PENGENALAN POLA SECARA STATISTIKA DENGAN
PENDEKATAN MODEL DINAMIS AUTOREGRESIVE DAN
DISTRIBUSI LAG
SKRIPSI
HENDRA ANDY MULIA PANJAITAN
090823069
KEMENTRIAN PENDIDIKAN NASIONAL DAN KEBUDAYAAN
UNIVERSITAS SUMATERA UTARA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
DEPARTEMEN MATEMATIKA
PENGENALAN POLA SECARA STATISTIKA DENGAN
PENDEKATAN MODEL DINAMIS AUTOREGRESIVE DAN
DISTRIBUSI LAG
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
HENDRA ANDY MULIA PANJAITAN
090823069
KEMENTRIAN PENDIDIKAN NASIONAL DAN KEBUDAYAAN
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : PENGENALAN POLA SECARA STATISTIKA
DENGAN PENDEKATAN MODEL DINAMIS AUTOREGRESIVE DAN DISTRIBUSI LAG
Kategori : SKRIPSI
Nama : HENDRA ANDY MULIA PANJAITAN
Nomor Induk Mahasiswa : 090823069
Program Studi : S1 STATISTIKA EKSTENSI
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (MIPA) UNIVERSITAS SUMATERAUTARA
Diluluskan di
Medan, Agustus 2013
Komisi Pembimbing :
Pembimbing 2, Pembimbing 1,
Drs Djakaria Sebayang, M.Si Drs. H.Haluddin Panjaitan
NIP. 19511227 198503 1 002 NIP. 19460309 197902 1 001
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU
Prof. Dr. Tulus, M.Si
PERNYATAAN
PENGENALAN POLA SECARA STATISTIKA DENGAN
PENDEKATAN MODEL DINAMIS AUTOREGRESIVE DAN
DISTRIBUSI LAG
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Agustus 2013
ii
PERSETUJUAN
Judul : STUDI PENENTUAN PRIORITAS
PENGEMBANGAN PARIWISATA PROPINSI
SUMATERA UTARA DENGANFUZZY-
ANALYTICALHIERARCHY PROCESS
Kategori : SKRIPSI
Nama : ANDRI CANDRA SIAHAAN
NomorIndukMahasiswa : 090823039
Program Studi : SARJANA (S1) MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PERNGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Agustus 2013 KomisiPembimbing :
Pembimbing 2 Pembimbing 1
Drs, RachmadSitepu, M.Si Drs. PasukatSembiring, M.Si
NIP. 195304181987031001 NIP. 19531113 1985031002
Diketahui / DisetujuiOleh
DepartemenMatematika FMIPA USU Ketua,
iii
PERNYATAAN
STUDI PENENTUAN PRIORITAS PENGEMBANGAN PARIWISATA
PROPINSI SUMATERA UTARA DENGAN FUZZY-ANALYTICAL
HIERARCHY PROCESS
SKRIPSI
Sayamengakuibahwaskripsiiniadalahhasilkerjasayasendiri,
kecualibeberapakutipandanringkasan yang masing-masingdisebutkansumbernya.
Medan, Agustus 2013
iv
PENGHARGAAN
PujidansyukurpenulispanjatkankepadaTuhan Yang MahaEsa, atassegalaberkatdankasihkarunia-Nya, penulisberhasilmenyelesaikanskripsiinidalamwaktu
yang telahditetapkan.
Melaluipenghargaanini, sayainginmenyampaikan rasa terimakasih yang paling tulusdansebesar-besarnyakepada :
1. BapakDrs. PasukatSembiring, M.Siselakupembimbing I danBapakDrs. RachmadSitepu, M.Siselakupembimbing II saya, yang telahmemberikanwaktu, panduanpemikirandantenagasertapenuhkepercayaankepadasayadalammenyelesaikanskrips iini.
2. Bapak Prof. Dr. Tulus, M.SiselakuKetuaDepartemenMatematikadanBapak Drs. PengarapenBangun, M.SiselakuKoordinatorEkstensiMatematika FMIPA USU.
3. Bapak Drs. PengarapenBangun, M.SidanBapakDrs. GimTarigan, M.Siselakudosenpembandingsaya, yang telahmemberikan saran maupunmasukan demi kesempurnaanskripsiini.
4. SeluruhStafPengajarMatematikasertaStafPegawaiAdministrasi di FMIPA USU.
5. Orang tuatercinta Aristan Br Lumban Gaolatassegalakasihsayang, doadandukungan moral danmaterilselamaperkuliahansampaiselesainyaskripsiini.
6. Adik-adik saya Elisa Putri, Michael, Listhon Albertho, Juan Carlos dan orang yang saya kasihi Ruth DJ Pakpahanyang selamainimemberikandukungan, semangatdandoabagisaya.
7. Semuateman-temanmahasiswaEkstensiMatematikaStatistika 09 yang telahmembantudalamkelancaranskripsiini.
8. Dan semuapihak yang telahmembantudalam proses penyelesaianskripsiinibaiksecaralangsungmaupuntidaklangsung.
SemogaTuhan Yang MahaEsa yang akanselalumembalaskebaikankalian
semua yang telahberbuatbanyakuntuksayadanberkat-NYA yang
akanselalumelimpahihidupkita.
v
ABSTRAK
Fuzzy-Analytical Hirearchi ProcessmerupakanpenggabunganantarametodeAnalytical
Hirearchi Processdenganpendekatanfuzzy.DimanapadametodefuzzyAnalytical
Hirearchi ProcessdigunakanTriangular Fuzzy Number (TFN), untukmenggantikan
“tabelskalaSaaty” padaAnalytical Hirearchi Process.Triangular Fuzzy Numberinilah
yang membuatpengambilankeputusan multi kriteria yang
biasadiselesaikandenganAnalytical Hirearchi
Processakandiselesaikandenganpendekatanfuzzy dimanaTriangular Fuzzy
Numbertersebut yang
digunakanuntukmenggambarkanvariabel-variabellinguistikdanmemberikannilai yang
pastidalammatriksperbandinganberpasangan. Triangular Fuzzy
Numberdisimbolkandengan��= (�,�,�), dimana� ≤ � ≤ � dan � adalah nilai
terendah, � adalah nilai tengah, � adalah nilai teratas. Pada penerapannya, metode
Fuzzy AHP digunakanpada data simulasi yang
sudahdisusundalammatriksperbandinganberpasangandalampenentuanprioritaspengem
banganpariwisatapropinsisumaterautara.Beberapalangkahdalampenentuanprioritasnya
denganmenggunakanFuzzy AHP yaitumendefinisikannilaifuzzy synthetic extent
untuki-objek, menentukantingkatkeyakinandaribilanganfuzzy(��1dan ��2),
menentukanvektorbobot (�′), kemudian yang
terakhirvektorbobottersebutakandinormalkankembalisehingga� bukan lagi
vi
ABSTRACT
Fuzzy-Analytical Process Hirearchi a merger between Hirearchi Process Analytical
method with fuzzy approach. Where the fuzzy Analytical methods used Hirearchi
Process Triangular Fuzzy Number (TFN), to replace "table Saaty scale" on Hirearchi
Analytical Process. Triangular Fuzzy Number is what makes multi-criteria decision
making commonly solved by Hirearchi Analytical Process will be completed by fuzzy
approach where the Triangular Fuzzy Number is used to describe the linguistic
variables and give an exact value in the pairwise comparison matrix. Triangular Fuzzy
Number symbolized by, where and is the lowest value, is the middle value, is the top
value. In practice, Fuzzy AHP method used in the simulation data that has been
compiled in a pairwise comparison matrix in the prioritization of the development of
tourism in North Sumatra province. Some steps in the determination of priorities by
using Fuzzy AHP is to define the value of fuzzy synthetic extent for the i-object,
determine the level of confidence of fuzzy numbers (and), determine the weight vector
(), then the final weight vector will be normalized so that the number is no longer a
vii
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan ` iv
Abstrak v
Abstract vi
Daftar Isi vii
DaftarTabel ix
DaftarGambar x
BAB 1 PENDAHULUAN 1
1.1 LatarBelakang 1
1.2 PerumusanMasalah 3
1.3 BatasanMasalah 3
1.4TinjaunanPustaka 3
1.5 TujuanPenelitian 4
1.6 ManfaatPenelitian 4
1.7MetodologiPenelitian 4
BAB 2 LANDASAN TEORI 6
2.1 KawasanPengembanganPariwisataNasional 6
2.2 Analytical Hierarchy Process (AHP) 8
2.2.1Prinsipdasar AHP 9
2.2.2PenghitunganBobotElemendalamMetode AHP 11
2.3TeoriHimpunanFuzzy 14
2.3.1HimpunaKlasik(Crisp) 15
2.3.2HimpunanKabur 15
2.4Fuzzy AHP 18
viii
BAB 3 PEMBAHASAN 23
3.1 Data KawasanPengembanganPariwisataNasionaldi Sumatera Utara 23
3.2 PembobotanTiapAlternatifTerhadapKriteria Dana 26
3.3 PembobotanTiapAlternatifTerhadapKriteriaManfaat 27
3.4PembobotanTiapAlternatifTerhadapKriteriaWaktu 27
3.5PembobotanTiapAlternatifTerhadapKriteria Target 28
3.6Total BobotPrioritas 30
BAB 4 KESIMPULAN DAN SARAN 31
4.1 Kesimpulan 31
4.2 Saran 32
DAFTAR PUSTAKA 33
LAMPIRAN 34
LampiranA :PerhitunganPembobotanTiapAlternatifTerhadapKriteria Dana 34
LampiranB :PerhitunganPembobotanTiapAlternatifTerhadapKriteriaManfaat 36
LampiranC :PerhitunganPembobotanTiapAlternatifTerhadapKriteriaWaktu 38
ix
DAFTAR TABEL
Halaman
Tabel 2.1 SkalaSaaty (Mulyono,2004) 11
Tabel 2.2 MatriksPerbandinganBerpasangan 12
Tabel 2.3 Index Random (RI) 14
Tabel 2.4 FungsiKeanggotaanBilanganFuzzy (Fuzzy Membership Function)
19Tabel 3.1 MatriksPerbandinganBerpasanganFuzzyuntukSemuaKriteria
23
Tabel 3.2 MatriksPerbandinganBerpasanganFuzzyuntukSemuaKriteria
yangDisederhanakan 24
Tabel 3.3 MatriksPerbandinganBerpasanganFuzzyuntukKriteria Dana 26
Tabel 3.4 MatriksPerbandinganBerpasanganFuzzyuntukKriteriaManfaat 27
Tabel 3.5 MatriksPerbandinganBerpasanganFuzzyuntukKriteriaWaktu 28
x
DAFTAR GAMBAR
Halaman
Gambar 2.1 StrukturHirarki 10
Gambar 2.2 Representasi Linear Naik 17
Gambar 2.3 Representasi Linear Turun 17
Gambar 2.4 FungsiKeanggotaanSegitiga 18
Gambar 2.5 FungsiKeanggotaanTrapesium 18
xi
DAFTAR ISI
HalamanH
ALAMAN JUDUL ...
