Indoor navigation for the visually impaired has received a lot of attention in recent years, and the increase in research or development related to the topic. Signs and labels are actively used for indoor navigation systems; however, it is not beneficial for the visually impaired.

Problem Statement and Motivation
At the end of this project, the project will be developed with a camera that reads store brands in the mall. The project will use a camera, built-in microphone headset or earphone, and Jupyter notebook software.
Project Objectives
This project aims to help the visually impaired community to navigate on their own without much trouble. Henceforth, the visually impaired community will have equal rights with the rest of society.
Background Information
Furthermore, society will benefit from this project because it helps the visually impaired community to have a greater chance of finding employment. Finally, the visually impaired community will participate more in various activities, and society will have a positive perspective on this community.
Report Organization
4 system reduces reliance on a guide or walking stick and helps blind and visually impaired people enjoy the same privilege as the average everyday person.
Previous work of Indoor navigation for the visually impaired
- Indoor Navigation using Radio Frequency Identification (RFID)
- RGB-D camera based wearable navigation system for the visually impaired
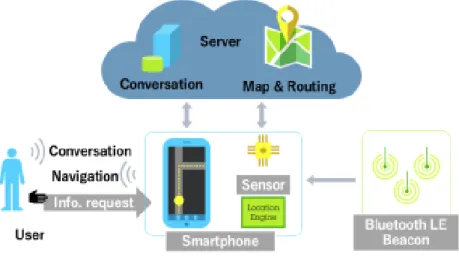
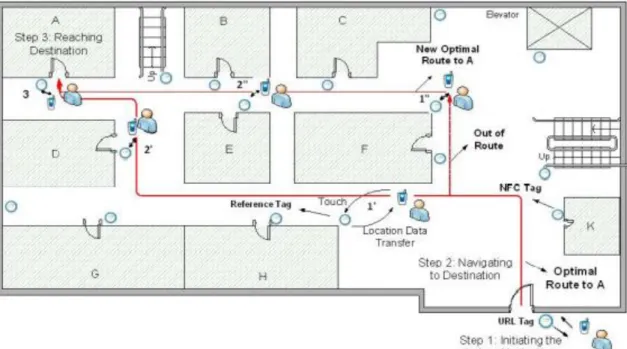
- Development of an Indoor Navigation using Near Field Communication (NFC) NFC is a bidirectional range, wireless communication technology, and figure .1 shows
- Indoor Navigation and Product Recognition for Blind People Assisted Shopping The system used a platform known as “BlindShopping” which uses a map to identify ID from
- Blind User Wearable Audio Assistance for Indoor Navigation Based on Visual Markers and Ultrasonic Obstacle Detection
- Smartphone-Based Blind Indoor Navigation Assistant with Semantic Features in a Large-Scale Environment
- Enabling Independent Navigation for Visually Impaired People through a Wearable Vision-Based Feedback System
- Indoor Navigation using Radio Frequency Identity
- RGB-D Camera Based Wearable Navigation System for Visually Impaired
- Development of an Indoor Navigation Near Field Communication (NFC)
- Indoor Navigation and Product Navigation for Blind People Assisted Shopping The limitation of this work is that the system requires visually impaired to scan QR code or
- Smartphone-Based Blind Indoor Navigation Assistant with Semantic Features in a Large-Scale Environment
- Enabling Independent Navigation for Visually Impaired People through a Wearable Vision-Based Feedback System
Based on the article, the system will interact with the visually impaired for a startup navigation task. By issuing the command "product" or drawing a "P", the system will ask the user to hold his smartphone to point at the shelf so that the camera can scan the QR code and inform the user of the product details.
![Figure 2.1.2.1 overview of the RGB-D camera based wearable navigation system [19]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216414.0/21.892.137.755.543.809/figure-overview-rgb-d-camera-based-wearable-navigation.webp)
Proposed Solution
- Programming Language- Python
- Firmware/ Operating System-Windows
- Yolo
- Convolutional Neural Network (CNN)
The IOU uses the confidence score to determine the object class which is obtained through the bounding box prediction made by each grid cell. The last layer of the CNN contains the feature losses corresponding to the classes.
![Table 2.4.3.1 Yolo techniques description [29]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216414.0/34.892.136.754.950.1127/table-yolo-techniques-description.webp)
System Evaluation Methodology .1 Confusion Matrix
- Accuracy Score
- Classification Report
- Datasets
- Timeline
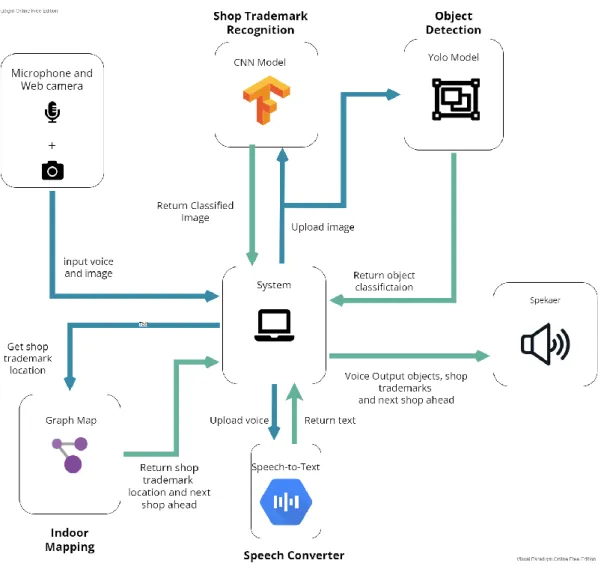
The CNN model will process the image and classify it as store brand or not as a result. In this function, it will check the current location of the store brand and find the next store ahead. The system will finally display all the results such as the item detected, the current location of the store brand and the next store in front of you.
