudo pada frekuensi yang tinggi dan rendah. Hasil dari proses pre-emphasis didapatkan melalui Persamaan 2.1. Hasil akhir setelah sinyal suara melewati kedua proses tersebut adalah suatu sinyal suara yang memiliki kualitas lebih baik dan tidak terdapat noise di dalamnya.
[ ] = �[ ] − x �[ − ] (2.1)
Dimana: y[n] = sinyal hasil pre-emphasis
s(n) = sinyal sebelum pre-emphasis
= 0.97
2.3.2. Frame Blocking
Frame blocking merupakan suatu tahapan yang berfungsi untuk memisahkan sinyal suara menjadi beberapa frame. Sinyal yang sudah berbentuk frame-frame menyimpan informasi-informasi yang nantinya dikonversi menjadi vektor akustik. Tiap frame
memiliki panjang yang sama dan tiap frame dipisahkan oleh overlapping. Jumlah
overlapping setengah dari panjang frame. Overlapping berfungsi untuk mempertahankan nilai yang tersimpan di dalam frame agar tidak hilang ketika dilakukan pemrosesan pada tahapan-tahapan berikutnya. Jumlah frame dari suatu sinyal suara dihitung melalui Persamaan 2.2.
J(f) = ((I – N)/M) + 1 (2.2)
Dimana: J(f) = jumlah frame I = sample rate N = frame size
M = jumlah overlapping
2.3.3. Windowing
hamming windows. Hal ini dikarenakan tingkat kerumitan formulanya yang rendah dan kefektivitasannya yang tinggi. Hasil akhir dari metode ini ditentukan dengan mengalikan frame dengan formula hamming windows. Persamaan hamming windows
ditunjukkan pada Persamaan 2.3.
= − cos �
�− , (2.3)
Dimana : w(n) = windowing
N = lebar filter n = waktu diskrit
α = 0.54
β = 0.46
2.3.4. Fast Fourier Transform (FFT)
Frame-frame yang sudah difilter pada tahap sebelumnya masih mengacu pada domain waktu. Frame tersebut harus diubah dari yang mengacu pada domain waktu menjadi domain frekuensi. Algoritma yang digunakan untuk mengkonversi frame tersebut adalah Fast Fourier Transform (FFT). Algoritma tersebut merupakan pengembangan dari algoritma Discrete Fourier Transform (DFT). FFT digunakan karena memiliki pemrosesan yang lebih cepat dan lebih optimal dibandingkan dengan DFT. Selain menghasilkan frame yang mengacu pada domain frekuensi, FFT juga menghasilkan besaran power spectrum. Power spectrum adalah besaran kuat lemahnya frekuensi yang muncul di dalam frame. Rumus FFT untuk mengubah sinyal suara dari domain waktu ke domain frekuensi ditunjukkan pada Persamaan 2.4.
� = ∑� cos � /
= − sin �� (2.4)
Dimana : F(k) = hasil FFT f(n) = sinyal masukan N = jumlah sample
2.3.5. Mel-filtering
Indra pendengaran manusia dalam mepersepsikan suatu suara memiliki daya tangkap yang lebih baik ketika suara tersebut memiliki frekuensi yang rendah dibandingkan dengan frekuensi yang tinggi. Misalnya dalam menangkap suara lolongan anjing yang berada dikejauhan, indra pendengaran manusia mampu lebih cepat mengenalinya dibandingkan dengan suara desingan pesawat jet yang memiliki frekuensi tinggi. Frekuensi linear pada sinyal suara tersebut dipersepsikan dengan menggunakan skala
mel. Skala mel ini merupakan satuan dalam mengukur pola yang terbentuk dari ciri suatu pengenalan sinyal suara.
Tahapan ini mengimplementasikan tahapan penerimaan persepsi pada manusia dengan mengubah frekuensi linear menjadi mel-spectrum. Mel-spectrum merupakan pola suara yang terbentuk dari besar kecil frekuensi yang mucul di dalam suatu area yang ada pada frame dan besarannya dihitung dalam skala mel. Sinyal suara frekuensi linear yang sudah berskala mel akan difilter sebanyak jumlah filter yang ditentukan agar menghasilkan pola suara yang disebut dengan mel-spectrum. Proses filter inilah yang mendasari tahapan ini diberi nama mel-filtering.