iH
ALAMAN PERSETUJUAN ...
iiH
ALAMAN PERNYATAAN...
iii
HALAMAN PENGESAHAN... iv
PERSEMBAHAN ... viA BSTRAK ... vii
ABSTRACT... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... x
DAFTAR SIMBOL ... xiii DAFTAR GAMBAR ... xiv
DAFTAR TABEL ... xv
DAFTAR LAMPIRAN... xvi
BABI PENDAHULUAN 1.1. LatarBelakang Masalah... 1
1.2. RumusanMasalah... 3
1.3. Batasan Masalah ... 4
1.4. Tinjauan Pustaka... 4
1.5. Tujuan Penulisan ... 6
1.6. Manfaat Penulisan... 6
xiii
BABII LANDASAN TEORI
2.1. Data... 8
1. Data Berkala(Time Series) ... 8
2. Data SeleksiSilang(Cross Section) ... 8
2.2. Variansi Populasi... 8
2.3. Matriks... 9
1. DefinisiMatriks... 9
2. TransposeMatriks... 9
3. InversMatriks... 10
4. OperasiMatriks... 11
1. RegresiLinear Sederhana... 13
2. RegresiLinear Berganda... 14
1. Koefisien Determinasi... 15
2. Koefisien Korelasi... 16
2.6. MetodeKuadratTerkecil(Least Square Method) ... 17
2.7. KesalahanStandarEstimasi... 23
2.8. AsumsiKlasik... 24
2.9. PenyimpanganAsumsiKlasik... 25
BABIII PEMBAHASAN 3.1.. Metode-MetodedalamMenentukanPersamaanDinamisDistribusi LagDugaan... 28
1. MetodeKoyck... 28
3.2. Metode-Metode dalam Menentukan Persamaan Dinamis Autoregressive Dugaan... 31
BABIV PENUTUP
4.1. Kesimpulan... 45
4.2. Saran... 47
DAFTAR PUSTAKA ... 48
xv
DAFTAR SIMBOL
σ2
:variansipopulasi
µ :rata-rata hitunguntukpopulasi
N : banyaknya data pengamatan
Y : variabeltakbebas
X : variabelbebas
α :intersep
β :koefisienregresi /slope
ε :kesalahanpengganggu
n : ukuranpopulasi
r2 :koefisiendeterminasi
r : koefisenkorelasi
ei :taksirandarifaktorgangguanεi
X' : transpose darimatriksX
βˆ : penaksirkoefisienregresi
Se :kesalahanstandarestimasi(standarerrorofestimate)
C :rata-ratatingkatpenurunandaridistribusilag
DAFTAR GAMBAR
Gambar 2.1 MetodeKuadratTerkecil... 21
xvii
DAFTAR TABEL
Tabel3.1 PembelianPerlengkapandanPenjualan... 37
Tabel3.2 PembelianPerlengkapandanPenjualanSetelahdimasukkanVaria
belLag... 38
Tabel3.3. PendapatanNasionaldanInvestasi... 41
DAFTAR LAMPIRAN
Lampiran 1 OutputEviewsmetodeKoyck... 47
DAFTAR SIMBOL
σ2
: variansipopulasi
µ : rata-rata hitunguntukpopulasi
N : banyaknya data pengamatan
Y : variabeltakbebas
X : variabelbebas
α : intersep
β : koefisienregresi /slope
ε : kesalahanpengganggu
n : ukuranpopulasi
r2 : koefisiendeterminasi
r : koefisenkorelasi
ei : taksirandarifaktorgangguanεi
X' : transpose darimatriksX
βˆ : penaksirkoefisienregresi
Se : kesalahanstandarestimasi(standarerrorofestimate)
C :rata-ratatingkatpenurunandaridistribusilag
v
ABSTRAK
Fuzzy-Analytical Hirearchi ProcessmerupakanpenggabunganantarametodeAnalytical
Hirearchi Processdenganpendekatanfuzzy.DimanapadametodefuzzyAnalytical
Hirearchi ProcessdigunakanTriangular Fuzzy Number (TFN), untukmenggantikan
“tabelskalaSaaty” padaAnalytical Hirearchi Process.Triangular Fuzzy Numberinilah
yang membuatpengambilankeputusan multi kriteria yang
biasadiselesaikandenganAnalytical Hirearchi
Processakandiselesaikandenganpendekatanfuzzy dimanaTriangular Fuzzy
Numbertersebut yang
digunakanuntukmenggambarkanvariabel-variabellinguistikdanmemberikannilai yang
pastidalammatriksperbandinganberpasangan. Triangular Fuzzy
Numberdisimbolkandengan��= (�,�,�), dimana� ≤ � ≤ � dan � adalah nilai
terendah, � adalah nilai tengah, � adalah nilai teratas. Pada penerapannya, metode
Fuzzy AHP digunakanpada data simulasi yang
sudahdisusundalammatriksperbandinganberpasangandalampenentuanprioritaspengem
banganpariwisatapropinsisumaterautara.Beberapalangkahdalampenentuanprioritasnya
denganmenggunakanFuzzy AHP yaitumendefinisikannilaifuzzy synthetic extent
untuki-objek, menentukantingkatkeyakinandaribilanganfuzzy(��1dan ��2),
menentukanvektorbobot (�′), kemudian yang
terakhirvektorbobottersebutakandinormalkankembalisehingga� bukan lagi
vi
ABSTRACT
Fuzzy-Analytical Process Hirearchi a merger between Hirearchi Process Analytical
method with fuzzy approach. Where the fuzzy Analytical methods used Hirearchi
Process Triangular Fuzzy Number (TFN), to replace "table Saaty scale" on Hirearchi
Analytical Process. Triangular Fuzzy Number is what makes multi-criteria decision
making commonly solved by Hirearchi Analytical Process will be completed by fuzzy
approach where the Triangular Fuzzy Number is used to describe the linguistic
variables and give an exact value in the pairwise comparison matrix. Triangular Fuzzy
Number symbolized by, where and is the lowest value, is the middle value, is the top
value. In practice, Fuzzy AHP method used in the simulation data that has been
compiled in a pairwise comparison matrix in the prioritization of the development of
tourism in North Sumatra province. Some steps in the determination of priorities by
using Fuzzy AHP is to define the value of fuzzy synthetic extent for the i-object,
determine the level of confidence of fuzzy numbers (and), determine the weight vector
(), then the final weight vector will be normalized so that the number is no longer a
BAB I
PENDAHULUAN
1.1. Latar Belakang Masalah
Statistik sebagai alat perencanaan, monitoring dan evaluasi hasil suatu
kegiatan atau pembangunan sudah sangat memasyarakat di berbagai lapisan. Produk
Badan Pusat Statistik (BPS) seperti angka inflasi, pertumbuhan ekonomi, tingkat
kemiskinan, angka pengangguran, produksi pertanian/industri, harga bahan pokok,
dan banyak lagi selalu digunakan banyak pihak untuk menilai kinerja Pemerintah
atau sebagai bahan referensi kegiatannya sendiri. Sehingga catatan data masa lalu
(historical fact) menjadi bahan diskusi yang menarik untuk diperdebatkan, bahkan tak
jarang menyentuh validitas data tersebut. Apapun hasil proses deskriftif untuk
mengagregasi data masa lalu, informasi tentang apa yang sudah terjadi dapat menjadi
bahan acuan ke depan. Sebagai manusia, kita secara sadar atau tidak, selalu berusaha
memperkirakan apa yang akan terjadi di masa datang. Disiplin statistik memang
menyediakan alat untuk melihat situasi ke depan, yang paling terkenal tentu saja
adalah analisis regresi dan proyeksi sedangkan yang baru mulai digandrungi adalah
analisis deret waktu (time series analysis)..
