i
PEMBUATAN MODUL DELETE PADA APLIKASI FUZZY
TEMPORAL ASSOCIATION RULE MINING UNTUK DATA
TRANSAKSI
ZISSALWA HAFSARI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ii
PEMBUATAN MODUL DELETE PADA APLIKASI FUZZY
TEMPORAL ASSOCIATION RULE MINING UNTUK DATA
TRANSAKSI
ZISSALWA HAFSARI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
iii ABSTRACT
ZISSALWA HAFSARI. Developing Deletion Module in Temporal Association Rule Mining Application for Transaction Data. Under the direction of IMAS SUKAESIH SITANGGANG and ENDANG PURNAMA GIRI.
Transaction activities in supermarket produce large transaction data. It requires data mining techniques including association rule mining to extract patterns from the data. This research aims to implement the incremental updating technique to create association rules from expired data using fuzzy calendar on temporal database. The result is a deletion module which can find association rules without scanning the original entire database. The output are frequent itemsets and association rules in which some partitions are deleted from the original data set. The data used in this research are transaction data in a supermarket on period 1 March until 21 May 2004. The experiment was executed using support threshold values 20%, 30%, 40% and confidence threshold values 65%, 70%, 75% with early week or early year as the fuzzy calendar. By applying the deletion module the research obtains results that association rules generation are effective and efficient which means the process can produce interesting association rules in a relatively short time. For five partitions deleted data with support threshold 30% and confidence threshold 70%, one frequent itemset is generated and there is one association rule: 30(snack) → 80(milk). The execution time to generate association rules with deletion module is 13.984 seconds and the execution time without deletion module is 40.891 seconds with support threshold 40% and confidence threshold 75% based on the assumption in deletion module that frequent itemsets generated from the original data set are already provided.
iv Judul : Pembuatan Modul Delete pada Aplikasi Fuzzy Temporal Association Rule Mining untuk
Data Transaksi Nama : Zissalwa Hafsari NIM : G64052948
Menyetujui :
Pembimbing I,
Imas Sukaesih Sitanggang, S.Si, M.Kom NIP 197501301998022001
Pembimbing II,
Endang Purnama Giri, S.Kom, M.Kom NIP 198210102006041027
Mengetahui :
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Dr. Drh. Hasim, DEA NIP 196103281986011002
v PRAKATA
Puji syukur penulis panjatkan kepada Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul Pembuatan Modul Delete pada Aplikasi Fuzzy Temporal Association Rule Mining untuk Data Transaksi sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer di FMIPA, IPB.
Dalam kesempatan ini penulis ucapkan terima kasih kepada pihak-pihak yang telah turut membantu penulis dalam penyelesaian tugas akhir ini, yaitu:
1 Orang tua penulis atas doa, motivasi, dan kasih sayang yang tak pernah henti. Tak lupa untuk kakak-kakakku, Khairiah, Syaiful Amri, Zunnasyit, Alfiah, Alfis Suhaili, dan Endang Surapati Nasitah yang selalu memberikan dukungan dan nasihat selama penulis jauh dari mereka.
2 Ibu Imas S. Sitanggang, S.Si, M.Kom selaku pembimbing I dan Bapak Endang Purnama Giri, S.Kom, M.Kom selaku pembimbing II atas kesediaannya meluangkan waktu untuk memberikan saran dan bimbingannya selama penelitian dan penulisan tugas akhir ini.
3 Bapak Sony Hartono Wijaya S.Kom, M.Kom selaku moderator dan dosen penguji.
4 Seluruh dosen pengajar yang telah mendidik, membina dan membangun wawasan serta kepribadian penulis selama menuntut ilmu di Mayor Ilmu Komputer.
5 Anindra Ageng Jihado atas doa, semangat, dan keceriaan yang senantiasa mengisi hari-hari penulis.
6 Sahabat-sahabat V_Zone, Nty, Uni, Ninon, Vera, dan Karin (tanpa urutan) yang selalu ada untuk memberikan semangat, keceriaan, dan mengisi hari-hari penulis selama kuliah di Mayor Ilmu Komputer.
7 Teman-teman satu bimbingan, Prita, Lena, dan Fuad.
8 Sahabat-sahabat AK C, Dimas, Rafdi, Fathoni, Uud, Nelly, Cira, Ninon, dan Arifka.
9 Mega atas bantuannya terutama pada saat persiapan seminar dan sidang.
10 Ike dan Ifah atas semangat yang selalu diberikan.
11 Indah, Cira, Novi, dan semua teman-teman seperjuanganku Ilkomerz 42 atas kebersamaan dan persahabatan yang tidak akan terlupakan.
12 Teman-teman Wisma Harmony 1, Endah, Alda, Roisah, Resty, Prima, Mba Gita, Punky, Nida, dan Nikenserta semua pihak yang telah banyak membantu penulis dalam penyelesaian tugas akhir ini. Akhir kata, semoga karya ilmiah ini bermanfaat.
Bogor, Juni 2009
vi RIWAYAT HIDUP
Penulis lahir di Bengkalis, Riau pada tanggal 25 April 1987 dari Bapak H. Subari dan Ibu Hafsah. Tahun 2005 penulis lulus dari SMAN 1 Bengkalis dan pada tahun yang sama penulis lulus seleksi masuk IPB melalui jalur Undangan Seleksi Masuk IPB (USMI). Penulis diterima di Mayor Ilmu Komputer sebagai pilihan pertama dalam seleksi Sistem Mayor Minor IPB dengan Minor Manajemen Fungsional.
