APLIKASI ANALISIS DISKRIMINAN DALAM PENENTUAN
RASIO-RASIO KEUANGAN YANG MEMPENGARUHI
TINGKAT KESEHATAN PERUSAHAAN PADA
BURSA EFEK INDONESIA
SKRIPSI
MUHAMMAD ZULHAM 070803044
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
APLIKASI ANALISIS DISKRIMINAN DALAM PENENTUAN
RASIO-RASIO KEUANGAN YANG MEMPENGARUHI
TINGKAT KESEHATAN PERUSAHAAN PADA
BURSA EFEK INDONESIA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
MUHAMMAD ZULHAM 070803044
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : APLIKASI ANALISIS DISKRIMINAN DALAM
PENENTUAN RASIO-RASIO KEUANGAN YANG
MEMPENGARUHI TINGKAT KESEHATAN
PERUSAHAAN PADA BURSA EFEK INDONESIA
Kategori : SKRIPSI
Nama : MUHAMMAD ZULHAM
Nomor Induk Mahasiswa : 070803044
Program Studi : SARJANA (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Juni 2011
Komisi Pembimbing :
Pembimbing 2, Pembimbing 1,
Dra. Esther S M Nababan, M.Sc Drs. Henry Rani Sitepu, M.Si
NIP : 19610318 198711 2 001 NIP : 19530303 198303 1 002
Diketahui oleh
Departemen Matematika FMIPA USU Ketua,
Prof. Dr.Tulus, M.Si
PERNYATAAN
APLIKASI ANALISIS DISKRIMINAN DALAM PENENTUAN RASIO-RASIO KEUANGAN YANG MEMPENGARUHI TINGKAT KESEHATAN
PERUSAHAAN PADA BURSA EFEK INDONESIA
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juni 2011
PENGHARGAAN
Bismillahirrahmanirrahim
Puji dan syukur penulis sampaikan kepada Allah SWT, Tuhan semesta alam yang Maha Pengasih lagi Maha Penyayang karena berkat rahmat dan hidayah-Nya pulalah akhirnya penulis dapat menyelesaikan skripsi ini dengan baik. Shalawat berangkaikan salam penulis juga sampaikan kepada Rasulullah tercinta Muhammad SAW, semoga kita mendapatkan syafaat beliau di yaumil akhir kelak. Amin Yaa Rabbal Alamiin.
Dalam menyelesaikan skripsi ini penulis banyak menerima bantuan dan saran dari berbagai pihak. Pada kesempatan ini, penulis mengucapkan terima kasih kepada Bapak Dr. Sutarman, M.Sc, selaku Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Sumatera Utara. Bapak Prof. Dr. Tulus, M.Si dan Ibu Dra. Mardiningsih, M.Si selaku Ketua dan Sekretaris Departemen Matematika FMIPA USU. Bapak Drs. Henry Rani Sitepu, M.Si selaku dosen pembimbing I dan Ibu Dra. Esther S M Nababan, M.Sc selaku dosen pembimbing II yang telah memberikan panduan, dukungan moral, motivasi dan ilmu pengetahuan bagi penulis dalam menyelesaikan penelitian ini. Bapak Drs. Djenda Djudjur Ginting, MS selaku dosen penasehat akademik yang memberikan doa kepada penulis untuk dapat menyelesaikan skripsi ini. Seluruh Staf Pengajar Departemen Matematika dan pegawai Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Sumatera Utara.
Penulis juga mengucapkan terima kasih kepada kedua orang tua penulis yaitu ayahanda Mahlan Harahap dan terkhusus buat ibunda tercinta Mawar Dalimunthe, sosok ibu paling sempurna, penuh kasih dan yang selalu mengiringi langkah anak-anaknya dengan doa yang tulus serta perjuangan keras untuk pencapaian cita-cita anak-anaknya tanpa mengenal lelah dan keluh kesah. Adik-adik tersayang Zein Pahlawan dan Sri Indriani Putri beserta keluarga besar yang selalu memberikan doa dengan ikhlas demi keberhasilan penulis dalam menyelesaikan studi ini.
Terima kasih juga kepada sahabat suka duka penulis yaitu Septi, Harri, Maulia, Alumni XII IPA II, Senior maupun Junior beserta guru-guru di SMA N 3 Plus Rantau Utara. Teman seperjuangan penukis yaitu Rizqi, Mizwar, Nurdian, Nelly, Aprilia, Warsini, Memel, Kessy, Novita, Asih, Sheila, Nana, Hanum dan seluruh teman-teman di Matematika stambuk 2007. Buat Senior penulis yaitu Mahather, Juanda, Mandra, Aghni, Vikoh, Rina, Linda dan Astria, serta junior penulis yaitu Iqbal, Mifdhal, Ugi, Isnaini, Evi, Ningrum dan Suci. Tak lupa ucapan terima kasih terhadap organisasi IM Kubik, Akademika maimun, Himpunan Mahasiswa Matematika USU, Pemerintahan Mahasiswa USU dan semua pihak terkait yang mendukung penulis yang tak bisa disebutkan satu persatu.
Ucapan terima kasih yang sama juga penulis ucapkan kepada Reminda Suryani Tarigan dan Arni Susanti.
Terima kasih untuk semua pihak terkait, semoga Tuhan yang Maha Kuasa membalasnya dengan pahala dan mencatatnya sebagai amalan yang baik. Amin.
Penulis menyadari terdapat banyak kekurangan dalam penulisan ini. Oleh karena itu, penulis meminta saran dan kritik membangun dari pembaca yang dapat membuat tulisan ini lebih baik lagi.
Demikianlah yang dapat penulis sampaikan, atas perhatian dan kerjasamanya penulis ucapkan terima kasih. Semoga tulisan ini bermanfaat bagi siapa yang membutuhkan.
Medan, Juni 2011 Penulis,
ABSTRAK
Analisis diskriminan merupakan suatu analisis multivariat yang digunakan untuk mengklasifikasikan suatu objek penelitian ke dalam suatu kelompok yang telah ditentukan sebelumnya berdasarkan variabel-variabel tertentu yang akan membentuk suatu model prediktif. Model Analisis diskriminan harus memiliki data variabel dependen (non metrik) yang berupa data kategorikal atau nominal dan memiliki data independen (metrik) yang bersifat interval atau rasio dan data harus berdistribusi normal. Penggunaan analisis diskriminan dalam penelitian ini bertujuan untuk menentukan rasio-rasio keuangan yang mempengaruhi tingkat kesehatan perusahaan pada Bursa Efek Indonesia. Data yang digunakan dalam penelitian ini diperoleh dari Bursa Efek Indonesia dan diuji pengklasifikasiannya dengan menggunakan Prees`s-Q. Berdasarkan metode ini diperoleh hasil penelitian yang menunjukkan bahwa ada sepuluh rasio keuangan yang berpengaruh terhadap tingkat kesehatan perusahaan yaitu Aktiva lancar/Kewajiban lancar (X1) ,Laba Ditahan/Total Aktiva (X2), Laba
sebelum Bunga dan Pajak/Total Aktiva (X3), Total Kewajiban/Total Equitas (X4),
Penjualan/Total Aktiva (X5), Total Aktiva/Total Ekuitas (X6), Laba Kotor/Penjualan
(X7), Laba Bersih/Penjualan (X8), Laba Bersih/Total Aktiva (X9) dan Laba Bersih/Total
Ekuitas (X10). Dari kesepuluh rasio keuangan tersebut, rasio Laba sebelum Bunga dan
Pajak/Total Aktiva (X3) adalah rasio keuangan yang paling dominan dalam
mempengaruhi tingkat kesehatan perusahaan dengan tingkat akurasi klasifikasi sebesar 66,7% pada model yang dihasilkan analisis diskriminan.
