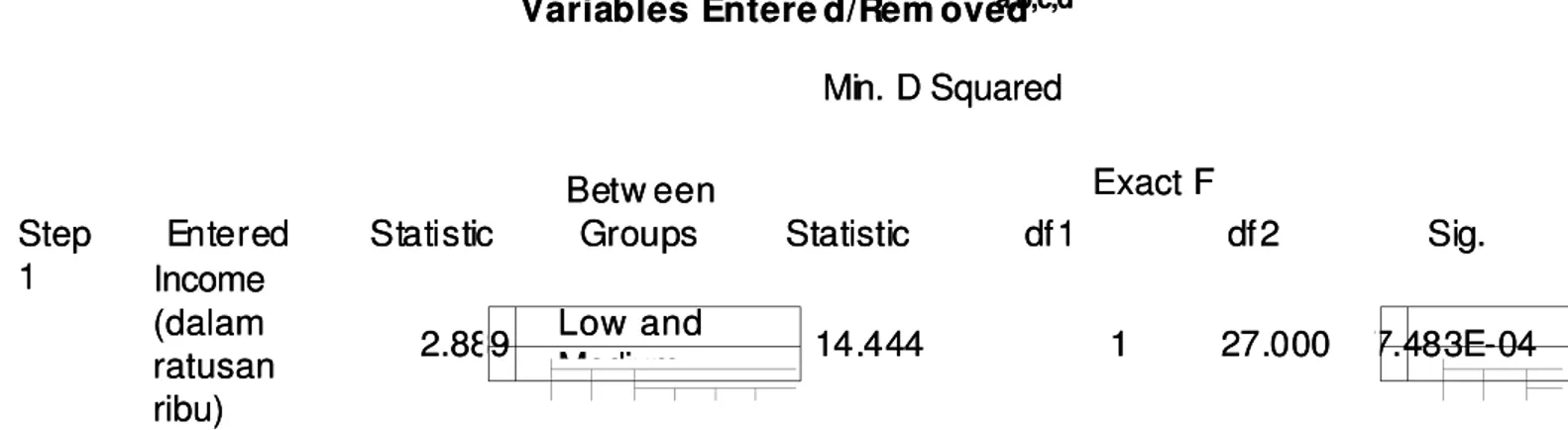
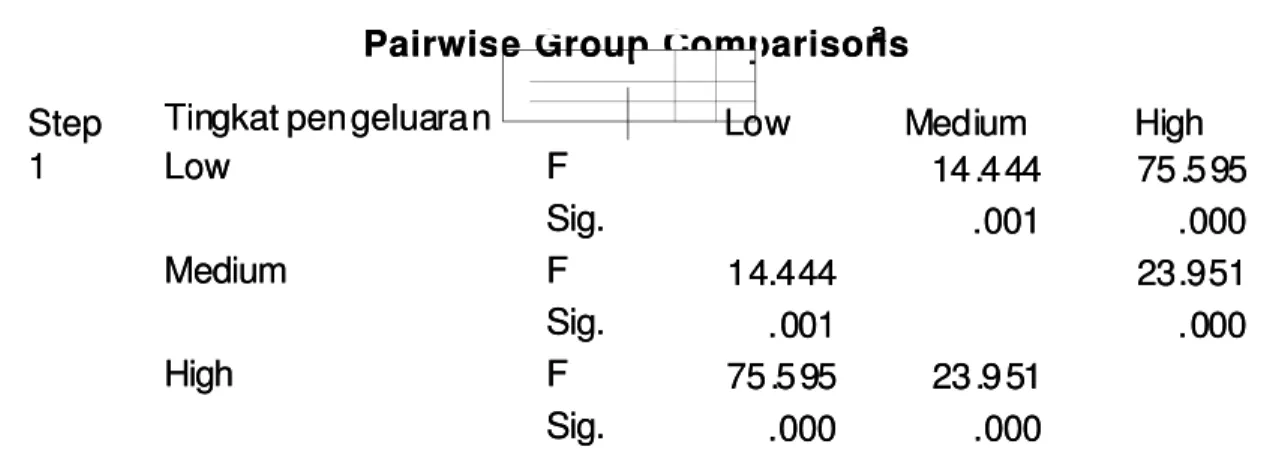
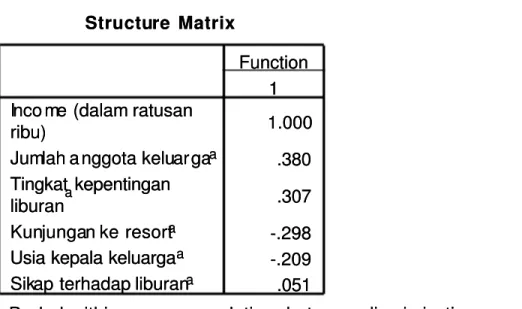
SEKILAS TENTANG SPSS
SEKILAS TENTANG SPSS
Salah satu program yang dapat digunakan untuk mengolah data melalui komputer adalah Salah satu program yang dapat digunakan untuk mengolah data melalui komputer adalah SPSS. Program ini telah dipakai pada berbagai macam industri untuk menyelesaikan berbagai SPSS. Program ini telah dipakai pada berbagai macam industri untuk menyelesaikan berbagai macam permasalahan seperti, riset perilaku konsumen, peramalan bisnis dsb. Selain itu SPSS macam permasalahan seperti, riset perilaku konsumen, peramalan bisnis dsb. Selain itu SPSS juga telah banyak dipergunakan di dunia pendidikan untuk membantu para akademisi dan juga telah banyak dipergunakan di dunia pendidikan untuk membantu para akademisi dan
mahasiswa dalam melakukan penelitian ilmiah. mahasiswa dalam melakukan penelitian ilmiah.
1
1.. KKOMOMPPUUTTERER
2
2.. SSTATATTISISTTIKIK
3 3 SSPPSSSS IINNPPUUT T DDAATTAA PPRROOSSEES S KKOOMMPPUUTTEERR OUTPUT DATA OUTPUT DATA (INFORMASI) (INFORMASI) INPUT DATA INPUT DATA INPUT DATA INPUT DATA dengan dengan DATADATA EDITOR EDITOR PROSES STATISTIK PROSES STATISTIK PROSES dengan PROSES dengan DATA EDITOR DATA EDITOR OUTPUT DATA OUTPUT DATA (DENGAN (DENGAN OUTPUT OUTPUT NAVIGATOR) NAVIGATOR) OUTPUT DATA OUTPUT DATA (INFORMASI) (INFORMASI)
Adapun cara memproses data melalui SPSS adalah sebagai berikut: Adapun cara memproses data melalui SPSS adalah sebagai berikut:
1.
1. Data yang akan diproses dimasukkan dalam menu DATA EDITOR yang secaraData yang akan diproses dimasukkan dalam menu DATA EDITOR yang secara otomatis muncul dilayar
otomatis muncul dilayar 2.
2. Data yang telah diinput kemudian diproses pada menu DATA EDITOR Data yang telah diinput kemudian diproses pada menu DATA EDITOR 3.
3. Hasil pengolahan data muncul di layar (window) lain yang disebut output navigator.Hasil pengolahan data muncul di layar (window) lain yang disebut output navigator. Hasilnya berupa:
Hasilnya berupa:
•• Teks atau tulisanTeks atau tulisan
•• TabelTabel
•• Bagan atau Grafik Bagan atau Grafik
Sebelum menentukan metoda pengolahan data yang sesuai dengan tujuan penelitian, maka Sebelum menentukan metoda pengolahan data yang sesuai dengan tujuan penelitian, maka para peneliti juga harus memahami karakteristik dari data yang ada sehingga metoda statistik para peneliti juga harus memahami karakteristik dari data yang ada sehingga metoda statistik yang digunakan tepat.
yang digunakan tepat.
Statistik Parametrik
Statistik Parametrik
Metoda statistik Parametrik akan tepat digunakan pada kondisi : Metoda statistik Parametrik akan tepat digunakan pada kondisi :
Tipe Data Interval/RasioTipe Data Interval/Rasio
Jumlah data >30Jumlah data >30
Catatan : apabila jumlah data < 30 akan tetapi distribusi populasi normal, maka Catatan : apabila jumlah data < 30 akan tetapi distribusi populasi normal, maka dapat menggunakan t test
dapat menggunakan t test
Statistik Non Parametrik
Statistik Non Parametrik
Metoda statistik Non Parametrik akan tepat digunakan pada kondisi : Metoda statistik Non Parametrik akan tepat digunakan pada kondisi :
Tipe Data Nominal/OrdinalTipe Data Nominal/Ordinal
Data tidak berdistribusi normalData tidak berdistribusi normal
PERSIAPAN DATA
PERSIAPAN DATA
A. SPSS DATA EDITOR
A. SPSS DATA EDITOR
Data editor menyediakan suatu metode yang mirip seperti lembaran buku kerja untuk Data editor menyediakan suatu metode yang mirip seperti lembaran buku kerja untuk membuat dan mengedit data dalam file. Data editor terbuka secara otomatis saat Anda membuat dan mengedit data dalam file. Data editor terbuka secara otomatis saat Anda membuka program SPSS.
membuka program SPSS.
Data editor menyediakan dua menu untuk melihat data Anda: Data editor menyediakan dua menu untuk melihat data Anda:
1.
1. Data view : menunjukkan nilai dari data aktual atauData view : menunjukkan nilai dari data aktual atau defined value labels defined value labels 2.
2. Variable view: memperlihatkan informasi mengenai semua variabel termasuk Variable view: memperlihatkan informasi mengenai semua variabel termasuk name,name, type, width, decimals, label, values, missing, column, align, measure
type, width, decimals, label, values, missing, column, align, measure ..
Dalam kedua menu tersebut, Anda dapat menambah, mengubah dan menghapus data Dalam kedua menu tersebut, Anda dapat menambah, mengubah dan menghapus data yang berada dalam file SPSS.
yang berada dalam file SPSS.