iv DAFTAR ISI
Halaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA Himpunan Fuzzy ... 2
Association Rules Mining ... 2
Fuzzy Calendar Algebra ... 2
Mining Fuzzy Temporal Association Rule ... 4
Incremental Updating ... 4
METODE PENELITIAN Proses Dasar Sistem ... 5
Lingkungan Pengembangan Sistem ... 6
HASIL DAN PEMBAHASAN Pembentukan Frequent Itemset Baru ... 7
Pembentukan Aturan Asosiasi Baru ... 8
KESIMPULAN DAN SARAN... Kesimpulan ... 10
Saran ... 10
DAFTAR PUSTAKA ... 11
v DAFTAR TABEL
Halaman
1 Fuzzy calendar dan fungsi keanggotaannya (µ) ... 4
2 Ilustrasi data transaksi untuk perhitungan modul delete ... 6
3 Banyaknya frequent itemset untuk data lama, data update (delete) dan data hapus ... 7
4 Frequent itemset untuk data lama, data update (delete) dan data hapus ... 7
5 Banyaknya aturan asosiasi dengan support threshold 20% untuk data lama, data update (delete) dan data hapus... 8
6 Aturan asosiasi dengan support threshold 20% untuk data lama, data update (delete) dan data hapus ... 9
7 Waktu eksekusi (detik) untuk data update dan data hapus pada tiga kombinasi threshold dengan jumlah partisi yang dihapus=1 ... 9
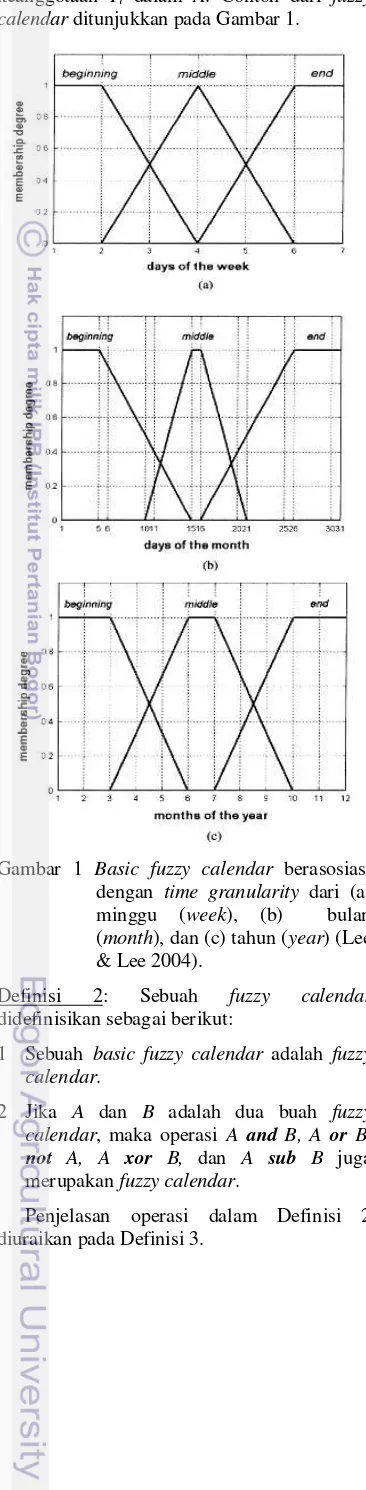
DAFTAR GAMBAR Halaman 1 Basic fuzzy calendar berasosiasi dengan time granularity dari (a) minggu (week), (b) bulan (month), dan (c) tahun (year) (Lee & Lee 2004) ... 3
2 Diagram alir proses deletion... 5
3 Waktu eksekusi (detik) untuk data update dan data hapus ... 10
DAFTAR LAMPIRAN Halaman 1 Ilustrasi proses tahapan pada modul delete sesuai dengan metode penelitian ... 13
2 Kode item barang yang ada pada data transaksi ... 15
3 Banyaknya frequent itemset baru (L’) dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6... 16
4 Frequent Itemset dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6 ... 16
5 Banyaknya aturan asosiasi (AR’) dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6 ... 18
6 Aturan asosiasi baru (AR’) dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6 ... 19
7 Waktu eksekusi aturan asosiasi dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6 ... 20
1 PENDAHULUAN
Latar Belakang
Kegiatan transaksi pembelian di supermarket menghasilkan data transaksi dengan cepat karena perhitungan pembelian dapat dilakukan dengan bantuan komputer. Data terus disimpan setiap hari secara periodik seiring dengan terus berlangsungnya transaksi pembelian. Akibatnya terdapat data transaksi yang dianggap kadaluarsa dan harus dihapus dari tempat penyimpanan. Akan tetapi, mungkin saja data tersebut masih mengandung pola-pola menarik yang berguna. Sehingga pihak pengelola data harus cermat dalam menentukan data yang dianggap kadaluarsa.
Semakin besarnya jumlah data transaksi yang tersedia dari berbagai sumber penyimpanan menyebabkan teknik penemuan pengetahuan secara automatis dari basis data yang besar menjadi sangat populer. Seperti banyak industri pada saat ini yang tertarik menggunakan assocition rule mining untuk menemukan hubungan antaritem dari basis data yang terkoleksi.
Association rule mining adalah salah satu teknik penemuan pengetahuan dalam bidang
data mining. Data mining sendiri merupakan proses ekstraksi informasi atau pola dalam basis data yang berukuran besar (Han & Kamber 2006). Teknik association rule mining yang digunakan dalam penelitian ini adalah fuzzy temporal association rule mining.
Dalam penelitian ini dilakukan pembuatan modul delete pada aplikasi fuzzy temporal assosiacion rule mining yang telah ada sebelumnya (Suminar 2007 & Wijayanti 2008). Modul ini merupakan bagian dari teknik incremental updating untuk menghasilkan aturan asosiasi dengan menggunakan fuzzy calendar pada data transaksi pembelian barang di supermaket.
Fuzzy calendar mempermudah pengguna untuk mendefinisikan waktu sesuai dengan keinginan mereka tanpa perlu mengetahui batasan waktu secara pasti. Misalnya pengguna ingin mengetahui pola yang menarik dari data awal minggu atau awal tahun. Awal minggu atau awal tahun
merupakan interval waktu yang dapat didefinisikan berbeda-beda pada setiap pengguna.
Modul ini dapat membantu kita menemukan pola baru ketika terdapat data
transaksi yang dihapus. Tidak perlu dilakukan penelusuran berulang-ulang terhadap basis data awal untuk menghasilkan pola-pola baru karena menggunakan informasi yang tersedia sebelumnya.
Tujuan Penelitian
Tujuan penelitian ini adalah :
1 Membuat modul delete pada aplikasi fuzzy temporal association rule mining yang telah dibangun pada penelitian sebelumnya (Suminar 2007 & Wijayanti 2008). Modul
delete digunakan ketika ingin melihat
frequent itemset dan association rule pada data yang telah di-update.
2 Membandingkan hasil yang diperoleh yaitu frequent itemset dan association rule
serta waktu eksekusi dengan implementasi modul delete dan tanpa menggunakan modul delete (data dihapus secara langsung).
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini dibatasi pada: 1 Menerapkan modul delete pada aplikasi
fuzzy temporal temporal association rule mining yang telah ada sebelumnya sehingga menghasilkan frequent itemset
dan association rule baru.
2 Melakukan percobaan terhadap data transaksi yang dihapus setiap partisi satu persatu secara langsung untuk melihat
frequent itemset dan association rule yang dihasilkan.
3 Data transaksi kadaluarsa dalam penelitian ini adalah data yang ingin dihapus mulai dari partisi-partisi awal pada setiap minggu.
4 Modul delete ini diterapkan pada data transaksi pembelian selama 11 minggu (1 Maret 2004 – 21 Mei 2004) di Sinar Mart Swalayan. Data ini telah melewati tahap praproses yang telah dilakukan pada penelitian sebelumnya (Suminar 2007). Manfaat Penelitian
2 TINJAUAN PUSTAKA
Himpunan Fuzzy
Himpunan fuzzy berbeda dengan himpunan
crisp atau boolean. Himpunan fuzzy memiliki fungsi keanggotaan yaitu himpunan yang menjelaskan hubungan antara anggota himpunan dengan derajat keanggotaannya yang berkisar antara nol sampai satu. Himpunan fuzzy memiliki membran
semipermeable yang anggotanya dibagi menjadi tiga, yaitu bukan anggota himpunan, anggota penuh dari himpunan, dan anggota sebagian dari himpunan (Cox 2004).
