35
BAB III
PELAKSANAAN PENELITIAN 3.1 Kerangka Pikir Pemodelan Nilai Tanah
Dalam penelitian ini dilakukan pengembangan metode penilaian tanah menggunakan metode analisis spasial dan Jaringan Syaraf Tiruan (JST). Metode JST digunakan karena karakteristik nilai tanah dipengaruhi oleh banyak variabel dan masing-masing variabel saling mempengaruhi satu dengan yang lain. Variabel lokasi dan aksesibilitas digunakan sebagai variabel utama dalam model nilai tanah mengingat bahwa variabel lokasi dan aksesibilitas adalah variabel yang sangat signifikan dalam model nilai tanah.
Model nilai tanah yang dikembangkan dalam penelitian ini diterapkan pada wilayah studi kasus Kecamatan Regol, Kota Bandung, Jawa Barat. Data sampel yang diperoleh sebanyak 143 data nilai tanah. Kecamatan Regol merupakan salah satu dari 26 kecamatan di Kota Bandung. Peta wilayah penelitian dapat dilihat pada Gambar III-1, sedangkan batas-batas wilayah Kecamatan Regol adalah sebagai berikut:
• Sebelah Utara berbatasan dengan Kecamatan Sumur Bandung • Sebelah Timur berbatasan dengan Kecamatan Lengkong • Sebelah Selatan berbatasan dengan Kecamatan Bandung Kidul • Sebelah Barat berbatasan dengan Kecamatan Astana Anyar
36
37 Sedangkan luas masing-masing kelurahan di Kecamatan Regol seperti terlihat pada Tabel III-1 berikut:
No Nama Kelurahan Luas Wilayah (m2)
1 Ancol 783917 2 Balonggede 551950 3 Ciateul 639461 4 Ciseureuh 625749 5 Cigereleng 780080 6 Pasirluyu 974173 7 Pungkur 394934
Tabel III-1 Luas Masing-masing Kelurahan di Kecamatan Regol 3.2 Persiapan
Pada tahap pesiapan dan perancangan model nilai tanah dilakukan kegiatan-kegiatan sebagai berikut:
1. Studi literatur terhadap beberapa penelitian terdahulu yang sesuai dengan topik kajian. Studi literatur juga dilakukan dengan landasan teori yang mendukung topik kajian antara lain masalah penilaian tanah, statistika, jaringan syaraf tiruan serta perangkat lunak pendukung penelitian.
2. Rancangan penelitian yang terdiri dari perumusan masalah penelitian, penentuan tujuan penelitian, penyusunan hipotesis serta metodologi penenlitian. Metodologi penelitian terdiri dari penentuan daerah studi, variabel penelitian yang digunakan, cara pengumpulan data, cara pengolahan data serta analisis penelitian.
3. Penentuan lokasi penelitian dengan pertimbangan ketersediaan data dan sumber daya yang ada. Kecamatan Regol, Kota Bandung, Jawa Barat, dipilih menjadi wilayah penelitian dengan pertimbangan data nilai telah tersedia dari peneliti sebelumnya (Nur'aini, 2011).
4. Penentuan variabel dilakukan dengan merujuk pada penelitian-penelitian sebelumnya dan disesuaikan dengan kondisi wilayah penelitian. Variabel-variabel yang digunakan dalam penelitian ini terdiri dari:
a. Variabel terikat, yaitu nilai tanah. b. Variabel bebas yang terdiri dari.
38 − Variabel eksogen, yang berupa jarak lurus dari centroid bidang tanah ke centroid pusat perdagangan, fasilitas kesehatan, sarana pendidikan, sedangkan jarak dari jalan utama terdekat menggunakan jarak buffer. − Variabel endogen, yaitu variabel yang melekat pada bidang tanah
yang meliputi lebar sisi depan bidang tanah, lebar jalan di depan bidang tanah, dan luas bidang tanah.
3.3 Pengumpulan Data
Dalam penelitian ini tahap-tahap pengumpulan data, pengolahan data, pembangunan model dan analisis model dilakukan dengan bantuan bahan dan alat berikut:
1. Digitasi peta blok bidang tanah serta analisis spasial menggunakan ArcGIS 9.3, perangkat lunak yang diproduksi ESRI.
2. Pemasukan dan pengolahan data regresi berganda serta analisis statistik pengujian regresi berganda dilakukan dengan menggunakan Microsoft Excel dan
SPSS 17.0.
3. Implementasi program jaringan syaraf tiruan dilakukan dengan menggunakan
Matlab R2010b.
4. Penulisan laporan penelitian dilakukan dengan menggunakan Microsoft Word.
Perangkat keras yang digunakan dalam penelitian ini adalah komputer notebook dengan spesifikasi sebagai berikut:
1. Processor Intel Core i3-2310M CPU @ 2.10 GHz 2. Harddisk 500 GB
3. RAM 2 GB
Pengumpulan data dilakukan untuk mendapatkan data variabel penelitian, yang terdiri atas data primer dan sekunder, antara lain:
1. Peta Bidang Tanah Kecamatan Regol, data ini merupakan data sekunder yang diperoleh dari Kantor Pertanahan Kota Bandung.
2. Peta Land Use Kota Bandung, data ini merupakan data sekunder yang diperoleh dari Dr. Andri Hernandi, ST., MSP.
3. Citra Satelit Kecamatan Regol, data ini merupakan data sekunder yang diperoleh dari Kantor Pertanahan Kota Bandung.
39 4. Jarak centroid dari variabel ke data sampel, data ini merupakan data primer yang diperoleh melalui analisis jarak lurus antar centroid menggunakan perangkat lunak ArcGIS 9.3 di atas Peta Blok Bidang Tanah Kecamatan Regol yang diperoleh dari Kantor Pertanahan Kota Bandung, dengan tahapan sebagai berikut: 1. Penandaan titik centroid (titik tengah) variabel penelitian dan titik centroid
data sampel.
