BAB 2
LANDASAN TEORI
2.1 Data
Data merupakan bentuk jamak dari datum yang merupakan informasi yang diperoleh dari satu satuan amatan.Pada umumnya informasi ini diperoleh melalui observasi (pengamatan) yang dilakukan terhadap sekumpulan individu. Informasi yang diperoleh memberikan gambaran, keterangan, atau fakta mengenai suatu persoalan dalam bentuk kategorik, huruf atau bilangan (Sugiarto, dkk, 2001)
2.1.1. Jenis Data
Data dapat golongan menurut jenisnya berdasarkan krikteria, yaitu : 1) Data kualitatif dan kuantitatif
a. Data Kualitatif
Data kualitatif adalah data yang sifatnya hanya menggolongkan saja.Termasuk dalam klasifikasi data tipe ini adalah data yang berskala ukur nominal dan ordinal.Sebagai contoh adalah data kepuasan pelanggan (tinggi, sedang, rendah).
b. Data Kuantitatif
2) Data internal dan eksternal
a. Data Internal merupakan data yang didapat Dari dalam perusahaan atau organisasi yang melakukan riset. Data ini menggambarkan keadaan dalam organisasi tersebut.
b. Data Eksternal merupakan data mengenai keadaan diluar organisasi, pada umumnya didapat dari pihak lain yang digunakan sebagai pembanding. Data eksternal itu sendiri terbagi atas dua bagian, yaitu :
1. Data Primer
Data primer adalah data yang langsung dikumpulkan oleh orang yang berkepentingan atau yang memakai data tersebut.Data ini diperoleh dari hasil wawancara atau kuesioner.
2. Data Sekunder
Data sekunder adalah data primer yang diperoleh dari pihak lain atau data primer yang telah diolah lebih lanjut dan disajikan. Sebagai contoh adalah data jumlah produksi suatu produk.
3) Data time series dan cross section
a. Data Time Series merupakan data yang dikumpulkan dari beberapa tahapan waktu secara kronologis, misalnya mingguan, bulanan, atau tahunan.
b. Data Cross Section merupakan data yang dikumpulkan pada waktu dan tempat tertentu saja, misalnya data hasil pengisian kuesioner tentang perilaku pembelian suatu produk shampo oleh responden pada bulan Juni 2011.
2.1.2.Skala Pengukuran
respon-respon yang diamati terhadap obyek-obyek, yang sering dipergunakan ialah ukuran-ukuran cacah, peringkat, panjang, volume, waktu, bobot dan lainya, dalm statistik dibedakan empat macam skala pengukuran yang mungkin dihasilkan, yaitu :
a. Skala Nominal
Skala ini menggolongkan obyek-obyek atau kejadian-kejadian ke dalam berbagai kategori untuk menunjukan kesamaan atau perbedaan ciri-ciriobjek.Kategori-kategori tersebut dilambangkan dengan kata-kata, huruf simbol, atau angka.
Contoh : 1. Pria 2. Wanita b. Skala Ordinal
Seperti halnya dalam skala nominal, kelompok-kelompok yang sudah didefinisikan sebelumnya juga menggunakan lambang angka tau huruf.Ukuran pada skala ordinal tidak memberikan nilai absolut pada obyek, tetapi hanya urutan (ranking) relatif saja.Contoh : ingin diketahui status sosial seseorang yaitu A rendah, B sedang dan C tinggi.
c. Skala Interval
Skala interval memberikan ciri angka kepada kelompok obyek yang mempunyai skala nominal dan ordinal, ditambah dengan jarak yang sama pada urutan obyeknya. Skala interval diberikan apabila kategori yang digunakan bisa dibedakan, diurutkan, mempunyai jarak tertentu, tetapi tidak bisa dibandingkan.
d. Skala Rasio
2.1.3. Metode Pengumpulan Data
Metode pengumpulan data menunjukan cara-cara yang dapat ditempuh untuk memperoleh data yang dibutuhkan (Sugiarto dkk,2001). Seperti yang telah dipelajari metode pengumpulan data terdiri dari metode pengumpulan data primer dan metode pengumpulan data skunder.
a. Metode Pengumpulan Data Primer
Data primer merupakan data yang diperoleh dari sumber pertama baik dari individu atau perorangan seperti hasil wawancara atau hasil dari pengisian kuesioner yang biasa dilakukan oleh peneliti.Pelaksanaannya dapat dilakukan dengan melakukan survei atau percobaan.
