Fakultas Ilmu Komputer
Universitas Brawijaya
1179
Sentiment Analysis Peringkasan Review Film Menggunakan Metode
Information Gain dan K-Nearest Neighbor
Ria Ine Pristiyanti1, Mochammad Ali Fauzi2, Lailil Muflikhah3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Review film berisi tentang sebuah opini dari seorang reviewer untuk mendeskripsikan sebuah film.
Penilaian mengenai isi dari review film dapat disebut dengan sentiment analysis. Sentiment analysis pada review film terbagi menjadi 2 yaitu berupa review positif dan review negatif. Pengelompokan hasil
sentiment analysis dapat dipermudah dengan metode klasifikasi k-nearest neighbor dimana metode ini
akan mencari dokumen yang memiliki kedekatan antara dokumen satu dengan yang lainnya. Pada umumnya, data review film memuat isi yang sangat panjang sehingga diperlukan feature selection atau pemangkasan fitur yang berguna untuk mengurangi dimensi pada saat proses klasifikasi. Pada penelitian ini menggunakan metode information gain untuk mengurangi banyak fitur yang digunakan pada saat proses klasifikasi. Metode ini akan memprediksi ada atau tidak adanya term dalam sebuah dokumen sehingga term yang sering muncul memiliki nilai information gain yang rendah sedangkan term yang jarang muncul atau hanya muncul pada salah satu kategori memiliki nilai information gain yang tinggi. Term dengan nilai information gain yang tinggi akan dapat digunakan untuk proses klasifikasi. Hasilnya penggunaan seluruh term untuk klasifikasi menghasilkan akurasi sebesar 92% dimana nilai akurasinya lebih baik dibandingkan dengan adanya feature selection karena adanya penghapusan term yang memiliki nilai information gain yang rendah.
Kata kunci: sentiment analysis, feature selection, k-nearest neighbor, information gain Abstract
The film reviews contain an opinion from a reviewer to describe a movie. Assessment of the content from the film review can be called by sentiment analysis. Sentiment analysis on movie review is divided into 2 parts, which are positive review and negative review. Grouping of sentiment analysis results can be simplified by the k-nearest neighbor classification method where this method will look for documents that have similarity between one to another document. In general, the movie review data contains very long content required by feature selection or pruning feature to reduce dimensions during classification process. In this case, the method of information gain is used to reduce many features during the classification process. This method will predict the presence or absence of term in a document so the term that frequently appear has low information gain value, however for the term that rarely appear or only appear in one category has high information gain value. The term with high information gain value will be able to be used for classification process. The result for using all of term for classification is 92% accuracy where the accuracy value is better than the feature selection due to the elimination of term having low information gain value.
Keywords: sentiment analysis, feature selection, k-nearest neighbor, information gain
1. PENDAHULUAN
Review tentang film merupakan kebutuhan
bagi semua orang untuk mendapatkan informasi mengenai sebuah film sehingga dapat digunakan
untuk membantu mendapatkan informasi
tentang isi film yang akan ditonton. Informasi
yang bisa didapat melalui sebuah review film adalah mengenai jalan cerita, aktor sampai dengan konflik yang terjadi di dalamnnya serta kelebihan dan kekurangan sebuah film. Informasi-informasi hasil review yang dibuat
kemudian digunakan sebagai bahan
pertimbangan dalam menentukan kualitas dari sebuah film sehingga pecinta film dapat
mengetahui sejauh mana film tersebut layak atau tidak layak di tonton.
Penilaian mengenai isi dari review film dapat disebut dengan sentiment analysis.
Sentiment analysis adalah proses penerapan natural language processing (NLP) dan analisis
teks untuk mengidentifikasi dan melakukan ektrak informasi subjektif dari sebuah teks (Hussein, 2016). Sentiment analysis dapat diaplikasikan menggunakan sebuah metode
klasifikasi untuk mempermudah dalam
pengelompokan data berupa data positif atau data negatif yaitu dengan menggunakan metode
k-nearest neighbor. Metode k-nearest neighbor
digunakan pada proses klasifikasi dalam sebuah penelitian karena memiliki kesederhanaan dimana prosesnya berdasarkan pada pendekatan pembobotan yang sederhana dan kemudahan dalam implementasi, adaptasi dan proses
learning serta memiliki nilai akurasi yang tinggi.