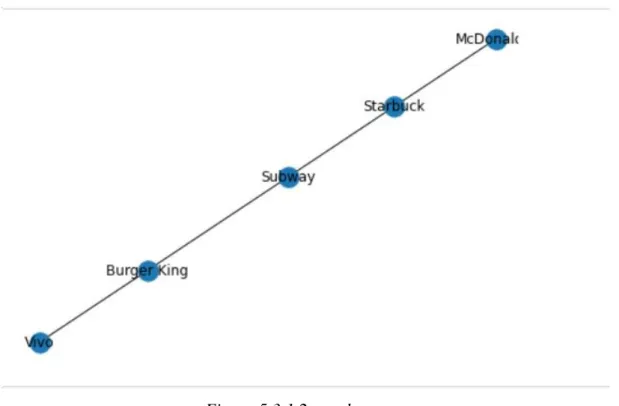
The Not Shop Trademark datasets are included to allow the CNN model to predict non-shop trademark if the camera captures random objects without any store signage. There are 14 images of Burger King, 12 images of McDonald's, 38 images that have no shop trademark and therefore are classified as Not Shop Trademark. Since there are no modals in the system that detect store brands, use these datasets to allow the CNN modal to recognize the environment without any store brand.
Project Flow Diagram
Apart from this, other features such as speech to text, voice to text, routing and next store features are implemented in the system. Finally, these features are tested to ensure the functionality of the features before the project work is completed.
System Block Diagram
- Shop Trademark Recognition
- Real Time Indoor Navigation System Methodology
- CNN Training Flow
- CNN Testing Implementation
- Graph Implementation
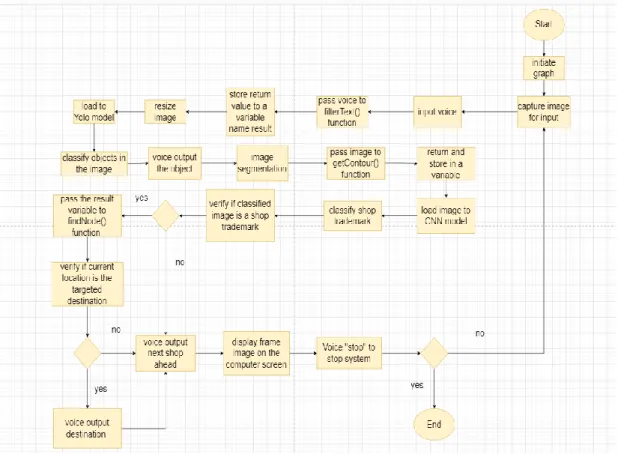
The image matrix will be predicted by the model and will produce the output. The next step will be to use a tag to mark the image on the subplot when it is displayed. Then the captured image will be saved in jpg format and saved in the system.
The image will be loaded into a variable and then the image variable will be converted to an image array. After the image is pre-processed, the model will calculate the layers of the image. The model will classify the image and compare it to the image in the validation dataset.
System Implementation
Software Setup
The Yolov3 used in this project is a pre-trained version produced by [28], where it can detect 85 objects and does not need to be retrained. This package is used in a project to create a graphic map for mapping interior spaces. The library also does not require the user to use an API (Application Programming Interface) to convert text to speech.
Pyttsx3 also works offline, which is appropriate in the project, so that it can handle text-to-speech when there is no internet. Speech Recognition is a python library that allows the user to use voice commands to instruct the system to perform a certain action. The library requires the user to train their speech to enable the system to understand the user's pronunciation.
Hardware Setup
System Operation
- Camera Display
This frame only displays the objects detected by the system, and the system will vote out the visually impaired to become aware. The system indicates that the next store goes from right to left by 1 edge. This icon indicates that the system is waiting for input voice from the visually impaired.
The visually impaired must call "computer" so the visually impaired confirm that the system is listening. If it does not visually call "computer", the system will not do anything and will continue to inform you of the brand name of the store, the object detected, the next store and the direction of the store if you arrive at the destination point. This can happen if visually impaired people speak softly or too quickly, causing the system to fail to detect the voice input.
