34 BAB IV
HASIL DAN PEMBAHASAN
4.1. Dokumen yang digunakan
Pada penelitian yang dilakukan oleh penulis ini menggunakan dua jenis dokumen, yaitu dokumen training dan dokumen uji. Kemudian dua jenis dokumen tersebut akan diinputkan ke dalam aplikasi yang dihasilkan dalam penelitian ini.
4.1.1 Dokumen Latih
Dokumen latih digunakan sebagai patokan bagaimana nanti dokumen uji nanti akan diklasifikasikan, yaitu dengan membuat sebuah pola persamaan yang akan dibandingkan antara dokumen training dengan dokumen uji. Dalam penelitian ini penulis mengambil dokumen latih dari peneliti sebelumnya yang berasal dari Cornel University. Dokumen latih yang akan digunakan dalam penelitian ini berisi sejumlah 300 dokumen komentar yang berlabel positif dan 300 dokumen komentar yang berlabel negatif.
35
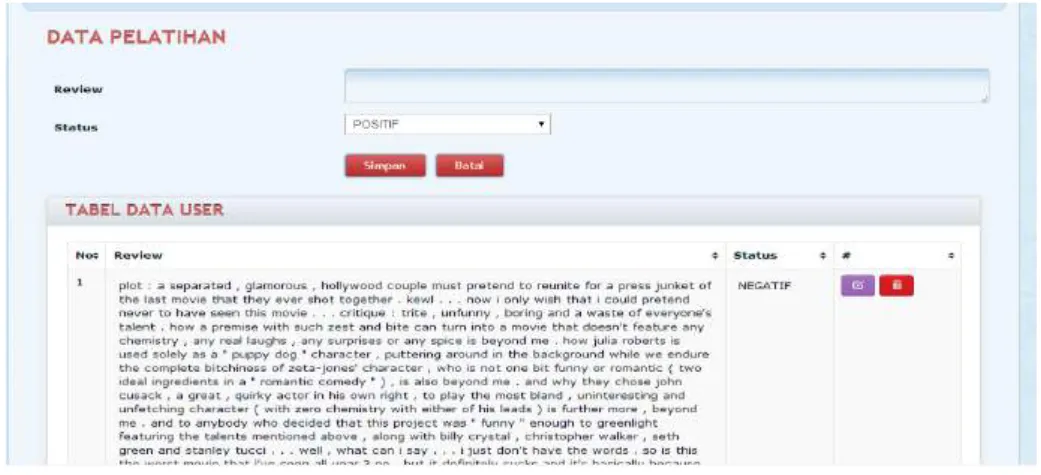
Gambar 4. 1 Menu Input Dokumen Latih
Gambar 4.1 adalah menu input dari dokumen latih, dokumen latih yang sudah dikumpulkan nanti akan diinputkan ke dalam aplikasi melalui menu tersebut.
4.1.2 Dokumen Uji
Dokumen testing yang dipakai dalam penelitian ini yaitu dokumen yang dikumpulkan oleh penulis dari komentar-komentar film di situs youtube. Kemudian untuk pelabelan dokumen testing ini dengan cara menyerahkannya dokumen yang sudah dikumpulkan penulis tersebut kepada ahli.