Penerapan klasifikasi sentiment analysis menjadi kalimat positif maupun negatif dapat dilakukan setelah pemangkasan pada data subjek yang digunakan untuk mengurangi fitur sehingga menghindari banyaknya dimensi yang digunakan pada saat proses klasifikasi (Khan., dkk, 2016). Review film dapat mempunyai ukuran dataset yang cukup besar baik itu pada data training maupun data testing.
Dimensi dan
fitur yang berlebihan akan meningkatkan
ruang pencarian semakin tinggi sehingga
akan
menyebabkan
kesulitan
dalam
memproses data dan akan menurunkan
kinerja serta membuat data tidak konsisten.
Analisis dan mining dalam data juga
membutuhkan waktu yang lama dalam
pemrosesan data. Pengurangan dimensi
dapat diterapkan untuk mengurangi dimensi
dari
data,
dimana
nantinya
akan
meningkatkan kinerja dari tehnik machine
learning dengan menghilangkan fitur yang
tidak perlu digunakan
. Penyelesaian dalam permasalahan penelitian ini menggunakan metode Information Gain yang akan mengukurbanyaknya bit yang dibutuhkan untuk
memprediksi kategori dengan mengetahui ada atau tidak adanya term dalam suatu dokumen (Singh., dkk, 2010). Information Gain
digunakan untuk mencari kriteria term yang baik dalam machine learning, dimana pada penelitian sebelumnya penerapan information gain dalam
feature selection pada dataset reuters sebanyak
21578 data dan menghasilkan nilai f-measure sebesar 0.86 (Uguz, 2011).
2. DASAR TEORI 2.1 Review Film
Film merupakan suatu selaput tipis yang dibuat dari seluloid dimana digunakan sebagai tempat gambar negatif yaitu tempat yang dibuat menjadi potret atau digunakan sebagai tempat gambar positif yaitu tempat untuk dimainkan di bioskop, film juga berarti sebagai lakon dalam cerita yaitu gambar hidup (KBBI, 1990).
Review merupakan sebuah teks yang
digunakan untuk meninjau suatu karya baik film, buku dan karya lainnya yang memiliki tujuan untuk mengetahui kualitas, kelebihan dan kekurangan yang ada pada karya tersebut serta untuk melakukan kritik terhadap suatu peristiwa atau karya seni bagi khalayak.
2.2 Text Mining
Text mining lebih luas dapat diartikan
sebagai proses mencari tahu secara intensif dimana pengguna berinteraksi dengan kumpulan
dokumen sepanjang waktu dengan
menggunakan serangkaian analisis. Kumpulan dokumen merupakan sumber data pada text
mining dan pola yang menarik tidak ditemukan
pada record database yang terbentuk melainkan pada data kata per kata yang tidak terstruktur pada kumpulan dokumen (Feldman., dkk, 2007).
2.3 Text Preprocessing
Proses preprocessing berfungsi untuk proses awal sebelum dokumen teks diolah pada tahap selanjutnya dimana akan dilakukan proses seleksi data yang akan di proses pada setiap dokumen. Proses ini terdiri dari beberapa proses pembersihan dokumen, yaitu case folding,
tokenizing, filtering/stopword removal dan
stemming (Nugroho, 2011). Dokumen terdiri dari beberapa teks namun tidak semua teks di dalam dokumen konsisten dalam penggunaan huruf kapital sehingga diperlukan case folding untuk mengubah teks dokumen menjadi suatu bentuk standar dimana pada tahap ini akan dirubah menjadi huruf kecil (lowercase).
Tokenizing adalah tahap yang dilakukan
setelah case folding, dimana pada tahap ini merupakan proses pemotongan string input berdasarkan tiap kata yang menyusunnya.
