PEMULUSAN EKSPONENSIAL GANDA BROWN DAN FUZZY TIME SERIES CHENG
SKRIPSI
HANA PUSPITA ANJANI SIREGAR 170803054
PROGRAM STUDI MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
MEDAN 2021
PEMULUSAN EKSPONENSIAL GANDA BROWN DAN FUZZY TIME SERIES CHENG
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
HANA PUSPITA ANJANI SIREGAR 170803054
PROGRAM STUDI MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
MEDAN 2021
ANALISIS DATA DERET WAKTU MENGGUNAKAN METODE PEMULUSAN EKSPONENSIAL GANDA BROWN DAN
FUZZY TIME SERIES CHENG
SKRIPSI
Saya menyatakan bahwa skripsi ini adalah hasil karya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 26 Juli 2021
Hana Puspita Anjani Siregar 170803054
i
ANALISIS DATA DERET WAKTU MENGGUNAKAN METODE PEMULUSAN EKSPONENSIAL GANDA BROWN DAN
FUZZY TIME SERIES CHENG
ABSTRAK
Penelitian ini dilakukan untuk menganalisis suatu data deret waktu pada kasus peramalan dengan melakukan perbandingan tingkat akurasi dari penggunaan metode pemulusan eksponensial ganda Brown dan metode fuzzy time series Cheng yang dibuat dengan 3 model kelas interval yang berbeda. Data yang digunakan dalam penelitian ini adalah data hasil produksi Tandan Buah Segar (TBS) kelapa sawit di PT. Perkebunan Milano Marbau selama 10 tahun dari Januari 2011 hingga Desember 2020. Berdasarkan hasil perhitungan, didapatkan bahwa data yang digunakan bersifat trend dan non musiman. Pada metode pemulusan eksponensial ganda Brown menggunakan parameter 𝛼 = 0,95 didapatkan tingkat akurasi sebesar 84,54% dengan nilai kesalahan MAPE 15,46% dan hasil ramalan yang menurun pada Januari hingga Mei 2021 secara berturut adalah 1.003,046; 901,088; 799,131; 697,173 dan 595,217.
Sedangkan pada metode fuzzy time series Cheng didapatkan hasil ramalan yang cenderung meningkat untuk ketiga model interval. Pada model 1 didapatkan tingkat akurasi sebesar 92,28% dengan nilai kesalahan MAPE 7,72% dan hasil ramalan secara berurutan 1.363,53; 1.501,867; 1.927,914; 1.927,914 dan 1.927,914. Pada model 2 didapatkan tingkat akurasi sebesar 90,53% dengan nilai kesalahan MAPE 9,47%. Pada model 3 didapatkan tingkat akurasi sebesar 92,05% dengan nilai kesalahan MAPE 7,95%. Sehingga dari seluruh metode dan model yang digunakan, metode yang menghasilkan tingkat akurasi paling baik adalah metode fuzzy time series Cheng model 1 dengan penggunaan 6 kelas interval.
Kata kunci: Deret Waktu, Pemulusan Eksponensial Ganda Brown, Fuzzy Time Series Cheng, MAPE.
ANALYSISOFTIMESERIES DATA USINGBROWN’S DOUBLE EXPONENTIAL SMOOTHINGMETHOD AND CHENG’S FUZZY TIME SERIES
ABSTRACT
This study aim to analyze a time series data on forecasting cases by comparing the accuracy of brown's use of the double exponential smoothing method and Cheng's fuzzy time series method created with 3 different interval class models.
The data used in this study is data from the production of Fresh Fruit Bunches (FFB) of palm oil in PT. Milano Marbau Plantation for 10 years from January 2011 to December 2020. Based on the calculation results, it is obtained that the data used is trend and non-seasonal. On Brown's double exponential smoothing method using parameters 𝛼 = 0.95 obtained an accuracy rate of 84.54% with a MAPE error value of 15.46% and the forecast results decreased in January to May 2021 respectively was 1,003,046; 901,088; 799,131; 697,173 and 595,217. While in the fuzzy time series cheng method obtained forecast results that tend to increase for all three interval models. On model 1 there was an accuracy rate of 92.28% with a MAPE error value of 7.72% and a consecutive forecast result of 1,363.53; 1.501,867;
1.927,914; 1,927,914 and 1,927,914. On model 2, an accuracy rate of 90.53% was obtained with a MAPE error value of 9.47%. On model 3, an accuracy rate of 92.05% was obtained with a MAPE error value of 7.95%. So of all the methods and models used, the method that produces the best level of accuracy is the Cheng’s fuzzy time series method model 1 with the use of 6 interval classes.
Keywords: Time Series, Brown’s Double Exponential Smoothing, Cheng’s Fuzzy Time Series, MAPE
Puji dan syukur penulis panjatkan kepada Allah SWT atas rahmat-Nya sehingga penulis dapat menyelesaikan penyusunan skripsi ini dengan judul “Analisis Data Deret Waktu Menggunakan Metode Pemulusan Eksponensial Ganda Brown dan Fuzzy Time Series Cheng” untuk melengkapi syarat memperoleh gelar S1-Matematika di Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara.
Terima kasih penulis sampaikan kepada Ibu Dr. Elly Rosmaini, M.Si selaku dosen pembimbing yang telah memberikan waktu, kritik serta saran yang membangun selama penulisan skripsi ini. Terima kasih kepada Bapak Dr. Drs. Open Darnius, M.Sc selaku dosen pembanding 1 dan Bapak Dr. Sutarman, M.Sc selaku dosen pembanding 2 yang telah memberikan kritik dan saran yang membangun dalam penyempurnaan skripsi ini. Terima kasih kepada Bapak Dr. Suyanto, M.Kom dan Bapak Drs. Rosman Siregar, M.Si selaku Ketua dan Sekretaris Departemen Matematika FMIPA USU. Terima kasih kepada Dekan FMIPA USU, Bapak dan Ibu dosen pengajar serta seluruh pegawai di FMIPA USU. Terima kasih kepada PT.
Perkebunan Milano Marbau yang telah mengizinkan penulis dalam hal pengambilan data penelitian. Terima kasih kepada orang-orang yang penulis kasihi yaitu Ayah, Ibu, serta Adik yang selalu menjadi bagian penting dalam memberi motivasi yang penulis perlukan. Terima kasih kepada seluruh teman-teman yang selalu membantu dan memberikan semangat kepada penulis. Semoga seluruh bentuk bantuan yang telah diberikan mendapat balasan yang lebih baik dari Allah SWT.
Penulis menyadari bahwa skripsi ini masih jauh dari kesempurnaan, maka dari itu penulis mengharapkan kritik dan saran yang membangun dalam menyempurnakan penulisan skripsi ini. Semoga skripsi ini dapat memberikan manfaat bagi para pembaca.
Medan, 26 Juli 2021
Hana Puspita Anjani Siregar 170803054
Halaman
PENGESAHAN SKRIPSI i
ABSTRAK ii
ABSTRACT iii
PENGHARGAAN iv
DAFTAR ISI v
DAFTAR TABEL vii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN ix
DAFTAR SINGKATAN x
BAB 1 PENDAHULUAN
1.1 Latar Belakang 1
1.2 Perumusan Masalah 3
1.3 Batasan Masalah 4
1.4 Tujuan Penelitian 4
1.5 Manfaat Penelitian 4
BAB 2 TINJAUAN PUSTAKA
2.1 Deret Waktu 5
2.2 Analisis Trend 8
2.3 Stasioneritas 8
2.4 Pengertian Peramalan 9
2.5 Jenis-Jenis Peramalan 9
2.6 Metode Pemulusan Eksponensial 10
2.7 Metode Pemulusan Eksponensial Ganda Brown 12
2.8 Logika Fuzzy 13
2.9 Fuzzy Time Series 15
2.10 Fuzzy Time Series Cheng 17
2.11 Kesalahan Meramal (Forecast Error) 20 BAB 3 METODE PENELITIAN
3.1 Waktu dan Data Penelitian 23
3.2 Pengolahan Data 23
BAB 4 HASIL DAN PEMBAHASAN
4.1 Sumber Data 25
4.2 Analisis Statistika Deskriptif 26
4.3 Plot dan Pola Data 27
4.4 Analisis Uji Stasioneritas 30
4.5 Analisis Data Deret Waktu Menggunakan Metode 32 Pemulusan Eksponensial Ganda Brown
4.6 Analisis Data Deret Waktu Menggunakan Metode 43 Fuzzy Time Series Cheng
4.7 Perbandingan Tingkat Akurasi Hasil Ramalan 75 BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 77
5.2 Saran 78
DAFTAR PUSTAKA 79
LAMPIRAN 81
Nomor
Tabel Judul Halaman
4.1 Hasil Produksi Tandan Buah Segar (TBS) Kelapa Sawit di
PT. Perkebunan Milano Marbau 2011 – 2015 25 4.2 Hasil Produksi Tandan Buah Segar (TBS) Kelapa Sawit di
