BAB II
LANDASAN TEORI
2.1 Email
Electronic mail (email) merupakan sebuah metode untuk mengirimkan pesan
dalam bentuk digital. Pesan ini biasanya dikirimkan melalui medium internet. Sebuah pesan elektronis terdiri dari isi, alamat pengirim, dan alamat-alamat yang dituju. Sistem email yang beroperasi di atas jaringan berbasis pada model store and forward. Sistem ini mengaplikasikan sebuah sistem server email yang menerima, meneruskan, mengirimkan, serta menyimpan pesan-pesan user, dimana user hanya perlu untuk mengkoneksikan pc mereka ke dalam jaringan (Anugroho, Winarno, & Rosyid, 2010).
Pengguna email memiliki sebuah mailbox (kotak surat) yang tersimpan dalam suatu mailserver. Mailbox memiliki sebuah alamat sebagai pengenal agar dapat berhubungan dengan mailbox lainnya, baik dalam bentuk penerimaan maupun pengiriman pesan, Pesan yang diterima akan ditampung dalam mailbox selanjutnya pemilik mailbox sewaktu-waktu dapat mengecek isinya, menjawab pesan, menghapus, atau menyunting dan mengirimkan pesan email (Sutanta, 2005).
Gambar 1 Cara Kerja Email (Anugroho, Winarno, & Rosyid, 2010)
Cara kerja email sebagaimana pada gambar di atas, menunjukkan bahwa
email yang dikirim belum tentu akan diteruskan ke komputer penerima (end user),
tetapi disimpan atau dikumpulkan dahulu dalam sebuah komputer server (host) yang akan online secara terus menerus (continue) dengan media penyimpanan (storage) yang relatif lebih besar dibanding komputer biasa. Komputer yang melayani penerimaan email secara terus-menerus tersebut biasa disebut dengan mailserver atau
mailhost (Anugroho, Winarno, & Rosyid, 2010).
2.2 Email Ham
Email ham merupakan istilah untuk email yang terkirim dengan benar atau
kepada penerima dengan tujuan yang jelas, bukan merupakan email dengan muatan yang tidak diinginkan oleh penerima.
Filter spam biasanya menggunakan email spam dan email ham sebagai data
pelatihan. Pengukuran kinerja filter spam dilakukan dengan melakukan uji coba terhadap sampel email spam dan ham (Cruz & Cormack, 2009)
2.3 Email Spam
Email spam dapat didefinisikan sebagai email yang dikirimkan kepada banyak
penerima yang berisikan hal-hal yang tidak diinginkan oleh pengguna komputer seperti iklan produk, pornografi dan lain sebagainya.
Para pelaku email spamming biasanya memiliki beragam tujuan, diantaranya adalah penipuan (misal : anda menjadi pemenang lotre, silahkan hubungi kami di alamat …), pencucian uang atau money laundering (menawarkan transaksi pekerjaan yang berhubungan dengan rekening bank), promosi produk (seperti obat-obatan), menyebarkan virus, trojan, worm dan sebagainya (Suryanto, 2007).
2.4 Data mining
Data mining adalah suatu istiah yang digunakan untuk menguraikan
penemuan pengetahuan di dalam database. Data mining adalah suatu proses yang menggunakan teknik statistik, matematika, kecerdasan buatan dan machine learning untuk mengektraksi dan mengidentifikasi informasi yang bermanfaat dan
pengetahuan yang terkait dari berbagai database besar (Turban, Aronson, & Liang, 2005).
Data mining merupakan proses analisis data menggunakan perangkat lunak
untuk menemukan pola dan aturan (rules) dalam himpunan data. Data mining dapat menganalisis data yang besar untuk menemukan pengetahuan guna mendukung pengambilan keputusan (Kusumo & Darmantoro, 2003).