Tokenizing akan memecah sekumpulan karakter
dalam suatu teks ke dalam suatu kata. Pada karakter lain selain alfabet akan dihilangkan sehingga dianggap sebagai delimiter seperti ‘.’, ’,’, ’”’, ’-‘, ’/’, ’[‘, ’}’, ’+’, ’_’, ’!’, ’@’ dan lain
sebagainya. Karakter lain yang akan dihapus adalah karakter whitespace yang dapat dianggap sebagai pemisah kata, dimana karakter ini seperti
enter, tabulasi, spasi. Karakter (‘), (.), (;), (:)
dapat memiliki peran yang cukup banyak sebagai pemisah kata.
Filtering adalah proses mengambil
kata-kata penting dari hasil tokenizing. Algoritme
stoplist (membuang kata yang dianggap kurang
penting) atau wordlist ( menyimpan kata penting) dalam sebuah dokumen digunakan pada tahap ini. Stemming adalah proses normalisasi dari kata hasil tokenizing dan telah dilakukan proses filtering diubah ke dalam bentuk kata dasar.
2.4 Algoritme Stemming Nazief Adriani
Algoritme stemming Nazief Adriani merupakan morphologi yang luas dimana akan menggabungkan maupun melakukan atau tidak melakukan rangkuman affixed yang terdiri dari
prefixes, suffixes, infixes dan confixes
(kombinasi prefixes dan suffixes).
2.5 Sastrawi Stemmer
Sastrawi stemmer merupakan library
sederhana yang memiliki desain mudah untuk digunakan. Library ini menerapkan algoritme Nazief dan Adriani yang kemudian ditingkatkan menjadi algoritme CS (Confix Stripping), ECS
(Enhanced Confix Stripping) dan Modified ECS.
Algoritme pada library ini dapat menyelesaikan
persoalan stemming seperti mencegah
overstemming dengan kamus, mencegah
understemming dengan aturan tambahan dan
mengurangi kata yang berbentuk jamak
.
2.6 Sentiment AnalysisSentiment analysis adalah bagian dari
opinion mining, yaitu sebuah proses dalam memahami, preprocessing yaitu mereduksi data dan mengolah sebuah data tekstual secara otomatis untuk mendapatkan informasi.
Sentiment analysis adalah proses penerapan natural language processing (NLP) dan analisis
teks untuk mengidentifikasi dan melakukan ektrak informasi subjektif dari sebuah teks (Hussein, 2016).
2.7 Klasifikasi
Klasifikasi merupakan proses pembagian data menjadi beberapa kelompok dimana memiliki sifat dependen dan independen dimana
setiap kelompok berperan sebagai sebuah kelas. Klasifikasi dokumen adalah mengelompokkan suatu dokumen ke dalam kelompok yang telah dikenal sebelumnya secara otomatis berdasarkan isi dokumen melalui sebuah penelitian untuk memperoleh informasi dengan mengembangkan sebuah metode klasifikasi (Tenenboim, L., dkk., 2008). Jadi klasifikasi diartikan sebagai menganalisis label kelas dari suatu data objek, label kelas sudah ada, Tujuannya untuk mengelompokkan pada kelas-kelas yang telah ditentukan.
2.8 K-Nearest Neighbor
Algoritme k-nearest neighbor merupakan salah satu metode untuk proses klasifikasi terhadap suatu objek berdasarkan data training yang memiliki jarak paling dekat dengan objek. Penentuan jarak dengan nilai terdekat atau terjauh dihitung berdasarkan jarak Euclidean (J. Nilson, 1996). Proses perhitungan K- Nearest
Neighbor (Han., dkk):
Preprocessing, langkah pertama adalah
menyiapkan data training dan mendapatkan
tuple himpunan 𝐷𝑆 = {(𝑑𝑖, 𝑐𝑗)| 0 ≤ 𝑖 < 𝑛, 0 ≤
𝑗 < 𝑚} dimana di adalah term vector
representation teks dokumen dan cj categori
label.
