KLASIFIKASI DENGAN
ANALISIS KOMPONEN UTAMA KERNEL
WIRDANIA USTAZA
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi dengan Analisis Komponen Utama Kernel adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Maret 2014
ABSTRAK
WIRDANIA USTAZA. Klasifikasi dengan Analisis Komponen Utama Kernel. Dibimbing oleh SISWADI dan TONI BAKHTIAR.
Analisis komponen utama (AKU) merupakan bentuk khusus dari AKU kernel dengan fungsi kernel linear. Tujuan dari studi ini ialah untuk menyelesaikan permasalahan data yang tak terpisah secara linear dan mengklasifikasikan suatu objek ke dalam suatu kelompok menggunakan AKU kernel sehingga diperoleh salah klasifikasi terkecil. Pengklasifikasian kelompok menggunakan AKU kernel diselesaikan dengan fungsi kernel linear dan Gauss. Hasil untuk data pengenalan anggur menunjukkan bahwa fungsi kernel linear dan Gauss (parameter 2.5) masing-masing memberikan 30.889% dan 17.416% salah klasifikasi.
Kata kunci: analisis komponen utama, kernel, salah klasifikasi
ABSTRACT
WIRDANIA USTAZA. Classification with Kernel Principal Component Analysis. Supervised by SISWADI and TONI BAKHTIAR.
Principal component analysis (PCA) is a special case of the kernel PCA with linear kernel function. The aim of this study is to resolve the data problem that is not linearly separated and to classify an object into a group by using kernel PCA to obtain the smallest classification error. Group classification using kernel PCA is performed by the linear and Gaussian kernel function. The result of the study shows for wine recognition data with the linear and Gaussian (parameter 2.5) kernel function produces 30.889% and 17.416% classification error, respectively.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains
pada
Program Studi Matematika
KLASIFIKASI DENGAN
ANALISIS KOMPONEN UTAMA KERNEL
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Klasifikasi dengan Analisis Komponen Utama Kernel Nama : Wirdania Ustaza
NIM : G54090057
Disetujui oleh
Prof Dr Ir Siswadi, MSc Pembimbing I
Dr Toni Bakhtiar, MSc Pembimbing II
Diketahui oleh
Dr Toni Bakhtiar, MSc Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Maret 2013 ini ialah analisis data, dengan judul Klasifikasi dengan Analisis Komponen Utama Kernel.
Terima kasih penulis ucapkan kepada Bapak Prof Dr Ir Siswadi MSc yang banyak memberikan saran, waktu, dan arahannya selama ini, terima kasih yaa pak. Terima kasih penulis ucapkan kepada Bapak Dr Toni Bakhtiar MSc selaku dosen pembimbing yang telah banyak memberikan saran dan Bapak Ir Ngakan Komang Khuta Ardana MSc yang telah banyak memberi saran. Ungkapan terima kasih juga disampaikan kepada Ayahku, Emakku, Ayekku, Maktoku seluruh keluarga besarku yang sudah memberikan doa dan semangat, kepada Danty, Meliza, Nindy, Vina, Risa, Ermi, Nisa, Ivon, Dewi, Fitria, Bu Susi, Ratri, Rizka, Nova, Nuke, Tika, Restu, Janah, Leli, Syahibah, Wanda, Ara, Farel, Iham, Ka Lina atas perhatian dan kasih sayangnya, serta kepada Evy, Bari, Rudy, Syukrio dan Meda yang sudah membantu dalam penggunaan software, kepada seluruh sahabat SMP, SMA, dan seluruh keluarga Matematika IPB, terima kasih atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 1
TINJAUAN PUSTAKA 2
Analisis Komponen Utama 2
Analisis Komponen Utama Kernel 5
METODE PENELITIAN 9
Data 9
Prosedur Analisis Data 9
HASIL DAN PEMBAHASAN 10
SIMPULAN DAN SARAN 17
Simpulan 19
Saran 19
DAFTAR PUSTAKA 20
LAMPIRAN 21
DAFTAR TABEL
6 Hasil salah klasifikasi (SK) fungsi Gauss 17
7 Hasil pengklasifikasian kelompok data dengan fungsi linear 18 8 Hasil pengklasifikasian kelompok data dengan fungsi Gauss 0=1 18 9 Hasil pengklasifikasian kelompok data dengan fungsi Gauss 0=2.5 18 10 Hasil pengklasifikasian kelompok data dengan fungsi Gauss 0=6 19
DAFTAR GAMBAR
1 Ide dasar AKU kernel 5
2 Ide utama metode kernel: memetakan data asal ke dimensi lebih tinggi
ruang fitur 6
3 Plot pencar dari beberapa pasang peubah data pengenalan anggur 10
4 AKU atau fungsi linear 13
5 Fungsi Gauss dengan parameter 0=1 13
6 Fungsi Gauss dengan parameter 0=1.25 13
7 Fungsi Gauss dengan parameter 0=1.5 13
8 Fungsi Gauss dengan parameter 0=1.75 14
9 Fungsi Gauss dengan parameter 0=2 14
10 Fungsi Gauss dengan parameter 0=2.25 14
11 Fungsi Gauss dengan parameter 0=2.5 14
12 Fungsi Gauss dengan parameter 0=2.75 14
13 Fungsi Gauss dengan parameter 0=3 14
14 Fungsi Gauss dengan parameter 0=3.25 14
15 Fungsi Gauss dengan parameter 0=3.5 14
16 Fungsi Gauss dengan parameter 0=3.75 15
17 Fungsi Gauss dengan parameter 0=4 15
18 Fungsi Gauss dengan parameter 0=4.25 15
19 Fungsi Gauss dengan parameter 0=4.5 15
20 Fungsi Gauss dengan parameter 0=4.75 15
21 Fungsi Gauss dengan parameter 0=5 15
22 Fungsi Gauss dengan parameter 0=5.25 15
23 Fungsi Gauss dengan parameter 0=5.5 15
24 Fungsi Gauss dengan parameter 0=5.75 16
25 Fungsi Gauss dengan parameter 0=6 16
26 Perbandingan hasil data pengenalan anggur 16
27 Perbandingan hasil data tanaman iris 17
DAFTAR LAMPIRAN
1 Data pengenalan anggur 21
PENDAHULUAN
Latar Belakang
