METODE PEMILIHAN FITUR DOKUMEN BAHASA
INDONESIA YANG TERKELOMPOK PADA MESIN
PENCARI
FITRIA RAHMADINA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Metode Pemilihan Fitur Dokumen Bahasa Indonesia yang Terkelompok pada Mesin Pencari adalah benar karya saya denganarahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
FITRIA RAHMADINA. Metode Pemilihan Fitur Dokumen Bahasa Indonesia yang Terkelompok pada Mesin Pencari.Dibimbing oleh JULIO ADISANTOSO.
Banyaknya informasi khususnya berupa dokumen dalam jumlah besar akan menghabiskan waktu dan tenaga apabila dilakukan pencarian secara manual. Pada ruang vektor, dokumen direpresentasikan dengan term.Semakin banyak term, maka semakin tinggi dimensi data sehingga semakin sulit untuk melakukan pencarian.Banyaknya jumlah dokumen mempengaruhi kinerja mesin pencari dalam mengembalikan dokumen yang relevan terhadap keinginan pengguna.Penelitian ini mengimplementasikan metode correlationcoefficient untuk kemudian dibandingkan dengan metode chi-square.Pada penelitian ini dihasilkan tingkat akurasi yang berbeda. Metode correlationcoefficient memiliki akurasi 68% sedangkan menggunakan metode chi-square dihasilkan akurasi sebesar 58%.
Kata kunci: correlation coefficient, chi-square, pemilihan fitur
ABSTRACT
FITRIA RAHMADINA. Feature Selection Method of Document Indonesian are Clustered in Search Engine. Supervised by JULIO ADISANTOSO.
The large amount of information particularly in the form of large quantities of documents will required a large amount of time and effort to search if done manually. On a vector space, documents are represented by terms. More terms mean higher-dimensional data which makes search more difficult to perform. A large number of documents affects the performance of the search engine to return the documents that are relevant to the user's desires. This study implements correlation coefficient method and compareit with the chi-square method. In this study different levels of accuracy are produced. Correlation coefficient method has an accuracy of 68% while the chi-square method produced an accuracy of 58%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
METODE PEMILIHAN FITUR DOKUMEN BAHASA
INDONESIA YANG TERKELOMPOK PADA MESIN
PENCARI
FITRIA RAHMADINA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi :Metode Pemilihan Fitur Dokumen Bahasa Indonesia yang Terkelompok pada Mesin Pencari
Nama : Fitria Rahmadina NIM : G64090059
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga tugas akhir dengan judul Metode Pemilihan Fitur Dokumen Bahasa Indonesia yang Terkelompok pada Mesin Pencari ini berhasil diselesaikan. Shalawat dan salam penulis sampaikan kepada Nabi Muhammad shallallahu ‘alaihi wassalam beserta keluarga, sahabat, dan pengikutnya yang tetap berada di jalan-Nya hingga akhir zaman.
Terima kasih penulis ucapkan kepada Bapak Ir Julio Adisantoso, MKom selaku pembimbing, serta Bapak Ahmad Ridha, SKom dan Bapak Sony Hartono Wijaya, SKom yang telah banyak memberi saran.Ungkapan terima kasih juga disampaikan kepada ayahanda Zarmen, ibunda Yunitawarmi, seluruh keluarga, teman-teman ILKOM46, sahabat, dan Pantom Wijaya atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Pengumpulan Dokumen 2
Praproses 4
Kueri 6
Similarity 6
Evaluasi 7
HASIL DAN PEMBAHASAN 7
Praproses 7
Pemilihan fitur 8
Pembobotan 9
Kueri 9
Similarity 10
Evaluasi 10
SIMPULAN DAN SARAN 11
Simpulan 11
Saran 11
DAFTAR PUSTAKA 11
DAFTAR TABEL
1 Ketergantungan tupel untuk metode pemilihan fitur 5
2 Nilai kritis untuk χ2untuk tingkat signifikansi α 5
3 Confusion Matrix 7
4 Kumpulan kueri uji 9
DAFTAR GAMBAR
1 Tahapan Penelitian 2 2 Contoh koleksi dokumen 3 3 Tabel dokumen pada database 84 Grafik recall precision 9
DAFTAR LAMPIRAN
1 Antarmuka Sistem 12
2 Hasil Sistem Correlation Coefficient 12
PENDAHULUAN
Latar Belakang
Banyaknya informasi khususnya berupa dokumen dalam jumlah besar akan menghabiskan waktu dan tenaga apabila dilakukan pencarian secara manual. Untuk itu pengembangan algoritme untuk mengelompokkan teks menggunakan bantuan komputer pun semakin dikembangkan.Peningkatan kebutuhan informasi dalam bentuk dokumen memerlukan teknik yang dapat mempermudah pencarian.