Similarity Measure, menggunakan TF x IDF untuk menghitung bobot setiap term dalam
dokumen, sebagai variasi untuk meningkatkan akurasi yang signifikan. Term Frequency merupakan jumlah kemunculan sebuah term dalam sebuah dokumen (Gebre., dkk). TF dapat dirumuskan pada persamaan berikut:
𝑤𝑡,𝑑= log(𝑡𝑓𝑡,𝑑+ 1) (1)
Inverse Document Frequency adalah log
dari kebalikan probabilitas term yang ditemukan di dalam dokumen. IDF dapat dirumuskan pada persamaan berikut:
𝑖𝑑𝑓𝑡= log( 𝑛
𝑛𝑡) (2)
Cosine similarity adalah fungsi yang
digunakan untuk menghitung kesamaan antara semua data training dengan dokumen X. Cosine
similarity dapat dirumuskan pada persamaan
berikut (Suguna, 2010): 𝑆𝐼𝑀 (𝑋, 𝑑𝑖) =
∑𝑚𝑗=1𝑥𝑗 .𝑑𝑖𝑗
√(∑𝑚𝑗=1𝑥𝑗)2 √ (∑𝑚𝑗=1𝑑𝑖𝑗)2
2.9 Feature Selection dan Information Gain
Feature selection biasa disebut variable
selection, attribute selection atau feature subset selection merupakan proses pemilihan fitur yang
relevan pada term yang menjadi target dari data
learning pada sebuah permasalahan.
Information gain adalah salah satu
pendekatan yang populer dimana digunakan sebagai kriteria penting dalam sebuah data teks dokumen. Dimana ide awalnya berasal dari
information theory. Berikut ini merupakan
persamaan dari information gain (Uguz, 2011): 𝐼𝐺(𝑡) = ∑|𝐶|𝑖=1𝑃(𝑐𝑖)log 𝑃(𝑐𝑖)
+𝑃(𝑡) ∑|𝐶|𝑖=1𝑃(𝑐𝑖|𝑡) log 𝑃(𝑐𝑖|𝑡) (4)
+𝑃(𝑡̅) ∑|𝐶|𝑖=1𝑃(𝑐𝑖|𝑡̅) log 𝑃(𝑐𝑖|𝑡̅)
Dimana ci adalah kategori, P(ci) adalah peluang
dari kategori, P(t) dan 𝑃(𝑡̅) adalah peluang term
t yang muncul atau tidak muncul dalam
dokumen. 𝑃(𝑐𝑖|𝑡) adalah peluang bersyarat
kategori pada term t yang muncul, dan 𝑃(𝑐𝑖|𝑡̅)
adalah peluang bersyarat kategori pada term t yang tidak muncul.
2.10 Evaluasi
Hasil klasifikasi dapat diuji dengan menggunakan metode pengujian dimana akan diukur tingkat akurasi sistem yang dibuat. Pengujian yang dapat dilakukan terdiri dari beberapa cara yaitu seperti accuracy, precision,
recall dan f-measure. Accuracy adalah sebuah
tingkat kedekatan antara nilai prediksi dengan nilai aktual. Precision merupakan jumlah jumlah dokumen relevan yang ditemukan dibagi dengan jumlah semua dokumen yang ditemukan. Recall merupakan jumlah dokumen relevan yang ditemukan dibagi dengan jumlah semua dokumen relevan di dalam koleksi (Pendit,
2008). F-measure merupakan kombinasi
precision dan recall sebagai harmonic mean.
