ABSTRACT
COMPARATION UNBIASED RATE OF SOME BOOTSTRAP SAMPLES IN SEMPLS USING R PROGRAM
By
Jordian Gevara
The purpose of this research is to compare the unbiased rate of some bootstrap samples and estimate the model in SEMPLS. The SEMPLS package was used to specify the model with mobile phone dataset from marketing research. Model parameterswere estimated by the SEMPLS function for sample sizes 250, 300, 350, 400, 450, and 500.Result shows thatbootstrap sample size 500 has the smallest residual compare to other sizes.
MEMBANDINGKAN KETAKBIASAN BEBERAPA UKURAN BOOTSTRAP SAMPLES DALAM SEMPLS MENGGUNAKAN
PROGRAM R
Oleh Jordian Gevara
Skripsi
Sebagai Salah Satu Syarat Untuk Memperoleh Gelar Sarjana Sains
Pada
Jurusan Matematika
Fakultas Matematika dan Ilmu Pengetahuan Alam
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS LAMPUNG
MEMBANDINGKAN KETAKBIASAN BEBERAPA UKURAN BOOTSTRAP SAMPLESDALAM SEMPLS MENGGUNAKAN
PROGRAM R
(Skripsi)
Oleh Jordian Gevara
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS LAMPUNG
DAFTAR ISI
Halaman
DAFTAR TABEL ... ... iii
DAFTAR GAMBAR ... ... v
I. PENDAHULUAN 1.1 Latar Belakang dan Masalah ... 1
1.2 Tujuan Penelitian ... 3
1.3 Manfaat Penelitian ... 3
II. TINJAUAN PUSTAKA 2.1 Standar SEM ... 4
2.2 SEM ... 5
2.2.1 Variabeldalam SEM ... 5
2.2.2 Model dalam SEM... 6
2.2.3 Asumsi-asumsi SEM ... 7
2.3 Distribusi Normal Multipeubah ... 11
2.4 Metode Pendugaan PLS ... 13
2.5 Uji kecocokan ... 16
2.6 Metode Bootstrap ... 16
III. METODOLOGI PENELITIAN 3.1 Waktu dan Tempat Penelitian ... 20
3.3 Langkah-Langkah Penelitian ... 20
IV. HASIL DAN PEMBAHAAN 4.1 Identifikasi Package SemPLS... 22
4.2 Spesifikasi Model ... 22
4.2.1 Spesifikasi Model Struktural ... 23
4.2.1 Spesifikasi Model Pengukuran ... 25
4.3 Membangkitkan Data Sebagai Variabel Indikator... 26
4.4 Membangun Model Dalam Struktur Blok dengan Fungsi plsm ... 32
4.5 Membangun Diagram Jalur dan Estimasi SemPLS ... 36
4.5.1 Diagram Jalur ... 37
4.5.2 Estimasi SemPLS ... 37
4.6 Bootstrap dengan Beberapa Ukuran n-boot SemPLS Menggunakan Selang Kepercayaan Bias-Corrected & Accelerated 90% ... 42
4.7 Membandingkan Hasil dari Beberapa Ukuran Bootstrap Samples ... 49
V. KESIMPULAN………..……….53 DAFTAR PUSTAKA
DAFTAR GAMBAR
Gambar Halaman
2.1 Teorema B. Efron ... 17
4.1 Model Sebab-Akibat dari ECSI. ... 23
4.2 Struktur Blok dari Variabel Laten Image ... 32
4.3 Struktur Blok dari Variabel Laten Expectation. ... 33
4.4 Struktur Blok dari Variabel Laten Satisfaction. ... 34
4.5 Struktur Blok dari Variabel Laten Value ... 34
4.6 Struktur Blok dari Variabel Laten Loyalty ... 35
4.7 Perubahan Outer Weights dalam 6 Iterasi ... 36
4.8 Diagram Jalur beserta Koefisien Beta ... 37
4.9 Estimasi Fungsi Densitas Kernel Residual. ... 42
4.10 Perubahan Bias λ11–λ 23 ... 49
4.11 Perubahan Bias λ31–λ37 ... 49
4.12 Perubahan Bias λ41–λ73 ... 50
4.13 Perubahan Bias β12–β25 ... 50
4.14 Perubahan Bias β34–β67 ... 50
4.15 Hasil Bootstrap dari Estimasi Koefisien Jalur. ... 51
DAFTAR TABEL
Tabel Halaman
4.1 Jalur Model Struktural ... 23
4.2 Pendekatan Matriks Model Struktural ... 24
