Tong Dong Ling____ (Promoter) from the Department of Computer Science, Faculty of Information and Communication Technology. I certify that this report entitled "CYBER PEST DETECTION: A MACHINE LEARNING APPROACH" is my own work, except as noted in the references. Machine learning is a hot topic and widely implemented in software, web applications and more.
This model combines a rule-based sentiment analysis approach and a supervised machine learning algorithm for text classification. The Support Vector Machine machine learning algorithm was selected after comparing with other algorithms such as Multinomial Naive Bayes, Decision Tree Classifier and Random Forest Classifier. A web-based application was created to test the effectiveness of the model by simulating the cyberbullying process that will occur on a social media site.
- Problem Statement and Motivation
- Objectives
- Project Scope and Direction
- Contributions
- Background Information
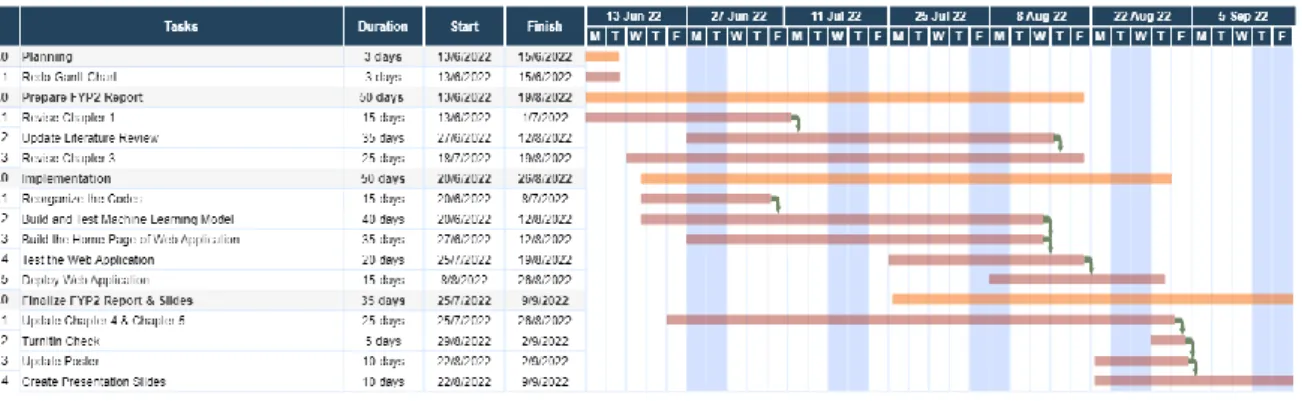
- Timeline
- Report Organization
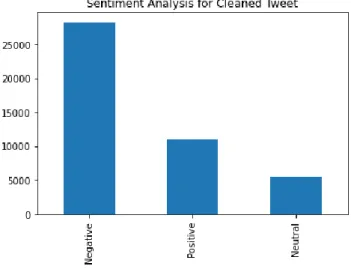
Therefore, the machine learning model will be trained to learn that a negative message represents the cyberbullying message. The model would be accurate to find the best parameters to build a better classifier. The web application consists of a database and data from the user will be stored in the database.
The cyberbullying classifier will be integrated into the web application to help the social media site monitor and keep track of cyberbullying activities. The web application functions like the posts that were classified as cyberbullying and the results would be displayed in a table that could be easily understood by the end user. The fourth chapter is about the design of machine learning model and web application.
Articles related to Machine Learning Model
- Cyberbullying Detection Using Machine Learning
- Automatic cyberbullying detection: A systematic review [4]
- Hybrid approach: naive bayes and sentiment VADER for analyzing
The strength of this study is that they extracted different features and used different machine learning classifications to find the model that has the best performance. Even though they took out several features to improve the models but the results were not good due to low f1 score and recall. The sentiment functions were trained with SVM and the model's results improved compared to the other 2 classifiers.
In this paper, the author combined VADER and Naive Bayes to predict the sentiments of YouTube comments [6]. The advantages of this article are that the accuracy of the model is improved by the hybrid approach. The weakness of this article is that only one machine learning model was used to train the model.
