ABSTRACT
ADE FRUANDTA. Identification of Mixed Tones On Piano Sounds Using Codebook. Supervised by AGUS BUONO.
It has been identified blend of tones, either as a single tone or a mix tones using the mel-frequency cepstrum coefficients (MFCC) as feature extraction and modeling of codebook for pattern recognition. The voices which used are the sound of piano and identified as 12 single-tones and 66 mix of single-tones recorded with 11 kHz on the duration of 1 second. The making of codebook is applied step by step, that is the codebook with the blend and the codebook of tones (single and mixed tones) which was developed using clustering techniques. The results of research showed that the optimum number of codewords is 20 with width of frames is 256 data, with an accuracy is 98.2%. However, there are some tones which are difficult to be identified, they are CC#, CD, CF, and A#B which has accuracy of each below 50%. For C# tone is more often recognized as C#D# tone, for the CC# tone is more often identified as C tone, for CD tone is more often recognized as C# tone, the CF tone is more often identified as C# tone and CF# tone, while for the A#B tone is more often identified with A# tone. Some errors happen in this recognition because those tones have similiar signal pattern so that they have the vector points which adjacent to each other.
IDENTIFIKASI CAMPURAN NADA PADA SUARA PIANO
MENGGUNAKAN CODEBOOK
ADE FRUANDTA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
IDENTIFIKASI CAMPURAN NADA PADA SUARA PIANO
MENGGUNAKAN CODEBOOK
ADE FRUANDTA
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
ADE FRUANDTA. Identification of Mixed Tones On Piano Sounds Using Codebook. Supervised by AGUS BUONO.
It has been identified blend of tones, either as a single tone or a mix tones using the mel-frequency cepstrum coefficients (MFCC) as feature extraction and modeling of codebook for pattern recognition. The voices which used are the sound of piano and identified as 12 single-tones and 66 mix of single-tones recorded with 11 kHz on the duration of 1 second. The making of codebook is applied step by step, that is the codebook with the blend and the codebook of tones (single and mixed tones) which was developed using clustering techniques. The results of research showed that the optimum number of codewords is 20 with width of frames is 256 data, with an accuracy is 98.2%. However, there are some tones which are difficult to be identified, they are CC#, CD, CF, and A#B which has accuracy of each below 50%. For C# tone is more often recognized as C#D# tone, for the CC# tone is more often identified as C tone, for CD tone is more often recognized as C# tone, the CF tone is more often identified as C# tone and CF# tone, while for the A#B tone is more often identified with A# tone. Some errors happen in this recognition because those tones have similiar signal pattern so that they have the vector points which adjacent to each other.
Judul : Identifikasi Campuran Nada Pada Suara Piano Menggunakan Codebook Nama : Ade Fruandta
NRP : G64070074
Menyetujui: Pembimbing
Dr. Ir. Agus Buono, M.Si, M.Kom. NIP. 19660702 199302 1 001
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 22 Februari 1989 dari pasangan Ir. H. Syafruddin dan Hj. Tety Aryani. Penulis merupakan anak ketiga dari tiga bersaudara.
Tahun 2007 penulis lulus dari SMA Negeri 2 Depok dan pada tahun yang sama penulis masuk Institut Pertanian Bogor (IPB) melalui jalur Ujian Saringan Masuk IPB (USMI). Penulis masuk Program S1 Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah SWT yang senantiasa memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tulisan ini dengan judul: Identifikasi Campuran Nada Pada Suara Piano Mengguanakan Codebook. Shalawat dan salam disampaikan kepada Nabi Muhammad SAW beserta keluarga, sahabat, dan pengikutnya yang tetap berada di jalan-Nya hingga akhir zaman.
Penulis mengucapkan terima kasih kepada Bapak Dr. Ir. Agus Buono, M.Si, M.Kom selaku pembimbing atas segala saran, kritik, dorongan, dan bimbingannya selama penelitian dan penyusunan tulisan ini. Ucapan terima kasih tak terhingga kepada orang tua atas nasihat, semangat, bantuan materi, dan doa-doanya. Selain itu penulis mengucapkan terima kasih kepada teman bimbingan dan teman-teman kosan wisma cemara atas doa, kebersamaan, diskusi, dan semangatnya yang telah membantu dalam penyelesaian skripsi ini. Serta kepada teman-teman Ilmu Komputer atas jalinan persahabatan selama ini terkhusus teman-teman Ilmu Komputer angkatan 44. Semoga tulisan ini bermanfaat dan dapat menambah wawasan ilmu pengetahuan bagi penulis khususnya dan pembaca umumnya.
Bogor, Mei 2011
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... vi
DAFTAR TABEL ... vi
DAFTAR LAMPIRAN... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat Penelitian ... 1
TINJAUANPUSTAKA ... 1
Nada dan Chord ... 1
Pemrosesan Sinyal Suara ... 2
Ekstraksi Sinyal Suara ... 2
K-Means ... 4
Codebook ... 4
METODE PENELITIAN ... 5
Kerangka Pemikiran ... 5
Pengambilan Data ... 5
Preprocessing ... 5
Pemodelan Codebook ... 6
Evaluasi ... 7
HASIL DAN PEMBAHASAN ... 7
Preprocessing ... 7
Pemodelan Codebook ... 7
Pengujian ... 7
Percobaan dengan Frame 128 ... 8
Percobaan dengan Frame 256 ... 9
Percobaan dengan Frame 512 ... 10
Percobaan dengan Suara Lain dan Octave Berbeda ... 10
KESIMPULAN DAN SARAN ... 11
Kesimpulan ... 11
Saran ... 11
DAFTAR GAMBAR
Halaman
1 Nada dasar pada piano. ... 2
2 Tahapan transformasi sinyal suara menjadi informasi. ... 2
3 Blok diagram proses MFCC. ... 3
4 Ilustrasi frame blocking pada sinyal suara. ... 3
5 Grafik fungsi window Hamming. ... 3
6 Frame sinyal sebelum proses windowing. ... 3
7 Frame sinyal setelah proses windowing... 3
8 Mel-frequency filter. ... 4
9 Codebook untuk setiap nada. ... 5
10 Ilustrasi prinsip dasar penggunaan codebook. ... 5
11 Diagram alur proses identifikasi campuran nada. ... 6
12 Model codebook berdasarkan kelompok nada. ... 6
13 Model codebook berdasarkan kelompok banyaknya campuran. ... 6
14 Alur pengenalan campuran nada. ... 8
15 Akurasi berdasarkan banyaknya campuran untuk setiap nilai frame. ... 8
16 Akurasi untuk setiap nilai K pada frame 128. ... 9
17 Sinyal nada A#B. ... 9
18 Sinyal nada A#. ... 9
19 Akurasi untuk setiap nilai K pada frame 256. ... 10
20 Akurasi untuk setiap nilai K pada frame 512. ... 10
DAFTAR TABEL
Halaman 1 Rataan nilai akurasi 78 nada pada frame 128 ... 82 Kesalahan pengenalan nada. ... 9
3 Rataan nilai akurasi 78 nada pada frame 256 ... 9
4 Rataan nilai akurasi 78 nada pada frame 512 ... 10
5 Akurasi pada suara selain suara piano ... 11
DAFTAR LAMPIRAN
Halaman 1 Tabel akurasi frame 128 ... 142 Tabel akurasi frame 256 ... 16
PENDAHULUAN
Latar Belakang
Manusia dianugrahi oleh Tuhan dua telinga yang memiliki fungsi untuk menangkap sinyal-sinyal suara. Namun untuk mengoptimalkan dari fungsi telinga tersebut manusia harus belajar memahami dan mengenali sinyal-sinyal suara yang masuk. Begitu juga untuk mengenali sebuah nada. Untuk seorang perfect pitch dalam mengenali sebuah nada adalah hal yang mudah karena telah melalui tahap latihan yang lama. Perfect pitch adalah kemampuan seseorang dalam mengenali dan mengidentifikasi nada-nada dari sebuah sinyal. Namun untuk seorang yang tidak memiliki kemampuan perfect pitch akan mengalami kesulitan dalam mengenali sebuah nada, sehingga dibutuhkan latihan untuk memiliki kemampuan perfect pitch.
Pengolahan Sinyal Digital (Digital Signal Processing) saat ini telah memegang peranan yang penting dalam ilmu pengetahuan dan teknologi. Salah satunya adalah pengenalan suara (voice recognition). Seperti penelitian yang telah dilakukan oleh Rudy Adipranata dan Resmana tentang pengenalan suara manusia. Dalam penelitian tersebut membahas tentang bagaimana cara mengenali suara manusia dari sebuah sinyal menggunakan jaringan saraf tiruan (Adipranata dan Resmana 1999). Selain untuk pengenalan suara manusia, pengenalan suara juga dapat dipakai dalam berbagai hal, salah satunya adalah pengenalan chord seperti penelitian yang telah dilakukan oleh Elgar Wisnudisastra dan Agus Buono pada tahun 2009 (Wisnudisastra dan Buono 2009). Pada penelitian tersebut, pemodelan chord pada gitar menggunakan codebook.