Association Rule Mining
Association rule mining merupakan teknik
datamining yang berguna untuk mengungkap aturan menarik yang tersembunyi dalam basis data besar (Tan et al 2006). Penggalian aturan asosiasi di antara record yang jumlahnya sangat banyak dapat membantu proses pengambilan keputusan (Han & Kamber 2006). Association rule adalah ekspresi implikasi yang dinyatakan dalam bentuk X→Y, dimana X dan Y adalah itemset terpisah (disjoint) yaitu (Tan et al 2006). Kekuatan dari aturan asosiasi dapat diukur dengan support dan confidence. Support
menentukan seberapa sering aturan tersebut diterapkan dalam dataset, sedangkan
confidence menentukan frekuensi item dalam
Y muncul dalam transaksi yang mengandung
X (Tan et al 2006).
Support
Definisi formal dari support adalah sebagai berikut (Tan et al 2006):
dengan adalalah support count dari
itemset dan N adalah total jumlah transaksi.
Confidence
Definisi formal dari confidence adalah sebagai berikut (Tan et al 2006):
dengan dan masing-masing
adalalah support count untuk itemset
dan X.
Sebagai contoh, terdapat aturan asosiasi {Milk, Diapers}→Beer. Support dan
confidence dari aturan tersebut dapat dihitung
jika diketahui jumlah total transaksi dan jumlah transaksi yang mengandung itemset
{Milk, Diapers} secara bersamaan. Misalnya, suatu supermarket memiliki 5 transaksi pembelian. Pembelian itemset {Milk, Diapers, Beer} terjadi secara bersamaan pada 2 transaksi pembelian. Artinya support count
untuk itemset {Milk, Diapers, Beer}adalah 2, sedangkan support untuk itemset tersebut adalah 2/5=0.4. Confidence dari aturan asosiasi tersebut diperoleh dengan membagi
support count dari {Milk, Diapers, Beer} dengan support count dari { Milk, Diapers } yaitu 2/3=0.67.
Strategi yang sering diambil untuk menyelesaikan permasalahan association rule
adalah dengan memecah masalah tersebut ke dalam dua pekerjaan utama (Tan et al 2006), yaitu
Pembangkitan frequent itemset yang bertujuan mencari semua itemset yang memenuhi nilai ambang support threshold.
Pembangkitan aturan, bertujuan mengekstrak seluruh aturan yang memiliki
confidence tinggi dari frequent itemset
yang telah ditemukan pada pekerjaan sebelumnya.
Fuzzy Calendar Algebra
Secara umum, kalender adalah koleksi terstruktur dari interval waktu (Lee & Lee 2004). Biasanya kita mendeskripsikan waktu dalam kalender dengan istilah awal minggu,
akhir minggu, awal tahun, akhir tahun dan sebagainya yang bersifat fuzzy. Untuk merumuskan pemikiran manusia tersebut ke dalam proses penemuan pengetahuan, teori
fuzzy diadopsi untuk mengkonstruksi kalender (Lee & Lee 2004). Konsep dan operasi fuzzy
diperkenalkan untuk membantu pengguna mengekspresikan kalender secara baik dan mudah. Dalam praktiknya, pengguna akan memilih sendiri fuzzy calendar yang digunakan untuk menemukan aturan asosiasi. Menurut Lee & Lee (2004), fuzzy calendar
memiliki tiga definisi yaitu sebagai berikut. Definisi 1: Sebuah basic fuzzy calendar, A, mencirikan sebuah proposisi fuzzy tentang koleksi dari interval waktu pada sebuah time granularity U, dideskripsikan sebagai fungsi keanggotaan
, dengan
untuk setiap interval waktu . Nilai
fungsi menyatakan derajat
(1)
3 keanggotaan Ti dalam A. Contoh dari fuzzy
calendar ditunjukkan pada Gambar 1.
Gambar 1 Basic fuzzy calendar berasosiasi dengan time granularity dari (a) minggu (week), (b) bulan (month), dan (c) tahun (year) (Lee & Lee 2004).
Definisi 2: Sebuah fuzzy calendar
didefinisikan sebagai berikut: merupakan fuzzy calendar.
Penjelasan operasi dalam Definisi 2 diuraikan pada Definisi 3.
Definisi 3: A dan B adalah fuzzy calendar
dengan fungsi keanggotaan µA dan µB
dengan penjelasan sebagai berikut:
1 A and B dinotasikan dengan , dengan fungsi keanggotaan didefinisikan oleh
(3)
dengan t adalah salah satu kelas dari operator-operator fuzzy intersection. 2 A or B dinotasikan dengan , dengan
fungsi keanggotaan didefinisikan oleh
(4) dengan s adalah salah satu kelas dari
operator-operator fuzzy union.
3 not A dinotasikan dengan komplemen dari
A, dengan fungsi keanggotaan didefinisikan oleh
(5) dengan c adalah salah satu kelas dari
operator komplemen fuzzy.
4 A xor B dinotasikan dengan perbedaan simetris dari A dan B, A B , dengan fungsi keanggotaan didefinisikan oleh
(6) 5 A sub B dinotasikan dengan pengurangan
kalender A dari B, A – B, dan
≡ (7) adalah hasil fungsi keanggotaan.
Dari persamaan 3 hingga persamaan 7 didapatkan rumus-rumus yang digunakan untuk mencari bobot pada tiap partisi pada data transaksi yang dibedakan berdasarkan pada tanggal. Rumus-rumus tersebut adalah (Lee & Lee 2004):
Tabel 1 menunjukkan fuzzy calendar
4 menggunakan fungsi derajat keanggotaan:
) (13) Mining Fuzzy Temporal Association Rule
Menurut Lee & Lee (2004), mining fuzzy temporal association rule adalah pembangkitan aturan asosiasi dari basis data
temporal dengan mengadopsi konsep fuzzy calendar. Mining fuzzy temporal association rule dibagi menjadi dua kasus. Kasus yang pertama adalah menentukan frequent itemset
pada basis data tunggal. Kasus ini telah dilakukan pada penelitian sebelumnya untuk data transaksi (Suminar 2007). Sedangkan kasus yang kedua adalah incremental updating
yang terdiri atas modul delete dan add.
Penelitian mengenai pembuatan modul add
telah dilakukan pada data transaksi (Wijayanti 2008). Sedangkan penelitian ini akan fokus pada pembuatan modul delete dari kasus kedua.
Perhitungan untuk modul delete secara umum menggunakan perhitungan sama seperti pada penelitian sebelumnya. Akan tetapi terdapat perbedaan dalam tahapan penemuan candidate 2-itemset baru (C2_baru),
weighted count ketika menentukan frequent itemset dan weighted count yang digunakan dalam penemuan association rule.
Incremental Updating
Incremental updating merupakan suatu proses penambahan data (add) dan proses pengurangan data (delete) pada basis data D
yang telah ada tanpa harus memeriksa basis data berulang-ulang. Basis data dibagi-bagi ke dalam beberapa partisi misalnya sebanyak n
partisi. Dalam hal ini ∆+ dan ∆-
masing-masing adalah data yang akan ditambahkan dan dihapus dari data D.