PT. Perkebunan Milano Marbau 2016 – 2020 26
4.3 Hasil Statistika Deskriptif 26
4.4 Perhitungan Trend Linier 28
4.5 Perhitungan MAPE dengan Nilai Parameter 33 4.6 Hasil Ramalan Bulan Januari – Mei 2021 Menggunakan
Metode Pemulusan Eksponensial Ganda Brown 42 4.7 Banyak Data untuk 3 Kelas pada FTS Cheng Model 1 44 4.8 Banyak Data untuk 5 Kelas pada FTS Cheng Model 1 44 4.9 Banyak Data untuk 6 Kelas pada FTS Cheng Model 1 44 4.10 Perhitungan Nilai Tengah pada FTS Cheng Model 1 45
4.11 Nilai Linguistik FTS Cheng Model 1 45
4.12 Fuzzifikasi fan FLR pada Data Aktual FTS Cheng Model 1 46
4.13 Pengelompokan FLRG FTS Cheng Model 1 46
4.14 Pembobotan FLRG FTS Cheng Model 1 46
4.15 Pembobotan Relasi Ternormalisasi FTS Cheng Model 1 47 4.16 Defuzzifikasi pada FLRG FTS Cheng Model 1 49 4.17 Hasil Ramalan pada Data Aktual FTS Cheng Model 1 49 4.18 Hasil Ramalan pada Januari – Mei 2021 Menggunakan
Metode FTS Cheng Model 1 50
4.19 Perhitungan Nilai Tengah pada FTS Cheng Model 2 53
4.20 Nilai Linguistik FTS Cheng Model 2 54
4.21 Fuzzifikasi fan FLR pada Data Aktual FTS Cheng Model 2 54
4.22 Pengelompokan FLRG FTS Cheng Model 2 55
4.23 Pembobotan FLRG FTS Cheng Model 2 55
4.24 Pembobotan Relasi Ternormalisasi FTS Cheng Model 2 56 4.25 Defuzzifikasi pada FLRG FTS Cheng Model 2 58 4.26 Hasil Ramalan pada Data Aktual FTS Cheng Model 2 59 4.27 Hasil Ramalan pada Januari – Mei 2021 Menggunakan
Metode FTS Cheng Model 2 59
4.28 Perhitungan Nilai Tengah pada FTS Cheng Model 3 63
4.29 Nilai Linguistik FTS Cheng Model 3 64
4.30 Fuzzifikasi fan FLR pada Data Aktual FTS Cheng Model 3 65
4.31 Pengelompokan FLRG FTS Cheng Model 3 65
4.32 Pembobotan FLRG FTS Cheng Model 3 66
4.33 Pembobotan Relasi Ternormalisasi FTS Cheng Model 3 67 4.34 Defuzzifikasi pada FLRG FTS Cheng Model 3 72 4.35 Hasil Ramalan pada Data Aktual FTS Cheng Model 3 72 4.36 Hasil Ramalan pada Januari – Mei 2021 Menggunakan
Metode FTS Cheng Model 3 73
Nomor
Gambar Judul Halaman
2.1 Pola Data Horizontal 6
2.2 Pola Data Musiman 6
2.3 Pola Data Siklis 7
2.4 Pola Data Trend Positif 7
2.5 Pola Data Trend Negatif 7
2.6 Kurva Representasi Linier Naik 13
2.7 Kurva Representasi Linier Turun 14
2.8 Kurva Representasi Segitiga 14
2.9 Kurva Representasi Trapesium 15
4.1 Plot Data Hasil Produksi TBS Kelapa Sawit 27
4.1 Garis Mean pada Plot Data Aktual 28
4.3 Garis Trend pada Plot Data Aktual 29
4.4 Plot Analisis Musiman 30
4.5 ACF pada Data Aktual 31
4.6 PACF pada Data Aktual 31
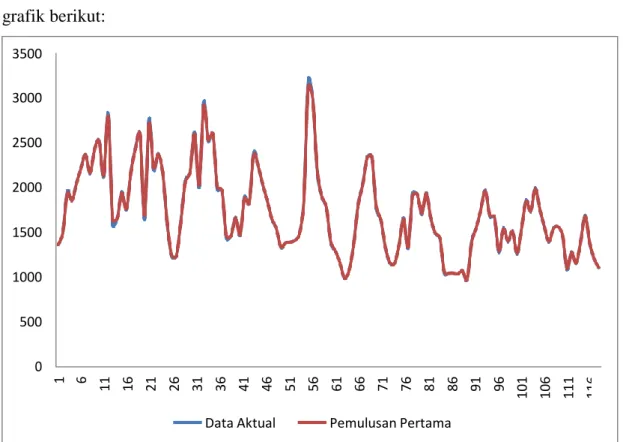
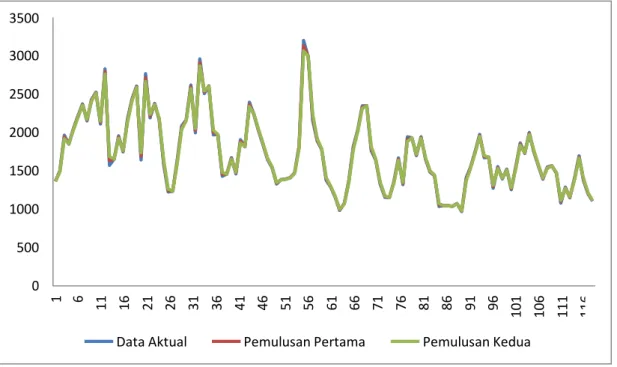
4.7 Plot Data Aktual dan Hasil Pemulusan Pertama 35 4.8 Plot Data Aktual dan Hasil Pemulusan Pertama dan Kedua 37 4.9 Plot Hasil Ramalan Menggunakan Metode Pemulusan
Eksponensial Ganda Brown 42
4.10 Plot Hasil Ramalan Menggunakan Metode Fuzzy Time Series
Cheng Model 1 50
4.11 Plot Hasil Ramalan Menggunakan Metode Fuzzy Time Series
Cheng Model 2 59
4.12 Plot Hasil Ramalan Menggunakan Metode Fuzzy Time Series
Cheng Model 2 73
4.13 Plot Perbandingan Data Aktual dengan Hasil Ramalan Metode Pemulusan Eksponensial Ganda Brown dan Fuzzy Time Series Cheng Model 1,2,3.
76
Nomor
Lampiran Judul Halaman
1 Surat Izin Pengambilan Data Riset 81
2 Surat Penerimaan Izin Pengambilan Data Riset 82 3 Data Hasil Produksi Tandan Buah Segar (TBS) Kelapa
Sawit di PT. Perkebunan Milano Marbau 83
4 Perhitungan Trend Linier 84
5 Nilai MAPE pada Parameter Metode Pemulusan
Eksponensial Ganda Brown 87
6
Nilai Pemulusan Pertama, Pemulusan Kedua, Konstanta, Slope dan Ramalan dengan Metode Pemulusan Eksponensial Ganda Brown
90 7 Fuzzifikasi, FLR dan Ramalan dengan Metode Fuzzy Time
Series Cheng Model 1 93
8 Nilai MAPE dengan Metode Fuzzy Time Series Cheng
Model 1 96
9 Fuzzifikasi, FLR dan Ramalan dengan Metode Fuzzy Time
Series Cheng Model 1 99
10 Nilai MAPE dengan Metode Fuzzy Time Series Cheng
Model 1 102
11 Fuzzifikasi, FLR dan Ramalan dengan Metode Fuzzy Time
Series Cheng Model 1 105
12 Nilai MAPE dengan Metode Fuzzy Time Series Cheng
Model 1 108
TBS : Tandan Buah Segar FTS : Fuzzy Time Series
PEG : Pemulusan Eksponensial Ganda FLR : Fuzzy Logical Relationship
FLRG : Fuzzy Logical Relationship Group MAPE : Mean Absolute Presentage Error MAD : Mean Absolute Deviation
MSE : Mean Square Error SSE : Sum of Square of Error ACF : Auto Correlation Function PACF : Partial Correlation Function
PENDAHULUAN
1.1 Latar Belakang
Deret waktu atau time series adalah kumpulan data sepanjang waktu secara berurutan dengan beberapa periode seperti dalam bentuk jam, hari, bulan atau tahun.
Data deret waktu dapat dianalisis untuk memprediksi suatu nilai di masa yang akan datang dengan mengamati pola data di masa lalu. Deret waktu memiliki pola data, yaitu pola data horizontal, musiman, siklis dan trend. Pola data ini yang akan menentukan baiknya suatu metode digunakan.
Peramalan (forecasting) adalah input dasar dalam proses pengambilan keputusan manajemen operasi dalam memberikan informasi tentang permintaan di masa mendatang dengan tujuan untuk menentukan berapa kapasitas atau persediaan yang diperlukan untuk membuat keputusan staffing, budget yang harus disiapkan untuk memenuhi kebutuhan dalam membuat suatu perencanaan (William J Stevenson, 2009).
Peramalan dengan model deret waktu bisa dilakukan dengan beberapa metode seperti pemulusan eksponensial, fuzzy time series, regresi linier, dan ARIMA.
Metode pemulusan eksponensial adalah bagian kategori metode deret waktu yang baik untuk digunakan dalam peralaman jangka pendek dengan pembobotan data di masa yang lalu secara eksponensial. Metode pemulusan eksponensial terdiri dari metode pemulusan eksponensial tunggal, metode pemulusan eksponensial tunggal dengan pendekatan adaptif, metode pemulusan eksponensial ganda dari Brown, metode pemulusan eksponensial tripel dari Brown, metode pemulusan eksponensial ganda dari Holt, metode pemulusan eksponensial tripel dari Winter, metode pemulusan eksponensial dengan klasifikasi Pegel’s dan metode eksponensial lainnya (Makridakis, 1999).
Makridakis (1999) menyatakan bahwa pemulusan eksponensial ganda Brown merupakan model yang bisa digunakan pada saat dasar pemikiran identik dengan rata-rata bergerak linier, karena pada pemulusan tunggal dan ganda ketinggalan dari data yang sebenarnya bilamana terdapat unsur trend. Kelebihan dari metode ini adalah data dan parameter yang digunakan lebih sedikit, serta lebih mudah dalam
mengolah data karena tidak memerlukan transformasi data apabila data non stasioner dan tidak menggunakan analisis autoregresi.
Penelitian mengenai peramalan data deret waktu dengan menggunakan metode pemulusan eksponensial sudah pernah dilakukan sebelumnya, seperti Zufra Inayah (2010) meneliti data deret waktu dan menyimpulkan bahwa peramalan yang dilakukan dengan pemulusan eksponensial ganda apabila data yang digunakan berpola trend secara naik atau turun bisa diselesaikan dengan menggunakan metode Brown sedangkan apabila data yang digunakan secara kontinu mengalami trend naik atau trend turun bisa menggunakan metode Holt. Metode pemulusan eksponensial ganda bisa dijadikan sebagai alternatif yang efisien untuk peramalan jangka pendek jika data yang digunakan diketahui dengan jumlah pengamatan atau titik kurang dari 50, pola data non stasioner dan tidak dipengaruhi musim.