DISCRIMINANT ANALYSIS APLICATION TO CHOOSE FINANCIAL RATIOS WHICH INFLUENCE COMPANY HEALTHNESS LEVEL
IN BURSA EFEK INDONESIA
ABSTRACT
Discriminant Analysis is a multivariate analysis which used to classificating experiment object to a group whom have variables certainly and make a predictive model. This model must have dependent (non metric) variable like categorical or nominal data and have independent (metric) variable like interval or ratio. Both of them must be normal distribution. In this research, discriminant analysis used to choosing financial ratios which make a influence of company healthness level in Bursa Efek Indonesia. In this research, data was taken of Bursa Efek Indonesia and test of classification use Prees`s-Q method. In this method, getting ten financial ratios which influence of company healthness level, they are Current Ratio (X1), Retained Earning to Total Assets (X2), Earning Before Interest and Taxes to Assets (X3), Debt to Equity Ratio (X4), Sales to Total Assets (X5), Equity Multiplier (X6), Gross P rofit Margin (X7), Net Profit Margin (X8), Return on Investment (X9) and Return on Equity (X10). The dominant financial ratios which most influence company healthness level is Earning Before Interest and Taxes to Assets (X3) with classification accuracy level is
DAFTAR ISI
Halaman
PERSETUJUAN ii
PERNYATAAN iii
PENGHARGAAN iv
ABSTRAK vi
ABSTRACT vii
DAFTAR ISI viii
DAFTAR TABEL ix
DAFTAR LAMPIRAN x
BAB 1. PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 3
1.3 Pembatasan Masalah 3
1.4 Tinjauan Pustaka 4
1.5 Tujuan Penelitian 6
1.6 Manfaat Penelitian 6
1.7 Metodologi Penelitian 7
2. LANDASAN TEORI 9
2.1 Variabel 9
2.2 Data 10
2.2.1 Data Menurut Sifatnya 10
2.2.2 Data Menurut Cara Memperolehnya 10
2.2.3 Data Menurut Waktu 11
2.2.4 Data Menurut Sumbernya 11
2.3 Analisis Korelasi 11
2.4 Analisis Diskriminan 13
2.4.1 Hal-Hal Pokok Tentang Analisis Diskriminan 13
2.4.2 Algoritma dan Model Matematis 16
2.5 Pengujian Hipotesis 23
3. PEMBAHASAN 25
3.1 Pengelompokkan Data 25
3.1.1 Sumber Data 25
3.1.2 Populasi 26
3.2 Analisis Data 27
3.2.1 Interpretasi Output 40
4. KESIMPULAN DAN SARAN 51
4.1 Kesimpulan 51
4.2 Saran 52
DAFTAR PUSTAKA 53
DAFTAR TABEL
Halaman Tabel 2.1 Format Data untuk Analisis Diskriminan 24
Tabel 3.1 Sampel Penelitian 34
Tabel 3.2 Interpretasi Koefisien Korelasi 36
Tabel 3.3 Uji Kesamaan Rata-Rata 38
Tabel 3.4 Hasil Output Uji Kesamaaan Matriks Covarians 39
Tabel 3.5 Hasil Uji Box`s M 39
Tabel 3.6 Grup Statistik 40
Tabel 3.7 Variabel dimasukkan/dibuanga,b,c,d 42
Tabel 3.8 Variabel Masuk dalam Analisis 42
Tabel 3.9 Variable Tidak Masuk dalam Analisis 43
Tabel 3.10 Nilai Eigen 44
Tabel 3.11 Wilk`s Lambda 45
Tabel 3.12 Koefisien Fungsi Diskriminan Kanonikal 46
Tabel 3.13 Struktur Matriks 46
Tabel 3.14 Koefisien Fungsi Diskriminan Kanonik 47
Tabel 3.15 Fungsi pada Grup Terpusat 47
Tabel 3.16 Peluang Utama Suatu Grup 49
DAFTAR LAMPIRAN
Lampiran A : Laporan Keuangan Perusahaan Terdaftar di BEI
Lampiran B : Rasio Keuangan
Lampiran C : Transformasi Data Berdasarkan SPSS Lampiran D : Hasil Output SPSS
Lampiran E : Defenisi Operasional Variabel Lampiran F : Tabel Distribusi Chi-Kuadrat Lampiran G : Tabel Distribusi F untuk α = 0,05
ABSTRAK
Analisis diskriminan merupakan suatu analisis multivariat yang digunakan untuk mengklasifikasikan suatu objek penelitian ke dalam suatu kelompok yang telah ditentukan sebelumnya berdasarkan variabel-variabel tertentu yang akan membentuk suatu model prediktif. Model Analisis diskriminan harus memiliki data variabel dependen (non metrik) yang berupa data kategorikal atau nominal dan memiliki data independen (metrik) yang bersifat interval atau rasio dan data harus berdistribusi normal. Penggunaan analisis diskriminan dalam penelitian ini bertujuan untuk menentukan rasio-rasio keuangan yang mempengaruhi tingkat kesehatan perusahaan pada Bursa Efek Indonesia. Data yang digunakan dalam penelitian ini diperoleh dari Bursa Efek Indonesia dan diuji pengklasifikasiannya dengan menggunakan Prees`s-Q. Berdasarkan metode ini diperoleh hasil penelitian yang menunjukkan bahwa ada sepuluh rasio keuangan yang berpengaruh terhadap tingkat kesehatan perusahaan yaitu Aktiva lancar/Kewajiban lancar (X1) ,Laba Ditahan/Total Aktiva (X2), Laba
sebelum Bunga dan Pajak/Total Aktiva (X3), Total Kewajiban/Total Equitas (X4),
Penjualan/Total Aktiva (X5), Total Aktiva/Total Ekuitas (X6), Laba Kotor/Penjualan
(X7), Laba Bersih/Penjualan (X8), Laba Bersih/Total Aktiva (X9) dan Laba Bersih/Total
Ekuitas (X10). Dari kesepuluh rasio keuangan tersebut, rasio Laba sebelum Bunga dan
Pajak/Total Aktiva (X3) adalah rasio keuangan yang paling dominan dalam
mempengaruhi tingkat kesehatan perusahaan dengan tingkat akurasi klasifikasi sebesar 66,7% pada model yang dihasilkan analisis diskriminan.
DISCRIMINANT ANALYSIS APLICATION TO CHOOSE FINANCIAL RATIOS WHICH INFLUENCE COMPANY HEALTHNESS LEVEL
IN BURSA EFEK INDONESIA
ABSTRACT
Discriminant Analysis is a multivariate analysis which used to classificating experiment object to a group whom have variables certainly and make a predictive model. This model must have dependent (non metric) variable like categorical or nominal data and have independent (metric) variable like interval or ratio. Both of them must be normal distribution. In this research, discriminant analysis used to choosing financial ratios which make a influence of company healthness level in Bursa Efek Indonesia. In this research, data was taken of Bursa Efek Indonesia and test of classification use Prees`s-Q method. In this method, getting ten financial ratios which influence of company healthness level, they are Current Ratio (X1), Retained Earning to Total Assets (X2), Earning Before Interest and Taxes to Assets (X3), Debt to Equity Ratio (X4), Sales to Total Assets (X5), Equity Multiplier (X6), Gross P rofit Margin (X7), Net Profit Margin (X8), Return on Investment (X9) and Return on Equity (X10). The dominant financial ratios which most influence company healthness level is Earning Before Interest and Taxes to Assets (X3) with classification accuracy level is
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Salah satu tujuan yang ingin dicapai dalam mendirikan suatu perusahan antara lain adalah untuk memperoleh keuntungan. Hal tersebut mesti diiringi dengan tingkat kesehatan perusahaan yang baik karena akan menarik minat investor untuk menanam modal ke perusahaan yang dimiliki. Perusahaan yang sehat ditandai dengan eksistensi dalam perekonomiannya yang berjalan sangat lancar sehingga memberikan efek positif terhadap citra maupun finansial perusahaan. Namun tidaklah selamanya perekonomian berjalan lancar karena pasti ada kegagalan yang dapat menghambat laju perekonomian perusahaan. Ada dua macam kegagalan yang akan menyebabkan terjadinya kebangkrutan, yaitu kegagalan ekonomi dan kegagalan keuangan. Kegagalan ekonomi suatu perusahaan dikaitkan dengan ketidakseimbangan antara pendapatan dengan pengeluaran. Sementara itu, sebuah perusahaan dikategorikan tidak sehat (bangkrut) jika perusahaan tersebut tidak mampu membayar kewajibannya pada waktu jatuh tempo, meskipun total seluruh pendapatan melebihi jumlah kewajiban-kewajiban perusahaan yang harus dibayar.
Menurut Parahita (2011), Tidak ada satu pun perusahaan yang dapat terhindar dari resiko kebangkrutan karena tidak ada bisnis yang dapat berjaya selamanya. Kombinasi dari melemahnya prospek industri ke depan digabungkan dengan
Untuk mengevaluasi tingkat kesehatan suatu perusahaan perlu dibentuk sebuah bentuk model peramalan dengan menggunakan salah satu teknik dalam statistik yaitu analisis diskriminan. Analisis diskriminan adalah suatu fungsi pembeda yang bertujuan untuk mengklasifikasikan suatu individu atau observasi ke dalam kelompok yang saling bebas (mutually exclusive/disjoint) dan menyeluruh (exhaustive) berdasarkan sejumlah faktor penjelas. Analisis diskriminan digunakan jika variabel tak bebasnya berupa kelompok, bisa dikotomus (dua kelompok, misalnya laki-laki dan perempuan) atau multidikotomus (lebih dari dua kelompok) sedangkan variabel bebasnya adalah berupa interval atau rasio. Selanjutnya dicari fungsi diskriminan yang dapat membedakan objek tertentu masuk kelompok yang mana dan fungsi diskriminan ini dibentuk dengan memaksimumkan jarak antar kelompok, sehingga memiliki kemampuan untuk membedakan antar kelompok.
Variabel bebas yang digunakan dalam penelitian ini adalah rasio-rasio keuangan yang biasa digunakan dalam Metode Altman dan ditambah dengan rasio-rasio keuangan lain dalam ilmu akuntansi dan yang diduga dapat mempengaruhi tingkat kesehatan keuangan. Rasio tersebut diantaranya adalah rasio antara total pendapatan dengan hutang lancar, rasio antara keuntungan yang ditahan dengan total pendapatan dan lain-lain. Dari rasio-rasio tersebut akan dapat diketahui rasio apa saja yang menjadi faktor utama dalam penentuan tingkat kesehatan perusahaan dengan menggunakan metode analisis diskriminan.
Ada juga beberapa metode serupa dalam bidang statistik yang dapat digunakan pada kasus dalam penelitian ini yaitu menentukan prediksi tingkat kesehatan suatu perusahaan. Namun metode analisis diskriminan ini diharapkan dapat memberikan gambaran yang lebih rinci karena metode ini mempunyai kemampuan sebagai alat analisis untuk membedakan suatu objek ke dalam suatu kelompok tertentu. Metode ini dapat digunakan tanpa perlu memperhatikan ukuran perusahaan. Metode ini mampu menghasilkan suatu penilaian, yaitu ZCU (Discriminant Score)
yang dapat digunakan untuk membuat prediksi. Jika ZCU mulai turun dengan tajam
Analisis diskriminan dalam penelitian ini dilakukan untuk melihat prediktor yang paling baik untuk mengolompokkan tingkat kesehatan perusahaan berdasarkan rasio-rasio keuangan yang mempengaruhinya. Pada penelitian ini terdapat dua kelompok tingkat kesehatan perusahaan sehingga hanya akan diperoleh satu fungsi diskriminan. Meskipun analisis regresi logistik juga dapat digunakan dalam hal ini namun analisis diskriminan lebih sesuai untuk digunakan. Jika tujuan analisis ini lebih mengarah untuk melihat probabilitas suatu pengklasifikasian objek ke dalam kelompok tertentu, sebaiknya menggunakan analisis regresi logistik.
Berdasarkan penjelasan tersebut penulis memilih judul “Aplikasi Analisis Diskriminan Dalam P enentuan Rasio-Rasio Keua ngan Yang Mempengaruhi Tingkat
Kesehatan Perusahaan Pada Bursa Efek Indonesia.”
