Pencarian Pola Klasifikasi Mahasiswa yang Tidak Memenuhi
Sisip Program Berdasarkan Nilai Tes Masuk Penerimaan
Mahasiswa Baru dan Latar Belakang Mahasiswa Universitas
Sanata Dharma dengan Menggunakan Algoritma C4.5
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Oleh :
Ni Made Kristianingsih Kuatra
07 5314 065
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
Finding Pattern Classification of Students that Do Not Fill
Sisip Program Based on Student Admission Test and Background of Students
of Sanata Dharma University Using C4.5 Algorithm
A Thesis
Presented As Partial Fullfillment of the Requirements
To Obtain the
Sarjana Komputer
Degree
By :
Ni Made Kristianingsih Kuatra
Student Number : 07 5314 065
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
HALAMAN PERSEMBAHAN
“Setiap
tujuan
dan keberhasilan dalam hidup ,
Berawal
dari sebuah
mimpi
…”
serta
“
Percaya
bahwa
Tuhan
akan selalu
membantu
mu,
Dalam
meraih
setiap tujuanmu…“
.: (,”)
Skripsi ini saya persembahkan kepada
. . . (“.) :.
+
Ida Sang Hyang Widhi Wasa, karena dengan bantuan dan persetujuanNya,
aku dapat menyelesaikan skripsi ini.
+
Keluargaku
,
Papa (I Ketut Kuatra)
dan
Mama (Ni Nyoman Kasilah)
serta
Kakakku
( I Gede Kasyanto Kuatra, S.IP.)
yang tercinta. Terimakasih atas doa, dukungan, dan
cinta yang diberikan yang tidak pernah berakhir untukku. (^_^)
+
Beibee Ciplugku
tercinta,
Markus Herjuno
dengan dukungan,
semangat, bantuan, lelucon, dan hiburan yang selalu kamu berikan
untukku. Terimakasih karena selalu menemaniku kemanapun aku
pergi. Terimakasih karena selalu ada disaat aku butuh kamu. ^^
+
Sahabat-sahabat seperjuanganku
,
Florensia Dwinta
(terimakasih buntel atas
bantuannya dalam segala hal),
Ana Suryaningsih
(terimakasih atas doa,
dukungan, dan semangatnya),
Mbak Agil Grisadha
(terimakasih mbak atas
semangat, doa, dan bantuannya),
Maria Anindita
,
Arum Citra
,
Andrias
Pratiwi
,
Mas Taufik
,
Amiko Bintoro
,
Albertus Dio
(terimakasih telah
mendukungku). Untuk
Cupliezt
dan semua temanku yang sudah ikut
ABSTRAK
Penambangan data
(data mining)
adalah proses pencarian informasi yang
bernilai di basis data yang besar, gudang data, atau
data
mart
. Dalam penulisan
tugas akhir ini, algoritma C4.5 diimplementasikan untuk pencarian pola
klasifikasi mahasiswa yang tidak memenuhi sisip program. Sisip program adalah
evaluasi hasil studi mahasiswa selama empat semester pertama untuk menentukan
apakah mahasiswa dapat melanjutkan studi atau harus meninggalkan program
studi yang bersangkutan. Data yang digunakan merupakan data penerimaan
mahasiswa baru jalur tes dan latar belakang mahasiswa program studi Teknik
Informatika Universitas Sanata Dharma dari tahun 2000 sampai dengan 2004.
Data yang digunakan berisi informasi tentang jenis kelamin, nilai penalaran
verbal, nilai kemampuan numerik, nilai penalaran mekanik, nilai hubungan ruang,
nilai bahasa inggris, pilihan, gelombang, kabupaten SMA, jurusan SMA,
keterangan SMA, dan status sisip program.
Program diuji dengan menggunakan teknik 5
fold cross validation
dengan
sampel data sebanyak 355 data. Hasil akurasi program adalah 66,19 %.
ABSTRACT
Data mining is a process of finding valuable information in large
databases, data warehouses, or data marts. In this thesis, C4.5 algorithm was
implemented to find the classification patterns of students that do not fill “sisip
program”. “Sisip program” is evaluation of students over four semesters of their
studies to determine whether students can continue their studies or having to
leave their study program. The data used is the regular student admissions data
along with student academic data of the students of the Informatics Engineering
Sanata Dharma University from year 2000 to 2004. Data used contain
information about sex, the score of verbal reasoning test, numerical ability test,
mechanical reasoning test, space relations test, English language test, chosen
study program, registration periods, district high school, high school majors,
school information, and status.
The program was verified using 5 fold cross validation technique towards
355 records. The accuracy of the program is 66.19 %.
KATA PENGANTAR
Puji syukur penulis panjatkan kehadirat Tuhan Yang Maha Esa,
yang telah melimpahkan berkat dan rahmatNya sehingga penulis dapat
menyelesaikan tugas akhir yang berjudul “
Pencarian Pola Klasifikasi
Mahasiswa yang Tidak Memenuhi Sisip Program Berdasarkan Nilai
Tes Masuk Penerimaan Mahasiswa Baru dan Latar Belakang
Mahasiswa Universitas Sanata Dharma dengan Menggunakan
Algoritma C4.5
”. Tugas akhir ini ditulis sebagai salah satu syarat
memperoleh gelar sarjana program studi Teknik Informatika, Fakultas
Sains dan Teknologi Universitas Sanata Dharma.
Dalam kesempatan ini, penulis mengucapkan terimakasih yang
sebesar-besarnya kepada :
1.
Ibu P.H. Prima Rosa, S.Si.,M.Sc., selaku Dosen Pembimbing atas
segala waktu, kesabaran, serta member kritik dan saran yang
membangun dalam membantu penyelesaian tugas akhir ini.
2.
Romo Dr. C. Kuntoro Adi, SJ.,MA.,M.Sc selaku Wakil Rektor III dan
Ibu Ridowati Gunawan, S.Kom.,M.T., selaku Ketua Program Studi
Teknik Informatika yang bertindak sebagai Dosen Penguji yang telah
berkenan memberikan motivasi, kritik, dan saran yang sangat berguna
bagi penulis.
3.
Seluruh staff pengajar Prodi Teknik Informatika yang telah
memberikan ilmu pengetahuan yang sangat berguna bagi penulis.
4.
Bapak Emanuel Bele Bau, Spd. selaku staff laboran yang telah
membantu dalam pelaksanaan tugas akhir.
6.
Pelatih dan teman-teman UKM Grisadha yang selalu menanyakan
perkembangan tugas akhir ini. Terimakasih atas dukungan dan
semangatnya.
7.
Seluruh teman-teman TI angkatan 2007 yang telah mendukung dan
tidak dapat disebutkan satu persatu.
Semoga skripsi ini dapat memberi manfaat yang cukup berarti khususnya
bagi penulis dan bagi pembaca pada umumnya. Semoga Tuhan Yang Maha Esa
senantiasa memberikan rahmatNya bagi kita semua. Amin.