2. Melakukan pengukuran jarak lurus antar centroid untuk mendapatkan data jarak dari variabel penelitian ke sampel penelitian.
Hasil pengukuran jarak lurus antar centroid dapat dilihat pada Gambar III-2 berikut:
Gambar III-2 Hasil Pengukuran jarak tempuh terpendek
5. Nilai tanah, data ini merupakan data sekunder yang diperoleh dari data penawaran dan transaksi jual beli di Kecamatan Regol berdasarkan hasil survey Kantor Pertanahan Kota Bandung. Data nilai tanah ini diperoleh melalui peneliti sebelumnya (Rina Nur’aini). Terhadap data nilai tanah tersebut telah dilakukan verifikasi dan penyesuaian (adjustment) jenis data dan waktu penilaian. (Data nilai tanah dapat dilihat pada Lampiran A).
6. Jarak buffer, ukuran jarak buffer dari jalan merupakan data primer yang diperoleh dengan cara melakukan buffer terhadap poros jalan Pada Peta Blok Bidang Tanah dengan interval buffer 10 m seperti pada Gambar III-3 berikut:
40
Gambar III-3 Jarak Buffer
7. Lebar sisi depan objek, merupakan data sekunder yang diperoleh dari peneliti sebelumnya (Rina Nur’aini), yang merupakan basis data Kantor Pertanahan Kota Bandung.
8. Lebar jalan, data ini merupakan data sekunder yang diperoleh dari peneliti sebelumnya (Rina Nur’aini), yang merupakan basis data Kantor Pertanahan Kota Bandung.
9. Luas tanah, data ini merupakan data sekunder yang diperoleh dari peneliti sebelumnya (Rina Nur’aini), yang merupakan basis data Kantor Pertanahan Kota Bandung.
Lokasi persebaran variabel eksogen yaitu pusat perdagangan, fasilitas kesehatan, sarana pendidikan dan jalan utama dapat dilihat pada Gambar III-4 sampai dengan Gambar III-7. (Daftar variabel bebas dapat dilihat pada Lampiran B dan Hasil pengumpulan data dapat dilihat pada Lampiran D)
41
42
43
44
45
3.4 Pengolahan Data
Tahapan pengolahan data ini diawali dengan melakukan analisis terhadap data masukan, analisis ini bertujuan untuk meningkatkan kualitas data masukan yang terdiri dari data nilai tanah dan data jarak sebelum digunakan dalam pemodelan.
Terhadap data nilai tanah dilakukan penyesuaian jenis data dan waktu penilaian, dimana hal ini telah dilakukan oleh peneliti terdahulu. Terhadap data nilai tanah juga dilakukan analisis statistik untuk melihat pola persebaran datanya dan kemudian dibagi dalam beberapa kelompok. Data nilai tanah juga dipisahkan dalam dua bagian yaitu data untuk pembentukan model dan data untuk pengujian model. Pembagian data ini berdasarkan proporsi masing-masing kelompok yang dilihat dari sebaran datanya seperti pada Gambar III-8 berikut:
Gambar III-8 Histogram Sebaran Data Nilai Tanah Kecamatan Regol
Untuk melihat lebih jelas sebaran data nilai tanah tersebut maka dipergunakan fasilitas boxplot dalam perangkat lunak SPSS 17.00, seperti yang terlihat pada Gambar III-9 berilut:
46
Gambar III-9 Boxplot Sebaran Data Nilai Tanah Kecamatan Regol
Dari Gambar III-9 di atas terlihat bahwa nilai ekstrim dari data nilai tanah yang ada yaitu nilai tanah yang lebih besar dari Rp. 15.000.000,-/m2. Data nilai tanah yang lebih besar dari Rp. 15.000.000,-/m2terlihat memisah jauh dari keseluruhan data. Dalam hasil analisis statistik dengan memanfaatkan boxplot tersebut, maka dalam kelanjutannya ada dua data sampel tanah yang tidak diikutsertkan pada pengolahan data berikutnya, yaitu data ekstrim atas dan data ekstrim bawah.
Dari set data nilai tanah yang baru juga dilihat sebarannya secara statistik seperti pada Gambar III-10 berikut:
47
Gambar III-10 Histogram Sebaran Data Nilai Tanah Dengan Set Data Baru
Dari Gambar III-10 tersebut terlihat bahwa frekuensi nilai tanah di Kecamatan Regol terbagi menjadi 3 (tiga) kategori. Untuk melihat lebih jelas klasifikasi sebaran data nilai tanah tersebut, maka dari set data yang baru juga dibuat grafik boxplot seperti pada Gambar III-11 berikut:
48 Klasifikasi data nilai tanah berdasarkan sebarannya menurut histogram dan boxplot tersebut terbagi dalam 3 (kategori) yang secara jelas dapat dilihat pada Tabel III-2 berikut:
Tabel III-2 Klasifikasi Nilai Tanah Kecamatan Regol No Klasifikasi Nilai Tanah per m2 Jumlah
Data Persen
1 Kurang dari Rp 6.000.000 127 90
2 Antara Rp 6.000.000 s/d Rp 8.500.000 8 6
3 Lebih dari Rp 8.500.000 6 4
Jumlah 141 100
Pembagian data training dan data testing kemudian dilakukan berdasarkan klasifikasi data pada Tabel III-2 di atas. Dari 141 data nilai tanah, dibagi 80% untuk training dan 20% sisanya sebagai testing. Data training digunakan untuk membentuk model, baik model regresi berganda maupun model jaringan syaraf tiruan. Data testing
digunakan untuk menguji model yang telah terbentuk. Jumlah data untuk training
dan testing masing-masing adalah:
Proporsi masing-masing kategori dalam training dan testing harus sesuai dengan proporsi masing-masing kategori dalam data keseluruhan. Proporsi masing-masing kategori ditunjukkan oleh persentase kategori tersebut, sehingga jumlah masing-masing kategori dalam data training dan testing adalah:
49
Untuk data training
Dengan demikian untuk data kategori 1 diambil 25 data secara acak dari 127 data untuk testing. Untuk data kategori 2 diambil dua data secara acak dari delapan data untuk testing, dan dari data kategori 3 diambil satu data secara acak dari enam data untuk testing. Pengambilan data secara acak dari setiap kategori dilakukan dengan menggunakan bantuan perangkat lunak Minitab, yaitu dengan melakukan pengambilan sampel secara acak tanpa pengembalian, sebanyak data testing yang diperlukan.