Berikut persamaan Accuracy , Precision, Recall
dan F-measure: Accuracy = 𝑇𝑃+𝑇𝑁 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁
(5) Precision = 𝑇𝑃 𝑇𝑃+𝐹𝑃 (6) Recall = 𝑇𝑃 𝑇𝑃+𝐹𝑁 (7) F-Measure = 2 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑥 𝑟𝑒𝑐𝑎𝑙𝑙 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑟𝑒𝑐𝑎𝑙𝑙 (8) 3. PERANCANGAN DAN IMPLEMENTASI
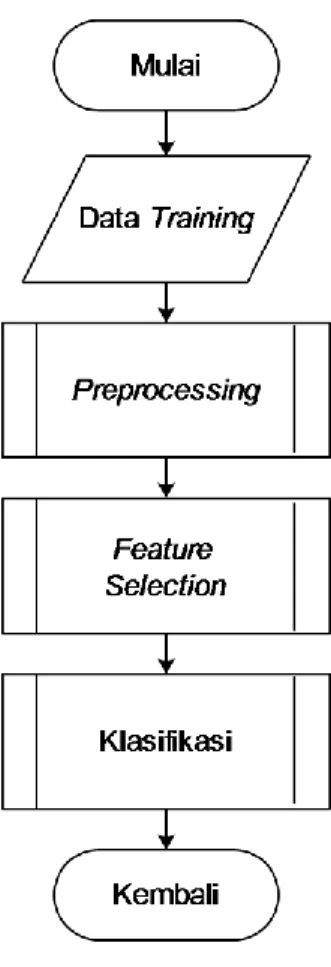
Proses dalam sistem ini ada tiga yaitu
preprocessing, feature selection untuk pengurangan fitur term dan klasifikasi menggunakan metode k-nearest neighbor. Ketiga proses memiliki sub proses dimana masing-masing tahapan akan lebih detail menjelaskan alur dari proses yang dijalankan. Berikut ini merupakan alur jalannya proses secara keseluruhan pada Gambar 1.
Gambar 1 Alur Proses Sentiment Analysis
Peringkasan Review Dengan Metode Information
Gain Dan K-Nearest Neighbor
Berdasarkan Gambar 1 sistem akan mengambil data training dan data testing yang akan dilakukan proses klasifikasi. Tahapan selanjutnya sistem akan melakukan proses
preprocessing data training dan data testing.
Pada data training setelah tahapan preprocessing selesai maka dilakukan proses feature selection yaitu penerapan metode pengurangan term untuk menghapus beberapa term yang dianggap tidak penting dalam sebuah dokumen dan akan digunakan sebagai term data training pada saat proses klasifikasi. Tahapan selanjutnya adalah pemilihan term untuk proses klasifikasi data dimana term yang digunakan pada data testing adalah term hasil preprocessing yang kemudian dicocokkan dengan hasil term dari proses feature
selection pada data training. Setelah tahap
pemilihan kata, tahap selanjutnya adalah klasifikasi data dimana pada tahap ini berfungsi untuk pengelompokkan review film sehingga hasilnya adalah sebuah review film yang termasuk dalam kategori review positif atau kategori review negatif.
4. PENGUJIAN DAN ANALISIS
Pada penelitian ini dilakukan beberapa pengujian terhadap hasil penerapan metode gabungan information gain dan k-nearest
neighbor.
4.1 Pengujian Nilai k K-Nearest Neighbor
Pengujian ini dilakukan dengan
menggunakan nilai k yang berbeda untuk mengetahui nilai k yang paling optimal yang akan digunakan untuk proses klasifikasi sehingga akan menghasilkan nilai akurasi yang optimal. Berikut ini merupakan hasil pengujian
accuracy, precision, recall dan f-measure variasi
penggunaan nilai k terdiri dari 1, 3, 5, 7, 9, 11, 13 dan 15:
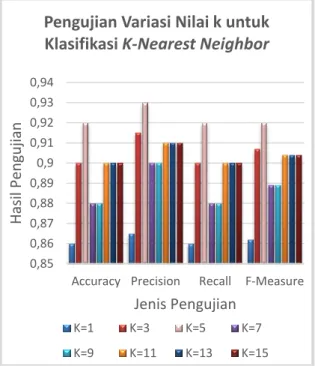
Gambar 2 Grafik Variasi nilai k
Proses klasifikasi data testing akan diproses untuk menentukan seberapa besar kemiripan antara data testing dan data training. Penentuan besar kemiripan data testing dengan data
training tergantung dengan nilai k tetangga
terdekat yang akan digunakan. Jika nilai k yang digunakan sesuai maka hasil klasifikasi akan
memiliki nilai akurasi yang tinggi namun jika nilai k yang digunakan tidak sesuai maka hasil akurasinya akan rendah. Berdasarkan Gambar 2 diatas nilai k yang paling optimal adalah ketika
k=5 karena memiliki nilai accuracy sebesar 92%
dimana nilai akurasinya merupakan nilai akurasi tertinggi dibandingkan dengan nilai akurasi pada nilai k yang lain serta nilai precision, recall dan
f-measure yang tinggi yaitu 0.93, 0.92 dan 0.92.