Penganalisaan runtun waktu dahulu menjadi pertentangan antara dua
kelompok ahli yaitu para ekonometrika dan para ahli runtun waktu. Para ahli
2
memformulasikan model regresi klasik untuk menganalisa perilaku data runtun
waktu, menganalisa tentang masalah simultanitas, dan kesalahan autokorelasi.
Sebaliknya, ahli runtun waktu membuat model perilaku runtun waktu dengan
mekanisme sendiri serta tidak begitu memperhatikan peranan variabel bebas X dan
variabel bebas Y. berdasarkan pendapat ini membuat para ahli ekonometrika ulang
pendekatannya terutama dalam menganalisis runtun waktu.
Ekonometrika merupakan suatu ilmu yang menganalisis fenomena ekonomi
dengan menggunakan teori ekonomi, matematika, dan statistika, yang berarti teori
ekonomi tersebut dirumuskan melalui hubungan matematika kemudian diterapkan
pada suatu data untuk dianalisis menggunakan metode statistika (Awat, 1995 : 3).
Hal yang banyak mendapat perhatian dalam ekonometrika adalah kesalahan
pengguna terutama dalam membuat perkiraan atau estimasi. Model ekonometrika
yang digunakan untuk mengukur hubungan antara variabel-variabel dapat dinyatakan
dalam bentuk model regresi linear. Model regresi linear merupakan salah satu
model ekonometrika yang berhubungan antar variabelnya satu arah, yang berarti
variabel tak bebas ditentukan oleh variabel bebas (Sumodiningrat, 1995 : 135).
Hubungan antara satu variabel bebas X dengan variabel bebas Y dapat dimodelkan
dengan Y = α + β X + ε atau beberapa variabel bebas X terhadap variabel tak bebas
Y dapat dimodelkan dengan :
Y = β0 + β1 Xi1 + β2 Xi2 + β3 Xi3 + …… + βn Xin + ε
Pada skripsi ini akan dibahas tentang model regresi linear yang
3
kurang memperhatikan waktu. Data yang digunakan adalah data runtun waktu (time
series). Model regresi dengan menggunakan rata runtun waktu tidak hanya
menggunakan pengaruh perubahan variabel bebas terhadap variabel tak bebas dalam
kurun waktu yang sama dan selama periode pengamatan yang sama, tetapi juga
menggunakan periode waktu sebelumnya. Waktu yang diperlukan bagi variabel
bebas X dalam mempengaruhi variabel tak bebas Y disebut beda kala atau lag
(Supranto, 1995 : 188).
Metode-metode yang digunakan dalam menentukan persamaan distribusi lag
dugaan antara lain metode Koyck, metode Almon, metode Jorgenson dan metode
Pascal. Pada skripsi ini hanya akan dibahas metode Koyck .
Keistimewaan dari model dinamis autoregressive dan model dinamis
distribusi lag adalah model tersebut telah membuat teori statis menjadi dinamis
karena model regresi yang biasanya mengabaikan pengaruh waktu, melalui model
autoregressive dan model dinamis distribusi lag waktu ikut diperhitungkan
(Supranto, 1995 : 200). Oleh karena itu, model autoregressive dan model dinamis
distirbusi lag sering disebut satu rangkaian dengan nama “Model Dinamis :
autoregressive dan Distribusi Lag”.
1.2.Rumusan Masalah
Berdasarkan latar belakang, penulis dapat mengemukakan rumusan masalah
4
1. Bagaimana menentukan persamaan dinamis distribusi lag dugaan dengan metode
Koyck .
2. Bagaimana menentukan persamaan dinamis autoregressive dugaan dan
mendeteksi autokorelasi dengan statistik h Durbin-Watson?
3. Bagaimana aplikasi model dinamis : autoregressive dan distribusi lag ?
1.3.Batasan Masalah
Pada skripsi ini akan dibahas tentang model regresi linear yang
memperhitungkan pengaruh waktu, karena kebanyakan dari model regresi linear
kurang memperhatikan waktu. Data yang digunakan adalah data runtun waktu (time
series). Model regresi dengan menggunakan rata runtun waktu tidak hanya
menggunakan pengaruh perubahan variabel bebas terhadap variabel tak bebas dalam
kurun waktu yang sama dan selama periode pengamatan yang sama, tetapi juga
menggunakan periode waktu sebelumnya. Waktu yang diperlukan bagi variabel
bebas X dalam mempengaruhi variabel tak bebas Y disebut beda kala atau lag.
1.4.Tinjauan Pustaka
Runtun waktu merupakan serangkaian pengamatan terhadap suatu peristiwa,
kejadian, yang diambil dari waktu ke waktu, serta dicatat secara teliti berdasarkan
urutan waktu, kemudian disusun sebagai data statistik. Analisis runtun waktu
merupakan analisis sekumpulan data dalam suatu periode waktu yang lampau yang
5
didasarkan bahwa perilaku manusia banyak dipengaruhi kondisi atau waktu
sebelumnya sehingga dalam hal ini faktor waktu sangat penting peranannya (Gurajati,
1995 : 5).
Ekonometrika merupakan suatu ilmu yang menganalisis fenomena ekonomi
dengan menggunakan teori ekonomi, matematika, dan statistika, yang berarti teori
ekonomi tersebut dirumuskan melalui hubungan matematika kemudian diterapkan
pada suatu data untuk dianalisis menggunakan metode statistika (Awat, 1995 : 3).
Model regresi dengan menggunakan rata runtun waktu tidak hanya
menggunakan pengaruh perubahan variabel bebas terhadap variabel tak bebas dalam
kurun waktu yang sama dan selama periode pengamatan yang sama, tetapi juga
menggunakan periode waktu sebelumnya. Waktu yang diperlukan bagi variabel
bebas X dalam mempengaruhi variabel tak bebas Y disebut beda kala atau lag
(Supranto, 1995 : 188).
Model regresi yang memuat variabel tak bebas yang dipengaruhi oleh
variabel bebas pada waktu t, serta dipengaruhi juga oleh variabel bebas pada waktu
t – 1, t – 2 dan seterusnya disebut model dinamis distribusi lag, sebab pengaruh
dari suatu atau beberapa variabel bebas X terhadap variabel tak bebas Y menyebar
(spread or distributed) ke beberapa periode waktu dengan Y1 = α + β0 Xt + β1 Xt-1
+ β2 Xt-2 +…… + εi. Model regresi yang memuat variabel tak bebas yang
dipengaruhi oleh variabel bebas pada waktu t, serta dipengaruhi juga oleh variabel
6
1.5.Tujuan Penulisan
Tujuan penulisan skripsi ini adalah :
1. Menjelaskan tentang metode Koyck dan uji statistik h Durbin-Watson dalam
menentukan persamaan dinamis : autoregressive dan distribusi lag dugaan.
2. Menjelaskan tentang aplikasi model dinamis autoregressive dan distribusi lag.
1.6.Manfaat Penulisan
Berdasarkan rumusan masalah dan tujuan penulisan yang telah dikemukakan,
maka manfaat penulisan skripsi ini adalah :
1. Bagi Penulis
Dengan mengetahui cara menentukan persamaan dinamis : autoregressive dan
distribusi lag, diharapkan dapat menambah pengetahuan tentang analisis regresi
beserta aplikasinya.
2. Bagi Ilmu Pengetahuan
Penulisan ini dapat dijadikan salah satu referensi bagi pihak yang
berkepentingan terutama dalam pengembangan analisis regresi.
1.7. Metodelogi Penelitian
Metodologi penelitian yang digunakan dalam skirpsi adalah dengan langkah-langkah
sebagai berikut:
1. Melakukan studi jurnal, buku, dan artikel di internet yang berhubungan dengan
7
autoregresive dan distribusi lag
2. Mencari data yang dapat dianalisis dengan pendekatan model dinamis
autoregresive dan distribusi lag.
3. Menganalisa data dengan menggunakan Metode Koyck digunakan untuk
menentukan persamaan dinamis distribusi lag dugaan yang panjang beda kala
(lag) tidak diketahui.langkah langkah sebagai berikut :
a. Langkah pertama yang dilakukan adalah membuat persamaan Koyck yaitu :
b. Yˆt=αˆ
( )
1−Cˆ +βˆ0X1+C Yt−1c. Selanjutnya, nilai-nilai αˆ ,βˆ0,C digunakan untuk mencari nilai
k 2 1
0,ˆ ,ˆ ...ˆ ˆ
,
ˆ β β β β
α dalam persamaan distirbusi lag dugaan yang panjang
beda kala (lag) tidak diketahui.
d. Pada persamaan Koyck terdapat Yt-1
e. Namun setelah menggunakan metode Koyck perlu dilakukan uji lanjutan
dengan menggunakan uji statistik h Durbin – Watson untuk mendeteksi
autokrelasi dalam model dinamis autoregressive. Uji statistik h Durbin –
Watson perlu dilakukan karena adanya Y
sebagai variabel bebas maka bersifat
autoregressive sehingga metode Koyck juga dapat digunakan untuk
menentukan persamaan dinamis autoregressive dugaan.
t-1 sebagai variabel bebas dalam
8
BAB II
LANDASAN TEORI
2.1.Data
Data merupakan bentuk jamak dari datum. Data merupakan kumpulan
informasi yang diperoleh melalui pengamatan (Hasan, 2005 : 12). Berdasarkan
waktu pengambilannya data dibedakan menjadi 2 yaitu :
1. Data berkala (time series data)
Data berkala (time series data) adalah data yang terkumpul dari waktu ke waktu
untuk memberikan gambaran perkembangan suatu hal.