Penelitian ini menentukan frequent itemset
yang dihasilkan dengan melakukan penghapusan transaksi (delete) secara bertahap untuk D-∆- dengan D-∆- adalah basis Penghapusan partisi tersebut dilakukan secara terurut. Dalam perhitungan, dibutuhkan informasi mengenai weighted count suatu
itemset (
σ
Pi(I))dan cumulative weigthed count(V).
σ
Pi(I) adalah hasil kali bobot denganjumlah transaksi yang mengandung itemset I
pada partisi ke-i. Sedangkan cumulative weigthed count (V) adalah jumlah
σ
Pi(I) dariseluruh partisi (Lee & Lee 2004). Cumulative weighted count threshold (M(h+1)n) adalah
mengandung informasi tentang I juga dihapus. Kemudian dilakukan update terhadap
weighted count dari setiap itemset dalam
mendapatkan candidate k-itemsetCk sehingga
5 itemset dari data
yang akan dihapus
Support threshold, confidence threshold, dan fuzzy calendar serta operator fuzzy
Mencari frequent
Gambar 2 Diagram alir proses deletion.
(19). Kemudian untuk menentukan frequent itemset dari C dilakukan scan basis data D
kembali. Frequent itemset yang diperoleh merupakan gabungan dari semua frequent itemset
(20).
METODE PENELITIAN
Proses Dasar Sistem
Proses dasar sistem mengacu pada proses dalam Knowledge Discovery in Database
(KDD). Proses tersebut diuraikan sebagai berikut.
1 Praproses Data
Praproses data meliputi tahap pembersihan data, transformasi data, dan seleksi data. Penelitian ini menggunakan data yang telah melalui tahap praproses data yang dilakukan dalam penelitian sebelumnya (Suminar 2007).
2 Data Mining
Tahap ini merupakan inti dari penelitian yaitu pembuatan modul delete. Tahap ini menggunakan fuzzy temporal association rule
dengan pengurangan data transaksi yang diajukan oleh Wan Jui Lee dan Shie Jue Lee (2004). Bagan dari tahapan data mining ini
diberikan pada Gambar 2. Sedangkan penjelasan mengenai tahap-tahapnya adalah sebagai berikut.
pada penelitian sebelumnya (Wijayanti 2008). Perhitungan V
dan σPi(I) sama seperti pada
penelitian sebelumnya (Suminar 2007). Sedangkan M(h+1)n adalah
weighted count threshold yang dimulai dari partisi h+1.
Kedua: Menggabungkan antara C2_baru
dengan frequent 2-itemset (L2) dari
data awal sebelum dihapus sehingga menghasilkan candidate
2-itemset terbaru (C2’). Candidate 2
item terbaru merupakan data baru (D’) yang akan digunakan untuk mencari frequent itemset baru (L’)
dan aturan asosiasi baru (AR’). Ketiga: Mencari candidate frequent itemset
baru (C’) yang didapat dari perluasan dari C2’ sehingga menjadi
C3’, C4’, sampai Ck’. Dalam hal ini,
6 pada Ck’ juga ter-update seperti
Persamaan 18 yaitu ’(I)
. Jika σD’(I)
≥ M(h+1)n maka Ck’ dapat menjadi
anggota frequent itemset baru (L’).
Keempat: Mencari semua kemungkinan aturan asosiasi terbaru berdasarkan pada L’ yang didapat serta menghitung weighted confidence
kemudian hasil confidence yang didapat akan dibandingkan dengan
confidence threshold yang telah didefinisikan oleh pengguna. Jika
weighted confidence lebih besar atau sama dengan confidence threshold maka aturan asosiasi tersebut dapat menjadi aturan asosiasi yang kuat (strongrule). Tabel 2 menyajikan contoh data transaksi pada modul delete. D adalah basis data awal,
sedangkan ∆-
adalah data yang akan dihapus. Tabel 2 Contoh data transaksi untuk
perhitungan modul delete
Tanggal TID Items
Ilustrasi secara lengkap mengenai perhitungan untuk mendapatkan aturan asosiasi disajikan pada Lampiran 1. Berikut ini adalah contoh perhitungan untuk menghasilkan C2_baru. Tanggal
merepresentasikan partisi, misalnya tanggal 15/09/2003 adalah Partisi 1, 16/09/2003 adalah Partisi 2, dan 17/09/2003 adalah Partisi 3. Misalkan diketahui support threshold=40% dan confidence threshold=75% serta fuzzy calendar yang dipilih adalah [(tengah bulan dan akhir tahun) or (akhir minggu dan awal tahun)].
Sedangkan informasi mengenai frequent 2 -itemset (L2) yang dihitung dari basis data
awal adalah AD, AE, AF, BF, DE, DF, dan
EF. Fungsi keanggotaan dari ketiga partisi tersebut secara terurut adalah w1=0.67,
w2=0.67, dan w3=0.536. Misalkan dalam hal
ini data yang akan dihapus adalah Partisi 1,
sehingga langkah-langkahnya adalah sebagai berikut:
1 Menghitung M(h+1)n menggunakan
persamaan (14) M(1+1)3=M23=1.447dimana i
adalah jumlah partisiyangakan dihapus. 2 Memeriksa C2 yang pertama kali
dihasilkan oleh partisi yang akan dihapus (Partisi 1). Jika V-σPi(I) ≥ M(h+1)n maka I
a Perangkat keras pada komputer personal:
Processor: AMD Athlon 64, 3000+
Memory: 1.2 GB
Harddisk 80 GB
Keyboard, mouse, dan monitor
b Perangkat lunak yang digunakan:
Sistem operasi: Microsoft® Windows XP Professional
MATLAB 7.0.1 sebagai bahasa pemrograman
Microsoft® Excel 2007 sebagai pengolah data.
HASIL DAN PEMBAHASAN
Dalam penelitian ini dilakukan pembangkitan fuzzy temporal association rule dengan adanya proses delete terhadap data transaksi. Secara umum, proses ini dibagi ke dalam 2 tahap, yaitu tahap pembangkitan frequent itemset dan tahap pembangkitan association rule. Tahap ini akan memperbaharui cumulative weighted count (V)dari partisi yang dihapus. Selain itu juga memperbaharui weighted count di setiap
frequent itemset (L).
Percobaan dilakukan dengan menggunakan data lama yang diperoleh dari penelitian sebelumnya berupa data minggu pertama Maret 2004 yang mengandung 7 partisi dan fuzzy calendar yang digunakan berupa awal minggu or awal tahun. Pemilihan kombinasi fuzzy calendar
berdasarkan pada data yang digunakan yaitu minggu pertama Maret yang berada pada awal tahun. Selain itu, penelitian sebelumnya juga menggunakan kombinasi fuzzy calendar
7
item barang yang ada pada data transaksi disajikan pada Lampiran 2.