B. MENU VARIABLE VIEW
B. MENU VARIABLE VIEW
Dalam variabel view terdapat 10 kolom yang terdiri dari: Dalam variabel view terdapat 10 kolom yang terdiri dari:
1.
1. NameName
Bagian ini untuk mengisi nama variabel yang terdapat dalam penelitian. SPSS selalu Bagian ini untuk mengisi nama variabel yang terdapat dalam penelitian. SPSS selalu menuliskan nama variabel dalam huruf kecil dengan jumlah karakter maksimal 8
menuliskan nama variabel dalam huruf kecil dengan jumlah karakter maksimal 8 huruf.huruf.
Variable view merupakan Variable view merupakan menu untuk memasukkan menu untuk memasukkan
semua variabel yang
semua variabel yang
diperlukan dalam analisis diperlukan dalam analisis Data view merupakan
Data view merupakan
menu untuk menu untuk memasukkan semua memasukkan semua responden responden
2.
2. TypeType
Kolom ini digunakan untuk menentukan tipe
Kolom ini digunakan untuk menentukan tipe data dari variabel yang akan dimasukkandata dari variabel yang akan dimasukkan ke dalam program SPSS.
ke dalam program SPSS.
Pada bagian ini Anda memiliki 8 pilihan jenis variabel. Namun jenis variabel yang paling Pada bagian ini Anda memiliki 8 pilihan jenis variabel. Namun jenis variabel yang paling sering digunakan adalah numeric, date dan string,
sering digunakan adalah numeric, date dan string,
Numeric digunakan untuk data yang berupa angka. Date digunakan untuk data tanggal, Numeric digunakan untuk data yang berupa angka. Date digunakan untuk data tanggal, biasanya dipergunakan dalam analisis
biasanya dipergunakan dalam analisis time series.time series. SedangkanSedangkan string string digunakan untuk digunakan untuk data yang berupa karakter.
data yang berupa karakter.
3.
3. WidthWidth
Pilihan ini menyediakan masukan antara 1 hingga 255 karakter untuk jenis variabel Pilihan ini menyediakan masukan antara 1 hingga 255 karakter untuk jenis variabel string
string . Pengisian angka WIDTH dapat dilakukan dengan mengetik jumlah karakter kyang. Pengisian angka WIDTH dapat dilakukan dengan mengetik jumlah karakter kyang diinginkan atau dengan menggunakan
diinginkan atau dengan menggunakan scroll number scroll number yang terletak di sebelah kananyang terletak di sebelah kanan kolom WIDTH.
kolom WIDTH.
4.
4. DecimalsDecimals
Desimal akan muncul untuk jenis variable numeric. Desimal akan muncul untuk jenis variable numeric.
Jumlah karakter untuk jenis Jumlah karakter untuk jenis variable string dapat di set variable string dapat di set dengan menggunakan dengan menggunakan scrollscroll number.
5.
5. LabelLabel
Label adalah keterangan yang lebih lengkap untuk nama variabel. Jika sebelumnya Label adalah keterangan yang lebih lengkap untuk nama variabel. Jika sebelumnya Anda hanya dibatasi untuk memberikan nama variabel sejumlah 8 karakter pada kolom Anda hanya dibatasi untuk memberikan nama variabel sejumlah 8 karakter pada kolom
name
name, maka pada bagian ini Anda dapat menuliskan nama variabel selengkap mungkin., maka pada bagian ini Anda dapat menuliskan nama variabel selengkap mungkin. Nama pada label ini juga yang akan muncul pada output SPSS.
Nama pada label ini juga yang akan muncul pada output SPSS.
6.
6. Value Labels Value Labels
Kolom value diisi untuk variabel yang memiliki kategorisasi tertentu yang mewakili Kolom value diisi untuk variabel yang memiliki kategorisasi tertentu yang mewakili data non numeric (misal 1= pria, 2 =wanita). Hal ini dapat lebih memudahkan pengisian data non numeric (misal 1= pria, 2 =wanita). Hal ini dapat lebih memudahkan pengisian data tanpa perlu melakukan pengetikan yang berulang-ulang. Jika anda meng-klik di data tanpa perlu melakukan pengetikan yang berulang-ulang. Jika anda meng-klik di bagian kanan kolom tersebut, maka akan muncul tampilan berikut ini:
bagian kanan kolom tersebut, maka akan muncul tampilan berikut ini:
7.
7. MissingMissing
Kolom ini dipergunakan untuk menjelaskan mengenai perlakuan terhadap data yang Kolom ini dipergunakan untuk menjelaskan mengenai perlakuan terhadap data yang hilang.
hilang.
8.
8. ColumnColumn
Kolom ini memberikan informasi mengenai lebar kolom yang diperlukan untuk Kolom ini memberikan informasi mengenai lebar kolom yang diperlukan untuk memasukkan data.
memasukkan data.
Diisi dengan angka, misal 1, Diisi dengan angka, misal 1, 2, 3 dst, sebanyak
2, 3 dst, sebanyak
kategorisasi yang ada untuk kategorisasi yang ada untuk variabel tsb.
variabel tsb.
Diisi dengan penjelasan Diisi dengan penjelasan atas angka
atas angka /kategorisasi/kategorisasi yang dibuat
9.
9. Align Align
Kolom ini menunjukkan mengenai letak atau posisi data, apakah ingin diletakkan di Kolom ini menunjukkan mengenai letak atau posisi data, apakah ingin diletakkan di sebelah kiri, kanan, atau tengah sel.
sebelah kiri, kanan, atau tengah sel.
10.
10. MeasureMeasure
Kolom ini merupakan kolom yang sangat penting dalam SPSS karena pemilihan jenis Kolom ini merupakan kolom yang sangat penting dalam SPSS karena pemilihan jenis pengukuran dalam kolom ini akan menentukan jenis analisis yang dipilih.
pengukuran dalam kolom ini akan menentukan jenis analisis yang dipilih.
C. MENU DATA VIEW
C. MENU DATA VIEW
Sebagian besar fitur dalam Data View hampir serupa dengan fitur dalam lembar kerja Sebagian besar fitur dalam Data View hampir serupa dengan fitur dalam lembar kerja (spreadsheet). Namun, dalam SPSS kita tetap menemukan beberapa macam aplikasi yang (spreadsheet). Namun, dalam SPSS kita tetap menemukan beberapa macam aplikasi yang berbeda:
berbeda:
1.
1. BarisBaris
Baris dalam menu ini menunjukkan jumlah kasus yang ada. Setiap baris dalam data Baris dalam menu ini menunjukkan jumlah kasus yang ada. Setiap baris dalam data view mewakili setiap kasus atau hasil observasi yang ada. Setiap responden dalam view mewakili setiap kasus atau hasil observasi yang ada. Setiap responden dalam penelitian mewakili satu kasus.
penelitian mewakili satu kasus.
Kolom Kolom variabel variabel Baris Baris menunjukkan menunjukkan setiap kasus setiap kasus /responden dalam /responden dalam penelitian penelitian Sel menunjukkan Sel menunjukkan nilai dari suatu data nilai dari suatu data
2.
2. KolomKolom
Kolom dalam menu Data View mewakili variabel atau karakteristik yang diukur dalam Kolom dalam menu Data View mewakili variabel atau karakteristik yang diukur dalam penelitian. Setiap item dalam kuesioner merupakan variabel.
penelitian. Setiap item dalam kuesioner merupakan variabel.
3. 3. SelSel
Sel dalam dalam data view berisi nilai dari setiap variabel untuk setiap kasus. Sel Sel dalam dalam data view berisi nilai dari setiap variabel untuk setiap kasus. Sel merupakan perpotongan dari kasus dan variabel. Sel hanya berisi nilai dari data dan tidak merupakan perpotongan dari kasus dan variabel. Sel hanya berisi nilai dari data dan tidak berisi rumus-rumus seperti halnya dalam lembar kerja yang terdapat dalam program Excel. berisi rumus-rumus seperti halnya dalam lembar kerja yang terdapat dalam program Excel.
Contoh cara memasukkan data ke SPSS. Contoh cara memasukkan data ke SPSS.
Seorang peneliti yang melakukan penelitian mengenai Seorang peneliti yang melakukan penelitian mengenai
Nomor Nomor
Responden Nama Usia Responden Nama Usia
Jenis Jenis Kelamin Pekerjaan Kelamin Pekerjaan Pendapatan Pendapatan (dalam Juta) (dalam Juta) Tingkat Tingkat Pendidikan Pendidikan 1
1 Diah Diah 38 38 Wanita Wanita Pegawai Pegawai Swasta Swasta 1 1 SMU/SederajatSMU/Sederajat 2
2 Andi Andi 27 27 Pria Pria Wiraswasta Wiraswasta 5 5 S1S1
3
3 Febi Febi 37 37 Wanita Wanita PNS PNS 2 2 S1S1
4
4 Anita Anita 39 39 Wanita Wanita PNS PNS 2 2 S1S1
5
5 Rina Rina 43 43 Wanita Wanita Pegawai Pegawai Swasta Swasta 6 6 S2S2 6
6 Ahmad Ahmad 49 49 Pria Pria Pegawai Swasta Pegawai Swasta 6 6 S2S2 7
7 Rani Rani 40 40 Wanita Wanita Wiraswasta Wiraswasta 6 6 SMU/SederajatSMU/Sederajat 8
8 Heri Heri 42 42 Pria Pria PNS PNS 2.5 2.5 S3S3
9
9 Iwan Iwan 29 29 Pria Pria Pegawai Pegawai Swasta Swasta 1.2 1.2 DiplomaDiploma 10
10 Dedi Dedi 26 26 Pria Pria PNS PNS 1.5 1.5 DiplomaDiploma
Dari data tersebut kita melihat bahwa terdapat kurang lebih 7 variabel untuk dimasukkan ke Dari data tersebut kita melihat bahwa terdapat kurang lebih 7 variabel untuk dimasukkan ke dalam program SPSS, yakni : Nomor responden, nama, usia, jenis kelamin, pekerjaan, dalam program SPSS, yakni : Nomor responden, nama, usia, jenis kelamin, pekerjaan, pendapatan
pendapatan (dalam juta rupiah) dan tingkat pendidikan.(dalam juta rupiah) dan tingkat pendidikan.
