KLASIFIKASI KEMUNCULAN TITIK PANAS PADA LAHAN
GAMBUT DI SUMATERA DAN KALIMANTAN DENGAN
MENGGUNAKAN ALGORITME POHON KEPUTUSAN C5.0
DHITA APRITA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Sumatera dan Kalimantan dengan Menggu-nakan Algoritme Pohon Keputusan C5.0 adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
DHITA APRITA. Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Su-matera dan Kalimantan dengan Menggunakan Algoritme Pohon Keputusan C5.0 . Dibawah bimbingan IMAS SUKAESIH SITANGGANG.
Prediksi kejadian kebakaran hutan dilakukan menggunakan titik panas sebagai indikator kebakaran hutan. Pada penelitian ini dilakukan klasifikasi kemunculan titik panas di lahan gambut di Sumatera dan Kalimantan. Algoritme yang digunakan dalam klasifikasi adalah C5.0 dengan model klasifikasi tree dan rule-based. Penerapan algoritme C5.0 pada dataset kebakaran hutan menghasilkan nilai akurasi terbesar pada dataset Sumatera tahun 2001 dan Kalimantan tahun 2001. Model pohon keputusan pada dataset Sumatera 2001 memiliki akurasi 88.98% dan model berbasis aturan memiliki akurasi 89.83%. Dari model pohon keputusan diperoleh 8 aturan klasifikasi sedangkan model berbasis aturan terdiri atas 7 aturan klasifikasi. Dari dataset Kalimantan 2001 dihasilkan model pohon keputusan dengan akurasi 71.91% dan model berbasis aturan dengan akurasi 71.91%. Dari model pohon keputusan diperoleh 2 aturan klasifikasi dan model berbasis aturan terdiri dari 2 aturan klasifikasi. Model dengan akurasi tertinggi diterapkan pada dataset baru 2015. Akurasi yang dihasilkan pada data baru Kalimantan tahun 2015 sebesar 42.22% dan Sumatera tahun 2015 sebesar 50.99%.
Kata kunci: C5.0; kebakaran hutan; klasifikasi; pohon keputusan; titik panas
ABSTRACT
DHITA APRITA. Classification of Hotspot Occurences on Peatlands in Suma-tra and Kalimantan using C5.0 Decision Tree Algorithm. Supervised by IMAS SUKAESIH SITANGGANG.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI KEMUNCULAN TITIK PANAS PADA LAHAN
GAMBUT DI SUMATERA DAN KALIMANTAN DENGAN
MENGGUNAKAN ALGORITME POHON KEPUTUSAN C5.0
DHITA APRITA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji :
Judul Skripsi : Klasifikasi Kemunculan Titik Panas Pada Lahan Gambut di
Sumatera dan Kalimantan dengan Menggunakan Algoritme Pohon Keputusan C5.0
Nama : Dhita Aprita NIM : G64134016
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Klasifikasi Kemunculan Titik Panas pada Lahan Gambut Di Sumatera dan Kalimantan dengan Menggunakan Algoritme Pohon Keputusan C5.0”. Skripsi ini disusun sebagai syarat mendapat gelar Sarjan Komputer (SKomp) pada Program Sarjana Ilmu Komputer di Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor (IPB).
Penulis mengucapkan terima kasih kepada semua pihak yang telah berperan dalam penelitian ini, di antaranya:
1 Ibu, Ayah, Kakak, adek dan keluarga lainnya yang telah memberikan dukungan, doa, motivasi, dan semangat untuk keberhasilan studi 2 Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku dosen
pembimbing yang telah memberikan bimbingan, saran, arahan, dan bantuan selama penyelesaian skripsi
3 Bapak Muhammad Ahsyar Agmalaro, SSi MKom dan Bapak Muhammad Abrar Istiadi, SKomp MKom selaku dosen penguji
4 Sahabat-sahabat terbaik penulis, serta teman-teman satu bimbingan, terima kasih atas doa, semangat, dan bantuannya
5 Seluruh dosen dan civitas akademika Departemen Ilmu Komputer IPB. Penulis berharap semoga skripsi ini bermanfaat bagi pihak yang membutuhkan.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Klasifikasi Data Menggunakan Algoritme C5.0 3
Data Penelitian 5
Tahapan Penelitian 8
Praproses Data 9
Pembagian Dataset 9
Pembuatan Model Klasifikasi Menggunakan Algoritme C5.0 9
Perhitungan Akurasi 10
Penerapan Model Terbaik Pada Data Baru 10
Lingkungan Pengembangan 10
HASIL DAN PEMBAHASAN 11
Praproses Data 11
Seleksi Data Titik Panas pada Lahan Gambut 11
Pembuatan Data Non Titik Panas 12
Pembuatan Dataset 14
Penambahan Atribut Primary Key 15
Klasifikasi Titik Panas Menggunakan Algoritme C5.0 15 Penerapan Terbaik Hasil Klasifikasi Titik Panas Pada Data Baru 20
SIMPULAN DAN SARAN 20
Simpulan 20
DAFTAR PUSTAKA 21
DAFTAR TABEL
1 Atribut data titik panas 5
2 Luas lahan gambut di Sumatera 7
3 Luas lahan gambut di Kalimantan 7
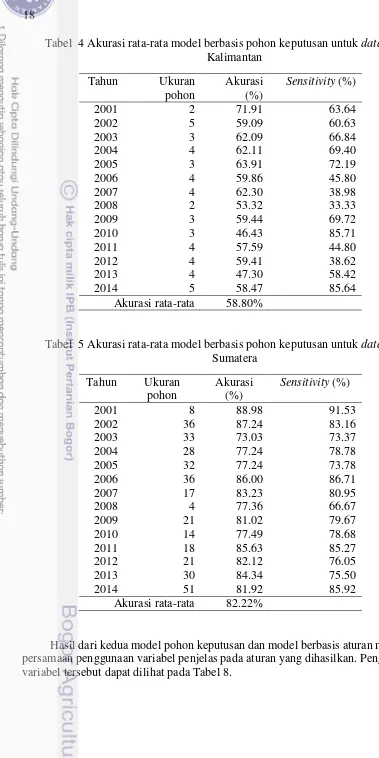
4 Akurasi rata-rata model berbasis pohon keputusan untuk dataset
Kalimantan 18
5 Akurasi rata-rata model berbasis pohon keputusan untuk dataset
Sumatera 18
6 Akurasi rata-rata model berbasis aturan untuk dataset
Kalimantan 19
7 Akurasi rata-rata pada model berbasis aturan untuk dataset
Sumatera 19
8 Penggunaan variabel penjelas pada model berbasis pohon
keputusan dan berbasis aturan 19
DAFTAR GAMBAR
1 Peta lahan gambut di Sumatera 6
2 Peta lahan gambut di Kalimantan 6
3 Tahapan penelitian 9
4 Jumlah data titik panas di Sumatera dan Kalimantan tahun
2001-2014 11
5 Hasil seleksi data titik panas pada lahan gambut 12
6 Hasil buffer titik panas 12
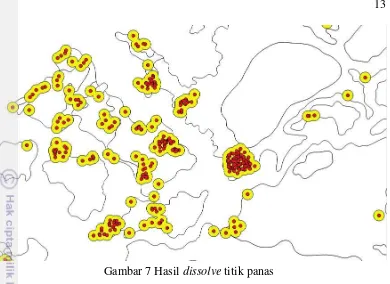
7 Hasil dissolve titik panas 13
8 Data titik panas dan non titik panas 13
DAFTAR LAMPIRAN
1 Contoh penggunaan algoritme C5.0 terhadap dataset kecil
kebakaran hutan 23
2 Model klasifikasi pohon keputusan dengan algoritme C5.0
menggunakan perangkat lunak R 26
3 Model klasifikasi berbasis aturan dengan algoritme C5.0
PENDAHULUAN
Latar Belakang
Kebakaran hutan di Indonesia pada saat ini dapat dipandang sebagai peristiwa bencana regional dan global. Tahun 1997, kebakaran lahan gambut di Sumatera dan Kalimantan telah menjadi berita utama. Hal ini disebabkan karena dampak dari kebakaran hutan sudah menjalar ke negara-negara tetangga dan gas-gas hasil pembakaran yang diemisikan ke atmosfer seperti karbondioksida berpotensi menimbulkan pemanasan global (Adinugroho et al. 2005).