Penelitian Elgar Wisnudisastra ini hanya sampai pada pengenalan chord tidak sampai nada-nada penyusun dari chord. Tidak semua orang mengetahui semua jenis chord bahkan chord-chord miring. Untuk itu dibutuhkan pengenalan lebih mendalam untuk chord hingga nada-nada penyusun dari chord tersebut.
Tujuan
Penelitian ini bertujuan untuk mengidentifikasi campuran nada pada suara piano menggunakan codebook sebagai pemodelan nada dan banyaknya campuran nada.
Ruang Lingkup
Adapun ruang lingkup dari penelitian ini antara lain:
1. Campuran nada yang akan dikenali hanya campuran nada pada satu octave dan maksimal 2 campuran nada.
2. Suara yang dikenali hanya dimainkan dengan cara ditekan secara serentak. 3. Suara yang dikenali hanya suara piano
pada keyboard Yamaha PSR 3000. Manfaat Penelitian
Penelitian ini diharapkan dapat membantu bagi masyarakat dalam mengenali dan mengidentifikasi campuran nada pada sebuah suara piano.
TINJAUANPUSTAKA Nada dan Chord
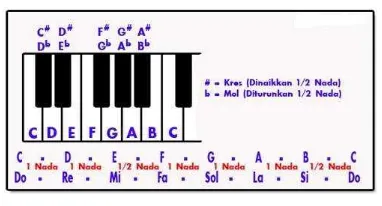
Nada adalah bunyi yang beraturan yang memiliki frekuensi tunggal tertentu. Setiap nada memiliki tinggi nada atau tala tertentu menurut frekuensinya. Terdapat 7 nada dasar yaitu : C = do, De = re, E = mi, F = fa, G = sol, A = la, B = si. Masing-masing dari nada dasar tersebut memiliki frekuensi yang berbeda-beda. Jarak antar nada disebut interval. Interval dari deretan nada C-D-E-F-G-A-B adalah 1-1-1/2-1-1-1/2. Jarak enam antara dua nada yang sama disebut satu octave. Contohnya adalah jarak antara nada C1 sampai nada C2. Nada C2 berada satu octave di atas nada C1.
Nada natural tersebut dapat dinaikkan atau diturunkan ½ nada. Nada yang dinaikkan ½ nada diberi simbol # (kres), sedangkan nada yang diturunkan ½ nada diberi simbol b (mol). Misal nada C dinaikkan ½ maka akan menjadi C# (C kres / Cis). Jika nada B diturunkan ½ maka akan menjadi Bb (B mol). Untuk nada E jika dinaikkan ½ maka akan menjadi E# atau sama dengan nada F karena jarak nada E dengan nada F adalah ½. Begitu pula pada nada B ke C. Untuk lebih jelasnya dapat dilihat pada Gambar 1.
tiga nada (triad), misalnya chord C terdiri atas C, E, dan G.
Gambar 1 Nada dasar pada piano. Pemrosesan Sinyal Suara
Sinyal suara merupakan gelombang yang tercipta dari tekanan udara yang berasal dari paru-paru yang berjalan melewati lintasan suara menuju mulut dan rongga hidung (Al-Akaidi 2007). Pemrosesan suara itu sendiri merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan (Buono 2009).
Sinyal secara umum dapat dikategorikan sesuai dengan peubah bebas waktu, yaitu: 1. Sinyal waktu kontinyu: kuantitas sinyal
terdefinisi pada setiap waktu dalam selang kontinyu. Sinyal waktu kontinyu disebut juga sinyal analog.
2. Sinyal waktu diskret: kuantitas sinyal terdefinisi pada waktu diskret tertentu, yang dalam hal ini jarak antar waktu tidak harus sama.
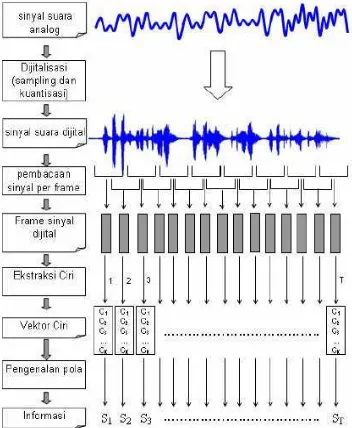
Secara umum proses transformasi tersebut terdiri atas digitalisasi sinyal analog, ekstraksi ciri dan diakhiri dengan pengenalan pola untuk klasifikasi, seperti yang terlihat pada Gambar 2.
Pengolahan sinyal analog menjadi sinyal digital dapat dilakukan melalui dua tahap yaitu sampling dan kuantisasi (Jurafsky 2007). Sampling adalah suatu proses untuk membagi suatu sinyal kontinyu (sinyal analog) dalam interval waktu yang telah ditentukan. Sampling ini dilakukan dengan mengubah sinyal analog menjadi sinyal digital dalam fungsi waktu. Pengubahan bentuk sinyal ini bertujuan untuk mempermudah memproses sinyal masukan yang berupa analog karena sinyal analog memiliki kepekaan terhadap noise yang rendah, sehingga sulit untuk memproses sinyal tersebut. Nilai dari hasil sampling tersebut dibulatkan ke nilai terdekat (rounding), atau bisa juga dengan pemotongan bagian sisa (truncating) sehingga menghasilkan sinyal suara digital dengan
mengekspresikannya menggunakan sejumlah digit tertentu dan proses ini yang dikenal dengan kuantisasi.
Gambar 2 Tahapan transformasi sinyal suara menjadi informasi (Jurafsky dalam Buono 2009).
Sinyal suara digital kemudian dilakukan proses pembacaan sinyal disetiap frame dengan lebar frame tertentu yang saling tumpang tindih. Proses ini dikenal dengan proses frame blocking. Barisan frame berisi informasi yang lengkap dari sebuah sinyal suara. Informasi yang terdapat dalam frame-frame tersebutdirepresentasikan dengan cara pengekstraksian ciri sehingga dihasilkan vektor-vektor yang nantinya digunakan dalam pengenalan pola.
Ekstraksi Sinyal Suara
Ekstraksi ciri merupakan proses untuk menentukan satu nilai atau vektor yang dapat dipergunakan sebagai penciri objek atau individu (Buono 2009). Terdapat banyak cara untuk merepresentasikan parameter sinyal suara, seperti Linear Prediction Coding (LPC), Mel-Frequency Cepstrum Coefficients (MFCC), dll.
proses MFCC dapat dilihat pada Gambar 3 (Do 1994).
Gambar 3 Blok diagram proses MFCC.
Frame blocking
Pada proses ini, sinyal suara disegmentasi menjadi beberapa frame yang saling tumpang tindih (overlap), hal ini dilakukan agar tidak ada sedikitpun sinyal yang hilang (deletion). Panjang frame biasanya memiliki panjang 10-30 ms atau 256-1024 data. Proses ini akan berlanjut sampai seluruh sinyal sudah masuk ke dalam satu atau lebih frame seperti yang diilustrasikan dalam Gambar 4.
Gambar 4 Ilustrasi frame blocking pada sinyal suara.
Windowing
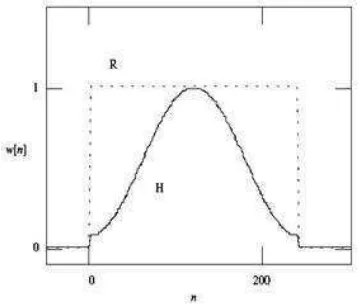
Sinyal analog yang sudah diubah menjadi sinyal digital dibaca frame demi frame dan pada setiap frame-nya dilakukan windowing dengan fungsi window tertentu. Proses windowing bertujuan untuk meminimalisasi ketidakberlanjutan sinyal pada awal dan akhir setiap frame (Do 1994). Dengan pertimbangan kesederhanaan formula dan nilai kinerja window, maka penggunaan window Hamming cukup beralasan (Buono 2009).
Jika kita definisikan window sebagai w(n), 0 ≤ n ≤ N– 1, dimana N adalah jumlah sampel pada setiap frame-nya, maka hasil dari windowing adalah sinyal:
y1(n) = x1(n) w(n), 0 ≤ n ≤ N– 1 dimana w(n) biasanya menggunakan window Hamming yang memiliki bentuk:
w(n) = 0.54 – 0.46 cos
– , 0 ≤ n ≤ N– 1
Grafik fungsi window Hamming dapat dilihat pada Gambar 5. Jika sebuah sinyal seperti pada Gambar 6 dikenakan fungsi window Hamming maka akan menghasilkan sinyal seperti pada Gambar 7.
Gambar 5 Grafik fungsi window Hamming.
Gambar 6 Frame sinyal sebelum proses windowing.
Gambar 7 Frame sinyal setelah proses windowing.
Fast Fourier Transform (FFT)
FFT adalah algoritme cepat untuk mengimplementasi discrete fourier transform Mel
spectrum Frame
Spectrum Speech
Mel cepstrum
Frame
blocking Windowing FFT
(DFT). FFT ini mengubah masing-masing frame N sampel dari domain waktu menjadi domain frekuensi yang didefinisikan sebagai berikut:
∑
, k= 0,1,2,…,N – 1
hasil rangkaian { } direpresentasikan sebagai berikut:
a. frekuensi positif 0 ≤ f ≤ yang merepresentasikan nilai 0 ≤ n ≤ – 1, b. frekuensi negatif < f < 0 yang
merepresentasikan nilai + 1 ≤ n≤ N– 1. Disini, berarti frequency sampling. Hasil dari tahapan ini biasanya disebut dengan spectrum atau periodogram.