4.3 Jalur Model Pengukuran ... 25
4.4 Model Pengukuran Dalam Pendekatan Matriks ... 26
4.5 Data ECSI untuk Variabel Laten Image………..………… 28
4.6 Data ECSI untuk Variabel Laten Expectation ... 29
4.7 Data ECSI untuk Variabel Laten Quality ... 29
4.8 Data ECSI untuk Variabel Laten Value ... 30
4.9 Data ECSI untuk Variabel Laten Satisfaction ... 30
4.10 Data ECSI untuk Variabel Laten Complaints ... 31
4.11 Data ECSI untuk Variabel Laten Loyalty ... 31
4.12 Hasil Estimasi untuk Model Struktural (Koefisien Jalur) ... 38
4.13 Hasil Estimasi untuk Model Pengukuran (Loading) ... 38
4.14 Hasil dari Fungsi Communality(ecsi) dan Redudancy(ecsi) ... 39
4.15 Hasil Dugaan Koefisien Jalur dari Fungsi pathCoeff(ecsi) ... 39
4.18 Hasil Dugaan loading Model Struktural dari Fungsi plsLoadings(ecsi) . 41
4.19 Hasil Ukuran Bootstrap Samples 250 ... 43
4.20 Hasil Ukuran Bootstrap Samples 300 ... 44
4.21 Hasil Ukuran Bootstrap Samples γ50……… 45
4.22 Hasil Ukuran Bootstrap Samples 400 ... 46
4.23 Hasil Ukuran Bootstrap Samples 450 ... 47
Moto
“Tidak Hadir Tanpa Pergi”
(JordianGevara)
“Dosen Baik MenghasilkanMahasiswa Baik”
PERSEMBAHAN
Dengansegala rasa syukurkehadirat Allah SWT atas segala nikmat dalam hidupku dan
dengan segala kerendahan hati, kupesembahkan karya kecilku untuk orang-orang yang telah
member makna dalam hidupku.
Teruntuk Bapak Joko Nugroho dan Ibu Suryati tercinta.
Saudara Kandung, FarizaArif, Julian Mahardika dan Zhefira Nauradelva.
RIWAYAT HIDUP
Penulis dilahirkan di Bandar Jaya pada tanggal 31 Mei 1993, sebagai anak ketiga dari empat bersaudara pasangan Bapak Joko Nugrogo dan Ibu Suryati.
Penulis telah menempuh pendidikan di Sekolah Dasar Negeri 2 Seputih Agung dan selesai pada tahun 2005, Sekolah Menengah Pertama Negeri 3 Terbanggi Besar dan selesai pada tahun 2008, dan Sekolah Menengah Atas Negeri 1 Seputih Agung dan selesai pada tahun 2011.
Pada tahun 2011 penulis diterima sebagai Mahasiswa Jurusan Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Lampung. Selama menjadi mahasiswa, penulis bergabung dalam organisasi Himpunan Mahasiswa Jurusan Matematika (HIMATIKA) sebagai anggota bidang eksternal periode 2012-2013 hingga periode 2013-2014.
SANWACANA
Puji syukur kehadirat Allah SWT yang telah melimpahkan berkah dan rahmatNya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Membandingkan Ketakbiasan Beberapa Ukuran Bootstrap Samples dalam SEMPLS
Menggunakan Program R”. Oleh karena itu, penulis ingin mengucapkan terimakasih kepada:
1. Bapak Drs. Eri Setiawan, M.Si. selaku pembimbing pertama. Terimakasih Bapak atas kesediaan waktu, tenaga, pemikiran, motivasi, dukungan, dan pengarahan dalam proses penyusunan skripsi ini.
2. Ibu Ir. Netti Herawati, M.Sc., Ph.D. selaku pembimbing kedua. Terimakasih Ibu atas kesediaan waktu, tenaga, pemikiran, motivasi, dukungan dan
pengarahan dalam proses penyusunan skripsi ini.
3. Ibu Widiarti, S.Si., M.Si. selaku pembahas. Terimakasih atas kesediaan waktu dan pemikiran Ibu dalam memberikan kritik dan saran yang membangun dalam proses penyusunan skripsi ini.