Analisis data adalah proses penyederhanaan data agar lebih mudah dibaca dan diinterpretasikan. Ada banyak alat yang dapat digunakan untuk menganalisis data baik secara manual ataupun dengan bantuan aplikasi komputer. Salah satunya ialah dengan menggunakan analisis statistika peubah ganda, yang sudah banyak berkembang di masyarakat. Analisis statistika peubah ganda mampu mengidentifikasi pola dalam data dan mengekspresikan data sedemikian rupa sehingga menyorot persamaan dan perbedaannya (Shen 2007). Salah satu cara dalam analisis statistika peubah ganda yang dapat digunakan untuk melakukan hal tersebut ialah analisis komponen utama. Analisis komponen utama (AKU) pertama kali diperkenalkan oleh Karl Pearson pada tahun 1901. AKU sering digunakan untuk mereduksi dimensi dari suatu matriks data yang terdiri atas sejumlah besar peubah yang saling berkorelasi menjadi sejumlah kecil peubah dan tidak saling berkorelasi, dengan tetap mempertahankan sebanyak mungkin informasi yang terkandung dalam matriks data baru (Jolliffe 2002). AKU menggunakan kombinasi linear antarpeubah untuk merepresentasikan suatu data. Namun, kombinasi linear ini tidak dapat memodelkan data yang kompleksitasnya tinggi dengan hubungan taklinear antarpeubah. Oleh karena itu diperlukan suatu metode untuk menyelesaikan masalah tersebut yaitu dengan menggunakan AKU kernel.
AKU merupakan bentuk khusus dari AKU kernel dengan fungsi kernel linear. Fungsi kernel memetakan data ke dimensi yang lebih tinggi dan membangun fungsi pemisah dalam ruang yang terpisahkan. Hal ini dilakukan dengan menghitung fungsi kernel yang memberikan nilai hasil kali dalam pada ruang fitur tanpa menunjukkan pemetaan secara eksplisit. AKU kernel juga sebagai metode berbasis memori, yaitu jika x adalah suatu objek maka menemukan skor untuk objek tersebut dapat menggunakan nilai eigen dan vektor eigen dari data asal (Nielsen dan Canty 2008). Karena dalam mengklasifikasikan suatu objek ke dalam suatu kelompok diperlukan beberapa peubah penciri yang dapat membedakan antara satu kelompok dengan kelompok lainnya, maka atas dasar inilah AKU kernel dapat digunakan dalam menyelesaikan pengklasifikasian suatu objek ke dalam suatu kelompok untuk memperoleh salah klasifikasi terkecil.
Tujuan
2
TINJAUAN PUSTAKA
Analisis Komponen Utama
Analisis komponen utama (AKU) adalah bagian dari analisis statistika peubah ganda yang banyak digunakan sebagai alat analisis pada data. AKU merupakan suatu teknik analisis data untuk mereduksi dimensi peubah asal yang saling berkorelasi menjadi peubah baru yang tidak saling berkorelasi sehingga lebih mudah dalam menjelaskan data yang digunakan.
AKU membentuk peubah baru yang merupakan kombinasi linear dari seluruh peubah asal, yang disebut komponen utama. Meskipun dibutuhkan p komponen untuk menunjukkan keseluruhan variasi data, seringkali variasi ini dapat diwakili oleh k komponen utama, dengan (Jollife 2002). Sehingga data asal yang mengandung n objek dengan p peubah dapat direduksi menjadi n objek dengan k komponen utama pertama.
Misalkan vektor peubah acak �� = 1, 2,…, memunyai matriks
kovarians Σ dengan nilai eigen �1 �2 � 0. Misalkan kombinasi
linear 1�� dari vektor � memiliki varians terbesar, dengan 1 merupakan vektor koefisien �11,�12,…,�1 , sehingga
1��= �11 1+�12 2+ +�1 = =1�1 �.
Kombinasi linear kedua, 2��, tidak berkorelasi dengan 1��. Kombinasi linear ini memiliki varians terbesar kedua, dan seterusnya, sehingga kombinasi linear ke-k,
��, memiliki varians maksimum ke-k dan tidak berkorelasi dengan kovarians antara peubah ke-i dan peubah ke-j dari X saat ≠ dan varians peubah ke-j saat = . Jika X memiliki nilai harapan E[X] maka kovarians X ialah
Untuk menentukan komponen utama pertama, pandang kombinasi linear pertama 1�� dan vektor 1 yang memaksimumkan var 1 = 1�� 1. Nilai
var 1 dapat terus membesar bila 1 dikalikan dengan suatu konstanta yang lebih
besar dari satu maka dibutuhkan batasan 1� 1 = 1, yaitu jumlah kuadrat elemen
1 sama dengan 1. Untuk komponen utama pertama yang ingin memaksimumkan
var 1 = var �� = 1�� 1 dengan kendala 1� 1 = 1 dapat diselesaikan
melalui persamaan Lagrange berikut
3 dengan �1 adalah pengganda Lagrange, kemudian mencari titik kritis dari persamaan Lagrange dapat dilakukan dengan cara mencari turunan pertama terhadap 1sebagai berikut: adalah nilai eigen dari � dan 1 merupakan vektor eigen yang bersesuaian. Untuk menentukan vektor eigen yang memberikan kombinasi linear 1�� dengan varians terbesar, kuantitas yang akan dimaksimumkan ialah Jika persamaan (2) dikalikan dengan 1� didapatkan
2 1�� 2−2�2 1� 2− � 1� 1 = 0
merupakan persamaan eigen dari matriks �. Dengan demikian �2 merupakan nilai eigen � dan 2 merupakan vektor eigen yang bersesuaian. Untuk menentukan
Karena nilai eigen terbesar pertama merupakan varians dari komponen utama pertama maka �2 dipilih nilai eigen terbesar kedua dari matriks �. Demikian juga dengan vektor eigen 2 merupakan vektor eigen yang bersesuaian dengan nilai eigen terbesar kedua �2.