Mel-Frequency Wrapping
Persepsi sistem pendengaran manusia terhadap frekuensi sinyal suara tidak dapat diukur dalam skala linear. Untuk setiap nada dengan frekuensi aktual, f, diukur dalam Hz, sebuah subjectivepitch diukur dalam sebuah skala yang disebut ‘mel’. Skala mel-frequency ialah sebuah frekuensi rendah yang bersifat linear di bawah 1000 Hz dan sebuah frekuensi tinggi yang bersifat logaritmik di atas 1000 Hz seperti yang diilustrasikan pada Gambar 8. Persamaan berikut menunjukkan hubungan skala mel dengan frekuensi dalam Hz:
mel(f) = 2595 * log10 (1 + f / 700)
Gambar 8 Mel-frequency filter.
Cepstrum
Langkah terakhir yaitu mengubah spektrum log mel menjadi domain waktu. Hasil ini disebut mel frequency cepstrum coefficient (MFCC). Cepstral dari spectrum suara merepresentasikan sifat-sifat spektral lokal sinyal untuk analisis frame yang
diketahui. Koefisien mel spectrum merupakan sebuah nilai riil sehingga kita dapat mengkonversinya ke dalam dominan waktu menggunakan Discrete Cosine Transform (DCT). Selanjutnya kita dapat menghitung MFCC sebagai , sebagai
= ∑ cos , dimana , k= 0, 2, …, K– 1 dan n= 0, 1, …, K – 1.
K-Means
K-means adalah salah satu algoritme pembelajaran unsupervised dalam menyelesaikan permasalahan klustering (MacQueen 1967). Langkah pertama yang dilakukan oleh algoritme ini adalah menentukan K initial centroid, di mana K adalah parameter spesifik yang ditentukan user, yang merupakan jumlah kluster yang diinginkan. Setiap titik atau objek kemudian ditempatkan pada centroid terdekat, dan kumpulan titik atau objek pada tiap centroid disebut kluster. Centroid pada setiap kluster kemudian akan berubah berdasarkan setiap objek yang ada pada kluster. Kemudian langkah penempatan objek dan perubahan centroid diulangi sampai tidak ada objek yang berpindah kluster. Algoritme dasar dari K-means adalah (Tan et al. 2006):
Select K points as initial centroids
repeat
Form K cluster by assigning each point to its closets centroid
Recompute the centroid of each cluster
until Centroids do not change
Terdapat fungsi objektif untuk menghitung tingkat error yang didefinisikan sebagai berikut:
pengenalan suara, masing-masing suara yang akan dikenali harus dibuatkan codebook-nya. Codebook dibentuk dengan cara membentuk kluster semua vektor ciri yang dijadikan sebagai training set dengan menggunakan klustering algorithm. Algoritme klustering yang akan dipakai adalah algoritme K-means. Ilustrasi codebook untuk setiap nada dapat dilihat pada Gambar 9.
Gambar 9 Codebook untuk setiap nada. Seperti yang telah diilustrasikan pada Gambar 10, prinsip dasar dalam penggunaan codebook adalah setiap suara yang masuk akan dihitung jaraknya ke setiap codebook yang telah dibuat. Kemudian jarak setiap sinyal suara ke codebook dihitung sebagai jumlah jarak setiap frame sinyal suara tersebut ke setiap codeword yang ada pada codebook. Kemudian dipilih codeword dengan jarak minimum. Setelah itu setiap sinyal suara yang masuk akan diidentifikasi berdasarkan jumlah dari jarak minimum tersebut.
Gambar 10 Ilustrasi prinsip dasar penggunaan codebook.
Perhitungan jarak dilakukan dengan menggunakan jarak euclid yang didefinisikan sebagai berikut:
∑
dimana x dan y adalah vektor yang akan dihitung jaraknya dengan D dimensi.
Jika dalam sinyal suara input O terdapat T frame dan merupakan masing-masing codeword yang ada pada codebook maka jarak sinyal input dengan codebook dapat dirumuskan:
∑ ( )
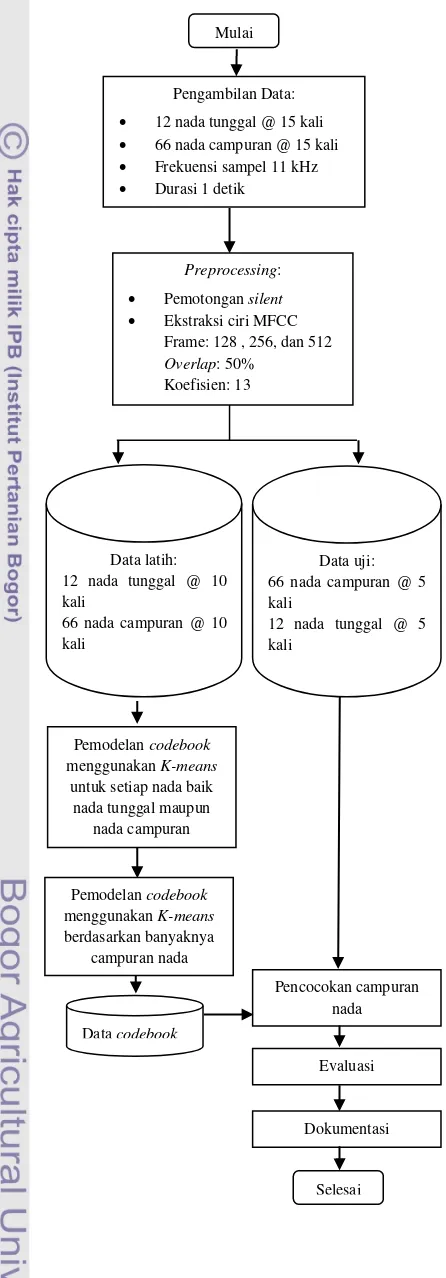
METODE PENELITIAN Kerangka Pemikiran
Penelitian ini dikembangkan dengan metode yang terdiri atas beberapa tahap yaitu: (1) pengambilan data, (2) preprocessing, (3) pemodelan codebook, (4) evaluasi. Alur metode ini dapat dilihat pada Gambar 11. Pengambilan Data
Suara yang akan digunakan dalam penelitian ini adalah suara grand piano yang terdapat di keyboard Yamaha PSR 3000. Nada yang diambil sebanyak 12 nada tunggal yang terdiri dari C, C#, D, D#, E, F, F#, G, G#, A, A#, dan B yang masing-masing akan diulang sebanyak 15 kali. Nada dua campuran diambil sebanyak 66 nada yang masing-masing akan diulang sebanyak 15 kali.
Nada yang telah diambil akan dibagi dua, yaitu data training dan data testing. Data training adalah 12 nada tunggal yang masing-masing nada 10 suara dan 66 nada dua campuran yang masing-masing nada 10 suara, sedangkan data testing adalah 66 nada campuran yang masing-masing nada lima suara dan 12 nada tunggal yang masing-masing nada lima suara. Total dari data training sebanyak 780 suara dan total dari data testing sebanyak 390 suara.
Data direkam langsung dengan keyboard melalui kabel yang dihubungkan langsung dengan komputer. Perekaman menggunakan software Matlab selama 1 detik, disimpan dalam file berformat WAV, dan sampling rate sebesar 11000 Hz. Proses perekaman dengan menekan secara serentak dengan tekanan yang berbeda. Tekanan yang diberikan ada yang keras, lembut, ditekan lama, dan sesaat.
Preprocessing
dengan menggunakan MFCC. Pada penelitian ini akan diteliti dengan lebar frame 128, 256, dan 512, overlap sebesar 50%, dan jumlah cepstral coefficient setiap frame sebanyak 13 koefisien.
Gambar 11 Diagram alur proses identifikasi campuran nada.
Pemodelan Codebook
Pada tahap ini akan dibuat codebook dari data training yang terdiri dari 120 suara nada tunggal dan 660 suara nada campuran yang telah melalui preprocessing. Tiap suara akan dikelompokkan berdasarkan nadanya dan setiap kelompok nada tersebut akan di-klustering dengan menggunakan K-means sehingga dihasilkan kluster-kluster yang berisi vektor-vektor berdasarkan kelompok nada seperti pada Gambar 12.
Gambar 12 Model codebook berdasarkan kelompok nada.
Banyaknya kluster yang diuji adalah 5, 10, 15, dan 20 dan dibuat codebook-nya.
Dari tiap kluster yang telah dikelompokkan berdasarkan nada tersebut akan dikelompokkan lagi berdasarkan banyaknya campuran nada yang dalam penelitian ini adalah nada tunggal dan nada dua campuran seperti pada Gambar 13. Setiap kelompok tersebut akan diklustering dengan nilai K sebesar 5, 10, 15, dan 20 dan dibuat codebook-nya.