Web Application Review
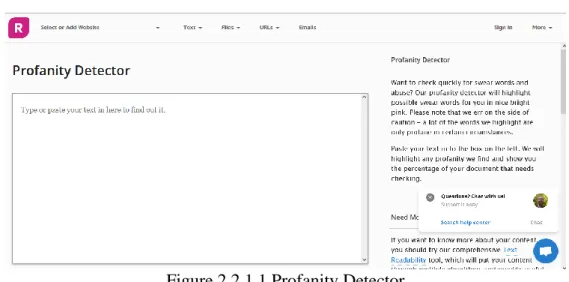
- Profanity Detector
SYSTEM METHODOLOGY/APPROACH
System Design Diagram
- System Architecture Diagram
- User Requirements
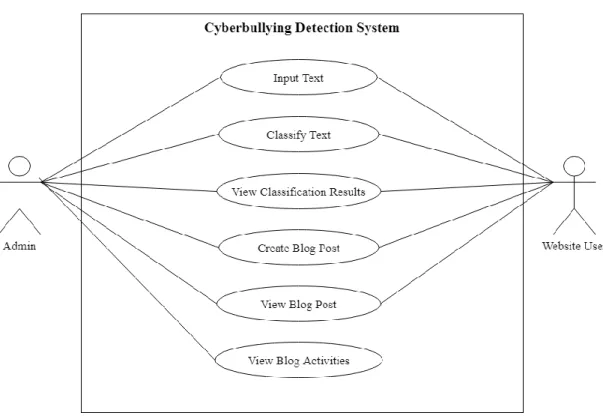
- Use Case Diagram and Description
4 System calls the function to determine the likelihood of cyberbullying for the administrator or website user. 4 The administrator or website user looks at the classification result, the offensive word found and the likelihood of cyberbullying. 5 The system clears the form and allows the administrator or website user to resubmit the form after reviewing the results.
REQ_F410 The system should clear the form and allow the administrator or website user to resubmit the form. 7 System calls the function to determine the likelihood of cyberbullying for the administrator or website user. 10 The system will clear the form and allow the administrator or website user to resubmit the form.
SYSTEM DESIGN
Machine Learning Model
- Data Preprocessing
- Data Labelling
- Find the Most Suitable Machine Learning Algorithm
- The Final Machine Learning Model
The plural form of the word may not be changed to the singular by lemmatization. After much consideration, lemmatization with post tag was chosen as the text normalization method for this data set to find the root of the word. Some of the columns will be removed as there are many columns generated during the data preprocessing phase.
Columns containing the text polarity score will be renamed "polarity". MCC was used to determine the performance of the model in predicting both classes. The accuracy result of the fine-tuned model was even better than the baseline model.
The number of true negatives of the tuned model decreased to only 311 samples. Based on the results shown above, the accuracy result of the fine-tuned model with TFIDF was the same as the basic model. The number of true negatives of the tuned model decreased from 379 to 307 samples.
An exact recall plot for both models with BOW was plotted to see the improvement in scores. It was observed that the towing score of the model improved and was slightly higher than the base model. The target data feature was created by tagging all messages with TextBlob.
The probability score would be used in the web application to find the probability of the message.

Web Application
- Creating a Database (SQLite)
- Wireframe of Web Pages
- Building a Corpus to Store All Abusive Words
- A Function to Determine the Likelihood of Cyberbullying
- Final Design of all Web Pages
It was easier to design a form because a class of the form would be defined and it could be reused on other web pages. This template was useful in this project because it would make the layout of the web page look the same. It uses a {{ % %}} to apply the base template settings to the targeted web pages.
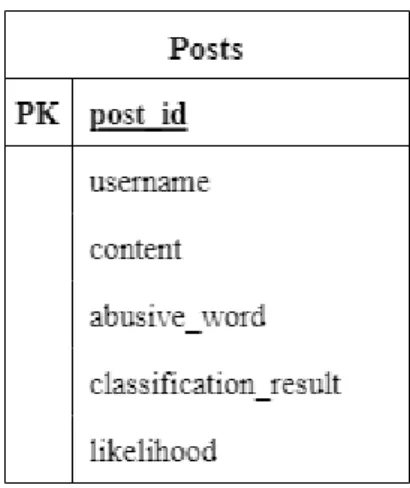
So, "navbar_admin.html" which has a navigation bar to go all three pages will be created in the "Stats.html" page. It will store the ID of the post, content of the post, username of the website user, tag of the website user, offensive word in the post, likelihood of cyberbullying based on the post. It will also have the following functions to detect abusive words in the text and the likelihood of cyberbullying.
The messages would be passed to the functions to find out the offending word and the likelihood of cyberbullying. On this web page, all information collected through the form is stored in the database. The features like finding offensive word and determining the probability of cyberbullying of messages would be used to populate the data in the database.
An administrator could access detailed information such as the post that was classified as cyberbullying and the name of the user who posted the post. The table would also consist of the username and likelihood of cyberbullying for the posts. It will display offensive words to the user on the index page, but these words will not be stored in the database.