Data mining meliputi tugas-tugas yang dikenal sebagai ekstraksi pengetahuan,
arkeologi data, eksplorasi data, pemrosesan pola data, data dredging, dan memanen informasi. Semua aktifitas ini dilakukan secara otomatis dan mengizinkan adanya penemuan cepat bahkan dapat dilakukan oleh non-programmer. Berikut ini karakteristik utama dan sasaran data mining (Turban, Aronson, & Liang, 2005).
- Data sering dikubur pada sebuah database yang sangat besar, yang kadang-kadang berisi data dari beberapa tahun. Dalam banyak kasus, data dihapus dan dikonsolidasi di dalam sebuah data warehouse.
- Lingkungan data mining biasanya adalah arsitektur klien / server atau arsitektur berbasis web.
- Peranti-peranti baru yang sopistikated, meliputi peranti visualisasi canggih, membantu memindah atau mengubur informasi dalam file-file perusahaan atau arsip catatan publik. Untuk menemukannya, perlu ada massaging dan sinkronisasi data untuk mendapatkan hasil yang tepat.
- User seringkali adalah pengguna akhir, diberdayakan oleh data drill dan peranti
query lainnya untuk mengajukan pertanyaan khusus dan mendapatkan jawaban
secara cepat dengan sedikit atau tanpa keterampilan pemrograman.
- Peranti data mining sudah digabung dengan spreadsheet dan peranti pengembangan perangkat lunak lainnya. Jadi, data yang sudah di-mining dapat dianalisis dan diproses dengan cepat dan mudah.
- Karena ada sejumlah besar data dan usaha pencarian massif, maka pemrosesan paralel untuk data mining kadang-kadang perlu digunakan.
Data mining dapat mempercepat analisis dengan memusatkan perhatian apda
variable yang paling penting. Rasio biaya / performa dari sistem komputer yang menurun drastis telah memungkinkan banyak organisasi untuk mulai menerapkan algoritma yang kompleks dari berbagai teknik data mining. Masing-masing kelas aplikasi data mining didukung oleh satu set pendekatan algoritmik untuk mengekstraksi hubungan-hubungan yang relevan di dalam data. Pendekatan ini berbeda di dalam kelas-kelas masalah yang dapat dipecahkan. Kelas tersebut adalah (Turban, Aronson, & Liang, 2005) :
- Klasifikasi : menyimpulkan karakteristik dari suatu kelompok tertentu. Metode ini meliputi penetapan suatu set data dengan satu set kelas yang telah diketahui, dan memetakan semua item lain ke dalam set data tersebut.
- Clustering : mengidentifikasi kelompok item yang sama-sama memiliki
- Asosiasi : mengidentifikasi hubungan antara berbagai peristiwa yang terjadi pada satu waktu. Pendekatan asosiasi menekankan sebuah kelas masalah yang dicirikan dengan analisis market basket.
- Sekuensi : sama dengan asosiasi kecuali bahwa hubungan terjadi pada lebih dari satu periode waktu.
- Regresi : digunakan untuk memetakan data untuk suatu nilai prediksi.
- Forecasting : mengestimasi nilai masa depan berdasarkan pola-pola di dalam
sekumpulan data.
- Teknik-teknik lain : umumnya berdasarkan pada metode kecerdasan buatan tingkat lanjut, meliputi pemikiran berbasis kasus, fuzzy logic, algoritma genetika dan transformasi berbasis fraktal.
Text mining merupakan sebuah proses yang sulit dilakukan karena data yang
diolah tidak terstruktur sehingga mengandung banyak data (kata) yang tidak relevan satu sama lain serta sulit melakukan pemilihan data yang sesuai dengan kebutuhan. Selain itu, terbuka kemungkinan ditemukannya banyak pola menarik dengan metode
data mining yang biasa digunakan untuk data bukan teks. Kesulitan lain yang
mungkin muncul adalah adanya informasi yang salah dalam teks, sinonim dan homonim dari kata yang menjadi data (Kurniati, Romadhony, Saleh, & Shaufiah, 2007).