Rita Ningsih dan Wulan Anggraeni (2018) juga melakukan penelitian dengan membandingkan nilai akurasi penggunaan metode fuzzy time series model Chen dan eksponensial ganda Brown pada kasus peramalan. Penelitian ini menyimpulkan bahwa tingkat kesalahan pemulusan ganda Brown lebih rendah yaitu bernilai 1,36%
dibandingkan metode fuzzy time series model Chen yang bernilai 2,05%.
Mika Layakana dan Said Iskandar (2020) melakukan perbandingan metode double moving average dan pemulusan eksponensial ganda pada data CPO Kelapa Sawit. Dari penelitian ini disimpulkan ramalan selama setahun dan dikatakan bahwa penggunaan metode pemulusan eksponensial ganda Brown memiliki nilai kesalahan yang lebih rendah dengan menggunakan nilai error MSE dan MAPE. Ia juga menyatakan bahwa metode double moving average tidak disarankan untuk data yang berpola trend.
Selanjutnya, selain metode pemulusan eksponensial ganda Brown, Cheng et.al. (2008) menyatakan bahwa metode fuzzy time series diaplikasikan pada masalah-masalah peramalan atau prediksi. Metode ini menggunakan himpunan fuzzy yaitu bernilai bukan riil tetapi linguistik. Hal ini mengakibatkan terdapat beberapa keunggulan dari penggunaan metode ini, seperti tidak bergantung pada asumsi data yang stasioner, bisa digunakan pada data historis yang relatif sedikit (Chen et.al., 2007). Terdapat beberapa model algoritma pada metode ini, seperti algoritma Song dan Chissom, algoritma Chen, algoritma Cheng dan algoritma Markov Chain.
Beberapa penelitian yang sudah dilakukan mengenai peramalan deret waktu menggunakan metode fuzzy time series adalah Sumartini et.al. (2017) meramalkan Indeks Harga Saham Gabungan menggunakan algoritma Cheng. Didapatkan bahwa tingkat akurasi ramalan yang dihasilkan tinggi yaitu 97,44%. Rahmawati et.al.
(2019) melakukan penelitian untuk memprediksi jumlah wisatawan yang ada di Sumatera Barat menggunakan algoritma Cheng dengan 36 titik data deret waktu.
Hasil penelitian mnyimpulkan metode ini cukup baik dengan nilai kesalahan MAPE sebesar 14,61%.
Arif Fadhillah et.al. (2020) melakukan perbandingan metode fuzzy time series dengan algoritma Chen dan algoritma Cheng. Dari hasil penelitian, ditemukan bahwa algoritma Cheng memiliki tingkat akurasi yang lebih baik dibandingkan algoritma Chen dengan perhitungan nilai kesalahan MAPE. Rifki Indra Perwira et.al. (2020) meramalkan hasil panen tanaman dengan menggunakan algoritma Cheng.
Disimpulkan bahwa metode ini berhasil digunakan dengan tingkat akurasi yang baik.
Berdasarkan uraian di atas, penulis ingin melakukan penelitian untuk melakukan perbandingan metode dengan menganalisis data deret waktu menggunakan metode pemulusan eksponensial ganda Brown dan fuzzy time series Cheng.
1.2 Perumusan Masalah
Berdasarkan latar belakang penelitian ini, diketahui bahwa metode pemulusan eksponensial ganda Brown dan fuzzy time series Cheng baik digunakan pada kasus peramalan dengan tingkat akurasi yang tinggi dengan kesamaannya yaitu bisa digunakan pada data yang mengandung unsur trend, non musiman dan tidak perlu transformasi data jika data non stasioner. Sehingga akan digunakan kedua metode peramalan tersebut pada pengolahan suatu data deret waktu. Selanjutnya masing- masing metode akan disimulasikan pada beberapa model yang berbeda untuk melihat bagaimana perbedaan hasil ramalan dan dengan metode serta model manakah yang akan menghasilkan tingkat akurasi lebih baik.
1.3 Batasan Masalah
Berdasarkan rumusan masalah, agar penelitian ini lebih fokus terhadap bahasan yang dituju maka diperlukan batasan-batasan masalah sebagai berikut:
1. Metode yang digunakan adalah metode pemulusan eksponensial ganda Brown dan fuzzy time series Cheng.
2. Penentuan tingkat akurasi dilakukan dengan menghitung nilai kesalahan meramal yaitu MAPE.
3. Contoh data deret waktu yang dianalisis adalah data sekunder jumlah produksi Tandan Buah Segar (TBS) kelapa sawit pada PT. Perkebunan Milano Marbau tahun 2011 – 2020.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah mengolah suatu data deret waktu untuk masalah peramalan dengan menggunakan metode pemulusan eksponensial ganda Brown dan fuzzy time series Cheng dengan simulasi beberapa model yang berbeda.
Selanjutnya akan dibandingkan hasil dari setiap model pada kedua metode tersebut untuk mengetahui tingkat akurasi yang lebih baik.
1.5 Manfaat Penelitian
Manfaat dari penelitian ini adalah memberikan alternatif dalam penyelesaian data deret waktu di masa lalu yang diolah untuk masalah peramalan masa yang akan datang menggunakan metode pemulusan eksponensial ganda Brown dan fuzzy time series Cheng agar menghasilkan tingkat akurasi yang baik.
BAB 2
TINJAUAN PUSTAKA
2.1 Deret Waktu (Time Series)
Deret waktu merupakan kumpulan data dari rangkaian nilai pengamatan pada periode waktu tertentu dengan interval yang sama panjang. Adapun contoh data deret waktu yaitu data produksi kelapa sawit dalam setahun dengan interval waktu setiap bulan, data penjualan botol minuman selama 10 tahun berturut dan data pemakaian bahan bakar setiap harinya dalam periode waktu satu bulan. Secara matematis, deret waktu dapat didefinisikan sebagai nilai-nilai Y1, Y2 , … dari suatu variabel Y pada titik-titik waktu t1, t2 , … , dengan demikian Y adalah suatu fungsi dari t dan dapat disimbolkan sebagai
Y = F(t) ( 2.1 )
(Murray R. dan Larry J., 2007).
Analisis percobaan data yang telah diamati pada titik waktu yang berbeda menimbulkan masalah baru dalam pemodelan statistika. Korelasi yang hadir dari pengambilan sampel data dari titik waktu yang berdekatan dapat membatasi penerapan metode statistika konvensional secara tradisional yang bergantung pada asumsi bahwa pengamatan tersebut adalah independen dan terdistribusi secara identik. Pendekatan sistematis yang dapat digunakan dalam permasalahan ini disebut dengan analisis deret waktu (Shumway, 1988).
Analisis deret waktu digunakan sebagai metode dalam mempelajari deret waktu yang bisa dalam bentuk materi dan juga peramalan. Tujuan dari analisis deret waktu adalah untuk mengetahui mekanisme tertentu, mengoptimalkan sistem kendali, serta melakukan peramalan suatu nilai pada masa yang akan datang. Untuk menggunakan data deret waktu pada peramalan, perlu dipenuhi beberapa asumsi seperti:
a. Terdapat hubungan antara kejadian pada masa yang akan datang dengan kejadian pada masa yang lalu.
b. Terdapat keterkaitan pola yang terjadi pada masa yang lalu dan berlanjut di masa yang akan datang.
Dalam melakukan peramalan dengan analisis deret waktu, hal yang perlu diperhatikan adalah ketepatan menentukan jenis pola data agar mendapatkan metode yang sesuai. Terdapat empat jenis pola data sebagai berikut :
a. Horizontal
Sebuah data disebut berpola horizontal apabila nilai data tersebut konstan berada di sekitar nilai rata-ratanya. Suatu produk dengan penjualan yang tidak meningkat atau menurun dalam waktu tertentu termasuk jenis horizontal. Bentuk pola data horizontal ditunjukkan pada gambar berikut:
Gambar 2.1 Pola Data Horizontal
b. Musiman (Seasonal)
Sebuah data disebut berpola data musiman apabila data tersebut memiliki pola perubahan yang berulang dari waktu ke waktu yang disebut juga memiliki pengaruh musiman. Nilai persentase dari variasi musiman dalam suatu data disebut juga sebagai indeks musiman. Bentuk pola data musiman ditunjukkan pada gambar berikut:
Gambar 2.2 Pola Data Musiman
c. Siklis (Cyclical)
Sebuah data disebut berpola data siklis apabila nilai dari data tersebut berada di sekitar garis trend untuk periode waktu yang panjang. Bentuk pola data siklis dituntukkan pada gambar berikut:
Gambar 2.3 Pola Data Siklis
d. Trend
Sebuah data disebut berpola data trend apabila nilai dari data tersebut cenderung naik atau turun secara kontinu untuk periode waktu yang panjang.
Pergerakan dalam trend yang cenderung naik disebut sebagai trend positif dan sebaliknya disebut sebagai trend negatif. Bentuk pola data trend ditunjukkan pada gambar berikut:
Gambar 2.4 Pola Data Trend Positif
Gambar 2.5 Pola Data Trend Negatif
2.2 Analisis Trend
Analisis trend merupakan metode yang digunakan untuk mengamati kecenderungan suatu data naik atau turun secara keseluruhan pada periode waktu tertentu. Persamaan trend linier adalah sebagai berikut:
𝑌 = 𝑎 + 𝑏X ( 2.2 )
Keterangan:
Y = deret waktu X = waktu
a, b = bilangan konstan.
Untuk menentukan nilai a dan b dapat dilakukan dengan menggunakan rumus berikut:
∑𝑛 Fi
𝑎 = i=1 𝑛 ( 2.3 )
dan
𝑏 = ∑𝑛 i=1 𝑛 KiFi
Ki2 ( 2.4 )
i=1
Keterangan:
Y = data deret waktu X = waktu
n = jumlah periode waktu.