Terhadap data variabel jarak dilakukan analisis hubungan terhadap nilai tanah dengan melihat diagram pencar hubungan data masing-masing variabel jarak terhadap nilai tanah. Salah satu contoh diagram pencar hubungan antara nilai tanah dengan jarak terhadap King Shopping Centre terlihat pada Gambar III-12 (Diagram pencar masing-masing variabel terhadap nilai tanah dapat dilihat pada Lampiran C).
50
Gambar III-12 Diagram Pencar Jarak dari King Shopping Centre Terhadap Nilai Tanah
Selanjutnya tahap pengolahan data dibedakan atas 2 (dua) kegiatan utama, yaitu pengolahan data menggunakan metode regresi dan pengolahan data menggunakan metode Jaringan Syaraf Tiruan (JST).
3.4.1 Pengolahan Data Menggunakan Metode Regresi
Pengolahan data menggunakan metode regresi menggunakan variabel penentu nilai tanah yakni jarak lurus antar centroid yang berupa jarak ke pusat perdagangan, jarak ke fasilitas kesehatan, jarak ke sarana pendidikan, dan jarak ke jalan utama, serta variabel endogen yang berupa lebar jalan depan objek, lebar sisi depan objek dan luas bidang tanah. Pengolahan data dibagi dalam dua tahap yaitu tahap pembentukan model dan tahap validasi model. Tahap pengolahan metode regresi dapat dilihat pada Gambar III-10 berikut:
0 5000000 10000000 15000000 20000000 25000000 30000000 0 500 1000 1500 2000 2500 3000 3500 N ila i T an ah (R p/ m 2) Jarak (m)
King Shopping Centre
51
Gambar III-13 Tahap Pengolahan Data Metode Regresi
Pemodelan dengan menggunakan metode regresi terdiri dari beberapa tahap di bawah ini:
a. Transformasi data
Transformasi data pada regresi berganda bertujuan untukmenormalisasi data agar semua data yang dugunakan untuk pembentukan model berada pada range yang samasehingga semua variabel bebas memberikan efek yang sama pada pembentukan model. Selanjutnya normalisasi data ini berkaitan dengan jenis model regresi yang akan digunakan yaitu model aditif (lin-lin) dan multiplikatif (log-log) dengan menggunakan jarak asli (x) dan juga jarak resiprokal (1/x), dimana proses normalisasi yang dilakukan adalah transformasi data ke dalam bentuk logaritma natural pada model multiplikatif dan juga transformasi data ke dalam bentuk resiprokalnya pada model aditif dan multiplikatif dengan jarak resiprok.
52 b. Reduksi variabel bebas
Proses reduksi variabel-variabel bebas dilakukan sebagai berikut:
1. Bentuk matriks (r) dari semua variabel yang ada. Matriks korelasi (r) berguna untuk mengetahui tingkat hubungan antara variabel bebas dengan variabel terikatnya serta antara variabel bebas. Berdasarkan analisis korelasi dapat diketahui korelasi antar variabel bebas bervariasi, mulai korelasi sangat rendah sampai sangat tinggi yang dapat dilihat pada Tabel III-3 (tabel korelasi lengkap antara variabel nilai tanah dapar dilihat pada lampiran)
Tabel III-3 Matriks korelasi ganda (r)
Nilai Tanah ITC Kebon Kalapa Yogy a Toser ba King Shopping Centre Plaza Parahyan gan Palaguna Plaza Alun Alun Nilai Tanah 1 -0.368 -0.440 -0.441 -0.435 -0.416 -0.425
ITC Kebon Kalapa -0.368 1 0.992 0.992 0.991 0.987 0.989
Yogya Toserba -0.440 0.992 1 1.000 1.000 0.998 0.999
2. Melakukan seleksi variabel menggunakan metode regresi stepwise
Ada beberapa pilihan metode yang dapat digunakan untuk melakukan seleksi variabel-variabel bebas dalam rangka membentuk model akhir regresi(Dillon & Goldstein, 1984). Metode yang paling popular digunakan yakni metode
stepwise, yang merupakan kombinasi dari forward dan backward selection. Variabel yang terpilih adalah variabel dengan nilai koefisien determinansi (R2) diatas 50%. Hasil seleksi variabel dengan menggunakan metode regresi stepwise dapat dilihat pada Tabel III-4 berikut:
Tabel III-4 Seleksi Variabel dengan Metode Regresi Stepwise No Model Variabel Y Variabel
X R
2
53 I Variabel Eksogen
1 Aditif Y X 0.652 6 (enam)
2 Aditif Y 1/X 0.761 14 (empat belas)
3 Multiplikatif Ln Y Ln X 0.338 4 (empat) 4 Multiplikatif Ln Y Ln 1/X 0.338 4 (empat) II Variabel Eksogen dan Endogen
1 Aditif Y X 0.662 5 (lima)
2 Aditif Y 1/X 0.732 6 (enam)
