1
DETEKSI OBYEK PEJALAN KAKGGUNAKAN METODE
PRINCIPAL COMPONENT ANALYSIS DAN SUPPORT VECTOR
MACHINE
Anugrah Pratama Effendi1, Yudhi Purwananto, S.Kom, M.Kom2, Rully Soelaiman, S.Kom, M.Kom3.
Fakultas Teknologi Informasi,
Institut Teknologi Sepuluh Nopember (ITS), Surabaya, 60111, Indonesia E-mail: [email protected]
Abstraksi
Deteksi obyek pejalan kaki lebih sulit daripada mendeteksi obyek lain karena orang dapat menunjukkan gerak yang bervariasi. Selain itu pejalan kaki juga memakai berbagai jenis dan warna pakaian yang berbeda. Oleh karena itu diperlukan suatu metode yang robust yang dapat mendeteksi variabilitas yang tinggi tersebut. Dalam tugas akhir ini sistem deteksi obyek yang diusulkan menggunakan Principal Component Analysis (PCA) yang digunakan untuk mereduksi dimensi dan klasifikasi menggunakan Support Vector Machine (SVM). Reduksi dimensi data ini dapat meningkatkan akurasi dan performa sistem. System ini dapat mendeteksi pejalan kaki dari depan dan belakang. Hasil uji coba terhadap metode yang dibuat ini memiliki tingkat akurasi hingga mencapai 95%..
Kata kunci : Principal Component Analysis ,Support
Vector Machine, Deteksi Obyek, Pejalan Kaki
1. Pendahuluan
Masalah deteksi obyek dapat dilihat seperti masalah klasifikasi, bagaimana membedakan obyek yang ingin dideteksi dengan obyek yang lain. Deteksi obyek pejalan kaki lebih sulit daripada mendeteksi obyek lain karena pejalan kaki dapat menunjukkan gerak yang bervariasi. Selain itu pejalan kaki juga memakai berbagai jenis dan warna pakaian yang berbeda[1]. Oleh karena itu diperlukan suatu metode yang robust yang dapat mendeteksi variabilitas yang tinggi tersebut.
Banyak sekali sistem deteksi obyek yang dibangun focus pada deteksi wajah. Ternyata metode yang digunakan untuk deteksi wajah dapat digunakan untuk deteksi obyek pejalan kaki. Banyak sekali sistem deteksi obyek pejalan kaki menggunkan informasi gerakan, kamera statis, atau focus pada tracking.
Dalam paper ini diimplementasikan sebuah sistem deteksi obyek pejalan kaki menggunakan PCA (Principal Component Analysis) sebagai metode untuk mereduksi dimensi[2] dan SVM (Support Vector Machine) sebagai metode untuk klasifikasi simana
sebuah citra masuk kedalam kelas pejalan kaki atau kelas bukan pejalan kaki.Deteksi obyek pejalan kaki ini dibangun pada citra statis dan gray level.
2. Principal Component Analysis
Salah satu metode yang digunakan pada deteksi obyek menggunakan metode Principal Component Analysis. Di dalam analisis data terdapat di mana obyek data memiliki fitur dalam jumlah besar sehingga reduksi fitur menjadi salah satu solusi dalam menyelesaikan masalah tersebut. Reduksi fitur dapat meningkatkan efisiensi dan akurasi dari analysis data. Salah satu metode yang digunakan untuk mereduksi fitur atau dimensi adalah PCA. PCA menghasilkan sejumlah vektor basis orthonormal dalam bentuk kumpulan vektor eigen dari suatu matriks kovarian tertentu, yang dapat secara optimal merepresentasikan distribusi data. Kumpulan vektor basis tersebut digunakan untuk membentuk suatu sub ruang data dengan dimensi yang lebih kecil dan merepresentasikan data baru dari data awal. Vektor-vektor basis yang membentuk ruang baru diperoleh dari proses pencarian vektor eigen (eigenvector) dan nilai eigen (eigenvalue) dari suatu matriks kovarian tertentu, sehingga ruang baru tersebut dapat disebut dengan ruang eigen.