Contoh : Data perkembangan harga 9 bahan pokok selama 10 bulan terakhir yang
dikumpulkan tiap bulan.
2. Data seleksi silang (cross section data)
Data seleksi silang (cross section data) merupakan data yang terkumpul dari
suatu waktu tertentu untuk memberikan gambaran keadaan atau kegiatan pada
waktu itu.
Contoh : sensus penduduk, 2010.
2.2.Variansi Populasi
Variansi populasi adalah jumlah kuadrat selisih nilai data pengamatan
dengan rata-rata hitung dibagi dengan banyaknya data pengamatan.
(
)
2N
1 i 2
Xi N
1
∑
=
µ − =
9
Akar dari variansi populasi adalah simpangan buku populasi (σ) (Walpole,
1995 : 33)
2.3.Matriks
Pada pembahasan berikut ini akan dikaji tentang matriks, transpose matriks,
invers matriks dan operasi matriks.
1. Defenisi 2.1 matriks (Anton, 1987 : 22)
Sebuah matriks adalah susunan segi empat siku-siku dari bilangan-bilangan
disebut dengan elemen atau anggota matriks. Sebuah matriks A berukuran m x n
adalah susunan mn bilangan real(elemen matriks) di dalam tanda kurung siku dan
disusun dalam m baris dan n kolom sebagai berikut :
= mn 2 m 1 m n 2 22 21 n 1 12 11 a ... a a a ... a a a ... a a A
2. Defenisi 2.2. Transpose matrik (Anton, 1987 : 27)
Jika suatu matriks A berukuran mxn, maka matriks transpose A akan berukuran
nxm atau dengan kata lain elemen baris dari matriks Aakan menjadi elemen
kolom matriks A (baris jadi kolom).
Jika
[ ]
= 21 22 2n
n 1 12 11 ij a ... a a a ... a a a A
10
[ ]
= = mn 2 m 1 m n 2 22 21 n 1 12 11 T ij T a ... a a a ... a a a ... a a a A dimana T ija = aji, 1 ≤ I ≤ m , 1 ≤ j ≤ n.
3. Defenisi 2.3. Invers Matriks (Anton, 1987 : 34)\
Jika terdapat matriks A yang berukuran n x n dan matriks B yang berukuran
n x n sedemikian sehingga AB = BA = I maka matriks B disebut invers A. Jika
A dan B adalah matriks bujur sangkar dengan ordo yang sama dan AB = BA = 1,
maka B dikatakan invers dari A (ditulis A-1) dan A dikatakan invers dari B (ditulis
B-1
Jika A = , maka A-1 = )..
1
• Bilangan (ad-bc) disebut determinan dari matriks A =
Jika A =, maka A-1 = ad - bc
• Matriks A mempunyai invers jika Determinan A ¹ 0 dan disebut matriks non
singular.
Jika determinan A = 0 maka A disebut matriks singular.
Sifat A . A-1 = A-1 . A = I
11
Perluasan
A . B = I ® A = B-1 B = A-1
A . B = C ® A = C . B-1 B = A-1
Sifat-Sifat
. C
1. (At)t = A
2. (A + B)t = At + Bt
3. (A . B)t = Bt . At
4. (A-t)-t = A
5. (A . B)-1 = B-1 . A-1
6. A . B = C ® |A| . |B| = |C|
4. Operasi Matriks
a. Penjumlahan Dua Matriks
Jika A =
[ ]
a dan B = ij[ ]
b adalah matriks-matriks berukuran ij m x n maka A +B adalah matriks C =
[ ]
C berukuran ij m x n , dengan cij = aij + bijDiketahui :
+ 1≤ i ≤ j ≤
n.
Matriks
= 21 22 2n
n 1 12
11
a ... a a
a ... a a
A dan matriks
= 21 22 2n
n 1 12
11
b ... b b
b ... b b
12 Sehingga + + + + + + + + + = + = mn mn 2 m 2 m 1 m 1 m n 2 n 2 22 22 21 21 n 1 n 1 12 12 11 11 b a ... b a b a b a ... b a b a b a ... b a b a B A C
b. Selisih Dua Matriks
Jika A =
[ ]
a dan B = ij[ ]
b adalah matriks-matriks berukuran ij m x n makaselisih antara A dan B adalah matriks D =
[ ]
D dengan dij ij = aij + bijDiketahui :
+ 1≤ i ≤
j ≤ n.
Matriks = mn 2 m 1 m n 2 22 21 n 1 12 11 a ... a a a ... a a a ... a a A
dan matriks
13
c. Perkalian Matriks
Jika A =
[ ]
a adalah matrik berukuran ij m x p dan B =[ ]
b ijadalah matriks berukuran p x n dengan 1 ≤ i ≤ j ≤ n mak a
perkalian A dan B adalah matriks C =
[ ]
C yang berukuran ij m x n , denganpj ip j 2 2 i ij 1 i
ij a b a b ... a b
c = + + +
∑
= ≤ ≤ ≤ ≤ = p 1 k kj
ik b ,1 i m,1 j n a Diketahui : Matriks = mn 2 m 1 m n 2 22 21 n 1 12 11 a ... a a a ... a a a ... a a A
dan matriks
= pn 2 p 1 p n 2 22 21 n 1 12 11 b ... b b b ... b b b ... b b B Sehingga + + + + + + + + + + + + + + + + + + = = pn mp n 2 2 m n 1 1 m 1 p mp 21 2 m 11 1 m pn p 1 n 2 12 n 1 21 1 p p 2 21 22 21 21 pn p 1 n 2 12 n 1 11 1 p p 1 21 12 11 11 b a .... b a b a ... b a .... b a b a b a .... b a b a ... b a .... b a b a b a .... b a b a ... b a .... b a b a B x A C 2.4.Regresi Linear
Regresi linear adalah regresi yang variabel bebasnya (variabel X) berpangkat
paling tinggi 1. Regresi linear dibedakan menjadi 2 yaitu :
1. Regresi Linear Sederhana
14
Y = α + β X + ε (2.2)
Dengan :
Y : variabel tak bebas X : variabel bebas α : intersep
β : koefisien regresi / slope
ε : kesalahan pengganggu yang berarti nilai-nilai variabel lain tidak dimasukkan dalam persamaan, dengan ε∼ N
( )
0;σ22. Regresi Linear Berganda
Regresi linear berganda adalah regresi yang variabel tak bebasnya (Y)
dihubungkan lebih dari satu variabel bebas (X1, X2, X3, ….., Xn
(Hasan, 2005 : 269).
)
Bentuk umum model regresi linear berganda :
Y = β0 + β1 + βi1 + βi2 + β3 Xi3+ …… + βn Xin+ εi
Dengan :
(2.2)
Yi
β : intersep
: variabel tak bebas
β1, β2, β3,…. βn X
: koefisien regresi i1, Xi2, Xi3, ….. Xik
εi : variabel bebas
( )
2; 0 σ
: kesalahan pengganggu yang berarti nilai-nilai variabel lain tidak dimasukkan dalam persamaan, dengan ε∼ N
i : pengamatan ke-i (i = 1, 2, …., n) n : ukuran sampel
(2.3) dapat diuraikan menjadi :
Y1 = β0 + β1X11 + β2X12 + β3X13 + …… + βn X1n+ ε
Y
1
2 = β0 + β1X21 + β2X22 + β3X23 + …… + βn X2n+ ε
2
15
Apabila dituliskan dalam bentuk matriks menjadi :
ε ε ε + β β β + β β β = n 2 1 n 2 1 nn 3 n 2 n 1 n n 2 23 22 21 n 1 13 12 11 0 0 0 n 2 1 X X X X X X X X X X X X Y Y Y
Secara ringkas dapat dituliskan :
Y = XB + ε (2.4)
2.5.Analisa Korelasi
Analisa korelasi adalah analisis yang dilakukan untuk mengetahui derajat
hubungan linear antara suatu variabel dengan variabel yang lain (Algifari, 2000 : 45).
Ukuran statistik yang dapat menggambarkan hubungan antara suatu variabel dengan
variabel yang lain adalah :
1. Koefisien Determinasi
Koefisien determinasi digunakan untuk mengetahui ada tidaknya
hubungan antara dua variabel (Algifari, 2000 : 45). Besarnya koefisien
determinasi dapat dihitung dengan rumus :
(
)
(
)
22 2 Y Y Yˆ Y 1 r − − −
= (2.5)
Dengan : r2
16
Rumus (2.5) digunakan untuk menghitung besarnya koefisien determinasi pada
regresi linear sederhana.
2. Koefisien korelasi
Menurut Algifari (200 : 51) koefisien korelasi (r) dapat digunakan untuk :
a. Mengetahui keeratan hubungan antara dua variabel
Besarnya koefisien korelasi antara dua variabel adalah – 1 ≤ r ≤ 1.
Jika dua variabel mempunyai nilai r = 0 berarti antara dua variabel tidak ada
hubungan tetapi jika dua variabel mempunyai r = +1 atau r = – 1 maka dua
variabel tersebut mempunyai hubungan sempurna.
b. Menentukan arah hubungan antara dua variabel
Tanda (+) dan (–) yang terdapat pada koefisien korelasi
menunjukkan arah hubungan antara dua variabel.