4. Drs. Rudi Ruswandi, M.Si.selakupembimbingakademik yang selalu memberi arahan, memberi nasihat dan meluangkan waktunya kepada penulis selama proses perkuliahan.
6. Bapak Prof Suharso, Ph.D. selaku Dekan FMIPA Universitas Lampung. 7. Ibunda Lusiana, Bapak Tamrin, Bapak Drajat, dan Staf Jurusan Matematika. 8. Bapak, Ibu, Mamas dan Adik tercinta yang telahbanyak member dukungan, do’a,
danmotivasi kepada penulis sehingga skripsi inidapatdiselesaikan.
9. Sherly Lestari yang selalu mendukung dan menjadi penyemangat penulis dalam menyelesaikan skripsi ini.
10. Sahabat-sahabat penulis Ahmad, Asmawi, Dias, Eko, Erik, Gusti, Haidir, Helmi, Ibrahim, Iril, Joko, Reno, Sepria, Wesly, seluruh anggota kost dan kontrakan seperjuangan penulis. Terimakasih atas kebersamaannya dan dukungan kalian selamaini. Semoga akan terus berlanjut sampai kapanpun. 11. Kawan-kawan satu bimbingan, tetap semangat dan jangan menyerah karena
kita pasti bisa. Terimakasih atas bantuan dan dukungannya dalam menyelesaikan skripsi ini.
12. Seluruh rekan seperjuangan Matematika angkatan 2011. Terimakasih atas keakraban dan kebersamaan selama ini.
13. Semua pihak yang telah memberikan bantuan dalam menyelesaikan skripsi ini yang tidak dapat penulis sebutkan satupersatu.
Penulis menyadari bahwa skripsi ini masih jauh dari sempurna, tapi besarharapan penulis semoga skripsi ini bermanfaat bagi semua pihak yang memerlukannya.
Bandar Lampung, Desember 2015 Penulis,
I. PENDAHULUAN
1.1Latar Belakang dan Masalah
Pemodelan persamaan struktural atau yang sering disebut juga Structural Equation Modeling (SEM) merupakan sebuah metode yang terbentuk karena adanya masalah pengukuran suatu variabel dimana terdapat suatu variabel yang tidak dapat diukur secara langsung. Variabel yang tidak dapat diamati secara langsung disebut variabel laten, contohnya yakni kecerdasan seseorang, kesetiaan seseorang, kepuasan seseorang dan lain sebagainya. Besarnya hubungan antara variabel laten ditandai dengan besar koefisien jalur. Selain variabel laten, SEM memiliki variabel indikator yaitu variabel dapat diukur secara langsung dan merupakan indikasi untuk variabel latennya, contoh variabel indikator adalah nilai ujian seseorang, nilai indeks prestasi seseorang, dan lain sebagainya yang
merupakan indikator untuk menilai kecerdasan seseorang. Adanya hubungan dari variabel indikator ke variabel laten tersebut dinamakan loadings.
3
Metode PLS digunakan karena dalam metode ini tidak memerlukan asumsi kenormalan data.
SEM menggunakan PLS (semPLS) memiliki model struktural yang digunakan untuk melakukan uji kausalitasdan model pengukuran yang digunakan untuk uji kesahihan (validity) dan uji keterandalan (reliability). Apabila data pengamatan sudah memenuhi uji kebenarannya maka dapat melangkah ke tahap bootstrap dengan beberapa ukuran yang berbeda dengan tujuan melihat perbedaan dari masing-masing ukuran. Dengan menggunakan bantuan package semPLS program R yang telah disediakannya fungsi-fungsi tertentu di dalamnya, sehingga cukup dengan memasukkan perintah-perintah tertentu untuk melakukan proses seperti pendugaan nilai hubungan antarvariabel yakni koefisien jalur dan outer loading. Koefisien jalur dapat disajikan dalam bentuk grafik seperti density-plotdan
parallel-plot. Dengan melihat perbedaan nilai bias dari beberapa ukuran bootstrap samples (n-boot), bias yang semakin mendekati nol merupakan ukuran yang baik digunakan.
Di dalam penelitianini akan dikaji beberapa ukuran n-boot mulai dari 250, 300, 350, 400, 450, hingga 500 menggunakan selang kepercayaan Bias-Corrected and Accelerated (BCa) 90% untuk membandingkan ketakbiasan. Ukuran
3
semPLS menggunakan program R telah disediakan package semPLS di dalam program.