Salah satu cara penanggulangan terhadap bencana kebakaran hutan di Indonesia adalah melakukan pemantauan terhadap titik panas (hotspot). Hotspot merupakan suatu objek permukaan bumi yang memiliki suhu relatif lebih tinggi dibandingkan dengan sekitarnya yang dapat deteksi oleh satelit. Area tersebut direpresentasikan dalam suatu titik yang memiliki koordinat tertentu (Awang 2014). Data titik panas dapat dijadikan sebagai salah satu indikator kemungkinan terjadinya kebakaran, tetapi masih perlu dilakukan pemantauan dan pengecekan ulang di lapangan untuk mengetahui apakah dapat diperlukan penindakan lebih lanjut atau tidak.
Tacconi (2003) menyebutkan 3 masalah utama terkait dengan kebakaran hutan di Indonesia yaitu (1) pencemaran kabut asap, emisi karbon dan dampak terkait lainnya; (2) degradasi hutan, deforestasi dan hilangnya hasil hutan dan berbagai jasa lingkungan serta (3) kerugian di sektor pedesaan akibat kebakaran hutan dan anomali cuaca yang dipicu oleh kebakaran hutan. Oleh karena itu, dibutuhkan suatu sistem untuk membantu mengurangi terjadinya kebakaran hutan. Data kebakaran hutan umumnya berukuran besar, data titik panas merupakan data spasial. Untuk analisis data berukuran besar salah satu metode yang dapat untuk digunakan adalah teknik data mining. Penggunaan teknik data mining mampu mengolah dan menganalisis data yang berukuran besar.
Salah satu penggunaan data mining dalam pengolahan data titik panas ialah klasifikasi. Klasifikasi adalah proses menemukan model (fungsi) yang menggambarkan dan membedakan kelas data atau konsep. Model yang diturunkan berdasarkan analisis set data pelatihan (yaitu, objek data yang label kelas diketahui). Model ini digunakan untuk memprediksi label kelas objek yang label kelas tidak diketahui (Han et al. 2012).
Penelitian Sitanggang et al. (2014) menggunakan algoritme ID3 memiliki akurasi sebesar 49.02% , C4.5 memiliki akurasi sebesar 65.24%, dan menghasilkan akurasi dari algoritme spatial decision tree sebesar 71.66%. Hasil penelitian tersebut menyimpulkan bahwa melibatkan hubungan spasial dalam algoritme pohon keputusan menghasilkan pengklasifikasi yang lebih baik untuk memprediksi terjadinya titik panas.
2
Algoritme pohon keputusan C5.0 yang merupakan penyempurnaan dari algoritme sebelumnya yaitu, ID3 dan C4.5 yang diperkenalkan terlebih dahulu oleh J.Ross Quinlan. Algoritme C5.0 menghasilkan pohon keputusan yang lebih sederhana dan penggunaan memori yang lebih efisien. Algoritme C5.0 dapat mengklasifikasikan model klasifikasi berstruktur pohon (tree) dan aturan (rule-based). Penggunaan algoritme C5.0 untuk mendapatkan model klasifikasi dengan hasil tingkat akurasi yang lebih tinggi dibandingkan dengan ID3 dan C4.5. Model klasifikasi dibuat dengan menggunakan bahasa pemograman R dengan package yang telah tersedia. Pada R, algortime C5.0 sebagai pengembangan dari algoritme C4.5. Oleh karena itu, pada penelitian ini akan dibangun model klasifikasi kemunculan titik panas pada lahan gambut di Pulau Sumatera dan Kalimantan dengan menggunakan algoritme C5.0. Pemodelan klasifikasi dibangun untuk memprediksi kejadian kemunculan titik panas dengan beberapa data latih dan data uji menggunakan teknik 10—fold cross validation.
Perumusan Masalah
Berdasarkan latar belakang di atas, maka perumusan masalah pada penelitian ini adalah:
1 Bagaimana penerapan algoritme C5.0 untuk mengklasifikasikan kemunculan titik panas di lahan gambut di Sumatera dan Kalimantan? 2 Bagaimana membuat model klasifikasi kemunculan titik panas di lahan
gambut di Sumatera dan Kalimantan?
3 Bagaimana karakteristik lahan gambut yang berpotensi munculnya titik panas?
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan algoritme pohon keputusan C5.0 pada data titik panas di lahan gambut di Pulau Sumatera dan Kalimantan tahun 2001-2014 untuk membuat model klasifikasi kejadian kemunculan titik panas.
Manfaat Penelitian
Model klasifikasi kemunculan titik panas yang dihasilkan pada penelitian ini diharapkan dapat membantu untuk memprediksi kejadian titik panas di masa mendatang sehingga dapat membantu dalam pencegahan kebakaran hutan.
Ruang Lingkup Penelitian
Lingkup dari penelitian ini, yaitu:
1 Karakteristik lahan gambut yang dianalisis yaitu tipe lahan gambut, tutupan lahan gambut, dan kedalaman lahan gambut.
2 Implementasi algoritme C5.0 menggunakan package C50 yang sudah tersedia pada perangkat lunak RStudio.
3
METODE
Klasifikasi Data Menggunakan Algoritme C5.0
Algoritme C5.0 adalah perluasan dari algoritme C4.5 dan juga ID3 (Patil et al. 2012). C5.0 adalah algoritme klasifikasi yang dapat menangani kumpulan data besar. C5.0 lebih baik daripada C4.5 dalam hal kecepatan, memori dan efisiensi. Model C5.0 bekerja dengan memisahkan sampel berdasarkan bidang yang menyediakan keuntungan informasi dengan maksimum. Model C5.0 dapat membagi sampel berdasarkan nilai information gain terbesar. Atribut yang memiliki information gain terbesar akan dipilih sebagai parent atau untuk node selanjutnya.
Sebuah pohon keputusan adalah classifier yang direpresentasikan sebagai struktur pohon, di mana masing-masing simpul adalah simpul daun. Klasifikasi yang berlaku untuk semua kasus yang mencapai daun atau node non-leaf, beberapa tes dilakukan pada nilai atribut tunggal, dengan satu cabang dan sub-pohon untuk setiap kemungkinan hasil tes. Node dalam pohon keputusan melibatkan pengujian atribut tertentu. Biasanya, tes pada node membandingkan nilai atribut dengan konstan. Namun, beberapa pohon membandingkan dua atribut satu sama lain, atau menggunakan beberapa fungsi dari satu atau lebih atribut. Node daun memberikan klasifikasi yang berlaku untuk semua kasus yang mencapai daun, atau satu set klasifikasi, atau distribusi probabilitas atas semua klasifikasi yang mungkin (Witten et al. 2011). Algoritme generate decision tree adalah sebagai berikut (Han et al. 2012):
1 Partisi data, D, data latih yang telah ditentukan label kelasnya 2 Attribute_list, himpunan yang terdiri dari kandidat atribut
3 Attribute_selection_method, prosedur untuk menentukan kriteria pemotongan yang partisi tuple data terbaik ke kelas masing-masing. Algoritme klasifikasi pohon keputusan adalah sebagai berikut (Han et al. 2012):