Yogyakarta, 7 November 2011
Ni Made Kristianingsih Kuatra
DAFTAR ISI
Halaman Judul ... i
Halaman Judul (Inggris) ... ii
Halaman Persetujuan ... iii
Halaman Pengesahan ... iv
Halaman Persembahan ... v
Halaman Pernyataan Keaslian Karya ... vi
Abstrak ... vii
Abstract
... viii
Lembar Pernyataan Persetujuan ... ix
Kata Pengantar ... x
Daftar Isi ... xii
Daftar Tabel ... xv
Daftar Gambar ... xvi
BAB I PENDAHULUAN ... 1
I.1 Latar Belakang ... 1
I.2 Perumusan Masalah ... 3
I.3 Tujuan Penelitian ... 3
I.4 Batasan Masalah ... 4
I.5 Luaran ... 5
I.6 Kegunaan ... 5
I.7 Metodologi Penelitian ... 5
I.8 Sistematika Penulisan ... 6
BAB II LANDASAN TEORI ... 8
II.1 Penambangan Data ... 8
II.2 Proses Penambangan Data ... 8
II.3 Teknik Klasifikasi ... 11
II.4 Pohon Keputusan ... 11
II.5 Manfaat Pohon Keputusan ... 12
II.6 Kelebihan Pohon Keputusan ... 12
II.8 Algoritma C4.5 ... 13
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 16
III.1 Identifikasi Sistem ... 16
III.2 Pemrosesan Data Awal,
Input
Sistem, Proses Sistem, dan
Output
Sistem ... 17
III.2.1 Pemrosesan Data Awal ... 19
III.3 Perancangan Umum Sistem ... 26
III.3.1 Masukan Sistem ... 26
III.3.2 Proses Sistem ... 28
III.3.3
Output
Sistem ... 29
III.3.4 Diagram
Use Case
... 30
III.3.5 Narasi
Use Case
... 32
III.3.6 Diagram Konteks ... 35
III.3.7 Diagram Aktifitas ... 36
III.3.7.1 Diagram Aktifitas
Login
... 36
III.3.7.2 Diagram Aktifitas Tambah Data Pelatihan ... 37
III.3.7.3 Diagram Aktifitas Transformasi Data Pelatihan ... 38
III.3.7.4 Diagram Aktifitas Pola Klasifikasi ... 39
III.3.7.5 Diagram Aktifitas Simpan Aturan ... 40
III.3.7.6 Diagram Aktifitas Prediksi ... 41
III.3.7.7 Diagram Aktifitas
Logout
... 41
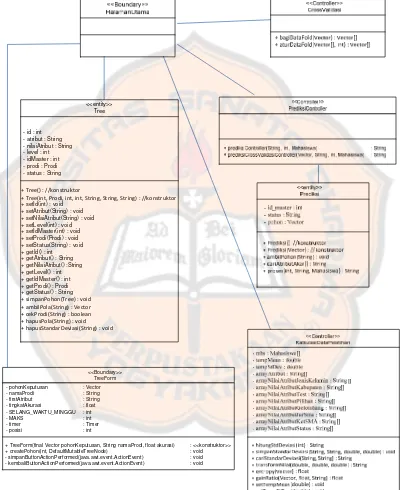
III.3.8 Diagram Kelas Analisis ... 42
III.3.9 Diagram Sekuensial ... 43
III.3.9.1 Diagram Sekuensial
Login
... 43
III.3.9.2 Diagram Sekuensial Tambah Data Pelatihan ... 43
III.3.9.3 Diagram Sekuensial Transformasi Data Pelatihan ... 44
III.3.9.4 Diagram Sekuensial Pola Klasifikasi ... 44
III.3.9.5 Diagram Sekuensial Simpan Pola ... 45
III.3.9.6 Diagram Sekuensial Prediksi ... 45
III.3.10 Diagram Kelas Desain ... 46
III.3.10.1
Use Case
Login
... 46
III.3.10.2
Use Case
Tambah Data Pelatihan ... 47
III.3.10.3
Use Case
Transformasi data ... 48
III.3.10.5
Use Case
Simpan Aturan ... 50
III.3.10.6
Use Case
Prediksi ... 51
III.3.11 Algoritma Method-Method Penting dalam Kelas... 52
III.3.12 Perancangan Struktur Data ... 60
III.3.13 Perancangan Basis Data ... 61
III.3.14 Perancangan Antarmuka dengan Pengguna ... 63
III.3.14.1 Halaman
Login
... 63
III.3.14.2 Halaman Utama ... 63
III.3.14.3 Halaman Pencarian Pola ... 64
III.3.14.4 Halaman
Tree Form
... 65
III.3.14.5 Halaman Awal Prediksi ... 65
III.3.14.6 Halaman DataPersonalForm ... 66
III.3.14.7 Halaman DataKelompokForm ... 67
BAB IV IMPLEMENTASI SISTEM ... 68
IV.1 Spesifikasi Perangkat Lunak dan Perangkat Keras ... 68
IV.2 Implementasi
Use Case
... 68
IV.3 Implementasi Diagram Kelas ... 75
IV.3.1
Package Boundary
... 75
IV.3.2
Package Controller
... 81
IV.3.3
Package Entity
... 105
BAB V ANALISIS HASIL ... 117
V.1 Analisis Hasil Program ... 117
V.2 Kelebihan dan Kekurangan Program ... 126
BAB VI KESIMPULAN DAN SARAN ... 127
VI.I Kesimpulan ... 127
VI.2 Saran ... 128
DAFTAR PUSTAKA ... 129
LAMPIRAN ... 131
DAFTAR TABEL
Tabel 3. 1Tabel atribut data mentah ... 17
Tabel 3.2 Aturan transformasi data nilai tes masuk ... 21
Tabel 3.3 Variabel
input
... 22
Tabel 3.4 Contoh pembagian 5
folds cross validation
dalam 355 data ... 24
Tabel 3.5 Atribut
Input
Sistem ... 26
Tabel 3.6 Deskripsi
Use Case
... 31
Tabel 3.7 Narasi
Use Case Login
... 32
Tabel 3.8 Narasi
Use Case
Tambah
Data Pelatihan ... 32
Tabel 3.9 Narasi
Use Case
Pembersihan
Data
Pelatihan ... 33
Tabel 3.1 Narasi
Use Case
Pola Klasifikasi ... 33
Tabel 3.11 Narasi
Use Case
Simpan Aturan ... 34
Tabel 3.12 Narasi
Use Case
Prediksi ... 34
Tabel 3.13 Narasi
Use Case
Logout
... 35
Tabel 3.14 Keterangan tiap atribut dalam
Vector
... 60
Tabel 5.1 Hasil pengujian 5
fold cross validation
... 120
Tabel 5.2 Data sampel yang diambil ... 121
Tabel 5.3 Pembagian data kedalam 2 kelas ... 121
Tabel 5.4 Pembagian data kedalam 5
fold
... 122
Tabel 5.5 Hasil prediksi data
fold
1 ... 122
Tabel 5.6 Hasil prediksi data
fold
2 ... 123
Tabel 5.7 Hasil prediksi data
fold
3 ... 123
Tabel 5.8 Hasil prediksi data
fold
4 ... 123
Tabel 5.9 Hasil prediksi data
fold
5 ... 124
DAFTAR GAMBAR
Gambar 2. 1 Tahapan dalam
Data Mining
... 9
Gambar 2.2
Data Mining
dan Teknologi basis data lainnya ... 10
Gambar 2.3 Algoritma C4.5 ... 13
Gambar 3.1
Flowchart
proses sistem ... 29
Gambar 3.2 Diagram
Use Case
... 30
Gambar 3.3 Diagram Konteks ... 35
Gambar 3.4 Diagram Aktifitas
Login
... 36
Gambar 3.5 Diagram Aktifitas Tambah Data Pelatihan ... 37
Gambar 3.6 Diagram Aktifitas Transformasi Data Pelatihan ... 38
Gambar 3.7 Diagram Aktifitas Pola Klasifikasi ... 39
Gambar 3.8 Diagram Aktifitas Simpan Aturan... 40
Gambar 3.9 Diagram Aktifitas Prediksi ... 41
Gambar 3.10 Diagram Aktifitas
Logout
... 41
Gambar 3.11 Kelas Analisis Keseluruhan ... 42
Gambar 3.12 Diagram Sekuensial
Login
... 43
Gambar 3.13 Diagram Sekuensial Tambah Data Pelatihan ... 43
Gambar 3.14 Diagram Sekuensial Transformasi Data Pelatihan ... 44
Gambar 3.15 Diagram Sekuensial Pola Klasifikasi ... 44
Gambar 3.16 Diagram Sekuensial Simpan Pola ... 45
Gambar 3.17 Diagram Sekuensial Prediksi ... 45
Gambar 3.18 Diagram Kelas
Use Case
Login
... 46
Gambar 3.19 Diagram Kelas
Use Case
Tambah Data Pelatihan ... 47
Gambar 3.20 Diagram Kelas
Use Case
Transformasi data ... 48
Gambar 3.21 Diagram Kelas
