This is to confirm that ___ Ong Zi Leong ___ (ID No: __18ACB02522 ) has completed a final year project entitled “__Text Recognition (OCR) for digitizing patient records using CNN___” under the supervision of __Dr. Aun YiChiet__ (Supervisor) from _Computer and Communication Technology_ Department, Faculty of _Information and Communication Technology_. I understand that the University will upload an electronic copy of my final year project in pdf format to the UTAR Institutional Repository, which will be readily accessible to the UTAR community and the public.
I would also like to thank my family and friends who have often supported me and motivated me to complete this project. Although current OCR methods can accurately transcribe printed (structured) text, they often fail to recognize unstructured or handwritten text. This project proposed a text recognition method to recognize handwritten text on clinical patient data using Convolutional Neural Network (CNN).
The preliminary results showed that the proposed model achieved a classification accuracy of 93.75%, while Tesseract (the advanced OCR) scored 69.79%.
Introduction
- Problem Statement and Motivation
- Project Scope
- Project Objectives
- Impact, significance and contribution
- Background information
- Patient Management System
- Convolutional Neural Network (CNN)
- Optical Character Recognition (OCR)
- Report Organization
The project aims to use computer vision to digitize patient data from paper records to develop a patient management system to handle general tasks in the clinic and. Patient information in the paper-based record can be scanned and converted to the machine-coded file. With this technology, the time required for data transformation can be reduced and at the same time reduce the human error in data processing.
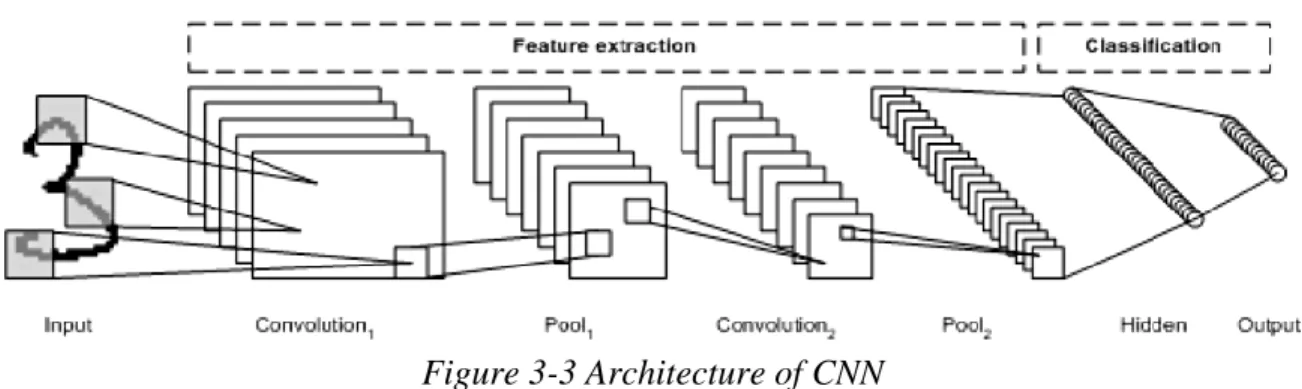
Before a patient management system is established, patient information will be recorded on paper and stored in physical storage facilities. Convolutional Neural Network (CNN) is a popular deep learning algorithm proposed by Yann LeCun in the late 90s. The convolution operation will pass through the activation function to learn complex patterns in the data.
Using OCR, text can be extracted in the form of image files or PDF files.