Gambar 13 Model codebook berdasarkan kelompok banyaknya campuran. Mulai
Pengambilan Data:
12 nada tunggal @ 15 kali
66 nada campuran @ 15 kali
Frekuensi sampel 11 kHz
Durasi 1 detik
Data uji: 66 nada campuran @ 5 kali
12 nada tunggal @ 5 kali
Pemodelan codebook menggunakan K-means
untuk setiap nada baik nada tunggal maupun
nada campuran
Pencocokan campuran nada
Evaluasi
Dokumentasi
Selesai Data codebook
Data latih: 12 nada tunggal @ 10 kali
66 nada campuran @ 10 kali
Pemodelan codebook menggunakan K-means berdasarkan banyaknya
campuran nada
Preprocessing:
Pemotongan silent
Ekstraksi ciri MFCC Frame: 128 , 256, dan 512 Overlap: 50%
Dalam penelitian ini terdapat dua model codebook yang telah dijelaskan sebelumnya, yang pertama model codebook berdasarkan nada dan codebook berdasarkan banyaknya campuran nada.
Evaluasi
Evaluasi sistem ini melihat akurasi identifikasi campuran nada pada suara piano. Data yang digunakan adalah 1170 suara yang terdiri atas 286 nada campuran yang masing-masing lima suara dan 12 nada tunggal yang masing-masing lima suara. Untuk perhitungan tingkat akurasi identifikasi campuran nada dilakukan dengan membandingkan jumlah output yang benar diidentifikasi oleh sistem dengan jumlah seluruh data yang diuji. Persentase tingkat akurasi dihitung dengan fungsi berikut: dahulu dilakukan pemotongan silent yang akan diteruskan dengan ekstraksi ciri menggunakan MFCC. Dalam pemakaiannya terdapat lima parameter yang harus digunakan yaitu suara, sampling rate, frame, overlap, dan cepstral coefficient. Pemilihan nilai untuk sampling rate, overlap, dan cepstral coefficient berturut-turut adalah 11000 Hz, 50%, dan 13. Untuk nilai frame akan diuji dengan nilai 128, 256, dan 512. Proses ekstraksi ini akan dilakukan terhadap semua data. MFCC mengubah data menjadi sebuah matriks yang berisikan vektor-vektor yang menunjukkan ciri spectral dari data tersebut. Pemodelan Codebook
Pada proses pembuatan codebook, data yang digunakan adalah data training yang berupa vektor ciri dari suara piano yang telah direkam dan melewati praprocessing. Terdapat dua jenis model codebook yang akan dimodelkan yaitu codebook tiap nada baik tunggal maupun campuran dan codebook berdasarkan banyaknya campuran nada.
1. Pemodelan codebook tiap nada
Terdapat 12 jenis nada tunggal dan 66 jenis nada dua campuran yang masing-masing berjumlah 10 suara yang akan dimodelkan
codebook-nya. Tiap jenis nada akan dikelompokkan dan melalui proses klustering dengan K-means. Nilai K yang akan diuji adalah5, 10, 15, dan 20 untuk tiap frame yang diuji yang masing-masing frame adalah 128, 256, dan 512. Setelah melalui proses klustering akan didapatkan vektor-vektor centroid yang mencirikan masing-masing dari jenis nada baik nada tunggal maupun nada dua campuran.
2. Pemodelan codebook berdasarkan banyaknya campuran nada
Dari hasil model codebook untuk tiap nada, akan digunakan dalam pemodelan codebook berdasarkan banyaknya campuran nada. Tiap nada akan dipisahkan berdasarkan banyaknya campuran nada. Dalam hal ini satu campuran dan dua campuran. Setelah dipisahkan maka akan diproses dengan klustering menggunakan K-means. Nilai K yang akan diuji adalah 5, 10, 15, dan 20 untuk tiap frame yang diuji yang masing-masing frame adalah 128, 256, dan 512. Setelah melalui proses klustering akan didapatkan vektor-vektor centroid yang mencirikan masing-masing banyaknya campuran yang ada.
Pengujian
Pengujian akan dilakukan dengan data testing yang telah direkam dengan sampling rate 11000 Hz. Banyaknya data testing ini adalah 12 nada tunggal dan 66 nada dua campuran yang masing-masing nada memiliki lima suara. Data testing ini akan melewati preprocessing untuk pemebersihan data dan pencirian data. Setelah melalui preprocessing masing-masing suara akan dikenali berdasarkan model codebook yang telah dibuat sebelumnya dengan mencari jarak yang terdekat dengan model. Untuk tahap awal suara yang akan dikenali berdasarkan banyaknya campuran pada suara tersebut. Setelah diketahui banyaknya campuran pada suara tersebut maka akan dikenali jenis nadanya berdasarkan banyaknya campuran nada. Alur pengenalan campuran nada dapat dilihat pada Gambar 14.
Untuk akurasi setiap frame dapat dilihat paling tinggi saat nada tunggal dengan frame 256 dengan akurasi 99,56%.
Gambar 14 Alur pengenalan campuran nada.
Gambar 15 Akurasi berdasarkan banyaknya campuran untuk setiap nilai frame.
Percobaan dengan Frame 128
Pada percobaan ini overlap dan koefisien yang dipakai untuk setiap jenis nada dan codebook masing-masing adalah 50% dan 13. Setiap nada pada data testing akan diuji dengan mencari jarak yang terdekat dengan
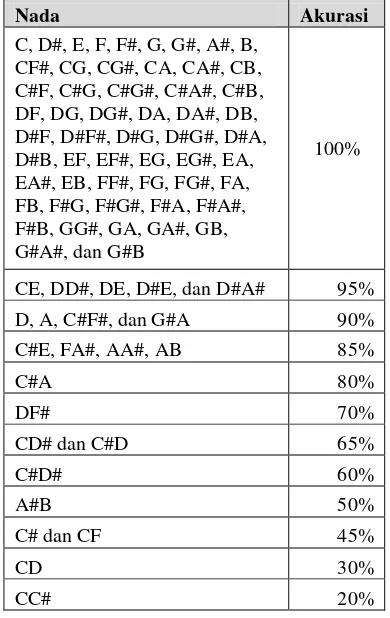
model codebook dengan nilai K sebesar 5, 10, 15, dan 20. Rataan tingkat akurasi untuk setiap nada saat frame 128 dapat dilihat pada Tabel 1. Nilai akurasi tersebut didapatkan dengan merata-ratakan total dari nilai akurasi yang dihasilkan oleh setiap nada untuk seluruh nilai K.
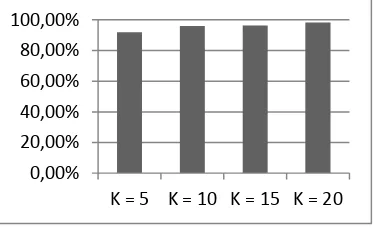
Tabel 1 Rataan nilai akurasi 78 nada pada frame 128 tersebut didapatkan akurasi tertinggi saat K bernilai 15 dengan nilai akurasi 94,36%. Dari Gambar 16 dapat disimpulkan bahwa K yang optimum dalam memodelkan codebook pada frame 128 adalah saat K bernilai 15.
Terdapat nada-nada yang sulit dikenali yang memiliki akurasi kurang dari sama dengan 50% adalah A#B, C#, CC#, CD, dan CF yang memiliki nilai masing-masing 50%, 45%, 20%, 30%, dan 45%. Untuk nada-nada yang sulit dikenali ini lebih sering dikenali dengan nada-nada yang terdekatnya yang memiliki jarak interval setengah sampai satu interval. Kesalahan pengenalan pada nada-nada tersebut dapat dilihat pada Tabel 2.
Gambar 16 Akurasi untuk setiap nilai K pada frame 128.
Tabel 2 Kesalahan pengenalan nada.
Nada Kesalahan Pengenalan A#B A# dan B
C# C#D#
CC# C
CD C# dan C
CF CF# dan C
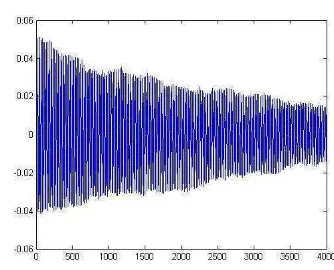
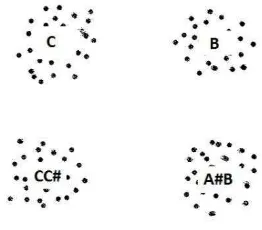
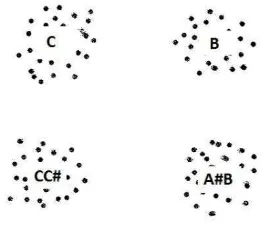
Salah satu faktor dari kesalahan pengenalan tersebut adalah pola dari sinyal-sinyal tersebut mirip sehingga saat nada-nada tersebut dicirikan akan menghasilkan titik-titik yang saling berdekatan. Dapat dilihat pada Gambar 17 adalah sinyal nada A#B sedangkan pada Gambar 18 adalah sinyal nada A#.
Gambar 17 Sinyal nada A#B.
Gambar 18 Sinyal nada A#.
Percobaan dengan Frame 256
Pada percobaan ini overlap dan koefisien yang dipakai untuk setiap jenis nada dan codebook masing-masing adalah 50% dan 13. Setiap nada pada data testing akan diuji dengan mencari jarak yang terdekat dengan model codebook dengan nilai K sebesar 5, 10, 15, dan 20. Rataan tingkat akurasi untuk setiap nada saat frame 256 dapat dilihat pada Tabel 3. Nilai akurasi tersebut didapatkan dengan merata-ratakan total dari nilai akurasi yang dihasilkan oleh setiap nada untuk seluruh nilai K.