3 Multiplikatif Ln Y Ln X 0.441 4 (empat) 4 Multiplikatif Ln Y Ln 1/X 0.441 4 (empat)
c. Model awal
Dari hasil seleksi variabel menggunakan metode regresi stepwise, selanjutnya variabel terseleksi digunakan dalam penyusunan model awal. Hasil pembentukan model awal terlihat pada Tabel III-5 berikut:
Tabel III-5 Hasil Pemodelan Awal
No Variabel Eksogen Aditif (x) Aditif (1/x) Multiplikatif
(x)
Multiplikatif (1/x)
1 ITC Kebon Kalapa 17,697
2 Pasar Kota Kembang 59,041
3 SMK Pasundan 1 27,297 -38,483,425
4 SDS YAY Dewi Sartika -37,171 2,665,698,598
5 JL Moh Toha 2,163 6 SMP Negeri 43 -67,836 680,412,101 -0.696 0.696 7 SDS Bina Talenta 744,595,547 8 Universitas Langlangbuana -655,702,870 0.944 -0.944 9 JL BKR 44,696,990 -0.252 0.252 10 JL Pungkur 44,616,221 11 JL Moh Ramdan 26,265,519 -0.168 0.168 12 Yogya Toserba -4,463,988,409
54
14 SMA Pasundan 1 2,080,654,125
15 JL Asia Afrika -2,315,840,332
16 JL Dewi Sartika 91,913,963
17 SD Mochammad Toha 2,3,4 -302,002,587
No Variabel Eksogen dan Endogen Aditif (x) Aditif (1/x) Multiplikatif (x)
Multiplikatif (1/x)
1 Puskesmas Pasirluyu -1,053
2 Lebar Jalan 310,841 301,663 0.525 0.525
3 King Shopping Centre 8,898
4 Puskesmas Pasundan 17,169
5 SMP Negeri 43 -26,869 699,303,058
6 SDS YAY Dewi Sartika 1,556,484,354 -0.749 0.749
7 JL BKR 38,148,520 -0.242 0.242
8 Yogya Toserba -1,436,466,410
9 Universitas Langlangbuana -343,493,326 0.658* -0.658*
d. Pengujian model regresi
Sebelum proses pemodelan dilanjutkan ke tahap berikutnya, maka perlu dilakukan penguian-pengujian sehingga dapat diperoleh variabel-variabel yang signifikan. Disamping itu pada tahap ini akan dihasilkan model yang telah memenuhi aturan-aturan pemodelan, baik secara a priori ekonomi, maupun uji-uji statistik dan asumsi-asumsi klasik analisis regresi.
1. Uji kriteria a priori ekonomi
Uji kriteria a priori ekonomi dilakukan dengan cara membandingkan kesesuian tanda antara koefisien parameter yang diperoleh, dengan anggapan umum yang berlaku. Apabila tanda koefisien parameter regresi sesuai dengan teori, maka variabel tersebut lolos dari uji kriteria ekonomi. Sebaliknya, jika tanda dari koefisien tidak sesuai dengan teori, maka variabel tersebut tidak lolos uji.
Terkait dengan pengujian variabel dengan uji a priori ekonomi, maka perlu dibuat hipotesis yang terdiri dari:
a) Jarak ke pusat perdagangan terdekat mempunyai hubungan negatif terhadap nilai tanah, yang bermakna bahwa semakin jauh lokasi obyek dari pusat perdagangan terdekat akan semakin rendah nilai tanahnya dan sebaliknya (positif jika jarak yang digunakan adalah jarak resiprokal).
55 b) Jarak ke fasilitas kesehatan terdekat mempunyai hubungan negatif terhadap nilai tanah, yang bermakna bahwa semakin jauh lokasi obyek dari fasilitas kesehatan terdekat akan semakin rendah nilai tanahnya dan sebaliknya (positif jika jarak yang digunakan adalah jarak resiprokal). c) Jarak ke sarana pendidikan terdekat mempunyai hubungan negatif
terhadap nilai tanah, yang bermakna bahwa semakin jauh lokasi obyek dari sarana pendidikan terdekat akan semakin rendah nilai tanahnya dan sebaliknya (positif jika jarak yang digunakan adalah jarak resiprokal). d) Jarak ke jalan utama terdekat mempunyai hubungan negatif terhadap nilai
tanah, yang bermakna bahwa semakin jauh lokasi obyek dari jalan utama terdekat akan semakin rendah nilai tanahnya dan sebaliknya (positif jika jarak yang digunakan adalah jarak resiprokal).
e) Lebar sisi depan bidang tanah mempunyai hubungan positif terhadap nilai tanah, yang bermakna bahwa semakin lebar sisi depan suatu bidang tanah akan semakin tinggi nilai tanahnya dan sebaliknya.
f) Lebar jalan di depan bidang tanah mempunyai hubungan positif terhadap nilai tanah, yang bermakna bahwa semakin lebar jalan di depan suatu bidang tanah akan semakin tinggi nilai tanahnya dan sebaliknya.
g) Luas bidang tanah mempunyai hubungan positif terhadap nilai tanah, yang bermakna bahwa semakin luas suatu bidang tanah akan semakin tinggi nilai tanahnya dan sebaliknya.