1.2 Perumusan Masalah
Rumusan masalah dalam penelitian ini adalah:
1. Bagaimana Analisis Diskriminan dapat digunakan dalam mengukur tingkat kesehatan suatu perusahaan.
2. Bagaimana mengklasifikasikan tingkat kesehatan perusahaan pada Bursa Efek Indonesia sesuai dengan rasio keuangan yang mempengaruhinya.
1.3 Pembatasan Masalah
Pembatasan masalah dalam penelitian ini adalah:
1. Penelitian ini hanya dilakukan pada perusahaan-perusahaan terdaftar pada Bursa Efek Indonesia.
1.4 Tinjauan Pustaka
Fakhrurozi (2007), melakukan penelitian tentang pengaruh kebangkrutan bank terhadap harga saham perbankan yang terdaftar di Bursa Efek Jakarta dan dengan menggunakan teknik statistika analisis diskriminan berganda altman, peneliti menyimpulkan bahwa dari tahun 2003 sampai dengan tahun 2005 seluruh perusahaan perbankan masuk dalam kategori bangkrut.
Selain itu Heru Airlangga (2000) juga melakukan penelitian yang menitikberatkan terhadap rasio analisis keuangan dengan menggunakan multiple discriminant analysis altman sebagai alat untuk memprediksi kebangkrutan suatu perusahaan yang menggunakan data dari laporan neraca keuangan PT Wihani Grafindo dan peneliti tersebut menarik kesimpulan bahwa perusahaan PT Wihani Grafindo adalah perusahaan yang memiliki kondisi keuangan yang rawan akan terjadinya kebangkrutan. Berdasarkan hasil tersebut, maka penulis mengajukan saran-saran yaitu: perusahaan sebaiknya mengurangi proporsi penggunaan hutang dan meningkatkan proporsi modal sendiri. Hal ini dilakukan untuk mengurangi beban bunga yang harus ditanggung perusahaan apabila perusahaan menggunakan hutang dalam struktur modalnya. Selain itu, perusahaan harus mampu meningkatkan volume penjualan tiap tahunnya dengan cara lebih mengintensifkan Bagian Pemasaran untuk melakukan promosi ke setiap instansi, baik itu pemerintah maupun swasta agar mendapatkan order dari instansi tersebut.
Model analisis diskriminan berkenaan dengan kombinasi linear yang bentuknya sebagai berikut:
Di = b0 + b1Xi1 + b2Xi2 + b3Xi3 + … + bjXij
Keterangan:
bo = Intersep
bj = Slope (kemiringan) Xji = variabel bebas
Dalam Analisis Diskriminan ada beberapa asumsi yang harus dipenuhi yaitu:
1. Multivariate Normality
Bila menggunakan teknik analisis multivariat dengan analisis diskriminan, variabel independen seharusnya berdistribusi normal. Jika data tidak berdistribusi normal, hal ini akan menyebabkan masalah pada ketepatan fungsi (model) diskriminan. Regresi Logistik bisa dijadikan alternatif metode jika memang data tidak berdistribusi normal.
2. Matriks kovarians dari semua variabel independen harusnya sama (equal). 3. Tidak adanya data yang sangat ekstrim (outlier) pada variabel independen. Jika
ada data outlier yang tetap diproses, hal ini berakibat berkurangnya ketepatan klasifikasi dari fungsi diskriminan.
4. Tidak adanya multikolinearitas antar variabel independen. Multikolinearitas terjadi bila ada variabel independen yang berkolerasi sangat kuat dengan variabel independen lainnya (Yasril hal 77).
penelitiannya, Beaver memutuskan bahwa dari kedua kelompok perusahaan tersebut, lima dari rasio prediktor yang telah dimodelkan Altman tersebut menunjukkan hasil yang signifikan antara perusahaan yang sehat maupun yang gagal. Para investor pun mengakuinya dan membawa informasi rasio keuangan tersebut ke harga saham.
Adnan dan Kurniasih (2000:147) dalam Analisis Tingkat Kesehata n Perusahaan untuk Memprediksi Potensi Kebangkrutan dengan Pendekatan Altman. penelitian ini memperkuat formula dan penelitian yang telah dilakukan oleh Altman, karena hasil penelitiannya menunjukkan bahwa sepuluh perusahaan yang menjadi objek penelitiannya setelah dianalisis dengan menggunakan formula yang telah ditemukan Altman, seluruhnya mempunyai rasio keuangan dengan tingkat resiko keuangan yang tinggi karena rasionya di bawah 1,20.Penelitian ini juga membuktikan bahwa kebangkrutan perusahaan dapat diukur dua tahun sebelum perusahaan itu mengalami kebangkrutan.
1.5 Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk mendiskriminasi (mengelompokkan) rasio-rasio keuangan yang mempengaruhi tingkat kesehatan suatu perusahaan serta mengetahui rasio keuangan yang lebih dominan mempengaruhi tingkat kesehatan perusahaan.
1.6 Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut:
1. Memberi informasi mengenai kondisi kinerja keuangan perusahaan dan menjadikannya sebagai bahan pertimbangan untuk pengambilan keputusan yang berkaitan dengan masalah keuangan.
1.7 Metodologi Penelitian
Langkah-langkah yang digunakan dalam penelitian ini adalah sebagai berikut: a. Pengumpulan Data
Dalam penelitian ini data yang digunakan adalah data sekunder. Data sekunder ini berasal dari catatan laporan keuangan beberapa perusahaan Listing (pencantuman suatu Efek dalam daftar Efek yang tercatat di Bursa sehingga dapat diperdagangkan di Bursa) maupun perusahaan Delisting (penghapusan Efek dari daftar Efek yang tercatat di Bursa sehingga Efek tersebut tidak dapat diperdagangkan di Bursa) pada Bursa Efek
Indonesia (BEI) tahun 2008. Berdasarkan peraturan pencatatan Bursa Efek Jakarta No. 1B tahun 2000 dan 2001 menyebutkan kriteria perusahaan Delisting adalah sebagai berikut:
1. Selama tiga tahun berturut-turut menderita rugi atau terdapat saldo rugi sebesar 50% atau lebih dari modal disetor dalam neraca perusahaan pada tahun terakhir.
2. Selama tiga tahun berturut-turut tidak membayar deviden tunai (untuk saham) dan melakukan tiga kali cedera janji (untuk obligasi).
3. Jumlah modal sendiri kurang dari Rp 3.000.000.000,- (tiga miliar rupiah). 4. Jumlah pemegang saham kurang dari seratus pemodal (orang/badan) selama
tiga bulan berturut-turut berdasarkan laporan bulanan emiten/Biro Administrasi Efek.
5. Selama 6 bulan berturut-turut tidak terjadi transaksi.
6. Laporan keuangan yang disusun tidak sesuai dengan prinsip akuntansi yang berlaku umum dan ketentuan yang ditetapkan oleh BAPEPAM.
7. Melanggar ketentuan bursa pada khususnya dan ketentuan pasar modal pada umumnya.
8. Melakukan tindakan-tindakan yang melanggar kepentingan umum berdasarkan keputusan instansi yang berwenang.
9. Perusahaan dilikuidasi baik karena merger, penggabungan, bangkrut, dibubarkan (reksadana) atau alasan lainnya.
10.Perusahaan dinyatakan bangkrut oleh pengadilan.
b. Pengolahan Data
Metode analisis data yang digunakan adalah teknik analisis diskriminan dengan tahapan sebagai berikut:
a) Memisahkan faktor ke dalam faktor dependen dan faktor independen. b) Melakukan analisis univariat untuk mengetahui kenormalan data. c) Melakukan analisis bivariat untuk melihat korelasi antarvariabel. d) Melakukan Uji Equality.
e) Pembentukan Fungsi Diskriminan.
f) Menguji signifikansi dari fungsi diskriminan.
BAB 2
LANDASAN TEORI
2.1 Variabel
Variabel ialah sesuatu yang nilainya berubah-ubah menurut waktu atau berbeda menurut elemen/tempat. Umumnya nilai karakteristik merupakan variabel
dan diberi simbol huruf X.
Variabel berasal dari kata vary yang berarti ”berubah” dan able yang berarti ”dapat”, maka setiap variabel dapat diberi nilai dan nilai itu dapat berubah-ubah. Nilai tersebut dapat berupa nilai kualitatitif atau kuantitatif. Variabel penelitian pada hakikatnya adalah segala sesuatu yang berbentuk apa saja yang ditetapkan oleh peneliti untuk dipelajari sehingga diperoleh informasi tentang hal tersebut, kemudian ditarik kesimpulannya, (Sugiyono, 2007).
Menurut hubungan antara suatu variabel dengan variabel lainnya, variabel terbagi atas beberapa yaitu:
a) Variabel independen (independent variable) atau variabel bebas yaitu yang menjadi sebab terjadinya (terpengaruhnya) variabel dependent (variabel tak bebas).
b) Variabel dependen (dependent variable) atau variabel tak bebas yaitu variabel yang nilainya dipengaruhi oleh variabel independen.
c) Variabel moderator yaitu variabel yang memperkuat atau memperlemah hubungan antara suatu variabel dependent dengan independent.
e) Variabel kontrol, yaitu variabel yang dapat dikendalikan oleh peneliti.
2.2 Data
Data merupakan kumpulan keterangan atau fakta yang diperoleh dari satu populasi atau lebih. Data yang baik, benar dan sesuai dengan model menentukan kualitas kebijakan/ keputusan yang akan diambil terhadap suatu masalah dari populasi yang akan dikaji. Menurut Kamus Besar Bahasa Indonesia, pengertian data adalah keterangan yang benar dan nyata. Tujuan dari pengumpulan data adalah :
1. Untuk memperoleh gambaran suatu keadaan. 2. Sebagai dasar pengambilan suatu keputusan.
Menurut Richard Lungan (2006), dalam berbagai aplikasi, data dapat dibedakan sebagai berikut:
2.2.1 Menurut sifatnya
Menurut sifatnya data dibedakan atas:
a. Data Kualitatif, disajikan bukan dalam bentuk bilangan-bilangan (non-numerik), Misalnya jenis kelamin mahasiswa suatu fakultas pada Perguruan Tinggi Negeri.
b. Data Kuantitatif, disajikan dalam bentuk bilangan-bilangan, Misalnya jumlah mahasiswa menurut jurusan pada fakultas suatu Perguruan Tinggi Negeri.