2.3 Stasioneritas
Stasioneritas terjadi ketika data tidak mengalami pertumbuhan dan penurunan. Sebuah data dapat dikatakan stasioner ketika nilai rata-rata dan variansi di sekitar rata-rata data tersebut bernilai konstan pada periode waktu tertentu (Makridakis, 1999). Suatu data deret waktu disebut stasioner ketika pola datanya tidak mengandung unsur trend naik maupun turun.
∑
2.4 Pengertian Peramalan
Menurut Murahartawaty (2009), peramalan merupakan penggunaan variabel dari suatu data di masa lalu untuk memperkirakan nilainya di masa yang akan datang. Peramalan suatu nilai di masa yang akan datang ditujukan untuk memperbaiki hal yang terjadi di masa lalu menjadi lebih baik kedepannya. Hal ini terjadi akibat kinerja di masa lalu yang akan berulang di masa yang akan datang.
Heizer dan Render (2009) menyatakan bahwa peramalan adalah seni dan ilmu untuk memperkirakan kejadian di masa depan. Hal ini bisa dilakukan dengan menggunakan data yang ada pada waktu yang lalu dan memproyeksikannya dengan model matematis yang telah disesuaikan untuk masa yang akan datang. Selain itu, Heizer dan Render (2009) menyatakan bahwa peramalan (forecasting) memiliki tujuan sebagai berikut:
a. Untuk mengkaji kebijakan yang berlaku pada masa yang lalu dan pada masa saat ini dan melihat bagaimana pengaruhnya di masa yang akan datang.
b. Peramalan diperlukan karena adanya time lag antara saat suatu kebijakan yang ditetapkan dengan saat implementasi.
c. Peramalan merupakan dasar penyusunan untuk meningkatkan efektivitas suatu rencana.
2.5 Jenis-Jenis Peramalan
Menurut Herjanto (2008), peramalan dapat dibagi menjadi tiga jenis berdasarkan horizon waktu sebagai berikut :
a. Peramalan jangka panjang
Peramalan jangka panjang merupakan jenis peramalan yang menggunakan data dengan waktu yang terdiri lebih dari 18 bulan.
b. Peramalan jangka menengah
Peramalan jangka menengah merupakan jenis peramalan yang menggunakan data dengan waktu yang terdiri antara 3 hingga 18 bulan.
c. Peramalan jangka pendek
Peramalan jangka pendek merupakan jenis peramalan yang menggunakan data dengan waktu yang terdiri kurang dari 3 bulan.
Menurut Ginting (2007), peramalan dibagi menjadi dua jenis berdasarkan sifat penyusunannya sebagai berikut :
a. Peramalan subjektif
Peramalan subjektif merupakan jenis peramalan yang didasarkan dengan perasaan atau intuisi penelitinya.
b. Peramalan objektif
Peramalan objektif merupakan jenis peramalan yang didasarkan dengan data pada masa yang lalu dan dianalisa dengan menggunakan metode-metode tertentu.
2.6 Metode Pemulusan Eksponensial
Metode pemulusan eksponensial merupakan suatu prosedur untuk menghaluskan nilai dari data terdahulu dengan runtut waktu tertentu secara terus- menerus dengan cara eksponensial (Trihendradi, 2005).
Menurut Makridakis (1999), penggunaan metode pemulusan eksponensial dilakukan pada saat nilai pengamatan menurun secara eksponensial dari pengamatan terakhir menuju data yang lalu. Metode ini terdiri atas pemulusan eksponensial tunggal, pemulusan eksponensial ganda, pemulusan eksponensial tripel dan pemulusan eksponensial lainnya yang lebih rumit. Setiap metode memiliki kesamaan, yaitu nilai data yang baru akan lebih besar dibandingkan nilai data yang lebih lama.
Bentuk persamaan umum dari metode pemulusan eksponensial adalah sebagai berikut :
𝑆𝑡 = 𝛼X𝑡 + (1 − 𝛼)𝑆𝑡−1 ( 2.5)
Bentuk persamaan tersebut jika diperluas akan menjadi :
𝑆𝑡 = 𝛼X1 + 𝛼(1 − 𝛼)X𝑡−1 + 𝛼(1 − 𝛼)2X𝑡−2 + ⋯ + (1 − 𝛼)𝑛𝑆𝑡−(𝑛−1) ( 2.6 ) (Arora, et.al., 2006).
Keterangan:
S = ramalan untuk suatu periode
𝛼 = parameter pemulusan bernilai antara 0 dan 1 X = nilai aktual pada suatu periode.
Permasalahan yang secara umum ditemui dalam penggunaan metode pemulusan eksponensial adalah memperkirakan konstanta parameter pemulusan yang tepat. Berikut adalah cara untuk memilih nilai parameter:
a. Jika pola historis dari data aktual yang digunakan sangat tidak stabil pada periode waktu tertentu, maka nilai parameter yang dipilih adalah mendekati satu.
b. Jika pola historis dari data aktual yang digunakan relatif stabil pada periode waktu tertentu, maka nilai parameter yang dipilih adalah mendekati nol.
Terdapat beberapa jenis dari metode ini, diantaranya : a. Pemulusan Eksponensial Tunggal
Metode pemulusan eksponensial tunggal baik digunakan untuk data yang bersifat stasioner, tidak menunjukkan pola maupun trend didalamnya dan diaplikasikan untuk peramalan jangka pendek. Terdapat dua model dalam pemulusan ini yaitu pemulusan eksponensial tunggal satu parameter (one parameter) dan pemulusan eksponensial tunggal melalui pendekatan aditif (ARRES).
b. Pemulusan Eksponensial Ganda
Metode pemulusan eksponensial ganda baik digunakan untuk data yang menunjukkan pola trend. Terdapat dua model dalam pemulusan ini yaitu pemulusan eksponensial ganda satu parameter dari Brown dan pemulusan eksponensial ganda dua parameter dari Holt.
c. Pemulusan Eksponensial Tripel
Metode pemulusan eksponensial tripel baik digunakan untuk data yang menunjukkan adanya pola trend dan bersifat musiman. Terdapat dua model dalam pemulusan ini yaitu pemulusan eksponensial kuadratik satu parameter dari Brown dan pemulusan eksponensial berdasarkan kecenderungan musiman tiga parameter dari Winter.
d. Pemulusan Eksponensial Menurut Klasifikasi Pegel’s
Metode ini baik digunakan untuk mempertimbangkan pemisahan aspek trend dan musiman. Terdapat dua model dalam pemulusan ini yaitu bersifat aditif (linier) dan multiplikatif (non linier).
2.7 Metode Pemulusan Eksponensial Ganda Brown
Metode pemulusan eksponensial ganda Brown berdasar pada nilai rata-rata bergerak linier. Hal ini dikarenakan kedua nilai pemulusan tunggal dan data yang digunakan mengandung unsur trend. Kelebihan dari metode ini adalah dapat menggunakan data dengan parameter yang lebih sedikit, serta tidak memerlukan transformasi data ketika data yang digunakan non stasioner dan tidak menggunakan analisis autoregresi. Penggunaan metode ini identik rata-rata bergerak ganda, di mana perhitungan pertama menghasilkan nilai yang menyerupai galat sistematis.
Nilai galat tersebut akan dikurangi dengan selisih dari nilai pemulusan pertama dan nilai pemulusan kedua. Pemulusan eksponensial ganda Brown ini menggunakan satu parameter α pada pemulusan pertama dan kedua (Makridakis, 1999).
Perhitungan yang digunakan pada metode ini adalah sebagai berikut : a. Menentukan nilai pemulusan eksponensial tunggal (pertama)
𝑆′ = 𝛼X𝑡 + (1 − 𝛼)𝑆′ ( 2.7 )
𝑡 𝑡−1
b. Menentukan nilai pemulusan eksponensial ganda (kedua)
𝑆′′ = 𝛼𝑆′ + (1 − 𝛼)𝑆′′ ( 2.8 )
𝑡 𝑡 𝑡−1
c. Menentukan nilai pemulusan secara keseluruhan 𝑎𝑡 = 𝑆′ + (𝑆′ + 𝑆′′)
𝑡 𝑡 𝑡
𝑎𝑡 = 2𝑆′ − 𝑆′′ ( 2.9 )
𝑡 𝑡
d. Menentukan nilai pemulusan trend
𝑏 = 𝛼 (𝑆′ − 𝑆′′) ( 2.10 )
𝑡 1−𝛼 𝑡 𝑡
e. Menentukan nilai ramalan
𝐹𝑡+𝑚 = 𝑎𝑡 + 𝑚𝑏𝑡 ( 2.11 )
Keterangan:
𝑆′𝑡 = nilai pemulusan eksponensial tunggal pada periode ke-t 𝑆′𝑡−1 = nilai pemulusan eksponensial tunggal pada periode ke-t-1 𝑆′′𝑡 = nilai pemulusan eksponensial ganda pada periode ke-t 𝑆′′𝑡−1 = nilai pemulusan eksponensial ganda pada periode ke-t-1 X𝑡 = nilai data aktual pada periode ke-t
𝑎𝑡 = nilai pemulusan keseluruhan pada periode ke-t 𝑏𝑡 = nilai pemulusan trend pada periode ke-t
𝛼 = nilai konstanta pemulusan 𝑚 = periode ke depan
𝐹𝑡+𝑚 = ramalan untuk m periode ke depan.
Dalam penggunaan rumus tersebut, harus ada nilai 𝑆′𝑡−1 dan 𝑆′′𝑡−1. Namun apabila nilai t = 1, nilai-nilai tersebut tidak tersedia. Penentuan nilai-nilai ini harus dilakukan di awal periode, sehingga untuk mengatasi hal ini dapat dilakukan dengan menetapkan nilai tersebut sama dengan nilai data aktual (X1) (Makridakis, Wheelwright dan McGee, 1999).