Penghapusan partisi dilakukan dengan memasukkan jumlah partisi yang akan dihapus. Selain itu percobaan ini menggunakan ketentuan yang sama pada penelitian sebelumnya yaitu penggunaan
support (20%, 30%, dan 40%) dan
confidence threshold (65%, 70%, dan 75%). Dengan menggunakan ketentuan yang sama diharapkan dapat memudahkan pihak lain untuk membandingkan hasil dari percobaan penelitian ini dengan penelitian sebelumnya. Pembentukan Frequent Itemset Baru
Dalam percobaan, pembangkitan frequent itemset dan association rule dari data lama juga dilakukan. Hal ini dikarenakan dalam pembangkitan frequent itemset dan
association rule baru membutuhkan informasi dari pemrosesan data lama yaitu
candidate 2-itemset (C2) dan frequent
2-itemset (L2). Akan tetapi, dalam pembahasan
selanjutnya hanya fokus pada perhitungan
frequent itemset dan association rule baru (modul delete) karena diasumsikan informasi dari data lama telah dihitung dan disimpan dalam suatu ruang penyimpanan seperti file .xls, sehingga tidak perlu memproses data lama.
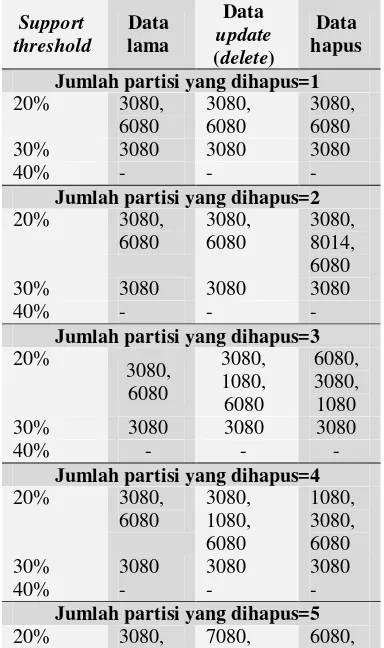
Tabel 3 menunjukkan banyaknya frequent itemset yang terbentuk dari data lama (tidak ada partisi yang dihapus), data update (modul
delete), dan data hapus (partisi dihapus langsung dari awal) untuk support threshold
20%, 30%, dan 40%.
Jumlah partisi yang dihapus=1
20% 2 2 2
30% 1 1 1
40% 0 0 0
Jumlah partisi yang dihapus=2
20% 2 2 3
30% 1 1 1
40% 0 0 0
Jumlah partisi yang dihapus=3
20% 2 3 3
30% 1 1 1
40% 0 0 0
Jumlah partisi yang dihapus=4
20% 2 3 3
Jumlah partisi yang dihapus=5
20% 2 4 2
30% 1 1 2
40% 0 0 1
Jumlah partisi yang dihapus=6
20% 2 0 0
30% 1 0 0
40% 0 0 0
Informasi yang dihasilkan dari pemrosesan data lama dapat digunakan berulang-ulang dalam modul delete. Dari Tabel 3 terlihat bahwa data update dan data hapus mengalami peningkatan jumlah
frequent itemset. Hal ini disebabkan oleh semakin meningkatnya nilai weighted count itemset(σD’(I)) seiring dengan meningkatnya
jumlah partisi yang dihapus sehingga semakin banyak itemset yang lolos menjadi
L’. Lampiran 3 menyajikan banyaknya
frequent itemset untuk semua minggu dan semua jumlah partisi yang dihapus.
Tabel 4 Frequent itemset untuk data lama,
Jumlah partisi yang dihapus=1
20% 3080,
Jumlah partisi yang dihapus=2
20% 3080,
Jumlah partisi yang dihapus=3 20%
Jumlah partisi yang dihapus=4
20% 3080,
Jumlah partisi yang dihapus=5
8
Jumlah partisi yang dihapus=6
20% 3080,
6080
- -
30% 3080 - -
40% - - -
Tabel 4 menyajikan frequent itemset atau barang-barang yang sering dibeli pada waktu tertentu (minggu pertama Maret 2004). Barang-barang tersebut adalah barang dengan ID 10 (mie instant), 14 (sabun), 30 (susu), 60 (permen), 70 (minuman), dan 80 (snack).
Frequent itemset yang dihasilkan terdiri atas 2 item untuk data lama, data update, dan data hapus.
Pada support threshold 40%, hampir pada setiap jumlah partisi yang dihapus, data
update dan data hapus tidak menghasilkan L
baru. Karena candidate itemset yang dihasilkan tidak memiliki nilai cumulative weighted count di atas weighted count threshold. Hanya saja pada jumlah partisi yang dihapus= 5, pada data hapus terbentuk 1
frequent itemset yaitu 3080. Artinya susu (30) dan snack (80) muncul secara bersamaan pada waktu tersebut. Lampiran 4 menyajikan
frequent itemset untuk semua minggu dan semua jumlah partisi yang dihapus.
Pembentukan Aturan Asosiasi Baru
Pembentukan aturan asosiasi baru membutuhkan informasi mengenai frequent itemset yang telah dibangkitkan pada tahap sebelumnya. Perhitungan untuk menemukan aturan asosiasi ini hampir sama dengan penelitian sebelumnya, yang berbeda adalah pada data yang diproses, yaitu data yang telah melewati proses update (delete). Dari frequent itemset yang ada, dibangkitkan semua kemungkinan kombinasi aturan asosiasi. Kemudian dihitung weighted confidence dari setiap kombinasi tersebut. Seperti yang telah digambarkan pada sub bab sebelumnya bahwa aturan asosiasi yang memiliki weighted confidence di atas confidence threshold
merupakan strongrule, dan sisanya dibuang.
Beberapa percobaan dengan menggunakan
confidence threshold 65%, 70%, dan 75%
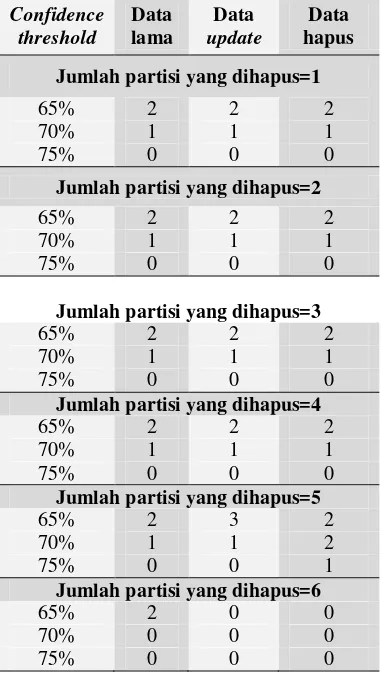
telah dilakukan. Pada Tabel 5 dapat dilihat banyaknya aturan asosiasi yang terbentuk pada support threshold terendah yaitu 20% untuk data lama, data update (modul delete), dan data hapus (data yang telah dihapus beberapa partisi dari file .xls). Lampiran 5 menyajikan banyaknya aturan asosiasi untuk semua minggu dan semua jumlah partisi yang dihapus. Aturan asosiasi yang dihasilkan dengan modul delete memiliki jumlah dan kode item yang hampir sama dengan aturan asosiasi yang dihasilkan dari data yang diproses tanpa menggunakan modul delete.