Hasil uji a priori ekonomi dapat dilihat pada Tabel III-6 berikut:
Tabel III-6 Uji a priori Ekonomi
No Variabel Eksogen Aditif (x) Aditif (1/x) Multiplikatif
(x)
Multiplikatif (1/x)
1 ITC Kebon Kalapa 17,697*
2 Pasar Kota Kembang 59,041*
3 SMK Pasundan 1 27,297* -38,483,425*
4 SDS YAY Dewi Sartika -37,171 2,665,698,598
5 JL Moh Toha 2,163*
6 SMP Negeri 43 -67,836 680,412,101 -0.696 0.696
7 SDS Bina Talenta 744,595,547
56
9 JL BKR 44,696,990 -0.252 0.252
10 JL Pungkur 44,616,221
11 JL Moh Ramdan 26,265,519 -0.168 0.168
12 Yogya Toserba -4,463,988,409*
13 JL Ibu Inggrit Garnasih 30,815,237
14 SMA Pasundan 1 2,080,654,125
15 JL Asia Afrika -2,315,840,332*
16 JL Dewi Sartika 91,913,963
17 SD Mochammad Toha 2,3,4 -302,002,587*
No Variabel Eksogen dan Endogen Aditif (x) Aditif (1/x) Multiplikatif (x)
Multiplikatif (1/x)
1 Puskesmas Pasirluyu -1,053
2 Lebar Jalan 310,841 301,663 0.525 0.525
3 King Shopping Centre 8,898*
4 Puskesmas Pasundan 17,169*
5 SMP Negeri 43 -26,869 699,303,058
6 SDS YAY Dewi Sartika 1,556,484,354 -0.749 0.749
7 JL BKR 38,148,520 -0.242 0.242
8 Yogya Toserba -1,436,466,410*
9 Universitas Langlangbuana -343,493,326* 0.658* -0.658*
2. Uji t
Uji ini digunakan untuk mengetahui apakah koefisien regresi secara individu berpengaruh terhadap variabel terikat. Pengujian ini dilakukan terhadap hasil regresi tahap kedua dimana semua variabel bebas sebelumnya telah lolos uji a priori ekonomi. Pengujian ini dilakukan dengan membandingkan antara nilai |t-hitung| dengan t-tabel. Jika |t-hitung| lebih besar daripada t-tabel maka dikatakan signifikan (lolos uji) dan sebaliknya (Gujarati, 2003)
Untuk melakukan pengujian t statistik, maka dilakukan regresi tahap selanjutnya dimana hanya melibatkan variabel bebas yang telah lolos pengujian a priori ekonomi sebelumnya.Hasil uji t dapat dilihat pada Tabel III-7 yang merupakan nilai |t-hitung| masing-masing variable model hasil regresi.
Tabel III-7Nilai t-hitung variabel model pada α=0,05
57
(1/x)
t tabel = 1.977 t tabel = 1.977 t tabel = 1.977 t tabel = 1.977
1 SDS YAY Dewi Sartika -2.079 5.430
2 SMP Negeri 43 1.696* 4.138 -6.117 6.117
3 SDS Bina Talenta 2.538
4 JL BKR 2.969 -2.455 2.455
5 JL Pungkur 1.892
6 JL Moh Ramdan 1.565* 1.534* -1.534*
7 JL Ibu Inggrit Garnasih 0.965
8 SMA Pasundan 1 -1.096*
9 JL Dewi Sartika 1.551*
No Variabel Eksogen dan
Endogen Aditif (x) Aditif (1/x) Multiplikatif (x)
Multiplikatif (1/x)
t tabel = 1.977 t tabel = 1.977 t tabel = 1.977 t tabel = 1.977
1 Puskesmas Pasirluyu 3.207
2 Lebar Jalan 6.239 7.095 5.368 5.368
3 SMP Negeri 43 1.304* 5.114
4 SDS YAY Dewi Sartika 6.346 -5.947 5.947
5 JL BKR 3.121 -1.491* 1.491*
3. Uji-F
Uji ini digunakan untuk mengetahui pengaruh variabel bebas yang digunakan dalam model secara bersama-sama terhadap variabel terikat (nilai tanah). Uji ini dilakukan dengan membandingkan nilai F-hitung dengan nilai F-tabel. Uji ini menggunakan uji dua sisis, dengan derajat kebebasan (degree of freedom) df1 = k-1 dan df2 = (n-k), dimana k adalah jumlah variabel independent dan
dependent dan n adalah jumlah sampel. Jika nilai F-hitung> nilai F-tabel
maka H0 ditolak (semua variabel bebas bukan merupakan penjelas yang
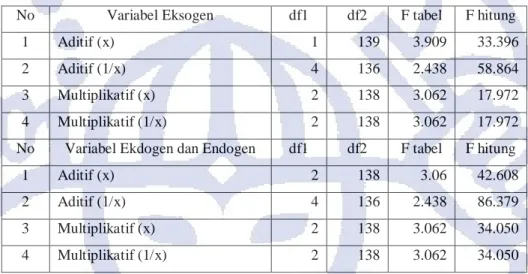
signifikan terhadapa variabel terikat), dan menerima Ha yaitu semua variabel bebas secara simultan merupakan penjelas yang signifikan terhadap variabel terikat (Gujarati, 2003). Untuk melakukan pengujian F statistik, maka dilakukan regresi tahap selanjutnya dengan hanya melibatkan variabel yang lolos uji sebelumnya. Hasil uji-F dapat dilihat pada Tabel III-8 berikut:
58
Tabel III-8 Hasil Uji-F (tes dua sisi pada α=0,05)
No Variabel Eksogen df1 df2 F tabel F hitung
1 Aditif (x) 1 139 3.909 33.396
2 Aditif (1/x) 4 136 2.438 58.864
3 Multiplikatif (x) 2 138 3.062 17.972
4 Multiplikatif (1/x) 2 138 3.062 17.972
No Variabel Ekdogen dan Endogen df1 df2 F tabel F hitung
1 Aditif (x) 2 138 3.06 42.608
2 Aditif (1/x) 4 136 2.438 86.379
3 Multiplikatif (x) 2 138 3.062 34.050
4 Multiplikatif (1/x) 2 138 3.062 34.050
4. Uji Multikolinieritas
Uji ini digunakan untuk mengetahui adanya hubungan linier diantara variabel-variabel bebas dalam model regresi yaitu ditunjukkan dengan adanya derajat kolinieritas yang tinggi di antara variabel-variabel bebas. Dengan kata lain merupakan keadaan dimana satu atau lebih variabel bebas dapat dinyatakan sebagai kombinasi dari variabel bebas lainnya.