4
eigen � yang bersesuaian dengan nilai eigen �3,�4,…,� , secara berturut-turut.
Secara umun, komponen utama ke-k dari X adalah �� dan
var[ �� ] =� untuk k=1, 2,…, p
dengan � merupakan nilai eigen � terbesar ke-k dan adalah vektor eigen yang bersesuaian. Total varians yang dijelaskan oleh komponen utama adalah =1� sehingga proporsi total varians dari k komponen utama pertama ialah �1+�2+ +�
�1+�2+ +� × 100%. Belum ada patokan baku berapa batas minimum banyaknya komponen utama, sebagian buku menyebutkan 70%, 80%, dan ada yang 90%.
Apabila satuan pengukuran untuk setiap peubah yang diamati tidak sama dan varians antarpeubah memiliki perbedaan cukup besar yang mengakibatkan salah satu peubah menjadi dominan dalam menentukan komponen utama maka biasanya digunakan matriks korelasi �. Bila peubah telah dibakukan sebagai berikut Selanjutnya matriks �∗ dikoreksi terhadap rataanya sehingga diperoleh matiks X,
�= − � �∗
Permasalahan ini biasa disebut juga sebagai formulasi primal. Formulasi primal sangat baik digunakan saat ukuran � , sehingga dapat meringkas dalam menyelesaikan masalah persamaan eigen. Selain formulasi primal dijelaskan pula tentang formulasi dual. Formulasi dual dianalisis dengan ��� � −1 yang berukuran �×� dalam amatan dapat menjadi sangat besar.
Formulasi dual memiliki permasalahan persamaan eigen sebagai berikut: ���
5 dengan � adalah nilai eigen dan adalah vektor eigen yang bersesuaian dengan � . Jika persamaan ini dikalikan �� dari kiri maka akan diperoleh diperoleh dari kedua formulasi adalah sama-sama � dan dengan mengasumsikan vektor eigen adalah vektor satuan 1 = � ∝ ���� = � −1 � � = akan sangat baik digunakan saat � . Keuntungan lainnya untuk � adalah bahwa unsur-unsur dari matriks �=���, yang mana diketahui sebagai matriks Gram, terdiri atas produk dalam (inner, dot atau scalar product) dari pengamatan peubah ganda dalam baris dari X, yaitu � �� (Nielsen dan Canty 2008).
Analisis Komponen Utama Kernel
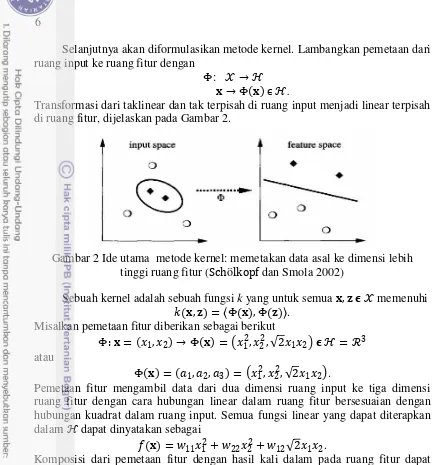
AKU adalah suatu metode yang biasa digunakan untuk mereduksi dimensi dari suatu matriks data. AKU menggunakan kombinasi linear antarpeubah untuk merepresentasikan suatu data, sehingga hanya dapat mengatasi hubungan linear antarpeubah. Namun, pada kenyataannya banyak data yang memiliki hubungan taklinear dan tak terpisah antarpeubah. Diperlukan suatu metode untuk menunjukkan bentuk taklinear dari AKU, yaitu dengan menggunakan AKU kernel. Dengan menggunakan fungsi kernel dapat menghitung komponen utama secara lebih efisien dalam dimensi lebih tinggi ruang fitur (ruang abstrak yang kadang tidak diketahui hasil pemetaannya). Transformasi dari taklinear di ruang input menjadi linear di ruang fitur, dijelaskan pada Gambar 1.
Gambar 1 Ide dasar AKU kernel (Sugiyama 2013)
6
Selanjutnya akan diformulasikan metode kernel. Lambangkan pemetaan dari ruang input ke ruang fitur dengan
Φ: � → ℋ � → Φ � ϵℋ.
Transformasi dari taklinear dan tak terpisah di ruang input menjadi linear terpisah di ruang fitur, dijelaskan pada Gambar 2.