1. Survei
Survei dilakukan apabila data yang dicari sebenarnya sudah ada dilapangan. Teknik pengumpulan data dengan cara survei bisa dilakukan dengan :
Wawancara dengan responden. Wawancara atau interview adalah suatu cara mengumpulkan data dengan menanyakan langsung kepada responden dalam suatu permasalahan. Pertanyaan-pertanyaan tersebut telah disiapkan terlebih dahulu sebagai kuesioner.
Angket atau kuesioner. Angket atau kuesioner adalah jawaban tertulis dari responden atas kuesioner yang diberikan. Dengan kuesioner, informasi yang dikumpulkan dapat lebih banyak dan tersebar merata dalam satu wilayah walaupun kenyataannya tidak semua kuesioner dikembalikan kepada peneliti.
2. Percobaan (experiment)
Cara percobaan dilakukan apabila data yang ingin diperolehbelum tersedia dan dengan demikian variabel yang akan diukur harus dibangkitkan melalui suatu percobaan.
b. Metode Pengumpulan Data Skunder
Metode ini sering disebut dengan metode dengan menggunakan bahan dokumen, karena dalam hal ini peneliti tidak secara langsung mengambil data sendiri tetapi meneliti dan memanfaatkan data atau dokumen yang dihasilkan dari pihak-pihak lain. Data skunder pada umumnya digunakan oleh peneliti untuk memberikan gambaran tambahan, gambaran perlengkapan ataupun untuk diproses lebih lanjut.
2.1.4 Populasi dan Sampel
Populasi merupakan keseluruhan unit atau individu dalam ruang lingkup yang ingin diteliti sedangkan sampel adalah sebagian anggota populasi yang dipilih dengan menggunakan prosedur tertentu sehingga diharapkan dapat mewakili populasinya (Sugiato dkk, 2001).
Suatu sampel yang baik atau benar akan dapat memberikan gambaran yang sebenarnya tentang populasi. Sehingga jika suatu penelitian sampelnya tidak diambil secara benar, maka hasilnya tidak akan dapat digeneralisasikan dan tidak dapat memberikan hasil yang tepat dalam menggambarkan keadaan sebenarnya dari populasi yang diteliti.
2.2 Statistik deskriptif
Statistik deskriptif adalah analisi yang berkaitan dengan pengumpulan dan penyajian data sehingga dapat memberikan informasi yang berguna.Analisis ini bertujuan menguraikan tentang sifat-sifat atau karakteristik dari suatu keadaan dan untuk membuat deskripsi atau gambaran yang sistematis dan akurat mengenai fakta-fakta, sifat-sifat dari fenomena yang diselidiki.Beberapa bentuk penyajian statistik deskriptif adalah tabel, diagram, grafik, histogram dan lainnya (Walpole, 1993).
Iqbal Hasan (2001:7) menjelaskan bahwa statistik deskriptif adalah bagian dari statistika yang mempelajari cara pengumpulan data dan penyajian data sehingga mudah dipahami. Statistika deskriptif hanya berhubungan dengan hal menguraikan atau memberikan keterangan-keterangan mengenai suatu data atau keadaan.Dengan kata statistika deskriptif berfungsi menerangkan keadaan, gejala, atau persoalan.Penarikan kesimpulan pada statistika deskriptif (jika ada) hanya ditujukan pada kumpulan data yang ada.
Bambang Suryoatmono (2004:18) menyatakan Statistika deskriptif adalah statistika yang menggunakan data pada suatu kelompok untuk menjelaskan atau menarik kesimpulan mengenai kelompok itu saja.
Menurut Sugiyono (2004:169), analisis deskriptif adalah statistik yang digunakan untuk menganalisa data dengan cara mendeskripsikan atau menggambarkan data yang telah terkumpul sebagaimana adanya tanpa bermaksud membuat kesimpulan yang berlaku untuk umum atau generalisasi.
2.2.1 Macam-macam Statistik Deskriptif
Ukuran numerik dibagi menjadi dua, yaitu ukuran pemusatan data, meliputi mean, median, modus, serta ukuran penyebaran data, meliputi rentang, variansi, dan simpangan baku.
a) Ukuran Pemusatan
Ukuran pemusatan atau ukuran lokasi adalah beberapa ukuran yang menyatakan dimana distribusi data tersebut terpusat.(Howell, 1982).Ukuran pemusatan berupa nilai tunggal yang bisa mewakili suatu kumpulan data dan karakteristiknya (menunjukkan pusat dari nilai data). Jenis-Jenis Ukuran Pemusatan antara lain:
1. Rata-rata (Mean)
Rata-rata merupakan ukuran pemusatan yang sangat sering digunakan.Keuntungan dari menghitung rata-rata adalah angka tersebut dapat digunakan sebagai gambaran atau wakil dari data yang diamati.Rata-rata peka dengan adanya nilai ekstrim atau pencilan.