Pada ruang vektor, dokumen direpresentasikan dengan term.Semakin banyak term maka semakin tinggi dimensi data dan dokumen yang ada semakin menyebar sehingga sulit untuk melakukan pencarian.Banyaknya jumlah dokumen mempengaruhi kinerja mesin pencari dalam mengembalikan dokumen yang relevan terhadap keinginan pengguna.
Salah satu cara untuk mengurangi dimensi data adalah melakukan pemilihan fitur. Suatu objek perlu diketahui fitur-fiturnya agar bisa dikenali dan bisa dibedakan dari objek yang lain. Berbagai metode dilakukan untuk melakukan seleksi fitur, karena tidak semua fitur mampu memberikan hasil yang baik.Dokumen yang digunakan pada seleksi fitur adalah dokumen yang terkelompok.
Beberapa metode pada pemilihan fitur diantaranya adalah documentfrequency, chi-square, dancorrelationcoefficient. Metode document frequency merupakan salah satu teknik pemilihan fitur yang menghitung kemunculan kata unik dalam suatu kumpulan dokumen. Metode ini menghasilkan akurasi yang lebih rendah jika dibandingkan dengan chi-squareHerawan (2011).
Penelitian ini mengusulkan penggunaan metode correlation coefficientsebagai pemilihan fitur dan membandingkannya dengan metode chi-square untuk dokumen bahasa Indonesia.Pemilihan metode correlation coefficient karena metode ini belum digunakan untuk dokumen bahasa Indonesia.Selain itu correlation coefficient memiliki kelebihan dibandingkan chi-square, yaitu bebas dari sebaran dan korelasi di dalam kelas lebih kuat dibandingkan di luar kelas.Oleh sebab itu diharapkan metode correlation coefficient ini menghasilkan akurasi yang lebih baik dibandingkan chi-square.
Perumusan Masalah
Perumusan masalah yang harus diselesaikan yaitu :
1 Apakah correlation coefficient lebih baik dibandingkan dengan chi-square? 2 Seberapa jauh correlation coefficient dapat menghasilkan ciri yang mampu
membedakan antarkelas?
2
Tujuan Penelitian
Tujuan utama dari penelitian ini adalah mengimplementasikan pemilihan fiturcorrelation coefficient pada dokumen berbahasa Indonesia dan membandingkan tingkat akurasinya dengan metode chi-square.
Ruang Lingkup Penelitian
Penelitian ini dibatasi dengan cakupan sebagai berikut : 1 Dokumen yang digunakan adalah dokumen bahasa Indonesia 2 Dokumen yang digunakan berformat XML.