Gambar 2 Ide utama metode kernel: memetakan data asal ke dimensi lebih tinggi ruang fitur (Schölkopf dan Smola 2002) ruang fitur dengan cara hubungan linear dalam ruang fitur bersesuaian dengan hubungan kuadrat dalam ruang input. Semua fungsi linear yang dapat diterapkan dalam ℋ dapat dinyatakan sebagai
� = 11 12 + 22 22+ 12 2 1 2. artinya dapat menghitung hasil kali dalam antara proyeksi dari dua titik ke dalam ruang fitur tanpa mengevaluasi koordinatnya secara eksplisit. Sebelum menggunakan fungsi kernel, haruslah ditentukan apa bentuk dari fungsi �,�
untuk memastikan bahwa itu adalah kernel untuk beberapa ruang fitur. Oleh karena itu, perlu diketahui beberapa hal yang berhubungan dengan fungsi kernel 1. Fungsi kernel harus simetrik
�,� = Φ � ,Φ � = Φ � ,Φ � = �,� . 2. Memenuhi ketaksamaan Cauchy-Schwarz
7 dihubungkan dengan matriks Gram G yang berelemen
= Φ � ,Φ � = � ,� .
Dalam kasus ini matriks G disebut juga sebagai matriks kernel K. Lambang standar untuk menggambarkan matriks kernel K adalah sebagai berikut
= Catat bahwa ℋ dapat memunyai perubahan dimensi yang besar dan mungkin tak terbatas (Shen 2007). Transformasi fungsi Φ mungkin taklinear dan mungkin tidak dapat dijelaskan secara eksplisit. Pemetaan oleh fungsi Φ terhadap X sehingga Φ berisi n objek dan q peubah dengan menghasilkan matriks data sebagai berikut:
Asumsikan bahwa data dalam ruang fitur memunyai rata-rata nol, sehingga
matriks kovarians memiliki bentuk
=Φ�Φ � −1 = 1 � −1 �=1� � � � � yang bersesuaian dengan eigen secara berturut-turut. Seperti pada AKU nilai eigen taknol untuk formulasi primal dan dual adalah sama dan vektor eigen dihubungkan dengan
= 1
� −1 � Φ
�
8
Mengulang kembali masalah persamaan eigen pada formulasi dual, untuk nilai eigen taknol � dan vektor eigen yang bersesuaian . Dengan mengganti produk dalam � � �� � dalam ΦΦ� dengan sebuah fungsi kernel � ,� =
yang berasal dari beberapa pemetaan Φ, diperoleh
= � −1 �
dengan =ΦΦ� adalah matriks berukuran �×�. Permasalahan nilai eigen tersebut normalnya diformulasikan tanpa faktor � −1,
= �
memberikan semua solusi dari vektor eigen dan (� −1)� dari nilai eigen. Sehingga dalam kasus ini = Φ� � dan = Φ �.
Untuk menemukan skor komponen utama kernel dari permasalahan nilai eigen, proyeksikan pemetaan � atas vektor eigen primal
� � � = � � �Φ� �
=� � � � �1 � �2 … � �� �
= � � �� �1 � � �� �2 … � � �� �� � = �,�1 �,�2 … �,�� �.
Pada kenyataannya tidak dapat diasumsikan bahwa data pada ruang fitur sudah terkoreksi terhadap nilai tengah. Oleh karena itu agar matriks Gram K terkoreksi terhadap nilai tengah gunakan ∗ = − � − � . Berikut merupakan tiga
Pada dasarnya ada fungsi kernel yang dapat diketahui jenis pemetaannya pada ruang fitur, misalnya fungsi kernel polinom dengan menggunakan
9
METODE PENELITIAN
Data
Data yang digunakan dalam penulisan karya ilmiah ini merupakan data sekunder sebagai data asal yang diperoleh melalui internet yaitu data tanaman iris (Fisher 1988) dan data pengenalan anggur (Forina 1991). Matriks data tanaman iris terdiri atas 150 objek dengan 3 kelompok yaitu Iris setosa, Iris virginica, dan Iris versicolor di mana setiap kelompok terdiri atas 50 objek dengan empat peubah yaitu panjang sepal, lebar sepal, panjang petal, dan lebar petal. Matriks data pengenalan anggur terdiri atas 178 objek dengan 3 kelompok di mana setiap kelompok terdiri atas 59, 71, dan 48 objek untuk kelompok 1, 2, dan 3 secara berturut-turut, dengan tiga belas peubah yaitu kadar alkohol, kadar asam malat, banyaknya abu, banyaknya alkali pada abu, kadar magnesium, kadar fenol, kadar flavonoid, kadar fenol yang bukan flavonoid, kadar proanthosianin, dan kadar prolina, intensitas warna dan warna berdasarkan tingkat kecerahannya, dan anggur yang diencerkan pada OD280/OD315 berdasarkan nilai serapannya.
Prosedur Analisis Data
Data asal merupakan data sekunder yang berasal dari data populasi tanaman iris dan data pengenalan anggur. Analisis data yang pertama dilakukan dalam karya ilmiah ini ialah mengamati plot pencar antarpeubah yang dihasilkan. Kemudian data asal distandarisasi. AKU kernel akan dianalisis menggunakan dua fungsi kernel yaitu linear dan Gauss. Matriks kernel dengan fungsi linear ialah bersesuaian dengan AKU dalam formulasi dual yaitu dalam bentuk ���. Matriks kernel fungsi Gauss= exp − � −�
0
2
dengan parameter 0=0.001 2 untuk data tanaman iris dan 0=1,1.25,…,6 untuk data pengenalan anggur. Tiga langkah berikut adalah perlu untuk menunjukkan AKU kernel:
1. Menentukan fungsi kernel yang akan digunakan dalam hal ini linear dan Gauss, kemudian menghitung hasil kali dalam matriks kernel = ( )
dengan = � ,� = � � ,� � . Matriks kernel juga harus dikoreksi terhadap nilai tengah setiap fungsi dengan ∗= − � −
� .
