It is hereby certified that Yong Hong Long (ID No: 19ACB05614) has completed this final year project titled "Anomaly Detection with Attention-Based Deep Autoencoder" under the supervision of Ts Dr Tan Hung Khoon (Supervisor) from the Department of Computer Science, Faculty of Information and Communication Technology directed by this report. Detection with ATTENTION-BASED DEEP AUTOENCODER” is my own work, except as cited in the references. Tan Hung Khoon who has given me this great opportunity to be involved in an anomaly detection project.
Anomaly detection has become one of the most trending topics in the information technology domain. Second, it is not practical to train an anomaly detection model with a huge amount of data in actual implementation. During the experiments, improvement can be observed by implementing the attention mechanisms on the baseline autoencoder and thus improving the accuracy of the anomaly detection.
LIST OF ABBREVIATIONS
INTRODUCTION
INTRODUCTION
- Anomaly Detection
- Problem Statement and Motivation
- Project Scope and Objectives .1 Project Scopes
- Project Objectives
Most of the anomaly detection model is in unsupervised mode because the abnormal data is often limited, ie. there are many more normal data than irregular data, since anomalies are rare in nature. However, the use of anomaly detection in videos is not popular due to its reliability. The inspiration for adding an attention mechanism to the anomaly detection model came from understanding this observation.
This project aims to emulate video anomaly detection models by building a deep learning model capable of performing anomaly detection on images. The flow of the proposed anomaly detection model should be as follows, the input is first changed and converted into the desired input format of the model. The goal of this project is to emulate the video anomaly detection model using a similar setup from [4] to build a Conv2D deep autoencoder for processing images.
![Figure 1-2: Anomalies in a two-dimensional dataset where the region with the minority of data points are anomalies [2]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/13.892.284.606.116.397/figure-anomalies-dimensional-dataset-region-minority-points-anomalies.webp)
LITERATURE REVIEW
LITERATURE REVIEW
- Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection [4]
- Memory-augmented Autoencoder
- Memory Module in MemAE
- Limitations and Proposed Solutions
- Few-Shot Scene Adaptive Anomaly Detection [7]
- Problem Setup
- Meta-learning Framework
- Convolutional Block Attention Module [10]
- Learn to Pay Attention [11]
The MemAE is an improved version of the autoencoder by adding a memory module in the middle of the encoder and decoder as shown in Figure 2-1. Similarly, the MemAE also has an encoder and decoder, but the output of the encoder (encoding) is not directly fed into the decoder, but used as a query to retrieve the most relevant items in memory via the attention-based sparse addressing, the retrieved item is then sent to the decoder for reconstruction. Because of the limited memory size and the sparse addressing technique, only a limited number of memory items can be addressed each time.
We understand that MemAE captures the important features (prototypical normal pattern) of the input data and stores them in the memory module, and then uses them to reconstruct the frame and detect anomalies based on the reconstruction error. Given an abnormal input frame, in Section 1.2 we demonstrated the concept of anomaly locality, where the exact region of the abnormal action is often occupied by only a limited portion of the input. Therefore, we want to include an attention mechanism on autoencoders, and an irregular input area could attract the attention of autoencoders.
The frame prediction-based anomaly detection model can also be denoted as fθ = x → y, where θ is the parameter of the model. Finally, the model takes the remaining frames of the video (except those for training). 10] introduced the Convolutional Block Attention Module (CBAM) as an attention mechanism that can boost model performance.
The input function can see it as a feature map from a convolution layer, and the refined feature is the enhanced feature map with characteristics of the image highlighted on it, such as edges, colors, background, etc. First, F' goes through the Channel Pool and it is decomposed into 2 channels (2 * h * w), where each of the 2 channels channel will be used by max pooled to max.chan. The proposed approach of [4] is as follows, intermediate outputs (feature maps) of the CNN model are taken out and act as local descriptors li of the input, and they are used to contribute to the final classification step proportionally to its compatibility with the final output (global image descriptor g) of the CNN model.
The match score measure will depend on the span between li and g in the high-dimensional feature space and the activation intensity of li.