Principal Component Analysis sukses digunakan di dalam pengenalan wajah dan pengenalan obyek. Persamaan standard PCA adalah sebagai berikut. Mengingat satu set dari M citra, masing-masing memiliki ukuran r x c. Masing-masing-masing citra Mi yang direpresentasikan sebagai vektor kolom Zn yang memiliki panjang rc. Rata-rata obyek didefinisikan dengan :
∑
==
M n n zz
M
11
μ
(1)C, kovarians matriks, didefinisikan dengan :
∑
=−
−
=
M i T n n n n zz
z
C
1)
)(
(
μ
μ
(2)2 Principal component merupakan vektor eigen dari kovarians matriks. Kemudian vektor-vektor eigen dalam matriks disusun terurut mengecil berdasarkan nilai eigennya. Jadi vektor kolom pertama dari matriks akan mempunyai nilai eigen yang lebih besar daripada nilai eigen untuk vektor kolom berikutnya.
Kumpulan vektor
p
dapat dihitung dengan menggunakan persamaan :(
n z)
zz
e
p
=
−
μ
(3)di mana
e
z merupakan vektor eigen dari kovarians matriks yang memili nilai eigen yang positif. p merupakan matriks yang digunakan untuk reduksi dimensi. Untuk mendapatkan data original dapat dengan menggunakan kumpulanp
yang bersesuaian, untuk merekonstruksi vektorz
n dapat dihitung dengan menggunakan persamaan :μ
+
=
e
p
z
n zT (4)Kemudian data asal
z
n diproyeksikan ke vektorp
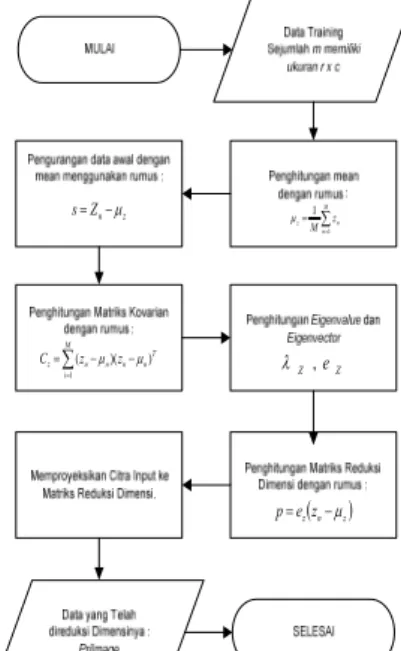
sehingga data asal tersebut akan berkurang dimensinya yang memeprcepat proses komputasi dan akurasi. Diagram alir dari proses Principal Component Analysis dapat dilihat pada gambar 1.∑ = = M n n z M z 1 1 μ z n Z s= −μ ∑= − − =M i T n n n n z z z C 1 ) )( ( μ μ Z Z,e λ (n z) zz e p= −μ
Gambar 1. Diagram alir Principal Component Analysis
3. Support Vector Machine
Di dalam teknik SVM ini berusaha menemukan fungsi pemisah (klasifier/hyperplane) terbaik diantara fungsi yang tidak terbatas jumlahnya untuk memisahkan dua macam obyek[3]. Hyperplane terbaik adalah hyperplane yang terletak di
tengah-tengah antara dua set obyek dari dua kelas. Mencari hyperplane terbaik ekuivalen dengan memaksimalkan margin atau jarak antara dua set obyek dari kelas yang berbeda.
Terdapat beberapa data yang tidak dapat dipisahkan secara linier atau non linearly separable data. Sehingga pelu dilakukan perubahan pada metode SVM yang biasa. Metode ini mentransformasikan data ke dalam dimensi ruang fitur (feature space) sehingga dapat dipisahkan secara linier pada feature space.
Feature space dalam prakteknya biasanya memiliki dimensi yang lebih tinggi dari vektor input (input space). Hal ini mengakibatkan komputasi pada feature space mungkin sangat besar, karena ada kemungkinan feature space dapat memiliki jumlah feature yang tidak terhingga. Selain itu, sulit mengetahui fungsi transformasi yang tepat. Untuk mengatasi masalah ini, pada SVM digunakan ”kernel trick”[4].