Literature Review
Overview of existing OCR engines
- Tesseract
- Google Cloud Vision
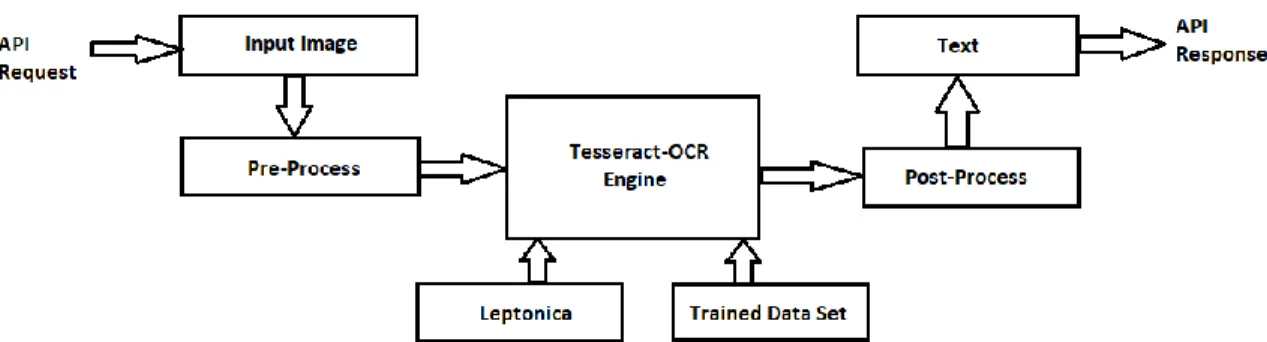
Faculty of Information and Communication Technology (Kampar Campus), UTAR 8 Figure 2-1 shows the flow of the OCR system. Each input image must go through a pre-processing process to improve the quality of the image. Techniques such as resizing, binarization, denoising and image rotation help to adjust the image quality for better further processing.
Although Tesseract is a powerful engine for converting text to machine coded formats, it does not have the same accuracy in recognizing handwritten text. There are 2 main annotations to help with text recognition which are TEXT_ANNOTATION and DOCUMENT_TEXT_DETECTION [6]. For DOCUMENT_TEXT_DETECTION, it's the same as TEXT_ANNOTATION, except it's built specifically for densely displayed text files like scanned books, and the output JSON file will contain the information in paragraphs, divisions, and blocks.
Similar to the Tesseract engine, DOCUMENT_TEXT_DETECTION in Google Cloud Vision can recognize handwritten text, but the output is not expected to be very high and accurate.
Comparison between existing OCR engines
Faculty of Information and Communication Technology (Kampar Campus), UTAR 10 According to Figure 2-2, although Google's text recognition model did not detect some lines of text, the segmentation of text recognition was better compared to document text recognition. In summary, both OCR algorithms are excellent at recognizing and detecting written text in images. However, both engines need to be further improved to achieve better accuracy in handwritten text recognition.
Review on related work
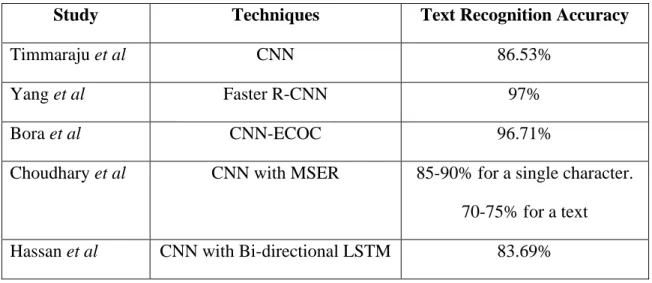
Faculty of Information and Communication Technology (Kampar Campus), UTAR 11 Yang et al. 2019) have proposed a faster R-CNN based method for handwritten text recognition. The Faster R-CNN performs well in object detection and can be considered a hybrid of Region Proposal Networks (RPNs) and Fast R-CNN [11]. They preprocessed handwritten text using VGG-19 as a pre-training model for Faster R-CNN and use CNN for character recognition.
Once the feature has been extracted from the input images, RPNs are used to generate possible candidate frames for the targets and feed the results to the Region of Interest (ROI) fusion layer to compute feature maps. As a consequence, they achieved high accuracy in character segmentation by converting character segmentation to object detection using Faster R-CNN. They achieve 99% for word character segmentation rate, 95% for letter character segmentation rate, and an average of 97% in character recognition.
In conclusion, they divided the problems into several subproblems and the results proved effective for the complex handwritten text recognition task. The ECOC classifier is trained with the features extracted from the input image and assigns them to all binary learners trained with a linear Support Vector Machine (SVM), where one category is positive and the other categories are negative. The results in the ECOC classifier are then translated into code words and compared to the generated coding matrix table.
