1
PHD (Pizza hut delivery) adalah perusahaan yang bergerak di bidang kuliner, menjual berbagai macam produk seperti pizza, pasta, snack dan lain lain. PHD dalam penjualan produk menerapkan sistem pengambilan produk di outlet langsung (takeaway) dan sistem pengantaran produk ke rumah customer (delivery). Untuk mengetahui pelayanan yang diberikan dari tiap outlet, maka PHD menyediakan wadah untuk berbagi pengalaman customer berupa penilaian terhadap outlet PHD yang dikunjunginya. Penilaian customer dapat disalurkan melalui website www.halopizzaindonesia.com. Hasil penilaian yang didapat dijadikan bahan evaluasi bagi perusahaan agar dapat tetap berkembang dan maju.Semua penilaian yang tersimpan di website tersebut akan didistribusikan ke masing-masing outlet PHD diseluruh Indonesia. Outlet Manager ditugaskan untuk menghitung persentase penilaian yang masuk seberapa besar kepuasan customer yang di dapat dengan cara mempelajari opini yang disampaikan oleh customer dan mengelompokkan penilaian berupa opini kedalam beberapa klasifikasi yaitu opini puas dan opini tidak puas.
penilaian, dan sikap terhadap suatu entitas seperti produk, pelayanan, peristiwa, dan topik. [1] Banyak metode dalam analisis sentimen diantaranya yaitu metode naive bayes, metode k-nearest neighbor(KNN), metode support vector machine (SVM) dsb. Masing – masing metode memiliki kelebihan dan kekurangan masing
– masing dan memiliki tingkat akurasi yang berbeda – beda. Berdasarkan penelitian sebelumnya pada pengklasifikasian text yang mencoba membandingkan tingkat akurasi dari 3 algoritma langsung yaitu metode naive bayes, metode k-nearest neighbor(KNN), metode support vector machine(SVM) didapat bahwa metode K-NN memiliki tingkat akurasi yang lebih tinggi dibandingkan dengan metode naive bayes dan metode support vector machine(SVM). [2]
Berdasarkan gambaran penjelasan diatas, maka dalam penelitian ini akan dilakukan analisis sentimen terhadap penilaian customer di PHD Karawitan menggunakan metode k-nearest neighbor.
Perumusan Masalah
Maka rumusan masalah yang didapat berdasarkan permasalahan yang diangkat adalah bagaimana cara membantu outlet manager dalam mengelompokkan penilaian customer secara otomatis, sehingga dapat dihitung persentase kepuasan customer di PHD Karawitan
Maksud dan Tujuan
Berdasarkan permasalahan yang akan diteliti, maka maksud dari penelitian ini adalah untuk membangun aplikasi yang mampu mengklasifikasikan penilaian customer di PHD Karawitan dengan menggunakan metode k-nearest neighbor
Tujuan yang akan dicapai dalam penelitian ini yaitu untuk membantu mempermudah outlet manager dalam mengelompokkan penilaian customer sehingga dapat dihitung persentase kepuasan customer di PHD Karawitan
Batasan Masalah
Ada pun Batasan masalah dalam penelitian ini adalah sebagai berikut :
1. Metode yang digunakan dalam analisis sentimen ini adalah K-Nearest Neighbor.
4. Data diperoleh dari wesite www.halopizzaindonesia.com yang sudah didistribusikan ke PHD Karawitan yang berbahasa indonesia.
5. Metode pembobotan yang digunakan adalah Term Frequency – Inverse Document Frequency (TF-IDF).
6. Proses stemming menggunakan algoritma nazief dan indriani.
7. Diklasifikasikan berdasarkan 2 kelas yaitu kelas sentimen puas dan sentimen tidak puas.
8. Dalam pengklasifikasian tidak selalu mendapatkan hasil 100% tepat. 9. Modeling Languange berbasis OO (Object-Oriented).
10. Metode pemograman berbasis OOP (Object Oriented Programming) Metodologi Penelitian
Metodologi penelitian merupakan sekumpulan peraturan, kegiatan dan prosedur yang digunakan oleh peneliti untuk memecahkan suatu masalah agar lebih efisien. Metode penelitian yang digunakan adalah metode deskriptif. Metode deskriptif merupakan metode penelitian yang menggambarkan suatu informasi, peristiwa, kejadian yang sedang terjadi saat sekarang secara sistematis, faktual dan akurat.
Metodologi Penelitian dalam penelitian ini menggunakan tiga proses metode yaitu metode pengumpulan data, metode pembangunan sistem analisis sentimen dan metode pembangunan perangkat lunak.
1.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan pada penelitian ini adalah: a. Observasi
Metode pengumpulan data dengan melakukan pengamatan secara langsung terhadap objek yang diteliti.
b. Studi Literatur
Sistem analisis sentimen yang akan dibangun akan melewati tahapantahapan pada gambar 1.1.
Gambar 1.1 Alur Pembangunan Sistem Analisis Sentimen Tahapannya terdiri dari :
a. Analisis Sumber Data
Data yang digunakan adalah data yang diperoleh dari website www.halopizzaindonesia.com yang sudah didistribusikan ke outlet PHD Karawitan. File data berformat .xls dan tahapan pengolahan data untuk selanjutnya akan dilakukan proses import data.
b. Preprocessing
Pada tahap ini, data yang terkumpul akan diproses sehingga data yang didapat menjadi lebih terstruktur dan mudah untuk diolah. Langkah - langkah preprocessing terdiri dari case folding, tokenizing, stopword removal dan stemming.
c. Pembobotan Kata
Pada tahap ini akan dilakukan proses pengekstrakan keyword menggunakan nilai TF-IDF (Term Frequency – Inverse Document Frequency). Term (kata) di ambil dari hasil proses prepocessing terakhir yaitu stemming. Nilai dari hasil pembobotan akan digunakan sebagai tahapan pengklasifikasian menggunakan metode k-nearest neigbor.
d. Klasifikasi Sentimen
Langkah selanjutnya adalah proses pengklasifikasian yang akan diproses menggunakan metode k-nearest neigbor untuk menentukan mana yang termasuk opini puas dan mana yang termasuk opini tidak puas.
e. Visualisasi
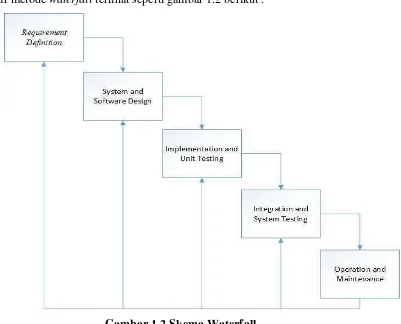
Metode pengembangan perangkat lunak yang digunakan pada penelitian ini adalah metode waterfall menurut referensi Ian Sommerville [3]. Secara garis besar metode waterfall terlihat seperti gambar 1.2 berikut :
Gambar 1.2 Skema Waterfall meliputi beberapa proses, diantaranya adalah sebagai berikut: 1. Requirement Definition
Tahap ini dilakukan analisis metode, algoritma dan kebutuhan yang diperlukan dalam pembangunan sistem. Analisis yang dilakukan anatara lain adalah analisis masalah, analisis masukan, analisis algoritma yang akan diimplementasikan pada sistem, analisis non-fungsional yang meliputi kebutuhan perangkat keras dan perangkat lunak, serta analisis fungsional.
2. System and Software Design
Tahapan inilah yang merupakan tahapan secara nyata dalam mengerjakan suatu sistem. dalam artian penggunaan komputer akan dimaksimalkan dalam tahapan ini. Tahap ini dilakukan pemrograman pada sistem yang dibungun, dalam tahap ini dilakukan implementasi algoritma pada sistem yang dibangun. Tahap ini juga dilakukan pemeriksaan terhadap sistem yang dibuat, apakah sudah memenuhi fungsi yang diinginkan atau belum.
4. Integration and System Testing
Di tahap ini dilakukan pengujian untuk mengetahui apakah sistem yang dibuat telah sesuai dengan desainnya dan untuk mengetahui apakah masih terdapat kesalahan atau tidak.
5. Operation and Maintenance
Mengoperasikan program dilingkungannya dan melakukan pemeliharaan, seperti
penyesuaian atau perubahan karena adaptasi dengan situasi sebenarnya.
Sistematika Penulisan
Penulisan Skripsi ini terbagi menjadi beberapa bab yang masing – masing bab membahas tentang :
BAB 1 PENDAHULUAN
Bab ini menjelaskan tentang latar belakang masalah, perumusan masalah, maksud dan tujuan, menentukan batasan masalah, serta menjelaskan mengenai metode penelitian dan sistematika penulisan.