2.5 Klasifikasi
Klasifikasi adalah suatu proses untuk mengelompokkan sejumlah data ke dalam kelas-kelas tertentu yang sudah diberikan berdasarkan kesamaan sifat dan pola yang terdapat dalam data-data tersebut. Secara umum, proses klasifikasi dimulai dengan diberikannya sejumlah data yang menjadi acuan untuk membuat aturan klasifikasi data. Data-data ini biasa disebut dengan training sets. Dari training sets tersebut kemudian dibuat suatu model untuk mengklasifikasikan data. Model tersebut kemudian digunakan sebagai acuan untuk mengklasifikasikan data-data yang belum diketahui kelasnya yang biasa disebut dengan test sets (Rifqi, Maharani, & Shaufiah, 2011).
Algoritma klasifikasi akan menghasilkan pola atau aturan yang dapat digunakan untuk memprediksi kelas. Dalam klasifikasi, terdapat target variable kelas. Tujuan dari algoritma klasifikasi adalah untuk menemukan relasi antara variable yang tergolong dalam kelas yang sama.
2.6 Support Vector Machines (SVM)
Support Vector Machines (SVM) merupakan sebuah metode pembelajaran
mesin yang dipopulerkan oleh Boser, Guyon, dan Vapnik pada tahun 1992. Proses pembelajaran pada SVM bertujuan untuk mendapatkan hipotesis berupa hyperplane terbaik yang tidak hanya meminimalkan empirical risk yaitu rata-rata error pada data pelatihan, tetapi juga memiliki generalisasi yang baik. Generalisasi adalah
kemampuan sebuah hipotesis untuk mengklasifikasikan data yang tidak terdapat dalam data pelatihan dengan benar. Untuk menjamin generalisasi ini, SVM bekerja berdasarkan prinsip structural risk minimization (SRM). SRM pada SVM digunakan untuk menjamin batas atas dari generalisasi pada data pengujian dengan cara mengontrol kapasitas (fleksibilitas) dari hipotesis hasil pembelajaran (Adhitia & Ayu, 2009).
Gambar di bawah ini memperlihatkan beberapa pola yang merupakan anggota dari dua buah kelas : +1 dan –1. Pola yang tergabung pada class –1 disimbolkan dengan warna merah (kotak), sedangkan pola pada class +1, disimbolkan dengan warna kuning (lingkaran). Problem klasifikasi dapat diterjemahkan dengan usaha menemukan garis (hyperplane) yang memisahkan antara kedua kelompok tersebut. Berbagai alternatif garis pemisah (discrimination boundaries) ditunjukkan pada gambar (a). Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane tersebut. dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan pola terdekat dari masing-masing kelas. Pola yang paling dekat ini disebut sebagai support vector. Garis solid pada gambar (b) menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah-tengah kedua kelas, sedangkan titik merah dan kuning yang berada dalam lingkaran hitam adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran pada SVM (Setiawan, 2012)
Gambar 2 SVM Berusaha Menemukan Hyperplane Terbaik yang Memisahkan Kelas –1 dan +1 (Setiawan, 2012)
2.6.1 Linear Support Vector Machines (SVM)
Data yang tersedia dinotasikan sebagai xi , sedangkan label masing-masing dinotasikan = {+1,-1} i y untuk i=1,2,3 …. l. Yang mana l adalah banyaknya data. Diasumsikan kedua class –1 dan +1 dapat terpisah secara sempurna oleh
hyperplane berdimensi d , yang didefinisikan (Nugroho, Witarto, & Handoko, 2003)
. b 0 (Nugroho, Witarto, & Handoko, 2003)
Data xi yang termasuk ke dalam kelas negatif adalah yang memenuhi pertidaksamaan berikut :
Adapun data xi yang tergolong ke dalam kelas positif, adalah yang memenuhi pertidaksamaan :