The data collected from the blog page will be analyzed in the statistics page to create a table to display the abusive words used by the user.
SYSTEM IMPLEMENTATION
- Hardware Setup
- Software Setup
- System Settings and Configuration
- System Operation (with Screenshot)
The color scheme was different on the stats page because it can only be accessed by the admin. The SQLAlchemy extension in Flask was used to create a simple database to store all input data from the user. Microsoft Visual Studio Code is an integrated development environment and code editor for writing and debugging web applications.
It should be run to ensure that all the packages were installed in the anaconda prompt. As shown below, the project directory must be specified to launch the notebook, such as "cd C:\CyberbullyingClassifier". Then, to run the flask app, type "flask run" on the terminal.
Click on the link to enter the web application and type "Ctrl+C" to exit the web application. Since the classifier is loaded into the web application, the user can see the results generated by the cyberbullying classifier. The form must be completed before submitting, it would display an error message if not completed.
When accessing the second web page, the user can click on the "Blog" in the navigation bar or copy and paste this link /blog_post at the end of the link. This link would be generated when the app was run on the terminal in Visual Studio Code. The details of the table are automatically updated when the user submits the form.
SYSTEM EVALUATION AND DISCUSSION
- System Testing and Performance Metrics
- Testing Setup and Result
- Project Challenges
- Objectives Evaluation
The system displays the abusive words found in the sentence, the classification of the sentence and the likelihood of it. Offensive words found in sentences, sentence classification and likelihood. The system will clear the form and allow the website administrator or user to re-submit the form.
The system displays a table of posts that are classified as cyberbullying, the username that posted the post, and the probability. The user can view all posts classified as cyberbullying and a list of offensive words. The dataset in this project contains many tweets related to cyberbullying and has a diverse topic.
The code cannot extract the string from the text, such as usernames from the dataset. Thus, the data set was divided into different groups to ensure that the computer's RAM is not used extensively. The main goal is to correctly predict the message that belongs to the class of cyberbullying.
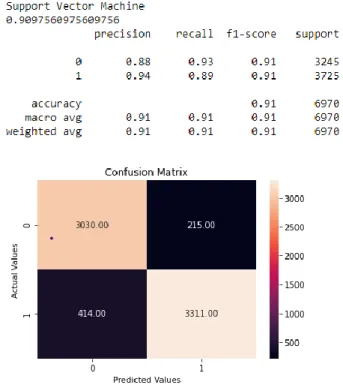
The results show that the accuracy score for identifying cyberbullying was high at 0.83 and close to one. The goal was to test whether a cyberbullying classification model would perform well in an online application to detect sentences with words that have offensive, insulting, or harmful meanings. The results show that it can work well in the web application and all the data has been stored in the database.
This project aims to find the most suitable machine learning algorithm that can correctly predict a message that has a negative meaning.

CONCLUSION AND RECOMMENDATION
Conclusion
Recommendation
Redhu, “Sentiment Analysis Using Text Mining: A Review,” International Journal of Data Science and Technology, vol. 11] Parul Pandey, “Simplifying Sentiment Analysis Using VADER in Python (in Social Media Text),” Medium, September Dyouri, “How to Build Your First Web App Using Flask and Python 3 | DigitalOcean,” www.digitalocean.com, August.
The details in the Gantt chart are not specific and need to be changed in it. Write a separate program to train the model with a different machine learning algorithm to select the one with the highest accuracy. Wrote a separate program to train the model with a different machine learning algorithm to select the one with the highest accuracy.
The accuracy of the model in the training dataset is high, but it did not perform well on the test dataset. It is a snippet of code on how to classify the message into different probability groups. Note Promoter/Candidate(s) is/are required to provide a soft copy of the full set of the Originality Report to the Faculty/Institute.
Based on the above results, I declare that I am satisfied with the originality of the final year project report submitted by my students as mentioned above.
![Table 3.1.4 Use Case Description for [F002]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216482.0/28.892.110.780.110.268/table-use-case-description-for-f.webp)
![Table 3.1.6 Use Case Description for [F003]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216482.0/29.892.104.781.102.645/table-use-case-description-for-f.webp)
![Table 3.1.7 Functional Requirements Listing for F004 3.1.3.8 Use Case Description for [F004]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216482.0/30.892.107.790.235.1118/table-functional-requirements-listing-f-use-case-description.webp)
![Table 3.1.12 Use Case Description for [F006]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216482.0/32.892.110.788.128.647/table-use-case-description-for-f.webp)