2. Median atau Nilai Tengah
Median merupakan suatu nilai ukuran pemusatan yang menempati posisi tengah setelah data diurutkan
3. Modus
Modus adalah nilai yang paling sering muncul dari serangkaian data.Modus tidak dapat digunakan sebagai gambaran mengenai data (Howell, 1982).
b) Ukuran Penyebaran Data/Dispersi (Dispersion)
Ukuran penyebaran adalah suatu ukuran baik parameter atau statistika untuk mengetahui seberapa besar penyimpangan data.Melalui ukuran penyebaran dapat diketahui seberapa jauh data-data menyebar dari titik pemusatannya.
Rentang (Range) dinotasikan sebagai R, menyatakan ukuran yang menunjukkan selisih nilai antara maksimum dan minimum.Rentang cukup baik digunakan untuk mengukur penyebaran data yang simetrik dan nilai datanya menyebar merata.Ukuran ini menjadi tidak relevan jika nilai data maksimum dan minimumnya merupakan nilai ekstrim.
2. Variansi (Variance=S2atau σ2)
Variansi (variance) dinotasikan sebagai S2 atau σ2 adalah ukuran
penyebaran data yang mengukur rata-rata kuadrat jarak seluruh titik pengamatan dari nilai tengah (meannya).
3. Simpangan Baku ( s )
Simpangan baku (standar deviation) dinotasikan sebagi s atau σ, menunjukkan rata-rata penyimpangan data dari harga rata-ratanya. Simpangan baku merupan akar pangkat dua dari variansi.
2.3 Regresi
2.3.1 Pengertian Regresi
Suatu model matematis yang dapat digunakan untuk mengetahui bentuk hubungan antara dua variabel atau lebih, dengan tujuan untuk membuat prediksi nilai suatu variabel dependen melalui variabel independen.
Analisis regresi adalah teknik statistika yang berguna untuk memeriksa danmemodelkan hubungan diantara variabel-variabel. Analisis regresi dapat digunakan untuk dua hal pokok, yaitu :
b) Untuk menaksir suatu variabel yang disebut variabel tak bebas (terikat) dengan variabel lain yang disebut variabel bebas berdasarkan hubungan yang ditunjukkan persamaan regresi tersebut.
Berdasarkan amatan dan analisis data, penyelesaian regresi ini dapat berupa persamaan linier maupun nonlinier.Oleh karena itu analisis regresi ini terbagi atas regresi linier dan regresi nonlinier.Yang termasuk ke dalam regresi linier adalah regresi linier sederhana, regresi linier berganda, dan sebagainya.Sedangkan yang termasuk regresi nonlinier adalah regresi model parabola kuadratik, model parabola kubik, model eksponen, model geometrik, regresi logistik, dan sebagainya.
2.3.2 Regresi Logistik
Analisis regresi logistik merupakan salah satu pendekatan model matematis yang digunakan untuk menganalisis hubungan satu atau dua variabel independen dengan sebuah variabel dependen kategorik yang bersifat dikotom / binary. Variabel kategorik yang dikotom merupakan variabel yang mempunyai dua nilai variasi yang mewakili kemunculan atau tidak adanya suatu kejadian yang diberi skor 0 atau 1 yaitu dalam hal ini mengenai kesadaran wajib pajak yaitu sadar atau tidak sadar.
Regresi logistik berbeda dengan regresi linear, karena pada regresi linear menggunakan variabel dependen numerik sedangkan pada regresi logistik menggunakan variabel dependen kategorik yang bersifat dikotomus.
denganmempertimbangkan variabel prediktor yang ada. Regresi logistik akan membentuk variabel prediktor/respon (log (p/(1-p)) yang merupakan kombinasi linier dari variabel independen. Nilai variabel prediktor ini kemudian ditransformasikan menjadi probabilitas dengan fungsi logit. Tujuan dari analisis regresi logistik adalah untuk memperoleh model yang paling baik (fit) dan sederhana yang dapat menggambarkan hubungan antara variabel dependen dan variabel independen.
