BAB 2
LANDASAN TEORI
Pada bab ini akan membahas landasan atas teori-teori yang bersifat ilmiah untuk mendukung penulisan skripsi ini. Teori-teori yang dibahas mengenai pengenalan pola, pengolahan citra, jaringan saraf tiruan propagasi balik, dan beberapa sub pokok pembahasan lainnya yang menjadi landasan dalam penulisan skripsi ini.
2.1 Pengenalan Pola
Pola adalah entitas yang terdefinisi dan dapat didefinisikan melalui ciri-cirinya (feature). Ciri-ciri tersebut digunakan untuk membedakan suatu pola dengan pola yang lain. Pengenalan pola bertujuan untuk menentukan kelompok untuk kategori pola berdasarkan ciri-ciri yang dimiliki oleh pola tersebut. Dengan kata lain pengenalan pola membedakan objek dengan objek lain.
Suatu sistem pengenalan pola melakukan:
1. Proses akuisisi data melalui sejumlah alat pengindraan atau sensor, 2. Mengatur bentuk representasi data,
3. Melakukan proses analisis dan klasifikasi data.
Tiga pendekatan pembuatan sistem pengenalan pola adalah Statistik (statistical), Sintaksis (syntactic) dan Jaringan Saraf Tiruan (neural network) (Schalkoff, 1992).
1. Statistik
Semakin banyak pola yang disimpan, maka sistem akan semakin cerdas. Salah satu contoh penerapannya banyak pada pola pengenalan iris scan.
Kelemahannya: hanya bergantung pada data yang disimpan saja, tidak memiliki sesuatu struktur yang unik yang dapat menjadi kunci pengenalan pola.
2. Sintaksis (rule)
Dengan rule/aturan maka sistem yang lebih terstruktur sehingga memiliki sesuatu ciri yang unik. Salah satu contoh penerapannya pada pola pengenalan sidik jari (fingerprint).
3. Jaringan Saraf Tiruan (JST)
Merupakan gabungan dari pendekatan statistik dan pendekatan sintaks. Dengan gabungan dari dua metode maka JST merupakan pengenalan pola yang lebih akurat. Salah satu contoh penerapannya pada pola pengenalan suatu citra JST merupakan suatu sistem yang dapat memproses informasi dengan meniru cara kerja jaringan saraf otak manusia.
Struktur sistem pengenalan pola ditunjukkan pada gambar 2.1. Sistem pengenalan pola ini terdiri dari suatu sensor (misalnya kamera, dan scanner), teknik prapengolahan, suatu algoritma atau mekanisme ekstraksi ciri dan algoritma untuk klasifikasi atau pengenalan (bergantung pada pendekatan yang dilakukan). Sebagai tambahan, biasanya beberapa data yang sudah diklasifikasikan diasumsikan telah tersedia untuk melatih sistem.
Sensor Prapengolahan Ekstraksi Ciri Algoritma
Klasifikasi
Pola data klasifikasi
Gambar 2.1 Struktur Sistem Pengenalan Pola
Prapengolahan adalah transformasi input (masukan) data mentah untuk membantu kemampuan komputasional dan pencarian ciri serta untuk mengurangi
noise (derau). Pada prapengolahan citra (sinyal) yang ditangkap oleh sensor akan
Kualitas ciri yang dihasilkan pada proses pemisahan ciri sangat bergantung pada hasil prapengolahan.
Klasifikasi merupakan tahap untuk mengelompokkan input data pada satu atau beberapa kelas berdasarkan hasil pencarian beberapa ciri yang signifikan dan pemrosesan atau analisis terhadap ciri itu. Setiap kelas terdiri dari sekumpulan objek yang memiliki kedekatan (kemiripan) ciri. (Munir, 2004; Putra, 2009)
2.2 Pengolahan Citra Digital
Citra atau gambar atau image merupakan suatu yang menggambarkan objek dan biasanya dalam bentuk dua dimensi. Citra merupakan suatu representasi kemiripan dari suatu objek atau benda. Citra digital didefinisikan sebagai representasi diskrit dari data spasial (tata letak) dan intensitas (warna) informasi (Solomon & Breckon, 2011).
Citra digital merupakan citra yang telah disimpan dalam bentuk file sehingga dapat diolah dengan menggunakan komputer. Pengolahan citra digital adalah istilah umum untuk berbagai macam teknik yang ada untuk memanipulasi dan memodifikasi citra dalam berbagai cara. Gambar 2.2 merupakan representasi koordinat pada citra digital. (0,0) x y width h e ig h t
Selanjutnya berdasarkan representasi sistem koordinat citra pada gambar 2.2 citra dapat direpresentasikan dalam bentuk matriks dua dimensi dimana kolom pada matriks merepresentasikan lebar (width) pada citra, dan baris pada matriks merepresentasikan tinggi (height) pada citra.
dimana:
j = height -1 i = width -1
(2.1)
Untuk mempermudah proses pengolahan citra biasanya digunakan citra biner. Citra biner (binary image) merupakan citra dimana piksel-pikselnya hanya memiliki dua buah nilai intensitas, biasanya 0 dan 1, dimana 0 menyatakan warna latar belakang (backgraound) dan 1 menyatakan warna tinta/objek (foreground) atau dalam bentuk angka 0 untuk warna hitam dan angka 255 untuk warna putih.
2.2.1 Binarization (Thresholding)
Binarization digunakan untuk membedakan gambar text dengan latar belakang pada
gambar huruf atau angka tersebut. Proses ini akan menghasilkan citra hitam putih yang bersih dari tingkat keabun (grayscale), atau dengan kata lain metode ini mengkonversi citra gray-level ke citra bilevel (binary image). Untuk mendapatkan citra grayscale digunakan persamaan (2.2) berikut:
dimana:
Igrayscale = citra grayscale Icolour = citra RGB (x,y) = koordinat citra
(x,y,c) = channel piksel pada kordinat (x,y), r untuk merah,
b untuk biru dan g untuk hijau α, β, γ = koefisien
Pembobotan nilai koefisien (α, β dan γ) berdasarkan nilai dari respon mata manusia, biasanya ketiga nilai yang digunakan adalan 0.333 (Solomon & Breckon, 2011).