2.2.1 Menurut cara memperolehnya
Menurut cara memperolehnya data dibedakan atas:
a) Data Primer, merupakan data yang langsung diperoleh dari lapangan melalui percobaan, survei dan observasi. Misalnya seorang peneliti ingin mengetahui hubungan antara besarnya biaya hidup yang dikeluarkan mahasiswa untuk ongkos dan tempat tinggal terhadap biaya hidup. Ongkos dan tempat tinggal tersebut merupakan data primer bagi peneliti bersangkutan.
tinggal. Data yang dipublikasikan oleh Biro Pusat Statistik selalu berupa data sekunder.
2.2.2 Menurut waktunya
Menurut waktu dapat dibedakan atas:
a) Data Silang, merupakan data yang dikumpulkan dalam waktu yang sifatnya temporer. Misalnya data hasil penelitian lamanya pendidikan mahasiswa pada suatu Perguruan Tinggi Negeri di tahun 2009.
b) Data Berkala, merupakan data yang dikumpulkan setiap periode tertentu. Misalnya jumlah mahasiswa matematika di FMIPA selama tahun 2000-2010.
2.2.3 Menurut sumbernya
Menurut sumbernya data dibedakan atas:
a) Data Internal, merupakan data yang dikumpulkan oleh unit kerja tertentu dalam lingkungannya untuk keperluannya sendiri. Misalnya data mahasiswa, dosen, pegawai, keuangan dan peralatan Perguruan Tinggi XYZ. Data ini merupakan data internal bagi perguruan tinggi tersebut.
b) Data Eksternal, merupakan data yang diambil dari unit lain. Misalnya data Perguruan Tinggi XYZ seperti yang disebut di atas kemudian digunakan oleh BPS, maka data tersebut merupakan data eksternal bagi BPS.
2.3 Analisis Korelasi
Analisis korelasi adalah metode yang digunakan untuk mengukur kekuatan atau derajat hubungan antara dua variabel atau lebih. Perhitungan derajat didasarkan pada persamaan regresi. Dalam ilmu statistika, istilah korelasi diartikan sebagai hubungan linier antara dua variabel atau lebih. Hubungan antara dua variabel dikenal dengan istilah biva riate correlation, sedangkan hubungan antar lebih dari dua variabel disebut
multivariate correlation.
Tujuan dilakukan analisis korelasi antara lain adalah:
b) Bila sudah ada hubungan, maka dapat digunakan untuk melihat tingkat keeratan hubungan antarvariabel.
c) Dan untuk memperoleh kejelasan dan kepastian apakah hubungan tersebut berari (meyakinkan/signifikan) atau tidak berarti.
Tinggi-rendah, kuat-lemah atau besar-kecilnya suatu korelasi dapat diketahui dengan melihat besar kecilnya suatu angka (koefisien) yang disebut angka indeks korelasi atau coefficient of correlation, yang disimbolkan dengan ρ atau r. Koefisien korelasi untuk data populasi disimbolkan dengan ρ, sedangkan korelasi untuk data sampel disimbolkan dengan r. Angka korelasi berkisar antara 0< r< 1. Perhatikan tanda plus minus (±) pada angka indeks korelasi. Tanda plus minus pada angka indeks korelasi ini fungsinya hanya untuk menunjukkan arah korelasi jadi bukan sebagai tanda aljabar. Apabila angka indeks korelasi bertanda plus (+) maka korelasi tersebut positif dan arah korelasi satu arah dan apabila angka indeks korelasi bertanda minus (-), maka korelasi tersebut negatif berlawanan arah, serta apabila angka indeks korelasi sama dengan 0, maka hal ini menunjukkan tidak ada korelasi. Dengan demikian, arah korelasi dapat dibedakan menjadi dua, yaitu yang bersifat satu arah dan yang sifatnya berlawanan arah.
Apabila terdapat dua buah variabel yaitu X dan Y yang keduanya memiliki tingkat pengukuran ordinal maka koefisien korelasi yang dapat dipergunakan adalah koefisien korelasi Spearman atau Spearman`s coefficient of (rank) correlation dan angka indeks korelasi Spearman dapat dihitung dengan menggunakan rumus berikut:
Keterangan:
= Koefisien korelasi Spearman
n = Banyaknya ukuran sampel
2.4 Analisis Diskriminan (Analisis Fungsi Pembeda)
Analisis Diskriminan merupakan suatu analisis multivariat yang digunakan untuk mengelompokkan suatu individu atau objek ke dalam suatu kelompok yang telah ditentukan sebelumnya berdasarkan variabel-variabel tertentu. Analisis diskriminan dapat digunakan jika variabel dependen terdiri dari dua kelompok atau lebih kelompok. Pengelompokkan pada analisis bersifat apriori, artinya seorang peneliti sudah mengetahui sebelumnya individu atau objek mana saja yang masuk ke dalam kelompok 1, 2, dan 3. Analisis diskriminan memiliki kemiripan dengan regresi linier berganda (multivariable regression). Perbedaannya adalah analisis diskriminan dipakai jika variabel dependennya kategori (menggunakan skala ordinal ataupun nominal) dan variabel independennya menggunakan skala metrik (interval dan rasio). Sedangkan dalam regresi berganda variabel dependennnya harus metrik dan variabelnya independen dapat berupa metrik maupun nonmetrik. Sama halnya dengan regresi berganda, dalam analisis diskriminan pun variabel dependen hanya satu sedangkan variabel independen banyak (multiple). Ada dua hal dalam analisis diskriminan, yaitu pengelompokan dan identifikasi sifat khas suatu kelompok yang dapat dilakukan sekaligus dengan analisis tersebut, dimana kelompok dikenal sebagai
group dan sifat khas dikenal sebagai variabel pembeda (discriminating variables). Antara kelompok dan variabel pembeda tersebut kemudian dibuat suatu hubungan fungsional yang disebut dengan fungsi diskriminan.
2.4.1 Hal-hal pokok tentang analisis diskriminan
Bentuk multivariat dari analisis diskriminan adalah dependen sehingga variabel dependen adalah variabel yang menjadi dasar pada analisis diskriminan. Variabel dependen bisa berupa kode grup 1 atau grup 2 atau lainnya.
Tujuan diskriminan secara umum adalah:
2. Jika ada perbedaan, variabel independen manakah pada fungsi diskriminan yang membuat perbedaan tersebut?
3. Membuat fungsi atau model diskriminan, yang pada dasarnya mirip dengan persamaan regresi.
4. Melakukan klasifikasi terhadap objek (dalam terminology SPSS disebut baris), Apakah suatu objek (bisa nama orang, nama tumbuhan, benda atau lainnya) termasuk pada kelompok 1 atau kelompok lainnya.
Proses dasar dari analisis diskriminan ialah:
a. Memisah variabel-variabel menjadi variabel dependen dan variabel independen. b. Menentukan metode untuk membuat Fungsi Diskriminan. Pada prinsipnya ada
dua metode dasar untuk itu, yakni :
Simultaneous Estimation, dimana semua variabel dimasukkan secara bersama-sama kemudian dilakukan proses analisis diskriminan.
Step-Wise Estimation, dimana variabel dimasukkan satu persatu kedalam model diskriminan. Pada proses ini, tentu ada variabel yang tetap ada pada model dan ada kemungkinan satu atau lebih variabel independen yang „dibuang‟ dari model.
c. Menguji signifikansi dari fungsi diskriminan yang telah terbentuk, menggunakanWilk‟s lambda, F test dan lainnya.
d. Menguji ketepatan klasifikasi dari fungsi diskriminan, termasuk mengetahui ketepatan klasifikasi secara individual dengan Casewise Diagnostics.
e. Melakukan interpretasi terhadap fungsi diskriminan tersebut. f. Melakukan uji validitas fungsi diskriminan.
Berikut ini beberapa asumsi yang harus dipenuhi agar model diskriminan dapat digunakan:
yakni distribusi data tersebut tidak menceng ke kiri atau menceng ke kanan. Uji normalitas pada statistika multivariat sebenarnya sangat kompleks, karena harus dilakukan pada seluruh variabel secara bersama-sama. Namun, uji ini bisa juga dilakukan pada setiap variabel dengan logika bahwa jika secara individual masing-masing variabel memenuhi asumsi normalitas, maka secara bersama sama (multivariat) variable-variabel tersebut juga bisa dianggap memenuhi asumsi normalitas. Hipotesis pengujiannya adalah sebagai berikut:
H0: Data berdistribusi normal. H1: Data tidak berdistribusi normal
Titik keputusan:
Bila P> 0,05 maka H0 diterima yang berarti data berdistribusi normal.
Bila P≤0,05 maka H0ditolak yang berarti data tidak berdistribusi normal.
Jika sebuah variabel mempunyai sebaran data yang tidak normal, maka perlakuan yang dimungkinkan agar menjadi normal, (Santoso, 2010):
a. Menambah jumlah data. Seperti pada kasus, bisa dicari 20 atau 30 atau sejumlah data baru untuk menambah ke-75 data berat badan konsumen yang sudah ada. Kemudian dengan jumlah data yang baru, dilakukan pengujian sekali lagi.
b. Menghilangkan data yang dianggap penyebab tidak normalnya data. Seperti pada variabel berat, jika dua data yang outlier dibuang, yakni berat 100 dan 120, kemudian diulang proses pengujian, mungkin data bisa menjadi normal. Jika belum normal, ulangi pengurangan data yang dianggap penyebab ketidaknormalan data. Namun demikian, pengurangan data harus dipertimbangkan apakah tidak mengaburkan tujuan penelitian karena hilangnya data-data yang seharusnya ada.
c. Dilakukan transformasi data, misal mengubah data ke logaritma atau kebentuk natural (ln) atau bentuk lainnya, kemudian dilakukan pengujian ulang.