1.2 Tujuan Penelitian
Tujuan dilakukannya penelitian ini adalah membandingkan nilai bias dari beberapa ukuran bootstrap samples serta mengestimasi hubungan antarvariabel semPLS.
1.3 Manfaat Penelitian
II. TINJAUAN PUSTAKA
2.1Standar SEM
Di dalamperilaku, pendidikan, kesehatan, dan sains sosial, teori substantif biasanya melibatkan dua jenis variable dengan nama variabel teramati dan variabel laten. Variabel teramati adalah variabel yang dapat diamati secara
langsung seperti nilai ujian, penghasilan, tekanan darah sistolik/diastolik dan berat badan seseorang. Variabel laten adalah variabel yang tidak dapat diamati secara langsung seperti kecerdasan, kepribadian, kondisi kesehatan, kemampuan dan tekanan darah.
Karakteristik dari sebuah variabel laten dapat diamati secara parsial oleh kombinasi linier dari beberapa variabel teramati. Contohnya, kemampuan kuantitatif dari siswa sekolah tercermin dari nilai-nilai matematika, fisika dan kimia siswa tersebut. Di dalam penelitian itu penting untuk membuktikan sebuah model yang patut untuk mengevaluasi sebuah hipotesis tentang dampak variabel laten dan variabel teramati terhadap variabel lainnya dan menulis galat-galat pengamatan ke dalam catatan. Structural Equation Modeling (SEM) merupakan sesuatu yang diakui sebagai metode statistik yang sangat penting untuk
5
2.2 SEM (Structural Equation Modeling)
SEM adalah salah satu teknik statistik yang digunakan untuk melakukan pengujian terhadap suatu model sebab akibat dengan menggunakan kombinasi teori yang ada. Dalam penggunaannya, SEM memiliki asumsi-asumsi yang mendasarinya. SEM memiliki variabel-variabeldan model-model di dalamnya, variabel-variabel dan model-model dalam SEM beserta asumsi yang
mendasarinya adalah sebagai berikut:
2.2.1 Variabeldalam SEM
a. Variabel Laten
Variabel kunci yang menjadi perhatian di dalam SEM adalah variabel laten, dimana variabel laten merupakan konsep abstrak, seperti perilaku orang, sikap, perasaan, dan motivasi. Variabel laten dapat diamati secara tidak langsung dan tidak sempurna melalui efeknya pada variabel teramati. SEM mempunyai 2 jenis variabel laten, yaitu eksogen dan endogen. SEM membedakan kedua jenis variabel ini berdasarkan keikutsertaan variabel sebagai variabel terkait pada persamaaan-persamaan dalam model. Variabel laten eksogen sebagai variabel bebas pada persamaan yang ada dalam model. Sedangkan variabel endogen merupakan variabel terikat pada persamaan yang ada dalam model.
b. VariabelTeramati (Indicator Variable)
6
menggunakan kuesioner, setiap pernyataan pada kuesioner mewakili sebuah variabel teramati.
2.2.2 Model dalam SEM
SEM memiliki model-model antara lain model strukturaldan model pengukuran, berikut ini gambaran kedua model.
a. Model struktural
Model struktural menggambarkan hubungan-hubungan yang ada diantara variabel-variabel laten. Variabel-variabel laten dibagi menjadi dua kelas, yaitu variable eksogen dan variable endogen. Hubungan-hubungan ini umumnya linear meskipun perluasan SEM memungkinkan untuk mengikutsertakan hubungan yang non-linear. Model struktural dapat dibuat dalam notasi sederhana
Dimana variabel Y merupakan matriks variabel laten, baik variabel eksogen maupun endogen. Nilai rentang error Z diasumsikan menjadi terpusat dengan .
b. Model Pengukuran
7
2.2.3 Asumsi-Asumsi SEM
Asumsi-asumsi yang mendasari penggunaan SEM adalah sebagai berikut: a. Distribusi Normal Multivariat.
Masing-masing indikator mempunyai nilai yang berdistribusi normal terhadap masing-masing indikator lainnya. Karena permulaan yang kecil normalitas multivariat dapat menuntun kearah perbedaan yang besar dalam pengujian chi-square, dengan demikian akan melemahkan kegunaannya. Secara umum, pelanggaran asumsi ini menaikkan chi-square sekalipun demikian didalam kondisi tertentu akan menurunkannya.