Tanda (+) pada r menunjukkan hubungan yang searah atau positif.
Tanda (–) pada r menunjukkan adanya hubungan berlawanan arah atau
negatif.
Besarnya koefisien korelasi dapat ditentukan dengan rumus :
( )
2 2( )
22
Y Y
n X
X n
Y X XY n r
Σ − Σ − Σ − Σ
Σ Σ − Σ
= (2.6)
Dengan :
r : besarnya koefisien korelasi X : variabel bebas
17
2.6.Metode Kuadrat Terkecil (Least Square Method)
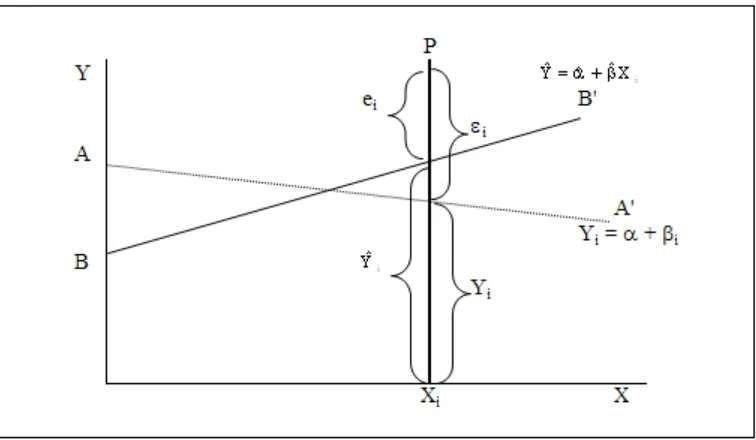
Berikut ini adalah gambar persamaan regresi yang sebenarnya dan persamaan
[image:42.612.117.495.188.408.2]regresi taksiran.
Gambar 2.1
Keterangan :
Persamaan regresi sebenarnya dinyatakan dengan Yi = α + βi Persamaan regresi dugaan dinyatakan dengan
i X ˆ ˆ Yˆ =α+β AA’ adalah garis regresi sebenarnya
BB’ adalah garis regresi dugaan
Titik P merupakan salah satu titik dari pengamatan data sampel ei taksiran dari faktor gangguan εi
Metode kuadrat terkecil adalah metode yang digunakan untuk menaksir β.
Prinsip dasar metode kuadrat terkecil adalah meminumkan jumlah kuadrat galat yaitu
meminimumkan
.
∑
2i
18
Untuk mendapatkan penaksir-penaksir bagi β, ditentukan dua vektor βˆ dan e
sebagai berikut :
n 2 1 k 1 0 e e e e dan ˆ ˆ ˆ ˆ = β β β = β
Persamaan hasil estimasi dapat ditulis :
Y = Xβˆ + e
e = Y – X βˆ (2.7)
Sehingga :
(
) (
)
(
)(
)
(
)(
)
β β + β − β − = β − β − = β − β − = β − β − = ˆ X ' X ' ˆ Y ' X ' ˆ ' ˆ ' X ' Y Y ' Y ˆ X Y ' X ' ˆ ' Y ˆ X Y ' ˆ ' X ' Y ˆ X Y ' ˆ X Y e ' e β β + β −=Y'Y 2ˆ'X'Y ˆ'X'Xˆ e
'
e (2.8)
Untuk meminimumkan e’e, dapat diperoleh dengan menurunkan secara parsial
terhadap βˆ serta menyamakan turunan dengan 0.
19
Selanjutnya kalikan kedua ruas dengan (X’X)–1
βˆ ' X ' X
diperoleh
= X’Y
(X’X)–1 X'X'βˆ = (X’X)–1
βˆ I
X’Y
= (X’X)–1
βˆ
X’
= (X’X)–1
Dengan :
X’Y (2.9)
X’ = transpose dari matriks x
βˆ
= penaksir koefisien regresi
Menurut (Sumodiningrat, 1995 : 188) untuk menguji sifat-sifat taksiran parameter
digunakan asumsi sebagai berikut :
1. E (ε) = 0
2. E (εε’) = σ2
Bukti :
I
n ... 2 1 ' dan
n 2 1
ε ε
ε = ε
ε ε ε
= ε
20 2 n 2 n 1 n n 2 2 2 1 2 n 1 2 1 2 1 .... .... .... ' ε ε ε ε ε ε ε ε ε ε ε ε ε ε ε = ε ε
[ ]
[ ]
[ ]
[ ]
[ ]
[ ]
[ ]
[ ]
[ ]
[ ]
2n 2 n 1 n n 2 2 2 1 2 n 1 2 1 2 1 E .... E E E .... E E E .... E E ' E ε ε ε ε ε ε ε ε ε ε ε ε ε ε ε = ε ε 2 2 2 .... 0 0 0 .... 0 0 .... 0 σ σ σ =
[ ]
danE[ ]
0(i 0j)E ε12 =σ2 εi εj = ≠
[ ]
I1 .... 0 0 0 .... 1 0 0 .... 0 1 '
E εε =σ2 = =σ 2
Apabila asumsi-asumsi sudah dipenuhi maka estimasi yang diperoleh dengan metode
kuadrat terkecil akan bersinar linear, tak bias, dan variansinya minimum yang dikenal
dengan sifat Best, Linear, Unbiased estimator (BLUE). Sifat-sifat penaksir
(estimator) dalam metode kuadrat kecil adalah :
1. Linear (Linearity)
βˆ = (X’X)–1
= (X’X)
X’Y
–1
21
= (X’X)–1 X’Xβ + (X’X)–1
= Iβ + (X’X)
Xε
–1
= β + (X’X) Xε
–1
Jadi,
Xε
βˆ merupakan fungsi linear dari β dan ε.
2. Tak bias (Unbiasedness)
Sifat tak bias berarti nilai harapan dari estimator yaitu E
[ ]
βˆ =β[ ]
[
(
)
]
[ ] (
[
)
]
(
)
[ ]
ε+ β =
ε +
β =
ε +
β = β
− − −
E ' X X ' X
' X X ' X E E
' X X ' X E ˆ E
1 1 1
Karena E [ε] = 0 maka E
[ ]
βˆ =βJadi, βˆ merupakan penaksir tak bias.
3. Variansi minimum
Estimator variansi minimum adalah estimator dengan variansi terkecil diantara
semua estimator untuk koefisien yang sama. Menurut Sudjana (1996 : 199) jika
1 ˆ
β dan βˆ2 merupakan dua estimator untuk β dengan var
( ) ( )
βˆ1 < βˆ2 maka βˆ1merupakan estimator bervariansi minimum.
Var
( )
βˆ1 dapat dicari sebagai berikut :22
(
)(
)
[
]
(
)
{
}
{
(
)
}
[
]
(
)
(
)
(
)
(
)
(
)
12 1 1 2 1 2 1 1 1 1 1 1 X ' X X ' X X ' X X ' X X ' X X I ' X X ' X ' X X ' X ' X X ' X E ˆ ˆ ˆ ˆ E − ε − − ε − ε − − − σ = σ = σ = ε ε = β − β β − β =
Akan ditunjukkan bahwa Var
( )
βˆ1 ≤Var( )
βˆ2Misalkan βˆ2 = [(X’X)–1
Dengan
+ B] Y
2 ˆ
β : penaksir alternatif yang linear dan tak bias bagi β
B : matriks konstanta yang diketahui
2 ˆ
β = [(X’X)–1 = [(X’X)
+ B] Y –1
= (X’X)
X’ + B] (Xβ + ε) –1
E
X’ (Xβ + ε) + B (Xβ + ε)
[ ]
βˆ2 = E [(X’X) –1= E [(X’X)
X’(Xβ + ε) + B (Xβ + ε)] –1
X’ Xβ + (X’X)–1
= β + B X B karena E (ε) = 0 X’ ε + B Xβ + ε]
Oleh karena diasumsikan βˆ2 merupakan estimator tak bias untuk β maka E
[ ]
βˆ2= β atau dengan kata lain B X B merupakan matriks 0.