Use Case
Pencarian pola ... 49
Gambar 3.22 Diagram Kelas
Use
Case
Simpan Aturan ... 50
Gambar 3.23 Diagram Kelas
Use Case
Prediksi ... 51
Gambar 3.25 Halaman
Login
... 63
Gambar 3.26 Halaman Utama ... 63
Gambar 3.27 Halaman Pencarian Pola ... 64
Gambar 3.28 Halaman
Tree Form
... 65
Gambar 3.29 Halaman Awal Prediksi ... 65
Gambar 3.30 Halaman DataPersonalForm ... 66
Gambar 3.31 Halaman DataKelompokForm ... 67
Gambar 4.1 Halaman
FormLogin
... 69
Gambar 4.2 Pemberitahuan pengguna berhasil
login
... 69
Gambar 4.3 Halaman Utama ... 69
Gambar 4.4 Halaman
Tab
Menu Pencarian Pola ... 71
Gambar 4.5 Halaman
File Chooser
untuk mengambil data ... 71
Gambar 4.6 Pemberitahuan
file
berhasil ditampilkan ... 71
Gambar 4.7 Pemberitahuan data berhasil di transformasi ... 72
Gambar 4.8 Pemberitahuan bahwa pohon sudah terbentuk ... 72
Gambar 4.9 Halaman
TreeForm
... 72
Gambar 4.10 Pemberitahuan pola berhasil disimpan ... 73
Gambar 4.11 Halaman Awal Prediksi ... 73
Gambar 4.12 Halaman DataPersonalForm ... 74
Gambar 4.13 Halaman DataKelompokForm ... 74
Gambar 5.1 Pola program studi TI ... 117
Gambar 5.2 Hasil akurasi sistem dengan data sampel ... 125
BAB I
PENDAHULUAN
I.1 Latar Belakang
Teknologi informasi berkembang seiring dengan perkembangan peradaban
manusia. Perkembangan teknologi informasi meliputi
hardware, software,
teknologi penyimpanan data (
storage
)
,
dan teknologi komunikasi. Sejak
terciptanya komputer, perkembangan media penyimpanan data (data
storage
)
berubah sangat signifikan. Hal ini disebabkan karena jumlah data yang meningkat
sepanjang waktu dan perlu disimpan dalam waktu yang lama. Data adalah
deskripsi dari sebuah fakta yang tersusun secara terstruktur[1]. Kumpulan data
yang tersimpan bila diolah dengan baik akan menghasilkan sebuah informasi yang
penting bagi penerimanya.
Universitas Sanata Dharma (USD) merupakan salah satu instansi yang
bergerak di bidang pendidikan yang memiliki data dalam jumlah besar. Setiap
tahunnya, Universitas Sanata Dharma menerima mahasiswa baru dalam jumlah
yang cukup banyak. Proses Seleksi Penerimaan Mahasiswa Baru (PMB) dapat
ditempuh melalui beberapa jalur antara lain jalur prestasi, jalur kerjasama dan
jalur reguler. Data mahasiswa baru yang terkumpul akan disimpan dan akan terus
bertambah setiap tahunnya. Apabila data tersebut tidak dimanfaatkan, akan
menjadi data sampah karena hanya akan memenuhi ruang penyimpanan data.
Dalam proses seleksi PMB jalur kerjasama dan reguler, USD memiliki kriteria
yang didasarkan pada :
2.
Pilihan program studi
Calon mahasiswa baru yang berhasil lolos seleksi tentunya adalah
mahasiswa yang terpilih karena memperoleh hasil tes di atas nilai standar yang
telah ditetapkan oleh USD untuk prodi yang dipilihnya. Dari hasil tes tersebut,
calon mahasiswa yang diterima nantinya diharapkan adalah calon mahasiswa yang
unggul yang dapat mengikuti kegiatan perkuliahan dengan lancar dan memperoleh
Indeks Prestasi (IP) yang baik. Namun kenyataannya, tidak demikian. Di USD
masih terdapat mahasiswa yang tidak dapat mengikuti kegiatan perkuliahan
dengan baik dan memperoleh IP yang memadai selama 4 semester pertama. Hal
ini mengakibatkan mahasiswa-mahasiswa tersebut terkena sisip program dan
dinyatakan tidak dapat melanjutkan kuliah (
drop out
) dari USD. Pertanyaan yang
muncul adalah bagaimana mengetahui pola klasifikasi mahasiswa yang terkena
sisip program USD dilihat dari nilai tes masuk PMB dan latar belakang
mahasiswa?
Pada tugas akhir ini akan dicari pola klasifikasi mahasiswa yang terkena
sisip program USD berdasarkan nilai tes masuk PMB jalur reguler yang meliputi
nilai penalaran verbal, nilai kemampuan numerik, nilai penalaran mekanik, nilai
bahasa inggris, nilai hubungan ruang, pilihan, gelombang, jenis kelamin, jurusan
SMA, keterangan SMA, dan kabupaten SMA. Penelitian ini dapat dilakukan
dengan memanfaatkan kumpulan basis data PMB dan mahasiswa pada
tahun-tahun sebelumnya. Untuk memperoleh pola yang diinginkan, tidak mungkin
dilakukan secara manual di kumpulan basis data yang besar. Salah satu caranya
adalah dengan menggunakan penambangan data. Istilah penambangan data (
data
mining
) merupakan proses pencarian informasi yang bernilai di basis data yang
Penggunaan penambangan data ini diharapkan mampu menyelesaikan
permasalahan di atas. Pola atau informasi yang diperoleh nantinya diharapkan
dapat digunakan oleh pihak universitas sebagai alat bantu dalam penyeleksian
penerimaan mahasiswa baru agar mahasiswa yang diterima adalah mahasiswa
yang nantinya tidak akan mengalami kegagalan (
drop out
). Selain itu dapat juga
digunakan oleh Dosen Pembimbing Akademik untuk memantau dan membimbing
mahasiswa dalam meningkatkan nilai prestasi akademiknya.
I.2 Perumusan Masalah
Dari latar belakang yang diuraikan di atas, maka perumusan masalah
dalam penelitian ini adalah :
1.
Bagaimana mengimplementasikan penambangan data pada data
mahasiswa USD untuk mengenali pola klasifikasi mahasiswa yang
tidak memenuhi sisip program USD berdasarkan nilai tes masuk PMB
dan latar belakang mahasiswa?
2.
Bagaimana memanfaatkan pola tersebut untuk memprediksi status
sisip program seorang mahasiswa?
I.3 Tujuan Penelitian
Tujuan penelitian dilihat dari permasalahan yang ada adalah :
1.
Dapat mengimplementasikan penambangan data terhadap data-data
yang diperoleh seperti nilai tes masuk PMB dan latar belakang
mahasiswa.
3.
Memprediksi status sisip program calon mahasiswa atau mahasiswa
baru agar nantinya mahasiswa tersebut tidak mengalami kegagalan di
pertengahan studi.
I.4 Batasan Masalah
Berikut ini adalah batasan masalah dalam penelitian Tugas Akhir :
1.