Setelah mendapatkan citra grayscale, citra biner dapat dibentuk dengan teknik
thresholding. Jika g(x, y) adalah sebuah nilai ambang (threshold) batas dari f(x, y)
yang terdapat pada gambar 2.2 dengan nilai threshold T. Nilai T digunakan untuk memisahkan antara object dengan background-nya, maka hasil threshold dapat ditulis sebagai berikut (Gonzales et al, 2004):
(2.3)
2.2.2 Penghilangan Derau (Noise Reduction)
Penghilangan derau bertujuan untuk menghindari distorsi pada saat segmentasi. Metode yang digunakan untuk penghilangan derau adalah median filter (Efford, 2000). Metode ini menggantikan piksel (x,y) dengan nilai tengah piksel disekitarnya. Pada gambar 2.3 terdapat representasi dari piksel citra dan ketetanggaannya yang akan digunakan untuk proses penghilangan derau, dimana p1 merupakan piksel tengah dan p2 sampai p9 merupakan piksel tetangga.
p9 p2 p3 p8 p1 p4 p7 p6 p5
Median filter merupakan metode rank filtering yang umum digunakan, metode ini memilih nilai peringkat tengah (middle-ranked) dari sebuah ketetanggaan (neighbourhood) sebagai nilai keluaran. Untuk ketetanggaan 3x3, nilai tengahnya adalah nilai kelima dari daftar terurut nilai tingkat abu-abu. Untuk sebuah ketetanggaan , dengan bilangan ganjil, maka nilai tengah terdapat pada posisi
.
Median filter sangat baik untuk meghilangkan beberapa jenis derau. Gambar 2.5(a) menunjukkan citra dengan impulse noise acak mempengaruhi 5 persen dari piksel. Gambar 2.4(b) menunjukkan hasil penghalusan derau gambar dengan menggunakan median filter 3x3 .
(a) (b)
Gambar 2.4 (a) Citra dengan impulse noise. (b) citra hasil median filter 3x3 (http://www.mathworks.com)
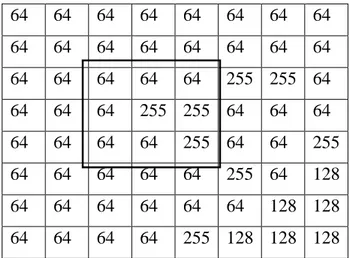
Median filter dapat menghilangkan impulse noise dengan memeriksa perhitungan yang dilakukan pada ketetanggaan 3x3 secara tunggal dari suatu citra. Pada gambar 2.5 merupakan contoh nilai-nilai piksel citra yang akan dihilangkan deraunya dengan menggunakan ketetanggan 3x3 (didalam kotak).
64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 64 255 255 64 64 64 64 255 255 64 64 64 64 64 64 64 255 64 64 255 64 64 64 64 64 255 64 128 64 64 64 64 64 64 128 128 64 64 64 64 255 128 128 128
Gambar 2.5 Sebuah ketetanggan 3x3 dalam bagian citra berderau
Untuk menerapkan median filter, kita tempatkan tingkat abu-abu pada sebuah daftar,
{64, 64, 64, 64, 255, 255, 64, 64, 255}, kemudian dafar diurutkan secara menaik, menghasilkan
{64, 64, 64, 64, 64, 64, 255, 255, 255}.
Median dari kumpulan nilai ini adalah 64. Nilai derau telah berpindah ke akhir daftar oleh karena itu tidak memepengaruhi pemilihan nilai piksel baru.
Median filter dapat mengeliminasi impulse noise jika piksel noise menempati kurang dari setengah area ketetanggaan. Pada gambar 2.4(a) dapat dilihat efek dari median filter pada gambar yang rusak dengan 20% impulse noise. Pada gambar 2.4(b) diterapkan sebuah median filter 3x3. Tingkat noise cukup tinggi, pada beberapa lokasi, sebuah keteganggaan 3x3 masih mengandung lebih dari 4 piksel noise. Akibatnya masih terdapat noise pada citra yang di-filter.
Langkah prosedural untuk median filter adalah sebagai berikut (Angel, 2010):
1. Misalkan matriks input citra
2. Kemudian tambahkan nilai 0 ke sekeliling matriks, sehingga didapatkan matris dengan ukuran atau
3. Tambahkan window dengan ukuran 3x3. Mulai dari matriks A(1,1) letakkan
window tersebut.
4. Nilai yang akan diganti adalah element tengah (nilai dari A(2,2))
5. Urutkan matriks window secara menaik (ascending)
6. Setelah pengurutan, matriks keluaran ditempatkan dengan nilai 0 pada posisi piksel (2,2) (matriks window). Nilai piksel output diperoleh menggunakan median dari piksel ketetanggaan.
7. Ulangi prosedur ini untuk semua nilai matriks input dengan menggeser
window keposisi berikutnya. Misal posisi A(1,2) dan seterusnya.
8. Matriks output =
2.2.3 Cropping
Cropping pada pengolahan citra berarti memotong satu bagian dari citra sehingga
diperoleh citra yang diharapkan. Ukuran pemotongan citra tersebut berubah sesuai dengan ukuran citra yang diambil. Cropping dilakukan pada koordinat (x,y) sampai pada koordinat (m,n). Oleh karena itu, pertama kali yang harus dilakukan adalah menentukan koordinat-koordinat tersebut. Penulis menyebutnya koordinat XL, YT, XR dan YB dimana x memiliki koordinat XL sampai XR (XL < x < XR) dengan selang [XL, XR] dan y memiliki koordinat YT sampai YB (YT < y < YB) dengan selang [YT, YB] didapat (XL, YT) adalah koordinat titik sudut kiri atas dan (XR, YB) adalah koordinat titik sudut kanan bawah maka ukuran pemotongan citra dapat dirumuskan sebagai berikut (Arief, 2010):
(2.4) (2.5)
dimana
w’ = ukuran lebar citra hasil cropping h’ = ukuran tinggi citra hasil cropping
2.2.4 Thinning
Thinning adalah operasi morfologi yang digunakan untuk menghapus piksel foreground yang terpilih dari gambar biner, bisanya digunakan untuk proses mencari
tulang dari sebuah objek (skeletonization). Thinning bertujuan untuk mengurangi ukuran dari suatu image (image size) dengan tetap mempertahankan informasi dan karakteristik penting dari image tersebut (Pardede, 2010).
Terdapat cukup banyak algoritma untuk image thinning dengan tingkat kompleksitas, efisiensi dan akurasi yang berbeda-beda. Citra yang digunakan untuk proses thinning adalah citra biner, jika data masukannya berupa citra RGB maka haruslah citra tersebut dimanipulasi menjadi citra grayscale, citra grayscale merupakan syarat guna menghasilkan suatu citra biner. Namun untuk mengubah citra grayscale menjadi citra biner dilakukan proses thresholding dahulu. Sehingga diperoleh citra threshold, jika citra threshold sudah diperoleh maka citra biner dapat dicari. Citra biner ini yang kemudian akan diproses dalam proses thinning. Citra hasil dari algoritma thinning biasanya disebut dengan skeleton (kerangka).