BAB 2 TINJAUAN PUSTAKA
Bab ini menjelaskan tentang analisis masalah dari model penelitian untuk memperlihatkan keterkaitan antar variabel yang diteliti serta model matematis untuk analisisnya serta menjelaskan secara rinci mengenai tahapan pengerjaan dengan pendekata analisis orientasi berbasis objek, yaitu dengan analisis kebutuhan fungsionalitas atau use case, class diagram, sequence diagram dan jaringan semantik. Selain itu terdapat juga perancangan user interface atau rancangan antarmuka untuk sistem yang akan dibangun.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini menjelaskan mengenai implementasi dari hasil tahapan analisis dan perancangan aplikasi yang dibangun. Serta berisi pengujian perangkat lunak seperti pengujian black box, pengujian confusion matrix dan pengujian beta. BAB 5 KESIMPULAN DAN SARAN
9 2.1 Tinjauan Perusahaan
Tinjauan Perusahaan adalah untuk mengetahui keadaan perusahaan diantaranya adalah sejarah perusahaan, struktur organisasi serta visi dan misi. 2.1.1 Sejarah Perusahaan
2.1.2 Struktur Organisasi Perusahaan
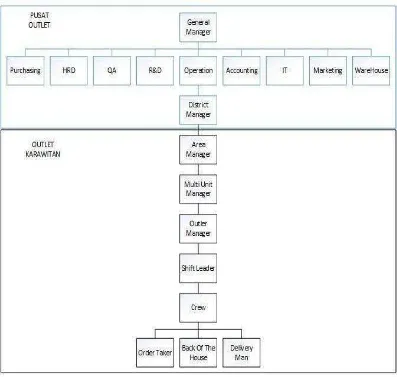
Struktur organisasi di Pizza Hut Delivery dapat dilihat dari gambar 2.1 berikut:
Gambar 2.1 Struktur Organisasi Perusahaan
Sistem organisasi sangat diperlukan untuk pengaturan tugas, tanggung jawab, dan wewenang dalam perusahaan. Berikut ini dijabarkan uraian singkat mengenai struktur organisasi di Pizza Hut Delivery.
1. General Manager
2. Purchasing
Departemen ini bertanggung jawab menyusun sistem pembelian untuk ingredient/bahan baku Ambil dan lokal yang dapat menjamin konsistensi ingredient/bahan baku sesuai dengan spesifikasi, sertifikat halal, dan pemasoknya. Selain itu, sesuai dengan daftar ingredient/bahan baku yang sudah disahkan oleh LPPOM/MUI.
3. Research and Development (R&D)
Departemen ini bertanggung jawab dalam mengembangkan atau menciptakan produk baru maupun menyempurnakan produk yang sudah ada, pengawasan kualitas untuk memenuhi kebutuhan pelanggan, menjamin kualitas produk yang dihasilkan sesuai dengan persyaratan pelanggan, serta membantu dan menjamin keberlangsungan semua sistem mutu yang dijalankan perusahaan. Ingredient/bahan baku yang digunakan untuk pengembangan produk baru harus sudah mendapatkan atau dalam proses sertifikasi halal.
4. Quality Assurance (QA)
Departemen QA bertanggung jawab dalam melakukan proses registrasi sertifikasi halal, pembuatan resep menu, melakukan pengawasan terhadap sanitasi lingkungan restoran, peralatan dan para karyawan, melakukan evaluasi performance supplier dengan menjalankan food safety dan quality system audit, dan melakukan evaluasi performance restoran atau melaksanakan audit internal terkait pengawasan proses produksi.
5. Human Resource Development (HRD)
dengan pihak luar dan keseluruhan aspek hukum yang berhubungan dengan perusahaan, seperti perizinan dengan pemerintah, sewa tanah dan gedung.
6. Operation
Departemen ini bertanggung jawab melakukan proses produksi sesuai dengan standar yang telah ditetapkan, melakukan proses dokumentasi administrasi keluar masuk ingredient/bahan baku, mengendalikan dan memonitor seluruh sistem di restoran, serta menyusun dan melaksanakan sistem penyimpanan ingredient yang dapat menjamin sistem halal. Dalam pelaksanaan tugasnya, operation terbagi menjadi beberapa bagian, antara lain:
a. District Manager (DM)
Membuat kebijakan umum di setiap area yang dipimpinnya. b. Area Manager (AM)
Memimpin beberapa outlet pada satu area dan bertanggung jawab tugas dan wewenang kepada District Manager.
c. Multi Unit Manager (MUM)
Membawahi 4-5 outlet dalam suatu wilayah. Memeriksa laporan dari Outlet Manager berupa laporan prestasi bisnis harian, dan laporan SOS. Laporan – laporan tersebut akan dianalisis oleh Multi Unit Manager(MUM)
d. Outlet Manager (OM)
Memegang penuh 1 outlet dan menjaga kelancaran aktivitas kerja. Selain itu melakukan pemesanan barang dan bahan baku pada supplier. Tugas lain dari OM adalah memberikan laporan-laporan administrasi kepada MUM dan AM.
e. Shift Leader (SL)
Memimpin dan menjamin kelancaran proses kerja pada shift yang dipimpinnya. Selain bertanggung jawab kepada OM tugas dari shift leader adalah melakukan pemesanan barang dan bahan baku pada supplier.
f. Crew Trainer (CT)
Memberikan pelatihan pada calon karyawan PHD. g. Crew
h. Order Taker
Pegawai yang bertugas menerima order dari customer dan menerima pembayaran. Tugas lainnya adalah menghitung persediaan barang dan bahan baku.
i. Back Of The House
Pegawai yang bertugas menyiapkan dan membuat produk yang dipesan oleh customer. Tugas lainnya adalah menghitung persediaan barang dan bahan baku.
j. Delivery Man
Pegawai yang bertugas mengirim produk yang dipesan oleh customer pada pembilan secara delivery. Tugas lainnya adalah menghitung persediaan barang dan bahan baku.
k. Accounting
Departemen ini bertanggung jawab atas keuangan perusahaan meliputi pengaturan aliran keuangan perusahaan, penyusunan sistem akuntansi, penyusunan anggaran perusahaan, menangani atau memproses masalah perpajakan, penyusunan laporan keuangan, melakukan analisis keuangan, serta melakukan kegiatan pembukuan yang terkait dengan administrasi kantor.
l. Information Technology (IT)
Departemen ini bertanggung jawab terhadap berlangsungnya kegiatan informasi baik secara internal maupun eksternal (pihak luar), melalui penyusunan sistem teknologi informasi, pengadaan perangkat komunikasi seperti komputer, hardware, software, dan jaringan (network) internet serta intranet, mengoperasikan dan memelihara infrastruktur IT, meliputi jaringan internet dan intranet, server, dan data center, serta melakukan pengembangan sistem layanan IT, termasuk pengembangan aplikasi sistem informasi.
m. Marketing
n. Warehouse
Departemen ini bertanggung jawab terhadap penerimaan, penyimpanan serta pengeluaran barang. Departemen ini juga bertugas membuat pemesanan barang pada purchasing, menjaga kestabilan keluar masuknya barang, melakukan dokumentasi terkait sistem penggudangan meliputi keluar masuknya barang, menjaga kualitas barang, berkoordinasi dengan divisi lain tentang pemakaian barang, melakukan cek stok fisik barang dengan stock card, serta melakukan penataan barang agar mudah dicari dan diambil.
2.1.3 Visi dan Misi
Visi dan misi Pizza Hut Delivery dirangkum dalam satu kalimat, yaitu “To be
Indonesia’s leading mid casual dining restaurant, offering great experience, and
the best pizza meal at affordable value” yang artinya menjadi pelopor kelas menengah kasual di Indonesia yang menawarkan pengalaman luar biasa dan pizza terbaik dengan harga terjangkau. Pizza Hut Delivery memiliki visi untuk menjadi yang terunggul pada tingkat restoran kelas menengah di Indonesia yang dicapai lewat misi menawarkan kenyamanan suasana yang terbaik dan menyajikan pizza terbaik dengan harga yang terjangkau.
Pizza Hut juga memiliki nilai-nilai organisasi yang dijadikan sebagai dasar dalam menjalankan organisasi serta membangun relasi dengan pelanggan, mitra usaha, dan pemegang saham. Keempat nilai tersebut antara lain :
1. Integritas, yaitu jujur dalam berpikir dan bekerja, dapat dipercaya, tulus, dan bersikap profesional saat berhubungan dengan rekan kerja, pelanggan, dan para supplier.
2. Keunggulan, yaitu melakukan pekerjaan yang lebih dari sekedar panggilan tugas dan melakukan lebih dari apa yang diharapkan.
3. Pertumbuhan Usaha, yaitu mengembangkan diri dan memperoleh keuntungan
4. Keuntungan, yaitu sedapat mungkin memberikan keuntungan kepada para pemegang saham dengan pengawasan dan peningkatan usaha penjualan.
2.2 Landasan Teori
Landasan teori ini merupakan bagian yang akan membahas tentang uraian pemecahan masalah yang akan ditemukan pemecahannya melalui pembahasan-pembahasan secara teoritis. Teori-teori yang akan dikemukakan merupakan dasar-dasar penulis untuk meneliti masalah – masalah yang akan dihadapi dalam penelitian. Mulai dari pembahasan mengenai sumber data dimana data itu diperoleh, kemudian penjelasan mengenai tahapan preprocessing, setelah data diperoleh kemudian dilakukan proses pembobotan (Term Weighting) Penjelasan teori – teori disini berkaitan dengan berbagai konsep dasar dan teori-teori yang berkaitan dalam pembangunan sistem analisis sentimen dengan menggunakan metode K-Nearest Neigbor.