2. Menyelesaikan permasalahan nilai eigen dan vektor eigen dari matriks ∗ dengan persamaan ∗ =� . Kemudian dipilih 2 nilai eigen terbesar dan vektor eigen yang bersesuaian. Dua nilai eigen ini adalah varians maksimum dari komponen utama 1 dan komponen utama 2 secara berturut-turut.
3. Untuk menemukan skor komponen utama kernel dari permasalahan nilai eigen, proyeksikan pemetaan x atas vektor eigen primal .
� � � =� � �Φ� �
= �,�1 �,�2 … �,�� � .
10
Pengklasifikasian kelompok dengan AKU kernel dilakukan menggunakan kuadrat jarak Euclid untuk ruang dimensi dua dengan menghitung jarak terdekat antara objek dengan rataan dari setiap kelompok sebagai berikut
� �0,� = �0− � � �0− �
dengan �0 adalah objek pada skor komponen utama dan � adalah rata-rata skor komponen utama dari data asal pada setiap kelompok. Evaluasi hasil dapat diperoleh dengan menghitung jumlah salah klasifikasi dari semua kelompok seperti yang diberikan pada Tabel 1.
dengan nkj= banyaknya anggota kelompok k yang diklasifikasikan menjadi anggota kelompok j.
HASIL DAN PEMBAHASAN
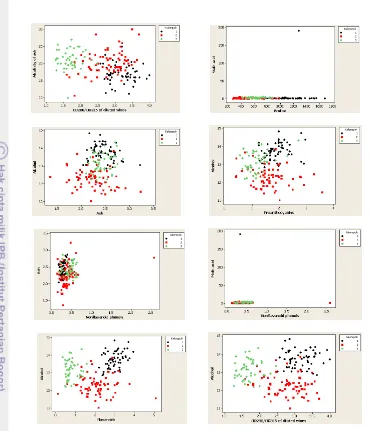
Analisis dilakukan terhadap data populasi tanaman iris dan data pengenalan anggur. Kedua data digunakan untuk memverifikasi hasil yang diperoleh menggunakan AKU kernel. Selanjutnya data yang memberikan hasil yang sama dengan karya ilmiah ini dipilih untuk dianalisis salah klasifikasinya dalam hal ini data pengenalan anggur. Gambar 3 memvisualisasikan plot pencar dari beberapa pasang peubah untuk data pengenalan anggur, diambil beberapa pasang peubah karena dimensi data yang cukup besar. Pada gambar terlihat bahwa plot pencar hanya terdiri atas satu kelompok yang berisi baik kelompok 1, 2, dan 3 yang tidak dapat dipisahkan dengan beberapa data menjadi pencilan. Hal ini tidak cukup baik bila digunakan dalam menganalisis struktur pada data dan akan menyulitkan dalam pengklasifikasian data objek ke dalam kelompok tersebut, karena akan menyebabkan salah klasifikasi yang cukup besar. Oleh karena itu, AKU kernel akan digunakan untuk menyelesaikan permasalahan ini.