1 Membuat simpul N;
2 Jika semua tupel di D memiliki kelas yang sama yaitu C.
Maka simpul N sebagai simpul daun dan diberi label dengan kelas C. 3 Jika attribute list kosong, maka
Jadikan simpul N sebagai simpul daun dan diberi label = nilai kelas terbanyak pada sampel
4 Menerapkan attribute selection method (D, attribute list) untuk memperoleh atribut uji terbaik
5 Beri label simpul N dengan atribut data uji
6 Jika atribut bernilai diskret dan diperbolehkan untuk dipisah, maka 7 Attribute list <- attribute list <- atribut uji
8 Untuk setiap nilai j dari atribut uji yang diketahui
Buat Dj menjadi kumpulan data tuple D untuk memenuhi hasil j
Jika Dj kosong maka
4
Selainnya, tambah cabang baru di bawah dengan memanggil fungsi generate decision tree (Dj attribute list) ke simpul N;
Kembalikan N;
Algoritme C5.0 memiliki tiga parameter input: D, attribute_list, dan attribute_selection_method. D merupakan satu set tuple pelatihan dan label kelas yang terkait. Attribute list menggambarkan suatu tupel. Attribute selection method menentukan prosedur untuk memilih atribut yang mengolah tuple menurut kelasnya. Prosedur ini membutuhkan ukuran atribut dengan information gain dan gini indeks. Algoritme pohon keputusan generate decision tree dimulai dari simpul tunggal, N, yang merepresentasikan data latih di D.
Model klasifikasi yang digunakan yaitu tree dan rule-based. Tree dimulai sebagai node tunggal, N mewakili tupel pelatihan D. Tree memiliki struktur pohon seperti flowchart yang masing-masing simpul internal non leaf node menunjukkan pengujian pada atribut, masing-masing cabang mewakili hasil dari pengujian dan masing-masing simpul daun merupakan label kelas. Root merupakan simpul paling atas pada struktur tree. Sedangkan rule-based cara yang baik untuk mewakili informasi atau pengetahuan. Aturan classifier menggunakan aturan IF (kondisi) – THEN (kesimpulan) untuk klasifikasi. IF merupakan bagian (or left side) dari aturan ini dikenal sebagai aturan prasyarat. Sedangkan THEN (or right side) merupakan bagian konsekuen (Han et al. 2012).
Penelitian ini menggunakan information gain sebagai ukuran pemilihan atribut. Atribut dengan information gain terbesar ditentukan sebagai atribut pemisah untuk simpul N. Ukuran pemilihan atribut didefinisikan sebagai berikut (Han et.al 2012):
Info D = − ∑mi=1pilog2(pi) (1) Dengan info (D) merupakan informasi yang dibutuhkan untuk mengklasifikasi label kelas sebuah tuple di D. pi adalah peluang bukan nol dengan
sebuah tuple acak di D memiliki kelas Ci dan ditentukan dengan |Ci,D|/|D|. Fungsi
log menggunakan basis 2, karena informasi yang dikodekan dalam bit. Info (D) juga dikenal sebagai entropy.
Partisi tuple di D pada beberapa atribut A memiliki nilai v yang berbeda {a1, a2, …, av} dari data latih. Atribut A digunakan untuk memisahkan D ke dalam v partisi atau sub himpunan {D1, D2, …, Dv}. ||DjD|| merupakan bobot partisi ke-j. Nilai
entropy yang dihasilkan untuk mengklasifikasi tuple dari D berdasarkan partisi oleh A adalah (Han et al. 2012):
InfoA D =∑vj=1|DDj| × Info(Dj) (2)
Information gain yang diperoleh pada atribut A adalah:
Gain A =Info D - InfoA D (3)
Gain (A) menyatakan berapa banyak cabang yang akan diperoleh pada A. Atribut A dengan information gain tertinggi informasi, Gain (A), dipilih sebagai atribut pada node N (Han et al. 2012).
5 dinyatakan sebagai pohon keputusan atau set aturan (aturan-aturan). Metode set aturan C4.5 ini terlalu lambat dan memakan banyak memori (RAM). C5.0 merupakan algoritme baru untuk memberikan aturan-aturan (ruleset), dan memperbaiki secara substansial. C5.0 memiliki beberapa jenis data baru selain yang tersedia di C4.5, termasuk tanggal, waktu, timestamp (tanggal dan waktu), atribut diskrit, dan label kasus. Beberapa perbedaan algoritme C4.5 dan C5.0 (Rulequest 2012) :
1 Akurasi: C5.0 memiliki tingkat kesalahan yang lebih rendah. C4.5 dan C5.0 memiliki akurasi prediksi yang sama, tetapi set aturanC5.0 lebih kecil.
2 Kecepatan: C5.0 jauh lebih cepat, menggunakan algoritme yang berbeda dan sangat dioptimalkan.
3 Memory: C5.0 umumnya lebih ringan dari C4.5.
Perbedaan utama antara C4.5 dan C5.0 adalah boosting, winnowing. Boosting adalah teknik untuk menghasilkan dan menggabungkan beberapa pengklasifikasi untuk meningkatkan akurasi prediksi. Winnowing adalah langkah seleksi fitur yang dilakukan sebelum pemodelan (Rulequest 2012).
Data Penelitian
Data yang digunakan pada penelitian ini adalah data titik panas di Pulau Su-matera dan Kalimantan pada tahun 2001-2014. Data ini diperoleh dari Moderate-resolution Imaging Spectroradiometer (MODIS) milik National Aeronautics and Space Administration (NASA). Sedangkan data untuk kedalaman lahan gambut dan jenis lahan gambut diperoleh dari Wetland International. Data yang digunakan merupakan data time series pemantauan kejadian titik panas dilakukan setiap hari, data ini masih harus dilakukan praproses data untuk mendapatkan data yang ingin diklasifikasi. Data titik panas dinyatakan dalam format CSV, dan data lahan gambut dinyatakan dengan format SHP. Atribut data titik panas dapat dilihat pada Tabel 1. Peta gambut di Pulau Sumatera dapat dilihat pada Gambar 1 dan di Pulau Kalimantan pada Gambar 2.
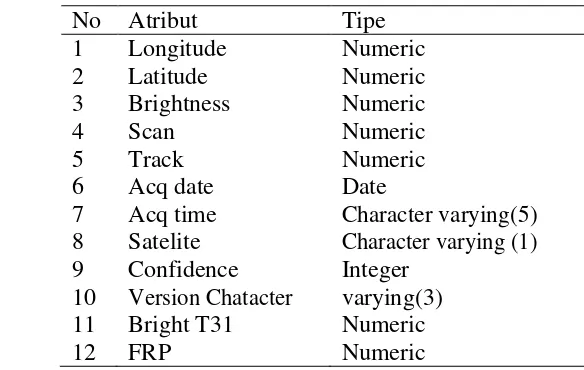
Tabel 1 Atribut data titik panas
No Atribut Tipe
1 Longitude Numeric
2 Latitude Numeric
3 Brightness Numeric
4 Scan Numeric
5 Track Numeric
6 Acq date Date
7 Acq time Character varying(5) 8 Satelite Character varying (1) 9 Confidence Integer
10 Version Chatacter varying(3) 11 Bright T31 Numeric
6
Gambar 1 Peta lahan gambut di Sumatera
Pada Gambar 1 terdapat beberapa jenis tipe gambut dan kedalaman lahan gambut di Sumatera dan Kalimantan. Sebagai contoh untuk mengetahui luas yang tipe gambutnya hemists/fibrists menggunakan perintah sebagai berikut:
SELECT soil AS type, sum(ST Area(geom))/10000 AS surface FROM peatland GROUP BY soil HAVING
soil=’Hemists/Fibrists’;
Dari perintah tersebut didapatkan jumlah luas area lahan gambut di Sumatera dapat dilihat pada Tabel 2. Tipe gambut yang memiliki luas area paling kecil di Pulau Sumatera yaitu hemists/mineral (90/10) sedang dengan luas area 0.62 ha.