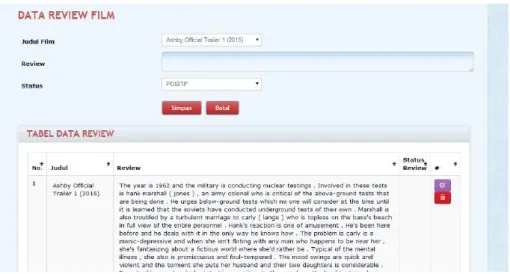
Gambar 4. 2 Menu Input Dokumen Uji 4.2. Preprocessing Dokumen
Sebelum masuk ke tahap klasifikasi, data-data tersebut haruslah melalui tahap preprocessing. Data-data yang berbentuk kalimat tersebut banyak mengandung kata-kata tidak perlu yang mengakibatkan beban kerja aplikasi menjadi berat. Langkah ini terdiri terdiri dari beberapa tahap yang tidak hanya untuk menghilangkan kata-kata, tetapi juga membuat sebuah pola yang berguna untuk pengklasifikasian nantinya. Berikut adalah gambar preprocessing dokumen yang dilakukan oleh aplikasi:
37
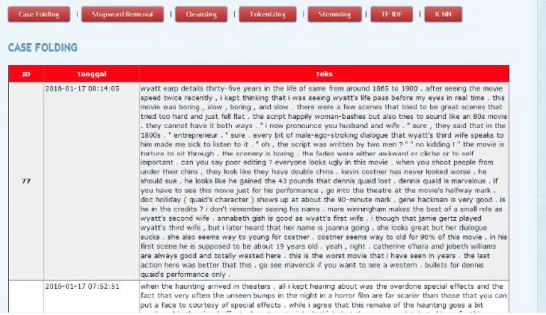
Gambar 4. 3 Hasil Case Folding
Gambar 6.3 Menunjukkan hasil dari case folding, data komentar yang bermula dari campuran huruf capital dan huruf kecil menjadi setara yaitu kecil semua.
Gambar 4.4. menampilkan langkah penyaringan kata-kata tidak bermakna yang akan memberi beban berat pada pemroresan. Penulis menggunakan 800 kata yang akan dihilangkan, data stopword removal ini juga disertakan dalam lampiran.
Gambar 4. 5 Hasil Cleansing
Pembersihan tidak hanya pada tahap stopword removal saja, pada gambar 4.5. dihasilkan langkah pembersihan juga yang akan menghilangkan berbagai macam tanda baca.
39
Gambar 4. 6 Hasil Tokenizing
Dalam tahap yang ada di gambar 4.6 yaitu data dokumen yang masih berbentuk panjang akan dipisahkan kata demi kata yang disebut tokenizing
Setiap kata yang sama bisa saja berubah apabila mendapat imbuhan kata, dan ini akan mengakibatkan satu kata yang harusnya diproses satu kali menjadi dua kali proses jika terjadi kasus semacam ini. Untuk mengatasi hal ini dilakukanlah stemming atau kata lainnya merubah menjadi kata dasar seperti gambar 4.7 diatas. Dalam penelitian ini penulis menggunakan metode stemming porter, metode ini bekerja dengan cara membuang akhiran kata karena dalam bahasa inggris tidak mengenal awalan.
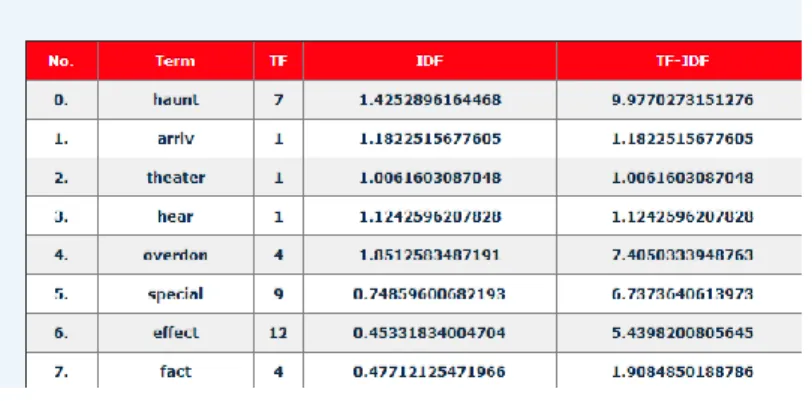
Gambar 4. 8 Hasil Pembobotan
Gambar 4.8 merupakan hasil dari pembobotan dokumen uji dengan metode TF-IDF. Hasil ini mengacu pada perhitungan TF-IDF yang sudah dijelaskan penulis pada bab 3.
4.3. Klasifikasi Dokumen
Klasifikasi algoritma k-nn bekerja dengan menggunakan nilai dari cosine similarity,yaitu dengan menghitung cosine similarity terlebih dahulu kemudian mengambil nilai tersebut sejumlah nilai k yang kita tentukan.