2.2.1 Analisis Sentimen
Analisis sentimen merupakan suatu cara dalam menganalisis pendapat, penilaian, dan sikap terhadap suatu entitas seperti produk, karakter orang, pelayanan, peristiwa dan topik. Salah satu contoh dari pengaplikasian analisis sentimen yaitu suatu perusahaan ingin menilai kinerja perusahaan tersebut dan perusahaan tersebut menyediakan layanan untuk menerima opini dari konsumen mengenai kinerja perusahaan tersebut. Analisis sentimen digunakan untuk mengelompokkan opini positif dan negatif dari customer yang datang kepada perusahaan. Fokus utama dari analisis sentimen adalah untuk menyatakan mana yang termasuk opini positif dan mana yang termasuk opini negatif. Salah satu contoh penggunaan analisis sentimen dalam dunia nyata adalah identifikasi kecenderungan pasar dan opini pasar terhadap suatu objek barang. [4]
menghindari kejadian serupa untuk meningkatkan sentimen. Kebutuhan-kebutuhan tersebut biasanya muncul ketika suatu pihak ingin mendapatkan sentimen publik yang baik atau melakukan pencitraan. Kebutuhan seperti ini biasa dimiliki oleh tokoh-tokoh publik, atau lebih khusus lagi tokoh politik seperti calon gubernur, calon presiden, menteri, atau ketua partai. Hal ini juga memungkinkan individu untuk mendapatkan sebuah pandangan tentang sesuatu (review) pada skala global.
2.2.2 Preprocessing
Preprocessing merupakan proses menggali, mengolah, mengatur informasi dengan cara menganalisis hubungannya, aturan-aturan yang ada di data tekstual semi terstruktur atau tidak terstruktur. Untuk memudahkan informasi yang diinginkan maka dilakukan langkah transformasi data ke dalam suatu format yang sesuai dengan kebutuhan pemakai. Proses ini disebut preprocessing dokumen. Setelah dalam bentuk yang lebih terstruktur dengan adanya proses diatas data dapat dijadikan sumber data yang dapat diolah lebih lanjut. tahapannya terdiri dari case folding, convert emoticon, tokenizing, stopword removal dan stemming. 1. Case Folding
Pada tahap ini, semua huruf akan diubah menjadi huruf kecil. langkah-langkah pada tahap case folding adalah sebagai berikut :
1. Memeriksa ukuran setiap karakter dari awal sampai akhir karakter.
2. Jika ditemukan karakter yang menggunakan huruf kapital (uppercase), maka huruf tersebut akan diubah menjadi huruf kecil (lowercase).
2. Convert Negation
Convert Negation merupakan proses konversi kata-kata negasi yang terdapat pada suatu opini, karena kata negasi mempunyai pengaruh dalam merubah nilai sentimen pada suatu tweet. Jika terdapat kata negasi maka akan disatukan dengan kata setelahnya. Kata - kata negasi tersebut meliputi kata “bukan”, “tidak”, “tak”,
“ga”,”gak”, “enggak”, “jangan”,dan ”nggak”.
2. Jika ditemukan opini yang mengandung kata – kata negasi maka akan disatukan kata negasi tersebut dengan kata setelah kata negasi tersebut.
3. Tokenizing
Tokenizing merupakan tahap pemotongan kalimat berdasarkan tiap kata yang menyusunnya. Proses ini melakukan penguraian deskripsi yang semula berupa kalimat-kalimat menjadi kata-kata dan menghilangkan simbol seperti titik(.), tanda seru(!), tanda tanya (?), koma(,), spasi, emoticon.
Langkah-langkah pada tahap tokenizing adalah sebagai berikut: 1. Kata yang digunakan adalah hasil dari convert negation.
2. Memotong setiap kata dalam kalimat berdasarkan pemisah kata yaitu spasi. 3. Menghilangkan simbol seperti titik(.), tanda seru(!), tanda tanya (?), koma(,), spasi, emoticon.
4. Stopword Removal
Stopword didefinisikan sebagai term yang tidak berhubungan dengan subyek
utama dari database meskipun kata tersebut sering kali hadir di dalam dokumen dan
kata yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu
kategori sentimen. Kata-kata tersebut dimasukkan kedalam daftar stopword yang
biasanya berupa :
1. Kata ganti orang. Hanya dapat digunakan untuk mengganti nomina orang, nama
orang, atau hal-hal lain yang dipersonifikasikan. Misalnya : ia, Saudara, Bapak, Ibu,
Tuan, Nyonya, Mba, Mr, Mrs, karyawan, karyawati, pegawai dsb
2. Kata ganti penanya. Misalnya : apa, kapan, mengapa, siapa, bagaimana, berapa, di mana, ke mana, di dsb
3. Kata ganti petunjuk. Misalnya : ini, itu dsb
4. Kata ganti penghubung. Misalnya : yang, dan, atau dsb
5. Kata irrelevant. Misalnya : salah satu, karena, sangat, juga, agak, dengan, harus, dari, dgn, dg, yg, oke dsb
Untuk lebih lengkapnya daftar kata stopword removal dicatumkan dalam lampiran.
2. Jika kata sama dengan yang ada pada daftar stopword, maka akan dihilangkan.
5. Stemming
Stemming merupakan tahap untuk mentransformasi kata-kata yang terdapat
dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan
aturan-aturan tertentu. Dengan menggunakan stemming dapat mengurangi variasi kata yang sebenarnya memiliki kata dasar yang sama. Salah satu algoritma stemming yaitu Algoritma Nazief dan Adriani.
Algoritma stemming Nazief dan Adriani dikembangkan berdasarkan aturan morfologi Bahasa Indonesia yang mengelompokkan imbuhan menjadi awalan (prefix), sisipan (infix), akhiran (suffix) dan gabungan awalan-akhiran (confixes). Algoritma ini menggunakan kamus kata dasar dan mendukung recoding, yakni penyusunan kembali kata-kata yang mengalami proses stemming berlebih. Algoritma stemming Nazief dan Adriani menggunakan morfologi imbuhan sebagai berikut :
1. Inflection suffixes merupakan kumpulan akhiran (suffixes) yang tidak
merubah kata dasar. Misalnya kata ‘makan’+’-lah’-> ’makanlah’. Inflection suffixes terbagi menjadi :
a. Particles (P) seperti : ‘-lah’ dan ‘-kah’. Contoh : tidurlah, siapakah.
b. Possesive pronouns (PP) seperti : ‘-ku’,’-mu’ dan ‘nya’. Contoh : kataku, katamu, katanya.
2. Derivation suffixes (DS) merupakan kumpulan akhiran (suffixes) yang langsung menempel pada kata dasar, seperti : ‘-i’, ‘-an’ dan ‘kan’. Misalnya kata
dasar ‘singkir’ ditambahderivation suffix ‘-kan’ menjadi ‘singkirkan’.
1. Kata yang belum di-stemming dicari pada kamus. Jika kata itu langsung ditemukan, berarti kata tersebut adalah kata dasar. Kata tersebut dikembalikan dan algoritma dihentikan.
2. Hilangkan inflectional suffixes terlebih dahulu. Jika hal ini berhasil dan suffix
adalah partikel (“lah” atau ”kah”), langkah ini dilakukan lagi untuk menghilangkan inflectional possessive pronoun suffixes (“ku”, “mu” atau”nya”).
3. Derivational suffix (“-i”, “-an” dan “kan”) kemudian dihilangkan. Lalu langkah ini dilanjutkan lagi untuk mengecek apakah masih ada derivational suffix yang tersisa, jika ada maka dihilangkan. Jika tidak ada lagi maka lakukan langkah selanjutnya.
4. Kemudian derivational prefix (“di-“,”ke-“,”se-“,”te-“,”be-“,”me-“ dan “per-“
“) dihilangkan. Lalu langkah ini dilanjutkan lagi untuk mengecek apakah masih ada derivational prefix yang tersisa, jika ada maka dihilangkan. Jika tidak ada lagi maka lakukan langkah selanjutnya.
5. Setelah tidak ada lagi imbuhan yang tersisa, maka algoritma ini dihentikan kemudian kata dasar tersebut dicari pada kamus, jika kata dasar tersebut ketemu berarti algoritma ini berhasil tapi jika kata dasar tersebut tidak ketemu pada kamus, maka dilakukan recoding.
6. Jika semua langkah telah dilakukan tetapi kata dasar tersebut tidak ditemukan pada kamus juga maka algoritma ini mengembalikan kata yang asli sebelum dilakukan stemming.
Proses stemming dalam penelitian ini merupakan proses terakhir dari tahap preprocessing, setelah opini hasil preprocessing sudah dilakukan maka dilakukan pembobotan kata agar opini bisa diklasifikasikan menggunakan metode KNN. 2.2.3 Pembobotan(Term Weighting)
Term weighting merupakan tahapan untuk memberikan suatu nilai/bobot pada term yang terdapat pada suatu dokumen yang telah berhasil diekstrak. Metode yang
akan digunakan untuk melakukan pembobotan terhadap term adalah pembobotan
TF-IDF. Metode Term Frequency-Inverse Document Frequency (TF-IDF) adalah cara
konsep untuk perhitungan bobot, yaitu Term frequency (TF) merupakan frekuensi kemunculan kata (t) pada kalimat (d). Document frequency (DF) adalah banyaknya kalimat dimana suatu kata (t) muncul. Bobot kata semakin besar jika sering muncul dalam suatu dokumen dan semakin kecil jika muncul dalam banyak dokumen. Pada Metode ini pembobotan kata dalam sebuah dokumen dilakukan dengan mengalikan nilai TF dan IDF. Pembobotan diperoleh berdasarkan jumlah kemunculan term dalam kalimat (TF) dan jumlah kemunculan term pada seluruh kalimat dalam dokumen (IDF).