2.8 Logika Fuzzy
Kusumadewi dan Purnomo (2004) menyatakan bahwa logika fuzzy pada awalnya dikemukakan oleh seorang profesor bernama Lotfi Asker Zadeh pada tahun 1965. Ia mengembangkan teori himpunan yang tiap anggotanya mempunyai derajat keanggotaan kontinu antara 0 hingga 1 dan disebut sebagai himpunan samar atau fuzzy. Nilai 0 pada himpunan fuzzy berarti salah, nilai 1 berarti benar dan nilai-nilai diantara 0 dan 1 berarti samar yang dimaksudkan bahwa nilai kebenaran sesuatu tidak hanya salah dan benar. Salah satu cara yang bisa dilakukan untuk mendapatkan nilai derajat keanggotaan adalah dengan pendekatan fungsi sebagai berikut:
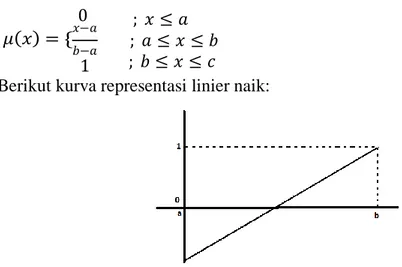
a. Representasi Kurva Linier
Hal ini dilakukan dengan melakukan pemetaan yang digambarkan sebagai garis lurus (linier). Terdapat dua keadaan garis linier, yaitu naik dan turun. Pada keadaan linier naik, fungsi keanggotaannya adalah sebagai berikut:
𝑥−𝑎 0 𝜇(𝑥) = {
𝑏−𝑎 1
; 𝑥 ≤ 𝑎
; 𝑎 ≤ 𝑥 ≤ 𝑏
; 𝑏 ≤ 𝑥 ≤ 𝑐 ( 2.12 )
Berikut kurva representasi linier naik:
Gambar 2.6 Kurva Representasi Linier Naik
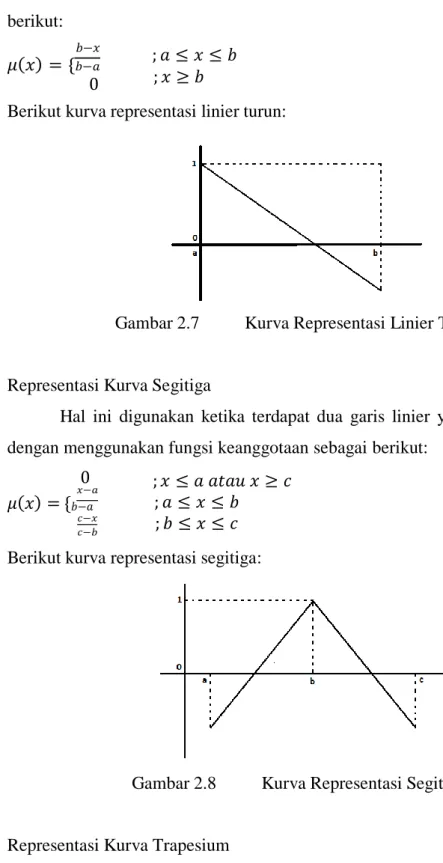
Sedangkan pada keadaan linier turun, fungsi keanggotaannya adalah sebagai berikut:
𝜇(𝑥) = {𝑏−𝑎 𝑏−𝑥
0
; 𝑎 ≤ 𝑥 ≤ 𝑏
( 2.13 )
; 𝑥 ≥ 𝑏
Berikut kurva representasi linier turun:
Gambar 2.7 Kurva Representasi Linier Turun
b. Representasi Kurva Segitiga
Hal ini digunakan ketika terdapat dua garis linier yaitu naik dan turun dengan menggunakan fungsi keanggotaan sebagai berikut:
𝑥−𝑎 0 𝜇(𝑥) = {𝑏−𝑎
𝑐−𝑥 𝑐−𝑏
; 𝑥 ≤ 𝑎 𝑎𝑡𝑎𝑢 𝑥 ≥ 𝑐
; 𝑎 ≤ 𝑥 ≤ 𝑏
; 𝑏 ≤ 𝑥 ≤ 𝑐 ( 2.14 )
Berikut kurva representasi segitiga:
Gambar 2.8 Kurva Representasi Segitiga
c. Representasi Kurva Trapesium
Kurva ini didasarkan seperti kurva segitiga, namun terdapat beberapa titik yang memiliki nilai keanggotaan 1. Fungsi keanggotaannya adalah sebagai berikut:
𝜇(𝑥) = ﻟ𝑥− 0
𝑏−𝑎
❪ 1 𝑐−𝑥
𝑐−𝑏
; 𝑥 ≤ 𝑎 𝑎𝑡𝑎𝑢 𝑥 ≥ 𝑐
; 𝑎 ≤ 𝑥 ≤ 𝑏
; 𝑏 ≤ 𝑥 ≤ 𝑐
; 𝑏 ≤ 𝑥 ≤ 𝑐
( 2.15 )
Berikut kurva representasi trapesium:
Gambar 2.9 Kurva Representasi Trapesium
Keterangan:
𝜇(𝑥) = fungsi keanggotaan a,b,c,d = batas kurva.
Himpunan fuzzy memiliki dua karakter, yaitu linguistik dan numerik. Linguistik mewakili keadaan dengan menggunakan bahasa alami, misalnya panas, hangat dan dingin. Sedangkan numerik mewakili keadaan dengan menunjukkan nilai (angka), misalnya 30,50 dan 75.
2.9 Fuzzy Time Series
Fuzzy time series merupakan metode yang diungkapkan oleh Song dan Chissom untuk melakukan peramalan atau prediksi dengan menggunakan data historis yang selanjutnya akan mengestimasi data yang akan terjadi di masa depan dengan memperhatikan prinsip-prinsip pada logika fuzzy. Dalam menentukan peramalan dengan fuzzy time series, digunakan nilai-nilai himpunan fuzzy yang diperoleh dari bilangan riil atas himpunan semestanya untuk menggantikan data historis yang akan digunakan (Tauryawati dan Irawan, 2014).
𝗅
Song dan Chissom (1994) mendefinisikan fuzzy time series sebagai berikut:
a. Melakukan pembentukan himpunan semesta (𝑈) dengan menggunakan rumus:
𝑈 = [𝑑𝑚i𝑛 − 𝑑1 ; 𝑑𝑚𝑎𝑥 + 𝑑2] ( 2.16 ) Keterangan:
𝑈 = himpunan semesta 𝑑𝑚i𝑛 = data terkecil 𝑑𝑚𝑎𝑥 = data terbesar
𝑑1, 𝑑2 = bilangan positif sembarang.
b. Membentuk beberapa interval yang sama pada himpunan semesta dengan rumus Sturges berikut:
1 + 3,322 𝑙𝑜𝑔(𝑛) ( 2.17 )
dengan n merupakan jumlah data observasi.
c. Jika 𝑈 adalah himpunan semesta, dengan 𝑈 = 𝑢1, 𝑢2, 𝑢3, … , 𝑢𝑛
Keterangan:
𝑈 = himpunan semesta
𝑢i = interval pada 𝑈, dengan i = 1, 2, 3, … , 𝑛 maka variabel linguistiknya dirumuskan menjadi:
𝐴 = 𝜇𝐴i(𝑈1) + 𝜇𝐴i(𝑈2) + ⋯ + 𝜇𝐴i(𝑈𝑛) ( 2.18 )
i 𝑈1 𝑈2 𝑈𝑛
dengan 𝜇𝐴i(𝑈1) merupakan derajat keanggotaan dari 𝑢i ke himpunan variabel linguistik 𝐴i, dengan 𝜇𝐴i(𝑈i) ∈ [0,1] dan 1 ≤ i ≤ 𝑛.
d. Bentuk nilai derajat keanggotaan dari 𝜇𝐴i(𝑈1) adalah sebagai berikut:
1 𝜇𝐴i(𝑈1) = {0,5
0
; ji𝑘𝑎 i = j
; ji𝑘𝑎 i = j − 1 𝑎𝑡𝑎𝑢 j + 1
; 𝑙𝑎i𝑛𝑛𝑦𝑎
( 2.19 ) Boaisha dan Amaitik (2010) membuat aturan dalam menentukan derajat keanggotaan, yaitu:
Aturan 1: Jika data aktual X𝑡 termasuk dalam 𝑢i maka nilai derajat keanggotaan 𝑢i adalah 1, 𝑢i+1 adalah 0,5, dan 0 untuk lainnya.
Aturan 2: Jika data aktual X𝑡 termasuk dalam 𝑢i, 1 ≤ i ≤ 𝑛 maka nilai derajat keanggotaan 𝑢i adalah 1, 𝑢i+1 dan 𝑢i−1 adalah 0,5, dan 0 untuk lainnya.
Aturan 3: Jika data aktual X𝑡 termasuk dalam 𝑢i maka nilai derajat keanggotaan 𝑢i adalah 1, 𝑢i−1 adalah 0,5, dan 0 untuk lainnya.
2.10 Fuzzy Time Series Cheng
Cheng, et.al. (2008) mengemukakan metode fuzzy time series untuk memperbaiki algoritma Chen yang masih memiliki kekurangan, yaitu tidak menghiraukan ada atau tidaknya pengulangan dan pembobotan nilai yang semakin kecil pada data yang lebih lama. Sehingga pada algoritma Cheng dalam menentukan interval digunakan Fuzzy Logical Relationship (FLR), yaitu memperhatikan seluruh hubungan serta membuat pembobotan sesuai dengan urutan data dan pengulangan yang terjadi. Peramalan data deret waktu dengan metode fuzzy time series Cheng ini dapat dilakukan dengan tahapan sebagai berikut:
a. Melakukan pembentukan himpunan semesta (𝑈) pada data aktual.