METODE
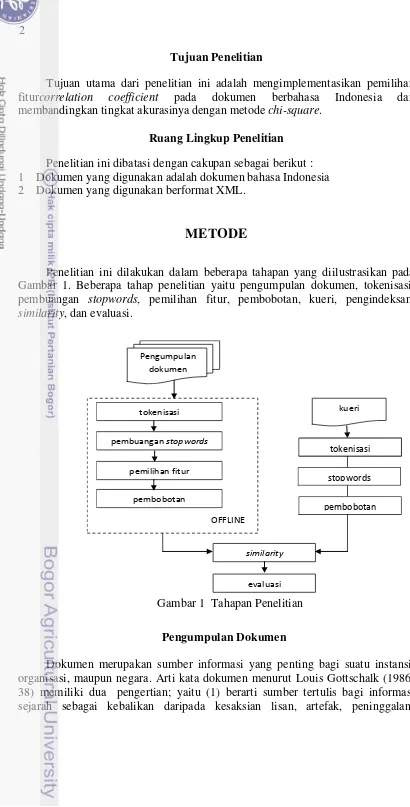
Penelitian ini dilakukan dalam beberapa tahapan yang diilustrasikan pada Gambar 1. Beberapa tahap penelitian yaitu pengumpulan dokumen, tokenisasi, pembuangan stopwords, pemilihan fitur, pembobotan, kueri, pengindeksan, similarity, dan evaluasi.
Pengumpulan Dokumen
Dokumen merupakan sumber informasi yang penting bagi suatu instansi, organisasi, maupun negara. Arti kata dokumen menurut Louis Gottschalk (1986; 38) memiliki dua pengertian; yaitu (1) berarti sumber tertulis bagi informasi sejarah sebagai kebalikan daripada kesaksian lisan, artefak,
peninggalan-Pengumpulan
Gambar 1 Tahapan Penelitian OFFLINE
tokenisasi
stopwords
3 peninggalan terlukis dan petilasan-petilasan arkeologis;(2) diperuntukkan bagi surat resmi dan surat negara seperti surat perjanjian, undang-undang, hibah, konsesi dan lainnya. Jadi, dokumen merupakan sumber tertulis atau sumber lisan yang digunakan sebagai pembuktian.
Proses pengumpulan dokumen merupakan pencatatan peristiwa atau hal atau kerakteristik sebagian atau keseluruhan populasi yang akan menunjang data atau penelitian. Ada beberapa teknik dalam pengumpulan data, diantaranya:
1 Wawancara (Esterberg, 2002) adalah pertemuan antara dua orang untuk bertukar informasi dan ide melalui tanya jawab sehingga dapat dikonstruksikan makna dalam suatu topik tertentu.
2 Observasi adalah pengumpulan data mengenai fenomena sosial dan gejala-gejala yang dilakukan dengan sengaja untuk dilakukan pencatatan.
3 Studi dokumentasi adalah mengumpulkan berkas berupa tulisan, gambar, karya yang memiliki kredibilitas yang tinggi.
Teknik pengumpulan data yang digunakan dalam penelitian ini adalah studi dokumentasi yang menggunakan koleksi dokumen tumbuhan obat dan hortikultura sebagai korpus.Dokumen yang digunakan sebagai dokumen pengujian adalah korpus hasil penelitian Herawan (2011) dan Sari (2012).Isi dari dokumen yang berkaitan dengan tumbuhan obat dan hortikultura ini tidak diubah sehingga ejaan dan tata bahasa yang salah tidak diperbaiki.Koleksi dokumen berjumlah 457 dan berformat XML dengan contoh yang terdapat pada Gambar 2.
Tag XML yang digunakan dalam koleksi dokumen ini adalah
• <dok></dok>, menunjukkan keseluruhan dokumen yang memiliki tag lain yang lebih jelas.
• <id></id>, menunjukkan ID dokumen.
• <kelas></kelas>, menunjukkan pengelompokan dari dokumen.
• <deskripsi></deskripsi>, menunjukkan isi dari dokumen. Gambar 2 Contoh koleksi dokumen <dok>
<id>1</id> <kelas>1</kelas>
<deskripsi> Bawang putih lokal saat ini sangat sulit dijumpai di pasaran setelah membanjirnya bawang putih impor ke Indonesia. Hal ini tentunya diperlukan upaya perbaikan produktivitas dan kualitas… </deskripsi>
4
Praproses
Praproses adalah sebuah tahapan memproses data input untuk menghasilkan output yang digunakan sebagai masukan untuk program lain. Dalam penelitian ini beberapa tahapan dalam praproses yaitu tokenisasi, pembuangan stopwords, pemilihan fitur, dan pembobotan.