7 Tabel 2 Luas lahan gambut di Sumatera
No Tipe gambut Luas (ha)
1 Hemists/Saprists (60/40) sedang 1.490.145.51 2 Saprists/min (50/50) dangkal 16.859.44 4 Saprists/min (30/70) sedang 9.911.09 5 Saprists/min (90/10) sedang 178.408.66
6 Hemists (100) dalam 2.200.51
7 Hemists/Saprists (60/40) dalam 639.263.33
8 Hemists (100) sedang 86.697.37
9 Saprists/min (50/50) dalam 7.748.18 10 Hemists/min(90/10) sangat dalam 30.179.83 11 Hemists/Saprists (60/40) sedang 211.082.30 12 Hemists/min (30/70) dangkal 308.112.73 13 Hemists/Saprists(60/40) sangat dalam 957.561.63 14 Saprists/Hemists (60/40) dalam 553.762.96 15 Saprists/Hemists (60/40) sedang 236.659.27 16 Hemists/min (90/10) dangkal 7.950.20 17 Hemists/Saprists (60/40) dangkal 49.355.05 18 Hemists/min (70/30) sedang 91.797.22 19 Saprists/min (30/70) dalam 12.671.89
20 Hemists/min (90/10) sedang 0.62
21 Hemists/min (50/50) dangkal 2.218.85 22 Saprists/min (50/50) sedang 118.152.45 23 Hemists/min (90/10) sedang 578.525.93 24 Fibrists/Saprists (60/40) sedang 10.721.83 25 Saprists/Hemists (60/40) sangat dalam 1.181.264.69 26 Hemists/min (30/70) sedang 308.958.76
27 Saprists (100) sedang 87.885.62
28 Saprists (100) dalam 35182.64
Pada Gambar 2 merupakan peta lahan gambut di Kalimantan. Untuk mengetahui luas mengetahui luas area lahan gambut di Kalimantan menggunakan perintah yang sama dengan menghitung luas area di Sumatera. Maka, luas area lahan gambut di Kalimantan dapat dilihat pada Tabel 3.
Tipe gambut yang memiliki luas area paling kecil di Pulau Kalimantan yaitu hemists/fibrists/saprists dengan luas area 3.028.58 ha.
Tabel 3 Luas lahan gambut di Kalimantan
No Tipe gambut Luas(ha)
1 Hemists/Fibrists 4.070.888.40
2 Hemists/Fibrists/Mineral 388.442.91
3 Hemists/Mineral 922.584.24
4 Saprists/Mineral 108.626.03
8
Lahan gambut mempunyai tingkat kematangan Fibrists (belum melapuk), Hemists (setengah melapuk), Saprists (sudah melapuk). Fibrists adalah tanah gambut yang relatif belum melapuk atau masih mentah, hemists adalah tanah gambut yang de-rajat dekomposisi bahan gambutnya tengahan, atau setengah melapuk dan saprists adalah tanah gambut yang derajat pelapukan bahan gambutnya sudah lanjut, atau sudah hancur seluruhnya (Wahyunto et al. 2005).
Kedalaman gambut dikategorikan menjadi D0, D1, D2, D3, dan D4. Nilai tersebut menunjukan tingkat kedalaman lahan gambut sebagai berikut (Sitanggang et al. 2012) :
1 D0 merupakan lahan gambut yang kedalamannya termasuk kriteria sangat dangkal atau sangat tipis yang mempunyai kedalamannya hanya mencapai < 50 cm.
2 D1 merupakan kriteria lahan gambut dangkal yang kedalamannya mencapai 50 cm hingga 100 cm
3 D2 kriteria lahan gambut cukup dalam yang kedalamannya mencapai 100 hingga 200 cm.
4 D3 termasuk kriteria lahan gambut dalam yang mempunyai kedalamannya mencapai 200 cm hingga 400 cm.
5 D4 merupakan kriteria lahan gambut sangat dalam atau sangat tebal kedala-mannya mencapai > 400 cm
Pada Tabel 3 terdapat 12 atribut yang didapatkan dari NASA. Namun, tidak semua attribut digunakan untuk melakukan pengklasifikasian titik panas. Atribut yang digunakan adalah longitude dan latitude untuk menentukan letak posisi koordinat dan confidence untuk menyeleksi tingkat kepercayaan titik panas 70%.
Tahapan Penelitian
9
Gambar 3 Tahapan penelitian
Praproses Data
Tahapan praproses data dilakukan untuk mendapatkan data yang siap untuk digunakan. Pada proses klasifikasi terdapat beberapa tahapan dalam melakukan praproses data yaitu data cleaning, dan data selection. Pembersihan data dilakukan untuk menghilangkan mising value atau membuang data yang tidak konsisten. Pemilihan data merupakan pengambilan data yang relevan yang akan digunakan untuk penelitian. Proses ini menyeleksi variabel data titik panas longitude, latitude, dan tanggal.
Pembagian Dataset
Untuk melakukan klasifikasi dataset dibagi menjadi data latih dan data uji. Data latih digunakan untuk membangun pohon keputusan, sedangkan data uji digunakan untuk menghitung akurasi pohon keputusan. Pembagian dataset menggunakan teknik 10-cross fold validation. 10-cross fold validation adalah sebuah metode yang membagi himpunan contoh secara acak menjadi K himpunan bagian (subset) (Fu 1994).
Pembuatan Model Klasifikasi Menggunakan Algoritme C5.0
10
Algoritme ini menggunakan ukuran information gain dalam membuat pohon keputusan. Data untuk membuat model klasifikasi yaitu data latih yang terdiri dari tahun 2001-2014. Model klasifikasi dibuat dengan menggunakan bahasa pemograman R dengan package yang telah tersedia yaitu C5.0. Algoritme C5.0 merupakan pengembangan algoritme C4.5. Contoh penggunaan algoritme C5.0 untuk dataset kecil dapat dilihat pada Lampiran 1.
Perhitungan Akurasi
Pada tahap ini akurasi dihitung dari model klasifikasi. Akurasi untuk menunjukkan tingkat kebenaran pengklasifikasian data terhadap kelas yang sebenarnya. Tingkat akurasi yang baik adalah tingkat akurasi yang mendekati 100%. Semakin tinggi tingkat akurasi maka semakin rendah kesalahan klasifikasi pada data baru. Dalam penelitian ini, metode yang digunakan dalam proses perhitungan akurasi adalah metode 10-cross fold validation. Akurasi diperoleh dari data uji dengan menggunakan rumus sebagai berikut:
Akurasi= ∑data uji yang benar diklasifikasikan∑data uji × 100 % (4)
Selain melakukan perhitungan akurasi, diperlukan juga sensitivity atau recall rate yang menunjukkan kemampuan model untuk mengenal kelas titik panas. Rumus yang digunakan untuk menghitung sensitivity sebagai berikut (Han et.al. 2012 ):
Sensitivity= True positive + false negativeTruepositive × 100 % (5)
Penerapan Model Terbaik Pada Data Baru
Pada penelitian ini model klasifikasi dengan model terbaik akan diterapkan pada data baru tahun 2015.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
Perangkat keras:
Processor Intel Core i3-370M RAM 2 GB DDR
320 GB hard disk drive Perangkat lunak:
Sistem operasi Microsoft Windows 7
Bahasa pemograman R-3.1. klasifikasi titik panas.
