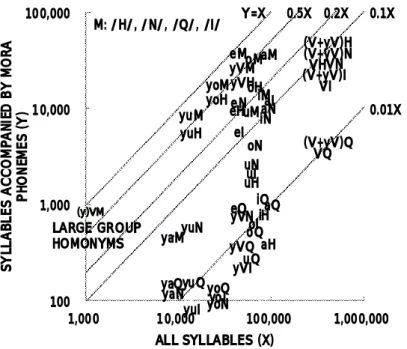
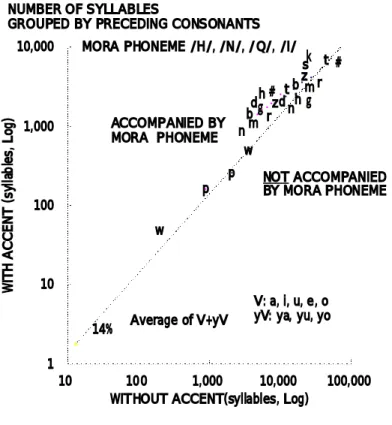
nihongo kyoiku ni okeru chu jokyu kanji goi kyoiku no kenkyu : waseda daigaku daigakuin nihongo kyoiku kenkyuka hakushi ronbun
Bebas
208
0
0
Teks penuh
(2)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)
(17)
(18)
(19)
(21)
(22)
(23)
(24)
(25)
Gambar

Dokumen terkait
Mengawali kata pengantar tugas akhir ini tiada yang lebih utama dari pada mengucapkan puji syukur kepada Tuhan Yang Maha Esa atas semua hikmat dan rahmat-Nya, penulis
Dengan demikian, filsafat ordinary language oleh Wittgenstein lebih menekankan pada aspek pragmatik bahasa, yaitu bagaimana penggunaan suatu istilah atau ungkapan
Studi yang berjudul “English Prepositional Phrases Using Prepositions “By”,“With”, and “Without” and Their Translation Equivalences in Indonesian adalah mengenai
Segala puji syukur hanya kepada Allah SWT atas segala limpah rahmat serta berkah hidayah yang telah diberikan Nya sehingga penulis dapat mneyelesaikan skripsi
Dari uraian di atas nampak bahwa masalah-masalah utama dalam konsumsi energi dan protein adalah tidak tercukupinya standar kecukupan minimum baik energi maupun protein pada
Kamis 14/05/2020 Strategi Penentuan Harga untuk Perusahaan. dengan Kekuatan Pasar dan Ekonomi Informasi
tersebut sudah menjadi tanah negara bebas.Oleh karena itu diperlukan pembuktian tertulis yang diketahui oleh Lurah atau Kepala Desa, dan Camat setempat, sehingga dapat
Selanjutnya untuk mengetahui kuantitas dan kualitas air tanah dilakukan pengukuran tinggi muka air tanah dan analisis terhadap parameter suhu, total dissolved