41
Gambar 4. 9 Hasil Klasifikasi K-NN
Dari gambar 4.9 diperlihatkan hasil klasifikasi dari aplikasi, pertama inputkan nilai k sejumlah yang kita inginkan, kemudian proses akan mengambil nilai cosine similarity sebanyak k yang kita tentukan, kemudian antara cosine yang bernilai negatif dan positif dijumlah dan nilai yang tertinggi adalah hasil dari klasifikasi.
4.4. Uji Coba
Untuk mengetahui nilai akurasi dari penerapan metode k-nn ini, penulis mencoba melakukan beberapa uji coba dengan enam skenario, yaitu dengan menggunakan data uji yang sama pada tiap skenario tetapi dengan data training yang berjumlah berbeda antara skenario satu dengan yang lainnya. Kemudian menghitung nilai akurasi pada tiap skenario dengan confusion matrix yang sudah dijelaskan pada bab 2 dan tabel confusion matrix akan disertakan pada lampiran.
Analisa confusion matrix disini penulis menitikberatkan pada nilai accuracy dan eror rate, semakin besar nilai accuracy maka semakin akurat klasifikasi dari penerapan metode k-nn ini, sebaliknya semakin tinggi nilai eror rate maka semakin rendah akurasi dari penerapan metode k-nn ini.
Uji coba skenario pertama penulis menggunakan data uji sebanyak 32 dan data training 120 dengan porsi 60 berlabel positif dan 60 berlabel negatif.
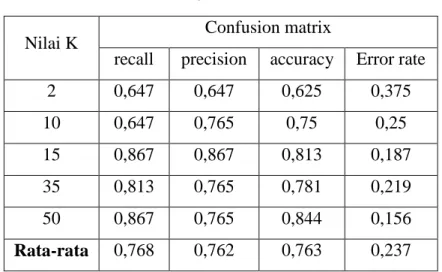
Tabel 4. 1 Uji Coba Skenario 1 Nilai K Confusion matrix
recall precision accuracy Error rate 2 0,647 0,647 0,625 0,375 10 0,647 0,765 0,75 0,25 15 0,867 0,867 0,813 0,187 35 0,813 0,765 0,781 0,219 50 0,867 0,765 0,844 0,156 Rata-rata 0,768 0,762 0,763 0,237
Dari skenario 1 yang mendapatkan hasil pada table 4.1 dapat diketahui nilai terendah dari accuracy adalah 0,625 pada k=2 dan nilai tertinggi 0,844 pada k=50. Sedangkan nilai eror rate terendah adalah 0,156 pada k= 50 dan nilai tertinggi 0,375 pada k=2.
Pada uji coba skenario 2 menggunakan data uji yang sama dan data training sebanyak 180 dengan porsi 90 berlabel positif dan 90 berlabel negatif. Pada skenario 2 ini mendapatkan hasil berikut:
43
Tabel 4. 2 Uji Coba Skenario 2 Nilai K Confusion matrix
recall Precision accuracy Error rate
2 0,643 0,529 0,594 0,406 10 0,765 0,765 0,75 0,25 15 0,786 0,647 0,719 0,219 35 0,929 0,765 0,843 0,156 50 1 0,722 0,844 0,156 Rata-rata 0,825 0,686 0,75 0,237
Hasil dari skenario 2 yang terdapat tabel 4.2 mempunyai hasil mirip dengan skenario 1 yaitu nilai tertinggi accuracy terdapat pada k= 50 yaitu 0,844 dan nilai terendah pada k= 2 yaitu 0,594. Begitu pula pada nilai error rate, nilai terendah pada k= 50 dan k= 35 yaitu 0,156 dan nilai tertinggi pada k= 2 yaitu 0,406.