Buka menu
Buka menu SPSS data editorSPSS data editor pada bagianpada bagian variable viewvariable view lalu masukkan data diataslalu masukkan data diatas dengan langkah sebagai berikut:
dengan langkah sebagai berikut:
1.
1. Nomor RespondenNomor Responden
Name.Name. Sesuai kasus letakkan pointer di bawah kolom Name,Sesuai kasus letakkan pointer di bawah kolom Name, klik ganda klik ganda padapada
sel tersebut lalu ketik nomor (bagian ini hanya dapat diisi oleh maksimal 8 sel tersebut lalu ketik nomor (bagian ini hanya dapat diisi oleh maksimal 8 karakter, tanpa mengizinkan adanya spasi)
Type.Type. Tipe data untuk nomor responden adalahTipe data untuk nomor responden adalah stringstring (non-numeric). Meskipun(non-numeric). Meskipun
nomor responden seolah-olah terlihat dalam bentuk angka (numeric), namun nomor responden seolah-olah terlihat dalam bentuk angka (numeric), namun sebetulnya angka tersebut sejenis dengan nomor-nomor lainnya yang hanya sebetulnya angka tersebut sejenis dengan nomor-nomor lainnya yang hanya menunjukkan identitas, seperti halnya nomor KTP, NPM, dsb, yang tidak akan menunjukkan identitas, seperti halnya nomor KTP, NPM, dsb, yang tidak akan diolah atau dianalisis.
diolah atau dianalisis.
Width.Width. Biarkan saja sesuai dengan default SPSS.Biarkan saja sesuai dengan default SPSS.
Decimals.Decimals. Tidak usah diisiTidak usah diisi
Label.Label. Untuk keseragaman ketik Nomor respondenUntuk keseragaman ketik Nomor responden
Values. Values. Karena nomor responden bukan merupakan data kuantitatif dan tidak Karena nomor responden bukan merupakan data kuantitatif dan tidak
memiliki kategorisasi, maka kita dapat mengabaikan pilihan ini. memiliki kategorisasi, maka kita dapat mengabaikan pilihan ini.
Missings.Missings. Dianggap tidak ada data yang hilang.Dianggap tidak ada data yang hilang.
Column.Column. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada.
Align. Align. Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni
kanan. kanan.
Measure.Measure. Untuk data kualitatif atau string, SPSS hanya menyediakan 2 pilihanUntuk data kualitatif atau string, SPSS hanya menyediakan 2 pilihan
yakni nominal atau ordinal. Untuk variabel ini kita memilih
yakni nominal atau ordinal. Untuk variabel ini kita memilih nominalnominal. karena. karena nomor responden tidak menunjukkan adanya perbedaan jenjang pada nomor responden tidak menunjukkan adanya perbedaan jenjang pada responden.
responden.
2.
2. NamaNama
Name.Name. Sesuai kasus letakkan pointer di bawah kolom Name,Sesuai kasus letakkan pointer di bawah kolom Name, klik ganda klik ganda padapada
sel tersebut lalu ketik nama sel tersebut lalu ketik nama
Type.Type. Tipe data untuk nama responden adalahTipe data untuk nama responden adalah stringstring (non-numeric).(non-numeric).
Width.Width. Biarkan saja sesuai dengan default SPSS.Biarkan saja sesuai dengan default SPSS.
Decimals.Decimals. Tidak usah diisiTidak usah diisi
Label.Label. Untuk keseragaman ketik Nama respodenUntuk keseragaman ketik Nama respoden
Values. Values. Karena nama responden bukan merupakan data kuantitatif dan tidak Karena nama responden bukan merupakan data kuantitatif dan tidak
memiliki kategorisasi, maka kita dapat mengabaikan pilihan ini. memiliki kategorisasi, maka kita dapat mengabaikan pilihan ini.
Missings.Missings. Dianggap tidak ada data yang hilang.Dianggap tidak ada data yang hilang.
Column.Column. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada.
Align. Align. Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni
kanan. kanan.
Measure.Measure. Untuk data kualitatif atau string, SPSS hanya menyediakan 2 pilihanUntuk data kualitatif atau string, SPSS hanya menyediakan 2 pilihan
yakni nominal atau ordinal. Untuk variabel ini kita memi
yakni nominal atau ordinal. Untuk variabel ini kita memi lihlih nominalnominal..
3.
3. UsiaUsia
Name.Name. Sesuai kasus letakkan pointer di bawah kolom Name,Sesuai kasus letakkan pointer di bawah kolom Name, klik ganda klik ganda padapada
sel tersebut lalu ketik usia sel tersebut lalu ketik usia
Type.Type. Tipe data untuk usia responden adalahTipe data untuk usia responden adalah numericnumeric..
Width.Width. Biarkan saja sesuai dengan default SPSS.Biarkan saja sesuai dengan default SPSS.
Decimals.Decimals. Tidak usah diisiTidak usah diisi
Label.Label. Untuk keseragaman ketik Usia respodenUntuk keseragaman ketik Usia respoden
Values. Values. Usia responden merupakan data kuantitatif yang tidak perlu kitaUsia responden merupakan data kuantitatif yang tidak perlu kita
kategorisasi, maka pilihan tersebut dapat diabaikan. kategorisasi, maka pilihan tersebut dapat diabaikan.
Missings.Missings. Dianggap tidak ada data yang hilang.Dianggap tidak ada data yang hilang.
Column.Column. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada.
Align. Align. Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni
kanan. kanan.
Measure.Measure. Untuk data kuantitatif atau numeric, SPSS menyediakan 3 pilihanUntuk data kuantitatif atau numeric, SPSS menyediakan 3 pilihan
yakni nominal, ordinal dan scale. Untuk variabel ini kita memilih
yakni nominal, ordinal dan scale. Untuk variabel ini kita memilih scalescale karenakarena datanya bersifat rasio. Yang mana SPSS menggabungkan data interval dan rasio datanya bersifat rasio. Yang mana SPSS menggabungkan data interval dan rasio ke dalam satu jenis yakni scale.
ke dalam satu jenis yakni scale.
4.
4. Jenis KelaminJenis Kelamin
Name.Name. Sesuai kasus letakkan pointer di bawah kolom Name,Sesuai kasus letakkan pointer di bawah kolom Name, klik ganda klik ganda padapada
sel tersebut lalu ketik jenis kelamin sel tersebut lalu ketik jenis kelamin
Type.Type. Tipe data untuk jenis kelamin responden adalahTipe data untuk jenis kelamin responden adalah stringstring (non-numeric).(non-numeric).
Namun untuk mempermudah pengisian data, kita dapat membuat kategorisasi Namun untuk mempermudah pengisian data, kita dapat membuat kategorisasi pria dan wanita ke dalam angka. Untuk itu kita pilih numeric.
pria dan wanita ke dalam angka. Untuk itu kita pilih numeric.
Width.Width. Biarkan saja sesuai dengan default SPSS.Biarkan saja sesuai dengan default SPSS.
Decimals.Decimals. Tidak usah diisiTidak usah diisi
Label.Label. Untuk keseragaman ketik jenis kelamin respodenUntuk keseragaman ketik jenis kelamin respoden
Values. Values. Karena jenis kelamin responden akan kita kategorisasi, maka kita dapatKarena jenis kelamin responden akan kita kategorisasi, maka kita dapat
mengklik pilihan ini, lalu akan muncul tampilan berikut ini mengklik pilihan ini, lalu akan muncul tampilan berikut ini Untuk kesepakatan, beri kategorisasi 1= Pria dan 2= wanita Untuk kesepakatan, beri kategorisasi 1= Pria dan 2= wanita
Missings.Missings. Dianggap tidak ada data yang hilang.Dianggap tidak ada data yang hilang.
Column.Column. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada.
Align. Align. Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni
kanan. kanan.
Measure.Measure. Untuk data string dengan value, SPSS akan menyediakan 3 pilihanUntuk data string dengan value, SPSS akan menyediakan 3 pilihan
yakni nominal, ordinal dan scale. Untuk variabel ini kita memilih
yakni nominal, ordinal dan scale. Untuk variabel ini kita memilih nominalnominal karenakarena angka yang kita berikan hanya dimaksudkan untuk kategorisasi.
angka yang kita berikan hanya dimaksudkan untuk kategorisasi.
5.
5. PekerjaanPekerjaan
Name.Name. Sesuai kasus letakkan pointer di bawah kolom Name,Sesuai kasus letakkan pointer di bawah kolom Name, klik ganda klik ganda padapada
sel tersebut lalu ketik kerja. sel tersebut lalu ketik kerja.
Type.Type. Tipe data untuk pekerjaaan responden adalahTipe data untuk pekerjaaan responden adalah numericnumeric karena kita akankarena kita akan
melakukan kategorisasi terhadap pekerjaan responden. melakukan kategorisasi terhadap pekerjaan responden.
Width.Width. Biarkan saja sesuai dengan default SPSS.Biarkan saja sesuai dengan default SPSS.
Decimals.Decimals. Tidak usah diisiTidak usah diisi
Label.Label. Untuk keseragaman ketik pekerjaan responden.Untuk keseragaman ketik pekerjaan responden.