They observed a 0.6% improvement in testing accuracy and achieved 97.71% accuracy in both training and testing after the trained AlexNet features were fed into the ECOC classifier. Faculty of Information and Communication Technology (Kampar Campus), UTAR 12 Choudhary et al. 2018) have proposed an approach using Maximum Stable Outer Regions (MSER) for text region detection and CNN for character recognition. The proposed technique achieves a recognition rate of 85-90% for individual characters and 70-75% for the overall text recognition rate of a single image. 2019) have used two-way Long-Short-Term Memory (LSTM) as classifier and CNN for character segmentation.
While for handwritten text, the sliding window technique is used to cross the text line for character segmentation and the values are fed into RNN to learn the shape of the character, Faster has proposed to use R-CNN to detect the block in the documents. Based on Table 2-2, the Faster R-CNN proposed by Yang et al. achieved the highest accuracy in text recognition among the reviewed papers.
Proposed Approach
- Datasets
- Methodology
- Model Overview
- Implementation Issues and Challenges
- Timeline
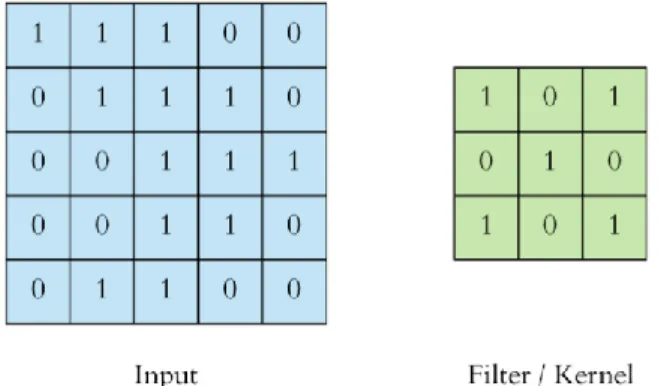
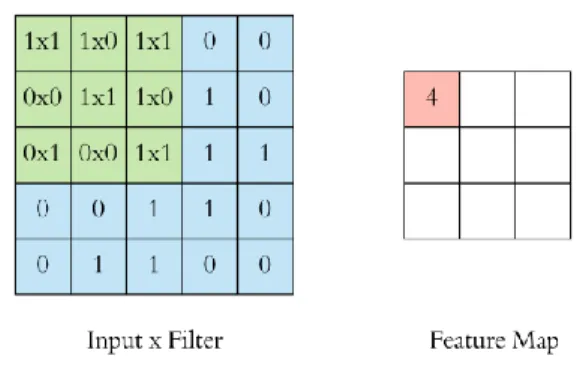
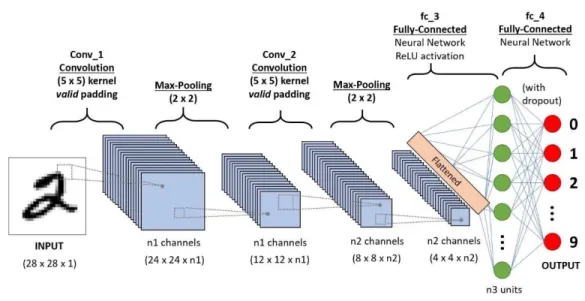
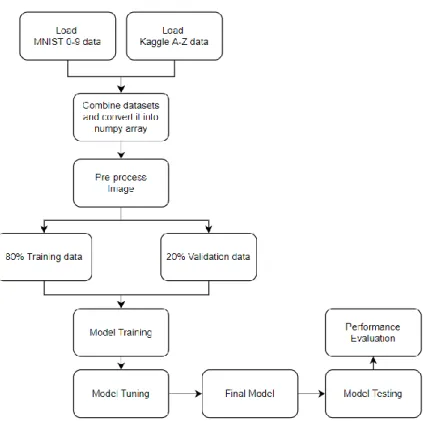
If the output is unsatisfactory, certain modifications, such as hyperparameter tuning and data augmentation, are made to improve the accuracy of the model. Finally, performance evaluation is performed to check the results of the model using several methods such as confusion matrix, F1 score, precision and recall. 32 (3x3) filter was assigned to slide over the input image to extract the feature of the image and generate the feature map.