Nilai IDF sebuah term dihitung menggunakan persamaan di bawah: Wd.t = TFd.t * IDFt... (2.1)
Keterangan :
W = bobot kalimat ke-d d = Kalimat ke-d TF = term frequency t = Kata(term) ke-t IDF = inverse document frequency
Menghitung bobot (W) masing-masing dokumen dengan persamaan di bawah: IDF = log (
Dfi N
)... (2.2)
Keterangan :
IDF = inverse document frequency N = Jumlah kalimat yang berisi term(t) Dfi = Jumlah kemunculan term terhadap D
Pembobotan kata dilakukan setelah melalui tahap preprocessing, nilai dari hasil pembobotan kata maka akan digunakan untuk menghitung nilai kemiripan antar dokumen(Cosine Similarity) yang dimana merupakan tahap dalam pengklasifikasian opini menggunakan metode KNN.
Berikut merupakan langkah – langkah dalam pembobotan :
1. Buat Susunan per record kata – kata baik opini data latih ataupun data uji, kata – kata yang muncul lebih dari 1 hanya dituliskan 1x
3. Hitung jumlah Kata – kata yang muncul di semua data latih dan uji(df) 4. Hitung Idf menggunakan persamaan (2.2)
Kalikan masing – masing W dengan masing – masing Tf sesuai dengan pasanganya. Contoh : Tf(i) *W(i)
2.2.4 Klasifikasi
Secara harfiah klasifikasi merupakan penggolongan atau pengelompokkan. Ada beberapa pengertian mengenai klasifikasi, namun jika berbicara berhubungan dengan text mining, klasifikasi yaitu proses pencarian sekumpulan model atau fungsi yang menggambarkan dan membedakan kelas data,yang tujuanya untuk memprediksi kelas dari suatu obyek yang belum diketahui kelasnya. Ada 2 proses klasifikasi yaitu membangun model klasifikasi dari sekumpulan kelas data yang sudah didefinisikan sebelumnya atau biasa disebut data training set dan menggunakan model tersebut untuk klasifikasi tes data serta mengukur akurasi dari model. Klasifikasi dapat dimanfaatkan dalam berbagai aplikasi seperti diagnosa medis, selective marketing, pengajuan kredit perbankan, email dan analisis sentimen. Model klasifikasi dapat disajikan dalam berbagai macam model klasifikasi seperti decision trees, naïve bayes classifier, k-nearest neighbor classifier, neural network dan lain-lain
2.2.4.1. K-Nearest Neighbor
K-Nearest Neighbor (KNN) adalah suatu metode yang menggunakan algoritma supervised dimana hasil dari query instance yang baru diklasifikan berdasarkan mayoritas dari kategori pada KNN. Tujuan dari algoritma ini adalah mengklasifikasikan obyek baru bedasarkan atribut dan training sample. Classifier tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan pada memori. Diberikan titik query, akan ditemukan sejumlah k obyek atau (titik training) yang paling dekat dengan titik query. Klasifikasi menggunakan voting terbanyak diantara klasifikasi dari k obyek.. algoritma KNN menggunakan klasifikasi ketetanggaan sebagai nilai prediksi dari query instance yang baru.
masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menjadi bagian-bagian berdasarkan klasifikasi training sample. Pada fase training, algoritma ini hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi data training sample. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk testing data (yang klasifikasinya tidak diketahui). Jarak dari vektor baru yang ini terhadap seluruh vektor training sample dihitung dan sejumlah k buah yang paling dekat diambil. Titik yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak dari titik-titik tersebut.
Nilai k yang terbaik untuk algoritma ini tergantung pada data training. k dipilih dengan nilai ganjil akan mendapatkan hasil yang lebih baik dibandingkan dengan k dengan nilai genap, karena akan relevan terhadap kasus, dengan kategori yang sama nilai jumlahnya. nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Ketepatan algoritma KNN sangat dipengaruhi oleh ada atau tidaknya fitur-fitur yang tidak relevan atau jika bobot fitur-fitur tersebut tidak setara dengan relevansinya terhadap klasifikasi. Riset terhadap algoritma ini sebagian besar membahas bagaimana memilih dan memberi bobot terhadap fitur agar performa klasifikasi menjadi lebih baik.
KNN memiliki beberapa kelebihan yaitu ketangguhan terhadap training data yang memiliki banyak noise dan efektif apabila training data-nya besar. Sedangkan, kelemahan KNN adalah KNN perlu menentukan nilai dari parameter k (jumlah dari tetangga terdekat), training berdasarkan jarak tidak jelas mengenai jenis jarak apa yang harus digunakan dan atribut mana yang harus digunakan untuk mendapatkan hasil terbaik, dan biaya komputasi cukup tinggi karena diperlukan perhitungan jarak dari tiap query instance pada keseluruhan training sample. [6]
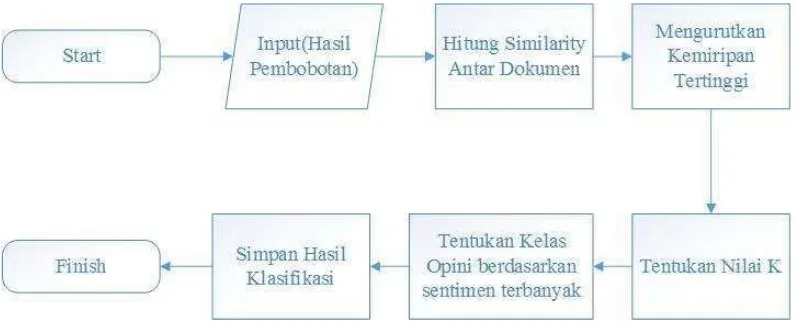
Gambar 2.2 Diagram alir K-Nearest Neighbor
1. Hitung jarak antara data sampel (data uji) dengan data latih yang telah dibangun. Salah satu persamaan dalam menghitung jarak kedekatan dapat menggunakan persamaan 2.3 Cosine Similarity.
2. Menentukan parameter nilai k = jumlah tetanggaan terdekat bebas. 3. Mengurutkan jarak terkecil dari data uji
4. Pasangkan kategori sesuai dengan kesesuaian
5. Cari jumlah terbanyak dari tetanggaan terdekat Kemudian tetapkan kategori. Jarak yang digunakan dalam penelitian ini adalah Cosine Similarity. [7]
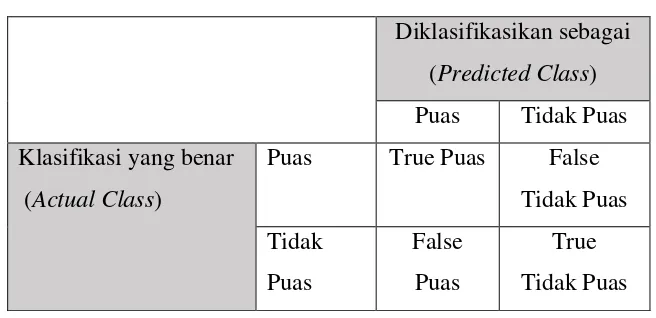
umumnya dievaluasi dengan menggunakan data dalam matriks. Tabel berikut menunjukkan confusion matrix untuk klasifikasi dua kelas.
Metode ini menggunakan tabel matriks seperti pada Tabel 2.3 jika data set
True puas adalah jumlah record puas yang diklasifikasikan sebagai puas, false puas adalah jumlah record puas yang diklasifikasikan sebagai tidak puas, false tidak puas adalah jumlah record tidak puas yang diklasifikasikan sebagai puas, true tidak puas adalah jumlah record tidak puas yang diklasifikasikan sebagai tidak puas. Setiap kolom dari confusion matrix merupakan contoh di kelas yang telah diprediksi, sedangkan setiap baris mewakili contoh di kelas yang sebenarnya. Setelah didapat true puas, false tidak puas, true tidak puas dan false tidak puas, selanjutnya hitung untuk menghitung nilai akurasinya. Berikut persamaan dari akurasi.
subset yang berukuran sama. Pertama, pilih satu dari kedua subset tersebut untuk training dan satu lagi untuk testing. Kemudian dilakukan pertukaran fungsi dari subset sedemikian sehingga subset yang sebelumnya sebagai training set menjadi test set demikian sebaliknya. Pendekatan ini dinamakan two-fold cross validation. Total error diperoleh dengan menjumlahkan error –error untuk kedua proses tersebut.