Pada penelitian ini kemiripan antara data
training dan data testing sangat dekat. Isi
dokumen terdiri dari beberapa kalimat yang panjang sehingga term pada data testing dan data
training relevan. Pada beberapa data isi
dokumen mengandung term yang tidak termasuk ke dalam kategori yang sebenarnya namun
karena jumlahnya tidak banyak maka
kecenderungan dokumen untuk tidak termasuk ke dalam kategori yang sesuai sangat kecil sehingga kebanyakan dokumen termasuk ke dalam kategori yang sebenarnya.
4.2 Pengujian Variasi Penggunaan Jumlah Term Hasil Information Gain untuk Klasifikasi
Pengujian ini berfungsi untuk mengetahui pengaruh variasi banyaknya term data training yang digunakan terhadap hasil klasifikasi menggunakan k-nearest neighbor. Pemilihan banyaknya term data training yang digunakan untuk proses klasifikasi berdasarkan hasil perhitungan information gain pada masing-masing term. Hasil information gain pada masing-masing term diurutkan dari nilai tertinggi ke rendah. Term dengan nilai
information gain tertinggi memiliki peluang
untuk digunakan pada saat proses klasifikasi, sebaliknya term yang memiliki nilai information
gain yang lebih rendah tidak akan digunakan
untuk proses klasifikasi. Variasi banyaknya jumlah term data training yang digunakan pada saat proses klasifikasi adalah 33% dan 66% term dengan nilai information gain tertinggi dari jumlah seluruh term pada data training. Term data testing yang akan diuji kemudian dicocokkan dengan hasil term information gain pada saat klasifikasi untuk menentukan seberapa besar kemiripan antara data testing dan data
training. Hasil pengujian accuracy, precision, recall dan f-measure variasi jumlah term seperti
pada Gambar 3: 0,85 0,86 0,87 0,88 0,89 0,9 0,91 0,92 0,93 0,94
Accuracy Precision Recall F-Measure
H asi l P en gu jia n Jenis Pengujian
Pengujian Variasi Nilai k untuk
Klasifikasi K-Nearest Neighbor
K=1 K=3 K=5 K=7
Gambar 3 Grafik Pengujian Jumlah Term hasil Information Gain
Gambar 3 menunjukkan hasil pengujian variasi penggunaan banyak jumlah term hasil
information gain untuk klasifikasi. Pada
penggunaan term sebesar 33% memiliki nilai akurasi rendah yaitu sebesar 0.5. Pada saat penggunaan term sebesar 66% memiliki akurasi sebesar yang lebih besar 0.78. Hal ini dipengaruhi beberapa faktor diantaranya adalah term yang seharusnya digunakan untuk klasifikasi memiliki nilai information gain yang rendah sehingga term dihapus dan tidak digunakan pada saat proses klasifikasi. Pada penelitian ini 33% term dengan nilai nilai
information gain tertinggi merupakan term yang
muncul satu kali pada data training sedangkan
term terendah adalah term yang muncul hampir
di semua data training. Selain itu, batas banyaknya pengambilan term berpengaruh terhadap term yang akan diambil, dimana term yang memiliki nilai information gain yang sama akan dihapus ketika batas telah ditentukan.