Variansi dari penaksir alternatif tersebut dapat dicari sebagai berikut :
Var
( ) (
)
23
(
)(
)
(
)
[
]
{
}
{
[
[
]
]
}
[
]
(
)
[
]
(
)
[
]
{
}
{
[
(
)
]
(
)
}
[
]
(
)
(
)
{
}
[
(
)
(
)
{
}
]
(
)
{
}
{
(
)
}
[
]
(
)
{
}
{
(
)
}
[
]
(
)
{
}
{
(
)
}
[
]
(
)
{
}
[ ]
{
(
)
}
(
)
{
}
{
(
)
}
(
)
(
)
(
) (
)
{
}
(
)
{
X'X BB'}
karenaBX 0' B B ' B ' X X ' X X ' X BX X ' X X ' X X ' X I ' B X X ' X B ' X X ' X I ' B X X ' X ' E B ' X X ' X ' B X X ' X ' B ' X X ' X E ' B ' X X ' X ' B ' X X ' X E 0 X B karena B ' X X ' X B ' X X ' X E B X B ' X X ' X X ' X X ' X B X B ' X X ' X X ' X X ' X E X B ' X X ' X B X B ' X X ' X E Y B ' X X ' X Y B ' X X ' X E ˆ ˆ E 1 2 E 1 1 1 1 2 E 1 1 2 E 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 = + σ = + + + σ = + + σ = + εε + = + εε + = ε + ε ε + ε = = ε + ε ε + ε = β − ε + β + ε + β β − ε + β + ε + β = β − ε + β + − ε + β + = β − + β − + = β − β β − β = − − − − − − − − − − − − − − − − − − − − − − −
Var
( )
ˆ (X'X) 2E BB' 12 E
2 =σ +σ
β −
Jadi, Var
( )
βˆ1 ≤Var( )
βˆ2 sehingga terbukti memiliki variansi minimum.2.7.Kesalahan Standar Estimasi (Standar Error Of Estimate)
Proses selanjutnya dalam analisis regresi adalah menentukan ketepatan
persamaan yang dihasilkan untuk mengestimasi nilai variabel tak bebas dengan
metode kuadrat terkecil. Kesalahan Standar Estimasi (Standar Error Of Estimate)
yang dinotasikan dengan Se. Besarnya kesalahan standar estimasi menunjukkan
ketepatan persamaan estimasi untuk menjelaskan nilai variabel tak bebas yang
sesungguhnya. Semakin kecil nilai kesalahan standar estimasi makin tinggi
24
ketepatan persamaan estimasi dapat digunakan kesalahan Standar Estimasi (Standar
Error Of Estimate) ditentukan dengan rumus :
(
)
2 n
Yˆ Y S
2
e −
− =
(2.10)
Rumus alternatif yang dapat digunakan untuk menentukan kesalahan standar
estimasi (standar error of estimate) adalah sebagai berikut :
2 n
XY ˆ Y ˆ Y S
2
e −
Σ β − Σ α − Σ
= (2.11)
Rumus (2.10) dan (2.11) digunakan untuk menghitung besarnya kesalahan
standar estimasi (standar error of estimate) pada model regresi linear sederhana yaitu
: Y = α + β X + ε. Nilai 2 dalam n – 2 menunjukkan banyaknya parameter dalam
model regresi linear sederhana yaitu α dan β sehingga dalam rumus (2.10) dan
(2.11) dibagi dengan n – 2.
2.8.Asumsi Klasik
Model regresi yang diperoleh dari metode kuadrat terkecil merupakan model
regresi yang menghasilkan estimator linear tak bias yang terbaik (BLUE). Menurut
Supranto (1987 : 281), kondisi BLUE ini akan terjadi jika dipenuhi beberapa asumsi
klasik sebagai berikut :
25
Non-Multikolinearitas berarti antara variabel bebas yang satu dengan variabel
bebas yang lain dalam model regresi tidak saling berhubungan secara sempurna
atau mendekati sempurna.
2. Homoskedasitisitas
Homoskedasitisitas berarti var (εi) = E (εj) = σ2
3. Non-Autokorelasi
.
Non-Autokorelasi berarti model tidak dipengaruhi waktu yang berarti Cov (εi, εj
4. Nilai rata-rata kesalahan penganggu (error) populasi adalah 0 atau E (ε
)
= 0, i ≠ j. Menurut model asumsi klasik, nilai suatu variabel saat ini tidak akan
berpengaruh terhadap nilai variabel lain pada masa yang akan datang.
i
5. Variabel bebas adalah non-stokastik yang berarti tetap pada sampel ke sampel
atau tidak berkorelasi dengan kesalahan penganggu ε
) = 0
untuk i = 1, 2, …., n.
t
6. Distribusi kesalahan (error) adalah normal ε .
i ∼ N (0;σ2) atau kesalahan
penganggu mengikuti distribusi normal dengan rata-rata 0 dan variansi σ2.
2.9.Penyimpangan Asumsi Klasik
Penyimpangan terhadap asumsi-asumsi dasar tersebut dalam regresi akan
menimbulkan beberapa masalah seperti kesalahan standar estimasi untuk
26
koefisiennya kurang akurat lagi yang akhirnya dapat menimbulkan kesimpulan yang
salah. Penyimpangan dari asumsi dasar tersebut meliputi :
1. Multikolenearitas
Defenisi 2.4. (Supranto, 1989 : 293)
Multikolinearitas berarti bahwa antar variabel bebas yang terdapat dalam model
regresi memiliki hubungan sempurna atau mendekati sempurna atau dengan kata
lain koefisien korelasinya tinggi bahkan mendekati 1.
2. Heteroskedasitisitas
Defenisi 2.5 (Supranto, 1989 : 281)
Heteroskedasitisitas berarti variansi variabel Y dalam model tidak sama untuk
semua pengamatan.
3. Autokorelasi
Defenisi 2.6 (Supranto, 1989 : 285)
Autokorelasi berarti terdapat korelasi antar anggota sampel Y atau data
pengamatan diurutkan berdasarkan waktu. Autokorelasi biasanya muncul pada
regresi yang menggunakan data berkala (time series) karena dalam data berkala
(time series), data masa sekarang dipengaruhi oleh data pada masa-masa
BAB III
PEMBAHASAN
Model regresi linear yang sering ditemui tidak memperhatikan pengaruh
waktu karena pada umumnya model regresi linear cenderung mengasumsikan bahwa
pengaruh variabel bebas terhadap variabel tak bebas terjadi dalam kurun waktu yang
sama. Namun, dalam model regresi linear juga terdapat model regresi yang
memperhatikan pengaruh waktu. Waktu yang diperlukan bagi variabel bebas X dalam
mempengaruhi variabel tak bebas Y disebut bedakala atau “a lag” atau “a time lag”
(Supranto, 1995 : 188). Ada 2 macam model regresi linear yang memperhatikan
pengaruh waktu yaitu :
1. Model Dinamis Distribusi Lag
Suatu variabel tak bebas apabila dipengaruhi oleh variabel bebas pada
waktu t, serta dipengaruhi juga oleh variabel bebas pada waktu t – 1, t – 2 dan
seterusnya disebut model dinamis distribusi lag. Model dinamis distribusi lag
ada 2 jenis yaitu :
a. Model Infinite Lag
Model : Yt = α + β0 Xt + β1 Xt-1 + β2 Xt-2 + …. + εt
28
Model : Yt = α + β0 Xt + β1 Xt-1 + β2 Xt-2 + …. +βk Xt-k + εt
Model (3.2) disebut model finite lag sebab panjang beda kalanya diketahui
yaitu sebesar k. (3.2)
2. Model Dinamis Autoregressive
Apabila variabel tak bebas dipengaruhi oleh variabel bebas pada waktu t,
serta dipengaruhi juga oleh variabel tak bebas itu sendiri pada waktu t – 1 maka
model tersebut disebut autoregressive dengan :
Yt = α + β0 Xt + β1 Xt-1 + εt
3.1. Metode-Metode Dalam Menentukan Persamaan Dinamis Distribusi Lag
Dugaan
Dua metode yang dapat digunakan untuk menentukan persamaan dinamis
disebut lag dugaan adalah :
1. Metode Koyck
Metode Koyck didasarkan asumsi bahwa semakin jauh jarak lag variabel
bebas dari periode sekarang maka semakin kecil pengaruh variabel lag terhadap
variabel tak bebas. Koyck mengusulkan suatu metode untuk memperkirakan mode
dinamis distribusi lag dengan mengasumsikan bahwa semua koefisien β mempunyai
tanda sama. Koyck menganggap bahwa koefisien menurun secara geometris sebagai
berikut :
29
Dengan :
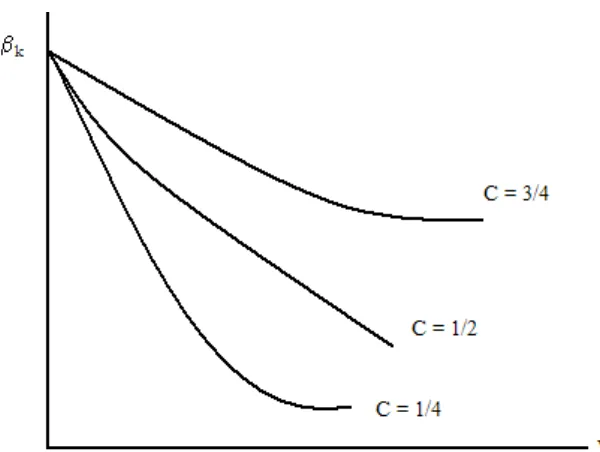
C : rata-rata tingkat penurunan dari distribusi lag dengan nilai 0 < C < 1 1 – C : kecepatan penyesuaian
(3.3) mempunyai arti bahwa nilai setiap koefisien β lebih kecil dengan nilai
sebelumnya atau yang mendahuluinya (0 < C < 1). Secara grafis, dapat dilihat pada
[image:54.612.119.419.252.478.2]gamabr sebagai berikut :
Gambar 3.1. Penurunan Koefisien β dalam model Koyck
(3.3) apabila diuraikan akan menjadi :
β0 = β1 β1 = β1 β2 = β1 CC 2
β3 = β1 C (3.4)
3
30
Model (3.5) sukar digunakan untuk memperkirakan koefisien-koefisien yang
banyak sekali dan juga parameter C yang masuk kedalam mode dalam bentuk yang
tidak linear. Akhirnya Koyck mencari jalan keluar dengan mengambil beda kala 1
periode berdasarkan (3.5) yaitu :
Yt-1 = α + β0 Xt-1 + β0 C Xt-2 + β0 C2 Xt-3 + …. +εt-1
(3.6) dikalikan dengan C diperoleh : (3.6)
CYt-1 = α C + β0 C Xt-1 + β0 C2 Xt-2 + β0 C3 Xt-3 + …. + C εt
(3.5) dikurangi (3.7) menjadi : (3.7)
Yt – CYt-1 = α (1 – C) + β0 Xt + (εt – C εt-1
Secara umum (3.8) dapat dituliskan menjadi : )
(3.8)
Yt = α (1 – C) + β0 Xt + C Yt-1 + Vt
Dengan V (3.9)
t = εt – C εt-1
Prosedur sampai ditemukannya model (3.9) dikenal dengan nama transformasi
Koyck. Model (3.9) inilah yang disebut dengan model Koyck. .