Tokenisasi
Manning et al. (2008) menjelaskan bahwa tokenisasi adalah proses pemenggalan (parsing) kata menjadi unit kecil yang disebut token dan pada saat yang sama membuang karakter tertentu seperti tanda baca yang terdapat pada dokumen. Hal ini dilakukan agar setiap kata dapat diketahui frekuensi kemunculan pada suatu dokumen.
Pembuangan Stopwords
Stopwords adalah kata-kata yang jumlahnya sangat besar sehingga tidak perlu digunakan sebagai penciri dokumen.Selain itu stopwords juga digunakan untuk mengurangi jumlah kata yang harus diproses.Sekitar 80% dari kata yang sering muncul di dokumen tidak berguna dalam proses information retrieval. Kata-kata yang termasuk dalam stopwords disimpan dalam database dan dikumpulkan sehingga sistem yang akan dibangun mengenali terlebih dahulu kata-kata yang termasuk dalam stopwords dan tidak menghitungnya pada pembobotan kata.
Sangat banyak stopwords yang terdapat di dalam Bahasa Indonesia.Stopwords tersebut berasal dari kata hubung, kata depan, dan sebagainya. Pada penelitian ini stopwords yang digunakan diambil dari berbagai sumber dan berjumlah lebih dari 1300 kata.
Pemilihan Fitur
Pemilihan fitur adalah proses memilih bagian dari term yang ada di data latih. Pemilihan fitur dokumen memiliki dua tujuan utama yaitu membuat data latih yang diterapkan oleh sistem klasifikasi menjadi lebih sederhana serta untuk meningkatkan akurasi sistem klasifikasi. Peningkatan akurasi sistem klasifikasi disebabkan karena pada proses penghilangan fitur akan menghilangkan kata-kata yang bukan merupakan penciri dokumen (Manning et al. 2008).
5
Correlation coefficient merupakan suatu metodeuntuk mengukur tingkat korelasi antara variabel, yang memiliki nilai antara -1 sampai 1. Nilai correlation coefficient menghasilkan +1 dan -1 menandakan bahwa variabel tersebut linear. Sedangkan tanda positif atau negatif menandakan bahwa variabel memiliki korelasi yang positif atau negatif. Jika nilai yang dihasilkan 0, menandakan bahwa tidak ada hubungan yang linear antara variabel. Untuk sebuah dataset yang terdiri dari N dokumen, correlation coefficient didefinisikan dalam persamaan berikut (Biricik et al. 2011):
cc (t, ci) =�[�(�,�)�(¬�,¬�)−�(¬�,�)�(�,¬�)]
�(�)�(¬�)�(�)�((¬�)
dengan N adalah banyaknya dokumen,P(C,t) adalah peluang dokumen yang ada di kelasC dan termt,P(C, ¬t) adalah peluang dokumen yang ada di kelasC tetapi tidak mengandungtermt,P(¬C,t) adalah peluang dokumen yang bukan kelasC tetapi mengandungtermt,P(¬C, ¬t) adalah peluang dokumen yang bukan kelasC dan tidak mengandungtermt, �(�,�) = ��(�,�)
Hasil dari metode correlation coefficient akan dibandingkan dengan metode chi-square yaitu mengevaluasi fitur secara individual dengan menghitung statistik chi-square-nya yang berhubungan dengan kelasnya. Tujuannya adalah menguji hubungan atau pengaruh dua buah variabel nominal dan mengukur kuatnya hubungan antara variabel yang satu dengan variabel lainnya (Saputra 2011).Chi-square adalah salah satu seleksi fitur yang mampu menghilangkan banyak fitur tanpa mengurangi tingkat akurasi.Nilai kritis χ2untuk tingkat signifikansi α ditunjukkan oleh Tabel 2. Nilai χ2adalah:
χ2
Tabel 1 Ketergantungan tupel untuk metode pemilihan fitur
t ¬t
C df(C,t) df(C, ¬t)
6
Pembobotan
Di dalam praproses, pembobotan kata merupakan suatu tahapan yang sangat penting.Tujuannya untuk memberikan suatu nilai atau bobot pada term yang terdapat pada suatu dokumen.Bobot pada setiap term bergantung pada metode pembobotan.Makin sering suatu kata muncul pada suatu dokumen, maka diduga semakin penting kata itu untuk dokumen tersebut.