2. Matriks varians-kovarians variabel penjelas berukuran P xP pada kedua kelompok harus sama.
2.4.2 Algoritma dan model matematis
Secara ringkas, langkah-langkah dalam analisis diskriminan adalah sebagai berikut: 1. Pengecekan adanya kemungkinan hubungan linier antara variabel penjelas. Untuk
point ini, dilakukan dengan bantuan matriks korelasi (pembentukan matriks korelasi sudah difasilitasi pada analisis diskriminan). Pada output SPSS, matriks korelasi bisa dilihat pada pooled Within-Groups Matrices.
2. Uji vektor rata-rata kedua kelompok
Pengujian terhadap vektor nilai rataan antar kelompok dilakukan dengan hipotesa: H0 : 0 = 1 = 2 = ...= k
H1 : Sedikitnya ada dua kelompok yang berbeda
Statistik uji yang digunakan dalam pengujian hipotesis tersebut adalah statistik
V-Bartlett yang menyebar mengikuti sebaran Chi-kuadrat (2) dengan derajat bebas
p(k - 1), apabila H0 diterima. Statistik V-Bartlett diperoleh melalui:
( 1)( ) 2
ln()
n p k V
dimana:
n = banyaknya pengamatan
p = banyaknya peubah dalam fungsi diskriminan
k = banyaknya kelompok
B W W Wilk’s lambda
dalam hal ini:
B = matrik jumlah kuadrat dan hasil kali data antar kelompok. =
k i i ii X X X X
n
1
)' )(
(
Xij = pengamatan ke-j kelompok ke-i
i
X = vektor rataan kelompok ke-i
ni = jumlah pengamatan pada kelompok ke-i, X = vektor rataan total
Titik Keputusan:
H0: Ada perbedaan vektor nilai rataan antarkelompok. H1: Tidak ada perbedaan vektor nilai rataan antarkelompok
Jika V 2p(k1),(1) maka H0 diterima.
Jika V > 2p(k1),(1) maka H0 ditolak.
Bila dari hasil pengujian ada perbedaan vektor nilai rataan, maka fungsi diskriminan layak disusun untuk mengkaji hubungan antar kelompok serta berguna untuk mengelompokkan suatu objek ke salah satu kelompok tersebut. Diharapkan dalam uji ini adalah hipotesis nol ditolak, sehingga kita mempunyai informasi awal bahwa variabel yang sedang diteliti memang membedakan kedua kelompok. Pada SPSS, uji ini dilakukan secara univariate (jadi yang diuji bukan berupa vektor), dengan bantuan table Tests of Equality of Group Means.
3. Dilanjutkan pemeriksaan asumsi homoskedastisitas dengan uji Box‟s M. Untuk menguji kesamaan matriks peragam (
) antar kelompok digunakan hipotesis:H0 : 0 = 1 = 2 = ....k = .
H1 : Sedikitnya ada dua kelompok yang berbeda.
Statistik uji yang digunakan adalah statistik Box’s M, yaitu:
-2ln* =
jk j j S n k n W k
n ln ( ) 1ln
1
*
= 1 ( )/2 2 / ) 1 ( )
/( n k
k j n j k n W S j
dimana:k = banyaknya kelompok.
W / (n-k) = matrik ragam-peragam dalam kelompok gabungan.
Sj = matrik ragam-peragam kelompok ke-j.
Bila H0 diterima, maka (-2ln*)/b akan mengikuti sebaran F dengan derajat
bebas v1 dan v2 pada taraf signifikansi , dimana: v1 = (1/2)(k–1)p(p + 1)
v2 = (v1+ 2) / (a2 –a12) b = v1/ (1 –a1 - v1/ v2)
a1 =
kj nj n k
p k p p 1 3 ) ( 1 ) 1 ( 1 ) 1 )( 1 ( 6 1 3 2
a2 =
kj nj n k
k p p 1 2 2 ) ( 1 ) 1 ( 1 ) 1 ( 6 ) 2 )( 1 (
p = jumlah peubah pembeda dalam fungsi diskriminan.
Asumsikan dalam uji ini hipotesis nol tidak ditolak H0:
1 2. Hipotesis:H0 : matriks kovarians grup adalah sama
H1 : matriks kovarians grup adalah berbeda secara nyata
Jika (-2ln*)/b > Fv1,v2, berarti H0 diterima
Jika (-2ln*)/bFv1,v2,berarti H1 ditolak
Sama tidaknya grup kovarians matriks juga bisa dilihat dari tabel output Log Determinant. Jika dalam pengujian ini H0 ditolak maka proses lanjutan seharusnya
4. Pembentukan model diskriminan a. Fungsi Diskriminan
Fungsi diskriminan merupakan fungsi atau kombinasi linier peubah-peubah asal yang akan menghasilkan cara terbaik dalam pemisahan kelompok-kelompok. Fungsi ini akan memberikan nilai-nilai yang sedekat mungkin dalam kelompok dan sejauh mungkin antar kelompo. Banyaknya fungsi diskriminan yang terbentuk secara umum tergantung dari min(p,k-1), dengan p adalah banyaknya peubah pembeda dan k adalah banyaknya kelompok yang telah ditetapkan. Fungsi diskriminan ini diartikan sebagai keragaman peubah yang terpilih sebagai kekuatan pembeda. Apabila fungsi diskriminan yang terbentuk sebanyak lebih dari satu fungsi, maka dapat dikatakan bahwa fungsi diskriminan pertama akan menjadi kekuatan pembeda yang paling besar, demikian berturut-turut untuk fungsi berikutnya. Fungsi diskriminan yang terbentuk mempunyai bentuk umum berupa persamaan linier (Fisher’s Sample Linear
Discriminant Function) yaitu:
p p j
jx x
x x
y1 ˆ11 1ˆ12 2 ˆ1 ˆ1
p p j
jx x
x x
y2 ˆ21 1ˆ22 2 ˆ2 ˆ2 ………. p ip j ij i i
i x x x x
y ˆ1 1ˆ 2 2 ˆ ˆ
……… p qp j qj q q
q x x x x
y ˆ 1 1 ˆ 2 2 ˆ ˆ
dengan i=1,2,…,q (min p,k-1); j=1,2,…,p atau dapat ditulis sebagai: yˆ'x
dimana: ˆ= a = Vektor koefisien pembobot fungsi diskriminan. y = skor diskriminan.
X = Vektor variabel acak yang dimasukkan ke dalam fungsi diskriminan.
= Vektor nilai rata-rata variabel acak dari kelompok pertama.
= Vektor nilai rata-rata variabel acak dari kelompok kedua.
= Invers matriks gabungan.
Sehingga,
Nilai ˆ dipilih sedemikian sehingga fungsi diskriminan berbeda sebesar mungkin antara kelompok, atau sehingga rasio antara jumlah kuadrat antar kelompok dengan jumlah kuadrat dalam kelompok maksimum.
b. Pembentukan Fungsi Linier (dengan bantuan SPSS)
Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam model dapat dilihat pada tabel Canonical Discriminant Function Coefficient. Tabel ini akan dihasilkan pada output apabila pilihan Function Coefficient bagian Unstanda rdized
diaktifkan.
c. Menghitung discriminant score
Setelah dibentuk fungsi liniernya, maka dapat dihitung skor diskriminan untuk tiap observasi dengan memasukkan nilai-nilai variabel penjelasnya.
d. Menghitung Cutting Score
Untuk memprediksi responden mana masuk golongan mana, kita dapat menggunakan
2
A B
ce
Z Z
Z
dengan :
Zce= cutting score untuk grup yang sama ukuran ZA= centroid grup A
ZB= Centroid grup B
Apabila dua grup berbeda ukuran, rumus cutting score yang digunakan adalah:
B
A B A
CU
A B
N Z N Z
Z
N N
dengan :
ZCU= Cutting score untuk grup tak sama ukuran NA= Jumlah anggota grup A
NB= Jumlah anggota grup B ZA= Centroid grup A
ZB= Centroid grup B
Kemudian nilai-nilai discriminant score tiap obsservasi akan dibandingkan dengan cutting score, sehingga dapat diklasifikasikan suatu obsevasi akan termasuk kedalam kelompok yang mana.
e. Penggolongan objek atau individu
Suatu observasi dengan karakteristik x akan diklasifikasikan sebagai anggota suatu kelompok, misalnya kelompok 1 atau kelompok 2. Untuk penggolongan tersebut ada dua macam cara yang dapat dilakukan yaitu:
1. Menggunakan titik tengah m
Titik tengah m dari diantara dua rata-rata contoh (kelompok 1 dan kelompok 2) ditentukan melalui:
Dengan aturan penggolongan sebagai berikut:
b. Jika y0≤ m atau y0– m ≤ 0 maka masukkan objek ke dalam kelompok 2.
Keterangan :
y0 = skor diskriminan dari objek tersebut.
2. Menggunakan statistika Wald-Anderson (W)
Statistik Wald-Anderson (W) dapat dirumuskan sebagai berikut:
Kriteria penggolongan berdasarkan statistik W adalah: a. Jika W > 0 maka masukkan objek ke dalam kelompok 1. b. Jika W < 0 maka masukkan objek ke dalam kelompok 2.
f. Perhitungan Hit Ratio
Setelah semua observasi diprediksi keanggotaannya, dapat dihitung hit ratio, yaitu rasio antara observasi yang tepat pengklasifikasiannya dengan total seluruh observasi. Misalkan ada sebanyak n observasi, akan dibentuk fungsi linier dengan observasi sebanyak n-1. Observasi yang tidak disertakan dalam pembentukan fungsi linier ini akan diprediksi keanggotaannya dengan fungsi yang sudah dibentuk tadi. Proses ini akan diulang dengan kombinasi observasi yang berbeda-beda, sehingga fungsi linier yang dibentuk ada sebanyak n. Inilah yang disebut dengan metode Leave One Out.