Pada model (3.1) parameter α dan β yang diperkirakan banyaknya tak
31
tiga parameter yaitu α, β dan C. Nilai α, β dan C selanjutnya digunakan untuk
menentukan koefisien distribusi lag dugaan yaitu dengan rumus : βk = β0 Ck.
Namun, ada hal yang harus diperhatikan dalam transformasi Koyck yaitu adanya Yt-1
yang diikutsertakan sebagai salah satu variabel bebas sehingga model (3.9) bersifat
autoregressive.
3.2.Metode Dalam Menentukan Persamaan Dinamis Autoregressive Dugaan
Pada pembahasan model dinamis distribusi lag dikenal model Koyck yaitu :
Y1 = α (1 – C) + β0 Xt + CYt-1 +( εt – εt-1
Model (3.19) mempunyai bentuk sama dengan model dinamis autoregressive :
) (3.19)
Y1 = α0 + α1 Xt + α2 Yt-1 + V1
Jadi, model (3.19) bersifat autoregressive. (3.20)
Namun, metode kuadrat terkecil tidak dapat digunakan dalam persamaan dinamis
autoregressive dugaan karena :
1. Adanya variabel-variabel bebas yang stokastik.
2. Adanya autokorelasi.
Oleh karena itu, untuk mengetahui adanya autokorelasi dalam model dinamis
autoregressive perlu mengenali sifat-sifat Vt
Asumsikan bahwa ε
terlebih dahulu.
32
Varian (εi) = E (ej) = σ2
2. Non-Autokorelasi
, sama untuk semua kesalahan penganggu.
Cov (εi, εj
Berdasarkan asumsi tentang ε ) = 0 i ≠ j
t, jika Vt adalah autokorelasi maka harus dibuktikan
bahwa : E(Vt Vt-1) = – Cσ2
Bukti :
(3.21)
Misalnya dalam model Koyck kesalahan penganggu Vt = (εt – Cεt-1). Adanya
E(Vt Vt-1) maka ada Yt-1 muncul dalam model Koyck sebagai variabel bebas,
sehingga Yt-1 tersebut akan berkorelasi dengan kesalahan penganggu Vt melalui
kehadiran dari εt-1
Kebenaran persamaan (3.33) adalah sebagai berikut : didalamnya.
(
)
[
(
)(
)
]
[
]
[
]
[
]
[
]
[
1 t 2]
2 2 1 t 1 2 t 1 1 t 1 2 t 1 t 2 2 1 t 2 t t 1 t t 2 t 1 t 1 t t 1 -t t E C E C E C E C C C E C C E V V E − − − − − − − − − − − − ε ε + ε ε − ε ε − ε ε = ε − ε + ε − ε ε − ε ε = ε − ε ε − ε =
Berdasarkan asumsi diketahui bahwa Cov antara kesalahan penganggu εt
( )
2 1 t− εadalah 0
dan asumsi E = σ2
E
sehingga diperoleh :
(
Vt Vt-1)
= – C E( )
2 1 t− ε= – C σ
Jadi, terbukti bahwa E 2
(
Vt Vt-1)
= – Cσ2 sehingga VtImplikasi yang terjadi dalam model Koyck adalah variabel bebas Y mempunyai autokorelasi.
t-1
33
berkorelasi dengan kesalahan penganggu maka pemerkira (estimator) dengan
metode kuadrat terkecil selain bias juga tak konsisten, walaupun sampel
diperbesa sampai tak terhingga, pemerkira (estimator) tidak akan mendekati nilai
populasi yang sebenarnya. Oleh karena itu, perkiraan dengan model Koyck
dengan metode kuadrat terkecil belum tentu benar.
Metode Koyck tetap dapat digunakan dalam menentukan persamaan
dinamis autoregressive dugaan karena dalam model Koyck terdapat variabel
Yt-1 yang diikutsertakan sebagai salah satu variabel bebas sehingga model Koyck
bersifat autoregressive. Namun, setelah menggunakan metode Koyck perlu
dilakukan uji lanjutan yaitu dengan menggunakan metode statistik
Durbin-Watson untuk mendeteksi adanya autokorelasi dalam autoregressive sebab
keikutsertaan Yt-1
Statistik d Durbin-Watson merupakan cara yang dapat digunakan untuk
mendeteksi adanya autokorelasi dalam autoregressive. Statistik d Durbin-Watson
didefenisikan sebagai berikut :
sebagai salah satu variabel bebas kemungkinan menyebabkan
autokorelasi.
2 t
1 t t 2
1 t 2
t 2
d
ε Σ
ε ε Σ − ε Σ + ε Σ
= − − (3.22)
Oleh karena, Σε2t, Σε2t−1 berbeda hanya satu observasi maka nilainya
34
ε Σ
ε ε Σ −
≈ −
2 t
1 t t 1 2
d (3.23)
Dengan ≈ berarti mendekati atau hampir sama.
Jika didefenisikan 2 t
1 t t pˆ
ε Σ
ε ε Σ
= − maka (3.23) dapat dituliskan menjadi :
d = 2 (1 – pˆ )
pˆ = 1 – ½ d
Namun, penggunaan statistik d Durbin-Watson harus memperhatikan
asumsi-asumsi sebagai berikut :
1. Model regresi harus mencakup titik potong (interept) dan tidak boleh
melalui titik asal (origin) yiatu dalam bentuk Yt = α + β Xt + εt bukan Yt = β
Xt + εt
2. Kesalahan penganggu ε .
t diperoleh dengan autoregressive order-pertaam yaitu : εt = εt-1 + µt
3. Model regresi tidak mencakup variabel beda kala (lag). .
Berdasarkan asumsi ketiga, maka statistik d Durbin-Watson ini tidak
dapat dipergunakan untuk autokorelasi dalam model dinamis autoregressive. Jika
menghitung nilai d untuk model yang demikian maka dengan sendirinya terjadi
bias. Akhirnya Durbin mengusulkan suatu uji yang disebut statistik h
Durbin-Watson yaitu :
( )
[
Var a2]
n 1
n pˆ
h
−
35
Dengan
pˆ : perkiraan koefisien autokorelasi order pertama
n : banyaknya elemen sampel
a2 : koefisien regresi Y
Var(a
t-1
2) : variansi a2
Nilai
pˆ didekati dengan nilai statistik d, dengan rumus :
pˆ = 1 – ½ d
Dengan d adalah statistik Durbin-Watson.
Rumus (3.24) dapat dituliskan :
( )
[
Var a2]
n 1
n )
d 2 / 1 1 ( h
− −
= (3.25)
Langkah-langkah yang dilakukan untuk pengujian autokorelasi adalah :
1. Hipotesis :
H0
H
: tidak terdapat autokorelasi dalam autoregressive.
i
2. α = 0.05
: terdapat autokorelasi dalam autoregressive.
3. Statistik Uji :
( )
[
Vara2]
n 1
n )
d 2 / 1 1 ( h
− −
=
36
5. Perhitungan
Perhitungan dilakukan dengan mensubsitusikan suatu nilai pada statistik
uji.
6. Kesimpulan
Penarikan kesimpulan berdasarkan kriteria keputusan yang diambil.
Ada catatan tentang statistik h Durbin-Watson yaitu :
1. Statistik h Durbin-Watson tidak memperhatikan banyaknya variabel X atau
banyaknya variabel beda kala (lag) dari Y karena yang diperlukan hanya
variansi a2
2. Apabila setelah dilakukan uji hipotesis terdapat kesimpulan tidak terdapat
autokorelasi dalam autoregressive maka pengujian hipotesis berhenti
sehingga persamaan dinamis autoregressive dugaan yang diuji dinyatakan
benar. .
3. Apabila setelah dilakukan uji hipotesis terdapat kesimpulan terdapat
autokorelasi dalam autoregressive maka yang harus dilakukan adalah
memperbesar ukuran sampel karena Durbin-Watson membuat statistik h
Durbin-Watson diutamakan untuk sampel besar. Setelah data ditambah
dilakukan uji hipotesis kembali sampai pengujian persamaan dinamis
autoregressive dugaan dinyatakan benar.
37
Setelah mempelajari metode Koyck dan uji statistik Durbin-Watson, penulis
akan mencoba mengaplikasikannya melalui contoh kasus berikut ini :
Contoh kasus berikut ini hanya akan membahas penerapan metode Koyck yang
bersumber dari buku Supranto (1995 : 183) dengan perubahan variabel.