Values. Values. Meskipun pekerjaan responden bukan merupakan data kuantitatif Meskipun pekerjaan responden bukan merupakan data kuantitatif
namun ia
namun ia memiliki kategorisasi, mmemiliki kategorisasi, maka kita akaka kita akan melakukan langkah an melakukan langkah yang samayang sama seperti yang dilakukan pada variabel sebelumnya. Untuk kesepakatan kita akan seperti yang dilakukan pada variabel sebelumnya. Untuk kesepakatan kita akan menggolongkan pekerjaan responden ke dalam tiga golongan.
menggolongkan pekerjaan responden ke dalam tiga golongan. 1= PNS, 2= Pegawai swasta, 3= Wiraswasta
1= PNS, 2= Pegawai swasta, 3= Wiraswasta
Missings.Missings. Dianggap tidak ada data yang hilang.Dianggap tidak ada data yang hilang.
Column.Column. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada.
Align. Align. Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni
kanan. kanan.
Measure.Measure. Untuk data kualitatif yang dikategorisasi menjadi numerik, SPSSUntuk data kualitatif yang dikategorisasi menjadi numerik, SPSS
menyediakan 3 pilihan yakni nominal, ordinal dan scale. Untuk variabel ini kita menyediakan 3 pilihan yakni nominal, ordinal dan scale. Untuk variabel ini kita memilih
memilih nominalnominal..
6.
6. Pendapatan (dalam juta rupiah)Pendapatan (dalam juta rupiah)
Name.Name. Sesuai kasus letakkan pointer di bawah kolom Name,Sesuai kasus letakkan pointer di bawah kolom Name, klik ganda klik ganda padapada
sel tersebut lalu ketik income. sel tersebut lalu ketik income.
Type.Type. Tipe data Tipe data untuk income untuk income adalah numeric.adalah numeric.
Width.Width. Biarkan saja sesuai dengan default SPSS.Biarkan saja sesuai dengan default SPSS.
Label.Label. Untuk keseragaman ketik Pendapatan respoden.Untuk keseragaman ketik Pendapatan respoden.
Values. Values. Pendapatan responden merupakan data kuantitatif yang tidak memilikiPendapatan responden merupakan data kuantitatif yang tidak memiliki
kategorisasi, maka kita dapat mengabaikan pilihan ini. kategorisasi, maka kita dapat mengabaikan pilihan ini.
Missings.Missings. Dianggap tidak ada data yang hilang.Dianggap tidak ada data yang hilang.
Column.Column. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada. Abaikan pilihan ini sehingga kita akan menggunakan default yang ada.
Align. Align. Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni Abaikan pilihan ini sehingga akan menggunakan default dari SPSS yakni
kanan. kanan.
Measure.Measure. Untuk data kuantitatif atau numeric, SPSS menyediakan 3 pilihanUntuk data kuantitatif atau numeric, SPSS menyediakan 3 pilihan
yakni nominal, ordinal dan scale. Untuk variabel ini kita memilih scale karena yakni nominal, ordinal dan scale. Untuk variabel ini kita memilih scale karena datanya bersifat
datanya bersifat rasiorasio. Yang mana SPSS menggabungkan data interval dan rasio. Yang mana SPSS menggabungkan data interval dan rasio ke dalam satu jenis yakni scale.
ke dalam satu jenis yakni scale.
7.
7. Tingkat pendidikanTingkat pendidikan
Name.Name. Sesuai kasus letakkan pointer di bawah kolom Name,Sesuai kasus letakkan pointer di bawah kolom Name, klik ganda klik ganda
pada sel tersebut lalu ketik edukasi. pada sel tersebut lalu ketik edukasi.
Type.Type. Tipe data untuk pendidikan responden adalahTipe data untuk pendidikan responden adalah numericnumeric karena kitakarena kita
akan melakukan kategorisasi terhadap pendidikan responden. akan melakukan kategorisasi terhadap pendidikan responden.
Width.Width. Biarkan saja sesuai dengan default SPSS.Biarkan saja sesuai dengan default SPSS.
Decimals.Decimals. Tidak usah diisiTidak usah diisi
Label.Label. Untuk keseragaman ketik pendidikan responden.Untuk keseragaman ketik pendidikan responden.
Values. Values. Meskipun pendidikan responden bukan merupakan data kuantitatif Meskipun pendidikan responden bukan merupakan data kuantitatif
namun ia
namun ia memiliki kategorisasi, memiliki kategorisasi, maka kita maka kita akan melakukakan melakukan langkah an langkah yangyang sama
sama seperti yang dilakukan seperti yang dilakukan pada variabel sebpada variabel sebelumnya. Untuk keseelumnya. Untuk kesepakatanpakatan kita akan menggolongkan pendidikan responden ke dalam tujuh golongan kita akan menggolongkan pendidikan responden ke dalam tujuh golongan 1= SD/sederajat, 2= SMP/sederajat, 3= SMU/sederajat, 4=Diploma, 5=S1, 1= SD/sederajat, 2= SMP/sederajat, 3= SMU/sederajat, 4=Diploma, 5=S1, 6=S2, 7=S3.
6=S2, 7=S3.
Missings.Missings. Dianggap tidak ada data yang hilang.Dianggap tidak ada data yang hilang.
Column.Column. Abaikan pilihan ini sehingga kita akan menggunakan default yang Abaikan pilihan ini sehingga kita akan menggunakan default yang
ada. ada.
Align. Align. Abaikan pilihan ini sehingga akan menggunakan default dari SPSS Abaikan pilihan ini sehingga akan menggunakan default dari SPSS
yakni kanan. yakni kanan.
Measure.Measure. Untuk data kualitatif atau string yang dikategorisasi kedalamUntuk data kualitatif atau string yang dikategorisasi kedalam
angka, SPSS menyediakan 3 pilihan yakni nominal, ordinal dan rasio. Untuk angka, SPSS menyediakan 3 pilihan yakni nominal, ordinal dan rasio. Untuk variabel ini kita memilih
variabel ini kita memilih nominanominal.l.
Setelah Anda memasukkan semua data tersebut, maka pada menu variable Setelah Anda memasukkan semua data tersebut, maka pada menu variable view akan tampak tampilan berikut ini:
view akan tampak tampilan berikut ini:
Setelah selesai, masukkan data untuk masing-masing responden secara berurutan. Setelah selesai, masukkan data untuk masing-masing responden secara berurutan. Sehingga tampak tampilan berikut ini
Setelah semua data dimasukkan, simpanlah file tersebut dengan memilih menu utama
Setelah semua data dimasukkan, simpanlah file tersebut dengan memilih menu utama FILEFILE,, lalu pilih
lalu pilih Save As...Save As... kemudian simpan file tersebut sebagaikemudian simpan file tersebut sebagai DESKRIPTIF UNTUK DESKRIPTIF UNTUK KESERAGAMAN.
PENGOLAHAN DATA
PENGOLAHAN DATA
UJI
UJI BEDA
BEDA :
: t
t Test
Test dan
dan ANOVA
ANOVA
Uji beda pada dasarnya dapat dilakukan melalui berbagai teknik. Dua diantara teknik analisis Uji beda pada dasarnya dapat dilakukan melalui berbagai teknik. Dua diantara teknik analisis untuk uji beda adalah t test dan ANOVA. Uji beda pada prinsipnya dapat dilakukan pada untuk uji beda adalah t test dan ANOVA. Uji beda pada prinsipnya dapat dilakukan pada minimal dua kelompok yang mendapatkan perlakuan yang berbeda.
minimal dua kelompok yang mendapatkan perlakuan yang berbeda.
Adapun perbedaan t test dilakukan jika uji beda hanya terdiri dari 2 kelompok saja (1 sampel Adapun perbedaan t test dilakukan jika uji beda hanya terdiri dari 2 kelompok saja (1 sampel
atau 2
atau 2 sampel). Sedangakan sampel). Sedangakan ANOVA dANOVA dilakukan jika ilakukan jika kita ingin mkita ingin membandingkan perbedaanembandingkan perbedaan antara berbagai kelompok yang jumlahnya lebih besar dari 2.
antara berbagai kelompok yang jumlahnya lebih besar dari 2.
A.
A. INDEPENDENINDEPENDENT SAMPEL T SAMPEL t-TESTt-TEST
Pada uji beda ini, maka peneliti ingin mengetahui apakah dua kelompok yang ada berasal Pada uji beda ini, maka peneliti ingin mengetahui apakah dua kelompok yang ada berasal dari populasi
dari populasi yang sama atau yang sama atau tidak. Untuk mengetahui hal tersebut tidak. Untuk mengetahui hal tersebut biasanya seorang penelitibiasanya seorang peneliti memberikan perlakuan yang berbeda pada dua kelompok yang ada.
memberikan perlakuan yang berbeda pada dua kelompok yang ada.
Perhatikan kata „independen‟ atau „bebas‟, yang berarti tidak ada hubungan antara dua Perhatikan kata „independen‟ atau „bebas‟, yang berarti tidak ada hubungan antara dua sampel yang akan di uji. Hal ini berbeda dengan uji berpasangan (Paired sample t-Test), sampel yang akan di uji. Hal ini berbeda dengan uji berpasangan (Paired sample t-Test), dimana satu kasus
dimana satu kasus diobservasi lebih dari sekadiobservasi lebih dari sekali. li. Dalam uji independen satu Dalam uji independen satu kasus hanya dikasus hanya di data
data satu satu kali.kali.