Regresi logistik dibagi menjadi dua, yaitu : 1) Regresi logistik sederhana
Digunakan untuk mengetahui hubungan antara satu variabel independen dengan satu variabel dependen yang bersifat dikotomus.
2) Regresi logistik ganda
Digunakan untuk mengetahui hubungan antara beberapa variabel independen dengan satu variavel dependen yang bersifat dikotomus.
2.3.3 Asumsi Regresi Logistik
Regresi logistik tidak membutuhkan hubungan linear antara variabel
independen dan variabel dependen.
Regresi logistik dapat menyeleksi hubungan karena menggunakan pendekatan non linear log transformasi untuk memprediksi ods ratio.
Odsdalam regresi logistik sering dinyatakan sebagai probability
(peluang).
Variabel independen tidak memerlukan asumsi multivariate normality. Asumsi homokedaksitas tidak diperlukan.
2.3.4 Persamaan Regresi Logistik
Regresi logistik adalah bentuk khusus analisis regresi dengan variabel respon bersifat kategorik dan variabel prediktor bersifat kategorik, kontinu atau gabungan antara keduanya. Regresi logistik ini digunakan untuk menguji apakah probabilitas terjadinya variabel terikat dapat diprediksi dengan variabel bebasnya. Sartono dalam syafrizal dkk (2010) menerangkan bahwa regresi logistik telah banyak digunakan secara luas sebagai salah satu alat analisis pemodelan ketika variabel responnya (Y) bersifat biner. Istilah biner merujuk pada penggunaan dua buah bilangan 0 dan 1 untuk menggantikan dua kategori pada variabel respon. Pendugaan koefisien model regresi logistik tidak dapat dilakukan dengan metode kuadrat terkecil (ordinary least square) seperti halnya regresi linier karena pelanggaran asumsi kehomogenan ragam. Metode kemungkinan maksimum (maksimum likelihood) menjadi salah satu alternatif yang dapat digunakan.
Menurut Yasril (2008) fungsibasis logistik adalah :
z
e = bilangan natural (2,71828182)
j
)
= peluang tingkat suatu kejadian sehingga
Menurut Yasril (2008) Statistik uji Wald untuk uji signifikansi parameter regresi logistik :
= nilai koefisien regresi logistik untuk variabel ke-i
i
SE = nilai standard error untuk variabel ke-i
k = jumlah variabel bebas yang digunakan = taraf nyata
Keterangan :
0
L = Maksimum Likelihood dari model reduksi (Reduced Model) atau model yang terdiri dari konstanta saja.
p
L = Maksimum Likelihood dari model penuh (Full Model) atau dengan semua variabel bebas.
Menurut Hosmer Lemeshow (1989) rumus untuk menyatakan odds ratio adalah :
= peluang kejadian kelompok pertama
0 = peluang kejadian kelompok kedua
2.4 Konsep Kesejahteraan
Menurut Kolle (1974) dalam Bintarto (1989), kesejahteraan dapat diukur dari beberapa aspek kehidupan, yaitu :
1) Dengan melihat kualitas hidup dari segi materi, seperti kualitas rumah, bahan pangan dan sebagianya.
2) Dengan melihat kualitas hidup dari segi fisik, seperti kesehatan tubuh, lingkungan alam, dan sebagainya.
3) Dengan melihat kualitas hidup dari segi mental, seperti fasilitas pendidikan, lingkungan budaya, dan sebagainya.
4) Dengan melihat kualitas hidup dari segi spiritual, seperti moral, etika, keserasian penyesuaian, dan sebagainya.
(somatic status), seperti nutrisi, kesehatan, harapan hidup, dan sebagianya; (2) dengan melihat pada tingkat mentalnya, (mental/educational status) seperti pendidikan, pekerjaan, dan sebagainya; (3) dengan melihat pada integrasi dan kedudukan social (sosial status)
Todaro (2003) mengemukakan bahwa kesejahteraan masyarakat menengah kebawah dapat direpresentasikan dari tingkat hidup masyarakat.Tingkat hidup masyarakat ditandai dengan terentaskannya dari kemiskinan, tingkat kesehatan yang lebih baik, perolehan tingkat pendidikan yang lebih tinggi, dan tingkat produktivitas masyarakat.