8
Chi-square yang meninggi dapat mengarahkan peneliti berpikir bahwa model-model yang sudah dibuat memerlukan modifikasi. Kurangnya normalitas multivariat biasanya menaikkan statistik chi-square. Misalnya, statistik
keselarasan chi-square secara keseluruhan untuk model yang bersangkutan akan bias kearah kesalahan tipe 1, yaitu menolak suatu model yang seharusnya diterima. Pelanggaran terhadap normalitas multivariat juga cenderung
menurunkan (deflate) kesalahan-kesalahan standar mulai dari menengah sampai ke tingkat tinggi. Kesalahan-kesalahan yang lebih kecil dari yang seharusnya terjadi mempunyai makna jalur-jalur regresi dan kovarian-kovarian faktor / kesalahan didapati akan menjadi signifikan secara statistik dibandingkan dengan seharusnya yang terjadi.
b. Linearitas
SEM mempunyai asumsi adanya hubungan linear antara variabel-variabel indikator dan variabel-variabel laten, serta antara variabel-variabel laten sendiri. Sekalipun demikian, sebagaimana halnya dengan regresi, peneliti dimungkinkan untuk menambah transformasi eksponensial, logaritma, atau non-linear lainnya dari suatu variabel asli ke dalam model yang dimaksud.
c. Pengukuran Tidak Langsung (Indirect measurement)
Secara tipikal, semua variabel dalam model merupakan variabel-variabel laten.
d. Indikator Jamak
9
dimana hanya ada satu indikator di setiap variabel laten. Kesalahan pemodelan dalam SEM membutuhkan adanya lebih dari satu pengukuran untuk masing-masing variabel laten.
e. Rekursifitas
Suatu model disebut rekursif jika semua anak panah menuju satu arah, tidak ada factor pengulangan (feedback looping), dan faktor gangguan (disturbance terms) atau kesalahan residual untuk variabel-variabel endogenous yang tidak
dikorelasikan. Dengan kata lain, model-model rekursif merupakan model-model dimana semua anak panah mempunyai satu arah tanpa putaran umpan balik dan peneliti dapat membuat asumsi kovarian–kovarian gangguan kesalahan semua 0. Dapat diartikan bahwa semua variabel yang tidak diukur yang merupakan determinan dari variabel-variabel endogenous tidak dikorelasikan satu dengan lainnya sehingga tidak membentuk feedback loops. Model–model dengan gangguan kesalahan yang berkorelasi dapat diperlakukan sebagai model rekursif hanya jika tidak ada pengaruh-pengaruh langsung diantara variabel-variabel endogen.
f. Ketepatan yang Tinggi
Apakah data berupa data interval atau ordinal, data-data tersebut harus
10
g. Residual-Residual Acak dan Kecil
Rata-rata residual–residual atau kovarian hasil pengitungan yang diestimasikan minus harus sebesar 0, sebagaimana dalam regresi. Suatu model yang sesuai akan hanya mempunyai residual – residual kecil. Residual–residual besar menunjukkan kesalahan spesifikasi model, sebagai contoh, beberapa jalur mungkin diperlukan untuk ditambahkan ke dalam model tersebut.
h. Gangguan Kesalahan yang Tidak Berkorelasi (Uncorrelated Error Terms)
Seperti di dalam regresi, maka gangguan kesalahan diasumsikan saja. Sekalipun demikian, jika memang ada dan dispesifikasi secara eksplsit dalam model oleh peneliti, maka kesalahan yang berkorelasi (correlated error) dapat diestimasikan dan dibuat modelnya dalam SEM.
i. Kesalahan Residual yang Tidak Berkorelasi (Uncorrelated Residual Error)
Kovarian nilai–nilai variabel tergantung yang diprediksi dan residual–residual harus sebesar 0.
j. Multikolinearitas yang Lengkap
11
k. Ukuran Sampel
Ukuran sampel tidak boleh kecil, karena SEM bergantung pada pengujian-pengujian yang sensitif terhadap ukuran sampel dan magnitude perbedaan-perbedaan matrices kovarian. Secara teori, untuk ukuran sampelnya berkisar antara 200 - 400 untuk model-model yang mempunyai indikator antara 10 - 15. Satu survei terhadap 72 penelitian yang menggunakan SEM didapatkan median sukuran sampel sebanyak 198. Sampel di bawah 100 akan kurang baik hasilnya jika menggunakan SEM (Sarwono, 2007).