11
HASIL DAN PEMBAHASAN
Praproses Data
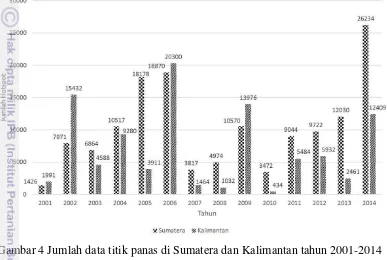
Tahap pertama penelitian ini adalah melakukan praproses data. Data titik panas yang diperoleh harus melalui tahap ini agar menghasilkan data yang relevan dan siap digunakan dalam tahap klasifikasi. Pada tahapan praproses data menggunakan Quantum GIS dan PostgreSQL. Sebelum praproses dilakukan, data titik panas dibagi per tahun. Data titik panas yang lengkap dalam 12 bulan yaitu tahun 2001-2014. Jumlah data titik panas pertahun dapat dilihat pada Gambar 4.
Gambar 4 Jumlah data titik panas di Sumatera dan Kalimantan tahun 2001-2014 Jumlah titik panas terbanyak terdapat di Sumatera yaitu pada tahun 2014 dengan titik panas 26234 dan di Kalimantan titik panas terbanyak terdapat pada tahun 2006 dengan jumlah titik panas sebanyak 20300.
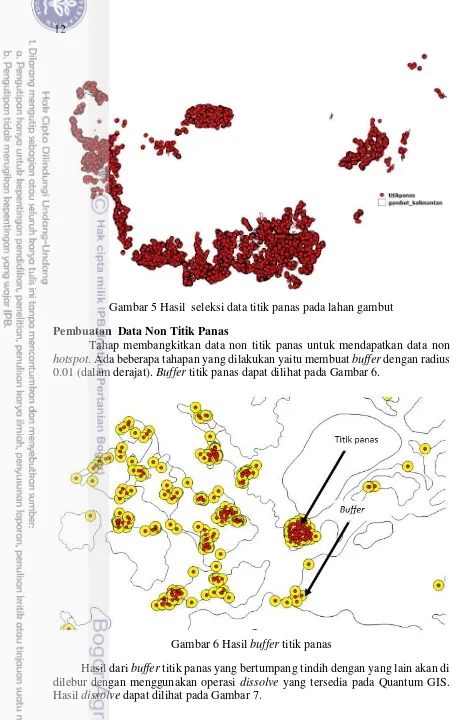
Seleksi Data Titik Panas pada Lahan Gambut
12
Gambar 5 Hasil seleksi data titik panas pada lahan gambut
Pembuatan Data Non Titik Panas
Tahap membangkitkan data non titik panas untuk mendapatkan data non hotspot. Ada beberapa tahapan yang dilakukan yaitu membuat buffer dengan radius 0.01 (dalam derajat). Buffer titik panas dapat dilihat pada Gambar 6.
Gambar 6 Hasil buffer titik panas
13
Gambar 7 Hasil dissolve titik panas
Poligon hasil titik panas dissolve dibuat pada lahan gambut dengan menggunakan operasi difference. Poligon operasi difference digunakan untuk memisahkan antara titik panas dengan non titik panas. Untuk mendapatkan data non titik panas dilakukan operasi pembangkitan random point. Hasil dari random point dapat dilihat pada Gambar 8.
Gambar 8 Data titik panas dan non titik panas
14
Pembuatan Dataset
Pada pembuatan dataset digunakan atribut kelas yang terdiri dari nilai TRUE dan nilai FALSE. Nilai TRUE menyatakan kejadian titik panas, dan nilai FALSE menyatakan bukan kejadian titik panas. Pembuatan dataset dilakukan menggunakan PostgresSQL. Pembuatan dataset dengan atribut kelas menggunakan SQL yaitu :
1 Membuat satu tabel baru bernama target2001, tabel target2001 berisi beberapa atribut yang diambil dari tabel titik_panas yang mempunyai nilai confidence 70% . Pernyataan SQL untuk langkah tersebut, yaitu :
CREATE TABLE target2001 AS SELECT gid, geom,
longitude, latitude, acq_date, acq_time,
confidence, class FROM reptitikpanas2001 WHERE
confidence >= 70%.
Tabel target2001 terdiri dari 889 record data titik panas di tahun 2001. 2 Menambahkan satu kolom di dalam tabel false alarm bernama class
dengan nilai default F atau FALSE. Pernyataan SQL untuk langkah tersebut, yaitu :
ALTER TABLE randompoints2001 ADD COLUMN class char DEFAULT 'F';
3 Menambahkan satu kolom di dalam tabel titik_panas bernama class dengan nilai default T atau TRUE. Pernyataan SQL untuk langkah tersebut, yaitu :
ALTER TABLE reptitikpanas2001 ADD COLUMN class char DEFAULT 'T';
4 Penggabungan target2001 dan titik acak (non titik panas) dibangkitkan sejumlah 889 titik acak.
INSERT INTO target2001 (gid,geom,class) SELECT gid,geom,class FROM randompoints2001;
5 Membuat tabel dataset1
Dataset1 terdiri dari 7 variabel yaitu gid, gid0, the_geom, confidence, class, depth, dan type. Variabel type menunjukkan tipe dari lahan gambut. Dataset yang akan diolah untuk klasifikasi terdiri dari 4 variabel yaitu class, depth, type. Query yang digunakan untuk membuat dataset tersebut sebagai berikut:
CREATE TABLE dataset1 AS SELECT t.gid, t.gid0, t.geom, t.confidence, t.class, g.depth, g.type FROM target2001 AS t, gambut_kalimantan AS g WHERE ST_Within( t.geom, g.geom) ORDER BY gid; 6 Membuat dataset2 yang akan menjadi input algoritme pohon keputusan.
15
Penambahan Atribut Primary Key
Penambahan atribut yang bertipe SERIAL dengan nama gid. Atribut gid ini dibuat sebagai nilai terurut datadi dalam tabel target2001, dan gid yang sebelumnya diubah menjadi gid0, gid0 merupakan primary key asli namun tidak terurut. Perubahan atribut ini dengan menggunakan SQL yaitu:
1 SQL untuk mengubah nama kolom gid menjadi gid0
ALTER TABLE target2001 RENAME COLUMN gid TO gid0; 2 Menambahkan kolom bernama gid dengan tipe data BIGSERIAL sebagai
primary key baru
ALTER TABLE target2001 ADD COLUMN gid BIGSERIAL PRIMARY KEY;
Penambahan gid digunakan untuk membuat dataset1. Selanjutnya data yang telah diproses dapat diexport menjadi format Comma delimited (.CSV) untuk implementasi algoritme C5.0 pada R. Setelah melakukan penambahan gid dan mengubah nama kolom gid maka selanjutnya dilakukan pemuatan dataset ke Quantum GIS untuk tahap selanjutnya yaitu klasifikasi titik panas menggunakan algoritme C5.0.