Metode yang popular digunakan untuk memetakan dari input space ke feature space yaitu metode kernel polynomial. Fungsi kernel polynomial memiliki bentuk persamaan,
(
) (
(
)
)
n j i j ix
x
x
x
K
,
=
,
+
1
(5) Proses pencarian hyperplane/klasifier pada feature space sama dengan pencarian hyperplane pada data yang dipisahkan secara linier pada input space.Penghitungan jarak
d
(
w
,
b
;
x
)
titikx
dari hyperplane(
w
,
b
)
adalah,w
b
x
w
x
b
w
d
i+
=
,
)
;
,
(
(6)
Hyperplane optimal diperoleh dari memaksimalkan margin,
ρ
, berdasarkan batasan yang diberikan persamaan berikut ini.l
i
i
b
x
w
y
i i+
≥
=
=
K
,
1
,
1
,
(7)
Sehingga jarak antara bidang pembatas dapat diketahui
w
2
sama dengan meminimumkan
w
2. Oleh karena itu hyperplane yang memisahkan data secara optimal dapat diminimalkan menjadi,2
2
1
)
(
w
=
w
Φ
(8)dengan batasan persamaan (7). Agar lebih mudah untuk diselesaikan, persamaan (8) diubah ke dalam persamaan Lagrange(Lagrangian) yang ditunjukkan pada persamaan berikut ini,
3 ) 1 ] , [ ( 2 1 ) , , ( 1 2 − + − = Φ
∑
= b x w y w b w l i i i i α α (9)di mana
α
merupakan Lagrange multipliers. Lagrangian harus diminimalkan terhadapw
,b
dan memaksimalkan terhadapα ≥
0. Primal Lagragian klasik memungkinkan untuk diubah ke dual agar lebih mudah dalam penyelesaiannya,∑
∑∑
= = = + − = l k k j i j l i l j i j i yy x x W 1 1 1 , 2 1 max ) ( max α αα α α α (10)dan oleh karena itu solusi dari masalah diatas diberikan persamaan,
∑
∑∑
= = = − = l k k j i j l i l j i j i yy x x 1 1 1 * , 2 1 min arg αα α α α (11) dengan batasan:l
i
i≥
0
,
=
1
,
K
α
0
1=
∑
= l j j jy
α
(12)Terdapat nilai αi untuk setiap data pelatihan.
Data pelatihan yang memiliki nilai αi > 0 adalah
support vector sedangkan sisanya memiliki nilai αi =
0. Dengan demikian fungsi keputusan yang dihasilkan hanya dipengaruhi oleh support vector.
Proses penghitungan nilai αi dapat dilakukan
menggunakan quadratic programming yang telah disediakan dengan merumuskannya ke dalam quadratic programming problem dan diselesaikan dengan library yang banyak tersedia dalam analisa numerik.
Untuk menyelesaikan masalah pada non linearly separable data harus melakukan modifikasi pada beberapa fungsi yang ada. Pada persamaan (11) harus ditambahkan fungsi kernel K(x,x’) yang yang melakukan pemetaan dari non-linear ke feature space.Sehingga persamaan (11) berubah menjadi :
∑
∑∑
= = = − = l k k j i j l i l j i j i x x K y y 1 1 1 * , 2 1 min arg αα α α α (13)tetapi constraint yang digunakkan tetap seperti yang ada pada persamaan (12).
Sehingga fungsi klasifikasi pada non lineary separable data dapat dirumuskan menjadi :
( )
x
y
K
(
x
x
)
b
f
ns i d i i i d=
∑
+
=,
1α
(3-13)dimana xi adalah support vector, ns = jumlah support
vector dan xd adalah data yang akan diklasifikasikan.
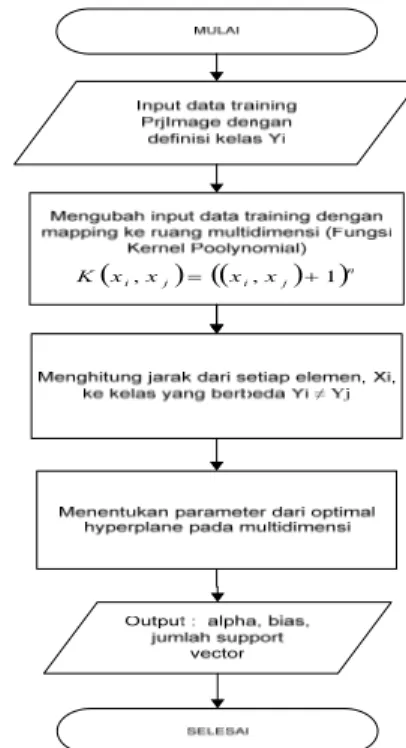
Dalam implementasinya proses klasifikasi dibagi menjadi 2 tahap yaitu training dan testing. Diagram proses training dapat dilihat pada gambar 2.