Tabel 5 Banyaknya aturan asosiasi dengan
support threshold 20% untuk data
Jumlah partisi yang dihapus=1
65% 2 2 2
70% 1 1 1
75% 0 0 0
Jumlah partisi yang dihapus=2
65% 2 2 2
70% 1 1 1
75% 0 0 0
Jumlah partisi yang dihapus=3
65% 2 2 2
70% 1 1 1
75% 0 0 0
Jumlah partisi yang dihapus=4
65% 2 2 2
70% 1 1 1
75% 0 0 0
Jumlah partisi yang dihapus=5
65% 2 3 2
70% 1 1 2
75% 0 0 1
Jumlah partisi yang dihapus=6
65% 2 0 0
70% 0 0 0
75% 0 0 0
9
confidence semakin besar dan semakin banyak aturan asosiasi yang lolos dari confidence threshold. Lain halnya dengan jumlah partisi yang dihapus=6, yaitu tidak dihasilkan aturan asosiasi baik pada data update, maupun data hapus. Hal ini disebabkan oleh tidak dihasilkannya frequent itemset pada perhitungan sebelumnya sehingga tidak ada kombinasi aturan asosiasi. Lampiran 6 menyajikan aturan asosiasi untuk semua minggu dan semua jumlah partisi yang dihapus.
Tabel 6 Aturan asosiasi dengan support threshold 20% untuk data lama, data
update dan data hapus Confidence Jumlah partisi yang dihapus=1
65% 30→80
60→80 30→80 60→80 30→80 60→80
70% 30→80 30→80 30→80
75% - - -
Jumlah partisi yang dihapus=2
65% 30→80
60→80 30→8060→80 30→80 60→80
70% 30→80 30→80 30→80
75% - - -
Jumlah partisi yang dihapus=3
65% 30→80
60→80 30→80 60→80 60→80 30→80
70% 30→80 30→80 30→80
75% - - -
Jumlah partisi yang dihapus=4
65% 30→80,
60→80 30→80 60→80 30→80,60→80
70% 30→80 30→80 30→80
75% - - -
Jumlah partisi yang dihapus=5
65% 30→80
Jumlah partisi yang dihapus=6
65% 30→80,
60→80 - -
70% 30→80 - -
75% - - -
Berdasarkan pada Tabel 6 aturan-aturan asosiasi yang terbentuk pada data update dan data hapus hanya terdiri atas 2 item. Pada jumlah partisi yang dihapus=5 dengan
confidence threshold 75%, pemrosesan data
update tidak menghasilkan aturan asosiasi apapun. Pada data update, aturan asosiasi
30→80 muncul hampir pada setiap
perhitungan jumlah partisi yang dihapus. Tabel 7 Waktu eksekusi (detik) untuk data
update dan data hapus pada tiga kombinasi threshold dengan jumlah partisi yang dihapus=1
Tabel 7 menampilkan waktu eksekusi (detik) pemrosesan data update dan data hapus sampai menghasilkan aturan asosiasi pada tiga kombinasi threshold. Waktu eksekusi tercepat terjadi pada data update dengan support dan
confidence threshold masing-masing 40% dan 75% yaitu 3.157 detik. Pada threshold yang sama, waktu eksekusi untuk data hapus menghabiskan waktu 40.891 detik. Lampiran 7 menyajikan waktu eksekusi untuk semua minggu dan semua jumlah partisi yang dihapus.
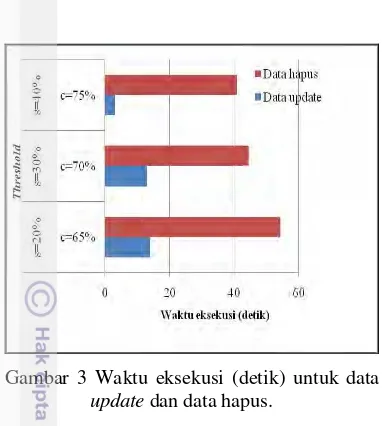
Gambar 3 menyajikan grafik waktu eksekusi (detik) untuk pembentukan aturan asosiasi untuk data update dan data hapus yang diperoleh dari penjumlahan waktu eksekusi pembangkitan frequent itemset dan aturan asosiasi. Gambar tersebut merupakan salah satu contoh waktu eksekusi yaitu diambil dari waktu eksekusi untuk jumlah partisi yang dihapus=1. Sedangkan untuk jumlah partisi yang dihapus=2 sampai dengan 6, disajikan pada Lampiran 8.
Dari Gambar 3 dapat dilihat bahwa waktu eksekusi pada kedua jenis data semakin cepat seiring dengan meningkatnya support dan
10 Gambar 3 Waktu eksekusi (detik) untuk data
update dan data hapus.
Perbedaan waktu eksekusi antara data
update dan data hapus sangat signifikan. Seperti yang diperlihatkan pada Gambar 3, bahwa waktu eksekusi untuk data update lebih cepat dibandingkan dengan waktu eksekusi data hapus untuk semua kombinasi threshold.
Lampiran 8 menyajikan grafik waktu eksekusi untuk semua minggu dan semua jumlah partisi yang dihapus.
Hal ini disebabkan oleh perbedaan proses perhitungan kedua jenis data tersebut. Perhitungan data update semakin cepat karena tidak membaca basis data secara keseluruhan (dari awal), tetapi hanya dengan menggunakan informasi yang telah dihasilkan oleh pemrosesan data awal (data asli sebelum ada modul delete). Dalam pembahasan ini diasumsikan frequent itemset dari data lama sudah tersedia. Sehingga pada saat ingin menggunakan modul delete tidak perlu lagi memproses data lama. Sedangkan perhitungan data hapus dilakukan dengan membaca basis data dari awal, dan membangkitkan semua kombinasi candidate itemset dari data tersebut sampai menghasilkan aturan asosiasi. Sehingga dapat dikatakan bahwa penemuan aturan asosiasi dengan modul delete jauh lebih cepat dibandingkan dengan penemuan aturan asosiasi jika data yang kadaluarsa dihapus langsung dari data transaksi awal.
KESIMPULAN DAN SARAN
Kesimpulan
Modul delete yang ditambahkan pada aplikasi fuzzy temporal association rule
mampu menghasilkan aturan asosiasi dengan cara yang efektif dan efisien ketika terdapat data transaksi yang ingin dihapus dari data transaksi.
Berdasarkan pada hasil penelitian yang telah dilakukan terhadap data transakasi Sinar Mart Swalayan dengan menggunakan modul
delete dan tanpa menggunakan modul delete
diperoleh kesimpulan sebagai berikut:
1 Frequent itemset yang dihasilkan dengan menggunakan modul delete tidak jauh berbeda jumlahnya dengan jumlah
frequent itemset yang dihasilkan tanpa menggunakan modul delete. Pembangkitan
frequent itemset dengan modul delete
maupun tanpa modul delete sama-sama hanya menghasilkan 2 kombinasi item. 2 Jumlah aturan asosiasi hampir sama yang
dihasilkan dengan modul delete dan tanpa modul delete. Aturan asosiasi semakin cepat terbentuk seiring dengan meningkatnya support dan confidence threshold.