Klasifikasi Titik Panas Menggunakan Algoritme C5.0
Implementasi algoritme C5.0 tersedia pada perangkat lunak R dalam package C50. Algoritme C5.0 menghasilkan model klasifikasi berupa model pohon keputusan dan model berbasis aturan. Model berbasis aturan dihasilkan dari model berbasis aturan yang memiliki kondisi if-then menghasilkan kondisi yang tidak sama. Model berbasis aturan memiliki banyak aturan yang dapat disederhanakan dan dipangkas sehingga aturan yang diturunkan dapat berjumlah sedikit dari aturan yang dihasilkan oleh model berbasis pohon keputusan. Untuk mendapatkan model pohon keputusan dan model berbasis aturan dilakukan terlebih dahulu partisi data latih dan data uji. Partisi data ini menggunakan 10-fold cross validation. Untuk membangun model klasifikasi dengan algoritme C5.0 dilakukan perintah berikut:
1 Membaca dataset yang akan digunakan
>Dataset <- read.csv("D://dataset.csv") >set.seed(9850)}
2 Pembagian data menggunakan cross fold validation
>folds<-cut(seq(1,nrow(dataset)),breaks=10, labels=FALSE)
>for(i in 1:10){
>testIndexes <- which(folds==i, arr.ind=TRUE) >testData <- dataset[testIndexes, ]
>trainData <- dataset[-testIndexes,] 3 Pembuatan model pohon keputusan menggunakan perintah berikut:
>oneTree <- C5.0(CLASS~., data=trainData) >oneTree
>summary(oneTree)
4 Nilai akurasi dari model pohon keputusan dihitung menggunakan fungsi predict. Data yang digunakan adalah data uji. Berikut perintah untuk melakukan predict by tree:
16
>postResample(oneTreePred,testData $CLASS) 5 Pembuatan model berbasis aturan diperoleh dengan menggunakan
perintah sebagai berikut:
>rules<-C5.0(CLASS~,data=trainData, >rules=TRUE) >rules
>summary(rules)
6 Dari model berbasis aturan dihitung akurasi menggunakan data uji.Untuk melakukan predict by rule dilakukan perintah berikut:
>rulesPred <- predict(rules,testData)
>postResample(predict(rules,testData),testData $CLASS)
Dari tahapan implementasi menggunakan algoritme C5.0 dengan menggunakan perangkat lunak R, diperoleh model berbasis pohon keputusan untuk dataset Pulau Kalimantan dan Sumatera untuk setiap tahunnya. Akurasi model pohon keputusan dapat dilihat pada Tabel 4 untuk dataset Kalimantan dan untuk nilai akurasi dataset Sumatera dapat dilihat pada Tabel 5. Akurasi model berbasis aturan untuk dataset Kalimantan dapat dilihat pada Tabel 6 dan akurasi dataset Sumatera pada Tabel 7.
Akurasi rata-rata didapatkan dari jumlah akurasi seluruh dataset dibagi dengan jumlah dataset. Akurasi rata-rata yang diperoleh dari model pohon keputusan untuk dataset Kalimantan sebesar 58.80% dan dataset Sumatera sebesar 82.22%. Sedangkan akurasi rata-rata model berbasis aturan untuk dataset Kalimantan sebesar 58.82% dan dataset Sumatera sebesar 81.86%.
Akurasi tertinggi dari model berbasis pohon keputusan dan berbasis aturan yaitu pada dataset Sumatera tahun 2001 dan dataset Kalimantan 2001. Dataset Sumatera 2001 menghasilkan model berbasis pohon keputusan dengan akurasi sebesar 88.98% dan model berbasis aturan dengan akurasi sebesar 89.83 % terdapat 12 dari 118 data yang diklasifikasikan tidak benar oleh model pohon keputusan dan model berbasis aturan.
Untuk dataset Kalimantan 2001 model berbasis pohon keputusan dan model berbasis aturan memiliki akurasi sebesar 71.91% terdapat 57 dari 178 data titik panas yang diklasifikasikan tidak benar oleh model pohon keputusan dan model berbasis aturan. Data latih untuk Sumatera tahun 2001 sebanyak 3156 data dan data uji sebanyak 351 data dari 3507 data dan pada dataset Kalimantan tahun 2001 data latih sebanyak 1601 data dan data uji sebanyak 178 data dari 1779 data.
Model klasifikasi dengan menggunakan algoritme C5.0 pada dataset di Pulau Sumatera tahun 2001 menghasilkan pohon keputusan dengan banyaknya aturan sebesar 8 aturan dan model berbasis aturan yang terdiri dari 7 aturan. Model klasifikasi yang dihasilkan oleh model pohon keputusan secara lengkap dapat dilihat pada Lampiran 2 dan model klasifikasi yang dihasilkan oleh model berbasis aturan dapat dilihat pada Lampiran 3.
Beberapa aturan yang dihasilkan oleh pohon keputusan untuk dataset Sumatera tahun 2001 sebagai berikut:
17 2 IF tipe gambut in (Hemists/mineral (30/70), dangkal), (Saprists (100), sedang), (Saprists/Hemists (60/40), dalam), (Saprists/Hemists (60/40), sedang), (Saprists/ mineral (90/10), sedang), AND tutupan lahan = Kelapa sawit pada bekas hutan rawa > 5 tahun THEN Non hostpot (44/11) Aturan ke-1 menyatakan jika tipe lahan gambut adalah (Hemists/mineral (90/10), sedang) atau (Hemists/Saprists (60/40), dalam) atau (Hemists/Saprists (60/40), sangat dalam) atau (Hemists/Saprists (60/40), sedang) atau (Saprists (100), dalam) dan jika kedalaman gambut adalah cukup dalam maka wilayah tersebut diprediksi terdapat kemunculan titik panas.
Aturan ke-2 menyatakan jika tipe gambut adalah (Hemists/min (30/70), dangkal) atau (Saprists(100), sedang) atau (Saprists/Hemists (60/40), dalam) atau (Saprists/Hemists (60/40), sedang) atau (Saprists/mineral (90/10), sedang) dan tutupan lahan adalah kelapa sawit pada bekas hutan rawa > 5 tahun maka wilayah tersebut diprediksi tidak terjadi kemunculan titik panas. Nilai (67/23) menyatakan 67 data tergolong kelas hotspot dan 23 data bukan kelas hotspot.
Beberapa Aturan yang dihasilkan dari dataset Sumatera tahun 2001 untuk model berbasis aturan sebagai berikut:
1 IF tipe gambut in {(Hemists/mineral (90/10), sedang), (Hemists/Saprists (60/40), dalam), (Hemists/Saprists (60/40), sangat dalam), (Hemists/Saprists (60/40), sedang), (Saprists (100), dalam)} THEN hotspot (184/38, lift 1.6).
2 IF tipe gambut in {(Hemists/mineral (30/70),dangkal), (Hemists/mineral(30/70), sedang), (Hemists/mineral(90/10),sedang), (Hemists/Saprists(60/40),dalam),(Hemists/Saprists (60/40),sedang), (Saprists/Hemists(60/40),dalam), (Saprists/Hemists(60/40),sedang), (Saprists/Hemists (60/40),sedang),(Saprists/mineral (90/10),sedang)} AND tutupan lahan in {(Belukar rawa, Kelapa pada bekas hutan rawa > 5 tahun)} THEN Non hotspot (150/27, lift 1.6).
Aturan ke-1 menyatakan jika tipe gambut adalah {(Hemists/mineral (90/10), sedang) atau (Hemists/Saprists (60/40), dalam) atau (Hemists/Saprists(60/40), sangat dalam) atau (Hemists/Saprists (60/40), sedang) atau (Saprists (100), dalam)} maka wilayah tersebut diprediksi terdapat kemunculan titik panas. Aturan ke-2 menyatakan jika tipe gambut adalah {(Hemists/mineral (30/70), dangkal) atau (Hemists/mineral (30/70), sedang) atau (Hemists/mineral (90/10), sedang) atau (Hemists/Saprists(60/40), dalam) atau (Hemists/Saprists (60/40), sedang) atau (Saprists/Hemists(60/40), dalam), (Saprists/Hemists(60/40), sedang) atau (Saprists/Hemists (60/40), sedang) atau (Saprists/mineral (90/10), sedang)} AND tutupan lahan adalah Belukar rawa, Kelapa pada bekas hutan rawa > 5 tahun maka wilayah tersebut diprediksi tidak terdapat kemunculan titik panas.