Salah satu cara untuk mendeteksi masalah multikolinieritas yaitu dengan melihat nilai VIF (Variance Inflation Factor) dari variabel bebas. Jika nilai VIF < 10 maka hasil tersebut mengundikasikan bahwa tidak terdapat gejala multikolinieritas yang serius (berderajat rendah).
Untuk melakukan pengujian multikolinieritas, maka dilakukan regresi tahap berikutnya dimana hanya melibatkan variabel beas yang telah lolos pengujian sebelumnya. Nilai VIF variabel pada masing-masing model dapat dilihat pada Tabel III-9 berikut:
Tabel III-9 Nilai VIF Masing-Masing Variabel
No Variabel Eksogen Aditif
(x) Aditif (1/x) Multiplikatif (x) Multiplikatif (1/x)
1 SDS YAY Dewi Sartika 1.000 2.236
2 SMP Negeri 43 2.244 1.026 1.026
59
4 JL BKR 1.084 1.026 1.026
No Variabel Eksogen dan Endogen Aditif (x) Aditif (1/x) Multiplikatif (x) Multiplikatif (1/x) 1 Puskesmas Pasirluyu 1.015 2 Lebar Jalan 1.015 1.048 1.005 1.005 3 SMP Negeri 43 2.245
4 SDS YAY Dewi Sartika 2.209 1.005 1.005
5 JL BKR 1.033
5. Uji heteroskedastisitas
Heteroskedastisitas adalah suatu keadaan adanya varian yang tidak konstan dari variabel pengganggu. Dalam penelitian ini fenomena heteroskedastisitas dilakukan dengan Uji Glejser, yaitu dengan meregresikan variabel-variabel bebas terhadap nilai absolut residualnya(Gujarati, 2003). Setelah itu dilihat angka signifikansi variabel tersebut. Jika lebih besar dari nilai α yang digunakan maka variabel tersebut bebas dari heteroskedastisitas. Berdasarkan pengujian heteroskedastisitas diperoleh hasil pengujian seperti terlihat pada Tabel III-10 yang merupakan nilai signifikansi masing-masing variabel terhadap model.
Tabel III-10 Nilai Signifikanasi Masing-masing Variabel Terhadap Model
No Variabel Eksogen Aditif
(x) Aditif (1/x) Multiplikatif (x) Multiplikatif (1/x)
1 SDS YAY Dewi Sartika .000* .243
2 SMP Negeri 43 .274 .343 .303
3 SDS Bina Talenta .820
4 JL BKR .456 .303 .303
No Variabel Eksogen dan Endogen Aditif (x) Aditif (1/x) Multiplikatif (x) Multiplikatif (1/x) 1 Puskesmas Pasirluyu .000* 2 Lebar Jalan .003* 0.078 0.209 0.209 3 SMP Negeri 43 0.094
4 SDS YAY Dewi Sartika 0.995 0.962 0.962
5 JL BKR 0.07
60 Setelah malalui berbagai pengujian model maka didapatkan model akhir yang telah memenuhi aturan-aturan pembentukan model. Pemilihan model regresi dilakukan didasarkan nilai koefisien determinansi (R2) dari model yang tersisa yang ditunjukkan pada Tabel IV-11 berikut:
Tabel III-11Nilai Koefisien Determinansi Masing-masing Model Regresi
No Variabel Eksogen R2 Std Error
1 Aditif (1/x) 0.623 1654827.403
2 Multiplikatif (x) 0.195 0.747
3 Multiplikatif (1/x) 0.195 0.747
No Variabel Ekdogen dan Endogen R2 Std Error
1 Aditif (1/x) 0.573 1760552.108
2 Multiplikatif (x) 0.321 0.686
3 Multiplikatif (1/x) 0.321 0.686
f. Validasi model ditujukan untuk mengetahui seberapa akurat model terpilih untuk memprediksi nilai tanah di wilayah penelitian. Validasi dilakukan dengan menerapkan model terhadap data testing. Hasil validasi model dapat dilihat pada Tabel III-12 berikut:
Tabel III-12 Hasil Validasi Model Regresi No Uraian Data Validasi Batasan
1 PRD 1,41 0,98 < x < 1,03
2 COD 36,6 x ≤ 20%
3.4.2 Pengolahan Data Menggunakan Metode Jaringan Syaraf Tiruan
Pengolahan data menggunakan metode JST dibagi dalam 2 (dua) tahap yaitu tahap pembentukan model dan tahap validasi model. Tahap pengolahan data metode JST dapat dilihat pada Gambar III-11 berikut:
61
Gambar III-14 Tahap Pengolahan Data Metode Jaringan Syaraf Tiruan
Pemodelan dengan menggunakan metode regresi terdiri dari beberapa tahap di bawah ini:
a. Normalisasi Data (Preprocessing)
Proses Training pada JST akan lebih efisien dan efektif apabila data-data yang masuk berada pada suatu range tertentu. Menyajikan data mentah secara langsung pada JST akan membuat neuron mengalami saturasi dan gagal melakukan training. Oleh karena itu, data input harus melalui proses normalisasi terlebih dahulu sehingga berada pada range yang sama dengan fungsi aktivasinya, yaitu antara 0 sampai 1. Proses normalisasi dilakukan dengan menggunakan Persamaan II-17
62 Tahapan seleksi variabeldimaksudkan untuk mendapatkan variabel-variabel yang mempengaruhi nilai tanah secara signifikan, untuk digunakan dalam pemodelan.Di dalam JST dikenal suatu algoritma dalam penyeleksian variabel yang disebut dengan Input Variabel Selection Method (IVS).Algoritma IVS diklasifikasikan dalam tiga kelas utama yaitu wrapper, embedded danfilter(May, Dandy, & Maier, 2011). Dalam penelitian ini algoritma IVS yang digunakan adalah wrapper.