3 Waktu eksekusi yang dibutuhkan untuk membangkitkan aturan asosiasi untuk penghapusan data lebih cepat menggunakan modul delete dari pada tanpa menggunakan modul delete. Saran
Pada penelitian ini masih terdapat beberapa kekurangan yang dapat diperbaiki selanjutnya, yaitu:
1 Operasi fuzzy pada penelitian ini masih menggunakan satu operasi, sehingga dapat diperbaiki dengan menambahkan operasi
fuzzy lebih dari satu operasi.
2 Penambahan jenis fuzzy calendar
11 DAFTAR PUSTAKA
Cox E. 2004. Fuzzy Modeling and Genetic Algorithms for Data Mining and Exploration. Elseiver Inc. San Francisco, USA.
Han J, Kamber M. 2006. Data Mining: Concepts and Techniques. San Diego, USA: Morgan-Kauffman.
Lee WJ, Lee SJ. 2004. Discovery of Fuzzy Temporal Association Rules. IEEE Transactions On Systems, Man, and Cybernetics, Vol. 34, No. 6.
Suminar HR. 2007. Pengembangan Aplikasi
Fuzzy Temporal Association Rule Mining
(Studi Kasus : Data Transaksi Pasar Swalayan) [Skripsi]. Bogor: Departemen Ilmu Komputer, FMIPA, Institut Pertanian Bogor.
Tan, P.N., Steinbach, M., & Umar, V.K. 2006.
Introduction to Data Mining. Boston : Pearson Education, Inc.
Wijayanti TE. 2008. Incremental Updating
12
13 Lampiran 1 Ilustrasi proses tahapan pada modul delete sesuai dengan metode penelitian
Informasi yang diketahui dari data yang lalu yaitu: a Data transaksi awal (sebelum dihapus):
Partisi Tanggal TID Item
b Support threshold=40% dan Confidence threshold=75 % c w1=0.67
Pertama: Mencari candidate 2-itemsetdari data yang akan dihapus (∆-). Langkah 1: Menghitung M(h+1)n=1.447
%
Langkah 2: Memeriksa C2 yang dihasilkan dari data awal yang partisi awalnya adalah
P1. C2 dari data lalu yang partisi awalnya P1adalah AD, AE, DE, DF.
Sehingga didapatkan C2 yang memiliki V- σPi(I) ≥ M(h+1)n yaitu AD, AE,
dan DF. Diperoleh C2_baru yaitu AB, AD, AE, AF, BF, DF, EF.
Kedua: Menggabungkan C2_barudengan L2 dari hasil penelitian sebelumnya menjadi C2’.
C2’= C2_baru L2= {AB, AD, AE, AF, BF, DE, DF, EF}.
Ketiga: Mencari candidate frequent itemset terbaru (C’) dari perluasan C2’. C3’= C2’* C2’={ABF, ADE, ADF, AEF, DEF}
C4’= C3’*C3’={ADEF}
C’ = { AB, AD, AE, AF, BF, DE, DF, EF, ABF, ADE, ADF, AEF, DEF, ADEF } Keempat: Menentukan C’ yang dapat menjadi frequent itemset karena cumulative weighted
count- nya lebih besar dari weighted count threshold(M(h+1)n). Sehingga, itemset yang
frequent adalah sebagai berikut: , , , AF, BF, DF, EF, ABF, ADF, AEF.
Pengecekan tersebut diilustrasikan sebagai berikut.
C' Cumulative weighted count baru
14 Lampiran 1 Lanjutan
C' Cumulative weighted count baru
AE 1.876
Kelima: Mencari association rule dari L’ tersebut dengan menghitung weighted confidence
untuk setiap kombinasi aturan asosiasi.
AR Weighted
Sehingga aturan asosiasi yang memenuhi confidence threshold adalah sebagai berikut.
No AR Weighted Confidence
15 Lampiran 2 Kode item barang yang ada pada data transaksi
Kode Nama 10 mie instant 11 saus kecap 12 makanan kaleng 13 lotion
14 sabun 15 shampo 16 obat nyamuk 17 pengharum ruangan 18 bumbu dapur 19 tepung 20 minyak goreng 21 susu bayi 22 rokok 23 baterai 24 eskrim 25 sosis
26 perlengkapan komputer 27 obat
28 pasta gigi 29 multivitamin 30 susu
31 perlengkapan bayi 32 handuk
33 perlengkapan dapur 34 tissue
35 sandal 36 korek
37 pembersih lantai 38 pencuci piring 40 kopi
50 makanan pokok 60 permen
70 minuman 80 snack
16 Lampiran 3 Banyaknya frequent itemset baru (L’) dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6
Lampiran 4 Frequent Itemset dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6
No Minggu/Bulan Partisi 1 Partisi 2 Partisi 3 Partisi 4 Partisi 5 Partisi 6
20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40%
1 Minggu 1 Maret 3080 3080 - 3080 3080 - 3080 3080 - 3080 3080 - 7080 3080 - - - -
6080 6080 1080 1080 3080
6080 6080 1080
6080
2 Minggu 2 Maret 1080 3080 - 1080 3080 - 1080 3080 - 1080 3080 - 1080 3080 - - - -
3080 3080 3080 3080 3080
6080 6080 6080 6080 6080
8014 8014 8014 8014 8014
3 Minggu 3 Maret 3080 - 3080 - 3080 - - 1080 3080 - 1080 3080 - - - -
7080 7080 7080 3080 7080 3080 7080
7080 7080
8014 3014
No Minggu/Bulan Partisi 1 Partisi 2 Partisi 3 Partisi 4 Partisi 5 Partisi 6
20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40%
1 Minggu 1 Maret 2 1 0 2 1 0 3 1 0 3 1 0 4 1 0 0 0 0
2 Minggu 2 Maret 4 1 0 4 1 0 4 1 0 4 1 0 4 1 0 0 0 0
3 Minggu 3 Maret 2 0 0 2 0 0 2 0 0 5 2 0 6 2 0 0 0 0
4 Minggu 4 Maret 2 1 0 2 1 0 2 1 0 2 1 0 3 0 0 0 0 0
5 Minggu 1 April 6 0 0 6 1 0 6 0 0 6 0 0 7 2 0 0 0 0
6 Minggu 2 April 4 1 0 5 1 0 5 1 0 5 1 0 5 0 0 0 0 0
7 Minggu 3 April 3 1 0 4 1 0 3 1 0 3 1 0 3 0 0 0 0 0