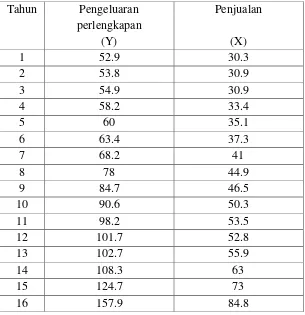
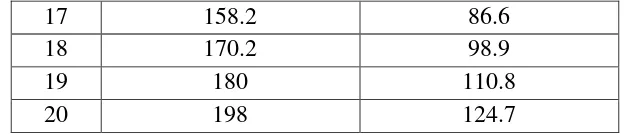
Variabel dilakukan untuk mengetahui hubungan antara pembelian perlengkapan
dan hasil penjualan suatu perusahaan selama 20 tahun. Berdasarkan data
pembelian perlengkapan dan hasil penjualan dalam tabel 3.3 akan ditunjukkan
[image:62.612.169.474.379.694.2]persamaan dinamis distribusi lag dugaan dengan menggunakan metode Koyck.
Tabel 3.1. Pembelian Perlengkapan dan Hasil Penjualan
Tahun Pengeluaran perlengkapan
(Y)
Penjualan
(X)
1 52.9 30.3
2 53.8 30.9
3 54.9 30.9
4 58.2 33.4
5 60 35.1
6 63.4 37.3
7 68.2 41
8 78 44.9
9 84.7 46.5
10 90.6 50.3
11 98.2 53.5
12 101.7 52.8
13 102.7 55.9
38
17 158.2 86.6
18 170.2 98.9
19 180 110.8
20 198 124.7
Penyelesaian :
Penaksiran dengan metode Koyck
Y1 = α + (1 – C) + β0 X1 + C Yt-1 + Vt dengan Vt = εt – CEt-1
Asumsikan bahwa V
t memenuhi semua asumsi klasik yang berkenaan dengan
[image:63.612.163.476.104.171.2]faktor gangguan. Pengamatan model ini menjadi :
Tabel 3.2. Pembelian Perlengkapan dan Penjualan Setelah Dimasukkan Lag
Tahun (Y) (Yt-1) (X)
2 53.8 52.9 30.9
3 54.9 53.8 30.9
4 58.2 54.9 33.4
5 60 58.2 35.1
6 63.4 60 37.3
7 68.2 63.4 41
8 78 68.2 44.9
9 84.7 78 46.5
10 90.6 84.7 50.3
11 98.2 90.6 53.5
12 101.7 98.2 52.8
13 102.7 101.7 55.9
39
15 124.7 108.3 73
16 157.9 124.7 84.8
17 158.2 157.9 86.6
18 170.2 158.2 98.9
19 180 17.2 110.8
20 198 180 124.7
Berdasarkan tabel 3.4, persamaan hasil transformasi Koyck dapat diduga dengan
menggunakan program Eviews 7. Persamaan dugaannya adalah sebagai berikut :
t Yˆ
= 2.7268 + 0.9407 Xt + 0.4682 Yt-1 R2
Persamaan
= 0.99
t Yˆ
= 2.7268 + 0.9407 Xt + 0.4682 Yt-1
Berdasarkan persamaan diatas diketahui :
dapat dituliskan dalam
bentuk persamaan dinamis distribusi lag dugaan dengan cara sebagai
40
t Yˆ
= 5.1275 + 0.9407 Xt + 0.4404 Xt-1 + 0.2062 Xt-2 + 0.09655 Xt-3
+ 0.04520 Xt-4 + ….. + 0.4682 Y
Bisa diamati bahwa pengaruh dari lag Y menurun secara geometris. t-1
Berdasarkan model Yˆt = 2.7268 + 0.9407 Xt + 0.4682 Yt-1 diketahui bahwa
nilai koefisien dari Yt-1
Berikut ini adalah penaksiran model dinamis autoregressive dengan
menggunakan statistik h Durbin-Watson. Data diambil dari buku Rao & Milter
(1995 : 44)
bernilai positif yaitu sebesar 0.4682. nilai 0.4682
berarti bahwa apabila penjualan naik sebesar 1% maka pengeluaran perlengkapan
akan naik sebesar 0.4682%.
Suatu penelitian dilakukan untuk mengetahui hubungan antara pendapatan
nasional dan investasi suatu negara. Penelitian dilakukan selama 13 tahun yaitu
dari tahun 1991 sampai dengan 2003. Berdasarkan data pendapatan nasional dan
investasi pada tabel 3.5 akan ditunjukkan :
a. Persamaan dinamis autoregressive dugaan.
b. Cara mendeteksi autokorelasi dalam model dinamis autoregressive dengan
41
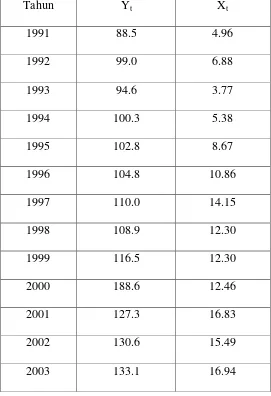
Tabel 3.3. Pendapatan Nasional dan Investasi
Tahun Yt Xt
1991 88.5 4.96
1992 99.0 6.88
1993 94.6 3.77
1994 100.3 5.38
1995 102.8 8.67
1996 104.8 10.86
1997 110.0 14.15
1998 108.9 12.30
1999 116.5 12.30
2000 188.6 12.46
2001 127.3 16.83
2002 130.6 15.49
2003 133.1 16.94
Penyelesaian :
a. Setelah dimasukkan lag untuk Yt sehingga menjadi autoregressive maka
42
Tabel 3.4. Pendapatan Nasional dan Investasi setelah dimasukkan lag
Tahun Yt Yt-1 Xt
1992 99.0 88.5 6.88
1993 94.6 99.0 3.77
1994 100.3 94.6 5.38
1995 102.8 100.3 8.67
1996 104.8 102.8 10.86
1997 110.0 104.8 14.15
1998 108.9 110.0 12.30
1999 116.5 108.9 12.30
2000 188.6 116.5 12.46
2001 127.3 188.6 16.83
2002 130.6 127.3 15.49
2003 133.1 130.6 16.94
Persamaan hasil transformasi Koyck dapat diduga dengan menggunakan
program Eviews 5.1. Persamaan dugaannya adalah sebagai berikut :
t Yˆ
= 11.31 + 0.406 Xt + 0.887 Yt-1 (11 .41) (0.455) (.147)
43
Nilai (11.41), (0.455), (0.147) merupakan nilai kesalahan standar estimasi
(standar error estimasi).
Var (d2) dapat diperoleh dengan mengkuadratkan standar error estimasi a2
b. Cara mendeteksi autokorelasi dalam mode dinamis autoregressive adalah
dengan melakukan pengujian sebagai berikut :
.
1. Hipotesis :
H0
H
: tidak terdapat autokorelasi dalam autoregressive.
i
2. α = 0.05
: terdapat autokorelasi dalam autoregressive.
3. Statistik Uji :
[
( )
]
2 a Var n 1n )
d 2 / 1 1 ( h
− −
=
4. Kriteria Keputusan :
H0 ditolak jika hhit > htabel
H
0 diterima jika hhit < htabel
5. Perhitungan
Karena n = 13 maka statistik h dapat dihitung sebagai berikut :
(
0.147)
1.42 131
13 )
d 2 / 1 1 (
h 2 =−
− −
=
44
6. Kesimpulan
Karena hhit < htabel yaitu – 1.42 < 1.711 maka H0
t Yˆ
diterima sehingga dapat
disimpulkan bahwa tidak ada autokorelasi dalam persamaan dinamis
autoregressive sehingga :
= 11.31 + 0.406 Xt + 0.887 Yt-1 (11 .41) (0.455) (.147)
bernilai benar.
Pada model tersebut terlihat bahwa :
a. Koefisien regresi pada variabel Xt
b. Koefisien regresi pada variabel Y
bertanda positif berarti bahwa
hubungan antara investasi dan pendapatan nasional searah. Semakin
besar investasi maka semakin besar pendapatan nasional.
t-1 bertanda positif berarti bahwa
hubungan antara pendapatan nasional tahun sekarang dan
pendapatan nasional tahun sebelumnya. Semakin pendapatan nasional
tahun sebelumnya maka pendapatan nasional tahun sekarang semakin
BAB IV
PENUTUP
4.1.Kesimpulan
Berikut ini akan diberikan kesimpulan yang dapat diambil dari pembahasan
skripsi dengan judul “Model Dinamis : Autoregressive dan Distribusi Lag” yaitu :
Model dinamis : Autoregressive dan Distribusi Lag merupakan bentuk dari model
regresi linear yang memperhitungkan peranan waktu. Waktu yang diperlukan bagi
variabel bebas X untuk berpengaruh terhadap variabel tak bebas Y disebut dengan
beda kala (lag). Metode yang digunakan untuk menentukan persamaan dinamis
distribusi lag dugaan adalah :
I. Metode Koyck
Metode Koyck digunakan jika panjang beda kala (lag) tidak diketahui.
Langkah-langkah yang dilakukan adalah :
1. Dalam contoh kasus diketahui nilai-nilai Xt dan Yt, kemudian dengan
menggunakan nilai-nilai dari Yt dapat dihitung nilai-nilai Yt-1
2. Nilai-nilai dari X
.
t, Yt, dan Yt-1
( )
1 Cˆ , ˆ ,danCˆ ˆ − β0α
diolah dengan menggunakan program
Eviews 7 diperoleh nilai . Apabila dituliskan dalam
persamaan hasil tranformasi Koyck menjadi :
46
4. Menghitung nilai-nilai βˆ1,βˆ2,βˆ3.... dengan rumus βˆk =βˆ0 Cˆk,
k = 0, 1, 2, ….
5. Dengan menghitung nilai αˆ,βˆ1,βˆ2,βˆ