Langkah awal pada tahapan ini yaitu membuat filterbank dengan mengubah frekuensi linear menjadi mel-frequency. Filterbank adalah susunan filter yang digunakan untuk memfilter frekuensi sinyal suara menjadi mel-spectrum. Mel-frequency adalah skala frekuensi linear yang memiliki besaran nilai dibawah 1000 Hz dan besaran skala logaritmik diatas 1000 Hz. Satuan mel-frequency tidak lagi Hz melainkan mel. Sebelum diubah ke dalam skala mel, harus ditentukan terlebih dahulu frekuensi terendah dan tertinggi yang dimiliki suatu frekuensi linear. Kemudian ubah kedua frekuensi tersebut dengan menggunakan Persamaan 2.5. Mel-frequecy tersebut dipecah kedalam N jumlah filter dimana tiap mel-frequency memiliki selisih besaran yang sama berasarkan nilai mel-frequency terendah dan tertinggi.
M(f) = 1125 x ln(1 + f/700) (2.5)
Dimana : M(f) = mel-frequency
Mel-frquency yang berjumlah N filter tersebut diubah kembali menjadi frekuensi linear. Proses pengubahan tersebut dihitung menggunakan Persamaan 2.6. Frekuensi linear tersebut dibulatkan menjadi nilai FFT berdasarkan nilai FFT bin terdekat. Pembulatan ini dilakukan karena nilai frekuensi linear yang didapat pada Persamaan 2.6 tidak memiliki resolusi yang tepat untuk meletakkan nilai frekuensi linear tersebut pada filterbank. Nilai FFT bin didapatkan dari setengah nilai FFT yang telah ditentukan. Prosesnya pembulatannya dihitung menggunakan Persamaan 2.7.
M-1(m) = 700 x (exp(m/1125) – 1) (2.6)
Dimana : M-1(m) = frekuensi linear m = mel-frequency
f(i) = floor((nfft + 1) x h(i) / S) (2.7)
Dimana : f(i) = nilai FFT tiap frekuensi
nfft = nilai FFT yang sudah ditentukan h(i) = frekuensi linear
S = sampling rate
Filter-filter yang sudah memiliki nilai tersebut kemudian disusun membentuk
filterbank. Penyusunan filter ini dilakukan berdasarkan Persamaan 2.8. Sinyal suara yang masuk akan difilter menggunakan filterbank yang sudah tersusun tersebut. Tiap filter akan menganalisa dan membentuk pola kuat lemah frekuensi dari suatu frame di dalam sinyal suara berdasarkan power spectrum. Pola yang terbentuk inilah yang disebut dengan mel-spectrum dan menjadi ciri karakteristik suatu sinyal suara. Sinyal hasil mel-filtering didapatkan melalui Persamaan 2.9.
�
= {
�−� �− � � −� �−
� �+ −� � �+ −� �
� �− ≤ � ≤ � ��<� �− � � ≤ � ≤� �+
� >� �+
Dimana : � = mel-filterbank
m = jumlah filter k = nilai FFT
f = nilai FFT tiap filter
� = ∗log +
�� (2.9)
Dimana : � = koefisien filterbank pada frekuensi j( ≤ ≤ � = magnitude spectrum pada frekuensi j
2.3.6. Discrete Cosine Transform (DCT)
Langkah ini merupakan tahapan terakhir dari algoritma MFCC yaitu mengubah mel-spectrum kembali ke dalam domain waktu. Hasilnya disebut dengan cepstral coefficient
yang merupakan koefisien yang mencirikan suatu sinyal suara. Cepstral coefficient
dihasilkan dengan menggunakan Persamaan 2.8. Jumlah cepstral coefficient yang dihasilkan sama dengan jumlah mel-spectrum yang diproses, tetapi hanya 12 cepstral coefficient terendah yang dipakai pada proses klasifikasi. Nilai pada koefisien ini disebut dengan vektor akustik yang menjadi variabel dalam menentukan ciri suatu suara.
̃ = ∑
�=(
�̃ ) cos [
−
��]
(2.8)
Dimana : �̃ = mel-spectrum
̃ = cepstral-coefficient
K = jumlah koefisien
2.4. Vector Quantization (VQ)
ini, proses komputasi yang dilakukan sistem akan menjadi sangat kompleks dan hal ini akan membebani kinerja sistem.