Gambar III-15 Wrapper
Algoritma wrapper adalah yang pertama dari 3 kelas dasar dalam algoritma penyeleksian variabel input untuk JST. Wrapper adalah metode IVS yang paling sederhana untuk diformulasikan. Efisiensi dari metode wrapper bergantung pada kemampuan model dalam merepresentasikan hubungan antar data, salah satu teknik yang banyak digunakan dalam metode wrapper adalah Single Variable Regression (SVR). Pendekatan SVR adalah dengan cara mengkonstruksi model JST menggunakan masing-masing variabel kandidat dan kemudian diurutkan berdasarkan performansi dan kekuatan modelnya. Kekuatan model disini direpresentasikan dalam nilai koefisien determinansi (R2). Variabel yang dapat menghasilkan model JST dengan koefisien determinansi lebih dari 50% terpilih sebagai variabel input untuk model utama JST. Hasil seleksi variabel dapat dilihat pada Tabel III-13 berikut:
Tabel III-13 Hasil Analisis Determinansi Variabel dengan Jarak Asli
No Kode Variabel R2
Pusat Perdagangan
1 CBD1 ITC Kebon Kalapa 0.393
2 CBD2 Yogya Toserba 0.678*
63
4 CBD4 Plaza Parahyangan 0.591*
5 CBD5 Palaguna Plaza 0.503*
6 CBD6 Alun Alun 0.578*
7 CBD7 Pasar Kota Kembang 0.780*
Fasilitas Kesehatan
8 K1 Rumah Sakit Sartika Asih 0.651*
9 K2 Klinik Bali Pengobatan YPPKK 0.666*
10 K3 Puskesmas Pasirluyu 0.601*
11 K4 Puskesmas Mohammad Ramdan 0.530*
12 K5 Klinik Aviati 0.718* 13 K6 Puskesmas Pasundan 0.567* Sarana Pendidikan 14 P1 SD Mengger Girang 1,2 0.698* 15 P2 SMA 11 Maret 0.617* 16 P3 SD BBK Priangan 3,5 0.719* 17 P4 SMA Negeri 11 0.378
Tabel III-13 (Lanjutan) Sarana Pendidikan
18 P5 SDN Pasir Jaya 0.748*
19 P6 SDS Bina Talenta 0.324
20 P7 SMA Muhammadiyah 1 0.658*
21 P8 SDS, SMAK Kalam Kudus 0.383
22 P9 SD Ciateul 0.566*
23 P10 Universitas Langlangbuana 0.519*
24 P11 SD Mochammad Toha 2,3,4 0.328
25 P12 SDS Yos Sudarso 0.474
64
27 P14 SMP Negeri 3 0.317
28 P15 SMP Negeri 10 0.473
29 P16 SMEA Pasundan 0.505*
30 P17 SMK Pasundan 1 0.473
31 P18 SDS YAY Dewi Sartika 0.753*
32 P19 SDS Assalam 1,2 0.603* 33 P20 SMP Negeri 43 0.700* 34 P21 SMA Pasundan 1 0.578* 35 P22 SD Kotabaru 0.485 Jalan 36 J1 JL Soekarno Hatta 0.692* 37 J2 JL Asia Afrika 0.51* 38 J3 JL Moh Ramdan 0.638* 39 J4 JL Moh Toha 0.205 40 J5 JL Otista 0.669* 41 J6 JL BKR 0.577* 42 J7 JL Pungkur 0.148 43 J8 JL Dewi Sartika 0.65* 44 J9 JL Kepatihan 0.621*
45 J10 JL Ibu Inggrit Garnasih 0.271
46 J11 JL Dalem Kaum 0.46 47 J12 JL Balonggede 0.471 Endogen 49 LD Lebar Depan 0.238 50 LJ Lebar Jalan 0.277 51 LU Luas 0.511* c. Pembentukan Model
1. Perancangan Arsitektur Jaringan
Model JST yang digunakan pada penelitian ini menggunakan jenis Multi Layer Perceptron (MLP). Jaringan terdiri dari lapisan masukan dengan jumlah node sesuai dengan banyaknya variabel. Dua lapisan tersembunyi dan sebuah lapisan keluaran dengan 1 (satu) node. Lapisan keluaran pada jaringan syaraf tiruan hanya mempunyai satu node. Nilai node tersebut merupakan prediksi nilai tanah model jaringan syaraf tiruan.
65 Untuk mendapatkan struktur JST yang paling optimal dilakukan beberapa tahap pengujian yaitu:
a) Uji pengaruh learning rate, mse goal, dan momentum.