11
12
Tabel 2 Deskripsi data pengenalan anggur No
Tabel 3 Fungsi kernel yang diaplikasikan
No. Jenis fungsi Fungsi Par. 0
1 Linear � ,� =��� -
2 Gauss �,� = exp(− � − � 2 02) 1, 1.25,…, 6
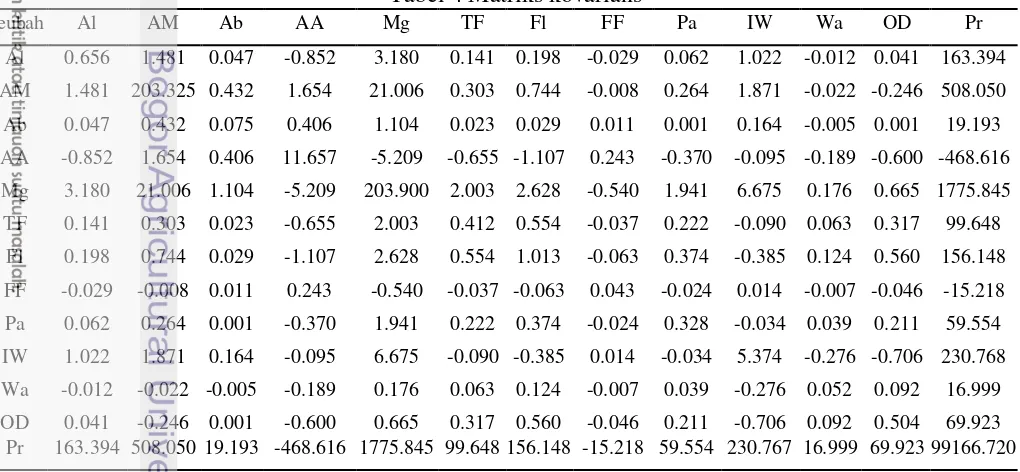
13 Tabel 5 Matriks korelasi
No Peubah Al AM Ab AA Mg TF Fl FF Pa IW Wa OD Pr
1 Al 1.000 0.128 0.214 -0.308 0.275 0.271 0.243 -0.174 0.133 0.544 -0.064 0.071 0.641
2 AM 0.128 1.000 0.110 0.034 0.103 0.033 0.052 -0.003 0.032 0.057 -0.007 -0.024 0.113
3 Ab 0.214 0.110 1.000 0.433 0.282 0.128 0.106 0.196 0.008 0.258 -0.075 0.003 0.222
4 AA -0.308 0.034 0.433 1.000 -0.107 -0.299 -0.322 0.344 -0.189 -0.012 -0.242 -0.248 -0.436
5 Mg 0.275 0.103 0.282 -0.107 1.000 0.218 0.183 -0.183 0.237 0.202 0.054 0.066 0.395
6 TF 0.271 0.033 0.128 -0.299 0.218 1.000 0.858 -0.281 0.605 -0.061 0.430 0.695 0.493
7 Fl 0.243 0.052 0.106 -0.322 0.183 0.858 1.000 -0.300 0.648 -0.165 0.539 0.784 0.493
8 FF -0.174 -0.003 0.196 0.344 -0.183 -0.281 -0.300 1.000 -0.199 0.029 -0.150 -0.312 -0.234
9 Pa 0.133 0.032 0.008 -0.189 0.237 0.605 0.648 -0.199 1.000 -0.025 0.296 0.519 0.330
10 IW 0.544 0.057 0.258 -0.012 0.202 -0.061 -0.165 0.029 -0.025 1.000 -0.522 -0.429 0.316
11 Wa -0.064 -0.007 -0.075 -0.242 0.054 0.430 0.539 -0.150 0.296 -0.522 1.000 0.565 0.236
12 OD 0.071 -0.024 0.003 -0.248 0.066 0.695 0.784 -0.312 0.519 -0.429 0.565 1.000 0.313
13 Pr 0.641 0.113 0.222 -0.436 0.395 0.493 0.493 -0.234 0.330 0.316 0.236 0.313 1.000
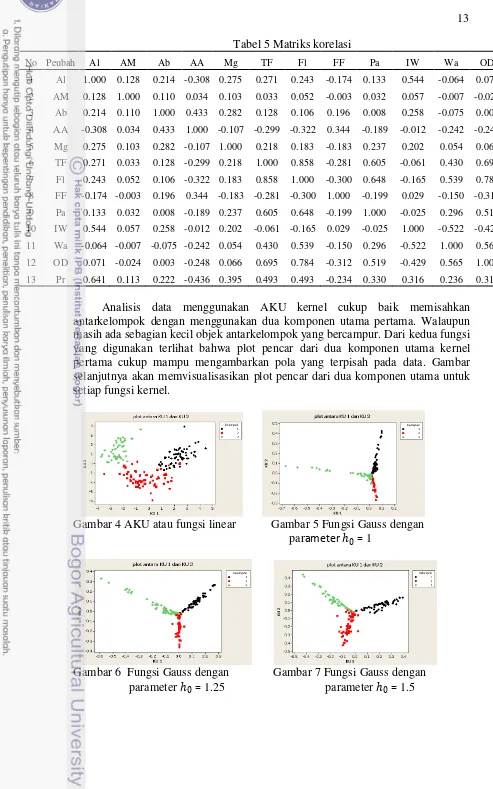
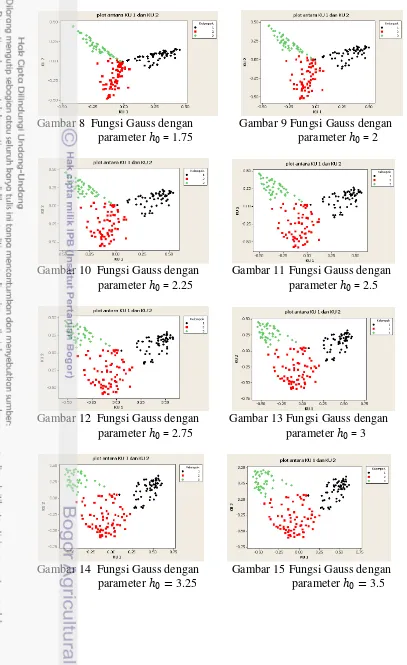
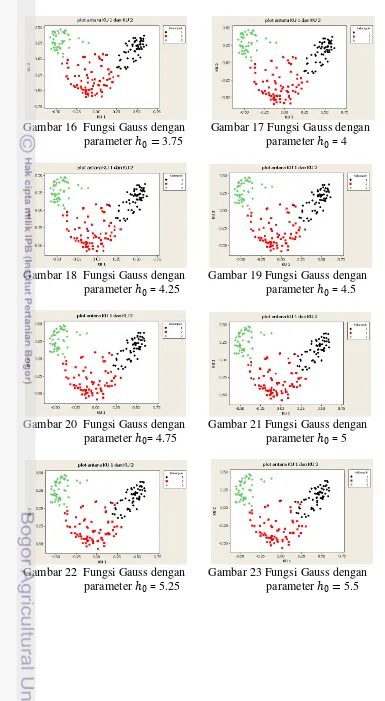
Analisis data menggunakan AKU kernel cukup baik memisahkan antarkelompok dengan menggunakan dua komponen utama pertama. Walaupun masih ada sebagian kecil objek antarkelompok yang bercampur. Dari kedua fungsi yang digunakan terlihat bahwa plot pencar dari dua komponen utama kernel pertama cukup mampu mengambarkan pola yang terpisah pada data. Gambar selanjutnya akan memvisualisasikan plot pencar dari dua komponen utama untuk setiap fungsi kernel.