Data mahasiswa yang ditambang diambil dari data PMB Jalur Reguler dan
data akademik Program Studi TI Universitas Sanata Dharma tahun
2000-2004 yang diperoleh dari Biro Administrasi Perencanaan dan Sistem
Informasi (BAPSI). Atribut data yang diperoleh sebagai berikut :
1.
Tahun angkatan
2.
Kode prodi
3.
NIM
4.
Nomor Induk Mahasiswa (NIM)
5.
Jenis Kelamin
6.
Nilai tes masuk PMB yang meliputi :
a.
Nilai penalaran verbal
b.
Nilai kemampuan numerik
c.
Nilai penalaran mekanik
d.
Nilai bahasa inggris
e.
Nilai hubungan ruang
f.
Nilai final
7.
Rangking
8.
Rangking2
9.
Pilihan
13.
Asal sma
14.
SKS 4
15.
IPK 40b
16.
IPK4b
17.
KabSmu3
18.
KabSMA
2.
Penelitian ini hanya menerapkan metode pohon keputusan dengan
menggunakan algoritma C4.5.
I.5 Luaran
Sebuah aplikasi yang mampu menemukan pola yang diinginkan secara
otomatis dengan menggunakan latar belakang mahasiswa, nilai tes masuk PMB
dan dapat memprediksi calon mahasiswa yang akan diterima atau mahasiswa baru
agar tidak mengalami kegagalan (
drop out
) pada pertengahan studi.
I.6 Kegunaan
Hasil dari luaran ini diharapkan dapat digunakan oleh pihak universitas
khususnya Kaprodi sebagai alat bantu dalam penyeleksian calon mahasiswa yang
akan diterima agar tidak mengalami kegagalan (
drop out
). Selain itu diharapkan
bagi Dosen Pembimbing Akademik, dapat membantu dalam memantau dan
membimbing mahasiswa yang terancam terkena sisip program untuk dapat
meningkatkan prestasi akademiknya.
I.7 Metodologi Penelitian
Metodologi yang digunakan untuk menyelesaikan masalah pada tugas
akhir ini adalah[3]:
1.
Pembersihan data
derau yang ada dalam data tersebut, seperti data yang tidak relevan,
data yang salah ketik maupun data kosong yang tidak diperlukan.
2.
Integrasi data
Merupakan penggabungan data dari beberapa sumber agar seluruh
data terangkum dalam satu tabel utuh.
3.
Seleksi data
Pada proses ini menyeleksi data dimana data yang relevan diambil
dari
database.
4.
Transformasi data
Mengubah data kedalam bentuk yang sesuai untuk ditambang.
5.
Penambangan data
Penerapan teknik penambangan data untuk mengekstrak pola
. Dalam
tugas akhir ini menggunakan algoritma C4.5.
6.
Evaluasi pola
Untuk mengidentifikasikan pola yang penting dan menarik untuk
merepresentasikan sebuah pengetahuan.
7.
Presentasi Pengetahuan
Pada tahap ini pola yang didapat direpresentasikan kepada pengguna
akhir kedalam bentuk yang dapat dipahami.
I.8 Sistematika Penulisan
Sistematika penulisan dalam tugas akhir ini, adalah sebagai berikut :
BAB I. PENDAHULUAN
Bab Pendahuluan akan dijelaskan mengenai latar belakang masalah,
perumusan masalah, tujuan penelitian, batasan masalah, luaran, kegunaan,
metodologi penelitian dan sistematika pembahasan.
BAB II. LANDASAN TEORI
penulisan tugas akhir, meliputi : penambangan data, proses penambangan data,
teknik klasifikasi, pohon keputusan, manfaat pohon keputusan, kelebihan pohon
keputusan, kekurangan pohon keputusan, dan algoritma C4.5
BAB III. ANALISIS DAN PERANCANGAN SISTEM
Bab Analisis dan Perancangan Sistem berisi tentang identifikasi sistem,
pemrosesan data awal,
input
sistem, proses sistem,
output
sistem, dan
perancangan sistem.
BAB IV. IMPLEMENTASI
Bab implementasi berisi tentang implementasi metode pohon keputusan
dan hasil implementasi dari algoritma yang
digunakan
, yaitu algoritma C4.5.
BAB V. ANALISIS
Bab Analisis berisi tentang hasil analisis dari hasil
output
yang diperoleh.
BAB VI. KESIMPULAN DAN SARAN
Bab Kesimpulan dan Saran berisi tentang kesimpulan yang dapat diambil
dari seluruh hasil dan analisis yang diperoleh.
BAB II
LANDASAN TEORI
II.1 Penambangan Data
Istilah penambangan data (
data mining
) merupakan proses pencarian
informasi yang bernilai di basis data yang besar, gudang data, atau data
mart
. Alat
penambangan data mengidentifikasi pola yang sebelumnya tersembunyi dalam
satu langkah [2].
Beberapa pengertian penambangan data menurut sejumlah penulis adalah:
1.
Definisi sederhana dari penambangan data menurut Yudho [3]
adalah “
ekstraksi informasi atau pola yang penting atau menarik
dari data yang ada di database yang besar
”.
2.
Penambangan data menurut Mitra & Acharya [4] adalah “
suatu
data percobaan untuk memperoleh informasi yang berguna yang
tersimpan dalam basisdata yang sangat besar
”.
Dari pengertian diatas, dapat diartikan bahwa penambangan data sebagai
proses pengambilan pola atau informasi pada data dalam jumlah besar yang
tersimpan dalam basis data.
II.2 Proses Penambangan Data
Proses penambangan data tidak dapat dipisahkan dengan
Knowledge
Discovery in Database
(KDD), karena penambangan data merupakan salah satu
tahap dari proses KDD yang mempergunakan analisa data dan penggunaan
algoritma, sehingga menghasilkan pola-pola khusus dalam basis data yang besar
[5].
1.
Pembersihan data
Proses ini dilakukan untuk membuang data yang tidak konsisten dan
derau yang ada dalam data tersebut, seperti data yang tidak relevan,
data yang salah ketik maupun data kosong yang tidak diperlukan.
2.
Integrasi data
Merupakan penggabungan data dari beberapa sumber agar seluruh
data terangkum dalam satu tabel utuh.
3.
Seleksi data
Pada proses ini menyeleksi data dimana data yang relevan diambil
dari
database.
4.
Transformasi data
Mengubah data kedalam bentuk yang sesuai untuk ditambang.
5.
Penambangan data
Penerapan teknik penambangan data untuk mengekstrak pola
. Dalam
tugas akhir ini menggunakan algoritma C4.5.
6.
Evaluasi pola
Untuk mengidentifikasikan pola yang penting dan menarik untuk
merepresentasikan sebuah pengetahuan.
7.
Presentasi Pengetahuan
Pada tahap ini pola yang didapat direpresentasikan kepada pengguna
akhir kedalam bentuk yang dapat dipahami.
Tahapan tersebut dapat diilustrasikan kedalam gambar berikut :
Suatu sistem mungkin saja menghasilkan banyak sekali pola, namun tidak
semua pola tersebut adalah pola yang penting dan menarik. Ukuran suatu pola
yang menarik dan penting adalah jika pola tersebut mudah dimengerti oleh
manusia, bermanfaat, valid atau benar pada data baru atau data tes, membenarkan
hipotesis.