VQ melakukan kompresi vektor akustik dengan memetakan sejumlah vektor akustik ke dalam suatu suatu area terbatas yang terdapat pada suatu ruang vektor dua dimensi. Tiap area disebut dengan cluster dan tiap area diwakilkan dengan codeword.
Codeword merupakan titik pusat (centroid) yang ada pada suatu area. Kumpulan dari
codeword disebut dengan codebook. Codebook inilah yang menjadi referensi dalam proses klasifikasi data.
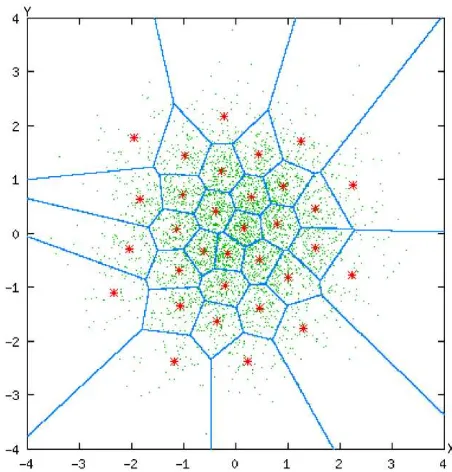
Visualisasi codebook dapat dilihat pada gambar 2.2. Gambar tersebut tediri dari tiga elemen utama, yaitu titik berwarna hijau, bintang berwarna merah dan garis berwarna biru yang membentuk sebuah area. Codebook tersebut digambarkan pada suatu ruang dengan garis vertikal menunjukkan nilai imajiner vektor dan garis horizontal menunjukkan nilai real vektor. Titik berwarna hijau menunjukkan vektor akustik yang tersebar diseluruh ruang vektor. Bintang berwarna merah menunjukkan
codeword yang menjadi representasi dari suatu cluster. Garis biru membatasi tiap cluster dan menjadi acuan posisi vektor akustik berada di cluster yang mana.
VQterbagi menjadi dua proses utama, yaitu feature training dan matching. Feature training merupakan proses perekaman data latih dan memetakannya menjadi codebook
yang menjadi referensi dalam melakukan proses klasifikasi. Proses feature training hanya memproses data latih, data uji akan langsung masuk proses matching. Matching
merupakan proses klasifikasi dengan mencocokkan pola vektor akustik data uji dengan
codebook data latih.
Pada feature-training, vektor akustik data latih akan dipetakan menjadi codebook
untuk kemudian disimpan ke dalam VQ model atau ke dalam database. VQ model adalah file berbentuk teks berekstensi vq. Proses pemetaan dan pembentukan codebook
menggunakan algoritma LBG (Linde, Buzo, Gray) yang diimplementasikan pada proses rekursif berikut (Linde, et. al., 1980):
1. Rancang sebuah vektor codebook yang menjadi acuan dari keseluruhan vektor data latih.
2. Gandakan vektor codebook dengan membagi masing-masing codebook menurut aturan:
+ = + � (2.9) − = + � (2.10)
Dimana n bernilai dari 1 sampai ukuran codebook yang sudah ditentukan dan ε
adalah parameter splitting yang bernilai 0,01. 3. Nearest Neighbour Search
Vektor data latih yang berkumpul pada area tertentu dikelompokkan. Untuk tiap vektor data latih, temukan codeword terdekat yang menjadi titik pusat codebook. Kelompokkan vektor data latih berdasarkan codeword terdekat yang akan membentuk sebuah cluster.
4. Buat codeword baru pada masing-masing cluster dengan menentukan titik pusat dari kumpulan vektor akustik yang ada di dalam cluster tersebut.
5. Iterasi 1
Lakukan pengulangan langkah 3 dan langkah 4 sampai jarak rata rata dibawah jarak rata ambang batas yang telah ditetapkan.
6. Iterasi 2
Proses matching melakukan klasifikasi dengan memetakan vektor akustik data uji dengan codebook yang sudah dilatih pada feature training dan menghitung jarak rata-rata terdekat. Hasil klasifikasi ditentukan dari jarak rata-rata-rata-rata antara vektor akustik data uji dengan codeword yang ada pada codebook. Jarak akustik data dengan codeword
yang ada pada codebook disebut dengan VQ distortion. VQ distortion dihitung menggunakan Persamaan 2.11.