𝑈 = [𝑑𝑚i𝑛, 𝑑𝑚𝑎𝑥] ( 2.20 )
Keterangan:
𝑈 = himpunan semesta 𝑑𝑚i𝑛 = nilai data yang terkecil
𝑑𝑚𝑎𝑥 = nilai data yang terbesar.
b. Melakukan penentuan interval kelas menggunakan distribusi frekuensi. Dalam hal ini terdapat beberapa model untuk menentukan banyaknya kelas pada data deret waktu, seperti:
1. Membagi himpunan semesta menjadi beberapa kelas interval yang sama panjangnya. Selanjutnya setelah interval terbentuk, dilakukan perhitungan banyaknya data pada setiap interval kelas. Apabila jumlah data pada interval melebihi batas rata-rata dari jumlah data untuk setiap interval, maka interval tersebut dapat dibagi lagi menjadi dua interval yang sama panjang hingga banyaknya data pada interval tidak melebihi rata-ratanya.
a) Menentukan rentang (range).
𝑅 = 𝑑𝑚𝑎𝑥 − 𝑑𝑚i𝑛 ( 2.21 )
b) Menentukan lebar interval.
𝐼 = 𝑅
𝑝
c) Menentukan nilai tengah.
( 2.22 )
𝑚i = 𝐵𝑎𝑡𝑎𝑠 𝐴𝑡𝑎𝑠+𝐵𝑎𝑡𝑎𝑠 𝐵𝑎w𝑎ℎ
2 ( 2.23 )
2. Menggunakan persamaan Sturges dengan cara sebagai berikut:
a) Menentukan rentang (range).
𝑅 = 𝑑𝑚𝑎𝑥 − 𝑑𝑚i𝑛 ( 2.24 )
b) Menentukan banyak interval kelas menggunakan persamaan Sturges.
𝐾 = 1 + 3,322 log(𝑛) ( 2.25 )
c) Menentukan lebar interval.
𝐼 = 𝑅
𝐾
d) Menentukan nilai tengah.
( 2.26 )
𝑚i = 𝐵𝑎𝑡𝑎𝑠 𝐴𝑡𝑎𝑠+𝐵𝑎𝑡𝑎𝑠 𝐵𝑎w𝑎ℎ
2 ( 2.27 )
3. Menggunakan perhitungan berbasis rata-rata dari data yang diberikan dengan cara sebagai berikut:
a) Menentukan nilai absolut dari rata-rata selisih data.
𝑀𝑒𝑎𝑛 = 𝑛 𝑡=1 |𝑑𝑛 𝑡+1−𝑑𝑡| ( 2.28 ) b) Menentukan lebar interval.
𝑙 = 𝑀𝑒𝑎𝑛 2
c) Menentukan banyak interval kelas.
𝑝 = 𝑑𝑚𝑎𝑥−𝑑𝑙 𝑚i𝑛
d) Menentukan nilai tengah.
( 2.29 )
( 2.30 )
𝑚i = 𝐵𝑎𝑡𝑎𝑠 𝐴𝑡𝑎𝑠+𝐵𝑎𝑡𝑎𝑠 𝐵𝑎w𝑎ℎ
2 ( 2.31 )
Keterangan:
𝑅 = rentang (range) 𝑑𝑚𝑎𝑥 = data terbesar 𝑑𝑚i𝑛 = data terkecil.
𝐼 = lebar interval 𝑝 = banyak kelas 𝑚i = nilai tengah 𝑛 = banyak data
𝐾 = banyak kelas pada persamaan Sturges 𝑑 = data pada suatu periode.
∑
c. Mendefinisikan himpunan fuzzy 𝐴i serta melakukan fuzzifikasi terhadap data aktual yang digunakan. Dalam hal ini dimisalkan 𝐴1, 𝐴2, 𝐴3, … , 𝐴𝑝 merupakan himpunan fuzzy dengan nilai linguistik, maka didefinisikan variabel linguistik himpunan fuzzy pada himpunan semesta (𝑈) sebagai berikut:
𝐴 = 𝜇𝐴i(𝑢1) + 𝜇𝐴i(𝑢2) + 𝜇𝐴i(𝑢3) + ⋯ + 𝜇𝐴i(𝑢𝑛) ( 2.32 )
i 𝑢1 𝑢2 𝑢3 𝑢𝑛
dengan 𝜇𝐴i merupakan fungsi keanggotaan dari himpunan fuzzy 𝐴i, sehingga 𝜇𝐴i: 𝑈 → [0,1]. Jika 𝑢i merupakan keanggotaan dari 𝐴i maka𝜇𝐴i(𝑢i) merupakan derajat keanggotaan dari 𝑢i terhadap 𝐴i. Definisi tersebut apabila diperluas akan menjadi seperti berikut:
𝐴1 = {𝑢1|1} + {𝑢2|0,5} + {𝑢3|0} + {𝑢4|0} + ⋯ + {𝑢𝑛|0}
𝐴2 = {𝑢1|0,5} + {𝑢2|1} + {𝑢3|0,5} + {𝑢4|0} + ⋯ + {𝑢𝑛|0}
𝐴3 = {𝑢1|0} + {𝑢2|0,5} + {𝑢3|1} + {𝑢4|0} + ⋯ + {𝑢𝑛|0} ( 2.33 )
❪
𝐴𝑝 = {𝑢1|0} + {𝑢2|0} + {𝑢3|0} + ⋯ + {𝑢𝑛−1|0,5} + {𝑢𝑛|1}
d. Membuat tabel Fuzzy Logical Relationship (FLR) dari data aktual yang disimbolkan dengan 𝐴i → 𝐴j, di mana 𝐴i merupakan current state dan 𝐴j
merupakan next state.
e. Melakukan pembobotan dari relasi FLR menjadi Fuzzy Logical Relationship Group (FLRG). Hal ini dilakukan dengan memasukkan seluruh hubungan dan melakukan pembobotan berdasarkan dari urutan data dan pengulangan data yang sama. Pembentukan matriks pembobotan dilakukan dengan menggabungkan FLR yang mempunyai current state (𝐴i) yang sama menjadi satu grup.
Pembobotan yang didapat dari relasi FLR selanjutnya diubah menjadi bentuk matriks pembobot (W) yang dituliskan sebagai berikut:
W11 W12 W = [W21 W21
❪ ❪ W𝑛1 W𝑛2 Keterangan:
⋯ W1𝑛
⋯ W2𝑛
] ( 2.34 )
Wij ❪
⋯ W𝑛
W = matriks pembobot
Wij = bobot matriks pada baris ke-i dan kolom ke-j, dengan i, j = 1,2,3, … , 𝑛
f. Melakukan transfer bobot FLRG yang sudah dibuat ke dalam bentuk matriks pembobot bar terstandarisasi (W*) yang didapatkan dengan menggunakan rumus
W* = 𝖶ij ( 2.35 )
𝑛 i=1 𝖶i
Bentuk persamaannya adalah sebagai berikut:
W* =
W11* W12*
W21* W22* ⋯ W1𝑛*
⋯ W* 2𝑛* ( 2.36 )
❪ ❪ Wij ❪
[W𝑛1* W𝑛2* ⋯ W *]
𝑛
g. Melakukan penentuan defuzzifikasi untuk nilai peramalan (𝐹) dengan cara mengalikan W* dengan nilai tengah (𝑚i) yang didapatkan menggunakan persamaan matriks pembobotan terstandarisasi. Sehingga akan terbentuk perhitungan peramalan sebagai berikut:
𝐹i = Wi1*(𝑚1) + Wi2*(𝑚2) + ⋯ + Wi𝑛*(𝑚𝑛) ( 2.37 ) Jika hasil fuzzifikasi pada periode ke-i adalah 𝐴i, dan 𝐴i tidak mempunyai FLR pada FLRG dengan kondisi di mana 𝐴i → Ø yang nilai maksimum derajat keanggotaannya terdapat pada 𝑢i, maka nilai 𝐹i merupakan nilai tengah dari 𝑢i, yaitu 𝑚i (Fahmi, et.al., 2013).
2.11 Kesalahan Meramal (Forecast Error)
Setiap model peramalan yang telah dilakukan harus diketahui keakuratannya.
Untuk mengetahui tingkat keakuratan dapat dilakukan dengan mencari nilai kesalahan (error) yang didefinisikan sebagai berikut :
𝑒𝑡 = X𝑡 − 𝐹𝑡 ( 2.38 )
dengan
𝐹𝑡 = 𝐹𝑡−1 + 𝛼(X𝑡 − 𝐹𝑡−1) ( 2.39 )
Keterangan: 𝑒𝑡 = nilai kesalahan meramal pada periode t X𝑡 = nilai peramalan pada periode t
𝐹𝑡 = nilai aktual pada periode t 𝐹𝑡−1= nilai aktual pada periode t-1
∑
𝛼 = parameter.
Jika nilai kesalahan semakin besar, maka tingkat keakuratan dari hasil ramalan akan semakin kecil.
Model peramalan yang akan divalidasi nilai kesalahannya dapat menggunakan sejumlah indikator seperti rata-rata penyimpangan mutlak (Mean Absolute Deviation), rata-rata kuadrat terkecil (Mean Square Error), rata-rata presentase kesalahan mutlak (Mean Absolute Presentage Error), dan jumlah kuadrat penyimpangan (Sum of Square of Error).
a. Rata-Rata Penyimpangan Absolut (Mean Absolute Deviation)
Mean Absolute Deviation (MAD) merupakan indikator yang digunakan untuk mengukur ketepatan ramalan dengan cara menghitung nilai rata-rata kesalahan dalam perkiraan. MAD mengevaluasi metode peramalan menggunakan jumlah dari kesalahan-kesalahan yang bernilai mutlak. MAD biasa digunakan untuk mengukur kesalahan ramalan pada unit yang sama sebagai deret asli. Nilai MAD dirumuskan sebagai berikut.