Penambangan data berbeda dengan gudang data dan OLAP (
On-Line
Analytical Processing
). OLAP adalah basis data yang khusus digunakan untuk
menunjang proses pengambilan keputusan (
decision making
). Teknologi yang ada
di gudang data dan OLAP dimanfaatkan penuh untuk melakukan penambangan
data[7]. Gambar 2.2 berikut menunjukkan posisi masing-masing teknologi
basisdata:
Gambar 2.2 Data Mining dan Teknologi basis data lainnya[6]
Dari gambar diatas terlihat bahwa teknologi gudang data digunakan untuk
melakukan OLAP sehingga dimungkinkan pengguna untuk menganalisa data
operasional sehari-hari dengan berbagai sudut pandang dan sangat berguna untuk
mengevaluasi suatu bisnis. Untuk mendapatkan informasi yang tidak diketahui
secara manual, diperlukan satu tahap lagi yaitu aplikasi teknik penambangan data.
II.3 Teknik Klasifikasi
Beberapa teknik yang sering disebut dalam literatur penambangan data
antara lain yaitu
association rule mining
, klastering, klasifikasi,
neural network
,
algoritma genetika, dan lain-lain.
Proses teknik klasifikasi terdiri dari dua tahap, yaitu[7]:
1.
Membangun model
Menggambarkan satu
set
dari kelas-kelas yang ditentukan sebelumnya.
Masing-masing sampel diasumsikan merupakan kepunyaan suatu kelas yang
sudah diketahui berdasarkan nilai-nilai atributnya. Kelas ditentukan oleh atribut
label kelas. Sampel yang digunakan untuk membangun model disebut himpunan
pelatihan. Model direpresentasikan sebagai pola klasifikasi, pohon keputusan, atau
formula matematis.
2.
Penggunaan model
Bertujuan untuk mengklasifikasikan objek yang baru akan didapatkan atau
tidak dikenal. Penilaian akurasi model menggunakan suatu himpunan tes. Label
yang sudah diketahui dari contoh himpunan tes dibandingkan dengan hasil
klasifikasi model. Tingkat akurasi adalah persentase dari contoh himpunan tes
yang diklasifikasikan secara benar oleh model.
II.4 Pohon Keputusan
Pohon Keputusan (
decision tree
) adalah suatu
flowchart
yang seperti
struktur pohon yang merupakan representasi suatu grafik kumpulan dari aturan
pada klasifikasi[7]. Struktur pohon dapat dijelaskan sebagai berikut:
1.
Setiap titik
node
bagian dalam merupakan sebuah atribut.
2.
Setiap cabang (
branch
) merupakan keluaran dari suatu logikal
tes, dan
II.5 Manfaat Pohon Keputusan
Pohon keputusan adalah salah satu metode klasifikasi yang paling populer
karena mudah untuk diinterpretasi oleh manusia. Konsep dari pohon keputusan
adalah mengubah data menjadi pohon keputusan dan aturan-aturan keputusan.
Manfaat utama dari penggunaan pohon keputusan adalah sebagai berikut[8] :
1.
Kemampuannya untuk membagi proses pengambilan keputusan
yang kompleks menjadi lebih simpel sehingga pengambil
keputusan akan lebih menginterpretasikan solusi dari
permasalahan.
2.
Pohon Keputusan juga berguna untuk mengeksplorasi data,
menemukan hubungan tersembunyi antara sejumlah calon variabel
input
dengan sebuah variabel target.
3.
Pohon keputusan memadukan antara eksplorasi data dan
pemodelan, sehingga sangat bagus sebagai langkah awal dalam
proses pemodelan bahkan ketika dijadikan sebagai model akhir dari
beberapa teknik lain.
II.6 Kelebihan Pohon Keputusan
Kelebihan dari metode pohon keputusan adalah[8]:
1.
Daerah pengambilan keputusan yang sebelumnya kompleks dan
sangat global, dapat diubah menjadi lebih simpel dan spesifik.
2.
Eliminasi perhitungan-perhitungan yang tidak diperlukan, karena
ketika menggunakan metode pohon keputusan maka sampel diuji
hanya berdasarkan kriteria atau kelas tertentu.
yang lebih konvensional.
II.7 Kekurangan Pohon Keputusan
Kekurangan dari metode keputusan adalah [8] :
1.
Terjadi
overlap
terutama ketika kelas-kelas dan kriteria yang
digunakan jumlahnya sangat banyak. Hal tersebut juga dapat
menyebabkan meningkatnya waktu pengambilan keputusan dan
jumlah memori yang diperlukan.
2.
Pengakumulasian jumlah
error
dari setiap tingkat dalam sebuah
pohon keputusan yang besar.
3.
Kesulitan dalam mendesain pohon keputusan yang optimal.
4.
Hasil kualitas keputusan yang didapatkan dari metode pohon
keputusan sangat tergantung pada bagaimana pohon tersebut didesain.
II.8 Algoritma C4.5
Salah satu algoritma induksi pohon keputusan yaitu ID3 (
Iterative
Dichotomiser 3
). ID3 dikembangkan oleh J. Ross Quinlan. Dalam prosedur
algoritma ID3,
input
berupa sampel pelatihan, label pelatihan dan atribut.
Algoritma C4.5 merupakan pengembangan dari ID3. Sedangkan pada perangkat
lunak
open source
WEKA mempunyai versi sendiri C4.5 yang dikenal sebagai
J48 [8]. Berikut adalah algoritma C4.5:
Pohon dibangun dengan cara membagi data secara rekursif hingga tiap
bagian terdiri dari data yang berasal dari kelas yang sama. Bentuk pemecahan
(
split)
yang digunakan untuk membagi data tergantung dari jenis atribut yang
digunakan dalam
split
. Algoritma C4.5 dapat menangani data numerik (kontinyu)
dan diskret.
Jika suatu himpunan data mempunyai beberapa
record
dengan beberapa
nilai variabel tidak ada (
missing value
), dan jika jumlah pengamatan terbatas
maka atribut dengan
missing value
dapat diganti dengan nilai rata-rata dari
variabel yang bersangkutan[8].
Untuk melakukan pemisahan obyek (
split)
dilakukan tes terhadap atribut
dengan mengukur tingkat ketidakmurnian pada sebuah simpul (
node)
. Pada
algoritma C4.5 digunakan rasio perolehan (
gain ratio
). Sebelum menghitung rasio
perolehan, perlu menghitung dulu nilai informasi dalam satuan
bits
dari suatu
kumpulan objek. Cara menghitungnya dilakukan dengan menggunakan konsep
entropi. Nilai entropi dapat dihitung dengan rumus 2.1:
Entropi(S) = -P
-log
2P
+- P
-log
2P
- -………..………… (2.1)
Keterangan :
S
=
ruang (data) sampel yang digunakan untuk pelatihan,
p+
=
jumlah yang bersolusi positif atau mendukung pada data sampel
untuk kriteria tertentu, dan
p-
= jumlah yang bersolusi negatif atau tidak mendukung pada data
sampel untuk kriteria tertentu.
Kemudian menghitung perolehan informasi dari
output
data atau variabel
dependent
S
yang dikelompokkan berdasarkan atribut A, dinotasikan dengan
gain
(
S
,A). Perolehan informasi
, gain
(
S
,A), dari atribut A relatif terhadap
output
data
S
|Si| = jumlah kasus pada partisi ke-i
|S| = jumlah kasus dalam S
Untuk menghitung rasio perolehan perlu diketahui suatu
term
baru yang
disebut pemisahan informasi
(SplitInfo
). Pemisahan informasi dihitung dengan
cara :
dengan menggunakan atribut A yang mempunyai sebanyak
c
nilai. Selanjutnya
rasio perolehan (
gainRatio
) dihitung dengan cara:
BAB III
ANALISIS DAN PERANCANGAN SISTEM
III.1 Identifikasi Sistem
Setiap tahunnya, Universitas Sanata Dharma membuka seleksi Penerimaan
Mahasiswa Baru (PMB). Calon mahasiswa baru yang melalui jalur reguler harus
melewati serangkaian tes tertulis. Tes tertulis meliputi tes penalaran verbal,
kemampuan numerik, kemampuan mekanik, bahasa inggris, dan hubungan ruang.