Uji Beda Uji Beda
t Test t Test
(Uji beda antara 2 Kelompok) (Uji beda antara 2 Kelompok)
ANOVA ANOVA
(Uji beda > 2 kelompok) (Uji beda > 2 kelompok)
Independent sample Independent sample t test t test Paired sample Paired sample t test t test One way One way ANOVA ANOVA Two Way Two Way ANOVA ANOVA
Kasus : Kasus :
Contohnya adalah Seorang marketer ingin mengetahui bagaimana kondisi penjualan Contohnya adalah Seorang marketer ingin mengetahui bagaimana kondisi penjualan produk
produk penghisap penghisap debu debu di di dua dua wilayah wilayah pemasarannya, pemasarannya, yakni yakni Jakarta Jakarta Pusat Pusat dan dan JakartaJakarta Selatan selama 2 tahun (8 kuartal) berturut-turut. Hasil penjualan dari masing-masing daerah Selatan selama 2 tahun (8 kuartal) berturut-turut. Hasil penjualan dari masing-masing daerah selama 8 kuartal tersebut adalah sebagai berikut:
selama 8 kuartal tersebut adalah sebagai berikut: Kuartal
Kuartal Daerah Daerah Penjualan Penjualan Penjualan Penjualan (dalam (dalam unit)unit) 1
1 Jakarta Jakarta Selatan Selatan 120120
2
2 Jakarta Jakarta Selatan Selatan 133133
3
3 Jakarta Jakarta Selatan Selatan 124124
4
4 Jakarta Jakarta Selatan Selatan 168168
5
5 Jakarta Jakarta Selatan Selatan 137137
6
6 Jakarta Jakarta Selatan Selatan 145145
7
7 Jakarta Jakarta Selatan Selatan 267267
8
8 Jakarta Jakarta Selatan Selatan 300300
1
1 Jakarta Jakarta Pusat Pusat 245245
2
2 Jakarta Jakarta Pusat Pusat 432432
3
3 Jakarta Jakarta Pusat Pusat 222222
4
4 Jakarta Jakarta Pusat Pusat 543543
5
5 Jakarta Jakarta Pusat Pusat 221221
6
6 Jakarta Jakarta Pusat Pusat 156156
7
7 Jakarta Jakarta Pusat Pusat 425425
8
8 Jakarta Jakarta Pusat Pusat 189189
Keterangan: Keterangan:
Kasus di atas terdiri atas dua sampel yang bebas satu dengan yang lain, yaitu sampel daerah Kasus di atas terdiri atas dua sampel yang bebas satu dengan yang lain, yaitu sampel daerah Jakarta Pusat dan Jakarta Selatan.
Jakarta Pusat dan Jakarta Selatan.
Disini populasi diketahui berdistribusi normal dan karena sampel sedikit, dipakai uji t untuk Disini populasi diketahui berdistribusi normal dan karena sampel sedikit, dipakai uji t untuk dua sampel.
dua sampel.
Pengolahan data dengan SPSS Pengolahan data dengan SPSS
Langkah-langkah : Langkah-langkah :
buka lembarbuka lembar t test 1t test 1
dari menu utama SPSS pilih menudari menu utama SPSS pilih menu Analyze Analyze, kemudian pilih submenu, kemudian pilih submenu Compare-
Compare-Means.
Means. Dari serangkaian pilihan test, sesuai kasus pilihDari serangkaian pilihan test, sesuai kasus pilih independent-samples tindependent-samples t test
test
Pengisian : Pengisian :
Test variable(s) atau variabel yang akan di uji. Oleh karena di sini akan diujiTest variable(s) atau variabel yang akan di uji. Oleh karena di sini akan diuji
data penjualan, maka masukkan variabel
data penjualan, maka masukkan variabel penjualanpenjualan..
Grouping variabel atau variabel group. Oleh karena variabel pengelompokkanGrouping variabel atau variabel group. Oleh karena variabel pengelompokkan
ada pada variabel daerah maka
ada pada variabel daerah maka masukkan variabelmasukkan variabel daerahdaerah
Pengisian Group : klikmouse padaPengisian Group : klikmouse pada Define Group,Define Group, tampak di layar :tampak di layar :
--untuk group 1, isi dengan 1 yang berarti grup 1 berisi tanda 1 atau „untuk group 1, isi dengan 1 yang berarti grup 1 berisi tanda 1 atau „ JakartaJakarta Selatan
Selatan‟ ‟
--untuk group 2, isi denguntuk group 2, isi dengan 2, yang berarti „an 2, yang berarti „Jakarta PusatJakarta Pusat‟ ‟ setelah pengisian selesai, tekan
setelah pengisian selesai, tekan ContinueContinue untuk melanjutkan ke menuuntuk melanjutkan ke menu sebelumnya.
sebelumnya.
Untuk kolomUntuk kolom OptionOption atau pilihan yang lain, dengan mengklik mouse akanatau pilihan yang lain, dengan mengklik mouse akan
tampak dilayar : tampak dilayar :
Pengisian : Pengisian :
-- untuk Confidence Interval atau tingkat kepercayaan, biarkan pada angkauntuk Confidence Interval atau tingkat kepercayaan, biarkan pada angka default 95%
default 95%
-- untuk Missing Values ata data yang hilang. Oleh karena dalam kasus semuauntuk Missing Values ata data yang hilang. Oleh karena dalam kasus semua pasangan data komplit (tidak ada yang kosong), maka abaikan saja bagian pasangan data komplit (tidak ada yang kosong), maka abaikan saja bagian ini.
ini.
-- TekanTekan ContinueContinue jika pengisian di anggap selesai.jika pengisian di anggap selesai.
Tekan OK untuk mengakhiri pengisian prosedur analisis. Terlihat SPSSTekan OK untuk mengakhiri pengisian prosedur analisis. Terlihat SPSS
melakukan pekerjaan analisis dan terlihat output SPSS. melakukan pekerjaan analisis dan terlihat output SPSS.
Output SPPS dan Analisis Output SPPS dan Analisis
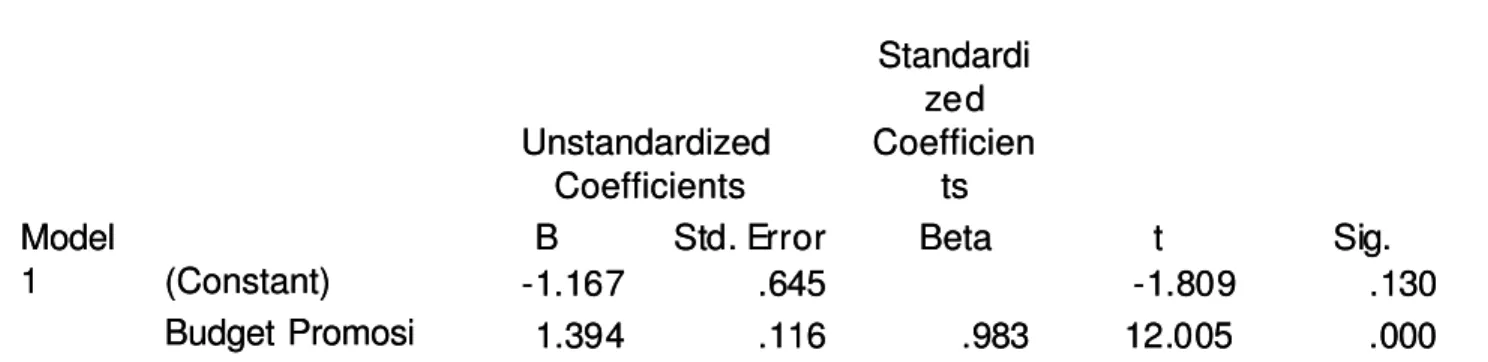
Berikut output dari independent t test : Berikut output dari independent t test :
Group Statistics Group Statistics 8 1 8 17744..2255000 0 6699..5555773 3 2244..55992222 8 3 0 8 3 044..112 52 50 0 114 14 1..6600775 5 550 .0 .0 60 65588 Daerah Daerah Jakarta Selatan Jakarta Selatan Jakarta Pusat Jakarta Pusat Penjualan (unit) Penjualan (unit) N N MMeeaan n SSttdd. . DDeevviiaattiioonn Std. E Std. Errrroror Mean Mean
Pada bagian pertama terlihat ringkasan statistik dari kedua sampel. Untuk penjualan di Pada bagian pertama terlihat ringkasan statistik dari kedua sampel. Untuk penjualan di daerah Jakarta Selatan (tanda 1) mempunyai penjualan rata-rata sebesar 174, 25 unit daerah Jakarta Selatan (tanda 1) mempunyai penjualan rata-rata sebesar 174, 25 unit (dibulatkan menjadi 174 unit), yang jauh di bawah penjualan rata-rata Jakarta Pusat (dibulatkan menjadi 174 unit), yang jauh di bawah penjualan rata-rata Jakarta Pusat yaitu sebesar 304 unit penghisap debu.
yaitu sebesar 304 unit penghisap debu.
Independent S
Independent Samples Teamples Te stst
8
8..00554 4 ..00113 3 --22..33228 8 114 4 ..00335 5 --112299..8877550 0 5555..7777996 6 --224499..5511003 3 --1100..22339977 --22..332 8 2 8 1100..1 91 92 2 ..00442 2 --112299..88775 0 5 0 555 .5 .7 77 7996 6 --225 35 3..88443 0 3 0 --55..99007700 E
Equal vqual v ariancesariances assumed assumed E
Equal vqual v ariancesariances not assumed not assumed P
Penjualan (enjualan ( unit)unit)
F
F SSiigg.. Levene's T Levene's Test foest fo rr Equality of Variances Equality of Variances
t
t ddf f SSiigg. . ((22--ttaaiilleedd))
Mean Mean Difference Difference Std. E Std. Errorro rr D Diif f ef f er er enncce e LLo w eo w er r UUppppe re r 95% Confidence 95% Confidence Interval of the Interval of the Difference Difference t-test for Equality of Means
t-test for Equality of Means
Pertama analisis mengg
Pertama analisis menggunakan F test, untuk unakan F test, untuk menguji apakah ada menguji apakah ada kesamaan varianskesamaan varians pada data penjualan di Jakarta Selatan dan Jakarta Pusat.
pada data penjualan di Jakarta Selatan dan Jakarta Pusat.