Hit Ratio 100%
1
1
k
i i k
i ic
n n
Keterangan: ni = jumlah observasi dari i yang tepat dikelompokkan pada i
nij = jumlah observasi dari i yang salah dikelompokkan pada ij
dengan i=1,2,…,k dan j=1,2,…,k
g. Kriteria posterior probability
pada sheet SPSS dengan mengaktifkan option probabilities of group membership pada bagian Save di kotak dialog utama.
k k
k k kp f x
p k x
p f x
dimana :
pk= prior probability kelompok ke-k dan
1 1/ 2 / 1exp 1 / 2
2 p z k k
fi x f x x x
Suatu observasi dengan karakteristik x akan diklasifikasikan sebagai anggota kelompok 0 jika p k
0 x
p k
1 x
. Nilai-nilai posterior probability inilah yang mengisi kolom di 1_1 dan kolom di 1_2 pada sheet SPSS.h. Akurasi statisik, dapat di uji secara statistik apakah klasifikasi yang dilakukan (dengan menggunakan fungsi diskriminan) akurat atau tidak. Uji statistik tersebut adalah prees-Q Statistik. Ukuran sederhana ini membandingkan jumlah kasus yang diklasifikasi secara tepat dengan ukuran sampel dan jumlah grup. Nilai yang diperoleh dari perhitunngan kemudian dibandingkan dengan nilai kritis (critical velue) yang diambil dari tabel Chi-Square dan tingkat keyakinan sesuai yang diinginkan. Statistik Q ditulis dengan rumus:
2 Pr 1 N nK ees Q N k dengan :N = ukuran total sampel
n = jumlah kasus yang diklasifikasi secara tepat
K = jumlah grup
2.5 Pengujian Hipotesis
dalam semua grup adalah sama. Dalam SPSS, uji dilakukan dengan menggunakan Wilks‟λ. Jika dilakukan pengujian sekaligus beberapa fungsi sebagaimana dilakukan pada analisis diskriminan, statistik Wilks‟ λ adalah hasil λ univariat untuk setiap fungsi. Kemudian, tingkat signifikansi diestimasi berdasarkan chi-squa re yang telah ditransformasi secara statistik. Setelah hasil analisis diketahui, kemudian dilihat apakah Wilks‟ λ berasosiasi dengan fungsi diskriminan. Selanjutnya, angka ini ditransformasi menjadi chi-quare dengan derajat kebebasan (df) yang akan digunakan dalam pengambilan kesimpulan dengan uji kriteria hipotesis berikut:
H0: Tidak ada perbedaan antara perusahaan yang tidak sehat dan sehat H1: Ada perbedaan antara perusahaan yang tidak sehat dan sehat
Dengan titik keputusan sebagai berikut:
Jika F hitung > F tabel maka H0ditolak
Jika F hitung _ F tabel maka H1diterima
Selanjutnya dengan menggunakan nilai F, dapat di ambil keputusan untuk menerima atau menolak H0. Jika H0 diterima, akan memberikan kesimpulan bahwa
tidak ada perbedaan antara perusahaan yang bangkrut dengan perusahaan yang sehat. Sebaliknya jika H0 ditolak maka terdapat perbedaan antara perusahaan yang bangkrut
BAB 3
PEMBAHASAN
Pada bab ini peneliti ingin menunjukkan hasil dari analisis diskriminan untuk mengelompokkan rasio-rasio keuangan yang mempengaruhi tingkat kesehatan perusahaan.
3.1 Pengelompokkan Data
Data yang diolah dapat dikelompokkan sebagai berikut:
3.1.1 Sumber data
Dalam penelitian ini data yang digunakan adalah data sekunder. Data sekunder ini berasal dari catatan laporan keuangan beberapa perusahaan yang terdaftar (Listing)
maupun yang telah dihapus karena kondisi perusahaan yang mengalami krisis keuangan (Delisting). Beberapa laporan keuangan tersebut adalah Aktiva lancar/Kewajuban lancar (Current Ratio) disimbolkan dengan X1,Laba Ditahan/Total
Aktiva (Retained Earning to Total Assets) disimbolkan dengan X2, Laba sebelum
Bunga dan Pajak/Total Aktiva (Earning Before Interest and Taxes to Assets)
disimbolkan dengan X3, Total Kewajiban/Total Equitas (Debt to Equity Ratio)
disimbolkan dengan X4, Penjualan/Total Aktiva (Sales to Total Assets) disimbolkan
dengan X5, Total Aktiva/Total Ekuitas (Equity Multiplier) disimbolkan dengan X6,
Laba Kotor/Penjualan (Gross P rofit Margin) disimbolkan dengan X7, Laba
Bersih/Penjualan (Net P rofit Margin) disimbolkan dengan X8, Laba Bersih/Total
3.1.2 Populasi
[image:40.595.103.533.414.763.2]Populasi adalah semua unsur dari masalah yang inigin diamati ataupun diteliti. Populasi dalam penelitian ini adalah perusahaan-perusahaan pada Bursa Efek Indonesia dengan jumlah perusahaan pada Bursa Efek Indonsia (BEI) sebanyak 435 Perusahaan. Pemilihan perusahaan pada BEI diharapkan dapat memudahkan akses mendapatkan data, informasi, hemat waktu penelitian dan biaya murah. Populasi diketahui bersifat homogen dan tersebar secara proporsional merata ke setiap perusahaan dan juga diasumsikan bahwa populasi berdistribusi normal. Pengambilan sampel pada penelitian ini adalah bersifat purposive sampling yaitu mengambil sampel berdasarkan beberapa pertimbangan sehingga sampel yang dipilih benar-benar representatif sehingga jumlah sampel yang diambil dalam penelitian ini adalah 30 Perusahaan.
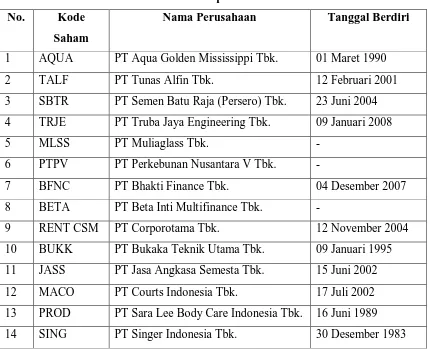
Tabel 3.1 Sampel Penelitian
No. Kode
Saham
Nama Perusahaan Tanggal Berdiri
1 AQUA PT Aqua Golden Mississippi Tbk. 01 Maret 1990
2 TALF PT Tunas Alfin Tbk. 12 Februari 2001
3 SBTR PT Semen Batu Raja (Persero) Tbk. 23 Juni 2004 4 TRJE PT Truba Jaya Engineering Tbk. 09 Januari 2008
5 MLSS PT Muliaglass Tbk. -
6 PTPV PT Perkebunan Nusantara V Tbk. -
7 BFNC PT Bhakti Finance Tbk. 04 Desember 2007
8 BETA PT Beta Inti Multifinance Tbk. -
9 RENT CSM PT Corporotama Tbk. 12 November 2004
10 BUKK PT Bukaka Teknik Utama Tbk. 09 Januari 1995 11 JASS PT Jasa Angkasa Semesta Tbk. 15 Juni 2002
12 MACO PT Courts Indonesia Tbk. 17 Juli 2002
13 PROD PT Sara Lee Body Care Indonesia Tbk. 16 Juni 1989
15 SKBM PT Sekar Bumi Tbk. 05 Januari 1993
16 ASBI PT Asuransi Bintang Tbk. 29 November 1989
17 BTEL PT Bakrie Telecom Tbk. 03 Februari 2006
18 BUMI PT Bumi Resources Tbk. 30 Juli 1990
19 ELTY PT Bakrieland Development Tbk. 30 Oktober 1995
20 GTBO PT Garda Tujuh Buana Tbk. -
21 INAF PT Indofarma Tbk. 17 April 2001
22 LMSH PT Lionmesh Prima Tbk. 04 Juni 1990
23 LPKR PT Lippo Karawaci Tbk. 28 Juni 1986
24 PRAS PT Prima Alloy Steel Universal Tbk. 12 Juli 1990
25 PYFA PT Pyridam Farma Tbk. 16 Oktober 2001
26 SONA PT Sona Topas Tourism Industry Tbk. 12 Juli 1992
27 TBMS PT Tembaga Mulia Semanan Tbk. 30 September 1993 28 TOTL PT Total Bangun Persada Tbk. 25 juli 2006
29 TMPO PT Tempo Inti Media Tbk. 08 Januari 2001
30 ELSA PT Elnusa Tbk. 06 Februari 2008
a). Sumber Data : www.jsx.co.id
b). Data diolah penulis
3.2 Analisis Data
Analisis diskriminan dimulai dengan hal-hal yang sederhana yaitu pemilihan variabel dependen dan variabel independen. Variabel dependen harus bersifat kategorik sedangkan variabel independen harus bersifat numerik. Kemudian melakukan analisis univariat untuk mengetahui kenormalan data. Klasifikasi normal ketika
1 2 , anggap bahwa kepadatan bersama dari X`
= [X1, X2, ..., Xp] untuk
populasi 1dan 2 diberikan oleh
1 1/ 2
/
1
exp 1 / 2
2 p z k k
fi x f x x x
Anggap bahwa parameter-parameter populasi µ1, µ2 dan
diketahui. Hal ini dilihatberdistribusi normal. Dari hasil test Kolmogorov Smirnov terlihat bahwa ada 6 faktor yang tidak berdistribusi normal, yaitu ,Laba Ditahan/Total Aktiva (X2), Laba sebelum
Bunga dan Pajak/Total Aktiva (X3), Total Ekuitas Saham)/Total Kewajiban (X4), Laba
Kotor/Penjualan (X7), Laba Bersih/Penjualan (X8) dan Laba Bersih/Total Ekuitas
(Saham) (X10). Karena memiliki nilai p Kolmogorov Smirnov < 0,05. Maka dilakukan
usaha untuk menormalkan distribusi data dengan proses transformasi data. Dari hasil tes Kolmogorov Smirnov terlihat bahwa keenam nilai tersebut telah berubah menjadi > 0,05, secara berurut yaitu (0,959), (0,667), (0,715), (0,999), (0,712), (0,590), yang memperlihatkan bahwa faktor ini telah berdistribusi normal. Dengan demikian faktor tersebut akan diikutsertakan dalam analisis selanjutnya.