4.3 Pengujian Variasi Penggunaan Jumlah Term Berdasarkan Threshold Nilai Information Gain
Pengujian ini berfungsi untuk mengetahui pengaruh dari pemilihan jumlah term pada saat proses klasifikasi. Term dengan nilai
information gain yang sama akan dianggap
sebagai term yang sama sehingga term tetap digunakan meskipun batas term telah ditentukan. Hasil pengujian jumlah term seperti pada
Gambar 4:
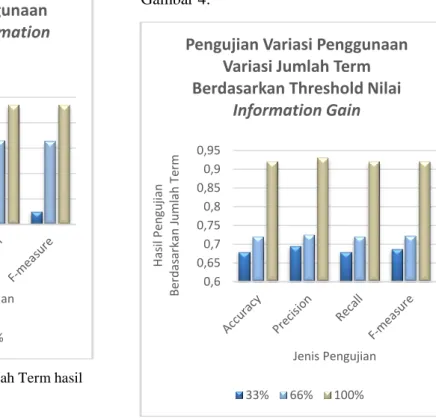
Gambar 4 Grafik Pengujian Variasi Penggunaan
Jumlah Term Berdasarkan Threshold nilai
Information Gain
Gambar 4 menunjukkan semakin besar jumlah term yang digunakan semakin besar nilai akurasinya. Penggunaan 66% jumlah term memiliki nilai akurasi yang lebih besar dari
penggunaan 33% jumlah term. Jika
dibandingkan dengan pengujian sebelumnya pengujian ini memiliki peningkatan nilai akurasi pada saat penggunaan term sebesar 33%. Pada saat penggunaan jumlah term 33% dari jumlah seluruh term dimana term yang memiliki nilai
information gain yang sama akan digunakan
pada saat proses klasifikasi menghasilkan akurasi sebesar 0.68 dan hasilnya lebih baik dibandingkan dengan penggunaan 33% jumlah
term tanpa memperhatikan term nilai
information gain yang sama. Sedangkan pada
saat penggunaan jumlah term 66% dengan memperhatikan nilai information gain yang sama memiliki nilai akurasi yang lebih rendah
dibandingkan dengan penggunaan 66%
penggunaan jumlah term sesuai batas yang ditentukan. Pada pengujian sebelumnya hasil 66% jumlah term yang digunakan pada saat proses klasifikasi memiliki jumlah term yang lebih banyak pada salah satu kategori namun pada pengujian ini 66% jumlah term yang digunakan untuk klasifikasi memiliki jumlah yang sama pada masing-masing kategori 0,45 0,55 0,65 0,75 0,85 0,95 H as il P en gu jian Ber d as ark an Ba n yak T erm Jenis Pengujan
Pengujian Variasi Penggunaan
Jumlah Term Hasil Information
Gain
33% 66% 100% 0,6 0,65 0,7 0,75 0,8 0,85 0,9 0,95 H as il P en gu jian Ber d as ark an Ju mlah T erm Jenis PengujianPengujian Variasi Penggunaan
Variasi Jumlah Term
Berdasarkan Threshold Nilai
Information Gain
sehingga masing-masing data memiliki peluang yang sama. Hasilnya adalah pengklasifikasian data berdasarkan nilai kedekatan data testing pada masing-masing kategori.
5. KESIMPULAN
Berdasarkan hasil pengujian dan analisis hasil penelitian ini dapat diambil kesimpulan bahwa pada saat pemilihan term yang digunakan untuk proses klasifikasi menggunakan metode
information gain menghasilkan term unik
dimana term yang muncul sekali memiliki nilai
information gain tertinggi. Term yang hanya
muncul pada salah satu kategori memiliki nilai
information gain lebih tinggi jika dibandingkan
dengan term yang muncul pada semua kategori. Term yang memiliki nilai information gain terendah adalah term yang muncul pada hampir semua data training. Nilai information gain akan berpengaruh terhadap term yang akan digunakan pada saat proses klasifikasi, dimana term yang memiliki nilai information gain yang tinggi maka akan digunakan pada saat proses klasifikasi sedangkan term dengan nilai
information gain terendah akan dihapus. Pada
pengujian nilai k, penggunaan k=5 merupakan penggunaan k yang optimal untuk proses klasifikasi menggunakan metode k-nearest
neighbor dimana menghasilkan nilai akurasi
sebesar 92%.
Pada pengujian variasi jumlah term yang digunakan untuk proses klasifikasi berbanding lurus dengan hasil akurasi, dimana semakin sedikit jumlah term yang digunakan maka semakin kecil hasil akurasi sebaliknya semakin besar jumlah term yang digunakan maka semakin besar nilai akurasinya, sedangkan pada pengujian banyak jumlah term yang digunakan berdasarkan threshold nilai information gain penggunaan 66% dari jumlah term memiliki nilai akurasi yang lebih rendah jika dibandingkan dengan penggunaan 66% tanpa memperhatikan nilai information gain yang sama. Pengujian penggunaan term hasil
information gain berpengaruh terhadap hasil
klasifikasi menggunakan k-nearest neighbor. Hasilnya perpaduan antara penggunaan feature
selection dengan metode information gain
dengan metode k-nearest neighbor
menghasilkan akurasi yang rendah dibandingkan dengan metode k-nearest neighbor karena term yang relevan memiliki nilai information gain yang rendah sehingga akan dihapus pada saat
proses feature selection dan tidak digunakan pada saat proses klasifikasi.