𝑀𝐴𝐷 = 1 ∑𝑛 |𝑒 | ( 2.40 )
𝑛 𝑡=1 𝑡
b. Rata-Rata Kuadrat Terkecil (Mean Square Error)
Mean Squared Error (MSE) merupakan indikator yang digunakan untuk mengatur kesalahan dalam peramalan yang besar. Pendekatan ini menguadratkan kesalahan-kesalahan yang ada dan menghasilkan kesalahan sedang yang mungkin lebih baik dibandingkan dengan kesalahan kecil. Nilai MSE dirumuskan sebagai berikut :
𝑀𝑆𝐸 = 1 ∑𝑛 |𝑒 2| ( 2.41 )
𝑛 𝑡=1 𝑡
c. Rata-Rata Presentase Kesalahan Absolut (Mean Absolute Presentage Error) Mean Absolute Percentage Error (MAPE) merupakan indikator yang digunakan untuk mengetahui besarnya kesalahan dalam peramalan yang dibandingkan dengan nilai aktual. Pendekatan ini biasa digunakan pada saat variabel dalam ramalan tersebut dianggap penting. Pendekatan ini menggunakan kesalahan mutlak pada tiap periode untuk kemudian dibagi dengan nilai observasi yang aktual. Selanjutnya dengan menggunakan kesalahan mutlak pada tiap periode dibagi dengan nilai observasi yang nyata untuk periode itu dan
𝑡=1
menghitung persentase kesalahan meramalnya. Nilai MAPE dirumuskan sebagai berikut :
𝑀𝐴𝑃𝐸 = 1 ∑𝑛 𝑒𝑡 𝑥 100% ( 2.42 )
𝑛 𝑡=1 K𝑡
d. Jumlah Kuadrat Penyimpangan (Sum of Square for Error)
Sum of Square for Error (SSE) merupakan indikator yang dapat didapatkan dengan cara menjumlahkan seuruh hasil kuadrat dari kesalahan. Nilai SSE dirumuskan sebagai berikut :
𝑆𝑆𝐸 = ∑𝑛 𝑒𝑡2 ( 2.43 )
BAB 3
METODE PENELITIAN
3.1 Waktu dan Sumber Data Penelitian
1. Penelitian ini dilaksanakan pada bulan Maret – Mei 2021.
2. Data yang digunakan dalam penelitian ini merupakan data sekunder hasil produksi Tandan Buah Segar (TBS) Kelapa Sawit di PT. Perkebunan Milano Marbau.
3.2 Pengolahan Data
Data yang digunakan kemudian diolah dengan langkah-langkah sebagai berikut:
1. Studi Pustaka.
Pengumpulan referensi berupa buku dan jurnal nasional maupun internasional yang berkaitan dengan data deret berkala, metode pemulusan eksponensial ganda Brown dan metode fuzzy time series Cheng.
2. Melakukan analisis statistika deskriptif terhadap data deret waktu yang digunakan.
3. Membuat plot data dan mengidentifikasi pola data deret waktu.
4. Melakukan analisis uji stasioneritas pada data deret waktu yang digunakan.
5. Melakukan analisis data deret waktu dengan menggunakan metode pemulusan ganda Brown.
a. Menentukan nilai parameter.
b. Menentukan tingkat akurasi dengan menghitung nilai kesalahan meramal MAPE.
c. Menentukan nilai pemulusan eksponensial pertama.
d. Menentukan nilai pemulusan eksponensial kedua.
e. Menentukan nilai pemulusan secara keseluruhan.
f. Menentukan nilai pemulusan trend.
g. Menentukan nilai ramalan.
6. Melakukan analisis data deret waktu menggunakan metode fuzzy time series Cheng dengan 3 model himpunan yang berbeda.
a. Menentukan bentuk himpunan semesta data aktual.
24
b. Menentukan bentuk interval dan nilai linguistik.
c. Melakukan fuzzifikasi pada data aktual.
d. Menentukan Fuzzy Logic Relations (FLR) dan Fuzzy Logic Relations Group (FLRG).
e. Menentukan pembobotan.
f. Menentukan pembentukan pembobotan dinormalisasi.
g. Melakukan defuzzifikasi nilai peramalan.
h. Menentukan tingkat akurasi dengan menghitung nilai kesalahan meramal MAPE.
7. Membandingkan tingkat akurasi hasil perhitungan metode pemulusan eksponensial ganda Brown dan fuzzy time series Cheng dengan 3 model himpunan yang berbeda.
8. Menentukan hasil dan kesimpulan.
BAB 4
HASIL DAN PEMBAHASAN
4.1 Sumber Data
Data yang digunakan adalah data sekunder hasil produksi Tandan Buah Segar (TBS) Kelapa Sawit di PT. Perkebunan Milano Marbau pada tahun 2011 – 2020.
Tabel 4.1 Hasil Produksi Tandan Buah Segar (TBS) Kelapa Sawit di PT.
Perkebunan Milano Marbau 2011 – 2015
Tahun 2011 2012 2013 2014 2015
Jan 1.363,53 1.573,23 1.583,03 1.974,36 1.539,99 Feb 1.498,99 1.655,03 1.224,85 1.428,48 1.328,31 Mar 1.965,77 1.956,83 1.233,98 1.459,16 1.387,40 Apr 1.849,06 1.749,17 1.636,00 1.673,71 1.393,38 Mei 2.048,60 2.183,93 2.087,80 1.463,44 1.411,18 Jun 2.219,44 2.443,97 2.165,33 1.908,06 1.473,26 Jul 2.375,76 2.608,14 2.620,64 1.813,54 1.825,74 Ags 2.152,58 1.643,77 1.998,27 2.395,04 3.202,13 Sep 2.434,06 2.770,23 2.960,84 2.234,35 2.990,75 Okt 2.527,57 2.191,41 2.509,79 2.027,04 2.161,95 Nov 2.113,06 2.383,12 2.610,33 1.845,91 1.889,43 Des 1.831,98 2.166,20 1.971,32 1.645.94 1.778,61
Tabel 4.2 Hasil Produksi Tandan Buah Segar (TBS) Kelapa Sawit di PT.
Perkebunan Milano Marbau 2016 – 2020
Tahun 2016 2017 2018 2019 2020
Jan 1.376,23 1.323,35 1.439,45 1.679,32 1.391,23 Feb 1.290,76 1.155,76 1.034,40 1.273,79 1.550,60 Mar 1.158,10 1.152,46 1.046,95 1.555,80 1.567,53 Apr 982,82 1.365,16 1.038,47 1.395,22 1.472,43 Mei 1.077,59 1.668,96 1.075,58 1.522,27 1.078,91 Jun 1.372,11 1.321,13 970,54 1.255,65 1.288,80 Jul 1.819,99 1.944,76 1.409,65 1.556,69 1.151,26 Ags 2.037,45 1.931,15 1.556,40 1.865,05 1.405,72 Sep 2.348,45 1.698,59 1.756,44 1.727,76 1.696,35 Okt 2.351,80 1.946,69 1.976,08 2.001,14 1.371,91 Nov 1.761,61 1.651,31 1.674,15 1.754,13 1.198,59 Des 1.639,73 1.484,45 1.528,58 1.562,64 1.105,23
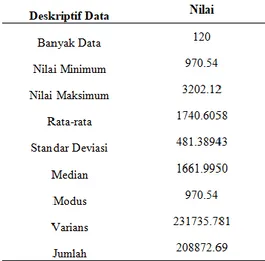
4.2 Analisis Statistika Deskriptif
Penyelesaian statistika deskriptif dilakukan dengan menggunakan aplikasi SPSS dengan hasil sebagai berikut:
Tabel 4.3 Hasil Statistika Deskriptif
Dari hasil tersebut, diketahui bahwa banyaknya data deret waktu yang akan digunakan adalah sebanyak 120 data hasil produksi setiap bulannya untuk tahun 2011 hingga 2020 dengan nilai rata-rata (mean) sebesar 1.740,61. Pada Tabel 4.3 terlihat bahwa nilai minimum pada data adalah 970,54 dan nilai maksimum adalah 3.202,12 yang berarti perubahan hasil produksi cukup banyak.
4.3 Plot dan Pola Data
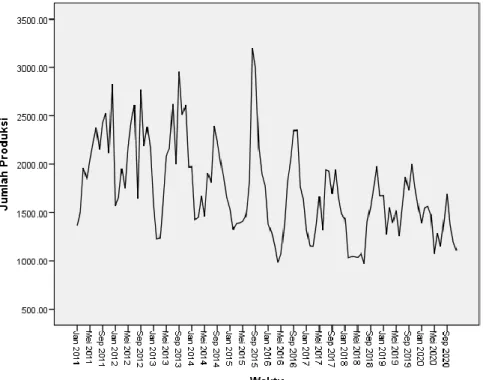
Data deret waktu diubah ke dalam bentuk plot sebagai berikut:
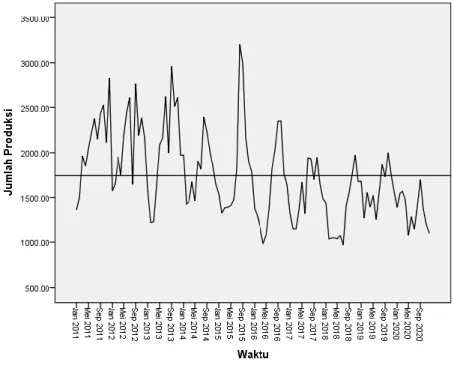
Gambar 4.1 Plot Data Hasil Produksi TBS Kelapa Sawit
Pada Gambar 4.1 didapatkan bahwa plot data produksi terlihat data naik turun tidak beraturan. Jika ditarik garis mean, maka akan tampak seperti gambar berikut:
Gambar 4.2 Garis Mean pada Plot Data Aktual
Selanjutnya akan dilakukan analisis adanya trend pada pola data. Analisis trend dilakukan untuk mengamati kecenderungan keseluruhan data naik atau turun. Dalam hal ini akan dibentuk persamaan trend linier dengan menggunakan metode kuadrat terkecil yang terdapat pada persamaan ( 2.2 ), ( 2.3 ) dan ( 2.4 ).