Menurut Badan Pusat Statistik (BPS), kesejahteraan merupakan representasi yang bersifat kompleks karena mempunyai keterkaitan multidimensi. Secara umum kesejahteraan dapat diukur dari sisi demografi, kecukupan pangan, pendidikan, kesehatan, ketenagakerjaan, dan kondisi lingkungan. Kemiskinan merupakan bentuk ketidakmampuan untuk meraih kesejahteraan di pandang dari sisi ekonomi dalam memenuhi kebutuhan dasar makanan dan bukan makanan yang diukur dari sisi pengeluaran.
2.4 Faktor Kesejahteraan Rumah Tangga
Dalam mengukur kesejahteraan rumah tangga diperlukan indikator moneter, indikator yag banyak digunakan adalah indikator pendapatan dan pengelaran (BPS 2009 dan The Worl Bank, 2007). Indikator pengeluaran dalam hal ini disebut juga konsumsi, dipilih karena sifatnya tetap dan relatif stabil terhadap berfluktuasinya pendapatan dari tahun ke tahun.
makanan dan indikator kesehatan, indikator kesejahteraan lainnya, serta partisipasi politik dan akses kepada informasi.
Jumlah anggota rumah tangga diduga mempunyai keterkaitan erat dengan kesejahteraan rumah tangga karena kemiskinan dihitung berdasarkan pengeluaran dan jumlah anggota rumah tangga.makin besar jumlah anggota rumah tangga, akan makin besar pula resiko untuk menadi miskin apabila pendapatannya tidak meningkat (Faturokhman dan molo, 1995). Usia kepala rumah tangga juga berkaitan dengan kesejahteraan rumah tangga walaupun hubungannya tidak begitu jelas, akan tetapi ada kecendrungan bahwa kepala rumah tangga yang lebih sejahtera lebih tua dibandingkan kepala rumah tangga yang kurang sejahtera.
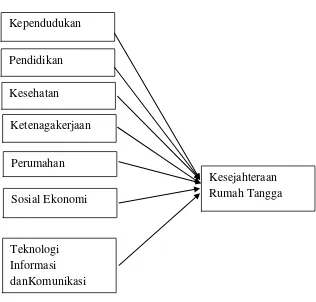
2.6 Kerangka Pemikiran Dan Hipotesis 2.6.1 Kerangka Pemikiran
Berdasarkan uraian diatas, gambaran menyeluruh faktor-faktor yang mempengaruhi kesejahteraan rumah tangga dapat digambarkan dalam kerangka pemikiran sebagai berikut :
Gambar 2.1
Skema Kerangka Pemikiran Kependudukan
Pendidikan
Kesehatan
Ketenagakerjaan
Perumahan
Sosial Ekonomi
Teknologi Informasi danKomunikasi
2.6.2 Hipotesis
Hipotesis merupakan pengujian statistik yang didasari oleh suatu asumsi alternatif lain (Siagi dan Sugiato,2000). Berdasarkan teori dan kerangka pemikiran yang telah dibuat, maka dapat dibuat hipotesis dari penelitian sebagai berikut :
H0 : Variabel prediktor tidak mempunyai pengaruh signifikan terhadap variabel respon.
H1 : Variabel prediktor mempunyai pengaruh signifikan terhadap variabel respon. Dimana variabel responnya adalah kesejahteraan rumah tangga di Kabupaten Serdang Bedagai (Y) dan variabel prediktornya adalah sebagai berikut :
1. Faktor kependudukan yang dapat diketahui dari jenis kelamin kepala rumah tangga (X1), usia kepala rumah tangga (X2), status perkawinan kepala rumah tangga (X3) dan jumlah anggota rumah tangga (X4). 2. Faktor pendidikan yang dapat diketahui dari ijazah tertinggi yang dimiliki
kepala rumah tangga (X5).
3. Faktor kesehatan ditinjau dari kesehatan kepala rumah tangga selama satu bulan terakhir (X6).
4. Faktor ketenagakerjaan yang terdiri dari Kegiatan utama kepala rumah tangga (X7), lapangan usaha utama kepala rumah tangga (X8), status pekerjaan utama kepala rumah tangga (X9).
5. Faktor sosial ekonomi yang dapat diketahui dari pengalaman membeli beras raskin selama tiga bulan terakhir (X10).
6. Faktor perumahan yang terdiri dari status penguasaan bangunan tempat tinggal (X11), sumber air minum (X12), cara memperoleh air minum (X13), dan bahan bakar/energi utama untuk memasak (X14).