Ada beberapa faktor dalam penentuan bobot diantaranya:
1 Faktor lokal, yaitu bagaimana bobot suatu kata di suatu dokumen tanpa dipengaruhi dokumen lain. Makin sering suatu kata muncul di suatu dokumen, maka semakin penting kata tersebut. Kelemahannya adalah apabila kata muncul dalam semua dokumen, maka frekuensinya akan membingungkan. 2 Faktor global, yaitu bagaimana keberadaan kata di dokumen lain. Menilai
faktor global dapat dilakukan dengan documentfrequency (df). Jika nilai df nya besar, maka makin tidak penting sebuah kata.
Pembobotan yang digunakan dalam penelitian ini adalah pembobotan tf-idf. Term frequency (tf) merupakan frekuensi kemunculan suatu term t pada dokumen d. Documentfrequency (df) merupakan banyaknya dokumen di dalam korpus yang mengandung kata tertentu (Manning et al 2008).
Jika suatu kata t sering muncul dalam dokumen, maka dokumen tersebut perlu dipertimbangkan. Namun kata-kata yang sering muncul tetapi kurang merepresentasikan isi dokumen harus dihilangkan seperti stopwords. Kecenderungan nilai bobot yaitu berbading lurus dengan frekuensi term t pada dokumen serta berbanding terbalik dengan banyaknya dokumen yang mengandung suatu term t. Pembobotan tf-idf memberikan bobot pada term t dalam dokumen d dengan nilai:
���,� × ����
dengan tft,d merupakan frekuensi term t pada dokumen d dan idf = log �
���.
Sedangkan dftmerupakan jumlah dokumen yang mengandung term t. Kueri
Kueri adalah kemampuan untuk menampilkan suatu data dari database dimana mengambil dari tabel-tabel yang ada di database, namun tabel tersebut tidak semua ditampilkan sesuai dengan yang kita inginkan.Pemrosesan kueri sama halnya dengan praproses dokumen, yaitu melalui tahap tokenisasi, pembuangan stopwords, dan proses penghitungan pembobotan. Kueri yang dimasukkan akan dilakukan pengindeksan.
Similarity
7
Hasil cosine yang semakin tinggi menunjukkan bahwa dokumen tersebut memiliki tingkat kemiripan yang besar dari kueri yang diinputkan sedangkan hasil ukuran cosine yang rendah menunjukan bahwa kemiripan suatu dokumen terhadap kueri adalah kecil, dengan kata lain menunjukan bahwa dokumen tersebut tidak relevan terhadap kueri tersebut.
Evaluasi
Evaluasi kinerja sistem temu kembali informasi dilakukan dengan menghitung nilai recall dan precision. Recall adalah proporsi jumlah dokumen yang dapat ditemukan kembali oleh sebuah proses pencarian di sistem IR. Sedangkan precision adalah proporsi jumlah dokumen yang ditemukan dan dianggap relevan untuk kebutuhan pencari informasi.Precision mengindikasikan kualitas himpunan jawaban, tapi tidak melihat total semua dokumen yang relevan dalam kumpulan dokumen.
recall = jumlahdokumenrelevanyangditemukan
jumlahsemuadokumenrelevandidalamkoleksi= �� ��+��
precision = jumlahdokumenrelevanyangditemukan
jumlahsemuadokumenyangditemukan =
�� ��+��
Gagasan ini dapat diperjelas dengan memeriksa kontingensi berikut Tabel 3.