The depth of the feature map is determined by the number of filters set for our layer. So, as a result of the convolutional layers, a total of 32 layers of feature maps are produced for our case. So after the second hidden layer, the output size of the merged convolution layer changes from (24x24x26) to (12x12x64) for our case.
The output layer scores of the model are then fed into this function to calculate the classification probabilities for each class. The score for each class from the output layer is passed to a function that calculates its exponential value and divides it by the sum of the exponential values of all classes to obtain the final probability. zi represents the score we want to calculate and the denominator is the sum of the exponential of all zk values to obtain the final result.
The result of the Softmax function is modified by the scores of the other classes in the output layer. Evaluation measures are used to determine the performance of the model based on our training. To calculate the accuracy of our classifier, the total true predicted number is divided by the total number of the data.
The precision then indicates how many of the positive predictions in the class are correct. In addition, this can lead to poor prediction results and reduce the accuracy of the prediction.
Experimental Setup and Result
- Overview
- Performance evaluation
- Text Predictions on Plain Text
- Comparison between the proposed model and Tesseract engine
- Text Predictions on Patient Medical Record Form
- Extracting Region of Interest
- Evaluation of Model Prediction for Patient Medical Records
- Time consumed on manual transcribe and AI transcribe
- Error rate between manual transcribe and AI transcribe
- Future Remarks
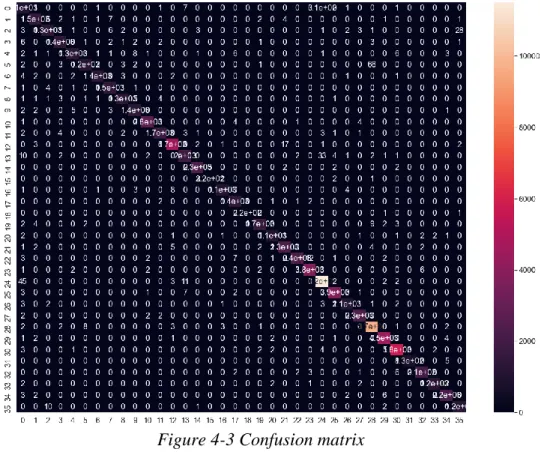
Faculty of Information and Communication Technology (Kampar Campus), UTAR 24 An increase in the losses in the validation data indicates a slight overfitting of the model. The table above shows the classification report of the proposed models, including accuracy, F1 score, precision and recall for each class. As a result, we need to crop the region of interest and enter it into the model for prediction.
Faculty of Information and Communication Technology (Campus Campus), UTAR 28 Figure 4-4 The original form of the patient's medical documentation. Faculty of Information and Communication Technology (Kampus Kampus), UTAR 29 Figure 4-5 Mask created over the region of interest. Faculty of Information and Communication Technology (Campus Campus), UTAR 30 According to Figure 4-5, the region of interest is masked with a rectangle that indicates the location where text detection and recognition is required.
A total of 50 patient medical charts with all the different data are sent to the model for prediction. The cropped images will be sent to the model, and after a certain pre-processing process, the accuracy of text recognition will be tested. Some incorrect results exist due to system confusion for the characters o or 0, z or 2.
Faculty of Information and Communication Technology (Kampar Campus), UTAR 31 4.5 Time spent on hand transcribing and AI transcribing. The model was evaluated by comparing the process time of manual transcription and artificial intelligence transcription. To evaluate the effectiveness of the model built on the transcription of the patient's medical records into xml files, 50 examples of medical reports were provided as input to the model.
Faculty of Information and Communication Technology (Kampar Campus), UTAR 32 Figure 4-8 XML file generated by website. Faculty of Information and Communication Technology (Kampar Campus), UTAR 33 Figure 4-10 Process time taken for manual transcription.
Conclusion
Project Review
Future Work
Golovko et al., “Deep Convolutional Neural Network for Image Recognition of Text Documents,” CEUR Workshop Proc., vol. Faculty of Information and Communication Technologies (Kampus Kampus), UTAR A-17 FACULTY OF INFORMATION AND COMMUNICATION TECHNOLOGIES. Based on the above results, I declare that I am satisfied with the originality of the final year project report submitted by my students as mentioned above.