Setelah diketahui data-data berdistribusi normal, maka dilakukan uji kolinearitas yaitu untuk mendeteksi korelasi antara faktor independen (Kolinearitas). Selanjutnya dilakukan pengujian pearson correlation terhadap semua faktor independen yang termasuk dalam distribusi normal , dimana bila r > 0,8 terjadi masalah kolinearitas. Dari uji test correlation menggunakan program SPSS bahwa tidak ada data yang memiliki r > 0.8, artinya tidak ada masalah kolinearitas.
Korelasi Pearson P roduct Moment dilambangkan dengan r, dengan ketentuan nilai r tidak lebih dari harga (-1 ≤ r ≤ 1). Apabila nilai r = -1 artinya korelasi negatif sempurna; r = 0 artinya tidak ada korelasi ; r = 1 berarti korelasinya sangat kuat. Tingkat hubungan nilai indeks korelasi dinyatakan sebagai berikut:
Tabel 3.2 Interpretasi Koefisien Korelasi
Interval Koefisien Tingkat Hubungan
0,800 – 1,000 Sangat Kuat
0,600 – 0,799 Kuat
0,400 – 0,599 Cukup Lemah
0,200 – 0,399 Lemah
0,000 – 0,199 Sangat Lemah
Dari output SPSS dapat diketahui korelasi antara X1 dengan X2, X1 dengan X4, X1 dengan X5 dan seterusnya hingga X9 dengan X10. Adapun beberapa penjelasan
1. Korelasi antara Current Ratio (X1) dengan Retained Earning to Total Assets (X2)
Berdasarkan perhitungan diperoleh nilai korelasi antara faktor Current Ratio (X1)
dan faktor Retained Earning to Total Assets (X2) sebesar 0,056. Angka tersebut
menunjukkan sangat lemahnya korelasi antara Nilai Current Ratio dengan nila
Retained Earning to Total Assets (dibawah 0,5) sedangkan tanda (+) menunjukkan arah hubungan yang sama atau searah, yaitu semakin tinggi nilai Current Ratio
maka akan membuat nilai Retained Earning to Total Assets juga tinggi dan sebaliknya.
Korelasi antara dua faktor tidak signifikan karena angka signifikan 0,770 > 0,05.
2. Korelasi antara Current Ratio (X1) dengan Earning Before Interest and Taxes to Total Assets (X3).
Berdasarkan perhitungan diperoleh nilai korelasi antara faktor Current Ratio (X1)
dan faktor Earning Before Interest and Taxes to Total Assets (X3). sebesar -0,296.
Angka tersebut menunjukkan sangat lemahnya korelasi antara Nilai Current Ratio
dengan nilai Earning Before Interest and Taxes to Total Assets (dibawah 0,5) sedangkan tanda (-) menunjukkan arah hubungan yang berlawanan, yaitu semakin tinggi nilai Current Ratio maka akan membuat nilai Return Of Assets semakin rendah dan sebaliknya.
Korelasi antara dua faktor tidak signifikan karena angka signifikan 0,112 > 0,05.
3. Korelasi antara Current Ratio (X1) dengan Debt to Equity Ratio (X4)
Berdasarkan perhitungan diperoleh nilai korelasi antara faktor Current Ratio dan fakto Debt to Equity Ratio (X4). sebesar -0,828. Angka tersebut menunjukkan
sangat lemahnya korelasi antara Nilai Current Ratio dengan nilai Debt to Equity Ratio (dibawah 0,5), sedangkan tanda (-) menunjukkan arah hubungan yang berlawanan, yaitu semakin tinggi nilai Current Ratio maka akan membuat nilai
Debt to Equity Ratio semakin rendah dan sebaliknya.
Korelasi antara dua faktor adalah signifikan karena angka signifikan 0,000 > 0,05. 4. Korelasi antara Earning Before Taxes to Assets (X3) dengan Debt to Equity Ratio
(X4)
menunjukkan korelasi antara Nilai Current Ratio dengan nilai Debt to Equity Ratio
adalah cukup lemah (dibawah 0,5), sedangkan tanda (+) menunjukkan arah hubungan yang sama atau searah, yaitu semakin tinggi nilai Current Ratio maka akan membuat nilai Debt to Equity Ratio semakin tinggi juga dan sebaliknya. Korelasi antara dua faktor adalah signifikan karena angka signifikan 0,006 > 0,05.
5. Korelasi antara Net Profit Margin (X8) dengan Return on Investment (X9)
Berdasarkan perhitungan diperoleh nilai korelasi antara faktor Net Profit Margin
dan faktor Return on Investment. sebesar 0,790. Angka tersebut menunjukkan kuatnya korelasi antara nilai Net Profit Margin dengan nilai Return on Investment
(diatas 0,5), sedangkan tanda (+) menunjukkan arah hubungan yang sama atau searah, yaitu semakin tinggi nilai Net Profit Margin maka akan membuat nilai
Return on Investment semakin tinggi juga dan sebaliknya.
Korelasi antara dua faktor adalah signifikan karena angka signifikan 0,000 > 0,05.
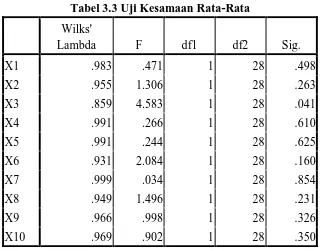
Dari hasil uji kesamaan rata-rata terlihat hanya satu variabel yang sama (equal) karena mempunyai nilai p < 0,05 yaitu X1 sehingga hanya rasio ini yang masuk ke dalam
[image:44.595.156.477.398.649.2]analisis selanjutnya.
Tabel 3.3 Uji Kesamaan Rata-Rata Wilks'
Lambda F df1 df2 Sig.
X1 .983 .471 1 28 .498
X2 .955 1.306 1 28 .263
X3 .859 4.583 1 28 .041
X4 .991 .266 1 28 .610
X5 .991 .244 1 28 .625
X6 .931 2.084 1 28 .160
X7 .999 .034 1 28 .854
X8 .949 1.496 1 28 .231
X9 .966 .998 1 28 .326
Tabel 3.4 Hasil Output Uji Kesamaan Matriks Kovarian
[image:45.595.225.407.393.516.2]Sama tidaknya grup matriks kovarian juga dapat dilihat dari tabel output log determinan pada tabel Box`s M. Dari hasil output diatas dapat dilihat bahwa angka log determinan untuk kelompok tidak sehat (-1,396) dan sehat (-1,780) tidak memiliki banyak perbedaan sehingga dapat dikatakan bahwa grup matriks kovarian akan relatif sama untuk kedua kelompok.
Tabel 3.5 Hasil Uji Box`s M
Box's M .515
F Approx. .497
df1 1
df2 2352.000
Sig. .481
Dari hasil uji equality antara grup matriks kovarian terlihat bahwa nilai p pada Box`s M > 0,05 (0,481). Dengan demikian data diatas sudah memenuhi asumsi equality.
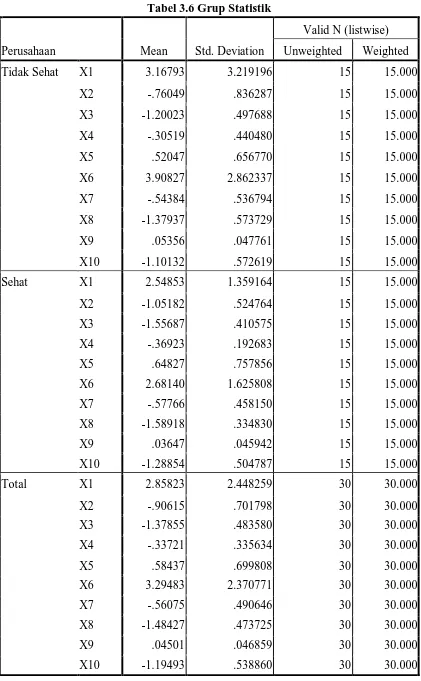
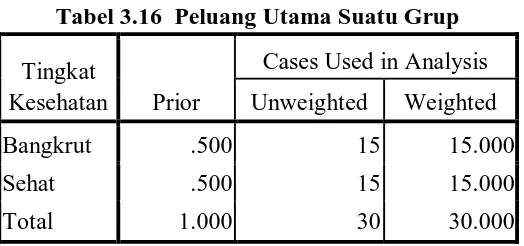
Tabel grup statistik pada dasarnya terdiri dari data statistik deskriptif yang utama, yaitu rata-rata dan standard deviasi dari kedua grup. Dari tabel 3.6 grup statistik terlihat bahwa ada 15 Perusahaan yang bangkrut dan ada 15 perusahaan yang sehat dan total seluruh perusahaan adalah 15 + 15 = 30 perusahaan.