Table 3 Confusion Matrix
Relevant Nonrelevant
Retrieved true positives (tp) false positives(fp)
Not retrieved false negatives (fn) true negatives (tn)
HASIL DAN PEMBAHASAN
Praproses
8
hortikultura. Keseluruhan dokumen disimpan dengan format XML (Extensible Markup Language).
Dokumen dimasukkan ke dalam database sehingga didapatkan tabel yang bernama ‘dokumen’ untuk selanjutnya dilakukan tokenisasi.Contoh tabel dokumen dapat dilihat pada Gambar 3.Hasil tokenisasi tersebut diproses kembali agar kata-kata stopwords yang ada di dalamnya dapat dihilangkan.Hasil dari pembuangan stopwords disimpan dalam tabel yang bernama ‘tokenisasi’ sehingga didapatkan sebanyak 6802 kata unik.
Gambar 3 Tabel dokumen pada database
Pemilihan Fitur
Kata unik merupakan hasil keluaran dari tahap praproses. Kata unik ini diproses lagi pada tahap pemilihan fitur. Tahapan pemilihan fitur dokumen diajukan terhadap dua metode yang berbeda. Metode pemilihan fitur dokumen yang pertama menggunakan teknik chi-square dan metode yang kedua menggunakan correlation coefficient.
1 Chi-square
Pemilihan fitur dengan metode ini dilakukan pada seluruh dokumen. Nilai
signifikansi (taraf nyata α) yang digunakan adalah 0,01. Pemilihan taraf nyata ini
dikarenakan pada teknik tersebut memiliki tingkat akurasi pengelompokan yang lebih baik. Artinya semua kata yang memiliki nilai χ2 lebih kecil dari 6,63 tidak dapat digunakan untuk proses selanjutnya.
Hasil dari tahapan ini adalah 4021 kata unik pada kelas tumbuhan obat. Sedangkan pada kelas hortikultura terdapat 761 kata unik. Hasil dari kedua kelas disimpan dalam fail teks bernama ‘kata_unik_chi’. Untuk chi-square hanya kumpulan kata inilah yang akan digunakan pada tahap selanjutnya.
2 Correlation Coefficient
9 Sehingga hanya kata-kata yang dihasilkan pada taraf inilah yang akan digunakan untuk pengelompokan. Nilai signifikansi ini menghasilkan nilai correlation coefficient yang positif, artinya kata-kata yang bukan merupakan penciri yang baik tidak dihasilkan dan tidak digunakan pada tahap selanjutnya.
Hasil dari tahapan correlation coefficient pada kelas tumbuhan obat menghasilkan 4349 kata unik. Sedangkan pada kelas hortikultura terdapat 964 kata unik. Hasil dari kedua kelas digabung dan disimpan dalam fail teks bernama ‘kata_unik_corr’.
Pembobotan
Tahap pembobotan dokumen dilakukan dengan tf-idf.Kedua jenis kata unik yang telah dihasilkan dari metode correlation coefficient dan chi-square dihitung bobotnya. Hasil pembobotan ini disimpan dalam fail teks dengan nama‘tf_idf_chi’ dan ‘tf_idf_corr’. Penghitungan bobot term pada masing-masing dokumen ini kemudian digunakan dalam proses temu kembali informasi.
Kueri
Kueri yang digunakan dalam penelitian ini berjumlah 24 kueri. Pada kumpulan kueri tersebut dilakukan proses tokenisasi. Contoh kueri akan ditampilkan pada Tabel 3.