Mahasiswa yang diterima adalah mahasiswa yang memiliki nilai di atas standar
yang telah ditentukan pihak universitas. Dapat dikatakan bahwa mahasiswa yang
diterima adalah mahasiswa pilihan yang diharapkan dapat lulus dengan nilai yang
baik. Namun kenyataannya, tidak semua mahasiswa yang terpilih dapat mengikuti
kegiatan perkuliahan dengan baik dan memperoleh nilai IPK yang memadai.
Setiap tahunnya dapat ditemukan mahasiswa yang memperoleh nilai IPK di
bawah rata-rata selama 4 semester sehingga mahasiswa tersebut tidak dapat
melanjutkan kuliahnya (
drop out
). Evaluasi sisip program yang dimuat dalam
buku panduan akademik tahun 2007 sama dengan buku panduan akademik tahun
2002 sehingga peraturan tersebut dapat digunakan dalam penelitian. Adapun
ketentuan penilaian hasil belajar sisip program USD yang dimuat dalam buku
panduan akademik tahun 2007 adalah sebagai berikut :
“Mahasiswa boleh melanjutkan studi di Program Studi yang bersangkutan
apabila pada akhir semester IV dapat mengumpulkan sekurang-kurangnya 40 sks
dengan IPK sekurang-kurangnya 2,00. Apabila dalam waktu empat semester
tersebut mahasiswa mampu mengumpulkan lebih dari 40 sks, maka untuk
evaluasi tersebut diambil 40 sks dengan nilai tertinggi”.
Untuk itu diperlukan penelitian untuk menemukan bagaimana pola
kelamin, kabupaten SMA, pilihan, gelombang, jurusan SMA, keterangan SMA,
nilai tes masuk meliputi : nilai penalaran verbal, kemampuan numerik, penalaran
mekanik, hubungan ruang, dan bahasa inggris.
Data yang digunakan dalam penelitian ini adalah data mahasiswa prodi TI
dari angkatan 2000-2004. Data tersebut akan diolah menggunakan algoritma
penambangan data C4.5 dengan konsep pohon keputusan untuk menemukan pola
klasifikasi mahasiswa yang terkena sisip program.
III.2 Pemrosesan Data Awal, Input Sistem, Proses Sistem, dan Output Sistem
Obyek yang digunakan dalam Tugas Akhir ini adalah Universitas Sanata
Dharma, yang setiap masih ada beberapa mahasiswa yang tidak memenuhi sisip
program Universitas Sanata Dharma.
Untuk pencarian pola klasifikasi mahasiswa yang tidak memenuhi sisip
program Universitas Sanata Dharma, maka dapat dilakukan penelitian dengan
menggunakan proses pengumpulan data terlebih dahulu. Atribut data yang
diperoleh adalah sebagai berikut :
Tabel 3.1 Tabel atribut data mentah
No Nama
atribut
Keterangan
Nilai
tes masuk penalaran
8
Nilai hubungan ruang Atribut ini
menyimpan data nilai
tes masuk hubungan
ruang
0,1,2,3,4,5,6,7,8,9,10
9
Nilai bahasa inggris
Atribut ini
menyimpan data nilai
13 Gelombang
Atribut
ini
18 SKS4
Atribut
ini
Dari data mentah yang diperoleh, untuk menentukan status sisip program
mahasiswa diperoleh dari atribut sks4 dan ipk40b berdasarkan dari ketentuan
penilaian hasil belajar sisip program USD.
III.2.1 Pemrosesan Data Awal
Sebelum data diolah menggunakan sistem yang akan dibuat, dilakukan
pemrosesan data awal terlebih dahulu. Penjelasannya sebagai berikut :
1.
Pembersihan Data (Data Cleaning)
Tahap pembersihan data akan dilakukan terhadap data-data mahasiswa
yang bernilai
null
atau kosong pada nilai tes masuk PMB. Pembersihan data
dilakukan apabila kolom pada nilai penalaran verbal, nilai kemampuan numerik,
nilai penalaran mekanik, nilai hubungan ruang dan nilai bahasa inggris yang
bernilai
null
atau kosong. Diasumsikan bila seluruh nilai tes masuk PMB bernilai
null
atau kosong adalah mahasiswa yang masuk universitas melalui jalur prestasi.
Selain itu, pembersihan data juga dilakukan apabila dalam satu baris data terdapat
salah satu atau lebih atribut yang bernilai
null
atau kosong.
data, ada 26 baris data yang memiliki nilai
null
di seluruh atribut nilai tes masuk
sehingga data tersebut harus dihapus. Setelah itu diperoleh sebanyak 375 data.
Dari 375 data, terdapat 20 data yang salah satu atau lebih atributnya bernilai
null
sehingga 20 data tersebut juga dihapus. Sehingga data yang akan digunakan
dalam tahap selanjutnya sebanyak 355 data. Selain itu, proses pembersihan data
dilakukan penyeragaman nama terhadap data yang tidak konsisten. Contoh data
yang tidak konsisten, seperti : kabupaten SMA dituliskan dengan Yogyakarta atau
Yogya.
2.
Integrasi Data (Data Integration)
Pada tahap ini dilakukan penggabungan data kedalam satu tabel yang utuh.
Data yang dikumpulkan yang berasal dari
file
yang berbeda akan dikelompokkan
menjadi satu, agar seluruh data dapat terangkum yang kemudian dipilih dan
diubah menjadi bentuk yang sesuai untuk ditambang. Namun karena data yang
diperoleh hanya berasal dari satu
file
saja yang bertipe
excel
, sehingga tidak perlu
dilakukan proses penggabungan data pada tahap ini.
3.
Penyeleksian Data (Data Selection)
Pada tahap ini dilakukan tahap pembuangan data-data yang tidak
diperlukan atau dibutuhkan seperti data-data yang kurang relevan dalam
penelitian. Dari data mentah yang diperoleh, atribut yang dihapus adalah tahun
angkatan, kode prodi, nomor induk mahasiswa, nilai final, rangking, rangking2,
asal SMA/SMK, asal kabupaten, sks4, ipk40b, ipk4b, KabSmu3 karena dianggap
tidak dapat dijadikan variabel penentu dalam pencarian pola. Atribut data yang
diperoleh dari hasil proses seleksi adalah sebagai berikut :
1.
Jenis Kelamin
2.
Nilai tes masuk PMB yang meliputi :
a.
Nilai penalaran verbal
b.
Nilai kemampuan numerik
d.
Nilai bahasa inggris
e.
Nilai hubungan ruang
3.
Pilihan
4.
Gelombang
5.
Keterangan SMA
6.
Kabupaten SMA
7.
Jurusan SMA
8.
Status
4.
Transformasi Data (Data Transformation)
Pada tahap ini dilakukan peringkasan data atau proses pengubahan data
mentah menjadi data yang mudah dikelola. Dari data yang diperoleh, sebagian
besar berupa angka yang beragam, sehingga perlu dilakukan pengelompokan data
berdasarkan jangkauan tertentu. Sedangkan untuk data non numerik tidak
dilakukan transformasi data. Dalam penelitian ini, transformasi data dilakukan
terhadap atribut nilai tes masuk yang meliputi : penalaran verbal, kemampuan
numerik, penalaran mekanik, bahasa inggris, dan hubungan ruang yang semula
berupa nilai numerik yang berkisar antara 0-10 ditransformasi menjadi nilai
interval menggunakan konsep hirarki, sehingga menjadi nilai diskrit A,B,C, dan
D. Dengan mengasumsikan data nilai berdistribusi normal, diterapkan aturan
transformasi sebagai berikut[9] :
Tabel 3.2 Aturan Transformasi Data Nilai Tes Masuk
Nilai_final Formula
D
nilai tes< rata
nilai_
tes– 1,5 * stdev
nilai_
tesC rata
nilai_
tes– 1,5 * stdev
nilai_
tes≤
nilai tes< rata
nilai_
tesB rata
nilai_
tes≤
nilai tes< rata
nilai_
tes+1,5 * stdev
nilai_
tes5.