( ) (( ) )n j i j i x x x x K , = , +1
Gambar 2 Diagram alir training SVM
sedangkan diagram alir proses testing pada SVM dapat dilihat pada gambar 3.
4
4. Uji Coba dan Evaluasi
4.1. Uji Coba Terhadap Penambahan Jumlah Data Training
Pada skenario pertama ini dilakukan penambahan jumlah data training baik data training pejalan kaki maupun data training bukan pejalan kaki kemudian dilakukan analisis pengaruhnya terhadap tingkat akurasi dalam uji coba terhadap suatu data testing yang dipilih secara random. Pada uji coba ini jumlah data random yang akan diuji berjumlah 500 pejalan kaki dan 500 bukan pejalan kaki, kernel yang digunakan kernel polynomial dan nilai pangkat kernel 2. Selain itu pada uji coba ini jumlah principal component yang diambil juga tetap yaitu 175 pada data pejalan kaki dan 175 pada data bukan pejalan kaki.Hasil keluaran uji coba terhadap penambahan jumlah data training dapat dilihat pada tabel 1.
Tabel 1 Perbandingan akurasi terhadap penambahan jumlah data training pejalan kaki
dan bukan pejalan kaki
Jumlah data training pejalan kaki Jumlah data training bukan pejalan kaki Tingkat Akurasi (%) terhadap data testing 200 400 73.70 % 225 450 66.10 % 250 500 60.40 % 275 550 57.30 % 300 600 57.40 %
Dari hasil yang terlihat pada tabel 1 tersebut dapat dianalisis bahwa penambahan jumlah data training pejalan kaki maupun data training bukan pejalan kaki tidak berpengaruh terhadap tingkat akurasi jika jumlah principal component yang diambil tetap. Hal ini disebabkan karena jumlah principal component yang diambil belum tentu mewakili variasi dari jumlah penambahan data.
4.2. Uji Coba Terhadap Penambahan Jumlah Principal Component
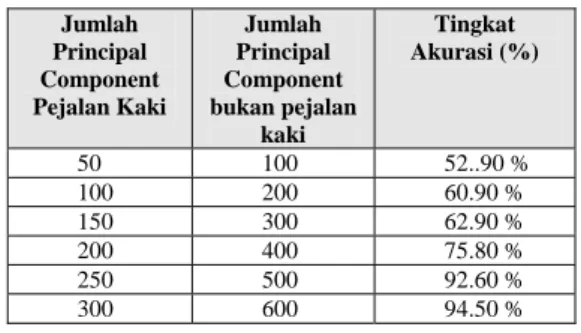
Pada skenario ketiga ini dilakukan penambahan jumlah principal component yang diambil baik dari data training pejalan kaki maupun data training bukan pejalan kaki kemudian dilakukan analisis pengaruhnya terhadap tingkat akurasi dalam uji coba terhadap suatu data testing yang dipilih secara random. Pada uji coba ini jumlah data random yang akan diuji berjumlah 500 pejalan kaki dan 500 bukan pejalan kaki. Hasil keluaran uji coba terhadap penambahan jumlah principal component yang diambil dilihat pada tabel 3. Dalam uji coba ini kernel yang digunakan kernel polynomial dan nilai pangkat kernel polynomial 4.
Tabel 2 Perbandingan tingkat akurasi terhadap penambahan jumlah principal component yang
diambil Jumlah Principal Component Pejalan Kaki Jumlah Principal Component bukan pejalan kaki Tingkat Akurasi (%) 50 100 52..90 % 100 200 60.90 % 150 300 62.90 % 200 400 75.80 % 250 500 92.60 % 300 600 94.50 %
Dari hasil yang terlihat pada tabel 2 tersebut dapat dianalisis bahwa penambahan jumlah principal component pejalan kaki berpengaruh terhadap tingkat akurasi. Hal ini disebabkan karena penambahan jumlah principal component pejalan kaki yang diambil dapat meningkatkan variasi data yang diambil sehingga benar-benar mewakili variasi data training yang digunakan.