Setiap record digunakan tepat satu kali untuk training dan satu kali untuk testing. Metode k-fold cross-validation mengeneralisasi pendekatan ini dengan mensegmentasi data ke dalam k partisi berukuran sama. Selama proses, salah satu dari partisi dipilih untuk testing, sedangkan sisanya digunakan untuk training. Prosedur ini diulangi k kali sedemikian sehingga setiap partisi digunakan untuk testing tepat satu kali. Total error ditentukan dengan menjumlahkan error untuk semua k proses tersebut [9].
Metode k-fold cross-validation menetapkan k = N, ukuran dari data set. Metode ini dinamakan pendekatan leave-one-out, setiap test set hanya mengandung satu record. Pendekatan ini memiliki keuntungan dalam pengunaan sebanyak mungkin data untuk training. Test set bersifat mutually exclusive dan secara efektif mencakup keseluruhan data set. Kekurangan dari pendekatan ini adalah banyaknya komputasi untuk mengulangi prosedur sebanyak N kali.
K-fold cross-validation adalah salah satu teknik untuk mengevaluasi keakuratan model, dengan ciri-ciri [10]:
1. Mempartisi data secara random ke dalam k buah himpunan/fold yaitu D1, D2, ..Dk. Setiap kelompok mempunyai jumlah yang hampir sama.
2. Pada perulangan i, gunakan Di sebagai data uji dan himpunan lainnya sebagai data pelatihan Contoh :
a. Pada perulangan ke-1 : D1 sebagai data uji dan D2 s.d .Dk sebagai data pelatihan
b. Pada perulangan ke-2 : D2 sebagai data uji dan D1, D3 s.d. Dk sebagai data pelatihanan dan seterusnya
Sebagai gambaran jika kita melakukan 3-Fold Cross-Validation maka desain data eksperimenya adalah sebagai berikut :
Dataset :
Tabel 2.2 Data Set
K1 K2 K3
Data Subset :
Tabel 2.3 Data Subset
Eksperimen ke Training Testing
1. K2, K3 K1
2. K1, K3 K2
3. K1, K2 K3
Untuk mendapatkan nilai akurasi ataupun ukuran penilaian lainnya dari hasil subset yang kita lakukan, dapat diambil nilai rataan dari seluruh subset tersebut. 2.3.Object Oriented Programming
OOP (Object Oriented Programming) adalah suatu metode pemrograman yang berorientasi kepada objek. Tujuan dari OOP yaitu untuk mempermudah pengembangan program dengan cara mengikuti model yang telah ada di kehidupan sehari-hari. Jadi setiap bagian dari suatu permasalahan adalah objek, dan objek merupakan gabungan dari beberapa objek yang lebih kecil. Adapun konsep pada pemrograman berorientasi objek ini yaitu:
1. Class
Class yaitu penggambaran dari sebuah objek atau benda, sifat objek, dan juga apa yang bisa dilakukan oleh objek tersebut.
2. Object
3. Abstraction
Abstarction adalah suatu cara untuk melihat suatu object dalam bentuk yang lebih sederhana. Dengan Abstraction, suatu sistem yang kompleks dapat dipandang sebagai kumpulan subsistem-subsistem yang lebih sederhana,
4. Encapsulation
Encapsulation yaitu membungkus suatu objek sehingga pada saat kita akan memakai objek tersebut kita tidak perlu lagi tahu tentang detail bagaimana suatu action itu terjadi.
5. Polymorphisms
Polymorphisms merupakan suatu object bisa bertindak lain terhadap
message/method yang sama. Dalam OOP, diterapkan tipe polymorphism melalui proses yang disebut overloading. Dapat dilakukan dalam implementasi metode yang berbeda pada sebuah object yang mempunyai nama yang sama.
6. Inheritance
2.4.Unified Modeling Languange
UML adalah sebuah bahasa yang berdasarkan grafik/gambar untuk memvisualisasi, menspesifikasikan, membangun, dan pendokumentasian dari sebuah sistem pengembangan software berbasis OO (Object-Oriented). Diagram – diagram yang ada pada di UML diantaranya adalah sebagai berikut :
1. Use Case Diagram
Use case diagram digunakan untuk memodelkan bisnis proses berdasarkan perspektif pengguna sistem. Use case diagram terdiri atas diagram untuk use case dan actor. Actor merepresentasikan orang yang akan mengoperasikan atau orang yang berinteraksi dengan sistem aplikasi. Fungsi Use case diagram yaitu Menjelaskan fasilitas – fasilitas yang ada sesuai dengan kebutuhan.
2. Activity Diagram
Activity diagram adalah proses yang menggambarkan berbagai alir aktivitas dalam sistem yang sedang dirancang, bagaimana masing-masing alir berawal, dan gambaran – gambaran kemungkinan yang terjadi, dan bagaimana alir berakhir. 3. Sequence Diagram
Sequence diagram menjelaskan secara detil urutan proses yang dilakukan dalam sistem untuk mencapai tujuan dari use case. Interaksi yang terjadi antar class, operasi apa saja yang terlibat, urutan antar operasi, dan informasi yang diperlukan oleh masing-masing operasi. Fungsi sequence diagram untuk menggambarkan perilaku pada sebuah scenario. Kegunaannya untuk menunjukkan rangkaian pesan yang dikirim antara object juga interaksi antara object, sesuatu yang terjadi pada titik tertentu dalam eksekusi sistem.
4. Class Diagram
85
Berdasarkan hasil implementasi dan pengujian yang telah dilakukan pada sistem analisis sentimen dengan menggunakan metode K-nearest neigbor ini maka dapat diambil kesimpulan bahwa, sistem analisis sentimen ini dapat mengklasifikasikan opini secara otomatis dan dapat memberikan informasi mengenai persentase sentimen puas dan sentimen tidak puas sehingga dapat membantu mempermudah pekerjaan Outlet Manager khususnya dalam pengklasifikasian penilaian customer(opini).
5.2 Saran
Saran untuk pengembangan lebih lanjut, yaitu sebagai berikut:
1. Penambahan jumlah data latih untuk mendapatkan hasil yang lebih baik saat klasifikasi penilaian customer.
1. DATA PRIBADI
Nama : Taufik Hidayat Supratman
Jenis Kelamin : Laki-Laki
Tempat, Tanggal Lahir : Bandung, 24 Oktober 1993
Agama : Islam
Kewarganegaraan : Indonesia
Status : Belum Kawin
Anak ke : 4 dari 4 bersaudara
Alamat : Jalan Pasir Huni No 69 RT 01 RW 09
No. Telepon : 089502242525
Email : [email protected]
2. RIWAYAT PENDIDIKAN
1. Sekolah Dasar : SDN Pasir Luyu III
Tahun Ajaran (1999 -2005) 2. Sekolah Menengah Pertama : SMP 11 Maret Bandung
Tahun Ajaran (2005-2008) 3. Sekolah Menengah Atas : SMAN 8 Bandung
Tahun Ajaran (2008-2011) 4. Perguruan Tinggi : Universitas Komputer Indonesia
Tahun Ajaran (2011-2015) Demikian riwayat hidup ini saya buat dengan sebenar-benarnya dalam keadaan sadar dan tanpa paksaan.
Bandung, 19 Agustus 2015
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
TAUFIK HIDAYAT SUPRATMAN
10111395
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
v
ABSTRACT ... ii
vi
vii
87
[2] K. Khamar, "Short Text Classification Using KNN Based on Distance Function," International journal of advanced research in computer and communication engineering, 2013.
[3] I. Sommerville, Software Engineering, jakarta: Erlangga, 2003. [4] B. P. a. L. Lee, ""Opinion Mining and Sentiment Analysis","
Foundations and Trends in Information Retrieval, vol II, no 1-2, pp.
1-135.
[5] Agusta, "Perbandingan Algoritma Stemming Porter Dengan Algoritma Nazief & Adriani Untuk Stemming Dokumen Teks Bahasa Indonesia," Konferensi Nasional Sistem dan Informatika, 2009. [6] Evan, Buku TA : K-Nearest Neigbor(KNN), Jakarta: Informatika,
2010.
[7] D. E. Garcia, "The Classic Vector Space Model (Description, Advantages and Limitations of the Classic Vector Space Model)," 2005.
[8] K. a. Provost, "On Applied Research in Machine Learning," In Editorial for the Special Issue on Applications of Machine Learning and the Knowledge Discovery Process, 1998.
[9] J.Han, "Data Mining : Concepts and techniques, Morgan Kaufman,," 2006.
[10] Nugroho, "SVM : Paradigma Baru dalam Softcomputing dan Aplikasinya," Konferensi Nasional Sistem & Informatika, 2008. [11] Sudarsono, "[Online] Analisis Dan Perancangan Sistem," Available :
MENGGUNAKAN METODE K-NEAREST NEIGBOR
Taufik Hidayat Supratman
Teknik Informatika –Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
E-mail : [email protected]
ABSTRAK
PHD (Pizza hut delivery) menyediakan wadah untuk berbagi pengalaman customer berupa penilaian terhadap outlet PHD yang dikunjunginya yang dapat disalurkan melalui website www.halopizzaindonesia.com. Opini yang masuk akan didistribusikan ke masing-masing outlet PHD termasuk outlet PHD Karawitan. Outlet Manager ditugaskan untuk menghitung persentase penilaian kepuasan customer dengan cara mempelajari opini
yang disampaikan oleh customer dan
mengelompokkan penilaian kedalam beberapa klasifikasi yaitu opini puas dan opini tidak puas. Jumlah penilaian yang banyak membuat outlet manager mengalami kesulitan dikarenakan harus mengelompokkan opini satu persatu dari sekian banyaknya opini yang ada lalu menghitung persentase kepuasan customer secara manual.