Umumnya suatu algoritma thinning yang dilakukan terhadap citra biner seharusnya memenuhi kriteria-kriteria sebagai berikut:
1. Skeleton dari citra kira-kira berada di bagian tengah dari citra awal sebelum dilakukan thinning.
2. Citra hasil dari algoritma thinning harus tetap menjaga struktur keterhubungan yang sama dengan citra awal.
3. Suatu skeleton seharusnya memiliki bentuk yang hampir mirip dengan citra awal.
4. Suatu skeleton seharusnya mengandung jumlah piksel yang seminimal mungkin namun tetap memenuhi kriteria-kriteria sebelumnya
Hasil dari operasi thinning pada citra biner yang sederhana dapat dilihat pada gambar 2.6. Dimana gambar 2.6(a) merupakan citra asli sebelum dilakukan proses
thinning dan gambar 2.6(b) merupakan citra hasil proses thinning.
(a) (b)
Gambar 2.6 (a) Pola awal (b) Pola hasil Thinning (http://homepages.inf.ed.ac.uk)
Sebagian besar algoritma thinning merupakan algoritma yang besifat iteratif. Dalam sebuah penelusuran piksel sisi diperiksa berdasarkan beberapa kriteria untuk menentukan apakah suatu piksel sisi dihapus atau tidak. Banyaknya jumlah penelusuran yang terjadi dihitung berdasarkan jumlah loop (perulangan) yang terjadi. Ada beberapa jenis algoritma thinning yaitu sequential dan paralel. Jenis sequential menggunakan hasil dari penelusuran sebelumnya dan hasil yang didapatkan sejauh ini dalam penelusuran yang sekarang untuk memproses piksel yang sekarang. Jadi pada setiap ujung penelusuran sejumlah piksel telah diproses terlebih dahulu. Hasil ini dapat digunakan secepatnya untuk memproses piksel selanjutnya. Sedangkan jenis
parallel, hanya hasil dari penelusuran sebelumnya yang mempengaruhi keputusan
untuk menghapus suatu titik pada penelusuran yang sekarang.
Algoritma ZhangSuen adalah algoritma thinning untuk citra biner, dimana piksel background citra bernilai 0, dan piksel foreground (region) bernilai 1. Algoritma ini cocok digunakan untuk bentuk yang diperpanjang (elongated) dan dalam aplikasi OCR (Optical Character Recognition). Algoritma ini terdiri dari beberapa penelusuran, dimana setiap penelusurannya terdiri dari 2 langkah dasar yang diaplikasikan terhadap titik objek (titik batas) region. Titik objek ini dapat
didefinisikan sebagai sembarang titik yang pikselnya bernilai 1, dan memiliki paling sedikit 1 piksel dari 8-ketetanggaannya yang bernilai 0.
Setiap iterasi dari metode ini terdiri dari dua sub-iterasi yang berurutan yang dilakukan terhadap contour points dari wilayah citra. Contour point adalah setiap piksel dengan nilai 1 dan memiliki setidaknya satu 8-neighbor yang memiliki nilai 0. Dengan informasi ini, langkah pertama adalah menandai contour point p untuk dihapus jika semua kondisi ini dipenuhi:
(a) 2 ≤ N(p1) ≤ 6; (b) S(p1) = 1; (c) p2 . p4 . p6 = 0; (d) p4 . p6 . p8 = 0;
dimana N(p1) adalah jumlah tetangga dari p1 yang tidak 0; yaitu, N(p1) = p2 + p3 + ... + p8 + p9 dan S(p1) adalah jumlah dari transisi 0-1 pada urutan p2, p3, ..., p8, p9.
Dan pada langkah kedua, kondisi (a) dan (b) sama dengan langkah pertama, sedangkan kondisi (c) dan (d) diubah menjadi:
(c‟) p2 . p4 . p8 = 0; (d‟) p2 . p6 . p8 = 0;
Langkah pertama dilakukan terhadap semua border pixel di citra. Jika salah satu dari keempat kondisi di atas tidak dipenuhi atau dilanggar maka nilai piksel yang bersangkutan tidak diubah. Sebaliknya jika semua kondisi tersebut dipenuhi maka piksel tersebut ditandai untuk penghapusan.
Piksel yang telah ditandai tidak akan dihapus sebelum semua border points selesai diproses. Hal ini berguna untuk mencegah perubahan struktur data. Setelah langkah 1 selesai dilakukan untuk semua border points maka dilakukan penghapusan untuk titik yang telah ditandai (diubah menjadi 0). Setelah itu dilakukan langkah 2 pada data hasil dari langkah 1 dengan cara yang sama dengan langkah 1 sehingga, dalam satu kali iterasi urutan algoritmanya terdiri dari:
(1) Menjalankan langkah 1 untuk menandai border points yang akan dihapus, (2) hapus titik-titik yang ditandai dengan menggantinya menjadi angka 0,
(3) menjalankan langkah 2 pada sisa border points yang pada langkah 1 belum dihapus lalu yang sesuai dengan semua kondisi yang seharusnya dipenuhi pada langkah 2 kemudian ditandai untuk dihapus,
(4) hapus titik-titik yang ditandai dengan menggantinya menjadi angka 0.
Prosedur ini dilakukan secara iteratif sampai tidak ada lagi titik yang dapat dihapus, pada saat algoritma ini selesai maka akan dihasilkan skeleton dari citra awal (Zhang & Suen, 1984).
2.2.5 Ekstraksi Ciri (Feature Extraction)
Feature extraction merupakan suatu metode untuk mendapatkan karateristik dari suatu
citra (dalam hal ini citra tersebut merupakan suatu karakter berupa huruf dan angka). Dengan feature exktraction maka citra yang satu dengan yang lain dapat dibedakan dengan memperhatikan ciri yang terdapat pada citra itu sendiri. Beberapa metode
feature extraction yang ada adalah sebagai berikut (Mulyo et al., 2004):
1. Pixel Mapping
Pixel mapping merupakan metode feature extraction yang sederhana. Metode
ini merupakan kelanjutan proses thresholding, dimana suatu citra telah berubah warnanya menjadi hitam atau putih. Pixel mapping merupakan suatu pemetaan dari citra yang disimpan ke dalam array, dimana piksel yang berwana hitam mempunyai nilai 1 sedangkan piksel yang berwarna putih mempunyai nilai 0. Contoh dari penerapan pixel mapping dapat dilihat pada gambar 2.7.
Gambar 2.7 Contoh Feature Extraction dengan Pixel Mapping
2. Image Compression
Pada metode ini citra dibagi menjadi daerah. Misalkan input citra berukuran piksel dan citra dibagi menjadi daerah, dimana masing-masing daerah terdiri dari piksel (gambar 2.8).
Gambar 2.8 Citra berukuran 32 x 32 piksel yang terbangi menjadi 8 x 8 daerah
Pada gambar 2.8 terlihat bahwa citra asli yang berukuran piksel menjadi citra berukuran piksel, dimana setiap 1 pikselnya mewakili piksel citra asli. Dengan kata lain bahwa setiap daerah piksel dikompresi menjadi 1 nilai pixel.