Penambangan Data (Data Mining)
Data yang telah diperoleh akan diolah dan dianalisis menggunakan pohon
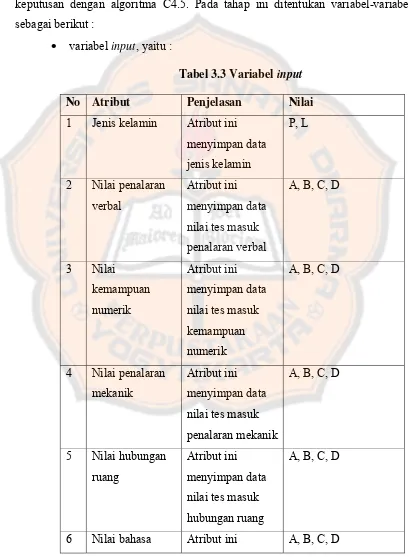
keputusan dengan algoritma C4.5. Pada tahap ini ditentukan variabel-variabel
sebagai berikut :
•
variabel
input
, yaitu :
Tabel 3.3 Variabel input
No
Atribut Penjelasan
Nilai
inggris menyimpan
data
8
Keterangan SMA Atribut ini
menyimpan
10
Kabupaten SMA
Atribut ini
menyimpan asal
keputusannya dan hasil prediksi status sisip program.
Contoh perhitungan data menggunakan algoritma C4.5 dalam proses
pembentukan pola dapat dilihat di lampiran 1.
6.
Evaluasi Pola yang Ditemukan (Pattern Evaluation)
Pada tahap ini adalah hasil dari penambangan data berupa pola khusus
yang akan dievaluasi atau diteliti lagi apakah hasilnya sudah sesuai atau belum.
Pada Tugas Akhir ini pengukuran tingkat akurasi data dilakukan dengan
menggunakan 5-
folds cross validation
.
Pembagian data dalam tahap ini mengacu pada metode stratifikasi
sampling yaitu dengan membagi populasi menjadi beberapa lapisan yang tidak
saling tumpang tindih, sehingga lapisan yang terbentuk merupakan sub
populasi[10].
Untuk hal ini, populasi dibedakan berdasarkan kelas keputusannya
yaitu “Tidak sisip program” dan “Sisip program”. Setelah data terbagi menjadi 2
kelas, kemudian dilakukan pembagian ke dalam 5 bagian untuk setiap kelas secara
acak. Misalkan data prodi TI berjumlah 355 data. Data tersebut meliputi 314 data
“Tidak Sisip Program” dan 41 data “Sisip Program”. Berikut adalah contoh tabel
pembagian data ke dalam 5
fold
.
Tabel 3.4 Contoh pembagian 5 folds cross validation dalam 355 data
Fold
Kelas Tidak Sisip
Program
Kelas Sisip Program
Fold
1
Data 42,47,52,57,62,dst
Data 1,6,11,16,21,26,dst
Fold
2
Data 43,48,53,58,63,dst
Data 2,7,12,17,22,27,dst
Fold
3
Data 44,49,54,59,64,dst
Data 3,8,13,18,23,28,dst
Fold
4
Data 45,50,55,60,65,dst
Data 4,9,14,19,24,29,dst
Fold
5
Data 46,51,56,61,66,dst
Data 5,10,15,20,25,30,dst
Dari tabel 3.2, proses iterasi dalam sistem akan dilakukan sebanyak 5
1.
Iterasi pertama
Pada iterasi 1, data pada
fold
1 untuk setiap kelas akan menjadi data uji
sedangkan
fold
2 sampai
fold
5 sebagai data pelatihan.
2.
Iterasi kedua
Pada iterasi 2, data pada
fold
2 untuk setiap kelas akan menjadi data uji
sedangkan
fold
1,
fold
3,
fold
4, dan
fold
5 sebagai data pelatihan.
3.
Iterasi ketiga
Pada iterasi 3, data pada
fold
3 untuk setiap kelas akan menjadi data uji
sedangkan
fold
1,
fold
2,
fold
4,dan
fold
5 sebagai data pelatihan.
4.
Iterasi keempat
Pada iterasi 4, data pada
fold
4 untuk setiap kelas akan menjadi data uji
sedangkan
fold
1,
fold
2,
fold
3, dan
fold
5 sebagai data pelatihan.
5.
Iterasi kelima
Pada iterasi 5, data pada
fold
5 untuk setiap kelas akan menjadi data uji
sedangkan
fold
1,
fold
2,
fold
3, dan
fold
4 sebagai data pelatihan.
Pembagian ke dalam 5
fold
untuk setiap kelas dilakukan agar seluruh data
yang digunakan dapat terbagi rata dan jumlah data “Tidak Sisip Program” dan
“Sisip Program” yang ada dalam masing-masing
fold
seimbang. Diharapkan
dengan jumlah data yang seimbang dalam setiap
fold
akan menghasilkan tingkat
akurasi yang baik.
7.
Presentasi Pengetahuan (Knowledge Presentation)
Akhir dari penelitian yang akan dilakukan pembuatan aplikasi dengan
tampilan antarmuka yang mudah dimengerti oleh pengguna karena pola yang
III.3 Perancangan Umum Sistem
III.3.1 Masukan Sistem
Data yang menjadi masukan dalam sistem dibagi menjadi dua bagian yaitu
data yang digunakan untuk data pelatihan dan data yang digunakan untuk data uji.
Data pelatihan terdiri dari 12 atribut meliputi : jenis kelamin, nilai penalaran
verbal, nilai kemampuan numerik, nilai penalaran mekanik, nilai hubungan ruang,
nilai bahasa inggris, pilihan, gelombang, kabupaten SMA, jurusan SMA,
keterangan SMA dan status. Atribut tersebut dijabarkan dalam tabel 3.5 berikut
ini :
Tabel 3.5 Atribut Input Sistem
No
Atribut Penjelasan
Nilai
keputusan berupa :
sisip progam atau
tidak sisip program
program
Sedangkan masukan untuk data uji sebenarnya hampir sama dengan data
pelatihan, hanya saja dianggap belum memiliki atribut status karena pada data uji
akan diprediksi bagaimana status mahasiswa tersebut.
III.3.2 Proses Sistem
Masukan sistem akan diproses menggunakan algoritma C4.5. Berikut
adalah proses dari sistem :
a.
Data masukan akan melalui proses transformasi
yaitu
mengklasifikasi nilai tes masuk mahasiswa menjadi empat bagian
yaitu : A, B, C, dan D.
b.
Data nilai tes yang telah ditransformasikan dalam jangkauan
A,B,C, dan D akan dijadikan sebagai data pelatihan untuk proses
pembentukan pohon menggunakan algoritma C4.5.
c.
Proses pembentukan pohon berawal dari menghitung nilai
GainRatio
setiap atribut dan mencari nilai
GainRatio
terbaik yang
akan menjadi simpul akar. Proses pembentukan pohon dilakukan
secara rekursif sampai seluruh data memiliki kelas.
d.
Setelah perhitungan selesai akan ditampilkan hasil pohon yang
terbentuk.
e.
Pada proses pengujian dilakukan dengan membagi data kedalam 5
Selain itu, secara umum proses sistem juga dijabarkan dalam bentuk
flowchart
sebagai berikut :
III.3.3 Output Sistem
Keluaran sistem sebagai berikut :
a.