18
Tabel 4 Akurasi rata-rata model berbasis pohon keputusan untuk dataset Kalimantan
Tabel 5 Akurasi rata-rata model berbasis pohon keputusan untuk dataset Sumatera
19 Tabel 6 Akurasi rata-rata model berbasis aturan untuk dataset Kalimantan
Tahun Jumlah
Tabel 7 Akurasi rata-rata pada model berbasis aturan untuk dataset Sumatera Tahun Jumlah
Tabel 8 Penggunaan variabel penjelas pada model berbasis pohon keputusan dan berbasis aturan
Variabel Presentase penggunaan variabel
Model pohon keputusan Model berbasis aturan
Tutupan lahan 100% 93.66%
Tipe gambut 100% 91.13%
20
Tabel 8 menunjukan bahwa kedua model tersebut menggunakan tiga variabel penjelas yang sama untuk klasifikasi yaitu tutupan lahan, tipe gambut, dan kedalaman gambut. Pada model pohon keputusan variabel tutupan lahan gambut digunakan 100%. Penggunaan variabel ini menyatakan bahwa pada setiap aturan pohon keputusan terdapat variabel tutupan lahan gambut. Sedangkan pada model berbasis aturan variabel tutupan lahan gambut digunakan sebesar 93.66% yang menyatakan bahwa tidak semua aturan mengandung variabel tutupan lahan.
Nilai akurasi tertinggi untuk model pohon keputusan pada dataset Kalimantan 71.91% yaitu pada tahun 2001 dan 71.91% untuk model berbasis aturan. Model pohon keputusan menghasilkan 2 aturan dan model berbasis aturan juga terdiri dari 2 aturan. Aturan-aturan tersebut adalah
1 IF kedalaman gambut {100-200,200-400,50-100} THEN Non hotspot (882/256)
2 IF kedalaman gambut in {400-800,800-1200} THEN Hotspot (719/171) Aturan ke-1 menyatakan bahwa jika kedalaman lahan gambut adalah 100-200 atau 100-200-400 atau 50-100 maka wilayah tersebut diprediksi tidak terdapat kemunculan titik panas. Aturan ke-2 menyatakan bahwa jika kedalaman lahan gambut adalah 400-800 atau 800-1200 maka wilayah tersebut diprediksi terdapat kejadian kemunculan titik panas. Nilai (719/171) adalah 719 tergolong kelas yang benar diprediksi sebagai titik panas dan 171 adalah data yang tidak benar diklasifikasikan sebagai kelas titik panas.
Penerapan Terbaik Hasil Klasifikasi Titik Panas Pada Data Baru
Algoritme C5.0 diterapkan pada dataset baru yaitu dataset Kalimantan tahun 2015 dan dataset Sumatera tahun 2015. Data latih yang digunakan adalah data latih dari masing-masing Pulau yang menghasilkan model klasifikasi dengan akurasi tertinggi, yaitu data Kalimantan tahun 2001 dan Sumatera tahun 2001. Akurasi yang dihasilkan pada data baru Pulau Kalimantan sebesar 42.22% untuk model berbasis pohon keputusan dan 42.22% untuk akurasi berbasis aturan. Dataset Kalimantan 2001 digunakan sebagai data latih dan dataset Kalimantan 2015 sebagai data uji Jumlah data latih yang digunakan sebanyak 1780 data, dan data uji sebanyak 46 data. Pada data baru Pulau Sumatera menghasilkan akurasi sebesar 50.99% untuk model berbasis pohon keputusan dan 50.99% untuk model berbasis aturan. Dataset Sumatera 2001 digunakan sebagai data latih dan dataset Sumatera 2015 sebagai data uji. Jumlah data latih yang digunakan sebanyak 3508 data dan data uji sebanyak 1056 data.
Dari hasil penerapan model pada dataset baru menggunakan algoritme C5.0, maka dapat dinyatakan model yang dihasilkan dapat mengklasifikasi dengan baik data titik panas.
SIMPULAN DAN SARAN
Simpulan
21 titik panas menggunakan algoritme C5.0 yang merupakan pengembangan dari C4.5. Dataset yang menghasilkan model klasfikasi dengan akurasi tertinggi yaitu dataset Sumatera tahun 2001 dan Kalimantan tahun 2001. Nilai akurasi tertinggi dari model berbasis pohon keputusan pada dataset Sumatera tahun 2001 adalah 88.98% dengan jumlah aturan sebanyak 8 aturan dan model berbasis aturan sebesar 89.93% terdiri dari 7 aturan. Akurasi yang dihasilkan pada dataset Kalimantan tahun 2001 untuk model berbasis pohon keputusan sebesar 71.91% dengan jumlah aturan sebanyak 2 aturan dan model berbasis aturan sebesar 71.91% dengan jumlah aturan sebanyak 2 aturan. Penerapan model pada data baru menghasilkan akurasi model klasifikasi untuk dataset Kalimantan tahun 2015 sebesar 42.22% dan dataset Sumatera tahun 2015 sebesar 50.99%. Algoritme C5.0 berhasil diterapkan untuk memprediksi kemunculan titik panas pada lahan gambut berdasarkan tipe lahan gambut dan kedalaman lahan gambut.
Saran
Saran yang dapat dilanjutkan untuk penelitian selanjutnya yaitu pengembangan aplikasi Shiny dengan menggunakan dataset pada penelitian ini dan penggunaan aplikasi Shiny yang di adopsi dari penelitian sebelumnya.
DAFTAR PUSTAKA
Adinugroho, WC, INN Suryadiputra, BH Sharjo, dan L Siboro. 2005. Panduan Pengendalian Kebakaran Hutan dan Lahan Gambut. Bogor (ID) Wetlands International-Indonesia Programme dan Widlife Habitat Canada: Proyek Climate Change, Forests dan Peatlands in Indonesia.
Awang. 2014. Hotspot hanyalah indikator bukan kejadian kebakaran hutan/lahan. [Internet]. [diunduh 2015 Nov 20]. Tersedia pada: http//lapan.go.id/index.php//subblog/read/2014/840/Hotspot:Hanyalah
Indikator-Bukan-Kejadian-Kebakaran-Hutan/Lahan.
Fu, L. 1994. Neural Network in Computers Intelligence. Singapura (SG): McGraw-Hill.
Han J, Kamber M, Pei J. 2012. Data Mining: Concepts and Techniques. 3rd ed. Massachusetts (US): Morgan Kaufmann Publishers.
Patil N, Lathi R, chitre V. 2012. Customer card classification based on C5.0 & CART algorithms. International Journal of Engineering Research and Applications (IJERA). 2:164-167.
Rulequest. 2012. Data mining tools see5 and C5.0. [Internet]. [diunduh 2015 Nov 20]. Tersedia pada: http//rulequest.com/see5-comparison.html.
Siknun GP. 2015. Aplikasi klasifikasi berbasis web untuk data kebakaran hutan menggunakan framework shiny dan algoritme C5.0 [skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor. Sitanggang IS, Yaakob R, Mustapha N, Ainuddin AN. 2012. Application of
22
Sitanggang IS, Yaakob R, Mustapha N, Ainuddin AN. 2014. A decision tree based on spatial relationships for predicting hotspots in peatlands. Telkomnika. 12(2):511-518.doi:10.12928/TELKOMNIKA.v12i2.2036.
Tacconi L. 2003. Kebakaran Hutan di Indonesia: Penyebab, Biaya, dan Implikasi Kebijakan. Bogor (ID): Center for International Forestry Research (CIFOR). Wahyunto, Ritung.S, Suparto, dan H.Subagjo. 2005. Sebaran Gambut dan
Kandungan Karbon di Sumatera dan Kalimantan. Bogor (ID) Weatlands International-Indonesia Programme dan Widlife Habitat Canada: Proyek Climate Change, Forests dan Peatlands in Indonesia.