Pengujian ini bertujuan untuk mendapatkan nilai faktor pembelajaran yang paling optimal untuk pembentukan model nilai tanah. Pengujian dilakukan dengan beberapa variasi nilai learning rate, mse goal, dan momentumdan menganggap parameter yang lain konstan. Dari pengujian didapatkan hasil sesuai Tabel III-14 hingga Tabel III-16 berikut:
Tabel III-14 Hasil Pengujian Learning Rate Learning rate (η) Waktu pembelajaran (ms)
0.2 6780 0.3 7100 0.4 7020 0.5 7030 0.6 6920 0.7 6960 0.8 7030 0.9 7120
Tabel III-15 Hasil Pengujian Mse Goal Mse goal (λ) Waktu pembelajaran (ms)
0.0001 6840
0.001 7130
0.01 7860
Tabel III-16 Hasil Pengujian Momentum Momentum (ε) Waktu pembelajaran (ms)
0.2 7470
0.3 7390
66 0.5 8220 0.6 7370 0.7 7900 0.8 8250 0.9 7760
Dalam sistem ini digunakan Learning rate0.2, mse goal 0.0001 dan
momentum 0.6
b) Uji pengaruh jumlah neuron pada hidden layer
Pengujian ini bertujuan untuk mendapatkan jumlah neuron pada hidden layeryang paling optimal untuk pemodelan nilai tanah. Untuk mendapatkan jumlah neuron pada lapisan tersembunyi yang paling optimal dilihat dari koefisien determinansipengujian jaringan pada data testing dan waktu prosesnya. Hasil pengujian pengaruh jumlah neuron pada hidden layer ditunjukkan pada Tabel III-17berikut:
Tabel III-17 Hasil Pengujian Pengaruh Jumlah Neuron Pada Hidden Layer Hidden layer 1 Hidden Layer 2 R2 Testing Waktu (ms)
10 5 0.421 6870
20 10 0.233 8630
40 20 0.240 9120
Pada sistem JST dalam penelitian ini jumlah neuronyang ditentukan untuk menempati hidden layer adalah 10 neuron pada hidden layer pertama dan 5 neuron pada hidden layer kedua.
Uji Pengaruh fungsi aktivasi
Pengujian ini bertujuan mendapatkan fungsi aktivsi yang paling optimal dalam pembentukan model. Hasil dari pengujian ini ditunjukkan pada Tabel III-18 berikut:
Tabel III-18 Hasil Pengujian Fungsi Aktivasi Fungsi aktivasi: input-hidden 1-hidden 2-output R2 Testing Sigmoid bipolar-Sigmoid biner-Identitas 0.412 Sigmoid biner-Sigmoid bipolar-Identitas 0.120 Sigmoid bipolar-Sigmoid bipolar-Identitas 0.117
67 Sigmoid biner-Sigmoid biner-Identitas 0.217
Fungsi aktivasi yang digunakan adalah fungsi sigmoid bipolar dari lapisan masukan ke lapisan tersembunyi pertama, fungsi sigmoid biner dari lapisan tersembunyi pertama ke lapisan tersembunyi kedua, dan fungsi identitas dari lapisan tersembunyi kedua ke lapisan keluaran.
c) Nilai bobot (weight) dan bias
JST belajar dengan cara meng-update bobot. Bobot yang tersimpan dari proses training akan digunakan untuk melakukan proses testing. Pada awal proses training akan dilakukan inisialisasi nilai bobot jaringan termasuk juga nilai bobot bias untuk hidden layer danoutputlayer dengan nilai yang kecil. Pada sistem JST dalam penelitian ini nilai bobot jaringan termasuk nilai bobot untuk bias ditentukan secara acak antara 0 (nol) sampai 1 (satu).
d) Iterasi maksimum
Iterasi maksimum merupakan salah satu syarat kondisi pelatihan jaringan berhenti selain toleransi error. Nilai iterasi ini nantinya akan dibandingkan dengan proses perulangan selam sistem melakukan proses training, jika toleransi error belum memenuhi juga selama beberapa waktu, maka sistem akan berhenti jika perulangan dilakukan melebihi iterasi maksimum. Pada pelatihan ini digunakan iterasi maksimum sebesar 3000.
3. Penerapan Sistem Pelatihan JST
Secara garis besar penerapan sistem pelatihan JST dalam program komputer terdapat dua tahap komputasi yaitu:
a) Tahap Belajar
Pada tahap ini proses dimulai dengan memasukkan pola-pola belajar ke dalam jaringan. Dengan mengguanakan pola-pola ini jaringan akan mengubah-ubah bobot yang menjadi penghubung antara node. Satu periode dimana seluruh pola belajar telah diproses disebut 1 (satu) iterasi. Pada setiap 1 iterasi dilakukan evaluasi terhadap keluaran jaringan. Tahap ini berlangsung pada beberapa iterasi dan berhenti setelah jaringan menemukan bobot yang sesuai dimana suatu keadaan yang diinginkan telah terpenuhi. Selanjutnya bobot ini menjadi dasar pengetahuan pada
68 tahap pengenalan. Pada tahap ini digunakan data yang digunakan adalah data training.
b) Tahap Pengenalan
Pada tahap ini dilakukan pengenalan terhadap suatu pola masukan dengan menggunakan bobot hasil tahap belajar. Tahap pengenalan dilakuakan dengan menerapkan model terhadap data testing. Akurasi model JST hasil tahap pengenalan dapat dilihat pada Tabel III-19 berikut:
Tabel III-19 Akurasi Model JST
Uraian Nilai R2 Model 0.906 RMSe Model 23476.8 R2 Uji 0.401 RMSe uji 5845047 R2 semua data 0.780 RMSe total 2625716
d. Denormalisasi Data (Postprocessing)
Nilai output yang dihasilkan oleh jaringan berkisar antara 0 (nol) sampai dengan 1 (satu) akibat dari proses normalisasi yang dilakukan sebelumnya, sehingga perlu dilakukan proses denormalisasi atau postprocessing yang berguna untuk mengkonversikan kembali hasil output jaringan menjadi nilai tanah normal.Denormalisasi data dilakukan dengan menggunakan Persamaan III-18. e. Validasi Model
Validasi model ditujukan untuk mengetahui seberapa akurat model terpilih untuk memprediksi nilai tanah di wilayah penelitian. Validasi dilakukan dengan menerapkan model terhadap data testing. Hasil validasi model dapat dilihat pada Tabel III-20 berikut:
Tabel III-20 Validasi Model JST
Uraian Data Validasi Batasan PRD 1.26 0,98 < x < 1,03