Log Determinant
Perusahaan Rank
Log Determinant
Tidak Sehat 1 -1.396
Sehat 1 -1.780
Tabel 3.6 Grup Statistik
Perusahaan Mean Std. Deviation
Valid N (listwise) Unweighted Weighted
Tidak Sehat X1 3.16793 3.219196 15 15.000
X2 -.76049 .836287 15 15.000
X3 -1.20023 .497688 15 15.000
X4 -.30519 .440480 15 15.000
X5 .52047 .656770 15 15.000
X6 3.90827 2.862337 15 15.000
X7 -.54384 .536794 15 15.000
X8 -1.37937 .573729 15 15.000
X9 .05356 .047761 15 15.000
X10 -1.10132 .572619 15 15.000
Sehat X1 2.54853 1.359164 15 15.000
X2 -1.05182 .524764 15 15.000
X3 -1.55687 .410575 15 15.000
X4 -.36923 .192683 15 15.000
X5 .64827 .757856 15 15.000
X6 2.68140 1.625808 15 15.000
X7 -.57766 .458150 15 15.000
X8 -1.58918 .334830 15 15.000
X9 .03647 .045942 15 15.000
X10 -1.28854 .504787 15 15.000
Total X1 2.85823 2.448259 30 30.000
X2 -.90615 .701798 30 30.000
X3 -1.37855 .483580 30 30.000
X4 -.33721 .335634 30 30.000
X5 .58437 .699808 30 30.000
X6 3.29483 2.370771 30 30.000
X7 -.56075 .490646 30 30.000
X8 -1.48427 .473725 30 30.000
X9 .04501 .046859 30 30.000
Dapat diketahui bahwa penilaian tingkat kesehatan perusahaan terhadap faktor yang telah ditentukan. Penilaian ini berdasarkan perbandingan rata-rata (mean) tiap variabel untuk grup “bangkrut” dan “sehat”. Semakin besar koefisien semakin bagus pula perusahaan menilai rasio keuangan. Pada rasio keuangan current ratio (X1) misalnya,
nilai mean untuk grup tidak sehat (3,16793) lebih tinggi daripada nilai mean grup sehat (2,85823). Hal ini berarti bahwa perusahaan yang memiliki catatan laporan keuangan dimana current ratio nya bernilai tinggi (menjauhi nol) maka akan menjadiu salah satu rasio keuangan yang memberi dampak kurang baik terhadap kesehatan perusahaan.
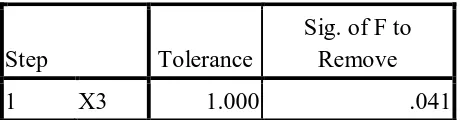
[image:47.595.110.525.371.475.2]Tabel Variabel Entered dari analisis 1 (Stepwise Statistik) menunjukkan rasio keuangan apa saja yang Mauk ke dalam fungsi diskriminan, dimana nilai p < 0,05.
Tabel 3.7 Variabel dimasukkan/dibuanga,b,c,d
Step Entered
Min. D Squared
Statistic
Between Groups
Exact F
Statistic df1 df2 Sig.
1 X3 .611 Tidak Sehat
and Sehat
4.583 1 28.000 .041
Pada langkah masing-masing variabel yang memaksimumkan jarak mahalanobis antara dua grup tertutup yang
dimasukkan.
a. Banyaknya langkah maksimum adalah 20.
b. Nilai signifikan maksimum adalah 0,05.
c. Nilai signifikan minimum adalah 0,10.
d. Toleransi F atau VIN tidak cukup untuk perhitungan selanjutnya.
[image:47.595.202.432.694.754.2]Karena menggunakan metode Stepwise Discrimina nt Analysis dan dapat dilihat langkah-langkah pemilihan rasio keuangan yang masuk ke dalam fungsi diskriminan seperti pada tabel pada variabel dalam analisis berikut:
Tabel 3.8 Variabel Masuk dalam Analisis
Step Tolerance
Sig. of F to Remove
a). Pada tahap pertama, rasio keuangan Earning Before Interest and Taxes to Total Assets (X3) masuk ke dalam fungsi diskriminan karena hanya rasio tersebut yang
[image:48.595.118.511.194.652.2]memiliki nilai p < 0,05 (0,041).
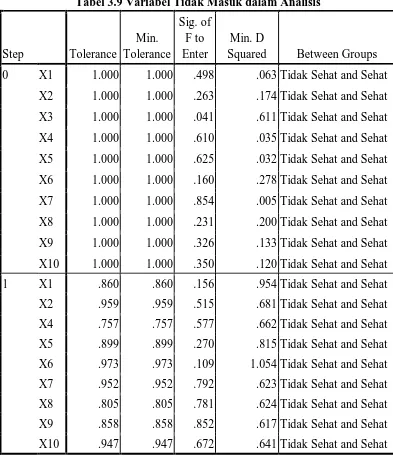
Tabel 3.9 Variabel Tidak Masuk dalam Analisis
Step Tolerance
Min. Tolerance
Sig. of F to Enter
Min. D
Squared Between Groups 0 X1 1.000 1.000 .498 .063 Tidak Sehat and Sehat
X2 1.000 1.000 .263 .174 Tidak Sehat and Sehat X3 1.000 1.000 .041 .611 Tidak Sehat and Sehat X4 1.000 1.000 .610 .035 Tidak Sehat and Sehat X5 1.000 1.000 .625 .032 Tidak Sehat and Sehat X6 1.000 1.000 .160 .278 Tidak Sehat and Sehat X7 1.000 1.000 .854 .005 Tidak Sehat and Sehat X8 1.000 1.000 .231 .200 Tidak Sehat and Sehat X9 1.000 1.000 .326 .133 Tidak Sehat and Sehat X10 1.000 1.000 .350 .120 Tidak Sehat and Sehat 1 X1 .860 .860 .156 .954 Tidak Sehat and Sehat X2 .959 .959 .515 .681 Tidak Sehat and Sehat X4 .757 .757 .577 .662 Tidak Sehat and Sehat X5 .899 .899 .270 .815 Tidak Sehat and Sehat X6 .973 .973 .109 1.054 Tidak Sehat and Sehat X7 .952 .952 .792 .623 Tidak Sehat and Sehat X8 .805 .805 .781 .624 Tidak Sehat and Sehat X9 .858 .858 .852 .617 Tidak Sehat and Sehat X10 .947 .947 .672 .641 Tidak Sehat and Sehat
paling kecil. Rasio yang tersisa pada tahap akhir adalah rasio yang tidak masuk dalam fungsi diskriminan karena nilai p > 0,05.
[image:49.595.157.478.190.265.2]b). Nilai Eigen
Tabel 3.10 Nilai Eigen Functi
on Eigenvalue
% of
Variance Cumulative %
Canonical Correlation
1 .164a 100.0 100.0 .375
Nilai eigen menunjukkan perbandingan varians antarkelompok dengan varians dalam kelompok. Semakin besar nilai eigenvalue berarti semakin besar fungsi diskriminan. Selain itu terlihat bahwa fungsi diskriminan menjelaskan 100% dari total varians..
c). Uji Signifikan
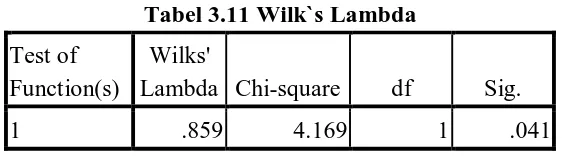
Untuk mengetahui nilai signifikansi dari fungsi diskriminan yang terbentuk, dilihat dari Wilk`s Lambda pada Summary of Canonical Discriminant Function.
Tabel 3.11 Wilk`s Lambda Test of
Function(s)
Wilks'
Lambda Chi-square df Sig.
1 .859 4.169 1 .041
Dari output diatas terlihat bahwa hasil signifikansi dari uji Wilk`s Lambda < 0,05 (0,041). Angka ini kemudian ditransformasi menjadi chi-square dengan derajat kebebasan (df) sebesar 1. Nilai chi-square adah dengan nilai 4,169. Maka dapat disimpulkan bahwa cukup bukti untuk menolak H0 dengan tingkat kesalahan 0,041
[image:49.595.176.458.474.552.2]Tabel 3.12 Koefisien Fungsi Diskriminan Kanonikal
Function 1
X3 1.000
[image:50.595.211.420.154.220.2]Pada tabel diatas akan diperlihatkan rasio mana yang menjadi stronger discriminant factor. Terlihat bahwa rasio Earning Before Interest and taxes to total assets (X3) merupakan stronger discriminant factor.
Tabel 3.13 Struktur Matriks Function
1
X3 1.000
X4a .493
X8a .442
X9a .377
X1a -.374
X5a .318
X10a .230
X7a .220
X2a .203
X6a -.166
[image:50.595.211.422.343.592.2]d). Koefisien Fungsi Diskriminan Kanonik
[image:51.595.172.458.196.279.2]Kegunaan fungsi ini untuk mengetahui sebuah kasus (dalam kasus ini adalah sebuah perusahaan) masuk ke dalam kelompok yang satu atau ke kelompok yang lainnya.
Tabel 3.14 Koefisien Fungsi Diskriminan Kanonik
Function 1
X3 2.192
(Constant) 3.022
Dengan menggunakan koefisien fungsi diskriminan kanonik maka dapat dibentuk fungsi diskriminan, yaitu:
D = 3,022 + 2,192X3
e). Fungsi pada grup terpusat, memperlihatkan nilai rata-rata tiap kelompok. Oleh karena ada dua tipe tingkat kesehatan perusahaan maka dikatakan Two Group Discriminant, Grup yang satu memiliki centroid (group means) positif (0,391) dan grup yang lain memiliki centroid negatif (-0,391).
Tabel 3.15 Fungsi pada Grup Terpusat
Perusahaan
Function 1
Tidak Sehat .391
Sehat -.391
[image:51.595.187.446.537.630.2]Gambar



Dokumen terkait
Metode penelitian ini adalah kuantitatif. Sampel pada penelitian ini adalah 26 informan. Teknik pengumpulan data menggunakan kuesioner, observasi, dan
1) Programming learning platform helps the students to learn basic java programming by using heuristic method where the students have to solve all of the problems that the
Telah dapat dibuat suatu aplikasi untuk simulasi tata-letak departemen berorientasi proses sebagai bagian dari sistem informasi manufaktur yang memiliki kemampuan untuk
[r]
Dengan demikian kami Panitia mengumumkan bahwa Pemenang Lelang Pengadaan Asuransi Pemeliharaan Kesehatan Anggota DPRD Kota jambi Tahun 2012 sebagai berikut :.. Calon Pemenang
Berdasarkan hasil penelitian terdahulu yang berkaitan dengan pengaruh rasio keuangan terutama current ratio, debt to equity ratio, return on asset, total asset turnover
“K egiatan mahasiswa baru diawali dengan pengenalan kultur akademik Fakultas Teknik UNY sehingga diharapkan para mahasiswa baru dapat me mahami cara belajar pada level
DAFTAR PENERIMA MAJALAH TRIBRATA NEWS POLDA SULTRA SATKER POLRES KONAWE SELATAN TAHUN 2016.. NO NAMA PANGKAT JABATAN