2.3 Distribusi Normal Multipeubah
Pembahasan distribusi normal multipeubah diawali dengan mengemukakan konsep distribusi normal univariat dan chi kuadrat. Peubah tunggal Z
didefinisikan mempunyai distribusi normal univariat baku jika dan hanya jika fungsi densitas peluang atau probability density function (pdf):
(
√ ) [ ]
dengan median = 0 & varians = 1.
Fungsi distribusi kumulatif dan fungsi pembangkit momen peubah acak Z yang mempunyai distribusi normal univariat baku masing-masing diberikan berikut
N(z: 0,1) = ∫ -∞ < z < ∞ dan Mz(t) =
Bukti
12
∫ √
∫
∫
■ Terbukti.
Misalkan peubah acak berikut ini , ..., independen dan identik
berdistribusi normal dengan nilai tengah 0 dan varians 1. Distribusi marjinal adalah
untuk i = 1,2, ... , n. Karena adalah peubah acak independen dan identik maka distribusi peluang gabungan vektor acak , ..., ’ adalah
Bentuk terakhir ini dilambangkan dengan
13
2.4Metode Pendugaan PLS
Metode pendugaan yang digunakan pada penelitian ini adalah metode kuadrat terkecil parsial atau Partial Least Square (PLS).
PLS adalah teknik statistika multivariat yang melakukan pembandingan antara variabel dependen berganda dan variabel independen berganda. PLS adalah salah satu metode statistika SEM berbasis varian yang secara simultan dapat melakukan pengujian model pengukuran sekaligus pengujian model struktural. Model
pengukuran digunakan untuk uji validitas dan reliabilitas, sedangkan model struktural digunakan untuk uji kausalitas (pengujian hipotesis dengan model prediksi). Perbedaan mendasar PLS yang merupakan SEM berbasis varian dengan LISREL atau AMOS yang berbasis kovarian adalah tujuan penggunaanya. SEM berbasis kovarian bertujuan untuk mengestimasi model untuk pengujian atau konfirmasi teori, sedangkan SEM berbasis varian bertujuan untuk memprediksi model untuk pengembangan teori.
Sebagai alat untuk model prediksi, untuk menghindari masalah intedeminancy, yaitu skor faktor yang berbeda dihitung dari model faktor tunggal yang dihasilkan. PLS mengasumsikan bahwa semua ukuran varian adalah varian yang dijelaskan sehingga pendekatan estimasi variabel laten dianggap sebagai kombinasi linear dari indikator. Dalam menggunakan metode PLS, ada beberapa langkah-langkah yang harus dilaksanakan seperti berikut ini
1. Merancang Model Struktural (inner model)
14
a. Teori
b. Hasil penelitian empiris
c. Analogi, hubungan antar variabel pada bidang ilmu lain
d. Normatif, misal peraturan pemerintah, undang-undang, dan lain sebagainya
e. Rasional (PLS: bisa ekplorasi hubungan antar variabel) 2. Merancang Model Pengukuran (outer model)
Pada SEM semua bersifat refleksif, model pengukuran tidak penting. Namun pada PLS perancangan outer model sangat penting yaitu reflektif atau formatif.
3. Kontruksi diagram jalur.
4. Konversi diagram jalur ke bentuk persamaan. 5. Estimasi parameter.
6. EstimasiJaluryang menghubungkan antar variabel laten (koefesien jalur) dan antara variabel laten dengan indikatornya (loading).
7. Evaluasi kecocokan model. 8. Outer Model refleksif.
15
9. Outer Modelformatif
Untuk model penelitian yang menggunakan outer model formatif dievaluasi berdasarkan pada substantive content-nya yaitu dengan melihat signifikansi dan weight.
10. Inner Model GOF
Diukur menggunakan Q-square predictive relevance. Rumus Q-Square:
Q 2 =1-(1-R1 2 )(1-Rβ β )….(1-Rp2 )
Dimana R1 β , Rβ β…Rpβ adalah R square variabel endogen dalam model.
Interpretasi Q2 sama dengan koefesien determinasi total dalam analisis jalur (mirip dengan R2 pada regresi).