Untuk mempermudah pekerjaan outlet manager
terutama khusus dalam pengelompokkan penilaian berupa opini customer, maka diperlukan suatu metode yang dapat menganalisis opini secara otomatis. Salah satu cara yang dapat digunakan untuk mengelompokan opini yaitu dengan menggunakan metode analisis sentimen. Metode analisis sentimen yang di gunakan dalam penelitian ini yaitu menggunakan algoritma K-nearest neigbor. Tahapannya terdiri dari preprocessing, pembobotan kata, dan klasifikasi k-nearest neigbor.
Berdasarkan hasil implementasi dan pengujian yang telah dilakukan algoritma k-nearest neigbor dapat diterapkan pada kasus penelitian customer di PHD Karawitan dan dapat membantu mempermudah
outlet manager dengan pengelompokkan penilaian
opini puas dan opini tidak puas secara otomatis serta dapat menghitung persentase opini tersebut.
Kata kunci : K-nearest neigbor, Opini, Pizza Hut
delivery, PHD.
1. PENDAHULUAN
PHD (Pizza hut delivery) adalah perusahaan yang bergerak di bidang kuliner. Untuk mengetahui pelayanan yang diberikan dari tiap outlet, maka
PHD menyediakan wadah untuk berbagi
pengalaman customer berupa penilaian terhadap outlet PHD yang dikunjunginya. Penilaian customer
dapat disalurkan melalui website
www.halopizzaindonesia.com. Semua penilaian yang tersimpan di website tersebut akan didistribusikan ke masing-masing outlet PHD diseluruh Indonesia. Outlet Manager ditugaskan untuk menghitung persentase penilaian yang masuk seberapa besar kepuasan customer yang di dapat dengan cara mempelajari opini yang disampaikan oleh customer
Dalam penelitian ini outlet PHD yang akan dijadikan tempat penelitian yaitu outlet PHD Karawitan. Jumlah penilaian yang banyak membuat outlet manager mengalami kesulitan dikarenakan harus mengelompokkan opini satu persatu dari sekian banyaknya opini yang ada lalu menghitung persentase kepuasan customer secara manual. Salah satu cara yang dapat digunakan untuk mengelompokan opini yaitu dengan menggunakan metode analisis sentimen.
Analisis sentimen merupakan suatu metode dalam menganalisis pendapat, penilaian, dan sikap terhadap suatu entitas seperti produk, pelayanan, peristiwa, dan topik. [1] Berdasarkan penelitian sebelumnya pada pengklasifikasian text yang mencoba membandingkan tingkat akurasi dari 3 algoritma langsung yaitu metode naive bayes, metode k-nearest neighbor(KNN), metode support vector machine(SVM) didapat bahwa metode K-NN memiliki tingkat akurasi yang lebih tinggi dibandingkan dengan metode naive bayes dan metode support vector machine(SVM). [2].
1.1Metode Pembangunan Analisis Sentimen
Sistem analisis sentimen yang akan dibangun akan melewati tahapan tahapan terdiri dari :
a. Analisis Sumber Data
sehingga data yang didapat menjadi lebih terstruktur dan mudah untuk diolah. Langkah - langkah preprocessing terdiri dari case folding, tokenizing, stopword removal dan stemming.
c. Pembobotan Kata
Pada tahap ini akan dilakukan proses pengekstrakan keyword menggunakan nilai TF-IDF (Term Frequency – Inverse Document Frequency). Term (kata) di ambil dari hasil proses prepocessing terakhir yaitu stemming. Nilai dari hasil pembobotan akan digunakan sebagai tahapan pengklasifikasian menggunakan metode k-nearest neigbor.
d. Klasifikasi Sentimen
Langkah selanjutnya adalah proses pengklasifikasian yang akan diproses menggunakan metode k-nearest neigbor untuk menentukan mana yang termasuk opini puas dan mana yang termasuk opini tidak puas. e. Visualisasi
Hasil dari tahap klasifikasi sentimen akan digambarkan dalam bentuk diagram lingkaran. Data diambil dari jumlah opini puas dan opini tidak puas lalu ditampilkan dalam bentuk persentase pada diagram
1.2Metode Pembangunan Perangkat Lunak
Metode pengembangan perangkat lunak yang digunakan pada penelitian ini adalah metode waterfall menurut referensi Ian Sommerville [3]. Secara garis besar metode waterfall terlihat seperti gambar 1.1 berikut :
Gambar 1.1 Metode Waterfall
2 ISI PENELITIAN
2.1 Analisis Sentimen
Analisis sentimen merupakan suatu cara dalam menganalisis pendapat, penilaian, dan sikap terhadap suatu entitas seperti produk, karakter orang, pelayanan, peristiwa dan topic. Salah satu contoh penggunaan analisis sentimen dalam dunia nyata adalah identifikasi kecenderungan pasar dan opini pasar terhadap suatu objek barang. [4]
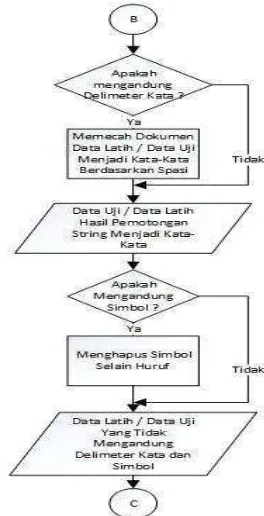
menganalisis hubungannya, aturan-aturan yang ada di data tekstual semi terstruktur atau tidak terstruktur. bagian – bagian tahapan dari preprocessing, dapat dijelaskan dengan menggunakan flowchart berjenis Flowchart Sistem, yaitu bagan yang menunjukkan alur kerja atau apa yang sedang dikerjakan di dalam sistem secara keseluruhan dan menjelaskan urutan dari prosedur-prosedur yang ada di dalam sistem [11].
1. Case Folding
Pada tahap ini, semua huruf akan diubah menjadi huruf kecil.
langkah-langkah pada tahap case folding adalah sebagai berikut :
1. Memeriksa ukuran setiap karakter dari awal sampai akhir karakter.
2. Jika ditemukan karakter yang menggunakan huruf kapital (uppercase), maka huruf tersebut akan diubah menjadi huruf kecil (lowercase). Berikut flowchart case folding terlihat pada gambar 2.1
Gambar 2.1Flowchart Case folding
2. Convert Negation
adalah sebagai berikut :
1. Kata yang digunakan adalah hasil dari case folding
2. Jika ditemukan opini yang mengandung kata – kata negasi maka akan disatukan kata negasi tersebut dengan kata setelah kata negasi tersebut.
Berikut flowchart Convert Negation terlihat pada gambar 2.2
Gambar 2.2 flowchart Convert Negation
3. Tokenizing
Tokenizing merupakan tahap pemotongan kalimat berdasarkan tiap kata yang menyusunnya. Proses ini melakukan penguraian deskripsi yang semula berupa kalimat-kalimat menjadi kata-kata dan menghilangkan simbol seperti titik(.), tanda seru(!), tanda tanya (?), koma(,), spasi, emoticon. Langkah-langkah pada tahap tokenizing adalah sebagai berikut:
1. Kata yang digunakan adalah hasil dari convert negation.
2. Memotong setiap kata dalam kalimat berdasarkan pemisah kata yaitu spasi.
3. Menghilangkan simbol seperti titik(.), tanda seru(!), tanda tanya (?), koma(,), spasi, emoticon. Berikut flowchart Tokenizing terlihat pada gambar 2.3
Gambar 2.3 flowchart Tokenizing
4. Stopword Removal
Stopword didefinisikan sebagai term yang tidak berhubungan dengan subyek utama dari database meskipun kata tersebut sering kali hadir di dalam dokumen dan kata yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu kategori sentimen.
Kata-kata tersebut dimasukkan kedalam daftar stopword yang biasanya berupa :
1. Kata ganti orang. Hanya dapat digunakan untuk mengganti nomina orang, nama orang, atau hal-hal lain yang dipersonifikasikan. Misalnya : ia, Saudara, Bapak, Ibu, Tuan, Nyonya, Mba, Mr, Mrs, karyawan, karyawati, pegawai dsb
2. Kata ganti penanya. Misalnya : apa, kapan, mengapa, siapa, bagaimana, berapa, di mana, ke mana, di dsb
3. Kata ganti petunjuk. Misalnya : ini, itu dsb 4. Kata ganti penghubung. Misalnya : yang, dan, atau dsb
5. Kata irrelevant. Misalnya : salah satu, karena, sangat, juga, agak, dengan, harus, dari, dgn, dg, yg, oke dsb
Langkah-langkah pada stopword removal adalah sebagai berikut:
1. Kata hasil tokenizing akan dibandingkan dengan daftar stopword.Dilakukan pengecekan apakah kata sama dengan daftar stopword atau tidak.