,
= √∑
=−
+
+
(2.11)Dimana : = komponen ke-j dari vektor masukan
= komponen ke-j dari codeword
Proses klasifikasinya dimulai dengan memilih secara random codebook data latih yang akan dijadikan acuan. Kemudian hitung jumlah codeword yang ada pada codebook
tersebut. Kelompokkan vektor akustik data uji ke dalam codebook tersebut berdasarkan jarak terdekat antar vektor akustik dengan codeword menjadi suatu cluster yang jumlahnya sama dengan jumlah codeword. Hitung rata-rata VQ distortion pada seluruh bagian codebook. Jika nilai rata-rata pada codebook tersebut sudah didapatkan, lakukan pengulangan proses pada semua codebook yang dijadikan referensi. Bandingkan nilai rata-rata tiap codebook. Codebook yang memiliki nilai terkecil merupakan codebook
yang cocok dengan vektor akustik data uji yang masuk dan merupakan hasil dari proses klasifikasi.
2.5. Cloud Computing
Cloud computing menjadi teknologi baru paling popular dan menjadi sebuah revolusi di dalam dunia teknologi komputer. Teknologi ini merubah cara pandang orang dalam menggunakan komputer dan memiliki dampak besar dalam industri teknologi informasi. Teknologi ini membuat orang-orang jadi ketergantungan terhadap internet. Karena internet berperan besar dalam penerapan teknologi cloud computing. Pemrosesan dan penyimpanan data semua dilakukan melalui perantara internet.
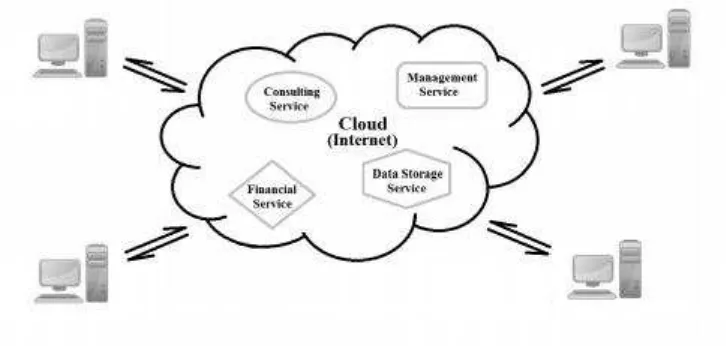
Untuk mendefenisikan cloud computing, terlebih dahulu harus dijelaskan maksud penggunaan kata cloud yang dalam bahasa Indonesia berarti awan. Penggunaan kata
1990 ketika Virtual Private Network (VPN) pertama kali dikenalkan (Hu, et. al., 2011). Daripada menggunakan kabel data untuk mengirimkan informasi, perusahaan telepon lebih memilih menggunakan VPN untuk menghubungkan provider dengan customers. VPN membuat provider menawarkan ukuran bandwidth yang sama tetapi biayanya lebih rendah dengan terus-menerus merubah rute jaringan secara real-time untuk mengakomodasi perubahan penggunaan jaringan yang selalu berubah-ubah. Hal ini membuat alur data dari provider ke costumers sangat sulit untuk diprediksi. Tanggung jawab provider dalam menjaga jaringan ini direpresentasikan sebagai awan (cloud). Penamaan cloud terus dipakai untuk proses dan pengiriman data yang tidak kelihatan bentuk fisik hardware untuk pemrosesannya oleh user dan pada masa sekarang merujuk pada internet sebagai medianya. Sehingga cloud computing dapat didefenisikan sebagai suatu teknologi yang pemrosesan, penyimpanan dan pengiriman data yang semuanya dilakukan melalui media internet. Defenisi ini divisualisasikan pada gambar 2.3.