Tabel 3 Kumpulan kueri uji
Nomor Kueri 22 Kalsium Oksalat 23 Obat
10
Similarity
Hasil pembobotan dokumen digunakan untuk menghitung kemiripan kueri dengan dokumen. Setiap kata unik yang telah dihasilkan oleh metode correlation coefficient dan chi-square dihitung tf, df dan idf-nya. Untuk menghitung bobot antara dokumen dengan kueri digunakan similarity cosine. Nilai idf dari masing-masing metode dikalikan dengan nilai tf-nya. Setelah itu dihitung panjang vektor kedua metode. Sehingga didapatkan nilai dari similarity cosine.
Evaluasi
Pada tahap evaluasi, dilakukan penghitunganrecall, precision, serta Average Precision (AVP). Dokumen yang relevan dapat dicari dengan kueri yang berjumlah 24 tersebut, salah satu caranya adalah membaca seluruh dokumen. Dengan ini proses recall dan precision dapat dihasilkan. Hasil nilai precision untuk masing-masing kueri dirata-ratakan, sehingga didapatkan nilai AVP.AVP dihitung berdasarkan 11 standard recall levels, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan1.0 dengan menggunakan interpolasi maksimum.
Dari tahap ini didapatkan bahwa tingkat akurasi sistem correlation coefficient memiliki nilai yang lebih besar jika dibandingkan tingkat akurasi pada metode chi-square. Antarmuka sistem, sistem correlation coefficient, dan sistem chi-squaredicantumkan pada Lampiran 1, 2, dan 3.Akurasi yang didapatkan untuk correlation coefficient sebesar 68%, sedangkan pada metode chi-square didapatkan akurasi sebesar 58%. Gambar 4 adalah grafik perbandingan nilai recall dan precision antara dua metode yang telah digunakan sebagai penciri dokumen.
Gambar 4 Grafik Recall Precision 0.00
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
11
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang dilakukan, dapat disimpulkan bahwa pemilihan fitur dengan menggunakan metode chi-square dan correlation coefficient berhasil digunakan terhadap dokumen yang ada. Tingkat akurasi yang didapatkan dengan menggunakan metode correlation coefficient adalah 68%. Sedangkan tingkat akurasi dengan metode chi-square adalah 58%. Dari perbedaan ini dapat disimpukan bahwa metode correlation coefficient lebih baik dibandingkan dengan metode chi-square jika digunakan pada dokumen ini.
Saran
Beberapa hal yang perlu dikembangkan dalam penelitian ini adalah
1 Pada penelitian selanjutnya disarankan agar menggunakan metode pemilihan fitur lain yang belum digunakan untuk dokumen bahasa Indonesia. Sehingga dapat dihasilkan keakuratan yang paling baik dalam penggunanan metode pemilihan fitur.
2 Penelitian ini menggunakan pembobotan tf-idf. Disarankan agar menggunakan metode pembobotan lain yang lebih beragam.
DAFTAR PUSTAKA
Biricik G, Diri B, Sönmez AC. 2011. Abstract feature extraction for text classification.Vol(no):1-23. doi:10.3906/elk-1102-1015.
Esterberg KG. 2002. Qualitative Methods in Social Research. India (IN): McGraw Hill.
Gottschalk LA. 1986. Content Analysis of Verbal Behaviour: Significance in Clinical Medicine and Psychiatry. Prancis: Lavoisier SAS.
Herawan Y. 2011. Ekstraksi ciri dokumen tumbuhan obat menggunakan Chi-kuadrat dengan klasifikasi naive Bayes [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Manning, Raghavan, Schutze. 2008. An Intoduction to Information Retrieval. Cambridge (UK): Cambridge Univ Pr.
Rowler J. 1995. Multimedia kiosks in retailing. International Journal of Retail & Distribution Management. 23(5):32-40.
12
Lampiran 1 Antarmuka Sistem
14
RIWAYAT HIDUP
Penulis dilahirkan di Bukittinggi pada tanggal 21 Maret 1992 dari pasangan Zarmen dan Yunitawarmi. Penulis merupakan anak pertama dari empat bersaudara.