2. Jika kata sama dengan yang ada pada daftar stopword, maka akan dihilangkan.
Gambar 2.4 flowchart StopWord Removal
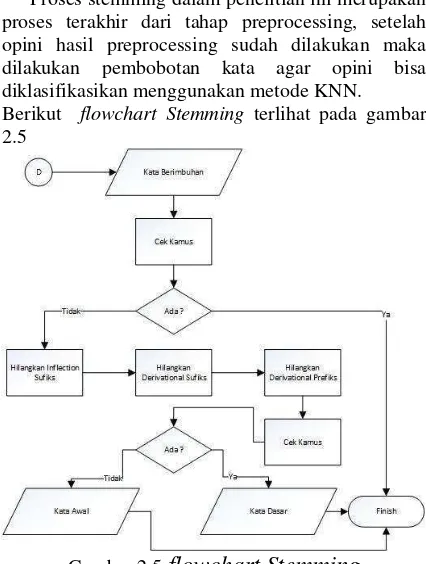
5. Stemming
Stemming merupakan tahap untuk
mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Dengan menggunakan stemming dapat mengurangi variasi kata yang sebenarnya memiliki kata dasar yang sama. Salah satu algoritma stemming yaitu Algoritma Nazief dan Adriani[5].
Langkah – langkah stemming menggunakan Algoritma Nazief dan Adriani adalah sebagai berikut :
1. Kata yang belum di-stemming dicari pada kamus. Jika kata itu langsung ditemukan, berarti kata tersebut adalah kata dasar. Kata tersebut dikembalikan dan algoritma dihentikan.
2. Hilangkan inflectional suffixes terlebih dahulu.
Jika hal ini berhasil dan suffix adalah partikel (“lah” atau ”kah”), langkah ini dilakukan lagi untuk
menghilangkan inflectional possessive pronoun
suffixes (“ku”, “mu” atau”nya”).
3. Derivational suffix (“-i”, “-an” dan “kan”) kemudian dihilangkan. Lalu langkah ini dilanjutkan lagi untuk mengecek apakah masih ada derivational suffix yang tersisa, jika ada maka dihilangkan. Jika tidak ada lagi maka lakukan langkah selanjutnya. 4. Kemudian derivational prefix (“di-“,”ke-“,”se
-“,”te-“,”be-“,”me-“ dan “per-“ “) dihilangkan. Lalu langkah ini dilanjutkan lagi untuk mengecek apakah masih ada derivational prefix yang tersisa, jika ada maka dihilangkan. Jika tidak ada lagi maka lakukan langkah selanjutnya.
Proses stemming dalam penelitian ini merupakan proses terakhir dari tahap preprocessing, setelah opini hasil preprocessing sudah dilakukan maka dilakukan pembobotan kata agar opini bisa diklasifikasikan menggunakan metode KNN. Berikut flowchart Stemming terlihat pada gambar 2.5
Gambar 2.5 flowchart Stemming
2.2.2Pembobotan Kata(TF IDF)
Term weighting merupakan tahapan untuk memberikan suatu nilai/bobot pada term yang terdapat pada suatu dokumen setelah melewati preprocessing.
Idf = log ( Dfi
N
) (2.2)
IDF = inverse document frequency N = Jumlah kalimat yang berisi term(t) Dfi = Jumlah kemunculan term terhadap D
Pembobotan kata dilakukan setelah melalui tahap preprocessing, nilai dari hasil pembobotan kata maka akan digunakan untuk menghitung nilai kemiripan antar dokumen(Cosine Similarity) yang dimana merupakan tahap dalam pengklasifikasian opini menggunakan metode KNN.
2. Isi angka 1 apabila katanya muncul di setiap (tf) baik data latih atau data uji, apabila tidak muncul isi angka 0
3. Hitung jumlah Kata – kata yang muncul di semua data latih dan uji(df)
4. Hitung Idf menggunakan persamaan (2.2) Kalikan masing – masing W dengan masing – masing Tf sesuai dengan pasanganya. Contoh : Tf(i) *W(i)
Contoh kasus :
k1 : layanan cepat ramah
k2 : layanan kurang muas kurang sopan
Tabel 2.1 PembobotaN Kata
Hasil nilai dari pembobotan akan digunakan untuk perhitungan cosine simmilirity pada metode KNN.
2.2.3 Klasifikasi K-Nearest Neigbor(KNN)
K-Nearest Neighbor (KNN) adalah suatu metode yang menggunakan algoritma supervised dimana hasil dari query instance yang baru diklasifikan berdasarkan mayoritas dari kategori pada KNN. KNN memiliki beberapa kelebihan yaitu ketangguhan terhadap training data yang memiliki banyak noise dan efektif apabila training data-nya besar. Sedangkan, kelemahan KNN adalah KNN perlu menentukan nilai dari parameter k (jumlah dari tetangga terdekat), training berdasarkan jarak tidak jelas mengenai jenis jarak apa yang harus digunakan dan atribut mana yang harus digunakan untuk mendapatkan hasil terbaik, dan biaya komputasi cukup tinggi karena diperlukan perhitungan jarak dari tiap query instance pada keseluruhan training sample. [6].
Gambar 2.6 Alir Diagram K-Nearest Neigbor(KNN)
dalam menghitung jarak kedekatan Cosine Similarity.
3. Mengurutkan jarak terkecil dari data uji 4. Pasangkan kategori sesuai dengan kesesuaian Cari jumlah terbanyak dari tetanggaan terdekat Kemudian tetapkan kategori. [7]
2.2.4Pengujian Confusion Matrix
Confusion Matrix [8] berisi informasi tentang klasifikasi aktual dan yang telah diprediksi yang dilakukan oleh sistem klasifikasi. Kinerja sistem tersebut umumnya dievaluasi dengan menggunakan data dalam matriks. Tabel berikut menunjukkan confusion matrix untuk klasifikasi dua kelas.
Tabel 2.2 Confusion Matrix
2.2.5Pengujian K-Fold Cross-Validation
Dalam pendekatan K-fold cross-validation, setiap record digunakan beberapa kali dalam jumlah yang sama untuk training dan tepat sekali untuk testing. Untuk mengilustrasikan metode ini, anggaplah seperti mempartisi data ke dalam dua subset yang berukuran sama. Pertama, pilih satu dari kedua subset tersebut untuk training dan satu lagi untuk testing. Kemudian dilakukan pertukaran fungsi dari subset sedemikian sehingga subset yang
dengan menjumlahkan error –error untuk kedua proses tersebut.Setiap record digunakan tepat satu kali untuk training dan satu kali untuk testing. Metode k-fold cross-validation mengeneralisasi pendekatan ini dengan mensegmentasi data ke dalam k partisi berukuran sama. Selama proses, salah satu dari partisi dipilih untuk testing, sedangkan sisanya digunakan untuk training. Prosedur ini diulangi k kali sedemikian sehingga setiap partisi digunakan untuk testing tepat satu kali. Total error ditentukan dengan menjumlahkan error untuk semua k proses tersebut [9].
Metode k-fold cross-validation menetapkan k = N, ukuran dari data set. Metode ini dinamakan pendekatan leave-one-out, setiap test set hanya mengandung satu record. Pendekatan ini memiliki keuntungan dalam pengunaan sebanyak mungkin data untuk training. Test set bersifat mutually exclusive dan secara efektif mencakup keseluruhan data set. Kekurangan dari pendekatan ini adalah banyaknya komputasi untuk mengulangi prosedur sebanyak N kali.
K-fold cross-validation adalah salah satu teknik untuk mengevaluasi keakuratan model, dengan ciri-ciri [10]:
1. Mempartisi data secara random ke dalam k buah himpunan/fold yaitu D1, D2, ..Dk. Setiap kelompok mempunyai jumlah yang hampir sama.
2. Pada perulangan i, gunakan Di sebagai data uji dan himpunan lainnya sebagai data pelatihan Contoh :
a. Pada perulangan ke-1 : D1 sebagai data uji dan D2 s.d .Dk sebagai data pelatihan
b. Pada perulangan ke-2 : D2 sebagai data uji dan D1, D3 s.d. Dk sebagai data pelatihanan dan seterusnya
c. Melakukan training dan pengujian sebanyak k kali
d. Menghitung keakuratan dengan rumus.
Sebagai gambaran jika kita melakukan 3-Fold Cross-Validation maka desain data eksperimenya adalah sebagai berikut :
Dataset : Tabel 1.3 Data Set
K1 K2 K3
Data Subset : Tabel Error! No text of specified
style in document..4 Data Subset
Eksperimen ke Training Testing
1. K2, K3 K1
2. K1, K3 K2
3. K1, K2 K3
Pengujian blackbox yang akan digunakan dalam penelitian ini yaitu pengujian fungsional. Pada pengujian ini, perangkat lunak di uji untuk persyaratan fungsional. Pengujian dilakukan dalam bentuk tertulis untuk memeriksa apakah aplikasi berjalan seperti yang diharapkan. Pengujian fungsional meliputi seberapa baik sistem melaksanakan fungsinya. [12] .
contoh kasus pengujian blackbox :
Pengujian black box yang dilakukan pada aplikasi yang dibuat dibagi menjadi 2 bagian, yaitu skenario pengujian, kasus dan hasil pengujian. 1. Skenario Pengujian
Skenario pengujian menjelaskan pengujian terhadap sistem yang ada pada aplikasi analisis sentimen ini. Skenario pengujian yang akan dilakukan pada aplikasi ini selengkapnya dapat
dilihat pada Tabel 2.5.