23
LAMPIRAN
Lampiran 1 Contoh penggunaan algoritme C5.0 terhadap dataset kecil kebakaran hutan
Berikut ini disajikan contoh dataset kebakaran hutan. Kelas C1 (titik panas) dan C2 (non titik panas).
Tabel 1.1 Contoh dataset kebakaran hutan Kedalaman gambut Tipe gambut Kelas
200-400 Hemists/Fibrists C1 200-400 Hemists/Fibrists C1 50-100 Hemists/Mineral C1 50-100 Hemists/Fibrists C2 100-200 Hemists/Mineral C2 100-200 Hemists/Fibrists C1 50-100 Hemists/Mineral C1 100-200 Hemists/Fibrists C1 200-400 Hemists/Fibrists C2 50-100 Hemists/Fibrists C2
Dengan menggunakan data pada Tabel 1.1 data yang digunakan terdiri dari 6 data sebagai data latih dan 4 data digunakan untuk data uji. Tahap ini dimulai dengan melakukan seleksi atribut menggunakan formula information gain yang terdapat pada algoritma C5.0, sehingga diperoleh nilai gain untuk masing-masing atribut, atribut dengan nilai gain tertinggi akan menjadu parent bagi node-node selanjutnya. Node-node tersebut didapat dari atribut-atribut yang memiliki nilai gaiun yang lebih kecil dari nilai gain atribut parent. Data latih dicari nilai information gainnya yaitu,
I(4;2) = - 46 log2 (46) - 26 log2(26) = 0.924
Nilai 4 didapat dari jumlah kelas C1 dan 2 dari jumlah kelas C2. Dengan menggunakan formula yang sama dilakukan pemilihan atribut, dihitung rasio nilai C1 dan C2 dari seluruh atribut. Tabel 1.2 atribut kedalaman gambut dengan jumlah kelas C1 dan C2 untuk menghitung gain di setiap atributnya.
Tabel 1.2 Atribut kedalaman gambut dengan jumlah kelas C1 dan C2
Atribut Kelas
C1 C2
200-400 2 0
50-100 1 1
100-200 1 1
24
2 Kedalaman gambut = 50-100
I , = − log2 − log2( ) =
3 Kedalaman gambut = 100-200
I (1,1)= - log2 − log2( ) =
Nilai gain yang dihasilkan dari atribut kedalaman gambut yaitu: 0.924 - (
6 � − (6 � ) − (6 � ) = . 6
Untuk tahap selanjutnya hal yang sama yaitu penerapan formula information gain dilakukan terhadap atribut tipe gambut. Pada Tabel 1.3 atribut tipe gambut dengan jumlah kelas C1 dan C2.
Tabel 1.3 Atribut tipe gambut dengan jumlah kelas C1 dan C2
Atribut Kelas
C1 C2
Hemists/fibrists 3 1
Hemists/mineral 1 1
Menghitung gain pada atribut tipe gambut: 1 Tipe gambut = hemists/fibrists
I(3,1) = - log2( ) − log2( ) = .8
2 Tipe gambut = Hemists/mineral
I(1,1) = - 12log2(12 − 12log2(12 =0.05 Information gain yang dihasilkan dari atribut tipe gambut yaitu:
0.924 - (46 x 0.812) - (26x 1) = 0.05
25 Lampiran 1 Lanjutan
Gambar 1.1 Bentuk decision tree dataset kebakaran hutan
Setelah menentukan parent untuk pohon keputusan maka dilakukan pengujian dengan data uji. Data uji yang digunakan terdapat 4 data yang terdiri 2 kelas C1 dan 2 kelas C2. Berikut data uji dapat dilihat pada Tabel 1.4.
Tabel 1.4 Contoh data uji pada dataset kebakaran hutan Kedalaman gambut Tipe gambut
Kelas Aktual
Kelas Prediksi 50-100 Hemists/Mineral C1 C1 100-200 Hemists/Fibrists C1 C1 200-400 Hemists/Fibrists C2 C1 50-100 Hemists/Fibrists C2 C2
Pengujian data menghasilkan 3 data benar diklasifikasi dan 1 data tidak benar diklasifikasi. Maka akurasi yang dihasilkan yaitu:
3
4x 100% = 75%
26
Lampiran 2 Model klasifikasi pohon keputusan dengan algoritme C5.0 menggunakan perangkat lunak R
Tutupan_lahan = Kelapa sawit pada bekas hutan rawa > 5 th: C1 (0)
Tutupan_lahan in {(Hutan rawa,Sawah dan kelapa),
: (Sawah intensif (padi - palawija/bera),
jeruk),
: (Sawah tadah hujan (padi -
palawija/bera)),
: (Semak, rumput pada bekas sawah)}:
:...Tipe gambut in {(Hemists/min (30/70), dangkal), (Hemists/mineral (30/70), sedang),
: Tipe gambut in {(Hemists/mineral (90/10), sedang), (Hemists/Saprists (60/40), dalam),
: (Hemists/Saprists (60/40), sangat dalam), : (Hemists/Saprists (60/40), sedang),
: (Saprists (100), dalam)}: Hotspot (67/23) Tutupan lahan in {(Belukar rawa, Kebun karet), (Kelapa pada bekas hutan rawa > 5 tahun,
: (Kelapa sawit pada bekas hutan rawa > 5 :...Tipe gambut in {(Hemists/mineral(50/50), dangkal), (Hemists/mineral (70/30), sedang),
27
Tutupan lahan in {(Kebun karet), (Kelapa sawit pada bekas hutan rawa > 5 tahun),
Tipe gambut in {(Hemists/mineral (30/70), dangkal), (Saprists (100), sedang),
: (Saprists/Hemists (60/40), dalam), : (Saprists/Hemists (60/40), sedang), : (Saprists/min (90/10), sedang)}: Tutupan lahan = Kelapa sawit pada bekas hutan rawa > 5 tahun: Non Hotspot (44/11)
28
Lampiran 3 Model klasifikasi berbasis aturan dengan algoritme C5.0 menggunakan perangkat lunak R
Rule 1: (89/3, lift 1.9)
Tipe gambut in {(Hemists/Saprists (60/40),dalam),
(Hemists/Saprists (60/40),sedang)} Tutupan lahan in {(Kebun karet), (Kelapa sawit pada bekas hutan rawa > 5 tahun),
Tipe gambut in {(Hemists/mineral (50/50), dangkal), (Hemists/Saprists (60/40), sangat dalam), (Saprists (100),dalam),
(Saprists/Hemists (60/40), sangat dalam)}
Tutupan lahan in {(Belukar rawa), (Kebun karet),
(Kelapa pada bekas hutan rawa > 5
-> class Hotspot [0.903]
Rule 3: (191/25, lift 1.7)
Tutupan lahan in {(Kebun karet), (Kelapa sawit pada bekas hutan rawa < 5 tahun),
-> class Hotspot [0.865]
Rule 4: (184/38, lift 1.6)
Tipe gambut in {(Hemists/mineral (90/10), sedang), (Hemists/Saprists (60/40), dalam),
29
Tipe gambut in {(Hemists/mineral (30/70), dangkal), (Hemists/mineral (30/70), sedang),
Tutupan lahan in {(Hutan rawa), (Sawah dan kelapa), (Sawah intensif (padi -
Tipe gambut in {(Hemists/mineraal (30/70), dangkal), (Hemists/mineral (30/70), sedang),
Tutupan lahan in {(Belukar rawa), (Kelapa pada bekas hutan rawa > 5 tahun)}
-> class C2 [0.816]
Rule 7: (44/11, lift 1.5)
Tipe gambut in {(Hemists/mineral (30/70), dangkal),
(Saprists/Hemists (60/40), dalam), (Saprists/Hemists (60/40), sedang), (Saprists/mineral (90/10), sedang)}
30