![Figure 2-2: An overview of the Model-Agnostic Meta-Learning algorithm for Scene-Adaptive Anomaly Detection [7]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/20.892.143.750.330.717/figure-overview-agnostic-learning-algorithm-adaptive-anomaly-detection.webp)
PROPOSED APPROACH
PROPOSED APPROACH
- System Requirements
- System Design
- General Flow of Proposed Model
- Attention Mechanism
- Model Architecture
- Baseline Deep Autoencoder
- CBAM-based Deep Autoencoder
- Attention-based Deep Autoencoder
Then the refined feature map goes through the convolutional encoder layer and CBAM in a similar process, producing a more refined feature map for the latent representation space. For the attention mechanism proposed by [11], the attention calculation block takes the intermediate encoder outputs and sums them with the final encoder output to produce a similarity weight. Then the similarity weight is used to improve the intermediate outputs of the encoder and is then fed into the bottleneck layer of the autoencoder.
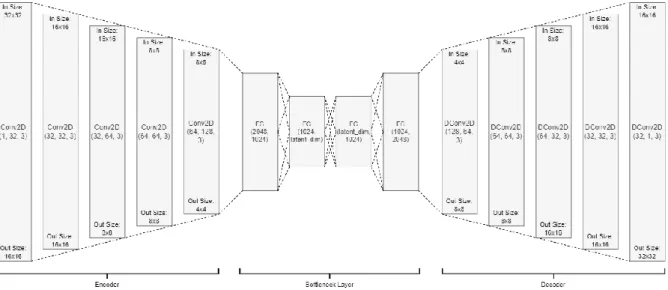
The encoder consists of five 2D convolutional (Conv2D) blocks, and each block contains a 2D convolutional layer, a 2D batch normalization layer, and a Leaky Rectified Linear Unit (Leaky ReLU) activation layer with a negative slope of 0.2. The number of input channels, output channels and kernel size of the convolutional layers are shown in the figure (input, output, kernel). It serves to learn the extracted functions from the encoder, and can be thought of as a space containing the latent representation of the input.
The next 2 models proposed in this project are attention-based and are implemented on the base model encoder to improve the model to pay attention to and learn from the most representative features of the input. The second model proposed in this project is inspired by [10], where CBAM is implemented on the model encoder. The output of the second Conv2D block will pass through the CBAM block 1 to obtain a refined output.
The output is refined again by the CBAM block 2 when the function maps of the fourth Conv2D block are obtained. The fifth Conv2D block receives twice-refined function maps and feeds them into latent representation space to learn about function-emphasized outputs. The output of the second Conv2D and fourth Conv2D blocks is extracted and fed into attention block 1 and attention block 2, respectively.
The attention calculation takes place in the blocks where the intermediate feature maps will be enhanced by the global feature maps, after which the output is concatenated and fed into the bottleneck layer.
EXPERIMENTS
EXPERIMENTS
- Experiment Settings
- Dataset
- Training and Evaluation Setup
- Experiment with Different Model Settings MNIST dataset is used for each experiment
- Anomaly Detection Performance Analysis
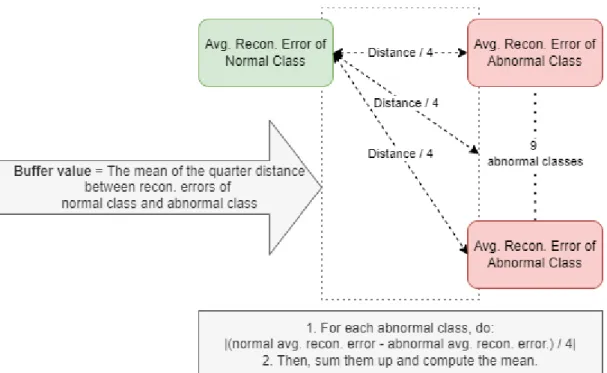
The set size used is 256 with 50 epochs, the early stopping mechanism is implemented where the model will stop training when convergence is reached. The proposed threshold value is obtained by calculating the normal class reconstruction error using training data, with an addition of a buffer value above it to allow more samples to be correctly identified. The proposed buffer value is the average of the quarter distance between the average reconstruction loss of the normal class and the average reconstruction loss of the abnormal classes.
Supposing there are n number of abnormal classes, 𝛼 denotes the average reconstruction loss of the abnormal class, 𝛽 denotes the average reconstruction loss of the normal class, then this can be expressed in . Any reconstruction error between the original input and the reconstructed input higher than the threshold is considered anomalies, and vice versa. Note that the average reconstruction loss is calculated here using training data, but not test data to boost.