Hipotesis Hipotesis
Hipotesis untuk kasus ini adalah : Hipotesis untuk kasus ini adalah : Ho
Ho : : Kedua Kedua varians varians populasi populasi adalah adalah identik identik (varians (varians populasi populasi penjualan penjualan di di JakartaJakarta Selatan
Selatan dan Jdan Jakarta Pusat akarta Pusat adalah samadalah sama)a) Hi
Hi : : kedua kedua varians varians populasi populasi tidak tidak identik identik (varians (varians populasi populasi penjualan penjualan di di JakartaJakarta Selatan dan Jakarta Pusat adalah berbeda)
Selatan dan Jakarta Pusat adalah berbeda)
Pengambilan Keputusan Pengambilan Keputusan Dasar pengambilan keputusan : Dasar pengambilan keputusan :
Jika probabilitas > 0,05, Ho di tolak Jika probabilitas > 0,05, Ho di tolak Jika probabilitas < 0,05, Hi di terima Jika probabilitas < 0,05, Hi di terima
Keputusan : Keputusan :
Terlihat bahwa F hitung untuk tinggi badan dengan Equal variance assumed Terlihat bahwa F hitung untuk tinggi badan dengan Equal variance assumed (diasumsi kedua varians sama atau menggunakan pooled variance t test) adalah (diasumsi kedua varians sama atau menggunakan pooled variance t test) adalah 8.054 dengan probabilita 0,013. oleh karena probabilita
8.054 dengan probabilita 0,013. oleh karena probabilita < 0,05 maka Ho ditolak, atau< 0,05 maka Ho ditolak, atau kedua varians benar-benar berbeda.
kedua varians benar-benar berbeda.
Perbedaan yang nyata dari kedua varians membuat penggunaan varians untuk Perbedaan yang nyata dari kedua varians membuat penggunaan varians untuk membandingkan rata-rata populasi dengan t test, sebaiknya menggunakan dasar membandingkan rata-rata populasi dengan t test, sebaiknya menggunakan dasar Equal variance not assumed
Equal variance not assumed (diasumsi kedua varians tidak sama).(diasumsi kedua varians tidak sama).
Selanjutnya dilakukan analisis dengan memakai t test untuk asumsi varians tidak Selanjutnya dilakukan analisis dengan memakai t test untuk asumsi varians tidak sama.
sama.
Hipotesis Hipotesis
Hipotesis untuk kasus ini : Hipotesis untuk kasus ini : Ho
Ho : : kedua kedua rata-rata rata-rata populasi populasi adalah adalah identik identik (rata-rata (rata-rata populasi populasi penjualan penjualan didi Jakarta Selatan
Jakarta Selatan dan Jakarta dan Jakarta Pusat adalah Pusat adalah sama)sama) Hi
Hi : : kedua kedua rata-rata rata-rata populasi populasi adalah adalah tidak tidak identik identik (rata-rata (rata-rata populasi populasi penjualanpenjualan di Jakarta Se
di Jakarta Selatan latan dan Jakarta dan Jakarta Pusat adalah Pusat adalah sama)sama)
Keputusan Keputusan
Terlihat bahwa t hitung untuk penjualan dengan Equal varianced not assumed Terlihat bahwa t hitung untuk penjualan dengan Equal varianced not assumed (diasumsi kedua varians tidak sama atau menggunakan separate varians test) adalah (diasumsi kedua varians tidak sama atau menggunakan separate varians test) adalah -2,328 dengan probabilita 0,042. Oleh karena probabilita < 0,05, maka Ho di tolak -2,328 dengan probabilita 0,042. Oleh karena probabilita < 0,05, maka Ho di tolak atau kedua rata-rata (mean
atau kedua rata-rata (mean) populasi penjualan di ) populasi penjualan di Jakarta Selatan Jakarta Selatan dan Jakarta Pusdan Jakarta Pusatat adalah berbeda berbeda, dalam artian Jakarta Pusat mempunyai rata-rata penjualan adalah berbeda berbeda, dalam artian Jakarta Pusat mempunyai rata-rata penjualan yang lebih dari Jakarta Selatan.
yang lebih dari Jakarta Selatan.
B.
B. PAIRED SAMPLE T-TESTPAIRED SAMPLE T-TEST
Paired Sampel yang berpasangan diartikan sebagai sebuah sampel dengan subyek yang sama Paired Sampel yang berpasangan diartikan sebagai sebuah sampel dengan subyek yang sama namun mengalami dua perlakuan atau pengukuran yang berbeda, seperti Subjek X akan namun mengalami dua perlakuan atau pengukuran yang berbeda, seperti Subjek X akan mendapat perlakuan
mendapat perlakuan I I kemudian pkemudian perlakuan II.erlakuan II.
Kasus Kasus
Sebuah Universitas berusaha meningkatkan kemampuan staf pengajar mereka dalam Sebuah Universitas berusaha meningkatkan kemampuan staf pengajar mereka dalam berbahasa Inggris dengan memberikan pelatihan selama 1 semester. Untuk mengetahui berbahasa Inggris dengan memberikan pelatihan selama 1 semester. Untuk mengetahui keberhasilan program pelatihan tersebut, pihak Universitas mengadakan
keberhasilan program pelatihan tersebut, pihak Universitas mengadakan pretest pretest dandan posttest posttest pada beberapa
pada beberapa staf pengajar yastaf pengajar yang mengikuti program ng mengikuti program tersebut. tersebut. Berikut ini data perolehanBerikut ini data perolehan nilai mereka dalam sebuah
Subyek
Subyek Pretest Pretest PosttestPosttest
1 1 60 60 107107 2 2 85 85 111111 3 3 90 90 117117 4 4 110 110 125125 5 5 115 115 122122
Dari data diatas, kita melihat bahwa seorang subyek mengalami dua perlakuan yang sama, Dari data diatas, kita melihat bahwa seorang subyek mengalami dua perlakuan yang sama, untuk itu kita menggunakan analisis paired sample t
untuk itu kita menggunakan analisis paired sample t -test.-test.
Pengolahan Data dengan SPSS Pengolahan Data dengan SPSS
Buka fileBuka file paired t testpaired t test
Dari menu utama SPSS pilih menuDari menu utama SPSS pilih menu Analyze, Analyze, kemudian pilih submenukemudian pilih submenu Compare-
Compare-Means.
Means. Dari serangkaian pilihan test, sesuai kasus pilihDari serangkaian pilihan test, sesuai kasus pilih Paired-Samples T Test.Paired-Samples T Test. Tampak di layar :
Tampak di layar :
Paired Variable(s)Paired Variable(s) atau Variabel yang akan diuji. Karena di sini yang akan diujiatau Variabel yang akan diuji. Karena di sini yang akan diuji
adalah data
adalah data pretestpretest dandan posttest ,posttest , klik mouse pada variabelklik mouse pada variabel pretestpretest kemudian klik kemudian klik mouse sekali lagi pada variabel
mouse sekali lagi pada variabel posttest.posttest. Maka terlihat pada kolom Current SelectionMaka terlihat pada kolom Current Selection dibawah, terdapat keter
dibawah, terdapat keterangan untuk variabel angan untuk variabel 1 dan 2. 1 dan 2. Kemudian klik mKemudian klik mouse padaouse pada tanda > (yang sebelah atas), maka Paired Variables terlihat tanda tanda > (yang sebelah atas), maka Paired Variables terlihat tanda pretest...posttest.
pretest...posttest.
Keterangan : variabel pretest dan posttest harus dipilih secara bersamaan. Jika tidak, Keterangan : variabel pretest dan posttest harus dipilih secara bersamaan. Jika tidak, SPSS tidak bisa menginput dalam kolom Paired Variables, dengan tidak aktifnya SPSS tidak bisa menginput dalam kolom Paired Variables, dengan tidak aktifnya tanda
tanda
Untuk
Untuk Confidence IntervalConfidence Interval atau tingkat kepercayaan. Sebagai default, SPSSatau tingkat kepercayaan. Sebagai default, SPSS menggunakan tingkat kepercayaan 95% atau tingkat
menggunakan tingkat kepercayaan 95% atau tingkat signifikansi 100%-95%=5%signifikansi 100%-95%=5% Untuk
Untuk Missing ValuesMissing Values atau data yang hilang. Oleh karena dalam kasus semuaatau data yang hilang. Oleh karena dalam kasus semua pasangan data lengkap (tidak ada yang kosong), maka abaikan saja bagian ini (tetap pasangan data lengkap (tidak ada yang kosong), maka abaikan saja bagian ini (tetap pada default dari SPSS yaitu Exclude cases analysis by analysis).
pada default dari SPSS yaitu Exclude cases analysis by analysis). Tekan
Tekan ContinueContinue jika pengisian selesai, sekarang SPSS akan kembali ke kotak dialogjika pengisian selesai, sekarang SPSS akan kembali ke kotak dialog utama uji t paired.
utama uji t paired.
Kemudian tekan OK untuk mengakhiri pengisian prosedur analisis. Terlihat SPSSKemudian tekan OK untuk mengakhiri pengisian prosedur analisis. Terlihat SPSS
melakukan pekerjaan analisis dan terlihat output SPSS melakukan pekerjaan analisis dan terlihat output SPSS
Interpretasi Output SPSS Interpretasi Output SPSS Berikut output dari uji_t_paired : Berikut output dari uji_t_paired :
Pa
Paired ired SSampamp llee s s StaStatistictisticss
9 922..0000000 0 5 5 2211..9966559 9 99..88223344 1 11166..4400000 0 5 5 7..47466999 9 33..33440077 prettest prettest posttest posttest Pair Pair 1 1 M Meeaan n N N SSttdd. . DDeevviiaattiioonn Std. Error Std. Error Mean Mean
Pada bagian pertama terlihat ringkasan statistik dari kedua sampel. Untuk kemampuan Pada bagian pertama terlihat ringkasan statistik dari kedua sampel. Untuk kemampuan rata-rata para staf pengajar dalam berbahasa inggris sebelum mengikuti pelatihan adalah rata-rata para staf pengajar dalam berbahasa inggris sebelum mengikuti pelatihan adalah sebesar 92. Sedangkan setelah mengikuti pelatihan
sebesar 92. Sedangkan setelah mengikuti pelatihan adalah sebesar 116.4.adalah sebesar 116.4.