Gambar 4 AKU atau fungsi linear Gambar 5 Fungsi Gauss dengan
parameter 0= 1
14
Gambar 8 Fungsi Gauss dengan Gambar 9 Fungsi Gauss dengan parameter 0= 1.75 parameter 0 = 2
Gambar 10 Fungsi Gauss dengan Gambar 11 Fungsi Gauss dengan parameter 0= 2.25 parameter 0= 2.5
Gambar 12 Fungsi Gauss dengan Gambar 13 Fungsi Gauss dengan parameter 0= 2.75 parameter 0 = 3
15
Gambar 16 Fungsi Gauss dengan Gambar 17 Fungsi Gauss dengan parameter 0 = 3.75 parameter 0= 4
Gambar 18 Fungsi Gauss dengan Gambar 19 Fungsi Gauss dengan parameter 0= 4.25 parameter 0= 4.5
Gambar 20 Fungsi Gauss dengan Gambar 21 Fungsi Gauss dengan parameter 0= 4.75 parameter 0= 5
16
Gambar 24 Fungsi Gauss dengan Gambar 25 Fungsi Gauss dengan parameter 0= 5.75 parameter 0 = 6
Dengan menggunakan dua komponen utama pertama, fungsi kernel linear dan Gauss memberikan hasil pemisahan antarkelompok yang lebih baik jika dibandingkan dengan plot pencar antarpeubah. Dalam karya ilmiah ini dilakukan perbandingan pada dua buah data yaitu data tanaman iris dan data pengenalan anggur. Keduanya memiliki perbandingan dengan artikel dalam jurnal yang sudah ada, hasilnya dijelaskan dalam Gambar 26 dan 27. Pada data pengenalan anggur yang dijelaskan dalam Lampiran 1 untuk fungsi Gauss dengan parameter
0 = 3 diperoleh hasil yang cukup baik dan relatif sama dengan yang diperoleh
pada artikel dalam jurnal. Nilai dan vektor eigen untuk 0= 3 dijelaskan dalam Lampiran 2.
(a) (b)
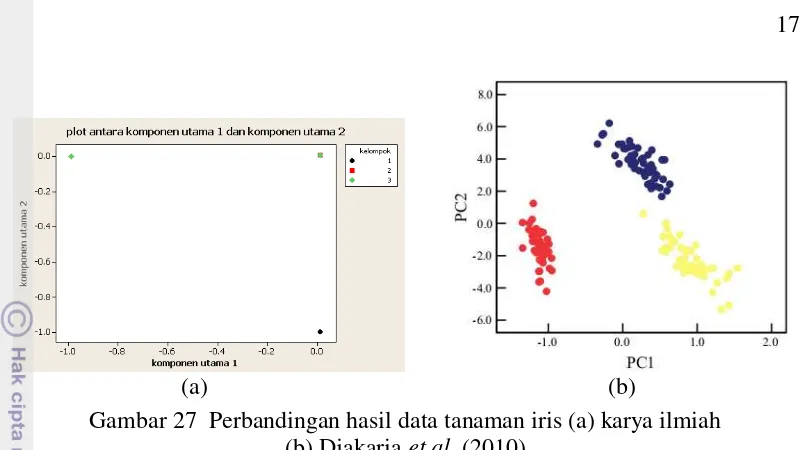
Gambar 26 Perbandingan hasil data pengenalan anggur (a) karya ilmiah (b) Sugiyama (2013)
Pemisahan data tanaman iris menggunakan AKU kernel sebelumnya telah dikerjakan dan menghasilkan plot yang berbeda dengan yang dijelaskan oleh Djakaria et al. (2010). Karena jurnal tersebut hanya menggunakan fungsi kernel Gauss dengan tidak menjelaskan setiap parameter yang digunakan, sehingga perbedaan ini sulit diketahui di mana letaknya. Walaupun ada satu parameter yang dijelaskan yaitu untuk parameter 0= 0.001 2 namun hasilnya tetap sangat
17
(a) (b)
Gambar 27 Perbandingan hasil data tanaman iris (a) karya ilmiah (b) Djakaria et al. (2010)
Karena tidak mungkin kedua hasil benar, maka kemungkinan salah satu ada yang salah atau kedua-duanya salah. Oleh karena itu diperlukan penelusuran selanjutnya yang dapat memberikan hasil yang baik dan benar untuk dalam penggunaan AKU kernel.
Setelah diperoleh hasil pemisahan yang cukup baik antarkelompok, selanjutnya akan dibahas tentang pengklasifikasian kelompok menggunakan AKU kernel. Pengklasifikasian ini akan membandingkan dua fungsi kernel yaitu fungsi linear (bersesuaian dengan AKU) dan Gauss. Analisis data yang dilakukan pada prosedur analisis data ialah untuk data yang distandarisasi. Pada Tabel 7, 8, 9, dan 10 dijelaskan hasil yang diperoleh menggunakan fungsi kernel linear dan Gauss. Pada Tabel 6 dijelaskan jumlah kesalahan untuk setiap parameter dari fungsi Gauss, serta grafiknya.
Tabel 6 Hasil salah klasifikasi (SK) fungsi Gauss
h0 1 1.25 1.5 1.75 2 2.25 2.5 2.75 3 3.25 3.5
SK 58 65 59 37 53 56 31 61 38 38 41
%SK 32.58% 36.51% 33.15% 20.78% 29.77% 31.46% 17.42% 34.27% 21.35% 21.58% 23.03
h0 3.75 4 4.25 4.5 4.75 5 5.25 5.5 5.75 6
SK 66 45 45 47 71 73 52 50 51 70
%SK 37.08% 25.3% 25.3% 26.4% 39.88% 41.01% 29.2% 28.09% 28.65% 39.33%
Semula diperkirakan ada tren kuadrat dari salah klasifikasi yang dapat digunakan untuk menduga hasil klasifikasi terkecil dengan menggunakan regresi kuadratik untuk nilai parameter 0 yang digunakan. Namun, hasil yang diperoleh
terlihat pada Gambar 28 yaitu terjadi perubahan banyaknya salah klasifikasi yang tidak teratur. Selanjutnya akan digunakan AKU kernel untuk menyelesaikan klasifikasi kelompok. Pada dasarnya studi dilakukan pada fungsi Gauss untuk parameter 0= 1, 1.25, …, 6. Namun, untuk memberikan gambaran hasilnya, dipilih tiga parameter dengan nilai kesalahan yang berbeda-beda yaitu untuk
18
Gambar 28 Grafik kesalahan klasifikasi
Fungsi linear memiliki salah klasifikasi sebesar 30.89%. Terlihat bahwa salah klasifikasi kelompok menggunakan fungsi ini banyak terdapat pada kelompok 3. Hal ini terjadi karena antarkelompok ini memang sulit dipisahkan secara keseluruhan dan juga karena jarak yang berdekatan antarkelompok.