In addition to detecting anomalies, we can also examine how well the model can reconstruct an image by observing the reconstructed image and the original image with naked eyes, and the reconstruction error is also calculated for a more accurate evaluation. During training with the MNIST dataset, the training loss of each time slot is tracked. Then, unseen normal class data is fed into the model to obtain mean evaluation loss to check if the model is overequipped with the training set.
Finally, the average reconstruction error is calculated using the training data of the normal class and a buffer value is added to act as an abnormal detection threshold. According to the results, the CBAM-based auto-encoder is generally the most successful model as it has the smallest reconstruction error when reconstructing normal class data and produces the largest reconstruction error when reconstructing abnormal class data. Using only the average reconstruction error of the normal training data, each model gives us a precision of 1,000, but a somewhat low recall rate, meaning that it allows too much abnormal data to be categorized as normal data.
Always remember that there is no absolute answer as to which threshold value is the best, it depends entirely on the model's usage.
CONCLUSION
CONCLUSION
APPENDIX
- Reconstruction Results of Unseen Data using Models Trained on Class “1” Data Baseline
- Reconstruction Results of Unseen Data using Models Trained on All Training Data Baseline
- Training Loss of each Model Baseline
- Confusion Matrices of the Models using Models Trained on Class “1” Data Baseline
- Confusion Matrices of the Models using Models Trained on Class “1” Data with Buffered Threshold Values
- Overall Precision-recall Curve using Models Trained on Class “1” Data
- Overall Precision-recall Curve using Models using Models Trained on Class “1”
Confusion matrices of the models using models trained on Class "1" data with buffered thresholds Buffered thresholds.
FINAL YEAR PROJECT WEEKLY REPORT
- WORK DONE
- WORK TO BE DONE
- SELF EVALUATION OF THE PROGRESS Progress too slow
- PROBLEMS ENCOUNTERED
- SELF EVALUATION OF THE PROGRESS Too slow, need pace up
- SELF EVALUATION OF THE PROGRESS
I researched Dong Gong's work in depth and found it too difficult. The original idea of IIPSPW and FYP I is too difficult to achieve and plans to reduce the scope of the project.
POSTER
PLAGIARISM CHECK RESULT
The originality parameters required and the restrictions approved by UTAR are as follows: i) The overall similarity index is 20% and below, and. ii) Match of individual sources listed must be less than 3% each and (iii) Matching texts in continuous block must not exceed 8 words. Note: Parameters (i) – (ii) will exclude quotes, bibliography and text matching that are less than 8 words. Note The Supervisor/Candidate(s) must/are required to provide the Faculty/Institute with a full copy of the complete set of originality report.
Based on the above findings, I hereby declare that I am satisfied with the originality of the final project report submitted by my students as mentioned above. Form Title: Supervisor's Comments on Originality Report Generated by Turnitin for Final Project Report Submission (for undergraduate programs).
UNIVERSITI TUNKU ABDUL RAHMAN
![Figure 1-1: Anomaly where the data pattern does not conform with expected behaviour [6]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/12.892.217.670.781.994/figure-anomaly-data-pattern-does-conform-expected-behaviour.webp)
![Figure 1-3: Anomaly locality in a household burglary video [5].](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/14.892.290.606.854.1085/figure-anomaly-locality-household-burglary-video.webp)
![Figure 2-1: An overview of the Memory-augmented Autoencoder [4].](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/17.892.143.749.245.506/figure-overview-memory-augmented-autoencoder.webp)
![Figure 2-3: Summary of the meta-training phase [7].](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/22.892.175.717.781.1003/figure-summary-meta-training-phase.webp)
![Figure 2-4: The overall view of Convolutional Block Attention Module [10].](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/23.892.127.767.275.463/figure-overall-view-convolutional-block-attention-module.webp)
![Figure 2-5: Channel Attention Module [10].](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/23.892.116.775.677.828/figure-channel-attention-module.webp)
![Figure 2-6: Spatial Attention Module [10].](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/24.892.146.756.191.401/figure-spatial-attention-module.webp)
![Figure 2-7: The overview of the attention mechanism introduced by [11].](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216502.0/24.892.174.727.822.1051/figure-overview-attention-mechanism-introduced.webp)