Tabel 2.5 Skenario Pengujian blackbox
2. Kasus dan Hasil Pengujian
Kasus dan hasil pengujian berisi pemaparan dari rencana pengujian yang telah disusun pada skenario pengujian. Pengujian ini dilakukan secara black box dengan memperhatikan setiap kasus yang akan di uji. Berikut ini pemaparan dari setiap butir pengujian yang terdapat pada skenario pengujian: a. Pengujian Pengolahan Data Latih
Pengujian Pengolahan Data Latih memaparkan pengujian yang dilakukan terhadap aktivitas pengguna saat akan melakukan pengambilan data latih. Pengujian pengolahan data latih yang akan dilakukan pada aplikasi ini selengkapnya dapat dilihat pada Tabel 2.6.
Tabel 2.6 Pengujian Pengolahan Data Latih Kasus Yang
No. Komponen Yang Di uji Jenis Pengujian 1. Proses Pengolahan Data
3. Proses Klasifikasi Black Box
pengujian yang dilakukan terhadap aktivitas pengguna saat akan melakukan pengambilan data uji. Pengujian pengolahan data uji yang akan dilakukan pada aplikasi ini selengkapnya dapat dilihat pada Tabel 2.7.
Tabel 2.7 Pengujian Ambil Data Uji Kasus Yang
Pengujian klasifikasi memaparkan pengujian yang dilakukan terhadap aktivitas pengguna saat akan melakukan klasifikasi opini. Pengujian klasifikasi yang akan dilakukan pada aplikasi ini selengkapnya dapat dilihat pada Tabel 2.8.
Tabel 2.8 Pengujian Klasifikasi
Pengujian visualisasi memaparkan pengujian yang dilakukan terhadap aktivitas pengguna saat akan melakukan visualisasi ke dalam diagram lingkaran. Pengujian Visualisasi yang akan dilakukan pada aplikasi ini selengkapnya dapat dilihat pada Tabel 2.9.
Berdasarkan hasil implementasi dan pengujian yang telah dilakukan pada sistem analisis sentimen dengan menggunakan metode K-nearest neigbor ini maka dapat diambil kesimpulan bahwa, sistem analisis sentimen ini dapat mengklasifikasikan opini secara otomatis dan dapat memberikan informasi mengenai persentase sentimen puas dan sentimen tidak puas sehingga dapat membantu mempermudah pekerjaan Outlet Manager khususnya dalam pengklasifikasian penilaian customer(opini).
3.2 SARAN
Saran untuk pengembangan lebih lanjut, yaitu sebagai berikut:
1. Penambahan jumlah data latih untuk mendapatkan hasil yang lebih baik saat klasifikasi penilaian customer.
2. Pengoptimalan waktu dalam pemprosesan sistem.
DAFTAR PUSTAKA
[1] B. Liu, "Sentiment Analysis and Opinion Mining, Morgan & Claypool," 2012.
[2] K. Khamar, "Short Text Classification Using KNN Based on Distance Function," International journal of advanced research in computer and communication engineering, 2013.
[3] I. Sommerville, Software Engineering, jakarta: Erlangga, 2003.
[4] B. P. a. L. Lee, ""Opinion Mining and Sentiment Analysis"," Foundations and Trends in Information Retrieval, vol II, no 1-2, pp. 1-135.
[5] Agusta, "Perbandingan Algoritma Stemming Porter Dengan Algoritma Nazief & Adriani Untuk Stemming Dokumen Teks Bahasa Indonesia," Konferensi Nasional Sistem dan Informatika, 2009.
[6] Evan, Buku TA : K-Nearest Neigbor(KNN), Jakarta: Informatika, 2010.
[7] D. E. Garcia, "The Classic Vector Space Model (Description, Advantages and Limitations of the Classic Vector Space Model)," 2005.
[9] J.Han, "Data Mining : Concepts and techniques, Morgan Kaufman,," 2006.
[10] Nugroho, "SVM : Paradigma Baru dalam Softcomputing dan Aplikasinya," Konferensi Nasional Sistem & Informatika, 2008.
[11] Sudarsono, "[Online] Analisis Dan Perancangan
Sistem," Available :
sdarsono.staff.gunadarma.ac.id/Downloads/files/165 12/Flowchart.pdf [Accessed 15 Agustus 2015].
K - NEAREST NEIGHBOR
Taufik Hidayat Supratman
Informatics Engineering – Indonesia Computer University Dipatiukur Street No. 112-114 Bandung
E-mail : [email protected]
ABSTRACT
PHD (Pizza hut delivery) provides a forum to share their customer experiences in the form of an assessment of the PHD who visited the outlet can be
channeled through the website
www.halopizzaindonesia.com. Opinion received will be distributed to each outlet including an outlet PHD PHD Karawitan. Outlet Manager assigned to calculate the percentage of customer satisfaction assessment by studying the opinions submitted by the customer and group assessment into several classifications are satisfied opinion and opinions are not satisfied. Number of ratings that many have difficulty making the outlet manager must classify opinion because each one of the many opinions there and then calculate the percentage of customer satisfaction manually.
To facilitate the work, especially outlet manager specialized in grouping assessment such as customer opinion, we need a method that can automatically analyze opinion. One way that can be used to categorize the opinion that by using sentiment analysis. Sentiment analysis methods were used in this research is using the K-nearest algorithm neigbor. Consists of the preprocessing stage, weighting word, and classification k-nearest neigbor. Based on the results of the implementation and testing that has been performed k-nearest neigbor algorithm can be applied to a case study in PHD Karawitan customer and can help simplify the outlet manager with grouping assessment satisfied opinion and opinions are not satisfied automatically, and can calculate the percentage of that opinion.
Keywords: K-nearest neigbor, Opinion, Pizza Hut delivery, PHD.
1. INTRODUCTION
PHD (Pizza hut delivery) is a company engaged in the culinary field. To determine the services provided from each outlet, then PHD provides a forum to share their customer experiences in the
form of an assessment of the PHD outlets were visited. Assessment customers can be routed via the website www.halopizzaindonesia.com. All ratings stored in the website will be distributed to the respective outlets throughout Indonesia PHD. Outlet Manager assigned to calculate the percentage of how much the assessment of incoming customer satisfaction in the can by studying the opinion delivered by the customer
In this research, PHD outlets that will be a place of research that Karawitan PHD outlet. Number of ratings that many have difficulty making the outlet manager must classify opinion because each one of the many opinions there and then calculate the percentage of customer satisfaction manually. One way that can be used to categorize the opinion that by using sentiment analysis.
Sentiment analysis is a method in analyzing opinions, judgments, and attitudes to an entity such as products, services, events, and topics. [1] Based on previous research on the classification of text that tries to compare the accuracy of three algorithms direct the method Naive Bayes, method of k-nearest neighbor (KNN), the method of support vector machine (SVM) found that the method of K-NN has a greater degree of accuracy compared with the Naive Bayes method and the method of support vector machine (SVM). [2].
1.1Method Development Sentiment Analysis
Sentiment analysis system that will be built will pass through the stages of the stages consisting of: a. Analysis of Data Sources
The data used is the data obtained from the website www.halopizzaindonesia.com already distributed to outlets PHD Karawitan. .xls Format data files and data processing for the next stage will be the process of import data.
b. Preprocessing
Inverse Document Frequency). Term (words) taken from the results of the last prepocessing are stemming. The value of the weighting results will be used as a classification stage using k-nearest neigbor.
d. Sentiment Classification
The next step is the classification process will be processed using the k-nearest neigbor to determine which ones included satisfied opinion and which included opinions are not satisfied.
e. Visualization
Results of sentiment classification phase will be described in the form of pie charts. Data taken from the number of satisfied opinion and opinions are not satisfied then displayed as a percentage of the diagram
1.2Method of Software Development
Software development methods used in this study is the waterfall method according to Ian Sommerville reference [ 3 ] . Broadly speaking the method waterfall looks like Figure 1.1 below :
Figure 1.1 waterfall method according to Ian identification of market trends and market opinion to an object goods . [ 4 ]
2.2.1Preprocessing
Preprocessing the digging process, process, organize the information by analyzing the
flowchart Flowchart manifold system, which is a chart that shows the workflow or what is being done in the overall system and explain the sequence of procedures that exist in the system [11].
1. Case Folding
At this stage, all the letters will be converted to lowercase.
measures in case of folding stages are as follows :
1. Check the size of each character from the beginning to the end of the character .
2. If it is found that the character using capital letters ( uppercase) , then the letter will be converted to lowercase ( lowercase ) . The following flowchart folding case shown in Figure 2.1
Figure 2.1 flowchart case folding
2. Convert negation
Convert negation is the process of converting the words of negation that there is an opinion, because the word negation have an influence in changing the value of sentiment in a tweet. If there is a negation said it will be merged with the word thereafter. Said - said the negation includes the word “bukan”,
“tidak”, “tak”, “ga”,”gak”, “enggak”, “jangan”, dan ”nggak”.