Tabel 7 Hasil pengklasifikasian kelompok data dengan fungsi linear Kelompok 32.584%. Terlihat bahwa salah klasifikasi kelompok menggunakan fungsi ini banyak terdapat pada kelompok 3. Hal ini juga terjadi karena antarkelompok ini memang sulit dipisahkan secara keseluruhan dan juga karena jarak yang berdekatan antarkelompok. Hasil ini relatif mirip dengan fungsi kernel linear.
Tabel 8 Hasil pengklasifikasian kelompok data dengan fungsi Gauss 0=1 Kelompok
Fungsi Gauss dengan parameter 0=2.5 memiliki salah klasifikasi sebesar 17.416%. Terlihat bahwa salah klasifikasi kelompok menggunakan fungsi ini banyak terdapat pada kelompok 2. Hal ini berbeda dengan yang hasil diperoleh sebelumnya.
19 bahwa salah klasifikasi kelompok menggunakan fungsi ini banyak terdapat pada kelompok 2. Hasil salah klasifikasi yang dipeoleh cukup besar dan kurang baik digunakan untuk klasifikasi kelompok.
Tabel 10 Hasil pengklasifikasian kelompok data dengan fungsi Gauss 0=6 Kelompok
Pengklasifikasian menggunakan fungsi Gauss dengan menggunakan parameter 0 = 1, 2.5, 6 memiliki hasil salah klasifikasi sebesar 32.584%, 17.416% dan 39.326% secara berturut-turut. Terlihat bahwa salah klasifikasi kelompok menggunakan fungsi ini banyak terdapat pada setiap kelompok bergantung pada parameter. Hal ini terjadi karena dalam pemilihan parameter untuk fungsi kernel belum ada ketentuannya, hanya disesuaikan berdasarkan hasil atau tipe plot yang lebih baik.
SIMPULAN DAN SARAN
Simpulan
Visualisasi data menggunakan AKU kernel akan menghasilkan berbagai bentuk plot pencar untuk dua komponen utama pertama bergantung pemilihan fungsi kernelnya. Dalam pemilihan fungsi kernel yang tepat akan memberikan pola linear terpisah pada data sehingga akan mempermudah saat menganalisis. Hasil untuk data pengenalan anggur menunjukkan bahwa fungsi kernel linear dan Gauss (parameter 2.5) masing-masing menghasilkan salah klasifikasi sebesar 30.889% dan 17.416%.
Saran
20
DAFTAR PUSTAKA
Fisher RA. 1988. Iris Plants Database. [Internet]. [diunduh 2014 Jan 20]. Tersedia pada: http://archive.ics.uci.edu/ml/machine-learning-databases/iris/
iris.data.
Forina M. 1991. Wine Recognition Data. [Internet]. [diunduh 2014 Jan 20]. Tersedia pada: http://archive.ics.uci.edu/ml/machine-learning-databases/wine/ wine.data.
Djakaria I, Guritno S, Kartiko SH. 2010. Visualisasi Data Iris Menggunakan Analisis Komponen Utama dan Analisis Komponen Utama Kernel. Jurnal Ilmu Dasar. 11(1):31-38.
Johnson RA, Wichern DW. 2007. Applied Multivariate Statistical Analysis. 6th ed. New Jersey (US): Pearson Education.
Jolliffe IT. 2002. Principal Component Analysis. 2nd ed. New York (US): Springer-Verlag.
Nielsen AA, Canty MJ. 2008. Kernel Principal Component Analysis for Change Detection. Image and Signal for Remote Sensing XIV. 7109. Doi:10.1117 /12.800141.
Shen Y. 2007. Outlier Detection Using the Smallest Kernel Principal Component. Philadelphia (US): Temple University.
Schölkopf B, Smola AJ. 2002. Learning with Kernels. London (UK): The MIT Press.
25
170 3 13.4 4.6 2.86 25 112 1.98 0.96 0.27 1.11 8.5 0.67 1.92 630
171 3 12.2 3.03 2.32 19 96 1.25 0.49 0.4 0.73 5.5 0.66 1.83 510
172 3 12.77 2.39 2.28 19.5 86 1.39 0.51 0.38 0.64 9.89 0.57 1.63 470
173 3 14.16 2.51 2.48 20 91 1.68 0.7 0.44 1.24 9.7 0.62 1.71 660
174 3 13.71 5.65 2.45 20.5 95 1.68 0.61 0.52 1.06 7.7 0.64 1.74 740
175 3 13.4 3.91 2.48 23 102 1.8 0.75 0.43 1.41 7.3 0.7 1.56 750
176 3 13.27 4.28 2.26 20 120 1.59 0.69 0.43 1.35 10.2 0.59 1.56 835
177 3 13.17 2.59 2.37 10 120 1.65 0.68 0.53 1.46 9.3 0.6 1.62 840
26
Lampiran 2 Data nilai eigen dan vector eigen untuk fungsi Gauss h0=3
Empat vektor eigen terurut Sepuluh nilai eigen terurut
29