11. Uji Hipotesis
Hipotesis statistik untuk outer model: H0: i = 0, vs H1: i ≠ 0
Hipotesis statistik untuk inner model: Variabel eksogen terhadap endogen: H0 : i = 0, vs H1 : i ≠ 0
Hipotesis statistik untuk inner model: Variabel endogen terhadap endogen: H0 : i = 0, vs H1 : i ≠ 0
12. Statistik uji
t-test; p-value ≤ 0,05 (alpha 5%); signifikan Outer model signifikan: indikator bersifat valid Inner model signifikan: terdapat pengaruh signifikan
16
PLS sebagai model prediksi tidak mengasumsikan distribusi tertentu untuk mengestimasi parameter dan memprediksi hubungan kausalitas. Oleh karena itu, teknik parametrik untuk menguji signifikansi parameter tidak diperlukan dan model evaluasi untuk prediksi bersifat non-parametrik. Evaluasi model PLS dilakukan dengan mengevaluasi outer model dan inner model. Outer model merupakan model pengukuran untuk menilai validitas dan reliabilitas model. Melalui proses iterasi alogaritma, parameter model pengukuran (validitas konvergen, validitas diskriminan, composite realiability dan crombach’s alpha) diperoleh, termasuk nilai R2 sebagai parameter ketepatan model prediksi. Inner model merupakan model struktural untuk memprediksi hubungan kausalitas antar variabel laten. Melalui proses bootstrapping, parameter uji Tstatistik diperoleh untuk memprediksi adanya hubungan kasualitas (Jogiyanto dan Abdillah, 2009).
2.5 Uji Kecocokan
Setelah melakukan estimasi yang menghasilkan nilai parameter, perlu dilakukan pemeriksaan tingkat kecocokan. Pada tahap ini kita akan memeriksa tingkat kecocokan antara data dengan model, validitas dan reabilitas model pengukuran, dan signifikansi koefisien-koefisien dari model struktural(Wijanto, 2008).
2.6 Metode Bootstrap
Bootstrap diperkenalkan oleh Bradley Efron pada tahun 1979. Istilah bootstrap berasal dari “pull oneself up by one’s bootstrap”, yang berarti berpijak diatas kaki
17
sumber daya minimal adalah data yang sedikit, data yang menyimpang dari asumsi tertentu, atau data yang tidak mempunyai asumsi apapun tentang distribusi populasinya. Teknik ini mampu menciptakan ukuran-ukuran dari ketakpastian dan bias, khususnya pada estimasi parameter dari variabel-variabel yang independen dan berdistribusi identik.
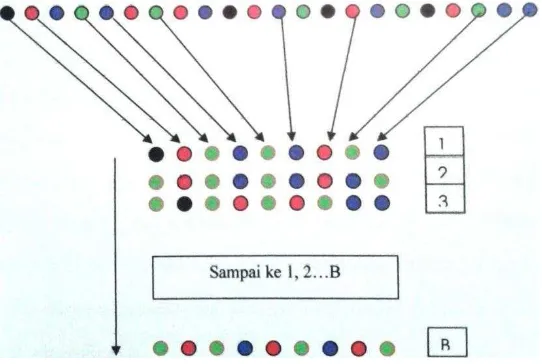
Gambar 2.1Teorema B. Efron
Bootstrap adalah teknik resampling yang bertujuan untuk menaksir galat baku dan selang kepercayaan parameter populasi, seperti mean, median, proporsi, koefisien korelasi, dan regresi dengan tidak selalu memperhatikan asumsi distribusi.
18
formulasi analitis yang sulit dilakukan sehingga dimungkinkan akurasi penduganya tidak valid.
Bootstrap memungkinkan seseorang untuk melakukan inferensi statistik tanpa membuat asumsi distribusi yang kuat dan tidak memerlukan formulasi analitis untuk distribusi sampling suatu penduga. Sebagai pengganti, bootstrap
menggunakan distribusi empiris untuk mengestimasi distribusi sampling. Jadi jika penyelesaian analitik tidak mungkin dilakukan dimana anggapan (suatu distribusi, misalnya kenormalan data) tidak dipenuhi maka dengan menggunakan bootstrap masih dapat dilakukan suatu inferensi.