Pa
Paired Samples ired Samples CCorreorre lalationstions
5
5 ..99446 6 ..001155
prettest & posttest prettest & posttest Pair 1
Pair 1
N
N CCoorrrreellaattiioon n SSiigg..
Bagian kedua output adalah hasil korelasi antara kedua variabel, yang menghasilkan Bagian kedua output adalah hasil korelasi antara kedua variabel, yang menghasilkan angka 0,946 dengan nilai probabilitas sebesar 0,015. Hal ini menyatakan bahwa korelasi angka 0,946 dengan nilai probabilitas sebesar 0,015. Hal ini menyatakan bahwa korelasi antara nilai pretest dan posttest sangat nyata.
antara nilai pretest dan posttest sangat nyata.
Pa
Paired Samples Teired Samples Te stst
--2244..4400000 0 1155..0099330 0 66..7744998 8 --4433..1144005 5 --55..6655995 5 --33..66115 5 4 4 ..002222 prettest - posttest prettest - posttest Pair 1 Pair 1 M
Mean ean StStd. d. DeDeviaviatitionon
Std. Error Std. Error M Meeaan n LLoow ew er r UUppppeerr 95% Confidence 95% Confidence IInterval of nterval of thethe
Difference Difference P
Paired aired DDifif ferencesferences
t
Hipotesis Hipotesis
Hipotesis untuk kasus ini adalah : Hipotesis untuk kasus ini adalah :
Ho
Ho : : Kedua Kedua rata-rata rata-rata populasi populasi adalah adalah identik identik (rata-rata (rata-rata nilai nilai pretest pretest dan dan posttestposttest tidak berbeda secara nyata)
tidak berbeda secara nyata) Hi
Hi : : Kedua Kedua rata-rata rata-rata populasi populasi adalah adalah tidak tidak identik identik (rata-rata (rata-rata nilai nilai pretest pretest dandan posttest adalah memang berbeda secara nyata)
posttest adalah memang berbeda secara nyata)
Pengambilan Keputusan Pengambilan Keputusan
Dasar pengambilan keputusan berdasarkan nilai probabilitas: Dasar pengambilan keputusan berdasarkan nilai probabilitas:
jika probabilita > 0,05 ; maka Ho ditolak jika probabilita > 0,05 ; maka Ho ditolak jika probabilita < 0,05 ; maka Ho ditolak jika probabilita < 0,05 ; maka Ho ditolak
Keputusan: Keputusan:
Terlihat bahwa t hitung adalah -3.615 dengan probabilitas 0,022 oleh karena probabilitas Terlihat bahwa t hitung adalah -3.615 dengan probabilitas 0,022 oleh karena probabilitas < 0,05
< 0,05 maka Ho ditolak maka Ho ditolak atau atau kedua rata-rata populasi adkedua rata-rata populasi adalah tidak identik (rata-rata nalah tidak identik (rata-rata nilaiilai pretest dan
pretest dan posttest posttest berbeda secara berbeda secara nyata)nyata)
ANOVA 1 ARAH (ONE-WAY ANOVA) ANOVA 1 ARAH (ONE-WAY ANOVA)
Tujuan utama dari ANOVA adalah untuk membandingkan
Tujuan utama dari ANOVA adalah untuk membandingkan mean mean dari tiga kelompok atau lebih,dari tiga kelompok atau lebih, untuk memberikan informasi apakah perbedaan yang teramati (
untuk memberikan informasi apakah perbedaan yang teramati (observed differences observed differences ) antar) antar kelompok tersebut terjadi karena kebetulan
kelompok tersebut terjadi karena kebetulan (chance) (chance) atau karena suatu pengaruh tertentuatau karena suatu pengaruh tertentu yang bersifat sistematis
yang bersifat sistematis (systematic effect) (systematic effect) ..
Analisis Varians (ANO
Analisis Varians (ANOVA) mensyaratkan adanya VA) mensyaratkan adanya Variabel Dependen (DV) yang mVariabel Dependen (DV) yang memiliki skalaemiliki skala interval atau rasio
interval atau rasio dan satu dan satu atau lebih Variabel atau lebih Variabel Independen Independen (IV) yang (IV) yang seluruhnya bersifatseluruhnya bersifat kategori atau yang merupakan kombinasi dari variabel bersifat kategorik dengan variabel kategori atau yang merupakan kombinasi dari variabel bersifat kategorik dengan variabel berskala interval atau rasio.
berskala interval atau rasio.
ANOVA berusaha membandingkan variabilitas skor yang terjadi
ANOVA berusaha membandingkan variabilitas skor yang terjadi dalam suatu kelompok (withindalam suatu kelompok (within group, yakni variabilitas yang disebabkan oleh
group, yakni variabilitas yang disebabkan oleh sampling error sampling error itu sendiri) dengan variabilitasitu sendiri) dengan variabilitas yang terjadi antar kelompok (between group, yakni variabilitas yang disebabkan karena efek yang terjadi antar kelompok (between group, yakni variabilitas yang disebabkan karena efek dari suatu perlakuan/
dari suatu perlakuan/treatment treatment dan variabilitas yang disebabkan karenadan variabilitas yang disebabkan karena sampling error sampling error ).).
Post Hoc Test Post Hoc Test
Konsep ANOVA sesungguhnya hampir sama dengan t-test, hanya saja ANOVA biasanya Konsep ANOVA sesungguhnya hampir sama dengan t-test, hanya saja ANOVA biasanya membedakan lebih dari dua kelompok. Pada ANOVA kita biasanya akan melakukan apa yang membedakan lebih dari dua kelompok. Pada ANOVA kita biasanya akan melakukan apa yang disebut Post hoc test. Hal ini dilakukan untuk membandingkan satu kelompok dengan disebut Post hoc test. Hal ini dilakukan untuk membandingkan satu kelompok dengan kelompok lainnya satau per satu dan tidak secara bersamaan. Proses ini pada dasarnya sama kelompok lainnya satau per satu dan tidak secara bersamaan. Proses ini pada dasarnya sama
C. C.
dengan uji beda t-test. Adapun metode-metode dalam post hoc test tergolong banyak sekali dengan uji beda t-test. Adapun metode-metode dalam post hoc test tergolong banyak sekali jumlahnya. Penulis hanya akan membahas dua metode saja di sini.
jumlahnya. Penulis hanya akan membahas dua metode saja di sini. 1.
1. Scheffe’s TestScheffe’s Test
Metode ini paling banyak digunakan untuk melakukan post hoc comparison. Metode Metode ini paling banyak digunakan untuk melakukan post hoc comparison. Metode tersebut memungkinkan peneliti untuk membandingkan mean secara berpasangan tersebut memungkinkan peneliti untuk membandingkan mean secara berpasangan dengan kombinasi yang sangat kompleks.
dengan kombinasi yang sangat kompleks.
Dalam setiap post hoc comparison, distribusi t dapat kita gunakan untuk menentukan Dalam setiap post hoc comparison, distribusi t dapat kita gunakan untuk menentukan apakah perbedaaan mean yang terjadi antara dua kelompok sampel terjadi secara apakah perbedaaan mean yang terjadi antara dua kelompok sampel terjadi secara sistematis atau kebetulan semata.
sistematis atau kebetulan semata.
Untuk setiap perbandingan, maka hipotesis nol dan hipotesis alternative yang kita buat Untuk setiap perbandingan, maka hipotesis nol dan hipotesis alternative yang kita buat ditulis untuk menunjukkan kontras yang terjadi antar
ditulis untuk menunjukkan kontras yang terjadi antar populasi (C) : Hpopulasi (C) : Hoo:C=0 dan H:C=0 dan H11:C:C 0.0.
2.
2. Tukey’s HSD TestTukey’s HSD Test
Tukey‟s HSD (Honestly Significant Difference) test dirancang untuk
Tukey‟s HSD (Honestly Significant Difference) test dirancang untuk dapat melakukandapat melakukan perbandingan mean antar kelompok pada semua tingkat signifikansi tes. Tes ini jauh perbandingan mean antar kelompok pada semua tingkat signifikansi tes. Tes ini jauh lebih kuat dibandingkan Scheffe‟s test. , namun tidak dapat digunakan untuk menguji lebih kuat dibandingkan Scheffe‟s test. , namun tidak dapat digunakan untuk menguji perbandingan yang bersifat kompleks.
perbandingan yang bersifat kompleks.
Kasus Kasus
Seorang pengusaha ingin mengatahui apakah terdapat perbedaan penjualan pada tiga Seorang pengusaha ingin mengatahui apakah terdapat perbedaan penjualan pada tiga strategi distribusi yang dipilihnya (intensif, selektif dan eksklusif). Sebagai seorang konsultan, strategi distribusi yang dipilihnya (intensif, selektif dan eksklusif). Sebagai seorang konsultan, lakukanlah analisis terhadap data penjualan (dalam milyar rupiah) yang dimiliki oleh lakukanlah analisis terhadap data penjualan (dalam milyar rupiah) yang dimiliki oleh pengusaha tersebut!
pengusaha tersebut!
Intensif Selektif Eksklusif
Intensif Selektif Eksklusif
5 5 1 1 33 6 6 2 2 33 8 8 3 3 44
Kasus diatas memiliki satu variabel independen berjenis kategorik, yakni strategi distribusi. Kasus diatas memiliki satu variabel independen berjenis kategorik, yakni strategi distribusi. Variabel dependen-nya berskala metric yakni penjualan.
Variabel dependen-nya berskala metric yakni penjualan. Pengolahan data dengan SPSS
Pengolahan data dengan SPSS Buka lembar kerja / file
Buka lembar kerja / file one way anovaone way anova sesuai kasus diatas, atau jika sudah terbuka,sesuai kasus diatas, atau jika sudah terbuka, ikuti prosedur berikut ini:
Dari menu utama SPSS, pilih menuDari menu utama SPSS, pilih menu Analyze Analyze, kemudian pilih submenu, kemudian pilih submenu Compare-
Compare-Means Means..