System Evaluation and Discussion
System Testing and Performance Metrics .1 System Training result
- Test Set Predicted Result
- Confusion Matrix
- Accuracy, Recall, Precision, and F1 score Result
There were about 108 datasets in the test sets and about 14 images were falsely detected out of all. The system manages to classify images that are not trademarks at all as there are 3 images in Figure 6.1.2.1 are images of random objects. 14 images were false negatives which means that 14 images were positive images but were predicted as negative while another 14 images were false positives indicating that 14 negative images were predicted as positive images.
Since the model.evaluate() function depended on the number of steps to produce the final accuracy of the test set, it is tedious to run multiple times to obtain the final accuracy, and by using the sklearn library, the final accuracy could be obtained immediately. This indicated that the modal had high accuracy in predicting correctly on the total positive images, as 91% of the positive images were correctly predicted, while 9% of the positive images were incorrect. The modal can predict 86% actual positive images, but 14% of the images were incorrectly predicted, causing the system to falsely inform the visually impaired that they are not at the correct destination, even though they actually arrive at their targeted store.

Testing Setup and Result
- Starbuck Result
- Voice Command Result
The system managed to correctly classify the store's trademark and also managed to detect a chair in the image. For direction, the system succeeded in determining the direction and the displayed result is to the left. The direction of the store trademark is determined to be forward by the system.
The system correctly predicted the store brand and the object detected by the system is a car. The system shows the CNN model has classified the image as Starbuck, although the actual image is McDonald's. Sometimes the system can classify the environment as a store brand which is shown in figure 6.2.6.2.

Comparison of Testing Result Between Real Time and Testing datasets After running the system on the testing datasets and in real time, it shows that the
- Unresolved Challenges
- Resolved Challenges
74 When the text is split into a list of strings, the system will loop through and verify if any of the strings is a trademark. If the strings do not have any trademarks, the function will return null in the main function and the system will set "Not Shop Trademark" as the default value. Due to the implementation of speech-to-text and text-to-speech, the system will take more than 3 seconds to process the image and produce the result.
The feature requires matching the store's branding so that the system can recognize that it is on the left or right side. An object detection model may need many datasets to train and localize the object, and the model will need a GPE to run the system to allow the model to learn quickly. This pre-built Yolo model helps the system detect many objects, although some detections may be false.
Objective Evaluation
Store brand data is not widely available online, so without any of the data sets it is impossible to train the model. However, the photo taken by the phone has low resolution, which the model will need more time to train, and the number of data sets taken is not large due to the limited storage capacity. This project requires object detection so that it can inform visually impaired people about objects ahead, however training a model to detect is laborious and may require a lot of effort and time.
The pre-trained model was able to detect 85 objects and the model is compatible to run on a CPU. The direction of the store brand needs to be improved as it uses a contour and a bounding rectangle to determine the x-axis coordination. The direction should be more accurate if the system performs store brand detection, which will get a more accurate store brand direction result.
Conclusion and Recommendation
Conclusion
The system has some shortcomings such as slow performance when running Yolo, false prediction or detection by both the CNN and Yolo model. Wrong direction given by the system, therefore some recommendations are needed to improve the system in the future. Implement GPU type Yolo model for the system to process the image faster and smoother.
Train the CNN model to perform store brand detection so that the system can provide more accurate direction of the store brand and inform the visually impaired when the system has detected a store brand. Design an indoor mapping to allow the system to keep track of the visually impaired location within the mall. Implement multithreading to allow text-to-speech and speech-to-text to run simultaneously reducing system lag.
Appendix A: WEEKLY REPORT
APPENDIX B: Poster
APPENDIX C: PLAGARISM CHECK RESULT
Final year project title Indoor navigation for the visually impaired to read store trade mark. The originality parameters required and the restrictions approved by UTAR are as follows: i) The overall similarity index is 20% and below, and. ii) Match of individual sources listed must be less than 3% each and (iii) Matching texts in continuous block must not exceed 8 words. Note: Parameters (i) – (ii) will exclude quotes, bibliography and text matching that are less than 8 words.
Note Supervisor/candidate(s) are expected to provide a soft copy of the complete set of originality report to Faculty/Institute. Based on the above results, I hereby declare that I am satisfied with the originality of the Final Year Project Report submitted by my student(s) as mentioned above. Form title: Supervisor's comments on originality report generated by Turnitin for submission of final year project report (for undergraduate programs).
APPENDIX D: CHECKLIST
UNIVERSITI TUNKU ABDUL RAHMAN
![Figure 2.1.3.1: overview of the RGB-D camera based wearable navigation system [2]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216414.0/23.892.133.724.324.576/figure-overview-rgb-d-camera-based-wearable-navigation.webp)
![Figure 2.1.4.2 shows the BlindShopping distributed architecture that was done by the author [6]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216414.0/26.892.236.645.104.333/figure-shows-blindshopping-distributed-architecture-author.webp)
![Figure 2.1.5.2:the propose software architecture [18],](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216414.0/26.892.249.667.778.1062/figure-the-propose-software-architecture.webp)