Gambar 2.9 Citra berukuran 32 x 32 piksel setelah dikompresi menjadi 8 x 8 piksel
Pada gambar 2.9 terlihat bahwa setiap pixel mempunyai nilai feature
extraction yang berbeda. Daerah-daerah tersebut mempunyai nilai antara 0 dan 1, hal
tersebut dapat dilihat pada tingkat keabu-abuan warna tiap pikselnya. Untuk mencari nilai image compression dari tiap piksel, digunakan persamaan berikut:
dimana:
v = nilai image compression
M = jumlah piksel daerah dalam satu baris N = jumlah piksel daerah dalam satu kolom f(x,y) = jumlah binary pixel pada suatu posisi (x,y)
(2.6)
2.2.6 Segmentasi
Segmentasi digunakan untuk mendapatkan karakter dari suatu citra kata. Adapun metode segmentasi yang dipakai dengan menggunakan algoritma Heuristic (Lecolinet & Baret, 1994; Rodrigues & Gay Thome 2000). Metode dari algoritma segmentasi
Heuristic berdasarkan terhadap sebuah konstruksi pengambilan keputusan dengan
sistem tree dan berdasarkan pada penggunaan profil histogram yang telah tercipta dan diproporsikan oleh suatu kata.
Profil proyeksi merupakan sebuah struktur data yang digunakan untuk menyimpan sejumlah piksel yang bukan merupakan background ketika suatu citra diproyeksikan melalui sumbu X dan Y pada persamaan (2.7). Setiap sel dari vektor proyeksi dikaitan dengan jumlah piksel yang terletak di atas posisi threshold yang telah ditentukan, biasanya warna latar belakang (background) (persamaan (2.8)) dan (2.9)) sebuah proyeksi histogram alternatif mengambil rata-rata dari intensitas piksel yang terkait (Rodrigues & Gay Thome 2000).
(2.8)
(2.9)
Dimana X dan Y merupakan sumbu horizontal dan vertikal, h merepresentasikan ketinggian gambar (ukuran vertikal) untuk X atau lebar (ukuran horizontal) bagi Y dan v merepresentasikan ukuran dari gambar. Ide utama dari metode yang termasuk dalam konstruksi tree dengan proses pengulangan, terletak dari data pada histogram yang telah mencapai performa yang ditentukan. Tingkat kesuksesan ditentukan dari kriteria heuristic tersebut.
Algoritma Heuristic merupakan metode dimana proses segmentasi dimulai dengan pencarian titik-titik segmentasi yang valid melalui metode ekstraksi sebuah kata. Proses segmentasi ini dapat lebih dipahami proses kerjanya dengan memperhatikan kondisi histogram dari tiap-tiap karakter yang masih dalam 1 kelompok kata. Untuk membantu proses segmentasi, maka pada saat prosess pemotongan kata dilakukan juga pengecekan terhadap ketentuan tipografi. Pada dasarnya ada tiga jenis tipografi dari kata yang terbentuk. Dari ketiga pola di atas sangat membantu dalam proses segmentasi. Hal ini dapat dilihat ketika dilakukannya proses histogram vertikal.
(a)
(c)
Gambar 2.10 (a) Citra asli (b) Histogram horizontal (http://serc.carleton.edu) (c) Histogram vertikal (http://www.blogdivvy.com)
Dari pola histogram (gambar 2.10(b) dan gambar 2.10(c)) yang dilakukan pada citra asli (gambar 2.10(a)) , maka dapat telihat bahwa titik pemotongan karakter dilakukan saat tinggi kurva mendekati nilai X atau Y minimum.
2.3 Jaringan Saraf Tiruan (JST)
Kecerdasan buatan atau Artificial Intelligence (AI) adalah bagian dari Computer
Science yang mencoba memberikan kemampuan manusia (seperti manusia) kepada
komputer. Salah satu cara untuk memberikan computer kemampuan manusia adalah dengan menggunakan jaringan saraf tiruan. Otak manusia merupakan contoh dari jaringan saraf tiruan. Otak manusia terdiri dari jaringan yang terdiri dari miliaran neuron yang saling terhubung. Neuron adalah sel individual yang dapat memproses informasi dan kemudian mengaktifkan neuron yang lain untuk melanjutkan proses (Heaton, 2005).
Jaringan saraf tiruan adalah merupakan salah satu representasi buatan dari otak manusia yang selalu mencoba untuk mensimulasikan proses pembelajaran pada otak manusia tersebut. Istilah buatan digunakan karena jaringan saraf ini diimplementasikan dengan menggunakan program computer yang mampu menyelesaikan sejumlah proses perhitungan selama proses pembelajaran. Sistem
pemrosesan informasi yang memiliki karakteristik kinerja tertentu yang sama dengan jaringan saraf biologis. Jaringan saraf tiruan telah dikembangkan sebagai generalisasi model matematika dari kognisi manusia atau saraf biologis, berdasarkan asumsi bahwa:
1. Pengolahan informasi terjadi pada elemen-elemen sederhana yang disebut neuron.
2. Sinyal dilewatkan di antara neuron melalui link koneksi.
3. Sambungan setiap link memiliki bobot terkait, dalam jaringan saraf yang khas, mengalikan sinyal yang ditransmisikan.
4. Setiap neuron menerapkan fungsi aktivasi (biasanya nonliniear) untuk input (jumlah bobot sinyal input) untuk menentukan sinyal output (Fausett, 1994)
2.3.1 Konsep dasar jaringan syaraf tiruan
Jaringan saraf tiruan adalah prosesor tersebar paralel yang sangat besar yang memiliki kecenderungan untuk menyimpan pengetahuan yang bersifat pengalaman dan membuatnya siap untuk digunakan. JST menyerupai otak manusia dalam dua hal, yaitu:
1. Pengetahuan diperoleh jaringan melalui proses belajar.
2. Kekuatan hubungan antar sel syaraf (neuron) yang dikenal sebagai bobot-bobot sinaptik digunakan untuk menyimpan pengetahuan.
Pembagian arsitektur jaringan saraf tiruan bias dilihat dari kerangka kerja dan skema interkoneksi. Kerangka kerja jaringan saraf tiruan bisa dilihat jumlah lapisan (layer) dan jumlah node pada setia lapisan. Lapisan-lapisan penyusun jaringan saraf tiruan dapat dibagi menjadi tiga, yaitu
1. Lapisan input
Node-node di dalam lapisan input disebut unit-unit input. Unit-unit input menerima input dari dunia luar. Input yang dimasukkan merupakan penggambaran dari suatu masalah.
2. Lapisan tersembunyi
Node-node di dalam lapisan terembunyi disebut unit-unit tersembunyi. output dari lapisan ini tidak secara langsung dapat diamati.