Gambar 2.3 Visualisasi Defenisi Cloud Computing (Hu, et. al., 2011)
Cloud computing memungkinkan terjadinya pertukaran informasi antar perangkat yang berbeda-beda. Misalnya data yang diproses oleh komputer, hasil pemrosesannya dapat dilihat oleh smartphone. Hal ini bisa terjadi melalui application programming interfaces (API) yang ditanamkan pada masing-masing aplikasi pada tiap perangkat sama(Hu, et. al., 2011). Bahasa pemrograman pada tiap aplikasinya biasanya bersifat
Cloud computing sangat bergantung pada internet, web service dan server. Tiga hal ini bisa menjadi kelemahan dan bisa juga menjadi kelebihan dari teknologi ini. Internet menjadi media penyampaian informasi pada cloud computing. Tanpa internet, pemrosesan pada teknologi cloud computing tidak akan berjalan dan dengan internet, user selalu bisa melihat hasil pemrosesan dimanapun dia berada dan pada perangkat apapun yang ia gunakan. Web service dan server saling berkaitan, karena web service
merupakan sebuah pelayanan pemrosesan yang dilakukan di internet berdasarkan
script-script perintah yang disimpan di dalam server. Server menjadi tempat penyimpanan segala hasil dan pemrosesan yang dilakukan cloud computing. Hal ini menjadi kelemahan dari sisi privasi dan keamanan, karena jika server berhasil dibobol oleh pihak tertentu maka seluruh data hasil pemrosesan yang ada di server bisa diketahui dan dipergunakan untuk memperoleh keuntungan financial yang merugikan banyak pihak (Ahmed & Hossain, 2014). Dan disisi lain, penggunaan server dan web service ini membuat pemrosesan diperangkat lebih cepat dan tidak memerlukan ruang penyimpanan pada perangkat. Oleh karena itu, pihak developer yang ingin menerapkan
cloud computing pada aplikasinya harus menerapkan tingkat keamanan yang tinggi agar user yang menggunakan aplikasinya menjadi lebih nyaman.
2.6. Representational State Transfer (REST)
REST adalah suatu model arsitektur aplikasi yang membuat data ditampilkan, diakses dan dimodifikasi di internet (Hamad, et. al., 2010). Di dalam arsitektur REST, data dan fungsi-fungsinya berada di dalam suatu sumber dan sumber tersebut diakses menggunakan Uniform Resource Identifier (URL) atau bisa dikatakan REST bekerja dengan bernavigasi melalui URL untuk melaksanakan aktivitas tertentu. Arsitektur REST dibuat berdasarkan arsitektur client-server dan dirancang menggunakan protocol HTTP (Hamad, et. al., 2010). Hal inilah yang membuat REST menjadi ringan dan memiliki performa yang handal.
menjadi salah satu elemen penting dalam menerapkan teknologi cloud computing
karena prinsipnya yang menghubungkan antar perangkat melalui jaringan internet.
Kelebihan yang dimiliki RESTful sebagai sebuah web service dijelaskan sebagai berikut (Hamad, et. al., 2010):
1. Waktu dalam merespon dan memuat data lebih sedikit dibandingkan web service
lain
2. Meningkatkan jangkauan server dengan mengurangi kebutuhan untuk menjaga bentuk komunikasi.
3. Hanya memerlukan sebuah browser untuk mengakses aplikasi apapun dan dari sumber manapun.
4. Tidak membutuhkan mekanisme tambahan untuk mengakses suatu sumber yang terpisah karena arsitekturnya sudah dirancang untuk mengatasi hal tersebut.
5. Memiliki kemampuan menambahkan dukungan untuk jenis konten baru tanpa mengurangi dukungan terhadap konten yang lama.
2.7. Penelitian Terdahulu
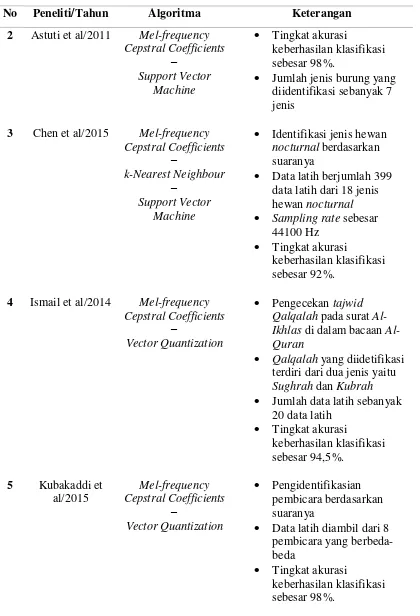
Jafar et al (2013) menggunakan algoritma MFCC untuk melakukan fitur ekstraksi dan menggunakan algoritma k-Nearest Neighbour (kNN) untuk melakukan proses identifikasi jenis katak berdasarkan suaranya. Sebanyak 750 data latih dari 15 jenis katak yang ada dihutan Malaysia direkam dengan sampling rate 48000 Hz. Data latih direkam terus selama 4 jam tanpa henti. Penelitian ini menunjukkan bahwa kolaborasi MFCC dengan kNN untuk mengidentifikasi 15 jenis katak di hutan Malaysia menghasilkan akurasi sebesar 85,7%.