Tabel 3 Rataan nilai akurasi 78 nada pada frame 256 tersebut didapatkan akurasi tertinggi saat K bernilai 20 dengan nilai akurasi 98,21%. Jika dibandingkan nilai akurasi frame 128 dengan 256 untuk setiap nilai K dapat dikatakan pencirian nada dengan frame 256 lebih baik dari pada frame 128 karena akurasi untuk setiap nilai Kframe 256 lebih tinggi dari pada frame 128. Dari Gambar 19 dapat disimpulkan bahwa seiring nilai kluster dinaikkan maka tingkat akurasi akan semakin naik pula.
Terdapat nada-nada yang sulit dikenali yang memiliki akurasi kurang dari sama dengan 50% adalah CC# dan A#B yang memiliki nilai masing-masing 35% dan 25%. Untuk nada-nada yang sulit dikenali ini lebih sering dikenali dengan nada-nada yang terdekatnya yang memiliki jarak interval setengah sampai satu interval. Pada nada CC# lebih sering dikenali dengan nada C sedangkan pada nada A#B lebih sering dikenali dengan nada A# dan B.
Gambar 19 Akurasi untuk setiap nilai K pada frame 256.
Percobaan dengan Frame 512
Pada percobaan ini overlap dan koefisien yang dipakai untuk setiap jenis nada dan codebook masing-masing adalah 50% dan 13. Setiap nada pada data testing akan diuji dengan mencari jarak yang terdekat dengan model codebook dengan nilai K sebesar 5, 10, 15, dan 20. Rataan tingkat akurasi untuk setiap nada saat frame 512 dapat dilihat pada Tabel 4. Nilai akurasi tersebut didapatkan dengan merata-ratakan total dari nilai akurasi yang dihasilkan oleh setiap nada untuk seluruh nilai K.
Pada percobaan dengan frame 512 ini akan diuji dengan nilai K 5, 10, 15, dan 20. Untuk grafik akurasi di setiap nilai K dapat dilihat pada Gambar 20. Dari hasil percobaan tersebut didapatkan akurasi tertinggi saat K bernilai 20 dengan nilai akurasi 97,95%. Hasil akurasi ini sedikit lebih kecil dari pada akurasi saat frame 256 dan K bernilai 20 dengan selisih 0,26. Dari Gambar 20 dapat disimpulkan bahwa seiring nilai kluster dinaikan maka tingkat akurasi akan semakin naik pula.
Terdapat nada-nada yang sulit dikenali yang memiliki akurasi kurang dari sama dengan 50% adalah CC# dan A#B yang memiliki nilai masing-masing 45% dan 40%. Untuk nada-nada yang sulit dikenali ini lebih sering dikenali dengan nada-nada yang terdekatnya yang memiliki jarak interval
setengah sampai satu interval. Pada nada CC# lebih sering dikenali dengan nada C 512 akurasi tertinggi saat frame 512.
Tabel 4 Rataan nilai akurasi 78 nada pada frame 512
Gambar 20 Akurasi untuk setiap nilai K pada frame 512.
Percobaan dengan Suara Lain dan Octave
Berbeda
string, gitar, saxophone, dan flute. Diambil dua nada masing-masing nada satu campuran dan nada dua campuran secara acak yaitu nada C#G dan F. Setiap nada memiliki lima suara untuk diuji yang dicirikan dengan frame 256 dan K bernilai 20. Dapat dilihat pada Tabel 5, untuk pengenalan pada nada C#G cukup bagus, namun tidak untuk pengenalan pada nada F yang sama sekali tidak dapat dikenali. Pada hasil tersebut dapat disimpulkan bahwa pemodelan codebook yang telah dibuat sebelumnya dapat mengidentifikasi campuran nada dengan jenis suara yang berbeda meskipun dengan keterbatasan terhadap nada-nada tertentu.
Tabel 5 Akurasi pada suara selain suara piano
Suara C#G F dikenali. Hal ini dikarenakan perbedaan tinggi frekuensi di setiap octave sehingga berbedanya titik-titik penciri di setiap octave. Perbedaan titik-titik penciri di setiap octave dikarenakan ekstraksi ciri MFCC mencirikan sebuah sinyal suara berdasarkan frekuensi dari sinyal suara tersebut.
KESIMPULAN DAN SARAN Kesimpulan
Penelitian ini telah berhasil dalam mengimplementasikan metode codebook dalam mengidentifikasi campuran nada pada suara piano. Akurasi tertinggi didapat saat frame 256 dan K 20 dengan nilai akurasi sebesar 98,2051%. Namun untuk pemodelan nada CC# dan A#B akan lebih baik jika di cirikan dengan frame masing-masing 128 dan 512.
Dari nada-nada yang sulit dikenali seperti C#, CC#, CD, CF, dan A#B lebih banyak dikenali dengan nada-nada yang terdekat dengannya yang memiliki jarak setengah atau satu octave. Kesalahan dalam pengenalan ini dikarenakan nada-nada tersebut memiliki pola sinyal yang mirip sehingga jarak nada-nada tersebut berdekatan yang menyebabkan sulit untuk dikenali.
Pemodelan codebook ini masih dapat mengenali dan mengidentifkasi campuran nada pada suara selain suara piano meskipun dengan keterbatasan terhadap nada-nada tertentu. Namun tidak untuk octave yang berbeda.
Saran
Penelitian ini masih sangat sederhana sehingga memungkinkan untuk dikembangkan lebih lanjut. Saran-saran yang dapat diberikan untuk pengembangan lebih lanjut adalah: 1. Pada penelitian ini nada yang dimodelkan
hanya berada pada satu octave sehingga jika dimasukkan dengan nada yang sama namun dengan octave yang berbeda maka akan salah dikenali. Dengan demikian disarankan untuk memodelkan semua octave pada piano untuk dimodelkan. 2. Banyaknya campuran pada penelitian ini
hanya dua campuran, sehingga disarankan untuk memodelkan semua kemungkinan campuran yang ada.
3. Nada campuran yang dapat dikenali hanya berada pada satu octave, jika terdapat campuran yang masing-masing berbeda octave maka tidak dapat dikenali. Dengan demikian disarankan untuk memodelkan campuran nada yang masing-masing berbeda octave.
4. Mencoba metode dinamik frame dalam pencirian suara.
5. Memodelkan codebook untuk setiap nada dengan menggabungkan semua vektor di setiap frame dan dikumpulkan menjadi sebuah codebook.
DAFTAR PUSTAKA
Adipranata R, Resmana. 1999. Pengenalan Suara Manusia Dengan Menggunakan LPC dan Jaringan Saraf Tiruan Propagasi Balik. Prosiding Seminar Nasioanl I Kecerdasan Komputasional. Universitas Indonesia, 20-21 Juli 1999.
Al-Kaidi M. 2007. Fractal Speech Processing. Cambridge University Press. Buono, A. 2009. Representasi Nilai HOS dan
HMM. [Disertasi]. Depok: Program Studi Ilmu Komputer, Universitas Indonesia. Do MN. 1994. DSP Mini-Project: An
Automatic Speaker Recognition System. Fausett, L. (1994). Fundamentals of Neural
Network.Prentice Hall, Englewood Cliffs, NJ.
Hendro. 2004. Panduan Praktis Improvisasi Gitar. Jakarta: Puspa Swara.
Jurafsky D, Martin JH. 2007. Speech and Language Processing An Introduction to
Natural Language Processing,
Computational Linguistic, and Speech Recognition. New Jersey: Prentice Hall. McQueen, J. B. 1967. Some Methods for
classification and Analysis of Multivariate Observations, Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press.
Tan P, Michael S, dan Vipin K. 2006. Introduction to Data Mining. Addison Wesley.