3. Lapisan output
Node-node pada lapisan output disebut unit-unit output. Keluaran atau output dari lapisan ini merupakan output jaringan saraf tiruan terhadap suatu permasalahan
Mengenai pengelompokan jaringan saraf tiruan, ada pula yang membaginya ke dalam dua kelompok, yaitu jaringan saraf tiruan umpan maju (feed-forward networks) dan jaringan saraf tiruan berulang/umpan balik (recurrent/feedback networks). Jaringan saraf tiruan umpan maju adalah graf yang tidak mempunyai loop, sedangkan jaringan saraf tiruan berulang/umpan balik dirincikan dengan adanya loop-loop koneksi balik.
Pendapat lain mengenai arsitektur jaringan saraf tiruan adalah sebagai berikut 1. Jaringan lapis tunggal (single layer net)
Jaringan yang memiliki arsitektur jenis ini hanya memiliki satu buah lapisan bobot koneksi. Jaringan lapisan-tunggal terdiri dari unir-unir input yang menerima sinyal dari dunia luar, dan unit-unit output dimana nilainya dapat dilihat sebagai respon dari jaringan saraf tiruan tersebut.
2. Jaringan multilapis (multilayer net)
Merupakan jaringan dengan satu atau lenih lapisan tersembunyi. Jaringan multilapis memiliki kemampuan lebih dalam memecahkan masalah bila dibandingkan dengen single layer net, namun pelatihannya mungkin lebih rumit.
3. Jaringan kompetitif
Pada jaringan ini sekumpulan neuron bersaing untuk menapatkan hak menjadi aktif.
2.3.2 Model syaraf (neuron)
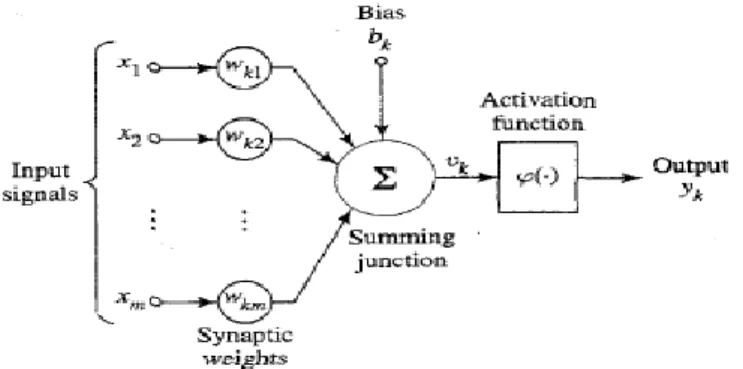
Sebuah neuron adalah sebuah unit pengeolahan informasi yang merupakan dasar untuk pengoperasian jaringan saraf tiruan. Gambar 2.8 (Haykin, 1999) menunjukkan model dari sebuah neuron, yang merupakan bentuk dasar untuk merancang jaringan saraf tiruan. Satu neuron terdiri dari tiga bagian dasar yaitu (Siang, 2009):
1. Himpunan unit-unit yang dihubungkan dengan jalur koneksi. Jalur-jalur tesebut memiliki bobot/keluaran yang berbeda-beda. Bobot yang bernilai positif akan memperkuat sinyal dan yang bernilai negatif akan memperlemah sinyal yang dibawanya. Jumlah, struktur dan pola hubungan antar unit-unit tersebut akan menentukan arsitektur jaringan (dan juga model yang terbentuk). 2. Suatu unit penjumlahan yang akan menjumlahkan input-input sinyal yang
sudah dikalikan dengan bobotnya.
3. Fungsi aktivasi yang akan menentukan apakah sinyal dari input neuron akan diteruskan ke neuron lain ataukan tidak.
Gambar 2.11 Model Nonlinear Neuron
2.3.3 Fungsi Aktivasi dan Error
Fungsi aktivasi merupakan bagian penting dalam tahap perhitungan JST karena dipakai untuk menentukan keluaran dari suatu neuron. Beberapa fungsi aktivasi yang dipakai dalam JST adalah:
1. Fungsi sigmoid biner (logsig)
Fungsi ini pada umumnya digunakan untuk jaringan syaraf yang dilatih dengan menggunakan metode backpropagation. Fungsi sigmoid biner memiliki nilai
antara 0 sampai 1. Oleh karena itu, fungsi ini sering digunakan untuk jaringan syaraf yang membutuhkan nilai output yang terletak pada interval 0 sampai 1. Fungsi sigmoid biner dirumuskan sebagai:
(2.10)
dengan (2.11)
2. Fungsi sigmoid bipolar (tansig)
Fungsi sigmoid bipolar hampir sama dengan fungsi sigmoid biner, hanya saja fungsi ini memiliki range antara 1 sampai -1. Fungsi sigmoid bipolar dirumuskan sebagai:
(2.12)
dengan (2.13)
Pada tahap pembelajaran di dalam algoritma propagasi balik, diperlukan suatu kondisi untuk menghentikan proses pembelajaran. Berbagai kondisi seperti squared
error, total squared error, dan mean squared error dapat digunakan untuk
menghentikan proses pembelajaran. Definisi dari masing-masing kondisi tersebut diatas adalah sebagai berikut:
1. squared error, adalah jumlah dari masing-masing kuadrat dari perbedaan antara target yang telah ditentukan dengan keluaran yang dihasilkan oleh jaringan setiap neuron pada lapisan keluaran.
2. sum squared error (SSE), adalah jumlah squared error untuk setiap pasangan pelatihan.
3. mean squared error (MSE), bisa berarti squared error dibagi dengan jumlah neuron pada lapisan keluaran atau sum squared error dibagi dengan jumlah pasangan pelatihan.
Pada umumnya digunakan total squared error di dalam algoritma propagasi balik, tetapi pada dasarnya ketiga kondisi tersebut mempunyai kemiripan yaitu sebagai informasi error yang telah didefinisikan untuk menghentikan proses pembelajaran. Harga dari error yang telah didefinisikan, sebelumnya sudah ditentukan dan jika harga
error yang dihitung pada tahap pembelajaran lebih kecil dari harga error yang telah
didefinisikan maka proses pembelajaran dihentikan. Harga dari error yang didefinisikan untuk menghentikan proses pembelajaran akan menentukan ketepatan jaringan pada saat pengenalan pola dan lamanya proses pembelajaran. Semakin kecil harga error yang didefinisikan akan menyebabkan semakin tinggi tingkat ketepatan jaringan pada saat pengenalan pola nanti, tetapi proses pembelajaran menjadi semakin lama dan sebaliknya.
Dimana:
n = banyaknya pola pelatihan k = banyaknya keluaran
tkn = nilai terget keluaran yang diinginkan ykn = nilai keluaran actual
(2.14)
Sebagai contoh akan dilakukan perhitungan nilai SSE. Jika pada suatu JST terdapat 2 pola masukan dan menghasilkan pola keluaran sebagai berikut:
Pola Input Nilai Output Aktual Nilai Output Target
1111 0.99 -0.01 1 0
1001 0.82 0.90 1 1
Jika nilai error yang diinginkan adalah 0.1, maka perhitungan nilai SSE ialah:
SSE = 0.5 * ((1-0.99)2 + (0-(-0.01))2 + (1-0.82)2 + (1-0.9)2) SSE = 0.5 * ((0.01)2 + (0.01)2 + (0.18)2 + (0.1)2)
SSE = 0.5 * (0.0001 + 0.0001 + 0.324 + 0.01) SSE = 0.5 * (0.3342)
Karena SSE > 0.1 maka jaringan dianggap belum mengenali pola, sehingga perlu dilakukan iterasi kembali agar jaringan mencapai error yang diinginkan.