Untuk menentukan nilai a dan b maka akan digunakan data pada tabel berikut:
Tabel 4.4 Perhitungan Trend Linier
No Waktu
Jumlah Produksi
(𝑌)
𝑋 𝑋𝑌 𝑋2
1 Januari 2011 1.363,53 -119 -162.260,07 13.689 2 Februari 2011 1.498,99 -117 -175.381,83 13.689
❪ ❪ ❪ ❪ ❪ ❪
59 Desember 2015 1.778,61 -1 -1.778,61 1
60 Januari 2016 1.376,23 1 1.376,23 1
❪ ❪ ❪ ❪ ❪ ❪
119 November 2020 1.198,59 117 140.235,03 13.689 120 Desember 2020 1.105,23 119 131.522,37 14.161 Jumlah: 208.872,69 -1.990.758,53 575.960 Perhitungan trend linier selengkapnya disajikan pada lampiran 4.
Pada Tabel 4.4 nilai 𝑋 ditentukan dengan cara mencari nilai tengah pada data deret waktu. Diketahui bahwa data yang digunakan adalah data genap karena berjumlah 120, maka nilai tengah data tersebut berada pada data nomor 110 dan 111 yang diberi
i=1
nilai 0. Selanjutnya, untuk data yang berada di bawah 0 diberi nilai 1, 3, 5, …, 117, 119 dan data yang berada di atas 0 diberi nilai -1, -3, -5, …, -117, -119.
Langkah selanjutnya adalah melakukan perhitungan nilai a dan b sebagai berikut:
∑120 𝑌i
𝑎 = =
120
208.872,69
120 = 1.740,60575 ≈ 1.740,61
∑𝑛 Xi𝑌i −1.990.758,53
𝑏 = i=1 = = −3,46
𝑛 i=1 Xi2 575.960
Nilai a dan b yang sudah didapatkan kemudian disubstitusikan ke persamaan ( 2.2 ).
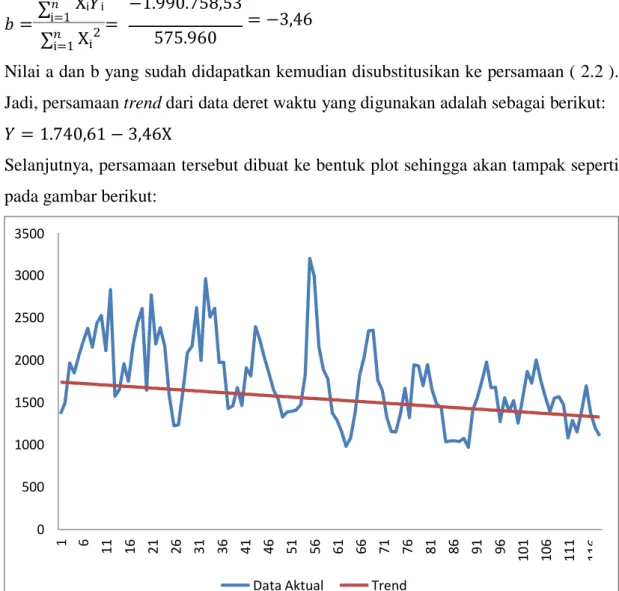
Jadi, persamaan trend dari data deret waktu yang digunakan adalah sebagai berikut:
𝑌 = 1.740,61 − 3,46X
Selanjutnya, persamaan tersebut dibuat ke bentuk plot sehingga akan tampak seperti pada gambar berikut:
Gambar 4.3 Garis Trend pada Plot Data Aktual
Dalam hal ini berarti pola data cenderung semakin menurun atau disebut sebagai trend negatif.
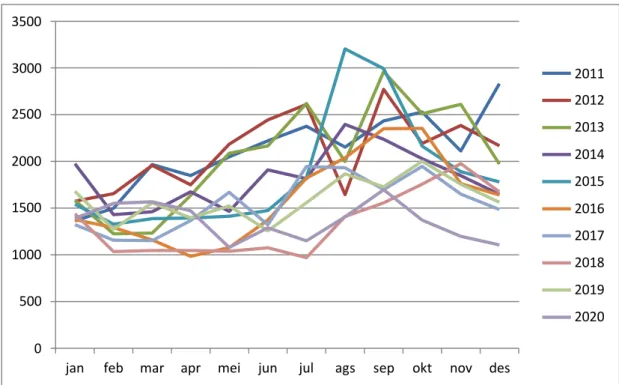
Setelah melakukan analisis trend, hal yang akan dilakukan selanjutnya adalah melakukan analisis musiman. Jika data dibuat ke dalam bentuk plot dengan memisahkan data tiap tahun, maka akan terbentuk plot seperti berikut:
3500
3000
2500
2000
1500
1000
500
0
Data Aktual Trend
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96 101 106 111 116
∑
Gambar 4.4 Plot Analisis Musiman
Pada Gambar 4.4 dapat dilihat bahwa hasil produksi setiap bulannya di tahun yang berbeda tidak mengalami pola musiman.
Maka dari pemaparan sebelumnya, dinyatakan bahwa data deret waktu hasil produksi TBS kelapa sawit mengalami trend dan tidak mengandung unsur musiman.
4.4 Analisis Uji Stasioneritas
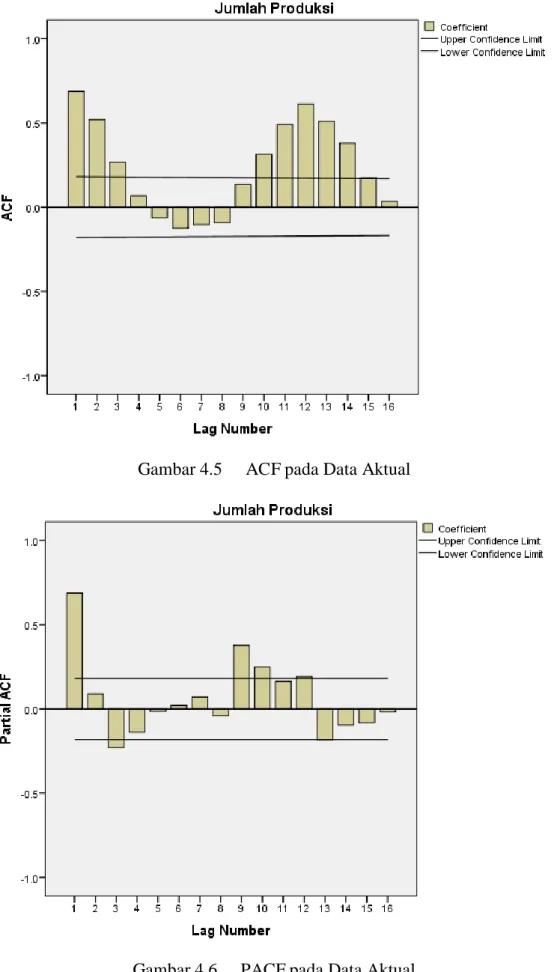
Suatu data dikatakan stasioner apabila memiliki nilai rata-rata dan varians yang konstan. Data yang stasioner adalah data yang tidak mengandung unsur trend dan unsur musiman. Dari hasil yang sudah didapati sebelumnya, diketahui bahwa data deret waktu hasil produksi TBS kelapa sawit yang digunakan non musiman namun mengandung unsur trend, maka data tersebut non stasioner. Namun, untuk lebih rincinya akan dilakukan pengujian stasioneritas data melalui pengamatan korelogram Auto Correlation Function (ACF) dan Partial Auto Correlation Function (PACF). ACF adalah korelasi yang terjadi antara data deret waktu ( 𝑥𝑡 ) dan ( 𝑥𝑡+𝑘 ) yang dipisahkan dalam lag ( 𝑘 ). Sedangkan PACF adalah korelasi yang terjadi pada data deret waktu ( 𝑥𝑡 ) dan ( 𝑥𝑡+𝑘 ) dengan menghilangkan atau tidak memperhatikan nilai data diantaranya. Hasil perhitungan ACF dan PACF dengan bantuan aplikasi SPSS sebagai berikut:
3500
3000
2500
2000
1500
1000
500
2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 0
jan feb mar apr mei jun jul ags sep okt nov des
Gambar 4.5 ACF pada Data Aktual
Gambar 4.6 PACF pada Data Aktual
Dari hasil korelogram ACF dan PACF didapatkan bahwa data tidak signifikan pada beberapa lag, hal ini menunjukkan bahwa data non stasioner. Dalam penggunaan metode pemulusan eksponensial ganda Brown dan fuzzy time series bisa dilakukan pada data yang non stasioner sehingga tidak perlu dilakukan transformasi data.
4.5 Analisis Data Deret Waktu Menggunakan Metode Pemulusan Eksponensial Ganda Brown
1. Menentukan Nilai Parameter
Berdasarkan cara untuk memilih nilai parameter, dikatakan bahwa:
1) Jika pola historis dari data aktual yang digunakan sangat tidak stabil pada periode waktu tertentu, maka nilai yang dipilih adalah mendekati satu.
2) Jika pola historis dari data aktual yang digunakan relatif stabil pada periode waktu tertentu, maka nilai yang dipilih adalah mendekati nol.
Pola data dari data deret waktu yang digunakan tidak stabil pada periode waktu tertentu, maka akan dipilih nilai parameter secara trial and error yang mendekati satu yaitu 0,7; 0,8; 0,9; 0,95 dan 0,96.
2. Menentukan Nilai Kesalahan Meramal
Tahap selanjutnya adalah menentukan nilai kesalahan meramal untuk mengetahui tingkat akurasi hasil peramalan. Dalam hal ini akan digunakan indikator Mean Absolut Presentage Error (MAPE) untuk nilai-nilai parameter (𝛼) yang sudah ditentukan sebelumnya, yaitu 0,7; 0,8; 0,9; 0,95 dan 0,96 dengan menggunakan rumus pada persamaan ( 2.42 ). Sebelumya akan dihitung nilai 𝐹𝑡 untuk tiap periode terlebih dahulu dengan menggunakan persamaan ( 2.39 )
𝐹𝑡 = 𝐹𝑡−1 + 𝛼(X𝑡 − 𝐹𝑡−1).
Perhitungan nilai MAPE adalah sebagai berikut:
Dengan menggunakan nilai 𝛼 = 0,7.
Untuk t = 1 : 𝐹1 = 1.363,53