Kemudian skenario 3 penulis masih menggunakan data uji yang sama dan data training sebanyak 210 dengan porsi 90 berlabel positif dan 120 berlabel negatif. Skenario 3 ini mendapatkan hasil berikut:
Tabel 4. 3 Uji Coba Skenario 3 Nilai K Confusion matrix
recall precision accuracy Error rate
2 0,75 0,667 0,688 0,313
10 0,652 0,882 0,688 0,313
15 0,7 0,875 0,75 0,25
50 0,727 0,941 0,781 0,219
Rata-rata 0,726 0,861 0,750 0,25
Pada skenario ke 3 ini mendapatkan hasil yang lebih baik dari sebelumnya yaitu nilai tertinggi 81,579% dan nilai terendah 55,263% yang mempunyai rata-rata sebanyak 70,526%.
Kemudian pada skenario 4 ini penulis mencoba menggunakan data training dengan jumlah yang sama dengan skenario 3 tetapi dengan porsi yang berbeda, yaitu 120 dokumen berlabel positif dan 90 berlabel negatif.
Tabel 4. 4 Uji Coba Skenario 4
Nilai K Confusion matrix
recall Precision accuracy Error rate
2 0,692 0,529 0,625 0,375 10 0,818 0,5 0,656 0,344 15 0,889 0,444 0,656 0,344 35 1 0,471 0,719 0,281 50 1 0,412 0,688 0,313 Rata-rata 0,88 0,177 0,669 0,331
Walaupun jumlah dokumen training sama dengan skenario 3, ternyata dalam skenario 4 mendapatkan hasil yang berbeda. Pada skenario 4 ini nilai tertinggi accuracy mencapai angka 0,719 dan nilai terendah 0,625. Sedangkan nilai error rate tertinggi yaitu 0,375 dan nilai terendah 0,281. Skenario 3 dan 4 ini membuktikan pengaruh dari penentuan jumlah porsi yang tepat dari setiap label.
45
Pada skenario 5 ini, penulis menambahkan jumlah dokumen training yaitu 240 dokumen dengan porsi seimbang yaitu 120 berlabel positif dan 120 berlabel negatif. Uji coba skenario 5 ini mendapatkan hasil seperti pada tabel 4.5 dibawah ini:
Tabel 4. 5 Uji Coba Skenario 5
Nilai K Confusion matrix
recall Precision accuracy Error rate
2 0,706 0,706 0,688 0,313 10 0,789 0,882 0,813 0,188 15 0,813 0,765 0,781 0,219 35 0,933 0,824 0,875 0,125 50 1 0,765 0,875 0,125 Rata-rata 0,848 0,788 0,806 0,150
Dapat dilihat dengan menambahkan jumlah dokumen training ternyata nilai accuracy dan error rate meningkat dengar rata-rata yang baik. Accuracy tertinggi yaitu 0,875 pada k=35 dan 50, sedangkan nilai terendahnya adalah 0,688 pada k=2 dengan rata-rata 0,806. Kemudian error rate tertinggi adalah 0,313 pada k= 2, sedangkan nilai terendahnya adalah 0,125 pada k= 50 dengan rata-rata 0,150.
Skenario terakhir penulis mencoba menggunakan data yang sama dengan skenario 5 yaitu 120 dokumen berlabel positif dan 120 berlabel negatif, yang membedakan adalah pada skenario 6 ini penulis mencoba menggunakan pengujian tanpa stemming.
Tabel 4. 6 Uji Coba Skenario 6
Nilai K Confusion matrix
recall Precision accuracy Error rate
2 0,667 0,706 0,656 0,343 10 0,813 0,765 0,781 0,219 15 0,869 0,765 0,813 0,188 35 0,929 0,765 0,844 0,156 50 1 0,765 0,875 0,125 Rata-rata 0,856 0,753 0,794 0,206
Dari tabel 4.6 diketahui ternyata stemming mempunyai peranan dalam akurasi penelitian ini walaupun tidak terlalu signifikan. Dari skenario 6 didapatkan hasil accuracy tertinggi adalah 0,875 dan nilai terendahnya 0,656. Sedangkan error rate tertinggi adalah 0,343 dan nilai terendahnya 0,125.