2.3.4 Proses Belajar
Belajar merupakan suatu proses dimana parameter-parameter bebas JST diadaptasikan melalui suatu proses perangsangan berkelanjutan oleh lingkungan dimana jaringan berada. Berdasarkan algoritma pelatihannya, maka JST terbagi menjadi dua yaitu:
1. Supervised Learning (Pembelajaran Terawasi)
Metode pembelajaran ini memerlukan pengawasan dari luar atau pelabelan data sampel yang digunakan dalam proses belajar. Dimana Jaringan belajar dari sekumpulan pola masukan dan keluaran. Sehingga pada saat pelatihan diperlukan pola yang terdiri dari vector masukan dan vektor target yang diinginkan. Vektor masukan dimasukkan ke dalam jaringan yang kemudian menghasilkan vektor keluaran yang selanjutnya dibandingkan dengan vektor target. Selisih kedua vector tersebut menghasilkan galat (error) yang digunakan sebagai dasar untuk mengubah matriks koneksi sedemikian rupa sehingga galat semakin mengecil pada siklus berikutnya.
2. Unsupervised Learning (Pembelajaran tak Terawasi)
Metode pembelajaran ini jaringan saraf tiruan mengorganisasi dirinya sendiri untuk membentuk vektor-vektor input yang serupa, tanpa menggunakan data atau contoh-contoh pelatihan. Struktur menggunakan dasar data atau kolerasi antara pola-pola data yang dieksplorasi. Paradigma pembelajaran ini mengorganisasi pola-pola ke dalam kategori-kategori berdasarkan kolerasi yang ada.
2.3.5 Propagasi Balik
Metode propagasi balik merupakan metode yang sangat baik dalam menagani masalah pengenalan pola-pola kompleks. Metode ini merupakan metode jaringan saraf tiruan yang popluler. Beberapa contoh aplikasi yang melibatkan metode ini adalah
pengompresian data, pendeteksian virus computer, pengidentifikasian objek, sintesis suara dari teks, dan lain-lain.
Istilah “propagasi baik” (atau “perambatan kembali”) diambil dari cara kerja jaringan ini, yaitu bahwa gradient error unit-unit tersembunyi diturunkan dari penyiaran kembali error-error yang diasosiasikan dengan unit-unit output. Hal ini karena nilai target untuk unit-unit trersembunyi tidak diberikan.
Metode ini menurunkan gradien untuk meminimalkan penjumlahan error kuadrat output jaringan. Nama lain dari propagasi balik adalah aturan delta yang digeneralisasi.
2.3.5.1 Arsitektur
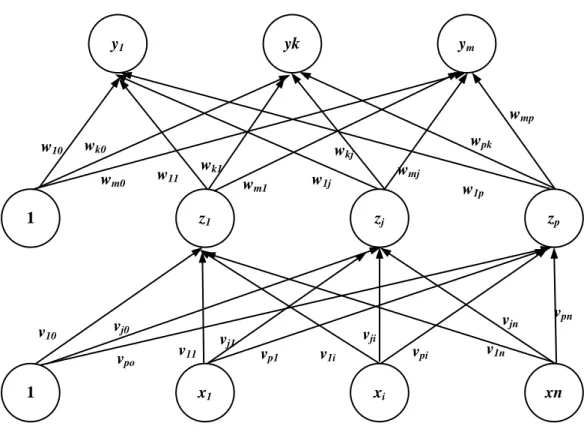
Di dalam jaringan propagasi balik, setiap unit yang berada di lapisan input terhubung dengan setiap unit yang ada di lapisan tersembunyi. Hal serupa berlaku pula pada lapisan tersembunyi. Setiap unit yang ada di lapisan tersembunyi terhubung dengan setiap unit yang ada di lapisan output. Pada gambar 2.9 terdapat arsitektur JST propagasi balik dengan menggunakan satu layer tersembunyi (Fausett, 1994).
y1 yk ym z1 zj zp 1 x1 xi xn 1 v10 vj0 vpo v11 vj1 vp1 v1i vji vpi v1n vjn vpn w10 wk0 wm0 w11 wk1 wm1 w1j wkj wmj w1p wpk wmp
Gambar 2.12 Jaringan saraf tiruan propagasi balik dengan satu lapisan tersembunyi.
Jaringan saraf tiruan propagasi balik terdiri dari banyak lapisan (multilayer neural networks):
1. Lapisan input (1 buah). Lapisan input terdiri dari neuron-neuron atau unit-unit input, mulai dari unit input 1 sampai unit input n.
2. Lapisan tesembunyi (minimal 1). Lapisan tersembunyi terdiri dari unit-unit tersembunyi mulai dari unit tersembunyi 1 sampai unit tersembunyi p.
3. Lapisan output (1 buah). Lapisan output terdiri dari unit-unit outut mulai dari unit output 1 sampai unit output m. n, p, m masing-masing adalah bialangan integer sembarang menurut arsitektur jaringan saraf tiruan yang dirancang. v0j dan w0k masing-masing adalah bias untuk unit tersembunyi ke-j dan unit output ke-k. Bias vj0 dan wk0 berprilaku sepertu bobot di mana output bias ini selalu sama dengan 1. vji adalah bobot koneksi antara unit ke-i lapisan input dengan unit ke-j lapisan tersembunyi, sedangkan wkj adalah bobot koneksi antara unit ke-j lapisan tersembunyi dengan unit ke-k lapisan output.
2.3.5.2 Jumlah Lapisan Tersembunyi yang Digunakan
Satu buah lapisan tersembunyi bisa dikatakan cukup memadai untuk menyelesaikan masalah sembarang fungsi pendekatan. Dengan menggunakan lebih dari satu buah lapisan tersembunyi, kadang-kadang suatu masalah lebih mudah untuk diselesaikan. Mengenai banyaknya jumlah lapisam tersembunyi yang dibutuhkan, tidak terdapat ketentuan khusus (Puspitaningrum, 2006).
2.3.5.3 Jumlah Neuron di Lapisan Tersembunyi
Menentukan jumlah neuron di lapisan tersembunyi merupakan bagian terpenting dalam menentukan rancangan arsitektur jaringan saraf tiruan secara keseluruhan. Meskipun lapis tersembunyi ini tidak berinteraksi dengan lingkungan eksternal, lapisan ini memiliki pengaruh besar terhadap hasil akhir jaringan. Jumlah lapis tersembunyi dan jumlah neuron pada masing-masing lapis tersembunyi harus dipertimbangkan dengan cermat.