. 1 (Nugroho, Witarto, & Handoko, 2003)
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara
hyperplane dan titik terdekatnya, yaitu1/ ||w||. Hal ini dapat dirumuskan sebagai
Quadratic Programming (QP) problem, yaitu mencari titik minimal persamaan
(Setiawan, 2012) :
12|| ||2(Setiawan, 2012) menjadi :
. b 1 0, i (Setiawan, 2012)
Problem ini dapat diselesaikan dengan Lagrange Multipliers :
, , | | ∑ αi w. xı b 1 (Setiawan, 2012)
αi adalah Langrange multiplier yang yang bernilai nol atau positif. Untuk menyelesaikan masalah tersebut pertama-tama meminimalkan L terhadap w dan b, dan memaksimalkan L terhadap αi Dengan memodifikasi persamaan di atas,
maximization problem di atas dapat direpresentasikan dalam αi, sebagai berikut
∑l αi 1 12 , 1αiαj Setiawan, 2012 menjadi : 0, ∑ αiyi 0 Setiawan, 2012
2.6.1.1 Soft Margin
Penjelasan di atas berdasarkan asumsi bahwa kedua belah class dapat terpisah secara sempurna oleh hyperplane. Akan tetapi, umumnya dua buah class pada input
space tidak dapat terpisah secara sempurna. Hal ini menyebabkan optimasi tidak
dapat diselesaikan. Untuk mengatasi masalah ini, SVM dirumuskan ulang dengan memperkenalkan teknik soft margin. Untuk itu, perlu dimasukkan slack variable εi, menjadi (Nugroho, 2003) :
. 1 , (Nugroho, Witarto, & Handoko, 2003)
Dengan demikian persamaan menjadi sebagai berikut :
, 12|| ||2 ∑ 1 (Nugroho, Witarto, & Handoko, 2003)
2.6.2 Non-Linear Support Vector Machines (SVM)
Pada umumnya masalah dalam domain dunia nyata jarang yang bersifat linear
separable, kebanyakan bersifat non linear. Untuk menyelesaikan problem non linear,
SVM dimodifikasi dengan memasukkan fungsi kernel. Dalam non linear SVM, data dipetakan oleh fungsi ke ruang vektor yang berdimensi lebih tinggi. Pada ruang vektor yang baru ini, hyperplane yang memisahkan kedua kelas tersebut dapat dikonstruksikan. Ilustrasi dari konsep ini dapat dilihat pada gambar dibawah ini (Yuanita, Fatichah, & Yuhana, 2010):
Gambar 3 Fungsi Φ Memetakan Data ke Ruang Vektor yang Berdimensi Lebih Tinggi (Yuanita, Fatichah, & Yuhana, 2010)
Beberapa jenis fungsi dapat dipakai sebagai kernel K tercantum pada table di bawah ini :
Tabel 1 Kernel yang Umum Dipakai dalam SVM (Nugroho, Witarto, & Handoko, 2003)
Nama Kernel Definisi
Polynomial , . 1
Gaussian , exp || ||
)
Sigmoid , tanh .
Selanjutnya klasifikasi non linear pada SVM terhadap test sample x dirumuskan sebagai berikut :
.
αiyi x . xi b ,
αiyi K x, xi b
, (Nugroho, Witarto, & Handoko, 2003)
2.7 K Nearest Neighbor (kNN)
K-Nearest Neighbors (KNN) adalah suatu metode yang menggunakan
algoritma supervised dimana hasil dari query instance yang baru diklasifikasikan berdasarkan mayoritas dari kategori pada KNN. Tujuan dari algoritma ini adalah mengklasifikasi objek baru berdasakan atribut dan training sample. Classifier tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan pada memori. (Andaruresmi, Rizal, & Magdalena, 2009).
Algoritma metode KNN sangatlah sederhana, bekerja dengan berdasarkan pada jarak terpendek dari query instance ke training sample untuk menentukan KNN nya. Setelah mengumpulkan KNN, kemudian diambil mayoritas dari KNN untuk dijadikan prediksi dari query instance. Data untuk algoritma KNN terdiri dari beberapa atribut multi-variate Xi yang akan digunakan untuk mengklasifikasikan Y. Data dari KNN dapat dalam skala ukuran apapun, dari ordinal ke nominal (Wakhidah, 2012).