Dasar pendekatan bootstrap adalah dengan memperlakukan sampel sebagai populasi dan dengan menggunakan sampling Monte Carlo untuk membangkitkan dan mengkonstruksi penduga empiris dari distribusi sampling statistik. Distribusi sampling dapat dipandang sebagai harga-harga statistik yang dihitung dari sejumlah tak terhingga sampel acak berukuran n dari suatu populasi yang diberikan. Sampling Monte Carlo mengambil konsep ini untuk membangun distribusi sampling suatu penduga dengan mengambil sejumlah besar sampel berukuran n secara acak dari populasi dan menghitung statistik tersebut dari harga-harga distribusi sampling tersebut.
Metode bootstrap adalah melakukan resampling terhadap sampel awal x (berukuran n) secara satu per satu dengan pengembalian. Dengan prosedur ini didapat sampel baru.
19
Prosedur resampling tersebut diulang sebanyak B kali. Sehingga didapat sampel-sampel bootstrap sebanyak B berikut
Selanjutnya dari tiap-tiap sampel bootstrap dihitung penduganya untuk mendapatkan t(x), maka diperoleh penduga-penduga bootstrapnya ( , . Dengan distribusi bootstrap untuk sampel nilai tengah oleh resampling
dari setiap sampel.
Tahapan/Prosedur bootstrap:
1. Sampel asal, dari eksperimen atau simulasi, berukuran . 2. Resampel dengan pengembalian, didapatkan resampel ke- (
3. Perhitungan penaksir setiap hasil resampel, didapatkan: ̂ ̂ ̂
; bentuk umumnya ̂ .
4. Perhitungan penaksir bootstrap:
̂ ̂ ∑ ̂
Keterangan: ̂ atau ̂ suatu penaksir parameter yang pada penerapannya dapat
III. METODOLOGI PENELITIAN
3.1 Waktu dan Tempat Penelitian
Penelitianini dilaksanakan pada semester ganjil tahun ajaran 2015/2016bertempat di Jurusan Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Lampung.
3.2 Data Penelitian
Penelitian ini menggunakan data ordinal European Customer Satisfaction Index (ECSI) sebagai variabel indikator yang termuat dalam package semPLS (Monecke dan Liesch, 2012).
3.3 Langkah-Langkah Penelitian
Dengan menggunakan perangkat bantuan R,langkah-langkah penelitian yang dilakukan adalah sebagai berikut
1. Mengidentifikasi package semPLS dalam program. 2. Spesifikasi model.
3. Membangkitkan data sebagai variabel indikator
21
5. Membangun diagram jalur dan estimasi semPLS.
6. Bootstraping denganbeberapa ukuran n-bootsemPLS menggunakan selang kepercayaan BCa 90%.
V. KESIMPULAN
Berdasarkan hasil dari bootstraping estimasi semPLS menggunakan data provider telefon genggam ECSI dapat disimpulkan bahwa:
1. Bootstrap samples dengan ukuran 500 memiliki residual terkecil
dibandingkan ukuran 250, 300, 350, 400, dan 450. Sehingga ketakbiasan ukuran n-boot 500 lebih baik daripada ukuran lainnya.
DAFTAR PUSTAKA
Davidson dan Hinkley. 1997. Bootstrap Methods of Their Application. Cambridge, University Press, Inggris.
Efron, B. danTibshirani, R. 1993. An Introduction to the Bootstrap. Chapenan & Hall/CRC. Boca Raton, Florida.
Fox, J., Nie, Z., dan Byrnes, J. 2012. sem: Structural Equation Models. R package version 3.0-0, URL http://CRAN.R-project.org/package=sem.
Gansner E., Koutsofios E., North S. 2006. Drawing Graph with DOT. Technical Report, AT&T Research,
URL http://www.graphviz.org/Documentation/dotguide.pdf.
Jogiyanto dan Abdillah, W. 2009. Konsep dan Aplikasi PLS untuk Penelitian Empiris. Fakultas Bisnis Universitas Gajah Mada, Yogyakarta.
Lee, S. Y. 2007. SEM: A Bayesian Approach. John Wiley & Sons, Ltd, England. Monecke, A. dan Leisch, F. 2012. semPLS:Structural Equation Modeling Using
Partial Least Squares. Journal of Statistical Software. 48:1-32.
Mustofa dan Warsono. 2009. Model Linear danAplikasinya.SinarBaruAlgesindo, Bandung.
Narimawati, U. dan Sarwono, J.2007. Structural Equation Model (SEM) Dalam Riset Ekonomi: Menggunakan LISREL. Gava Media, Yogyakarta.
Shao dan Tu. 1995. The Jacknife and Boostrap. University of Winconscin, Madison.