Berdasarkan kesimpulan yang ada, apabila pembaca ingin mengembangkan penelitian lebih lanjut ada beberapa kriteria lain yaitu diperlukan pengujian dengan menggunakan metode feature
selection yang lain selain information gain untuk
mengetahui metode feature selection lain memiliki nilai akurasi yang lebih baik atau tidak. Selain itu, diperlukan pengujian dengan menggunakan metode klasifikasi yang lain untuk mengetahui nilai akurasi jika digabungkan dengan metode information gain.
Metode information gain tidak dapat membedakan antara term sentiment analysis dengan kata bukan sentiment analysis. Oleh karena itu pada penelitian selanjutnya diperlukan metode yang dapat membedakan antara term
sentiment analysis atau bukan. Membedakan
antara term positif dan negatif diperlukan jika term yang menunjukkan sentiment terdiri dari dua suku kata untuk mengetahui term yang merupakan term positif atau term negatif. Oleh karena itu pada penelitian selanjutnya diperlukan metode untuk menggabungkan dua suku kata yang berdampingan menjadi satu suku kata yang merupakan term positif atau negatif.
DAFTAR PUSTAKA
Feldman, Ronen and James Sanger., 2007. The
Text Mining Handbook. Cambridge:
Cambridge University Press.
Cambridge.
Gebre, B., Zampieri, M., Wittenburg, P., Heskes, T., Improving Native Language Identification with TF-IDF Weighting.
Han, X., Liu, J., Shen, Z., Miao., An Optimized
K-Nearest Neighbor Algorithm for Large Scale Hierarchical Text Classification.
Hussein, D.M., 2016. A Survey on Sentiment
Analysis Challenges, Cairo: Journal of
King Saud University.
J. Nilsson, Nill., 1996. Introduction To Machine
Learning. Stanford University.
Khan, M.T., Durrani, M., Ali, A., Inayat, I., Khalid, S., Khan, H., 2016. Sentiment
analysis and the complex natural language, Pakista: Complex adaptive
system modeling.
Nugroho, Eko., 2011. Perancangan Sistem
Dengan Menggunakan Algoritma Robin-Karp. Program Studi Ilmu
Komputer, Jurusan Matematika,
Fakultas Matematika dan Ilmu
Pengetahuan Alam, Universitas
Brawijaya Malang.
Pendit, Putu Laxman., 2008. Perpustakaan
Digital Dari A Sampai Z. Jakarta: Cita
Karya Karsa Mandiri.
Singh, S.R., Murthy, H.A., Gonsalves, T.A., 2010. Feature Selection for Text
Classification Based on Gini Coeficient of Inequality, 10, pp.76-85.
Suguna, N., Thanushkodi, K., 2010. An
Improved K-Nearest Neighbor Classification Using Genetic Algorithm.
Tenenboim, L., Shapira, B., & Shoval, P., 2008.
Ontology-based classification of news in an electronic news paper Paper presented at Intelligent Information and Engineering Systems Conference.
Bulgaria.
Tim Penyusun Kamus Pusat Pembinaan dan Pengembangan Bahasa, 1990. Kamus
Besar Bahasa Indonesia, Jakarta: Balai
Pustaka.
Uguz, H., 2011. A Two-Stage Feature Selection
Method For Text Categorization By Using Information Gain, Principal Component Analysis And Genetic Algorithm, pp. 1024-1032, Turkey:
Elsevier.
Wicaksono, A. F., Nio, Ellen., Myaeng, S. H., 2013. Unsupervised approach for
sentiment analysis on Indonesian Movie Reviews. Korea: Korea Advance Institute of Science and Technology.