Berikut ini adalah langkah-langkah menghitung k Nearest Neighbor (kNN) (Sari, 2011):
1. Tentukan parameter k (jumlah tetangga terdekat)
2. Hitung jarak antara data yang masuk dan semua sampel latih yang sudah ada dengan Euclidean Distance. Rumus Euclidean Distance adalah sebagai berikut :
, ∑ (Sari, 2011)
Di mana :
i.j : matriks yang akan diukur jaraknya n : jumlah data pada matriks
x : nilai matriks
3. tentukan K label data yang mempunyai jarak yang minimal 4. Klasifikasikan data baru ke dalam label data yang mayoritas
Pada fase training, algoritma ini hanya melakukan penyimpanan
vektor-vektor fitur dan klasifikasi data training sample. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk testing data (yang klasifikasinya tidak diketahui). Jarak dari vektor baru yang ini terhadap seluruh vektor training sample dihitung dan sejumlah k buah yang paling dekat diambil. Titik yang baru klasifikasinya diprediksikan
termasuk pada klasifikasi terbanyak dari titik-titik tersebut (Sikki, 2009).
Sebagai contoh, untuk mengestimasi p(x) dari n training sample dapat memusatkan pada sebuah sel disekitar x dan membiarkannya tumbuh hingga meliputi k samples. Samples tersebut adalah KNN dari x. Jika densitasnya tinggi di dekat x, maka sel akan berukuran relatif kecil yang berarti memiliki resolusi yang baik. Jika densitas rendah, sel akan tumbuh lebih besar, tetapi akan berhenti setelah memasuki wilayah yang memiliki densitas tinggi (Sikki, 2009).
Gambar 5 kNN Mengestimasi Densitas Dua Dimensi dengan k=5 (Sikki, 2009)
Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Nilai k yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation. Kasus khusus dimana klasifikasi diprediksikan berdasarkan training data yang paling dekat (dengan kata lain, k = 1) disebut algoritma nearest neighbor (Sikki, 2009).
KNN memiliki beberapa kelebihan yaitu bahwa dia tangguh terhadap training data yang noisy dan efektif apabila training data-nya besar. Sedangkan kelemahan dari KNN adalah KNN perlu menentukan nilai dari parameter K (jumlah dari tetangga terdekat), pembelajaran berdasarkan jarak tidak jelas mengenai jenis jarak apa yang harus digunakan dan atribut mana yang harus digunakan untuk
perhitungan jarak dari tiap query instance pada keseluruhan training sample (Wakhidah, 2012).
2.8 Naïve Bayes Classifier (NBC)
Naïve Bayes Classifier (NBC) merupakan metode terbaru yang digunakan
untuk mengklasifikasikan sekumpulan dokumen. Algoritma ini memanfaatkan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman di masa sebelumnya (Anugroho, Winarno, & Rosyid, 2010).
Klasifikasi–klasifikasi Bayes adalah klasifikasi statistik yang dapat memprediksi kelas suatu anggota probabilitas. Untuk klasifikasi Bayes sederhana yang lebih dikenal sebagai Naïve Bayesian Classifier (NBC) dapat diasumsikan bahwa efek dari suatu nilai atribut sebuah kelas yang diberikan adalah bebas dari atribut-atribut lain. Asumsi ini disebut class conditional independence yang dibuat untuk memudahkan perhitungan-perhitungan pengertian ini dianggap “naive”, dalam bahasa lebih sederhana naïve itu mengasumsikan bahwa kemunculan suatu term kata dalam suatu kalimat tidak dipengaruhi kemungkinan kata-kata yang lain dalam kalimat padahal dalam kenyataanya bahwa kemungkinan kata dalam kalimat sangat dipengaruhi kemungkinan keberadaan kata-kata yang dalam kalimat. Dalam Naïve Bayes diasumsikan prediksi atribut adalah tidak tergantung pada kelas atau tidak dipengaruhi atribut laten (Darujati & Gumelar, 2012).