Menampilkan jumlah data yang dimasukkan
b.
Menampilkan pola dari proses klasifikasi
III.3.4 Diagram Use Case
Tabel 3.6 Deskripsi Use Case
No ID
Use Case
Nama Use Case Deskripsi
1 PKSP-01
Login
Use case
ini berfungsi untuk
mengidentifikasi pengguna
dengan memasukkan data
username
dan
password
2 PKSP-02
Tambah
Data
Pelatihan
Use case
ini berfungsi untuk
memasukkan data pelatihan
dan ditampilkan dalam
sistem.
3 PKSP-03
Transformasi
Data
Use case
ini berfungsi untuk
melakukan pembersihan data
dan transformasi data pada
data pelatihan yang akan
diolah.
4 PKSP-04
Pola
Klasifikasi
Use case
ini berfungsi untuk
mengolah data pelatihan
menjadi bentuk pohon
keputusan.
5 PKSP-05
Simpan
Aturan
Use case
ini berfungsi untuk
menyimpan pola klasifikasi
6 PKSP-06
Prediksi
Use case
ini berfungsi untuk
melakukan prediksi status
sisip program untuk data
individu dan data kelompok.
7 PKSP-07
Logout
Use case
ini berfungsi untuk
III.3.5 Narasi Use Case
ID Use case
: PKSP-01
Nama use case
:
Login
Aktor
:
Pengguna
Deskripsi
:
Use case ini berfungsi untuk mengidentifikasi pengguna
dengan memasukkan data username dan password.
Skenario
:
Tabel 3.7
Narasi Use Case Login
Aksi Actor
Reaksi Sistem
1. Pengguna memasukkan data
username dan password pada
halaman login.
2.
mengautentifikasi nama dan
password (apakah sesuai dengan
data yang disimpan)
3.
menampilkan halaman utama
ID Use case
: PKSP-02
Nama use case
:
Tambah Data Pelatihan
Aktor
:
Pengguna
Deskripsi
:
Use case ini berfungsi untuk memasukkan data pelatihan
dan menampilkan kedalam sistem.
Skenario
:
Tabel 3.8
Narasi Use Case Tambah Data Pelatihan
Aksi Actor
Reaksi Sistem
1. Pengguna memasukkan data
pelatihan dengan menekan tombol
browse pada halaman pre-proses
pencarian pola.
2.
Pengguna memilih file data
tampilkan
3.
Sistem melakukan proses
menampilkan data pelatihan
kedalam tabel.
ID Use case
: PKSP-03
Nama use case
:
Transformasi Data
Aktor
:
Pengguna
Deskripsi
:
Use case ini berfungsi untuk melakukan transformasi data
pada data pelatihan yang akan diolah.
Skenario
:
Tabel 3.9
Narasi Use Case Pembersihan Data Pelatihan
Aksi Actor
Reaksi Sistem
1. Pengguna memasukkan data
pelatihan dengan menekan tombol
browse, dan tampilkan pada
halaman pre-proses pencarian
pola.
2.
Pengguna menekan tombol
transformasi
3.
Sistem melakukan proses
transformasi data
4.
Sistem menampilkan pesan bahwa
”proses transformasi data
berhasil”
ID Use case
: PKSP-04
Nama use case
:
Pola Klasifikasi
Aktor
:
Pengguna
Deskripsi
:
Use case ini berfungsi untuk mengolah data pelatihan
menjadi bentuk pohon keputusan.
Skenario
:
Tabel 3.10 Narasi Use Case Pola Klasifikasi
1. Pengguna menekan tombol
proses
2.
Sistem mengolah data
pelatihan menjadi pola yang
dicari.
3.
Sistem menampilkan halaman
pohon keputusan.
ID Use case
: PKSP-05
Nama use case
:
Simpan aturan
Aktor
:
Pengguna
Deskripsi
:
Use case ini berfungsi untuk menyimpan pola klasifikasi.
Skenario
:
Tabel 3.11 Narasi Use Case Simpan Aturan
Aksi Actor
Reaksi Sistem
1. sistem menampilkan halaman
pohon keputusan.
2.
Pengguna menekan tombol
simpan
3.
Sistem menyimpan aturan
kedalam database.
ID Use case
: PKSP-06
Nama use case
:
Prediksi
Aktor
:
Pengguna
Deskripsi
:
Use case ini berfungsi untuk melakukan prediksi status
sisip program untuk data individu dan data kelompok.
Skenario
:
Tabel 3.12 Narasi Use Case Prediksi
Aksi Actor
Reaksi Sistem
1. sistem menampilkan halaman utama
2.
Pengguna memilih tab menu
3.
Sistem menampilkan halaman awal
prediksi
4.
Pengguna memilih salah
satu antara data personal
atau data kelompok
5.
Sistem menampilkan halaman
input data uji
6.
Pengguna memilih program
studi, dan memasukkan
data-data sesuai dengan
atribut yang ditampilkan
dari database. Pengguna
menekan tombol proses.
7.
Sistem menampilkan hasil prediksi
status mahasiswa.
ID Use case
: PKSP-07
Nama use case
:
Logout
Aktor
:
Pengguna
Deskripsi
:
Use case ini berfungsi untuk keluar dari sistem.
Skenario
:
Tabel 3.13 Narasi Use Case Logout
Aksi Actor
Reaksi Sistem
1. sistem menampilkan halaman
utama
2. Pengguna menekan tombol
keluar
3. keluar dari sistem
III.3.6 Diagram Konteks
Berikut adalah diagram alur data masuk dan keluar antara pengguna dan
sistem.
Sistem Pencarian Pola Klasifikasi Sisip Program Mahasiswa USD
Data
pelatihan
,
data
tes
III.3.7 Diagram Aktifitas
Gambar 3.3 Diagram Konteks
III.3.7.1 Diagram Aktifitas Login
Pengguna
Sistem
Awal
Menjalankan sistem
Pencarian Kriteria Sisip Program USD
Menampilkan form login
Masukan username, password
Tekan tombol login
Mengautentifikasi pengguna
Gambar
3.4
Diagram
Aktifitas
Login
Tampil pesan error dan form
login
Menampilkan halaman utama
Akhir
no
Apakahdata cocok
III.3.7.2 Diagram Aktifitas Tambah Data Pelatihan
Gambar
3.5
Diagram
Aktifitas
Tambah
Data
Pengguna
Sistem
Awal
Menjalankan sistem Pencarian Pola Sisip Program USD
Menampilkan halaman Data Pelatihan
Tekan tombol
browse
Menampilkan file chooser
Pilih file data pelatihan
Tekan
tombol
Open
Tekan
tombol
tampilkan
Menampilkan
data
dalam
tabel
III.3.7.3 Diagram Aktifitas Transformasi Data Pelatihan
Gambar
3.6
Diagram
Aktifitas
Transformasi
Data
Pelatihan
Pengguna
Sistem
Awal
Tekan
tombol
transformasi
Menjalankan proses transformasi data
![Gambar 2.1 Tahapan dalam Data Mining[6]](https://thumb-ap.123doks.com/thumbv2/123dok/1718240.2082869/26.595.98.514.95.733/gambar-tahapan-dalam-data-mining.webp)
![Gambar 2.2 Data Mining dan Teknologi basis data lainnya[6]](https://thumb-ap.123doks.com/thumbv2/123dok/1718240.2082869/27.595.101.502.301.602/gambar-data-mining-dan-teknologi-basis-data-lainnya.webp)
![Gambar 2.3 Algoritma C4.5 [8]](https://thumb-ap.123doks.com/thumbv2/123dok/1718240.2082869/30.595.100.510.191.742/gambar-algoritma-c.webp)