8 Minggu 4 April 3 0 0 2 0 0 3 0 0 4 0 0 2 0 0 0 0 0
9 Minggu 1 Mei 5 0 0 5 0 0 4 0 0 5 0 0 0 0 0 0 0 0
10 Minggu 2 Mei 3 1 0 3 1 0 3 2 0 3 2 0 7 1 0 0 0 0
17 Lampiran 4 Lanjutan
No Minggu/Bulan Partisi 1 Partisi 2 Partisi 3 Partisi 4 Partisi 5 Partisi 6
20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40%
4 Minggu 4 Maret 3080 - - 3080 7080 - 3080 7080 - 3080 - - 3080 - - - - -
7080 7080 7080 3080 7080 3070
7080
5 Minggu 1 April 1080 - - 1080 3080 - 1080 - - 1080 - - 1080 7080 - - - -
7080 7080 7080 7080 6070 3080
3080 3080 3080 3080 7080
3070 3070 6080 6080 3080
6080 6080 8014 8014 6080
8014 8014 1014 1014 8014
1014
6 Minggu 2 April 1080 3080 - 1080 3080 - 1080 3080 - 1080 - - 1080 - - - - -
3070 3070 3070 3070 3070
3080 3080 3080 3080 3080
7080 7080 7080 7080 7080
8014 8014 8014 8014
7 Minggu 3 April 7080 7080 - 7080 7080 - 7080 7080 - 7080 7080 - 7080 7080 - - - -
3080 3080 3080 3080 3080
8014 8014 8014 8014 8014
1080
8 Minggu 4 April 3080 - - 3080 7080 - 3080 7080 - 3080 3080 - 3080 - - - - -
7080 7080 7080 7080 3070
7080
9 Minggu 1 Mei 3080 - - 3080 - - 3080 - - 3080 - - - -
7080 7080 7080 7080
8014 8014 8014 8014
1080 1080 1080 1080
6080 6080 6080
18 Lampiran 4 Lanjutan
No Minggu/Bulan Partisi 1 Partisi 2 Partisi 3 Partisi 4 Partisi 5 Partisi 6
20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40%
7080 - - 7080 - - 7080 7080 - 7080 7080 - 7080 - - 7080 - -
3070 3070 3070 3070 3070 8014
8014 6070 1070 7014
11 Minggu 3 Mei 3080 - - 3080 - - 3080 - - 3080 - - 3080 - - - - -
7080 7080 7080 8014
1014 4014 5014
Lampiran 5 Banyaknya aturan asosiasi (AR’) dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6
No Minggu/Bulan Partisi 1 Partisi 2 Partisi 4 Partisi 5 Partisi 6
20% 30% 40% 20% 30% 20% 30% 40% 20% 30% 40% 20% 30% 40%
1 Minggu 1 Maret 2 1 0 2 1 1 1 0 1 1 0 0 0 0
2 Minggu 2 Maret 3 1 0 4 1 4 1 0 4 1 0 0 0 0
3 Minggu 3 Maret 1 0 0 0 0 4 1 0 4 2 0 0 0 0
4 Minggu 4 Maret 2 0 0 2 1 2 1 0 3 0 0 0 0 0
5 Minggu 1 April 3 0 0 3 1 4 0 0 5 2 0 0 0 0
6 Minggu 2 April 2 1 0 2 1 1 1 0 2 0 0 0 0 0
7 Minggu 3 April 3 1 0 4 1 2 1 0 3 0 0 0 0 0
8 Minggu 4 April 2 0 0 2 0 3 0 0 2 0 0 0 0 0
9 Minggu 1 Mei 4 0 0 4 0 4 0 0 0 0 0 0 0 0
10 Minggu 2 Mei 1 0 0 1 0 1 0 0 2 0 0 0 0 0
19 Lampiran 6 Aturan asosiasi baru (AR’) dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6
No Minggu/Bulan Partisi 1 Partisi 2 Partisi 3 Partisi 4 Partisi 5 Partisi 6
20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40%
1 Minggu 1 Maret 30 80 30→80 - 30→80 30→80 - 30→80 30→80 - 30→80 30→80 - 30→80 30→80 - - - -
60→80 60→80 60→80
2 Minggu 2 Maaret 10→80 30→80 - 10→80 30→80 - 10→80 30→80 - 10→80 30→80 - 10→80 30→80 - - - -
30→80 30→80 30→80 30→80 30→80
60→80 60→80 60→80 60→80 60→80
14→80 14→80 14→80 14→80
3 Minggu 3 Maret 70→80 - - - 70→80 - - 10→80 70→80 - 10→80 30→80 - - - -
30→80 30→80 70→80
70→80 70→80
14→80 14→80
4 Minggu 4 Maret 30→80 - - 30→80 70→80 - 30→80 70→80 - 30→80 - - 30→80 - - - - -
70→80 70→80 70→80 30→80 70→80 70→80
80→70
5 Minggu 1 April 70→80 - - 70→80 30→80 - 70→80 - - 70→80 - - 10→80 70→80 - - - -
30→80 30→80 30→80 30→80 70→80 30→80
60→80 60→80 60→80 60→80 30→80
10→14 10→14 60→80
10→14
6 Minggu 2 April 30→80 30→80 - 30→80 30→80 - 30→80 30→80 - 30→80 30→80 - 30→80 - - - - -
70→80 70→80 70→80 14→80
7 Minggu 3 April 70→80 70→80 - 70→80 70→80 - 70→80 70→80 - 70→80 70→80 - 70→80 70→80 - - - -
30→80 30→80 30→80 30→80 30→80
14→80 14→80 14→80 14→80
10→80
8 Minggu 4 April 30→80 - - 30→80 - - 30→80 - - 30→80 - - 30→80 - - - - -
60→80 60→80 60→80 70→80 60→80
60→80
9 Minggu 1 Mei 30→80 - - 30→80 - - 30→80 - - 30→80 - - - -
20 Lampiran 6 Lanjutan
No Minggu/Bulan Partisi 1 Partisi 2 Partisi 3 Partisi 4 Partisi 5 Partisi 6
20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40% 20% 30% 40%
10→80 10→80 10→80 10→80
60→80 60→80 60→80
10 Minggu 2 Mei 70→80 - - 70→80 - - 70→80 - - 70→80 - - 60→70 - - - - -
10→70
11 Minggu 3 Mei 30→80 - - - 10→14 - - - -
40→14 50→14
Lampiran 7 Waktu eksekusi (dalam detik) unutk mendapatkan aturan asosiasi dengan penghapusan data setiap minggu untuk jumlah partisi yang dihapus adalah 1, 2, 3, 4, 5, dan 6
Support Threshold
Confidence threshold
Partisi 1 Partisi 2 Partisi 3 Partisi 4 Partisi 5 Partisi 6 Data
update
Data hapus
Data update
Data hapus
Data update
Data hapus
Data update
Data hapus
Data update
Data hapus
Data update
21 Lampiran 8 Grafik waktu eksekusi untuk data update dan data hapus
a Jumlah partisi yang dihapus adalah 1
22 Lampiran 8 Lanjutan
c Jumlah partisi yang dihapus adalah 3
23 Lampiran 8 Lanjutan
e Jumlah partisi yang dihapus adalah 5