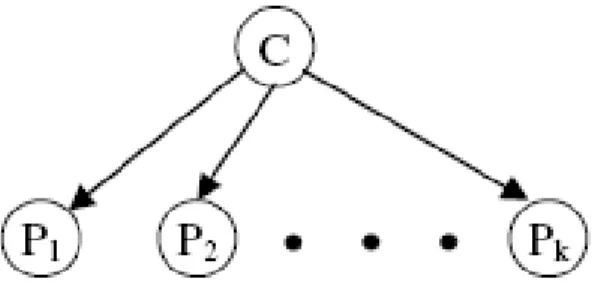
Gambar 6 Klasifikasi Naïve Bayes Sebagai Jaringan Bayes dengan Atribut Prediksi (P1, P2, …….Pk) dan Kelas (C) (Destuardi & Sumpeno, 2009)
C adalah adalah anggota kelas dan X adalah variabel acak sebuah vektor sebagai atribut nilai yang diamati. c mewakili nilai label kelas dan x mewakili nilai atribut vector yang diamati. Jika diberikan sejumlah x tes untuk klasifikasi maka probablitas tiap kelas untuk atribut prediksi vektor yang diamati adalah (Destuardi & Sumpeno, 2009) :
| | (Destuardi & Sumpeno, 2009)
X = x adalah mewakili kejadian dari X1=x1 ∩ X2=x2 ∩ …Xk=xk. Jumlah dari p(C=c | X=x) untuk semua kelas adalah 1 (Destuardi & Sumpeno, 2009).
Dari kelompok pendekatan berbasis numeris, pendekatan berbasis
probabilistic Naïve Bayes Classifier (NBC) memiliki beberapa kelebihan antara lain,
sederhana, cepat dan berakurasi tinggi. Metode NBC untuk klasifikasi atau kategorisasi teks menggunakan atribut kata yang muncul dalam suatu dokumen
independensi antar kata dalam dokumen tidak sepenuhnya dapat dipenuhi, tetapi kinerja NBC dalam klasifikasi relatif sangat bagus (Hamzah, 2012).
2.9 Tf-Idf
TF adalah algoritma pembobotan heuristik yang menentukan bobot dokumen berdasarkan kemunculan term (istilah). Semakin sering sebuah istilah muncul, semakin tinggi bobot dokumen untuk istilah tersebut, dan sebaliknya. Terdapat empat buah algoritma TF yaitu Raw TF, Logarithmic TF, Binary TF, Augmented TF. IDF merupakan banyaknya istilah tertentu dalam keseluruhan dokumen (Fitri, 2013)
Metode Tf-Idf (Terms Frequency-Invers Document Frequency) merupakan suatu cara untuk memberikan bobot hubungan suatu kata (term) terhadap dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot yaitu, frekuensi kemunculan sebuah kata di dalam sebuah dokumen tertentu dan inverse frekuensi dokumen yang mengandung kata tersebut. Frekuensi kemunculan kata di dalam dokumen yang diberikan menunjukkan seberapa penting kata tersebut di dalam dokumen tersebut. Frekuensi dokumen yang mengandung kata tersebut menunjukkan seberapa umum kata tersebut. Sehingga bobot hubungan antara sebuah kata dan sebuah dokumen akan tinggi apabila frekuensi kata tersebut tinggi didalam dokumen dan frekuensi keseluruhan dokumen yang mengandung kata tersebut yang rendah pada kumpulan dokumen (database) (Intan & Defeng, 2006).
log (Intan & Defeng, 2006)
Di mana :
Wij = bobot kata/term tj terhadap dokumen di Tfij = jumlah kemunculan kata/term tj dalam di
N = jumlah semua dokumen yang ada dalam database n = jumlah dokumen yang mengandung kata/term tj