Menggunakan terlalu sedikit neuron di lapisan tersembunyi akan menghasilkan sesuatu yang disebut underfitting. Underfitting terjadi ketika terlalu sedikit neuron di lapisan tersembunyi untuk dapat mendeteksi sinyal dalam satu set data yang rumit. Sebaliknya mennggunakan terlalu banyak neuron di lapisan tersembunyi akan menghasilkan sesuatu yang disebut overfitting. Overfitting terjadi ketika jaringan saraf memiliki banyak kapasitas pengolahan informasi sehingga sedikitnya jumlah informasi yang terdapat pada data pelatihan tidak cukup untuk melatih semua neuron di lapisan tersembunyi.
Ada banyak aturan yang digunakan untuk menentukan jumlah neuron di lapisan tersembunyi. Berikut adalah beberapa diantaranya adalah (Heaton, 2005):
1. Jumlah neuron lapisan tersembunyi harus diantara ukuran lapisan input dan lapisan output.
2. Jumlah neuron lapisan tersembunyi harus 2/3 dari ukuran neuron input, ditambah ukuran lapisan output.
3. Jumlah neuron lapis tersembunyi tidak pernah lebih dari dua kali ukuran lapisan input.
2.3.5.4 Algoritma
Cara kerja jaringan propagasi balik adalah sebagai berikut, mula-mula jaringan diinisialisasi dengan bobot yang diset dengan bilangan acak. Lalu contoh-contoh pelatihan dimasukkan ke dalam jaringan. Contoh pelatihan terdiri dari pasangan vektor input dan vektor target. Keluaran dari jaringan berupa sebuah vektor output aktual. Selanjutnya vektor output aktual jaringan dibandingkan dengan vektor output target untuk mengetahui apakah output jaringan sudah sesuai dengan yang diharapkan (output aktual sudah sama dengan output target).
Error yang timbul akibat perbedaan antara output aktual dengan output target
tersebut kemudian dihitung dan digunakan untuk mengupdate bobot-bobot yang relevan dengan jalan mempropagasikan kembali error. Setiap perubahan bobot yang terjadi diharapkan dapat mengurangi besar error. Epoch (siklus setiap pola pelatihan) seperti ini dilakukan pada semua set pelatihan sampai unjuk kerja jaringan mencapai tingkat yang diinginkan atau sampai kondisi berhenti terpenuhi. Setelah proses selesai, barulah diterapkan algoritma aplikasi.
Algoritma propagasi balik dapat dibagi ke dalam 2 bagian: 1. Algoritma pelatihan
Terdiri dari 3 tahap: tahap umpan maju pola pelatihan input, tahap pemprogasibalikan error, dan tahap pengaturan bobot.
2. Algoritma aplikasi
Yang digunakan hanyalah tahap umpan maju saja.
Berdasarkan gambar 2.9 berikut adalah proses pelatihan JST propagasi balik dengan sebuah lapis tersembunyi (Fausett, 1994):
a. Algoritma Pelatihan
Salah satu dari fungsi aktivasi yang djelaskan pada sub bab 2.3.3 dapat digunakan pada algoritma standar propagasi balik. Bentuk data (terutama nilai-nilai target) merupakan faktor penting dalam memilih fungsi yang sesuai. Berikut ini adalah algoritma pelatihan propagasi balik.
0. Inisialisasi bobot-bobot (dengan menggunakan nilai acak yang kecil).
1. While kondisi berhenti tidak terpenuhi do langkah ke-2 sampai langkah ke-9 2. Untuk setiap pasangan pola pelatihan, lakukan langkah ke-3 sampai langkah
ke-8.
3. Setiap unit input xi (dari unit ke-1 sampai unit ke-n pada lapisan input) mengirimkan sinyal input ke semua unit yang ada dilapisan atasnya (ke lapisan tersembunyi).
4. Pada setiap unit di lapisan tersembunyi zj (dari unit ke-1 sampai unit ke-p; i=1,...,n; j=1,...,p) sinyal output lapisan tersembunyinya dihitung dengan
menerapkan fungsi aktivasi terhadap penjumlahan sinyal-sinyal input berbobot
zi :
(2.15)
kemudian dikirim ke semua unit di lapisan atasnya.
5. Setiap unit di lapisan output yk (dari unit ke-1 sampai unit ke-m; i=1,...,n; k=1,...,m) dihtung sinyal outputnya dengan menerapkan fungsi aktivasi
terhadap penjumlahan sinyal-sinyal input bebobot zj bagi lapisan ini:
(2.16)
Tahap propagasi (perambatan) balik error:
6. Setiap unit output yk (dari unit ke-1 sampai unit ke-m; j=1,...,p; k=1,...,m) menerima pola target tk lalu informasi kesalahan lapisan output (δk) dihitung. δk dikirim ke lapisan bawahnya dan digunakan untuk menghitung besar koreksi bobot dan bias (∆wkj dan ∆wk0) antara lapisan tersembunyi dengan lapisan output:
(2.17)
(2.18) (2.19) Dengan merupakan laju pembelajaran yang digunakan.
7. Pada setiap unit di lapisan tersembunyi (dari unit ke-1 sampai unit ke-p;
i=1,...,n; j=1,...,p; k=1,...,m) dilakukan perhiutngan informasi kesalahan lapisan
tersembunyi (δj). δj kemudian digunakan untuk menghitung besar koreksi bobot dan bias (∆vji dan ∆vj0) antara lapisan input dan lapisan tersembunyi.
(2.20)
(2.21) (2.22) Dengan merupakan laju pembelajaran yang digunakan.
Tahap peng-update-an bobot dan bias:
8. Pada setiap unit output yk (dari unit ke-1 sampai unit ke-m) dilakukan peng-update-an bias dan bobot (j=0,...,p; k=1,...,m) sehingga bias dan bobot baru menjadi:
(2.23)
Dari unit ke-1 sampai unit ke-p di lapisan tersembunyi juga dilakukan peng-update-an pada bias dan bobotnya ( i=0,...,n; j=1,...,p):
(2.24) 9. Tes kondisi berhenti
b. Algoritma Aplikasi
Setelah dilakukan pelatihan, jaringan sarar tiruan propagasi balik dapat diterapkan dengan hanya menggunakan tahap umpan maju (feedforward) pada fase pelatihan. Berikut merupakan algoritma dari aplikasi propagasi balik.