4.3. Uji Coba Terhadap Penambahan Nilai Pangkat Kernel Polynomial
Pada skenario kedua ini dilakukan penambahan nilai pangkat kernel polynomial kemudian dilakukan analisis pengaruhnya terhadap tingkat akurasi dalam uji coba terhadap suatu data testing yang dipilih secara random. Pada uji coba ini jumlah data random yang akan diuji berjumlah 500 pejalan kaki dan 500 bukan pejalan kaki. Hasil keluaran uji coba terhadap penambahan nilai pangkat kernel polynomial dapat dilihat pada tabel 2. Dalam uji coba ini dilakukan dengan jumlah data 300 pada pejalan kaki dan 600 pada data bukan pejalan kaki.
Tabel 3 Perbandingan tingkat akurasi terhadap penambahan nilai pangkat kernel polynomial
Parameter kernel Tingkat Akurasi (%) 1 78.90 % 2 94.50 % 3 95.10 % 4 95.40 %
Dari hasil yang terlihat pada tabel 3 tersebut dapat dianalisis bahwa penambahan nilai pangkat kernel polynomial berpengaruh terhadap nilai akurasi yang dihasilkan. Tingkat akurasi data semakin meningkat sejalan dengan peningkatan nilai pangkat kernel polynomial.
Setelah dilakukan uji coba terhadap data testing yang sesuai dengan ukuran data template uji coba dilakukan terhadap data testing yang lain yang memiliki ukuran tidak sama dengan template. Dari hasil uji coba yang dilakukan pada setiap skenario satu sampai dengan skenario tiga data training yang memiliki tingkat akurasi terbaik didapatkan dengan
5 menggunakan kernel polynomial, parameter pankat kernel polynomial empat, dan principal component 300 pada pejalan kaki dan 600 pada data bukan pejalan kaki. Nilai akurasinya yaitu 95.40 %, dari hasil tersebut dilakukan uji coba terhadap data testing yang tidak sesuai ukurannya dengan data template. Hasil uji coba ini dapat dilihat pada gambar 4.
Gambar 4 Hasil uji coba terhadap data testing yang ukurannya berbeda dengan data template
Dari seluruh uji coba baik uji coba terhadap data testing yang memiliki ukuran sesuai dengan data template atau data yang memilliki ukuran tidak sama dengan data template dapat dianalisis bahwa tingkat akurasi dari proses deteksi pejalan kaki tidak hanya dipengaruhi oleh penambahan jumlah data training tetapi juga penambahan jumlah principal component yang diambil dan parameter kernel polynomial.
5. Kesimpulan
Dari uji coba yang telah dilakukan dan setelah menganalisis hasil pengujian terhadap deteksi obyek pejalan kaki menggunakan metode SVM DAN PCA ini dapat diambil beberapa kesimpulan antara lain: 1. Deteksi obyek pejalan kaki dapat menggunakan
metode PCA (Principal Component Analysis) dan SVM (Support Vector Machine).
2. Dari hasil uji coba yang telah dilakukan, tingkat akurasi dari proses deteksi pejalan kaki tidak hanya dipengaruhi oleh penambahan jumlah data training tetapi juga penambahan jumlah principal component yang diambil dan parameter kernel polynomial.
3. Dari hasil uji coba yang dilakukan tingkat akurasi terbaik ketika menggunakan 300 data training pejalan kaki dan 600 data bukan pejalan kaki,
dengan pengambilan 300 dan 600 jumlah principal component yang diambil. Tingkat akurasinya sebesar 94.50 %.
4. Dari hasil uji coba tingkat akurasi terbaik juga dipengaruhi nilai pangkat kernel polynomial. Tingkat akurasi terbaik sebesar 95.40 % yang dihasilkan dari nilai pangkat kernel polynomial 4.
6. DAFTAR PUSTAKA
[1] Malago´n-Borja, Luis., Fuentes, Olac.2007.
Object detection using image reconstruction with PCA. Image and Vision Computing.
[2] R. Gunn, Steve.1998. Support Vector Machines for Classification and Regression. Southampton [3] Sembiring, Krisantus. 2007. Penerapan Teknik
Support Vector Machine untuk Pendeteksian Intrusi padaJaringan. Bandung:Indonesia [4] Smith, Lindsay I. 2002. A tutorial on Principal