Lampiran 1 Tabel akurasi frame 128
Nada K = 5 K = 10 K = 15 K = 20
C 100% 100% 100% 100%
C# 60% 20% 0% 100%
D 60% 100% 100% 100%
D# 100% 100% 100% 100%
E 100% 100% 100% 100%
F 100% 100% 100% 100%
F# 100% 100% 100% 100%
G 100% 100% 100% 100%
G# 100% 100% 100% 100%
A 100% 100% 80% 80%
A# 100% 100% 100% 100%
B 100% 100% 100% 100%
CC# 40% 0% 20% 20%
CD 0% 0% 60% 60%
CD# 60% 40% 80% 80%
CE 100% 80% 100% 100%
CF 40% 40% 60% 40%
CF# 100% 100% 100% 100%
CG 100% 100% 100% 100%
CG# 100% 100% 100% 100%
CA 100% 100% 100% 100%
CA# 100% 100% 100% 100%
CB 100% 100% 100% 100%
C#D 80% 80% 100% 0%
C#D# 40% 100% 100% 0%
C#E 100% 100% 100% 40%
C#F 100% 100% 100% 100%
C#F# 80% 80% 100% 100%
C#G 100% 100% 100% 100%
C#G# 100% 100% 100% 100%
C#A 80% 80% 80% 80%
C#A# 100% 100% 100% 100%
C#B 100% 100% 100% 100%
DD# 80% 100% 100% 100%
DE 100% 80% 100% 100%
DF 100% 100% 100% 100%
DF# 100% 40% 100% 40%
DG 100% 100% 100% 100%
DG# 100% 100% 100% 100%
DA# 100% 100% 100% 100%
DB 100% 100% 100% 100%
D#E 100% 80% 100% 100%
D#F 100% 100% 100% 100%
D#F# 100% 100% 100% 100%
D#G 100% 100% 100% 100%
D#G# 100% 100% 100% 100%
D#A 100% 100% 100% 100%
D#A# 80% 100% 100% 100%
D#B 100% 100% 100% 100%
EF 100% 100% 100% 100%
EF# 100% 100% 100% 100%
EG 100% 100% 100% 100%
EG# 100% 100% 100% 100%
EA 100% 100% 100% 100%
EA# 100% 100% 100% 100%
EB 100% 100% 100% 100%
FF# 100% 100% 100% 100%
FG 100% 100% 100% 100%
FG# 100% 100% 100% 100%
FA 100% 100% 100% 100%
FA# 80% 80% 80% 100%
FB 100% 100% 100% 100%
F#G 100% 100% 100% 100%
F#G# 100% 100% 100% 100%
F#A 100% 100% 100% 100%
F#A# 100% 100% 100% 100%
F#B 100% 100% 100% 100%
GG# 100% 100% 100% 100%
GA 100% 100% 100% 100%
GA# 100% 100% 100% 100%
GB 100% 100% 100% 100%
G#A 80% 80% 100% 100%
G#A# 100% 100% 100% 100%
G#B 100% 100% 100% 100%
AA# 60% 80% 100% 100%
AB 40% 100% 100% 100%
Lampiran 2 Tabel akurasi frame 256
Nada K = 5 K = 10 K = 15 K = 20
C 100% 100% 100% 100%
C# 100% 100% 100% 100%
D 100% 100% 100% 100%
D# 100% 100% 100% 100%
E 100% 100% 100% 100%
F 100% 100% 100% 100%
F# 100% 100% 100% 100%
G 100% 100% 100% 100%
G# 100% 100% 100% 100%
A 80% 100% 100% 100%
A# 100% 100% 100% 100%
B 100% 100% 100% 100%
CC# 0% 40% 80% 20%
CD 100% 100% 100% 100%
CD# 100% 100% 100% 100%
CE 100% 100% 100% 100%
CF 100% 100% 100% 100%
CF# 100% 100% 100% 100%
CG 100% 100% 100% 100%
CG# 100% 100% 100% 100%
CA 100% 100% 100% 100%
CA# 100% 100% 100% 100%
CB 80% 100% 100% 100%
C#D 80% 60% 60% 100%
C#D# 100% 80% 100% 100%
C#E 100% 100% 100% 100%
C#F 100% 100% 100% 100%
C#F# 100% 100% 100% 100%
C#G 100% 100% 100% 100%
C#G# 100% 100% 100% 100%
C#A 100% 100% 100% 100%
C#A# 100% 100% 100% 100%
C#B 100% 100% 100% 100%
DD# 100% 100% 100% 100%
DE 100% 100% 100% 100%
DF 100% 100% 100% 100%
DF# 100% 100% 100% 100%
DG 100% 100% 100% 100%
DA 100% 100% 100% 100%
DA# 100% 100% 100% 100%
DB 100% 100% 100% 100%
D#E 60% 80% 100% 40%
D#F 100% 100% 100% 100%
D#F# 100% 100% 100% 100%
D#G 100% 100% 100% 100%
D#G# 100% 100% 100% 100%
D#A 100% 100% 100% 100%
D#A# 100% 100% 100% 100%
D#B 100% 100% 100% 100%
EF 100% 100% 100% 100%
EF# 100% 100% 100% 100%
EG 60% 100% 100% 100%
EG# 100% 100% 100% 100%
EA 100% 100% 100% 100%
EA# 100% 100% 100% 100%
EB 100% 100% 100% 100%
FF# 80% 80% 100% 100%
FG 40% 100% 80% 100%
FG# 100% 100% 100% 100%
FA 100% 100% 100% 100%
FA# 100% 100% 100% 100%
FB 100% 100% 100% 100%
F#G 100% 100% 80% 100%
F#G# 100% 100% 100% 100%
F#A 100% 100% 100% 100%
F#A# 100% 100% 100% 100%
F#B 100% 100% 100% 100%
GG# 100% 100% 100% 100%
GA 100% 100% 100% 100%
GA# 100% 100% 100% 100%
GB 100% 100% 100% 100%
G#A 80% 80% 60% 100%
G#A# 100% 100% 100% 100%
G#B 100% 100% 100% 100%
AA# 0% 60% 60% 100%
AB 0% 100% 80% 100%
Lampiran 3 Tabel akurasi frame 512
Nada K = 5 K = 10 K = 15 K = 20
C 100% 100% 100% 100%
C# 100% 80% 100% 100%
D 100% 80% 100% 100%
D# 100% 100% 100% 100%
E 100% 100% 100% 100%
F 100% 100% 100% 100%
F# 100% 100% 100% 100%
G 100% 100% 100% 100%
G# 100% 100% 100% 100%
A 100% 100% 100% 100%
A# 100% 100% 40% 100%
B 100% 100% 100% 100%
CC# 0% 60% 20% 100%
CD 100% 100% 100% 100%
CD# 80% 100% 100% 100%
CE 100% 100% 100% 100%
CF 100% 100% 100% 100%
CF# 100% 100% 100% 100%
CG 100% 100% 100% 100%
CG# 100% 100% 100% 100%
CA 100% 100% 100% 100%
CA# 100% 100% 100% 100%
CB 100% 100% 100% 20%
C#D 100% 100% 80% 100%
C#D# 100% 100% 100% 100%
C#E 100% 100% 100% 100%
C#F 100% 100% 100% 100%
C#F# 100% 100% 100% 100%
C#G 100% 100% 100% 100%
C#G# 100% 100% 100% 100%
C#A 100% 100% 100% 100%
C#A# 100% 100% 100% 100%
C#B 100% 100% 100% 100%
DD# 100% 100% 80% 100%
DE 100% 100% 100% 100%
DF 100% 100% 100% 100%
DF# 80% 100% 100% 100%
DG# 100% 100% 100% 100%
DA 100% 100% 100% 100%
DA# 100% 100% 100% 100%
DB 100% 100% 100% 100%
D#E 80% 40% 60% 80%
D#F 100% 100% 100% 100%
D#F# 100% 100% 100% 100%
D#G 100% 100% 100% 100%
D#G# 100% 100% 100% 100%
D#A 100% 100% 100% 100%
D#A# 100% 100% 100% 100%
D#B 100% 100% 100% 100%
EF 100% 100% 100% 100%
EF# 100% 100% 100% 100%
EG 40% 100% 100% 100%
EG# 100% 100% 100% 100%
EA 100% 100% 100% 100%
EA# 100% 100% 100% 100%
EB 80% 100% 100% 100%
FF# 80% 100% 100% 100%
FG 0% 100% 100% 100%
FG# 100% 100% 100% 100%
FA 100% 100% 100% 100%
FA# 100% 100% 100% 100%
FB 100% 100% 100% 100%
F#G 80% 100% 100% 100%
F#G# 100% 100% 100% 100%
F#A 100% 100% 100% 100%
F#A# 100% 100% 100% 100%
F#B 100% 100% 100% 100%
GG# 100% 100% 100% 100%
GA 100% 100% 100% 100%
GA# 100% 100% 100% 100%
GB 100% 100% 100% 100%
G#A 80% 60% 100% 80%
G#A# 100% 100% 100% 100%
G#B 100% 100% 100% 100%
AA# 60% 100% 100% 100%
AB 0% 100% 100% 100%
Penguji:
1. Musthofa, S.Kom, M.Sc
PENDAHULUAN
Latar Belakang
Manusia dianugrahi oleh Tuhan dua telinga yang memiliki fungsi untuk menangkap sinyal-sinyal suara. Namun untuk mengoptimalkan dari fungsi telinga tersebut manusia harus belajar memahami dan mengenali sinyal-sinyal suara yang masuk. Begitu juga untuk mengenali sebuah nada. Untuk seorang perfect pitch dalam mengenali sebuah nada adalah hal yang mudah karena telah melalui tahap latihan yang lama. Perfect pitch adalah kemampuan seseorang dalam mengenali dan mengidentifikasi nada-nada dari sebuah sinyal. Namun untuk seorang yang tidak memiliki kemampuan perfect pitch akan mengalami kesulitan dalam mengenali sebuah nada, sehingga dibutuhkan latihan untuk memiliki kemampuan perfect pitch.
Pengolahan Sinyal Digital (Digital Signal Processing) saat ini telah memegang peranan yang penting dalam ilmu pengetahuan dan teknologi. Salah satunya adalah pengenalan suara (voice recognition). Seperti penelitian yang telah dilakukan oleh Rudy Adipranata dan Resmana tentang pengenalan suara manusia. Dalam penelitian tersebut membahas tentang bagaimana cara mengenali suara manusia dari sebuah sinyal menggunakan jaringan saraf tiruan (Adipranata dan Resmana 1999). Selain untuk pengenalan suara manusia, pengenalan suara juga dapat dipakai dalam berbagai hal, salah satunya adalah pengenalan chord seperti penelitian yang telah dilakukan oleh Elgar Wisnudisastra dan Agus Buono pada tahun 2009 (Wisnudisastra dan Buono 2009). Pada penelitian tersebut, pemodelan chord pada gitar menggunakan codebook.