Astuti et al (2011) menggunakan algoritma MFCC untuk melakukan fitur ekstraksi dan menggunakan algoritma Support Vector Machine (SVM) untuk melakukan proses identifikasi jenis burung berdasarkan suaranya. Aktivitas dari beberapa burung tertentu yang tidak normal menjadi acuan akan terjadinya suatu bencana alam. Penelitian ini mengklasifikasi 7 jenis burung dengan proses perekaman suara menggunakan sampling rate 16000 Hz. Penelitian ini menunujukkan bahwa kolaborasi MFCC dengan SVM untuk mengidentifikasi 7 jenis burung menghasilkan akurasi sebesar 98%.
jenis hewan nocturnal berdasarkan suaranya. Sebanyak 339 data latih dari 18 jenis hewan nocturnal direkam dengan sampling rate 44100 Hz. Penelitian ini menunjukkan bahwa kolaborasi MFCC dengan SVM-kNN untuk mengidentifikasi 18 jenis hewan
nocturnal menghasilkan akurasi sebesar 92%.
Ismail et al (2014) menggunakan algoritma MFCC untuk melakukan fitur ekstraksi dan menggunakan algoritma Vector Quantization (VQ) untuk melakukan pengecekan
tajwidQalqalah pada pembacaan surat Al-Ikhlas di dalam Al-Quran. Qalqalah terbagi menjadi dua jenis yaitu Sughrah dan Kubrah. Data latih diambil dari Qalqalah yang muncul pada surat Al-Ikhlas dan tiap-tiap Qalqalah dilakukan perekaman data latih sebanyak 10 data latih sehingga total 20 data latih. Penelitian ini menunjukkan bahwa kolaborasi MFCC dengan VQ untuk melakukan pengecekan tajwid Qalqalah pada pembacaan surat Al-Ikhlas di dalam Al-Quran menghasilkan akurasi sebesar 94,5%.
Kubakaddi et al (2015) menggunakan algoritma MFCC untuk melakukan fitur ekstraksi dan menggunakan algoritma Vector Quantization (VQ) mengidentifikasi pembicara berdasarkan suaranya. Data latih diambil dari 8 orang yang berbeda. Penelitian ini menunjukkan bahwa kolaborasi MFCC dengan VQ untuk mengidentifikasi 8 pembicara menghasilkan akurasi sebesar 98%.
Tabel 2.1. Penelitian Terdahulu
No Peneliti/Tahun Algoritma Keterangan
1 Jaafar et al/2013 Mel-frequency Cepstral Coefficients
Tabel 2.1. Penelitian Terdahulu (Lanjutan)
No Peneliti/Tahun Algoritma Keterangan
2 Astuti et al/2011 Mel-frequency Cepstral Coefficients
3 Chen et al/2015 Mel-frequency Cepstral Coefficients
Perbedaan penelitian yang dilakukan dengan penelitian terdahulu adalah penelitian ini mendeteksi keberadaan katak berdasarkan suaranya, bukan melakukan identifikasi jenis katak. Hasil klasifikasinya hanya menunjukkan apakah suara yang berhasil direkam suara katak atau bukan. Adapun metode yang diimplementasikan pada penelitian ini adalah sebagai berikut:
1. Metode fitur ekstraksi menggunakan algoritma Mel-frequency Cepstral Coefficients
(MFCC) yang mengubah sinyal suara menjadi koefisien-koefisien yang memiliki nilai vektor akustik sebagai ciri suatu sinyal suara.
2. Metode klasifikasi dengan menggunakan algoritma Vector Quantization (VQ). Algoritma ini terbagi menjadi dua tahapan yaitu feature training yang berfungsi untuk membentuk codebook dan matching yang berfungsi untuk melakukan klasifikasi berdasarkan jarak terdekat vektor akustik yang masuk dengan codeword
pada codebook.