Dari serangkaian pilihan test, sesuai kasus pilih
One-Dari serangkaian pilihan test, sesuai kasus pilih One-Way Anova…Way Anova… Klik pilihan tersebut, maka tampak dilayar:
Klik pilihan tersebut, maka tampak dilayar:
Pengisian: Pengisian:
Dependent ListDependent List atau variabel dependen yang akan diuji. Oleh karena yang akanatau variabel dependen yang akan diuji. Oleh karena yang akan
diuji tingkat penjualan, maka klik variabel tingkat penjualan, kemudian klik tanda> diuji tingkat penjualan, maka klik variabel tingkat penjualan, kemudian klik tanda> (yang sebelah atas), maka variabel tingkat penjualan berpindah ke Dependent List. (yang sebelah atas), maka variabel tingkat penjualan berpindah ke Dependent List.
Factor atau grupFactor atau grup.Oleh karena itu, variabel pengelompokkan ada pada variabel.Oleh karena itu, variabel pengelompokkan ada pada variabel
strategi promosi, maka klik strategi promosi, kemudian klik tanda >, maka variabel strategi promosi, maka klik strategi promosi, kemudian klik tanda >, maka variabel jenis strategi promosi akan berpindah ke Factor. Untuk kolom Option atau pilihan lain jenis strategi promosi akan berpindah ke Factor. Untuk kolom Option atau pilihan lain
dengan mengkliknya maka tampak di layar: dengan mengkliknya maka tampak di layar:
Pengisian: Pengisian:
Untuk Statistics atau perhitungan statistic yang akan dilakukan, untuk keseragaman Untuk Statistics atau perhitungan statistic yang akan dilakukan, untuk keseragaman akan dipilih Descriptive dan Homogeinity of Variance. Untuk itu, klik kedua pilihan akan dipilih Descriptive dan Homogeinity of Variance. Untuk itu, klik kedua pilihan tersebut. tersebut. Interpretasi Output SPSS: Interpretasi Output SPSS: Descriptives Descriptives penjualan penjualan 3 3 66..3333333 3 11..5522775 5 ..8888119 9 2..52533888 8 1100..1122779 9 55..000 0 88..0000 3 3 22..0000000 0 11..0000000 0 ..5577774 4 --..4488441 1 44..4488441 1 11..000 0 33..0000 3 3 33..3333333 3 ..5577774 4 ..3333333 3 1..81899991 1 44..7766776 6 33..000 0 44..0000 9 9 33..8888889 9 22..1144773 3 ..7711558 8 2..22233883 3 55..5533995 5 11..000 0 88..0000 intensif intensif selektif selektif eksklusif eksklusif Total Total N N MMeea n a n S tS td . d . DDeev iv iaat it io n o n S tS td . d . EEr rr ro r o r LLo w e r o w e r B oB ouun d n d UUppppe r e r B oB ou nu ndd 95% Confidence Interval for 95% Confidence Interval for
Mean Mean
Mi
Dapat diketahui bahwa rata-rata penjualan pada melalui strategi intensif adalah sebesar 6, 3 Dapat diketahui bahwa rata-rata penjualan pada melalui strategi intensif adalah sebesar 6, 3 milyar.
milyar.
Penjualan terendah untuk strategi intensif adalah sebesar 5 milyar, dan tertinggi adalah 8 Penjualan terendah untuk strategi intensif adalah sebesar 5 milyar, dan tertinggi adalah 8 milyar
milyar
Penjualan dengan strategi lainnya dapat diinterpretasikan dengan cara yang sama. Penjualan dengan strategi lainnya dapat diinterpretasikan dengan cara yang sama.
Tes
Tes t of t of HHomogenomogen eity of Variaeity of Variancesnces penjualan penjualan 1 1..22117 7 2 2 6 6 ..336600 Levene Levene S
Sttaattiissttiic c ddff1 1 ddff2 2 SSiigg..
Analisis Homogeneity of Variances ini bertujuan untuk menguji berlaku tidaknya asumsi untuk Analisis Homogeneity of Variances ini bertujuan untuk menguji berlaku tidaknya asumsi untuk ANOVA, yaitu apakah penjualan dengan menggunakan ketiga strategi promosi yang ada ANOVA, yaitu apakah penjualan dengan menggunakan ketiga strategi promosi yang ada
mempunyai varians yang sama: mempunyai varians yang sama:
Hipotesis pada bagian ini adalah: Hipotesis pada bagian ini adalah: Ho:
Ho: Ketiga Ketiga varians varians populasi populasi adalah adalah identik identik Hi: Kedua varians populasi tidak identik Hi: Kedua varians populasi tidak identik
Pengambilan keputusan: Pengambilan keputusan:
jika probabilita > 0,05 ; maka Ho diterima jika probabilita > 0,05 ; maka Ho diterima jika probabilita < 0,05 ; maka Ho ditolak jika probabilita < 0,05 ; maka Ho ditolak
Keputusan: Keputusan:
dari informasi diatas, Sig 0,360 >dari 0,05. oleh karena itu Ho diterima. Dengan kata lain dari informasi diatas, Sig 0,360 >dari 0,05. oleh karena itu Ho diterima. Dengan kata lain varians identik. varians identik. ANOVA ANOVA penjualan penjualan 2 299..55556 6 2 2 1144..77778 8 1122..00991 1 ..000088 7 7..33333 3 6 6 11..222222 3 366..88889 9 88 Betw
Betw een Groeen Groupsups Withi
Within Grn Gr oupsoups Total
Total
Sum of Sum of S
Sqquuaarrees s ddf f MMeeaan n SSqquuaarre e F F SSiigg..
Bagian ini menguji apak
Hipotesis pada bagian ini adalah: Hipotesis pada bagian ini adalah: Ho: K
Ho: Ketiga mean etiga mean populasi populasi adalah identik adalah identik Hi: Kedua mean populasi tidak identik Hi: Kedua mean populasi tidak identik
Pengambilan keputusan Pengambilan keputusan Berdasar nilai signifikansi: Berdasar nilai signifikansi:
Jika Sig >0,05 maka Ho diterima Jika Sig >0,05 maka Ho diterima Jika Sig<0,05 maka Ho ditolak Jika Sig<0,05 maka Ho ditolak
Signifikansi analisis ini adalah sebesar 0,008 berarti <0,05. Hal ini menunjukkan bahwa Signifikansi analisis ini adalah sebesar 0,008 berarti <0,05. Hal ini menunjukkan bahwa rata-rata penjualan dengan menggunakan tiga strategi promosi tersebut berbeda secara signifikan rata penjualan dengan menggunakan tiga strategi promosi tersebut berbeda secara signifikan
Multiple Comparisons Multiple Comparisons Dependent Var
Dependent Var iabliable: pe: p enjualaenjualann
4 4..33333333* * ..9900227 7 ..00007 7 11..5566337 7 77..11003300 3 3..00000000* * ..9900227 7 ..00337 7 ..2233003 3 55..77669977 --44..33333333* * ..9900227 7 ..00007 7 --77..1100330 0 --11..55663377 --11..3333333 3 ..9900227 7 ..33665 5 --44..1100330 0 11..44336633 --33..00000000* * ..9900227 7 ..00337 7 --55..7766997 7 --..22330033 1 1..3333333 3 ..9900227 7 ..33665 5 --11..4433663 3 44..11003300 4 4..33333333* * ..9900227 7 ..00009 9 11..4433882 2 77..22228844 3 3..00000000* * ..9900227 7 ..00444 4 ..1100449 9 55..88995511 --44..33333333* * ..9900227 7 ..00009 9 --77..2222884 4 --11..44338822 --11..3333333 3 ..9900227 7 ..33994 4 --44..2222884 4 11..55661188 --33..00000000* * ..9900227 7 ..00444 4 --55..8899551 1 --..11004499 1 1..3333333 3 ..9900227 7 ..33994 4 --11..5566118 8 44..22228844 (J) promosi (J) promosi selektif selektif eksklusif eksklusif intensif intensif eksklusif eksklusif intensif intensif selektif selektif selektif selektif eksklusif eksklusif intensif intensif eksklusif eksklusif intensif intensif selektif selektif (I) promosi (I) promosi intensif intensif selektif selektif eksklusif eksklusif intensif intensif selektif selektif eksklusif eksklusif Tuke Tukey y HSDHSD Scheffe Scheffe Mean Mean Difference Difference ( I ( I- J- J) ) S tS td . d . EEr rr ro r o r S iS igg. . Lo w eLo w er r BBoouun d n d UUppppe r e r BBoou nu ndd 95% Confidence Interval 95% Confidence Interval
The mean difference is significant at the .05 level. The mean difference is significant at the .05 level. *.
*.
Setelah kita mengetahui bahwa terdapat perbedaan yang signifikan pada ketiga daerah, Setelah kita mengetahui bahwa terdapat perbedaan yang signifikan pada ketiga daerah, maka kita akan berusaha untuk mengetahui perbedaan antara satu strategi dengan strategi maka kita akan berusaha untuk mengetahui perbedaan antara satu strategi dengan strategi lainnya.
lainnya.
Scheffe Test. Scheffe Test.
Catatan: Tanda * pada kolom mean differences menunjukkan bahwa perbedaan yang ada Catatan: Tanda * pada kolom mean differences menunjukkan bahwa perbedaan yang ada tergolong signifikan.
tergolong signifikan.
-- Perbandingan antara strategi intensif dengan strategi selektif tergolong signifikan,Perbandingan antara strategi intensif dengan strategi selektif tergolong signifikan, begitu pun perbandingan antara strategi intensif dengan strategi ekslusif tergolong begitu pun perbandingan antara strategi intensif dengan strategi ekslusif tergolong signifikan.
signifikan.
Interpretasi yang sama di lakukan terhadap strategi lainnya. Interpretasi yang sama di lakukan terhadap strategi lainnya.