Penelitian Elgar Wisnudisastra ini hanya sampai pada pengenalan chord tidak sampai nada-nada penyusun dari chord. Tidak semua orang mengetahui semua jenis chord bahkan chord-chord miring. Untuk itu dibutuhkan pengenalan lebih mendalam untuk chord hingga nada-nada penyusun dari chord tersebut.
Tujuan
Penelitian ini bertujuan untuk mengidentifikasi campuran nada pada suara piano menggunakan codebook sebagai pemodelan nada dan banyaknya campuran nada.
Ruang Lingkup
Adapun ruang lingkup dari penelitian ini antara lain:
1. Campuran nada yang akan dikenali hanya campuran nada pada satu octave dan maksimal 2 campuran nada.
2. Suara yang dikenali hanya dimainkan dengan cara ditekan secara serentak. 3. Suara yang dikenali hanya suara piano
pada keyboard Yamaha PSR 3000. Manfaat Penelitian
Penelitian ini diharapkan dapat membantu bagi masyarakat dalam mengenali dan mengidentifikasi campuran nada pada sebuah suara piano.
TINJAUANPUSTAKA Nada dan Chord
Nada adalah bunyi yang beraturan yang memiliki frekuensi tunggal tertentu. Setiap nada memiliki tinggi nada atau tala tertentu menurut frekuensinya. Terdapat 7 nada dasar yaitu : C = do, De = re, E = mi, F = fa, G = sol, A = la, B = si. Masing-masing dari nada dasar tersebut memiliki frekuensi yang berbeda-beda. Jarak antar nada disebut interval. Interval dari deretan nada C-D-E-F-G-A-B adalah 1-1-1/2-1-1-1/2. Jarak enam antara dua nada yang sama disebut satu octave. Contohnya adalah jarak antara nada C1 sampai nada C2. Nada C2 berada satu octave di atas nada C1.
Nada natural tersebut dapat dinaikkan atau diturunkan ½ nada. Nada yang dinaikkan ½ nada diberi simbol # (kres), sedangkan nada yang diturunkan ½ nada diberi simbol b (mol). Misal nada C dinaikkan ½ maka akan menjadi C# (C kres / Cis). Jika nada B diturunkan ½ maka akan menjadi Bb (B mol). Untuk nada E jika dinaikkan ½ maka akan menjadi E# atau sama dengan nada F karena jarak nada E dengan nada F adalah ½. Begitu pula pada nada B ke C. Untuk lebih jelasnya dapat dilihat pada Gambar 1.
PENDAHULUAN
Latar Belakang
Manusia dianugrahi oleh Tuhan dua telinga yang memiliki fungsi untuk menangkap sinyal-sinyal suara. Namun untuk mengoptimalkan dari fungsi telinga tersebut manusia harus belajar memahami dan mengenali sinyal-sinyal suara yang masuk. Begitu juga untuk mengenali sebuah nada. Untuk seorang perfect pitch dalam mengenali sebuah nada adalah hal yang mudah karena telah melalui tahap latihan yang lama. Perfect pitch adalah kemampuan seseorang dalam mengenali dan mengidentifikasi nada-nada dari sebuah sinyal. Namun untuk seorang yang tidak memiliki kemampuan perfect pitch akan mengalami kesulitan dalam mengenali sebuah nada, sehingga dibutuhkan latihan untuk memiliki kemampuan perfect pitch.
Pengolahan Sinyal Digital (Digital Signal Processing) saat ini telah memegang peranan yang penting dalam ilmu pengetahuan dan teknologi. Salah satunya adalah pengenalan suara (voice recognition). Seperti penelitian yang telah dilakukan oleh Rudy Adipranata dan Resmana tentang pengenalan suara manusia. Dalam penelitian tersebut membahas tentang bagaimana cara mengenali suara manusia dari sebuah sinyal menggunakan jaringan saraf tiruan (Adipranata dan Resmana 1999). Selain untuk pengenalan suara manusia, pengenalan suara juga dapat dipakai dalam berbagai hal, salah satunya adalah pengenalan chord seperti penelitian yang telah dilakukan oleh Elgar Wisnudisastra dan Agus Buono pada tahun 2009 (Wisnudisastra dan Buono 2009). Pada penelitian tersebut, pemodelan chord pada gitar menggunakan codebook.
Penelitian Elgar Wisnudisastra ini hanya sampai pada pengenalan chord tidak sampai nada-nada penyusun dari chord. Tidak semua orang mengetahui semua jenis chord bahkan chord-chord miring. Untuk itu dibutuhkan pengenalan lebih mendalam untuk chord hingga nada-nada penyusun dari chord tersebut.
Tujuan
Penelitian ini bertujuan untuk mengidentifikasi campuran nada pada suara piano menggunakan codebook sebagai pemodelan nada dan banyaknya campuran nada.
Ruang Lingkup
Adapun ruang lingkup dari penelitian ini antara lain:
1. Campuran nada yang akan dikenali hanya campuran nada pada satu octave dan maksimal 2 campuran nada.
2. Suara yang dikenali hanya dimainkan dengan cara ditekan secara serentak. 3. Suara yang dikenali hanya suara piano
pada keyboard Yamaha PSR 3000. Manfaat Penelitian
Penelitian ini diharapkan dapat membantu bagi masyarakat dalam mengenali dan mengidentifikasi campuran nada pada sebuah suara piano.
TINJAUANPUSTAKA Nada dan Chord
Nada adalah bunyi yang beraturan yang memiliki frekuensi tunggal tertentu. Setiap nada memiliki tinggi nada atau tala tertentu menurut frekuensinya. Terdapat 7 nada dasar yaitu : C = do, De = re, E = mi, F = fa, G = sol, A = la, B = si. Masing-masing dari nada dasar tersebut memiliki frekuensi yang berbeda-beda. Jarak antar nada disebut interval. Interval dari deretan nada C-D-E-F-G-A-B adalah 1-1-1/2-1-1-1/2. Jarak enam antara dua nada yang sama disebut satu octave. Contohnya adalah jarak antara nada C1 sampai nada C2. Nada C2 berada satu octave di atas nada C1.
Nada natural tersebut dapat dinaikkan atau diturunkan ½ nada. Nada yang dinaikkan ½ nada diberi simbol # (kres), sedangkan nada yang diturunkan ½ nada diberi simbol b (mol). Misal nada C dinaikkan ½ maka akan menjadi C# (C kres / Cis). Jika nada B diturunkan ½ maka akan menjadi Bb (B mol). Untuk nada E jika dinaikkan ½ maka akan menjadi E# atau sama dengan nada F karena jarak nada E dengan nada F adalah ½. Begitu pula pada nada B ke C. Untuk lebih jelasnya dapat dilihat pada Gambar 1.
tiga nada (triad), misalnya chord C terdiri atas C, E, dan G.
Gambar 1 Nada dasar pada piano. Pemrosesan Sinyal Suara
Sinyal suara merupakan gelombang yang tercipta dari tekanan udara yang berasal dari paru-paru yang berjalan melewati lintasan suara menuju mulut dan rongga hidung (Al-Akaidi 2007). Pemrosesan suara itu sendiri merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan (Buono 2009).
Sinyal secara umum dapat dikategorikan sesuai dengan peubah bebas waktu, yaitu: 1. Sinyal waktu kontinyu: kuantitas sinyal
terdefinisi pada setiap waktu dalam selang kontinyu. Sinyal waktu kontinyu disebut juga sinyal analog.
2. Sinyal waktu diskret: kuantitas sinyal terdefinisi pada waktu diskret tertentu, yang dalam hal ini jarak antar waktu tidak harus sama.
Secara umum proses transformasi tersebut terdiri atas digitalisasi sinyal analog, ekstraksi ciri dan diakhiri dengan pengenalan pola untuk klasifikasi, seperti yang terlihat pada Gambar 2.
Pengolahan sinyal analog menjadi sinyal digital dapat dilakukan melalui dua tahap yaitu sampling dan kuantisasi (Jurafsky 2007). Sampling adalah suatu proses untuk membagi suatu sinyal kontinyu (sinyal analog) dalam interval waktu yang telah ditentukan. Sampling ini dilakukan dengan mengubah sinyal analog menjadi sinyal digital dalam fungsi waktu. Pengubahan bentuk sinyal ini bertujuan untuk mempermudah memproses sinyal masukan yang berupa analog karena sinyal analog memiliki kepekaan terhadap noise yang rendah, sehingga sulit untuk memproses sinyal tersebut. Nilai dari hasil sampling tersebut dibulatkan ke nilai terdekat (rounding), atau bisa juga dengan pemotongan bagian sisa (truncating) sehingga menghasilkan sinyal suara digital dengan
mengekspresikannya menggunakan sejumlah digit tertentu dan proses ini yang dikenal dengan kuantisasi.
Gambar 2 Tahapan transformasi sinyal suara menjadi informasi (Jurafsky dalam Buono 2009).