0. Inisialisasi bobot. Bobot ini diambil dari bobot-bobot terakhir yang diperoleh dari algoritma pelatihan.
1. Untuk setiap vektor input, lakukan langkah ke-2 sampai ke-4.
2. Setiap unit input xi (dari unit ke-1 sampai unit ke-n pada lapisan input; i=1,...,n) menerima sinyal input pengujian xi dan menyiarkan sinyal xi ke semua unit pada lapisan di atasnya (unit-unit tersembunyi)
3. Setiap unit di lapisan tersembunyi zj (unit ke-1 sampai unit ke-p; i=1,...,n; j=1,...,p) menghitung sinyal outputnya dengan menerapkan fungsi aktivasi
terhadap penjumlahan sinyal-sinyal input xi. Sinyal output dari lapisan tersembunyi kemudian dikirim ke semua unit pada lapisan di atasnya, dengan menggunakan persamaan (2.15) pada proses pelatihan:
4. Setiap unit output yk (ke-1 sampai unit ke-m; j=1,...,p; k=1,...,m) menghitung sinyal outputnya dengan menerapakan fungsi aktivasi terhadap penjumlahan sinyal-sinyal input bagi lapisan ini, yaitu sinyal-sinyal input zj dari lapisan tersembunyi, dengan menggunakan persamaan (2.16) pada proses pelatihan :
2.3.6 Optimalitas Arsitektur Backpropagation
Masalah utama yang terdapat dalam backpropagation ialah lamanya proses iterasi yang dilakukan. Backpropagation tidak dapat memastikan berapa epoch yang harus
dilalui sampai pola yang diinginkan terpenuhi. Oleh karena itu terdapat beberapa cara yang digunakan untuk mengoptimalkan proses iterasi (Puspitaningrum, 2006), yaitu:
1. Pemilihan bobot dan bias awal
Bobot awal merupakan unsur yang terpenting dalam pembentukan jaringan yang baik, karena bobot awal mempengaruhi kecepatan iterasi jaringan dalam mengenali pola. Bobot awal standar yang biasa dipakai dalam melakukan proses komputasi dinilai memberikan waktu yang lama. Inisialisasi Nguyen
Widrow merupakan modifikasi sederhana bobot-bobot dan bias ke unit
tersembunyi yang mampu meningkatkan kecepatan jaringan dalam proses pelatihan jaringan. Inisialisasi Nguyen Widrow didefinisikan dengan persamaan:
Dimana:
n = jumlah neuron pada lapisan input
p = jumlah neuron pada lapisan tersembunyi β = faktor skala
(2.25)
Prosedur inisialisasi Nguyen Widrow ialah:
a. Inisialisasi bobot-bobot (vji) lama dengan bilangan acak dalam interval [-0.5, 0.5]
b. Hitung
(2.26)
c. Bobot baru yang dipakai sebagai inisialisasi
(2.27)
d. Bias baru yang dipakai sebagai inisialisasi vj0 = bilangan acak dalam interval
(2.28)
2. Momentum
Penambahan parameter momentum dalam tahap pengoreksian nilai bobot dapat mempercepat proses pelatihan yaitu dengan memodifikasi nilai bobot
pada iterasi (t+1) yang nilainya ditentukan oleh nilai bobot pada iterasi ke-t dan (t-1). μ adalah konsanta yang menyatakan parameter momentum yang nilainya 0 ≤ μ ≤1. Maka persamaan untuk menentukan bobot baru ialah:
dimana:
wkj(t) = bobot awal pola kedua (hasil dari iterasi pola pertama)
wkj (t −1) = bobot awal pada iterasi pola pertama
(2.29)
dimana:
vji(t) = bobot awal pola kedua (hasil iterasi pola pertama) vji(t-1)= bobot awal pada iterasi pertama
(2.30)
2.4 Data Flow Diagram (DFD)
Data Flow Diagram (DFD) adalah suatu model logika data atau proses yang dibuat untuk menggambarkan dari mana asal data dan kemana tujuan data yang keluar dari sistem, dimana data disimpan, proses apa yang menghasilkan data tersebut dan interaksi antara data yang tersimpan dan proses yang dikenakan pada data tersebut. DFD menunjukan hubungan antar data pada sistem dan proses pada sistem. Dengan kata lain DFD merupakan suatu cara untuk menggambarkan bangaimana data dip roses dalam sebuah sistem (Sommerville, 2007).
DFD dapat digunakan untuk mewakili sistem atau perangkat lunak pada setiap level abstraksi. DFD dapat dibagi menjadi beberapa level yang mewakili tingkatan aliran informasi dan detail fungsional. Oleh karena itu DFD menyediakan mekanisme untuk pemodelan fungsional serta pemodelan arus informasi. Menurut Yourdan dan DeMarco (1987) komponen DFD terdiri dari:
1. Terminator mewakili entitas eksternal yang berkomunikasi dengan sistem yang sedang dikembangkan. Biasanya terminator dikenal external entity.
2. Komponen proses menggambarkan bagian dari sistem yang mentransformasikan input menjadi output.
3. Komponen data store digunakan untuk membuat model sekumpulan paket data dan diberi nama dengan kata benda jamak yang biasanya database.
4. Alur data merupakan komponen yang menunjukan arah menuju ke dan keluar dari suatu proses.
Adapun lambang DFD yang digunakan terdapat pada gambar 2.10.
terminator proses Data store Alur data
Gambar 2.13 Komponen Data Flow Diagram
DFD level 0 disebut juga sebuah model dasar sistem atau model konteks (diagram konteks), yang mewakili element seluruh perangkat lunak sebagai satu gelembung (proses) tunggal dengan data input atau output yang ditunjukkan dengan panah keluar dan panah masuk (Pressman, 2001).
Notasi dasar yang digunakan untuk mengembangkan sebuah DFD tidak dengan sendirinya cukup menjelaskan persyaratan untuk perangkar lunak. Notasi grafid harus ditambah dengan teks deskriptif. Spesifikasi proses (PSPEC) dapat digunakan untuk menentukan rinciaan pengolahan tersirat oleh gelembung dalam DFD. Spesifikasi proses menggambarkan masukan ke fungsi algoritma yang diterapkan untuk mengubah input dan output yang dihasilkan. Selain itu PSPEC menunjukkan pembatasan dan keterbatasan yang ditetapkan pada proses (fungsi), karakteristik kinerja yang dapat mempengaruhi cara dimana proses tersebut dilaksanakan.
2.5 Plat nomor Kendaraan
Tanda Nomor Kendaraan Bermotor (TNKB), atau sering kali disebut plat nomor atau nomor polisi (nopol), adalah plat aluminium tanda kendaraan bermotor di Indonesia yang telah didaftarkan pada Kantor Bersama Samsat.
Spesifikasi teknis dari Tanda Nomor Kendaraan Bermotor :
1. Panjang plat nomor kendaraan buat mobil 39,5 cm 2. Lebar plat nomor kendaraan buat mobil 13,5 cm 3. Panjang plat nomor kendaraan buat motor 27,5 cm 4. Lebar plat nomor kendaraan buat motor 11 cm
5. Latar belakang untuk plat kendaraan pribadi warna hitam