Sinyal suara digital kemudian dilakukan proses pembacaan sinyal disetiap frame dengan lebar frame tertentu yang saling tumpang tindih. Proses ini dikenal dengan proses frame blocking. Barisan frame berisi informasi yang lengkap dari sebuah sinyal suara. Informasi yang terdapat dalam frame-frame tersebutdirepresentasikan dengan cara pengekstraksian ciri sehingga dihasilkan vektor-vektor yang nantinya digunakan dalam pengenalan pola.
Ekstraksi Sinyal Suara
Ekstraksi ciri merupakan proses untuk menentukan satu nilai atau vektor yang dapat dipergunakan sebagai penciri objek atau individu (Buono 2009). Terdapat banyak cara untuk merepresentasikan parameter sinyal suara, seperti Linear Prediction Coding (LPC), Mel-Frequency Cepstrum Coefficients (MFCC), dll.
proses MFCC dapat dilihat pada Gambar 3 (Do 1994).
Gambar 3 Blok diagram proses MFCC.
Frame blocking
Pada proses ini, sinyal suara disegmentasi menjadi beberapa frame yang saling tumpang tindih (overlap), hal ini dilakukan agar tidak ada sedikitpun sinyal yang hilang (deletion). Panjang frame biasanya memiliki panjang 10-30 ms atau 256-1024 data. Proses ini akan berlanjut sampai seluruh sinyal sudah masuk ke dalam satu atau lebih frame seperti yang diilustrasikan dalam Gambar 4.
Gambar 4 Ilustrasi frame blocking pada sinyal suara.
Windowing
Sinyal analog yang sudah diubah menjadi sinyal digital dibaca frame demi frame dan pada setiap frame-nya dilakukan windowing dengan fungsi window tertentu. Proses windowing bertujuan untuk meminimalisasi ketidakberlanjutan sinyal pada awal dan akhir setiap frame (Do 1994). Dengan pertimbangan kesederhanaan formula dan nilai kinerja window, maka penggunaan window Hamming cukup beralasan (Buono 2009).
Jika kita definisikan window sebagai w(n), 0 ≤ n ≤ N– 1, dimana N adalah jumlah sampel pada setiap frame-nya, maka hasil dari windowing adalah sinyal:
y1(n) = x1(n) w(n), 0 ≤ n ≤ N– 1 dimana w(n) biasanya menggunakan window Hamming yang memiliki bentuk:
w(n) = 0.54 – 0.46 cos
– , 0 ≤ n ≤ N– 1
Grafik fungsi window Hamming dapat dilihat pada Gambar 5. Jika sebuah sinyal seperti pada Gambar 6 dikenakan fungsi window Hamming maka akan menghasilkan sinyal seperti pada Gambar 7.
Gambar 5 Grafik fungsi window Hamming.
Gambar 6 Frame sinyal sebelum proses windowing.
Gambar 7 Frame sinyal setelah proses windowing.
Fast Fourier Transform (FFT)
FFT adalah algoritme cepat untuk mengimplementasi discrete fourier transform Mel
spectrum Frame
Spectrum Speech
Mel cepstrum
Frame
blocking Windowing FFT
(DFT). FFT ini mengubah masing-masing frame N sampel dari domain waktu menjadi domain frekuensi yang didefinisikan sebagai berikut:
∑
, k= 0,1,2,…,N – 1
hasil rangkaian { } direpresentasikan sebagai berikut:
a. frekuensi positif 0 ≤ f ≤ yang merepresentasikan nilai 0 ≤ n ≤ – 1, b. frekuensi negatif < f < 0 yang
merepresentasikan nilai + 1 ≤ n≤ N– 1. Disini, berarti frequency sampling. Hasil dari tahapan ini biasanya disebut dengan spectrum atau periodogram.
Mel-Frequency Wrapping
Persepsi sistem pendengaran manusia terhadap frekuensi sinyal suara tidak dapat diukur dalam skala linear. Untuk setiap nada dengan frekuensi aktual, f, diukur dalam Hz, sebuah subjectivepitch diukur dalam sebuah skala yang disebut ‘mel’. Skala mel-frequency ialah sebuah frekuensi rendah yang bersifat linear di bawah 1000 Hz dan sebuah frekuensi tinggi yang bersifat logaritmik di atas 1000 Hz seperti yang diilustrasikan pada Gambar 8. Persamaan berikut menunjukkan hubungan skala mel dengan frekuensi dalam Hz:
mel(f) = 2595 * log10 (1 + f / 700)
Gambar 8 Mel-frequency filter.
Cepstrum
Langkah terakhir yaitu mengubah spektrum log mel menjadi domain waktu. Hasil ini disebut mel frequency cepstrum coefficient (MFCC). Cepstral dari spectrum suara merepresentasikan sifat-sifat spektral lokal sinyal untuk analisis frame yang
diketahui. Koefisien mel spectrum merupakan sebuah nilai riil sehingga kita dapat mengkonversinya ke dalam dominan waktu menggunakan Discrete Cosine Transform (DCT). Selanjutnya kita dapat menghitung MFCC sebagai , sebagai
= ∑ cos , dimana , k= 0, 2, …, K– 1 dan n= 0, 1, …, K – 1.
K-Means
K-means adalah salah satu algoritme pembelajaran unsupervised dalam menyelesaikan permasalahan klustering (MacQueen 1967). Langkah pertama yang dilakukan oleh algoritme ini adalah menentukan K initial centroid, di mana K adalah parameter spesifik yang ditentukan user, yang merupakan jumlah kluster yang diinginkan. Setiap titik atau objek kemudian ditempatkan pada centroid terdekat, dan kumpulan titik atau objek pada tiap centroid disebut kluster. Centroid pada setiap kluster kemudian akan berubah berdasarkan setiap objek yang ada pada kluster. Kemudian langkah penempatan objek dan perubahan centroid diulangi sampai tidak ada objek yang berpindah kluster. Algoritme dasar dari K-means adalah (Tan et al. 2006):
Select K points as initial centroids
repeat
Form K cluster by assigning each point to its closets centroid
Recompute the centroid of each cluster
until Centroids do not change
Terdapat fungsi objektif untuk menghitung tingkat error yang didefinisikan sebagai berikut:
pengenalan suara, masing-masing suara yang akan dikenali harus dibuatkan codebook-nya. Codebook dibentuk dengan cara membentuk kluster semua vektor ciri yang dijadikan sebagai training set dengan menggunakan klustering algorithm. Algoritme klustering yang akan dipakai adalah algoritme K-means. Ilustrasi codebook untuk setiap nada dapat dilihat pada Gambar 9.
Gambar 9 Codebook untuk setiap nada. Seperti yang telah diilustrasikan pada Gambar 10, prinsip dasar dalam penggunaan codebook adalah setiap suara yang masuk akan dihitung jaraknya ke setiap codebook yang telah dibuat. Kemudian jarak setiap sinyal suara ke codebook dihitung sebagai jumlah jarak setiap frame sinyal suara tersebut ke setiap codeword yang ada pada codebook. Kemudian dipilih codeword dengan jarak minimum. Setelah itu setiap sinyal suara yang masuk akan diidentifikasi berdasarkan jumlah dari jarak minimum tersebut.
Gambar 10 Ilustrasi prinsip dasar penggunaan codebook.
Perhitungan jarak dilakukan dengan menggunakan jarak euclid yang didefinisikan sebagai berikut:
∑
dimana x dan y adalah vektor yang akan dihitung jaraknya dengan D dimensi.
Jika dalam sinyal suara input O terdapat T frame dan merupakan masing-masing codeword yang ada pada codebook maka jarak sinyal input dengan codebook dapat dirumuskan:
∑ ( )
METODE PENELITIAN Kerangka Pemikiran
Penelitian ini dikembangkan dengan metode yang terdiri atas beberapa tahap yaitu: (1) pengambilan data, (2) preprocessing, (3) pemodelan codebook, (4) evaluasi. Alur metode ini dapat dilihat pada Gambar 11. Pengambilan Data
Suara yang akan digunakan dalam penelitian ini adalah suara grand piano yang terdapat di keyboard Yamaha PSR 3000. Nada yang diambil sebanyak 12 nada tunggal yang terdiri dari C, C#, D, D#, E, F, F#, G, G#, A, A#, dan B yang masing-masing akan diulang sebanyak 15 kali. Nada dua campuran diambil sebanyak 66 nada yang masing-masing akan diulang sebanyak 15 kali.
Nada yang telah diambil akan dibagi dua, yaitu data training dan data testing. Data training adalah 12 nada tunggal yang masing-masing nada 10 suara dan 66 nada dua campuran yang masing-masing nada 10 suara, sedangkan data testing adalah 66 nada campuran yang masing-masing nada lima suara dan 12 nada tunggal yang masing-masing nada lima suara. Total dari data training sebanyak 780 suara dan total dari data testing sebanyak 390 suara.
Data direkam langsung dengan keyboard melalui kabel yang dihubungkan langsung dengan komputer. Perekaman menggunakan software Matlab selama 1 detik, disimpan dalam file berformat WAV, dan sampling rate sebesar 11000 Hz. Proses perekaman dengan menekan secara serentak dengan tekanan yang berbeda. Tekanan yang diberikan ada yang keras, lembut, ditekan lama, dan sesaat.
Preprocessing